
Beyond Standard Losses: Redefining Text-to-SQL with Task-Specific Optimization

 ,
, 
Abstract
1. Introduction
- Length-based training: Long queries cause problems because of error propagation in autoregressive generation. So, recent studies have tried to solve this problem by adding curriculum learning [22]. The plan is to start by teaching models how to predict short and simple questions. Then, as training continues, the model learns how to answer more complex and longer samples. In this paper, the RASAT sequence-to-sequence model is used, which is built on the T5 architecture, enhanced with relation-aware self-attention to capture structural relationships in SQL queries and database schemas.
- Hybrid architectures: Some researchers, such as Berdnyk and Colley [23] and Nguyen et al. [24], use reinforcement learning (RL) [25,26] to improve LLMs’ ability to convert text into SQL. To achieve this, they give the model rewards to help it make correct SQL queries that work properly on the database execution. On the one hand, Berdnyk and Collery use flan-t5-base [27] as the primary LLM for SQL generation and LLaMa-3-405B-Instruct LLM to reward function design. On the other hand, Nguyen et al. use T5-small and T5-base [28], allowing them to train and deploy on standard user hardware rather than requiring specialized cloud infrastructure.
- Workflow modification: Yuanzhen Xie and his team [29] concentrate on the workflow paradigm, which aims to improve how well and how widely LLMs solve problems through decomposition. They use OpenAI ChatGPT-3.5 and GPT-4 as their base models to carry out the training sessions. This technique uses the information determination module to get rid of unnecessary information. It also uses a new prompt structure based on problem classification, which improves how the model focuses. Also, there are self-correction and active learning modules. The idea is to make LLM problem solving more extensive.
- Two-stage learning: Ling Xiao et al. [30] present a method that divides training into two phases. In the first phase, the system understands the schema. In the second phase, the system generates the SQL query. According to the authors this has allowed them to make the model much better by making sure that the way the data is organized is correct before they start working on the questions. This approach also tries to reduce errors in complex queries involving joins or aggregations.
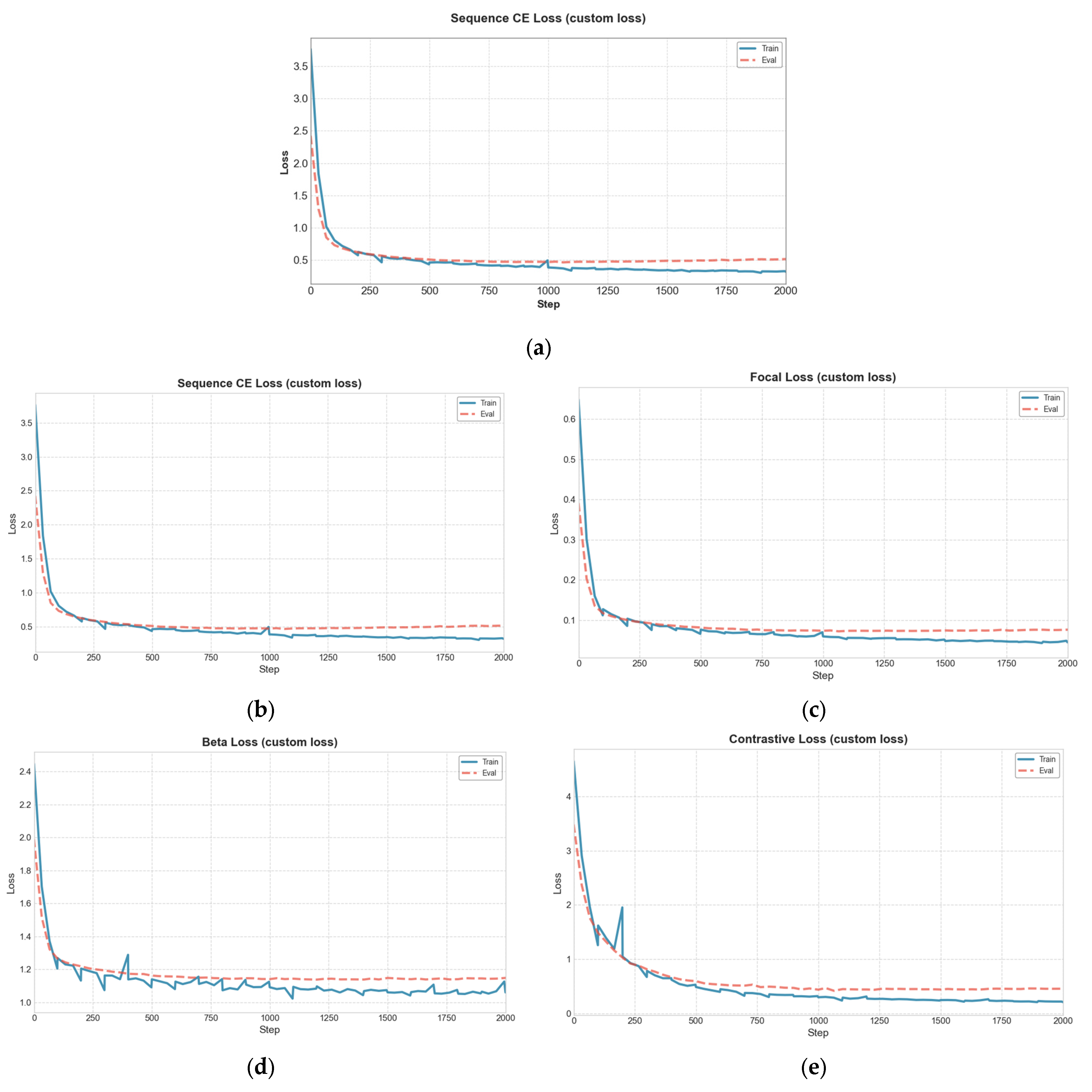
- Sequence-Matching Cross-Entropy Loss: Extends standard cross-entropy by weighting important token sequences (e.g., table names, error codes), allowing flexibility in their positions.
- Focal Loss: Addresses class imbalance by focusing on hard-to-predict tokens.
- F-beta Loss: Optimizes accuracy and recovery for critical token sequences, emphasizing recovery as training progresses.
- Contrastive Sequence Loss: Ensures correct relative distances between token sequences, preserving SQL structure.
