Abstract
Knowledge-graph-based recommendation aims to provide personalized recommendation services to users based on their historical interaction information, which is of great significance for shopping transaction rates and other aspects. With the rapid growth of online shopping, the knowledge graph constructed from users’ historical interaction data now incorporates multiattribute information, including timestamps, images, and textual content. The information of multiple modalities is difficult to effectively utilize due to their different representation structures and spaces. The existing methods attempt to utilize the above information through simple embedding representation and aggregation, but ignore targeted representation learning for information with different attributes and learning effective weights for aggregation. In addition, existing methods are not sufficient for effectively modeling temporal information. In this article, we propose MTR, a knowledge graph recommendation framework based on mixture of experts network. To achieve this goal, we use a mixture-of-experts network to learn targeted representations and weights of different product attributes for effective modeling and utilization. In addition, we effectively model the temporal information during the user shopping process. A thorough experimental study on popular benchmarks validates that MTR can achieve competitive results.
MSC:
94-11
1. Introduction
With the development of society, personalized shopping has become an essential and important part of people’s daily lives. Various historical information about shopping is constantly collected and aggregated into many classic shopping information datasets [1,2]. Personalized services driven by users’ historical shopping data significantly enhance shopping websites’ marketing performance. Moreover, they profoundly influence people’s daily lives through tailored experiences. Several knowledge-based shopping recommendation methods (KGs) are proposed, such as the multitask learning scheme based on KGs to enhance recommendation effectiveness [3] and the trust-based embedding technology based on recommendation-oriented KGs [4]. The method based on KGs requires high-precision modeling, which directly affects the accuracy of the final recommendation results.
In order to fully model, existing KG based recommendation methods often rely on various modeling methods to transform KG information into effective representations. This includes traditional text modeling methods [5], image modeling methods [6], and KG representation learning [7,8]. However, current KG-based recommendation methods struggle to effectively learn and weigh the final fused representation of multidimensional attributes (e.g., images and dynamic e-commerce data). In addition, current methods often have serious shortcomings in modeling time information. Specifically, for example, the Mandari method [9] only uses ViT [10], S-BERT [11], TransE [12], etc., to model image, text, and structural information from KG, but does not provide a targeted representation learning for the characteristics of each attribute information. It ignores the final design of the weight of the aggregation of different information of the representation of attributes. The defects mentioned above can easily lead to serious deficiencies in the accuracy of existing methods.
To address the key issues mentioned above, this paper proposes MTR, which is a framework for effective recommendation based on a mixture-of-experts model. Different experts have learned the characteristics of different attribute information in a targeted manner to form accurate representations, and ultimately learned effective combination weights, which are conducive to forming the final accurate representation. In addition, we also effectively model temporal information. Existing methods in multimodal KG recommendation fail to conduct targeted representation learning for different modalities and temporal information simultaneously, often focusing only on one aspect of modality or temporal information. Moreover, they do not dynamically learn the aggregation weights for different modalities and temporal information, resulting in insufficient modeling of effective information and limiting the capture of users’ dynamic interests. The method proposed in this paper effectively models multimodal and temporal information simultaneously and learns the aggregation weights effectively, which specifically addresses the shortcomings of previous methods, enhances the timeliness and personalization of recommendations, and better meets users’ dynamic needs.
Our contributions can be summarized as follows:
- We propose an effective framework based on the mixture-of-experts model, which combines experts for different attribute information and effectively learns the combined weights of each attribute information to form the final accurate representation, effectively improving the accuracy of shopping recommendations.
- We also effectively utilize time series information, further promoting the effective impact of shopping history information on future recommendations.
- Based on experimental results from two classic datasets in the real world, we validate the effectiveness of the proposed method.
2. Related Work
This study is mainly related to two aspects: KG embedding representation and KG-based recommendation. This section introduces the research status of these two aspects to facilitate readers’ understanding.
2.1. Knowledge Graph Embedding Representation
KG represents learning maps entities and relations in KGs to low-dimensional continuous vectors while preserving their structural and semantic information. It achieves efficient computation and inference through vectorized representation, supports tasks such as link prediction and entity classification, and enhances the utilization efficiency and application capability of KGs. The current traditional KG representation learning methods can be divided into three categories: methods based on translation distance, methods based on bilinear models, and methods based on neural networks. This section introduces and analyzes the research status of three types of strategies separately.
