
Sure Independence Screening for Ultrahigh-Dimensional Additive Model with Multivariate Response

Abstract
1. Introduction
2. Sure Independence Screening Using Random Vector Correlation
- (C1)
- The distribution of is absolutely continuous, and its density is bounded away from zero and infinity on , where a and b are finite real numbers.
- (C2)
- The nonparametric components , , belong to , where the rth derivative, , exists and satisfies the Lipschitz Condition with exponent : for some positive constant K. Here, r is a non-negative integer and such that .
- (C3)
- is bound: .
- (C4)
- The random error vector satisfies for all .
- (C5)
- for some and .
- (C6)
- There exist and such that and . Here, , , and are given in Fact 1 and Fact 3 of [7].
3. Iterative Sure Independence Screening Using Random Vector Correlation
| Algorithm 1 RVC-ISIS Algorithm |
|
4. Numerical Studies
- (i)
- : The average rank of in terms of the sorted list via the screening procedure based on 1000 replications. The higher the ranking of , the greater the probability of being selected.
- (ii)
- M: The minimum model size to include all active predictors. In other words, M represents the largest rank of the true predictors: , where is the true model. We report the , and quantiles of M from 1000 repetitions.
- (iii)
- : The proportion of important predictor being selected for a given model size in the 1000 replications.
- (iv)
- : The proportion of all active predictors being selected into the submodel with size over 1000 simulations.
5. Application
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Fan, J.; Lv, J. Sure independence screening for ultrahigh-dimensional feature space. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2008, 70, 849–911. [Google Scholar] [CrossRef]
- Fan, J.; Samworth, R.; Wu, Y. Ultrahigh-dimensional feature selection: Beyond the linear model. J. Mach. Learn. Res. 2009, 10, 2013–2038. [Google Scholar] [PubMed]
- Li, X.; Cheng, G.; Wang, L.; Lai, P.; Song, F. Ultrahigh-dimensional feature screening via projection. Comput. Stats Data Anal. 2017, 114, 88–104. [Google Scholar] [CrossRef]
- Liu, S.; Li, X.; Zhang, J. Ultrahigh-dimensional feature screening for additive model with multivariate response. J. Stat. Comput. Simul. 2020, 90, 775–799. [Google Scholar] [CrossRef]
