
A Polyp Segmentation Algorithm Based on Local Enhancement and Attention Mechanism


Abstract
1. Introduction
- Limited ability to capture detailed texture features: Current models struggle to effectively capture the detailed texture features of polyps, particularly when dealing with polyps that have complex shapes or unclear boundaries, which often leads to a decrease in segmentation accuracy;
- Challenges in modeling long-range dependencies: Long-range dependencies in polyp images, such as the overall shape of the polyp and its background context, are often difficult to model effectively. This is crucial for accurate segmentation of polyp regions, particularly in balancing local details with global context.
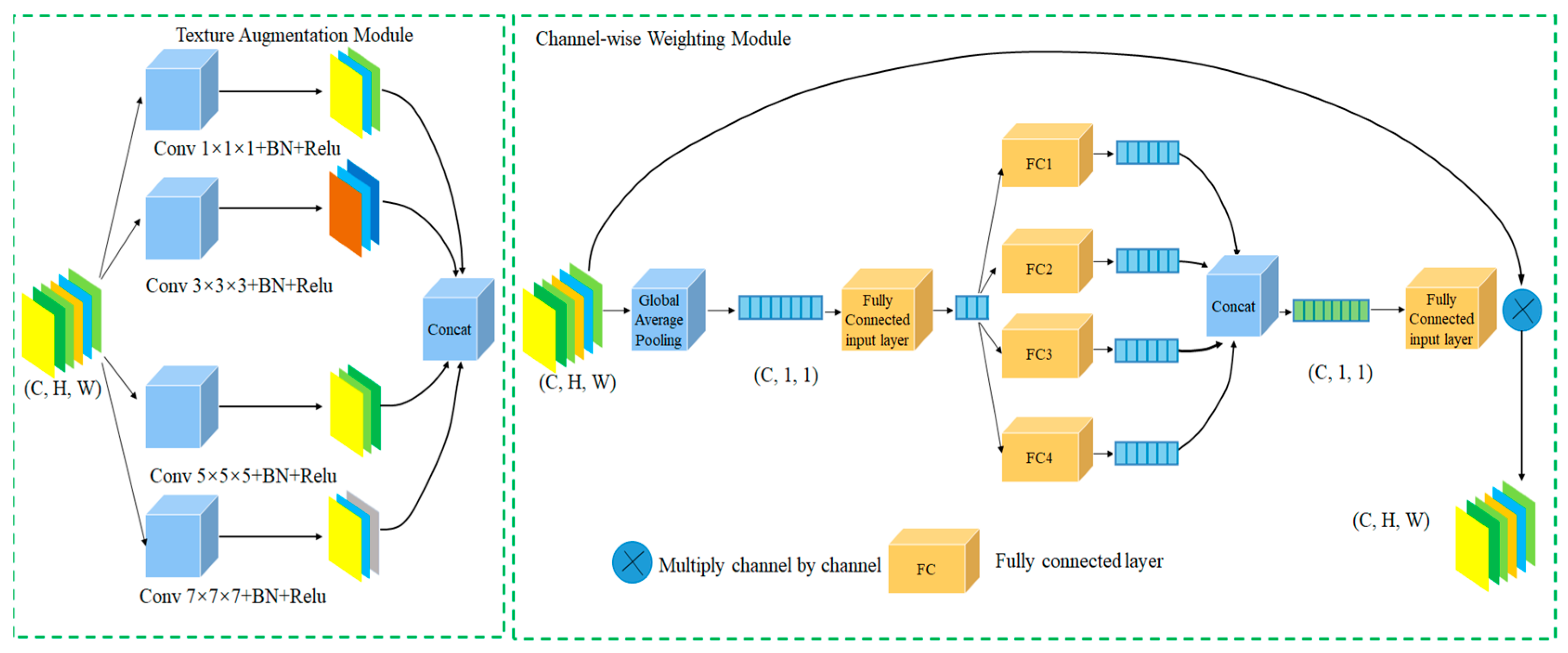
- Introduction of a local information enhancement module (LIEM): We design a local information enhancement module that strengthens texture feature extraction through a multi-kernel self-selective attention mechanism. During multi-kernel feature fusion, a dense channel attention mechanism is employed to increase the width of attention computations, enabling better modeling of relationships among different feature channels and enhancing the model’s understanding of polyp morphology and microstructural tissue;
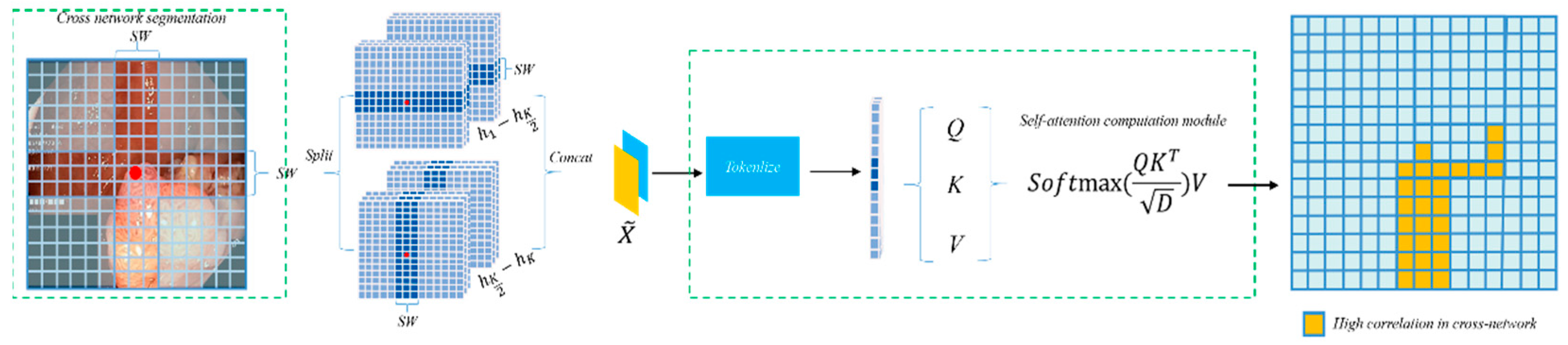
- Replacement of the Transformer module with a cross-shaped windows self-attention mechanism: Considering that polyp regions often exhibit indistinct boundaries, we introduce a Transformer based on cross-shaped windows self-attention to improve the semantic dependency perception of polyp regions, thereby better adapting the Transformer to polyp segmentation tasks.
2. Related Work
2.1. CNN for Polyp Segmentation
2.2. Transformer for Polyp Segmentation
3. Methodology
3.1. Overall Architecture
3.2. Local Information Enhancement Module
3.3. CSWin Self-Attention Transformer
4. Experiments and Results Analysis
4.1. Experimental Datasets
4.2. Experimental Setup and Evaluation Metrics
