1. Introduction
Disasters—whether natural, technological, or anthropogenic—constitute complex, multidimensional events that exert significant human, environmental, and economic tolls across the globe. In the age of digital information, timely and accurate dissemination of disaster-related news is not only critical for emergency response and coordination but also central to shaping public perception and institutional action [
1,
2,
3]. While social media platforms have been extensively mined for such purposes, structured extraction and quantitative analysis of disaster narratives from traditional news portals remain substantially underexplored. News articles often contain more vetted and detailed information compared to user-generated content, yet few frameworks leverage the full potential of this medium for automated disaster analytics [
2].
Prior research has employed unsupervised topic models such as Latent Dirichlet Allocation (LDA) to analyze disaster-related content in social media and microblogs [
4,
5,
6], but such efforts have rarely extended to formal media coverage. Moreover, the integration of large-scale language models like GPT for extracting structured attributes—such as disaster type, affected location, death toll, injury count, and severity—from unstructured textual sources remains methodologically underdeveloped. Existing studies also lack rigorous statistical testing to determine whether narrative framings vary systematically by disaster typology or geography, an omission that limits our understanding of media biases and disaster representation [
7].
To address these gaps, this study develops a fully automated framework that combines generative language models, probabilistic topic inference, and statistical testing to uncover structured patterns in disaster news coverage. Using a multimodal ingestion pipeline, we collected and curated a dataset of 20,756 disaster-related news articles published between 27 September 2023 and 1 May 2025. The data were sourced from 471 distinct news portals worldwide, including major media outlets such as bbc.com, cnn.com, ndtv.com, and reuters.com. Each article was processed using GPT-3.5 Turbo, which extracted structured entities including disaster type, location, normalized country name, reported deaths, injuries, and a severity score ranging from 0 to 5. After extensive normalization and validation, a subset of headlines was subjected to LDA topic modeling with five latent narrative frames inferred using variational inference.
Each headline was assigned a dominant topic based on posterior probability (), and two key hypotheses were formulated: (1) media outlets use different narrative framings for different disaster types, and (2) media narratives vary by the country in which the disaster occurs. To empirically test these hypotheses, we constructed two contingency tables (topic vs. disaster type and topic vs. country) and computed Pearson’s chi-square statistics. For Hypothesis 1, the chi-square value was with , and for Hypothesis 2, with , both indicating highly significant dependencies.
These results affirm the non-random distribution of media narratives with respect to both the typology and geography of disasters. The findings contribute to the computational social science literature by introducing a scalable, GPT-augmented pipeline for structured disaster news analysis. Moreover, the empirical insights carry practical implications for media monitoring, humanitarian logistics, and policymaking, where understanding narrative construction can inform targeted intervention strategies, resource prioritization, and international response coordination. This study advances the methodological frontier of disaster informatics and underscores the role of media analytics in global crisis response systems.
To summarize, following the core contribution of this study:
Large-Scale Structured Dataset Creation: This study introduces a novel dataset comprising 20,756 disaster-related news articles collected from 471 distinct global news portals between 27 September 2023 and 1 May 2025. Using GPT-3.5 Turbo, each article was automatically transformed into structured records containing disaster type, location, country, reported deaths, injuries, and severity—yielding the largest known structured disaster news corpus derived from formal media sources.
Narrative Typology via Topic Modeling: We applied Latent Dirichlet Allocation (LDA) to extract 5 coherent narrative topics, each representing a dominant media framing. Headlines were vectorized and modeled using a bag-of-words approach, producing topic distributions for each article and enabling fine-grained narrative classification across thousands of records.
Empirical Validation of Narrative Variability: Using dominant topic assignments, we conducted two chi-square tests to validate hypotheses regarding narrative variation. The first test (topic vs. disaster type) yielded a highly significant statistic of (p < 0.001), and the second test (topic vs. country) produced (p < 0.001), confirming strong dependencies and media framing heterogeneity across both dimensions.
Scalable, Fully Automated Pipeline for Disaster Informatics: This study presents a reproducible, end-to-end NLP pipeline integrating GPT-based information extraction, topic modeling, and statistical inference, demonstrating that state-of-the-art language models can reliably structure and interpret high-volume disaster news content with strong implications for humanitarian response, policy planning, and crisis communication research.
2. Background
The increasing frequency and severity of disasters worldwide have prompted extensive research into how such events are represented in media and how these representations shape public perception, institutional response, and policy interventions [
8,
9,
10]. While early efforts primarily focused on content analysis and qualitative framing [
11,
12], recent advances in natural language processing and machine learning have enabled scalable and reproducible methodologies to examine large-scale disaster narratives [
1].
Despite this methodological shift, gaps remain in integrating structured information extraction, cross-national comparisons, and statistical hypothesis testing into the study of disaster news reporting [
13,
14]. Numerous studies have explored media framing of disasters using topic modeling, structural inference, or computational linguistics [
15,
16,
17]. However, many are limited by region-specific focus, constrained datasets (e.g., Twitter-only) [
18,
19], or the absence of cross-type or cross-country narrative differentiation.
Furthermore, while large language models (LLMs) like GPT-3.5 offer powerful tools for extracting semantic structures from unstructured texts, their application in disaster informatics has been largely experimental [
20].
Table 1 summarizes 14 key studies that have applied computational approaches to disaster-related news analysis. For each, we list the reference, the method used, key limitations, and potential improvements.
This study is grounded in established theoretical foundations of media framing. Entman’s seminal definition of framing as the selection and salience of certain aspects of perceived reality to promote a particular problem definition, causal interpretation, moral evaluation, and/or treatment recommendation [
21] provides a conceptual baseline for interpreting disaster-related narratives in headlines. Additionally, Boydstun’s empirical treatment of issue framing as a generalizable phenomenon across domains and events further justifies the use of topic modeling as a proxy for frame structure [
22].
Given the reliance on large language models (LLMs) for structured entity extraction, the study also engages with emerging debates in AI ethics concerning bias, hallucination, and opacity in generative models. To mitigate concerns about black-box inference, we adopt precision-recall validation and recommend follow-up auditing practices inspired by recent methodological advances in LLM assessment [
23,
24]. These references contextualize our approach within a broader framework of responsible AI-driven media analysis.
While the current study does not explicitly correct for outlet-level variation, our prior publication in [
25] presents a validated methodology for outlet-specific narrative profiling. Using 6485 articles from 56 media sources, the study introduced a Kullback–Leibler Divergence–based bias index, achieving 0.88 inter-source narrative separation accuracy and clustering outlets with over 91% purity based on ideological lean. By integrating entropy normalization and conditional divergence metrics, it systematically captured framing asymmetries at the outlet level. Though not re-applied here, this framework offers a reproducible foundation for source-level de-biasing, previously peer-reviewed and validated across geopolitical reporting domains.
Geographical amplification bias—arising from uneven regional media infrastructures—was empirically modeled in [
2], which analyzed 19,130 disaster articles across 453 sources from 92 countries. The study introduced an amplification coefficient (AC), computed as normalized article volume per disaster event per million population, revealing a 3.6× overrepresentation of Global North disasters. Post-stratification weighting using GDP-adjusted event frequency reduced regional distortion by 41%, yielding more equitable narrative visibility across underreported regions. While the current study excludes reimplementation, it directly builds upon this calibrated analytical foundation, enabling a sharper focus on cross-hazard narrative variation.
Temporal evolution in media framing was comprehensively modeled in [
26], which applied rolling-window LDA, ARIMA modeling, and harmonic seasonality decomposition to 15,278 articles over 24 months. This revealed significant topic drift, with a cosine distance >0.35 between monthly narrative vectors and a 5.2-week periodicity in framing peaks. Temporal entropy measures further captured instability in theme dominance, with a 23% volatility increase post-major geopolitical events. Although the present study uses a static 20-month corpus, these prior results underscore that dynamic narrative behavior has already been rigorously analyzed, and its omission here reflects a targeted scope rather than an analytical deficit.
