We start with the construction of two scores to quantify the anomaly extent of a group’s low-density and high-density regions.
4.1.1. PPM of Exceedances
In this section, we propose a PPM framework that models the spatial configuration of exceedances with respect to a decision boundary in its full generality. We then derive an asymptotic distribution, valid as , which is used as an approximation to model the aggregate of exceedances.
Let
be a
d-dimensional random variable, with no distributional assumptions imposed on
. Consider a training set of normal groups (
), where each group (
) has a varying size (
), with
. The objective is to comprehensively quantify the unusual behavior of a group with respect to low-density regions, which entails characterizing the aggregate behavior of exceedances, as determined by a certain number of exceedances, and their various locations within low-density regions. The aggregate of exceedances within group
is given by
for large values of
. The low-density regions are defined by the decision boundary (
, where
is the threshold in the peak over threshold model introduced in Theorem 2).
As previously described, this study begins by analyzing the distribution of points across all training groups, which describes the probability space of
d-dimensional variable
. As our framework is not restricted to a particular density estimator, any suitable method could be adopted to estimate the probability density function (
). To illustrate this flexibility, We mention several representative alternatives, such as parametric models like Gaussian Mixture Models (GMMs), non-parametric approaches like Projection Pursuit Density Estimation (PPDE), and random projection-based techniques for high-dimensional data. In our experiments, we adopt
Kernel Density Estimation (KDE), a widely used non-parametric method that does not require prior assumptions about the data distribution. We explicitly clarify that KDE is used solely as an example and is not necessarily the optimal choice for all scenarios. Next, the transformation of
is applied, mapping the multivariate random variable (
) to the univariate random variable (
Y). Consequently, within each group (
), sample
is transformed into sample
within
as follows:
Therefore, the exceedances of
, whether they are extremely large (the right tail) or small (the left tail) values in the case of a univariate
X or occupy diverse locations within low-density regions in the case of a multivariate
, correspond solely to the left tail of
Y. As
Y is the probability density, it is bounded below by zero, which guarantees the existence of an extreme value distribution in its left tail. Moreover, Clifton et al. [
35] proved that the distribution of minima (
) can be approximated by a Weibull distribution. A Weibull distribution, with a lower bound at zero, describes the behavior of small values of densities near zero [
30]. To correct the skewness in the distribution of
Y near zero, a logarithmic transformation (
) is applied:
mapping the short tail of the Weibull distribution near zero to the right tail of a Gumbel distribution for maxima:
where
denotes a cumulative distribution within the Gumbel family. In this way, the multivariate, complex, low-density regions (
) are transformed into regions
on the real line. The significance of transforming
to
Z not only lies in mapping low-density regions from a high-dimensional space to the right tail in a one-dimensional space but also in making it possible to exploit the well-established theoretical results for the Gumbel case (
) in EVT. Within a group (
) of
n observations of
Z, we study those points that exceed the threshold (
) and consider them as an aggregate:
where
denotes the number of exceedances in
w.r.t.
. In what follows, we derive an analytical result to determine the asymptotic distribution of such aggregate of exceedances as
. Note that, although i.i.d. random variables are considered, the results can be applied to time series data by considering the residuals after fitting a time series model.
To tackle the above problem in its full generality,
is viewed as a realized non-empty point pattern of a PPM. First, the probabilistic model of individual exceedances is derived using the limiting property (
3) in Theorem 2 for
(i.e., the Gumbel case). As a result, for large
n, the likelihood of an exceedance
can be approximated by:
where
and
and
are defined in (
5). Second, the aggregating behavior of these exceedances is analyzed. The aggregate of exceedances with respect to low-density regions is fully characterized by the counting measure introduced in
Section 3.2. From
Section 3.1, it follows that
where
and
. These approximations motivate the definition of a probability measure, referred to as
the PPM of exceedances, with the following likelihood:
where
k denotes the observed size of
and
. In the theorem below, we prove that the distribution of the likelihoods (
) is asymptotically given by a random variable (
) of mixed type. Random variables of mixed type are neither discrete nor continuous but are a mixture of both [
36]. The discrete component results from the likelihoods (
) that describe cases when there are no exceedances in
. This corresponds to a discontinuity in the CDF that can be described using the Heaviside step function:
Theorem 4. Consider a random variable (Z) that satisfies the following limiting property:where , with , is determined by a sequence of thresholds in whichThe random variables () of likelihoods (), as defined in (9), converge in distribution to a random variable () with the CDF:where denotes the CDF of an Erlang distribution with shape parameter k and scale 1 and . In particular, it holds that Proof. First, we determine the distribution of
given the number of exceedances (
). We have
According to (
11), the rescaled exceedances (
) converge in distribution to an exponential random variable with a scale of
as
. Therefore, according to the continuous mapping theorem (stating that convergence is preserved by a continuous transformation [
29]), the sum of
k such independent exceedances converges to the distribution of a sum of
k exponential random variables with a scale of
. Thus, the limiting distribution of
, conditioned on
, is given by an Erlang distribution with shape parameter
k and rate parameter 1.
