1. Introduction
In the 21st century, the internet has become an essential component in everyday life, including education, health, etc. One of the essential impacts of this is that the efficiency and optimisation of tasks can be realised through the use of the internet daily. As a result of this rapid increase in the use and adoption of the internet, the medical field has begun to use technology to aid in quicker and more efficient decision-making processes and procedures. As an example of this high usage of technology, approximately 375 million computed tomography (CT) scans are performed worldwide each year, with this number increasing by 3–4% annually [
1]. This global statistical figure represents the growing importance of CT scanning in modern healthcare diagnostics and treatment planning. CT scans are predominantly used for performing CT-based exams, including but not limited to evaluating cerebrovascular diseases, sinusitis, fractures, etc.; their advantages include speed and accuracy, as well as having the ability to diagnose many conditions [
2,
3]. This research paper presents a machine learning-based technique used for the detection of image artefacts, namely (1) the metal and (2) ring artefacts that are obtained from Toshiba medical equipment. Furthermore, this research paper’s objective is to present a comprehensive comparison of four different machine learning models, both symmetric and asymmetric, namely (1) CNN, (2) VGG16, (3) Inception_V3, and (4) the Resnet50 model, and evaluate the most effective and efficient model based on the results.
The remainder of this paper is set out as follows:
Section 2 discusses the research questions,
Section 3 presents the aims and objectives of this research paper, and
Section 4 presents the related work.
Section 5 presents the technical model development,
Section 6 presents the results and discussion, and the paper’s conclusion and contribution are elaborated in
Section 7.
2. Research Questions
A process that recognises artefacts without human intervention is worth investigating to help optimise processes and reduce diagnostic time. Hence, the following research question was set:
3. Aims and Objectives
This research paper aims to compare four different machine learning algorithms against each other and identify the most effective and efficient model based on artefact detection accuracy for the purpose of enabling quicker artefact detection without human intervention.
The objectives of the research design were the following:
The study aims to evaluate the best-performing model by comparing its accuracy and loss percentage with other models. While it is crucial to consider additional parameters for clinical applications, particularly in machine learning, this study focuses solely on accuracy and loss. These metrics were addressed and compared across four different models.
4. Background and Related Work
The development and use of automated technology in the medical field are increasing rapidly, hence the need to conduct this research, looking at both ring and metal artefact detection using Toshiba equipment. Huang et al. [
4] presented a residual learning approach based on a convolution neural network (CNN) to reduce metal artefacts in a cervical CT scan. This model framework is in line with this research model, the “CNN model”, which is compared against transfer learning models. Furthermore, magnetic resonant imaging (MRI) is used in conjunction with the CT scanners. In resonance, Zhong et al. [
5] proposed the method of self-attention ensemble lightweight CNN transfer learning by combining signal processing via continuous wavelet transform for fault diagnosis. Zhong et al.’s model did not experience any challenges, such as the need for dataset optimisation.
Additionally, Rathore et al. [
6] presented prognostic and diagnostic maintenance models utilising machine learning for identification and equipment inspection. However, these models do relate to the research paper’s objectives of automated artefact detection without human intervention. Eldib et al. [
7] proposed a corrective method for a cone beam CT by correcting the defective pixels which had values close to zero or were saturated in a projection domain. Subsequently, Salplachta et al. [
8] introduced a new ring artefact reduction procedure that combined several ideas from existing methods into one complex and robust approach. Carrizales et al. [
9] presented the U-net convolution neural network (CNN) model, which was used for artefact detection on more than 23,000 coronal slices extracted from 98 four-dimensional computed tomography (4DCTC) scans. The model performance evaluation was performed using receiver operating characteristics (ROCs) in comparison with manual identification. Carrizales et al.’s research paper thus produces conclusive results and is related to the impact that 4IR can play in advancing efficient artefact detection without human intervention. Sun [
10] investigates the artefacts found in a gastrointestinal disorder, with challenges such as assessing image quality with no reference display, while others are poorly interpretable. The researcher made use of a convolution neural network for the detection of these artefacts to quantitatively assess the quality of endoscopic images by enhancing the feature pyramid structure and incorporating channel attention mechanisms into the feature extraction. The researcher addresses a critical challenge of endoscopy; however, this research paper suggests that robust feature extraction was not required, as the images collected from the Toshiba equipment were visible enough for utilisation in all the optimised models that are currently under investigation. Upon investigating the convolution neural network’s application in such a study, it is imperative to conclusively investigate the impact of data transferred using the “transfer learning” approach against the existing results to determine the best-performing algorithm without any human intervention. In support of this research paper, Kanwal et al. [
11] presented a mixture of experts (MoE) scheme for detecting four artefacts, namely damaged tissue blur, folded tissue, air bubbles, and historically irrelevant blood from whole-slide images (WSIs) utilising deep convolution neural networks. This research paper is in line with the current research, with the primary focus of reducing human error in terms of artefact detection in the medical field.
