Diabetes is a chronic disease characterized by insufficient insulin secretion from the pancreas or a decrease in the body’s sensitivity to insulin, resulting in an increase in blood sugar levels [
1,
2,
3]. According to the statistics of the China Diabetes Market Report: 2024–2032, China is presently the nation with the greatest number of diabetics globally, and the prevalence of diabetes has risen to about 12%. Long-term complications of diabetes can result in serious vision problems, with DR serving as the primary cause of blindness among individuals aged 20–64 [
4]. DR is a severe eye complication resulting from diabetes, characterized by thinning of the retinal blood vessel wall, hemorrhage, fluid exudation, macular edema, and abnormal angiogenesis. These pathological changes may eventually lead to vision loss or even blindness [
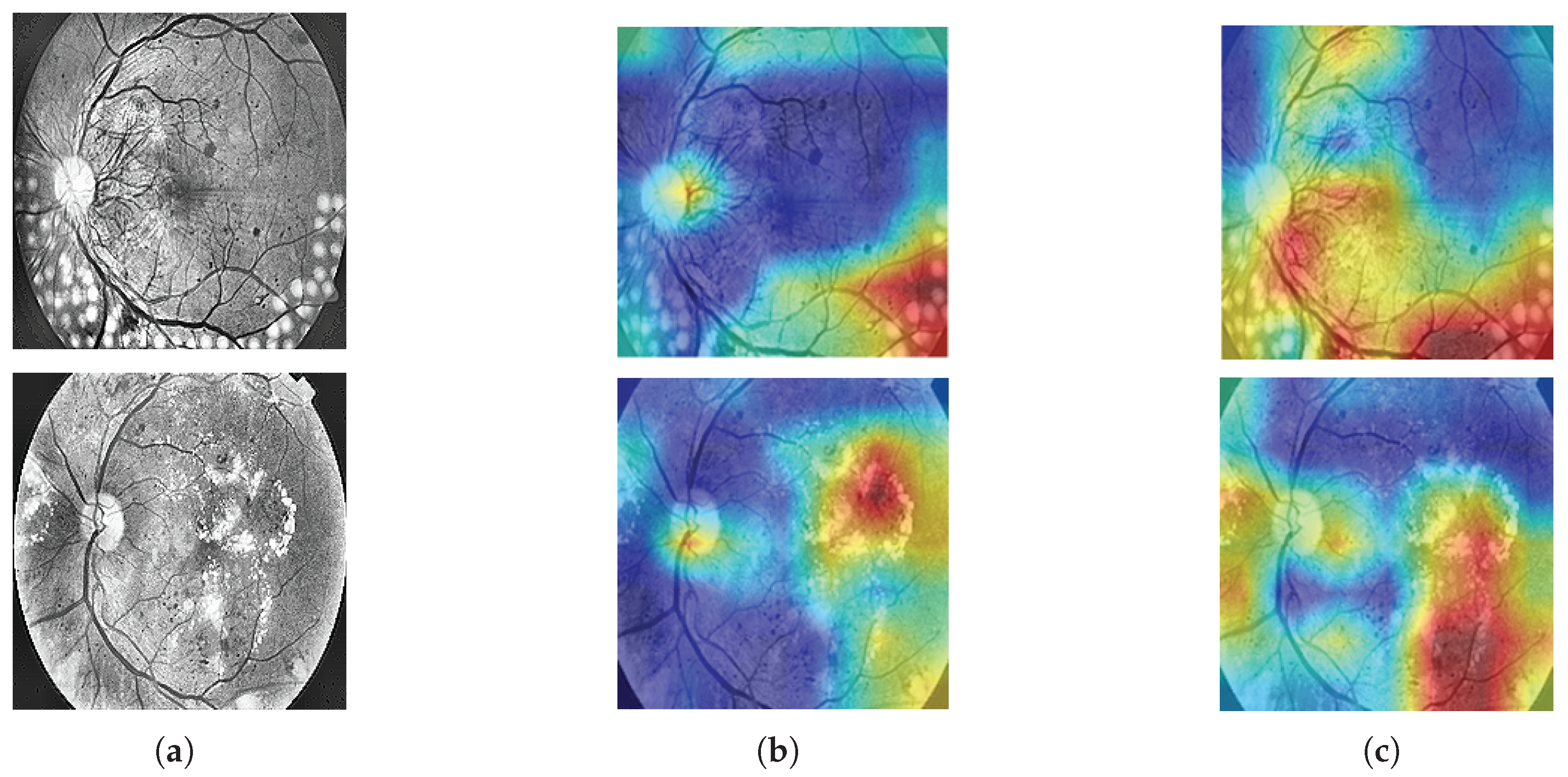
5]. The pathologic features of DR include microaneurysms (MAs), hard exudates (EXs), soft exudates (SEs), and hemorrhages (HEs) [
6]. Based on the International Clinical Diabetic Retinopathy Scale (ICDRS), the types of DR are classified as normal, mild nonproliferative, moderately nonproliferative, severe nonproliferative, and proliferative. These five types of DR are illustrated in
Figure 1 below.