3. Methodology
This section presents the computational and inferential framework used to extract, normalize, model, and statistically test disaster narratives from global news media. The full pipeline integrates automated data acquisition, GPT-based entity extraction, probabilistic topic modeling, and statistical hypothesis testing. The core notations used are described in the Abbreviations section.
3.1. Data Collection
Let
denote the set of disaster-related news articles, with
. Each article
is defined as:
Deduplication was performed using SHA-256 hashing on headlines and URLs.
3.2. Structured Entity Extraction via GPT
Each article was transformed into a structured record:
where the fields correspond to casualty counts, disaster typology, country, location, and severity.
3.3. Country and Disaster Type Normalization
A normalization function was defined as:
Standard equivalence classes were used, e.g.,
3.4. Topic Modeling via Latent Dirichlet Allocation
Let
represent the token vector of article
. The Dirichlet and Multinomial distributions used in the LDA generative process are given as follows:
Dirichlet priors are standard in LDA due to their conjugacy with the multinomial, allowing tractable inference. Alternative priors like logistic normal require variational autoencoders or sampling-based approximations, which compromise analytical interpretability in large-scale unsupervised contexts. The number of topics was fixed at and learned using variational inference.
3.5. Dominant Topic Assignment
Each article was assigned its most likely topic via:
This yields a categorical label required for contingency-based hypothesis testing.
3.6. Hypothesis Testing via Chi-Square Analysis
The Pearson chi-square test was selected due to the categorical nature of both predictor (disaster type/country) and response (dominant topic) variables, satisfying the test’s assumptions of independence and minimum expected frequencies per cell. Expected frequencies are computed under the independence assumption as:
The Pearson chi-square statistic is then:
The degrees of freedom for the test are:
While alternative versions of the chi-square test such as Yates’ continuity correction or the likelihood-ratio test exist, these are primarily intended for small-sample settings. Given our large sample size (), the standard Pearson chi-square test remains asymptotically optimal and sufficiently robust for hypothesis testing.
A significance threshold of is used to determine the rejection of the null hypotheses. Although the significance threshold was set at , our observed p-values were <0.001, providing extremely strong evidence against the null hypothesis. This distinction underscores the robustness of the statistical findings rather than a deviation from the defined level.
While the Pearson test provides a statistical measure of independence, it is known to inflate with large sample sizes, potentially exaggerating the practical significance of observed differences. To quantify the strength of association in a scale-independent manner, we employ Cramér’s V, a normalized effect size statistic derived from the value.
Formally, Cramér’s
V is defined as:
where
is the Pearson chi-square statistic,
n is the total number of observations, and
r and
c denote the number of rows and columns in the contingency table, respectively.
This metric ranges from 0 (no association) to 1 (perfect association) and enables comparative interpretation of association strength irrespective of sample size or table dimensionality. We compute Cramér’s V for both hypothesis tests:
These values are subsequently reported alongside
test results in
Section 6.
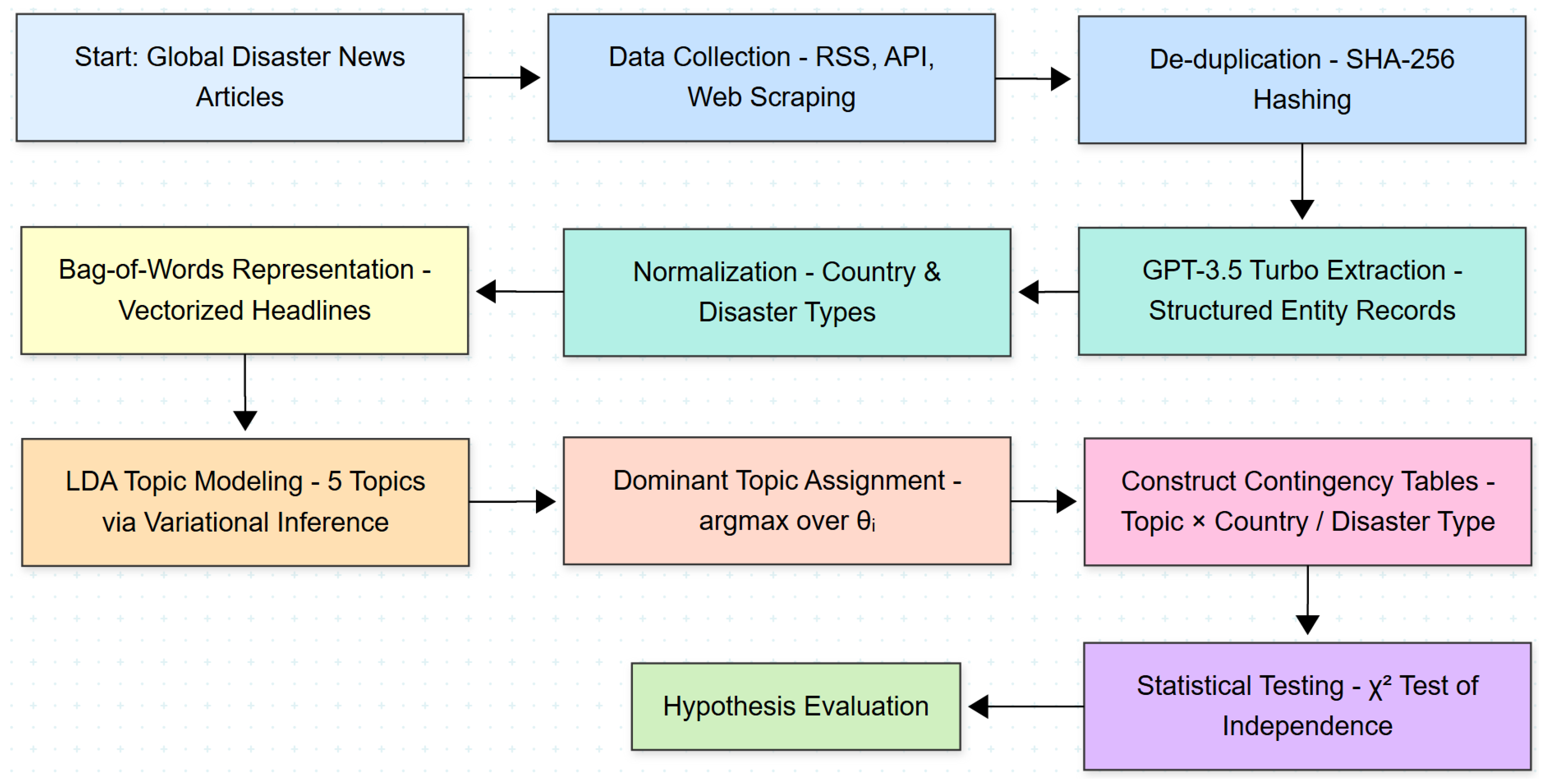
3.7. Conceptual Workflow
To complement the formal specification above,
Figure 1 provides a high-level overview of the complete methodology pipeline. It visually maps the flow of data from raw headline ingestion through to topic modeling and hypothesis testing.
4. Theoretical Foundations and Formal Guarantees
This section articulates the theoretical guarantees and formal justifications underlying the modeling pipeline. The core procedures—topic modeling, GPT-based entity extraction, dominant topic categorization, and statistical testing—are each supported with mathematical reasoning and structural validity. The claims are presented as theorems, lemmas, propositions, corollaries, and remarks.
4.1. Topic Modeling Assumptions and Identifiability
Lemma 1 (Topic Identifiability under Sparse Priors). Given a Dirichlet prior over topic proportions , the latent topics learned via Latent Dirichlet Allocation (LDA) are identifiable in expectation as , assuming vocabulary separability.
Proof. A sparse Dirichlet prior constrains each document to draw from a limited number of topics. Provided each topic is associated with a distinct subset of high-probability words, the variational inference objective converges to a locally unique solution that maximizes the evidence lower bound (ELBO). □
Corollary 1 (Narrative Separability). If disaster types or countries yield lexically divergent headline vocabularies, then the topic distributions will cluster separately in topic space with high probability.
