
A Survey of Loss Functions in Deep Learning



Abstract
1. Introduction
- This proposed paper reclassifies and summarizes the loss function of DL and incorporates metric loss into the division of loss functions.
- This proposed paper makes a more fine-grained division of regression, classification, and metric loss.
- This proposed paper looks forward to new trends of loss function, including compound loss and generative loss.
2. Motivation, Materials, and Methodology
3. Regression Loss
3.1. Quantity Difference Loss
3.1.1. Mean Bias Error Loss (MBE)
3.1.2. Mean Absolute Error Loss (MAE)
3.1.3. Mean Squared Error Loss (MSE)
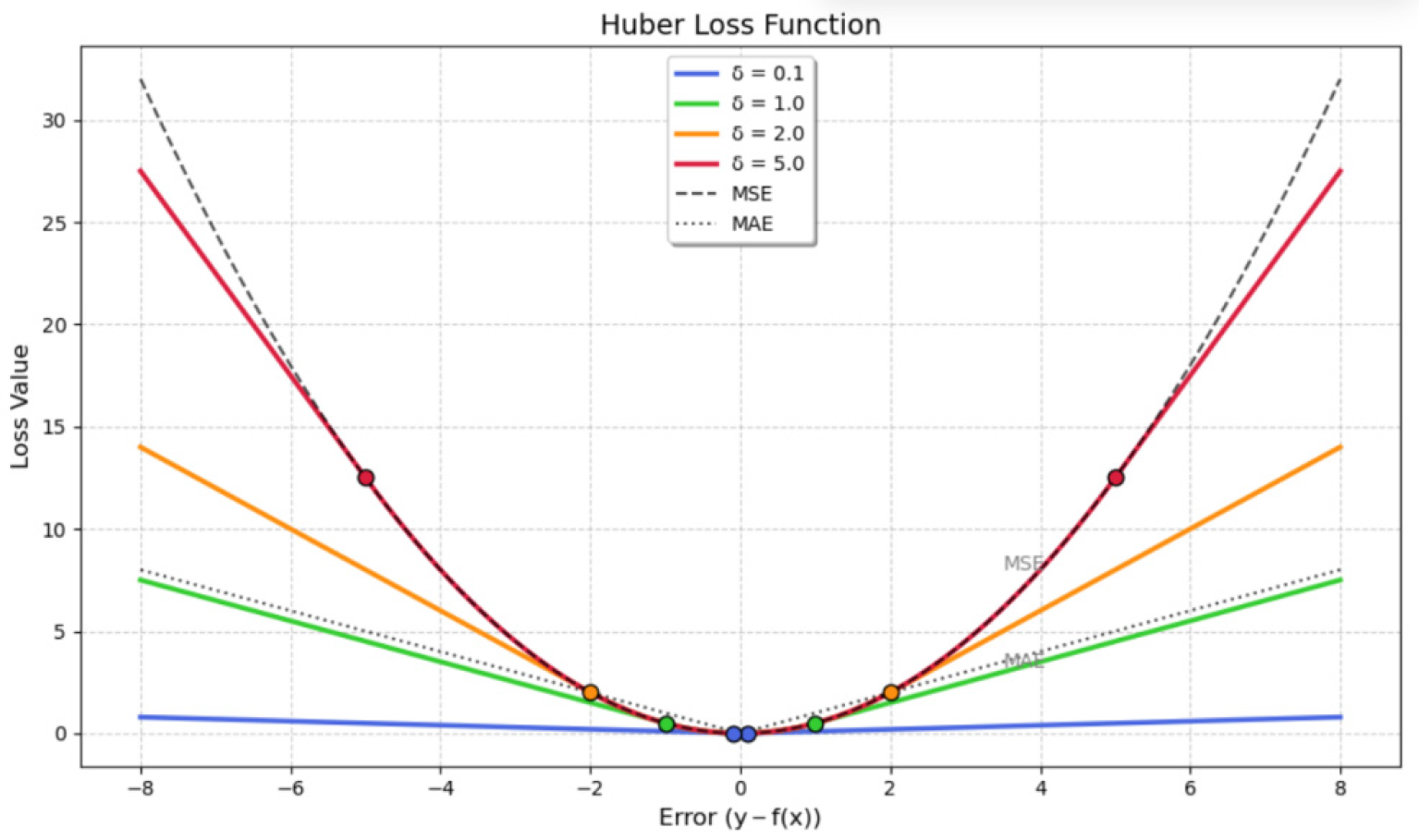
3.1.4. Huber Loss
3.1.5. Smooth L1 Loss
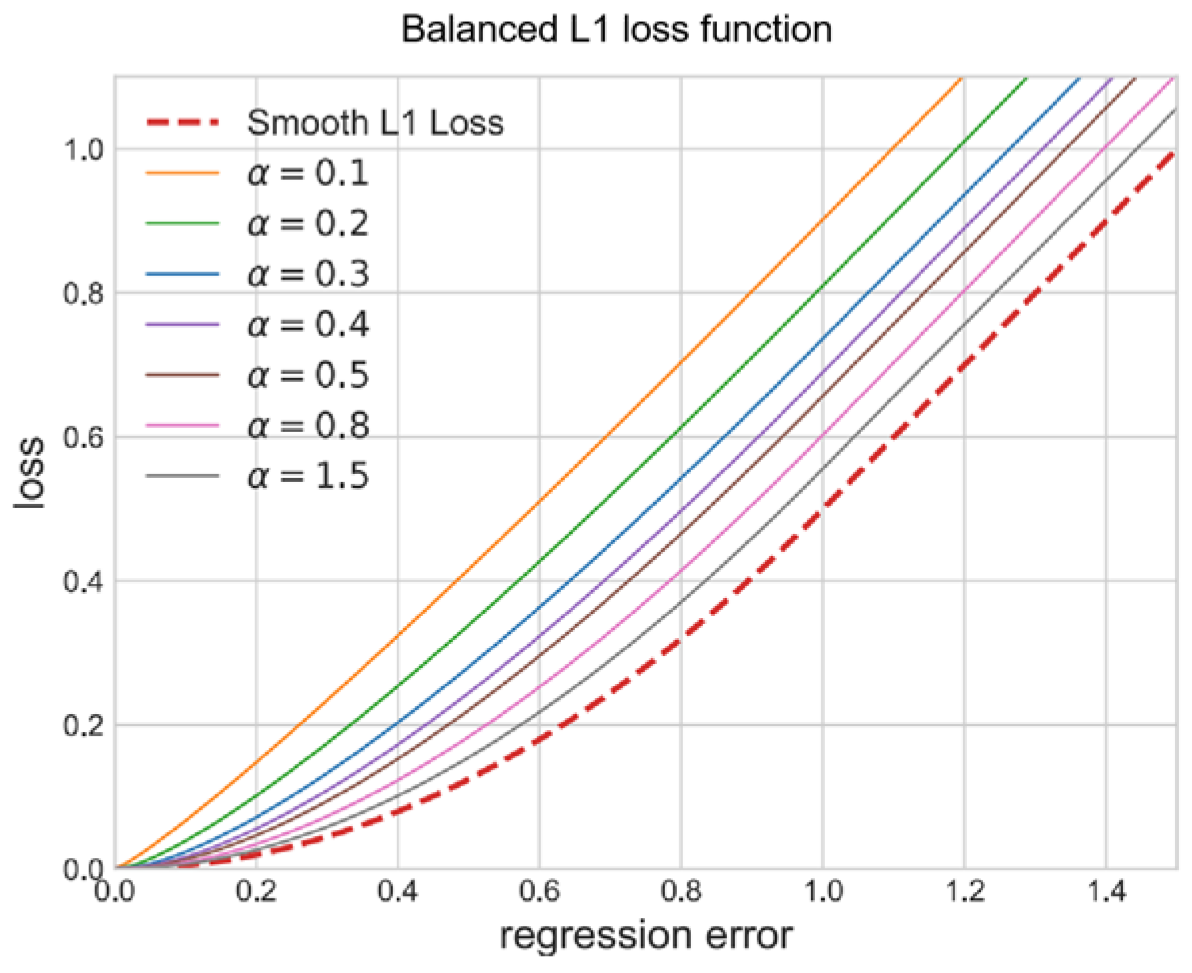
3.1.6. Balanced L1 Loss
3.1.7. Root Mean Squared Error Loss (RMSE)
3.1.8. Root Mean Squared Logarithmic Error Loss (RMSLE)
3.1.9. Log-Cosh Loss
3.1.10. Quantile Loss
3.2. Geometric Difference Loss
3.2.1. Intersection over Union Loss
3.2.2. Generalized IoU (GIoU) Loss
3.2.3. Distance IoU (DIoU) Loss and Complete IoU (CIoU) Loss
3.2.4. Efficient IoU (EIoU) Loss
3.2.5. SIoU Loss
3.2.6. Minimum Point Distance (MPD) IoU Loss
3.2.7. Pixel-IoU (PIoU) Loss
3.2.8. Alpha-IoU Loss
3.2.9. Inner-IoU Loss
4. Classification Loss
4.1. Margin Loss
4.1.1. Zero-One Loss
4.1.2. Hinge Loss
4.1.3. Smoothed Hinge Loss
4.1.4. Quadratic Smoothed Hinge Loss
4.1.5. Modified Huber Loss
4.1.6. Exponential Loss
4.2. Probability Loss
4.2.1. Binary Cross-Entropy Loss (BCE)
4.2.2. Categorical Cross-Entropy Loss (CCE)
4.2.3. Sparse Categorical Cross-Entropy Loss
4.2.4. Weighted Cross-Entropy Loss (WCE)
4.2.5. Balanced Cross-Entropy Loss (BaCE)
4.2.6. Label Smoothing Cross-Entropy Loss (Label Smoothing CE Loss)
4.2.7. Focal Loss
4.2.8. Gradient Harmonizing Mechanism (GHM) Loss
4.2.9. Class-Balanced Loss
4.2.10. Dice Loss
4.2.11. Log-Cosh Dice Loss
4.2.12. Generalized Dice Loss
4.2.13. Tversky Loss
4.2.14. Focal Tversky Loss
4.2.15. Sensitivity Specificity Loss
4.2.16. Poly Loss
4.2.17. Kullback–Leibler Divergence Loss
5. Metric Loss
5.1. Euclidean Distance Loss
5.1.1. Contrastive Loss
5.1.2. Triplet Loss
5.1.3. Center Loss
5.1.4. Range Loss and Center-Invariant Loss
5.2. Angular Margin Loss
5.2.1. Large-Margin Softmax (L-Softmax)
5.2.2. Angular Softmax (A-Softmax)
5.2.3. Additive Margin Softmax (AM-Softmax/CosFace)
5.2.4. Additive Angular Margin Loss (AcrFace)
5.2.5. Sub-Center Additive Angular Margin Loss (Sub-Center ArcFace)
5.2.6. Mis-Classified Vector Guided Softmax Loss (MV-Softmax)
5.2.7. Adaptive Curriculum Learning Loss (CurricularFace)
5.2.8. Quality Adaptive Margin Softmax Loss (AdaFace)
5.2.9. Sigmoid-Constrained Hypersphere Loss (SFace)
6. Conclusions and Prospects
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DL | Deep learning |
| GT | Ground truth |
| MAE | Mean absolute error loss |
