
Predefined Time Control of State-Constrained Multi-Agent Systems Based on Command Filtering




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- (1)
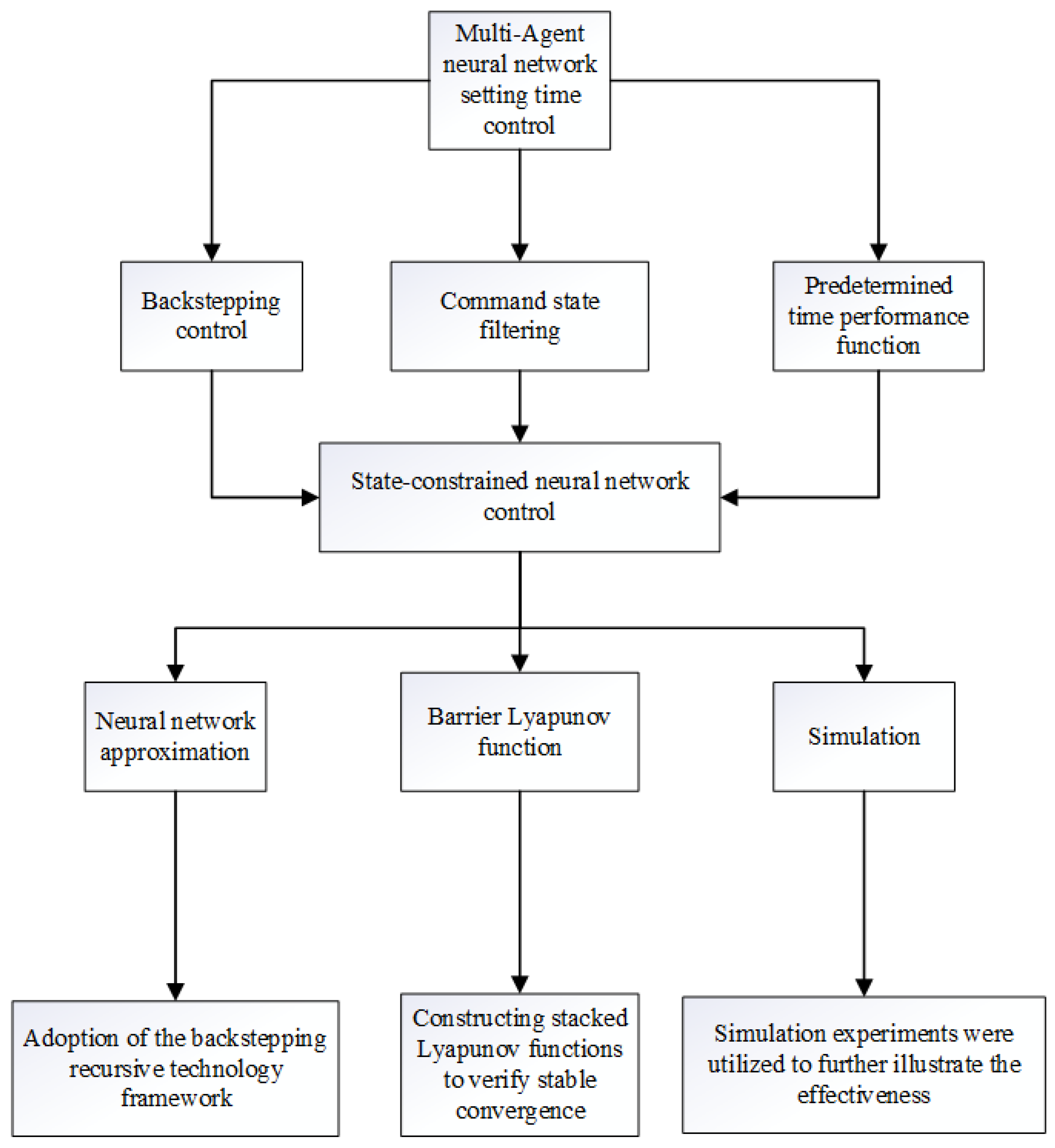
- To achieve predefined-time stability considering PPMs and state constraints, a new predefined-time performance function (PTPF) is developed. This PTPF is then integrated with a Barrier Lyapunov Function (BLF). The combination serves to enforce both transient and steady-state performance metrics, such as tracking error bounds and convergence rates. As a result, it can ensure that the error trajectories stay within the user-defined domains while complying with state constraints. By embedding time-varying gains and negative-definite terms into the controller, the closed-loop system achieves predefined-time stability—convergence within an arbitrarily predefined time , independent of initial conditions and design parameters.