Transfer learning is defined as a specific kind of machine learning where just a portion of the training data is utilised for producing another test dataset [
12]. Mostly aligned with the medical community, Kong et al. [
13] outlined the importance of utilising and developing automated techniques to assist in a bad lock due to the high number of demands experienced in the field, which justifies the need for this research study.
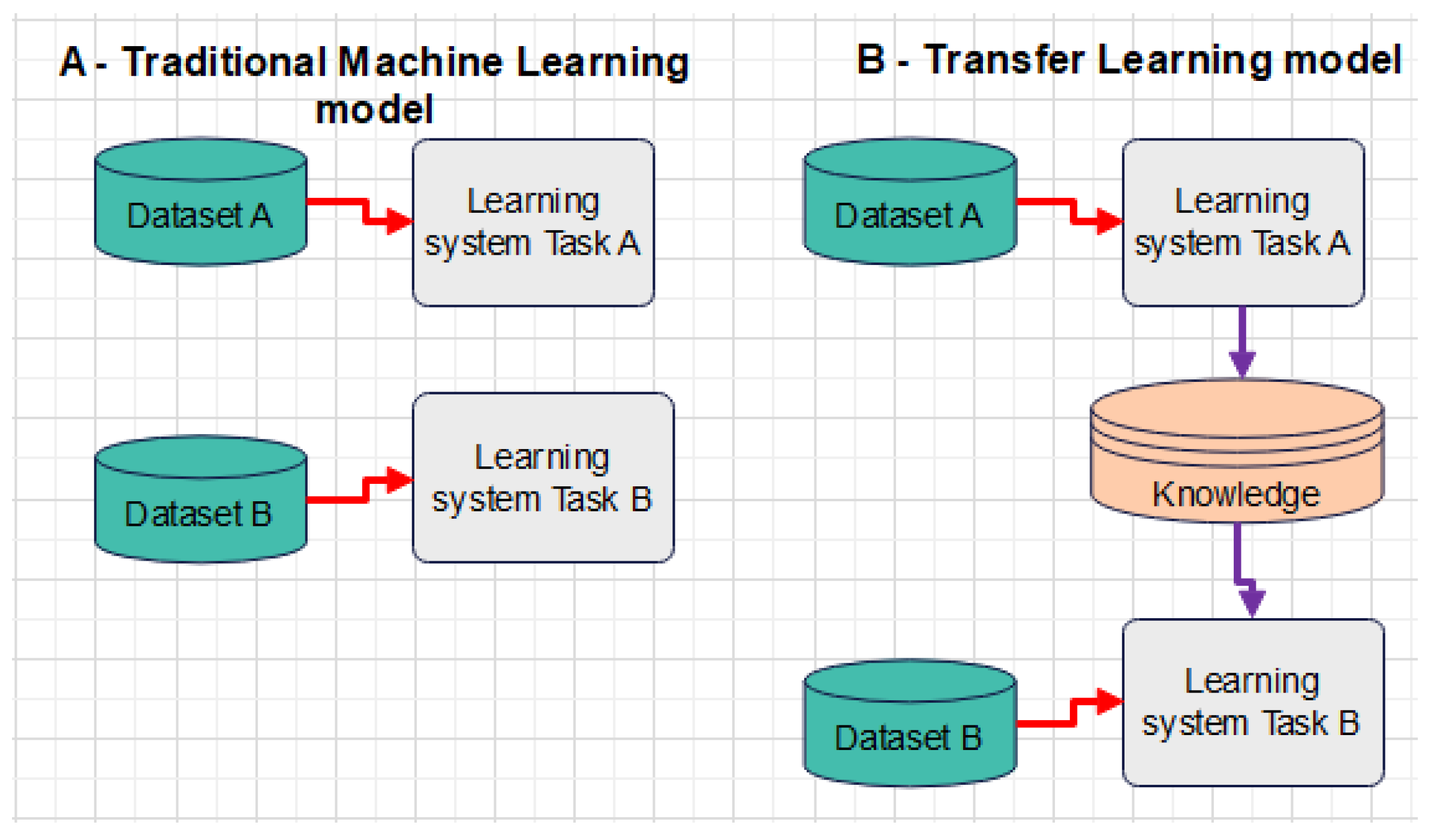
Figure 1 presents a distinct comparison made between a traditional ML model and transfer learning. As depicted in
Figure 1, traditional machine learning focuses only on the isolated task without any knowledge or information retention, while transfer learning relies on variables from completed machine learning tasks, such as features, labels, etc., which enable further data training.