| MBE | Mean bias error loss |
| MSE | Mean squared error loss |
| RMSE | Linear dichroism |
| RMSLE | Root mean squared logarithmic error loss |
| IoU | Intersection over Union |
| L-Softmax | Large-margin softmax |
| A-softmax | Angular softmax |
| AM-Softmax | Additive margin softmax |
| CosFace | Additive margin softmax |
| AcrFace | Additive angular margin loss |
| Sub-center ArcFace | Sub-center additive angular margin loss |
| MV-Softmax | Mis-classified vector guided softmax loss |
| CurricularFace | Adaptive curriculum learning loss |
| AdaFace | Quality adaptive margin softmax loss |
| SFace | Sigmoid-constrained hypersphere loss |
References
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Li, N.; Ma, L.; Yu, G.; Xue, B.; Zhang, M.; Jin, Y. Survey on Evolutionary Deep Learning: Principles, Algorithms, Applications and Open Issues. ACM Comput. Surv. 2024, 56, 1–34. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention Mechanisms in Computer Vision: A Survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Dessi, D.; Osborne, F.; Reforgiato Recupero, D.; Buscaldi, D.; Motta, E. SCICERO: A Deep Learning and NLP Approach for Generating Scientific Knowledge Graphs in the Computer Science Domain. Knowl. Based Syst. 2022, 258, 109945. [Google Scholar] [CrossRef]
- Ni, J.; Young, T.; Pandelea, V.; Xue, F.; Cambria, E. Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey. Artif. Intell. Rev. 2022, 56, 3055–3155. [Google Scholar] [CrossRef]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A Comprehensive Survey of Loss Functions in Machine Learning. Ann. Data Sci. 2020, 9, 187–212. [Google Scholar] [CrossRef]
- Jadon, A.; Patil, A.; Jadon, S. A comprehensive survey of regression-based loss functions for time series forecasting. In Proceedings of the International Conference on Data Management, Analytics & Innovation, Vellore, India, 19–21 January 2024; Springer Nature: Singapore, 2024; pp. 117–147. [Google Scholar]
- Ciampiconi, L.; Elwood, A.; Leonardi, M.; Mohamed, A.; Rozza, A. A survey and taxonomy of loss functions in machine learning. arXiv 2023, arXiv:2301.05579. [Google Scholar]
- El Jurdi, R.; Petitjean, C.; Honeine, P.; Cheplygina, V.; Abdallah, F. High-level prior-based loss functions for medical image segmentation: A survey. Comput. Vis. Image Und. 2021, 210, 103248. [Google Scholar] [CrossRef]
- Tian, Y.; Su, D.; Lauria, S.; Liu, X. Recent advances on loss functions in deep learning for computer vision. Neurocomputing 2022, 497, 129–158. [Google Scholar] [CrossRef]
- Hu, S.; Wang, X.; Lyu, S. Rank-based decomposable losses in machine learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13599–13620. [Google Scholar] [CrossRef]
- Berahmand, K.; Daneshfar, F.; Salehi, E.S.; Li, Y.; Xu, Y. Autoencoders and their applications in machine learning: A survey. Artif. Intell. Rev. 2024, 57, 28. [Google Scholar] [CrossRef]
