

BiEHFFNet: A Water Body Detection Network for SAR Images Based on Bi-Encoder and Hybrid Feature Fusion

Abstract
1. Introduction
- (1)
- A bi-encoder architecture combining ResNet and Swin Transformer is employed to jointly extract local texture details and global contextual semantics. This collaborative design enhances the completeness of feature representation and better characterizes the shape and boundaries of water bodies under complex backgrounds. In addition, the CBAM is incorporated to inhibit useless information of the output features of each ResNet stage.
- (2)
- A cross-attention-based hybrid feature fusion (CABHFF) module is proposed to fuse features from the bi-encoder. By integrating cross-attention and channel attention for learning feature weights, this module enables interaction and effective fusion between local and global features, thereby improving the model’s capability to capture water-related structures.
- (3)
- A multi-scale content-aware upsampling (MSCAU) module, which integrates ASPP and the lightweight CARAFE operator, is incorporated in the decoder part to enhance multi-scale feature representation and restore fine spatial details, thereby alleviating feature distortion during upsampling and improving the precision of water body detection.
- (4)
- A composite loss function is designed by combining Dice loss and Active Contour loss. This combination not only addresses class imbalance between water and non-water regions but also strengthens boundary constraints, further boosting the detection performance.
2. Materials and Methods
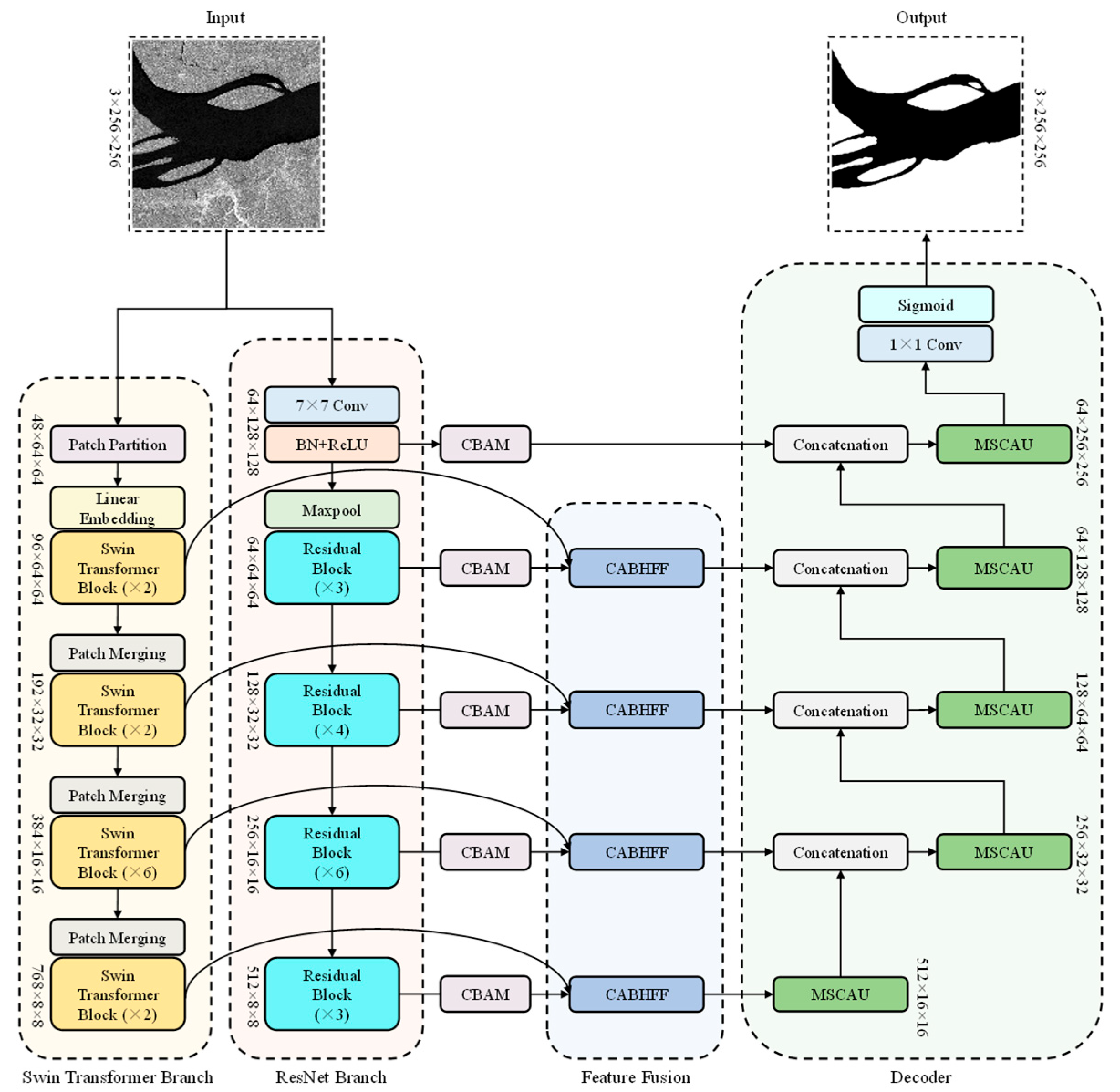
2.1. Encoder–Decoder Architecture
2.2. Attention Mechanism
3. Methodology
3.1. Encoder of BiEHFFNet
- (1)
- ResNet branch: This branch adopts a lightweight ResNet-34 [40] as the backbone network, leveraging its shallow residual structure to effectively model edge and texture features. Local fine-grained spatial representations are progressively extracted through its multi-level architecture, which consists of an initial convolution layer followed by four residual stages. The initial convolution layer comprises a standard convolution operation and a max pooling layer. The