- (2)
- (3)
- Compared with the adaptive predefined-time schemes in [30,31], the proposed approach sidesteps complex stability analyses and eases the conservative assumptions on the desired tracking signal. By utilizing command-filtered backstepping, the control design simplifies the implementation process and still retains robustness against uncertainties.
- (1)
- PTPF-BLF Integration: A time-varying PTPF adjusts error boundaries dynamically. The BLF ensures constraint satisfaction by penalizing proximity to state limits.
- (2)
- Time-Varying Control Synthesis: A command-filtered backstepping with time-varying gains enforces predefined-time convergence. Auxiliary terms compensate for filtering errors.
- (3)
- Stability Guarantees: Lyapunov analysis shows that all closed-loop signals are bounded. Tracking errors converge to a user-specified residual set within , and state constraints are strictly met.
2. Materials and Methods
- (1)
- Ensuring global predefined-time stability for all signals in the closed-loop system, where the predefined time can be arbitrarily chosen according to the design parameters.
- (2)
- The output signal can be conducted to follow the specified signal within the predefined-time interval , regardless of the design parameters and initial conditions.
- (3)
- The tracking control performance satisfies the required PPMs while ensuring that all states remain within the domains determined by the state constraints.
3. Main Results
3.1. Prescribed-Time Control Design
- The multi-agent system is a predefined-time consensus.
- And the upper bound of the settling time T is independent from the initial parameters. The settling time T satisfies.
- The controller is designed using the backstepping iterative method, which together with the obstacle Lyapunov function can achieve the desired results.
| Algorithm 1 Conjugate Gradient Algorithm with Dynamic Step-Size Control |
| Input: Multi-agent system model, predefined time , performance function parameters , filter parameters , and gain parameters Output: Control signal u
|
3.2. Stability Analysis
4. Simulation Examples
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Haimo, V.T. Finite time controllers. SIAM J. Control Optim. 1986, 24, 760–770. [Google Scholar] [CrossRef]
- Muralidharan, A.; Pedarsani, R.; Varaiya, P. Analysis of fixed-time control. Transp. Res. Part B Methodol. 2015, 73, 81–90. [Google Scholar] [CrossRef]
- Jiménez-Rodríguez, E.; Muñoz-Vázquez, A.J.; Sánchez-Torres, J.D.; Defoort, M.; Loukianov, A.G. A Lyapunov-like characterization of predefined-time stability. IEEE Trans. Autom. Control 2020, 65, 4922–4927. [Google Scholar] [CrossRef]
- Ren, X.X.; Yang, G.H. Adaptive control for nonlinear cyber-physical systems under false data injection attacks through sensor networks. Int. J. Robust Nonlinear Control 2020, 30, 65–79. [Google Scholar] [CrossRef]
- Zhao, N.; Tian, Y.; Zhang, H.; Herrera-Viedma, E. Fuzzy-based adaptive event-triggered control for nonlinear cyber-physical systems against deception attacks via a single parameter learning method. Inf. Sci. 2024, 657, 119948. [Google Scholar] [CrossRef]
- Kong, F.; Ni, H.; Zhu, Q.; Hu, C.; Huang, T. Fixed-time and predefined-time synchronization of discontinuous neutral-type competitive networks via non-chattering adaptive control strategy. IEEE Trans. Netw. Sci. Eng. 2023, 10, 3644–3657. [Google Scholar] [CrossRef]
