1. Introduction
Fractures are common and frequent injuries that occur regardless of age and may occur in any part of the body. If a fracture in a specific part of the body is not treated in time, it may have a serious impact on the patient’s health [
1]. Therefore, the timely and accurate diagnosis and treatment of fractures are crucial. Currently, medical imaging techniques have become a key tool for clinicians to assist in fracture diagnoses [
2], with X-rays being the method of choice for assessing the condition of patients with fractures [
3]. However, accurate interpretation of these images requires extensive clinical experience and expertise on the part of the physician. In clinical diagnosis, the omission or misdiagnosis of fractures occurs from time to time due to factors such as limited resources for senior doctors, a lack of experience in diagnostic imaging, and high clinical workloads [
4]. Therefore, the development of auxiliary diagnosis systems for fractures based on medical image analysis technology to improve the accuracy and efficiency of diagnoses has become a focus of attention in the fields of both academic and clinical practice.
At present, deep learning technology has achieved significant results in the field of medical image analysis [
5,
6]. This study mainly utilizes deep learning technology to achieve two tasks: image classification and object detection. In the field of fracture image classification, by analyzing medical images, the presence of fractures is determined, and the specific types of fractures are identified and classified. Kim et al. [
7] used the pre-trained Inception v3 model to identify fractures in the wrist. Urakawa et al. [
8] used the VGG16 model to detect fractures in the intertrochanteric femur. Studies [
9,
10,
11] on fracture recognition in other parts of the body have also achieved good results. Object detection models identify the lesion area and mark the possible fracture locations. Yahalomi et al. [
12] used Faster R-CNN to detect and localize distal radius fractures. Li et al. [
13] used the YOLO v3 model to automatically identify vertebral fractures and evaluated the diagnostic performance of the model through accuracy, sensitivity, and specificity analyses.
Currently, auxiliary diagnosis systems for fractures developed using deep learning technology have achieved certain results. Tomita et al. [
14] developed an automated fracture assessment tool capable of assisting in detecting the presence of osteoporotic fractures in patients during CT scans of the chest, abdomen, and pelvis. Arpitha et al. [
15] proposed a computer-aided diagnosis platform specifically for detecting, labeling, and segmenting the lumbar region in imaging data and further distinguishing the nature of spinal compression fractures, including whether they are benign or malignant.
In summary, the existing research mostly focuses on the diagnosis of fractures in a single part and fails to cover a wider range of fracture locations. Moreover, most studies do not involve the classification of fractured body parts. However, in actual medical applications, orthopedic surgeons need to make professional divisions based on skeletal parts and image types to help them make quick and accurate judgments on images from any part. Therefore, this paper proposes a two-stage upper limb fracture auxiliary diagnosis method that integrates body part classification and fracture diagnosis for multiple body parts and develops a corresponding fracture auxiliary diagnosis system to improve the diagnostic ability and diagnostic efficiency of orthopedic surgeons for fractures in different parts.
2. Materials and Methods
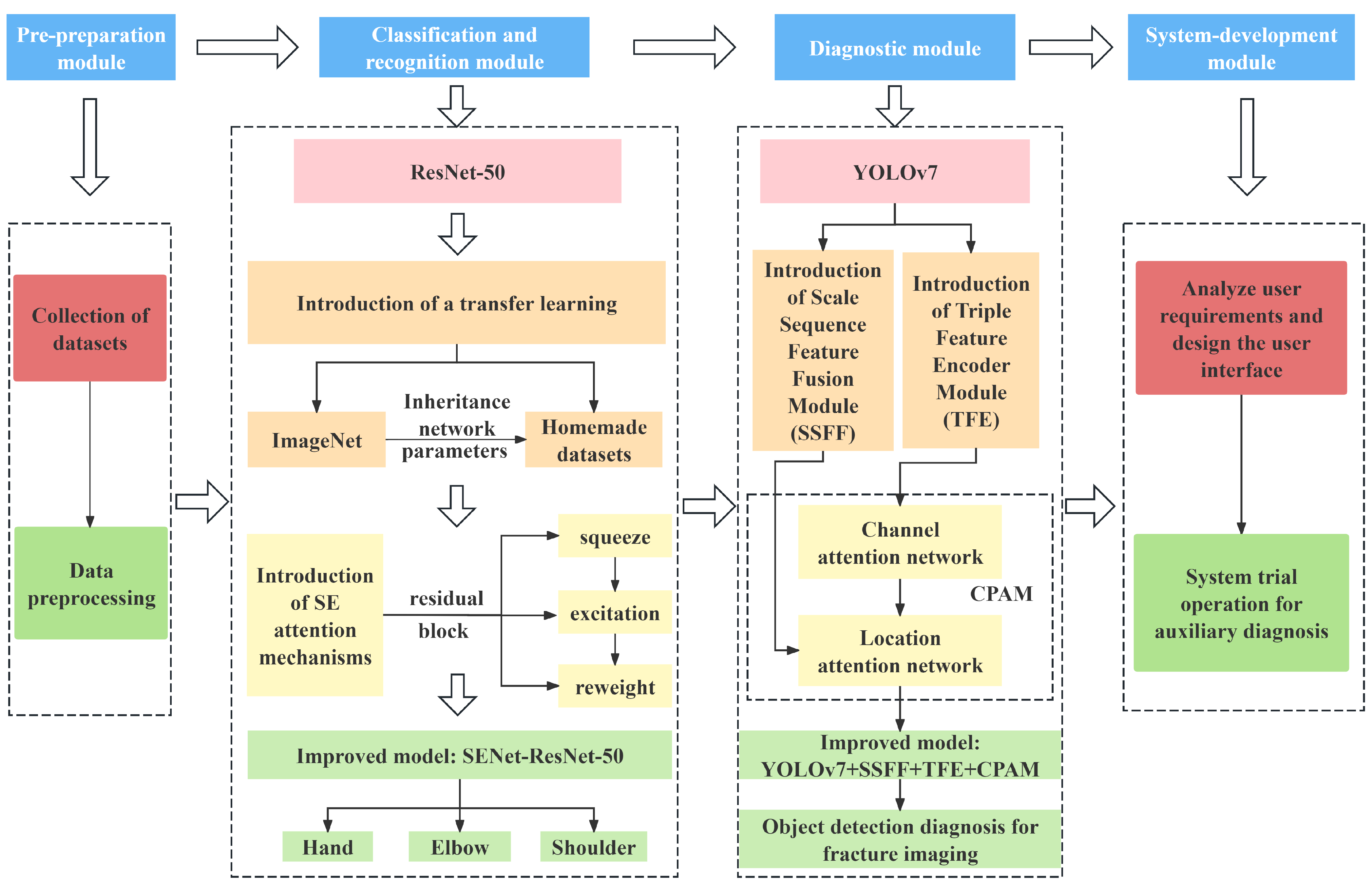
This study proposes an innovative two-stage upper limb fracture auxiliary diagnosis method, adopting a “classification-first, then diagnosis” strategy. As shown in
Figure 1, fracture images are first classified by location, and then specific diagnostic models for each location are applied to distinguishing abnormal types. Compared with single-stage diagnostic methods, this two-stage approach significantly improves the accuracy and applicability of auxiliary diagnoses of fractures in specific body parts. The method is designed in a modular fashion, including four parts: a pre-preparation module, a classification and recognition module, a diagnostic module, and a system-development module. The functions of each module are described in detail below.
