
A Spatiotemporal Convolutional Neural Network Model Based on Dual Attention Mechanism for Passenger Flow Prediction



Abstract
1. Introduction
- A comprehensive study of two types of features was conducted to achieve simultaneous forecasting of multi-site passenger flow data. The two types of features include: (a) Temporal features of passenger flow time-series data, and (b) spatial features based on metro inter-station connections and passenger travel networks.
- A spatiotemporal convolutional network (GDAM-CNN) model with a dual attention mechanism is proposed, where a convolutional neural network (CNN) embedded with a convolutional block attention module (CBAM) is fused with a gated recursive unit (GRU) network to achieve effective capture of spatiotemporal features in passenger flow data. The GDAM-CNN model significantly enhances prediction accuracy by dynamically filtering critical spatial patterns through attention mechanisms (CBAM) while adaptively modeling temporal dependencies via gated recurrent units (GRU). This unified architecture jointly optimizes complex nonlinear spatiotemporal relationships.
2. Literature Review
2.1. Traditional Statistical Methods
2.2. Nonparametric & Heuristic Models
2.3. Classical Neural Networks
2.4. Deep Neural Networks
2.5. Attention-Based Deep Models
3. Methods
3.1. Definition of Problems
3.2. Model Construction
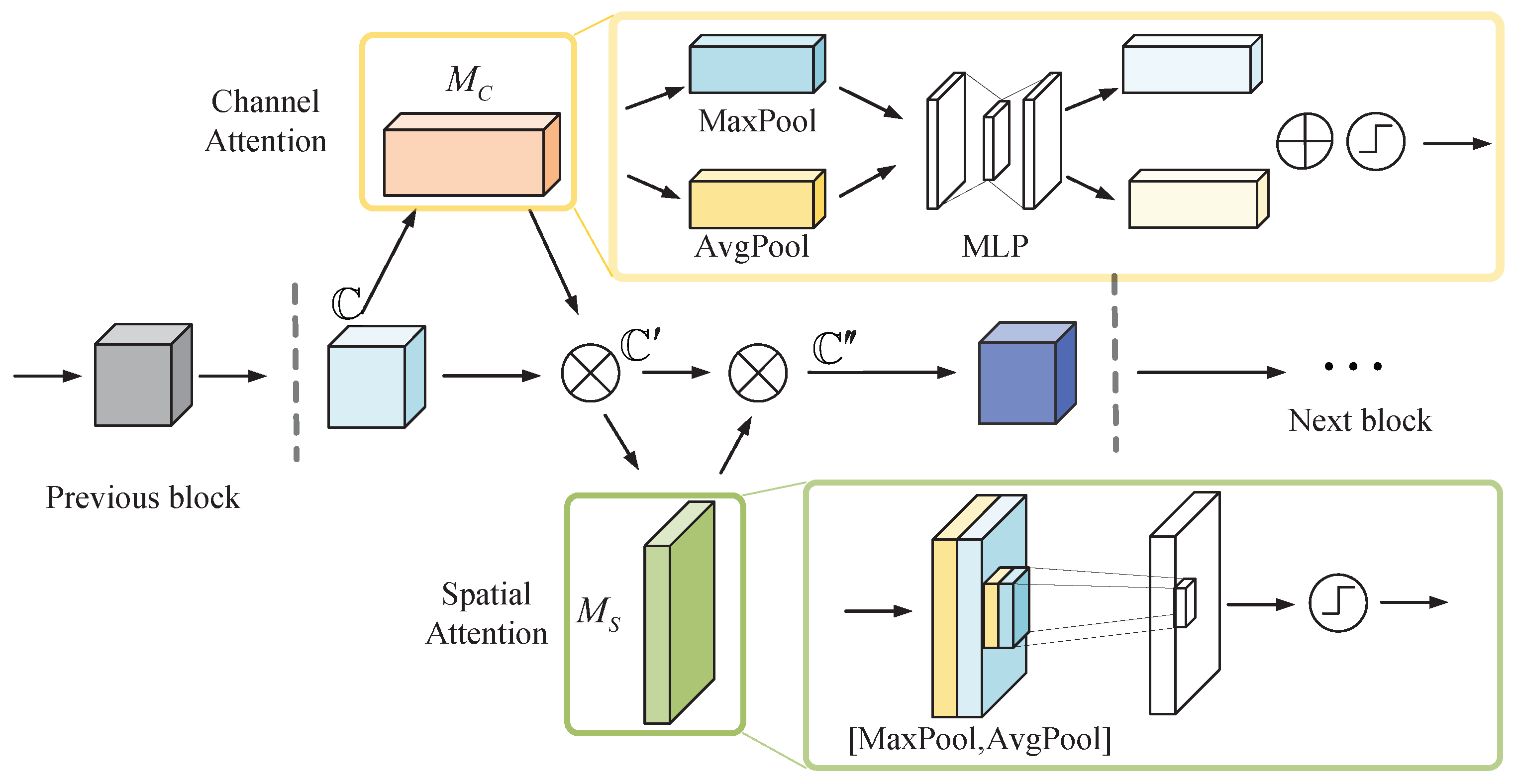
3.2.1. The CBAM Unit
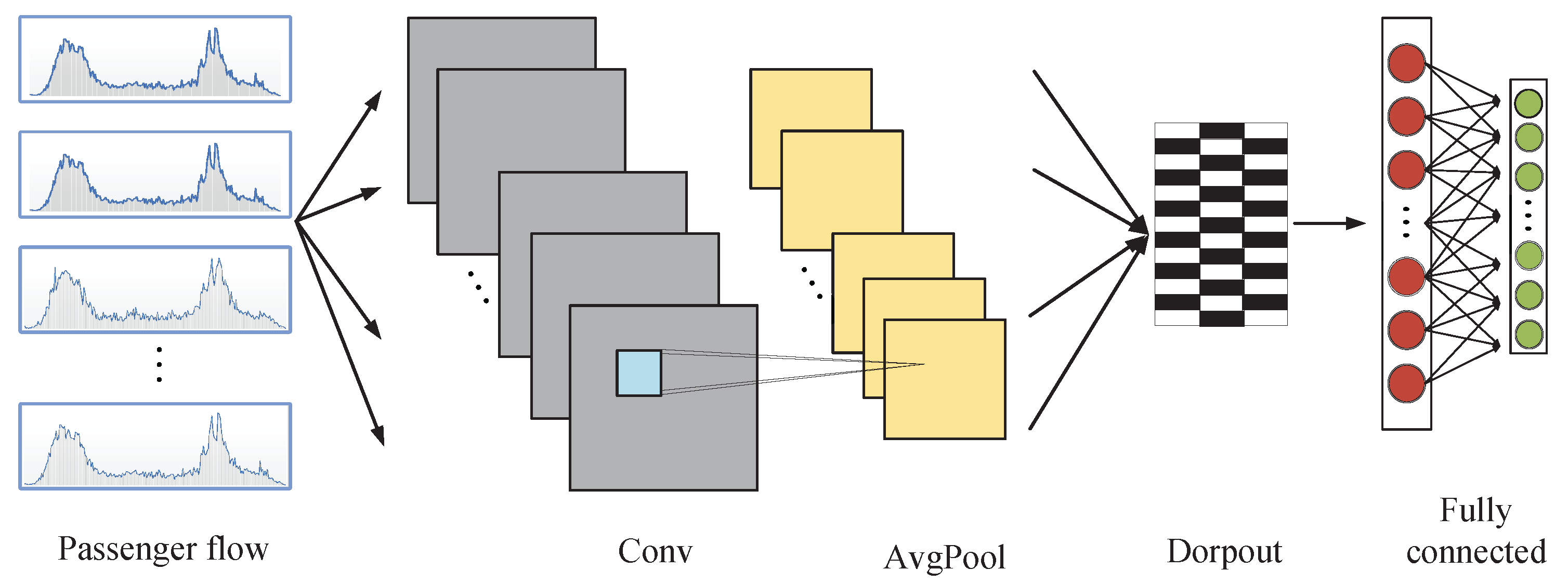
3.2.2. The CNN Model
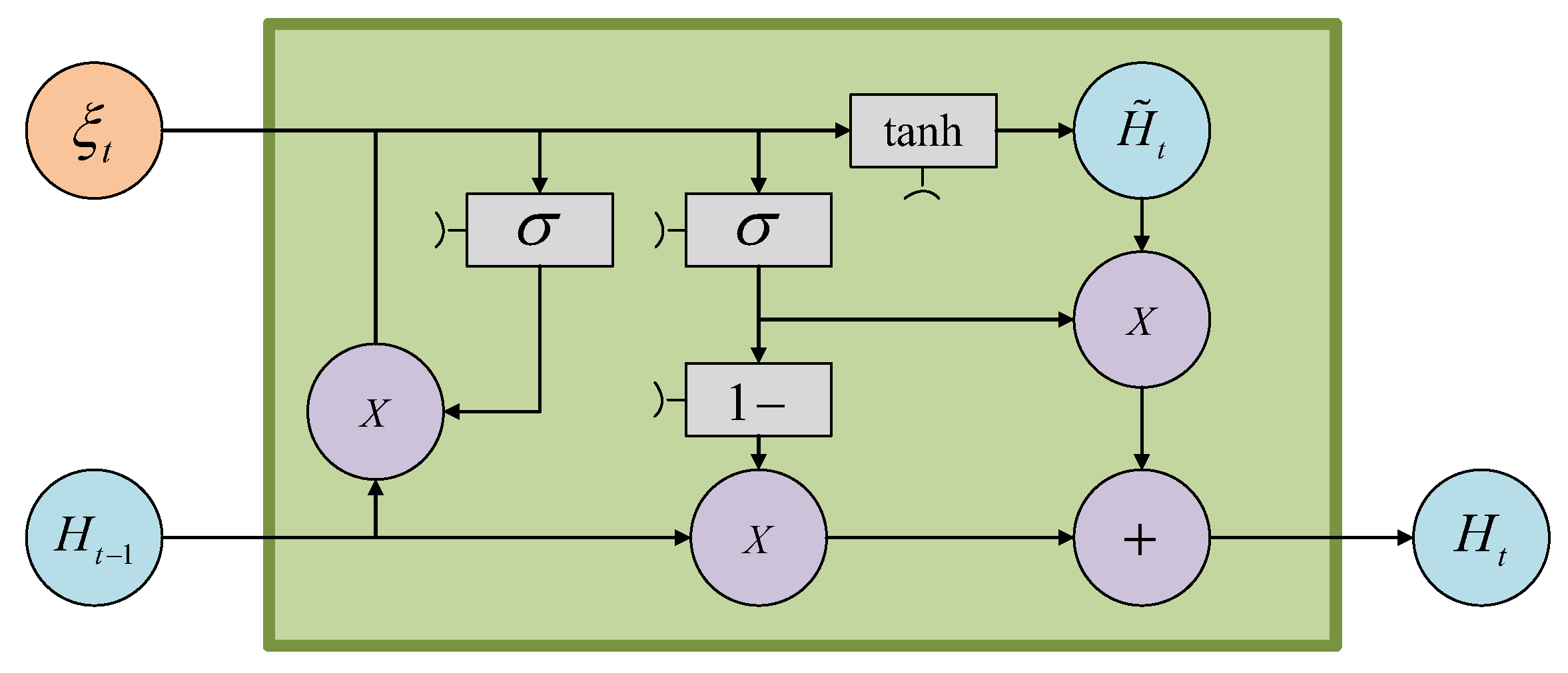
3.2.3. The GRU Model
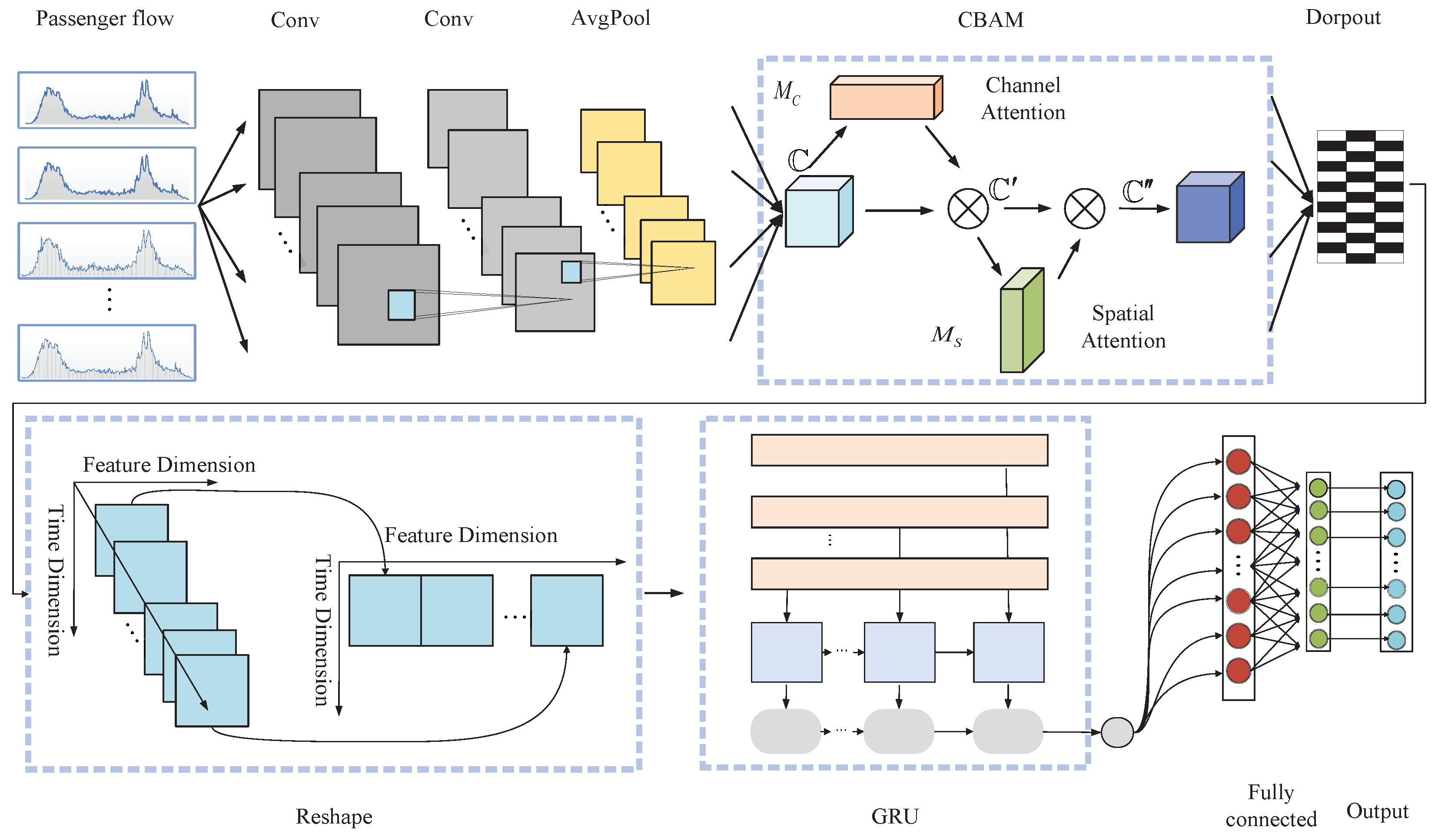
3.2.4. The GDAM-CNN Model
4. Experiment Results
4.1. Data Processing and Evaluation Metrics
4.2. Parameter Settings
4.3. Performance of the GDAM-CNN Model
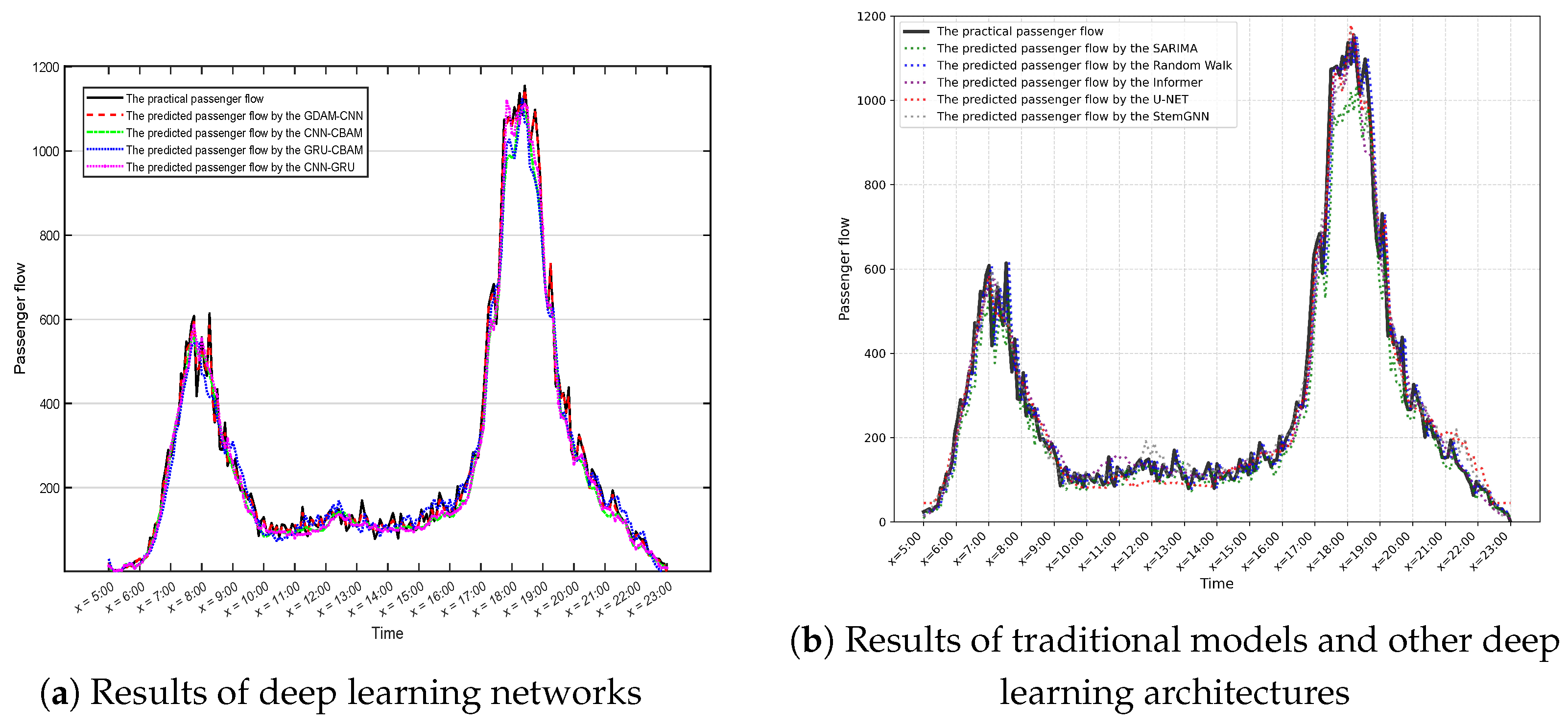
- The FCN model predicts poorly because it cannot effectively capture the temporal correlation between the data.
- Because it can capture the temporal correlation between the data well, the performance of the LSTM and the GRU models improves compared to the FCN, and both implementations are close under the MAE metric. Still, the GRU performs better under the RMSE metric. Meanwhile, during the experiments, we find that the training time of the GRU is shorter with the same network parameters, because each GRU unit uses fewer gate parameters than the LSTM unit, so we choose to use the GRU instead of the LSTM.
