1. Introduction
In the linear regression framework, the instrumental variable (IV) is one of the most widely applied methods to tackle endogeneity in empirical research. A valid IV must satisfy three conditions: (1) it must be excluded from the structural equation; (2) it must be uncorrelated with the structural error term; (3) it must be strongly correlated with the endogenous regressors. If any of these conditions fail, the conventional IV estimator will produce biased and inconsistent results. In many empirical applications, it is often debatable whether the exclusion and the orthogonality conditions hold. Furthermore, even when these two conditions are satisfied, a vast literature has studied the consequences of weak instruments, as instruments are often only weakly correlated with the endogenous variables.
It is well known that in linear models, the IV method is equivalent to ordinary least squares (OLS) regression that includes the reduced form residuals as additional regressors to control for endogeneity, a method known as the control function (CF) approach (see, e.g., [
1,
2]). While the two approaches obtain numerically identical estimators under strong instruments, the CF method offers a distinct conceptual advantage by allowing researchers to model the source of endogeneity directly in the structural equation. This flexibility makes the CF approach particularly appealing in settings with conditional heteroskedasticity, where variation in the second moments can be exploited to aid identification.
However, when instruments are weak, the residuals from the reduced form equation become nearly collinear with the endogenous regressors, leading to identification failure in the standard CF framework. In this paper, we propose a feasible CF approach that exploits time-varying volatility to address the identification issue in the absence of strong instruments. The idea is that heteroskedasticity generates variation in the scale of the reduced-form errors, which weakens their asymptotic collinearity with the endogenous variables. Earlier studies have applied similar logic in various scenarios. Ref. [
3] formulates a model and shows that the parameters can be identified when there are multiple known regimes of heteroskedasticity under certain conditions. Ref. [
4] explores the Markov-switching heteroskedascitiy to identify the correlation between trend inflation and inflation gap in an unobserved components model. In structural vector autoregressive framework, refs. [
5,
6] discuss how Markov-switching heteroskedasticity and stochastic volatility can aid identification.
The proposed method is developed under a general framework that allows for nonparametric time variation in volatility and does not require knowledge of the heteroskedasticity structure. We provide conditions under which the parameters of the structural model are identified and show that the proposed estimator is
-consistent and asymptotically normal. Unlike existing methods that rely on known heteroskedastic regimes [
3] or parametric specifications for the volatility process [
4,
5,
6], our approach allows for a nonparametric volatility process subject only to mild smoothness conditions. We derive the asymptotic distribution of the estimator and discuss inference procedures that account for generated regressors and time-varying second moments. In contrast to the standard generalized method of moments (GMM), our framework allows for consistent estimation and testing under weak instruments. A test for endogeneity is also developed, which is applicable even without valid instruments.
We apply the proposed method to estimate the elasticity of intertemporal substitution (EIS), a central parameter in macroeconomics and asset pricing. The EIS governs the trade-off between current and future consumption and plays a critical role in determining asset prices. The empirical literature has found mixed results for the value of EIS. While [
7] finds small values for the EIS, high values for EIS are required by models such as the long-run risk model of [
8], which has been successful in explaining the equity premium and other asset pricing puzzles. As pointed out by [
9,
10], weak instruments may explain the divergence in the empirical literature. Motivated by the well-documented time-varying volatility in financial returns (e.g., [
11]), we apply our proposed method to estimate the EIS using quarterly aggregate stock return data from eleven developed countries. We find that the confidence intervals obtained under our approach are much tighter than those derived from weak-instrument robust methods and broadly consistent with the literature.
This paper contributes to the literature on identification through heteroskedasticity by showing that smooth nonparametric volatility dynamics can serve as a source of identification when conventional instruments fail. It also contributes to the empirical macro-finance literature by providing new estimates of the EIS based on a control function approach that does not rely on instrument strength. The rest of the paper is organized as follows.
Section 2 presents the model specification and the identification conditions.
