
A Comparative Analysis of Fairness and Satisfaction in Multi-Agent Resource Allocation: Integrating Borda Count and K-Means Approaches with Distributive Justice Principles


Abstract
1. Introduction
2. Related Work
3. Theoretical Framework and Game Model
- Equality canon: the principle of equality is that all agents must be treated equally, meaning that agents must not be unfairly discriminated against unless they have other legitimate reasons to do so.
- Need canon: resources should be distributed according to each agent’s specific needs, ensuring that those in greater need receive priority.
- Productivity canon: agents must be rewarded for their productivity and the value they give to the system.
- Effort canon: individual efforts and sacrifices must be reflected in resources, and agents who actively participate in challenging conditions must be rewarded.
- Social Utility canon: when allocating resources, it is important to consider the social utility of the actions of each agent or the benefits of the community.
- Supply and Demand canon: resource allocation strategies should consider market dynamics such as supply and demand and adapt allocations to available resources and agents’ needs.
- Merits canon: the allocation of resources should be based on the abilities and achievements of the individual agent and should reward those who have made significant contributions.
3.1. The Linear Public Good Game
3.2. Rescher’s Canons
- : the agent is ranked in an increasing order of their average allocation in rounds:
- : the agent is ranked in an increasing order of their satisfaction , which measures the fairness with which they perceive their allocation in relation to them.
- : This function provides a variety of ways to ensure that agents that are systematically deficient in allocation or satisfaction will receive priority in future resource distributions, based on the number of rounds awarded to agents larger than zero:
