1. Introduction
Utilizing auxiliary data in survey sampling plays a significant role in enhancing the accuracy of estimators. To achieve better relative efficiency, methods such as ratio, regression, and product estimators incorporate supplementary details in addition to the primary study variables. For example, when estimating total household income, auxiliary metrics like the number of household members and overall expenditure can be helpful. Researchers have carried out extensive investigations to develop more effective estimators for various population parameters, including the mean, total, and median. Further insights into these improved estimators and their statistical characteristics can be found in related studies, see [
1,
2,
3,
4,
5] and references therein.
In the field of sampling theory, the use of auxiliary variables alongside the primary variable of interest is a widely recognized strategy to enhance the efficiency and accuracy of survey designs. This approach takes advantage of the correlation between the auxiliary and main variables to yield more reliable estimations. In many practical situations, the population mean of the variable under study is not known prior to data collection. In such cases, researchers often rely on a dual-phase sampling approach, also known as double sampling. This strategy involves conducting an initial phase to gather basic information, followed by a second phase focused on more detailed data collection. Typically, a large preliminary sample is drawn to collect data on auxiliary variables, and a smaller, more focused sample is then selected either from the initial group or independently, to observe both the auxiliary and study variables. Due to its efficiency and lower cost, dual-phase sampling is a valuable tool in survey research, particularly when prior knowledge of auxiliary data is lacking. A brief review of two-phase sampling was first introduced in [
6,
7]. Recently, two-phase sampling has gained significant attention because of its cost-effectiveness in screening variables. Several studies have explored different aspects of two-phase sampling, including [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17].
Survey data can sometimes include outliers or unusually large or small values, which may affect the reliability of statistical estimations. The presence of such extreme observations can distort the sample mean, potentially resulting in biased inferences. To address this, the authors in [
18] initially introduced two estimators based on linear transformations involving the minimum and maximum values of known auxiliary variables. However, this approach did not receive much attention until it was later revisited in [
19], who proposed improved ratio, product, and regression estimators by incorporating extreme value information of auxiliary variables for estimating population means. Building upon this, the authors in [
20] extended these ideas within a dual-phase sampling framework to enhance estimation accuracy. The authors in [
21] also explored different transformation techniques using extreme values of auxiliary variables to estimate the finite population mean. Further advancement was made by the authors in [
22], who suggested innovative methods for estimating the mean under stratified random sampling designs that account for extreme values. Additionally, the authors in [
23] introduced a novel group of estimators aimed at calculating population variance with minimal mean squared error by utilizing extreme value information. Most recently, the authors of [
24,
25,
26] proposed several new classes of efficient estimators for population variance by applying transformation strategies to extreme values. For more details, see [
27,
28,
29,
30,
31,
32] and references therein.
Although the removal of extreme observations from survey data might appear beneficial, retaining them can offer valuable insights, especially when auxiliary variables are involved. Classical estimators often suffer from increased mean square error (MSE) in the presence of such values, leading to reduced efficiency. Rather than excluding these outliers, this study treats the minimum and maximum values of auxiliary variables as informative features. Inspired by the work of [
22,
23], we introduce two innovative families of estimators that incorporate these extremes values and ranks of auxiliary data to enhance the estimation of the finite population mean within a two-phase sampling framework.
The proposed estimators are not only theoretically efficient but also highly applicable in practical settings where auxiliary information is partially available. In many real-world surveys, it is common to have access to auxiliary variables during a preliminary phase, while collecting detailed data on the study variable may be expensive or time-consuming. In such cases, utilizing the ranks and extreme values of auxiliary variables can significantly enhance the accuracy of population mean estimation. The following examples illustrate typical scenarios where the proposed methodology can be effectively applied:
Agricultural Surveys: When estimating average crop yield in a region, data on the number of acres cultivated (auxiliary variable) may be available from administrative records. The ranks (e.g., top 10 largest farms) and extreme values (smallest and largest land holdings) can enhance estimation accuracy, especially in two-phase sampling where detailed crop yield data is expensive to collect.
