1. Introduction
Recent trends in global food market instability, combined with the ongoing restructuring of China’s agricultural production methods, have underscored the necessity of ensuring self-sufficiency in terms of food. This is especially important for key agricultural products like soybeans, which play a vital role in China’s food security. The 2024 Central Government Document No. 1 explicitly emphasizes the need to safeguard food security and maintain subsidies for corn and soybean producers in China [
1]. These policies aim to incentivize soybean cultivation and expand planting areas, thereby influencing soybean market dynamics and price trends.
China’s reliance on imported soybeans further highlights the importance of price stability. Data provided by China Customs indicates that soybean imports in 2024 reached 105 million tons, accounting for approximately 50% of total domestic consumption. This dependence means that price fluctuations directly impact national food security and agricultural stability. Accurate soybean price predictions enable policymakers to formulate effective strategies, mitigate market risks for farmers, and increase economic benefits, thus contributing significantly to national development.
Various studies have employed different forecasting methods for soybean prices. Zhu et al. [
2] developed a soybean price forecasting model using an enhanced GM (1,1) model based on historical data. Xiong et al. [
3] proposed a dynamic model averaging (DMA) framework, identifying time-varying factors in soybean futures prices from both market and economic perspectives. Yang et al. [
4] proposed an optimized EEMD-SVR integrated forecasting method, while Zhang et al. [
5] developed a QR-RBF neural network model featuring indicators such as the consumer price index and soybean import volumes. Fan et al. [
6] created an LSTM model using daily closing prices.
However, most existing studies rely on single-frequency data for their forecasting models, whereas, in practice, a number of different, mixed-frequency factors influence soybean prices. These include macroeconomic data, which is typically reported at quarterly and monthly intervals, and such high-frequency data as weather conditions and investor sentiment, which are generally assessed on a daily basis. Traditional prediction models are unable to analyze variables of differing frequencies directly, requiring preprocessing to align them first; this is often carried out using interpolation methods that convert low-frequency data to high-frequency data, or by aggregating high-frequency data into low-frequency data. These processes may result in significant information loss due to the reduction in sample size. To address this, Ghysels et al. [
7] proposed a mixed-frequency data sampling (MIDAS) model, which integrates multi-frequency sample data into a unified framework. This improves prediction accuracy and speed by leveraging valuable information from high-frequency variables to improve the interpretation of low-frequency ones [
8]. Guo and Ma [
9] employed a Markov-switching mixed-frequency model (MS-MIDAS), which outperforms the standard MIDAS model in terms of predictive accuracy. Cai et al. [
10] introduced a novel reverse mixed-frequency data sampling model (R-MIDAS), which features a machine learning algorithm, and demonstrated superior performance across a number of different industries.
Despite its broad range of economic applications, the MIDAS model is rarely used in soybean price forecasting. Wang et al. extended the GARCH-MIDAS method, constructing the GARCH-MIDAS-W and GARCH-MIDAS-W-MBB models, introducing soybean volatility forecasting [
11]. Yu et al. explored the impact of meteorological disasters on the volatility of soybean futures returns using a mixed-frequency GARCH-MIDAS model and its extensions to capture short- and long-term market volatility [
12]. The current study aims to bridge this gap by employing a mixed-frequency data sampling method for the modeling and analysis of soybean prices.
This paper addresses the complexity of soybean price fluctuations by integrating machine learning into the MIDAS model, enabling the exploration of nonlinear, discontinuous information [
13,
14]. By analyzing historical data, the proposed approach aims to more accurately capture both short-term fluctuations and long-term trends in soybean prices, leveraging the combined advantages of high- and low-frequency information.
3. Empirical Analysis
3.1. Analysis of Factors Influencing Soybean Prices
This paper examines the key determinants of soybean prices based on a systematic review of 33 articles published between 2012 and 2024, which were found using the search term “soybean price influence factors” on the China National Knowledge Infrastructure (CNKI). After excluding any unrelated studies, the statistical results are presented in
Figure 2. This shows that most studies primarily focus on macroeconomic factors [
28,
29] and supply and demand dynamics [
30,
31], with limited investigation into weather conditions, public opinion on social media, and policy interventions.
