1. Introduction
Quantifying how often and how severely extreme events strike together is a central task in financial risk management and insurance but also in the natural sciences [
1,
2].
For the bivariate case, extreme-value copulas provide the canonical modeling framework [
3,
4]. Interestingly, their dependence structure is fully characterized by a single convex curve inside the unit square, the Pickands dependence function P(u) [
4,
5,
6]. Yet the practical application of extreme-value copulas has long been constrained by a significant bottleneck. Despite its theoretical elegance, the universe of known parametric families for P(u) remains remarkably small. This scarcity limits practical use whenever the amount and quality of data do not support fully nonparametric estimators [
7,
8,
9], creating a difficult trade-off between overly simplistic models and data-intensive nonparametric methods, a challenge that is particularly acute in fields like climate-related financial risks [
10].
A parallel literature on economic inequality studies the Lorenz curve, another convex curve in the unit square, for which decades of work have produced many tractable parametrizations and ready-made indices [
11,
12,
13]. This rich, well-established mathematical toolkit, we argue, holds the key to overcoming the aforementioned limitations in the parametric modeling of the Pickands dependence function.
The primary objective of this paper is to bridge the gap between inequality measurement and extreme-value theory, thereby providing a new, systematic engine for generating dependence models. We show that rotating the “Pickands triangle” by 45° and rescaling establishes a bijective map between Pickands and Lorenz curves. When some conditions are met, the map turns a Lorenz family into a closed-form Pickands model, and vice versa, thus systematically enlarging the catalog of tractable extreme-value copulas. Our work yields three further key innovations. First, the measure-generating function M of Pickands [
6] can be written explicitly in terms of the quantile function underlying the Lorenz curve, providing a constructive route to model specification irrespective of the inversion method. Second, classical inequality distances (e.g., the Gini and Pietra indices [
14]) translate into scale-free, rotation-invariant indices of global upper-tail dependence that complement local coefficients such as the index of upper-tail dependence
[
4]. Finally, our framework provides a clear economic interpretation for tail dependence, linking it directly to the concentration of risk. The use of Lorenz curves in dealing with copulas is not new [
15], but—to the best of our knowledge—this is the first attempt to use them in the realm of extreme-value copulas.
The usefulness of the Lorenz–Pickands link in financial risk management is supported by a growing body of empirical evidence on joint extremes. A seminal study [
16] showed how upper-tail dependence between major equity markets surges during crashes, challenging the efficacy of geographical diversification, and suggesting the use of extreme-value copulas. In [
17], the authors introduced diagnostics that compare fitted extreme-value surfaces with alternative copulas and documented that episodes of heightened tail co-movement coincide with higher risk premia and diminished hedging power. Subsequent work by [
18] quantified the economic stakes: switching from an elliptical to an extreme-value copula can raise the 99% Value-at-Risk of a diversified equity–bond portfolio by up to 30%, materially affecting capital requirements. Dynamic specifications that marry GARCH margins with conditional extreme-value copulas further improve forecasts of joint exceedances and back-testing performance [
19,
20]. In derivative pricing, basket and spread options valued under an extreme-value dependence structure reproduce observed tail-wing premiums better than Gaussian benchmarks [
21], reducing bid–ask disparities in energy and FX markets. Beyond market risk, [
22] applied covariate-dependent extreme-value copulas to operational losses, producing coherent business-line capital figures under the Basel framework. Empirical evidence also reveals that equity returns and implied volatility share common jumps [
23], commodity-linked credit exposures exhibit “wrong-way” behavior [
24], and regional catastrophe losses display marked spatial concentration [
25].
Together all these studies underscore that whenever simultaneous extremes matter for value—be it market, credit, or operational—extreme-value copulas capture the economics of contagion more faithfully than competing dependence models, and thus the study of the Pickands function becomes particularly relevant. Within our framework, any extreme-value copula becomes a problem we can tackle in the inequality space, providing additional tools for the analysis of the Pickands function, tail dependence, stress-testing, and decision making. Our work aims to provide the explicit mathematical machinery to make this connection rigorous and readily applicable, open the path—we hope—for further research.
This paper is organized as follows.
Section 2 revisits Pickands and Lorenz curves under a unified geometric lens.
Section 3 introduces the Lorenz–Pickands equivalence geometrically and via the so-called Gini coordinate system.
Section 4 covers examples of existing and new parametric families of Pickands functions via the Lorenz representation.
Section 5 deals with those situations in which either the Pickands or the Lorenz cannot be obtained in closed form.
Section 6 discusses the use of inequality indices in the context of tail dependence.
Section 7 is devoted to a measure-theoretic and constructive representation of the Pickands function via Lorenz curves.
Section 8 provides a novel representation of extreme-value copulas using the Lorenz–Pickands relation.
Section 9 provides an example of the use of the Pickands-Lorenz connection on actual financial data.
Section 10 concludes and opens paths for further research.
2. Preliminaries
In this section we recall the basics about the two curves we build our contribution upon: the Pickands dependence function [
5,
26] and the Lorenz curve [
11].
2.1. Extreme-Value Copulas and the Pickands Dependence Function
Copulas are an elegant way of representing multivariate distributions, by focusing attention on the embedded dependence structure. Thanks to Sklar’s theorem [
27], the joint distribution
J of a bivariate random vector
can be given as the combination of the marginal distributions
and
of
Y and
Z, and of a function
C called copula, such that
The function
C essentially accounts for the dependence between
Y and
Z, separating the joint behavior from the margins, and we refer to [
3] for a nice introduction. However, it is worth noticing that some scholars argue that the very act of separating the marginal distributions from the dependence structure using a copula can lead to an oversimplified and potentially misleading understanding of how variables truly interact, especially in a dynamic framework [
28].
Extreme-value copulas arise as the possible limit of copulas of component-wise maxima of i.i.d. (or strongly mixing stationary [
29]) random sequences [
4,
8]. These copulas prove to be extremely useful in risk management, to model joint extremes, or when dealing with data characterized by positive and possibly asymmetric dependence [
1,
2,
16].
In the bivariate case, a copula
C is an extreme-value copula if and only if it can be represented as
where
is a convex function, called Pickands dependence function [
5], satisfying
when
for every
, the random variables
Y and
Z are completely tail independent. Conversely, when
or
, we are in the case of perfect tail dependence. For all values of
in between, different degrees of tail dependence are reached [
6,
8]. In
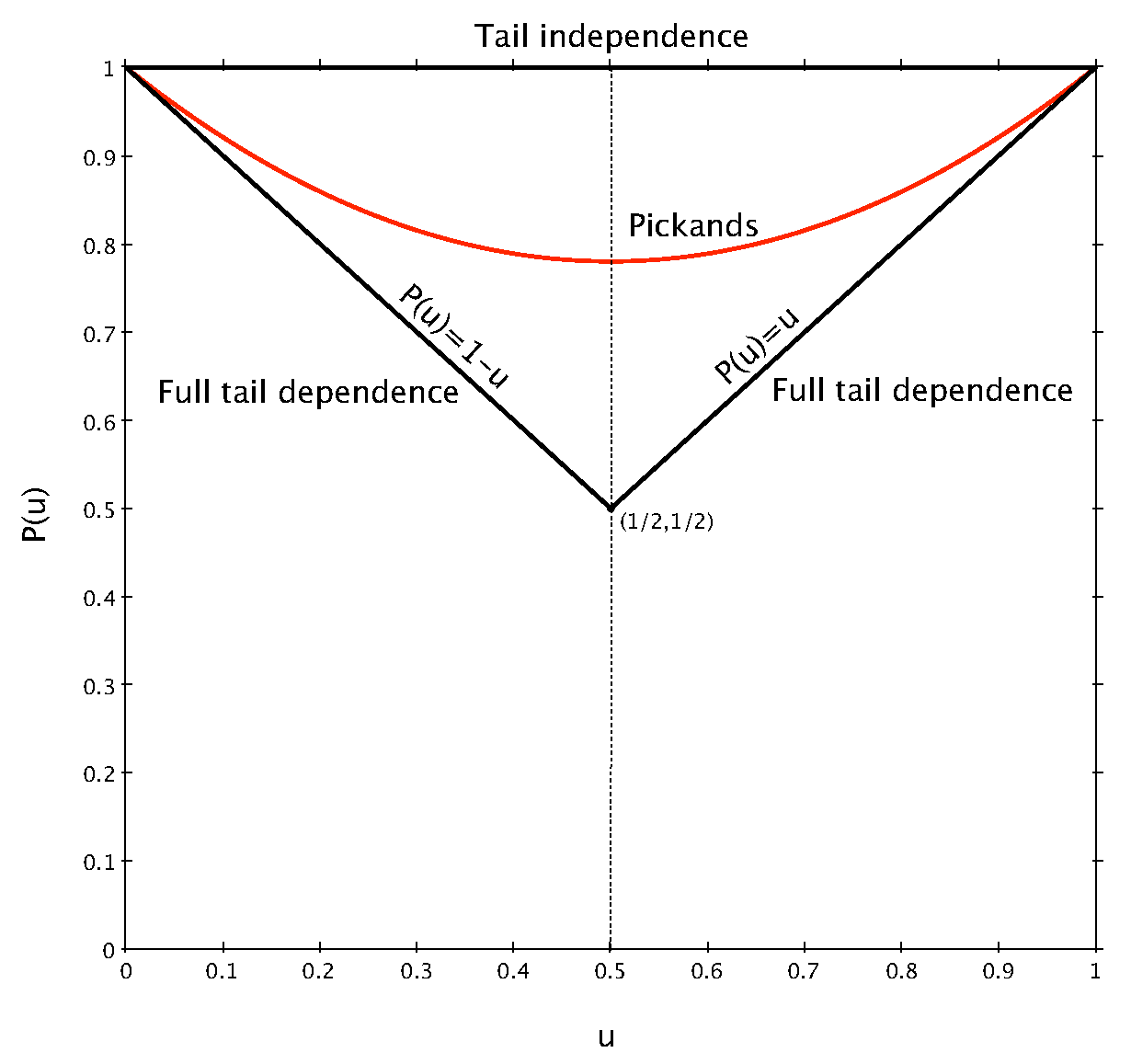
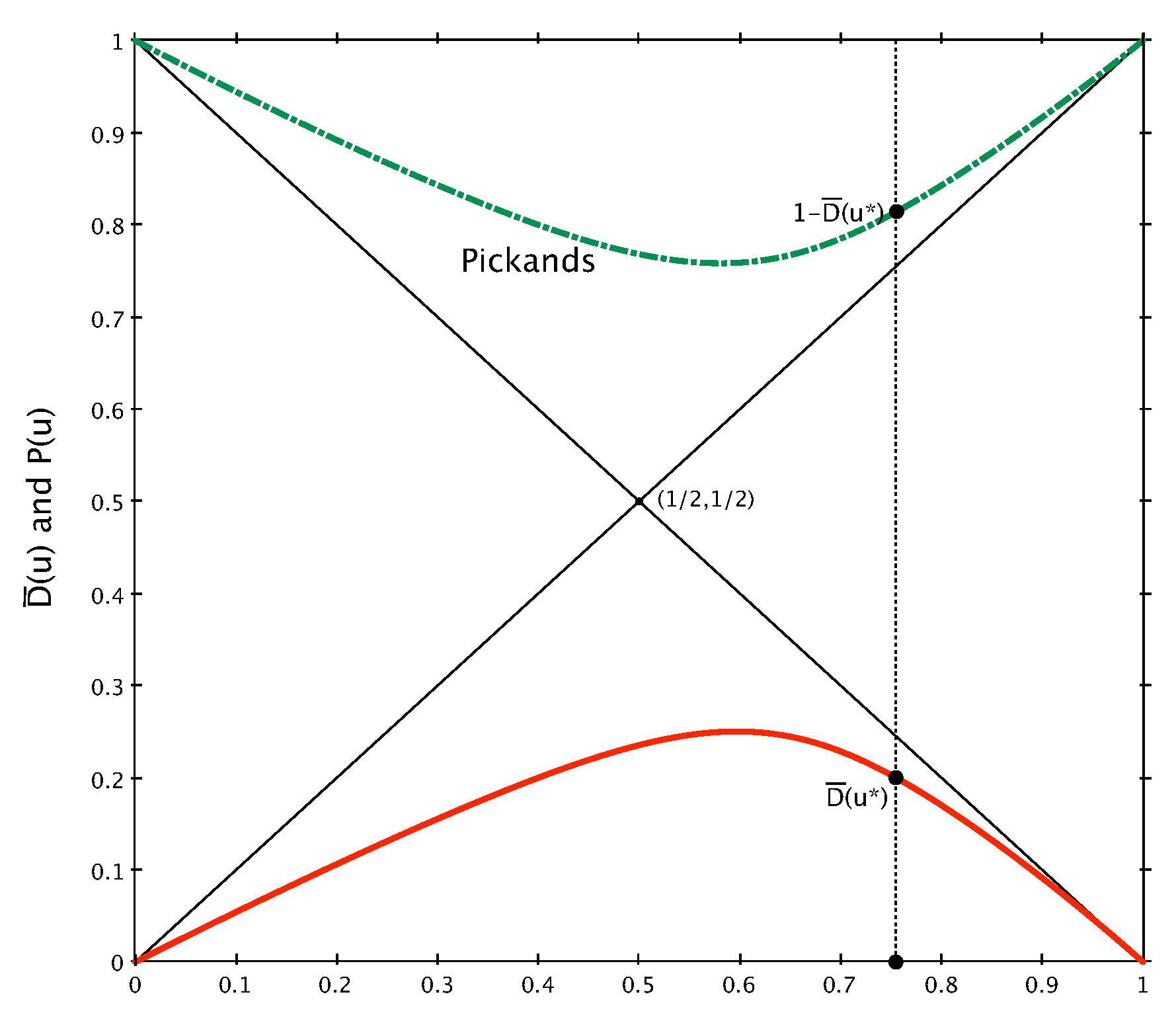
Figure 1 a graphical representation of
is given, where we see that the Pickands dependence function lives in the so-called Pickands triangle of vertices
,
, and
.