2.1.1. Methods Based on Translation Distance
The advantage of this method is that it is relatively simple, so it is widely adopted. The most classic translation-based method is the TransE model [13]. The basic idea of this type of method is that the embedding of the head entity plus the embedding of the relation should be close to the embedding of the tail entity. In addition, other similar methods are also proposed, such as TransH [14] and TransR [15], which are often based on various simple operations such as dot product and matrix multiplication to calculate the translation model of the fractional function.
2.1.2. Methods Based on Bilinear Model
Due to the limitations of simple representation learning operations and limited parameters generated by translation-based methods, bilinear-model-based methods are proposed to meet the needs of more complex representation scenarios, using bilinear models to generate embedded representations that can capture richer semantic information. The RESCAL [16] model uses vectors to represent entities, matrices to represent relations, and captures the internal interactions of triplets through custom scoring functions. DistMult [17] simplifies RESCAL by restricting its relational matrix to a diagonal matrix.
2.1.3. Methods Based on Neural Network
Due to the progressiveness of neural networks in various fields, this method is considered to be applied to the representation modeling of the knowledge atlas to aggregate the local neighborhood information of each node. For example, Liang et al. [18] propose three customized graph neural networks for different scenarios represented by KGs, including traditional KGs, multimodal KGs, and uncertain KGs; Jiang et al. [19] propose a graph intent neural network for KG inference to explore fine-grained entity representations that use both external and internal intent simultaneously. Due to the development of various semantic learning techniques, some emerging neural network methods are applied to the representation of KGs. For example, in the method of Li et al. [20], based on a generative adversarial network enhanced with structure, a structural encoder is used to introduce structural KG information into the generator and guide the generator to generate KG embeddings more accurately; Wang et al. [21] optimize the learning path of the KG embedding based on reinforcement learning to consider the relations between the elements of knowledge.
With the development and progress of the big data era, the demand for cross-domain applications in various industries is becoming increasingly strong. As an important tool for modeling graph data in various fields, KG representation learning has attracted a lot of attention.
2.2. Knowledge-Graph-Based Recommendation
Driven by personalized demands, knowledge-graph-based recommendation systems are gradually replacing traditional collaborative filtering methods and becoming the core technology for e-commerce, content platforms, and social media, especially in dealing with cold start and long tail problems. By mining the deep-level correlation between user behavior and entity relations in KGs, recommendation systems can more accurately predict user interests and improve recommendation diversity and interpretability [22]. In the field of recommendation systems, with the help of KGs, we aim to address the issue of insufficient diversity in recommendations by introducing new metrics, DEL modules, and CAU technology to improve the performance of KG-driven recommendation systems [23]. In the field of KG-enhanced recommendation systems, this paper proposes a knowledge graph contrastive learning framework, which solves the problems of KG sparsity and noise through KG enhancement mode and contrastive learning. Existing research captures high-order entity relations through modeling strategies, optimizes recommendation paths, and validates their effectiveness in scenarios such as movie recommendation [24] and product recommendation [25], gradually exploring various frameworks to meet user needs.
In recent years, research on recommendation systems has yielded emerging solutions across multiple dimensions. For multimodal and KG-enhanced recommendation, Meng et al. [26] use large language models to generate cross-modal features from text and image information, improving recommendation accuracy and richness. However, this approach incurs high computational costs and is suitable for applications with high recommendation quality requirements and ample computational resources. For temporal KG recommendation, Chen et al. [27] design a spatiotemporal transition model to capture user behavior patterns between adjacent POIs. This method is limited to POI scenarios and may not be easily extended to other recommendation tasks. In multimodal fusion KG recommendation, Wang et al. [28] propose a personalized recommendation framework to address modality interaction limitations and analyze existing multimodal graph construction methods. While this framework enhances recommendation personalization, its complexity may reduce model training and inference efficiency, making it suitable for applications requiring high personalization and processing multiple modalities. In MoE-based recommendation, Zhang et al. [29] introduce a hierarchical time-aware MoE for multimodal sequential recommendation, featuring a two-level MoE and multitask learning. This method captures users’ dynamic interests but has high model complexity, increasing training and inference costs. It is ideal for applications like video and social network recommendation that require handling multimodal sequential data and modeling dynamic user interests. In Table 1, we provide a comprehensive comparison for existing methods in four key dimensions: modality fusion, temporal modeling, knowledge graph integration, and MoE mechanisms.

Table 1.
Comparison of different methods/models across key dimensions.