Additionally, Grobe Hokamp et al. [
15,
16] made use of corrected image noise parameters by subtracting the standard deviation in areas with the presence of artefacts. Hokamp et al.’s study does not quantify the methodology and reason for the selection and identification of artefacts, which implies that noise is the only contributing factor. Mangold et al. [
17] proposed carrying out artefact quantification within the frequency domain. However, the presented literature demonstrates the need for automation in artefact detection but with differences in parameter settings. The presentation of the strengths and weaknesses of MAR methods is critical, i.e., commercial MAR methods are used routinely in clinics despite their weakness of achieving incomplete removal of artefacts with HU errors, while research-based traditional MAR algorithms do not require sinogram data but their weakness is their long processing time. In addition, Madesta et al. [
18] applied a deep learning detection simulation for respiration-related patient motion artefacts utilising a 3D patch-based approach for subsequent correction of artefacts. Madesta’s study looks at artefact correction, which is not in line with the current research that focuses on the use of machine learning to detect artefacts and compare effectiveness amongst different algorithms.
5. Methodological System Technical Development
The technical system development for this research paper is based on CNN implementation as the primary test algorithm. This section further presents the algorithm modelling techniques, including data acquisition and the implementation of transfer learning.
5.1. Algorithm Modelling Technique
This research paper makes use of convolutional neural networks (CNNs). A CNN, in the context of this research paper, was designed for an image dataset that contains convolution layers that compare overlapping rectangular patches of the input to small learnable weight metrics called “kernels/filters” that encode features, as depicted in
Figure 2.
Figure 2 depicts the convolution network. In the context of the convolution in this research paper, the input dataset for both artefacts is placed in the convolution model for feature extraction. This occurs after the model has been trained with 88 input image datasets. Upon completing this task, the results are transferred to the prediction model, 0, and the system automatically produces the output results. The full convolution network comprises the input dataset (metal and/or ring artefact). The CNN architecture in the context of this research paper is based on the application of the convolution model on the input dataset. The convolution structure, as presented in
Figure 2, comprises the input dataset that is transformed and passed to the feature extraction layer. In this layer, features such as edges, texture, and colour are detected. However, the input matrix dimension utilised in this algorithm is a 3 × 3 matrix that is applied to the image dataset.
In the convolution algorithm, stride is applied in the input dataset as follows: When the stride is 1, the filter is moved one pixel at a time. When the stride is 2, the filter is moved two pixels at a time, and so on. However, in the context of this algorithm, larger filter sizes and strides were used to reduce the size of a large image to a moderate size based on the 3 × 3 image dataset matrix. However, it is critical to note the steps described below before a CNN model can be constructed as follows. The process below depicts the process conducted in this research study and not the generic application of the CNN algorithm:
Commence the model filtering by utilising lower filter values such as 32 and begin to increase them layer-wise.
Construct the model with a layer of Conv2D.
Apply MaxPooling.
Use kernel_size based on an odd number, i.e., 3 × 3 matrix, as per the above algorithm.
Use the rely activation function.
Input shape image width and height, with a final dimension, such as colour channel.
Flatten the input after the CNN layers and add ANN layers.
Use the softmax activation function.
The modelling in
Figure 2 is based on a two-step approach: (1) mirror padding operation and (2) use of the softmax function. The softmax function is used to find the maximum parameters in the connected layer.