Knowing the Pickands dependence function
is particularly useful when dealing with bivariate extreme-value copulas. In fact, as is clear from Equation (
1), all the statistical inference on the copula
C and its dependence structure can be reduced to the inference on its Pickands function [
4].
2.2. The Lorenz Curve
Introduced by Max Lorenz in 1905 [
11], the Lorenz curve is a fundamental tool in the study of economic inequality and the distribution of wealth in the society [
30,
31].
Consider a positive random variable
X with continuous distribution function
, quantile function
and mean
. The Lorenz curve
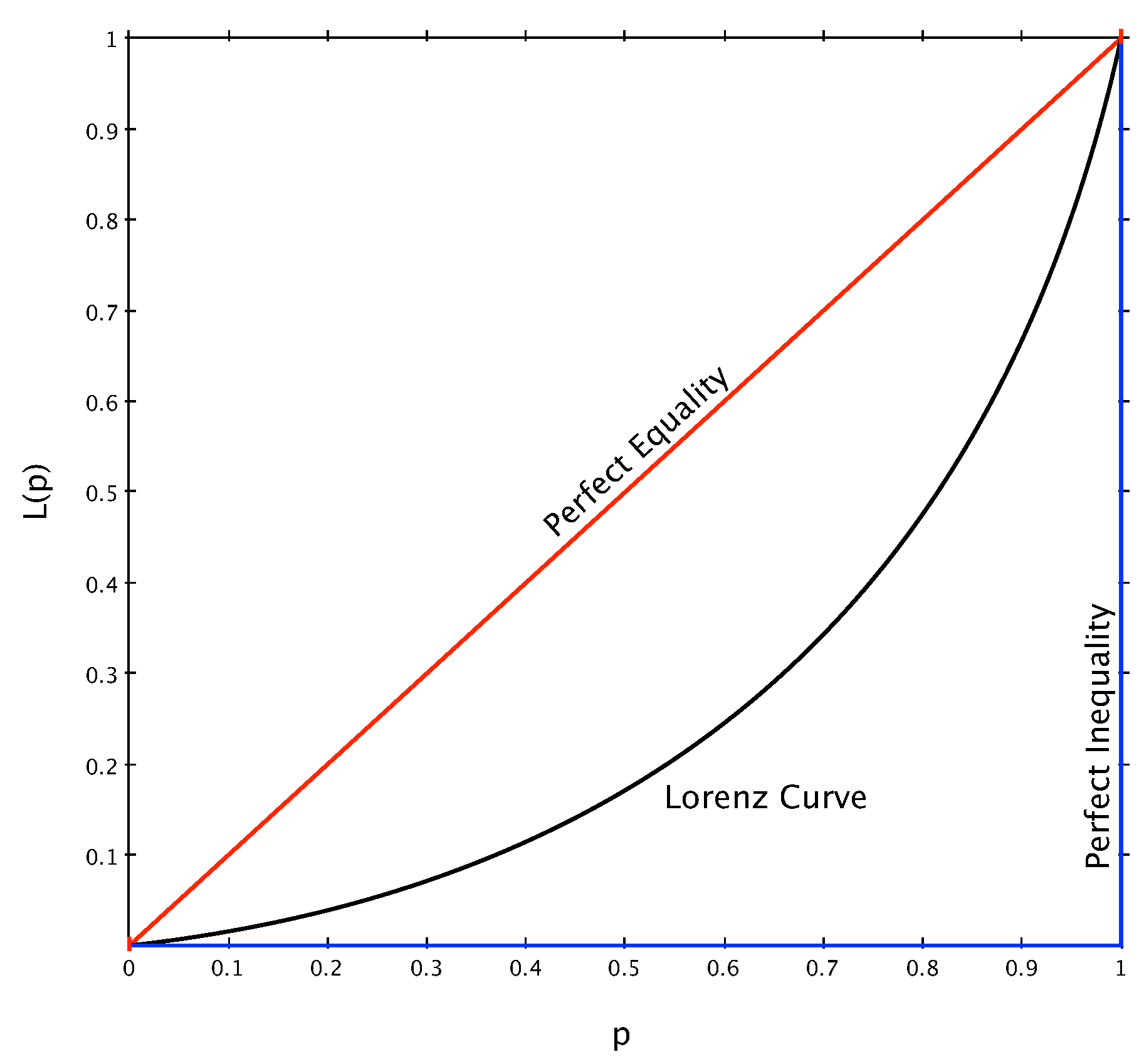
is commonly defined as
By construction the Lorenz curve is a convex increasing function that lies in the unit square, with
and
such that
. In terms of wealth distribution, the Lorenz curve tells us that
of the population owns
of the total wealth in the economy [
30], when wealth is distributed according to
.
The curve
is bounded from above by the so-called perfect equality line, i.e., the anti-diagonal of the unit square defined as
, and from below by the perfect inequality line, defined as
for
and
for
. The curve
represents the ideal situation in which every single individual in the economy possesses the exact same amount of wealth (i.e., there is no variability), while
indicates that one individual owns everything and all the others nothing (maximum variability). The Lorenz curve and its bounds are given in
Figure 2.
It is worth noticing that any convex increasing function defined within the triangle of vertices
, and such that
and
, is actually a Lorenz curve [
32], and given Equation (
2) it thus characterizes a given distribution function up to its mean.
Over the years, a huge variety of summary statistics have been developed to express specific features of the Lorenz curve. One of the most important examples is the family of concentration indices [
13], measuring the distance between the Lorenz curve and the perfect equality line. In more formal terms, a concentration (or distance or inequality) index is defined as
where the denominator is for normalization, so that
for all
.
High values of signal high variability in the data, leading to a high concentration of the wealth induced by the distribution . Therefore, when the random variable X reaches its maximum variability. Conversely, low values of signal low variability in the data, leading to a low concentration of wealth. When , X is nothing but a constant.
From Equation (
3) it is clear that, by varying the type of distance
, we can define different indices: the famous Gini index [
33,
34] is obtained by fixing
, while the Pietra index is obtained when
[
35].
Additional measures one can derive from
are related to its curvature and to its length and other geometric properties of the curve. We suggest [
13,
30] for more details.
3. From Pickands to Lorenz and Back
In
Figure 1 the Pickands dependence function appears as a convex function embedded in the right triangle with vertices
,
, and
.
Now, imagine first rotating this triangle counterclockwise by pivoting on the (1,1) vertex, until the segment lies on the diagonal . This corresponds to a 45-degree rotation. Then inflate all the edges of the triangle by a factor of , to make them unit length, thus also stretching the Pickands function within. The new triangle now coincides with the triangle of vertices (0,0), (1,0), and (1,1), and the convex, stretched, and now non-decreasing Pickands function can itself be seen as a Lorenz curve.
An immediate consequence of this geometrical transformation is that every Pickands function defines a unique Lorenz curve, but also that every Lorenz curve corresponds to a given Pickands function (the correspondence is one-to-one, as we shall see). This simple observation gives us the possibility of studying tail dependence using several tools from inequality studies, and to easily generate parametric families of Pickands functions by using the many Lorenz curves available in the literature.
The rotation and inflation procedure we have just described is useful to have an immediate understanding of the link between the Pickands dependence function and the Lorenz curve. However, it is not difficult to see that this rotation will generally give an implicit representation of one curve in terms of the other. This is due to the fact that the axes are not preserved. The
u-axis of the Pickands function in
Figure 1 does not correspond to the
-axis of the Lorenz curve in
Figure 2. In fact, after rotation, the
u-axis is parallel to the perfect equality line. For this reason, an alternative transformation of the Lorenz curve will prove more useful.
3.1. Remapping the Lorenz Curve
Let us consider an alternative representation of the Lorenz curve, in terms of the orthogonal distance of every point of
from the perfect equality line
. This perspective on the Lorenz curve connects to the Gini coordinate system, a framework originally introduced by Corrado Gini [
36] that remains underutilized and relatively obscure in the modern economic inequality literature, largely because his foundational work was primarily published in Italian during the first decades of the 20th century.
As we show in
Section 7, a very interesting feature of this alternative representation is that it naturally embeds a way of characterizing the measure generating function
M of the Pickands function [
6], in terms of the quantile function of any positive valued random variable with a finite mean.
