1. Introduction
Count data with an excessive number of zeros are widespread in fields such as ecology, health economics, transportation, criminology, and insurance analytics. In practice, observed zeros often arise from two distinct mechanisms: some zeros result from stochastic variability in a Poisson-like process (for example, a rare event that simply does not occur), while other zeros reflect a structural process that deterministically yields zero counts. Standard Poisson regression, which assumes equidispersion and independent event occurrences, cannot distinguish between these mechanisms. As a result, it frequently produces biased parameter estimates, underestimates standard errors, and delivers suboptimal predictive performance when applied to zero-inflated data.
Zero-Inflated Poisson (ZIP) models address part of this complexity by introducing a two-part mixture: one component that governs structural zeros and another that governs the count distribution. However, even this mixture imposes strict constraints on the shape of the count component. In many real-world applications, count distributions exhibit skewness, multimodality, heavy tails, or degrees of zero-inflation that exceed what a single Poisson family can accommodate. Empirical distributions may show multiple peaks due to mixed subpopulations, or have tails that are heavier than what the standard Poisson model allows. This can lead to systematic discrepancies in higher-order moments and tail probabilities.
Semiparametric and nonparametric extensions, such as transformation models, infinite-mixture formulations, and kernel-based likelihoods, have been proposed to capture these complex distributional characteristics. These methods improve flexibility, but often sacrifice interpretability and identifiability, complicate likelihood evaluation, or impose significant computational burdens, especially when working with moderate sample sizes or large-scale datasets. In applied settings, where transparent parameter meanings and efficient estimation are crucial, such a complexity may limit practical use.
These considerations motivate the need for a modeling framework that explicitly accounts for zero inflation while offering greater control over skewness, multimodality, and dispersion without relying on high-dimensional latent structures or prohibitive computation. The Zero Inflated Polynomially Adjusted Poisson (zPAP) model is designed to fill this gap: it retains an interpretable two-part structure for structural zeros and employs a polynomial tilt mechanism to enrich the shape of the count distribution. By allowing flexible adjustment of skewness, multimodality, and tail behavior, including excess zero inflation, zPAP aims to improve inferential accuracy and predictive performance in zero-inflated settings, while preserving theoretical rigor and computational tractability.
Comparative studies such as Mullahy [
1], Lambert [
2] and Ridout et al. [
3] emphasize that ZIP and hurdle models encode fundamentally different assumptions and must be selected carefully in empirical contexts. Extensions of ZIP models to address overdispersion have led to the use of alternative kernels such as the negative binomial (Greene [
4]), generalized Poisson, and Conway-Maxwell-Poisson (COM-Poisson) distributions (Shmueli et al. [
5], Sellers and Shmueli [
6]). These offer additional dispersion control and improved empirical fit. However, COM-Poisson, while flexible, often suffers from computational intractability due to the presence of intractable normalizing constants.
The proposed zPAP model addresses this limitation by integrating a polynomial adjustment into the Poisson component of a ZIP model. This idea builds upon a substantial body of prior work on orthogonal polynomial expansions and their applications to distributional approximation and density estimation. Im et al. [
7] introduced a least-squares criterion to estimate polynomial coefficients while ensuring non-negativity and robustness by making use of quadratic programming. In addition, Min et al. [
8] discussed approximations to discrete distributions of rank statistics. Ha [
9] applied Krawtchouk polynomial expansions to discrete distributions, demonstrating their capacity to approximate overdispersed and skewed data with improved fit and tail accuracy. Ha [
10] proposed a Charlier-series-based adjustment to model nonhomogeneous Poisson processes, capturing skewness and higher moments.
Collectively, this line of work provides the theoretical and methodological foundation for the zPAP model. By incorporating polynomial weight functions into a standard Poisson kernel within a zero-inflated structure, the zPAP framework retains interpretability, supports efficient estimation, and offers superior distributional flexibility. It enables practitioners to fit count data with complex features such as zero-inflation, overdispersion, multimodality and heavy tails, extending the reach of classical ZIP models while preserving computational feasibility. This novel framework retains the core structure of the standard ZIP model but introduces substantial flexibility into the count component through a parametric polynomial adjustment of the Poisson distribution. The central innovation of the zPAP model is a multiplicative polynomial adjuster, which reweights the Poisson kernel in a tractable and interpretable manner. This adjuster preserves parametric structure and ensures that the resulting distribution remains normalizable, enabling maximum-likelihood estimation. A low-degree nonnegative polynomial—such as cubic or quartic—is typically sufficient to capture key empirical features including overdispersion, skewness, and multimodality. The zPAP model thus provides a powerful yet interpretable framework for analyzing zero-inflated count data with complex distributional characteristics, bridging theoretical structure and practical flexibility for use in diverse applied domains.
2. Zero-Inflated Polynomial-Adjusted Poisson (zPAP) Distribution
Standard count data models such as Poisson or the negative binomial often miss ’excess zeros’, more zero counts than expected. The Zero-Inflated Polynomial-Adjusted Poisson (zPAP) distribution is designed to address this issue by explicitly modeling these two sources of zero observations. The model acknowledges that an observed zero count can originate from the component of ’structural zero’, with probability , or from the component of ’sampling zero’, where the underlying count generation process (in this case, polynomial adjusted Poisson (PAP)) happens to produce a zero. This dual nature of zeros is fundamental to the zPAP formulation. The parameter quantifies the probability of a zero that cannot be attributed to the PAP process, even if the PAP process itself has a non-negligible probability of producing a zero, .
The count-generating mechanism within the zPAP model is the PAP distribution. This distribution belongs to the broader class of Weighted Poisson Distributions (WPDs) as can be seen in del Castillo and Pérez-Casany [
11] and Ridout and Besbeas [
12], which offer a flexible framework for modeling count data, especially when overdispersion (variance greater than the mean) or underdispersion (variance less than the mean) is present. A WPD modifies a standard Poisson distribution by introducing a weight function,
, such that its probability mass function (PMF) is given by
where
is the PMF of the standard Poisson distribution and
is the expectation of the weight function under the standard Poisson, serving as a normalizing constant.