Public health studies: To estimate the average healthcare expenditure across households, auxiliary data like income levels or family size from census data can be used. Ranks of income groups (e.g., lowest and highest quintiles) and extreme income values can help refine estimates, particularly when full income data is unavailable in the first phase.
Educational statistics: In assessing the average test scores of students across a district, school-level data such as the number of teachers or school enrollment (auxiliary variables) are readily available. Using the ranks of schools based on size or resources, along with the extremes (smallest and largest schools), can improve estimates with limited test score data in the second phase.
Socioeconomic surveys: In household income and expenditure surveys, auxiliary variables like electricity usage or mobile phone ownership can be ranked, and extreme values (e.g., zero usage or very high usage) can serve as indicators to better estimate average household income.
The article is organized as follows:
Section 2 outlines the methodology of the study and introduces the notation used throughout the paper. A review of the existing estimators is provided in
Section 3. In
Section 4, we present a detailed discussion of the newly proposed classes of estimators.
Section 5 offers an in-depth mathematical comparison of these estimators. The simulation study, outlined in
Section 6, generates six distinct artificial populations using various probability distributions, validating the theoretical results discussed in
Section 5. This section also includes numerical examples that demonstrate the practical applications of the theoretical findings. Finally,
Section 7 summarizes the main conclusions of the study and proposes directions for future research.
2. Methodology and Notation
Consider a finite population consisting of N units. Let be the value of the study variable let denote the value of the auxiliary variable X, and let be the rank of the auxiliary variable W for the unit.
Let the population data The sample data collected in the first phase is denoted by , while the second phase sample data is represented by . In this paper, we propose two improved classes of estimators to estimate the finite population mean of Y in the presence of auxiliary variable X. The definition of the two-phase sampling scheme is as follows:
- 1.
In the first phase, a simple random sample without replacement of size is drawn from the population to provide an estimate of the population mean , allowing for an initial approximation before further analysis.
- 2.
In the second phase, a simple random sample without replacement of n observations (where ) is selected to observe the variables y and x, allowing for more precise measurements and further analysis of the relationship between them.
Suppose the average values for the main study variable (
), the auxiliary variable (
), and the corresponding ranks of the auxiliary variable (
) are described as follows:
and
The list of the important variables and different notations are given in
Table 1.
Define the population variances under simple random sampling without replacement (SRSWOR) for the study variable (
Y), the auxiliary variable (
X), and the ranked values of the auxiliary variable (
W) as follows:
and
respectively. Moreover, the population-level coefficients of variation corresponding to these variables are expressed as follows:
and
respectively. We also know that the population correlation coefficients between
Y and
X,
Y and
W, as well as
X and
W are given by
and
Simple random sampling without replacement is used to estimate the unknown population mean
. In the first phase, a random sample of
m units is selected from the population. The sample means
and
for the auxiliary variable
X and its ranked version
W are computed from this initial sample as follows:
while the first phase sample variances are expressed as
and
Additionally, let
,
, and
denote the sample means of the variables
Y,
X, and
W, respectively, calculated from the second-phase sample of size
n, such that
and
The second phase without replacement sample variances for these variables are defined as
and
3. Some Existing Estimators
In this section, we evaluate the bias and mean squared error characteristics of existing methods used to estimate the finite population mean and present a comparison with the newly proposed estimator classes.
The usual unbiased estimator to estimate the population mean
was proposed in [
6], which is given by
The variance of
is given by
where
represents the finite population mean in the two phase sampling method, and
denotes a sampling fraction difference or correction term applied to account for variations in sample sizes during the second phase.
The authors in [
7] suggested that a ratio type estimator for
in two-phase sampling be defined as
The expressions for bias and mean squared error (MSE) of
are expressed as follows:
and
where
represent the first phase and inter phase sampling correction terms, respectively.
The classical regression estimator
under two-phase sampling was proposed in [
7], which is defined as
where
is the sample regression coefficient.