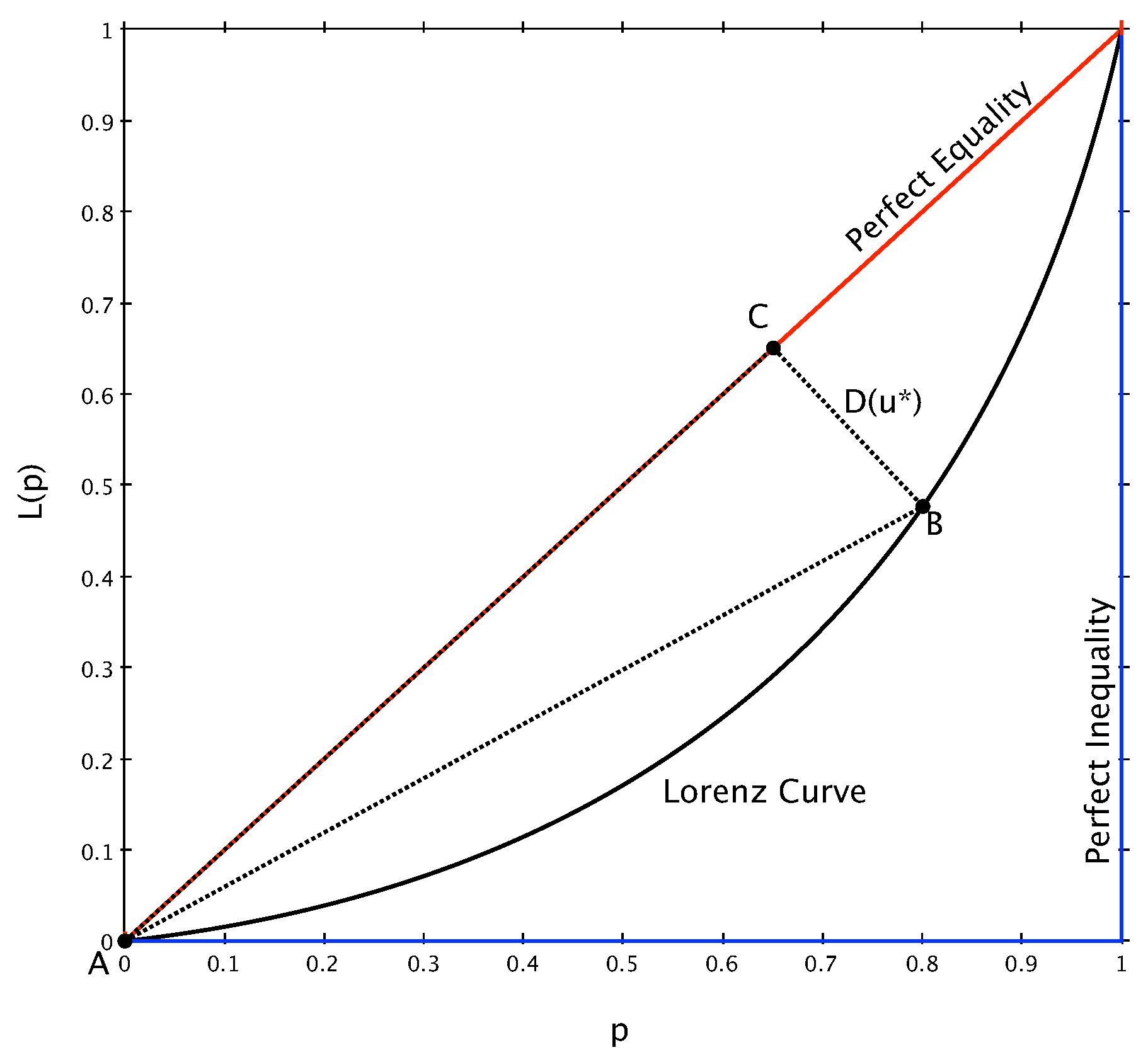
In
Figure 3 imagine we are interested in computing the length of the segment
, corresponding to the orthogonal distance of point B on
from the perfect equality line. By first computing segments
and
, we can easily apply the Pythagorean theorem to obtain
.
Let us consider a family of lines that are orthogonal to the perfect equality line, and that we can define
, with
. In
Figure 3, we can imagine that one of these lines, for
, passes through points B and C.
To find the length of
we first solve the system
to obtain point C, and from this we get
. Similarly, we can find the length of
starting from
To solve this system it is convenient to introduce the quantity
so that we have
The quantity
of Equation (
4) is nothing but the simple arithmetic mean of two Lorenz curves,
and
.
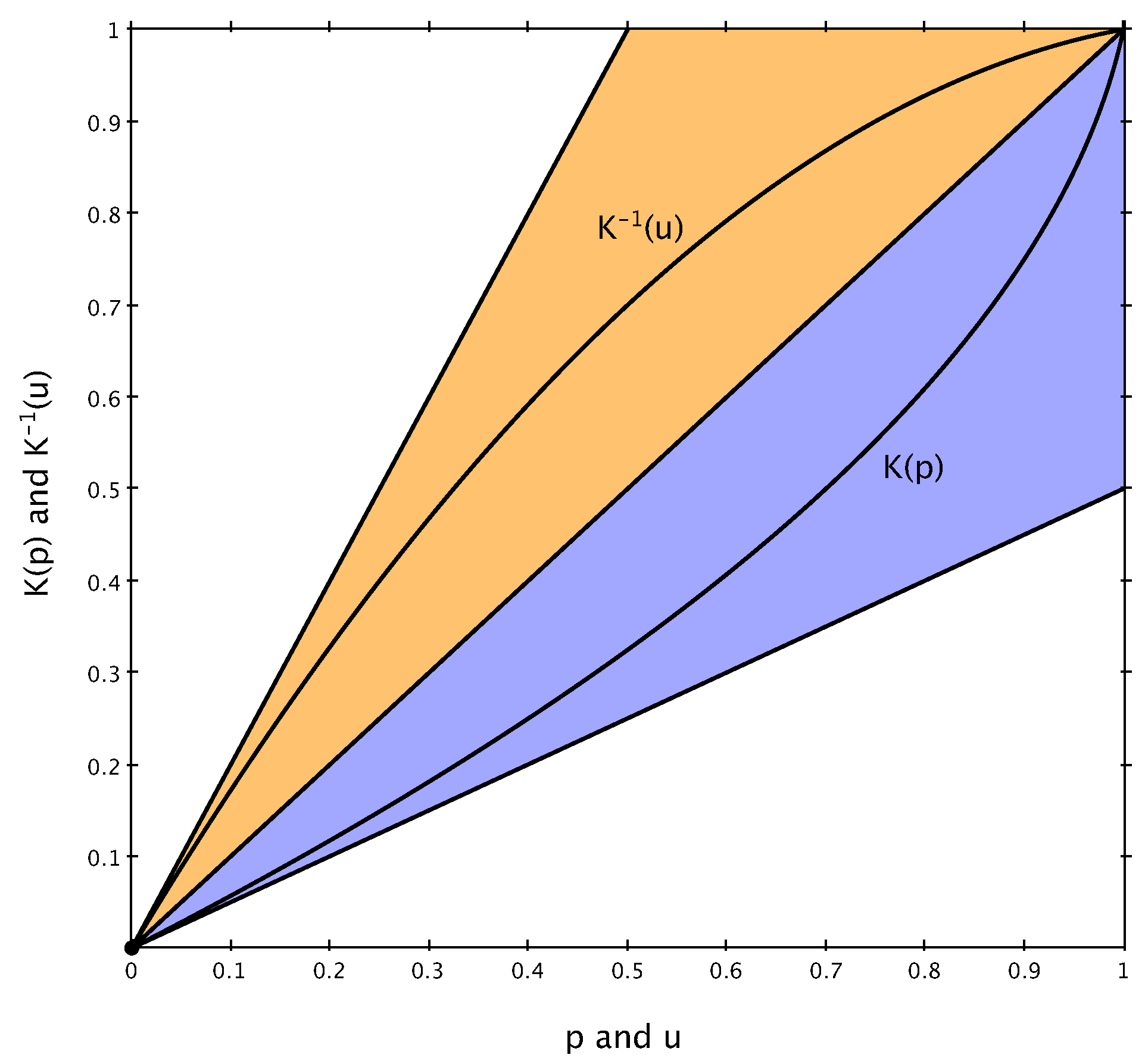
Proposition 1 clarifies some interesting properties of both
and its inverse
, and
Figure 4 shows their behavior in the unit square.
Proposition 1. Let , , be a Lorenz curve and set . Then:
- 1
K is a Lorenz curve satisfying for all ;
- 2
K is strictly increasing and convex on , and its inverse exists, is unique, and concave;
- 3
For all , it holds that .
Proof. By definition,
is the average of
and
p. Since
L is a Lorenz curve, we have
for all
, and
,
. Thus, for all
,
Moreover,
and
, so
K shares the same endpoints as a Lorenz curve. Convex combinations of Lorenz curves are again Lorenz curves (see [
37]), and since
K is a convex combination of
L and the identity
, it follows that
K is itself a Lorenz curve.
Because L is continuous, convex, and increasing, the sum is strictly increasing, and so is . Since the identity is linear, K inherits convexity from L. As K is strictly increasing and continuous on , it is invertible on its image , and the inverse is also continuous and increasing. The concavity of follows from the general result that the inverse of a convex, strictly increasing function is concave.
Since
satisfies
for all
, we can write the following:
and
. Let
. Rewriting the inequalities in terms of
p gives the following:
Therefore, for
, we get the following:
□
Now, coming back to Equation (
5), we find a solution for
and
, and
A simple application of the Pythagorean theorem then tells that
For different points B and C in
Figure 3, one will find different values of
u defining the orthogonal distance
. In general, for
, it is easy to verify that
.
Removing the factor
from
, let us define
where the possibility of removing the absolute value comes from the fact that
. Therefore,
is a concave function like the one in
Figure 5, lying in the triangle of vertices (0,0), (1/2,1/2), and (1,0), with
and
. It represents a remapping of a Lorenz curve in the Gini coordinate system [
36].
3.2. A New Representation of the Pickands Dependence Function
By mirroring the function
in the triangle of vertices (1,0), (1/2,1/2), and (1,1), we easily find a new convenient way of defining Pickands dependence functions. In fact
is a convex function lying in the triangle of vertices (1,0), (1/2,1/2), and (1,1), with
.
Figure 5 shows the correspondence between the functions
and
.
In its simplicity, Equation (
8) is very important to us: starting from a given Lorenz curve
, and via the remapping
, it allows us to define the Pickands function
. This also implies that, given the definition of the Lorenz curve
in Equation (
2), one can obtain a Pickands function starting from any positive random variable
X with a finite mean.
It is important to observe that deriving the Pickands dependence function from the Lorenz curve requires the inversion of the function . While a closed-form solution for may not always be attainable, the inversion can be efficiently handled through numerical methods. The properties of indeed ensure that the inversion process is well posed and numerically stable. Classical root-finding algorithms such as the Newton–Raphson method or bisection can be effectively employed to approximate to a desired degree of accuracy. Additionally, as already observed, the convex nature of guarantees the uniqueness of the inverse , further simplifying the implementation of numerical inversion techniques.
4. Parametric Families of Lorenz and Pickands
We have seen that for every Lorenz curve there exists a Pickands dependence function and vice versa. As a consequence, one can find the Lorenz curve paired to existing Pickands functions, and the class of parametric models for the Pickands function can be extended via the many Lorenz curves available in the literature [
14,
30,
37]. Here below we collect some examples.