The impact of soybean price subsidy policies on market prices operates through an indirect transmission mechanism—these policies influence soybean planting area decisions [
32], which subsequently alter supply volumes and ultimately affect market prices. This process exhibits significant temporal lag effects. Furthermore, the effectiveness of such subsidies is contingent upon external factors such as agricultural technology adoption levels and farm size heterogeneity [
33], which introduce additional variability in policy outcomes. Given these confounding influences, subsidy-related variables are excluded from the feature set in this study to maintain model interpretability and predictive stability.
Extreme weather events create complex dynamics for crop producers by reducing local yields while simultaneously driving up prices through widespread production losses [
34]. These price effects are further modulated by the El Niño Southern Oscillation (ENSO), with La Niña events exerting a particularly strong influence on both the soybean-to-corn price ratio and related hedging strategies [
35].
Advances in online technology, combined with media reports and public sentiment, have influenced commodity prices [
36]. Research by Li et al. developed a comprehensive list of influential factors using topic modeling, a text mining method, demonstrating that these identified factors, along with sentiment-based variables, are particularly effective in price forecasting. Their proposed framework showed superior performance in medium- and long-term forecasting over benchmark models [
37]. To address these omissions, this study incorporates weather data and public opinion factors into the forecasting model. A number of potential influencing factors for soybean prices were identified, along with their corresponding measurement indices, as presented in
Table 1.
3.2. Data Sources
The target variable, soybean price, is obtained from the National Bureau of Statistics of China (NBS) at a monthly frequency. Other data sources and variables for this study are detailed in
Table 1, covering the period from January 2012 to January 2024. The dataset consists of nine monthly frequency variables and four daily frequency variables. In order to ensure temporal consistency and to address data availability issues, the following standardized preprocessing procedures were applied to high-frequency data:
Baidu Index data were normalized to 30 daily observations per month;
USD-CNY exchange rate data (excluding weekends and holidays) were standardized to 20 observations per month;
If the number of data points exceeded the preset threshold, any surplus data were discarded; if it fell below the threshold, any gaps were filled using data from adjacent months.
This preprocessing protocol ensures data uniformity and temporal alignment for mixed-frequency analysis. The study period was divided into two subsets:
The temporal partitioning of our dataset follows standard practices in time series forecasting research, with training–testing splits systematically implemented within the conventional 60:40 to 80:20 ratio range [
38].
3.3. Variable Selection
A multidimensional variable screening method was used in this study to identify the key variables for the soybean price forecasting model. Monthly frequency data were analyzed to identify variables with a statistically significant relationship to soybean price by calculating the Pearson and Spearman correlation coefficients, followed by a double correlation test; the results are presented in
Table 2.
Table 2 demonstrates a statistically significant positive correlation between soybean prices and both the China Consumer Price Index and the Grain Consumer Price Index, consistent with conventional price transmission mechanisms whereby inflationary pressures increase production costs in agricultural inputs (e.g., fertilizers and transportation), consequently elevating commodity market prices [
39]. Furthermore, the corn and soybean markets exhibit a substitution relationship on the demand side (as evidenced by feed ingredient conversion) [
40]. Finally, El Niño events generally lead to warmer and drier conditions in some regions, which can reduce soybean yields, thereby increasing prices due to supply shortages [
41].
The input variables for daily frequency data were selected for optimal predictive accuracy based on the performance assessment of the univariate mixed frequency data sampling (MIDAS) model. The specific results are presented in
Table 3. The final variable selection results are collectively determined based on comprehensive analysis of both
Table 2 and
Table 3, where we retained only the optimal indicator at each frequency level. The Chinese consumer price index, corn price, El Niño index, exchange rate, and aggregated Baidu index for soybean price were identified as the key influencing factors for inclusion in the MIDAS-SVR prediction model.
3.4. Prediction Results and Analysis Based on the MIDAS-SVR Model
This study seeks to predict future soybean price trends by means of a MIDAS-SVR forecasting model. Preprocessed data were used to predict prices within the R programming environment, with the detailed methodology outlined in
Section 2. The model is initially trained with a training set to identify the optimal parameters for the MIDAS-SVR soybean price prediction model (refer to
Table 4).
Figure 3 illustrates the fitted values from the prediction model alongside the training set error metrics—the mean squared error (MSE) is 0.013, the mean absolute error (MAE) is 0.08, and the mean absolute percentage error (MAPE) is 1.36%. These results suggest that the model demonstrates high predictive accuracy.