The bias and mean squared error (MSE) of
are expressed as follows:
where
and
The authors in [
13] introduced exponential ratio and product-type estimators as alternative approaches for improved estimation, which are defined as follows:
and
The expressions for mean squared error of
and
are defined as follows:
and
where
The authors in [
14] proposed that a double sampling estimator for
is defined as
where
The expressions for bias and mean squared error (MSE) are expressed as follows:
and
4. Suggested an Improved Family of Estimators
In this section, we present enhanced estimators for estimating the finite population mean, based on the principles outlined in [
22,
23]. These estimators utilize the known extreme values of auxiliary variables, along with their ranks, within a two-phase sampling method to enhance the reliability of the results. The mathematical expressions for these estimators are outlined below:
and
where the scalar parameters
are restricted to the values
, while
represent unknown constants that require suitable selection to achieve reduced bias and lower mean squared error. On the other hand,
are fixed known constants. The auxiliary variable parameters are represented by
and
, whereas
and
indicate the range of values based on the maximum and minimum observations of the auxiliary variables. Additionally, various sub-forms of the proposed estimator-I are derived from Equation (
38) and summarized in
Table 2.
where
and
represents the normalized range of the auxiliary variable.
4.1. Properties of the Suggested Estimator-I
To analyze the properties of the first proposed class of estimators, we introduce the following error terms. Let
such that
,
.
Additionally, , , , , , , , , , , , , , , and
To explore the characteristics of the first proposed estimator, we express Equation (
38) in terms of error components.
where
By applying a first-order Taylor series expansion, we derive
Using (
40), the bias of
is given by
where
and
Squaring both sides of Equation (
40) and then taking the expected value leads to the first-order mean squared error (MSE), which is expressed as follows:
where
and
To find the optimal values of
and
, we minimize Equation (
42), resulting in the following expressions:
and
The bias and mean squared error (MSE) for
are minimized by substituting the optimal values of
and
into Equations (
41) and (
42), leading to the following results:
and
4.2. Properties of the Suggested Estimator-II
Next, we express Equation (
39) in terms of error components to derive the bias and mean squared error (MSE) of the second proposed estimator
i.e.,
where
and
By applying a first-order Taylor expansion, we derive
Using (
46), the bias of
is given by
After squaring both sides of (
46) and applying the expected value, we obtain a first-order mean squared error (MSE) as shown below:
After substituting the known values for
and
into Equations (
47) and (
48), we can express the bias and MSE for
. With a few simplifications, the resulting expressions are as follows:
and
5. Mathematical Comparison
In this section, the suggested estimators and are compared with existing estimators, including , , , , and .
5.1. Suggested Estimator-I
Condition (i): By (
24) and (
44),
Condition (ii): By (
27) and (
44),
Condition (iii): By (
30) and (
44),
Condition (iv): By (
33) and (
44),
Condition (v): By (
34) and (
44),
Condition (vi): By (
37) and (
44),
5.2. Suggested Estimator-II
Condition (vii): By (
24) and (
50),
For
that is,
,
Similarly, for
that is,
,
Whenever either condition (
51) or (
52) is satisfied, the estimator
shows improved performance, resulting in a lower mean squared error (MSE) compared to
, along with greater efficiency.
Condition (viii): By (
27) and (
50),
For
that is,
,
Similarly, for
that is,
,
Whenever either condition (
53) or (
54) is satisfied, the estimator
shows improved performance, resulting in a lower mean squared error (MSE) compared to
, along with greater efficiency.
Condition (ix): By (
30) and (
50),
For
that is,
,
Similarly, for
that is,
,
Whenever either condition (
55) or (
56) is satisfied, the estimator
shows improved performance, resulting in a lower mean squared error (MSE) compared to
, along with greater efficiency.
Condition (x): By (
33) and (
50),
For
that is,
,
Similarly, for
that is,
,
Whenever either condition (
57) or (
58) is satisfied, the estimator
shows improved performance, resulting in a lower mean squared error (MSE) compared to
, along with greater efficiency.
Condition (xi): By (
34) and (
50),
For
that is,
,
Similarly, for
that is,
,
Whenever either condition (
59) or (
60) is satisfied, the estimator
shows improved performance, resulting in a lower mean squared error (MSE) compared to
, along with greater efficiency.