four subsequent stages comprise multiple residual blocks, with output channel dimensions of 64, 128, 256, and 512, respectively. To enhance feature discrimination and reduce computational redundancy in the bi-branch structure, a CBAM is inserted after each residual stage. It sequentially applies channel and spatial attention to emphasize important features and suppress irrelevant background noise. This not only improves the network’s focus on water-relevant regions under complex backgrounds, but also reduces computational cost by refining feature responses before fusion. These features provide detailed support for precise water body boundary localization.
- (2)
- Swin Transformer branch: This branch uses the Swin Transformer architecture [41] to enhance the global semantic representation of SAR images by capturing long-range dependencies. Its multi-level architecture, which uses shifted window mechanisms, balances computational efficiency and contextual learning effectively by aggregating both local and global information. The structure consists of four stages, each of which is composed of multiple Swin Transformer blocks. To enable efficient feature fusion with the ResNet branch, the output channels of the Swin stages (originally 96, 192, 384, and 768) are adjusted to match the corresponding dimensions of the ResNet stage outputs. This bi-branch encoder design significantly enhances the model’s ability to identify water bodies amidst complex background interference.
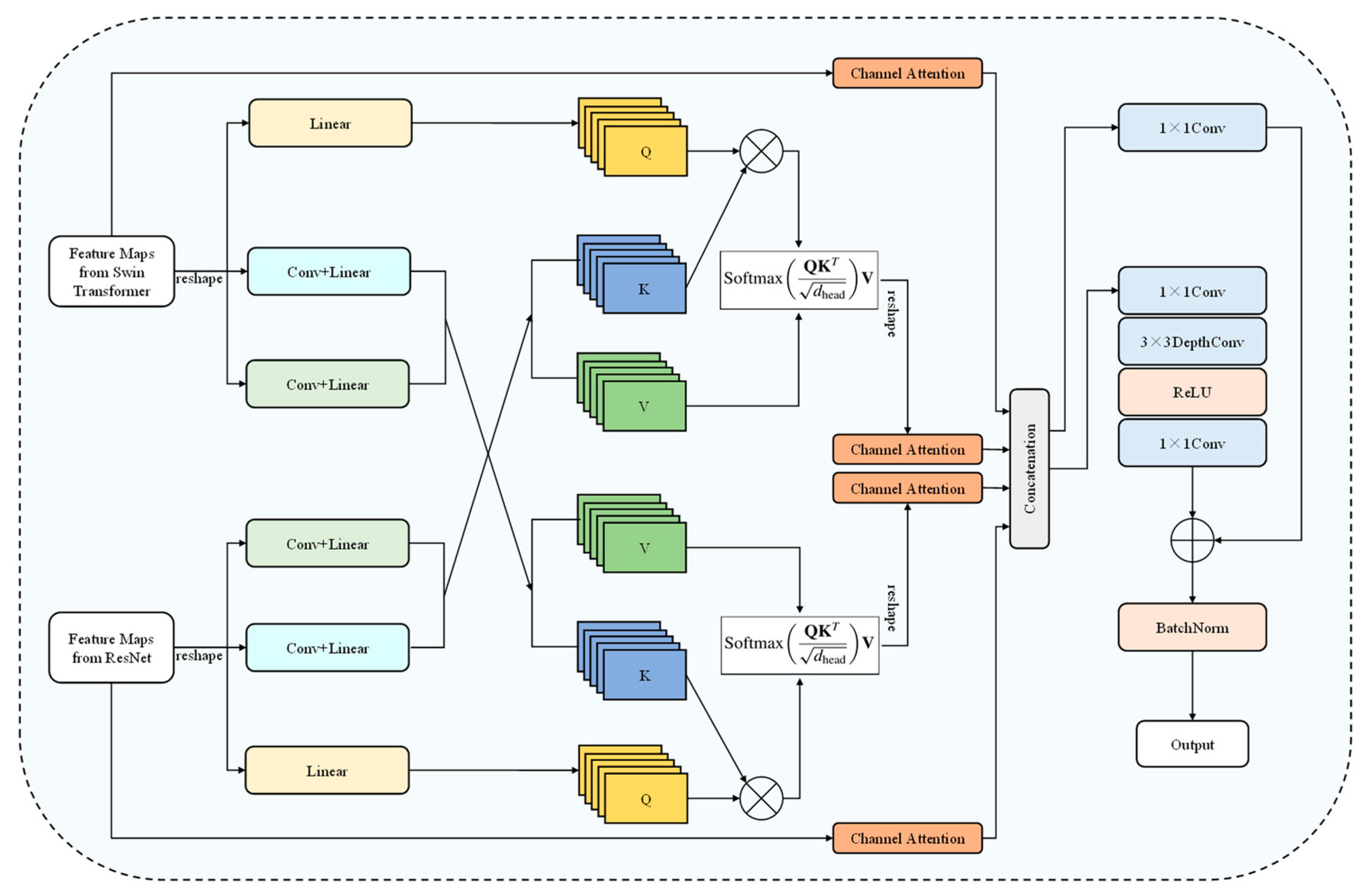
3.2. Cross-Attention-Based Hybrid Feature Fusion Module
- (1)
- Cross-attention-based local–global feature interaction: First, the input features from the ResNet and Swin Transformer encoders are individually processed through channel compression and linear projection to standardize their feature dimensions, making them suitable for the subsequent cross-attention computation. A bidirectional cross-attention pathway is then constructed. In one direction, the ResNet branch serves as the query, while the Swin branch provides the key and value, enabling global semantic features from Swin to guide and enhance the local representations of ResNet. Conversely, in