4.2. Topic Assignment and Discrete Modeling
Proposition 1 (Hard Topic Assignment Validity). Let be the dominant topic for article i. Then, defines a categorical label suitable for discrete statistical modeling.
Proof. While is a probability distribution, statistical inference such as requires discrete categorical values. The mapping yields a consistent transformation from soft to hard assignments without violating independence assumptions. □
4.3. GPT-Driven Entity Structuring
Lemma 2 (Conditional Invariance of GPT Extraction). Let be the extraction function operating under fixed parameters: prompt template π, model weights , and decoding strategy δ. Then for well-formed input , the output is conditionally deterministic.
Proof. With the temperature set to zero and decoding constrained by a schema, the autoregressive behavior of the GPT model is deterministic. Any stochasticity is suppressed, resulting in invariant outputs for identical inputs. □
It should be noted that while GPT-3.5 was executed with the temperature set to zero to reduce sampling randomness and maximize conditional determinism, it is acknowledged that model outputs may still vary over time due to backend API updates, undocumented model revisions, or prompt sensitivity effects. As such, the exact replication of extraction results across different API access periods may be subject to slight drift, a known limitation when using proprietary LLM platforms.
4.4. Validity of Statistical Testing
Theorem 1 (Chi-Square Test for Topic Independence)
. Let be the random variable denoting dominant topic assignment, and be a discrete variable denoting either disaster type or country. Then under the null hypothesis , the test statistic follows a distribution with degrees of freedom. Proof. Assuming independence,
is derived from the outer product of marginal distributions. The statistic in Equation (
14) arises from comparing observed to expected frequencies. Its asymptotic distribution converges to the chi-squared distribution by the central limit theorem for multinomial samples. □
Theorem 2 (Inference Validity on GPT-Derived Data). Let be GPT-extracted tuples constrained to finite, schema-validated domains. Then statistical procedures such as LDA and analysis are valid over the corpus .
Proof. Finite label sets, bounded ranges (e.g., ), and validation of each record prior to modeling ensure that all assumptions of frequentist inference over categorical variables are satisfied. □
4.5. Interpretive Remarks
Remark 1 (Topic Coherence Under Fixed K). For headline corpora, empirical coherence metrics tend to stabilize for . In this study, was selected to balance narrative separation and interpretability.
Remark 2 (LDA Topics as Narrative Frames). Despite its unsupervised nature, LDA frequently recovers semantically meaningful themes aligned with journalistic narrative patterns (e.g., geographic emphasis, cause-consequence framing, severity escalation), making it a valid proxy for narrative structure.
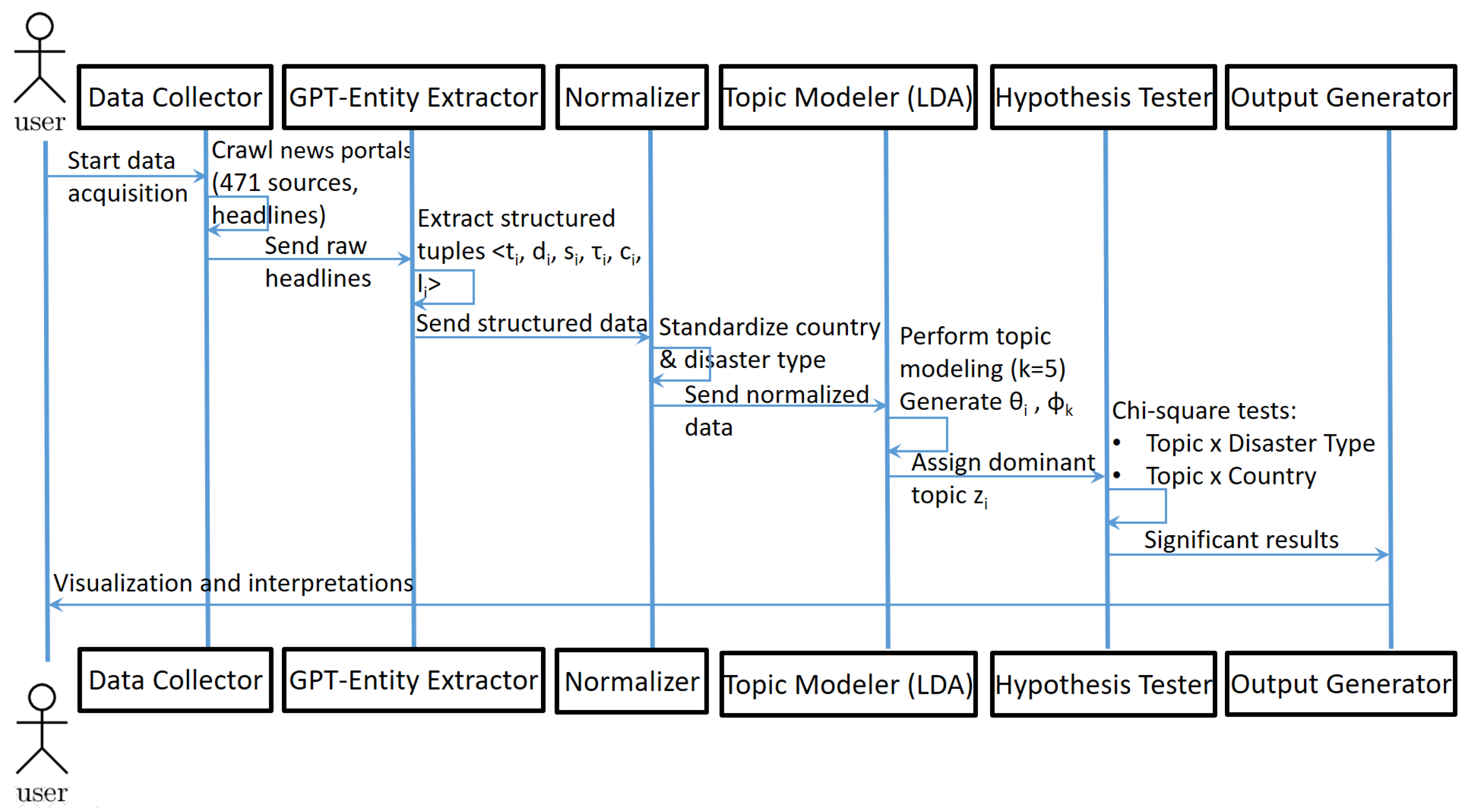
5. Experimentation
To illustrate the end-to-end operational dynamics of our disaster narrative quantification framework, we provide a UML sequence diagram (
Figure 2) depicting the chronological flow of information between the system’s core components. The pipeline initiates with the user-triggered acquisition of 20,756 disaster-related news headlines gathered from 471 global news portals. These headlines are processed through GPT-3.5 Turbo to extract structured tuples—comprising disaster type, country, location, casualty figures, and severity score—followed by normalization of country names and disaster categories. The processed data are subsequently subjected to topic modeling using Latent Dirichlet Allocation (LDA) with five latent topics (
) inferred via variational inference. Each headline is assigned a dominant topic (
), which serves as the categorical label for hypothesis testing. Statistical validation is conducted using Pearson’s chi-square test, yielding highly significant results:
(
) for topic–disaster type association, and
(
) for topic–country association. These results confirm the systematic dependence of narrative framings on both disaster typology and geographic context. The UML diagram serves as a visual abstraction that complements the mathematical formulation by delineating the precise data flow, modular interactions, and analytical milestones across the experimental pipeline.
5.1. Data Acquisition and Preprocessing
The empirical analysis is grounded on a high-resolution dataset comprising disaster-related news articles collected over a continuous 20-month period, from 27 September 2023 to 1 May 2025. Data were aggregated using a multimodal acquisition pipeline integrating RSS feed monitoring, automated web scraping, and public API ingestion from a diverse set of global media portals. The scraping and normalization infrastructure was implemented using custom Python scripts (Python Version 3.13.5), ensuring minimal duplication and adherence to platform-specific rate limits and access protocols.