- Not withholding resources ;
- Demanding only what is needed ; and
- Appropriating only what is allocated .
- -
- The focus is on procedural fairness (e.g., equality, need, effort) rather than rewarding past achievements or innate abilities.
- -
- The LPG framework assumes agents operate in a scarce, cooperative economy where contributions are measured via real-time provisions (pi) and demands (di), not historical merits.
4. Borda Count Method and K-Means Clustering for Multi-Criteria Decision Making
4.1. Borda Count Algorithm Formalization
4.1.1. Running Example
- Agent A: (100, 30, 15, 10, 5)
- Agent B: (80, 70, 40, 20, 15)
- Agent C: (60, 52, 50, 15, 12)
| Algorithm 1. Resource Allocation with Legitimate Claims |
| Input: |
| A = {A1, A2, …, An} |
| C = {C1, C2, …, Cm} |
| Si,j: Score of agent Ai for criterion Cj |
| Output: |
| Borda Scores Bi for each agent Ai |
| Ranked list of agents based on Bi |
| Begin |
| For each criterion Cj do |
| Sort agents Ai based on scores Si,j to assign ranks ri,j. |
| Pi,j ← n − rij + 1 / / each agent Ai for criterion Cj. |
| end for |
| for each agent Ai do |
| Bi = / / Calculate the total Borda score |
| Sort agents Ai in descending order of Bi to determine the final ranking. |
| end for |
| remaining_resources ← total_resources |
| for agent in agents do |
| if remaining_resources > 0 then |
| allocated_amount ← min (agent.requested_resources, remaining_resources) |
| agent.allocated_resources ← allocated_amount |
| remaining_resources ← remaining_resources − allocated_amount |
| else |
| break |
| end if |
| end for |
| End |
4.1.2. Complexity
4.2. K-Means Resource Allocation with Fairness Constraints
| Algorithm 2. K-means Resource Allocation with Fairness Constraints |
| // Step 1: Normalize and weight agent scores |