the other direction, the Swin branch is used as the query and the ResNet branch as the key and value, allowing local features from ResNet to refine the global semantics of Swin. For each attention direction, the attention scores are calculated by Softmax and used to weight value features via matrix multiplication to obtain the final enhanced outputs.
- (2)
- Channel-attention-based hybrid feature fusion: After the bidirectional cross-attention enhancement stage is complete, a residual connection is introduced to retain the original input features and improve robustness and feature variability. In the final fusion stage, four sets of features including the original features from both encoder branches, as well as the two cross-attention-enhanced features are used together to achieve comprehensive information integration. A channel attention module is applied to each feature to compute importance weights and adaptively balance their contributions. The four reweighted feature maps are then concatenated along the channel dimension, resulting in a weighted concatenation-based fusion that effectively integrates shallow spatial details and deep semantic information. The fused feature is further refined through a dual-branch residual structure to improve semantic coherence. One branch applies a standard convolution operation, while the other branch passes the features through a sequence of convolution, depthwise convolution, and ReLU activation, followed by another convolution to reduce the channel dimension. The outputs of the two branches are aggregated and standardized to produce the final fused representation. This CABHFF module, by integrating residual learning, attention guidance, and structured fusion, significantly enhances the interaction between the two encoder branches (ResNet and Swin), supporting complementary fusion of features from different sources. The proposed hybrid feature fusion module leverages residual preservation, spatially adaptive weighting, and structured fusion refinement to facilitate more effective interaction among heterogeneous features. Consequently, it substantially improves the representation of water bodies in complex backgrounds.