- Haoyue, B.; Mao, J.; Chan, S.-H.G. A survey on deep learning-based single image crowd counting: Network design, loss function and supervisory signal. Neurocomputing 2022, 508, 1–18. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D.-M.; Romero-González, J.-A.; Ramírez-Pedraza, A.; Chávez-Urbiola, E.A. A comprehensive survey of loss functions and metrics in deep learning. Artif. Intell. Rev. 2025, 58, 195. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Rubinstein, R.Y. Optimization of computer simulation models with rare events. Eur. J. Oper. Res. 1997, 99, 89–112. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, X.; Tang, X. Deeply learned face representations are sparse, selective, and robust. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2892–2900. [Google Scholar]
- Sepideh, E.; Khashei, M. Survey of the Loss Function in Classification Models: Comparative Study in Healthcare and Medicine. Multimed. Tools Appl. 2025, 84, 12765–12812. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, T.; Liu, J.; Wang, L.; Zhao, S. A Novel Soft Margin Loss Function for Deep Discriminative Embedding Learning. IEEE Access 2020, 8, 202785–202794. [Google Scholar] [CrossRef]
- Liu, H.; Shi, W.; Huang, W.; Guan, Q. A discriminatively learned feature embedding based on multi-loss fusion for person search. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1668–1672. [Google Scholar]
- Ben, D.; Shen, X.; Wang, J. Embedding learning. J. Am. Stat. Assoc. 2022, 117, 307–319. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-Margin Softmax Loss for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 507–516. [Google Scholar]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Viña del Mar, Chile, 27–29 October 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zhang, X.; Fang, Z.; Wen, Y.; Li, Z.; Qiao, Y. Range loss for deep face recognition with long-tailed training data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A comprehensive study on center loss for deep face recognition. Int. J. Comput. Vis. 2019, 127, 668–683. [Google Scholar] [CrossRef]
- Fernandez-Delgado, M.; Sirsat, M.S.; Cernadas, E.; Alawadi, S.; Barro, S.; Febrero-Bande, M. An Extensive Experimental Survey of Regression Methods. Neural Netw. 2019, 111, 11–34. [Google Scholar] [CrossRef] [PubMed]
- Dey, D.; Haque, M.S.; Islam, M.M.; Aishi, U.I.; Shammy, S.S.; Mayen, M.S.A.; Noor, S.T.A.; Uddin, M.J. The proper application of logistic regression model in complex survey data: A systematic review. BMC Med. Res. Methodol. 2025, 25, 15. [Google Scholar] [CrossRef] [PubMed]
- Huber, P.J. Robust estimation of a location parameter. In Breakthroughs in Statistics: Methodology and Distribution; Springer: New York, NY, USA, 1992; pp. 492–518. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Hodson, T.O. Root mean square error (RMSE) or mean absolute error (MAE): When to use them or not. Geosci. Model Dev. Discuss. 2022, 1–10. [Google Scholar] [CrossRef]