- We propose a new dynamic loss function specifically adapted to text-to-SQL conversion tasks. On the one hand, this loss combines standardized components in LLM training with novel token sequence-level targets (as opposed to the standard token-to-token target) with innovative components adapted from other AI tasks to emphasize structural and semantic correctness. On the other hand, custom weights are introduced in various aspects: static weights for important groups of words to emphasize aspects of our database that are considered most important; dynamic weights for the individual components of the cost function to focus on different parts of SQL as the tuning progresses.
- Our approach introduces schema alignment loss and logical consistency terms that adaptively focus on the most error-prone aspects of SQL summarization. Unlike other methods such as curriculum learning, which requires the stepwise preparation of data, our method automatically incorporates length-aware training. Moreover, in contrast to reinforcement learning approaches, it stays within the standard supervised learning process, which simplifies its implementation and deployment.
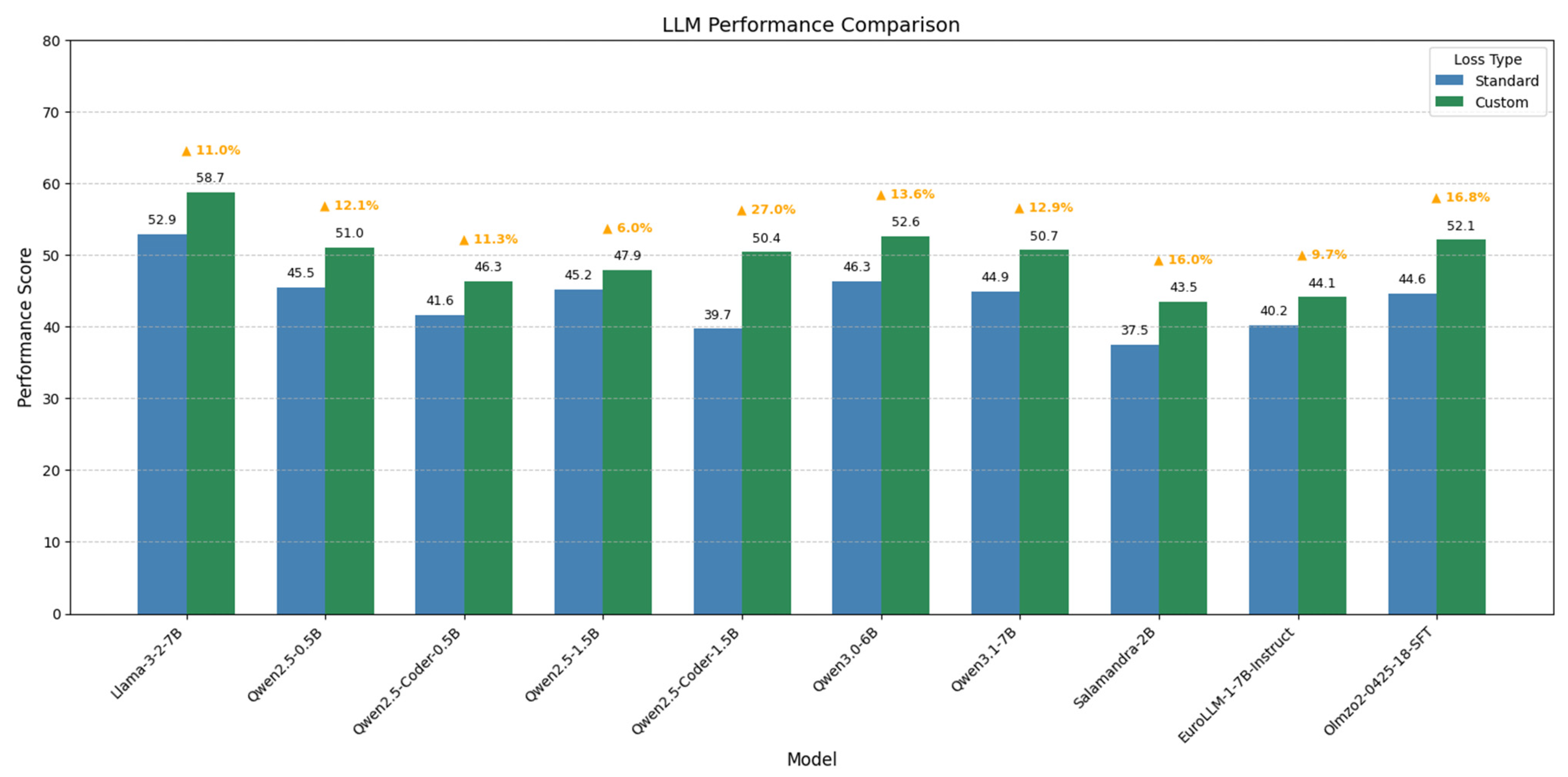
- Our proposed method is evaluated on multiple open-access models of less than 2B parameters, achieving more than 20% more improvement in some of the cases.