3.3. Decoder of BiEHFFNet
3.4. Loss Function
- (1)
- Dice Loss: This loss aims to enhance foreground recognition capability and overall detection accuracy. Dice loss is well suited for scenarios where the foreground occupies a small portion of the image. It boosts recall by maximizing the overlap between the predicted result and the ground truth mask, reducing the risk of missing small water bodies. The expression of the loss function is as follows:
- (2)
- Active Contour loss: To enhance the model’s ability to capture water boundary structures, an AC loss is introduced, which incorporates region-based energy and boundary smoothness constraints. This loss function integrates the principles of region energy and boundary regularization from classical Active Contour models within the training objective, serving as a structure-aware form of supervision. It guides the network to accurately delineate object regions and locate precise boundary positions, thereby improving the structural accuracy of water body detection. The AC loss consists of a region energy term and a boundary energy term, and is formally defined as follows:
- (3)
- Overall loss function: the final loss function used during training is defined as a weighted sum of the two sub-losses:
4. Experiments
4.1. Experiment Data
4.2. Evaluation Metrics
4.3. Experiment Setting
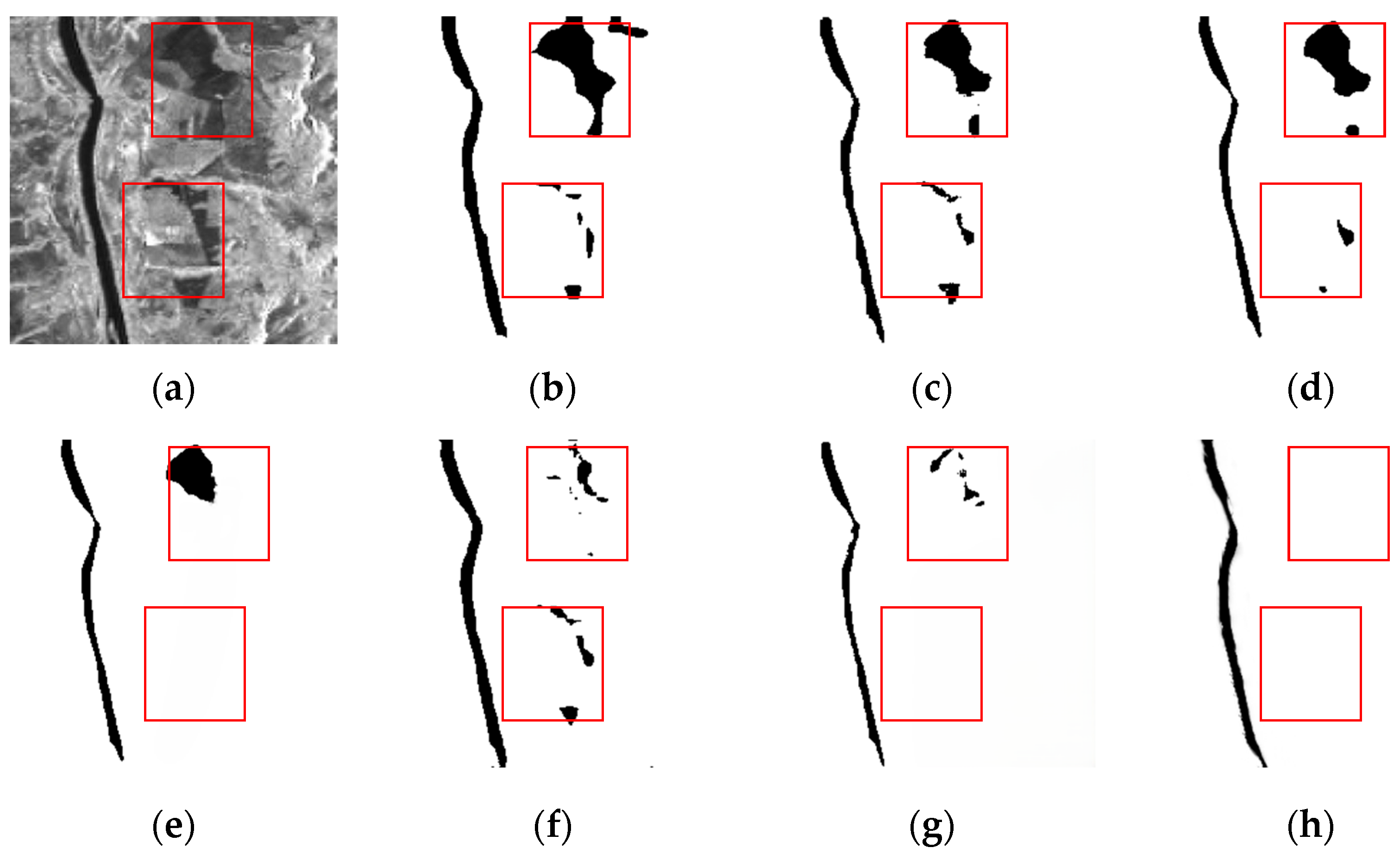
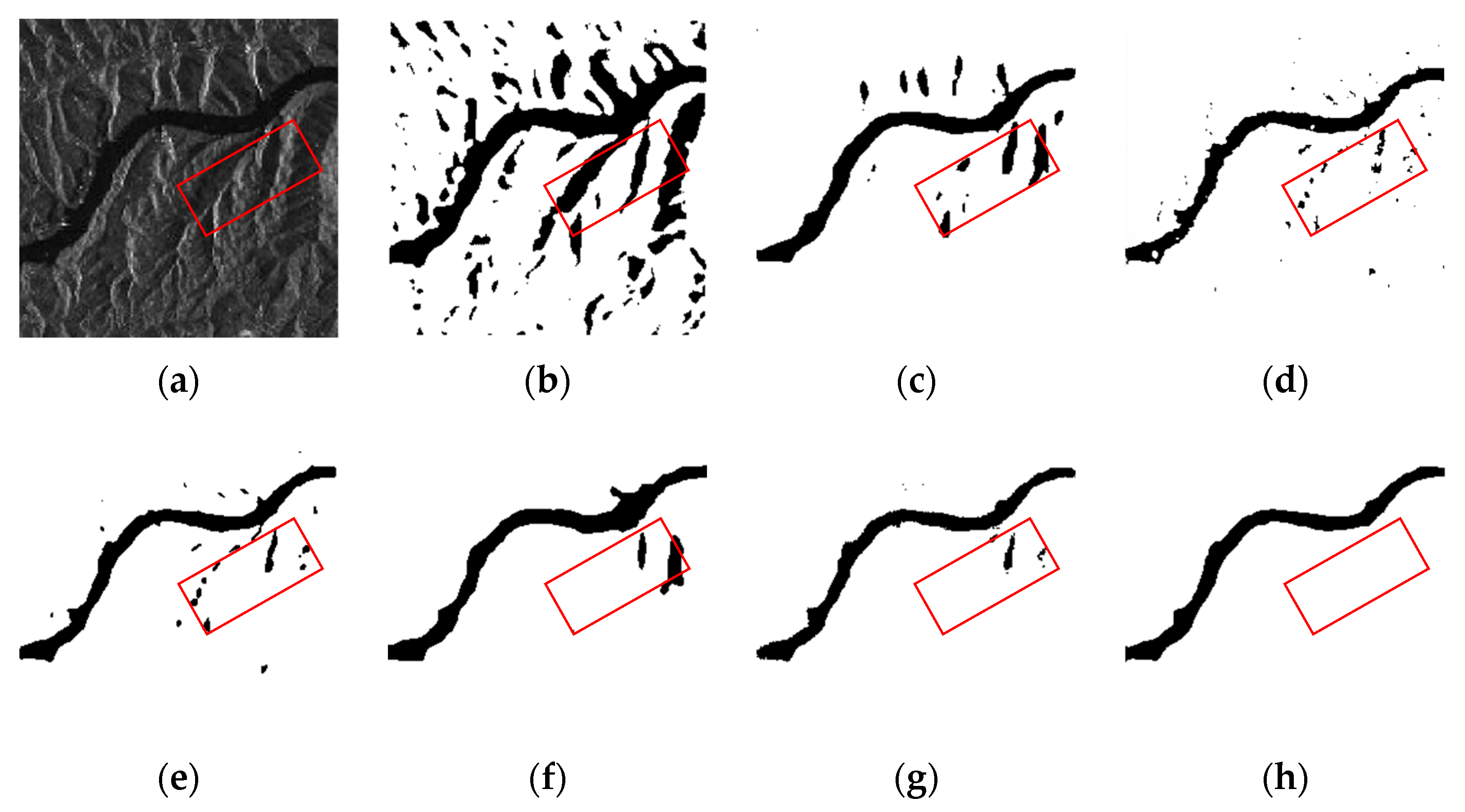
4.4. Comparison Experiments Against Other Models
4.5. Computational Complexity and Model Efficiency Analysis
4.6. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Amitrano, D.; Ciervo, F.; Di Martino, G.; Papa, M.N.; Iodice, A.; Koussoube, Y.; Mitidieri, F.; Riccio, D.; Ruello, G. Modeling watershed response in semiarid regions with high-resolution synthetic aperture radars. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2732–2745. [Google Scholar] [CrossRef]
- Pesaresi, M.; Benediktsson, J.A. A new approach for the morphological segmentation of high-resolution satellite imagery. IEEE Trans. Geosci. Remote Sens. 2001, 39, 309–320. [Google Scholar] [CrossRef]