Screening for DR facilitates the early detection and management of DR because it is often asymptomatic in the early stages. Many patients remain unaware of the condition until significant vision impairment occurs [
7,
8]. However, the number of DR patients continues to rise, while experienced ophthalmologists are both scarce and unevenly distributed [
9]. In addition, even professional ophthalmologists are susceptible to misdiagnosis. Therefore, the use of computer-aided diagnosis can effectively alleviate these challenges by reducing the workload of ophthalmologists, shortening examination times, and enabling patients to gain a faster understanding of their condition. In recent years, convolutional neural networks (CNNs) have achieved remarkable advancements in the domain of computer vision and have become an important tool for various applications. Benefiting from the powerful feature extraction capability of CNNs, they are widely used in DR classification tasks [
10,
11,
12]. To be specific, a neural network architecture named DcardNet is designed in [
13], which adopts adaptive rate dropout to improve classification accuracy and reliability and generates three independent classification levels to meet the needs of clinical diagnosis. The accuracy of the network in DR classification is better than that of the existing models, which could accurately identify patients who needed further diagnosis by ophthalmologists and provided important technical support for reducing the visual damage caused by DR. The application of the ResNet architecture in retinal image classification is developed in [
14]. Compared with other deep learning models, the ResNet-18 model with Swish activation function is experimentally proved to perform best. Ref. [
15] uses a fusion dark channel prior approach for color enhancement and uses the EfficientNetV2 model for DR lesion detection, which can achieve efficient classification. In [
16], a new approach is proposed to solve the problem of limited accuracy and interpretability of deep neural networks (DNNs) caused by limited datasets. Based on this method, the eye tracker is used to obtain the eye movement view of the ophthalmologist at the time of diagnosing DR and combined with the original fundus image (using OTSU fusion and weighted fusion). The attention guidance mechanism of Class Activation Map (CAM) regularization significantly improves the accuracy and interpretability of the early DR detection model. On the DIARETDB0 and DIARETDB1 public datasets, the accuracy of the model is 94% and 94.83%, respectively. However, despite the promising results achieved by CNN-based DR grading methods, several challenges remain in their practical clinical application. First, DR features do not exist in isolation but often appear at the same time and may appear in different combinations in different grades. It is easy to confuse and affect the diversity between categories. Second, there is a significant class imbalance in DR datasets, with certain grades being overrepresented, while others are underrepresented. As a result, models tend to focus disproportionately on the grades with abundant samples, neglecting those with fewer examples. This imbalance adversely affects the model’s generalization ability. The above two problems increase the complexity and difficulty of the DR grading task. The attention mechanism aids in capturing fine-grained features in the majority of computer vision tasks and has found extensive application in image classification [
17,
18,
19,
20]. To leverage this capability, a new DR classification model, CABNet, is addressed in [
21] to improve the model performance by learning global features through the Global Attention Module (GAB) and the Category Attention Block (CAB) learning specific local features. In [
22], in view of the fact that the classification model cannot highlight the important parts, an innovative texture attention mechanism network is introduced. This architecture first extracts image features using an encoder, then enhances key information through a specialized texture and spatial attention module, and finally performs accurate DR image classification via a feature fusion step. A novel convolutional network called MVDRNet is developed in [
23], which automatically detects DR by integrating multi-view fundus images and using deep convolutional neural networks (DCNNs) and attention mechanisms. Thus, the problem of incomplete lesion characteristics caused by visual field limitation in the single-view method can be solved. In [
24], a two-branch CNN-Trans model is proposed for fundus image classification. This model includes CNN-LSTM and ViT branches, where the CNN-LSTM branch extracts features through Xception, and combines LSTM and a coordinate attention mechanism to enhance feature extraction, and the ViT branch uses a self-attention mechanism to capture global features. They are fused to perform classification, achieving an accuracy of 80.68%, which is comparable to the best existing methods.