The only limitation on obtaining a closed-form result is the invertibility of the curve
. When this is not possible, numerical methods can always be used, as we discuss in
Section 5.
4.1. The Trivial Boundary Cases
As previously mentioned, the Pickands function for all , corresponding to complete tail independence, directly relates to the Lorenz curve of perfect equality, i.e., for .
At the opposite extreme, the Pickands function representing complete tail dependence, for , corresponds to the Lorenz curve of perfect inequality, defined as for .
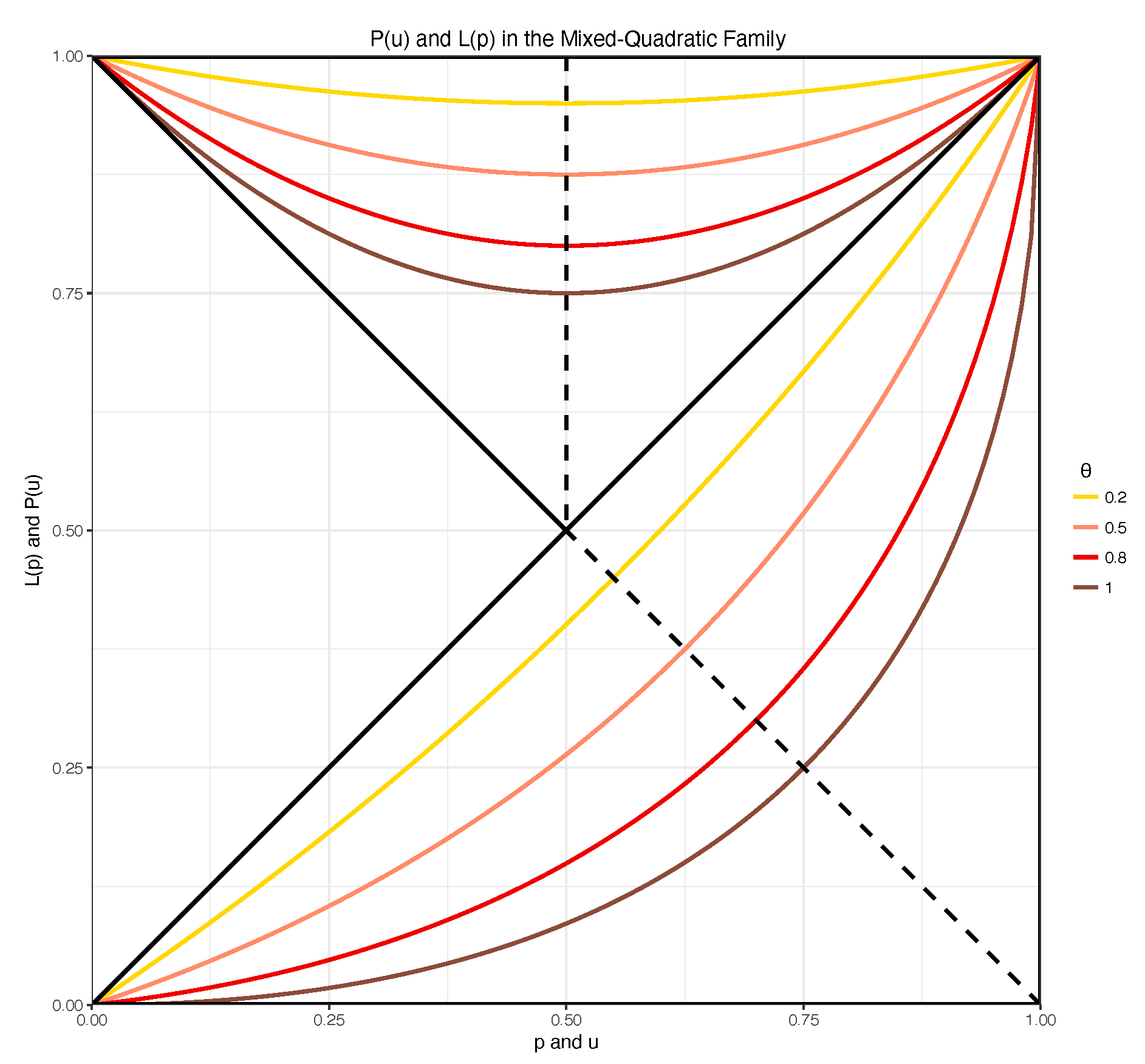
4.2. Tawn’s Mixed-Quadratic Family
Consider the Pickands function
This model easily characterizes independence for
, but it cannot deal with full dependence [
8]. Moreover, the function
is symmetric with respect to the vertical line passing through (1/2,0) and (1/2,1), and this implies that the margins of the corresponding copula are exchangeable.
The associated Lorenz curve is obtained as follows. From Equations (
8) and (
9), we know that
Recalling the properties of
, we easily derive
and then
Equation (
12) is interesting, as we recognize it as the elliptical Lorenz of the inequality studies literature [
32]. Up to re-parametrization, we can immediately rewrite Equation (
12) as
with
,
,
, and
, obtaining the original formulation of [
32]. The elliptical Lorenz preserves the symmetry of the original Pickands function, even if symmetry is now with respect to the diagonal of the unit square. In general, simple geometrical considerations guarantee that (a) symmetric Pickands functions correspond to (a) symmetric Lorenz curves, and vice versa. In [
30] a sufficient criterion for the symmetry of a Lorenz curve is given, and it can be used to discuss symmetry in the Pickands domain as well.
Figure 6 shows the relation between the Pickands and Lorenz curves in the mixed-quadratic family for different values of the parameter
.
Since there is a one-to-one correspondence between a given Lorenz curve and a Pickands model, and noting that the elliptical Lorenz is a 4-parameter family of curves, we can conclude that the mixed model for the Pickands defined in Equation (
9) is just a restriction of a larger class of models obtainable from the underlying Lorenz family. With this in mind one could ideally increase the flexibility of the 1-parameter mixed model by looking at the entire class of associated 4-parameter Lorenz curves.
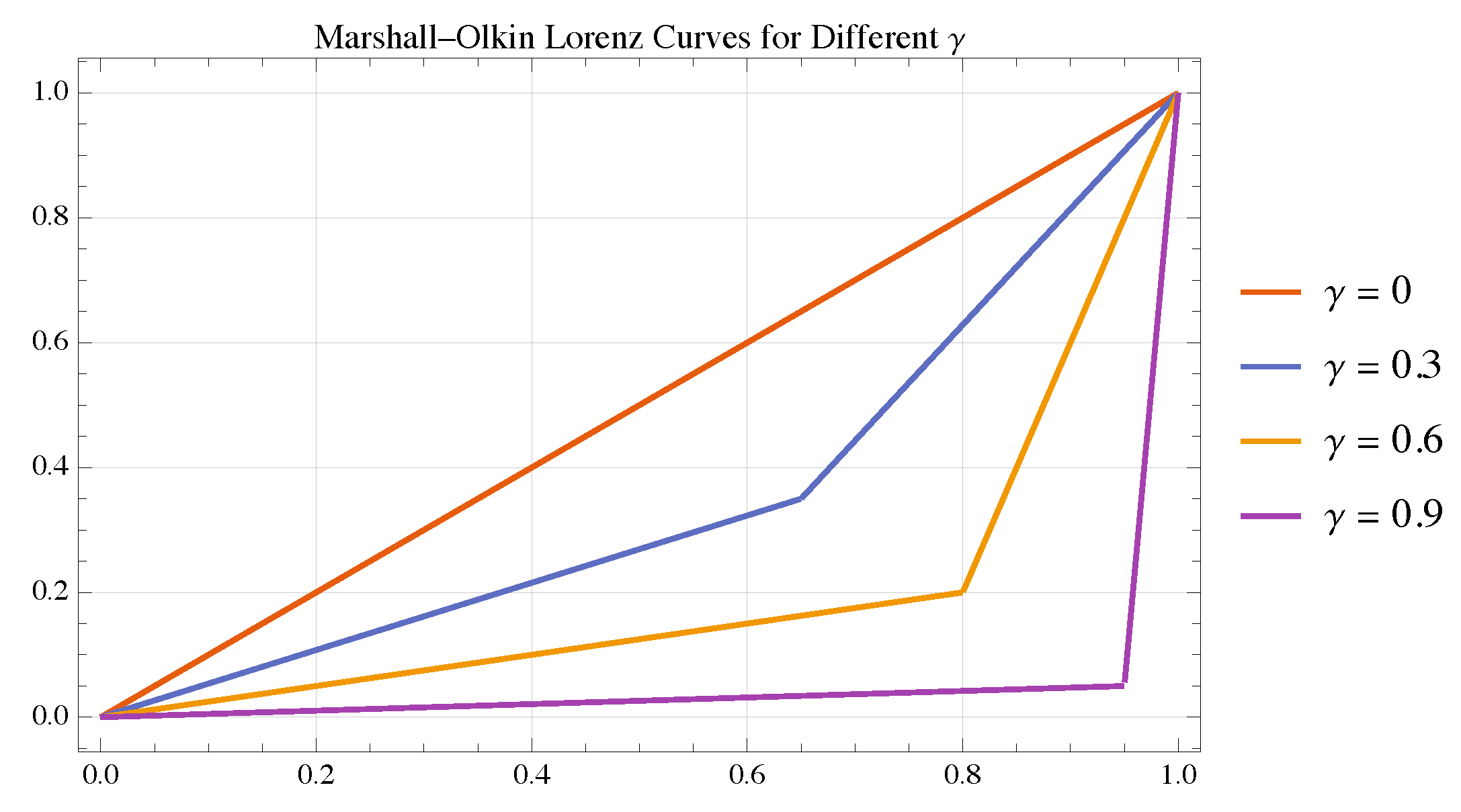
4.3. The Marshall–Olkin Case
Let us consider the Marshall–Olkin bivariate copula [
3], whose Pickands function, with parameter
, is given by the following equation:
This model interpolates between independence () and perfect dependence (). We focus on the non-degenerate case , where inversion is piecewise smooth.
Following our approach, we immediately get
which simplifies piecewise. For
, one has
, and
For
, it holds
, and
We now invert these expressions to recover
. For
, valid when
, we obtain
For
, valid when
, we obtain
Finally, recall the identity , which yields .
Substituting the expressions for
into this formula we get
for
. While, for
, we find
Hence, the Lorenz curve associated with the Marshall–Olkin bivariate copula is
Figure 7 shows the behavior of
for some values of
.
