

Conformal Segmentation in Industrial Surface Defect Detection with Statistical Guarantees

Abstract
1. Introduction
2. Related Works
2.1. Traditional Machine Vision-Based Defect Detection Methods
2.2. Deep Learning-Based Defect Detection Methods
2.3. Conformal Prediction and Conformal Risk Control
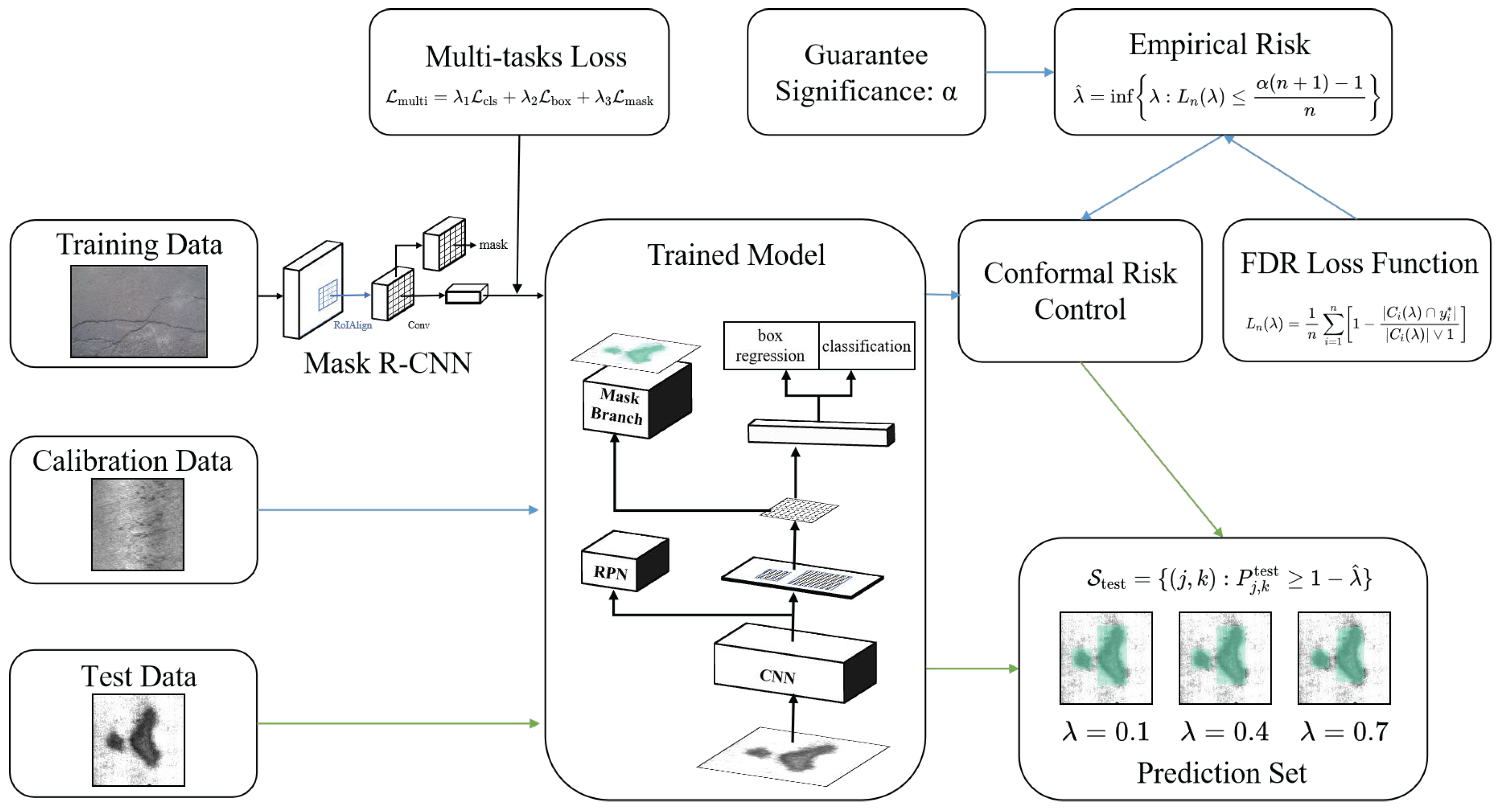
3. Proposed Approach
3.1. Workflow of the Approach
3.2. Mask R-CNN
- Bounding box coordinates ;
- Defect category label , where K denotes the predefined number of classes;
- Binary segmentation mask that precisely localizes defect pixels.
