1. Introduction
All stochastic sequences and their solutions share the same topological endowments or obey different laws. Determining when an unknown function of a sequence has the same topology as the sequence itself in a truly unbiased manner could be a natural way to test whether asymptotic behaviors can ensure convergence. In such a case, the model matches the observed data. Chichilnisky [
1] used weighted Hilbert spaces to identify the convergence of the Fourier coefficients of the unknown function that solves the stochastic sequence for all domains in bounded and unbounded spaces. A Hilbert space is complete and always reflexive. Therefore, solutions to stochastic partial differential equations are always endowed with the inner product that allows the closeness of the known and unknown sequences to be measured and to establish duality in the sense of being reflexive. In an unknown solution in a Hilbert space, the sequence
would always be isomorphic to a function of
that is jointly defined in a uniformly convex space. An observer testing the existence of duality will be biased when measured on the real line
. Bergstrom [
2] remarks that for a Hilbert space where continuous functions have bounded variation, the square integrable unknown function
requires
, representing a very strong restriction as it excludes important functions such as the constant, increasing, and cyclical types (see Chichilnisky [
1]).
The Banach space
is a complete normed space
of some dimension p, and it exists between the Hilbert space and a space M which is endowed with a metric and not a norm. In particular, if
with any choice of p is within
, then it is a Banach space. In addition, the vector probability space, defined by the triplet
is a
-finite measure, where X is the particular space,
represents the filtered measurable sets, and
is the measure. Then, more formally, a Banach space is defined as
, with f being
measurable. The direct implication is that
. Completeness means that any Cauchy, C, sequence with respect to the norm is convergent at the point that is in the space. The Banach norm
of the function f is given by
Geometrical considerations for normed spaces are dictated by the value of p. For instance, when , we have the space that includes all integrable functions f on X, and the satisfies the triangle inequality. When , is a Hilbert space and .
In general, only square integrable processes that are integrable functions are measurable and include all common functions such as “sup”, “inf”, and “lim”, are unique in being compatible with the desirable inner product property of the Hilbert space, and this guarantees reflexivity. Tsirelson [
3] showed an example in which the square integrable sequences are not always isomorphic to a uniformly convex space and they do not obey the same topological laws, while they have no inner product properties. The contribution of this paper is, therefore, to amplify the Hilbert space, with Banach
satisfying
for any
p in
. The purpose is, then, to extend the limits of measurement and identify the conditions for the duality of the unknown solution and its history via the observed stochastic process. For this, we assume that all functional forms will be measured in a Banach complete normal space, and this is where the
will be tested with some probability. We discuss the conditions under which it is isomorphic to a convex reflexive Banach dual space when the observed sequence inherits norms and an inner product. Yano K. [
4] demonstrate that the unknown solution space
does not depend on the known sequence metric
, and this invalidates the use of any functional model for explaining and predicting an unknown related process under orthogonality assumption in random processes. In general, duality and association cannot exist if the unobserved solution is not linked to the observed data. History plays no role in the formation of the new state, and generally speaking,
, with
V being some other independent sequence. Under this scenario, reversibility is impossible as there is an infinite number of starting points to map going backwards, rendering the course of the observed sequence unpredictable.
In this paper, we discuss the dependence and independence alternatives for a general stochastic solution process, and when the stochastic process takes values from Banach space, we examine under which conditions it can be reflexive. In particular, we examine whether the stochastic process depends on its known history. We argue that multidimensional integration has duality in a reflexive Banach space if the solution obeys the functional central limit theorem and its error is between the limits of dilation and erosion. Hence, there is isomorphism for closed and semi-open intervals and the desired inner product to define the orthogonality conditions. The evolution process depends on its history in three-quarters of all existing probability measures, and this necessarily implies that the integrable curves are quasi-periodic depending only on initial conditions that can be found in history, or indeed at the beginning of the cosmos. One possible scenario is, as Yano K. [
4] and Tsirelson [
3] suggested, that no model exists and reversibility is unattainable as it would map to infinite possible initial points. We offer a framework to evaluate these scenarios under different novel models that capture the general family of possible null hypotheses formulations. They can capture all possibilities of dependence and independence in both Banach and reflexive Banach spaces.
Still following their assumptions and adopting the compact G group and requiring duality in reflexive Banach space, we prove their dependence. We derive the orthogonality conditions and show that the unknown unique stochastic solution would depend on the observable history of the sequence, as in . The evolution process would depend on its history in three-quarters of all existing scenarios. When variation is outside the limits of dilation and erosion, the space will be composed of countably additive and possibly finitely additive measures with no functional representation in . Convergence will also fail in this scenario.
This paper contributes to several strands of the literature at the intersection of stochastic process theory, functional analysis in infinite-dimensional spaces, and empirical time series modeling under structural complexity. Below, we situate our work within four key domains: (1) duality and functional representation in Banach and Hilbert spaces; (2) dependence, orthogonality, and predictability in stochastic systems; (3) modeling nonstationary financial time series with structural breaks; and (4) empirical applications and computational limits in high-volatility environments.
The representation of stochastic processes in infinite-dimensional spaces has long been shaped by the use of Hilbert spaces due to their inner product structure and reflexivity [
1,
2]. However, this approach imposes strong topological restrictions—such as the exclusion of constant or monotonic functions—and often fails to accommodate non-smooth or heavy-tailed processes. Demonstrated by [
3] square-integrable sequences do not always exhibit topological equivalence with uniformly convex function spaces, posing limitations for models based solely on
spaces.
Recent advancements extend duality and learning representations to more general settings. For instance, [
5] explored duality principles in reproducing kernel Banach spaces (RKBS), offering a functional framework beyond Hilbert geometries. Further [
6] formalized the duality of spaces of càdlàg (right-continuous with left limits) processes, establishing foundational conditions for reflexivity in stochastic filtrations. We extend these approaches by situating the stochastic solution within a reflexive Banach space
for
, allowing for a more general functional topology. This enables the definition of duality between observed and unobserved sequences, even in the absence of inner products, and provides a novel isomorphism mapping via convolutional sequences in
. Unlike prior models, our construction supports a broader family of functional forms—including explosive, cyclic, and path-dependent dynamics—within a coherent probabilistic geometry.
In their work [
4] present a formal case in which the evolution process
is orthogonal to its observed history, invalidating the use of predictive functional forms. Under their framework, the absence of duality renders the process fundamentally irreversible and unpredictable. Davidson, in [
7,
8] explore related concerns in the context of I(0) processes and the functional central limit theorem. More recently, orthogonality structures have gained attention in spectral analysis and stochastic modeling. Generalized polynomial chaos expansions benefit from orthogonality in solving stochastic PDEs, though this work remains largely applied to physical systems [
9]. Our work complements these efforts by deriving a precise orthogonality condition,
which we use to classify regimes as martingale, trend-following, mean-reverting, or explosive.
Here, we reintroduce history as a structural feature of stochastic evolution, showing that in three-quarters of all probabilistic configurations, the solution is dependent on its past. The moment-generating function and its innovation serve as instruments for detecting and classifying the nature of dependence. This builds a dynamic model of predictability that is entirely endogenous to the data-generating process.
Traditional time series models—such as ARMA, GARCH, and their extensions—typically assume stationarity or impose transformations (e.g., differencing) to induce it [
10]. However, real-world financial series are nonstationary, exhibit volatility clustering, and often undergo abrupt structural changes. Structural break detection is typically addressed via exogenous methods, such as in [
11], though these are not integrated into the modeling process.