- Saleh, R.A.; Saleh, A.K. Statistical properties of the log-cosh loss function used in machine learning. arXiv 2022, arXiv:2208.04564. [Google Scholar]
- Chen, X.; Liu, W.; Mao, X.; Yang, Z. Distributed high-dimensional regression under a quantile loss function. J. Mach. Learn. Res. 2020, 21, 1–43. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 12–14 December 2016; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Qian, X.; Zhang, N.; Wang, W. Smooth giou loss for oriented object detection in remote sensing images. Remote Sens. 2023, 15, 1259. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; p. 34. [Google Scholar]
- He, Y.; Zhu, C.; Wang, J.; Savvides, M.; Zhang, X. Bounding box regression with uncertainty for accurate object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Ma, S.; Xu, Y. Mpdiou: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Chen, Z.; Chen, K.; Lin, W.; See, J.; Yu, H.; Ke, Y.; Yang, C. Piou loss: Towards accurate oriented object detection in complex environments. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part V 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 195–211. [Google Scholar]
- He, J.; Erfani, S.M.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.-S. α-IoU: A family of power intersection over union losses for bounding box regression. Adv. Neural Inf. Process. Syst. 2021, 34, 20230–20242. [Google Scholar]
- Zhang, H.; Xu, C.; Zhang, S. Inner-iou: More effective intersection over union loss with auxiliary bounding box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Zhang, G.P. Neural networks for classification: A survey. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2000, 30, 451–462. [Google Scholar] [CrossRef]
- Klepl, D.; Wu, M.; He, F. Graph neural network-based eeg classification: A survey. IEEE Trans. Neural Syst. Rehabil. Eng. 2024, 32, 493–503. [Google Scholar] [CrossRef]
- Kumar, V.; Singh, R.S.; Rambabu, M.; Dua, Y. Deep learning for hyperspectral image classification: A survey. Comput. Sci. Rev. 2024, 53, 100658. [Google Scholar] [CrossRef]
- Lin, Y. A note on margin-based loss functions in classification. Stat. Probab. Lett. 2004, 68, 73–82. [Google Scholar] [CrossRef]
- Levi, E.; Xiao, T.; Wang, X.; Darrell, T. Rethinking preventing class-collapsing in metric learning with margin-based losses. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10316–10325. [Google Scholar]
- Taslimitehrani, V.; Dong, G.; Pereira, N.L.; Panahiazar, M.; Pathak, J. Developing EHR-driven heart failure risk prediction models using CPXR (Log) with the probabilistic loss function. J. Biomed. Inform. 2016, 60, 260–269. [Google Scholar] [CrossRef]