The pre-preparation module: This module involves collecting or creating datasets according to the research objectives and preprocessing the datasets for subsequent research. In this study, multiple datasets, including MURA, GRAZPEDWRI-DX, and FracAtlas, were integrated into an upper limb fracture dataset comprising the hand, elbow, and shoulder.
The classification and recognition module: The core task of this module is to construct an upper limb fracture location recognition model based on the dataset. This study employs an improved ResNet-50 model incorporating transfer learning and the Squeeze-and-Excitation (SE) attention mechanism to enhance the recognition ability for upper limb fractures.
The diagnostic module: This module constructs specific fracture diagnostic models for each part, implementing the corresponding diagnosis models based on the classification results from the previous module. An improved YOLO model incorporating Scale Sequence Feature Fusion (SSFF) and Triple Feature Encoder (TFE) modules is used to build diagnosis models for the hand, elbow, and shoulder.
The system-development module: This module involves analyzing the user requirements, designing a user-friendly system interface, conducting system trials, and ensuring the system can complete the intended tasks and achieve all preset functions.
In the application of this method, researchers can select the appropriate models and optimization algorithms according to the actual research situation to develop more suitable auxiliary diagnosis systems. This study focuses on research into auxiliary diagnosis of upper limb fractures.
2.1. Data Collection and Preprocessing
By integrating real, publicly available patient fracture image data from multiple hospitals, this study constructs an upper limb fracture X-ray image dataset comprising the hand, elbow, and shoulder. The main datasets are briefly introduced as follows.
The MURA [
16] dataset provides 12,173 patients, 14,863 studies, and a total of 40,561 multi-angle X-ray images from Stanford Medical Center from between 2001 and 2012, covering seven areas of the upper extremities—the elbow, fingers, forearm, hand, humerus, shoulder, and wrist—classified as normal or abnormal.
The GRAZPEDWRI-DX [
17] dataset provides a total of 20,327 X-ray images of traumatic wrist injuries in children from 6091 patients who were treated at the University Hospital of Graz between 2008 and 2018, labeled with a variety of diagnostics by placing a bounding box, such as fractures, periosteal reactions, and other information.
The FracAtlas dataset [
18] is a collection of 4083 X-ray images from three major hospitals in Bangladesh with masks and bounding boxes and classification labels for each fracture instance.
The dataset constructed using this method contains the three categories of hand, elbow and shoulder, with 2000 cases of fracture images in each category, covering five types of diagnostic information, including fractures, periosteal reactions, pronator signs, soft tissues, and text. In addition, the following preprocessing operations were used in this study:
Data augmentation. To enhance the diversity of the medical image dataset for specific body regions, random cropping was used for data augmentatio;
Size transformation. The classification task dataset was resized to 224 × 224, and the object detection task dataset was resized to 640 × 640 to meet the training requirements of the corresponding models.
2.2. The Classification Recognition Stage—The Upper Limb Fracture Location Recognition Model
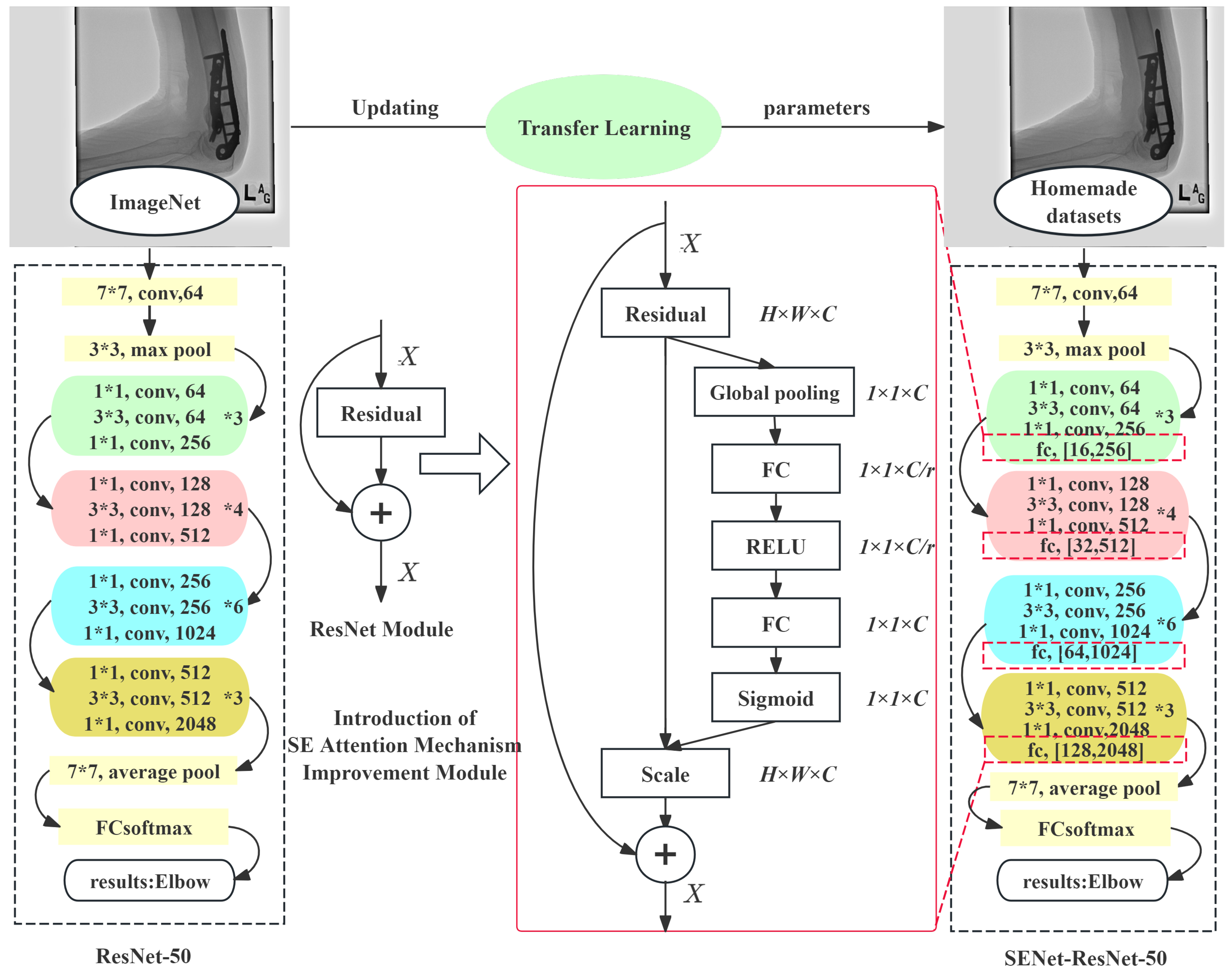
ResNet [
19], as a deep convolutional neural network model, introduces residual blocks, allowing the network to have a significantly increased number of layers while maintaining a good performance and solving the gradient vanishing problem often encountered in neural network training. This study employs an improved ResNet-50 model that integrated transfer learning and the Squeeze-and-Excitation (SE) attention mechanism to construct a more accurate upper limb fracture location recognition model.