The recent work by [
12] checked for multiple breaks without imposing prior distributional knowledge by proposing a nonparametric change-point detection approach to estimate the number of change points and their locations along the temporal axis.
The AREM model used in this study integrates break detection directly into its stochastic foundation via the behavior of the statistic and the divergence of . Rather than treating structural breaks as exogenous events, the model flags them as a breakdown of orthogonality, thereby internalizing regime shifts. Moreover, the recursive form provides a continuous, historical basis for modeling long memory and path dependence, rather than differencing away valuable information.
On the empirical front, studies have emphasized the need for forecasting models to perform under heavy tails and computational constraints. In particular, ref. [
13] introduced fractional Brownian motion to describe persistent memory, while [
14] proposed models that adapt to macro shifts via spline-GARCH processes. However, these models often require specific distributional assumptions or lack general theoretical foundations.
Recent comparative studies between econometric modeling and machine learning highlight the strengths and limitations of both approaches, particularly under complex dynamic conditions. For instance, ref. [
15] analyzed the forecasting of COVID-19’s spread using classical mathematical models versus machine learning techniques, showing that while machine learning often excels in short-term pattern recognition, structural mathematical models offer greater transparency, interpretability, and robustness—especially in the presence of regime shifts and noisy inputs. This trade-off is also relevant in financial time series forecasting, where structural stability and duality-based interpretability are critical. Furthermore, the increasing use of predictive models in financial infrastructure raises significant cybersecurity concerns, as model transparency affects vulnerability to adversarial attacks. Our model, based on recursive structural properties and orthogonality principles, is inherently interpretable, and thus potentially more resilient to such threats. This reinforces the value of functional–theoretic approaches alongside, and often in contrast to, black-box machine learning models.
The empirical application of AREM to diverse assets including Bitcoin, the S&P 500, and US Treasury bonds demonstrates forecasting accuracy between 73% and 93%. This robustness is achieved despite volatility, structural breaks, and nonstationarity, without relying on transformation or external break detection. Further, we formalize the model’s limits of computation via the divergence of dilation/erosion boundaries and propose extensions to switch estimation regimes when orthogonality fails. This positions AREM as both a theoretically grounded and practically adaptive forecasting tool.
In contrast to prior work that either imposes restrictive topologies (Hilbert spaces), neglects historical dependence (orthogonality assumptions), or addresses regime changes exogenously, this paper introduces a unified framework for stochastic modeling based on Banach space duality. Our contributions span foundational theory, the identification of dependence regimes, and high-performing empirical forecasting, all within a mathematically rigorous and computationally tractable setting.
The existing literature provides a rich and multi-dimensional foundation for understanding duality, orthogonality, and predictability in stochastic systems, particularly in the presence of nonstationarity, structural breaks, and nonlinear dependencies. While these works vary in domain and methodology from functional analysis to machine learning, they collectively emphasize the limitations of assuming independence between a stochastic process and its history, as well as the potential gains from exploiting the hidden structure through richer model representations. Others [
16] extends Tsirelson’s counterexample by constructing stochastic difference equations on general topological groups. His work demonstrates the existence of stochastic processes that are fundamentally irreversible and independent of their historical trajectories, offering an abstract mathematical example of how history may fail to determine the future. This view aligns with the theoretical boundary proposed by [
4], where orthogonality between a process and its past leads to unpredictability and non-reversibility. However, our model challenges this boundary by establishing conditions in reflexive Banach spaces under which dependence on history is restored for most probabilistic configurations. Research by [
17] produce a framework for duality in interacting stochastic systems using orthogonal polynomial expansions. By constructing dual processes, they demonstrate that complex dynamics can often be re-expressed in terms of more tractable counterparts. Similarly, we use orthogonality conditions and moment-generating functions to classify regimes of dependence, trend-following, and explosiveness within a unified data-generating process. Moreover [
18] offer an important shift by conducting functional time series analysis in Banach rather than Hilbert spaces. By abandoning the inner product structure, they develop new prediction methods under the supremum norm. Our model similarly adopts Banach topology, particularly for
, to embed historical dependence in spaces that better reflect the irregularity and volatility of real-world time series. This allows us to characterize duality and convergence in a setting where smoothness and completeness are not guaranteed by construction.
Recent econometric contributions, such as those by [
19,
20,
21], develop tools to detect structural breaks in regression relationships. These tests highlight the fragile nature of forecast models when exposed to regime shifts. In contrast to treating such breaks exogenously, our model internalizes them through shifts in the
statistic and the divergence of moment-generating functions. This endogeneity allows the AREM model to dynamically adapt to changing regimes, identifying pockets of predictability and divergence from orthogonality without manual intervention.
The question of whether predictability itself is episodic rather than constant is central to [
22]. These authors introduce rolling and recursive tests to identify such episodes, aligning with our notion that the orthogonality condition may hold only intermittently. We formalize this through a model where the evolution process
depends on its historical path in three-quarters of the probability space.
Modern forecasting research has expanded the toolkit beyond linear models. Studies such as those by [
23,
24,
25] explore the use of ensemble methods and hybrid models to improve forecast accuracy in the presence of complex, nonlinear dependencies. Our AREM model builds on this insight by incorporating ensemble structures that blend multiple predictors—some driven by theory, others by empirical fitting—under a common orthogonality framework.
Neural forecasting models, as reviewed by [
26], further extend this logic by allowing for the automatic learning of long memory, seasonality, and regime shifts. These architectures, particularly attention-based and sequence-to-sequence models, can be interpreted as data-driven analogues to our theoretically derived dual systems, while our model is not neural in implementation, it shares the architectural goal of tracking temporal dependencies through recursive structures and regime-adaptive filtering.
Other contributions, such as those by [
27,
28], stress the need for forecasting models that remain robust in the face of volatility clustering and regime instability. Our approach advances this line of research by constructing a theoretical space within the reflexive Banach framework, where such volatility is not just accommodated, but is endogenous to the model’s structural form.
The next section introduces dependency and a stochastic process that captures the past, present, and future. In
Section 3, we provide empirical estimations and results.
Section 4 presents the conclusions of this paper.
2. History Matters
We examine the limits of computation that are conditional on the properties endowed to generating the estimated processes. Let us consider the behavior of an unknown process, S, which presents a known correlation function,
, under a complete normed (Banach) space, so that the comparison of S and
can be performed through their respective norms,
, alone. Note that two norms are equivalent if
, for all
. Let us further assume that the relation between the two random processes,
and
, is characterized by
such that k varies in
,
is a standard Gaussian which shares a portion of information,
, with
,
and
behaves as a Markov chain, with transition probabilities given by
so that the law
is a given probability
on
, and Equation (
1) can be interpreted as a re-statement of the Tsirelson equation, where dependence is introduced by means of
. As we could always write
, this specification implies that
converges to a nonstationary unit root process.
We want to describe the group of laws of the probability
of all solutions of Equation (5), and also its behavior at the extreme boundaries
. The strong solutions set is
under the measure
as
. From Equation (
1), we write the identity
We can state that the measure
if
, meaning that the changes in
cannot be explained by the previous period’s relevant information when only the evolution of the
process is taken into account. We further assume that
and define
the moment-generating function for
:
so that the relation between two consecutive moment-generating functions can be written as
or, equivalently,
where
and
. If we then define the innovation,
, as the change between two consecutive moment-generating functions,
, Equation (
9) can be restated as
When the process S behaves as a martingale for a period of time, the correlation function will stay unchanged, , and ; otherwise, the moment-generating function, , must satisfy the general orthogonality conditions over the open interval .