- Lim, K.S.; Reidenbach, A.G.; Hua, B.K.; Mason, J.W.; Gerry, C.J.; Clemons, P.A.; Coley, C.W. Machine learning on DNA-encoded library count data using an uncertainty-aware probabilistic loss function. J. Chem. Inf. Model. 2022, 62, 2316–2331. [Google Scholar] [CrossRef] [PubMed]
- Buser, B. A training algorithm for optimal margin classifier. In Proceedings of the 5th Annual ACM Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Rennie, J.D.M. Smooth Hinge Classification; Massachusetts Institute of Technology: Cambridge, MA, USA, 2005. [Google Scholar]
- Zhang, T. Solving large scale linear prediction problems using stochastic gradient descent algorithms. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 116. [Google Scholar]
- Wyner, A.J. On boosting and the exponential loss. In Proceedings of the International Workshop on Artificial Intelligence and Statistics, PMLR, Key West, FL, USA, 3–6 January 2003; pp. 323–329. [Google Scholar]
- Rubinstein, R.Y. Combinatorial optimization, cross-entropy, ants and rare events. Stoch. Optim. Algorithms Appl. 2001, 303–363. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. Int. J. Comput. Vis. 2017, 125, 3–18. [Google Scholar] [CrossRef]
- Farhadpour, S.; Warner, T.A.; Maxwell, A.E. Selecting and Interpreting Multiclass Loss and Accuracy Assessment Metrics for Classifications with Class Imbalance: Guidance and Best Practices. Remote Sens. 2024, 16, 533. [Google Scholar] [CrossRef]
- Hosseini, S.M.; Baghshah, M.S. Dilated balanced cross entropy loss for medical image segmentation. Comput. Res. Repos. 2024, arXiv:2412.06045. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G.E. When does label smoothing help? Adv. Neural Inf. Process. Syst. 2019, 32, 4694–4703. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Li, B.; Liu, Y.; Wang, X. Gradient harmonized single-stage detector. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; p. 33. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.-Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Zhao, R.; Qian, B.; Zhang, X.; Li, Y.; Wei, R.; Liu, Y.; Pan, Y. Rethinking dice loss for medical image segmentation. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 851–860. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Proceedings of Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, 14 September 2017; Proceedings 3; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 240–248. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Quebec City, QC, Canada, 10 September 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 379–387. [Google Scholar]
- Abraham, N.; Khan, N.M. A novel focal tversky loss function with improved attention u-net for lesion segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 683–687. [Google Scholar]