The transfer learning strategy used in this study uses the weights of the ResNet-50 model pre-trained on ImageNet-1k [
20] as the initialization parameters, without freezing any layer’s parameters to adapt to the new upper limb fracture dataset. This approach allows all of the network parameters to participate in gradient descent and be updated, aiming to enhance the model’s recognition ability for new categories. By training on the new dataset, the model can more accurately identify different body parts.
SENet [
21] is integrated into the residual block of the ResNet-50 model to form an enhanced SENet-ResNet residual block. Applied to the fracture image classification recognition module, SENet adaptively adjusts the channel activations, enhancing the model’s discriminative power for image features without adding extra spatial dimensions. This enables the model to focus more precisely on key areas during fracture image location recognition, thereby improving the accuracy of fracture location identification. The structural comparison between the improved and original ResNet-50 models is shown in
Figure 2, where the numbers after ‘fc’ denote the output dimensions of the two fully connected layers in the SE module.
2.3. The Diagnosis Stage—A Fracture Diagnosis Model Based on Improved YOLOv7
Compared with traditional two-stage object detection models, YOLO series models have the advantages of a fast detection speed and ease of implementation and have been widely used in practical applications. To further enhance the model performance, inspired by Kang et al. [
22], this study introduces the Scale Sequence Feature Fusion (SSFF) and Triple Feature Encoder (TFE) modules into YOLOv7 and incorporates the Channel and Position Attention Mechanism (CPAM) [
22] to integrate the features from these two modules, improving the diagnostic accuracy of the method for multi-annotated types of fracture images during the diagnosis stage.
The introduction of the SSFF module, applied to the diagnosis process for fracture images, decomposes the fracture images into five levels of features, each capturing different details or scales of image information. After aligning the resolutions of all feature maps with the lowest-level feature map containing key information for small object detection, effective extraction of the scale sequence features is achieved. The introduction of the SSFF module enables the integration of the high-level information in deep feature maps with the detailed information in shallow feature maps, enhancing the model’s detection capability for small targets.
The latest Triple Feature Encoder (TFE) module [
22] can simultaneously focus on large-, medium-, and small-sized features, with an emphasis on amplifying features in large-sized feature maps to capture the image details better. After introducing the TFE module into the diagnostic model, the output feature maps of fracture images combine large-, medium-, and small-sized feature maps, maintaining the original resolution but increasing the number of channels threefold.
To integrate the detailed and multi-scale information introduced by the SSFF and TFE modules, this study introduces the Channel and Position Attention Mechanism (CPAM) [
22]. It includes a channel attention network and a position attention network. The channel attention network receives the detailed feature output image from the TFE module, while the position attention network processes the output from the SSFF module. The final combination enhances the focus on spatial positions.