Thus, we require the following on the left side:
and the right side of the interval has to be
The following ratio of probabilities is a square integrable process in
describing the behavior of the unknown function. To be convergent in the open interval, the relative likelihoods have to be a different value than one. Therefore, we consider
Strong solutions exist if and only if the infinite product is convergent to the Fisher information ratio in the Fourier space, where the periodic functions reside:
with
and
, and then it follows that
Chichilnisky also dealt with open Hilbert spaces, placing conditions on the asymptotic behavior of the unknown function, and in particular the Fourier estimator convergence at infinity. All the fixed points given by this solution for the stochastic process
are of the type
This is an example of the metrics of
space, describing the convolution of long and short memory of the processes. In fact, it is an adjusted Tsirelson stochastic process (see [
3]). We write the spread difference as a general process that combines in one functional form the Brownian and OU processes conditioned on the speed of reversion,
, and the intensity of those changes,
. It mixes the two stochastic distributions.
where
, with
.
A martingale process is one where the expected value of at the next step equals its current value, considering all past information. For to be a martingale, the drift term would need to be zero, or the expectation of future changes would need to balance out to zero. This is unlikely given the structure of the drift term unless very specific conditions are met regarding , r, , and the historical term .
Explosive behavior refers to moving away from any bound or mean at an accelerating rate. This could occur if dominates and grows without bounds, or the drift term consistently adds to without any counteracting mean-reversion force, and the influence of or the drift term grows over time. : The component decreases over time, modifying the impact of on its drift; while itself is not cyclical, it influences how the strength of the mean-reversion or trend component decays over time. , the historical term, integrates past values of S and . If (and thus ) incorporates cyclical behaviors, it could induce similar patterns in , depending on how significantly influences the overall drift.
First, we simplify the SDE for
by expanding the first term inside the square brackets and using the product rule for
:
Next, we apply Ito’s Lemma to the function
. Applying Ito’s Lemma to the function
, we obtain
using the fact that
,
, and
.
Substituting the expression for
in terms of
,
,
, and
, we obtain
using the fact that
and
is a function of past realizations of
, and is therefore deterministic.
We can integrate both sides of this equation from 0 to
t to obtain
Taking the exponential of both sides, we have
which is the solution for
.
The expected value of
is given by
Since we assume that converges to a long-run value z, we have .
We can simplify the integral by defining the function
. Then, we have
Therefore, the expected value of is .
To calculate the variance of
, we use the formula below. Using the expression for
, we can calculate the variance of
as follows:
Note that we have used the fact that , since is a product of past realizations of , which are independent of . We have also used the expression for in terms of .
Simplifying the above expression, we obtain
and the history of z converges to a generalized gamma distribution using Mellins transformation and Ramanujan’s theorem.
For the unbounded case, the upper and lower bounds in Equation (
24) relate to the outer limits of the isomophism, meaning that the probability space for
is isomorphic to the probability space for
. When there is isomorphism between probability spaces, there is effectively reversible real-time transformation of a Brownian
with respect to a reflexive Brownian
, such as
We relate to John Von Neumann’s mixed strategy inequality that justifies the existence of lower and upper bounds in u via the MaxMin and MinMax inequality:
Equation (
24) for unbounded isomorphic spaces will be
Asymptotically, the error term space will be isomorphic with respect to the probability space of
in Banach
B and will have a reflection in
. We rewrite the above sequence in a general form as follows:
and
where
is the memory component of the location functional.
Any sequence
in a Banach space
B is isomorphic to a convex sequence
, the dual image of the reflection
. These sequences will be of the same type and co-type under the isomorphism induced by the dual pairing
for any t,
and
, G is any convex and smooth function of continuous mappings of
. A Banach space is called smooth if its norm is smooth. More formally, the function in
,
is called
smooth and
. To bound the space, we can take
. If
, then we have the inner product in Hilbert space
, the inner product
in a Banach space, and the vector space
.
Here, we restate the functional central limit theorem (see, for instance, Davidson [
7], Davidson [
8]). The process
is I(0) if it is defined as (0,1), such that
or
where
. The process is Brownian as
. The Brownian process holds true, with
,
.
r is some intermediate value between zero and
s,
, if
. Since
is variance, it could take any positive value,
.
It is stated, [
4], that for a random variable to present identifiable (unique) dynamics, the autocovariance function needs to be non-degenerated. This implies that the autocovariance function should be defined within a strictly positive compact set and volatility does not need to be bounded from above.
Let any convergent sequence be
: as stated as in Equation (
1), it will have an isomorphic solution that will be dependent on its history if
.
The implications of this statement are that the unconditional moment-generating function (MGF), , and the conditional MGF, are not equal, and . In cases where , we reject the proposed model as for two random processes. Independence between them will be sustained as the MGF is constant, and in that case, .
When the sequence, which is subject to a concave function, converges to the Fisher information boundary, the functional central limit theorem holds. Then, the dependence guarantees the existence of a complete integrable system back in the Banach space, with the shape of a rugby ball moving in the phase space defined as the product of . In the coordinates of the torus, if Z is the inclination axis, then , where a vector space in Banach is foliated by the N-dimensional invariant tori . Here, the integrable curves are quasi-periodic, with some frequency , and depend only on . Under dependence, there exists a dense subfamily of these tori, bearing strong solutions. The area of the rugby ball will change shape according to the relative mass shift of the parts of “everything”, with the ratio .
3. Empirical Calculations
We validate our theoretical framework through an empirical analysis, employing an extensive dataset taken from Factset including daily prices from the S&P 500, 10-year US Treasury bonds, the EUR/USD exchange rate, Brent oil, and Bitcoin, covering the period from 1 January 2002 to 1 February 2024. The out-of-sample predictions, conducted from 17 February 2019 to 1 February 2024, demonstrate the model’s superior forecasting power. There is no specific event tied to that date, and it does not correspond to any structural break. However, beginning the out-of-sample window in early 2019 allows the model to be tested through several important macro-financial developments, including the COVID-19 crisis, the post-pandemic recovery, the onset of monetary tightening cycles and spikes in gas and oil prices in 2022, the war in Ukraine, and the macroeconomic uncertainty following the US election and trade policies introduced during the Trump administration.
Let us define
as a bounded stochastic sequence function dependent on the stochastic trajectory
. Building on Equation (
25), we introduce the autoregressive enhanced model (AREM) estimation equation as follows:
In our empirical implementation, we interpret the latent process
as being effectively captured by the simulated trajectory
, which reflects the evolution of the stochastic system governed by Equation (
30). The drift component
is computed as a rolling exponentially weighted moving average (EWMA) of log returns, serving as a proxy for
, the expected value of the latent memory-driven process. Likewise, the volatility
calibrated from in-sample data approximates
, the variance in the evolving structural signal.
Equation (
6) defines the recursive discrepancy process
, where
measures the forecast error between the simulated trajectory
and the realized asset price
. The multiplier
, constructed directly from observed prices, captures local curvature and persistence in the price series. It plays a dual role in our framework. First, it governs the propagation of forecast errors: when
, forecast discrepancies amplify, signaling instability or structural breaks; when
, the system reverts toward equilibrium, indicating mean-reverting behavior. More structurally,
acts as a state-switching mechanism that conditions the dynamics within Equation (
30). Depending on its value, the model shifts the weight placed on lagged returns and volatility-adjusted drift signals, thereby endogenously selecting between explosive, trending, or mean-reverting regimes. This switching is consistent with the theoretical formulation in Equation (17), where
aggregates past volatility-weighted expectations and plays a role in determining conditional behavior.