- Fan, J.; Song, R. Sure independence screening in generalized linear models with NP-dimensionality. Ann. Stat. 2010, 38, 3567–3604. [Google Scholar] [CrossRef]
- Zhu, L.P.; Li, L.; Li, R.; Zhu, L.X. Model-free feature screening for ultrahigh-dimensional data. J. Am. Stat. Assoc. 2011, 106, 1464–1475. [Google Scholar] [CrossRef]
- Fan, J.; Feng, Y.; Song, R. Nonparametric independence screening in sparse ultra-high-dimensional additive models. J. Am. Stat. Assoc. 2011, 106, 544–557. [Google Scholar] [CrossRef]
- Yuan, Y.; Billor, N. Sure independent screening for functional regression model. Commun. Stat.-Simul. Comput. 2024, 1–20. [Google Scholar] [CrossRef]
- Cui, H.; Zou, F.; Ling, L. Feature screening and error variance estimation for ultrahigh-dimensional linear model with measurement errors. Commun. Math. Stat. 2025, 13, 139–171. [Google Scholar] [CrossRef]
- Li, R.; Zhong, W.; Zhu, L. Feature screening via distance correlation learning. J. Am. Stat. Assoc. 2012, 107, 1129–1139. [Google Scholar] [CrossRef]
- Shao, X.; Zhang, J. Martingale difference correlation and its use in high-dimensional variable screening. J. Am. Stat. Assoc. 2014, 109, 1302–1318. [Google Scholar] [CrossRef]
- Cui, H.; Li, R.; Zhong, W. Model-free feature screening for ultrahigh-dimensional discriminant analysis. J. Am. Stat. Assoc. 2015, 110, 630–641. [Google Scholar] [CrossRef]
- Chen, S.; Lu, J. Quantile-Composited feature screening for ultrahigh-dimensional data. Mathematics 2023, 11, 2398. [Google Scholar] [CrossRef]
- Liu, R.; Deng, G.; He, H. Generalized Jaccard feature screening for ultra-high dimensional survival data. AIMS Math. 2024, 9, 27607–27626. [Google Scholar] [CrossRef]
- Sang, Y.; Dang, X. Grouped feature screening for ultrahigh-dimensional classification via Gini distance correlation. J. Multivar. Anal. 2024, 204, 105360. [Google Scholar] [CrossRef]
- Wu, J.; Cui, H. Model-free feature screening based on Hellinger distance for ultrahigh-dimensional data. Stat. Pap. 2024, 65, 5903–5930. [Google Scholar] [CrossRef]
- Zhong, W.; Li, Z.; Guo, W.; Cui, H. Semi-distance correlation and its applications. J. Am. Stat. Assoc. 2024, 119, 2919–2933. [Google Scholar] [CrossRef]