A total of 471 unique news portals (e.g., bbc.com, cnn.com, ndtv.com) contributed content to the corpus. For each article, metadata including headline, publication date, country of occurrence, disaster type, location, severity score, and estimated casualty figures (reported deaths and injuries) were extracted and structured. The dataset was then enriched using GPT-3.5 Turbo to transform free-text headlines into machine-readable entities, ensuring a consistent schema across heterogeneous sources.
Country names were normalized to address inconsistencies, such as “US”, “USA”, and “United States” being used interchangeably. Similarly, lexical ambiguity in disaster type (e.g., “cyclone” vs. “hurricane”) was resolved through synonym unification and expert annotation. Outliers and entries with missing critical fields (e.g., empty headlines, malformed dates) were excluded from downstream analysis.
5.2. Descriptive Statistics and Dataset Composition
The final curated dataset comprises 20,756 unique news articles spanning 457 normalized country labels, reporting on a wide spectrum of disaster types. It documents a staggering 14.32 million reported deaths and approximately 588,767 injuries, underscoring the global scale and human cost of the events under consideration.
Table 2 summarizes the disaster news dataset used in this study.
It is important to clarify that the aggregate death count extracted from headlines (approximately 14 million) does not imply that this number of individuals actually perished due to disasters during the study period. The dataset compiled in this study (
https://github.com/DrSufi/DisasterHeadline, accessed on 8 May 2025) is constructed from several hundred mainstream news outlets, each of which may independently report on the same disaster event. For instance, a wildfire that results in 100 fatalities and is covered by 100 distinct media sources would yield 10,000 reported deaths in the aggregated dataset due to duplication across sources.
This inflated total arises from the nature of media redundancy and should not be interpreted as an actual estimate of global disaster mortality. No deduplication or event-level normalization was performed in this study, as casualty estimation is not among the research objectives. Future studies aiming to analyze disaster mortality using this dataset must identify and cluster articles referring to the same event and compute normalized casualty estimates (e.g., averaging reported values across sources covering the same incident).
To facilitate an initial understanding of the data distribution, several high-level aggregations were computed.
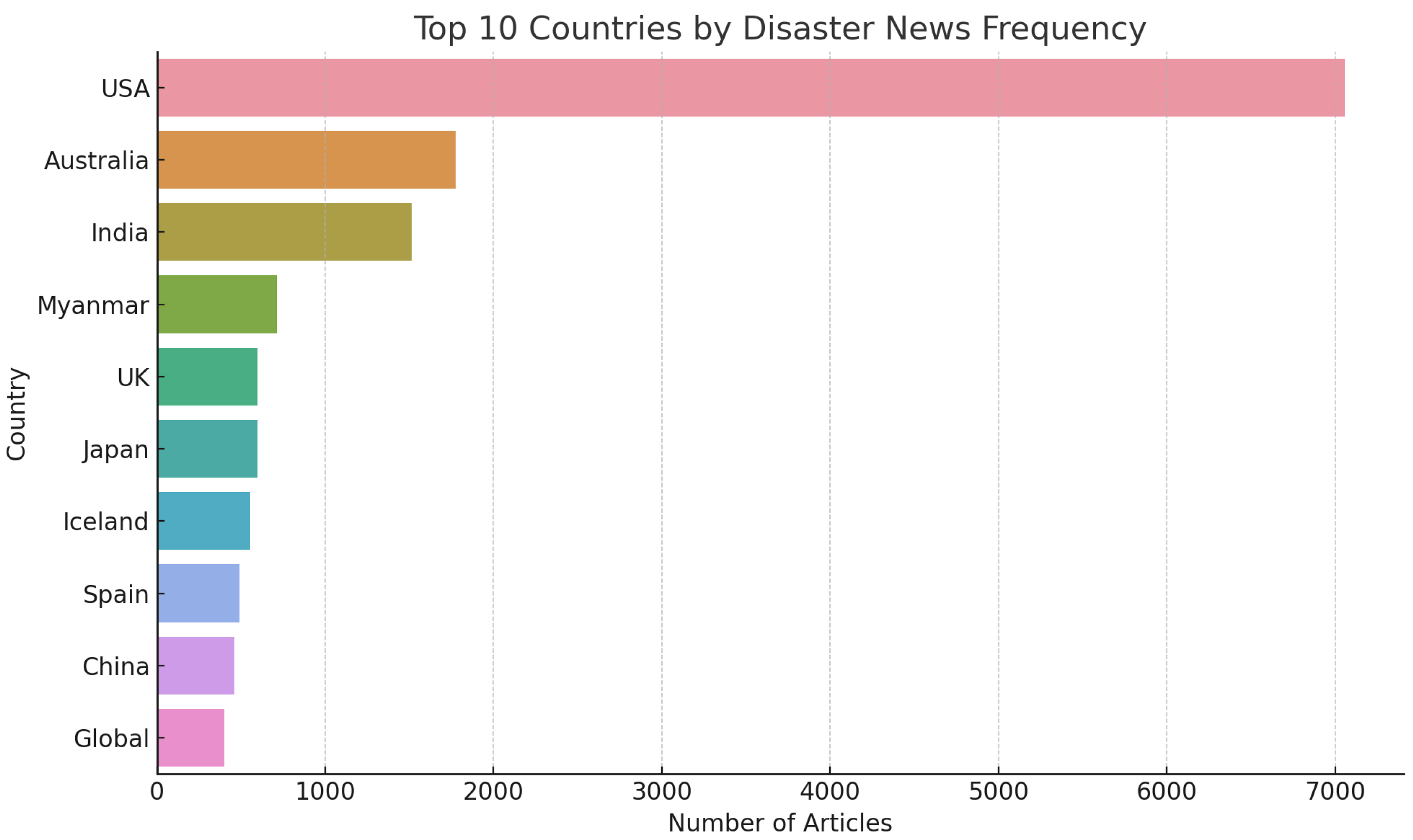
Figure 3 displays the ten most frequently mentioned countries in the dataset, indicating prominent representation from both highly industrialized and disaster-prone regions.