The primary objective of this implementation is to evaluate the model’s ability to replicate out-of-sample price trajectories using in-sample calibrated dynamics. These dynamics embed historical memory and are structurally aligned with the duality properties implied by our Banach space formulation.
The switching mechanism embedded in
, incorporating bounded adjustments through min and max operators as well as lagged return differentials, enables asymmetric adaptation to past price behavior. This is consistent with the recursive decay structure implied by the parameters
and
. We start by splitting our sample period in two and use the first section, comprising the initial 80% of the sample period, to perform an in-sample estimation of parameters. The remaining 20% is then used to perform an out-of-sample forecasting exercise, computing one-day-ahead prices and updating parameter estimates. The coefficients reported in
Table 1 correspond to the calibrated components of this filtering mechanism:
governs the weight on the lagged momentum term
,
features in the normalization of the drift signal
, and
r reflects the long-run drift anchoring the stochastic path of
. Together, these parameters define a data-driven recursive filter that aligns the simulated dynamics with the structural theoretical model.
To contrast the accuracy of the results, an MA model and a naive specification were also obtained for each series.
Table 1 presents the results for all assets, whereas the results for the entire series are presented in
Table 2. This table presents the relevant statistical measures: the mean square error, the root mean square error, the mean absolute error, and the direction accuracy. Here, we report the percentage of correct guesses for going up or down for the three models to illustrate the extent to which the proposed framework outperforms the alternatives; while
is commonly reported in forecasting studies, it may be artificially inflated when applied to level forecasts due to the high variance in price levels relative to returns. As such, it can overstate predictive accuracy in level-based models. We, therefore, emphasize directional accuracy as a more reliable and informative performance metric for evaluating whether the model correctly anticipates the direction of price movements, and
values are not reported. Our model yields a strikingly high percentage of correct predictions, ranging from 73% to 92%, in contrast to the 47% to 54% accuracy of naïve and moving average models.
The implications of
presented in
Section 2 will be discussed here using the S&P500, crude oil prices, 10-year US Treasury yield, Bitcoin, and EUR/USD exchange rate, and we map the
instances over the out-of-sample period, 2019–2025.
Recall that a martingale is a stochastic process where the expectation of the next step, given all the past steps, is equal to the present step:
S will behave like a martingale when there is no change in the correlation function , which means that and .
The expected future value is equal to the present value given all the information up to the present. When , the system seems to satisfy the martingale property because it implies no net gain or net loss in the expected value of S, given all the past values.
If , the process S does not behave as a martingale because the expectation of is not zero, indicating that the expected future value of S would not be its present value, thereby violating the martingale property. In summary, if , S behaves as a martingale. If , it does not.
If , from Equation , it could mean one of a few things: either or , assuming that is not zero.
From Equation , we see that if , then . This equation implies that the expected change becomes dependent on and , which could make the series diverge, oscillate, or go to zero depending on the terms.
Furthermore, would indicate that the S process is not a martingale in this situation since the expected future change in is not zero. Instead, it is influenced by the values of and . When , S will not behave like a martingale, and the behavior could be quite deterministic, depending on the specifics of and .
In this framework, . If , it implies that , given that is not zero. This suggests that either or (or both) is larger in magnitude than when considering the product.
When , , which means that the sign of will be opposite to . This implies that the moment-generating function will diverge from in a manner influenced by .
This indicates that the series S could be either increasing or decreasing, depending on the specifics of the other terms, but does not behave as a martingale because a martingale would require that the expectation of future changes is zero. Therefore, this suggests that the process S is expected to increase if it has increased in the past (or decrease if it has decreased in the past). This would indicate a kind of momentum or trend-following behavior.
In the case where , the term would be negative. If and are positive, then the expected value would be positive given that S has increased in the past, suggesting that S will continue to increase.
If tends to infinity, the term will tend to negative infinity, making the term extremely negative (assuming that is positive).
This implies that the change in the moment-generating function, , will also be extremely large (and negative), indicating an explosive behavior in the negative direction for S.
The condition indicates a divergence away from martingale behavior, where future values of S are expected to be the same as the current value given all past information. In fact, the future values of S would be expected to decrease rapidly, making the process far from a martingale.
Thus, if tends to infinity, S would likely show extremely volatile and downward behavior, and it would certainly not satisfy the martingale condition.
If tends to negative infinity, then the term will tend to positive infinity. This would make the term extremely large in the positive direction (assuming that is positive).
Similar to the case where tends to positive infinity, this would indicate a divergence from martingale behavior. A martingale process should have future values that are the same as the current value given all past information. In this case, the future values of S would be expected to increase rapidly, making the process explosive.
Further, if
and
, then
would be positive, because the product of two negative numbers is positive. If
and
, then
would be negative, because the product of a negative number and a positive number is negative. If
and
, then
would be zero. However, if
, it indicates some form of reversal or “flip” in the relationship from
to
, which could suggest some form of mean reversion or cyclical behavior in
S depending on the broader context. The derivation of orthogonality conditions enables the detection of whether the process
behaves as a martingale (
) or deviates toward trend-following, mean-reverting, or explosive behavior (
). These conditions support a regime classification framework embedded within the model, enhancing its interpretability and predictive power. Similar goals are pursued in [
29], who evaluate how time-varying idiosyncratic exposures impact return dynamics across regimes. Related methodologies [
19,
20] are developed for detecting structural breaks and forecast instability, though these are implemented as separate diagnostic tools. In contrast, our framework integrates regime identification directly into the stochastic process via analytically derived orthogonality weights, enabling the endogenous detection of evolving dynamics from within the model structure itself.