Condition (xii): By (
37) and (
50),
For
that is,
,
Similarly, for
that is,
,
Whenever either condition (
61) or (
62) is satisfied, the estimator
shows improved performance, resulting in a lower mean squared error (MSE) compared to
, along with greater efficiency.
6. Numerical Comparison
This section presents a comparative evaluation of the percent relative efficiency (PRE) between the proposed estimators and several established ones. The assessment utilizes both simulated datasets and three different real datasets. Through this analysis, we aim to offer a detailed understanding of how the proposed estimators perform in terms of accuracy and consistency across a range of practical applications.
6.1. Simulation Study
A simulation study is carried out in this section where the data of the auxiliary variable X are generated from six distinct populations, with each population structured according to a different probability distribution as listed below.
Population 1:
Population 2:
Population 3:
Population 4: ,
Population 5:
Population 6:
In the simulation study, the log-normal, exponential, and gamma distributions were selected to reflect realistic data structures commonly found in survey sampling. These distributions cover a range of positive skewness and variability, allowing for a robust evaluation of the proposed estimators. The log-normal distribution models highly skewed socio-economic variables such as income, the exponential distribution represents time-to-event data, and the gamma distribution provides flexibility to simulate various positively skewed datasets. This selection ensures that the simulation results are applicable to a wide range of practical scenarios where two-phase sampling techniques are employed.
The value of the study variable
Y is then derived based on the defined relationship or formula as follows:
where
represents the correlation coefficient between the dependent and independent variables, and
e is the error term
The mean squared errors (MSEs) and percent relative efficiency (PRE) of both the proposed and existing estimators were calculated using specific computational procedures implemented in R software (latest v. 4.4.0).
Step 1: We begin by generating a population consisting of 1000 observations, each obtained from the specified probability distributions mentioned above.
Step 2: A first-phase sample of size m is selected from a population of size N using simple random sampling without the replacement (SRSWOR) technique.
Step 3: The second-phase sample consisting of n units is subsequently selected from the initial sample by reapplying the SRSWOR approach.
Step 4: The population total and the lowest and maximum observations of the auxiliary variable, along with their ranks, are determined using the steps described above. We also find the optimal values of the proposed estimators for the unknown constants.
Step 5: Different sample sizes are obtained for each population using SRSWOR.
Step 6: The MSE and PRE values for all estimators discussed in this article are computed for each sample size.
Step 7: After 50,000 repetitions of Steps 5 and 6, the results for artificial populations are presented in Table 4, while Table 5 summarizes the findings for real datasets, all calculated using the formula provided below.
and
where
6.2. Numerical Examples
We calculated the mean squared errors (MSEs) by using the three different datasets in order to evaluate the effectiveness of different estimators. The goal is to evaluate the effectiveness of the proposed estimators. We describe the datasets in detail below, along with summary statistics:
Data 1. (Source: [
33], p. 226)
Y: departmental employment levels in 2012;
X: number of factories the departments registered in 2012;
W: ranking of the number of factories the departments registered in 2012.
Data 2. (Source: [
33], p. 135)
reports the total student population in educational institutions in 2012;
reports the total number of schools operated with government funding in 2012;
displays the position of each area based on the total number of schools funded by the government in 2012.
Data 3. (Source: [
1], p. 24)
Y: the cost of food for families directly influenced by their occupations;
X: the total weekly income earned by families reflecting their financial resources during that period;
W: the ranking of families based on their weekly income showing how their earnings compare to each other.
The datasets presented above are compiled in the summary statistics shown in
Table 3, while the comparison of percent relative efficiency (PRE) values between the newly proposed estimators and the existing ones is presented in Table 5.