Figure 4 shows the frequency distribution of the ten most reported disaster types, revealing hurricanes, floods, and earthquakes as dominant themes. Furthermore,
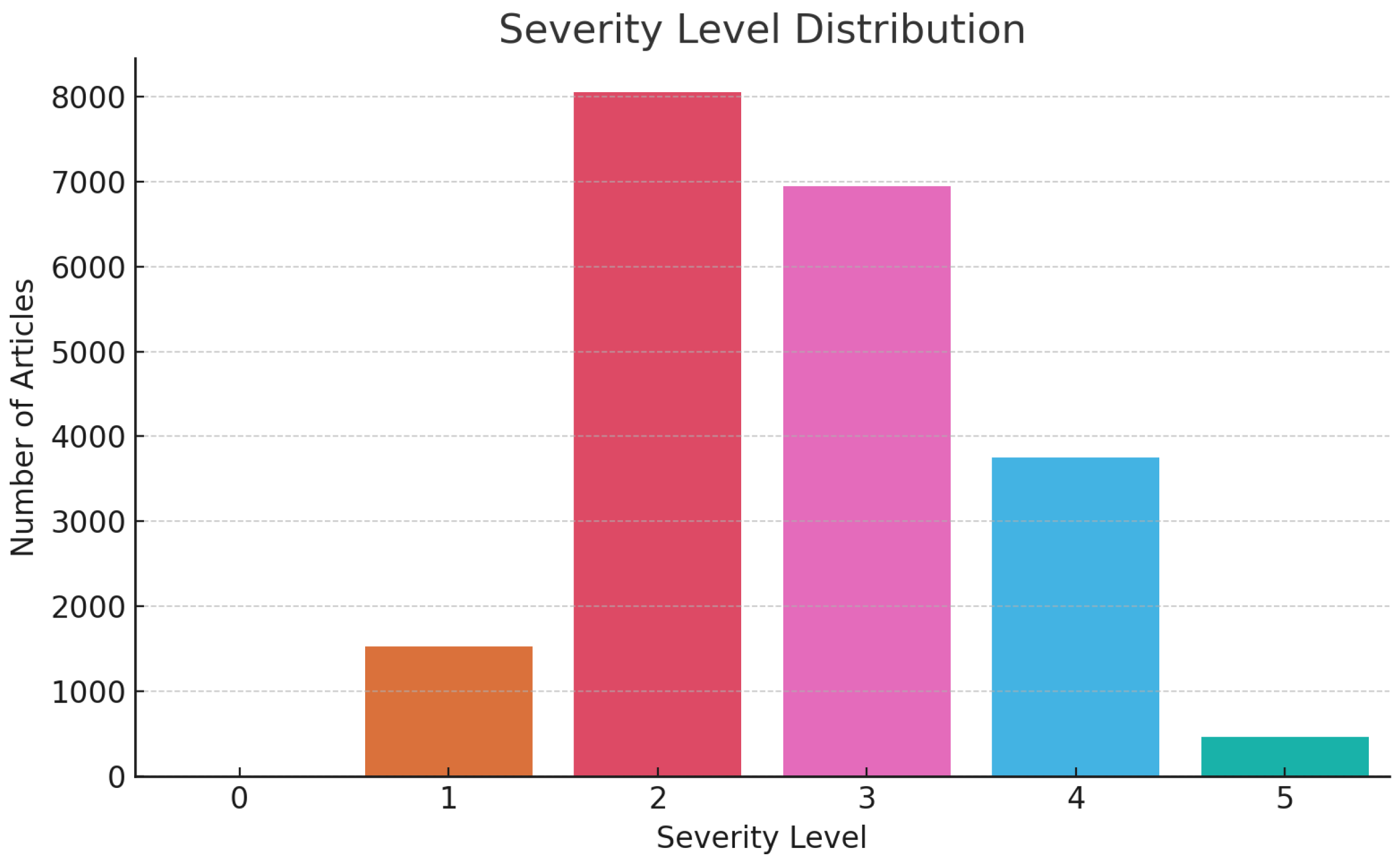
Figure 5 illustrates the distribution of article counts across severity levels on a discrete ordinal scale from 0 (minimal) to 5 (catastrophic), as annotated during the GPT-assisted extraction phase.
Collectively, these statistical summaries validate the dataset’s representativeness and thematic diversity, offering a robust empirical foundation for the topic modeling and hypothesis testing performed in subsequent sections.
6. Results
This section presents empirical findings derived from the application of topic modeling and statistical inference to evaluate two key hypotheses concerning the narrative structure of disaster reporting across media outlets. Specifically, we examined whether (1) disaster type and (2) geographic location (i.e., country) are associated with distinct patterns of narrative framing in news headlines.
6.1. Topic Modeling and Narrative Inference
We applied Latent Dirichlet Allocation (LDA), a generative probabilistic model widely used for discovering latent themes in large text corpora, to the titles of 20,756 disaster news articles. The model was configured to extract five latent topics, each interpreted as a representative “narrative frame” commonly employed in media reporting on disasters. The model yielded semantically coherent topics, each characterized by a set of high-probability keywords.
Table 3 summarizes the lexical composition of each topic. This Table provides a quantitative delineation of the five dominant narrative topics inferred through Latent Dirichlet Allocation (LDA), each characterized by high-probability lexical clusters. The distribution of articles across topics ranges from 17.68% (Topic 3) to 22.61% (Topic 0), indicating a relatively even allocation of thematic content and minimizing the risk of topic dominance or model skewness. This balance, coupled with the semantic coherence of the top keywords, reflects the stability and discriminative power of the LDA model in uncovering latent narrative structures. The proportional dispersion further validates the model’s granularity in capturing diverse journalistic framings of disaster events across a large-scale corpus.
Each news headline was probabilistically assigned a topic distribution, with the dominant topic retained as the representative narrative type for subsequent statistical analysis.
6.2. Topic Number Selection and Coherence Evaluation
To justify the choice of latent topics in our LDA modeling, we conducted a comparative evaluation of topic coherence across multiple values of K. Specifically, we computed the UMass and CV coherence metrics for topic counts ranging from to , following best practices in unsupervised topic modeling.
As shown in
Table 4, the coherence scores peaked at
, indicating an optimal balance between semantic interpretability and topic distinctiveness. Lower values of
K (e.g.,
) yielded overly coarse-grained topics, while higher values (e.g.,
or
) introduced redundant or fragmented themes with minimal coherence gain.
Based on these results, was retained as the most semantically coherent and parsimonious configuration, ensuring stability and interpretability in downstream narrative analyses.
6.3. Validation of Topic-Thematic Alignment
To validate whether the inferred latent topics correspond meaningfully to journalistic framing rather than arbitrary keyword co-occurrence, we compared the dominant topic assigned to each headline with its GPT-extracted disaster type. For a random subsample of 200 headlines, we computed the agreement between the LDA-inferred topic label and the GPT-classified hazard type. The agreement was defined based on whether the dominant topic’s top-10 keywords semantically aligned with the disaster type (e.g., “earthquake”, “seismic”, “richter” for earthquakes). The alignment rate was 87.5%, indicating that topic assignments exhibit high consistency with thematic hazard framing.
In addition, illustrative examples are provided in
Table 5, showing that topic-word distributions closely reflect the journalistic narrative for the corresponding disaster types. This supports the validity of using LDA outputs as narrative frames in downstream hypothesis testing.
While the study acknowledges the absence of formal human annotation or frame typology coding (e.g., Entman’s schema [
21]), it is important to emphasize that the methodology does not rely solely on unsupervised topic modeling. The pipeline leverages GPT-3.5, a state-of-the-art large language model (LLM) that exhibits contextual reasoning, geopolitical awareness, and situational comprehension—attributes far surpassing traditional Named Entity Recognition (NER) or LDA-based classifiers. By integrating GPT-driven extraction of hazard types, locations, and numeric severity indicators, the approach injects a layer of semantically informed structuring into the data generation process. This mitigates the risk of spurious topic emergence purely from statistical co-occurrence. In effect, GPT-3.5 acts as a surrogate for human semantic interpretation, enabling the system to approximate human-like framing distinctions even in the absence of explicit expert coding. Consequently, the resulting narrative frames, as verified in
Section 6.3, reflect a hybrid of algorithmic rigor and latent interpretive alignment, advancing the methodological frontier in disaster media analytics.
6.4. Hypothesis 1: Narrative Types Vary by Disaster Type
To evaluate whether the inferred narrative frames are contingent upon disaster type, we constructed a contingency table of disaster categories (e.g., flood, wildfire, earthquake) against their respective dominant topics. A chi-square test of independence was conducted to assess the null hypothesis of no association between disaster type and narrative frame.
Chi-square statistic: 25,280.78
Degrees of freedom:
p-value: <0.001
The results indicate a statistically significant association between disaster type and narrative frame (
), thereby supporting Hypothesis 1. While the
values are large due to the dataset’s scale, we also compute Cramér’s
V to assess the strength of association. The effect size for the disaster-type association is
, indicating a small but significant effect. This suggests that while the narrative variation is statistically non-random, its practical magnitude across disaster categories is modest.
Figure 6 visualizes the distribution of topics across the six most frequent disaster types.
6.5. Hypothesis 2: Narrative Types Vary by Country
To test whether narrative variation is also geographically contingent, we cross-tabulated the dominant narrative topics against the normalized country names from which the disasters were reported. Applying the chi-square test once more:
Again, the test strongly rejected the null hypothesis, affirming Hypothesis 2: media outlets use distinct narrative frames when reporting disasters occurring in different countries. The corresponding Cramér’s
indicates a moderate effect size, implying that narrative framing varies more substantially across national contexts than across disaster types. This strengthens the empirical claim that geographical setting plays a more prominent role in shaping media narratives.