2. Materials and Methods
2.1. Dataset
2.2. Loss Function
2.3. Dynamic Custom Loss Function
2.3.1. Sequence-Matching Cross-Entropy Loss
2.3.2. Focal Loss
2.3.3. F-Beta Loss
2.3.4. Contrastive Loss
2.3.5. Dynamic Custom Loss
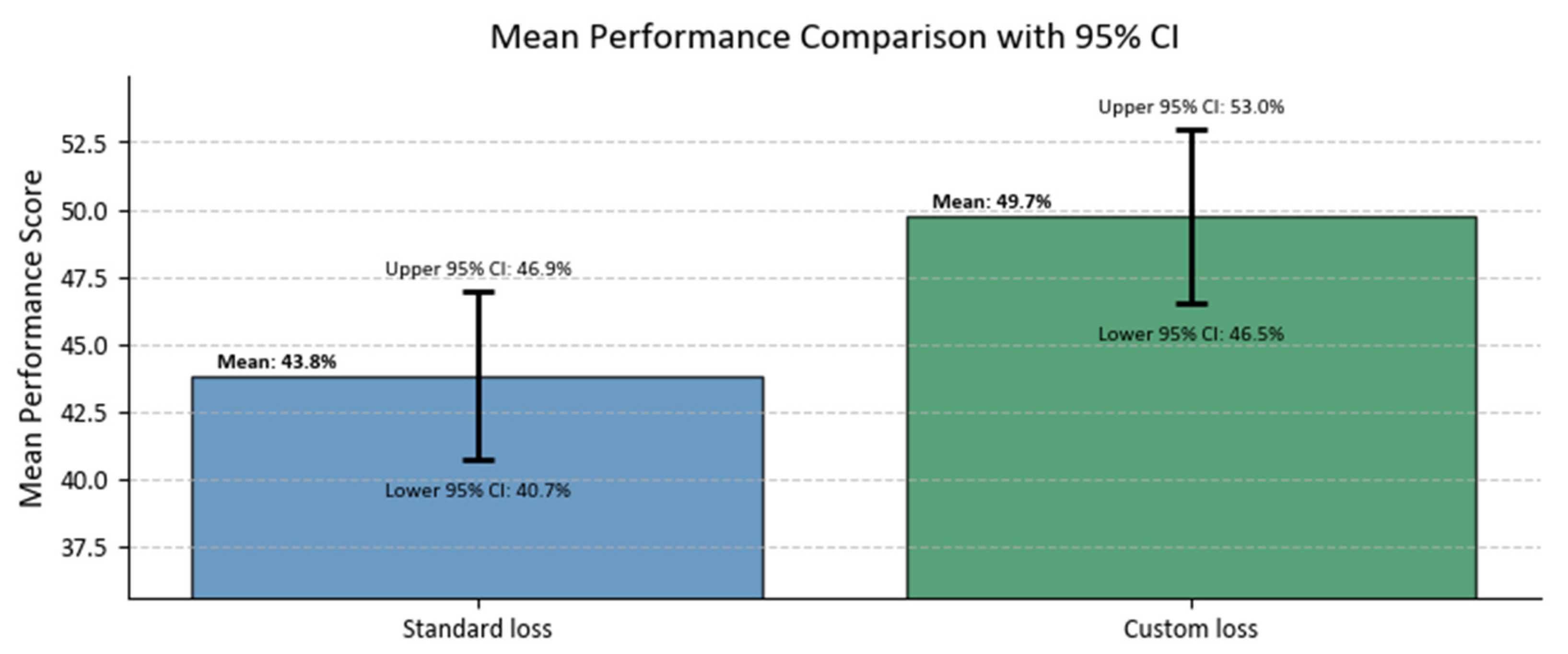
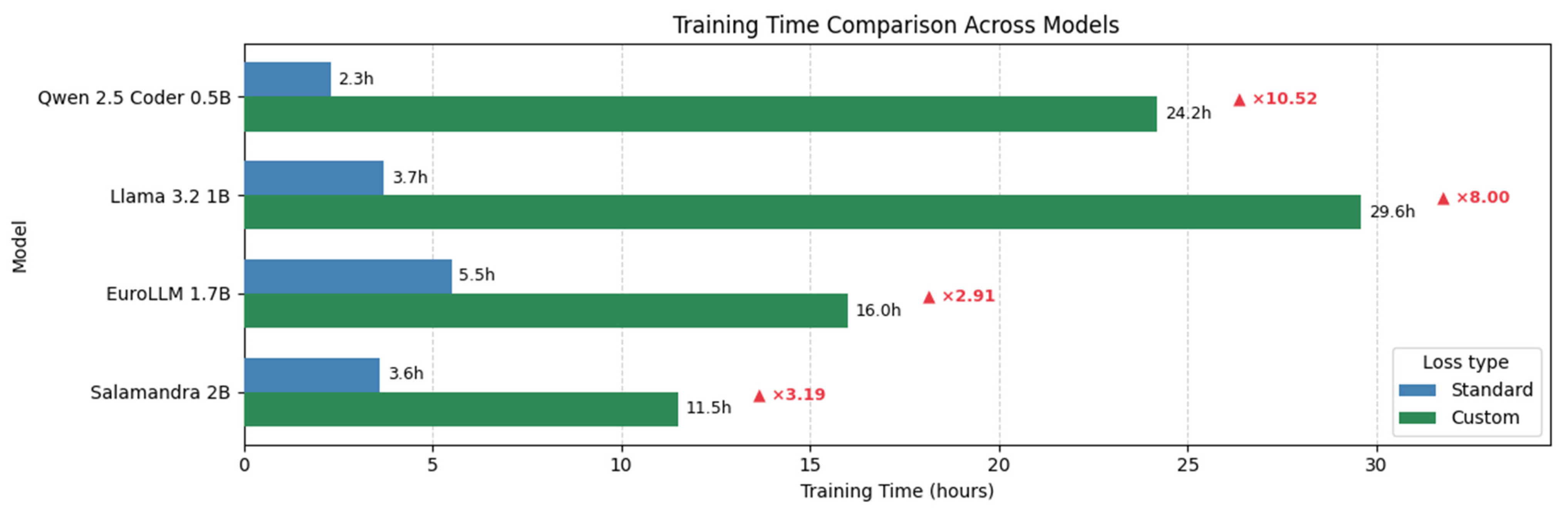
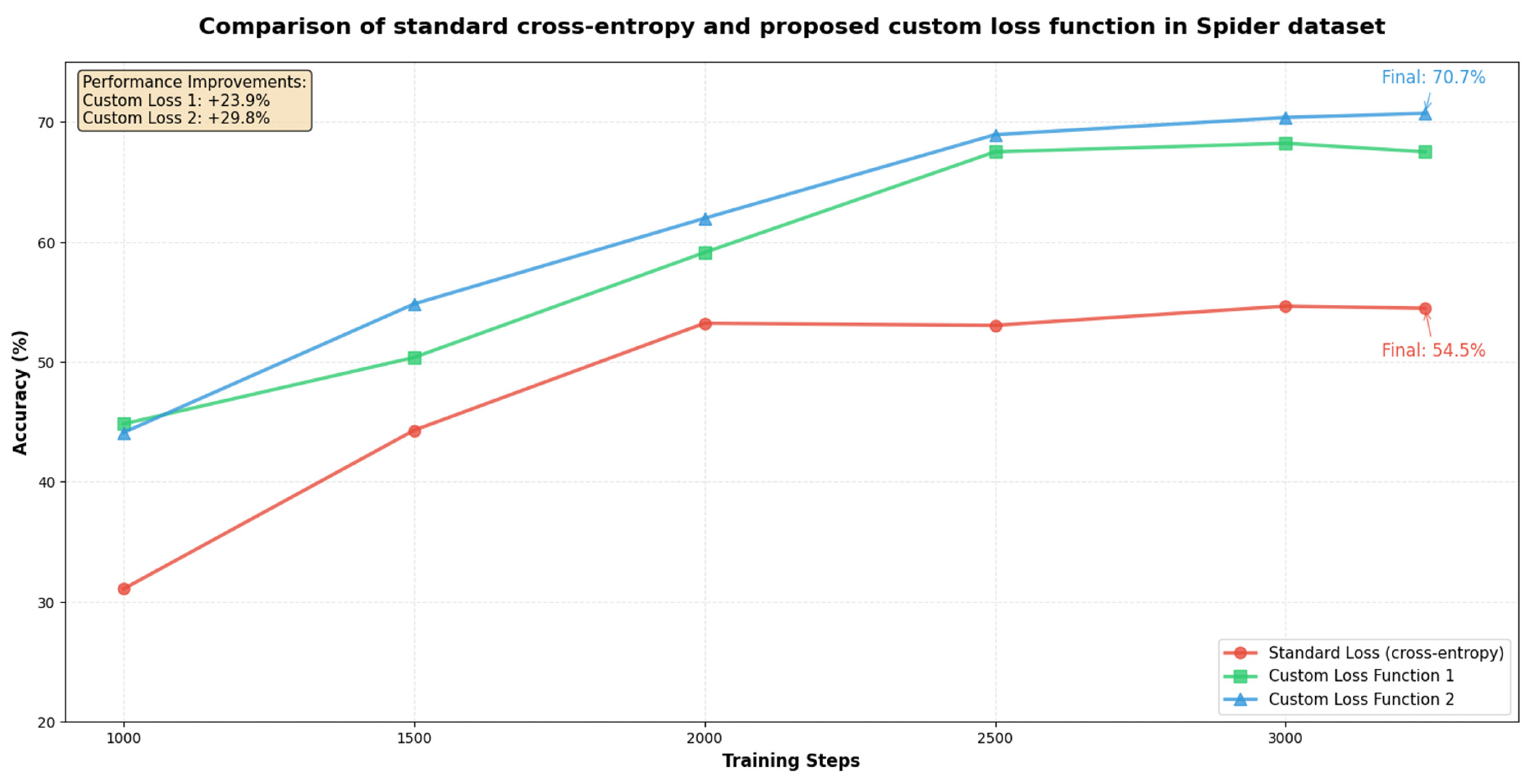
3. Results
- : Decreases from 1.0 to 0.3, reducing emphasis on sequence matching as training progresses to allow other components to refine complex structures.
- : Increases from 0.0 to 0.8, prioritizing hard-to-predict tokens (e.g., rare error codes) in later epochs.
- : Increases from 0.0 to 1.0, enhancing focus on precision and recall for critical token sequences.
- Remains constant, ensuring the consistent enforcement of structural integrity throughout training.
- Exact Query: This counts the number of cases where the LLM-generated SQL query exactly matches the ground truth (GT) SQL query. That includes matching keywords, table names, column names, conditions, and order of operations. Obviously, if the predicted query and its label are the same, the result in the database is the same. An example of an exact query is shown below:
Generated query SELECT TOP 10 Vehicle_Id, COUNT(*) AS FailureCount
FROM Failure_Codes
WHERE YEAR(Datetime) = 2021 AND Error_Code = ‘UH0043’
GROUP BY Vehicle_Id
ORDER BY FailureCount DESC;GT query SELECT TOP 10 Vehicle_Id, COUNT(*) AS FailureCount
FROM Failure_Codes
WHERE YEAR(Datetime) = 2021 AND Error_Code = ‘UH0043’
GROUP BY Vehicle_Id
ORDER BY FailureCount DESC; - Exact Result: This counts the number of cases where the result returned by executing the LLM-generated SQL query on the database exactly matches the result of the ground truth SQL query. This includes matching values, column names, and the order of rows and columns in the resulting table. An example of an exact result is shown below:
Generated query SELECT TOP 10 Vehicle_Id, COUNT(*) AS FailureCount
FROM Failure_Codes
WHERE
Datetime >= ‘2021-01-01’
AND Datetime < ‘2022-01-01’
AND Error_Code = ‘UH0043’
GROUP BY Vehicle_Id
ORDER BY FailureCount DESC;GT query SELECT TOP 10 Vehicle_Id, COUNT(*) AS FailureCount
FROM Failure_Codes
WHERE YEAR(Datetime) = 2021 AND Error_Code = ‘UH0043’
GROUP BY Vehicle_Id