Proposition 1 (PMF of the zPAP distribution).
Let Y be a random variable following the zero-inflated Polynomially Adjusted Poisson (zPAP) distribution with parameters π, λ, and α. Its probability mass function is where the underlying Polynomially Adjusted Poisson component has with as the normalizing constant. is a nonnegative polynomial weight that adjusts standard Poisson probabilities, π is the structural-zero probability, with , is the base Poisson rate, and α (scalar or vector) governs the form and degree of the polynomial T, tuning dispersion, tail behavior, and possible multimodality. By acting as a flexible, nonnegative weight on each count, the polynomial uniformly rescales the baseline Poisson probabilities to shape the overall distribution. Abstractly, T defines a family of count laws that interpolate between the classical Poisson () and richer alternatives with altered variance, skewness, and tail weight. When T increases in y, higher counts receive relatively more mass—enabling overdispersion and heavier tails—whereas a weight that diminishes for larger y can enforce underdispersion or non-monotonic modes. Thus, by choosing an appropriate nonconstant polynomial , one gains a unified mechanism to tune dispersion, multimodality, and tail behavior, all while preserving the core Poisson framework and ensuring a valid probability model.
Proposition 2 (Identifiability and Validity of the Polynomial Adjuster).
Let be the polynomial weight in the PAP component. To ensure the zPAP model defines a proper, identifiable count distribution with a unique interpretable fit, one must require that so that α lies in the convex cone Equivalently, one may insist on nonnegativity for all real , giving the semidefinite-friendly cone which admits an exact sum-of-squares characterization for some real polynomials and . In practice, enforcing the simpler constraint for all j is often sufficient and easy to implement. See Lasserre [13], Marshall [14] for details. Ensuring these identifiability and nonnegativity conditions is essential. Without them, the zPAP likelihood can become non-invertible, its moments undefined or non-computable, and any statistical inference drawn may be misleading or uninterpretable.
The normalizing constant
ensures that the weighted Poisson terms sum to one. Before using it in the zPAP PMF, we must verify that for every
and admissible
,
is both finite and strictly positive. These guarantees imply that
is a valid probability mass function. We now state the following result, which establishes that the normalizing constant yields a proper probability distribution.
Theorem 1 (Properties of the Normalizing Constant).
Let and define Then the following hold:- (a)
Convergence. For any fixed degree d and any , the series defining converges absolutely. In particular, since as and decays super-exponentially, one has - (b)
Positivity. Because , every term in the defining sum is non-negative, with at least one strictly positive term at . Hence - (c)
Moment Representation. Writing for the kth raw moment of a random variable, one obtains the finite-sum representationSince is a polynomial in λ of degree j (e.g., , , , etc.), this shows itself is a polynomial in λ of degree d, which is immediately computable without truncating an infinite sum. - (d)
Identifiability Constraint. Because multiplying all by a common constant leaves the ratio unchanged, one must fix a scale (e.g., ) to ensure the parameters are identifiable.
3. Maximum-Likelihood Estimation
Assuming an independent and identically distributed (i.i.d.) sample
, the joint likelihood function
is the product of the individual likelihood contributions:
where
is the indicator function, taking the value 1 if condition
A is true, and 0 otherwise. Using the counts of zero (
) and nonzero (
) observations, this can be written more compactly:
For simplicity,
will denote
in subsequent expressions where the context is clear. The log-likelihood function
yields
To further elaborate, substitute the definition
so that
The log-likelihood becomes
The logarithmic likelihood of the zPAP is broken down into four parts. First, every zero count contributes
which depends on
,
, and
and combines structural zeros with stochastic zeros from the PAP component. Next, each positive observation contributes
involving only
and reflecting that nonzeros must come from the PAP part. Then, the magnitudes of the positive counts enter through
which depends on
and
and represents the unnormalized PAP log-mass, i.e., the log of the PAP PMF numerator before division by
. Finally, all observations incur the term
again involving
and
, to ensure the PAP probabilities sum to one. Together, these four contributions form the full log-likelihood and precisely show how
,
, and
each enter the model.
A critical aspect revealed by the structure of the log-likelihood function is the intertwined nature of the estimation of and . The normalizing constant is a function of both and . Since appears in the log-likelihood for all observations (either directly or implicitly through ), its partial derivatives with respect to and appear in the respective score equations. Specifically, will involve , and will involve . This mathematical linkage means that the score equations for and , and , form a system of equations that must be solved simultaneously to obtain the MLEs and . Consequently, these parameters cannot be estimated independently within the PAP component. This interdependence can also lead to correlations between the estimators and , particularly if exhibits similar sensitivity to changes in both parameters. The complexity of , being an infinite sum, further complicates the analytical derivation and numerical computation of these derivatives.
The MLEs of the parameters
are found by solving the system of score equations
, where
is the score vector, defined as the vector of first-order partial derivatives of the log-likelihood function with respect to each parameter:
In order to have a partial derivative with respect to
, that is,
, we differentiate
ℓ with respect to
yields:
Setting
provides an equation that implicitly defines
in terms of
:
This expression for highlights its dependence on the estimated parameters of the PAP component through . The structure of is typical for mixture proportions in statistical models. It allows for an intuitive update for if and (and thus ) were known or estimated from a previous iteration. The equation essentially balances the observed zeros against those expected to arise from the PAP component (if all n observations were from that component, ), and those that are excess to this.
In order to have a partial derivative with respect to
, that is,
, the derivative with respect to
is more involved due to
’s presence in
(both in its numerator
and its denominator
) and in each
term (through
and the denominator
). Using the form
where
we obtain:
Equivalently, one may derive
by noting
. In particular, for
,
Hence, another equivalent form is
This expression highlights the complex interplay of terms involving the observed counts , the parameter , and the derivative of the normalizing constant .