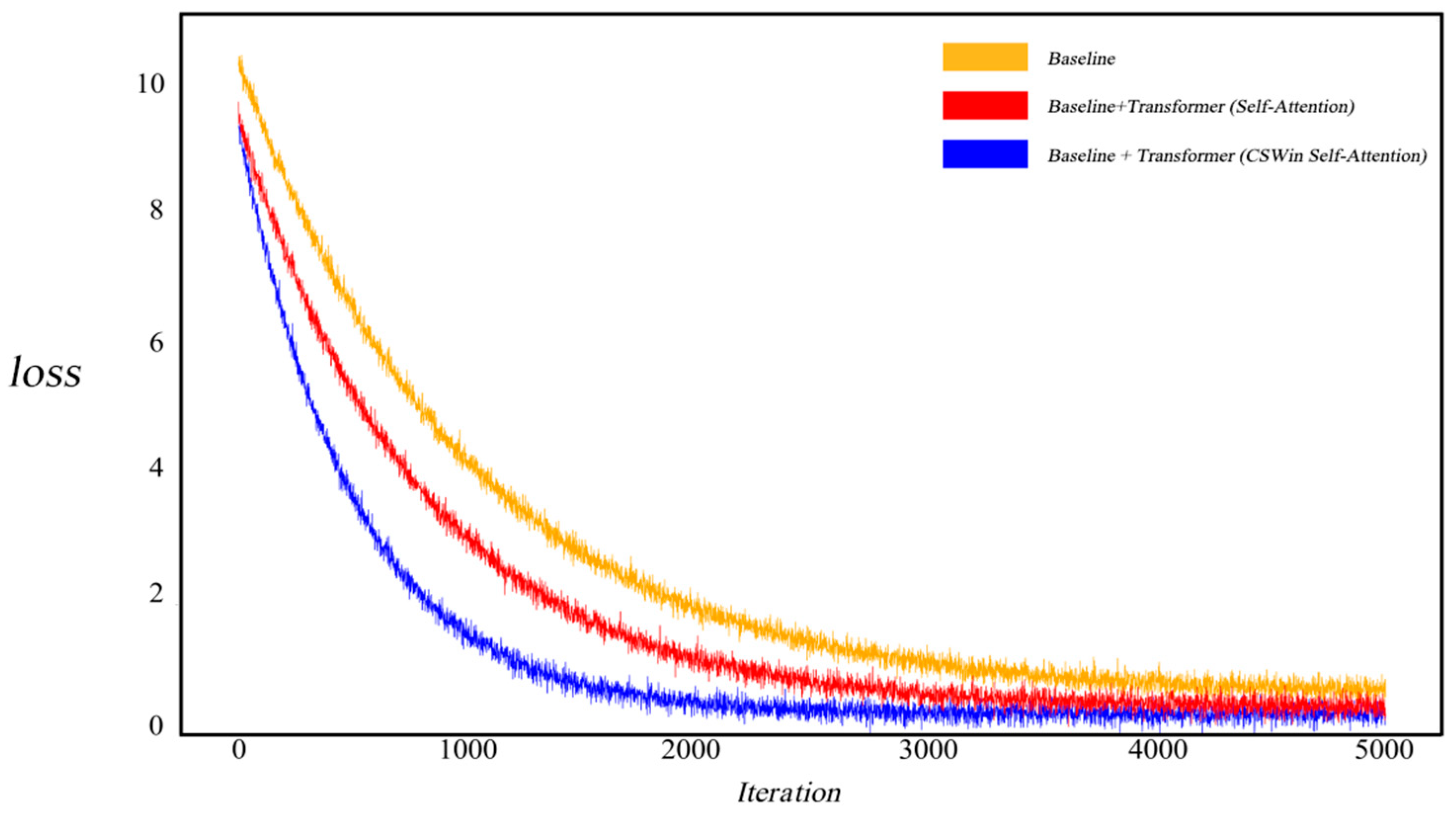
4.3. Ablation Study
4.4. Comparative Experiments
4.5. Model Complexity
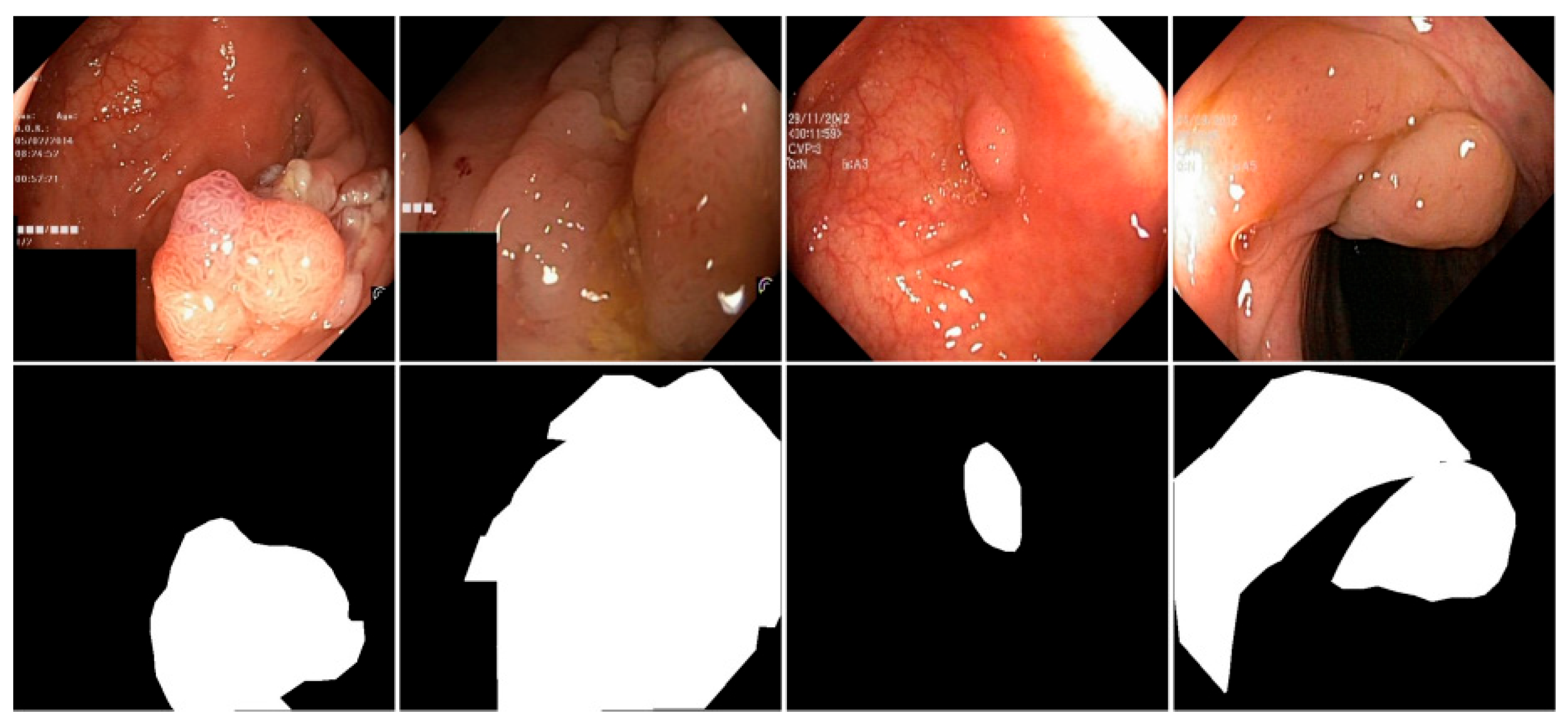
4.6. Visualization Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gupta, M.; Mishra, A. A systematic review of deep learning based image segmentation to detect Polypp. Artif. Intell. Rev. 2024, 57, 7. [Google Scholar] [CrossRef]
- Sánchez-Peralta, L.F.; Bote-Curiel, L.; Picón, A.; Sánchez-Margallo, F.M.; Pagador, J.B. Deep learning to find colorectal Polypps in colonoscopy: A systematic literature review. Artif. Intell. Med. 2020, 108, 101923. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Lv, F.; Chen, C.; Hao, A.; Li, S. Colorectal Polypp Segmentation in the Deep Learning Era: A Comprehensive Survey. arXiv preprint 2024, arXiv:2401.11734. [Google Scholar]
- Sasmal, P.; Bhuyan, M.K.; Dutta, S.; Iwahori, Y. An unsupervised approach of colonic Polypp segmentation using adaptive markov random fields. Pattern Recognit. Lett. 2022, 154, 7–15. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Vaswani, A. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4. Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Isensee, F.; Petersen, J.; Klein, A.; Zimmerer, D.; Jaeger, P.F.; Kohl, S.; Wasserthal, J.; Koehler, G.; Norajitra, T.; Wirkert, S.; et al. nnu-net: Self-adapting framework for u-net-based medical image segmentation. arXiv 2018, arXiv:1809.10486. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Johansen, D.; De Lange, T.; Halvorsen, P.; Johansen, H.D. Resunet++: An advanced architecture for medical image segmentation. In Proceedings of the 2019 IEEE International Symposium on Multimedia (ISM), San Diego, CA, USA, 9–11 December 2019; IEEE: New York, NU, USA, 2019; pp. 225–2255. [Google Scholar]
- Sharir, G.; Noy, A.; Zelnik-Manor, L. An image is worth 16 × 16 words, what is a video worth? arXiv 2021, arXiv:2103.13915. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2023; pp. 205–218. [Google Scholar]