ORDER BY FailureCount DESC; - Same Result: This counts the number of cases where the query result is logically the same, even if the column names differ or the column order is different in the results table. An example of the same result is shown below:
Generated query SELECT TOP 10 Vehicle_Id, COUNT(*) AS Num_of_failures
FROM Failure_Codes
WHERE Error_Code = ‘UH0043’ AND YEAR(Datetime) = 2021
GROUP BY Vehicle_Id
ORDER BY Num_of_failures DESC;GT query SELECT TOP 10 Vehicle_Id, COUNT(*) AS FailureCount
FROM Failure_Codes
WHERE YEAR(Datetime) = 2021 AND Error_Code = ‘UH0043’
GROUP BY Vehicle_Id
ORDER BY FailureCount DESC;
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| SQL | Structured Query Language |
| AI | Artificial Intelligence |
| DL | Deep Learning |
| LLM | Large Language Model |
| RL | Reinforcement Learning |
| CLLM | Consistency-Driven Language Models |
| SFT | Supervised Fine-Tuning |
| FLAT | Forget data only Loss AjustmenT |
| ML | Machine Learning |
| CI | Confidence Interval |
References
- Mohammadjafari, A.; Maida, A.S.; Gottumukkala, R. From Natural Language to SQL: Review of LLM-Based Text-to-SQL Systems. arXiv 2024, arXiv:2410.01066. [Google Scholar]
- Gan, Y.; Purver, M.; Woodward, J.R. A Review of Cross-Domain Text-to-SQL Models. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: Student Research Workshop, Suzhou, China, 4–7 December 2020. [Google Scholar]
- Baig, M.S.; Imran, A.; Yasin, A.; Butt, A.H.; Khan, M.I. Natural Language to SQL Queries: A Review. Int. J. Innov. Sci. Technol. 2022, 4, 147–162. [Google Scholar] [CrossRef]
- Fu, Y.; Ou, W.; Yu, Z.; Lin, Y. MIGA: A Unified Multi-Task Generation Framework for Conversational Text-to-SQL. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Askari, A.; Poelitz, C.; Tang, X. MAGIC: Generating Self-Correction Guideline for In-Context Text-to-SQL. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 27 February–2 March 2025. [Google Scholar]
- Chen, Z.; Chen, S.; White, M.; Mooney, R.; Payani, A.; Srinivasa, J.; Su, Y.; Sun, H. Text-to-SQL Error Correction with Language Models of Code. arXiv 2023, arXiv:2305.13073. [Google Scholar]
- Meyer, Y.; Emadi, M.; Nathawani, D.; Ramaswamy, L.; Boyd, K.; Van Segbroeck, M.; Grossman, M.; Mlocek, P.; Newberry, D. Synthetic-Text-To-SQL: A Synthetic Dataset for Training Language Models to Generate SQL Queries from Natural Language Prompts 2024. Available online: https://huggingface.co/datasets/gretelai/synthetic_text_to_sql (accessed on 14 March 2025).