Section 3 discusses the estimation and inference under the proposed framework.
Section 4 applies the method to the estimation of EIS.
Section 5 concludes.
2. Model Specification and Identification
We consider the following structural model with endogenous regressors,
where
is the scalar dependent variable, observed over
.
are the endogenous regressors, and
are instruments observed at lag
. This specification allows for other strictly exogenous variables to be partialled out, following the approach in [
12]. Our primary goal is to identify
, with
compact.
We define the
-field
generated by the history of observables
, and introduce the following definitions:
Assumption 1. (Mixing and Moment Conditions):
- 1.
The process and for are strong mixing (α-mixing) martingale difference sequences with respect to , with unit conditional variance.
- 2.
There exist , , and , such that and , for .
Assumption 1 assumes that both and have finite fourth moments. By this assumption and Lyapunov’s inequality, and exist for all , as do all expectations involving up to any four combinations of and , for . Note that by construction, .
To correct for endogeneity, we follow the control function approach. Conditional on
, we project the structural error term
on the reduced-form error term,
Substituting (3) into (1), we obtain the following transformed model:
The transformed error term plays a central role. The following lemma characterizes its orthogonality properties:
Lemma 1. Under Assumption 1, we can show that The proof of Lemma 1 is in
Appendix A. Lemma 1 shows that
is a martingale difference sequence and orthogonal to
,
, and
. Intuitively,
is orthogonal to
by the projection in (3). Since
is a transformation of
, and
is from the instruments and
, the orthogonality naturally extends to
and
. This orthogonality allows (4) to be used for consistent estimation, provided the model is identified.
However, when instruments are weak, the model in (4) is not always identifiable. We now formalize the identification strategy in this case.
Identification Strategy
When the instruments in (
2) are weak,
as
, and the regressors
, causing the control function term
and
to become collinear. This undermines identification in (4). We formalize this situation with the following assumption:
Assumption 2. - 1.
Orthogonality: .
- 2.
Finite second moments: .
- 3.
Local-to-zero reduced-form coefficients: , where ,
Assumption 2(1) assumes that the instruments satisfy the conventional orthogonality condition. Assumption 2(2) states that the instruments have a finite second moment for all
t. Both are standard in the literature. Assumption 2(3) captures a local-to-zero asymptotic framework, which is standard in the weak-instrument literature [
13]. It indicates that the instruments are increasingly uninformative as the sample size grows. In practice, this means that the predictive power of
for
is low, and
approximates the reduced-form error
. Applied researchers can assess this by checking first-stage F-statistics, small eigenvalues, or instability in 2SLS estimates. Modeling this weakness explicitly allows us to show how time-varying volatility can restore identification.
Under Assumption 2, . When volatility is constant over time, , both regressors in (4) become asymptotically collinear. In other words, the moment conditions derived from (4) collapse into a system of only p linearly independent equations for parameters. Identification fails due to collinearity.
To overcome this, we allow volatility to vary smoothly with the following assumption:
Assumption A3. - 1.
where , are non-stochastic, measurable, uniformly bounded on the interval , and satisfy Lipschitz condition, for all . , for all . - 2.
is not constant and nonsingular over t.
- 3.
where are constant for all t, .
When volatility varies smoothly over time, the standardization
introduces time-varying heterogeneity that breaks the collinearity between
and
. This restores full rank in the moment conditions implied by (4), allowing point identification of
. The time-varying volatility structure assumed in Assumption 3 is consistent with a wide range of economic environments where conditional second moments evolve smoothly over time. In macro-finance, stochastic volatility is a well-documented feature of asset returns (e.g., [
14,
15]). For instance, persistent changes in macroeconomic uncertainty or shifting investor sentiment can induce gradual fluctuations in return volatility. Our assumption accommodates such dynamics in a nonparametric form, allowing identification to be driven by economically plausible second-moment variation without requiring a specific structural model of volatility.