The improved YOLO network structure integrates the SSFF module, the TFE module, and the CPAM dual-attention combination module, with the rest of the architecture remaining the same as the original YOLO structure. Through these integrations, the improved YOLOv7 model, while retaining the advantages of the original architecture, significantly enhances the detection performance of the diagnostic model for the subtle abnormalities in fracture images, as shown in
Figure 3.
2.4. Development of the Fracture Auxiliary Diagnosis System
2.4.1. Analysis of the System Function and Workflow
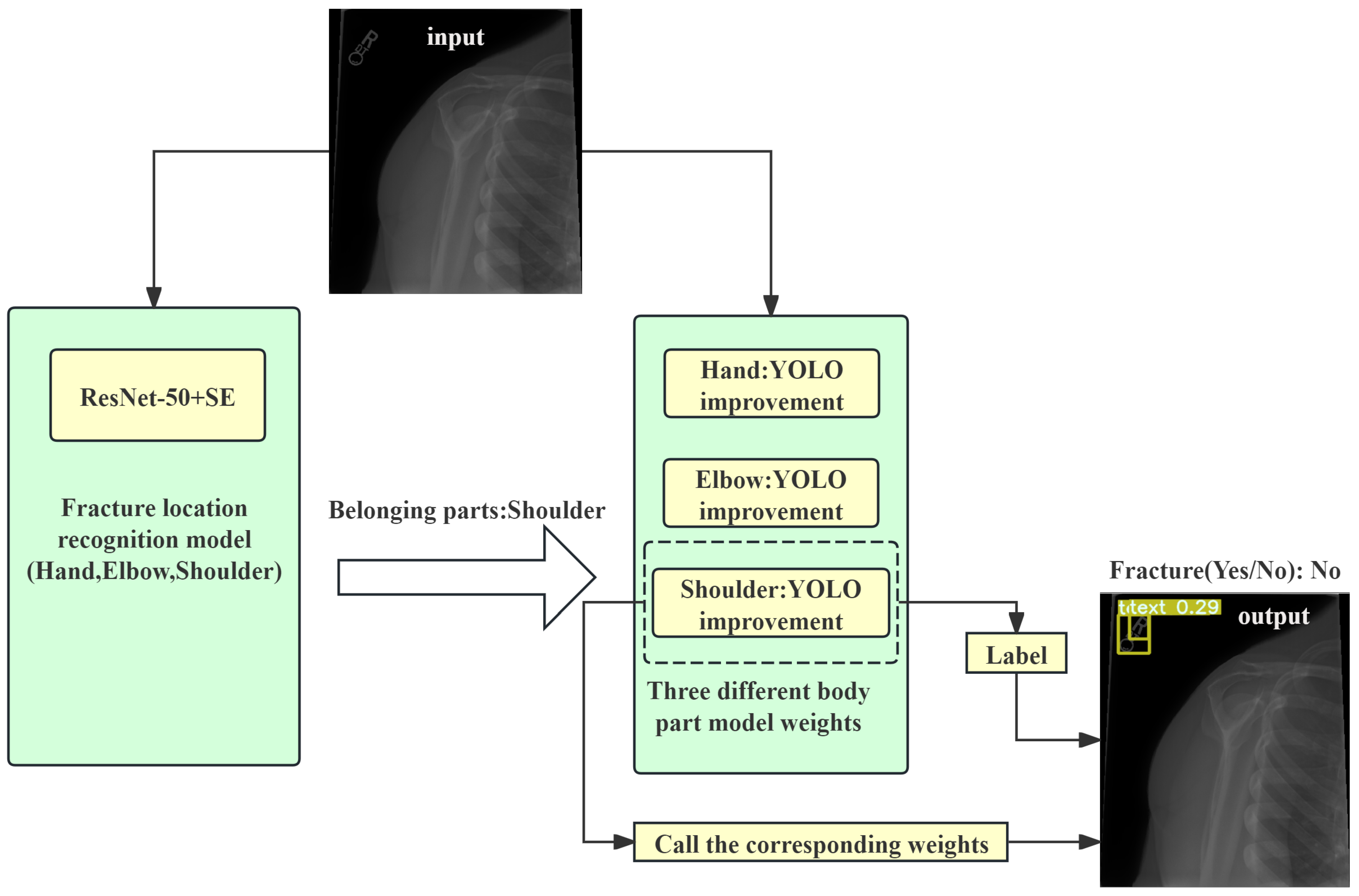
The two-stage system was implemented and tested in a simulated clinical environment. The system not only improved the diagnostic accuracy but also increased the efficiency of doctors in diagnosing fractures, demonstrating its potential for practical application. Based on the user requirements and the completeness of the auxiliary diagnosis system for fractures, the user experience interface designed in this study should include three main functions: upload, prediction, and display. Brief descriptions of these functions are as follows:
The upload function: This includes the functions of uploading fracture images and selecting the model weights. The upload function allows users to select images for detection from their computers. According to the design of this study, after an image is uploaded, it will first be classified by the location classification system, and then the corresponding object detection model weights will be called based on the classification results. Subsequent users can also upload their own newly trained target detection model weights based on this function.
The prediction function: This function is the core of the auxiliary diagnosis system, including body part classification detection in the fracture images and object detection of fracture regions. Users can easily trigger the prediction process through the buttons on the UI interface, and the system will automatically connect and call the corresponding prediction or detection functions.
The display function:This function is responsible for displaying the original images and diagnostic results. On the one hand, it shows the original fracture images before auxiliary diagnosis; on the other hand, it displays the images processed by the auxiliary diagnosis system, including the classification results and bounding boxes annotated by the target detection model.
Combining the above functional analysis, the fracture image auxiliary diagnosis system works by first dividing the input fracture images into parts and then calling the object detection models trained for the corresponding parts to annotate the fracture images, highlighting the suspected fracture areas and further categorizing abnormal types. A diagram of the specific workflow is shown in
Figure 4.
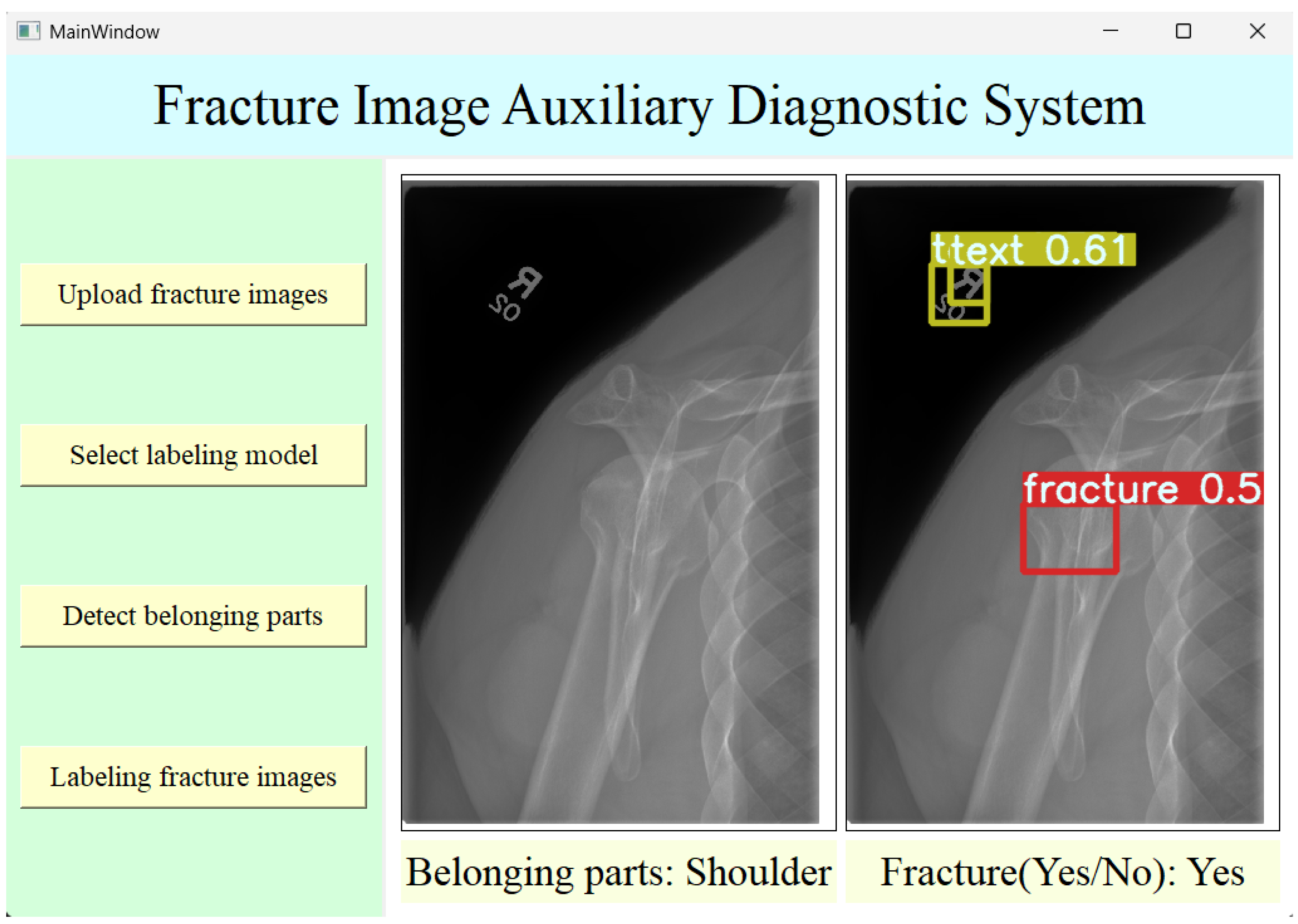
2.4.2. The Design of System Interfaces
The structure of the auxiliary diagnosis system designed in this study mainly consists of four layers: the user interface layer, the logic layer, the core functionality layer, and the data layer. The following is a brief description of each layer:
The user interface layer:A simple and practical UI interface was designed using Qt Designer to facilitate user operations.