And we derive the partial derivative(s) with respect to
, that is,
. If
is a vector
, then
is a vector of partial derivatives
Key components required are polynomial adjuster and normalizing constant, that is,
depends on the specific polynomial form of
. And
Alternatively, using
one obtains
where
. The difficulty stems from having to differentiate the polynomial weight function
and the normalizing constant
with respect to each component
.
The maximum-likelihood estimates
satisfy the score equations for the general case of
, that is, the three equations
,
and
for each component
. Apart from the obvious derivative of the zero-count term with respect to
, each score involves the derivative of the PAP probability
with respect to
or
. In turn, those derivatives require the sensitivity of the normalizing constant to each parameter. Concretely,
brings terms such as
and
, while
depends on
and
. Both
and
are infinite sums over
j, so there is no closed-form solution. This complexity, especially the appearance of
Z and its derivatives in every score, means that the MLE system must be solved numerically, and good initial values and careful computation of those infinite sums are essential for reliable estimation.
4. Regression Parameterization
Count regression models have been extensively developed to analyze nonnegative integer-valued results in a wide range of applications [
15,
16,
17,
18]. The proposed zPAP model can be extended into a regression framework by incorporating covariates, allowing the parameters
,
, and
to vary between observations. This extension improves the model’s capacity to capture heterogeneity in count data by linking distributional parameters to observed characteristics. Such regression-based formulations are particularly useful in settings where different covariates are believed to influence the zero-inflation and count-generating processes separately.
Let
,
, and
be vectors of covariates for the
ith observation, associated with parameters
,
, and
, respectively. These parameters are related to the covariates through appropriate link functions. For the probability of zero inflation
, we usually use a logit link to ensure
:
For the PAP rate parameter
, we use a log link to ensure
:
For the PAP adjustment parameter(s)
, the choice of link depends on its constraints. If
is a scalar and unconstrained, an identity link is natural:
If
must be positive, one may instead use a log link. When
is a vector, each component
can have its own link
:
The parameters to be estimated under this regression specification are the coefficient vectors , , and .
With parameters
,
, and
now dependent on covariates, the log-likelihood for the
ith observation is
, and the total log-likelihood is
The score equations are derived with respect to the regression coefficients
. For example, for a coefficient
(the
jth element of
), the score component is:
where
is the derivative of the
ith observation’s log-likelihood contribution with respect to
, analogous to the non-regression case but specific to observation
i,
is the derivative of the inverse link function. For the logit link,
and
is the
jth covariate entry for
, i.e.,
. Thus,
where
. Similar applications of the chain rule yield the score equations for
and
. The resulting score equations typically involve sums over all observations, with each term weighted by the respective covariates.
5. Numerical Examples
Due to the non-convex nature of the zPAP likelihood, we employ multiple random initializations (multistart strategy) to reduce the risk of convergence to a suboptimal local maximum. We accept the solution with the highest achieved log-likelihood value. While all parameters in the zPAP model are estimated jointly, the specific form of suggests the utility of iterative numerical procedures. Numerical optimization algorithms, such as quasi-Newton methods (e.g., BFGS), are required.
We utilized the Limited-Memory BFGS with bound constraints (L-BFGS-B) algorithm [
19] for complex computation in numerical examples. Optimizing
over
and
ensures that at each iterate,
,
, and
for all
y. We compute the maximum-likelihood estimator by directly optimizing the observed-data log-likelihood
subject to the constraints
This direct maximization approach avoids the slow “E-step/M-step” oscillations of EM algorithm and leverages curvature information via the approximate inverse-Hessian updates, resulting in substantially faster convergence to the global or high-quality local maxima of the zPAP log-likelihood.
5.1. Fish Catch Dataset
To illustrate the practical performance of the proposed zPAP model, we analyze the well-known
Fish Catch dataset, which has been used extensively in zero-inflated modeling literature. The dataset originates from the
COUNT data repository compiled by Hilbe [
20] and is available through several statistical software libraries. It contains records of recreational fishing trips on the Great Lakes and is characterized by a high frequency of zero counts, reflecting trips where no fish were caught.
All models are estimated by maximum likelihood using numerical optimization. The likelihood functions are derived from the model-specific probability mass functions, with parameter constraints and initialization tailored to each formulation. To accelerate convergence and avoid local maxima, we initialize the parameters using a method-of-moments approach. For the ZIP model, initial estimates of and are obtained by matching the empirical mean and variance to the theoretical expressions. For the zPAP model, we use the same moment-matched and as starting values and initialize the polynomial coefficients as , . For the zPAP model, the normalizing constant involves an infinite sum over y. In practice, we truncate the sum at a sufficiently large upper bound (e.g., ), chosen to ensure that the omitted tail has negligible effect on the computed probabilities.
To compare the relative quality of competing count-data models (e.g., standard ZIP versus various degrees of zPAP), we use two widely adopted information-criterion measures: the Akaike Information Criterion (AIC). These criteria quantify the trade-off between model fit and complexity by penalizing the maximized log-likelihood according to the number of estimated parameters.
Let
be the maximized log-likelihood for a model with parameter estimate
, and let
k denote the total number of free parameters in that model. Then,
and
Conceptually,
measures lack of fit (smaller is better), while the penalty term (
in AIC,
in BIC) discourages over-parameterization. Since
whenever
, BIC more strongly penalizes extra parameters in moderate-to-large samples.
As can be seen in the
Table 1, the ZIP model already fits the data very well, with a log-likelihood of −921.62 and moderate AIC/BIC values. Adding a first-degree polynomial adjuster (zPAP(1)) delivers a huge boost in fit (log-likelihood jumps to −671), showing that even a small weight function can capture departures from the basic ZIP. Moving to second and third degrees (zPAP(2) and zPAP(3)) yields further improvements (log-likelihoods of −668 and −661). The new
-coefficients for higher-order terms remain near zero (
,
), which means the model is only adjusting minor discrepancies with the ZIP baseline. Throughout, the core regression coefficients for
and
stay almost unchanged. This stability shows that zPAP is not overreacting or unstable; it simply adapts to small differences between the data and the ZIP fit, improving the model in a controlled and interpretable way. As summarized in
Table 2, the estimated structural zero probabilities (
) and Poisson means (
) for the observed data and each ZIP/zPAP model are reported.