5.2. System Modelling and Data Acquisition Process
From the different image datasets, a model was created where the system was trained and tested as per the algorithm setup. The initial process flow was to collect and prepare data. Images of the different artefacts were taken and placed into a folder, and the folder was labelled per artefact, i.e., ring/metal artefact. The model algorithm was created based on the convolution model, and the input datasets were trained. The model training took 50 iterations, and after the iterations, the model was tested, and the output evaluation and the system resilience and accuracy were also tested. The system was trained and tested against a set of reconstructed image datasets and solutions. The system was trained with 50 iterations using machine learning techniques. Upon the completion of the iterations, the system was tested and evaluated against the unknown data. The system model was evaluated based on the
Figure 3 design model on the unknown data, and these data were then used to determine the artefact type and possible solution(s). The image size used was 512 × 512 pixels per image, with the image dataset only focusing on metal and ring artefacts, as outlined in
Figure 3a,b.
Figure 4 presents the model design approach, where image datasets are created. This image dataset comprises raw data in which no filtering has been applied apart from enhancing the image brightness. The enhancement is performed to allow for a machine vision application for artefact detection without any system optimisation.
Figure 4 further presents the input dataset that is applied to the model in the convolution layer. Upon the successful application of the convolutions, the process is highlighted at the activation and Pooling2D layers. Additionally, the features are also applied in the convolution layer and the layer is flattened and placed in dense mode; as a result, the modelling is achievable.
5.3. Data Modelling and Data Transfer Learning
Data modelling is a critical part of a dataset as the data must be captured, compiled, and stored in a dataset. In the previous subsections, data modelling has been completed and simulated. However, it is imperative to incorporate data transfer learning in such a research paper to have conclusive results.
Figure 5 depicts the sequential model approach for data transfer learning.
Data transfer learning in this research paper was carried out by applying the process model outlined in
Figure 5. The actual processed dataset from the initial captured and processed dataset was loaded into the data transfer model. The dataset upload was conducted as follows:
Two test datasets were placed in two different directories, namely (1) a training dataset and (2) a testing dataset, to enable a distinction between the trained dataset and the test dataset. The dataset was split into two different folder structures, as indicated in
Figure 6.
The data from the dataset were split into two datasets, both with ring and metal artefacts. In splitting the datasets, the image data generator automatically labels all the data inside the ring folder as “ring folder” and the data in the metal folder as “metal folder”. This allows the data to pass easily into the neural network, utilising the following code snippet below:
img_width,img_height = 512,512
train_data_dir = ‘Dataset/train’
validation_data_dir = ‘Dataset*/test’
nb_train_samples = 88
nb_validation_samples = 38
epochs = 25
batch_size = 4
Furthermore, data optimisers were also introduced in this research paper to improve the decision-making processes and resource allocation while minimising the loss function, utilising the following code snippet:
expand_nested = True,rankdir(‘TB’)
print(model.summary())
from keras.optimizers import SGD
opt = SGD(lr = 0.001,momentum = 0.9)
The model summary presents the Tensorflow
TM output based on the model construction. The model construction correlates with
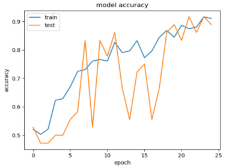
Figure 6 following the simulation. The selection of the epochs is not fixed at 25 epochs but more epochs are not required due to the dataset size of 21.1 MB per dataset. The addition of the sequence test epochs, involving 25, 30, and 35 epoch tests, was to determine the best performance without overfitting.
6. Results
6.1. Comparative Result Output
The reuse of dataset results within this research paper has been very impactful towards the conclusion of the results. The results outlined depict the image classification utilising data transfer learning. The reason for image classification is to resolve the pressing issues of identification and recognition accuracy. As a result, data transfer learning was used to evaluate the accuracy of the results against the initial linear regression results. The VGG16 model comprises 25, 30, 35, and 40 epoch tests.
Based on the convolution parameters outlined,
Table 1 depicts the data transfer results. The results presented outline the accuracy and data loss from the initial model that is now used in the data transfer. The test epoch correlates with the initial model’s tested epochs to balance the evaluation criteria and results.
The results from
Table 1 demonstrate the research findings as follows: Firstly, the 2 sets of image datasets commence from 88 input datasets to 170, with 25 epochs up to 40 epochs, respectively, for both the trained model and the testing model. The results demonstrate that the more images contained in the dataset, the higher the accuracy. However, the resilience of the algorithm is critical. For example, for 88-image datasets at 40 epochs, the model accuracy is high with the threshold of a successful model at 75%, but the model losses are more than 40%. Furthermore,
Table 2 presents the comparison between the VGG16 and the research model.