The logic layer: This layer was mainly implemented through Python (version 3.11.5) programming of the backend of the UI interface. The buttons in the UI interface are bound to various functions in the program through the backend logic. These functions are responsible for calling certain models, such as classification recognition or target detection, thereby enabling the execution of the corresponding functions by clicking buttons.
The core functionality layer:In the fracture image auxiliary diagnosis system designed in this study, the weights of the pre-trained optimal fracture image body part classification model and the fracture image target detection model are saved for easy calling through the classification model’s predict function and the target detection model’s detect function to achieve the corresponding functions.
The data layer: This mainly includes the datasets used during model training. This layer is generally not involved in the normal operation of the auxiliary diagnosis system. However, if the system needs to be maintained or adjusted, or if a hospital wishes to add new images to the dataset for training based on its clinical data, this layer will be involved.
Based on the above functions and the four-layer structure of the user interface, the user interface was designed using Qt Designer software. Modules such as QPushButton, QLabel, and QFrame can be used to complete functions such as creating buttons and text, image display, and final beautification of the user interface. After the basic design is completed, the interface’s construction is finished. The final running interface of the auxiliary diagnosis system is shown in
Figure 5.
3. Results
3.1. The Evaluation Metrics
The upper limb fracture location recognition model in this study uses a confusion matrix and evaluation metrics such as accuracy, precision, and sensitivity [
23] to assess the model performance. The binary confusion matrix is shown in
Table 1.
Here, TP, FP, FN, and TN represent the number of true positives, false positives, false negatives, and true negatives, respectively. The formulas for accuracy, precision, and sensitivity are as follows:
Additionally, the fracture diagnosis models for each part use the mean average precision (mAP) [
24] as the evaluation metric, with mAP0.5 and mAP0.5:0.95 being the primary indicators used in this study. mAP0.5 refers to the average precision calculated at an IoU threshold of 0.5.
mAP0.5:0.95 is the average of the calculated mean average precision over multiple IoU thresholds (from 0.5 to 0.95 in steps of 0.05).
3.2. The Experimental Results of the Recognition Model
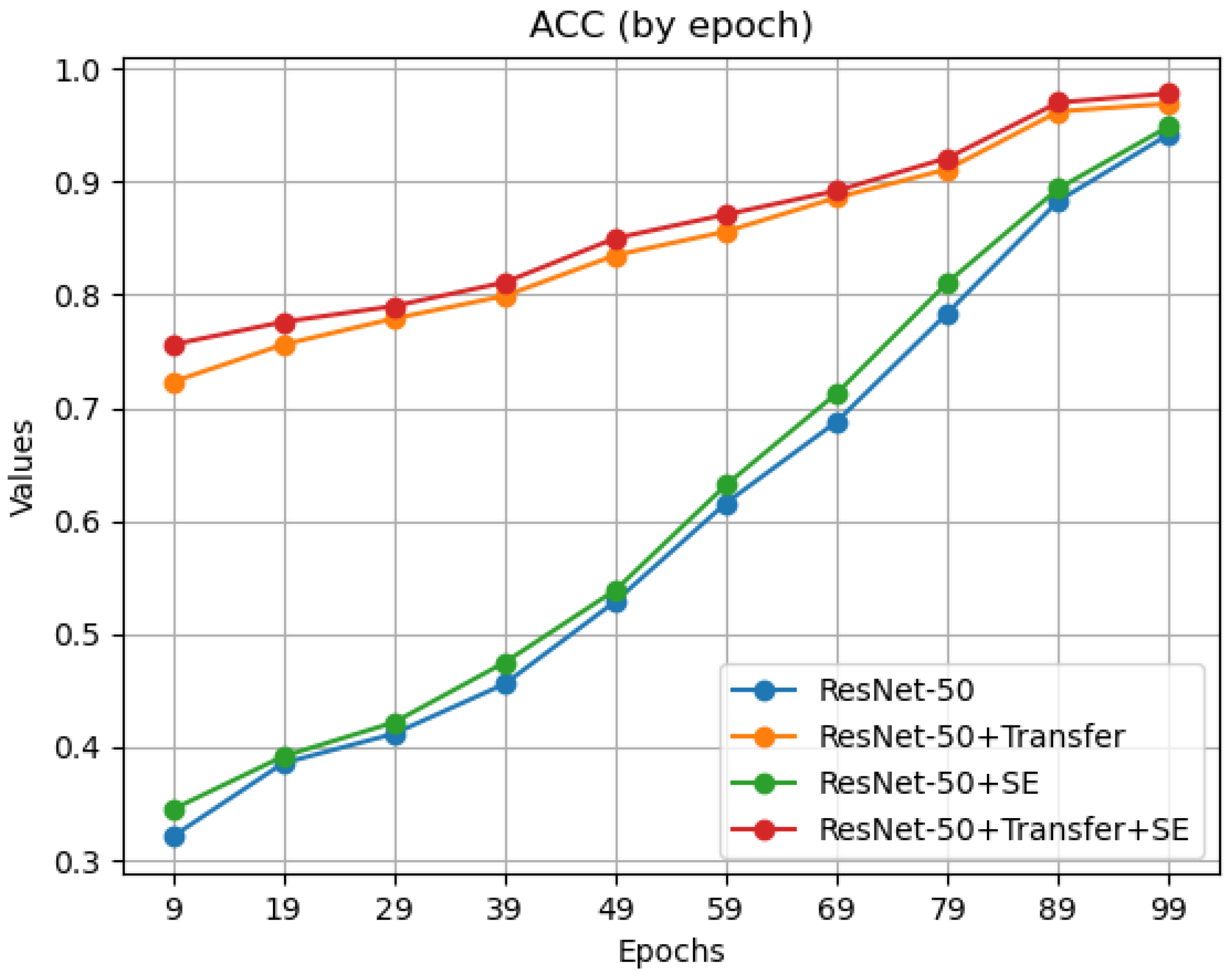
Both transfer learning and the introduction of the SE attention mechanism contribute to an improvement in the model’s classification performance. To further analyze how transfer learning and SE attention mechanisms affect the model performance, the accuracy during the training process was plotted every 10 epochs for the hand category, as shown in
Figure 6.