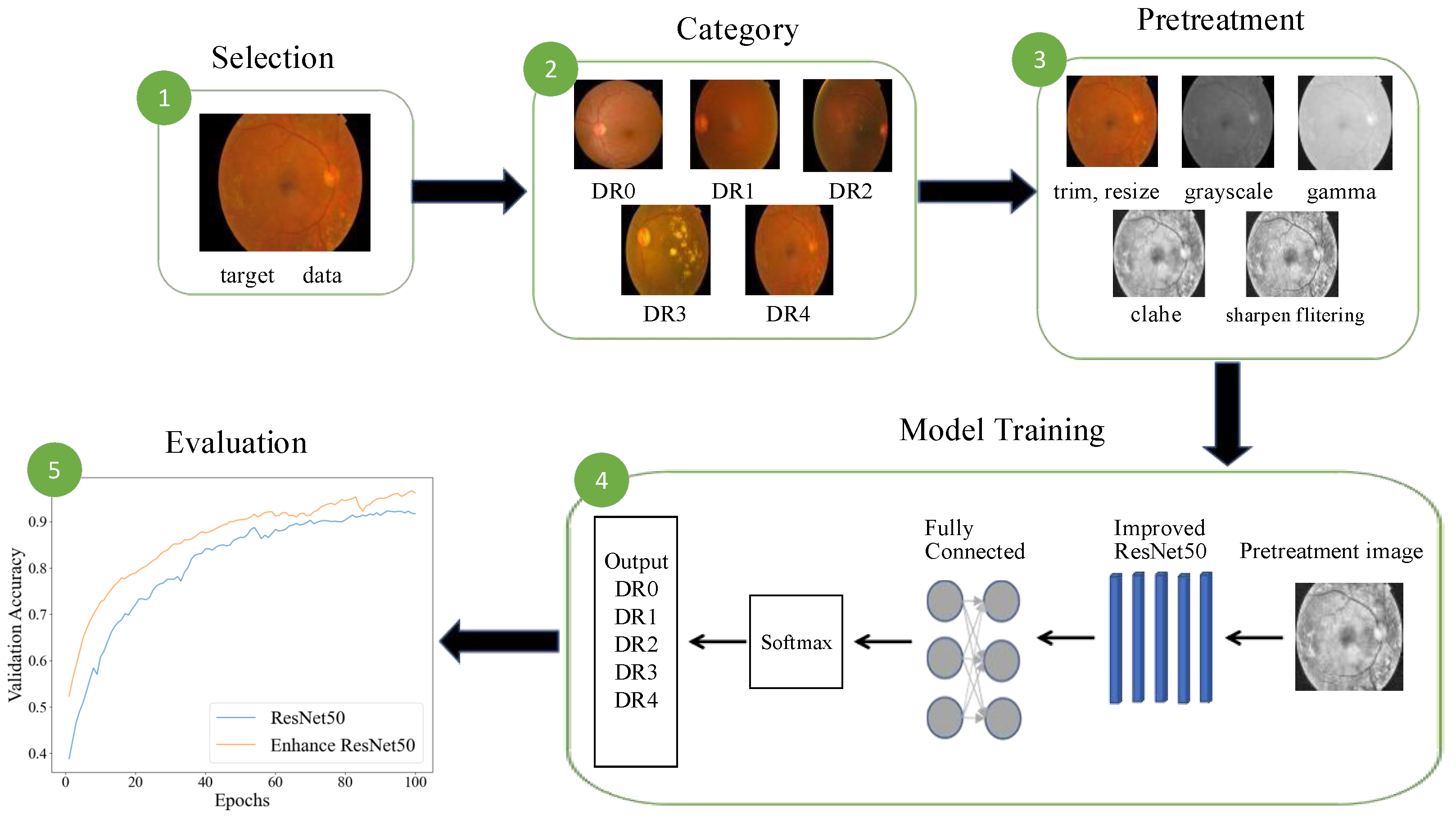
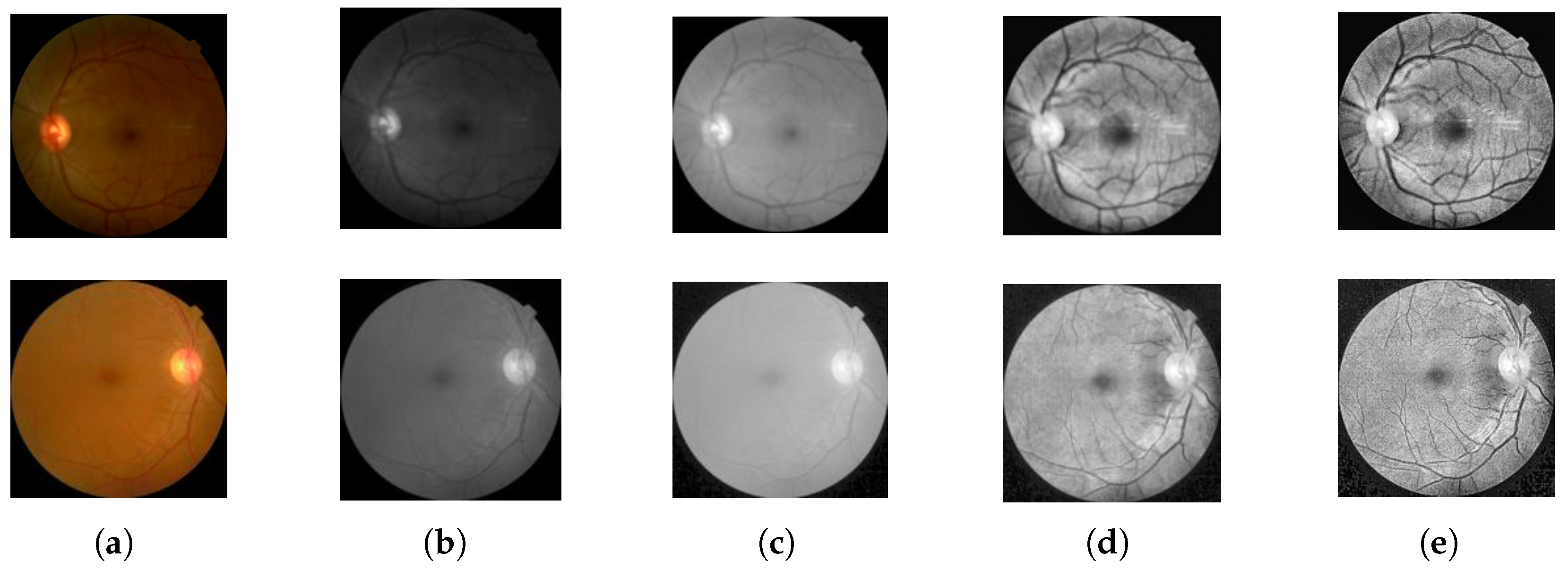
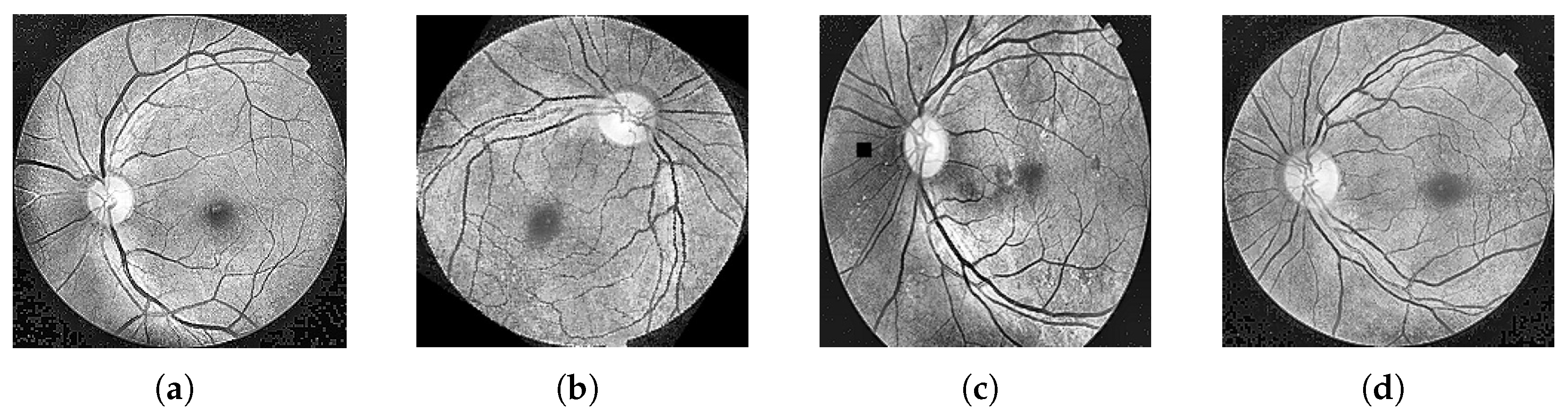
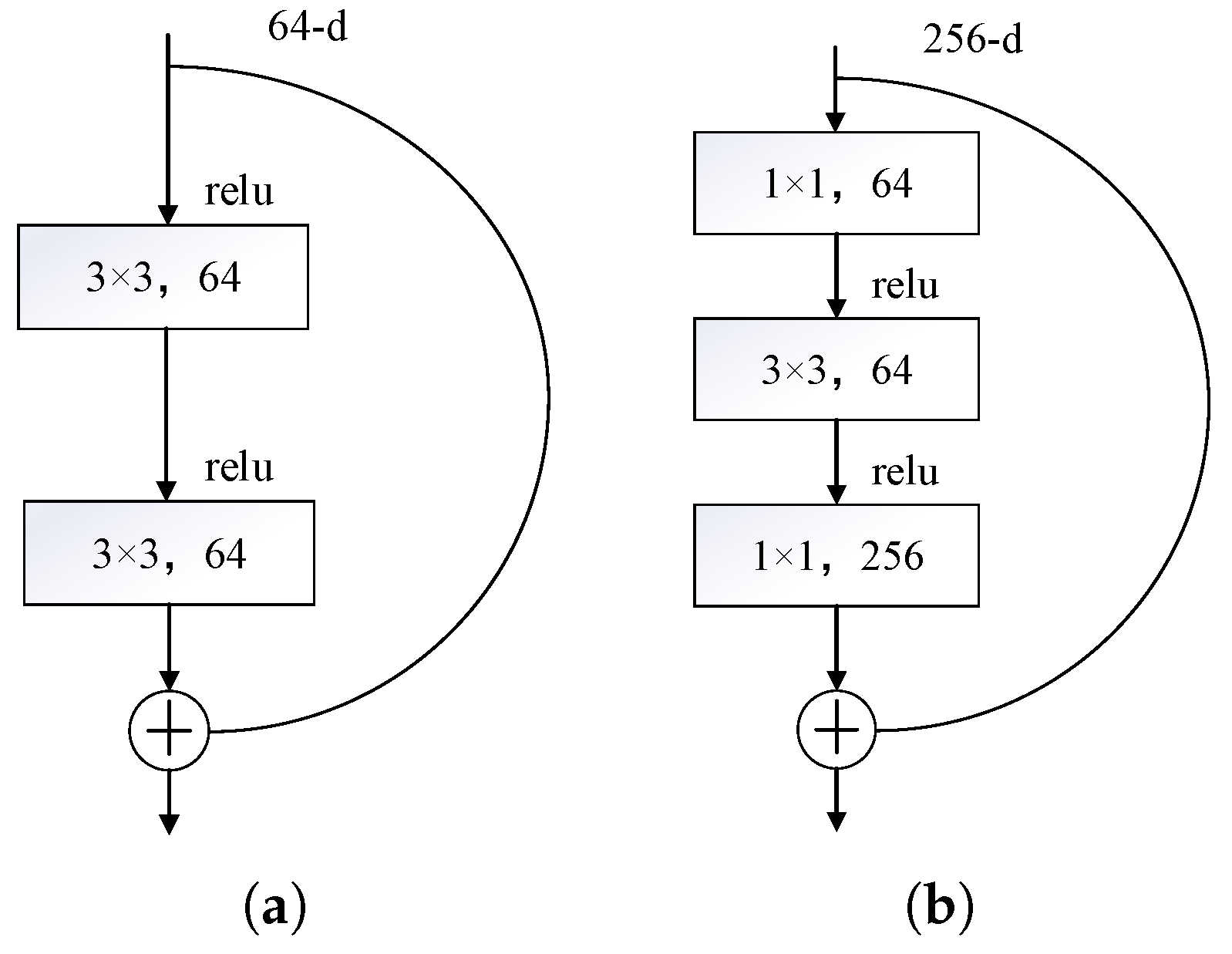
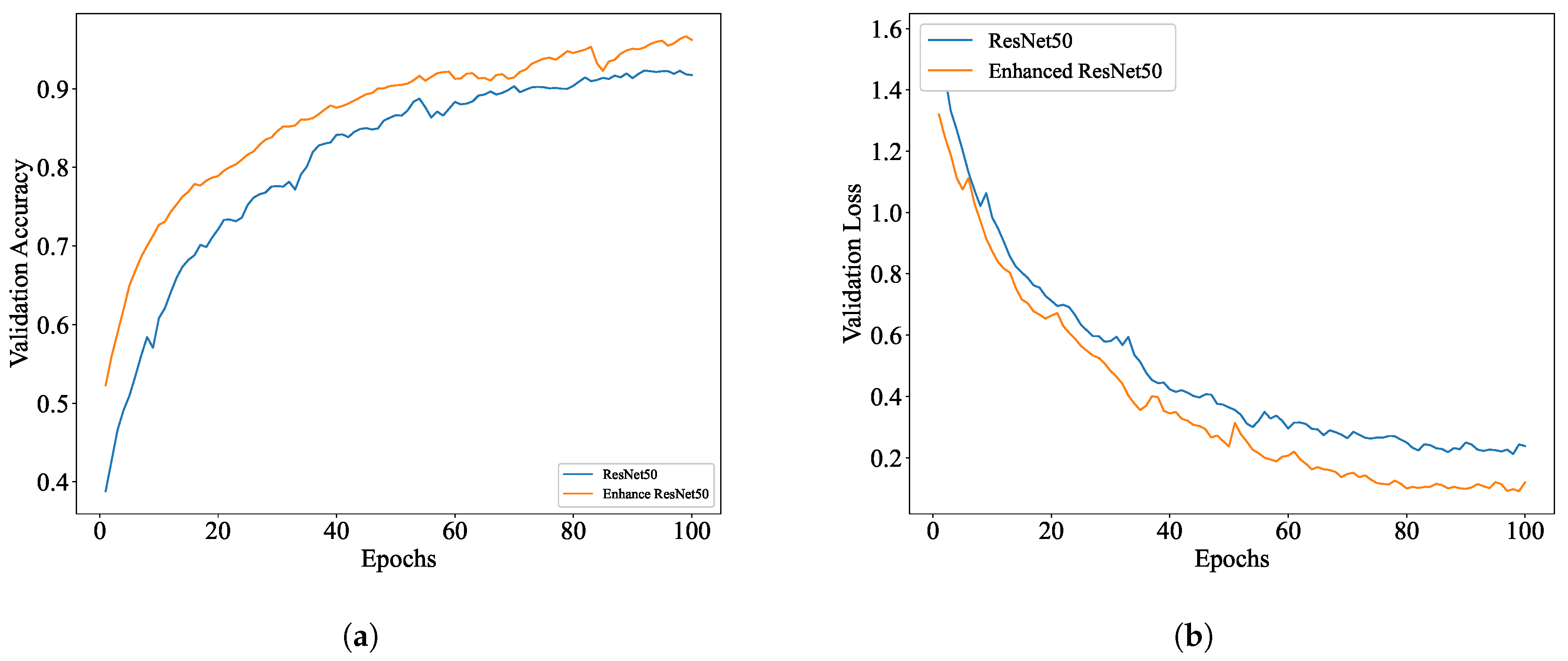
In addition to employing the attention mechanism to address the issue of fine-grained feature extraction, DR images often suffer from problems such as poor image quality and significant scale disparities. Regarding this observation, our research carries out image preprocessing and image augmentation by taking the classical model Resnet50 as the benchmark model. Meanwhile, the external attention mechanism is adopted to replace the 3 × 3 convolution of the residual structure, and multiscale convolution is further added at the residual connection branch to introduce a nonlinear transformation. This makes the residual connection no longer a simple linear identity mapping. To boost the model training process, the traditional SGD optimizer is replaced by the Sophia optimizer, which integrates the advantages of momentum and adaptive learning rates, enabling more efficient parameter adjustments during training. This accelerates convergence and improves training stability and overall model performance. The main enhancements are given as follows: (1) improved perception of image details, enabling the model to better handle the intricacies of DR classification; (2) enhanced expressive capability through nonlinear transformations, enriching the model’s capacity to represent complex patterns; (3) optimized training process, resulting in faster convergence and greater stability.