- Ding, K.; Zhu, Q.; Huang, T. Prefixed-time local intermittent sampling synchronization of stochastic multicoupling delay reaction–diffusion dynamic networks. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 718–732. [Google Scholar] [CrossRef]
- Kong, F.; Zhu, Q.; Huang, T. New fixed-time stability criteria of time-varying delayed discontinuous systems and application to discontinuous neutral-type neural networks. IEEE Trans. Cybern. 2021, 53, 2358–2367. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, J.; Liu, Z.; Yu, S. Robust Higher-Order Nonsingular Terminal Sliding Mode Control of Unknown Nonlinear Dynamic Systems. Mathematics 2025, 13, 1559. [Google Scholar] [CrossRef]
- Zhu, P.; Jin, S.; Bu, X.; Hou, Z. Distributed Data-Driven Control for a Connected Autonomous Vehicle Platoon Subjected to False Data Injection Attacks. IEEE Trans. Autom. Sci. Eng. 2023, 21, 7527–7538. [Google Scholar] [CrossRef]
- Savva, M.C. A Framework for the Detection, Localization, and Recovery from Jamming Attacks in the Internet of Things. Ph.D. Thesis, University of Cyprus, Nicosia, Cyprus, 2024. [Google Scholar]
- Verbitskiy, S.; Berikov, V.; Vyshegorodtsev, V. Eranns: Efficient residual audio neural networks for audio pattern recognition. Pattern Recognit. Lett. 2022, 161, 38–44. [Google Scholar] [CrossRef]
- Chang, C.K.; Chang, H.H.; Boyanapalli, B.K. Application of pulse sequence partial discharge based convolutional neural network in pattern recognition for underground cable joints. IEEE Trans. Dielectr. Electr. Insul. 2022, 29, 1070–1078. [Google Scholar] [CrossRef]
- Ciritsis, A.; Rossi, C.; Eberhard, M. Automatic classification of ultrasound breast lesions using a deep convolutional neural network mimicking human decision-making. Eur. Radiol. 2019, 29, 5458–5468. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Li, X.; Zhong, G. Semi-global fixed/predefined-time RNN models with comprehensive comparisons for time-variant neural computing. Neural Comput. Appl. 2023, 35, 1675–1693. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, W. Adaptive Neural Network Tracking Control for Nonlinear Systems with Multiple Actuator Constraints via Command Filter. Int. J. Appl. Math. Control Eng. 2023, 6, 206–214. [Google Scholar]
- Lia, M.; Wang, L.; Meng, L.; Chang, J. Dynamic Recognition of CAPTCHA Based on Convolutional Neural Network. Int. J. Appl. Math. Control Eng. 2023, 6, 198–205. [Google Scholar]
- Chen, W.; Zhang, Z. Globally stable adaptive backstepping fuzzy control for output-feedback systems with unknown high-frequency gain sign. Fuzzy Sets Syst. 2010, 161, 821–836. [Google Scholar] [CrossRef]
- Chen, W.S.; Li, J.M. Globally decentralized adaptive backstepping neural network tracking control for unknown nonlinear systems. Asian J. Control 2010, 12, 96–102. [Google Scholar] [CrossRef]
- Zheng, Y.; Sun, P.; Ren, Q.; Xu, W.; Zhu, D. A novel and efficient model pruning method for deep convolutional neural networks by evaluating the direct and indirect effects of filters. Neurocomputing 2024, 569, 127124. [Google Scholar] [CrossRef]
- López-González, C.I.; Gascó, E.; Barrientos-Espillco, F.; Besada-Portas, E.; Pajares, G. Filter pruning for convolutional neural networks in semantic image segmentation. Neural Netw. 2024, 169, 713–732. [Google Scholar] [CrossRef]
- Wang, Z.; Ruiz, L.; Ribeiro, A. Stability to deformations of manifold filters and manifold neural networks. IEEE Trans. Signal Process. 2024, 72, 2130–2146. [Google Scholar] [CrossRef]
- Yin, Q.; Mu, Q.; Bian, Y.; Ji, W.; Wang, L. Command filtered dual backstepping variable structure robust switching control of uncertain nonlinear system. Nonlinear Dyn. 2023, 111, 3953–3967. [Google Scholar] [CrossRef]