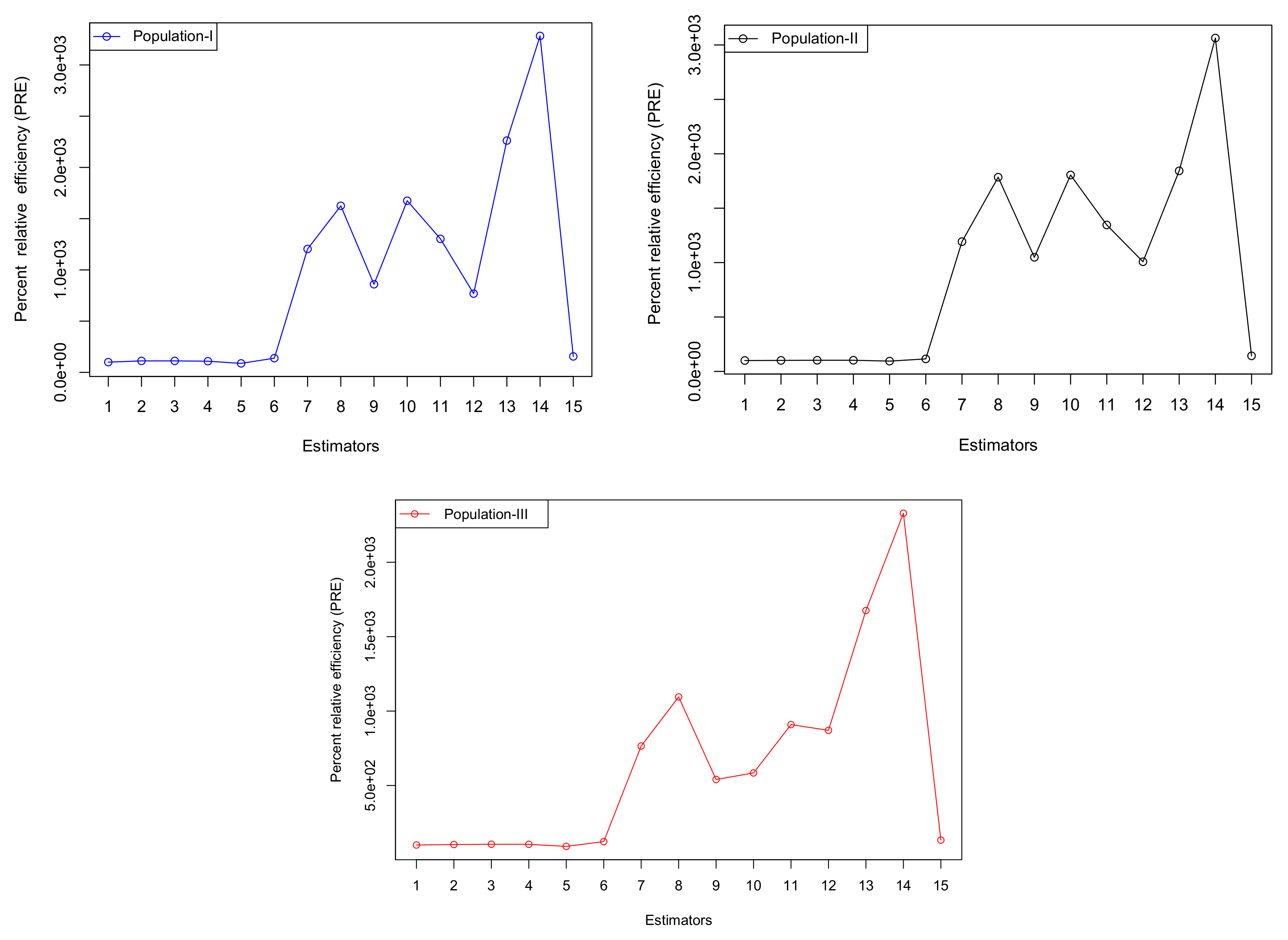
6.3. Discussion
Simulation studies and analysis of three real populations were conducted to evaluate the performance of the proposed estimators. The estimators were compared using the percent relative efficiency (PRE) criterion.
Table 4 shows the simulation results, including PRE values for both proposed and existing estimators, while
Table 5 summarizes the findings from the real populations. The following general conclusions can be drawn from these studies:
All simulated scenarios and real datasets show that the
values for all suggested estimators are higher than those of the existing estimators reported in the literature, as shown in
Table 4 and
Table 5. This demonstrates how well the suggested estimators perform in comparison to the existing ones.