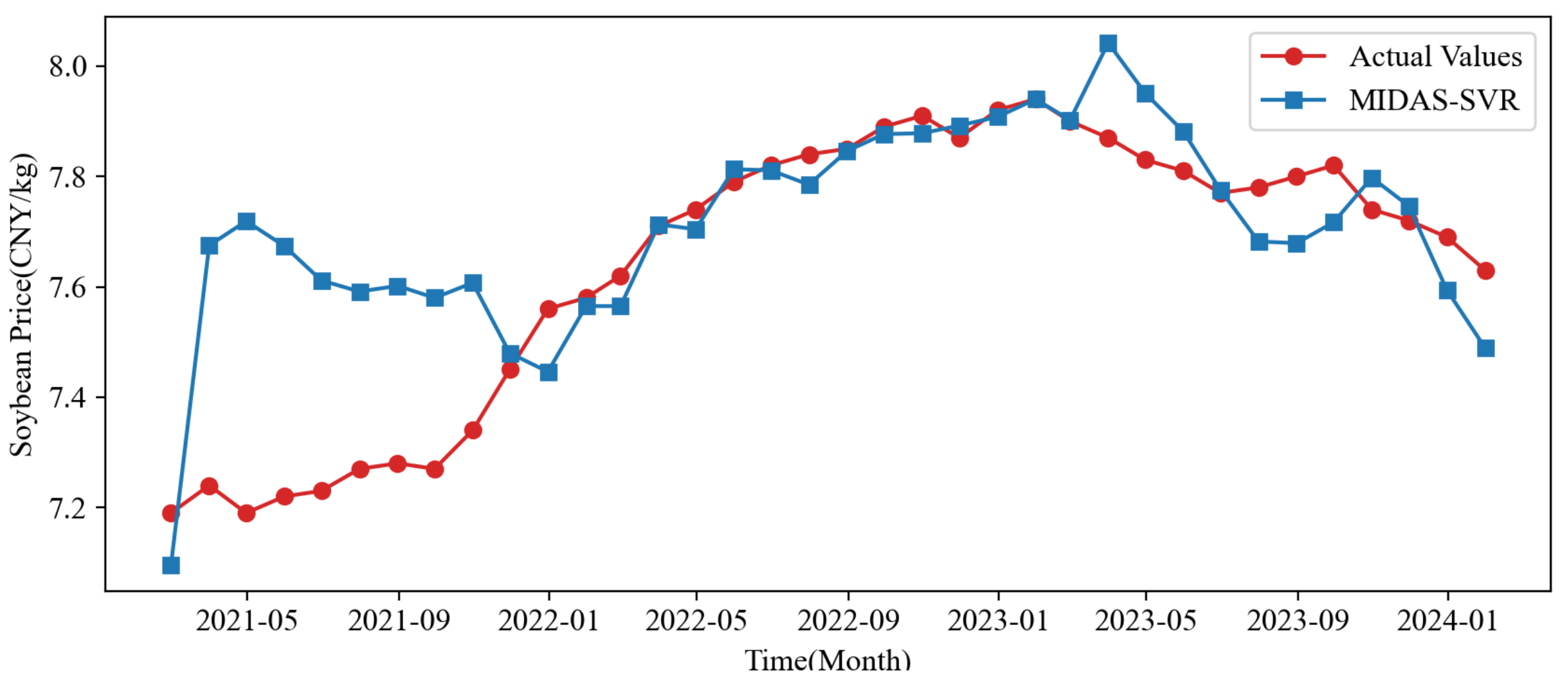
The variables for corn price, consumer price index, El Niño index, exchange rate, and Baidu soybean price index are arranged in ascending order. The notation represents the coefficient for the corn price variable while indicating the multiplicative relationship between the duration of the corn price cycle and that of the soybean price cycle, among other relationships. The MIDAS-SVR model was employed to predict soybean prices for the test sample covering February 2021 to January 2024, with the results presented in
Table 5 and
Figure 4. The prediction accuracy presented in
Table 5 exhibits an initial trend of gradual improvement, followed by a plateau. The inaccuracy encountered in 2021 is likely associated with the ongoing effects of the COVID-19 pandemic. In early 2021, the volatility of soybean market prices escalated significantly due to supply chain disruptions, demand variations, and policy changes instigated by the pandemic, resulting in the suboptimal performance of the model during initial forecasts. After that, the uncertainty impact of the pandemic on the market decreased, and the accuracy of the model improved. Beginning in November 2021, there was a marked reduction in the model’s prediction error, with the relative error stabilizing at approximately 1%. This suggests that the model was better at capturing price trends during the later phases of the epidemic.