- Lin, A.; Chen, B.; Xu, J.; Zhang, Z.; Lu, G.; Zhang, D. Ds-transunet: Dual swin transformer u-net for medical image segmentation. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, H.; Hu, Q. Transfuse: Fusing transformers and CNNs for medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part I 24. Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 14–24. [Google Scholar]
- Wang, H.; Cao, P.; Wang, J.; Zaiane, O.R. Uctransnet: Rethinking the skip connections in u-net from a channel-wise perspective with transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 2441–2449. [Google Scholar]
- Jha, A.; Kumar, A.; Pande, S.; Banerjee, B.; Chaudhuri, S. Mt-unet: A novel u-net based multi-task architecture for visual scene understanding. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; IEEE: New York, NU, USA, 2020; pp. 2191–2195. [Google Scholar]
- Xie, Y.; Zhang, J.; Shen, C.; Xia, Y. Cotr: Efficiently bridging CNN and transformer for 3d medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part III 24. Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 171–180. [Google Scholar]
- Duc, N.T.; Oanh, N.T.; Thuy, N.T.; Triet, T.M.; Dinh, V.S. Colonformer: An efficient transformer based method for colon Polypp segmentation. IEEE Access 2022, 10, 80575–80586. [Google Scholar] [CrossRef]
- Sanderson, E.; Matuszewski, B.J. FCN-transformer feature fusion for Polypp segmentation. In Annual Conference on Medical Image Understanding and Analysis; Springer International Publishing: Cham, Switzerland, 2022; pp. 892–907. [Google Scholar]
- Park, K.B.; Lee, J.Y. SwinE-Net: Hybrid deep learning approach to novel Polypp segmentation using convolutional neural network and Swin Transformer. J. Comput. Des. Eng. 2022, 9, 616–632. [Google Scholar] [CrossRef]
- Dong, B.; Wang, W.; Fan, D.P.; Li, J.; Fu, H.; Shao, L. Polypp-pvt: Polypp segmentation with pyramid vision transformers. arXiv 2021, arXiv:2108.06932. [Google Scholar]