The cumulative distribution function of
can be found using the law of total probability:
The latter part is the limiting CDF of
, which we denote as
. Transforming back to the original distribution by means of
, one obtains the desired result for
:
□
As a brief summary, we propose the likelihood measure (
) to evaluate group samples. The likelihood measure of a group is constructed based on the pattern of its exceedances—taking into account both the individual locations of low-density regions and their aggregate behavior. The derived analytical form (
) describes the distribution of this likelihood measure and plays a central role in quantifying the group’s probabilistic anomaly extent. Notably, similar to the Central Limit Theorem, a key advantage of EVT—the foundation of our framework—is that, while the asymptotic theory requires large
n values, in practice, the method often performs well even for moderate values of
n. To validate the analytical expression in (
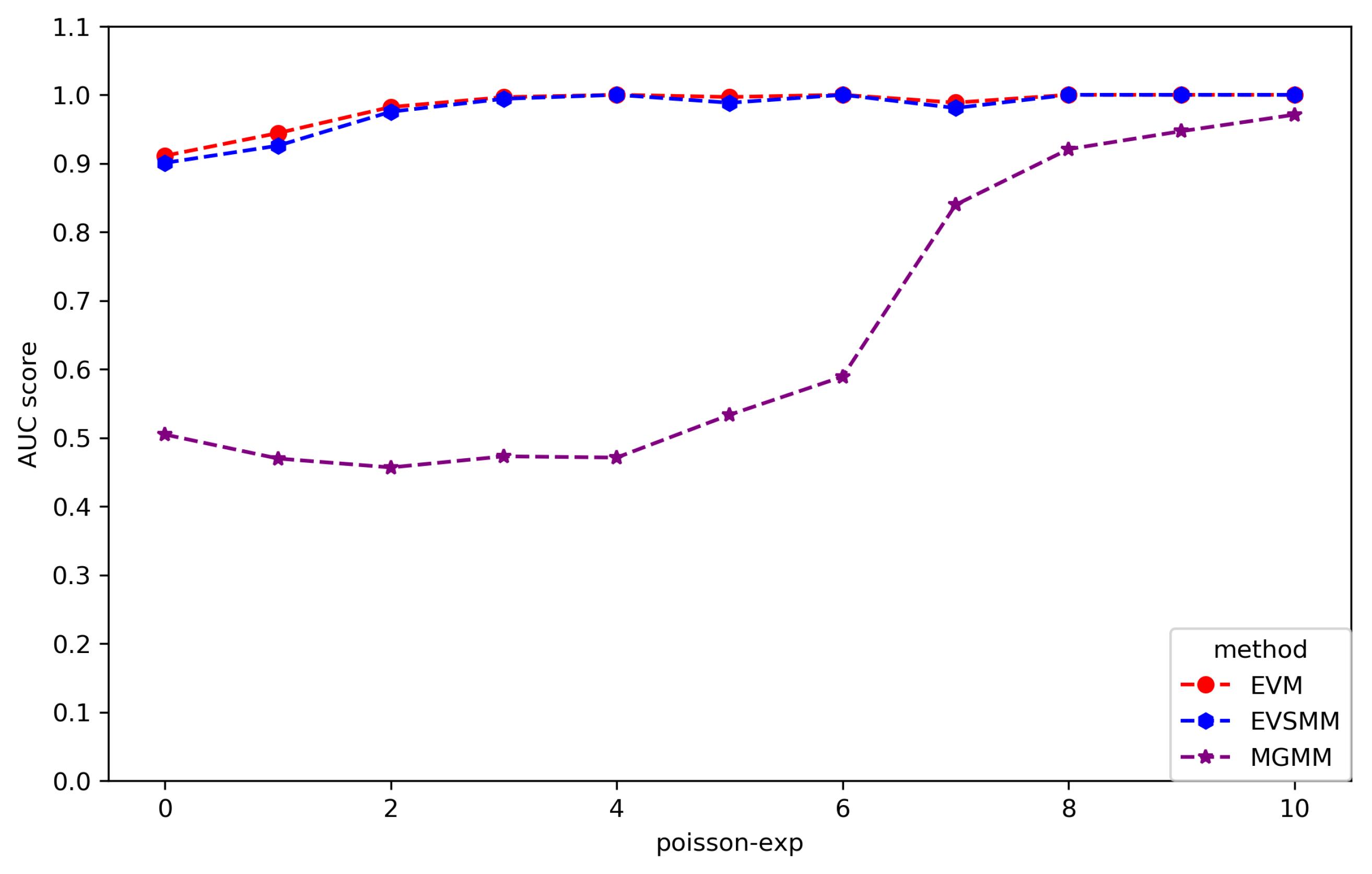
13), we conducted a simulation experiment. For this purpose, we generated 2000 groups from a one-dimensional standard Gaussian distribution (
), with each group size sampled from a Poisson distribution with a mean of 50. In practice, such group size selection entails a trade-off between bias and variance, as a small group size leads to an estimation bias, whereas a large group size results in an increased estimation variance. Next, the likelihood (
) is calculated for each group with respect to an aggregate of exceedances, and the CDF of the likelihood is examined. The empirical CDF of
is then compared with the asymptotic CDF given by (
13). As shown in
Figure 2, the empirical CDF approximates the analytical CDF quite well.