- Brosch, T.; Tang, L.Y.W.; Yoo, Y.; Li, D.K.B.; Traboulsee, A.; Tam, R.C. Deep 3D convolutional encoder networks with shortcuts for multiscale feature integration applied to multiple sclerosis lesion segmentation. IEEE Trans. Med. Imaging 2016, 35, 1229–1239. [Google Scholar] [CrossRef] [PubMed]
- Leng, Z.; Tan, M.; Liu, C.; Cubuk, E.D.; Shi, J.; Cheng, S.; Anguelov, D. PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning High-Precision Bounding Box for Rotated Object Detection Via Kullback-Leibler Divergence. In Proceedings of the Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34, pp. 18381–18394. [Google Scholar]
- Kanishima, Y.; Sudo, T.; Yanagihashi, H. Autoencoder with adaptive loss function for supervised anomaly detection. Procedia Comput. Sci. 2022, 207, 563–572. [Google Scholar] [CrossRef]
- Xing, E.P.; Ng, A.Y.; Jordan, M.I.; Russell, S.J. Distance metric learning with application to clustering with side-information. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–14 December 2002; p. 15. [Google Scholar]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep learning face representation by joint identification-verification. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; p. 27. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Sparsifying neural network connections for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. DeepID3: Face Recognition with Very Deep Neural Networks. Comput. Res. Repos. 2015, arXiv:1502.00873. [Google Scholar]
- Florian, S.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Parkhi, O.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the BMVC 2015-British Machine Vision Conference 2015, Swansea, UK, 7–10 September 2015; British Machine Vision Association: Durham, UK, 2015. [Google Scholar]
- Sankaranarayanan, S.; Alavi, A.; Castillo, C.D.; Chellappa, R. Triplet Probabilistic Embedding for Face Verification and Clustering. In Proceedings of the 2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS) Niagara Falls, Buffalo, NY, USA, 6–9 September 2016; pp. 1–8. [Google Scholar]
- Wu, Y.; Liu, H.; Li, J.; Fu, Y. Deep Face Recognition with Center Invariant Loss. In Proceedings of the ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 408–414. [Google Scholar]
- Liu, W.; Zhang, Y.-M.; Li, X.; Yu, Z.; Dai, B.; Zhao, T.; Song, L. Deep hyperspherical learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 4–9. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive Margin Softmax for Face Verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Yang, J.; Xue, N.; Kotsia, I.; Zafeiriou, S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4685–4694. [Google Scholar]
- Deng, J.; Guo, J.; Liu, T.; Gong, M.; Zafeiriou, S. Sub-center arcface: Boosting face recognition by large-scale noisy web faces. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 741–757. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, S.; Wang, S.; Fu, T.; Shi, H.; Mei, T. Mis-classified vector guided softmax loss for face recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; p. 34. [Google Scholar]