- Klemenjak, S.; Waske, B.; Valero, S.; Chanussot, J. Automatic detection of rivers in high-resolution SAR data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1364–1372. [Google Scholar] [CrossRef]
- Mondal, M.S.; Sharma, N.; Garg, P.K.; Bohm, B.; Flugel, W.A.; Garg, R.D.; Singh, R.P. Water area extraction using geocoded high resolution imagery of TerraSAR-X radar satellite in cloud prone Brahmaputra River valley. J. Geomat. 2009, 3, 9–12. [Google Scholar]
- Markert, K.N.; Chishtie, F.; Anderson, E.R.; Saah, D.; Griffin, R.E. On the merging of optical and SAR satellite imagery for surface water mapping applications. Results Phys. 2018, 9, 275–277. [Google Scholar] [CrossRef]
- Pulvirenti, L.; Pierdicca, N.; Chini, M.; Guerriero, L. An algorithm for operational flood mapping from synthetic aperture radar (SAR) data using fuzzy logic. Nat. Hazards Earth Syst. Sci. 2011, 11, 529–540. [Google Scholar] [CrossRef]
- Qin, Y.; Ban, Y.; Li, S. Water body mapping using Sentinel-1 SAR and Landsat data with modified decision tree algorithm. Remote Sens. 2019, 11, 1552. [Google Scholar]
- Gasnier, C.; Baillarin, S.; Fayolle, G. Automatic extraction and monitoring of water bodies from high-resolution satellite SAR images using external data and CRF. In Proceedings of the IGARSS, Valencia, Spain, 22–27 July 2018; pp. 2300–2303. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, T.; Ji, W.; Li, W.; Qin, C.; Wang, T.; Ren, Y.; Fang, Y.; Han, Z.; Jiao, L. EDWNet: A novel encoder-decoder architecture network for water body extraction from optical images. Remote Sens. 2024, 16, 4275. [Google Scholar] [CrossRef]
- Wang, J.; Jia, D.; Xue, J.; Wu, Z.; Song, W. Automatic water body extraction from SAR images based on MADF-Net. Remote Sens. 2024, 16, 3419. [Google Scholar] [CrossRef]
- Weng, Z.; Li, Q.; Zheng, Z.; Wang, L. SCR-Net: A dual-channel water body extraction model based on multi-spectral remote sensing imagery—A case study of Daihai Lake, China. Sensors 2025, 25, 763. [Google Scholar] [CrossRef] [PubMed]
- Yuan, D.; Wang, C.; Wu, L.; Yang, X.; Guo, Z.; Dang, X.; Zhao, J.; Li, N. Water stream extraction via feature-fused encoder-decoder network based on SAR images. Remote Sens. 2023, 15, 1559. [Google Scholar] [CrossRef]