Figure 1 displays the observed count distribution alongside the fitted frequencies for both models. The standard ZIP model already provides an accurate representation of the data, capturing the heavy zero-inflation and overall dispersion effectively. The zPAP model likewise achieves a comparable level of accuracy. Because the ZIP fit is strong to begin with, the polynomial adjustment in zPAP yields only marginal improvements in fit accuracy. Importantly, as the degree of the polynomial adjuster is increased, the zPAP estimates remain stable and do not deteriorate, demonstrating robustness even when higher-order terms are introduced.
We compare two count regression models on the Fish Catch dataset, ZIP and zPAP. Each model is composed of two components: a count component for the number of fish caught, and a zero-inflation component to model structural zeros. The structure of the covariates used is consistent across models to ensure fair comparison. We include one key covariate in each model: persons (number of individuals in the group) is used to model , and camper (a binary indicator of whether the group camped overnight) is used to model . Specifically, for each group i, we have and . Each model includes an intercept term. Each observation corresponds to a fishing trip, and the primary response variable is the number of fish caught, denoted by . The dataset includes the covariates of persons (number of individuals participating in the fishing party) and camper (binary indicator of whether the party camped overnight before the trip () or not ()). The persons variable is used as a covariate for modeling the Poisson mean in all fitted models, while camper is used to model the probability of structural zeros . These selections reflect intuitive hypotheses: a larger party may have higher expected catch rates (affecting ), while those who camped may differ systematically in their likelihood of catching zero fish due to differing engagement or fishing strategies (affecting ).
The Poisson mean parameter
is modeled via a log-linear regression using the number of persons in the fishing party
and the structural zero probability
is modeled through a logistic regression on the
camper indicator
. Then, in the zPAP model, the count distribution is adjusted by a degree-3 polynomial applied to the Poisson kernel—that is, the adjusted probability of count
y is proportional to:
The normalizing constant ensures this defines a proper PMF.
We summarizes the estimated parameters and model fit statistics for the ZIP and zPAP models applied to the Fish Catch dataset.
Table 3 reports the maximum-likelihood estimates for all model parameters, including regression coefficients in the count and zero-inflation components, and auxiliary parameters (
,
,
for zPAP). The coefficient
is positive across all models, indicating that groups with more persons are associated with higher expected catch counts. The coefficient