- Huang, Y.; Wang, Y.; Tai, Y.; Liu, X.; Shen, P.; Li, S.; Li, J.; Huang, F. Curricularface: Adaptive curriculum learning loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5901–5910. [Google Scholar] [CrossRef]
- Kim, M.; Jain, A.K.; Liu, X. AdaFace: Quality Adaptive Margin for Face Recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zhong, Y.; Deng, W.; Hu, J.; Zhao, D.; Li, X.; Wen, D. SFace: Sigmoid-Constrained Hypersphere Loss for Robust Face Recognition. IEEE Trans. Image Process. 2021, 30, 2587–2598. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.-Y.; Li, M.; Manchanda, M.; Batra, R.; Charizanis, K.; Mohan, A.; Warren, S.A.; Chamberlain, C.M.; Finn, D.; Hong, H.; et al. Compound loss of muscleblind-like function in myotonic dystrophy. EMBO Mol. Med. 2013, 5, 1887–1900. [Google Scholar] [CrossRef]
- Zhou, J.; Luo, X.; Rong, W.; Xu, H. Cloud removal for optical remote sensing imagery using distortion coding network combined with compound loss functions. Remote Sens. 2022, 14, 3452. [Google Scholar] [CrossRef]
- Ma, X.; Yao, G.; Zhang, F.; Wu, D. 3-D Seismic Fault Detection Using Recurrent Convolutional Neural Networks with Compound Loss. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Asgari Taghanaki, S.; Zheng, Y.; Zhou, S.K.; Georgescu, B.; Sharma, P.; Xu, D.; Comaniciu, D.; Hamarneh, G. Combo loss: Handling input and output imbalance in multi-organ segmentation. Comput. Med. Imaging Graph. 2019, 75, 24–33. [Google Scholar] [CrossRef]
- Wong, K.C.L.; Moradi, M.; Tang, H.; Syeda-Mahmood, T. 3D segmentation with exponential logarithmic loss for highly unbalanced object sizes. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2018, Proceedings of the 21st International Conference, Granada, Spain, 16–20 September 2018; Proceedings, Part III 11; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Frogner, C.; Zhang, C.; Mobahi, H.; Araya-Polo, M.; Poggio, T. Learning with a Wasserstein loss. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 11–12 December 2015; p. 28. [Google Scholar]
- Rad, M.S.; Bozorgtabar, B.; Marti, U.-V.; Basler, M.; Ekenel, H.K.; Thiran, J.-P. Srobb: Targeted perceptual loss for single image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Sun, Z.; Shen, F.; Huang, D.; Wang, Q.; Shu, X.; Yao, Y.; Tang, J. Pnp: Robust learning from noisy labels by probabilistic noise prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Neha, F.; Bhati, D.; Shukla, D.K.; Guercio, A.; Ward, B. Exploring AI text generation, retrieval-augmented generation, and detection technologies: A comprehensive overview. In Proceedings of the 2025 IEEE 15th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2025; IEEE: Piscataway, NJ, USA, 2025. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Galiana, L.I.; Gudino, L.C.; González, P.M. Ethics and artificial intelligence. Rev. Clínica Española (Engl. Ed.) 2024, 224, 178–186. [Google Scholar] [CrossRef]