3. Methodology
In this section, we describe the framework outline of our proposed model, and present each part of the model separately. The proposed framework mainly consists of three modules: mixture of experts (MoE) embedding module, attribute capture enhancement module, and judgment module. By integrating MoE with attention mechanisms, MTR significantly enhances the interpretability of recommendation results. The key lies in the visual analysis of gating network weights and attention scores, providing users with clear explanations for recommendations. The gating network learns weights for different modalities, intuitively reflecting the contribution of each attribute to the recommendation. For instance, if the image weight of a product is significantly higher than other modalities, the system can explain that the recommendation is “based on visual similarity”, thereby increasing user trust in the recommendation logic. In the attribute capture enhancement module, the attention mechanism generates attention scores, revealing the correlation strength between users’ historical behaviors and POIs. Historical records with high attention scores can be labeled as “high-frequency preferences”, indicating that recommendations are driven by long-term interests. By transforming complex multimodal and temporal modeling into intuitive, user-friendly explanations, MTR effectively balances recommendation accuracy with transparency. Our model structure diagram is shown in Figure 1. The detailed information is presented in the pseudocode (Algorithm 1).
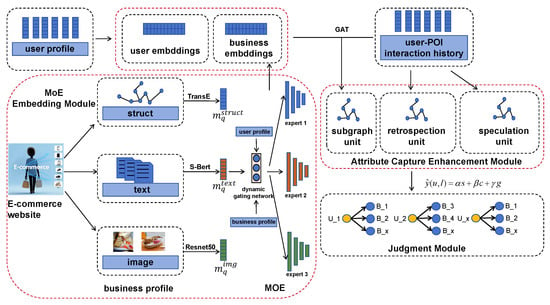
Figure 1.
The main framework of MTR.
3.1. MoE Embedding Module
To fully learn accurate embeddings of different modal attributes based on MoE and thoroughly learn the combined weights, we first extract initial representations based on information from different modalities: First, for the structural attributes, we obtain basic representation for ratings, categories, business hours based on TransE [13], etc. Second, regarding semantic attributes, we acquire the foundational embeddings of semantic information based on the S-Bert [35] model. Finally, for image attributes, we extract their initial image embeddings using ResNet50 [36].
| Algorithm 1 Multimodal next POI recommendation with MoE-based knowledge graph. |
|
We construct a two-layer multimodal KG . The Temporal Layer indicates the user’s access to location q at time r within the time slot . The Multimodal Layer connects POI with its modal information. To effectively integrate the three modalities, we introduce the MoE module. Firstly, we map each modal feature to the same dimension:
where , and denote the transform weight matrices. Then, the modal weights are calculated through a dynamic gating network based on the user profile and business profile:
where denotes the transform weight matrix, and Daynet denotes a dynamic gating network whose specific architecture will be detailed in Section 4.2. The final POI obtained through fusion is represented as follows:
where , using to guide subsequent graph modeling and prediction. We assign the three weight parameters equally here, where = 0.33, = 0.33, = 0.33.
The theoretical basis for using MoE in this framework is to learn the feature representations of different information levels (such as structure, text, and image) through different expert networks and to allocate weights through a dynamic gating network, thereby achieving effective fusion of multimodal information and personalized recommendations. This design can target the learning of features of different modalities and dynamically adjust the importance of each modality in the recommendation process, improving the accuracy and personalization of recommendations.
3.2. Attribute Capture Enhancement Module
To fully capture the multimodal information of multiple attributes and temporal attribute information, we perform attribute capture enhancement for both multimodal data and sequential data in the preprocessing stage of the MoE framework.
Subgraph Unit
We construct three graphs: User-User Graph , POI-POI Time Map , and POI-POI spatial map . Among them, the initial node vectors of and come from the previous multimodal fusion , and the user node vectors in are randomly initialized.