is negative in all models, suggesting that campers have lower odds of being structural zeros, possibly due to better preparation or more serious fishing intent. The zPAP model introduces additional flexibility via the polynomial adjustment: the signs and magnitudes of the estimated coefficients
,
, and
reflect the shape distortions applied to the baseline Poisson kernel. And in terms of log-likelihood and information criteria, the zPAP model achieves the highest likelihood and the lowest AIC and BIC values, indicating the best overall fit to the data. This confirms that adjusting the count distribution via a polynomial function offers substantial gains in model flexibility over ZIP.
5.2. Artificial Dataset
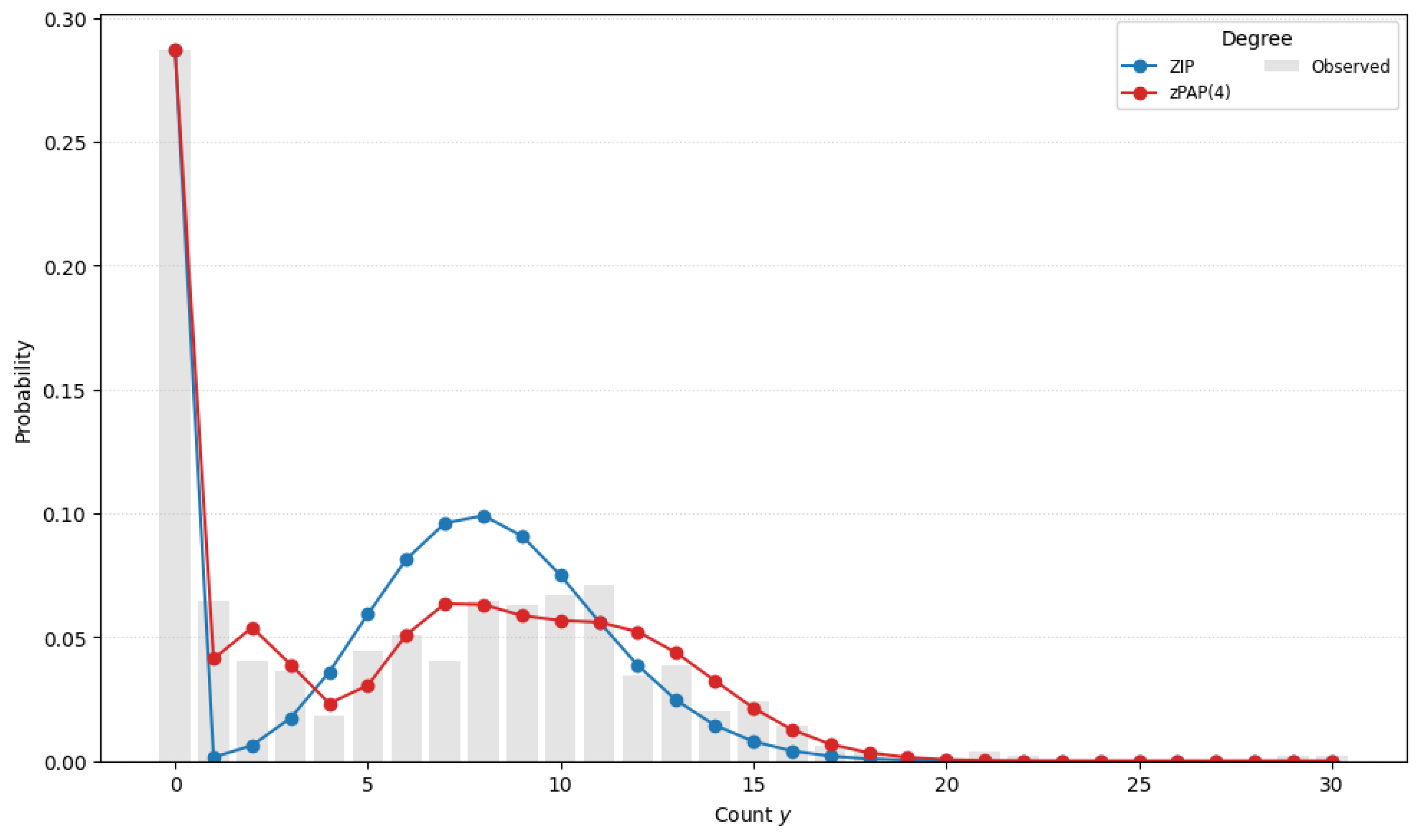
To evaluate the ability of the zPAP model to accommodate both zero-inflation and multimodal count behavior, we augmented the original Fish Catch dataset by superimposing an artificial latent subpopulation. Specifically, an additional set of the same number of observations was drawn from a Poisson distribution with mean and appended to the existing counts. As a result, the combined dataset retains the original zero-inflation while also exhibiting a pronounced secondary mode around 10. Creating this bimodal, zero-inflated dataset is crucial for two reasons: first, it provides a controlled setting in which to assess whether the zPAP model can simultaneously capture excess zeros and a second mass of high counts; second, it mimics real-world scenarios in which heterogeneous subpopulations (e.g., light versus heavy fish catchers) coexist, thereby demonstrating the practical utility of zPAP for complex count data.
Figure 2 overlays the data histogram with each model’s fitted frequencies. The ZIP curve is too narrow—it underestimates overall spread and fails to reproduce the second mode. As we increase the polynomial degree, the zPAP fit rapidly converges to the true distribution, accurately matching both the large spike at zero and the bimodal peaks.
Table 4 compares the observed proportion of zero counts in the data with the proportions predicted by each model. As before, the zPAP model provides the closest match, highlighting its capacity to leverage both covariates and the shape of the response distribution. The table presents the estimated Poisson means (
), zero-inflation parameters (
), and the resulting zero probabilities
across models of increasing polynomial degree. Although the zero-inflation parameter
varies with model complexity, the predicted zero probabilities remain close to the empirical value (≈0.2874). This demonstrates that the zPAP model—particularly at higher degrees—can flexibly adjust both
and the polynomial weights to accurately reproduce the observed zero mass, even under varying internal parameterizations.
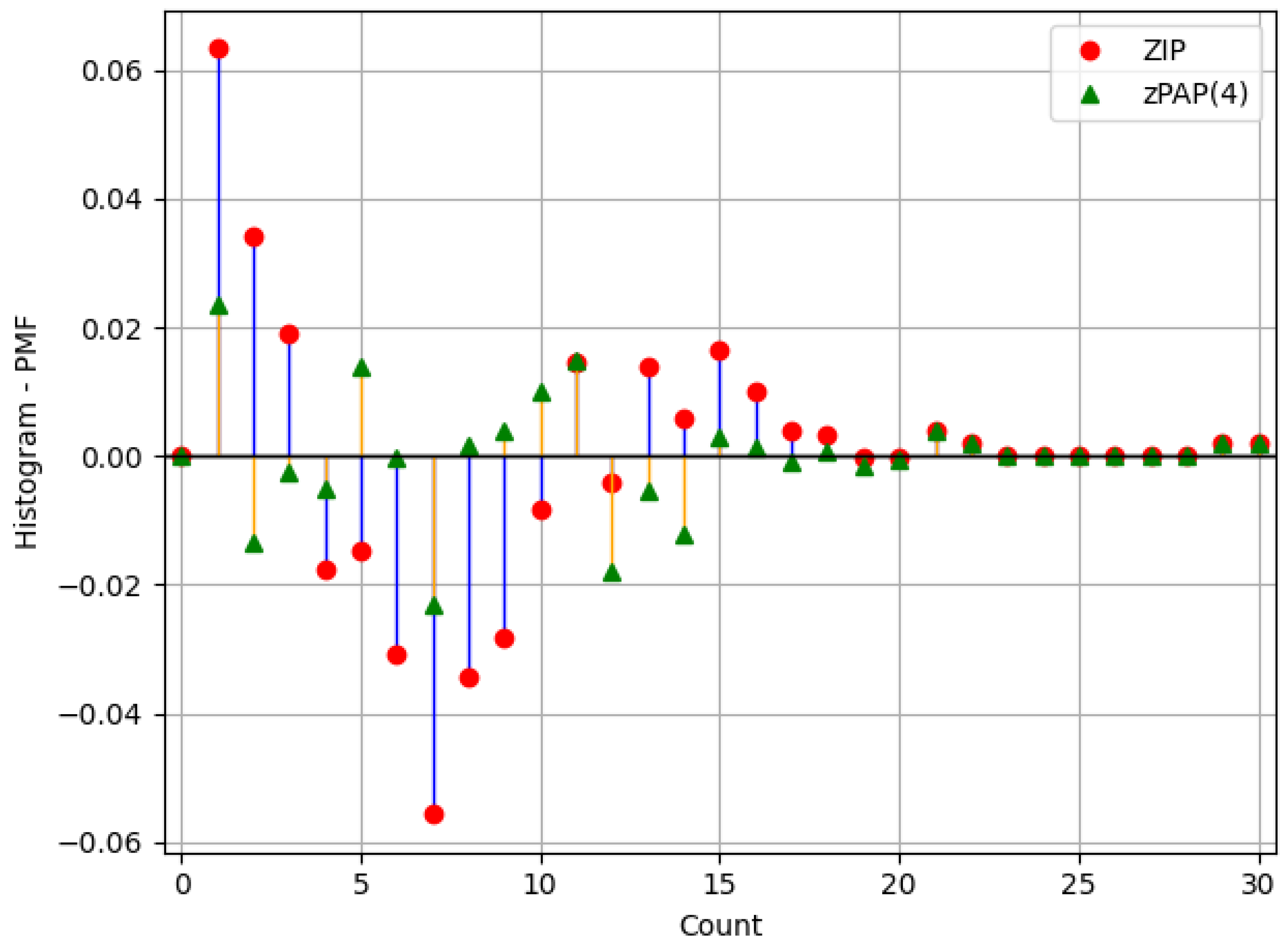
As can be seen in
Figure 3, the pointwise differences between the observed PMF and model predictions—ZIP (red dots) and zPAP(4) (green triangles)—demonstrate that the proposed fourth-degree zPAP model substantially reduces discrepancies across the entire range of count values, yielding a more accurate fit to the empirical distribution.