- European Union. Artificial Intelligence Act (Regulation EU 2024/1689). Official Journal of the European Union L 1689. 2024. Available online: https://eur-lex.europa.eu/eli/reg/2024/1689 (accessed on 18 July 2025).
- Cyberspace Administration of China. Interim Measures for the Management of Generative Artificial Intelligence Services (Order No. 15). 2023. Available online: http://www.cac.gov.cn (accessed on 18 July 2025).
- Neha, F.; Bhati, D.; Shukla, D.K.; Dalvi, S.M.; Mantzou, N.; Shubbar, S. U-net in medical image segmentation: A review of its applications across modalities. arXiv 2024, arXiv:2412.02242. [Google Scholar]
- Bhati, D.; Neha, F.; Amiruzzaman, M. A survey on explainable artificial intelligence (xai) techniques for visualizing deep learning models in medical imaging. J. Imaging 2024, 10, 239. [Google Scholar] [CrossRef]










































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Inclusion Criteria | Exclusion Criteria |
|---|---|---|
| preliminary screening | -it is a survey -survey topic is loss function | -not a survey -survey topic is others |
| secondary screening | -focus on loss function in deep learning rather than a single field | -only for loss functions in a single field, such as image segmentation |
| Database | Paper Volume of After Initial Search | Paper Volume of Surveys | Paper Volume After Preliminary Screening | Paper Volume After Secondary Screening |
|---|---|---|---|---|
| Web of Science | 528 | 138 | 12 | 6 |
| ACM Digital Library | 12,477 | 533 | 2 | 0 |
| ScienceDirect | 335 | 72 | 3 | 0 |
| Key Word | Paper Volume of After Initial Search | Paper Volume After Preliminary Screening | Paper Volume After Secondary Screening |
|---|---|---|---|
| TS = (“Loss Function” AND “IoU” AND “Bounding Box Regression”) | 86 | 33 | 8 |
| TS = (“Center Loss” AND “Improvement”) | 26 | 8 | 2 |
| TS = (“Loss Function” AND “Softmax” AND “Face recognition”) | 70 | 21 | 9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Liu, K.; Liu, S. A Survey of Loss Functions in Deep Learning. Mathematics 2025, 13, 2417. https://doi.org/10.3390/math13152417
Li C, Liu K, Liu S. A Survey of Loss Functions in Deep Learning. Mathematics. 2025; 13(15):2417. https://doi.org/10.3390/math13152417
Chicago/Turabian StyleLi, Caiyi, Kaishuai Liu, and Shuai Liu. 2025. "A Survey of Loss Functions in Deep Learning" Mathematics 13, no. 15: 2417. https://doi.org/10.3390/math13152417
APA StyleLi, C., Liu, K., & Liu, S. (2025). A Survey of Loss Functions in Deep Learning. Mathematics, 13(15), 2417. https://doi.org/10.3390/math13152417