To model the relations between neighboring nodes, we introduce the Graph Attention Network (GAT). The attention score of any node and its neighbor is calculated as follows:
where the LeakyReLU activation enables modeling of negative correlations, and denotes the shared weight matrix. To obtain interpretable attention distributions, we normalize the raw scores through the following:
After the normalization process, the node representation is then updated via weighted aggregation:
With being a nonlinear activation function for hierarchical feature propagation. We calculate node embeddings for each of the three graphs: , , , then merge two POI maps into . After that, we obtain the predicted score for the subgraph between the user and POI:
Retrospection Unit
This module specializes in handling users’ historical visit patterns. Given the historical behavior set within time slot :
where is a snapshot at time r, we first construct a gating vector to regulate historical information flow:
where , are trainable parameters, and z is time step unit. Then interaction with the historical behavior memory bank yields replication scores:
with softmax normalization producing historical behavior selection probabilities:
Speculation Unit
For predicting potential visits to new POIs, this component learns associations between user spatiotemporal contexts and unvisited locations. First, we generate a latent behavior query vector:
where , are trainable parameters, and r is time step unit, which outputs a probability distribution over new POIs:
The rationale for selecting the temporal modeling approach is grounded in the temporal nature of user behavior preferences, which exhibit distinct patterns across varying time intervals. By effectively modeling temporal information through techniques such as time-series modeling and temporal decay mechanisms, the model can capture the dynamic evolution of user behavior, thereby enhancing its ability to predict future user needs and, consequently, improving the timeliness and accuracy of recommendations. It is worth noting that the reason for choosing this approach to temporal processing over other alternatives is its ability to effectively integrate temporal information with graph-structured data. By employing the attention mechanism, it dynamically captures the temporal correlations between nodes, thereby better modeling the dynamic changes in user behavior and spatiotemporal associations. Compared with traditional recurrent neural networks (RNNs) or simple convolutional neural networks (CNNs), this module exhibits greater flexibility and adaptability when dealing with temporal-sequence data in multimodal KGs, enabling more accurate reflection of the evolution of user preferences over time.
3.3. Judgment Module
We merge the prediction results of the three modules to form the final recommendation score:
where , = 0.5, = 0.3, = 0.2, represents the predicted score of the structural subgraph, represents the score for CopyNet’s repetitive behavior, and represents the GenNet potential interest prediction score. We use the cross entropy loss function for training:
where represents the label, is the model parameter, is the L2 regularization coefficient.
4. Experiments
In this section, we conduct experiments to verify the effectiveness of our proposed model.
4.1. Experimental Setting
4.1.1. Dataset
We use two real-world datasets in our experiment, which are briefly introduced below.
The NYC dataset [37] is collected from the FourSquare dataset, which is currently widely used in various recommendation model experiments. This includes POI information of users in New York City from April 2012 to February 2013. It collects information including both images and comments.
The Yelp dataset [38] is widely used in various recommendation experiments, including users’ basic location information, location comment information, and location image information.
The Electronics dataset [39] is derived from the Amazon review dataset, which is currently widely utilized in diverse multimodal recommendation experiments. It encompasses rich information of electronic products on Amazon, including raw images, text reviews, and user ratings spanning a certain period.
4.1.2. Baselines
We compare five classic POI prediction models, one time-series prediction model, one multimodal prediction model, and one time-series multimodal prediction model. The introduction of various baseline indicators is as follows:
- FPMC [40]: It proposes the factorized personalized Markov chains (FPMC) method, which combines matrix factorization and Markov chains to solve the recommendation problem under limited data and improve the recommendation performance.
- ST-RNN [41]: It proposes Spatial Temporal Recurrent Neural Networks (ST-RNNs), which addresses the insufficiency of existing methods in modeling continuous time intervals and geographical distances and enhances the location prediction performance.
- DeepMove [34]: It proposes the DeepMove attentional recurrent network, which solves the problems such as complex sequential transitions and data sparsity in human mobility prediction, and improves the prediction performance and interpretability.
- LSTPM [33]: It proposes the Long-Term and Short-Term Preference Modeling (LSTPM) method, which solves the problem that existing recurrent neural networks (RNNs) methods in POI recommendation neglect long-term and short-term preferences as well as geographical relations, and enhances the recommendation reliability.
- STAN [32]: It proposes the Spatio-Temporal Attention Network (STAN) for location recommendation, which addresses the problem of not considering the associations between non-adjacent locations and non-consecutive visits, and outperforms existing methods.
- MKGAT [30]: It proposes the Multimodal Knowledge Graph Attention Network (MKGAT), which solves the problem that existing recommender systems ignore the diversity of data types in multimodal knowledge graphs, and improves the recommendation quality.
- RE-NET [31]: It proposes the Relation Embedded deep model (RE-Net) for Facial action units (AUs) detection, which addresses the problem of suboptimal ways of utilizing AU correlations, and improves the performance of AU detection and AU intensity estimation.
- Mandari [9]: It proposes the Multimodal Temporal Knowledge Graph-aware Sub-graph Embedding approach (Mandari), which constructs a multimodal temporal knowledge graph, solves the problems of multimodal data association and dynamic modeling of user preferences, and improves the performance of next-POI recommendation.
- DOGE [26]: It utilizes large language models to interpret image information under the guidance of textual data, generating cross-modal features that effectively enhance the relationship between text and image modalities.
- STKG-PLM [27]: It integrates contrastive learning and prompt-tuned pre-trained language models to enhance next POI recommendation.