3.5. Comparative Analysis
This study aims to rigorously evaluate the performance of the MIDAS-SVR model in forecasting soybean prices, particularly its capacity to analyze the intricate relationship between high-frequency factors and soybean prices. The MIDAS-SVR model is compared with five alternative models—a mixed-frequency data sampling (MIDAS) model, a traditional support vector regression (SVR) model using single-frequency data inputs (Baidu Index for Soybean Prices and average exchange rate), and a multilayer perceptron (MIDAS-MLP) model based on mixed-frequency data. The SVR model exclusively uses low-frequency data, specifically the monthly averages of the Baidu index and exchange rate variables. The MIDAS-MLP model parallels the MIDAS-SVR model by using predicted values from the MIDAS model as inputs for the MLP model; this is capable of directly processing mixed-frequency data, including high-frequency Baidu index and low-frequency economic indicators. We also compared the MIDAS-SVR model against standard time series models (auto-ARIMA and ETS).
Figure 5 displays the fitted values for each model, showing how the six fitting curves align with trends observed in the actual sample curves.
Figure 5 illustrates that the MIDAS model is less suitable for capturing soybean price trends than the other five models. In early 2016, mid-2017, and throughout 2019 and 2020, the fitted values of the MIDAS model exhibited significant deviations. The MIDAS-SVR and SVR models demonstrated a superior fit during that time period. Among the compared models, auto-ARIMA and ETS exhibit the highest fitting accuracy.
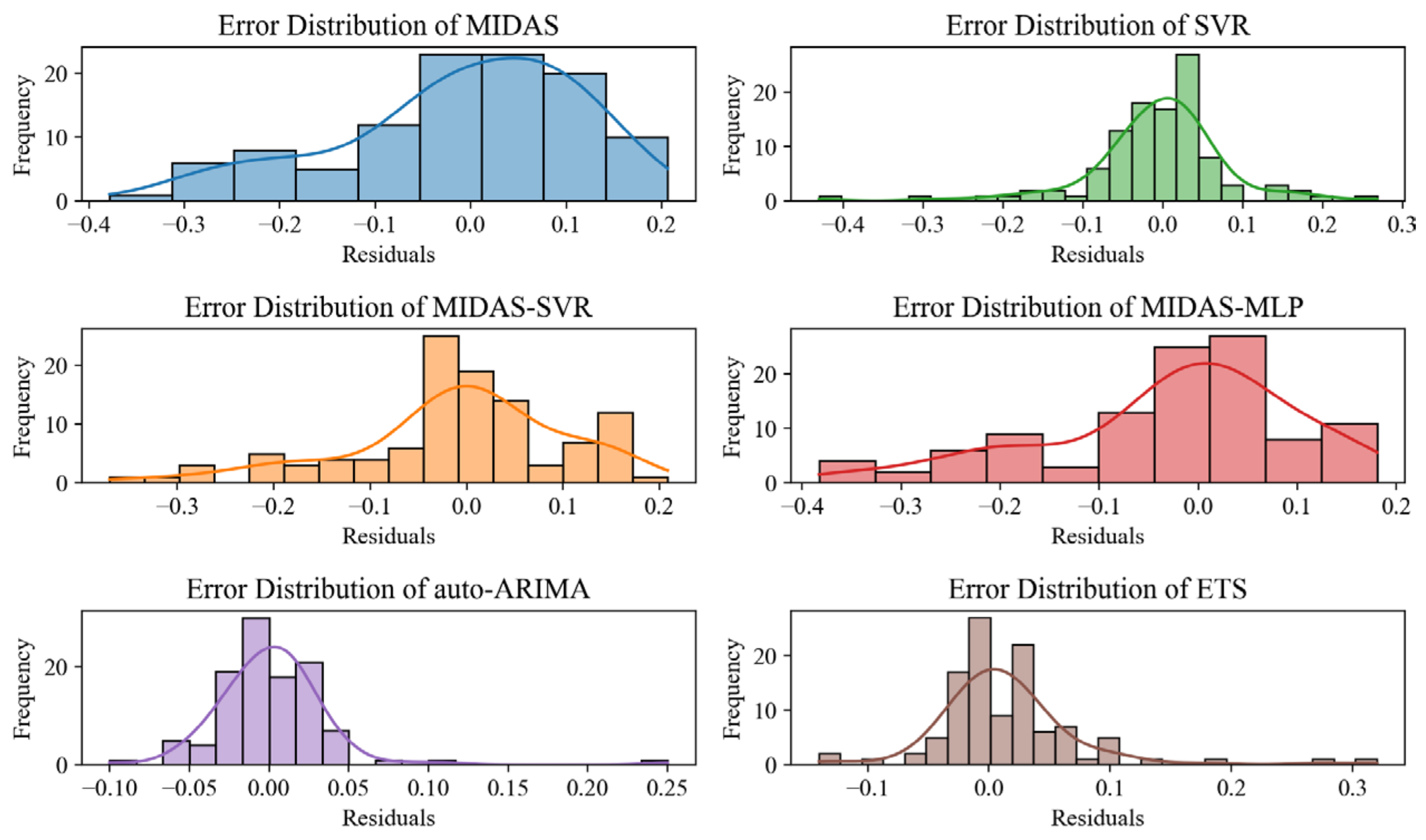
Figure 6 and
Figure 7 present the residual histograms and residual boxplots for the six models, respectively.