Based on the above analytical result, the first score is constructed using the expression of CDF
in (
13), which assesses the anomaly extent of a group (
) with respect to low-density regions. Addressing the multiple-hypothesis problem is critical, because as the number of points forming a group increases, the exceedances are expected to become more extreme, and their number is expected to grow. The proposed likelihood concept encompasses both the probability of each individual exceedance location and the probability of the size of the aggregate of exceedances within a group. Through the likelihood concept, all exceedances within a group are treated as a unified whole. Accordingly, the first score, termed the point-based group anomaly score, is defined as follows:
where
denotes the likelihood, as defined in (
9), of the aggregate of exceedances (
) with respect to the threshold (
). A high anomaly score (
) indicates that there is a small probability of observing a group with a lower likelihood of the aggregate of exceedances than
in any other group. We summarize the practical implementation of the model in Algorithm 1.
4.1.2. A Calibrated OCSMM Model
In this section, we construct the distribution-based group anomaly score by calibrating the OCSMM to quantify the anomaly extent of the group with respect to high-density regions. Basically, the OCSMM extends OCSVM by classifying groups (
) instead of individual points (
) [
37]. The core concept behind OCSMM involves applying the kernel trick to map the mean embeddings of training groups into a feature space, where they are separated from the origin by a hyperplane. For more details about OCSMM, we refer to
Appendix A.
| Algorithm 1 PPM of exceedances: point-based group anomaly score. |
Input: A set of normal groups ; a test group set ; the expected group size n; Output: The point-based anomaly score of the test group set .
- 1:
Select an appropriate density estimator to estimate based on all point samples from the normal groups in . Dimensionality reduction may optionally be applied prior to estimation, depending on the chosen estimator. - 2:
Apply the transformations and to all point samples (collected from the normal groups in ), yielding samples z of the variable Z. - 3:
Use the mean residual life plot based on the sample z to select a threshold for the variable Z. - 4:
Estimate the location parameter and scale parameter based on samples z using Equation ( 5), and compute the normalized threshold . - 5:
for each in the test group set do - 6:
Transform each point to , and obtain . - 7:
Extract the exceedances and compute the likelihood using Equation ( 9). - 8:
According to Theorem 4, compute the point-based anomaly score as . - 9:
end for - 10:
Obtain the point-based group anomaly scores for the test set as .
|
There are several key reasons for selecting OCSMM. First, it is specifically designed to capture the distribution characteristics within each normal group and demonstrates robustness to outliers in low-density regions, providing a stable and reliable representation of distribution information for the training group set with respect to high-density regions. This capability complements the model proposed in the previous section, which focuses on low-density regions. Second, OCSMM leverages the kernel trick, enabling efficient modeling of the decision boundaries for complex group structures. By using the mean kernel embeddings, OCSMM computes inner products in high-dimensional spaces without requiring explicit group feature transformations. Third, OCSMM is firmly grounded in statistical learning theory, kernel mean embedding theory, and optimization theory. Its formulation as a convex optimization problem, with clearly defined constraints, ensures that a unique global optimum can be reliably determined.
Although OCSMM provides a flexible and mathematically robust framework, its output is inherently binary, producing classifications without any probability estimates. While the decision function generates continuous scores, classification is determined solely by the sign of the output. These scores indicate relative distances from the decision boundary, but they do not provide a direct probabilistic interpretation.
As far as we are aware, there has been no prior research specifically focused on the probabilistic calibration of OCSMM. A critical challenge in this process is generating anomalous group samples, a necessary step for calibration due to the inherent scarcity of anomalous samples in both classical anomaly detection and group anomaly detection tasks. The following section details our calibration procedure, including the choice of the calibration method and the steps for generating anomalous groups.
We argue that, among various calibration methods, sigmoid fitting is particularly suitable for calibrating OCSMM. Unlike binning methods and isotonic regression, which often introduce discontinuities and risk overfitting, sigmoid fitting is specifically designed for binary classification problems and performs robustly on imbalanced data. In addition, sigmoid fitting offers flexibility and computational efficiency, which makes it advantageous for handling large datasets. Furthermore, sigmoid fitting assumes a monotonic relationship between decision scores and class probabilities, an assumption that aligns well with the behavior of OCSMM’s decision scores. Based on these considerations, sigmoid fitting was chosen as the calibration method.