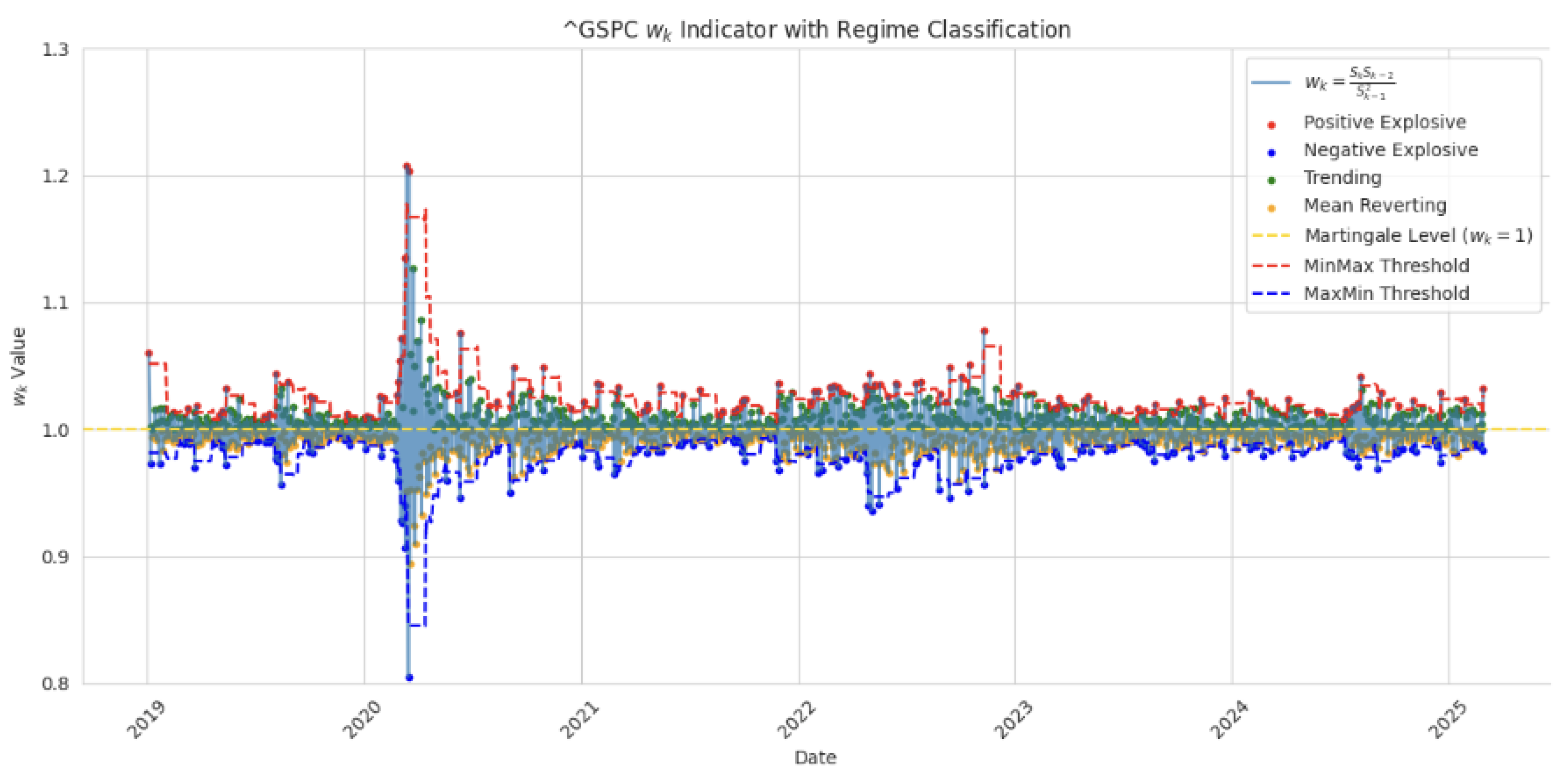
In
Figure 1, we filter the data to create a map of martingale, trending, mean reverting, and explosive values of the S&P500.
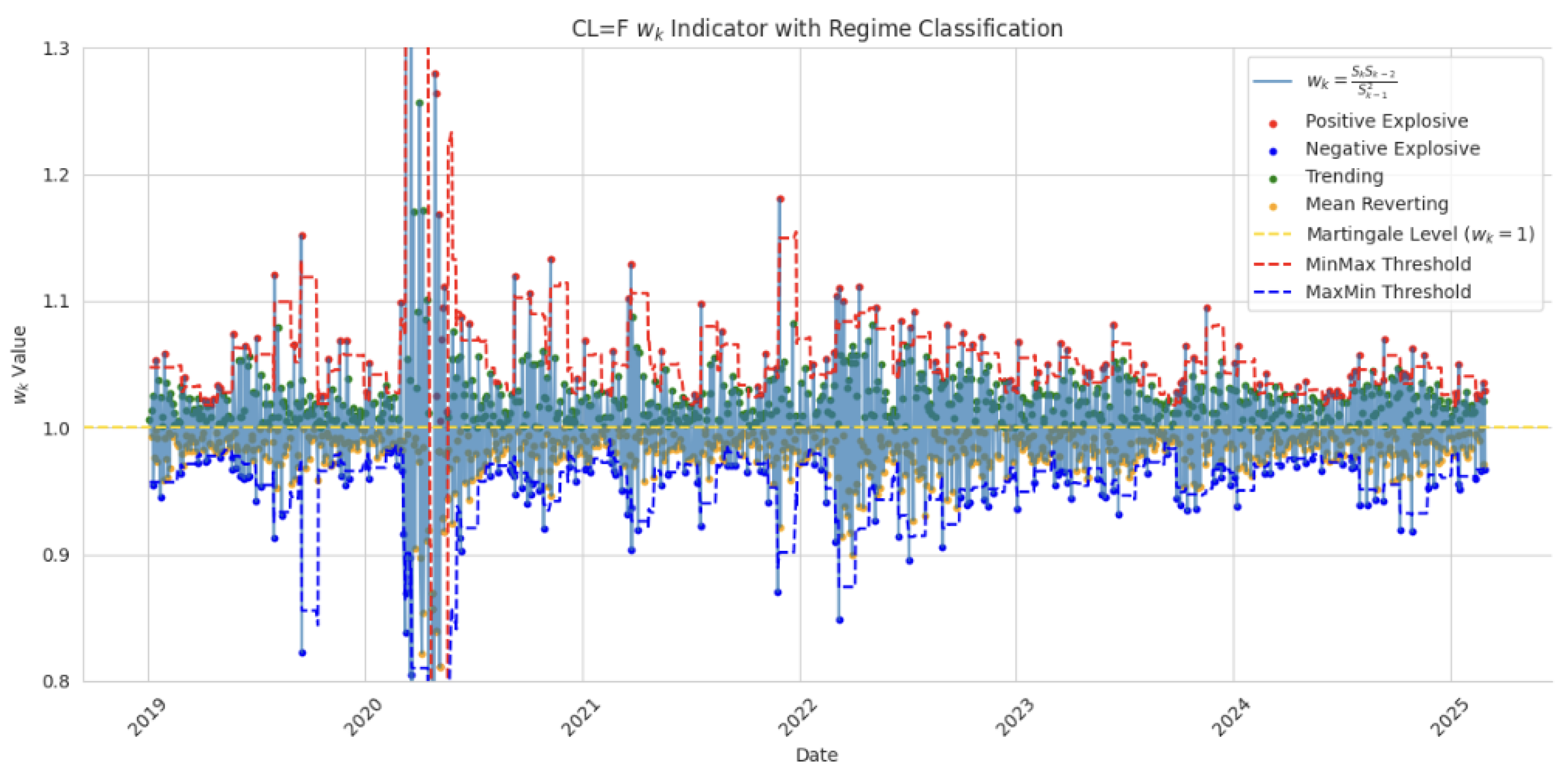
In
Figure 2, we filter the data to create a map of martingale, trending, mean reverting, and explosive values of crude oil.
In
Figure 3, we filter the data to create a map of martingale, trending, mean reverting, and explosive values of the 10-year US Treasury yield.