In addition, all suggested estimators have
values that are consistently higher than those of existing estimators, as demonstrated by the upward-trending graph lines in
Figure 1 and
Figure 2 for both simulation studies and real populations. This suggests that the suggested classes of estimators perform better than the existing ones, as evidenced by the inverse relationship between the
values for the suggested and existing estimators.
Table 4.
PRE of different estimators using the artificial populations.
Table 4.
PRE of different estimators using the artificial populations.
| Estimator | | | | | | |
|---|
| 100 | 100 | 100 | 100 | 100 | 100 |
| 105.839 | 107.971 | 108.983 | 110.287 | 111.064 | 114.373 |
| 118.317 | 120.643 | 113.286 | 115.735 | 127.677 | 129.607 |
| 123.695 | 126.703 | 122.730 | 131/398 | 140.342 | 146.740 |
| 91.973 | 98.514 | 87.843 | 93.665 | 92.081 | 97.192 |
| 123.787 | 126.812l | 130.209 | 134.947 | 140.556 | 145.389 |
| 508.112 | 683.541 | 576.577 | 616.447 | 704.186 | 818.293 |
| 974.074 | 1046.103 | 783.673 | 830.248 | 952.000 | 1035.902 |
| 423.399 | 559.205 | 530.387 | 569.895 | 619.075 | 691.546 |
| 1295.076 | 1331.667 | 807.595 | 844.140 | 1028.387 | 1102.939 |
| 1057.236 | 1203.164 | 784.793 | 847.426 | 1068.354 | 1178.732 |
| 393.263 | 583.854 | 539.394 | 589.307 | 673.846 | 720.480 |
| 1349.529 | 1559.195 | 1082.609 | 1132.379 | 1108.818 | 1266.757 |
| 1610.804 | 1793.650 | 1206.316 | 1476.295 | 1310.380 | 1420.820 |
| 169.632 | 175.107 | 147.969 | 173.367 | 181.864 | 197.643 |
Table 5.
PRE of different estimators using real populations.
Table 5.
PRE of different estimators using real populations.
| Estimator | PRE: Pop-I | PRE: Pop-II | PRE: Pop-III |
|---|
| 100 | 100 | 100 |
| 112.104 | 101.092 | 103.252 |
| 112.106 | 102.383 | 104.870 |
| 108.945 | 102.342 | 104.642 |
| 87.845 | 94.535 | 90.71429 |
| 138.664 | 114.875 | 122.651 |
| 1204.266 | 1192.485 | 765.188 |
| 1625.500 | 1784.690 | 1094.834 |
| 859.653 | 1048.866 | 540.278 |
| 1675.141 | 1805.001 | 584.391 |
| 1303.178 | 1345.824 | 909.167 |
| 768.419 | 1007.728 | 870.308 |
| 2262.137 | 1843.198 | 1675.656 |
| 3283.4 | 3063.480 | 2329.250 |
| 155.795 | 142.829 | 132.737 |
7. Conclusions
This article introduces new classes of efficient estimators for the finite population mean, utilizing the ranks of the auxiliary variable along with the known minimum and maximum values. To assess the properties of these estimators in comparison to existing ones, we derived theoretical conditions in
Section 5, demonstrating the improved efficiency of the proposed methods. To verify these conditions, simulation studies and analysis of various empirical datasets were carried out. The results indicate that the proposed estimators consistently outperform the existing ones in terms of percent relative efficiency (PRE), as illustrated in
Table 4. These findings are further supported by the empirical results in
Table 5, which validate the theoretical conditions established in
Section 5.
The simulation results and empirical studies clearly demonstrate that the proposed estimators outperform the other estimators under consideration in terms of efficiency. Among the proposed estimators, stands out as the most effective choice and is therefore strongly recommended for use.