Table 2 demonstrates a comparison of losses and accuracy between the research and VGG16 model. Based on the data provided, the VGG16 experienced a loss lower than 20% both on the trained and testing data, compared to the 18 and 25% achieved by the research model. This is due to the stability of the model, as VGG16 is a secondary model. Additionally, VGG16 further demonstrates stability, achieving 94 and 90%, while the research model demonstrates 92 and 91% accuracy.
6.2. Comparative Transfer Learning Results Output
Two additional models were further added, as indicated in
Table 3.
Table 3 demonstrates that the VGG16 model performs better than the three models on the training data, while the inception_V3 performs better in terms of the test model accuracy. Furthermore, ResNet50 experiences a high number of losses on the trained data compared to the other three models. Additionally, the ResNet50 model has shown a lower level of data loss in the test data, as presented in
Table 3.
7. Discussion/Conclusions
The purpose of using the image dataset was to evaluate the contribution of the image dataset size against the results, both for the initial model and the data transfer model. In this model, the results were evaluated based on accuracy and losses. The losses were evaluated independently of the overall model operation. The results demonstrate that the algorithm’s robustness does not depend entirely on the image number and size but is inclusive of the test image brightness. In this research paper, factors such as noise and F1-score were not part of the research scope. The CNN model demonstrates high accuracy in terms of detection and differentiation of the different artefacts (ring and metal). This paper thus presents the results obtained from the data transfer learning model. The test results demonstrate higher data losses than the CNN model. This is due to data reuse, parameter count, dataset size, and model stability, which affect the model feature output. However, this does not affect the model detection and differentiation accuracy; hence, the model passed the set 75% threshold.
Additionally, two more models were evaluated, namely the Inception_v3 and ResNet50, and compared against the research model and the VGG16 model. It can be seen that VGG16 performs better in terms of accuracy on both the testing and training data, while ResNet50 performs poorly in terms of loss compared to the other three models.
8. Future Studies
The proposed study has limitations in that the investigated dataset was collected from a single set of equipment (Toshiba equipment) and only two sets of image datasets (ring and metal artefacts) were investigated. The research paper did not take into account several factors, including noise, F1-score, precision, and training dynamics, when considering the results. This was due to the fact that the study primarily aimed to identify the most effective algorithm that can be used for either ring or metal detection within a medical setup for quick diagnosis purposes with less human error.
Therefore, in pursuit of this aim, other factors will be incorporated to address other clinical applications that were not covered in this research paper.
Author Contributions
Conceptualization, J.B.; Software, J.B. and L.L.; Validation, J.B., T.K., B.K. and L.L.; Writing—original draft, J.B.; Writing—review & editing, T.K.; Supervision, B.K.; Project administration, B.K.; Funding acquisition, B.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Central University of Technology, Free State.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this article:
| RSA | Rivest–Shamir–Adleman |
| DSA | Digital Signature Algorithm |
| AES | Advanced Encryption Standard |
| IDS | Iterative Deepening Search |
| DES | Data Encryption Standard |
| RMS | Root Mean Squared |
| E2EE | End-to-End Encryption |
| ML | Machine Learning |
| IDS | Intrusion Detection System |
References
- Fernandez, M. Frost & Sullivan. 2 September 2021. [Online]. Available online: https://www.frost.com/news/press-releases/high-end-global-computed-tomography-purchases-to-propel-the-high-end-ct-segment-revenue/ (accessed on 12 November 2024).