- The comparison of the GRU, the GRU-CBAM, the CNN, and the CNN-CBAM shows that integrating the CBAM module in the model can significantly improve the model performance, which proves that the CBAM can improve the performance of the model by increasing the focus on the main influencing factors while suppressing the focus on unimportant information.
- The CNN-GRU model performs better because the CNN and the GRU units give the model the ability to capture the spatial and temporal correlation between the data.
- The GDAM-CNN model performs best by comparison because it can not only focus on the focused information but also capture the spatiotemporal correlation between data, which integrally improves the model’s prediction performance.
- Traditional models (ARIMA and Random Walk) exhibit higher MAE and RSE compared to deep learning approaches. As can be seen from the table, compared to the GDAM-CNN prediction model proposed in this paper, the ARIMA method exhibits a 148.9% increase in MAE and a 190.3% increase in RMSE. Similarly, although the Random Walk outperforms the ARIMA, it shows 114% higher MAE and 137.7% higher RMSE than the GDAM-CNN. From the above analysis, it can be observed that the two traditional prediction methods exhibit higher MAE and RSE compared to deep learning approaches. This is because the ARIMA, as a linear statistical model, and the Random Walk, which assumes constant variance, fail to adequately model the complex nonlinearities and spatiotemporal dynamics inherent in the passenger flow data.
- From the table, it can be observed that the prediction results of the U-Net-style architecture method show a 79.2% higher MAE and 85% higher RMSE compared to the GDAM-CNN, yet it remains the best performing model among the three selected models. Among other deep learning models, the U-Net-style architecture method benefits from its effective multi-scale feature extraction architecture. This enables it to capture important patterns at different resolutions, achieving performance levels comparable to established models like the CNN and the LSTM.
- Models based on the Transformer architecture (Informer and StemGNN) demonstrate performance variations. Specifically, StemGNN, which combines spectral graph convolution, captures spatiotemporal patterns to a degree that yields results close to several baseline deep models such as GRU. Informer also attempts to model long sequences but achieves results similar to the weaker FCN baseline, highlighting the challenge of effectively applying pure Transformer variants to this specific passenger flow prediction task. Their performance, while superior to traditional methods, remains inferior to models like the CNN-GRU and the GDAM-CNN that are specifically designed or enhanced for spatiotemporal feature focus.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AFC | Automated Fare Collection |
| ARMA | Autoregressive Sliding Average Model |
| CBAM | Convolutional Block Attention Module |
| CNN | Convolutional Neural Network |
| GDAM-CNN | Gated Dual Attention Mechanism based Convolutional Neural Network |
| GML | Gaussian Maximum Likelihood |
| GRU | Gated Recursive Unit |
| HA | Historical Averaging |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| NR | Nonparametric Regression |
| RMSE | Root Mean Square Error |
References
- Zhou, S.; Liu, H.; Wang, B.; Chen, B.; Zhou, Y.; Chang, W. Public Norms in the Operation Scheme of Urban Rail Transit Express Trains: The Case of the Beijing Changping Line. Sustainability 2021, 13, 7187. [Google Scholar] [CrossRef]
- Song, H.; Gao, S.; Li, Y.; Liu, L.; Dong, H. Train-centric communication based autonomous train control system. IEEE Trans. Intell. Veh. 2023, 8, 721–731. [Google Scholar] [CrossRef]
- Wang, W.W. Study on Forecast of Railway Passenger Flow Volume under Influence of High-speed Railways. Railw. Transp. Econ. 2016, 38, 42–46. [Google Scholar]
- Sun, Y.; Leng, B.; Guan, W. A novel wavelet-SVM short-time passenger flow prediction in Beijing subway system. Neurocomputing 2015, 166, 109–121. [Google Scholar] [CrossRef]
- Sun, L.; Lu, Y.; Jin, J.G.; Lee, D.H.; Axhausen, K.W. An integrated Bayesian approach for passenger flow assignment in metro networks. Transp. Res. Part C Emerg. Technol. 2015, 52, 116–131. [Google Scholar] [CrossRef]