- Multi-KG4Rec [28]: It employs a modality fusion module to extract user modality preferences in a fine-grained manner.
- HM4SR [29]: It employs a hierarchical time-aware mixture-of-experts (MoE) framework with two-level gating and multitask learning strategies for multimodal sequential recommendation.
4.1.3. Evaluation Metrics
Hits@n, MRR, and Recall@k are used as the evaluation index of the experiment to evaluate the MTR model and the comparative models in its experiment. Hits@n indicates the average proportion of knowledge ranked less than n in link prediction, MRR represents the reciprocal of the average ranking, and Recall@k measures the proportion of all relevant items that are successfully included in the top k ranked results. The index calculation methods mentioned in the above indicators are defined as follows:
Mean Reciprocal Rank (MRR):
In this formula, Q represents the total number of queries, that is, the total number of query requests. denotes the rank of the first correct answer in the i-th query.
Hits@k:
Here, Q also represents the total number of queries. C represents the number of queries where the correct answer is included in the top k ranked results.
Recall@k:
In this formula, Q is the total number of queries. For the i-th query, (True Positives) denotes the number of relevant items that are ranked within the top k positions, and (False Negatives) denotes the number of relevant items that are ranked outside the top k positions. Recall@k thus reflects the ratio of correctly retrieved relevant items to all relevant items for each query, averaged across all queries.
4.2. Main Experiment Results and Analysis
We report the main experiment in Table 2 and Table 3, which shows that our main experiment results are currently the best compared to the baseline models. To follow the established research conventions in this field and ensure the comparability of results, we use Hits@n and MRR for evaluation on the NYC dataset and Yelp dataset, while Recall@k is employed for the Amazon Electronics dataset. Table 4 presents statistical significance tests that validate the effectiveness of our method. To ensure fairness, the hyperparameters of all baseline models are tuned to their optimal values. The experiments employ the Adam optimizer with a learning rate of 0.001. All parameters are initialized using xavier initialization, and the batch size is set to 1024. The model is trained for 30 epochs, with early stopping if the evaluation metrics no longer improve. The reason is that previous baseline models do not fully learn the representation and weights of different attributes of the KG in the context of temporal multimodality, and the vast majority of models do not fully explore the role and influence of temporal information in prediction.
Table 2.
Performance comparison between NYC and Yelp datasets based on different models.
Table 3.
Experimental results on Amazon Electronics dataset (recall metrics).
Table 4.
Statistical significance analysis of model performance improvements.
On a single RTX3090 with 24 GB of memory, experiments show that training the NYC dataset for 30 epochs takes about 3.8 h and peaks at 15 GB, with the parallel multimodal modeling stage being the bottleneck. Inference latency per batch meets real-time requirements. To scale to million-level data, we can apply subgraph sampling and MoE parallelism, reduce the depth of selected layers, and replace current heavy networks with lightweight counterparts, which is expected to cut memory usage markedly and still allow single-node deployment on the RTX3090, balancing cost and performance.
In the MTR framework, three expert networks are specifically employed. Dedicated expert networks are designed for structural information, textual information, and image information, respectively, to learn their respective feature representations. One gating network is utilized to compute the weights of different modalities. In the structure of the gating network, the input consists of the concatenation of the linearly transformed structural feature vectors, textual feature vectors, and image feature vectors. The hidden layer comprises two fully connected layers, which are used to learn the correlations between different modality features and their contributions to the final representation. The output layer employs a softmax function to convert the hidden layer outputs into weights for each modality, thereby dynamically allocating the importance of different modalities. In the MTR model, a dropout layer with a dropout rate of 0.2 is applied after the output of each modality feature extraction network. This helps to reduce the overfitting that may occur during the feature extraction stage and enables the model to focus more on learning the robustness of different modality features during training. Additionally, in the MoE module, after the outputs of the individual expert networks are multiplied by the weights from the gating network, another dropout layer with a dropout rate of 0.25 is added. This enhances the model’s generalization capability during the multimodal information fusion stage, preventing the model from over-relying on specific modalities due to the prominence of certain modality features in the fusion process. In the temporal modeling module, the time feature vector has a dimension of 24. For time series modeling, a single LSTM network with 128 hidden units is set up.