| for each agent Ai in A |
| for each criterion Cj in C |
| S_normalized[i][j] ← (sij − min(Cj))/(max(Cj) − min(Cj)) # Min-max normalization |
| S_weighted[i][j] ← S_normalized[i][j] * wj |
| // Step 2: Initialize cluster centroids |
| centroids ← Select K random agents as initial centroids |
| // Step 3: Cluster agents |
| repeat |
| // Assignment step |
| for each agent Ai in A |
| for each centroid k in 1…K |
| distance[i][k] ← EuclideanDistance(S_weighted[i], centroids[k]) |
| cluster_assignment[i] ← argmin_k(distance[i][k]) |
| // Update step |
| for each cluster k in 1…K |
| members ← {Ai | cluster_assignment[i] = k} |
| if members ≠ ∅ |
| centroids[k] ← mean(S_weighted[m] for all m in members) |
| until cluster assignments stabilize or max iterations reached |
| // Step 4: Allocate resources within clusters |
| remaining_resources ← R_total |
| for each cluster k in 1…K |
| members ← {Ai | cluster_assignment[i] = k} |
| cluster_need ← sum(di for all i in members) # di is agent Ai’s demand |
| // Fair allocation within cluster |
| for each agent Ai in members |
| if remaining_resources > 0 |
| allocation[i] ← min(di, (di/cluster_need) * (R_total/K)) |
| remaining_resources ← remaining_resources − allocation[i] |
| else |
| allocation[i] ← 0 |
| return cluster_assignment, allocation |
| End |
5. Experimental Results
5.1. Simulation Setup
Experimental Evaluation Metrics
- ○
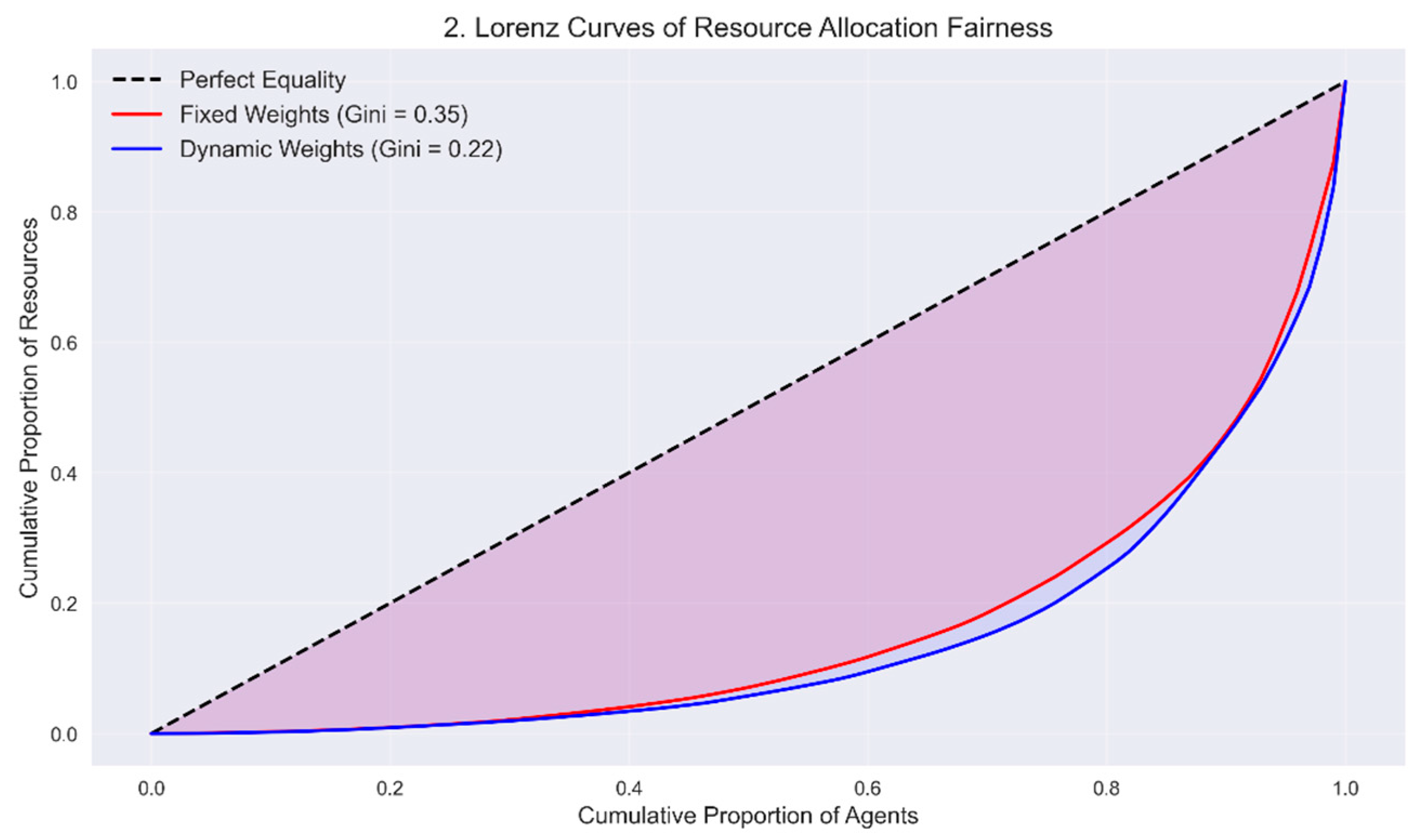
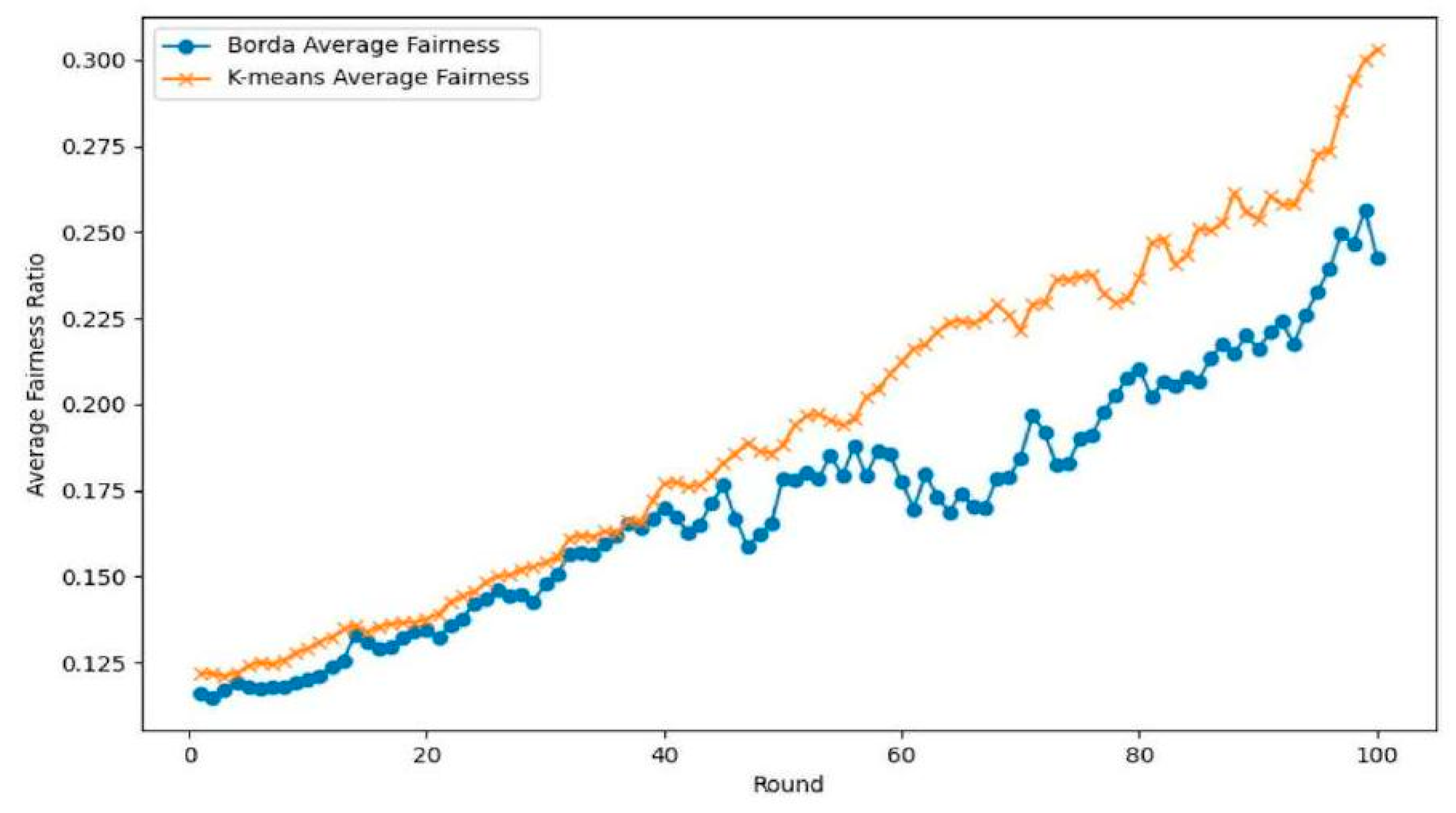
- Fairness ratio: Focus on the fairness of allocation between agents and examine the degree of distribution closer to the ideal proportionality between all agents. Here, the average fairness ratio across all agents is taken as follows:This reflects whether the distribution aligns with each agent’s relative share of total demand rather than individual fulfillment alone.