- Jing, Z.; Yin, X. Neural network-based prediction model for passenger flow in a large passenger station: An exploratory study. IEEE Access 2020, 8, 36876–36884. [Google Scholar] [CrossRef]
- Wang, X.; Li, S.; Tang, T.; Yang, L. Event-triggered predictive control for automatic train regulation and passenger flow in metro rail systems. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1782–1795. [Google Scholar] [CrossRef]
- Wang, X.; Wei, Y.; Wang, H.; Lu, Q.; Dong, H. The dynamic merge control for virtual coupling trains based on prescribed performance control. IEEE Trans. Ind. Inform. 2025, 21, 4779–4788. [Google Scholar] [CrossRef]
- Yin, J.; Tang, T.; Yang, L.; Gao, Z.; Ran, B. Energy-efficient metro train rescheduling with uncertain time-variant passenger demands: An approximate dynamic programming approach. Transp. Res. Part B Methodol. 2016, 91, 178–210. [Google Scholar] [CrossRef]
- Song, H.; Xu, M.; Cheng, Y.; Zeng, X.; Dong, H. Dynamic Hierarchical Optimization for Train-to-Train Communication System. Mathematics 2025, 13, 50. [Google Scholar] [CrossRef]
- Reddy, A.; Lu, A.; Kumar, S.; Bashmakov, V.; Rudenko, S. Entry-only automated fare-collection system data used to infer ridership, rider destinations, unlinked trips, and passenger miles. Transp. Res. Rec. 2009, 2110, 128–136. [Google Scholar] [CrossRef]
- Song, H.; Li, L.; Li, Y.; Tan, L.; Dong, H. Functional Safety and Performance Analysis of Autonomous Route Management for Autonomous Train Control System. IEEE Trans. Intell. Transp. Syst. 2024, 25, 13291–13304. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, G.; Liu, X.; Lyu, W. Verification and Analysis of Traffic Evaluation Indicators in Urban Transportation System Planning Based on Multi-Source Data—A Case Study of Qingdao City, China. IEEE Access 2019, 7, 110103–110115. [Google Scholar] [CrossRef]
- Bai, Y.; Sun, Z.; Zeng, B.; Deng, J.; Li, C. A multi-pattern deep fusion model for short-term bus passenger flow forecasting. Appl. Soft Comput. 2017, 58, 669–680. [Google Scholar] [CrossRef]
- Wei, Y.; Chen, M.C. Forecasting the short-term metro passenger flow with empirical mode decomposition and neural networks. Transp. Res. Part C Emerg. Technol. 2012, 21, 148–162. [Google Scholar] [CrossRef]
- Smith, B.L.; Williams, B.M.; Oswald, R.K. Comparison of parametric and nonparametric models for traffic flow forecasting. Transp. Res. Part C Emerg. Technol. 2002, 10, 303–321. [Google Scholar] [CrossRef]
- Zhang, G.; Patuwo, B.E.; Hu, M.Y. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Cao, L.; Liu, S.G.; Zeng, X.H.; He, P.; Yuan, Y. Passenger flow prediction based on particle filter optimization. Appl. Mech. Mater. 2013, 373–375, 1256–1260. [Google Scholar] [CrossRef]
- Smith, B.L.; Demetsky, M.J. Traffic flow forecasting: Comparison of modeling approaches. J. Transp. Eng. 1997, 123, 261–266. [Google Scholar] [CrossRef]
- Williams, B.M.; Durvasula, P.K.; Brown, D.E. Urban freeway traffic flow prediction: Application of seasonal autoregressive integrated moving average and exponential smoothing models. Transp. Res. Rec. 1998, 1644, 132–141. [Google Scholar] [CrossRef]
- Jiao, P.; Li, R.; Sun, T.; Hou, Z.; Ibrahim, A. Three revised kalman filtering models for short-term rail transit passenger flow prediction. Math. Probl. Eng. 2016. [Google Scholar] [CrossRef]
- Shekhar, S.; Williams, B.M. Adaptive seasonal time series models for forecasting short-term traffic flow. Transp. Res. Rec. 2007, 2024, 116–125. [Google Scholar] [CrossRef]
- Okutani, I.; Stephanedes, Y.J. Dynamic prediction of traffic volume through Kalman filtering theory. Transp. Res. Part B Methodol. 1984, 18, 1–11. [Google Scholar] [CrossRef]
- Yakowitz, S. Nearest-neighbour methods for time series analysis. J. Time Ser. Anal. 1987, 8, 235–247. [Google Scholar] [CrossRef]
- Karlsson, M.; Yakowitz, S. Rainfall-runoff forecasting methods, old and new. Stoch. Hydrol. Hydraul. 1987, 1, 303–318. [Google Scholar] [CrossRef]
- Oswald, R.K.; Scherer, W.T.; Smith, B.L. Traffic Flow Forecasting Using Approximate Nearest Neighbor Nonparametric Regression. 2000. Available online: https://rosap.ntl.bts.gov/view/dot/15834 (accessed on 17 June 2025).