- Tian, Z.; Lai, T.; Zhang, Z. Variation of conditional mean and its application in ultrahigh-dimensional feature screening. Commun. Stat.-Theory Methods 2025, 54, 352–382. [Google Scholar] [CrossRef]
- Li, L.; Ke, C.; Yin, X.; Yu, Z. Generalized martingale difference divergence: Detecting conditional mean independence with applications in variable screening. Comput. Stat. Data Anal. 2023, 180, 107618. [Google Scholar] [CrossRef]
- Liu, L.; Lian, H.; Huang, J. More efficient estimation of multivariate additive models based on tensor decomposition and penalization. computational statistics and data analysis. J. Mach. Learn. Res. 2024, 25, 1–27. [Google Scholar]
- Desai, N.; Baladandayuthapani, V.; Shinohara, R.; Morris, J. Covariance Assisted Multivariate Penalized Additive Regression (CoMPAdRe). J. Comput. Graph. Stat. 2024, 1–10. [Google Scholar] [CrossRef]
- Escoufier, Y. Le traitement des variables vectorielles. Biometrics 1973, 29, 751–760. [Google Scholar] [CrossRef]
- Zhong, W.; Zhu, L. An iterative approach to distance correlation-based sure independence screening. J. Stat. Comput. Simul. 2015, 85, 2331–2345. [Google Scholar] [CrossRef]
- Liu, J.; Li, R.; Wu, R. Feature selection for varying coefficient models with ultrahigh-dimensional covariates. J. Am. Stat. Assoc. 2014, 109, 266–274. [Google Scholar] [CrossRef]
- Spellman, P.T.; Sherlock, G.; Zhang, M.Q.; Iyer, V.R.; Anders, K.; Eisen, M.B.; Brown, P.O.; Botstein, D.; Futcher, B. Comprehensive identification of cell cycle–regulated genes of the yeast Saccharomyces cerevisiae by microarray hybridization. Mol. Biol. Cell 1998, 9, 3273–3297. [Google Scholar] [CrossRef]
- Lee, T.I.; Rinaldi, N.J.; Robert, F.; Odom, D.T.; Bar-Joseph, Z.; Gerber, G.K.; Hannett, N.M.; Harbison, C.T.; Thompson, C.M.; Young, R.A.; et al. Transcriptional regulatory networks in Saccharomyces cerevisiae. Science 2002, 298, 799–804. [Google Scholar] [CrossRef] [PubMed]
- Chun, H.; Keles, S. Sparse partial least squares regression for simultaneous dimension reduction and variable selection. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2010, 72, 3–25. [Google Scholar] [CrossRef]
- Wang, L.; Chen, G.; Li, H. Group SCAD regression analysis for microarray time course gene expression data. Bioinformatics 2007, 23, 1486–1494. [Google Scholar] [CrossRef]