3. Estimation and Inference
Under Assumptions 1–3, the structural model in (4) takes the form
where
is a martingale difference sequence orthogonal to
and
, as established in Lemma 1.
Let
, the population moment conditions are
Because the number of moment conditions equals the number of parameters, the system is just-identified. The optimal GMM estimator reduces to OLS, and no weighting matrix is required. In this case, the moment conditions do not benefit from reweighting, and the weighting matrix is effectively the identity.
If the values of
and
were known, the infeasible estimator could be written as
Theorem 1. Under Assumptions 1–3, and assuming and are known, the estimator in (6) satisfieswhere The proof of Theorem 1 is given in
Appendix A. Theorem 1 shows that the infeasible estimators are
consistent and asymptotically normally distributed when the true value of
and
are known. It also demonstrates the problem of weak instruments in the absence of time-varying variance. In particular, when
,
in Theorem 1 becomes
which is a singular matrix. Thus, the asymptotic variance–covariance matrix cannot be computed.
The estimators in Theorem 1 are infeasible in practice, as the true value of and are unknown. We propose a feasible estimator in the following subsection.
3.1. Feasible Estimation Procedure
In practice, we construct a feasible estimator by estimating
and
. Let
be the first stage OLS residuals from estimating reduced-form Equation (
2). We propose to use the generalized kernel proposed by [
16] to estimate the time-varying volatility.
Let
denote a bandwidth and let
denote a univariate generalized kernel function with the properties
if
or
; for all
,
We call a univariate generalized kernel function of order r.
The following example is taken from [
16]. Define
where
denotes the space of Lipschitz continuous functions on
. Define
and
as follows:
- (i)
The support of is and the support of is .
- (ii)
and . We note that . Now let
We can show that is a generalized kernel function of order r.
Assume the bandwidth parameter
satisfies
. The estimator
can be expressed as
where
Following [
16,
17], we can have the following convergence results under the above generalized kernel estimator,
A feasible estimator can be obtained by the following three-step approach.
Step 1: Estimate (1) by OLS, obtain a consistent estimator of , .
Step 2: Apply the generalized kernel estimator to estimate the time-varying variance–covariance matrix
, and calculate
as
. To estimate the time-varying variance–covariance matrix, we use a fourth-order Epanechnikov kernel for improved boundary performance and reduced bias, as recommended in [
16]. The bandwidths
were selected using leave-one-out cross-validation.
Step 3: Replace in (5) with and estimate the new model by OLS.
Follow Lemma 5.1 in [
18], the feasible approach can consistently estimate
and
. To make correct inference on
, however, we need to account for the generated regressors problem due to the estimation of
and
. The following Corollary 1 provides the asymptotic distribution of the feasible estimators.
Corollary 1. The feasible estimators have the following asymptotic distributionwhere Following [18,19], the exact form of includes adjustment terms involving the Jacobians of with respect to and , . 3.2. Testing Endogeneity Without Instruments
Theorem 1 also provides a useful result for testing endogeneity. Given the specification in (5),
; thus, when there exists no endogeneity,
. We can propose an extended version of the Hausman–Wu test [
20,
21] without valid instrument variables.
Corollary 2. Under the same assumptions in Theorem 1, a test for endogeneity can be established aswhere the test statistics , is the bottom right block of the in Theorem 1. It is worth noting that the proposed test in Corollary 2 does not suffer from the generated regressors problem. This is because when , (1) can be directly estimated by OLS and thus no extra uncertainty is introduced.
3.3. Inference and Robustness
The feasible estimator is
-consistent and asymptotically normal. Since the model is just-identified, no GMM weighting matrix is required, and the estimator is semiparametrically efficient under the maintained assumptions. The use of generalized kernels ensures uniform convergence of the volatility estimates, even near boundaries. As discussed in [
22,
23,
24], smooth time-varying volatility satisfies the regularity conditions necessary for applying central limit theorems in heteroskedastic environments. This justifies the use of Wald-type inference.