- Zhu, X.; Li, Q.; Cui, L.; Liu, Y. Large Language Model Enhanced Text-to-SQL Generation: A Survey. arXiv 2024, arXiv:2410.06011. [Google Scholar]
- Kaplan, R.M.; Webber, B.L. The Lunar Sciences Natural Language Information System. 1972. Available online: https://www.researchgate.net/publication/24285293_The_Lunar_Sciences_Natural_Language_Information_System (accessed on 18 April 2025).
- Kanburoğlu, A.B.; Tek, F.B. Text-to-SQL: A Methodical Review of Challenges and Models. Turk. J. Electr. Eng. Comput. Sci. 2024, 32, 403–419. [Google Scholar] [CrossRef]
- Lee, D.; Yoon, J.; Song, J.; Lee, S.; Yoon, S. One-Shot Learning for Text-to-SQL Generation. arXiv 2019, arXiv:1905.11499. [Google Scholar]
- Iyer, S.; Konstas, I.; Cheung, A.; Krishnamurthy, J.; Zettlemoyer, L. Learning a Neural Semantic Parser from User Feedback. arXiv 2017, arXiv:1704.08760. [Google Scholar] [CrossRef]
- Mellah, Y.; Rhouati, A.; Ettifouri, E.H.; Bouchentouf, T.; Belkasmi, M.G. SQL Generation from Natural Language: A Sequence-to-Sequence Model Powered by the Transformers Architecture and Association Rules. J. Comput. Sci. 2021, 17, 480–489. [Google Scholar] [CrossRef]
- Xu, K.; Wu, L.; Wang, Z.; Feng, Y.; Sheinin, V. SQL-to-Text Generation with Graph-to-Sequence Model. arXiv 2018, arXiv:1809.05255. [Google Scholar]
- Lin, K.; Bogin, B.; Neumann, M.; Berant, J.; Gardner, M. Grammar-Based Neural Text-to-SQL Generation. arXiv 2019, arXiv:1905.13326. [Google Scholar]
- Wu, K.; Wang, L.; Li, Z.; Xiao, X. Faster and Better Grammar-Based Text-to-SQL Parsing via Clause-Level Parallel Decoding and Alignment Loss. In CCF International Conference on Natural Language Processing and Chinese Computing; Springer Nature Switzerland: Cham, Switzerland, 2022. [Google Scholar] [CrossRef]
- Liu, A.; Hu, X.; Lin, L.; Wen, L. Semantic Enhanced Text-to-SQL Parsing via Iteratively Learning Schema Linking Graph. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Association for Computing Machinery, Washington, DC, USA, 14 August 2022; pp. 1021–1030. [Google Scholar]
- Zhang, Q.; Dong, J.; Chen, H.; Li, W.; Huang, F.; Huang, X. Structure Guided Large Language Model for SQL Generation. arXiv 2024, arXiv:2402.13284. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, C.; Liao, C.; Wang, J.; Zhao, X.; Yu, H.; Wang, J.; Li, J.; Shi, W. SQLfuse: Enhancing Text-to-SQL Performance through Comprehensive LLM Synergy. arXiv 2024, arXiv:2407.14568. [Google Scholar]
- Hong, Z.; Yuan, Z.; Zhang, Q.; Chen, H.; Dong, J.; Huang, F.; Huang, X. Next-Generation Database Interfaces: A Survey of LLM-Based Text-to-SQL. arXiv 2024, arXiv:2406.08426. [Google Scholar]
- Pourreza, M.; Talaei, S.; Sun, R.; Wan, X.; Li, H.; Mirhoseini, A.; Saberi, A.; Arik, S. Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL. arXiv 2025, arXiv:2503.23157. [Google Scholar]
- Zhang, Y.; Zhou, S.; Huang, G. SE-HCL: Schema Enhanced Hybrid Curriculum Learning for Multi-Turn Text-to-SQL. IEEE Access 2024, 12, 39902–39912. [Google Scholar] [CrossRef]
- Berdnyk, M.; Collery, M. LLM-Based SQL Generation with Reinforcement Learning. 2025. Available online: https://openreview.net/forum?id=84M0Jaiapl (accessed on 16 April 2025).