- Ni, H.; Li, J.; Wang, C.; Zhou, Z.; Wang, X. SDNet: Sandwich decoder network for waterbody segmentation in remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025; in press. [Google Scholar]
- Wang, J.; Wang, S.; Wang, F.; Zhou, Y.; Wang, Z.; Ji, J.; Xiong, Y.; Zhao, Q. FWENet: A deep convolutional neural network for flood water body extraction based on SAR images. Int. J. Digit. Earth 2022, 15, 345–361. [Google Scholar] [CrossRef]
- Saleh, T.; Weng, X.; Holail, S.; Hao, C.; Xia, G.-S. DAM-Net: Flood detection from SAR imagery using differential attention metric-based vision transformers. ISPRS J. Photogramm. Remote Sens. 2024, 212, 440–453. [Google Scholar] [CrossRef]
- Kang, J.; Guan, H.; Ma, L.; Wang, L.; Xu, Z.; Li, J. WaterFormer: A coupled transformer and CNN network for waterbody detection in optical remotely-sensed imagery. ISPRS J. Photogramm. Remote Sens. 2023, 206, 222–241. [Google Scholar] [CrossRef]
- He, Z.-F.; Shi, B.-J.; Zhang, Y.-H.; Li, S.-M. Remote sensing image segmentation of around plateau lakes based on multi-attention fusion. Acta Electron. Sin. 2023, 51, 885–895. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. U-Net++: A nested U-Net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.-W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1055–1059. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Hartwig, A. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. BASNet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 6478–6487. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Roy, A.; Saha, S. SCSE: A spatial-channel squeeze-and-excitation network for image segmentation. IEEE Trans. Image Process. 2020, 29, 3004–3014. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Liu, M.; Yin, H. Cross attention network for semantic segmentation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2364–2368. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the EEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Li, J.; Xu, Q.; He, X.; Liu, Z.; Zhang, D.; Wang, R.; Qu, R.; Qiu, G. CFFormer: Cross CNN-transformer channel attention and spatial feature fusion for improved segmentation of low quality medical images. arXiv 2025, arXiv:2501.03629. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; CVPR 2020. pp. 11534–11542. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE: Content-aware reassembly of features. In Proceedings of the EEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the IEEE International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Chen, X.; Williams, B.M.; Vallabhaneni, S.R.; Czanner, G.; Williams, R.; Zheng, Y. Learning Active Contour Models for Medical Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11632–11640. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Chen, J.; Mei, J.; Li, X.; Lu, Y.; Yu, Q.; Wei, Q.; Luo, X.; Xie, Y.; Adeli, E.; Wang, Y.; et al. TransUNet: Rethinking the U-Net architecture design for medical image segmentation through the lens of transformers. Med. Image Anal. 2024, 91, 103280. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dataset | IoU (%) | mIoU (%) | OA (%) | Re (%) | F1 (%) |
|---|---|---|---|---|---|---|
| UNet | ALOS PALSAR | 90.26 | 72.34 | 91.48 | 91.44 | 91.32 |
| Sen1-SAR | 68.23 | 68.37 | 78.62 | 78.61 | 82.72 | |
| ResUNet | ALOS PALSAR | 92.37 | 77.38 | 92.48 | 92.44 | 92.31 |
| Sen1-SAR | 73.24 | 73.61 | 81.21 | 81.23 | 84.41 | |
| UNet++ | ALOS PALSAR | 92.53 | 79.65 | 93.39 | 93.18 | 92.82 |
| Sen1-SAR | 75.28 | 76.12 | 80.31 | 80.39 | 83.05 | |
| DeepLabV3+ | ALOS PALSAR | 93.04 | 81.38 | 94.26 | 95.04 | 94.62 |
| Sen1-SAR | 77.23 | 77.04 | 85.26 | 85.23 | 87.14 | |
| SwinUNet | ALOS PALSAR | 94.16 | 82.47 | 94.69 | 95.30 | 94.91 |
| Sen1-SAR | 88.35 | 87.21 | 90.56 | 90.84 | 91.43 | |
| TransUNet | ALOS PALSAR | 95.40 | 83.89 | 95.26 | 96.24 | 95.89 |
| Sen1-SAR | 87.97 | 87.13 | 90.11 | 90.35 | 91.50 | |
| BiEHFFNet | ALOS PALSAR | 96.36 | 84.37 | 96.30 | 97.38 | 97.30 |
| Sen1-SAR | 91.24 | 88.39 | 93.47 | 92.08 | 93.71 |
| Method | FLOPs (G) | Parameters (M) | TPE (s) | FPS |
|---|---|---|---|---|
| UNet | 54.74 | 31.04 | 23.41 | 70.76 |
| ResUNet | 10.71 | 32.52 | 43.35 | 104.67 |
| UNet++ | 83.11 | 29.13 | 25.21 | 37.14 |
| DeepLabV3+ | 9.23 | 26.68 | 44.23 | 67.68 |