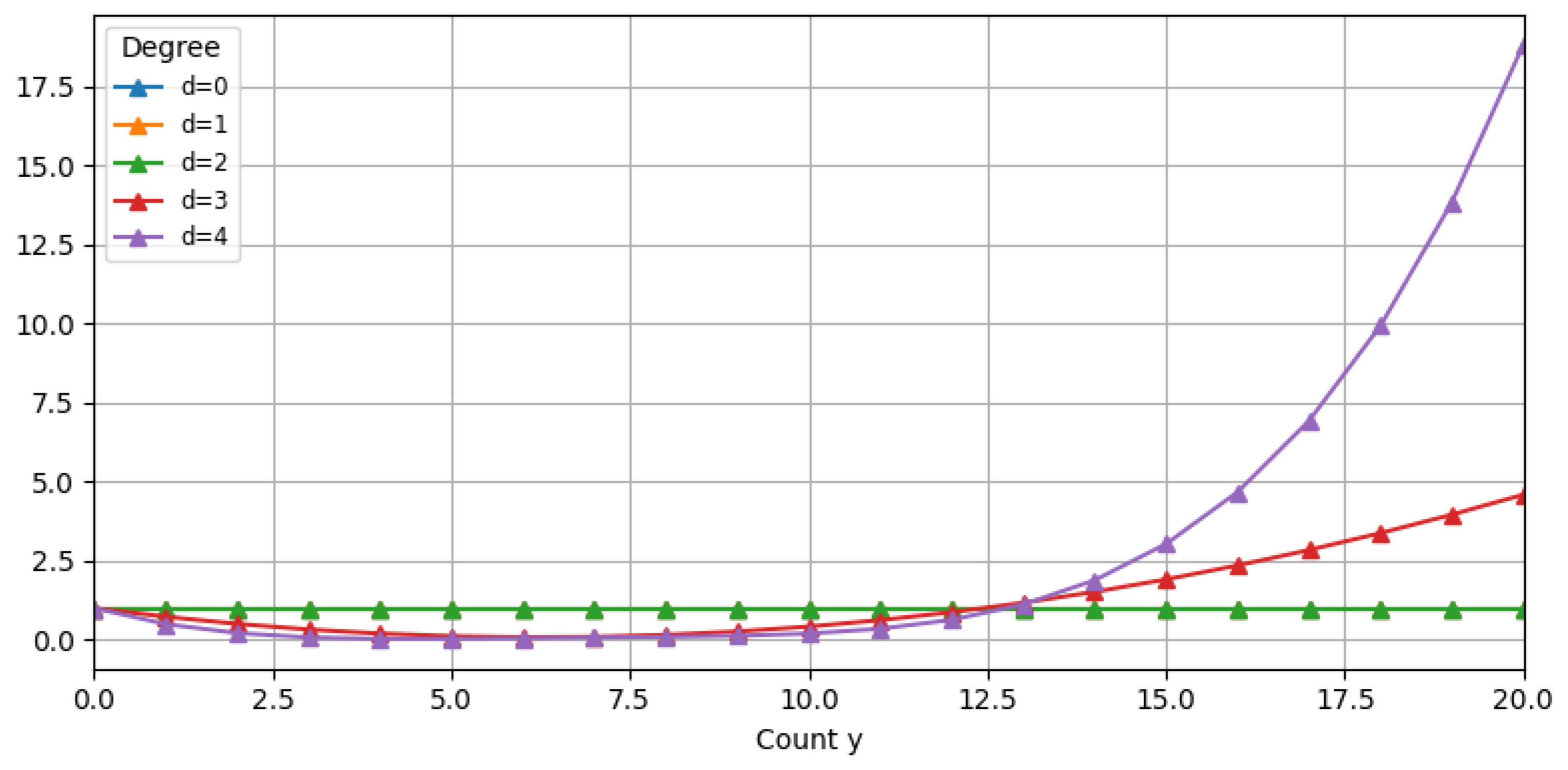
As illustrated in
Figure 4, and consistent with the discussion on the convergence of the normalizing constant in
Section 2 , the polynomial adjuster
grows at most as
as
. In contrast,
Figure 3 shows that the Poisson kernel
decays super-exponentially, ensuring that the overall model remains stable and capable of capturing heavy-tailed distributions effectively.
5.3. Constructing Bootstrap Confidence Intervals for MLEs
To rigorously assess the uncertainty associated with our MLEs for the proposed zPAP model, one must first establish their large-sample behavior. An analytical derivation of asymptotic properties, namely consistency, asymptotic normality, and efficiency, is mandatory to validate that MLEs converge to the true parameter values and achieve the lower bound of Cramér–Rao. In classical settings, these results follow from regularity conditions on the likelihood and are underpinned by the Fisher information matrix and the observed Hessian of the log-likelihood. However, for the zPAP framework the expressions for the Hessian matrix, the Fisher information matrix, and hence the asymptotic covariance matrix of the MLEs become complex. Closed-form second derivatives of the log-likelihood involve high-dimensional integrals and non-standard functions that preclude straightforward inversion and numerical stability, especially in finite samples.