The observation results indicate that after the introduction of the SE attention mechanism, the model’s accuracy increased slightly every 10 epochs, recognizing fracture images of different parts better. With transfer learning, the model’s accuracy significantly improved in the early stages of training (the first 10 epochs), thanks to pre-training. These data demonstrate that the introduction of transfer learning and the SE attention mechanism effectively improved the ResNet-50 model, with a performance significantly better than that of the original model.
Meanwhile, this study compared several models, including AlexNet, VGG, Inception V3, ResNet-34, the original ResNet-50, pre-trained ResNet-50, SE-ResNet-50, and the improved ResNet-50 used in this study, on the upper limb fracture dataset. The dataset was divided into a training set, a validation set, and a test set at a ratio of 6:2:2. Other parameters (such as a BatchSize of 64 and an initial learning rate of 0.0001) were kept consistent to ensure the accuracy of the experimental results. The accuracy and loss values of the models on the training set and the validation set are shown in
Table 2.
A comparison of the results on the classification performance on the test set is shown in
Table 3 below.
The results show that the improved model used in this study outperforms the other mainstream models in terms of its performance.
3.3. The Experimental Results of the Diagnosis Model
To verify the improvement effects of the modules mentioned in this paper on the baseline model, the following ablation experiments were designed: the baseline model, the YOLO model with the SSFF module, the YOLO model with the TFE module, the YOLO model with both the SSFF and TFE modules, and the final model with the SSFF, TFE, and CPAM modules. These models were trained under the same experimental parameters and hardware conditions, with the primary evaluation metrics being mAP0.5 and mAP0.5:0.95. The results are shown in
Table 4.
The results showed that the SSFF module improved mAP0.5 by 0.013 and mAP0.5:0.95 by 0.017, primarily by enhancing the detection of small-scale fractures. The TFE module further improved mAP0.5 by 0.006 and mAP0.5:0.95 by 0.008, demonstrating its effectiveness in capturing multi-scale features. Finally, the CPAM module contributed an additional 0.013 to mAP0.5 and 0.016 to mAP0.5:0.95 by refining the feature maps through channel and position attention. These modules effectively improved the model’s performance and enhanced the ability to diagnose small-region targets in fracture imaging diagnosis.
In addition to this, this study compared YOLOv5 [
25], YOLOv8 [
26], the YOLOv8-SENet improved model [
27], and the YOLOv8-CBAM improved model [
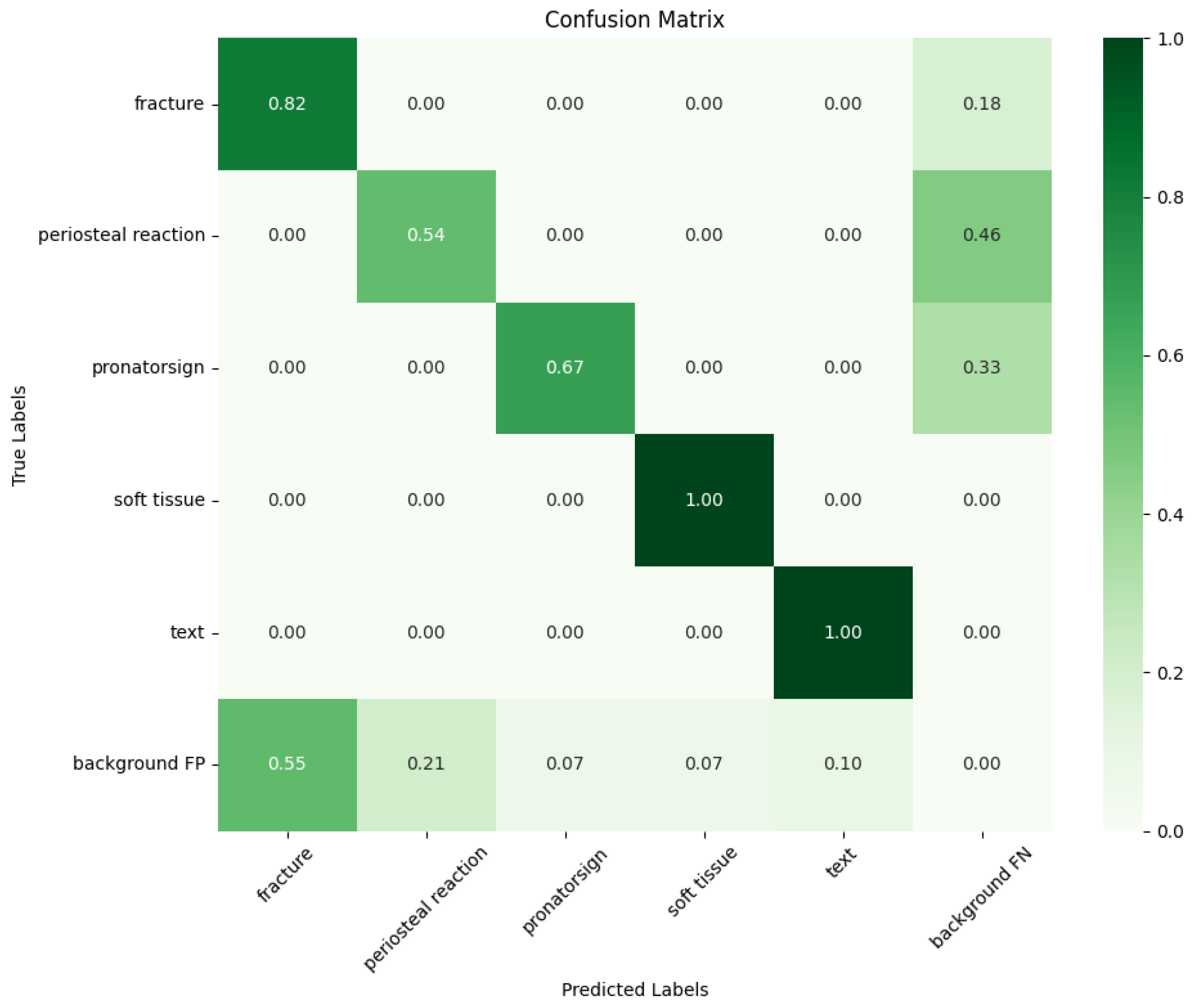
28]. All of the models were trained with the same default parameters (such as BatchSize and the IoU) and on the same device and cloud server for 100 epochs to minimize external influences. The YOLO improved model used in this study achieved the following indicators after training on the homemade dataset. The confusion matrix is obtained as shown in
Figure 7 below.