The decision function of the OCSMM model trained on the training group set is denoted as
. Let
represent the calibrated score of a group (
) based on the output of
. Then, sigmoid fitting is performed as follows:
where
g and
q are parameters estimated by solving the following regularized, unconstrained optimization problem:
where
and
for
. The numbers of samples labeled as 1 (
) and
(
) are denoted by
and
, respectively. For calibration related to a pointwise classifier (e.g., SVM or OCSVM), Platt used the Levenberg–Marquardt (LM) algorithm to solve (
18) [
38]. Later, this was improved by Lin et al. [
39], who demonstrated that (
18) is a convex optimization problem and presented a more robust algorithm with proven theoretical convergence to solve it.
To calibrate the group classifier OCSMM, it is essential to generate anomalous groups rather than individual anomalous points. Inspired by previous work on anomalous points [
40,
41,
42], we adapted these ideas for groups. To generate anomalous points, the central assumption is that, spatially, all such points lie outside high-density regions. Building upon this assumption, previous studies have focused on constructing anomalous points for an optimal calibration, where a threshold on the density (
) is determined to classify a point as anomalous or not. However, anomalous groups cannot be generated by the same approach as anomalous points, as they exhibit more complex structural behavior. Unlike anomalous points, anomalous groups may not only deviate spatially from high-density regions but can also significantly overlap with normal groups. These simulated groups are specifically constructed to introduce mild deviations from normal patterns near the decision boundary, serving as informative references for the calibration of the OCSMM score. Based on the above analysis, we propose the following algorithm for the generation of anomalous groups.
Algorithm 2 starts by generating the group centers. A key difference between Algorithm 2 and the pointwise calibration methods discussed earlier is that the threshold, a hyperparameter used to define the boundary of high-density regions, is removed. This modification allows group centers to be located in both high-density and low-density regions. The next step focuses on ensuring that anomalous groups exhibit as much diversity in their distribution characteristics as possible. To achieve this, the covariance matrix is generated randomly under constraints derived from the covariance matrices of the normal groups in the training set. Then, a new anomalous group for the calibration is generated by sampling from a multivariate Gaussian distribution, using the group center as the location and the generated covariance matrix as the scale.
| Algorithm 2 Generation of a set of anomalous groups () for the calibration. |
Input: A set of normal groups ; the number of anomalous groups h; the expected size of each anomalous group; Output: A set of anomalous groups of size h.
- 1:
Compute the centers and covariance matrices of the normal groups in the training set. Compute the center of all the centers and the average Euclidean distance r from the centers to . - 2:
Generate a set of h points uniformly within a hypersphere with center and radius . - 3:
for each in B do - 4:
Identify the nearest normal group in , where the distance is computed as the minimal Euclidean distance between and the centers in . A symmetric covariance matrix is generated based on the covariance matrix of the nearest group. Each element is randomly sampled from a uniform distribution between 0 and the corresponding element of the nearest group’s covariance matrix. The resulting matrix is symmetrized by adding it to its transpose and dividing by two. - 5:
Use as the center and the covariance matrix to generate a group of points randomly from a multivariate Gaussian distribution, with the number of points drawn from a Poisson distribution with mean . - 6:
end for - 7:
Obtain a set of anomalous groups .
|
Algorithm 2 avoids generating extreme groups that would be too easily detected and eliminates the need for the intricate threshold determination step required in methods of generating anomalous points. This design provides a pragmatic approach to addressing the scarcity of labeled group anomalies and aims to improve probabilistic interpretability rather than explicitly simulating specific unknown anomalous behavior. After obtaining the anomalous groups, the sigmoid calibration technique is applied. We then define a distribution-based anomaly score as the calibrated OCSMM score (
) to quantify how anomalous the high-density region of a group is. The overall steps for obtaining the distribution-based anomaly score (
) using calibrated OCSMM are summarized in Algorithm 3.
| Algorithm 3 The calibrated OCSMM: distribution-based group anomaly score. |
Input: A set of normal groups ; a test group set ; the number of anomalous groups h; the expected size n of each group; Output: The distribution-based anomaly score of the test group set .
- 1:
Train an OCSMM model based on the normal group set . - 2:
Using Algorithm 2, generate h anomalous groups, , with each group size drawn from a Poisson distribution with expectation parameter n. - 3:
Compute the OCSMM scores for the normal groups, , and the anomalous groups, , using the decision function of the trained OCSMM model. - 4:
Fit a sigmoid model to and by estimating the parameters g and q. - 5:
Apply the trained OCSMM model to compute the OCSMM scores for the test set, , and then use the trained sigmoid model to obtain the calibrated scores as .
|











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}