Figure 6 illustrates that the residuals of both the MIDAS model and the MIDAS-MLP model exhibit a distinctly left-skewed distribution, suggesting reduced stability.
Figure 7 illustrates that the error means for each model approach zero, suggesting reduced bias within the training set. Additional analysis of the error distributions indicates that the auto-ARIMA and ETS models exhibit more concentrated error distributions with reduced fluctuation ranges, demonstrating better predictive stability. The error distributions of the MIDAS model and the MIDAS-MLP model exhibit greater dispersion, suggesting a higher level of uncertainty in their prediction outcomes.
This study evaluated the forecasting performance of the MIDAS-SVR model by predicting soybean prices from February 2021 to January 2024 (test sample) using six different models. The results are presented in
Table 6 and
Figure 8.
The empirical results demonstrate significant performance limitations in traditional time series models, with ETS achieving 6.90% MAPE (MAE 0.50 and MSE 0.53) and auto-ARIMA performing substantially worse at 14.41% MAPE (MAE 1.74 and MSE 1.12) in out-of-sample testing. These limitations stem from fundamental structural constraints—while their linearity and stationarity assumptions provide protection against overfitting, they inherently restrict the models’ ability to capture complex nonlinear patterns. In contrast, our MIDAS-SVR framework achieves superior predictive accuracy (1.71% MAPE, MAE 0.04, and MSE 0.13), demonstrating reductions of 75.2%, 92.0%, and 75.5%, respectively, compared to ETS on these metrics. This performance advantage, extending to 88.1%, 97.7%, and 88.4% improvements over auto-ARIMA, validates that machine learning-enhanced mixed-frequency modeling can simultaneously achieve greater accuracy while maintaining robustness against overfitting.
Furthermore, comparative analysis reveals that MIDAS-SVR outperforms three alternative hybrid approaches—conventional MIDAS (4.16% MAPE), standard SVR (2.36% MAPE), and MIDAS-MLP (2.02% MAPE)—demonstrating the unique advantages of our proposed architecture in handling mixed-frequency data while avoiding overfitting.
3.6. Robustness Tests
Predictive robustness evaluates the stability and reliability of a predictive model’s outputs under varying conditions or environmental changes. This analysis seeks to confirm that the model consistently delivers accurate and reliable predictions in real-world applications, while also maintaining robust performance when confronted with data fluctuations, outliers, or unrealistic model assumptions. The paper employs two methods to assess the robustness of the model—a reduced training period (excluding the 2012 data) and an increased number of independent variables.
The MIDAS-SVR model was retrained by shortening the training set period (January 2013–January 2021), after which its predictive performance was assessed.
Table 7 indicates that the set error, measured by MAPE, is 2.15%. In addition, the mean absolute error (MAE) exhibits an increase of 0.03 units, while the mean square error (MSE) shows a relative rise of 0.01 units. This suggests that a reduction in the training set data results in inadequate historical information being captured by the model, potentially diminishing its capacity for generalization. The error remains within an acceptable range.