To overcome these challenges and still provide valid inference on artificial Fish Catch data characterized by zero inflation and bimodal Poisson counts, we employ a parametric bootstrap approach with replications. Specifically, we generate synthetic datasets by drawing from the fitted zPAP distribution at the estimated parameter values, re-estimate the MLEs for each replicate, and then use the empirical distribution of these bootstrap estimates to form confidence intervals. This procedure not only circumvents the analytical intractability of the model’s Hessian but also delivers accurate finite-sample inference.
We have implemented a parametric bootstrap procedure to compute standard errors, confidence intervals, and the full covariance matrix for the MLEs. By simulating 1000 bootstrap samples, this approach circumvents the analytical intractability of the model’s Hessian matrix and provides more reliable finite-sample inference. To assess the reliability of these intervals, we construct and evaluate coverage probabilities under the assumption of asymptotic normality to ensure that our intervals achieve the intended coverage in practice.
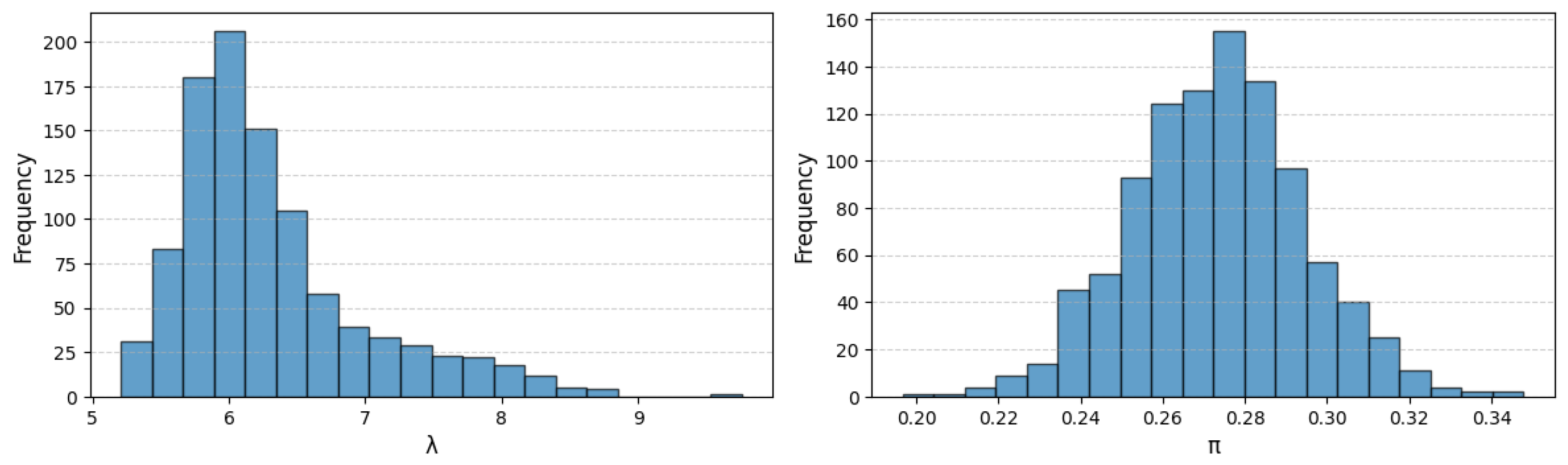
Figure 5 illustrates the bootstrap sampling distributions of the two parameters: in the left panel, the histogram of the Poisson mean
estimates is markedly right-skewed, with a long upper tail indicating occasional larger values, whereas in the right panel the distribution of the zero-inflation probability
estimates is symmetric and bell-shaped, closely matching the Gaussian curve expected under asymptotic normality.
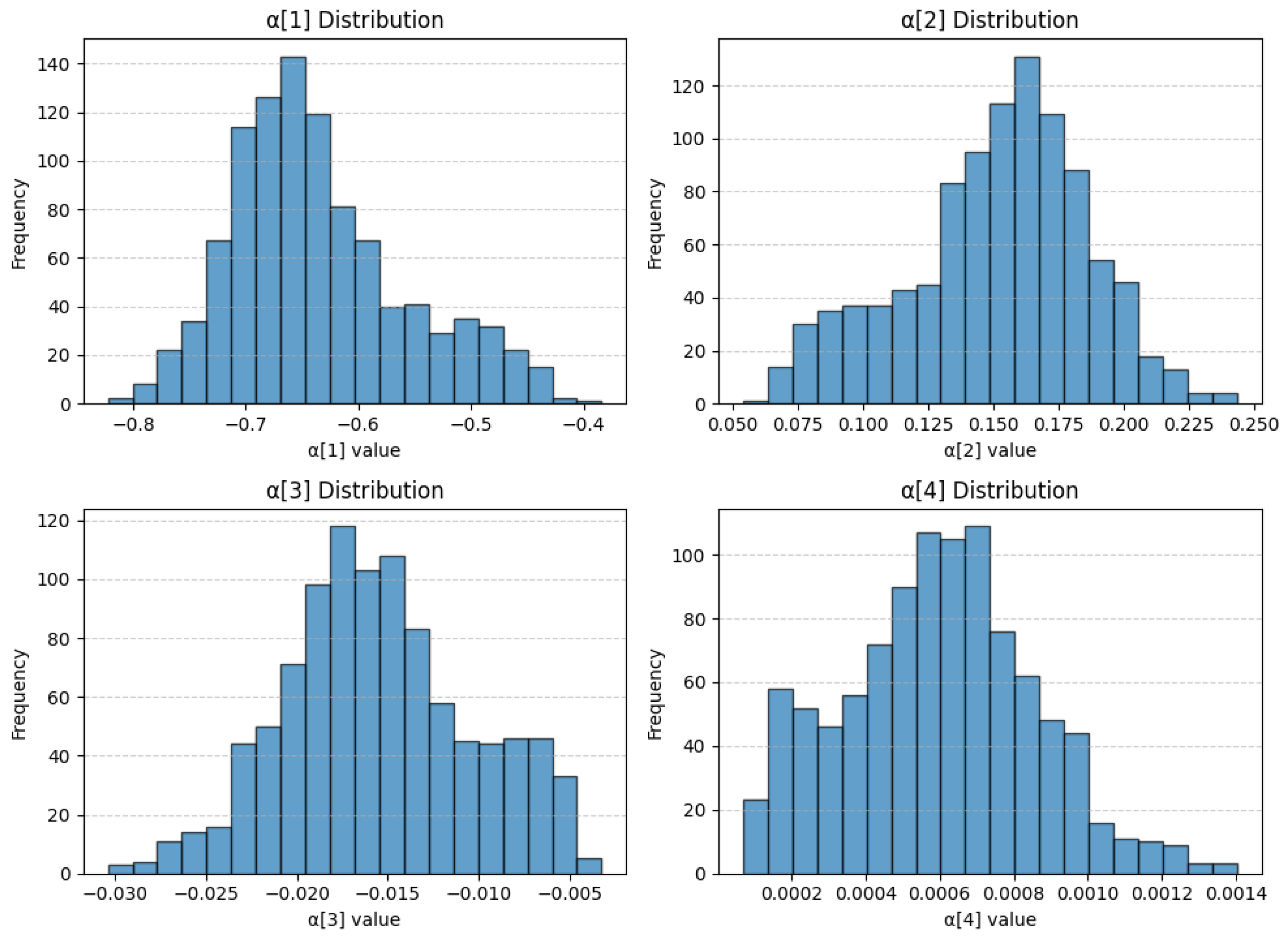
Figure 6 shows the bootstrap sampling distributions of the four degree-4 polynomial adjuster coefficients. While all four distributions are centered around their true values, none are perfectly symmetric. The distribution of
and
are noticeably right-skewed, with a pronounced upper tail, whereas
and
each exhibit left-skewness, reflected in their longer lower tails.
In
Table 5, each column summarizes a different aspect of the bootstrap-derived sampling distribution of the MLEs, all based on
replications. The “Mean” is the average of the
B bootstrap estimates for a given parameter. Because the bootstrap draws repeatedly from the fitted model, this empirical average serves not only as a point estimate but also as a simple bias check—if the bootstrap mean differs notably from the original MLE, it suggests small-sample bias. The “Standard Error” is calculated as the sample standard deviation of those
B estimates, that is,
and it quantifies the finite-sample variability of the estimator without relying on analytic Hessians or Fisher information.
The 95% confidence interval in the table is constructed by taking the 2.5th and 97.5th percentiles of the sorted bootstrap estimates. For example, for the interval encloses the central 95% of the values. This percentile method implicitly accounts for skewness in the bootstrap distribution, so that asymmetric intervals arise naturally when the sampling distribution is skewed.
Under the asymptotic-normality assumption, each 95% interval is formed as
Table 5 shows that these intervals achieve coverage probabilities very close to the nominal 95% level:
hits exactly 0.950,
comes in at 0.954, and
at 0.944. The scale parameter