Unlike conventional IV-GMM estimators, which are sensitive to weak instruments, our approach remains robust due to identification through time-varying volatility. The asymptotic distribution of our estimator is derived directly from moment conditions that remain informative even when the instruments are weak. As such, Wald-type inference remains valid under our framework, as long as the volatility process satisfies smoothness and regularity conditions. This distinction is critical in applications where traditional identification strategies are compromised.
4. Elasticity of Intertemporal Substitution: Consumption CAPM
The EIS is a central parameter in macroeconomics and asset pricing. It governs the intertemporal allocation of consumption and plays a crucial role in determining equilibrium asset returns. In recursive utility models, such as Epstein–Zin [
25,
26], the EIS appears as a structural determinant of households’ willingness to substitute consumption over time in response to changes in the real return rate.
Empirically, the estimation of the EIS has produced mixed results. Using asset return data, studies such as [
7] find small values of the EIS, while the long-run risk model in [
8] requires a high EIS to match observed risk premia. This controversy has been partly attributed to the weakness of conventional instruments used to address endogeneity in return-predictability regressions (see [
9,
10]).
We apply the proposed control function approach to estimate the EIS using quarterly aggregate stock return data without valid instruments. This empirical setting is particularly well suited to the method for two reasons. First, the estimation of EIS involves a canonical predictive regression that is widely known to suffer from weak predictive power. Second, stock returns exhibit well-documented time-varying volatility, which is precisely the source of identification exploited by our framework. Thus, the EIS application offers both policy relevance and methodological transparency.
Following standard consumption-based asset pricing theory, we start from the log-linearized Euler equation implied by the Epstein–Zin utility specification:
where
is log consumption growth,
is the log return on asset
i,
is the EIS, and
is a term that depends on the conditional variances and covariances of returns and consumption growth. We assume
to be constant over time to compare our results with [
10]. Empirically, EIS could be time-varying; we leave this for future research. In empirical work, expectations are replaced by realized values, and we get the following regression:
The variable represents the return on asset i. It may be correlated with the error term , making it endogenous in the regression. This correlation can arise for several reasons. First, both consumption growth and asset returns are influenced by common shocks to economic fundamentals. Second, forward-looking behavior by investors can cause returns to respond to information that also affects consumption decisions. As a result, estimating (10) using ordinary least squares would lead to biased and inconsistent estimates of the EIS.
To address this issue, researchers typically use instrumental variable methods. These instruments are constructed from lagged economic variables that are assumed to be correlated with returns but uncorrelated with the error term. Standard choices include past observations of interest rates, inflation, consumption growth, and the dividend–price ratio. However, as emphasized by [
7,
27], returns are difficult to predict in practice, and these instruments often have little explanatory power. This weak relationship between instruments and returns leads to unreliable estimates and very wide confidence intervals, which limit the usefulness of the results.
In line with the literature on weak instruments (e.g., [
13]), we examined the first-stage relationship by estimating the reduced-form return prediction:
where
is a set of instruments that consists of lagged values of nominal interest rates, inflation, consumption growth, and the log dividend–price ratio, each lagged twice to mitigate time aggregation bias, following [
28]. The data are quarterly and span various periods from 1947 to 1999, depending on the country. Stock returns are constructed from major stock market indices for eleven developed countries, and log consumption growth is calculated from real per capita consumption expenditures (for a full description of the data set, see [
7,
29]). The third and fourth columns in
Table 1 report corresponding F-statistics and partial
values for each country. These statistics confirm the weakness of the instruments, with F-statistics well below conventional thresholds and low partial
across the board. This supports the motivation for using a volatility-based identification strategy, as standard IV inference would likely suffer from low power and misleading coverage in such settings.