This paper introduces soybean meal price as an explanatory variable to address potential omitted variable bias in the existing literature on factors influencing soybean prices. Upon incorporating the soybean meal price variable, the MIDAS-SVR model was re-evaluated, revealing that the mean relative error (MAPE) of the test set increased by a mere 0.01% (refer to
Table 7). This suggests that the inclusion of explanatory variables slightly decreases the fitting accuracy on the training set while leaving prediction accuracy largely unaffected. The model presented in this paper successfully passed the robustness test, indicating that the research conclusions are very reliable.
4. Results and Discussion
Soybean prices are influenced by a variety of factors, including both macroeconomic data, which is typically reported on a quarterly basis, and low-frequency data, which is often available on a monthly basis. This paper employs a mixed-frequency data sampling (MIDAS) model to integrate daily data, such as weather and investor sentiment, with varying frequency sample data, all within a unified prediction framework. Our approach extends the work of Wang et al. (2023) by incorporating machine learning techniques to address known nonlinearity challenges in standard MIDAS applications [
11]. Given the complexity and nonlinear nature of soybean price fluctuations, this study leverages the strengths of machine learning in handling intricate data. By fully exploring the nonlinear and discontinuous aspects of the data, the research combines machine learning with a mixed-frequency data sampling model to develop a mixed-frequency support vector regression (MIDAS-SVR) prediction model for soybean prices. Empirical research on soybean price data in China from January 2012 to January 2024 indicates that the MIDAS-SVR model demonstrates optimal predictive performance and improved stability, leading to the following key conclusions:
There are four key dimensions that influence soybean prices: macroeconomic factors, supply and demand, weather, and public sentiment. Notably, the Consumer Price Index (CPI), corn prices, the El Niño Index, exchange rates, and the Baidu Index exhibit a significant correlation with fluctuations in soybean prices (
p-values < 0.05). These findings align with Ferreira et al.’s (2022) demonstration of weather impacts on soybean markets [
35].
The MIDAS-SVR model improves prediction accuracy by using the information contained in high-frequency data, thus improving on traditional methods that merely simplify high-frequency data to single-frequency data through direct averaging.
The MIDAS-SVR model demonstrates superior prediction accuracy and stability compared to other models, making it very suitable for capturing soybean price trends. The results obtained in this paper validate the MIDAS-SVR prediction model and offer new methodological support for soybean price prediction, opening up a wide range of theoretical and practical applications.
It should be noted that the current study has two main limitations: The model validation was conducted on a single commodity time series, and its generalizability to other agricultural markets requires further investigation. China-focused data may require calibration for global markets. Future research will expand the validation to multiple commodity markets and explore optimization techniques for practical implementation.

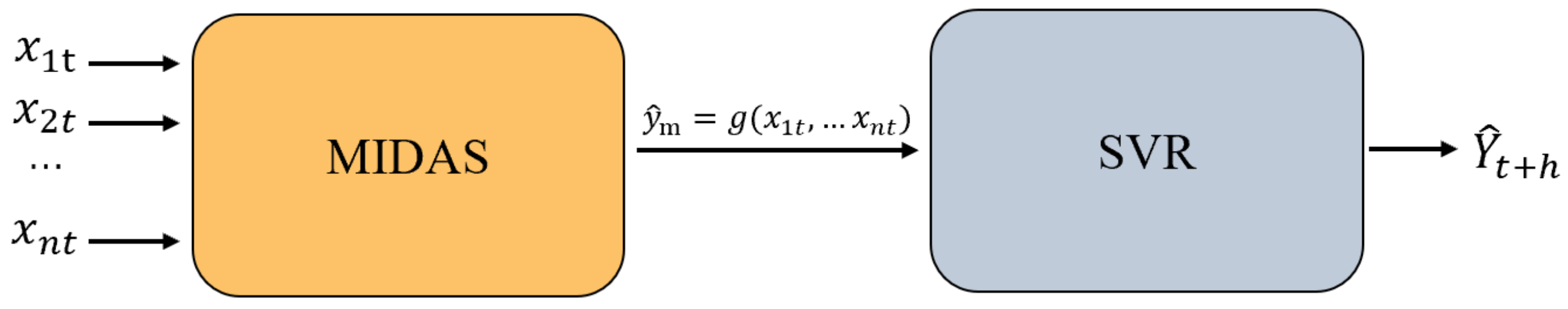






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}