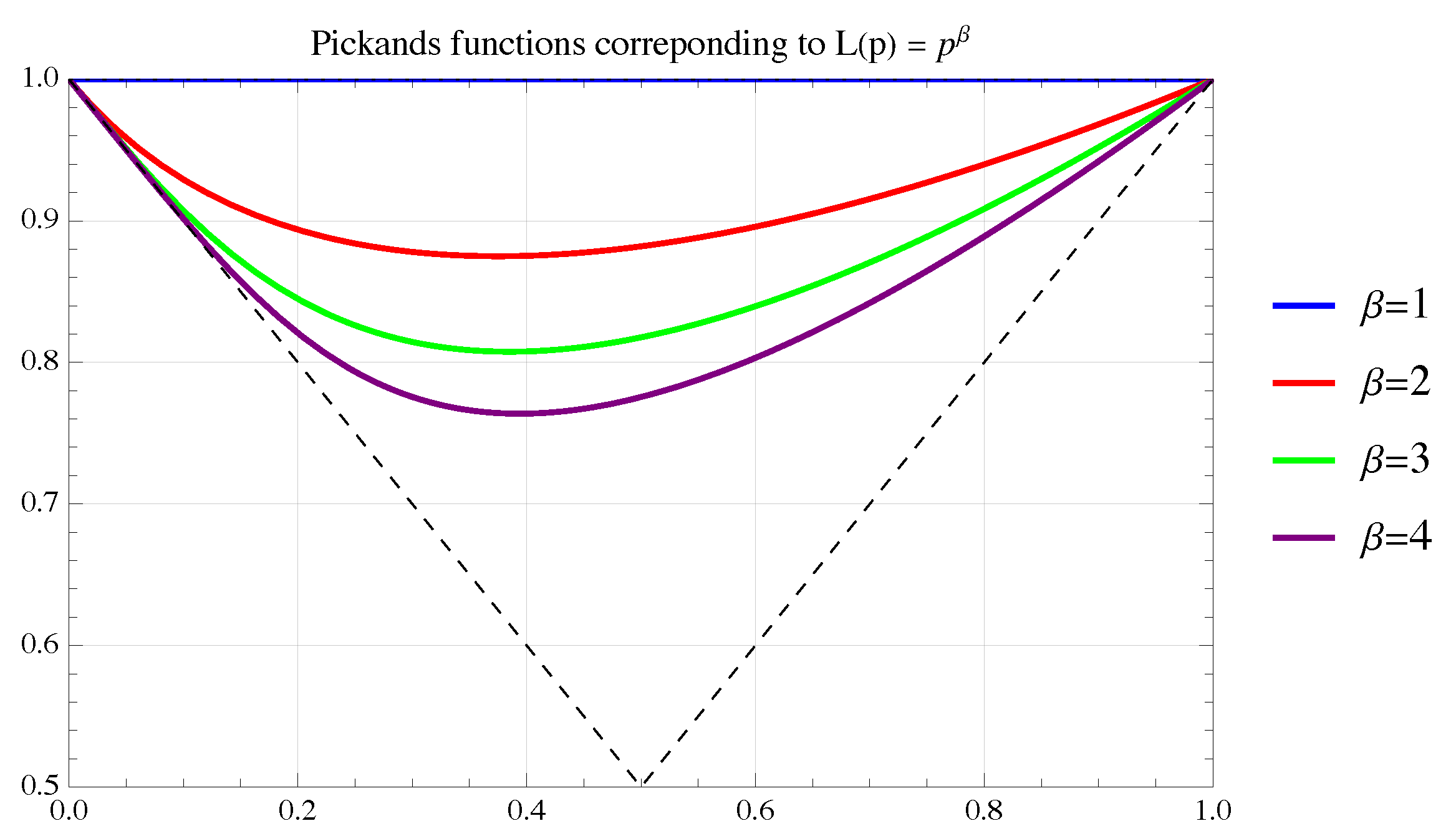
4.4. The Power-Law Lorenz and the Asymmetric Pickands
Consider the Lorenz curve defined by
The corresponding function
, required for the Lorenz-to-Pickands transformation, is explicitly given by
The inverse
admits closed-form expressions for certain values of
. For example, for
, we immediately find
For
, one obtains the simple analytical form
For
, things get a little more cumbersome, but the explicit solution is given by
Finally, for
, one has
where
Applying
then leads to the desired Pickands functions, which are characterized by an interesting asymmetry—inherited from
—as
Figure 8 shows.
For values of other than , solutions typically involve transcendental functions when in closed form, or require numerical methods for evaluation.
Remark 1. Asymmetry in the Pickands dependence function is particularly valuable, as it allows for directional differences in the dependence structure, capturing real-world (financial) scenarios more accurately [16,21]. In practical applications, this asymmetry can significantly enhance modeling accuracy, reflecting realistic situations where extreme events in one variable influence another variable differently than vice versa [4,6]. An asymmetric Pickands function, where , implies that the intensity of tail co-movement is conditional on the source of the extreme shock. The argument u in can be interpreted as the relative contribution of the first variable to the severity of the joint extreme event. A symmetric Pickands function, which is minimised at , imposes the restriction that tail dependence is strongest when both variables contribute equally to the joint extremes. It assumes the dependence structure is identical regardless of which variable leads the extreme event. An asymmetric Pickands function, with a minimum at , models a directional dependence. If , the tail dependence is strongest when an extreme event in the first variable is more severe than the corresponding event in the second; the first variable is thus the dominant driver of the joint extreme. If , the dependence is strongest when the second variable is the primary driver [4]. This property is crucial for moving beyond overly simplistic assumptions of balanced dependence and capturing the nuanced, often one-sided, nature of financial contagion and risk amplification. A well-known stylized fact is that large negative returns in the stock market (e.g., S&P 500) are typically accompanied by very large spikes in market volatility (e.g., the VIX index). However, the reverse relationship is weaker: a large spike in volatility does not always trigger a stock market crash of proportional magnitude. This implies an asymmetric tail dependence [38]. The relationship between the fiscal health of a government and its domestic banking sector is also known to be asymmetric. An extreme spike in sovereign bond yields (indicating a potential sovereign debt crisis) almost invariably triggers an extreme spike in the CDS spreads of its major banks, as they hold large amounts of government debt. Conversely, a crisis originating at a single bank may have a much weaker impact on the sovereign’s perceived creditworthiness, unless the bank is systemic [39]. Modeling this “doom loop” for stress-testing or pricing contingent credit products requires an asymmetric copula that correctly reflects that the ‘Sovereign Crisis → Bank Crisis’ link is much stronger in the tail than the reverse. 4.5. The Arnold Family
An interesting and flexible Lorenz curve is the one introduced by Arnold [
31,
37], defined as
where
F is the cumulative distribution function (CDF) of a unimodal random variable
X, and
is a parameter (one could also set
, but then trivially
). Such a Lorenz has been introduced as a generalization of the well-known lognormal Lorenz [
30], known as
where
is the CDF of a standard Gaussian random variable.
While Equation (
22) does not allow for the discovery of a closed form for the corresponding
—and we refer to
Section 5 for more details—one can look for a
F that allows for it. We here discuss two interesting cases.
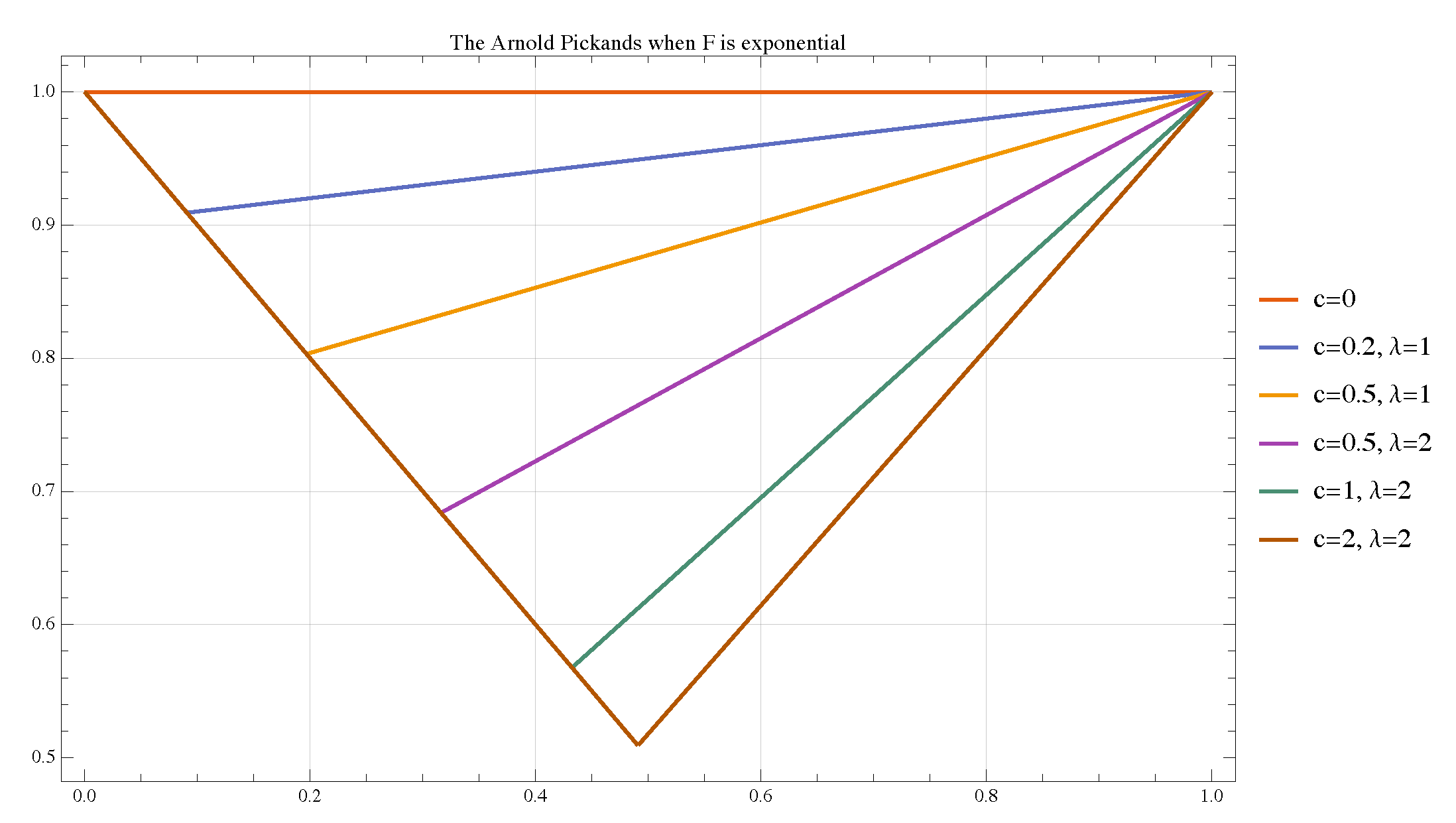
4.5.1. F Is Exponential
Let
F be the exponential CDF with a generic intensity parameter
. Clearly,
for
, and
for
.
The inverse of
F, for
, is
Next, we substitute
into Arnold’s definition of
as per Equation (
21). The argument for
F becomes
. Due to the piecewise nature of the exponential CDF, we must consider the sign of
. One immediately sees that
Let . Since and , we have .
Thus,
is a piecewise function. If
, we have
. If
, we get
The full Lorenz curve is therefore
which represents an interesting case of the Lorenz curve, in which a proportion of the population is allowed to have a null income or wealth.
Following our procedure to map the Lorenz curve to the Pickands dependence function, we then obtain
and
Exploiting
, we finally obtain the piecewise linear Pickands function
which is shown in
Figure 9 for different values of
c and
. For
, no matter
,
corresponds to the case of tail independence. For
, the larger the value of
c, the stronger the dependence, with
governing the asymmetry on the left-hand side (the minimum of
will always have
). For a large enough value of
c and
, the full tail dependence case can be recovered, and the minimum point becomes
.