In addition, our study examined the properties of the proposed efficient estimators within a two-phase sampling framework. Moving forward, there is significant potential to develop new estimators based on these findings, aiming to achieve even higher percent relative efficiency (PRE) values. Future research may focus on extending these estimators to more complex sampling designs, such as stratified or multistage sampling, to evaluate their effectiveness in various practical contexts. Furthermore, the use of machine learning methods for adaptive sampling may offer valuable perspectives on improving estimator efficiency. Exploring the application of these estimators in fields like environmental monitoring or healthcare data analysis can also lead to new opportunities for real-world implementation.
Author Contributions
Conceptualization, A.S.A. and F.A.A.; Methodology, A.S.A. and F.A.A.; Software, A.S.A. and F.A.A.; Validation, F.A.A.; Formal analysis, A.S.A. and F.A.A.; Investigation, A.S.A. and F.A.A.; Resources, A.S.A. and F.A.A.; Data curation, A.S.A. and F.A.A.; Writing—original draft, A.S.A.; Writing—review & editing, F.A.A.; Visualization, A.S.A. and F.A.A.; Supervision, F.A.A.; Project administration, F.A.A.; Funding acquisition, F.A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R515), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Cochran, W.B. Sampling Techniques; John Wiley and Sons: Hoboken, NJ, USA, 1963. [Google Scholar]
- Khoshnevisan, M.; Singh, R.; Chauhan, P.; Sawan, N. A general family of estimators for estimating population mean using known value of some population parameter (s). Far East J. Theor. Stat. 2007, 22, 181–191. [Google Scholar]
- Rueda, M.M.; Arcos, A.; Martınez-Miranda, M.D.; Román, Y. Some improved estimators of finite population quantile using auxiliary information in sample surveys. Comput. Stat. Data Anal. 2004, 45, 825–848. [Google Scholar] [CrossRef]
- Särndal, C.E. Sample survey theory vs. general statistical theory: Estimation of the population mean. Int. Stat. Rev. Rev. Int. Stat. 1972, 40, 1–12. [Google Scholar] [CrossRef]
- Tarima, S.; Pavlov, D. Using auxiliary information in statistical function estimation. ESAIM Probab. Stat. 2006, 10, 11–23. [Google Scholar] [CrossRef]
- Neyman, J. Contribution to the theory of sampling human populations. J. Am. Stat. Assoc. 1938, 33, 101–116. [Google Scholar] [CrossRef]
- Sukhatme, B.V. Some ratio-type estimators in two-phase sampling. J. Am. Stat. Assoc. 1962, 57, 628–632. [Google Scholar] [CrossRef]
- Erinola, A.Y.; Singh, R.V.K.; Audu, A.; James, T. Modified class of estimator for finite population mean under two-phase sampling using regression estimation approach. Asian J. Probab. Stat. 2021, 4, 52–64. [Google Scholar] [CrossRef]
- Garg, N.; Srivastava, M. A general class of estimators of a finite population mean using multi-auxiliary information under two stage sampling scheme. J. Reliab. Stat. Stud. 2009, 2, 103–118. [Google Scholar]
- Guha, S.; Chandra, H. Improved estimation of finite population mean in two-phase sampling with subsampling of the nonrespondents. Math. Popul. Stud. 2021, 28, 24–44. [Google Scholar] [CrossRef]
- Daraz, U.; Wu, J.; Agustiana, D.; Emam, W. Finite population variance estimation using Monte Carlo simulation and real life application. Symmetry 2025, 17, 84. [Google Scholar] [CrossRef]
- Daraz, U.; Agustiana, D.; Wu, J.; Emam, W. Twofold auxiliary information under two-phase sampling: An improved family of double-transformed variance estimators. Axioms 2025, 14, 64. [Google Scholar] [CrossRef]
- Singh, H.P.; Vishwakarma, G.K. Modified exponential ratio and product estimators for finite population mean in double sampling. Austrian J. Stat. 2007, 36, 217–225. [Google Scholar] [CrossRef]