In terms of the overall parameter size of the model, the MTR framework integrates the extraction of multimodal features, the MoE structure, and the temporal module, resulting in a substantial number of parameters. In terms of computational complexity, the MTR model is highly intensive. This is due to its integration of multimodal information and temporal-sequence modeling. Multimodal feature extraction alone requires a significant amount of computational resources, especially for image and text feature extraction. Moreover, when processing graph-structured data, the complexity of the temporal module is often proportional to the number of nodes and edges. Therefore, during the model training process, we employ reasonable optimizations (such as batch processing and parallel computing) and hardware acceleration (such as GPUs) to meet the requirements for efficient training and inference.
4.3. Ablation Study
In order to verify the effectiveness of MTR in combining mixed expert models and temporal information modeling, we remove the corresponding modules separately and allow the remaining parts to run independently for testing. The results of this experiment are reported in Table 5. From Table 5, it can be seen that for Hits@1 inthe evaluation indicators, the original experimental results were 2.96% higher than those without MTR, and 0.83% higher than those without time series modeling. All other indicators also decrease when one of the above modules is removed. This experiment fully verifies the importance of the mixture-of-experts model in fully representing and learning weights for various attributes, as well as the necessity of modeling temporal information. MoE uses a gating network to assign dynamic weights to three heterogeneous modalities—structure, text, and vision. Removing MoE deprives the model of these adaptive weights, leading to degraded multimodal performance. Deleting the temporal modeling module averages periodic historical behaviors, erases cyclical interests and spatiotemporal coupling, and excludes temporal context from representation updates, causing further performance decline.
Table 5.
Ablation study.
4.4. Hyperparameter Analysis
To verify the effectiveness of the weight parameters of Subgraph, CopyNet, and GenNet for the model, we conduct a parameter variation experiment. We report the results of this experiment in Figure 2. It can be seen that when the ratio of the three reaches 5:3:2, the various indicators of the experiment can be significantly better than other combinations of ratios. This confirms that subgraphs contribute more to the final prediction results and should be given more attention in model training.
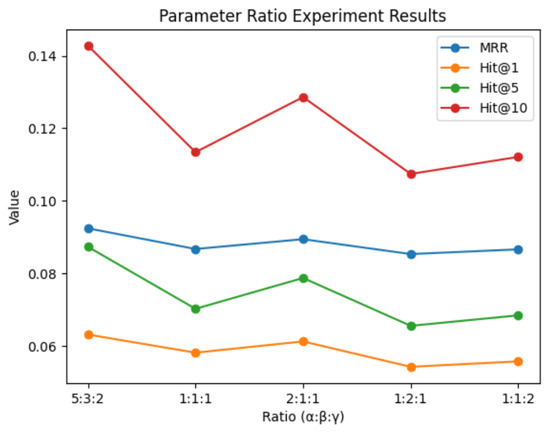
Figure 2.
Parameter ratio experiment results.
5. Conclusions
The existing knowledge graph multimodal recommendation methods attempt to utilize attribute information such as images and text through simple embedding representation and aggregation, but ignore targeted representation learning for different attribute information and learning effective weights for aggregation. In addition, existing methods are not sufficient to effectively model temporal information related to modeling. In this article, we propose a novel temporal multimodal knowledge graph recommendation framework MTR, which is based on a mixture-of-experts model for targeted representation learning and weight learning of various attribute information, and models temporal information. To demonstrate the effectiveness of MTR, we conduct extensive experiments on two real-world OKB datasets, and the results show that our framework outperformed all baselines in various experimental metrics.
Author Contributions
Methodology, B.L. and X.L.; formal analysis, B.L.; investigation, B.L., G.D., Z.L., Y.F., J.L., W.S., B.Z. and C.L.; data curation, B.L. and G.D.; writing—original draft preparation, B.L.; writing—review and editing, B.L.; visualization, B.L. and G.D.; funding acquisition, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research is sponsored by the Key R&D Program of Shandong Province, China (No. 2023CXGC010801) and the Shandong Provincial Natural Science Foundation (ZR2024LZH008).