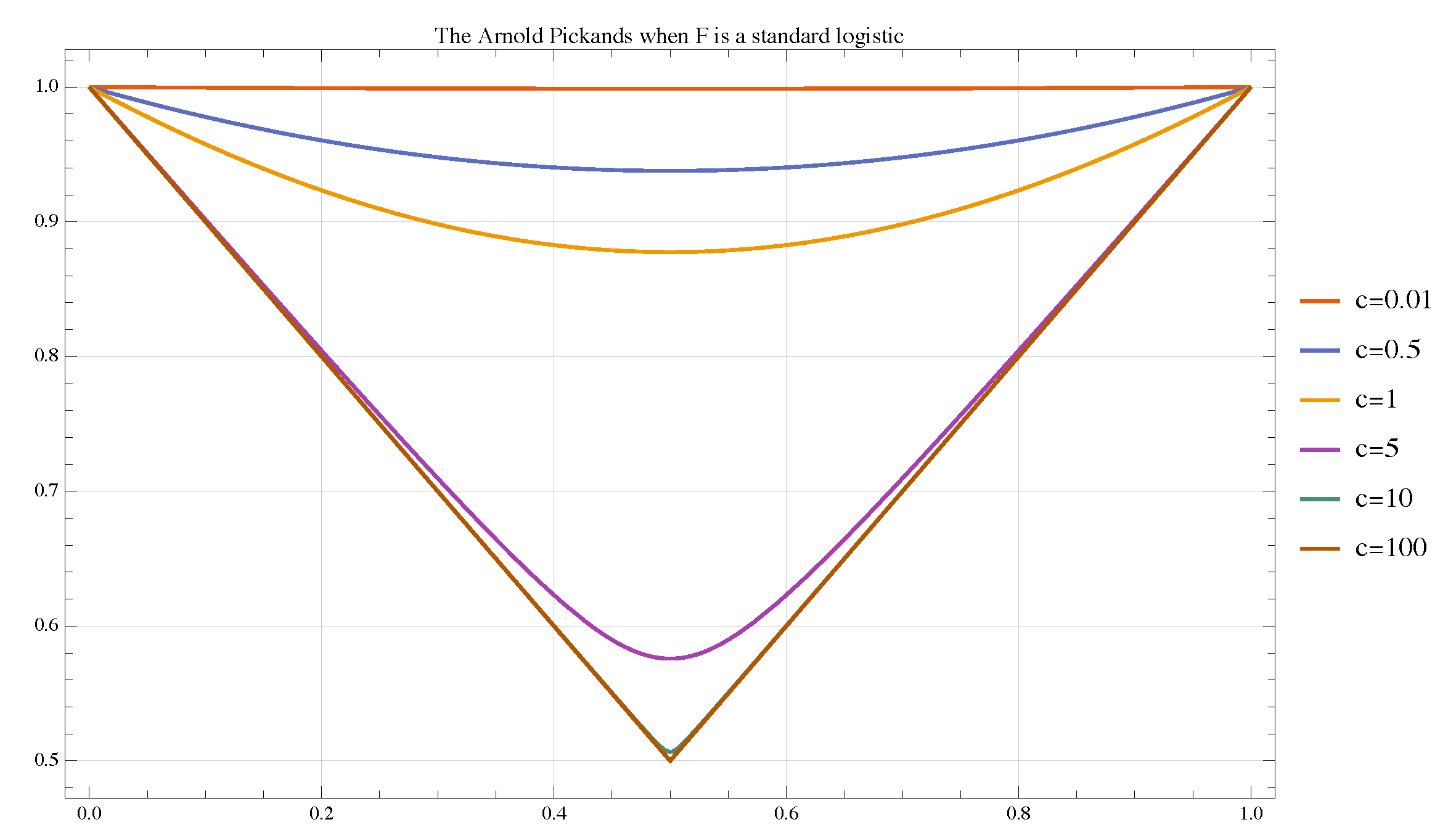
4.5.2. F Is a Standard Logistic
Let
F be a standard Logistic CDF, that is,
Applying Arnold’s definition as per Equation (
21), the corresponding Lorenz becomes
This leads to
To find
, we set
and solve for
p. This leads to the quadratic equation:
This is a quadratic equation of the form
, where
,
, and
. The solution for
is, therefore, of the form
.
For
, we select the appropriate sign for the square root to obtain the desired
. Thus,
is given by
and the Pickands function
follows.
Figure 10 shows that
is a symmetric Pickands, whose shape is governed by the parameter
c of the Arnold construction. For
, it approaches the tail independence case, while for
it moves towards perfect tail dependence.
4.6. Other Cases
Several other cases exist in which both the Lorenz and Pickands dependence functions admit analytical closed-form solutions. Typically, these special cases correspond to particular parameterizations of well-known Lorenz families.
An example is represented by the Lorenz curve derived from the classical Type I Pareto distribution [
30], which is given by
While this Lorenz curve generally requires numerical inversion to obtain the corresponding Pickands function, it admits closed-form results in specific cases.
For , the Lorenz curve simplifies to the perfect inequality line, yielding , i.e., perfect tail dependence.
For
, the Lorenz curve becomes
then
and
so that the asymmetric
follows, reaching its minimum
on the right end-side of the Pickands triangle, in
.
5. When Is Not Invertible
While several Lorenz–Pickands pairs admit closed-form expressions, many important and practically relevant cases do not. In these situations, the inversion of the function cannot be performed analytically. Nevertheless, the transformation remains fully constructive because the numerical inversion of is particularly robust.
For any target
, the root of the monotonic function
is sought on the bounded interval
, which guarantees convergence for standard bracketing algorithms. Furthermore, the analytical derivative
is strictly positive, allowing for the use of rapidly converging gradient-based solvers like the Newton–Raphson method. Given these properties, the problem is numerically manageable for standard scientific libraries, such as the
uniroot function in R or
FindRoot in Mathematica, which can perform this step with high precision and negligible cost. From an applied viewpoint, at present, the critical challenge is therefore not the numerical transformation, but the quality of the initial data used to obtain the nonparametric estimate of the dependence structure [
9], as we also note in
Section 9.
The numerical route enables the construction of Pickands functions from Lorenz curves, and vice versa, that would otherwise be inaccessible. In particular, it allows us to treat cases where the Lorenz curve involves logarithmic, exponential, or non-algebraic terms. Let us consider a couple of examples.
5.1. The Lognormal Lorenz
A Lorenz curve derived from a lognormally distributed random variable is given by the following equation:
where
and
are the standard normal CDF and quantile function, respectively. We have seen that it represent a special case of the more general construction by Arnold, as given in Equation (
21).
The associated function
is well defined and strictly increasing, but its inverse
cannot be expressed in closed form. Nevertheless, numerical inversion of
allows one to find the corresponding Pickands, as shown in
Figure 11. Since the lognormal Lorenz is known to be symmetric with respect to the antidiagonal of the unit square, the corresponding Pickands is symmetric with respect to
.
Remark 2. Equation (28) is of particular interest in financial and actuarial mathematics. Besides being a Lorenz curve, it is also the distortion function [40], known as the Wang transform [41], that governs the change in measure between the market measure and the risk neutral measure in the standard Black–Scholes framework. Moreover, in the theory of copulas, it has been used as a generator to define a class of non-strict Archimedean copulas characterized by asymptotic tail dependence, which can find applicability in operational risk management and the modeling of cat bonds [15]. 5.2. Hüsler–Reiss Copula
The Hüsler–Reiss copula [
42] is a famous extreme-value model that arises as the limit of component-wise maxima of Gaussian vectors. In its original definition, its symmetric Pickands dependence function is given by the following equation:
where
is once again the standard normal CDF, and
. While the expression is explicit, it is not in a form that can be easily inverted to recover a corresponding symmetric Lorenz curve in closed form. However, this is a task that can be easily conducted numerically, which is also true for the more recent asymmetric versions [
43].
6. Indices of (In)Equality and (In)Dependence
We have established a connection between and a unique associated with it. As this link bridges extreme value theory and the study of inequality, it allows us to introduce established inequality indices not merely as analogues, but as direct summary measures for the concentration, structure, and asymmetry of bivariate tail dependence.
This approach offers advantages over traditional scalar indices of tail dependence. For example, the widely used upper tail dependence coefficient [
4],
, quantifies the probability of joint extremes assuming a degree of symmetry (by focusing on
). While
offers a single useful value, it condenses the entire tail dependence structure into one point, potentially overlooking crucial aspects if the dependence is asymmetric. In contrast, inequality indices derived from the full
provide a more holistic understanding.
From the rich toolkit of inequality analysis, we select two prominent indices, the Gini coefficient and the Pietra index [
13,
30], to apply to
, thereby reinterpreting them as measures of tail dependence.
The Gini coefficient is widely used to measure inequality. Geometrically, it can be defined as twice the area between the Lorenz of perfect equality
and
, or
Clearly, in our setting indicates tail independence, because it would imply , and, therefore, for all . On the opposite side, corresponds to perfect inequality and thus perfect tail dependence. All other values of G from 0 to 1 represent increasing tail dependence.
The Pietra index measures the maximum vertical distance between the line of perfect equality and a Lorenz curve
, quantifying the maximum deviation from perfect equality, that is,
It is easy to see that
indicates tail independence, while
indicates perfect tail dependence. However, by going back to
Section 3, we can get additional insight, which makes
H particularly interesting when applied to tail dependence.
Let
be the minimum value of the Pickands function. By looking at
Figure 5, we immediately find that
in the Gini coordinate system. This tells us that
Calculating the Pietra index thus implicitly provides information on the (absolute) minimum of the Pickands function as well. This ensures H captures the true peak intensity of dependence, regardless of where it occurs.
Naturally,
can also be used to verify the symmetry of both the
and
. Let
be the value where
achieves its minimum
. We can define the asymmetry index
The value indicates a symmetric Pickands (and Lorenz) function where the strongest dependence (minimum value) occurs at . A non-zero S signifies asymmetry, with its sign indicating the direction of the skew in the dependence structure.
6.1. A Few Examples
Let us consider a few examples for the use of G, H, and S, leaving to the interesting reader the derivations for the other cases.
In the Tawn’s mixed family, the Pickands function is symmetric and equal to , . It follows that , and . Consequently, , (coinciding with ), and For this symmetric family, dependence increases with , as expected.
In the Marshall–Olkin copula, another symmetric case, , so that , and .
Let us now consider the power law case of
Section 4.4, where
, and
can be obtained in closed-form or numerically depending on the value of
. The Gini index is
, and dependence increases with
. The Pietra index is
for
, and
when
. From Equation (
30), we get that
, so that we do not need to optimize
to obtain it. The value
will be the one corresponding to
, and
S follows immediately.
Finally, let
be the symmetric Lorenz curve generated by a lognormal random variable of parameters
and
(note that
plays no role in the Lorenz curve). The Gini coefficient is
while the Pietra index equals
Both indices are strictly increasing functions of .
Even if the corresponding Pickands needs to be found numerically, as discussed in
Section 5, both
G and
H can be used to evaluate the dependence structure it induces. Further, we can easily derive
, and
also follows because of symmetry.