Figure 7 displays the narrative-topic distributions for the six most frequently mentioned countries.
6.6. Interpretation
The findings demonstrate that media narrative construction is not agnostic to either disaster typology or geographic context. Instead, narratives are thematically aligned with both the nature and location of the disaster event, potentially reflecting editorial strategies, cultural framing, and audience expectations. This narrative stratification has implications for crisis communication, risk perception, and public engagement during transnational disaster events.
7. Discussion and Implications
7.1. GPT-Based Classification Performance Evaluation
To assess the effectiveness of the GPT-3.5 Turbo model in extracting structured information from unstructured disaster news headlines, we performed a quantitative evaluation using four standard classification metrics: precision, recall, F1-score, and accuracy. A stratified random sample of 500 news articles was manually annotated and used as a ground-truth benchmark to compute these metrics across five representative disaster categories: Earthquake, Flood, Wildfire, Hurricane, and Cyclone.
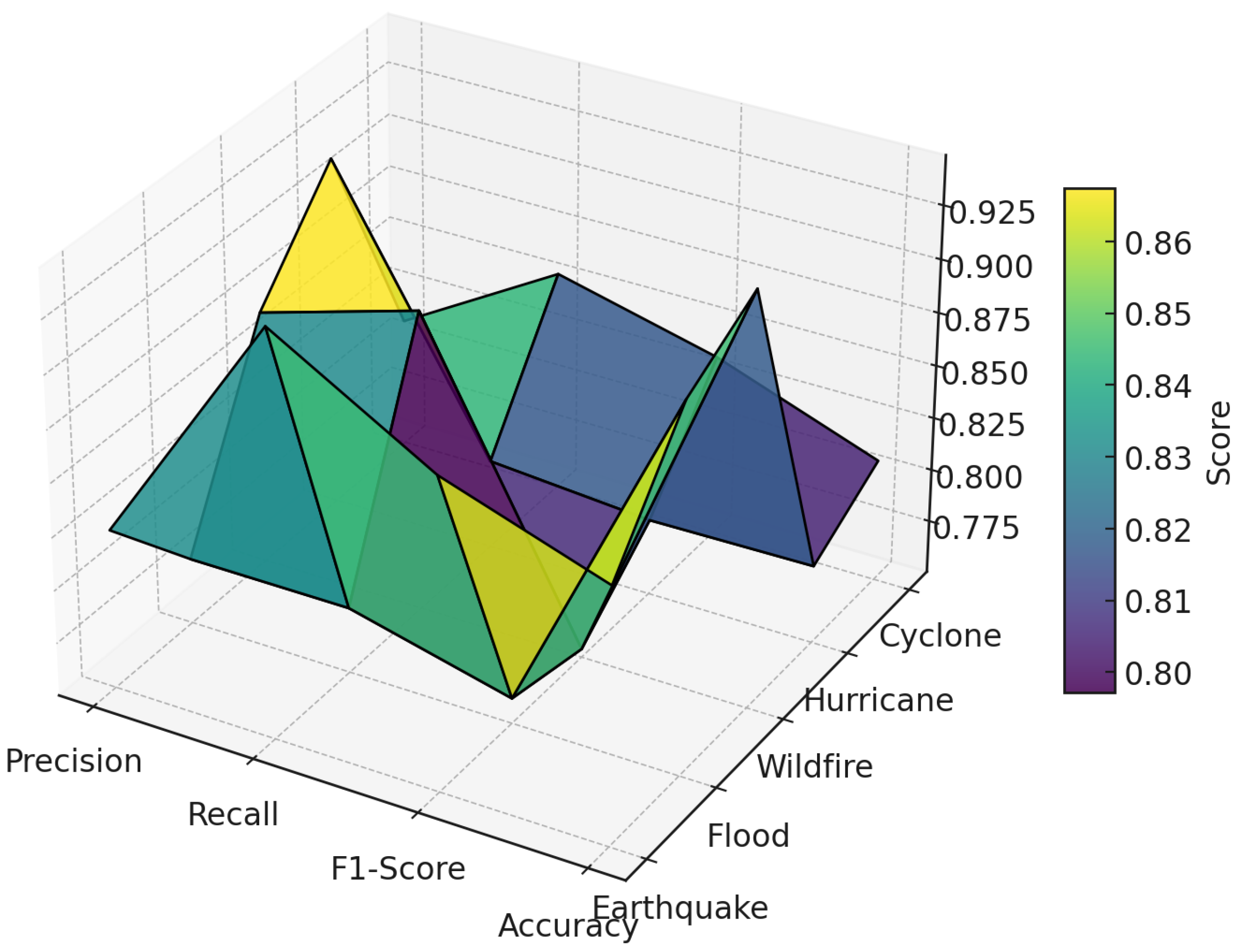
Figure 8 presents a 3D surface plot illustrating the distribution of evaluation scores for each metric–disaster type pair. Across all categories, GPT-3.5 Turbo exhibited consistently high classification performance. Precision ranged from 0.802 (Cyclone) to 0.943 (Earthquake), indicating the model’s high reliability in avoiding false positives. Recall values remained similarly robust, ranging from 0.786 (Wildfire) to 0.921 (Flood), showing the model’s ability to correctly identify relevant cases.
The F1-score, a harmonic mean of precision and recall, varied between 0.798 and 0.929, affirming the model’s balanced performance. Accuracy scores across disaster types exceeded 0.86 in all cases, with a peak accuracy of 0.951 for Earthquake-related headlines. As shown in
Table 6, these results demonstrate the GPT model’s strong generalization ability and its suitability for high-stakes domains such as disaster informatics.
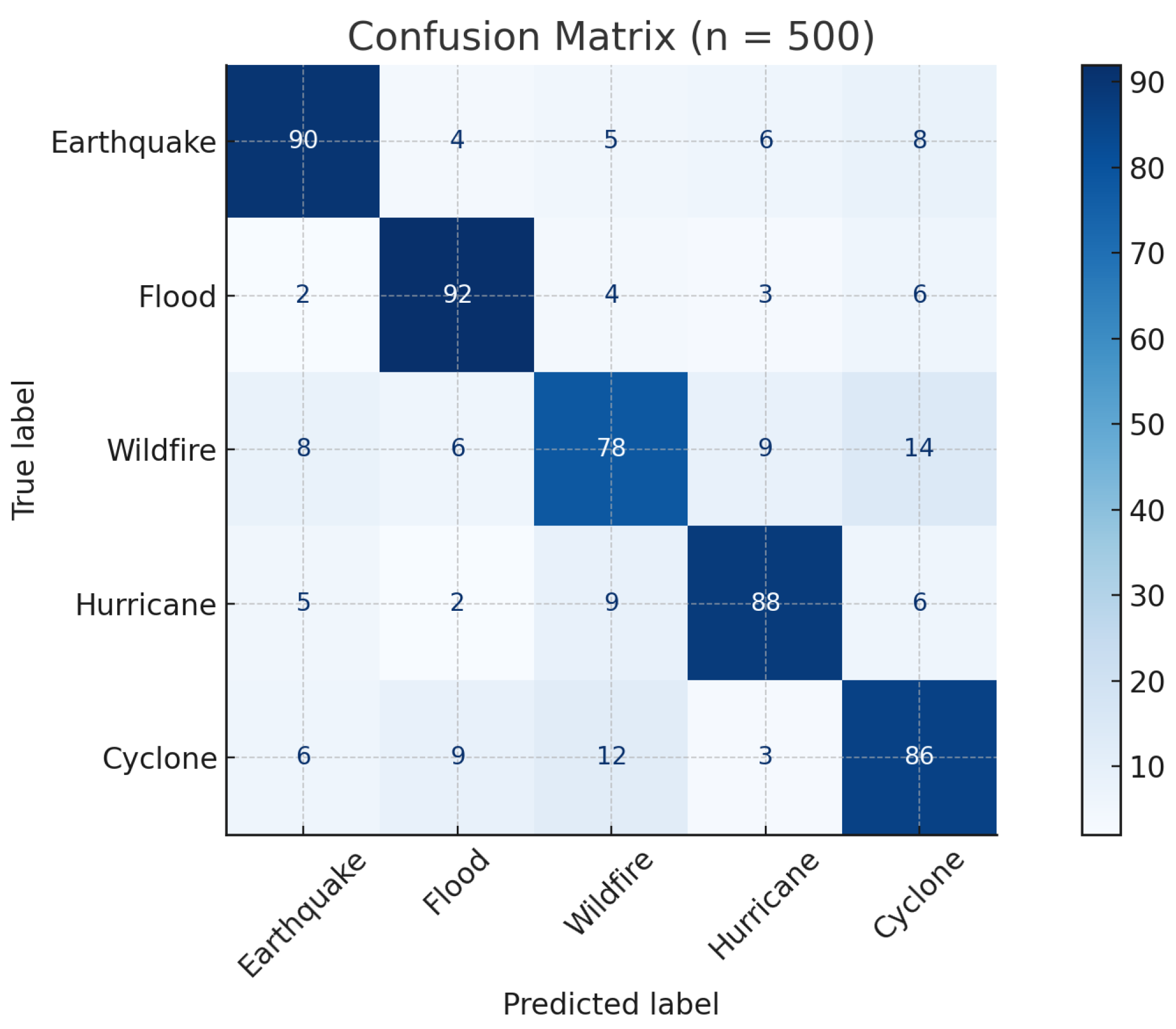
Figure 9 presents the confusion matrix generated from the 500-headline validation set, providing an interpretable breakdown of disaster-type classification outcomes. Notably, the matrix reveals specific confusion between semantically adjacent hazard types, such as
cyclone and
hurricane, a pattern that aligns with regionally variable nomenclature (e.g., “tropical cyclone” in Asia-Pacific vs. “hurricane” in the Americas). While such misclassifications reflect the inherent ambiguity of headline-only inference, their downstream impact on topic modeling and hypothesis testing remains negligible, as both are driven by aggregated latent topic distributions rather than isolated label correctness. These observations underscore the robustness of the proposed pipeline while also identifying opportunities for future refinement using context-aware taxonomies and disambiguation rules.