- Nguyen, X.-B.; Phan, X.-H.; Piccardi, M. Fine-Tuning Text-to-SQL Models with Reinforcement-Learning Training Objectives. Nat. Lang. Process. J. 2025, 10, 100135. [Google Scholar] [CrossRef]
- Pack Kaelbling, L.; Littman, M.L.; Moore, A.W.; Hall, S. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Ghasemi, M.; Ebrahimi, D. Introduction to Reinforcement Learning; MIT Press: Cambridge, MA, USA, 2024. [Google Scholar]
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, Y.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling Instruction-Finetuned Language Models. arXiv 2022, arXiv:2210.11416. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2023, arXiv:1910.10683. [Google Scholar]
- Xie, Y.; Jin, X.; Xie, T.; Lin, M.; Chen, L.; Yu, C.; Cheng, L.; Zhuo, C.; Hu, B.; Li, Z. Decomposition for Enhancing Attention: Improving LLM-Based Text-to-SQL through Workflow Paradigm. arXiv 2024, arXiv:2402.10671. [Google Scholar]
- Ling, X.; Liu, J.; Liu, J.; Wu, J.; Liu, J. Finetuning LLMs for Text-to-SQL with Two-Stage Progressive Learning. In Proceedings of the Natural Language Processing and Chinese Computing; Wong, D.F., Wei, Z., Yang, M., Eds.; Springer Nature Singapore: Singapore, 2025; pp. 449–461. [Google Scholar] [CrossRef]
- Kou, S.; Hu, L.; He, Z.; Deng, Z.; Zhang, H. CLLMs: Consistency Large Language Models. In Proceedings of the Forty-first International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Sow, D.; Woisetschläger, H.; Bulusu, S.; Wang, S.; Jacobsen, H.-A.; Liang, Y. Dynamic Loss-Based Sample Reweighting for Improved Large Language Model Pretraining. arXiv 2025, arXiv:2502.06733. [Google Scholar]
- Xie, S.; Chen, H.; Yu, F.; Sun, Z.; Wu, X. Minor SFT Loss for LLM Fine-Tune to Increase Performance and Reduce Model Deviation. arXiv 2024, arXiv:2408.10642. [Google Scholar] [CrossRef]
- Wang, Y.; Wei, J.; Liu, C.Y.; Pang, J.; Liu, Q.; Shah, A.P.; Bao, Y.; Liu, Y.; Wei, W. LLM Unlearning via Loss Adjustment with Only Forget Data. arXiv 2024, arXiv:2410.11143. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Xia, Y.; de Araujo, P.H.L.; Zaporojets, K.; Roth, B. Influences on LLM Calibration: A Study of Response Agreement, Loss Functions, and Prompt Styles. arXiv 2025, arXiv:2501.03991. [Google Scholar] [CrossRef]
- ChatGPT Guide What Is Cross-Entropy Loss: LLMs Explained—Chatgptguide. Available online: https://www.chatgptguide.ai/2024/03/03/what-is-cross-entropy-loss-llms-explained/ (accessed on 15 March 2025).
- Mao, A.; Mohri, M.; Zhong, Y. Cross-Entropy Loss Functions: Theoretical Analysis and Applications. arXiv 2023, arXiv:2304.07288. [Google Scholar] [CrossRef]
- Zhang, Z.; Sabuncu, M.R. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. arXiv 2018, arXiv:1805.07836. [Google Scholar] [CrossRef]
- Jerald Teo How Do Large Language Models Learn?|by Jerald Teo|Medium. Available online: https://medium.com/@jeraldteokj/visualising-loss-calculation-in-large-language-models-1af410a9d73d (accessed on 15 March 2025).
- Zhou, Z.; Huang, H.; Fang, B. Application of Weighted Cross-Entropy Loss Function in Intrusion Detection. J. Comput. Commun. 2021, 9, 1–21. [Google Scholar] [CrossRef]
- Fan, Y.; Li, R.; Zhang, G.; Shi, C.; Wang, X. A Weighted Cross-Entropy Loss for Mitigating LLM Hallucinations in Cross-Lingual Continual Pretraining. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Hyderabad, India, 6–11 April 2025. [Google Scholar] [CrossRef]
- Focal Loss Explained|Papers With Code. Available online: https://paperswithcode.com/method/focal-loss (accessed on 25 May 2025).
- Qué Es: Pérdida Focal—APRENDE ESTADÍSTICAS FÁCILMENTE. Available online: https://es.statisticseasily.com/glossario/what-is-focal-loss/ (accessed on 2 July 2025).
- Understanding F-Beta Score: 4 Metrics Explained Fast. Available online: https://www.numberanalytics.com/blog/understanding-fbeta-score-metrics (accessed on 25 May 2025).
- Fbeta_score—Scikit-Learn 1.7.0 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.fbeta_score.html (accessed on 2 July 2025).
- Lee, N.; Yang, H.; Yoo, H. A Surrogate Loss Function for Optimization of $F_\beta$ Score in Binary Classification with Imbalanced Data. arXiv 2021, arXiv:2104.01459. [Google Scholar]
- Contrastive Loss Explained. Contrastive Loss Has Been Used Recently…|by Brian Williams|TDS Archive|Medium. Available online: https://medium.com/data-science/contrastive-loss-explaned-159f2d4a87ec (accessed on 25 May 2025).
- Wang, F.; Liu, H. Understanding the Behaviour of Contrastive Loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2025. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The Llama 3 Herd of Models. arXiv 2024, arXiv:2407.21783. [Google Scholar] [CrossRef]
- Qwen; Yang, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Li, C.; Liu, D.; Huang, F.; et al. Qwen2.5 Technical Report. arXiv 2024, arXiv:2412.15115. [Google Scholar]
- Hui, B.; Yang, J.; Cui, Z.; Yang, J.; Liu, D.; Zhang, L.; Liu, T.; Zhang, J.; Yu, B.; Lu, K.; et al. Qwen2.5 Technical Report. arXiv 2024, arXiv:2409.12186. [Google Scholar] [CrossRef]
- Team, Q. Qwen3 2025.