6.2. The Risk Management Perspective
In the Pickands–Lorenz framework, the traditional economic concepts of inequality and concentration are repurposed to describe the structure of tail dependence. The core translation is simple: the “inequality of a wealth distribution” becomes the “concentration of joint tail risk”. A society where wealth is highly concentrated in a few hands is analogous to a system where tail risk is highly concentrated, meaning extreme events have a strong tendency to occur together under specific, identifiable conditions. This analogy allows us to imbue classical inequality indices with new, practical meaning for risk management, as already partially observed in [
44].
The Gini coefficient measures the total area between the line of perfect equality () and the Lorenz curve . In our context, it serves as a holistic, scalar measure of the overall concentration of tail dependence across all possible scenarios. In a sense, the Gini coefficient answers the question “How prevalent is tail risk in my system on average?” It is therefore a single number that summarizes the general propensity for joint extremes, much like a credit score summarizes overall creditworthiness.
A low Gini coefficient (near 0) corresponds to a Lorenz curve close to the equality line. This implies that the “risk contribution” is diffuse, and there is no strong, systematic tendency for joint extremes to occur. A high Gini coefficient (near 1) signifies a highly bowed Lorenz curve. This reflects a strong concentration of tail risk, where extreme, impactful events are highly likely to cluster together. A rising Gini for a couple of assets would signal an increasing vulnerability to joint crashes and a general erosion of diversification benefits in the tail.
We know that the Pietra index measures the maximum vertical distance between the line of perfect equality and the Lorenz curve. Its importance is clarified by its direct relationship to the Pickands function, as per Equation (
30), i.e.,
. This identity makes its interpretation in risk management clear: the Pietra index answers the question “What is the single most dangerous scenario for my portfolio in terms of dependence?” Since
represents the point of strongest tail dependence, the Pietra index directly quantifies this peak intensity of risk. While the Gini gives an average measure of dependence, the Pietra index isolates the single biggest vulnerability. A high Pietra index tells a risk manager that there exists a specific, identifiable scenario under which diversification benefits will most severely break down. It provides a measure of the magnitude of the worst-case dependence, which is crucial for setting risk limits and capital buffers.
The asymmetry index,
S, is derived from the location (
) of the minimum of the Pickands function. It does not measure the level of dependence, but rather diagnoses its nature. If
(
), the dependence structure is symmetric. The highest risk of a joint crash occurs when both risk factors contribute equally. This suggests a balanced co-movement, like that between two highly integrated stock markets (see, e.g.,
Section 9). If
, the dependence is asymmetric, indicating a “leader–follower” relationship in the tails, as already observed in
Section 4.4. For instance, if
(
), the greatest tail risk occurs when the first asset is the dominant driver of the joint event.
The asymmetry index is thus a diagnostic tool for identifying the source of contagion. It tells a risk manager whether to worry about general, systemic co-movement () or a specific, directional vulnerability where one part of the portfolio is much more likely to infect another (). This knowledge is invaluable for designing targeted hedging strategies and more realistic stress tests.
Together, these three indices provide a comprehensive dashboard for tail risk: Gini measures its overall prevalence, Pietra quantifies its peak intensity, and the asymmetry index identifies its primary driver.
6.3. Other Inequality Measures
Beyond the Gini and Pietra indices, our framework allows for the application of numerous other inequality measures to
and
, each offering different sensitivities and theoretical insights. For instance, the Theil Index, rooted in entropy theory, or the Atkinson Index, which incorporates an inequality aversion parameter, could be adapted to provide further nuanced perspectives on the structure of tail dependence [
13,
30,
31]. The choice of an index would depend on the specific aspect of “dependence concentration” or “extremal risk inequality” that one aims to highlight.
7. A Novel View of the Measure for the Pickands Dependence Function
The connection between
and
also allows for an alternative measure-theoretic view of the Pickands dependence function. In fact,
can be expressed via a famous integral representation [
6], namely
where
, and
is an arbitrary measure on
, with total mass
, and expectation
.
While this representation provides a theoretically appealing link between the Pickands dependence function and a measure
, a significant limitation has persisted in the literature: no constructive approach to explicitly determine
has been provided. Instead,
has remained an abstract entity, introduced as a formal object satisfying the given constraints. A data-driven estimator for
M is outlined in [
6]: one first estimates
P and then recovers
M by numerical differentiation [
7,
8]. While statistically useful, this route offers
M only implicitly and does not shed light on its analytic structure. This gap has hindered both the practical applicability of the integral representation of Equation (
31) and its theoretical utility in generating new parametric families of Pickands functions.
The Lorenz curve approach proposed here resolves this issue by establishing a direct and explicit construction of and M. By exploiting the one-to-one correspondence between Lorenz curves and Pickands functions, we can effectively transform the problem of identifying the measure into one of characterizing the Lorenz curve and its associated function.
Specifically, by combining Equations (
8) and (
31), we obtain the following representation of the measure
in terms of the inverse function
:
which can alternatively be expressed as follows:
Therefore, by specifying a Lorenz curve , or even the distribution function of a positive random variable X with a finite mean, we can represent the measure generating function M and its integral.
By differentiating Equation (
32) with respect to
u, and by exploiting the implicit function theorem to find the derivative of
, we can notice that
which can also be written as
for
, and where
is the quantile function of the random variable
X of which
is the Lorenz curve.
8. The Lorenz Representation of Extreme-Value Copulas
The framework developed in the preceding sections, linking to via the intermediary function , opens a new avenue for characterizing tail dependence. Beyond generating parametric families of Pickands functions, this connection allows us to directly construct bivariate extreme-value copulas from the ground up, starting from a given Lorenz curve.
Recall that a bivariate extreme-value copula
, with uniform margins
, can be expressed using its Pickands dependence function
as follows [
4]:
The argument maps the transformed marginals onto the domain of . Given our established relationship , we can now state the following proposition.
Proposition 2. Let be a valid Lorenz curve for . Define , and assume it is invertible, so that is well-defined, unique, concave, and strictly increasing for . Then, the unique bivariate extreme-value copula corresponding to the Lorenz curve is given by the following equation:for . Alternatively, letting and , the copula can be written as follows:for . Proof. The standard representation of a bivariate extreme-value copula is given by Equation (
36). Using the relationship
, where
, we substitute this into the exponent of Equation (
36), and we get
Substituting this back into the exponential function yields Equation (
37). Note that this exponent can also be written as
, where
, by substituting
into
and simplifying, which confirms consistency with the standard form involving
. The transformation to
and
directly yields Equation (
38). □
Proposition 2 provides an explicit bridge from the domain of inequality measurement (represented by ) to the direct specification of extreme-value dependence structures. Any valid Lorenz curve, through the transformation and its inverse, now uniquely defines a bivariate extreme-value copula. The adequate transformation of margins is inherently handled by the standard formulation of extreme-value copulas.
This result not only enriches the theoretical understanding of the interplay between these two fields but also provides a novel practical mechanism: one can now select a Lorenz curve based on economic or inequality criteria and immediately derive the corresponding tail behavior model for bivariate extremes.
Examples
We now illustrate Proposition 2 with some examples previously discussed in the context of Pickands and Lorenz functions. Let , , and . Then , where .
For the perfect equality Lorenz curve,
for all
, we get
. Therefore substituting into the extreme-value copula
This is the independence copula, , correctly reflecting that perfect equality in this framework corresponds to tail independence.
For the perfect inequality Lorenz curve, for and , we have . This implies the following: (1) if , then ; (2) if , then .
It follows that
Since
and
:
thus,
This is the Fréchet–Hoeffding upper bound, or comonotonicity copula, representing perfect positive dependence.
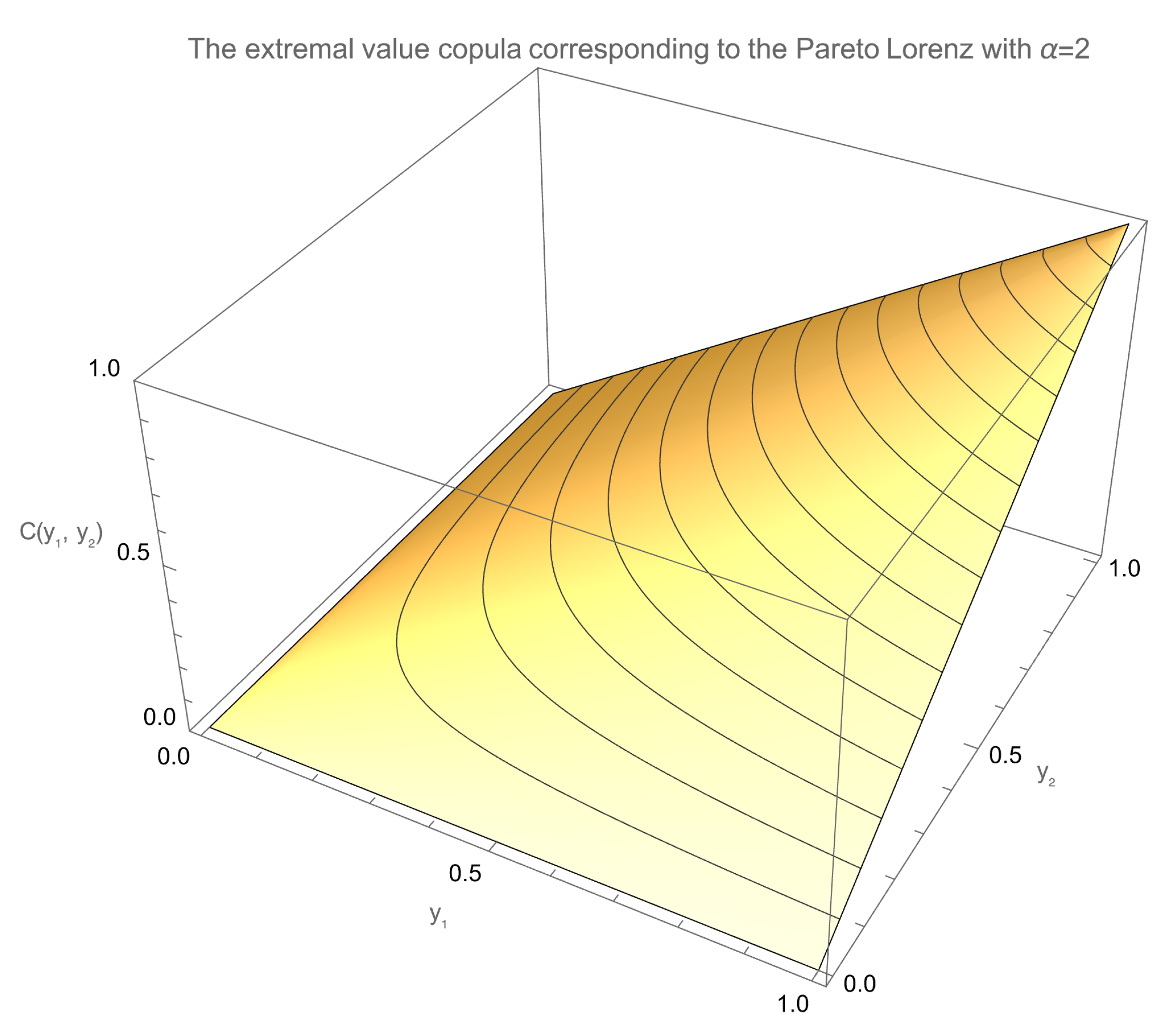
Now, let us consider the simple Pareto case of
Section 4.6, Equation (
25), so that
. We notice that
. From this we get the new copula
which is shown in
Figure 12. Or, equivalently, by substituting
,
9. A Simple Application: DAX vs. SMI
To illustrate the practical utility of the Lorenz–Pickands framework, we analyze the upper tail dependence between two major, highly integrated European stock markets: the German stock index DAX (GDAXI) and the Swiss Market Index (SMI). We use daily data spanning from 1 January 2003 to 31 May 2025, a period covering several distinct market regimes, including the 2008 global financial crisis and the COVID-19 pandemic.