- Clark, S. Traffic prediction using multivariate nonparametric regression. J. Transp. Eng. 2003, 129, 161–168. [Google Scholar] [CrossRef]
- Kindzerske, M.D.; Ni, D. Composite nearest neighbor nonparametric regression to improve traffic prediction. Transp. Res. Rec. 2007, 1993, 30–35. [Google Scholar] [CrossRef]
- Tang, Y.F.; Lam, W.H.K.; Ng, P.L.P. Comparison of four modeling techniques for short-term AADT forecasting in Hong Kong. J. Transp. Eng. 2003, 129, 271–277. [Google Scholar] [CrossRef]
- Van Arem, B.; Kirby, H.R.; Van Der Vlist, M.J.M.; Whittaker, J.C. Recent advances and applications in the field of short-term traffic forecasting. Int. J. Forecast. 1997, 13, 1–12. [Google Scholar] [CrossRef]
- Zhang, H.M. Recursive prediction of traffic conditions with neural network models. J. Transp. Eng. 2000, 126, 472–481. [Google Scholar] [CrossRef]
- Dia, H. An object-oriented neural network approach to short-term traffic forecasting. Eur. J. Oper. Res. 2001, 131, 253–261. [Google Scholar] [CrossRef]
- Zheng, W.; Lee, D.H.; Shi, Q. Short-term freeway traffic flow prediction: Bayesian combined neural network approach. J. Transp. Eng. 2006, 132, 114–121. [Google Scholar] [CrossRef]
- Chen, H.; Grant-Muller, S. Use of sequential learning for short-term traffic flow forecasting. Transp. Res. Part C Emerg. Technol. 2001, 9, 319–336. [Google Scholar] [CrossRef]
- Van Lint, J.W.C.; Hoogendoorn, S.P.; van Zuylen, H.J. Accurate freeway travel time prediction with state-space neural networks under missing data. Transp. Res. Part C Emerg. Technol. 2005, 13, 347–369. [Google Scholar] [CrossRef]
- Belhadi, A.; Djenouri, Y.; Djenouri, D.; Lin, J.C.-W. A recurrent neural network for urban long-term traffic flow forecasting. Appl. Intell. 2020, 50, 3252–3265. [Google Scholar] [CrossRef]
- Li, Z.; Li, C.; Cui, X.; Zhang, Z. Short-term Traffic Flow Prediction Based on Recurrent Neural Network. In Proceedings of the 2021 International Conference on Computer Communication and Artificial Intelligence (CCAI), Guangzhou, China, 7–9 May 2021; pp. 81–85. [Google Scholar]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Zhang, W.; Yu, Y.; Qi, Y.; Shu, F.; Wang, Y. Short-term traffic flow prediction based on spatio-temporal analysis and CNN deep learning. Transp. A Transp. Sci. 2019, 15, 1688–1711. [Google Scholar] [CrossRef]
- Yang, X.; Xue, Q.; Ding, M.; Wu, J.; Gao, Z. Short-term prediction of passenger volume for urban rail systems: A deep learning approach based on smart-card data. Int. J. Prod. Econ. 2021, 231, 107920. [Google Scholar] [CrossRef]
- Yang, X.; Xue, Q.; Yang, X.; Yin, H.; Qu, Y.; Li, X.; Wu, J. A novel prediction model for the inbound passenger flow of urban rail transit. Inf. Sci. 2021, 566, 347–363. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, F.; Cui, Z.; Guo, Y.; Zhu, Y. Deep learning architecture for short-term passenger flow forecasting in urban rail transit. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7004–7014. [Google Scholar] [CrossRef]
- Bai, J.; Zhu, J.; Song, Y.; Zhao, L.; Hou, Z.; Du, R.; Li, H. A3t-gcn: Attention temporal graph convolutional network for traffic forecasting. ISPRS Int. J. Geo-Inf. 2021, 10, 485. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, S.H.; Fernandes, S.L.; Zhu, Z.; Zhang, Y.D. AVNC: Attention-based VGG-style network for COVID-19 diagnosis by CBAM. IEEE Sens. J. 2021, 22, 17431–17438. [Google Scholar] [CrossRef] [PubMed]
- Cao, W.; Feng, Z.; Zhang, D.; Huang, Y. Facial expression recognition via a CBAM embedded network. Procedia Comput. Sci. 2020, 174, 463–477. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Z.; Jia, R. DeepPF: A deep learning based architecture for metro passenger flow prediction. Transp. Res. Part C Emerg. Technol. 2019, 101, 18–34. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Qin, L.; Ran, B.; Jiang, Z. A hybrid deep learning based traffic flow prediction method and its understanding. Transp. Res. Part C Emerg. Technol. 2018, 90, 166–180. [Google Scholar] [CrossRef]