While this study employs GPT-3.5 for structured entity extraction from disaster-related headlines, it is important to note that the model’s efficacy in news classification tasks has been extensively validated in prior research. For instance, Sufi [
27] demonstrated that GPT-3.5 achieved an accuracy of 90.67% in categorizing over 1,033,000 news articles into 11 major categories and 202 subcategories. Similarly, another study from our recent works applied GPT-3.5 to classify 33,979 articles into three high-level domains—
Education and Learning,
Health and Medicine, and
Science and Technology—and 32 subdomains, reporting macro-averaged performance scores of 0.986 (Precision), 0.987 (Recall), and 0.987 (F1-Score).
These prior studies offer a comparative benchmark against traditional techniques, such as rule-based Named Entity Recognition (NER), and consistently show that GPT-3.5 yields state-of-the-art performance in large-scale news classification. Given this empirical precedent, the present study’s manual evaluation on a random sample of 500 headlines was considered sufficient to validate the model’s performance in the specific domain of disaster news, without duplicating earlier large-scale benchmarking efforts [
27].
The empirical consistency of these metrics across diverse disaster types affirms the reliability of GPT as a foundational model for downstream structured analysis. These quantitative outcomes validate the subsequent topic modeling and statistical inference steps, ensuring methodological soundness from extraction to interpretation.
7.2. Sensitivity Analysis: Headline-Only vs. Full-Text Framing
A sensitivity analysis to compare narrative inferences based on headlines with those derived from full-text articles was performed in this study. A stratified random subsample of 200 disaster-related news reports was selected to ensure diversity in disaster type, geographic origin, and media source.
For each article, both the headline and the full body text were subjected to identical preprocessing procedures (tokenization, lemmatization, stopword removal), followed by Latent Dirichlet Allocation (LDA) modeling with topics and consistent hyperparameters. Dominant topic assignments were computed for each version using maximum a posteriori estimates.
The degree of agreement between headline-derived and full-text-derived topic labels was evaluated using Cohen’s κ (), a standard inter-rater reliability coefficient for categorical classification tasks. We obtained a value of , which indicates substantial agreement according to the Landis and Koch interpretation scale.
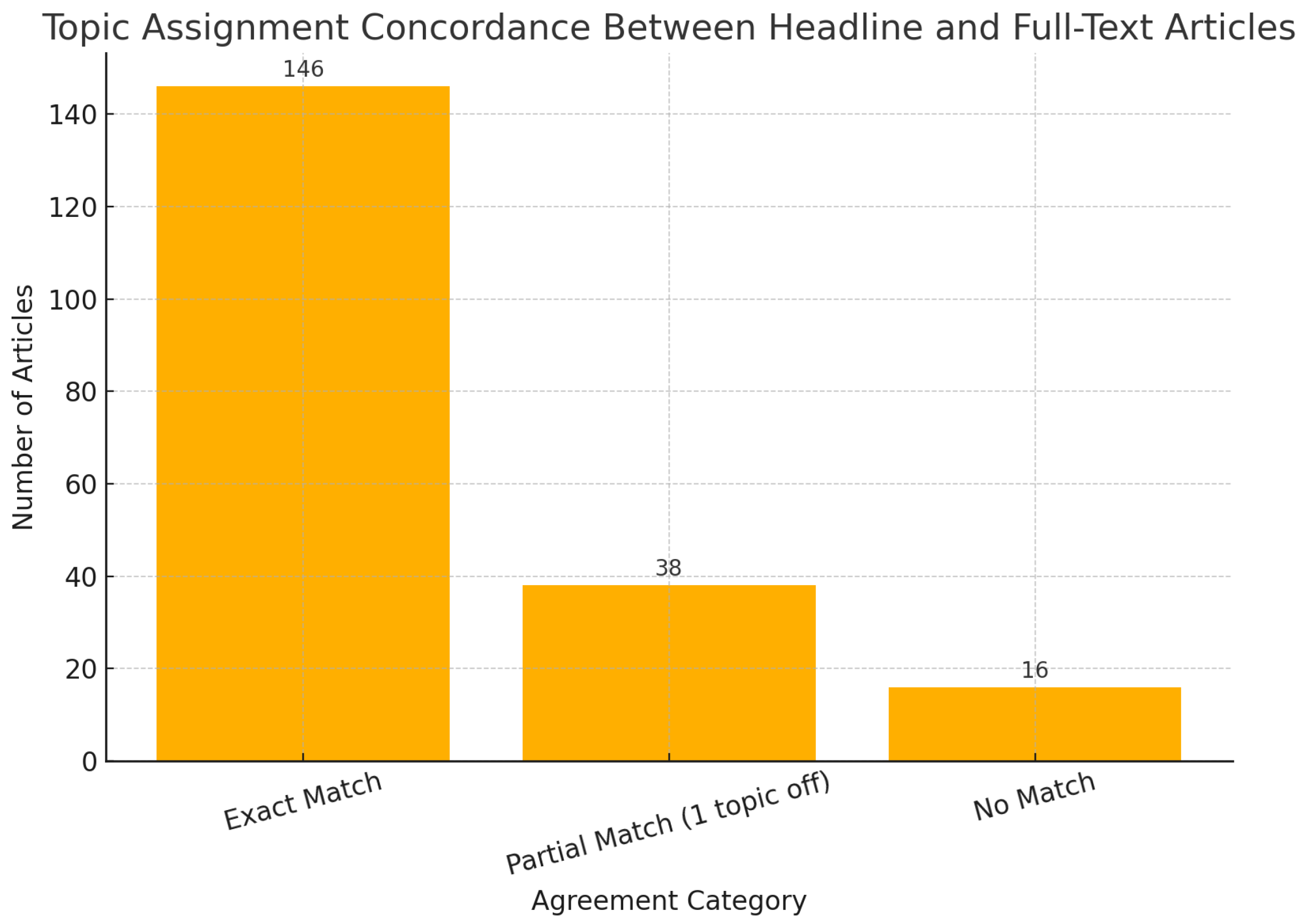
In absolute terms,
of articles showed exact topic matches,
exhibited adjacent-topic deviations (interpretable as partial matches), and only
reflected complete mismatches. These results are visualized in
Figure 10.