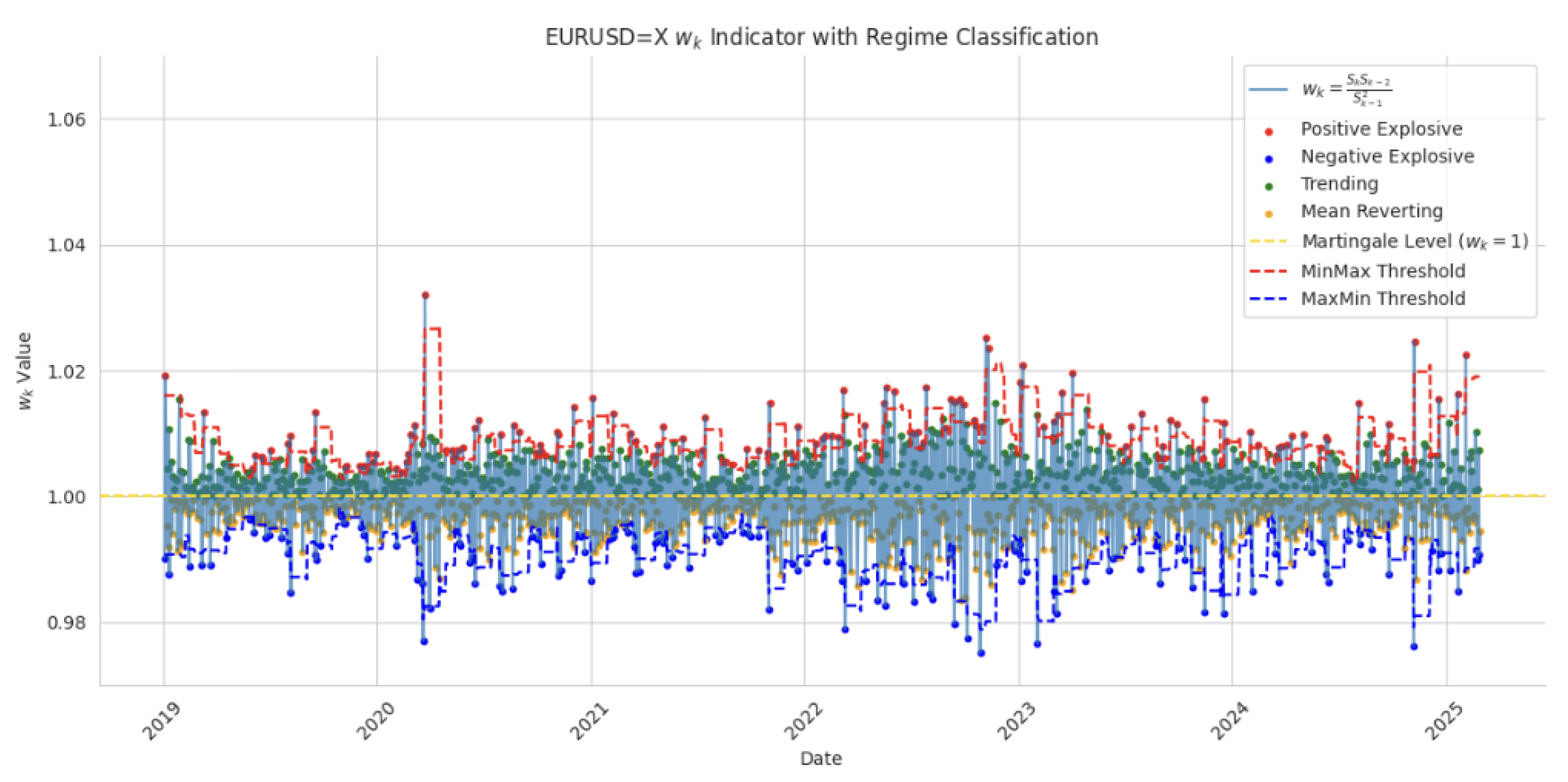
In
Figure 4, we filter the data to create a map of martingale, trending, mean reverting, and explosive values of the EUR/USD exchange rate.
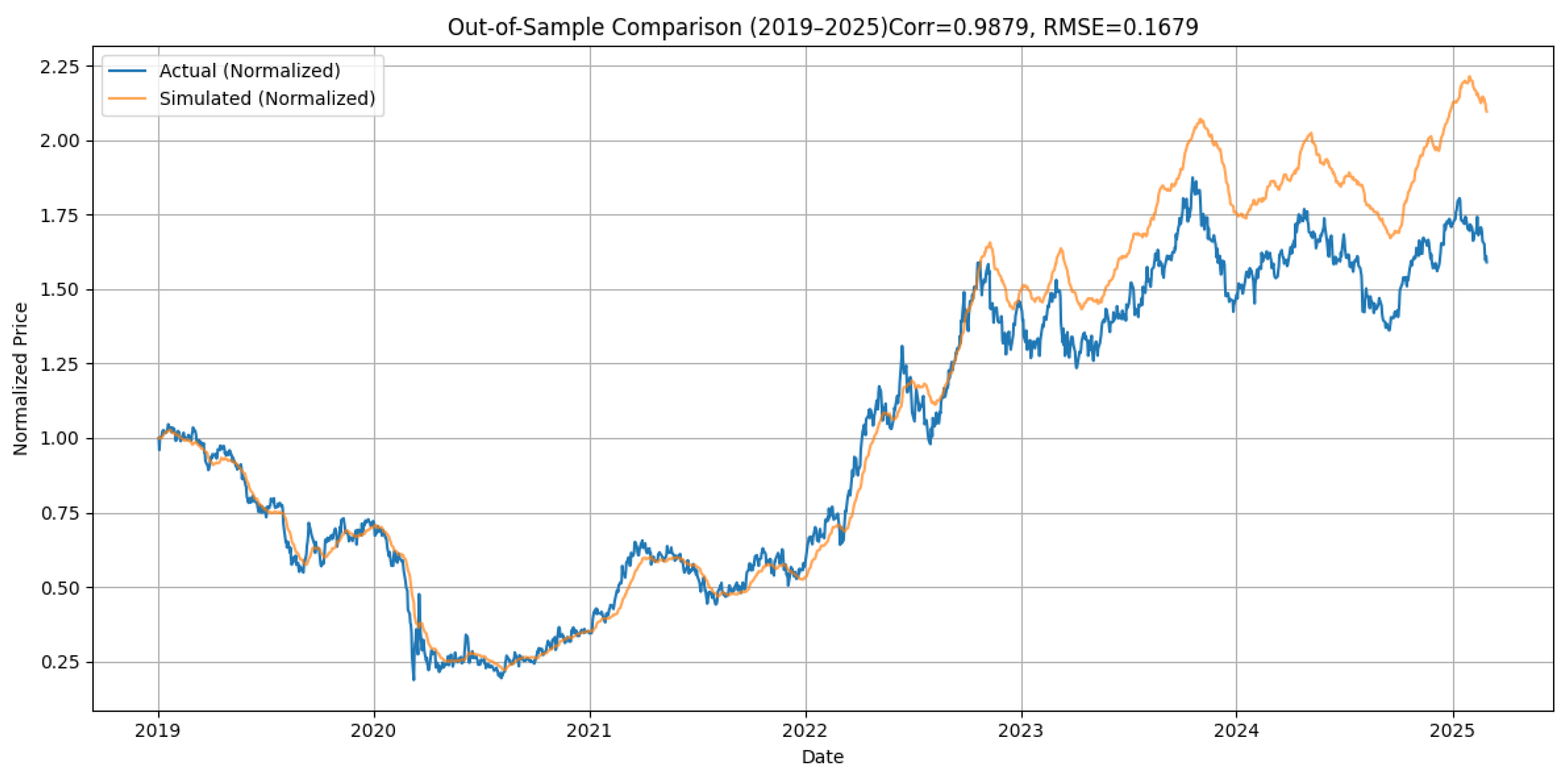
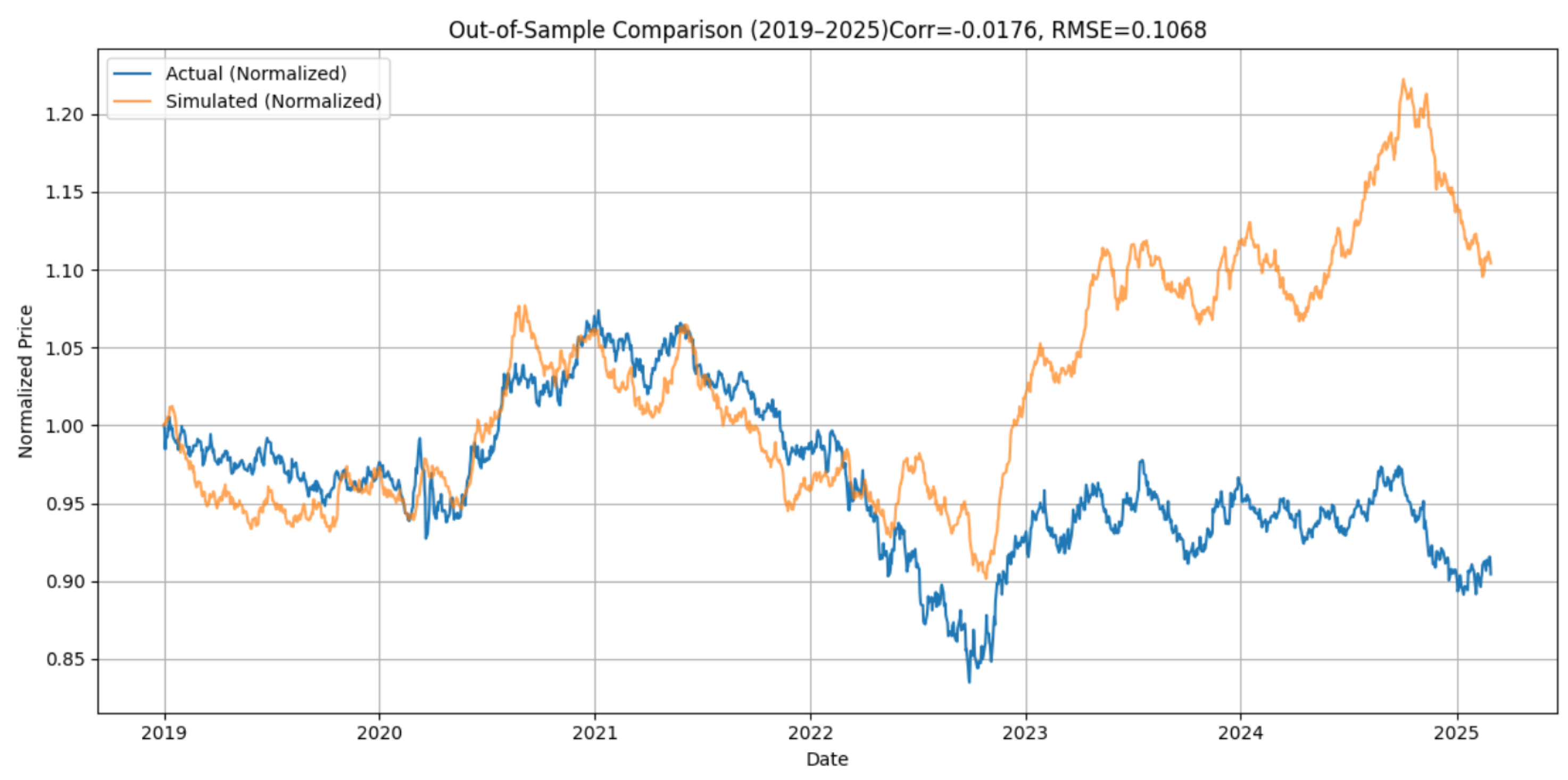
We evaluate the model based on five major financial instruments spanning equities, commodities, interest rates, cryptocurrencies, and foreign exchange rates. These include the S&P 500 Index (GSPC), crude oil prices (CL=F), the 10-year Treasury yield (TNX), Bitcoin (BTC-USD), and the EUR/USD exchange rate (EURUSD=X). For each case, the same model structure and calibration procedure are applied. All simulations are conducted over a six-year out-of-sample window (2019–2025). Since we performed out-of-sample comparison, we decided to extend our sample to March 2025. The