- Wang, X.; Xin, T.; Wang, H.; Zhu, L.; Cui, D. A generative adversarial network based learning approach to the autonomous decision making of high-speed trains. IEEE Trans. Veh. Technol. 2022, 71, 2399–2412. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Representative Models | Strengths | Limitations |
|---|---|---|---|
| Traditional Statistical | ARMA (Cao et al. [18]), Kalman Filter (Okutani et al. [23]) | Interpretable parameters; Computational efficiency | Linear assumption; Poor nonlinear fitting |
| Nonparametric & Heuristic | NR (Clark et al. [27]), GML (Tang et al. [29]) | Data-driven; Handles nonlinearity | High computational cost; Overfitting risk |
| Classical Neural Networks | TDNN (Zhang et al. [31]), TLRN (Dia et al. [32]) | Nonlinear mapping; Feature learning | Shallow architectures; Manual feature engineering |
| Deep neural networks | LSTM (Fu et al. [38]), CNN (Zhang et al. [39]) | Automatic feature extraction; Spatiotemporal modeling | Black-box nature; Hardware-intensive |
| Attention-Based Deep | A3T-GCN (Bai et al. [43]) | Dynamic feature weighting; Global context capture | Heuristic attention design; Untailored mechanisms |
| MAE/RMSE | GRU | 1 | 2 | 3 |
|---|---|---|---|---|
| CNN | ||||
| 1 | 24.171 ± 0.616 | 24.694 ± 1.693 | 25.102 ± 2.193 | |
| 34.536 ± 0.501 | 34.714 ± 2.348 | 34.943 ± 2.379 | ||
| 2 | 23.938 ± 0.892 | 23.954 ± 0.757 | 24.579 ± 1.180 | |
| 34.095 ± 0.980 | 34.151 ± 0.972 | 34.588 ± 1.673 | ||
| 3 | 24.691 ± 1.040 | 26.919 ± 3.522 | 24.393 ± 1.165 | |
| 35.736 ± 1.412 | 38.989 ± 4.909 | 35.384 ± 1.741 | ||
| MAE/RMSE | CNN | 32, 64 | 32, 128 | 64, 128 |
|---|---|---|---|---|
| GRU | ||||
| 32 | 24.649 ± 0.819 | 24.372 ± 0.691 | 24.134 ± 0.677 | |
| 35.170 ± 1.970 | 34.028 ± 0.952 | 34.374 ± 1.261 | ||
| 64 | 24.707 ± 0.460 | 22.988 ± 0.682 | 25.312 ± 0.129 | |
| 35.0659 ± 0.658 | 33.194 ± 0.910 | 36.727 ± 0.489 | ||
| 128 | 24.761 ± 1.206 | 25.242 ± 0.328 | 24.477 ± 1.249 | |
| 36.077 ± 2.061 | 36.123 ± 0.461 | 34.362 ± 1.386 | ||
| Step Size | MAE | RMSE |
|---|---|---|
| 6 | 26.290 ± 2.747 | 38.222 ± 3.494 |
| 8 | 24.201 ± 1.041 | 35.291 ± 1.643 |
| 10 | 23.170 ± 0.794 | 33.363 ± 1.410 |
| 12 | 24.731 ± 1.376 | 35.526 ± 2.061 |
| 14 | 25.175 ± 1.193 | 36.272 ± 2.200 |
| 16 | 25.772 ± 1.969 | 36.116 ± 3.697 |
| 18 | 26.014 ± 1.608 | 37.021 ± 2.264 |
| 20 | 24.867 ± 1.316 | 35.707 ± 2.553 |
| 22 | 25.624 ± 1.407 | 36.111 ± 2.189 |
| 24 | 24.037 ± 1.435 | 34.967 ± 2.309 |
| Model | The Model Uses Network Units and the Number of Neurons |
|---|---|
| FCN | FCN (128) |
| CNN | CNN (32),CNN (128) |
| LSTM | LSTM (64), LSTM (64) |
| GRU | GRU (64), GRU (64) |
| CNN-CBAM | CNN (32), CNN (128), CBAM |
| GRU-CBAM | GRU (64), GRU (64), CBAM |
| CNN-GRU | CNN (32), CNN (128), GRU (64) |
| GDAM-CNN | CNN (32), CNN (128), CBAM, GRU (64) |
| Model | MAE | RMSE |
|---|---|---|
| FCN | 33.26 | 46.22 |
| CNN | 27.45 | 40.83 |
| LSTM | 29.47 | 41.97 |
| GRU | 29.51 | 41.26 |
| CNN-GRU | 23.78 | 32.84 |
| CNN-CBAM | 25.06 | 36.11 |
| GRU-CBAM | 24.31 | 34.79 |
| GDAM-CNN | 16.71 | 22.09 |
| SARIMA | 41.25 | 64.13 |
| Random-Walk | 35.76 | 52.51 |
| Informer | 32.35 | 47.11 |
| U-NET | 29.94 | 40.87 |
| StemGNN | 30.10 | 43.15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Chen, H.; Lu, Q.; Wang, X.; Song, H.; Qin, L. A Spatiotemporal Convolutional Neural Network Model Based on Dual Attention Mechanism for Passenger Flow Prediction. Mathematics 2025, 13, 2316. https://doi.org/10.3390/math13142316
Li J, Chen H, Lu Q, Wang X, Song H, Qin L. A Spatiotemporal Convolutional Neural Network Model Based on Dual Attention Mechanism for Passenger Flow Prediction. Mathematics. 2025; 13(14):2316. https://doi.org/10.3390/math13142316
Chicago/Turabian StyleLi, Jinlong, Haoran Chen, Qiuzi Lu, Xi Wang, Haifeng Song, and Lunming Qin. 2025. "A Spatiotemporal Convolutional Neural Network Model Based on Dual Attention Mechanism for Passenger Flow Prediction" Mathematics 13, no. 14: 2316. https://doi.org/10.3390/math13142316
APA StyleLi, J., Chen, H., Lu, Q., Wang, X., Song, H., & Qin, L. (2025). A Spatiotemporal Convolutional Neural Network Model Based on Dual Attention Mechanism for Passenger Flow Prediction. Mathematics, 13(14), 2316. https://doi.org/10.3390/math13142316