- Tomar, N.K.; Shergill, A.; Rieders, B.; Bagci, U.; Jha, D. TransResU-Net: Transformer based ResU-Net for real-time colonoscopy Polypp segmentation. arXiv 2022, arXiv:2206.08985. [Google Scholar]
- Narayanan, M. SENetV2: Aggregated dense layer for channelwise and global representations. arXiv 2023, arXiv:2311.10807. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. CSWin transformer: A general vision transformer backbone withcross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12124–12134. [Google Scholar]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Halvorsen, P.; De Lange, T.; Johansen, D.; Johansen, H.D. Kvasir-seg: A segmented Polypp dataset. In Proceedings of the MultiMedia modeling: 26th international conference, MMM 2020, Daejeon, Republic of Korea, 5–8 January 2020; Proceedings, Part II 26. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 451–462. [Google Scholar]
- Silva, J.; Histace, A.; Romain, O.; Dray, X. Granado, Toward embedded detection of polyps in wce images for early diagnosis of colorectal cancer. Int. J. Comput. Assist. Radiol. Surg. 2014, 9, 283–293. [Google Scholar] [CrossRef] [PubMed]
- Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; Gil, D.; Rodríguez, C.; Vilariño, F. WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Comput. Med. Imaging Graph. 2015, 43, 99–111. [Google Scholar] [CrossRef] [PubMed]
- Tajbakhsh, N.; Gurudu, S.R.; Liang, J. Automated polyp detection in colonoscopy videos using shape and context information. IEEE Trans. Med. Imaging 2015, 35, 630–644. [Google Scholar] [CrossRef] [PubMed]
- Vázquez, D.; Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; López, A.M.; Romero, A.; Drozdzal, M.; Courville, A. A benchmark for endoluminal scene segmentation of colonoscopy images. J. Healthc. Eng. 2017, 2017, 4037190. [Google Scholar] [CrossRef] [PubMed]
- Fan, D.P.; Ji, G.P.; Zhou, T.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Pranet: Parallel reverse attention network for Polypp segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 263–273. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Model | Dice | mIoU | Precision | Recall |