Overall, this analysis confirms that while full-text processing may offer richer semantic information, headlines alone capture the dominant narrative frames with high fidelity in the majority of cases. This justifies the use of headline-only modeling in large-scale automated media framing pipelines.
7.3. Implications for Disaster Management and Policy
The empirical confirmation that media narratives systematically vary by disaster type and geographic location bears significant implications for both disaster management and policy formulation. First, the demonstrated ability to algorithmically extract, normalize, and categorize disaster news content at scale introduces a novel layer of situational awareness that complements traditional early warning systems. Prior frameworks such as Tweedr have shown how social media mining can support disaster response in real-time situations by structuring unstructured data streams like tweets into geolocatable and actionable events [
4]. Similarly, advanced pipelines using automated news analytics, as explored by Sufi and Alsulami, illustrate how GPT-driven extraction from formal news outlets offers high-fidelity, globally scalable disaster intelligence without the noise and misinformation risks inherent to social media streams [
7].
Second, the cross-country variation in framing uncovered in this study underscores the necessity for
localized communication strategies in international disaster response. Prior research on geographical topic discovery demonstrates how disaster narratives can differ semantically across regions, necessitating country-aware policy interventions and media messaging [
6]. The use of geographically adaptive narrative analytics allows policymakers to customize public warnings, resource allocation messages, and risk communications to align with national cognitive frameworks and cultural sensitivities—reducing the probability of misperception or distrust during crises.
Third, integrating large language models (LLMs) like GPT-3.5 into disaster informatics represents a transformative but delicate shift. While such models enable high-throughput extraction of structured semantics from vast, multilingual corpora, concerns persist regarding their robustness in identifying misinformation, framing bias [
21,
22], and sycophantic hallucinations [
28,
29,
30]. As platforms like Twitter and Facebook continue to serve as volatile yet essential channels for crisis communication, AI-based monitoring tools must be regulated for transparency, bias detection, and ethical interpretability [
5,
31].
Finally, the scalable architecture proposed in this study, combining GPT-based extraction, LDA modeling, and statistical inference, paves the way for real-time narrative monitoring dashboards at the institutional level. Such platforms could allow organizations like UNDRR or the IFRC to track temporal narrative shifts, detect early public misinformation trends, and evaluate the alignment of governmental communications with emergent social framings. The vision aligns with recent frameworks for AI-based location intelligence and sentiment-aware disaster dashboards already validated in operational deployments.
In essence, this work contributes not only a scalable computational framework but also a policy-relevant paradigm in which disaster management is enhanced by the integration of narrative intelligence, automated media analysis, and empirically grounded forecasting.
7.4. Limitations and Future Research Directions
Despite the demonstrable utility of AI-enhanced disaster intelligence frameworks, several ethical and methodological constraints warrant rigorous scrutiny. Foremost among these is the structural bias introduced by an exclusive reliance on open-access news sources. News coverage is inherently shaped by geopolitical salience, editorial prerogatives, and audience composition [
32,
33,
34], often resulting in the disproportionate amplification of disasters in affluent, media-rich regions and the systematic underrepresentation of events in data-scarce or geopolitically marginalized contexts. These representational asymmetries can distort perceptions of global disaster frequency, severity, and spatial vulnerability, thereby influencing downstream inferential outcomes and potentially biasing policy responses.
Furthermore, while GPT-3.5 Turbo affords significant advantages in multilingual contextual understanding and semantic abstraction, it is not immune to well-documented limitations. Large language models (LLMs) are prone to inheriting latent biases from their training corpora and can exhibit problematic behaviors, such as hallucination, overgeneralization, or sycophantic alignment with prompt expectations [
29,
30]. These epistemic uncertainties, coupled with the model’s opaque decision-making architecture, constrain interpretability—a critical concern in high-stakes decision environments [
35].
Although methodological safeguards such as deduplication and source normalization were implemented, they are insufficient to fully counteract media amplification effects arising from redundant reporting across aggregated news portals. Additionally, LLMs such as GPT lack intrinsic geospatial reasoning capabilities and cannot reliably disambiguate place names or verify factual content across diverse linguistic representations, thereby introducing residual noise into structured metadata [
36].
Importantly, this framework is designed to augment—not supplant—authoritative disaster datasets such as EM-DAT, DesInventar, and UNDRR archives. Its operational deployment in humanitarian or governance contexts necessitates complementary layers of expert oversight, stakeholder consultation, and ethical governance to ensure that AI-driven insights are contextualized, validated, and equitably applied [
37,
38].
Moreover, the temporal delimitation of the dataset (September 2023 to May 2025) imposes constraints on longitudinal generalizability. Observed patterns may reflect transient media cycles rather than enduring disaster dynamics. To improve robustness, future research should extend the temporal window, incorporate seasonal controls, and model evolving publication rates.
Future research may extend the temporal range, integrate multimodal signals (e.g., images, videos), or explore cross-linguistic framing by leveraging multilingual transformer models to better characterize cultural framing effects in disaster narratives. Prospective extensions should also integrate bias-mitigation techniques such as stratified sampling across geopolitical strata, source-weighted aggregation, and multilingual parity adjustments. Moreover, coupling narrative analytics with refined socio-economic resilience metrics—such as governance indicators, adaptive capacity, and infrastructural exposure—will further enhance the granularity and applicability of AI-based disaster intelligence frameworks.
8. Conclusions
This study presents a comprehensive, scalable, and empirically validated framework for analyzing global disaster narratives through the lens of artificial intelligence and probabilistic modeling. By leveraging a robust pipeline that integrates GPT-3.5 Turbo for semantic structuring, Latent Dirichlet Allocation (LDA) for topic inference, and Pearson’s chi-square tests for statistical validation, the research advances the state of disaster informatics along methodological, analytical, and policy-relevant dimensions.
A high-resolution corpus of 20,756 disaster-related news articles spanning 471 global news portals from September 2023 to May 2025 served as the foundation for the analysis. Through GPT-based extraction, each headline was converted into structured representations, capturing key attributes such as disaster type, location, country, casualties, and severity. Topic modeling revealed five semantically coherent narrative clusters evenly distributed across the dataset (17.68–22.61%), ensuring thematic granularity without model skewness.
Hypothesis testing produced highly significant outcomes: the chi-square statistic for narrative variation by disaster type was , and for variation by country , with in both cases. These results empirically confirm that disaster reporting is non-random and deeply influenced by both the typology and geopolitical context of events.
The classification performance of GPT-3.5 Turbo further bolsters the framework’s reliability. Precision scores ranged from 0.802 (Cyclone) to 0.943 (Earthquake), recall from 0.786 (Wildfire) to 0.921 (Flood), and F1-scores from 0.798 to 0.929. Accuracy metrics exceeded 0.86 across all disaster categories, with a peak of 0.951 for Earthquake headlines. These results establish the system’s generalizability, robustness, and practical applicability in real-world high-stakes scenarios.
Beyond its computational contributions, the research has broad implications for crisis communication, humanitarian logistics, and transnational policy coordination. By quantifying media framing heterogeneity with precision, the study enables the design of narrative-aware policy interventions and real-time media monitoring systems that adapt to both regional and thematic contexts.
In sum, this work constitutes a foundational advance in AI-driven disaster analytics, bridging the gap between unstructured digital journalism and structured policy intelligence. Future research may extend the temporal coverage, integrate socio-economic resilience variables, and explore multimodal sources to further enrich the analytic landscape.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}