3.3. CP and CRC
3.4. Construction for Prediction Sets
| Algorithm 1 Conformal risk control for image segmentation |
| Require: |
|
| Ensure: |
|
|
|
|
4. Experiments and Results
4.1. Data Sets and Benchmarks
- SIID: Derived from the industrial inspection platform of Severstal, a Russian steel giant, this data set contains 25,894 high-resolution images (2560 × 1600 pixels) covering four typical defect categories in cold-rolled steel production:
- Class 1: Edge cracks (37.2% prevalence);
- Class 2: Inclusions (28.5% prevalence);
- Class 3: Surface scratches (19.8% prevalence);
- Class 4: Rolled-in scale (14.5% prevalence);
This data set exhibits multi-scale defect characteristics under real industrial scenarios, with the smallest defect regions occupying only 0.03% of the image area. Each image contains up to three distinct defect categories, annotated with pixel-wise segmentation masks and multi-label classifications. The data acquisition process simulates complex industrial conditions, including production line vibrations and mist interference. The primary challenge is quantified bywhere denotes the average defect coverage ratio, highlighting the difficulty of small-target detection. - NEU Surface Defect Benchmark: A widely adopted academic standard comprising 1800 gray-scale images (200 × 200 pixels) uniformly covering six hot-rolled steel defect categories:
- Rolled-in scale (RS);
- Patches (Pa);
- Crazing (Cr);
- Pitted surface (PS);
- Inclusion (In);
- Scratches (Sc).
The data set provides dual annotations (bounding boxes and pixel-level masks). Its core challenge arises from the contrast between intra-class variation and inter-class similarity :where denotes a ResNet-50 feature extractor and measures cosine distance. This equation quantifies the degree of dissimilarity between intra-class and inter-class features within the data set. The numerator represents the average feature distance between samples of the same class (intra-class dissimilarity), while the denominator denotes the average feature distance between samples of different classes (inter-class dissimilarity). A ratio exceeding 1 indicates that intra-class variation is greater than inter-class dissimilarity, implying that samples from different classes are challenging to distinguish in the feature space, thereby increasing classification difficulty.
4.2. Implementation Details and Stochasticity
4.2.1. Data
4.2.2. Optimizer and Hyperparameters
4.2.3. Deterministic Validation
4.2.4. Model Initialization and Pretraining
4.3. Backbones for Mask R-CNN
- ResNet-50: A classic residual network comprising 50 layers (49 convolutional layers and 1 fully connected layer). It employs residual blocks with shortcut connections to mitigate gradient vanishing issues and optimizes computational efficiency through bottleneck design [25].
- ResNet-34: A lightweight variant of ResNet with 34 convolutional layers. It stacks BasicBlocks (dual 3 × 3 convolutions) to reduce computational complexity, making it suitable for low-resource scenarios [25].
- SqueezeNet: Utilizes reduced 3 × 3 convolution kernels and “Fire modules” (squeeze + expand layers) to compress parameters to 1.2 M. While achieving lower single-precision performance than standard ResNets, it is ideal for lightweight applications with relaxed accuracy requirements [26].
- ShuffleNetv2_x2: Addresses feature isolation in group convolutions via channel shuffle operations. The 2× width factor version balances a 0.6G FLOPs computational cost with 73.7% accuracy through depthwise separable convolutions and memory access optimization [27].
- MobileNetv3-Large: Combines inverted residual structures, depthwise separable convolutions, and squeeze–excitation (SE) modules for efficient feature extraction. Enhanced by h-swish activation, it achieves 75.2% accuracy [28].
- GhostNetv3: Generates redundant feature maps via cheap linear operations, augmented by reparameterization and knowledge distillation to strengthen feature representation [29].
- Generalization Failure from Data Set Dependency: Models exhibit drastic performance variations across data sets (e.g., ResNet-34 shows a 2.5-fold IoU difference), highlighting the strong dependence of deep learning models on training data distributions. This characteristic necessitates costly parameter/architecture reconfiguration for cross-scenario applications, undermining deployment stability.