|---|---|---|---|---|---|
| Kvasir-SEG | Baseline | 0.871 | 0.839 | 0.912 | 0.828 |
| Baseline + traditional convolutional | 0.883 | 0.852 | 0.913 | 0.848 | |
| Baseline + LIEM | 0.902 | 0.866 | 0.916 | 0.868 | |
| Baseline + Transformer (Self-Attention) | 0.884 | 0.845 | 0.914 | 0.833 | |
| Baseline + CSWin | 0.907 | 0.871 | 0.902 | 0.884 | |
| Baseline + LIEM + CSWin | 0.920 | 0.886 | 0.913 | 0.902 | |
| CVC-ClinicDB | Baseline | 0.910 | 0.879 | 0.898 | 0.892 |
| Baseline + traditional convolutional | 0.912 | 0.881 | 0.899 | 0.894 | |
| Baseline + LIEM | 0.915 | 0.884 | 0.902 | 0.896 | |
| Baseline + Transformer (Self-Attention) | 0.913 | 0.882 | 0.900 | 0.894 | |
| Baseline + CSWin | 0.919 | 0.889 | 0.909 | 0.905 | |
| Baseline + LIEM + CSWin | 0.928 | 0.899 | 0.918 | 0.935 |
| Datasets | Model | Dice | mIoU | Precision | Recall |
|---|---|---|---|---|---|
| Kvasir-SEG | U-Net [7] | 0.895 | 0.857 | 0.879 | 0.875 |
| FCN [5] | 0.904 | 0.868 | 0.908 | 0.874 | |
| U-Net++ [8] | 0.878 | 0.842 | 0.888 | 0.841 | |
| ResUnet [9] | 0.890 | 0.852 | 0.922 | 0.849 | |
| TransUnet [15] | 0.871 | 0.839 | 0.912 | 0.828 | |
| SwinUnet [16] | 0.868 | 0.829 | 0.841 | 0.854 | |
| PraNet [34] | 0.916 | 0.858 | 0.911 | 0.864 | |
| Polypp-PVT [25] | 0.918 | 0.860 | 0.912 | 0.875 | |
| PolypFormer | 0.920 | 0.886 | 0.913 | 0.902 | |
| CVC-ClinicDB | U-Net [7] | 0.839 | 0.816 | 0.807 | 0.909 |
| FCN [5] | 0.885 | 0.856 | 0.878 | 0.856 | |
| U-Net++ [8] | 0.878 | 0.847 | 0.843 | 0.878 | |
| ResUnet [9] | 0.901 | 0.871 | 0.908 | 0.868 | |
| TransUnet [15] | 0.910 | 0.879 | 0.898 | 0.892 | |
| SwinUnet [16] | 0.800 | 0.795 | 0.833 | 0.755 | |
| PraNet [34] | 0.915 | 0.882 | 0.905 | 0.908 | |
| Polypp-PVT [25] | 0.920 | 0.887 | 0.910 | 0.913 | |
| PolypFormer | 0.928 | 0.899 | 0.918 | 0.935 |
| Datasets | Model | Dice | mIoU |
|---|---|---|---|
| CVC-ColonDB | U-Net [7] | 0.792 | 0.701 |
| FCN [5] | 0.727 | 0.678 | |