- ○
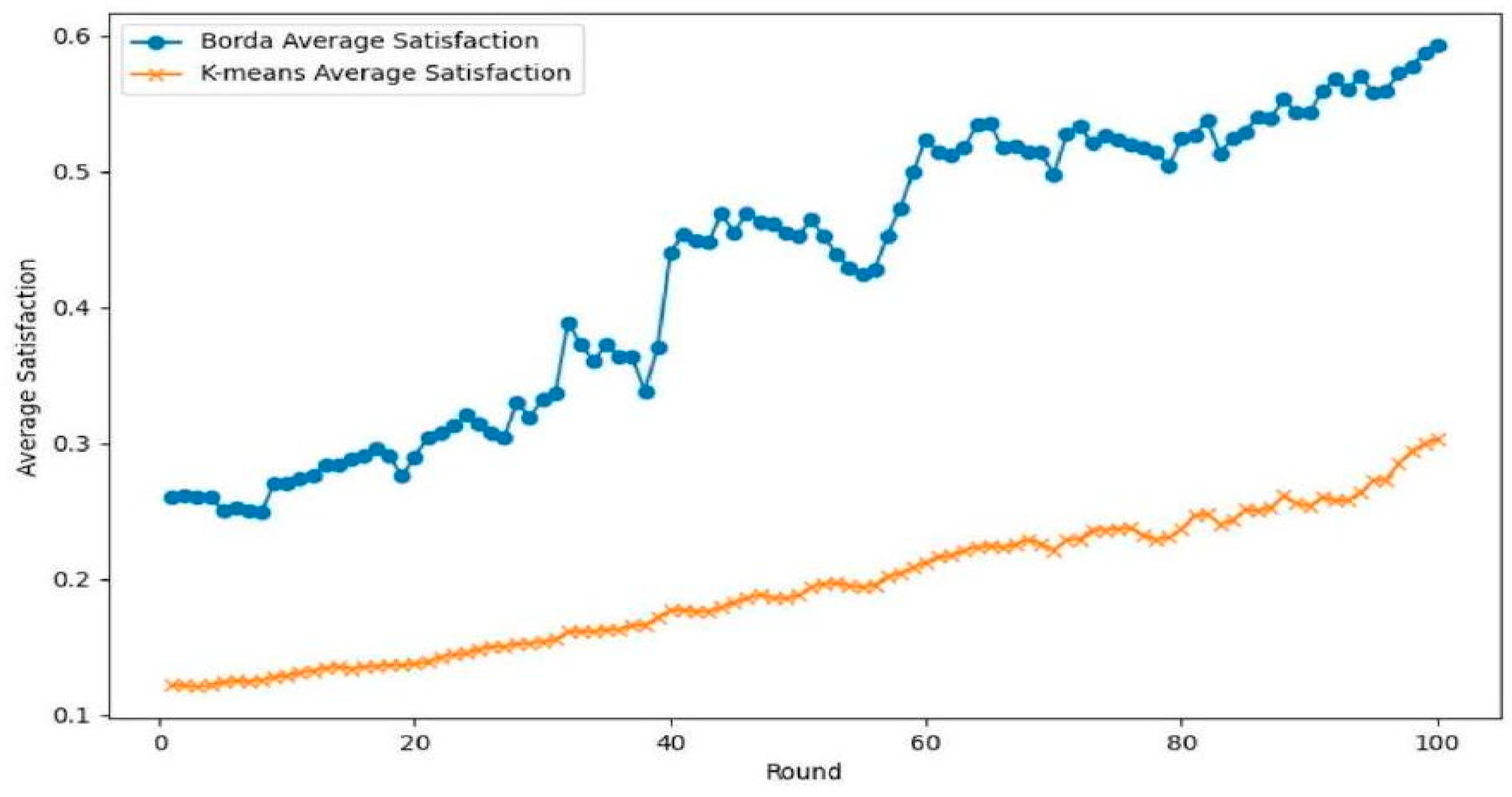
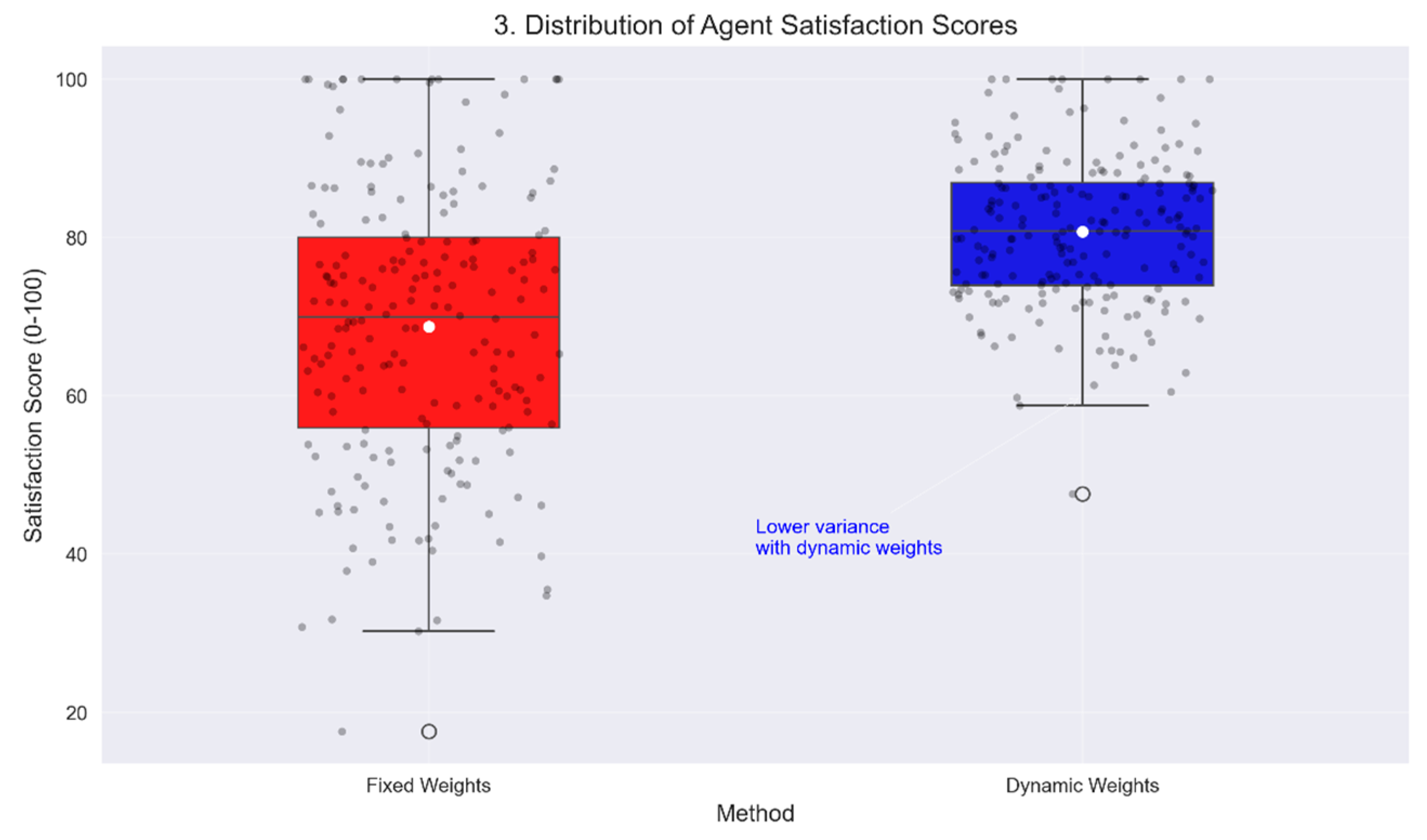
- Satisfaction: This measures how well each agent’s needs are met in absolute terms. Here, the satisfaction score of each agent is directly calculated as follows:The focus is on whether the resources meet the agent’s demand or need. High satisfaction means agents are receiving resources that fulfill a large percentage of their needs, irrespective of what other agents receive.