| SwinUNet | 5.916 | 27.15 | 32.22 | 123.65 |
| TransUNet | 24.68 | 93.23 | 62.02 | 54.18 |
| BiEHFFNet | 79.45 | 191.19 | 92.01 | 23.34 |
| Method | IoU (%) | mIoU (%) | OA (%) | Re (%) | F1 (%) |
|---|---|---|---|---|---|
| Baseline | 90.26 | 72.34 | 91.48 | 91.44 | 91.32 |
| Two-Branch | 92.37 | 77.38 | 92.48 | 92.44 | 92.31 |
| Two-Branch + CBAM | 92.53 | 79.65 | 93.39 | 93.18 | 92.82 |
| Two-Branch + CABHFF | 93.04 | 81.38 | 94.26 | 95.04 | 94.62 |
| Two-Branch + MSCAU | 92.76 | 80.53 | 93.82 | 93.64 | 93.07 |
| Two-Branch + CBAM + CABHFF | 95.40 | 83.89 | 95.26 | 96.24 | 95.89 |
| BiEHFFNet | 96.36 | 84.37 | 96.30 | 97.38 | 97.30 |
| Method | IoU (%) | mIoU (%) | OA (%) | Re (%) | F1 (%) |
|---|---|---|---|---|---|
| Baseline + BCE | 89.64 | 71.17 | 88.79 | 88.92 | 90.23 |
| Baseline + Dice | 89.93 | 71.42 | 89.21 | 90.32 | 90.74 |
| Baseline + Dice + AC (Ours) | 90.26 | 72.34 | 91.48 | 91.44 | 91.32 |
| BiEHFFNet + BCE | 95.53 | 80.65 | 95.39 | 96.07 | 95.42 |
| BiEHFFNet + Dice | 95.82 | 81.92 | 96.06 | 96.84 | 96.80 |
| BiEHFFNet + Dice + AC (Ours) | 96.36 | 84.37 | 96.30 | 97.38 | 97.30 |
| Dilation Group | F1 (%) | OA (%) |
|---|---|---|
| Group A (ours) | 97.30 | 96.30 |
| Group B | 96.72 | 96.01 |
| Group C | 95.64 | 95.57 |
| Group D | 95.22 | 95.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, B.; Huang, X.; Xue, F. BiEHFFNet: A Water Body Detection Network for SAR Images Based on Bi-Encoder and Hybrid Feature Fusion. Mathematics 2025, 13, 2347. https://doi.org/10.3390/math13152347
Han B, Huang X, Xue F. BiEHFFNet: A Water Body Detection Network for SAR Images Based on Bi-Encoder and Hybrid Feature Fusion. Mathematics. 2025; 13(15):2347. https://doi.org/10.3390/math13152347
Chicago/Turabian StyleHan, Bin, Xin Huang, and Feng Xue. 2025. "BiEHFFNet: A Water Body Detection Network for SAR Images Based on Bi-Encoder and Hybrid Feature Fusion" Mathematics 13, no. 15: 2347. https://doi.org/10.3390/math13152347
APA StyleHan, B., Huang, X., & Xue, F. (2025). BiEHFFNet: A Water Body Detection Network for SAR Images Based on Bi-Encoder and Hybrid Feature Fusion. Mathematics, 13(15), 2347. https://doi.org/10.3390/math13152347