- Muthyala, M.; Sorourifar, F.; Paulson, J.A. TorchSISSO: A PyTorch-based implementation of the sure independence screening and sparsifying operator for efficient and interpretable model discovery. Digit. Chem. Eng. 2024, 13, 100198. [Google Scholar] [CrossRef]
- Xie, W.; Yu, Y.; Huang, Q.; Yan, X.; Yang, Y.; Xiong, C.; Liu, Z.; Wan, J.; Gong, S.; Wang, L.; et al. Epidemiology and management patterns of chronic thromboembolic pulmonary hypertension in China: A systematic literature review and meta-analysis. Chin. Med J. 2025, 138, 1000–1002. [Google Scholar] [CrossRef]
- Song, Y.; Zhou, W.; Zhou, W.X. Large-scale inference of multivariate regression for heavy-tailed and asymmetric data. Stat. Sin. 2023, 33, 1831–1852. [Google Scholar] [CrossRef]
- Serfling, R.J. Approximation Theorems of Mathematical Statistics; John Wiley & Sons: Hoboken, NJ, USA, 1980. [Google Scholar]
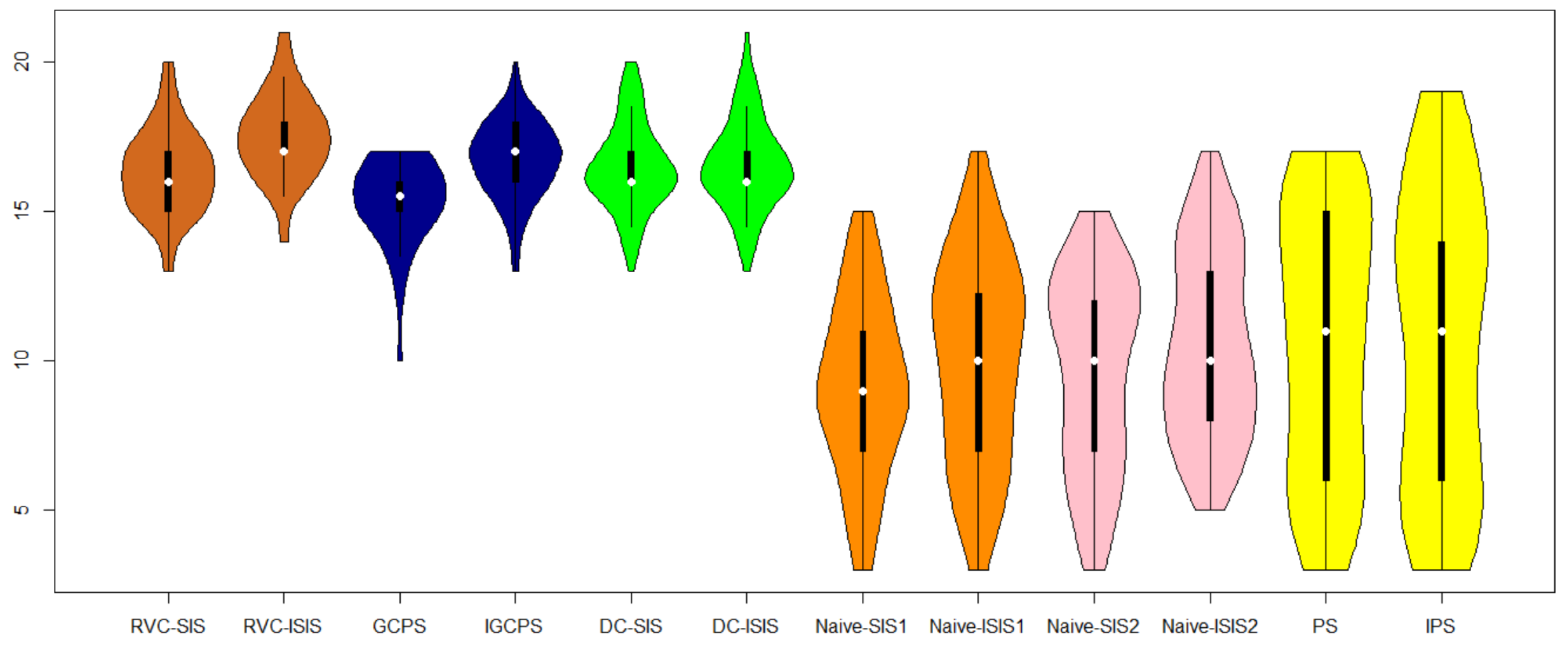
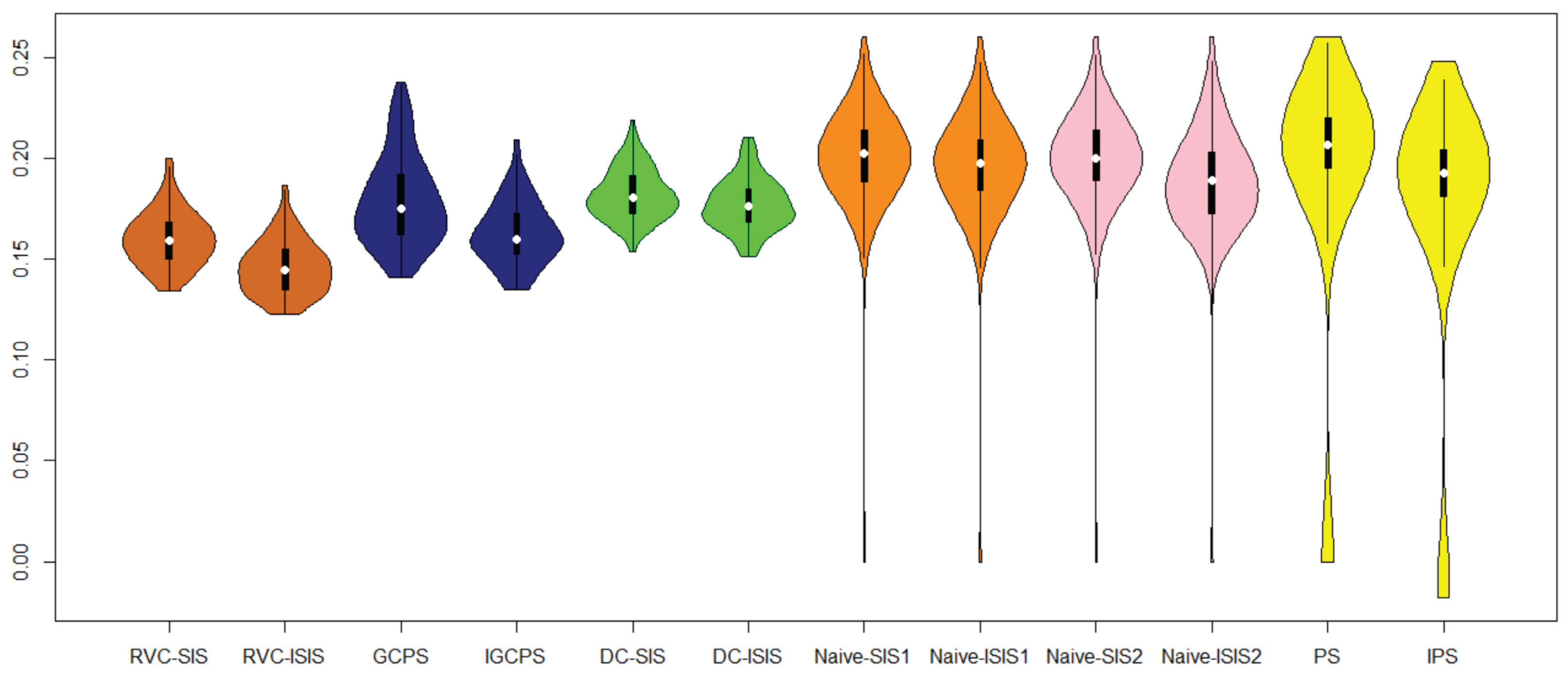

{kind=link}
{kind=link}
| Method | ||||||
|---|---|---|---|---|---|---|
| Example 1 | Naive-SIS1 | 4.108 | 2.48 | 2.002 | 2.488 | 4.056 |
| Naive-ISIS1 | 3.856 | 2.742 | 2.202 | 2.342 | 3.878 | |
| Naive-SIS2 | 3.71 | 2.726 | 2.408 | 2.722 | 3.634 | |
| Naive-ISIS2 | 4.236 | 3.056 | 2.408 | 2.546 | 2.886 | |
| PS | 2.94 | 2.998 | 2.99 | 2.988 | 3.084 | |
| IPS | 3.656 | 1.016 | 1.986 | 3.258 | 3.798 | |
| DC-SIS | 4.53 | 2.442 | 1.862 | 2.464 | 4.154 | |
| DC-ISIS | 4.38 | 2.347 | 2.036 | 2.898 | 3.956 | |
| GCPS | 4.653 | 2.462 | 1.362 | 2.474 | 4.468 | |
| IGCPS | 4.038 | 2.847 | 1.362 | 2.998 | 4.854 | |
| RVC-SIS | 4.156 | 2.45 | 1.898 | 2.494 | 4.114 | |
| RVC-ISIS | 3.832 | 2.55 | 2.134 | 2.256 | 4.234 | |
| Example 2 | Naive-SIS1 | 1006.022 | 617.534 | 1709.544 | 1774.618 | - |
| Naive-ISIS1 | 927.04 | 465.648 | 107.872 | 48.554 | - | |
| Naive-SIS2 | 1078.528 | 654.678 | 1737.142 | 1800.202 | - | |
| Naive-ISIS2 | 1032.746 | 509.788 | 149.616 | 41.562 | - | |
| PS | 1076.362 | 865.076 | 734.618 | 570.108 | - | |
| IPS | 1000.356 | 156.824 | 9.482 | 5.864 | - | |
| DC-SIS | 125.704 | 385.02 | 2.012 | 1 | - | |
| DC-ISIS | 19.254 | 14.596 | 2.316 | 1 | - | |
| GCPS | 1.035 | 677.842 | 345.654 | 887.356 | - | |
| IGCPS | 1.035 | 28.647 | 77.336 | 96.256 | - | |
| RVC-SIS | 8.618 | 8.12 | 2.232 | 1 | - | |
| RVC-ISIS | 7.756 | 4.61 | 2.536 | 1 | - | |