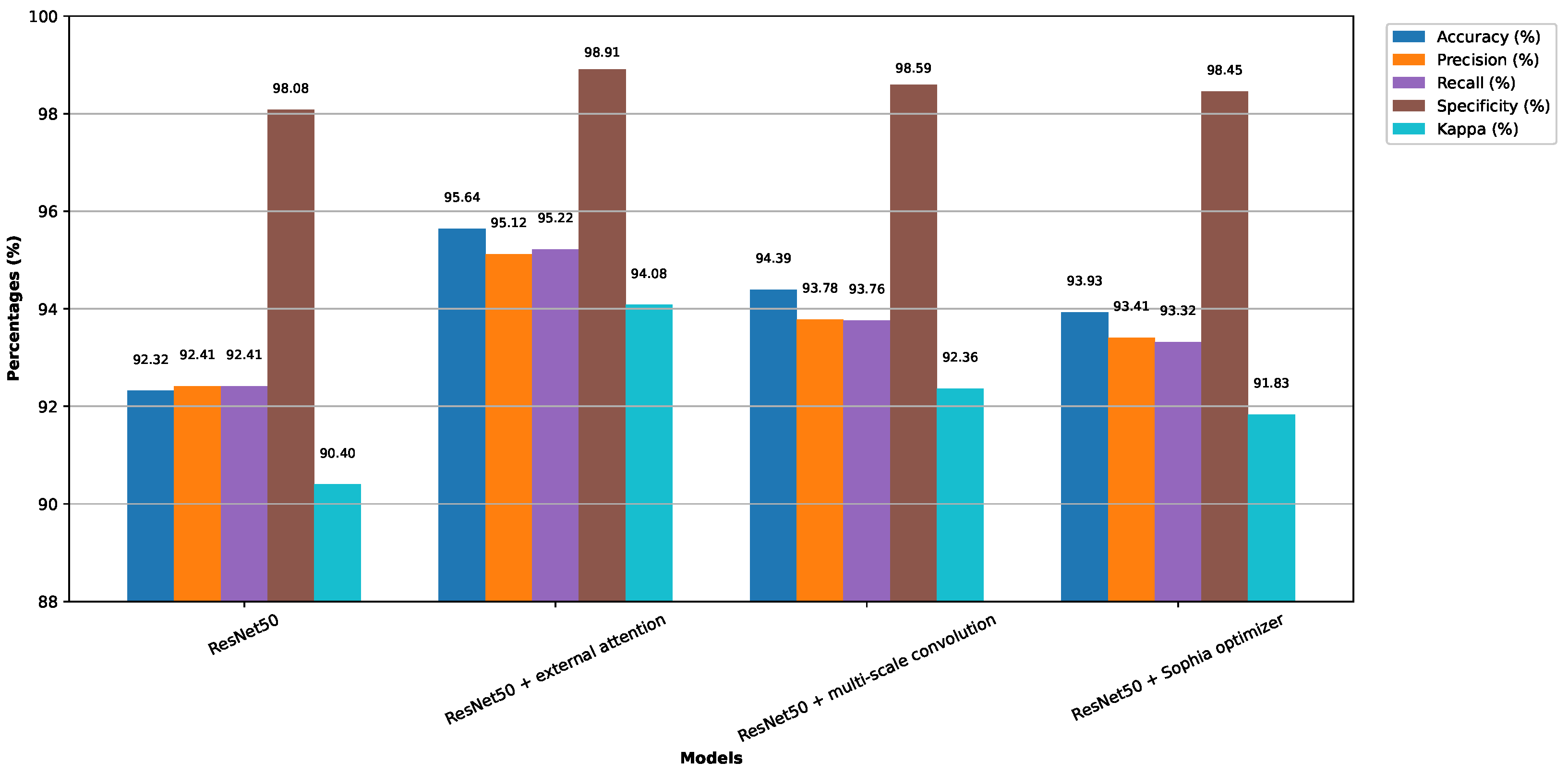


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}