macroeconomic uncertainty of the new US administration is now considered. using parameters estimated exclusively from data prior to 2019. This extended horizon allows us to test the model’s robustness without recalibration. As expected, the longer the model projects into the future without updating its parameters, the greater the divergence from actual market outcomes. Nevertheless, the model achieves remarkably strong performance across a range of assets.
The model shows excellent predictive alignment for Bitcoin (see
Figure 5), where explosive volatility and strong directional trends are mirrored closely by the simulated path.
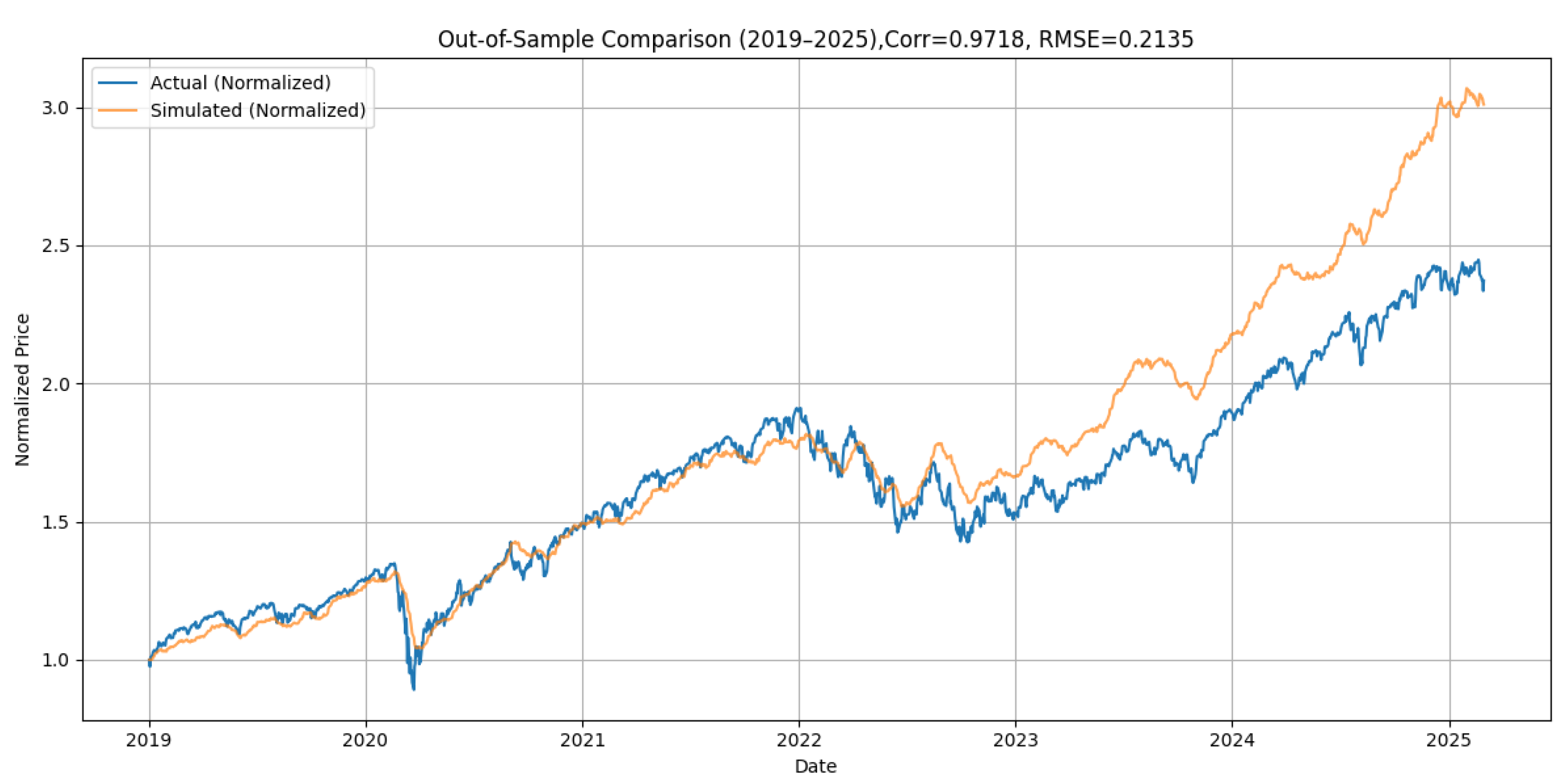
Similarly, in the S&P 500 Index (see
Figure 6), the simulation reproduces the equity market’s upward trajectory, including the COVID-19 shock and post-2020 bull run.