| Example 3 | Naive-SIS1 | 2.746 | 2.248 | 1.028 | 1002.92 | - |
| Naive-ISIS1 | 4.232 | 2.756 | 1.028 | 5.376 | - | |
| Naive-SIS2 | 2.646 | 2.358 | 1.052 | 1003.12 | - | |
| Naive-ISIS2 | 3.836 | 3.112 | 1.052 | 5.332 | - | |
| PS | 1.556 | 2.86 | 1.584 | 1014.08 | - | |
| IPS | 1.556 | 3.948 | 1.596 | 5.386 | - | |
| DC-SIS | 2.706 | 2.284 | 1.028 | 982.866 | - | |
| DC-ISIS | 4.112 | 2.878 | 1.028 | 5 | - | |
| GCPS | 2.732 | 2.342 | 1.126 | 856.562 | - | |
| IGCPS | 4.126 | 2.964 | 1.126 | 5.051 | - | |
| RVC-SIS | 2.734 | 2.236 | 1.032 | 965.084 | - | |
| RVC-ISIS | 4.216 | 2.758 | 1.032 | 5 | - | |
| Example 4 | Naive-SIS1 | 2.908 | 2.306 | 1.026 | 1010.838 | 12.572 |
| Naive-ISIS1 | 4.208 | 2.806 | 1.026 | 41.296 | 6.024 | |
| Naive-SIS2 | 2.668 | 2.452 | 1.036 | 1011.006 | 12.306 | |
| Naive-ISIS2 | 3.796 | 3.224 | 1.036 | 56.808 | 6.044 | |
| PS | 1.552 | 2.862 | 1.586 | 977.962 | 33.456 | |
| IPS | 1.552 | 3.904 | 1.586 | 72.238 | 5.638 | |
| DC-SIS | 2.894 | 2.316 | 1.032 | 968.662 | 22.386 | |
| DC-ISIS | 4.068 | 2.926 | 1.032 | 3.000 | 6.016 | |
| GCPS | 2.825 | 2.212 | 1.262 | 1126.124 | 36.746 | |
| IGCPS | 4.534 | 2.647 | 1.262 | 3.898 | 8.956 | |
| RVC-SIS | 3.054 | 2.264 | 1.044 | 989.44 | 22.552 | |
| RVC-ISIS | 4.134 | 2.838 | 1.044 | 3.000 | 6.106 |
| Method | |||||||
|---|---|---|---|---|---|---|---|
| Example 1 | Naive-SIS1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Naive-ISIS1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| Naive-SIS2 | 1 | 1 | 1 | 1 | 1 | 1 | |
| Naive-ISIS2 | 1 | 1 | 1 | 1 | 1 | 1 | |
| PS | 1 | 1 | 1 | 1 | 1 | 1 | |
| IPS | 1 | 1 | 1 | 1 | 1 | 1 | |
| DC-SIS | 1 | 1 | 1 | 1 | 1 | 1 | |
| DC-ISIS | 1 | 1 | 1 | 1 | 1 | 1 | |
| GCPS | 1 | 1 | 1 | 1 | 1 | 1 | |
| IGCPS | 1 | 1 | 1 | 1 | 1 | 1 | |
| RVC-SIS | 1 | 1 | 1 | 1 | 1 | 1 | |
| RVC-ISIS | 1 | 1 | 1 | 1 | 1 | 1 | |
| Example 2 | Naive-SIS1 | 0.026 | 0.168 | 0 | 0 | - | 0 |
| Naive-ISIS1 | 0.054 | 0.234 | 0.798 | 0.916 | - | 0.015 | |
| Naive-SIS2 | 0.028 | 0.176 | 0 | 0 | - | 0 | |
| Naive-ISIS2 | 0.055 | 0.220 | 0.702 | 0.916 | - | 0.02 | |
| PS | 0 | 0.070 | 0.110 | 0.130 | - | 0 | |
| IPS | 0.022 | 1 | 1 | - | 0.016 | ||
| DC-SIS | 0.628 | 0.268 | 1 | 1 | - | 0.158 | |
| DC-ISIS | 0.986 | 0.998 | 1 | 1 | - | 0.984 | |