- Ginat, D.; Gupta, R. Advances in Computer Tomography Imaging Technology. Annu. Rev. Biomed. Eng. 2014, 16, 431–453. [Google Scholar] [CrossRef] [PubMed]
- De Gonzalez, B.; Mahesh, M.; Kim, K.; Bhargavan, M.; Lewis, R. Projected cancerrisks from computed tomographic scans performed in the United States in 2007. Arch. Intern. Med. 2009, 169, 2071–2077. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Wang, J.; Tang, F.; Zhong, T.; Zhang, Y. Metal artefact reduction on cervical ct images by deep residual learning. Biomed. Eng. 2018, 17, 175. [Google Scholar]
- Zhong, H.; Lv, Y.; Yuan, R.; Yang, D. Bearing fault diagnosis using transfer learning and self-attention ensemble lightweight convolutional neural network. Neurocomputing 2022, 501, 765–777. [Google Scholar] [CrossRef]
- Rathore, S.; Mishra, S.; Paswan, M.; Sanjay, K. An overview of diagnostics and prognostics of rotating machines for timely maintenance intervention. IOP Conf. Ser. Mater. Sci. Eng. 2019, 691, 012054. [Google Scholar] [CrossRef]
- Eldib, M.; Hegazy, M.; Mun, Y.; Hye, M.; Cho, M.; Lee, S. A Ring Artifact Correction Method: Validation by Micro-CT Imaging with Flat-Panel Detectors and a 2D Photon-Counting Detector. Sensors 2017, 17, 269. [Google Scholar] [CrossRef] [PubMed]
- Salplachta, J.; Zikmund, T.; Zemek, M.; Brinek, A.; Takeda, Y.; Omote, K.; Kaiser, J. Complete Ring Artifacts Reduction Procedure for Lab-Based X-ray Nano CT System. Sensors 2021, 21, 238. [Google Scholar] [CrossRef] [PubMed]
- Carrizales, J.; Flakus, M.; Fairbourn, D.; Shao, W.; Gerard, S.; Bayouth, J.; Christensen, G.; Reinhardt, J. 4DCT image artifact detection using deep learning. Med. Phys. 2024, 52, 1096–1107. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Li, P.; Liang, Y.; Feng, Y.; Zhao, L. Detection of Image Artifacts Using Improved Cascade Region-Based CNN for Quality Assessment of Endoscopic Images. Bioengineering 2023, 10, 1288. [Google Scholar] [CrossRef] [PubMed]
- Kanwal, N.; Khoraminia, F.; Kiraz, U.; Mosquera-Zamudio, A.; Monteagudo, C.; Janssen, E.; Zuiverloon, T.; Rong, C.; Engan, K. Equipping computational pathology systems with artifact processing pipelines: A showcase for computation and performance trade-offs. BMC Med. Inform. Decis. Mak. 2024, 24, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Barwary, M.; Abdulazeez, M. Impact of deep learning on transfer learning: A review. Int. J. Sci. Bus. 2021, 5, 201–214. [Google Scholar]
- Kong, L.; Li, C.; Zhang, F.; Feng, Y.; Li, Z.; Luo, B. Leveraging multiple features for document sentiment classification. Inf. Sci. 2020, 518, 39–55. [Google Scholar] [CrossRef]
- Sarkar, D. A Comprehensive Hands-On Guide to Transfer Learning with Real-World Applications in Deep Learning. [Online]. 2018. Available online: https://towardsdatascience.com/a-comprehensive-hands-on-guide-to-transfer-learning-with-real-world-applications-in-deep-learning-212bf3b2f27a (accessed on 20 February 2024).
- Hokamp, G.; Neuhaus, V.; Abdullayev, N.; Laukamp, K.; Lennartz, S.; Mpotsaris, A.; Borggrefe, J. Reduction of artifacts caused by orthopedic hardware in the spine in spectral detector CT examinations using virtualmonoenergetic image reconstructions and metal-artifact reduction algorithms. Skelet. Radiol. 2018, 47, 195–201. [Google Scholar] [CrossRef] [PubMed]
- Laukamp, K.; Zopfs, D.; Lennartz, S.; Pennig, L.; Maintz, D.; Borggrefe, J.; Hokamp, G. Metal artifacts in patients with large dental implants and bridges: combination of metal artifact reduction algorithms and virtual monoenergetic images provides an approach to handle even strongest artifacts. Eur. Radiol. 2019, 29, 4228–4238. [Google Scholar] [CrossRef] [PubMed]
- Mangold, S.; Gatidis, S.; Luz, O.; König, B.; Schabel, C.; Bongers, M.; Flohr, T.; Claussen, C.; Thomas, C. Single-source dual-energy computed tomography: Use of monoenergetic extrapolation for a reduction of metal artefacts. Investig. Radiol. 2014, 49, 788–793. [Google Scholar] [CrossRef] [PubMed]
- Madesta, F.; Sentker, T.; Gauer, T.; Werner, R. Deep learning-based conditional inpaiting for restoration of artefact-affected 4D CT images. Med. Phys. 2023, 51, 3437–3454. [Google Scholar] [CrossRef] [PubMed]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}