5.2. Simulation Results
5.3. Sensitivity Analysis
5.4. Managerial Insights
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Q.; Li, W.; Mohajer, A. Load-aware continuous-time optimization for multi-agent systems: Toward dynamic resource allocation and real-time adaptability. Comput. Netw. 2024, 250, 110526. [Google Scholar] [CrossRef]
- Deng, Z.; Chen, T. Distributed algorithm design for constrained resource allocation problems with high-order multi-agent systems. Automatica 2022, 144, 110492. [Google Scholar] [CrossRef]
- Zhou, J.; Zhao, X.; Zhang, X.; Zhao, D.; Li, H. Task allocation for multi-agent systems based on distributed many-objective evolutionary algorithm and greedy algorithm. IEEE Access 2020, 8, 19306–19318. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, K.; Xu, L.; Gao, W.; Yang, T. Distributed event-triggered algorithms for multi-objective resource allocation problem. Unmanned Syst. 2024, 12, 331–340. [Google Scholar] [CrossRef]
- Liu, P.; An, K.; Lei, J.; Sun, Y.; Liu, W.; Chatzinotas, S. Computation rate maximization for SCMA-aided edge computing in IoT networks: A multi-agent reinforcement learning approach. IEEE Trans. Wirel. Commun. 2024, 23, 10414–10429. [Google Scholar] [CrossRef]
- Ferdous, J.; Bensebaa, F.; Milani, A.S.; Hewage, K.; Bhowmik, P.; Pelletier, N. Development of a generic decision tree for the integration of multi-criteria decision-making (MCDM) and multi-objective optimization (MOO) methods under uncertainty to facilitate sustainability assessment: A methodical review. Sustainability 2024, 16, 2684. [Google Scholar] [CrossRef]
- Sriram, S.; Ramachandran, M.; Chinnasamy, S.; Mathivanan, G. A review on multi-criteria decision-making and its application. REST J. Emerg. Trends Model. Manuf. 2022, 7, 101–107. [Google Scholar]
- Gebre, S.L.; Cattrysse, D.; Alemayehu, E.; Van Orshoven, J. Multi-criteria decision making methods to address rural land allocation problems: A systematic review. Int. Soil Water Conserv. Res. 2021, 9, 490–501. [Google Scholar] [CrossRef]
- Pourmand, E.; Mahjouri, N.; Hosseini, M.; Nik-Hemmat, F. A multi-criteria group decision making methodology using interval type2 fuzzy sets: Application to water resources management. Water Resour. Manag. 2020, 34, 4067–4092. [Google Scholar] [CrossRef]
- Khorsand, R.; Ramezanpour, M. An energy-efficient task-scheduling algorithm based on a multi-criteria decision-making method in cloud computing. Int. J. Commun. Syst. 2020, 33, e4379. [Google Scholar] [CrossRef]
- Rea, D.; Froehle, C.; Masterson, S.; Stettler, B.; Fermann, G.; Pancioli, A. Unequal but fair: Incorporating distributive justice in operational allocation models. Prod. Oper. Manag. 2021, 30, 2304–2320. [Google Scholar] [CrossRef]
- Chen, X.; Hooker, J.N. A guide to formulating fairness in an optimization model. Ann. Oper. Res. 2023, 326, 581–619. [Google Scholar] [CrossRef] [PubMed]
- Eke, C.I.; Shuib, L. The role of explainability and transparency in fostering trust in AI healthcare systems: A systematic literature review, open issues and potential solutions. Neural Comput. Appl. 2025, 37, 1999–2034. [Google Scholar] [CrossRef]
- Fazelpour, S.; Lipton, Z.C.; Danks, D. Algorithmic fairness and the situated dynamics of justice. Can. J. Philos. 2022, 52, 44–60. [Google Scholar] [CrossRef]
- Herrero, C.; Villar, A. Group decisions from individual rankings: The Borda–Condorcet rule. Eur. J. Oper. Res. 2021, 291, 757–765. [Google Scholar] [CrossRef]
- Heckelman, J.C.; Ragan, R. Symmetric scoring rules and a new characterization of the Borda count. Econ. Inq. 2021, 59, 287–299. [Google Scholar] [CrossRef]