- Absence of Universal Model Selection Criteria: Optimal models vary by data set (e.g., ShuffleNetv2_x2 excels on NEU but underperforms on SIID), indicating no “one-size-fits-all” solution for industrial defect detection. Extensive trial-and-error tuning is required for task-specific optimization, increasing implementation complexity.
- Decision Risks from Metric Conflicts: Significant precision–recall imbalances (e.g., MobileNetv3 achieves a 20.76% precision–recall gap on NEU) suggest improper optimization objectives or loss functions, elevating risks of false positives or missed defects. In real-world settings, such conflicts may induce quality control loopholes or unnecessary production line shutdowns.
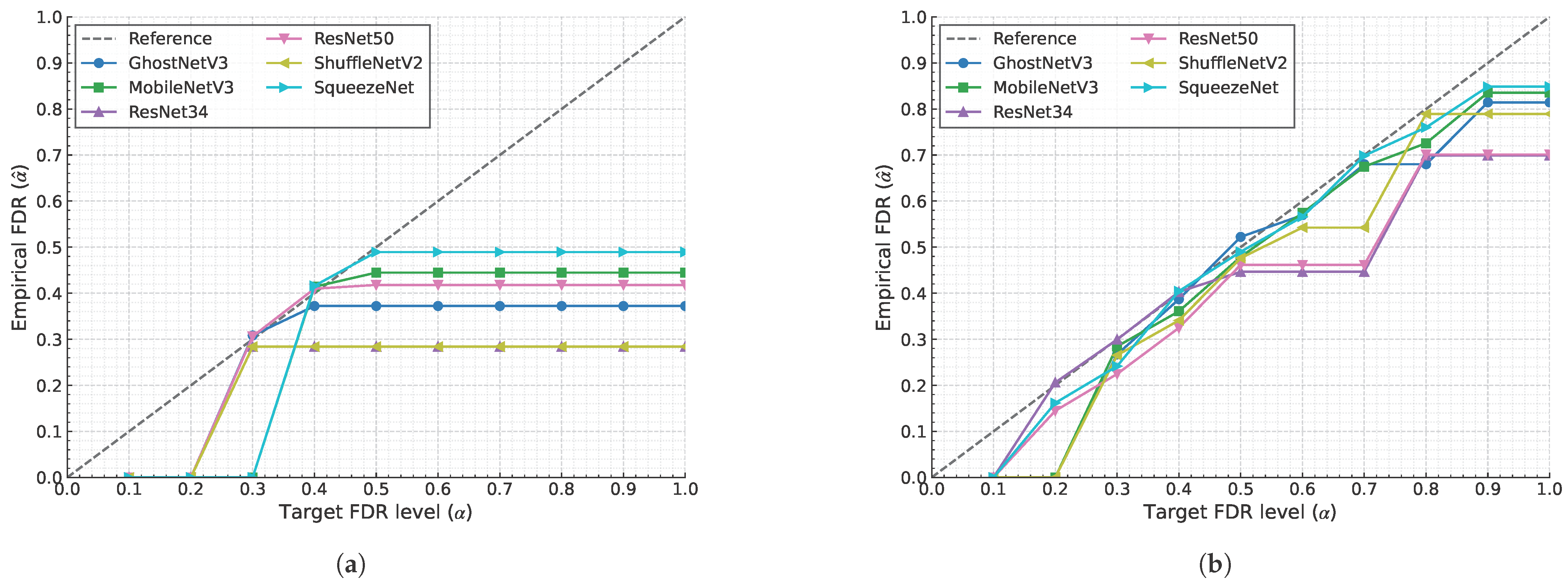
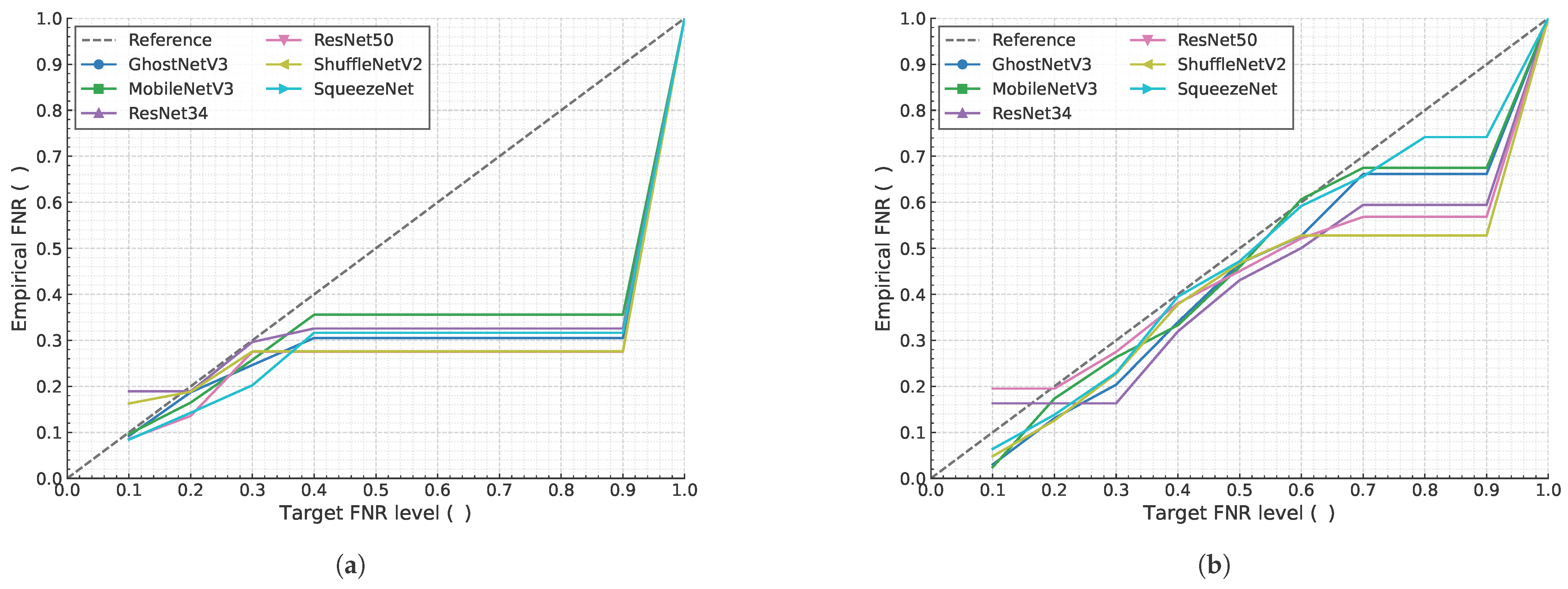
4.4. Guarantees
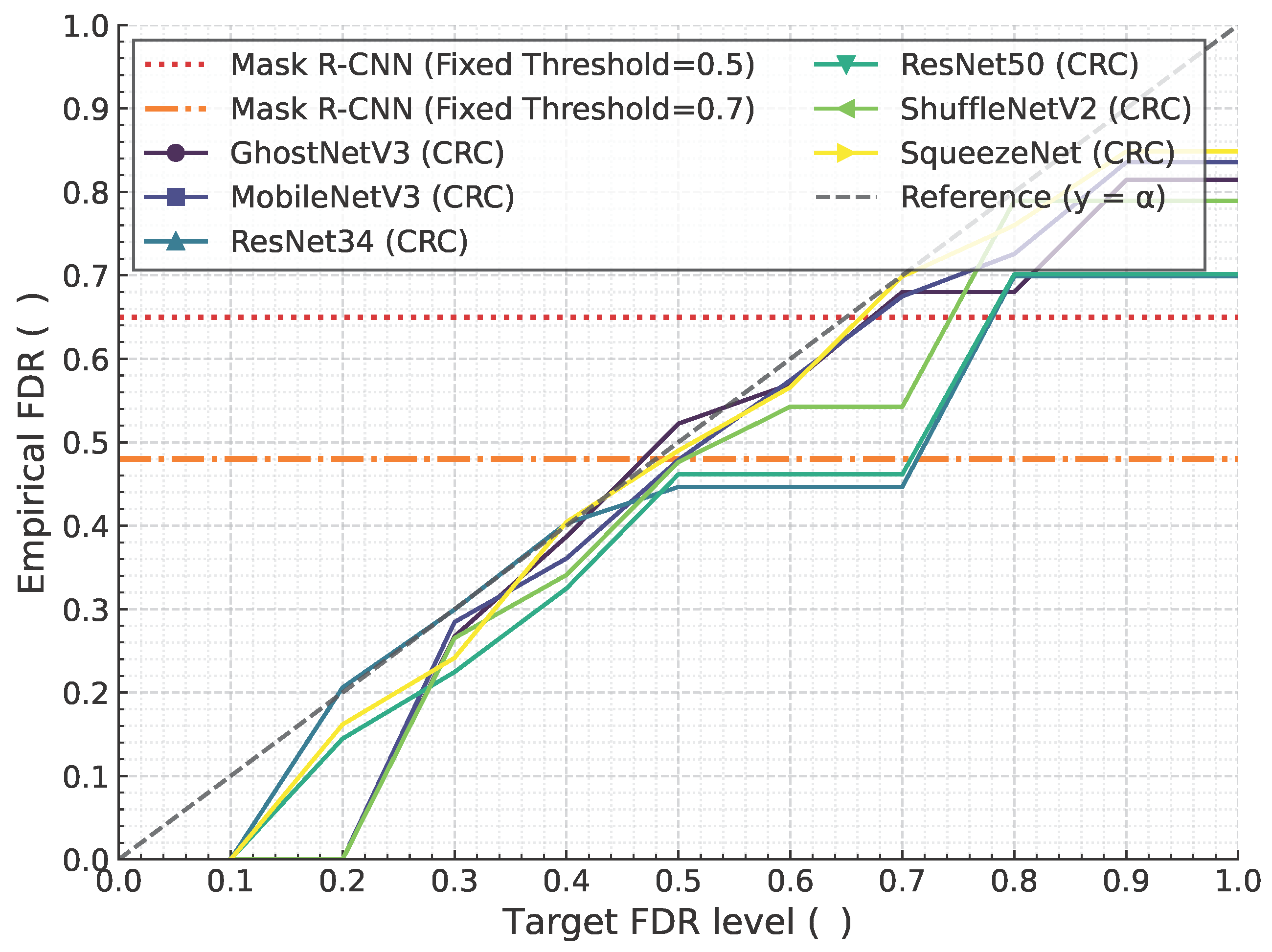
4.5. Comparison with Non-CRC Baseline