- Gonzalez-Agirre, A.; Pàmies, M.; Llop, J.; Baucells, I.; Da Dalt, S.; Tamayo, D.; Saiz, J.J.; Espuña, F.; Prats, J.; Aula-Blasco, J.; et al. Salamandra Technical Report. arXiv 2025, arXiv:2502.08489. [Google Scholar] [CrossRef]
- Martins, P.H.; Fernandes, P.; Alves, J.; Guerreiro, N.M.; Rei, R.; Alves, D.M.; Pombal, J.; Farajian, A.; Faysse, M.; Klimaszewski, M.; et al. EuroLLM: Multilingual Language Models for Europe. arXiv 2024, arXiv:2409.16235. [Google Scholar] [CrossRef]
- OLMo, T.; Walsh, P.; Soldaini, L.; Groeneveld, D.; Lo, K.; Arora, S.; Bhagia, A.; Gu, Y.; Huang, S.; Jordan, M.; et al. 2 OLMo 2 Furious. arXiv 2024, arXiv:2501.00656. [Google Scholar] [CrossRef]
- Probst, P.; Bischl, B. Tunability: Importance of Hyperparameters of Machine Learning Algorithms. J. Mach. Learn. Res. 2019, 20, 1–32. [Google Scholar]
- Jin, H. Hyperparameter Importance for Machine Learning Algorithms. arXiv 2022, arXiv:2201.05132. [Google Scholar] [CrossRef]
- Yu, T.; Zhang, R.; Yang, K.; Yasunaga, M.; Wang, D.; Li, Z.; Ma, J.; Li, I.; Yao, Q.; Roman, S.; et al. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. arXiv 2018, arXiv:1809.08887. [Google Scholar]
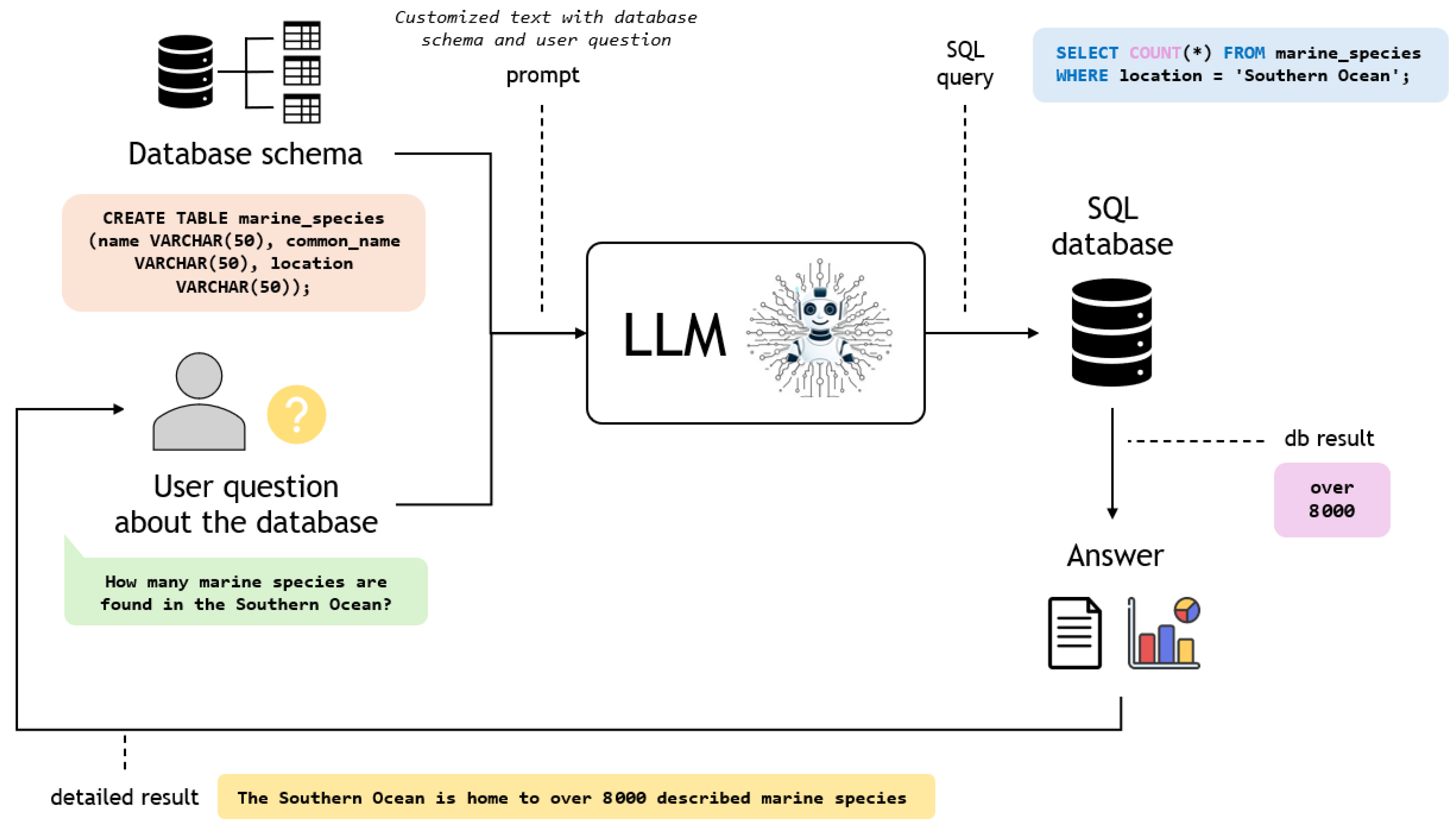
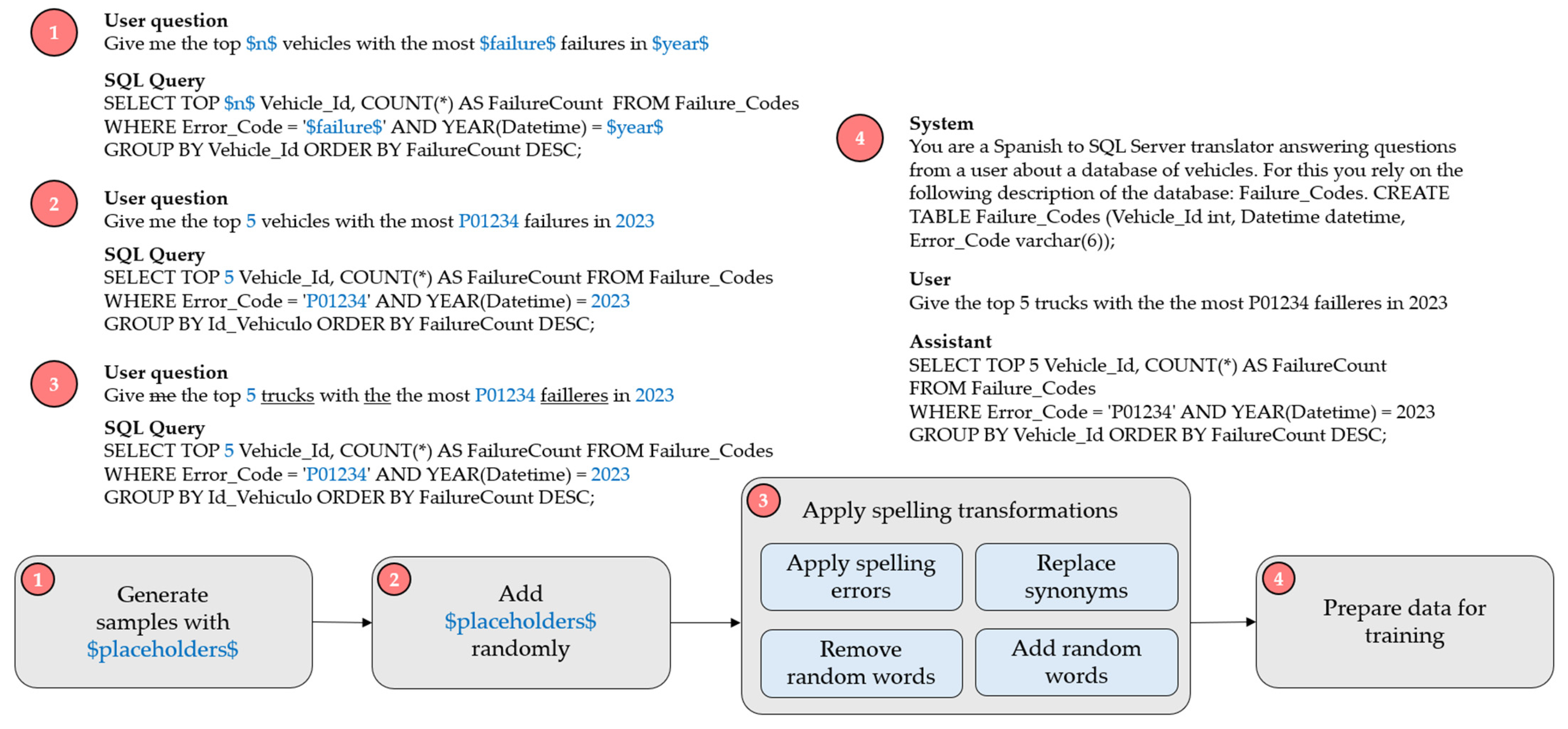


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technique | Description | Refs |
|---|---|---|
| Template-based | Earlier systems often relied on hand-crafted rules, but these struggled with complexity and domain shifts | [11] |
| Sequence-to-sequence Models | Neural architectures treat SQL statements as a sequence to be generated from the user’s question; however, they may overlook the structured nature of the database or the formal constraints of SQL | [12,13,14] |
| Grammar-based decoding | These methods factorize SQL into syntax components (SELECT, WHERE, GROUP BY, etc.) and predict each subcomponent separately, enforcing SQL consistency | [15,16] |
| Graph Encoding and Schema Linking | To handle the complexity of multi-table schemas and to better align question tokens with columns/tables, graph neural networks and linking mechanisms have been adopted | [17,18] |
| Large Language Models | Recent work uses large language models such as GPT or instruction-tuned transformers, relying on in-context learning or fine-tuning to parse complex queries with minimal additional supervision | [8] |
| User Question | SQL Query |