| GCPS | 1 | 0.156 | 0.278 | 0.002 | - | 0 | |
| IGCPS | 1 | 0.996 | 0.883 | 0.824 | - | 0.648 | |
| RVC-SIS | 0.964 | 0.982 | 1 | 1 | - | 0.966 | |
| RVC-ISIS | 0.988 | 0.996 | 1 | 1 | - | 0.986 | |
| Example 3 | Naive-SIS1 | 1 | 1 | 1 | 0 | - | 0 |
| Naive-ISIS1 | 1 | 1 | 1 | 1 | - | 1 | |
| Naive-SIS2 | 1 | 1 | 1 | 0 | - | 0 | |
| Naive-ISIS2 | 1 | 1 | 1 | 1 | - | 1 | |
| PS | 1 | 1 | 1 | 0 | - | 0 | |
| IPS | 1 | 1 | 1 | 1 | - | 1 | |
| DC-SIS | 1 | 1 | 1 | 0 | - | 0 | |
| DC-ISIS | 1 | 1 | 1 | 1 | - | 1 | |
| GCPS | 1 | 1 | 1 | 0 | - | 0 | |
| IGCPS | 1 | 1 | 1 | 1 | - | 1 | |
| RVC-SIS | 1 | 1 | 1 | 0 | - | 0 | |
| RVC-ISIS | 1 | 1 | 1 | 1 | - | 1 | |
| Example 4 | Naive-SIS1 | 1 | 1 | 1 | 0 | 1 | 0 |
| Naive-ISIS1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| Naive-SIS2 | 1 | 1 | 1 | 0 | 1 | 0 | |
| Naive-ISIS2 | 1 | 1 | 1 | 1 | 1 | 1 | |
| PS | 1 | 1 | 1 | 0 | 1 | 0 | |
| IPS | 1 | 1 | 1 | 1 | 1 | 1 | |
| DC-SIS | 1 | 1 | 1 | 0 | 1 | 0 | |
| DC-ISIS | 1 | 1 | 1 | 1 | 1 | 1 | |
| GCPS | 1 | 1 | 1 | 0 | 1 | 0 | |
| IGCPS | 1 | 1 | 1 | 1 | 1 | 1 | |
| RVC-SIS | 1 | 1 | 1 | 0 | 1 | 0 | |
| RVC-ISIS | 1 | 1 | 1 | 1 | 1 | 1 |
| Method | ||||||
|---|---|---|---|---|---|---|
| Example 1 | Naive-SIS1 | 5 | 5 | 5 | 5 | 6 |
| Naive-ISIS1 | 5 | 5 | 5 | 5 | 6 | |
| Naive-SIS2 | 5 | 5 | 5 | 5 | 6 | |
| Naive-ISIS2 | 5 | 5 | 5 | 5 | 6 | |
| PS | 5 | 5 | 5 | 5 | 5 | |
| IPS | 5 | 5 | 5 | 5 | 5 | |
| DC-SIS | 5 | 5 | 5 | 5 | 5 | |
| DC-ISIS | 5 | 5 | 5 | 5 | 5 | |
| GCPS | 5 | 5 | 5 | 5 | 5 | |
| IGCPS | 5 | 5 | 5 | 5 | 5 | |
| RVC-SIS | 5 | 5 | 5 | 5 | 6 | |
| RVC-ISIS | 5 | 5 | 5 | 5 | 6 | |
| Example 2 | Naive-SIS1 | 1668.45 | 1990.75 | 1969 | 1994 | 2000 |
| Naive-ISIS1 | 277.9 | 669 | 1015 | 1407.25 | 1887.05 | |
| Naive-SIS2 | 1713.4 | 1913 | 1975 | 1995 | 2000 | |
| Naive-ISIS2 | 261.25 | 724.95 | 1069 | 1466.5 | 1846.1 | |
| PS | 811.95 | 1215.25 | 1488.5 | 1739.25 | 1957.15 | |
| IPS | 122 | 512.75 | 982 | 1476.5 | 1940.4 | |
| DC-SIS | 22.95 | 122.75 | 315.5 | 653.5 | 1317.2 | |
| DC-ISIS | 5 | 5 | 9 | 12 | 40.1 | |
| GCPS | 280.56 | 634.85 | 948.32 | 1203.46 | 1568.12 | |
| IGCPS | 20.86 | 38.95 | 57.78 | 286.96 | 500.85 | |
| RVC-SIS | 4 | 4 | 4 | 7 | 46 | |
| RVC-ISIS | 4 | 4 | 4 | 7 | 38 | |
| Example 3 | Naive-SIS1 | 430.65 | 628.5 | 887.5 | 1326.25 | 1879.55 |