- Non-CRC Mask R-CNN: This standard approach uses a single, arbitrarily chosen confidence threshold (e.g., 0.5 or 0.7) to generate predictions. Its error rate (FDR or FNR) is a fixed, static property that cannot be controlled or guaranteed.
- CRC-enhanced Models: Our proposed framework dynamically calculates a statistically valid threshold based on a user-defined risk level ().
4.5.1. Guaranteed Control vs. Inflexible Performance
4.5.2. Practical Value
4.6. Generalization to Alternative Architectures: An Illustrative Comparison
- Seamless Integration: As shown in Panel (B) for both FDR and FNR, a high-performing alternative architecture like U-Net would integrate seamlessly into our CRC framework. It produces its own set of characteristic risk control curves, demonstrating that the methodology is not tied to the specific design of Mask R-CNN. For every backbone, the empirical risk (solid lines) is successfully controlled at or below the target risk level (dashed line), upholding the statistical guarantee.
- Architecture-Specific Performance Signature: The simulated U-Net curves in Panel (B) are intentionally distinct from the Mask R-CNN curves in Panel (A). In this simulation, we modeled U-Net as having slightly tighter risk control (lower empirical error for a given ). This reflects the real-world expectation that different architectures will have unique performance characteristics and prediction confidence profiles. Our CRC framework provides a principled way to quantify and compare these differences under a unified risk-management lens.
- Path for Future Work: This illustrative comparison validates our claim of model-agnosticism and provides a clear path for future research. A comprehensive study would involve fully training a U-Net (or other architectures like DeepLab) on the same data set and applying the CRC framework to empirically generate the curves shown here. This would allow for a rigorous, head-to-head comparison of which architecture-and-backbone combination provides the most favorable trade-off between raw performance and risk-control efficiency for a given industrial task.