exhibits slight under-coverage (0.933), while the highest-order coefficient
is slightly conservative (0.969), reflecting its very small variance and the corresponding tail behavior of its bootstrap distribution.
The matrix
is the empirical covariance of the bootstrap estimates for all six parameters, with rows and columns ordered as
. Each diagonal entry gives the bootstrap variance of that parameter (for example,
and
), which correspond to the squared standard errors reported in
Table 5. The much larger variance for
compared to
reflects greater sampling variability in the scale parameter under our model. Off-diagonal entries capture pairwise covariances. A positive covariance, such as
, indicates that bootstrap draws in which
is higher than its mean tend also to have larger
. Conversely, the negative covariance between
and
(
) shows that when
is relatively large,
tends to be smaller. The tiny covariances involving
are consistent with its very small variance (0.00000007), indicating that
is estimated with high precision and almost independently of the other coefficients.
6. Concluding Remarks
We introduced the zero-inflated Polynomially Adjusted Poisson (zPAP) model. It extends the usual zero-inflated Poisson to handle extra zeros, overdispersion, skewness, and even bimodal counts. The key idea is to multiply the Poisson kernel by a simple polynomial weight, while still using a logistic link for zero inflation.
In the main text, we gave the full mathematical setup. We wrote down the adjusted likelihood and showed how each parameter—zero-inflation probability , Poisson rate , and polynomial coefficients —can depend on covariates. We then derived the maximum-likelihood equations and explained how to compute them in practice. That discussion covers how to pick starting values, enforce identifiability constraints, and evaluate the normalizing constant and its derivatives. By spelling out the log-likelihood and score functions, we give both the theory and a clear recipe for implementation.
We tested the zPAP model on two datasets. First, we used the Fish Catch data, which has many zeros and high dispersion. Then, we created a mixed dataset by adding random Poisson counts to the Fish Catch observations, producing a clear bimodal pattern. In both cases, zPAP fit the data better than the standard ZIP model, handling multiple peaks and skewed shapes with ease. We generated 1000 bootstrap datasets by sampling from the fitted zPAP(4) model, re-estimating the MLEs on each replicate, and used the resulting estimate distributions to compute standard errors, confidence intervals, and the covariance matrix.
In summary, zPAP is a powerful yet interpretable extension of classical count models. It can flexibly capture a wide range of patterns in count data. Future work will first establish the large-sample properties of the zPAP maximum-likelihood estimators—proving consistency, asymptotic normality, and efficiency under standard regularity conditions. We will also investigate using an orthogonal polynomial basis for to improve numerical stability and interpretability. In addition, we plan to compare different fitting methods—such as the method of moments and least squares—against maximum likelihood to see how they perform in practice.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}