Inspired by the methodologies in seminal works such as [
19,
20,
45], we first filter the marginal raw log-returns of each index using an AR(1)-GARCH(1,1) model with Student’s-t innovations. This procedure is crucial as it accounts for stylized facts like volatility clustering and ensures that our dependence analysis reflects the true co-movement between market innovations rather than spurious correlations induced by heteroskedasticity [
19]. The resulting standardized residuals, which are approximately i.i.d., form the basis for our analysis.
Even if the AR(1)-GARCH(1,1) model is not the main goal of our experiment here, and we skip details, the parameter estimates confirm well-known market features. The AR(1) coefficient is not statistically significant at the
level in either series, which is consistent with (but does not prove!) weak-form market efficiency [
46]. The variance process, however, is characterized by high persistence (the sum of GARCH parameters is >0.96 for both indices), with a dominant
coefficient reflecting a strong volatility memory [
47]. Furthermore, the estimated shape parameters for the Student’s
t distribution are low, providing evidence of heavy tails [
2].
Once we have the bivariate standardized residuals, we can obtain a nonparametric estimate of the Pickands function,
. We tried a few alternatives, from the original approach by Pickands [
5] to the well-known Capéraà, Fougères, and Genest estimator [
7], also considering rank-based methods [
9]. For the purpose of this simple experiment, results are comparable, given the large amount of good quality data, and our discussion here is based on the original approach by Pickands.
We then transform
into its corresponding nonparametric Lorenz curve,
, by re-mapping the points according to the geometric argument of
Section 3. This empirical Lorenz curve serves as the target for fitting several parametric Lorenz models from
Section 4, including the Type I Pareto, the power law, and the Marshall–Olkin and the lognormal families.
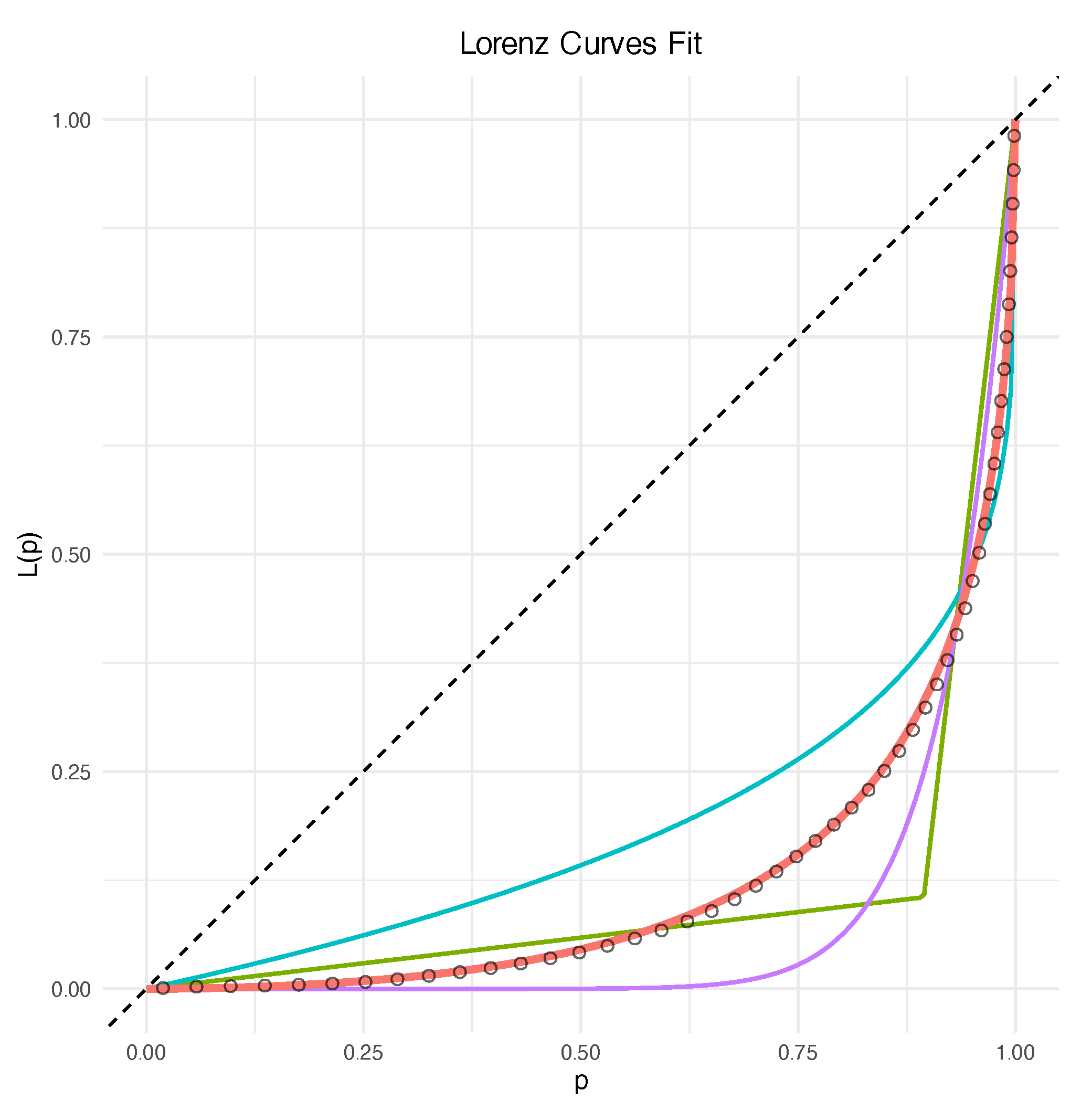
Model selection is performed using the Akaike Information Criterion (AIC) and confirmed by visual inspection. As shown in
Figure 13, the lognormal Lorenz model provides a decisively superior fit, with an estimated parameter of
. The other tested families, while representing best fits within their class, provide an unsatisfactory description of the empirical Lorenz curve for the DAX-SMI pair.
Once the parametric Lorenz curve is determined, we numerically invert the
function using a root-finder (such as
uniroot in R) to obtain the corresponding parametric Pickands function via Equation (
8).
Figure 14 shows this fitted Pickands function against the nonparametric estimate we started from. The close agreement between the two curves confirms the adequacy of the chosen model.
From the lognormal Lorenz model with parameter
, we compute the dependence indices discussed in
Section 6. The results, summarized in
Table 1, reveal a dependence structure that is both symmetric (in line with the symmetry of the lognormal Lorenz model, and the fact that we are considering two well-integrated markets) and strong.
A Gini coefficient of is high, indicating a dependence structure that is far from independence and exhibits significant concentration. This is unsurprising, given the strong economic interdependence between the German and Swiss markets. Because the best-fit model is symmetric (), the Pietra index H and the upper tail dependence coefficient coincide. Their value of indicates that if one market experiences an extreme positive event, there is an estimated 60.2% probability that the other market does as well, confirming relevant tail co-movement.
Remark 3. A crucial consideration for the practical application of our framework, which also represents a key avenue for future research, is its sensitivity to the initial, nonparametric estimation of the Pickands function. The entire chain of analysis—from the empirical Pickands points to the transformed Lorenz curve and the final fitted model—inherits the uncertainty from this first step. Estimators for tail dependence are notoriously data-hungry and can exhibit high variance, an issue compounded by the natural scarcity of data in the joint tails [1,9]. This sensitivity to the choice of estimator and its tuning parameters remains at present the primary bottleneck for the methodology, in those applications where data can be substantially limited. Future work could therefore focus on developing more robust statistical procedures to mitigate these issues. For instance, as we also state in Section 10 below, creating methods to fit Lorenz curve models directly to the data, thereby bypassing the explicit and often unstable estimation of the Pickands function, or developing regularization techniques inspired by inequality theory, could greatly enhance the applicability and reliability of the Pickands–Lorenz connection. 10. Conclusions and Future Directions
We have discussed a one-to-one, geometrically transparent link between two seemingly distant objects: the Pickands dependence function that encodes bivariate extreme-value copulas and the Lorenz curve that deals with economic inequality.
By rotating, rescaling, and “remapping” the traditional Pickands triangle, we have shown that every admissible corresponds to a unique Lorenz curve and vice versa. The mapping is constructive, so that decades of work on tractable Lorenz families can be translated directly into closed-form or easily numerically tractable Pickands functions.
The Lorenz–Pickands bridge enlarges the catalog of practical models, supplies new diagnostic instruments, and offers a fresh angle on the measure-generating function M for the Pickands dependence function and bivariate extreme-value copulas in general. Classical concentration indices like the Gini and the Pietra emerge as scale-free measures of tail dependence, complementing the existing tools.
Using the GDAXI and SMI indices, from Germany and Switzerland, respectively, we have provided a simple example of the application of our methodology. We found that the lognormal Lorenz generates a useful extremal copula to model the dependence between these two indices.
Several promising avenues remain open. Naturally, in terms of empirical analyses, more thorough investigations are needed to compare the performances of the Lorenz representation with existing alternatives, but also to develop those useful heuristics one can conceive by only addressing practical issues.
Further, the present work still relies on
to obtain an extreme-value copula. An ongoing project is to bypass
altogether and formulate existence, admissibility, and representation theorems directly in the Lorenz domain. The goal is a “Lorenz calculus” for extremes in which dependence models are manipulated, composed, and constrained using
only. Because
is tied to majorization and entropy [
48], this could better connect extreme-value dependence to information geometry.
The extension of the Lorenz approach to higher dimensions could also represent an interesting research path, though we envision two possible major issues. From one side, there is no unique generalization of a Lorenz curve in a multivariate framework. One could rely on Lorenz zonoids [
30], for instance, but a few alternatives are available in the literature [
37], and none appear a priori preferable. From the other side, the Pickands function itself becomes more difficult to treat in higher dimensions [
6], and this makes our whole construction more complicated. This is why a fully alternative Lorenz representation of extremal copulas seems to be a better (even if hard to find) option.
From a statistical perspective, standard estimators first recover
nonparametrically and only then translate results [
3,
4,
7]. Tailored procedures like kernel-type smoothers for
, minimum-distance fitting against Gini-style functionals, or Bayesian priors on Lorenz families could yield lower variance and naturally incorporate inequality-based regularization. Further, many applications call for time-varying or covariate-dependent copulas. The use of
could help in this direction, thanks to the results in the evolution and transformation of Lorenz curves [
14].
All in all, bridging tail dependence and inequality theory does more than simply adding a new trick to the modeler’s toolbox; it possibly sets the stage for a unified language between risk, concentration, and extremes, with many possible applications in finance, economics, and several other fields.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}