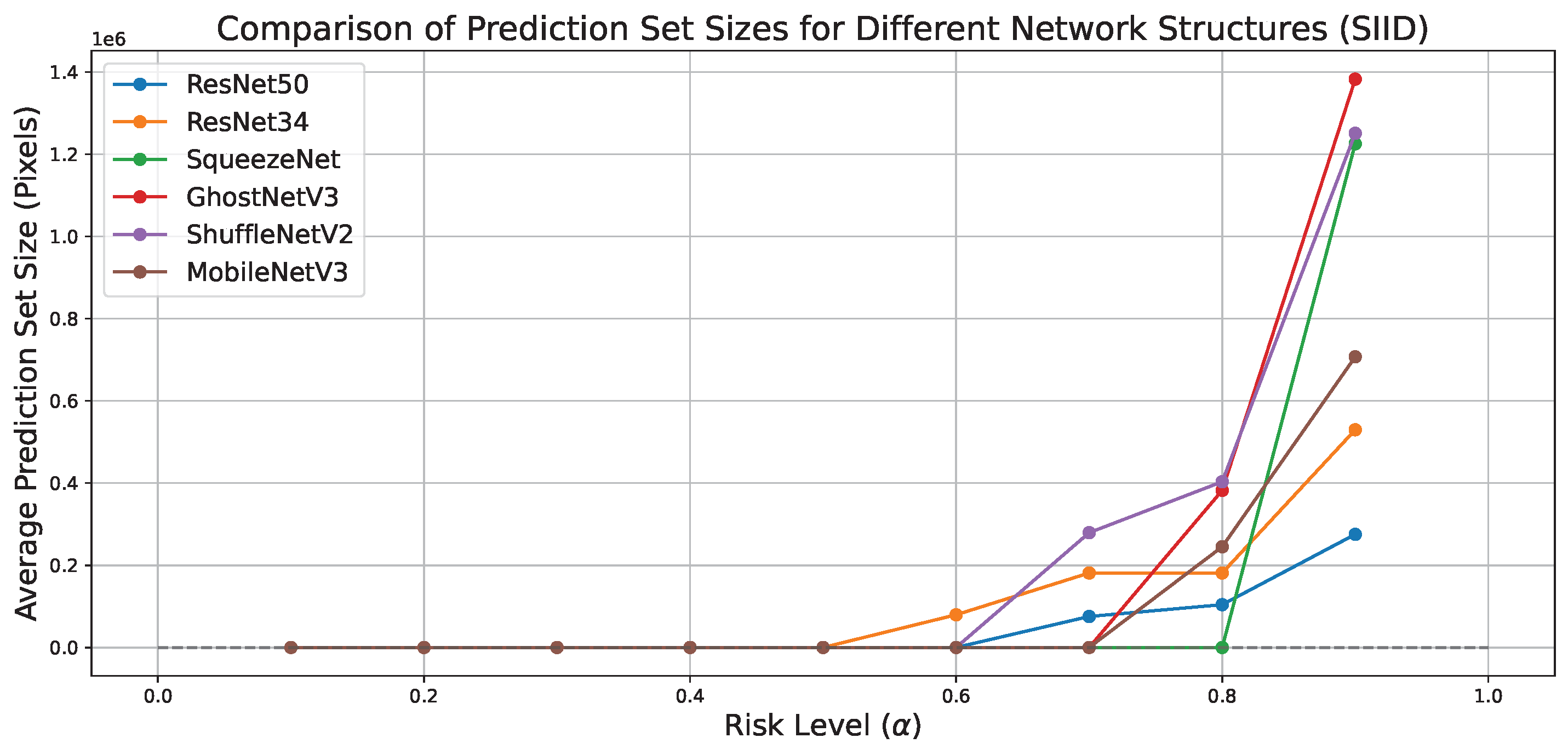
4.7. Correlation Between Risk Levels and Prediction Set Size
4.8. Ablation Study: Impact of Calibration Set Size on FNR Control
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Zhang, X.; Wang, J. Deep learning-based defect detection in steel manufacturing: A review. IEEE Trans. Ind. Informatics 2021, 17, 3061–3072. [Google Scholar]
- Wang, H.; Li, J.; Zhou, F. Deep learning for industrial defect detection: A comprehensive review. Pattern Recognit. 2020, 107, 107254. [Google Scholar]
- Xiao, Y.; Shao, H.; Feng, M.; Han, T.; Wan, J.; Liu, B. Towards trustworthy rotating machinery fault diagnosis via attention uncertainty in transformer. J. Manuf. Syst. 2023, 70, 186–201. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A survey of uncertainty in deep neural networks. Artif. Intell. Rev. 2023, 56 (Suppl. S1), 1513–1589. [Google Scholar] [CrossRef]
- Wang, Z.; Duan, J.; Yuan, C.; Chen, Q.; Chen, T.; Zhang, Y.; Wang, R.; Shi, X.; Xu, K. Word-sequence entropy: Towards uncertainty estimation in free-form medical question answering applications and beyond. Eng. Appl. Artif. Intell. 2025, 139, 109553. [Google Scholar] [CrossRef]
- Liu, K.; Wang, H.; Chen, H.; Qu, E.; Tian, Y.; Sun, H. Steel surface defect detection using a new haar–weibull-variance model in unsupervised manner. IEEE Trans. Instrum. Meas. 2017, 66, 2585–2596. [Google Scholar] [CrossRef]
- Chu, M.; Gong, R. Invariant feature extraction method based on smoothed local binary pattern for strip steel surface defect. ISIJ Int. 2015, 55, 1956–1962. [Google Scholar] [CrossRef]
- Dong, S.; Wang, P.; Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 2021, 40, 100379. [Google Scholar] [CrossRef]
- Song, G.; Song, K.; Yan, Y. Edrnet: Encoder–decoder residual network for salient object detection of strip steel surface defects. IEEE Trans. Instrum. Meas. 2020, 69, 9709–9719. [Google Scholar] [CrossRef]
- Huang, Z.; Wu, J.; Xie, F. Automatic surface defect segmentation for hot-rolled steel strip using depth-wise separable u-shape network. Mater. Lett. 2021, 301, 130271. [Google Scholar] [CrossRef]
- Vovk, V.; Gammerman, A.; Saunders, C. Machine-learning applications of algorithmic randomness. In Proceedings of the ICML ‘99: Proceedings of the Sixteenth International Conference on Machine Learning, San Francisco, CA, USA, 27–30 June 1999. [Google Scholar]