For the 10-year Treasury yield (see
Figure 7), the model tracks interest rate cycles and trend shifts with impressive consistency.
Crude oil price presents a complex but well-captured cycle of collapse, rebound, and stabilization, where the model captures not only the directional momentum, but also much of the cyclical behavior (see
Figure 8).
The EUR/USD exchange rate presents the greatest challenge due to its mean-reverting and policy-sensitive nature (see
Figure 9).However, we observe that between 2019 and mid-2022, the model reproduces the actual path with exceptional precision. As we move forward in time without updating the parameters, the error grows with resulting deterioration in fit in the latter part of the sample, after significant structural changes in macroeconomic conditions, particularly the divergence in ECB and Fed policy post pandemic. These limitations are not faults of the model structure per se, but rather a consequence of using static, pre-2019 parameters for a system that evolved dramatically in later years.
Although the overall fit deteriorates after mid-2022, the model reproduces the price path of EUR/USD from 2019 to early 2022 with impressive accuracy. This initial alignment validates the relevance of our structural drift specification before exogenous macro shocks and interest rate divergences distort the dynamics.
Most modern AI and machine learning forecasting systems, including LSTMs, neural regressors, and hybrid models, also target levels rather than returns. This is largely because price levels are directly observable, whereas returns are derived quantities that can amplify noise or obscure structural features of the data. Forecasting levels enables models to better retain information related to long-term growth trends and volatility persistence. In line with this, the AREM in this paper forecasts price levels, not returns. Price levels are explicitly driven by latent volatility and embedded growth rates that determine the dynamic trajectory of prices across time. These structural drivers—rather than differenced returns—form the natural foundation for modeling historically dependent stochastic processes.
Our model yields a strikingly high percentage of correct predictions, ranging from 73% to 92%, in contrast to the 47% to 54% accuracy of naïve and moving average models.
We measure whether the model correctly anticipates the direction of price movement, i.e., whether the price increased when the model predicted an upward movement. Directional accuracy is especially appropriate in the context of level forecasting, where capturing turning points and directional shifts is more meaningful than predicting raw return magnitudes. Furthermore, when the level forecasts achieve such high out-of-sample correlation—97% for Bitcoin, 98% for the S&P500, and 98% for 10-year Treasury yields—it also implies that the derived return series would exhibit similarly high correlation with realized returns. In other words, if the model replicates the level path of an asset with high fidelity, it necessarily captures the directional movements and the relative return dynamics implied by that trajectory.
The empirical validity is evaluated through a rigorous out-of-sample framework extending from 2019 to 2025, using parameter estimates calibrated exclusively on pre-2019 data. This represents one of the most extensive multi-asset out-of-sample validation exercises in the literature. Among the reviewed studies, no study offers a comparably long and continuous out-of-sample evaluation spanning daily data across multiple asset classes and lasting up to six years as that implemented in this paper; while some works such as [
21,
24] perform robust out-of-sample validations, their horizons are notably shorter and often limited to equity returns or quarterly macro-indicators. Refs. [
30,
31] focus primarily on in-sample or short-horizon predictive regressions. Among the related studies employing forecasting methods across dynamic systems, we note the comparative study by [
15], which contrasts classical mathematical models (SIR-type) with machine learning techniques in the context of COVID-19 spread prediction. Their analysis, focused on the Moscow region, evaluates short-term forecasts using multiple data-driven approaches, while their work highlights the potential of hybrid frameworks and explores modeling under uncertainty, the forecast horizon remains relatively limited—typically ranging from several days to a few weeks. Whereas Pavlyutin et al. emphasize model comparison under changing epidemic conditions, our work focuses on embedding historical dependence structurally and evaluating forecast accuracy in financial contexts subject to regime shifts and latent memory effects. In [
32] emphasize volatility decomposition and connectedness, but do not provide out-of-sample forecast evaluation. Our results therefore offer a rare example of sustained model performance over six years and across diverse asset classes—including equities, interest rates, FX, oil, and cryptocurrency—using consistent calibration and structure. This out-of-sample robustness is a distinguishing feature of our approach, validating the structural memory captured in the adaptive regime-awareness in AREM.
To provide a more quantitative benchmark against prior research, we summarize directional accuracy figures in
Table 3, drawing from recent papers addressing asset return predictability under various modeling assumptions. As shown, our AREM model delivers directional accuracy in the range of 73–93%, outperforming traditional models like Fama–MacBeth regressions [
33], which average around 60%, and moment-based approaches such as [
31], who report accuracies near 68% for U.S. equities. The frequency domain connectedness metrics of [
34], while insightful on volatility transmission, do not explicitly report predictive statistics. Similarly, ref. [
30] achieve an in sample
53%–75% using latent factor state-space models on international equity panels. The comparative advantage of our AREM framework lies in its ability to dynamically adapt to structural changes without requiring full state observability or restrictive moment assumptions. Overall, our empirical model stands favorably relative to both conventional econometric and modern ML-based alternatives.
To provide a comprehensive benchmark,
Table 3 consolidates the predictive performance of our models with a broad range of recent forecasting approaches in the literature. This table includes both statistical and machine learning frameworks, spanning structural econometric models, regime-switching techniques, neural networks, and hybrid systems. Our AREM model exhibits directional accuracy between 73% and 93%, placing it at the upper end of the performance spectrum. It achieves exceptionally high out-of-sample correlation with realized price levels—97% for Bitcoin, 98% for the S&P500, and 98% for 10-year Treasury yields—indicating its robustness in replicating price trajectories. These results are particularly notable given the long out-of-sample window (2019–2025) and fixed pre-2019 calibration. It performs competitively or exceeds the standards established in the literature across multiple metrics and asset domains.
By contrast, studies such as [
21,
24] report accuracies in the range of 70–85%, with varying assumptions and data scopes. Traditional econometric models, like those in [
31,
33] generally deliver lower directional accuracy (60–68%), and are often limited by static factor structures or moment conditions. Machine learning methods, such as those explored by [
23,
25,
27], achieve moderate-to-strong performance depending on the forecast horizon and asset class, but often lack interpretability. Other contributions, such as, [
18,
20,
34] provide valuable theoretical or diagnostic tools but do not report explicit out-of-sample metrics.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}