| U-Net++ [8] | 0.803 | 0.737 | |
| ResUnet [9] | 0.816 | 0.743 | |
| TransUnet [15] | 0.863 | 0.815 | |
| SwinUnet [16] | 0.845 | 0.797 | |
| PraNet [34] | 0.885 | 0.834 | |
| Polypp-PVT [25] | 0.897 | 0.847 | |
| PolypFormer | 0.917 | 0.852 | |
| EndoScene | U-Net [7] | 0.381 | 0.426 |
| FCN [5] | 0.437 | 0.423 | |
| U-Net++ [8] | 0.503 | 0.502 | |
| ResUnet [9] | 0.515 | 0.535 | |
| TransUnet [15] | 0.548 | 0.556 | |
| SwinUnet [16] | 0.575 | 0.548 | |
| PraNet [34] | 0.633 | 0.560 | |
| Polypp-PVT [25] | 0.657 | 0.563 | |
| PolypFormer | 0.693 | 0.617 | |
| ETIS | U-Net [7] | 0.707 | 0.715 |
| FCN [5] | 0.768 | 0.707 | |
| U-Net++ [8] | 0.814 | 0.784 | |
| ResUnet [9] | 0.825 | 0.806 | |
| TransUnet [15] | 0.861 | 0.813 | |
| SwinUnet [16] | 0.831 | 0.828 | |
| PraNet [34] | 0.875 | 0.826 | |
| Polypp-PVT [25] | 0.883 | 0.835 | |
| PolypFormer | 0.911 | 0.868 |
| Model | FLOPs (G) | Param (M) |
|---|---|---|
| U-Net [7] | 74.77 | 31.54 |
| FCN [5] | 80.05 | 33.30 |
| U-Net++ [8] | 110.30 | 47.15 |
| ResUnet [9] | 84.57 | 34.23 |
| TransUnet [15] | 154.26 | 105.93 |
| SwinUnet [16] | 124.10 | 62.38 |
| PraNet [34] | 84.89 | 32.23 |
| Polypp-PVT [25] | 99.01 | 52.91 |
| PolypFormer | 105.32 | 85.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, L.; Jiang, Y. A Polyp Segmentation Algorithm Based on Local Enhancement and Attention Mechanism. Mathematics 2025, 13, 1925. https://doi.org/10.3390/math13121925
Fan L, Jiang Y. A Polyp Segmentation Algorithm Based on Local Enhancement and Attention Mechanism. Mathematics. 2025; 13(12):1925. https://doi.org/10.3390/math13121925
Chicago/Turabian StyleFan, Lanxi, and Yu Jiang. 2025. "A Polyp Segmentation Algorithm Based on Local Enhancement and Attention Mechanism" Mathematics 13, no. 12: 1925. https://doi.org/10.3390/math13121925
APA StyleFan, L., & Jiang, Y. (2025). A Polyp Segmentation Algorithm Based on Local Enhancement and Attention Mechanism. Mathematics, 13(12), 1925. https://doi.org/10.3390/math13121925