- Angelopoulos, A.N.; Bates, S.; Fisch, A.; Lei, L.; Schuster, T. Conformal risk control. arXiv 2022, arXiv:2208.02814. [Google Scholar]
- Wang, Z.; Duan, J.; Cheng, L.; Zhang, Y.; Wang, Q.; Shi, X.; Xu, K.; Shen, H.T.; Zhu, X. Conu: Conformal uncertainty in large language models with correctness coverage guarantees. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; pp. 6886–6898. [Google Scholar]
- Hulsman, R.; Comte, V.; Bertolini, L.; Wiesenthal, T.; Gallardo, A.P.; Ceresa, M. Conformal risk control for pulmonary nodule detection. arXiv 2024, arXiv:2412.20167. [Google Scholar]
- Wang, Q.; Geng, T.; Wang, Z.; Wang, T.; Fu, B.; Zheng, F. Sample then identify: A general framework for risk control and assessment in multimodal large language models. In Proceedings of the Thirteenth International Conference on Learning Representations, Singapore, 24–28 April 2025. [Google Scholar]
- Wang, Z.; Wang, Q.; Zhang, Y.; Chen, T.; Zhu, X.; Shi, X.; Xu, K. Sconu: Selective conformal uncertainty in large language models. arXiv 2025, arXiv:2504.14154. [Google Scholar]
- Zhan, X.; Wang, Z.; Yang, M.; Luo, Z.; Wang, Y.; Li, G. An electronic nose-based assistive diagnostic prototype for lung cancer detection with conformal prediction. Measurement 2020, 158, 107588. [Google Scholar] [CrossRef]
- Arya Saboury and Mustafa Kemal Uyguroglu. Uncertainty-aware real-time visual anomaly detection with conformal prediction in dynamic indoor environments. IEEE Robot. Autom. Lett. 2025, 10, 4468–4475. [Google Scholar] [CrossRef]
- Mossina, L.; Dalmau, J.; Andéol, L. Conformal semantic image segmentation: Post-hoc quantification of predictive uncertainty. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 3574–3584. [Google Scholar]
- Andéol, L.; Fel, T.; Grancey, F.D.; Mossina, L. Confident object detection via conformal prediction and conformal risk control: An application to railway signaling. In Proceedings of the Conformal and Probabilistic Prediction with Applications, PMLR, Limassol, Cyprus, 13–15 September 2023; pp. 36–55. [Google Scholar]
- Dai, M.; Luo, W.; Li, T. Statistical guarantees of false discovery rate in medical instance segmentation tasks based on conformal risk control. arXiv 2025, arXiv:2504.04482. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Alexey Grishin and BorisV and iBardintsev and inversion and Oleg. Severstal: Steel Defect Detection. Kaggle. 2019. Available online: https://www.kaggle.com/competitions/severstal-steel-defect-detection (accessed on 15 October 2024).