Observation of the confusion matrix shows that the improved YOLO model performs well in recognizing the categories of soft tissue, fractures, and text. Below are the bar charts (
Figure 8) for the mAP values measured in the fracture category for each model (Model 1: YOLOv5 [
25]; Model 2: YOLOv8 [
26]; Model 3: YOLOv8-SENet [
27]; Model 4: YOLOv8-CBAM [
28], and the model used in this study), with the main evaluation metrics of mAP0.5 and mAP0.5:0.95.
Based on the above analysis, the YOLO improved model used in this study demonstrated the best performance for fracture type detection and diagnosis. Compared with other basic or existing improved YOLO models, this improved model can more effectively identify and locate subtle abnormalities in fracture images, enhancing the performance in fracture image diagnosis tasks.
3.4. Application Effects of the System
National Taiwan University first applied the YOLOv9 algorithm model to the GRAZPEDWRI-DX dataset, achieving a state-of-the-art (SOTA) performance, with mAP0.5:0.95 increasing to 43.73% [
29]. To verify the application effect of the system in diagnosing different parts, the following experiments were designed. First, 50 fracture images of the hand, elbow, and shoulder that were not in the training set were selected. Second, two methods were used for diagnosis. Method 1: Without prior part recognition and classification, the hand target detection model trained directly using the YOLOv9 algorithm model was used for diagnosis to simulate the optimal performance of a single-part auxiliary diagnosis system in current multi-part fracture cases. Method 2: The recognition model was first used to determine the part of the image, and then the corresponding part-specific object detection model was called for diagnosis, simulating the multi-part auxiliary diagnosis system designed in this study. The mAP0.5 value of the diagnosis model in the category of ‘fracture’ is used as the evaluation criterion, and the experimental results for the two scenarios are shown in
Table 5.
As shown in the table, Method 2 outperformed Method 1 in its diagnostic performance across three body parts and demonstrated a superior average performance. Although the model used demonstrated an excellent performance in this field, its performance may be reduced when facing multi-part diagnoses due to the complexity of part classification. It is only suitable as a single model for diagnosing a single part and does not show robustness. Method 2 achieved zero misclassifications in the initial classification stage and employed dedicated object detection models tailored to the hand, elbow, and shoulder. This targeted diagnostic strategy enabled significant improvements in diagnostic accuracy for the elbow and shoulder compared to that of Method 1, with the mAP0.5 metric increasing by 23.9% for the elbow and 24.0% for the shoulder.
This demonstrates that single-part fracture auxiliary diagnosis systems perform poorly in multi-part clinical applications. In contrast, the “classification-first, then detection” system proposed in this study significantly improves the accuracy, practicality, and scalability compared to those of traditional single-part auxiliary diagnosis systems when facing fractures in multiple body parts in a clinical environment.
4. Discussion
This study aims to address the limitations of the existing fracture image auxiliary diagnosis systems when facing fractures in various body parts and to improve their practicality and effectiveness in clinical settings. The main innovations and contributions of this study are as follows:
A novel “classification-first, then detection” method was proposed, and a corresponding auxiliary diagnosis system was developed. The system first classifies the fracture images by location and then calls the corresponding models for precise annotation and diagnosis, effectively enhancing its practicality and effectiveness in clinical applications. The system also features a user-friendly interface to provide auxiliary decision-making for clinicians.
Inspired by Kang et al. [
22], we enhanced our model by adopting their network architecture and innovatively applied it to fracture imaging diagnosis for the first time. This improvement boosted the model’s ability to detect subtle fracture types, offering strong support for subsequent research.
Simultaneously, there are still some limitations and imperfections in the research work of this paper.
The possibility that the input relationship of the TFE module in the diagnostic phase model can be inverted or independent remains in the theoretical investigation stage, and there is still a lack of substantive experiments to verify its invertibility or independence. Subsequently, we will design additional experiments to validate the feasibility of this idea.
In the proposed two-stage auxiliary diagnosis method, the models used in the classification and diagnosis phases have achieved promising results but have nott reached the state-of-the-art level or the optimal performance for their respective tasks. Future work will involve further research to identify higher-performing models to integrate into the proposed method.
For future developments in auxiliary diagnosis methods for fractures based on deep learning, the following directions are proposed based on the knowledge gained in this study: Firstly, the accuracy and efficiency of the auxiliary diagnosis system should be improved further by expanding the high-quality dataset, and then the application of the system should be promoted. Second, we wish to intelligently upgrade the future test result interface to not only provide diagnosis results but also automatically retrieve and recommend treatment plans from medical databases, helping physicians develop more accurate treatment plans for patients.
Author Contributions
Conceptualization: H.W. and D.Z. Methodology: D.Z. Software: H.W. Validation: H.W., D.Z., and Z.L. Formal analysis: D.Z. Investigation: D.Z. Resources: D.Z. Data curation: H.W. Writing—original draft preparation: Z.L. Writing—review and editing: H.W. Visualization: H.W. and Z.L. Supervision: D.Z. Project administration: D.Z. Funding acquisition: D.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62303098 and Grant 62173073, in part by China Postdoctoral Science Foundation under Grant 2022M720679, in part by the Liaoning Provincial Natural Science Foundation Joint Fund under Grant 2023-BSBA-104, in part by the Fundamental Research Funds for the Central Universities N25ZJL007, and in part by the Liaoning Provincial Science and Technology Plan Project-Technology Innovation Guidance of the Science and Technology Department under Grant 2023JH1/10400011.