- Ma, H.; Li, H.; Lu, R.; Huang, T. Adaptive event-triggered control for a class of nonlinear systems with periodic disturbances. Sci. China Inf. Sci. 2020, 63, 150212. [Google Scholar] [CrossRef]
- Li, B.; Xia, J.; Zhang, H.; Shen, H.; Wang, Z. Event-triggered adaptive fuzzy tracking control for stochastic nonlinear systems. J. Frankl. Inst. 2020, 357, 9505–9522. [Google Scholar] [CrossRef]
- Vafamand, N.; Arefi, M.M.; Anvari-Moghaddam, A. Advanced kalman filter-based backstepping control of AC microgrids: A command filter approach. IEEE Syst. J. 2022, 17, 1060–1070. [Google Scholar] [CrossRef]
- Ni, J.; Liu, L.; Tang, Y.; Liu, C. Predefined-time consensus tracking of second-order multiagent systems. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 2550–2560. [Google Scholar] [CrossRef]
- Zhang, Z.; Hu, S.; Chen, Q. Predefined-Time Sliding Mode Control for Attitude Tracking of Quadrotors. Int. J. Appl. Math. Control Eng. 2023, 6, 187–191. [Google Scholar]
- Liu, J.; Shi, J.; Wu, Y.; Wang, X.; Sun, J.; Sun, C. Event-based predefined-time second-order practical consensus with application to connected automated vehicles. IEEE Trans. Intell. Veh. 2023, 8, 4524–4535. [Google Scholar] [CrossRef]
- Muñoz-Vázquez, A.J.; Sánchez-Torres, J.D.; Defoort, M. Second-order predefined-time sliding-mode control of fractional-order systems. Asian J. Control 2022, 24, 74–82. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, H.; Wang, J. Finite-Time Bounded Control for Multitime-Scale Production-Inventory Systems Under Inventory Inaccuracy. IEEE Trans. Comput. Soc. Syst. 2024; early access. [Google Scholar]
- Wang, J.; Li, Y.; Wu, Y.; Liu, Z.; Chen, K.; Chen, C.P. Fixed-time formation control for uncertain nonlinear multi-agent systems with time-varying actuator failures. IEEE Trans. Fuzzy Syst. 2024, 32, 1965–1977. [Google Scholar] [CrossRef]
- Sui, S.; Chen, C.L.P.; Tong, S. Command Filter Based Predefined Time Adaptive Control for Nonlinear Systems. IEEE Trans. Autom. Control 2024, 69, 7863–7870. [Google Scholar] [CrossRef]
- Ji, Y.; Li, P.; Lin, Y.; Song, Y.; Gao, Q.; Liu, J. Predefined time attitude control of aircraft based on predefined time sliding mode control. Proc. Inst. Mech. Eng. Part I J. Syst. Control Eng. 2024, 239, 09596518241273990. [Google Scholar] [CrossRef]
- Riaz, S.; Li, B.; Qi, R.; Zhang, C. An adaptive predefined time sliding mode control for uncertain nonlinear cyber-physical servo system under cyber attacks. Sci. Rep. 2024, 14, 7361. [Google Scholar] [CrossRef] [PubMed]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Yu, X.; Zhu, Q.; Yu, Z. Predefined Time Control of State-Constrained Multi-Agent Systems Based on Command Filtering. Mathematics 2025, 13, 2151. https://doi.org/10.3390/math13132151
Zhang J, Yu X, Zhu Q, Yu Z. Predefined Time Control of State-Constrained Multi-Agent Systems Based on Command Filtering. Mathematics. 2025; 13(13):2151. https://doi.org/10.3390/math13132151
Chicago/Turabian StyleZhang, Jianhua, Xuan Yu, Quanmin Zhu, and Zhanyang Yu. 2025. "Predefined Time Control of State-Constrained Multi-Agent Systems Based on Command Filtering" Mathematics 13, no. 13: 2151. https://doi.org/10.3390/math13132151
APA StyleZhang, J., Yu, X., Zhu, Q., & Yu, Z. (2025). Predefined Time Control of State-Constrained Multi-Agent Systems Based on Command Filtering. Mathematics, 13(13), 2151. https://doi.org/10.3390/math13132151