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data are created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest. Author Changzhi Li was employed by the company IEIT SYSTEMS Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Jin, W.; Mao, H.; Li, Z.; Jiang, H.; Luo, C.; Wen, H.; Han, H.; Lu, H.; Wang, Z.; Li, R.; et al. Amazon-M2: A Multilingual Multi - locale Shopping Session Dataset for Recommendation and Text Generation. In Advances in Neural Information Processing Systems 36; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: New York, NY, USA, 2023; pp. 8006–8026. [Google Scholar]
- Park, M.; Oh, J. Enhancing E-Commerce Recommendation Systems with Multiple Item Purchase Data: A Bidirectional Encoder Representations from Transformers-Based Approach. Appl. Sci. 2024, 14, 7255. [Google Scholar] [CrossRef]
- Jiang, M.; Li, M.; Cao, W.; Yang, M.; Zhou, L. Multi-task convolutional deep neural network for recommendation based on knowledge graphs. Neurocomputing 2025, 619, 129136. [Google Scholar] [CrossRef]
- Huang, C.; Yu, F.; Wan, Z.; Li, F.; Ji, H.; Li, Y. Knowledge graph confidence-aware embedding for recommendation. Neural Netw. 2024, 180, 106601. [Google Scholar] [CrossRef] [PubMed]
- Zeng, J.; Wang, N.; Li, J. Knowledge-driven hierarchical intents modeling for recommendation. Expert Syst. Appl. 2025, 259, 125361. [Google Scholar] [CrossRef]
- Wang, F.; Zhu, X.; Cheng, X.; Zhang, Y.; Li, Y. MMKDGAT: Multi-modal Knowledge graph-aware Deep Graph Attention Network for remote sensing image recommendation. Expert Syst. Appl. 2024, 235, 121278. [Google Scholar] [CrossRef]
- Balloccu, G.; Boratto, L.; Fenu, G.; Marras, M.; Soccol, A. KGGLM: A Generative Language Model for Generalizable Knowledge Graph Representation Learning in Recommendation. In Proceedings of the 18th ACM Conference on Recommender Systems (RecSys ’24), Bari, Italy, 14–18 October 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 1079–1084. [Google Scholar] [CrossRef]
- Liu, X.; Liang, B.; Niu, J.; Sha, C.; Wu, D. Dual-graph co-representation learning for knowledge-Graph Enhanced Recommendation. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Liu, X.; Li, X.; Cao, Y.; Zhang, F.; Jin, X.; Chen, J. Mandari: Multi-Modal Temporal Knowledge Graph-aware Sub-graph Embedding for Next-POI Recommendation. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 1529–1534. [Google Scholar] [CrossRef]
- Zeng, W.; Li, M.; Xiong, W.; Tong, T.; Lu, W.J.; Tan, J.; Wang, R.; Huang, R. MPCViT: Searching for Accurate and Efficient MPC-Friendly Vision Transformer with Heterogeneous Attention. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 5029–5040. [Google Scholar] [CrossRef]
- Teng, X.; Zhang, L.; Gao, P.; Yu, C.; Sun, S. BERT-Driven stock price trend prediction utilizing tokenized stock data and multi-step optimization approach. Appl. Soft Comput. 2025, 170, 112627. [Google Scholar] [CrossRef]
- Yang, C.; Zheng, R.; Chen, X.; Wang, H. Content recommendation with two-level TransE predictors and interaction-aware embedding enhancement: An information seeking behavior perspective. Inf. Process. Manag. 2023, 60, 103402. [Google Scholar] [CrossRef]
- Song, D.; Zhang, F.; Lu, M.; Yang, S.; Huang, H. DTransE: Distributed Translating Embedding for Knowledge Graph. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 2509–2523. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence (AAAI’14), Québec, QC, Canada, 27–31 July 2014; AAAI Press: Washington, DC, USA, 2014; pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. Proc. Aaai Conf. Artif. Intell. 2015, 29, 1. [Google Scholar] [CrossRef]
- Nickel, M.; Tresp, V.; Kriegel, H. A three-way model for collective learning on multi-relational data. In Proceedings of the 28th International Conference on International Conference on Machine Learning (ICML’11), Omnipress, Madison, WI, USA, 2011, 28 June–2 Jully; pp. 809–816.