- Song, K.; Yan, Y. NEU Surface Defect Database; Northeastern University: Boston, MA, USA, 2013. Available online: http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list/index.htm (accessed on 18 October 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; J Dally, W.; Keutzer, K. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and< 0.5 mb model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, asudevan, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Liu, Z.; Hao, Z.; Han, K.; Tang, Y.; Wang, Y. Ghostnetv3: Exploring the training strategies for compact models. arXiv 2024, arXiv:2404.11202. [Google Scholar]
- Barber, R.F.; Candes, E.J.; Ramdas, A.; Tibshirani, R.J. Conformal prediction beyond exchangeability. Ann. Stat. 2023, 51, 816–845. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value | Description |
|---|---|---|
| Optimizer | SGD | Stochastic Gradient Descent |
| Initial Learning Rate | 0.002 | The starting learning rate |
| Momentum | 0.9 | The momentum factor for SGD |
| Weight Decay | 1 × 10−4 | L2 penalty (regularization) term |
| Batch Size | 48 | Number of images per iteration |
| Number of Epochs | 300 | Total training passes |
| LR Milestones | [200, 250] | Epochs for learning rate decay |
| LR Gamma | 0.1 | Multiplicative factor for decay |
| Backbone | SIID | NEU-DET | ||||
|---|---|---|---|---|---|---|
| IoU | Precision | Recall | IoU | Precision | Recall | |
| ResNet-50 | 0.1963 | 0.3478 | 0.2500 | 0.3570 | 0.5997 | 0.4504 |
| ResNet-34 | 0.1713 | 0.3845 | 0.2086 | 0.4328 | 0.7266 | 0.5036 |
| SqueezeNet | 0.0602 | 0.2422 | 0.1330 | 0.2512 | 0.5491 | 0.3573 |
| MobileNetv3 | 0.0814 | 0.2113 | 0.1113 | 0.2827 | 0.5833 | 0.3757 |
| ShuffleNetv2_x2 | 0.1354 | 0.3382 | 0.1708 | 0.5540 | 0.7522 | 0.6418 |
| GhostNetv3 | 0.0981 | 0.2422 | 0.1330 | 0.3836 | 0.6397 | 0.4775 |
| Target | Empirical FNR | Optimal (Split = 0.3/0.5/0.7) | |||
|---|---|---|---|---|---|
| Split = 0.3 | Split = 0.5 | Split = 0.7 | Values | Control Status | |
| 0.1 | 0.1039 | 0.0910 | 0.0890 | 0.572 / 0.538 / 0.544 | × / ✓ / ✓ |
| 0.2 | 0.1996 | 0.1826 | 0.1833 | 0.811 / 0.798 / 0.804 | ✓ / ✓ / ✓ |
| 0.3 | 0.2947 | 0.2796 | 0.2792 | 0.909 / 0.904 / 0.907 | ✓ / ✓ / ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, C.; Liu, Y. Conformal Segmentation in Industrial Surface Defect Detection with Statistical Guarantees. Mathematics 2025, 13, 2430. https://doi.org/10.3390/math13152430
Shen C, Liu Y. Conformal Segmentation in Industrial Surface Defect Detection with Statistical Guarantees. Mathematics. 2025; 13(15):2430. https://doi.org/10.3390/math13152430
Chicago/Turabian StyleShen, Cheng, and Yuewei Liu. 2025. "Conformal Segmentation in Industrial Surface Defect Detection with Statistical Guarantees" Mathematics 13, no. 15: 2430. https://doi.org/10.3390/math13152430
APA StyleShen, C., & Liu, Y. (2025). Conformal Segmentation in Industrial Surface Defect Detection with Statistical Guarantees. Mathematics, 13(15), 2430. https://doi.org/10.3390/math13152430