Data Availability Statement
Dataset available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Azam, M.A.; Khan, K.B.; Salahuddin, S.; Rehman, E.; Khan, S.A.; Khan, M.A.; Kadry, S.; Gandomi, A.H. A review on multimodal medical image fusion: Compendious analysis of medical modalities, multimodal databases, fusion techniques and quality metrics. Comput. Biol. Med. 2022, 144, 105253. [Google Scholar] [CrossRef]
- Di Medio, L.; Brandi, M.L. Advances in bone turnover markers. In Advances in Clinical Chemistry; Elsevier: Amsterdam, The Netherlands, 2021; Volume 105, pp. 101–140. [Google Scholar]
- Hardalaç, F.; Uysal, F.; Peker, O.; Çiçeklidağ, M.; Tolunay, T.; Tokgöz, N.; Kutbay, U.; Demirciler, B.; Mert, F. Fracture detection in wrist X-ray images using deep learning-based object detection models. Sensors 2022, 22, 1285. [Google Scholar] [CrossRef]
- Kalmet, P.H.; Sanduleanu, S.; Primakov, S.; Wu, G.; Jochems, A.; Refaee, T.; Ibrahim, A.; Hulst, L.v.; Lambin, P.; Poeze, M. Deep learning in fracture detection: A narrative review. Acta Orthop. 2020, 91, 215–220. [Google Scholar] [CrossRef]
- Zhang, D.; Gao, X. A digital twin dosing system for iron reverse flotation. J. Manuf. Syst. 2022, 63, 238–249. [Google Scholar] [CrossRef]
- Zhang, D.; Gao, X. Soft sensor of flotation froth grade classification based on hybrid deep neural network. Int. J. Prod. Res. 2021, 59, 4794–4810. [Google Scholar] [CrossRef]
- Kim, D.; MacKinnon, T. Artificial intelligence in fracture detection: Transfer learning from deep convolutional neural networks. Clin. Radiol. 2018, 73, 439–445. [Google Scholar] [CrossRef]
- Urakawa, T.; Tanaka, Y.; Goto, S.; Matsuzawa, H.; Watanabe, K.; Endo, N. Detecting intertrochanteric hip fractures with orthopedist-level accuracy using a deep convolutional neural network. Skelet. Radiol. 2019, 48, 239–244. [Google Scholar] [CrossRef]
- Gale, W.; Oakden-Rayner, L.; Carneiro, G.; Bradley, A.P.; Palmer, L.J. Detecting hip fractures with radiologist-level performance using deep neural networks. arXiv 2017, arXiv:1711.06504. [Google Scholar]
- Chung, S.W.; Han, S.S.; Lee, J.W.; Oh, K.S.; Kim, N.R.; Yoon, J.P.; Kim, J.Y.; Moon, S.H.; Kwon, J.; Lee, H.J.; et al. Automated detection and classification of the proximal humerus fracture by using deep learning algorithm. Acta Orthop. 2018, 89, 468–473. [Google Scholar] [CrossRef]
- Yu, J.; Yu, S.; Erdal, B.; Demirer, M.; Gupta, V.; Bigelow, M.; Salvador, A.; Rink, T.; Lenobel, S.; Prevedello, L.; et al. Detection and localisation of hip fractures on anteroposterior radiographs with artificial intelligence: Proof of concept. Clin. Radiol. 2020, 75, 237.e1–237.e9. [Google Scholar] [CrossRef]
- Yahalomi, E.; Chernofsky, M.; Werman, M. Detection of distal radius fractures trained by a small set of X-ray images and Faster R-CNN. In Intelligent Computing, Proceedings of the 2019 Computing Conference, London, UK, 16–17 July 2019; Springer: Cham, Switzerland, 2019; Volume 1, pp. 971–981. [Google Scholar]
- Li, Y.C.; Chen, H.H.; Lu, H.H.S.; Wu, H.T.H.; Chang, M.C.; Chou, P.H. Can a deep-learning model for the automated detection of vertebral fractures approach the performance level of human subspecialists? Clin. Orthop. Relat. Res. 2021, 479, 1598–1612. [Google Scholar] [CrossRef]
- Tomita, N.; Cheung, Y.Y.; Hassanpour, S. Deep neural networks for automatic detection of osteoporotic vertebral fractures on CT scans. Comput. Biol. Med. 2018, 98, 8–15. [Google Scholar] [CrossRef]
- Arpitha, A.; Rangarajan, L. Computational techniques to segment and classify lumbar compression fractures. Radiol. Medica 2020, 125, 551–560. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Irvin, J.; Bagul, A.; Ding, D.; Duan, T.; Mehta, H.; Yang, B.; Zhu, K.; Laird, D.; Ball, R.L.; et al. Mura: Large dataset for abnormality detection in musculoskeletal radiographs. arXiv 2017, arXiv:1712.06957. [Google Scholar]
- Binh, L.N.; Nhu, N.T.; Vy, V.P.T.; Son, D.L.H.; Hung, T.N.K.; Bach, N.; Huy, H.Q.; Tuan, L.V.; Le, N.Q.K.; Kang, J.H. Multi-Class Deep Learning Model for Detecting Pediatric Distal Forearm Fractures Based on the AO/OTA Classification. J. Imaging Inform. Med. 2024, 37, 725–733. [Google Scholar] [CrossRef]
- Abedeen, I.; Rahman, M.A.; Prottyasha, F.Z.; Ahmed, T.; Chowdhury, T.M.; Shatabda, S. Fracatlas: A dataset for fracture classification, localization and segmentation of musculoskeletal radiographs. Sci. Data 2023, 10, 521. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Kang, M.; Ting, C.M.; Ting, F.F.; Phan, R.C.W. ASF-YOLO: A novel YOLO model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 2024, 147, 105057. [Google Scholar] [CrossRef]
- Kavitha, V.R.; Jahir Hussain, F.B.; Chillakuru, P.; Shanmugam, P. Automated Classification of Liver Cancer Stages Using Deep Learning on Histopathological Images. Trait. Signal 2024, 41, 373–381. [Google Scholar] [CrossRef]
- Pereira, F.; Lopes, H.; Pinto, L.; Soares, F.; Vasconcelos, R.; Machado, J.; Carvalho, V. A Novel Deep Learning Approach for Yarn Hairiness Characterization Using an Improved YOLOv5 Algorithm. Appl. Sci. 2025, 15, 149. [Google Scholar] [CrossRef]
- Hua, Z.; Jiao, Y.; Zhang, T.; Wang, Z.; Shang, Y.; Song, H. Automatic location and recognition of horse freezing brand using rotational YOLOv5 deep learning network. Artif. Intell. Agric. 2024, 14, 21–30. [Google Scholar] [CrossRef]
- Ju, R.Y.; Cai, W. Fracture detection in pediatric wrist trauma X-ray images using YOLOv8 algorithm. Sci. Rep. 2023, 13, 20077. [Google Scholar] [CrossRef]
- Xiao, D.; Wang, H.; Liu, Y.; Li, W.; Li, H. DHSW-YOLO: A duck flock daily behavior recognition model adaptable to bright and dark conditions. Comput. Electron. Agric. 2024, 225, 109281. [Google Scholar] [CrossRef]
- Ji, S.; Sun, J.; Zhang, C. Phenotypic Image Recognition of Asparagus Stem Blight Based on Improved YOLOv8. Comput. Mater. Contin. 2024, 80, 4017–4029. [Google Scholar] [CrossRef]
- Chien, C.T.; Ju, R.Y.; Chou, K.Y.; Chiang, J.S. YOLOv9 for fracture detection in pediatric wrist trauma X-ray images. Electron. Lett. 2024, 60, e13248. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}