- Singh, H.P.; Espeio, M.R. Double sampling ratio-product estimator of a finite population mean in sample surveys. J. Appl. Stat. 2007, 34, 71–85. [Google Scholar] [CrossRef]
- Vishwakarma, G.K.; Zeeshan, S.M. Generalized ratio-cum-product estimator for finite population mean under two-phase sampling scheme. J. Mod. Appl. Stat. Methods 2020, 19, 1–16. [Google Scholar] [CrossRef]
- Zaman, T.; Kadilar, C. New class of exponential estimators for finite population mean in two-phase sampling. Commun. Stat.-Theory Methods 2021, 50, 874–889. [Google Scholar] [CrossRef]
- Albalawi, O. Estimation techniques utilizing dual auxiliary variables in stratified two-phase sampling. AIMS Math 2024, 9, 33139–33160. [Google Scholar] [CrossRef]
- Mohanty, S.; Sahoo, J. A note on improving the ratio method of estimation through linear transformation using certain known population parameters. Sankhyā Indian J. Stat. Ser. 1995, 57, 93–102. [Google Scholar]
- Khan, M.; Shabbir, J. Some improved ratio, product, and regression estimators of finite population mean when using minimum and maximum values. Sci. World J. 2013, 2013, 431868. [Google Scholar] [CrossRef]
- Khan, M. Improvement in estimating the finite population mean under maximum and minimum values in double sampling scheme. J. Stat. Appl. Probab. Lett. 2015, 2, 115–121. [Google Scholar]
- Walia, G.S.; Kaur, H.; Sharma, M. Ratio type estimator of population mean through efficient linear transformation. Am. J. Math. Stat. 2015, 5, 144–149. [Google Scholar]
- Daraz, U.; Shabbir, J.; Khan, H. Estimation of finite population mean by using minimum and maximum values in stratified random sampling. J. Mod. Appl. Stat. Methods 2018, 17, 1–15. [Google Scholar] [CrossRef]
- Daraz, U.; Khan, M. Estimation of variance of the difference-cum-ratio-type exponential estimator in simple random sampling. Res. Math. Stat. 2021, 8, 1899402. [Google Scholar] [CrossRef]
- Daraz, U.; Wu, J.; Albalawi, O. Double exponential ratio estimator of a finite population variance under extreme values in simple random sampling. Mathematics 2024, 12, 1737. [Google Scholar] [CrossRef]
- Alghamdi, A.S.; Alrweili, H. A comparative study of new ratio-type family of estimators under stratified two-phase sampling. Mathematics 2025, 13, 327. [Google Scholar] [CrossRef]
- Alghamdi, A.S.; Alrweili, H. New class of estimators for finite population mean under stratified double phase sampling with simulation and real-life application. Mathematics 2025, 13, 329. [Google Scholar] [CrossRef]
- Cekim, H.O.; Cingi, H. Some estimator types for population mean using linear transformation with the help of the minimum and maximum values of the auxiliary variable. Hacet. J. Math. Stat. 2017, 46, 685–694. [Google Scholar]
- Alomair, M.A.; Daraz, U. Dual transformation of auxiliary variables by using outliers in stratified random sampling. Mathematics 2024, 12, 2829. [Google Scholar] [CrossRef]
- Daraz, U.; Alomair, M.A.; Albalawi, O.; Al Naim, A.S. New techniques for estimating finite population variance using ranks of auxiliary variable in two-stage sampling. Mathematics 2024, 12, 2741. [Google Scholar] [CrossRef]
- Chatterjee, S.; Hadi, A.S. Regression Analysis by Example; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Daraz, U.; Wu, J.; Alomair, M.A.; Aldoghan, L.A. New classes of difference cum-ratio-type exponential estimators for a finite population variance in stratified random sampling. Heliyon 2024, 10, e33402. [Google Scholar] [CrossRef]
- Daraz, U.; Alomair, M.A.; Albalawi, O. Variance estimation under some transformation for both symmetric and asymmetric data. Symmetry 2024, 16, 957. [Google Scholar] [CrossRef]
- Bureau of Statistics. Punjab Development Statistics; Government of the Punjab: Lahore, Pakistan, 2013.
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}