We estimate (10) using the proposed control function approach. The reduced-form residuals
are obtained from (11), and standardized using an estimated conditional variance matrix
constructed via the kernel estimator described in
Section 3. The standardized residuals
are then used as control functions in the second-stage regression,
To estimate the time-varying volatility of returns, we apply the generalized kernel estimator described in
Section 3.1. We use a fourth-order Epanechnikov kernel for improved boundary performance and reduced bias, as recommended in [
16]. While the generalized kernel is theoretically more appealing, we found that the empirical results are robust to alternative kernel choices, including the quartic and Gaussian kernels. The bandwidths
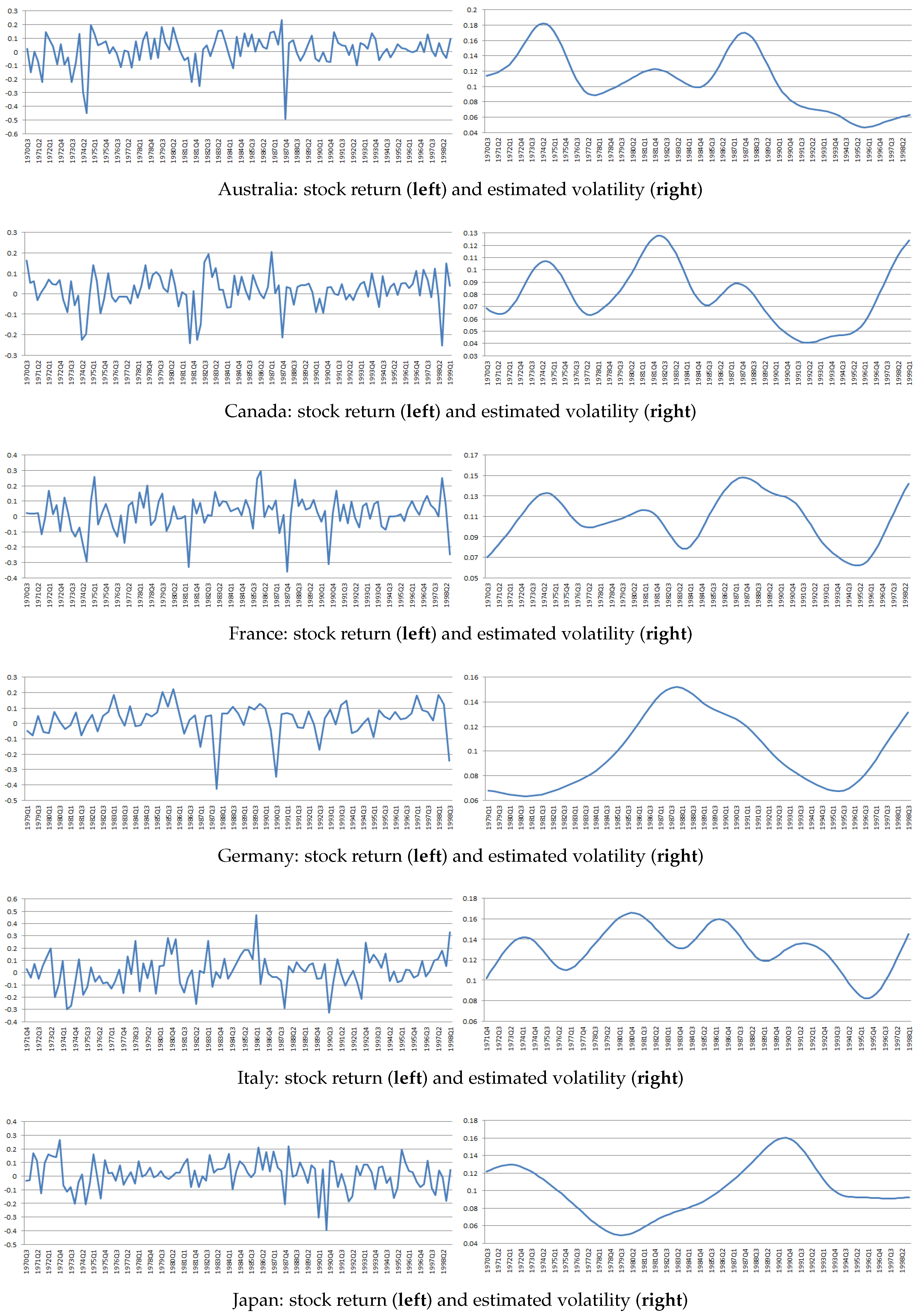
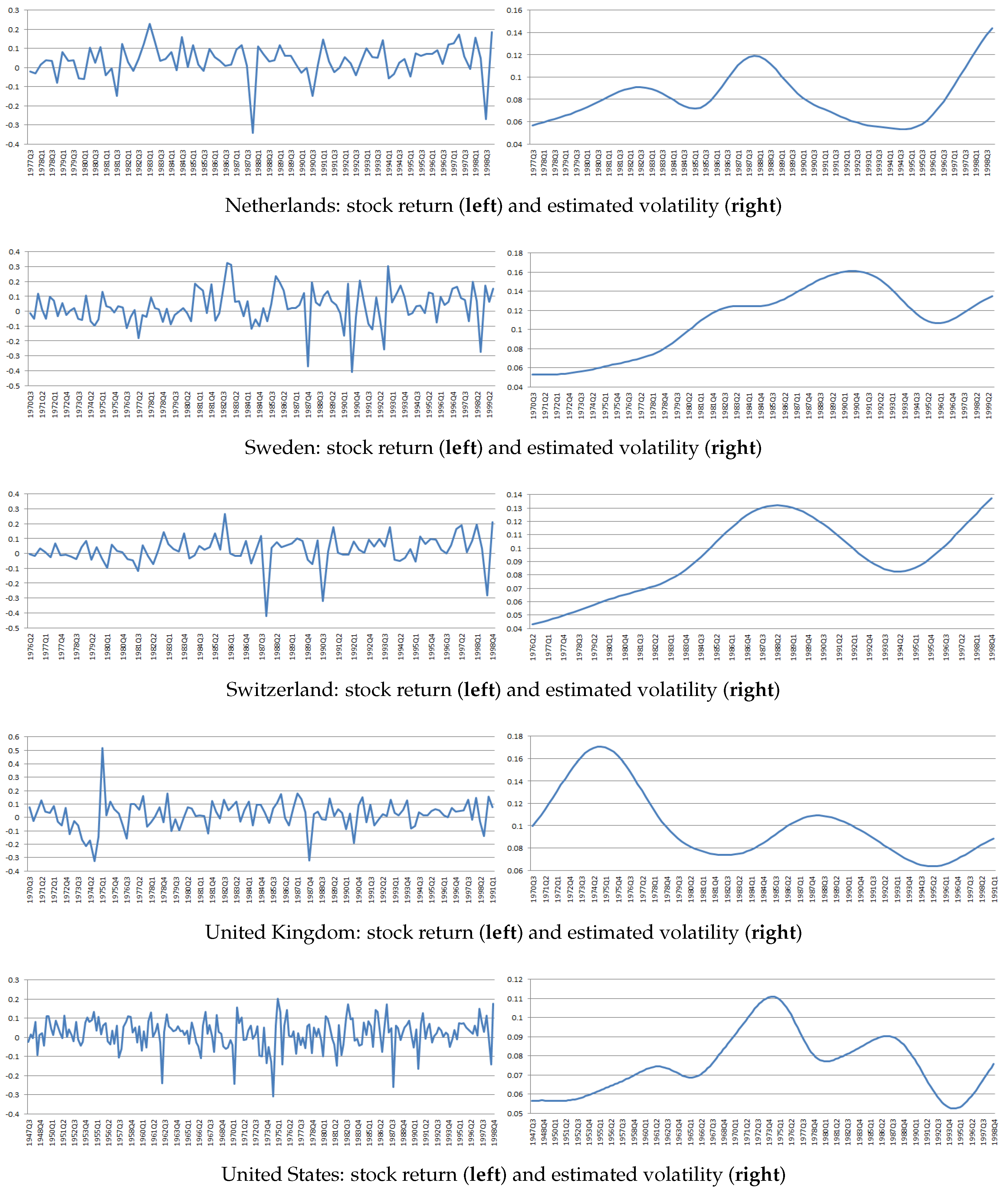
were selected using leave-one-out cross-validation using each country-specific sample. The volatilities of returns exhibit significant time variation across countries, as shown in
Figure 1 and
Figure 2. This provides empirical support for the identifying assumption of time-varying volatility. Furthermore, we calculate the correlation between between
and
to check whether the multicollinearity is avoided. The last column in
Table 1 reports the corresponding correlations between
and
for each country. The correlations are all substantially below unity, consistent with the theoretical argument that time-varying volatility restores identification.