- Du, L.; Gao, J. Risk and income evaluation decision model of PPP project based on fuzzy Borda method. Math. Probl. Eng. 2021, 2021, 6615593. [Google Scholar] [CrossRef]
- Neveling, M.; Rothe, J. Control complexity in Borda elections: Solving all open cases of offline control and some cases of online control. Artif. Intell. 2021, 298, 103508. [Google Scholar] [CrossRef]
- Ahmadi, A.; Herdiawan, D. The implementation of BORDA and PROMETHEE for decision making of Naval base selection. Decis. Sci. Lett. 2021, 10, 129–138. [Google Scholar] [CrossRef]
- Bahrini, A.; Riggs, R.J.; Esmaeili, M. Social choice rules, fallback bargaining, and related games in common resource conflicts. J. Hydrol. 2021, 602, 126663. [Google Scholar] [CrossRef]
- Ajay, P.; Nagaraj, B.; Jaya, J. Algorithm for Energy Resource Allocation and Sensor-Based Clustering in M2M Communication Systems. Wirel. Commun. Mob. Comput. 2022, 2022, 7815916. [Google Scholar] [CrossRef]
- Liu, X.; Jia, M.; Ding, H. Uplink resource allocation for multicarrier grouping cognitive internet of things based on K-means learning. Ad Hoc Netw. 2020, 96, 102002. [Google Scholar] [CrossRef]
- Ghadiri, M.; Samadi, S.; Vempala, S. Socially fair k-means clustering. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual, 3–10 March 2021; pp. 438–448. [Google Scholar]
- Ullah, I.; Youn, H.Y. Task classification and scheduling based on K-means clustering for edge computing. Wirel. Pers. Commun. 2020, 113, 2611–2624. [Google Scholar] [CrossRef]
- Pitt, J.; Busquets, D.; Macbeth, S. Distributive justice for self-organised common-pool resource management. In ACM Transactions on Autonomous and Adaptive Systems (TAAS); Association for Computing Machinery: New York, NY, USA, 2014; Volume 9, pp. 1–39. [Google Scholar]
- Quan, J.; Yang, W.; Li, X.; Wang, X.; Yang, J.B. Social exclusion with dynamic cost on the evolution of cooperation in spatial public goods games. Appl. Math. Comput. 2020, 372, 124994. [Google Scholar] [CrossRef]
- Pitt, J.; Schaumeier, J.; Busquets, D.; Macbeth, S. Self-Organising Common-Pool Resource Allocation and Canons of Distributive Justice. In Proceedings of the 2012 IEEE Sixth International Conference on Self-Adaptive and Self-Organizing Systems, Lyon, France, 10–14 September 2012. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criterion | Agent A Rank | Agent B Rank | Agent C Rank |
|---|---|---|---|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gharbi, A.; Ayari, M.; Albalawi, N.; El Touati, Y.; Klai, Z. A Comparative Analysis of Fairness and Satisfaction in Multi-Agent Resource Allocation: Integrating Borda Count and K-Means Approaches with Distributive Justice Principles. Mathematics 2025, 13, 2355. https://doi.org/10.3390/math13152355
Gharbi A, Ayari M, Albalawi N, El Touati Y, Klai Z. A Comparative Analysis of Fairness and Satisfaction in Multi-Agent Resource Allocation: Integrating Borda Count and K-Means Approaches with Distributive Justice Principles. Mathematics. 2025; 13(15):2355. https://doi.org/10.3390/math13152355
Chicago/Turabian StyleGharbi, Atef, Mohamed Ayari, Nasser Albalawi, Yamen El Touati, and Zeineb Klai. 2025. "A Comparative Analysis of Fairness and Satisfaction in Multi-Agent Resource Allocation: Integrating Borda Count and K-Means Approaches with Distributive Justice Principles" Mathematics 13, no. 15: 2355. https://doi.org/10.3390/math13152355
APA StyleGharbi, A., Ayari, M., Albalawi, N., El Touati, Y., & Klai, Z. (2025). A Comparative Analysis of Fairness and Satisfaction in Multi-Agent Resource Allocation: Integrating Borda Count and K-Means Approaches with Distributive Justice Principles. Mathematics, 13(15), 2355. https://doi.org/10.3390/math13152355