- Yang, B.; Yih, W.-t.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. arXiv 2015. [Google Scholar] [CrossRef]
- Liang, S. Knowledge Graph Embedding Based on Graph Neural Network. In Proceedings of the 2023 IEEE 39th International Conference on Data Engineering (ICDE), Anaheim, CA, USA, 3–7 April 2023; pp. 3908–3912. [Google Scholar] [CrossRef]
- Jiang, W.; Fu, Y.; Zhao, H.; Wan, J.; Pu, S. Graph Intention Neural Network for Knowledge Graph Reasoning. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Li, X.; Ma, J.; Yu, J.; Zhao, M.; Yu, M.; Liu, H.; Ding, W.; Yu, R. A structure-enhanced generative adversarial network for knowledge graph zero-shot relational learning. Inf. Sci. 2023, 629, 169–183. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y.; Sun, L.; Liu, Y.; Zhang, W.; Zhang, Y. Learning path design on knowledge graph by using reinforcement learning. In Proceedings of the 2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Istanbul, Türkiye, 5–8 December 2023. [Google Scholar]
- Liu, X.; Yang, L.; Liu, Z.; Yang, M.; Wang, C.; Peng, H.; Yu, P.S. Knowledge Graph Context-Enhanced Diversified Recommendation. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining (WSDM ’24), Merida, Mexico, 4–8 March 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 462–471. [Google Scholar] [CrossRef]
- Yang, Y.; Huang, C.; Xia, L.; Li, C. Knowledge Graph Contrastive Learning for Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22), Madrid, Spain, 11–15 July 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1434–1443. [Google Scholar] [CrossRef]
- Breitfuss, A.; Errou, K.; Kurteva, A.; Fensel, A. Representing emotions with knowledge graphs for movie recommendations. Future Gener. Comput. Syst. 2021, 125, 715–725. [Google Scholar] [CrossRef]
- Liu, S.; Lu, L.; Wang, B. Mining User–Item Interactions via Knowledge Graph for Recommendation. ACM Trans. Recomm. Syst. 2025, 3, 32. [Google Scholar] [CrossRef]
- Meng, F.; Meng, Z.; Jin, R.; Lin, R.; Wu, B. DOGE: LLMs-Enhanced Hyper-Knowledge Graph Recommender for Multimodal Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025; pp. 12399–12407. [Google Scholar]
- Chen, W.; Huang, H.; Zhang, Z.; Wang, T.; Lin, Y.; Chang, L.; Wan, H. Next-POI Recommendation via Spatial-Temporal Knowledge Graph Contrastive Learning and Trajectory Prompt. IEEE Trans. Knowl. Data Eng. 2025, 37, 3570–3582. [Google Scholar] [CrossRef]
- Wang, J.; Xie, H.; Zhang, S.; Qin, S.J.; Tao, X.; Wang, F.L.; Xu, X. Multimodal fusion framework based on knowledge graph for personalized recommendation. Expert Syst. Appl. 2025, 268, 126308. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, L.; Shen, D.; Wang, C.; Xiong, H. Hierarchical Time-Aware Mixture of Experts for Multi-Modal Sequential Recommendation. In Proceedings of the ACM on Web Conference, Sydney, Australia, 28 April–2 May 2025; pp. 3672–3682. [Google Scholar]
- Sun, R.; Cao, X.; Zhao, Y.; Wan, J.; Zhou, K. Multi-modal knowledge graphs for recommender systems. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 1405–1414. [Google Scholar]
- Yang, H.; Yin, L. Re-net: A relation embedded deep model for au occurrence and intensity estimation. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; pp. 137–153. [Google Scholar]
- Luo, Y.; Liu, Q.; Liu, Z. Stan: Spatio-temporal attention network for next location recommendation. In Proceedings of the web conference, Ljubljana, Slovenia, 19–23 April 2021; pp. 2177–2185. [Google Scholar]
- Sun, K.; Qian, T.; Chen, T.; Liang, Y.; Nguyen, Q.V.H.; Yin, H. Where to go next: Modeling long-and short-term user preferences for point-of-interest recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 214–221. [Google Scholar]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. Deepmove: Predicting human mobility with attentional recurrent networks. In Proceedings of the 2018 World Wide Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 1459–1468. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3982–3992. [Google Scholar]
- Boitel, E.; Mohasseb, A.; Haig, E. MIST: Multimodal emotion recognition using DeBERTa for text, Semi-CNN for speech, ResNet-50 for facial, and 3D-CNN for motion analysis. Expert Syst. Appl. 2025, 270, 126236. [Google Scholar] [CrossRef]
- Yang, D.; Zhang, D.; Zheng, V.W.; Yu, Z. Modeling User Activity Preference by Leveraging User Spatial Temporal Characteristics in LBSNs. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 129–142. [Google Scholar] [CrossRef]
- Zhang, Y.; Ai, Q.; Chen, X.; Bruce, W. Croft. 2017. Joint Representation Learning for Top-N Recommendation with Heterogeneous Information Sources. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (CIKM ’17). Association for Computing Machinery, New York, NY, USA, 6–10 November 2017; pp. 1449–1458. [Google Scholar] [CrossRef]
- McAuley, J.; Leskovec, J. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM conference on Recommender systems (RecSys ’13), New York, NY, USA, 12–16 October 2013; pp. 165–172. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personal ized markov chains for next-basket recommendation. In Proceedings of the 19th international conference on World wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next location: A recurrent model with spatial and temporal contexts. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 194–200. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).