Table 2 reports confidence intervals for the EIS estimated using our control function method and compares them to intervals derived from three commonly used weak-instrument robust tests: the Anderson–Rubin [
30], Kleibergen-LM [
31], and Conditional Likelihood Ratio [
32,
33], as reported in [
10]. In most cases, the confidence intervals obtained by three weak-instruments robust tests are extremely wide or unbounded, reflecting the limited power of conventional weak-IV methods. In contrast, our approach obtains narrower, informative intervals. The estimated EIS values are uniformly modest across countries, roughly in the −0.05 to 0.3 range, indicating a limited willingness of households to shift consumption over time. In economic terms, an EIS of this magnitude implies a strong preference for consumption smoothing. These findings are aligned with prior empirical findings that the EIS is typically low (e.g., [
7,
28]), standing in contrast to the much larger values (EIS well above 1) required by certain asset-pricing frameworks like long-run risk models [
8]. Moreover, our approach delivers considerably tighter confidence intervals than standard weak-IV methods, reflecting a substantial gain in identification power. The improved precision suggests that by exploiting time-varying volatility, we can estimate the EIS with much greater confidence. These results demonstrate the empirical relevance of the theoretical framework developed in earlier sections.
5. Concluding Remarks
This paper develops a feasible control function approach for identifying and estimating linear models with endogenous regressors without valid instruments. The method exploits time-varying volatility in the reduced-form errors as a source of identification, offering an alternative when conventional instrumental variable techniques are infeasible or unreliable.
The main contribution lies in demonstrating that conditional heteroskedasticity can restore identification even when valid instrumental variables are unavailable. By projecting the structural error term onto the reduced-form error terms and standardizing by the time-varying variance, the proposed estimator isolates exogenous variation that would otherwise be obscured by collinearity. Unlike approaches that rely on strong instruments, known heteroskedastic regimes [
3], or parametric volatility models [
4,
5,
6], our framework allows for smooth, nonparametric variation in second moments and does not require external exclusion restrictions.
We formally establish that the estimator is -consistent and asymptotically normal. Importantly, we show that the estimator remains valid under weak identification and heteroskedasticity, provided the volatility process satisfies mild regularity conditions. We also derive a test for endogeneity that does not require valid instruments, extending the logic of the Hausman–Wu test to settings where standard IV methods fail.
In an empirical application, we estimate the EIS using quarterly stock return and consumption data from eleven developed countries. The data exhibit substantial time variation in return volatility, consistent with the identifying assumptions. The proposed method produces confidence intervals that are narrower and more stable than those derived from conventional weak-instrument robust procedures, while remaining consistent with existing findings in the literature.
The results demonstrate both the empirical relevance and practical applicability of using heteroskedasticity as a source of identification. The approach provides a flexible alternative to instrument-based methods in settings where external instruments are weak, contested, or unavailable. More broadly, this framework suggests that structured time variation in second moments can offer credible identification strategies in a range of economic applications.



{kind=link}
{kind=link}