| Naive-ISIS1 | 5 | 5 | 5 | 5 | 5 | |
| Naive-SIS2 | 444.25 | 639 | 903.5 | 1343.5 | 1878.15 | |
| Naive-ISIS2 | 5 | 5 | 5 | 5 | 5 | |
| PS | 458.85 | 682.75 | 939 | 1325.75 | 1829.3 | |
| IPS | 4 | 4 | 4 | 5 | 5 | |
| DC-SIS | 337.75 | 590 | 871 | 1389.25 | 1828.3 | |
| DC-ISIS | 5 | 5 | 5 | 5 | 5 | |
| GCPS | 268.65 | 457.54 | 671.88 | 999.58 | 1509.98 | |
| IGCPS | 5 | 5 | 5 | 5 | 5 | |
| RVC-SIS | 284.65 | 596.75 | 880 | 1299.25 | 1811.35 | |
| RVC-ISIS | 5 | 5 | 5 | 5 | 5 | |
| Example 4 | Naive-SIS1 | 426.8 | 639.5 | 903 | 1394 | 1840.2 |
| Naive-ISIS1 | 6 | 6 | 6 | 6 | 6 | |
| Naive-SIS2 | 421.9 | 641.25 | 890.5 | 1368.25 | 1835.35 | |
| Naive-ISIS2 | 6 | 6 | 6 | 6 | 6 | |
| PS | 373.85 | 676.75 | 935 | 1253.25 | 1809.25 | |
| IPS | 5 | 5 | 5.5 | 6 | 7 | |
| DC-SIS | 304.9 | 609.75 | 922 | 1324.5 | 1809.05 | |
| DC-ISIS | 6 | 6 | 6 | 6 | 6 | |
| GCPS | 298.25 | 807.75 | 1130.42 | 1628.75 | 1811.50 | |
| IGCPS | 6 | 6 | 6 | 6 | 6 | |
| RVC-SIS | 258.95 | 572.5 | 934.5 | 1424.25 | 1876.15 | |
| RVC-ISIS | 6 | 6 | 6 | 6 | 6 |
| Method | AMSE | Standard Deviation |
|---|---|---|
| Naive-SIS1 | 0.1997 | 0.0281 |
| Naive-ISIS1 | 0.1959 | 0.0286 |
| Naive-SIS2 | 0.1991 | 0.0278 |
| Naive-ISIS2 | 0.1878 | 0.0288 |
| PS | 0.1898 | 0.0652 |
| IPS | 0.1749 | 0.0604 |
| DC-SIS | 0.1822 | 0.0124 |
| DC-ISIS | 0.1772 | 0.0126 |
| GCPS | 0.1668 | 0.0223 |
| IGCPS | 0.1629 | 0.0221 |
| RVC-SIS | 0.1601 | 0.0136 |
| RVC-ISIS | 0.1422 | 0.0134 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Liang, B. Sure Independence Screening for Ultrahigh-Dimensional Additive Model with Multivariate Response. Mathematics 2025, 13, 1558. https://doi.org/10.3390/math13101558
Chen Y, Liang B. Sure Independence Screening for Ultrahigh-Dimensional Additive Model with Multivariate Response. Mathematics. 2025; 13(10):1558. https://doi.org/10.3390/math13101558
Chicago/Turabian StyleChen, Yongshuai, and Baosheng Liang. 2025. "Sure Independence Screening for Ultrahigh-Dimensional Additive Model with Multivariate Response" Mathematics 13, no. 10: 1558. https://doi.org/10.3390/math13101558
APA StyleChen, Y., & Liang, B. (2025). Sure Independence Screening for Ultrahigh-Dimensional Additive Model with Multivariate Response. Mathematics, 13(10), 1558. https://doi.org/10.3390/math13101558