|---|---|
| Give me the top 10 vehicles with the most ‘UH0043’ failures in 2021 | SELECT TOP 10 Vehicle_Id, COUNT(*) AS FailureCount FROM Failure_Codes WHERE Error_Code = ‘UH0043’ AND YEAR(Datetime) = 2021 GROUP BY Vehicle_Id ORDER BY FailureCount DESC; |
| Could you tell me the top 5 vehicles that have been to the car workshop? | SELECT TOP 5 Vehicle_Id, COUNT(*) AS TotalEvents FROM Vehicle_Events GROUP BY Vehicle_Id ORDER BY TotalEvents DESC; |
| Which vehicle has been driven the longest distance? | SELECT TOP 1 Vehicle_Id, Distance FROM Fleet ORDER BY Distance DESC; |
| Show me what percentage of failures occur in each month of 2024 | SELECT MONTH(Datetime) AS Month, COUNT(*) AS Quantity FROM Failure_Codes WHERE YEAR(Datetime) = 2024 GROUP BY MONTH(Datetime); |
| Hyperparameter | Value |
|---|---|
| Number of epochs | 100 |
| Training and evaluation batch size | 8 |
| Gradient accumulation steps | 8 |
| Neftune noise alpha | 3 |
| Learning rate | 4 × 10−5 |
| Learning rate scheduler | Cosine |
| Optimizer | Paged AdamW 8bit |
| Lora | 128 |
| Lora dropout | 0.1 |
| Lora r | 64 |
| Training and validation samples | 2125|375 |
| Test samples (server) | 383 |
| Group | Weights |
|---|---|
| SQL | 3.0 |
| Tables | 5.0 |
| Columns | 5.0 |
| Vehicles | 5.0 |
| Errors | 5.0 |
| Vehicle body | 2.0 |
| Vehicle type | 2.5 |
| Vehicle group | 2.5 |
| Workshop | 2.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azurmendi, I.; Zulueta, E.; García, G.; Uriarte-Arrazola, N.; Lopez-Guede, J.M. Beyond Standard Losses: Redefining Text-to-SQL with Task-Specific Optimization. Mathematics 2025, 13, 2315. https://doi.org/10.3390/math13142315
Azurmendi I, Zulueta E, García G, Uriarte-Arrazola N, Lopez-Guede JM. Beyond Standard Losses: Redefining Text-to-SQL with Task-Specific Optimization. Mathematics. 2025; 13(14):2315. https://doi.org/10.3390/math13142315
Chicago/Turabian StyleAzurmendi, Iker, Ekaitz Zulueta, Gustavo García, Nekane Uriarte-Arrazola, and Jose Manuel Lopez-Guede. 2025. "Beyond Standard Losses: Redefining Text-to-SQL with Task-Specific Optimization" Mathematics 13, no. 14: 2315. https://doi.org/10.3390/math13142315
APA StyleAzurmendi, I., Zulueta, E., García, G., Uriarte-Arrazola, N., & Lopez-Guede, J. M. (2025). Beyond Standard Losses: Redefining Text-to-SQL with Task-Specific Optimization. Mathematics, 13(14), 2315. https://doi.org/10.3390/math13142315