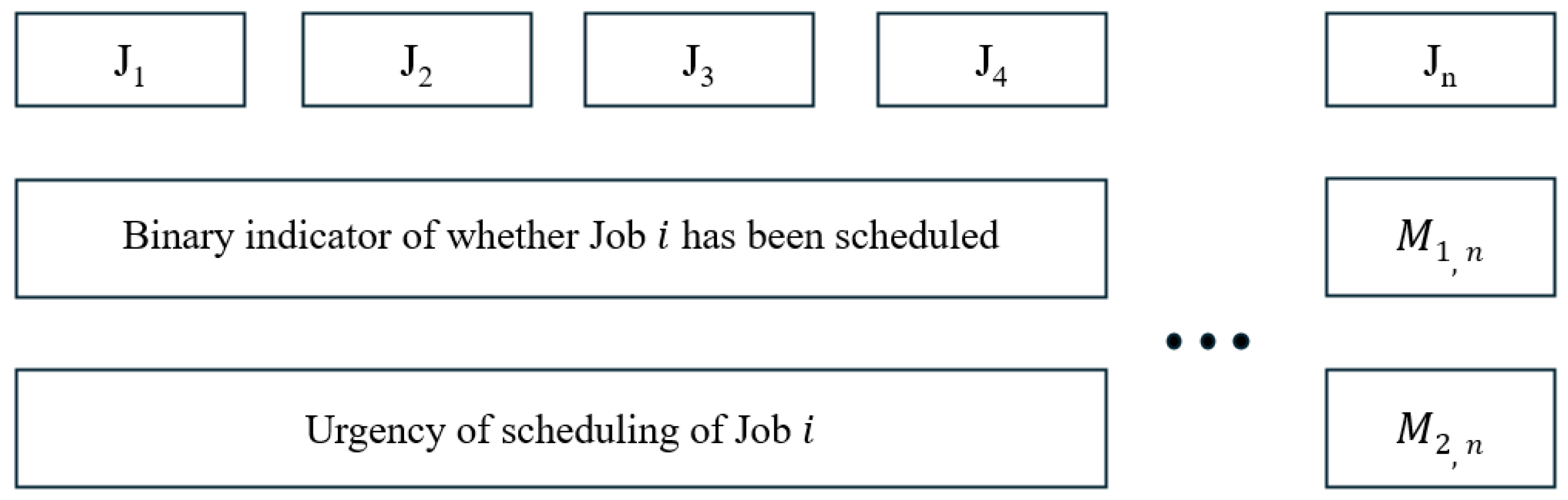
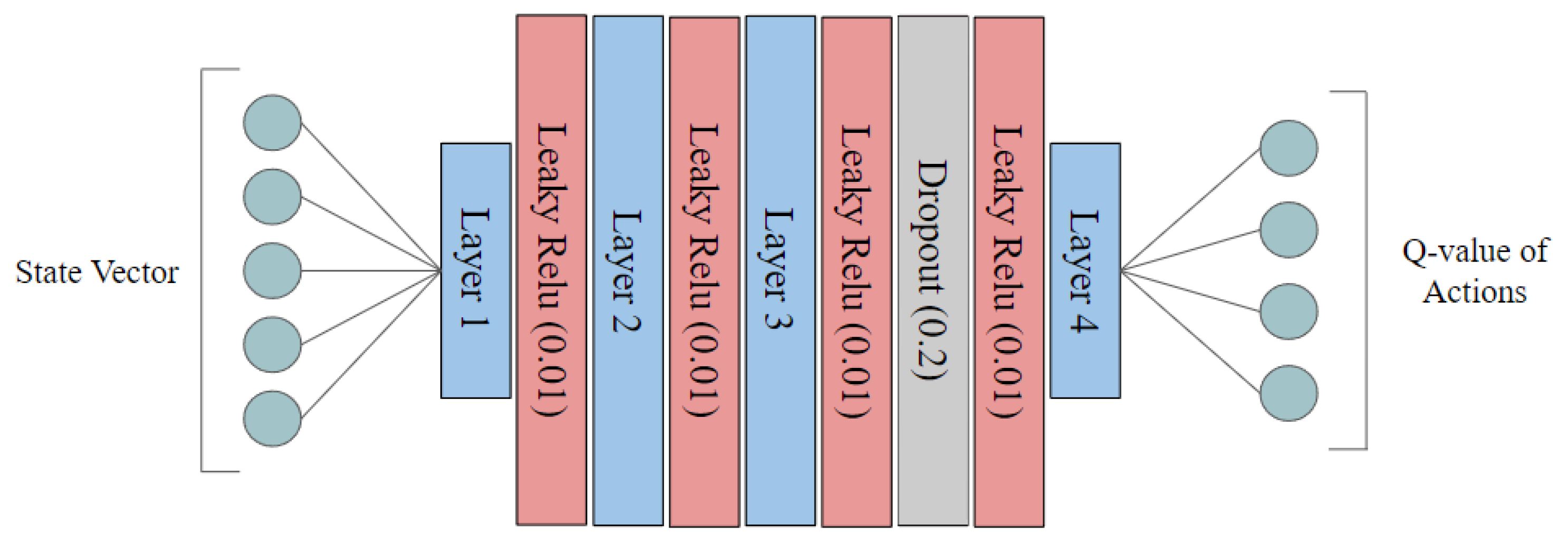
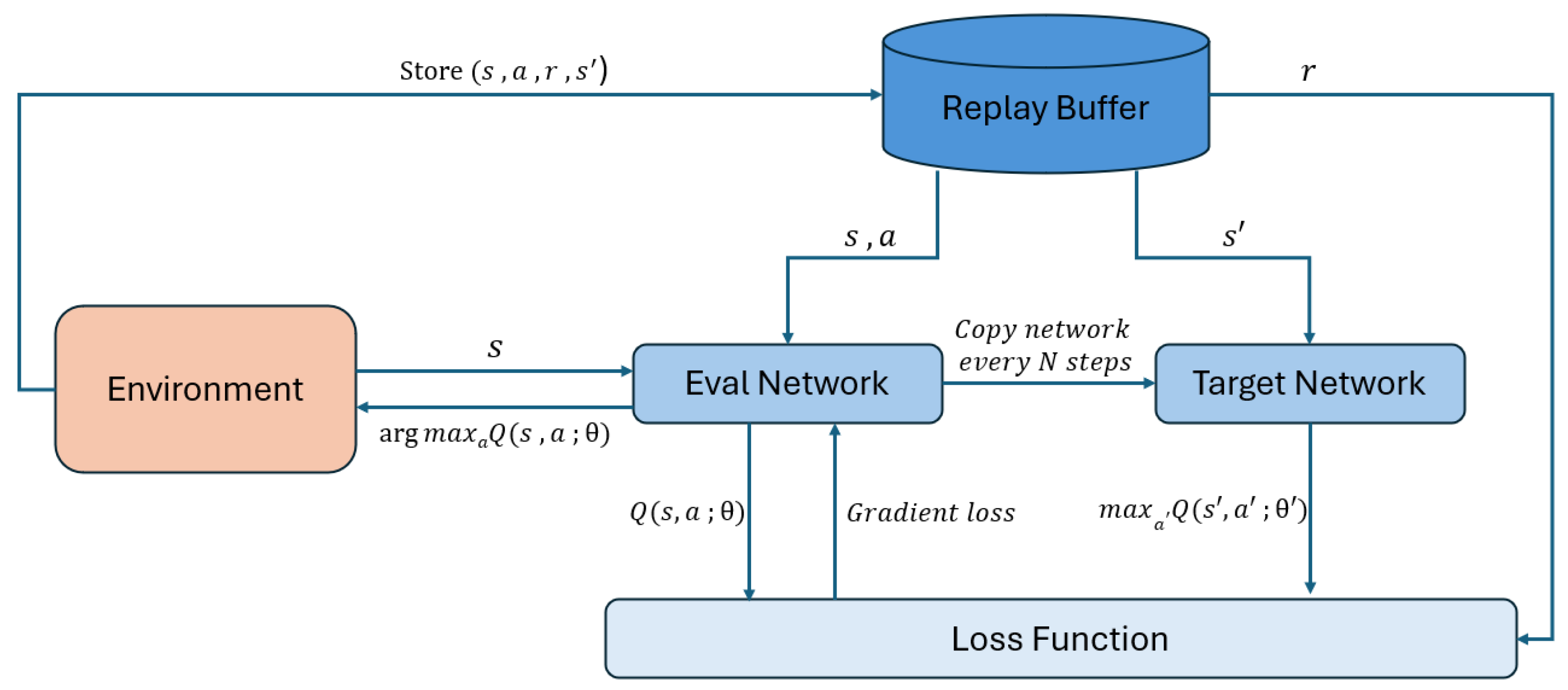
1. Introduction
Scheduling refers to allocating various limited resources such as materials, machines, technicians, vehicles, etc. to concerned economic activities over the time horizon, subject to technical constraints, so as to optimize certain managerial criteria. The makespan, the total completion time, the number of late jobs, and the total tardiness are among the widely used performance measures in industry and academia. Scheduling problems constitute a prominent research area in management science and operations research due to the theoretical interest and challenges as well as a wide spectrum practical applications in manufacturing, logistics, service, and project management, just to name a few. Along with the booming trend of artificial intelligence, machine learning techniques are widely adopted to tackle hard scheduling problems [
1]. In this paper, we use the total tardiness minimization problem as an example to illustrate the use of problem-specific optimization heuristic information to enrich the performance of a machine learning approach. Tardiness is the late deviation of order fulfillment beyond the due date quoted to its client. Total tardiness, one of the classical managerial criteria investigated in scheduling researches, is concerned about operational efficiency, customer satisfaction or service quality, and overall system performance. Consider the example instance of five jobs or production orders shown in
Table 1. Each job is characterized by a required production length and a due date quoted to its customer.
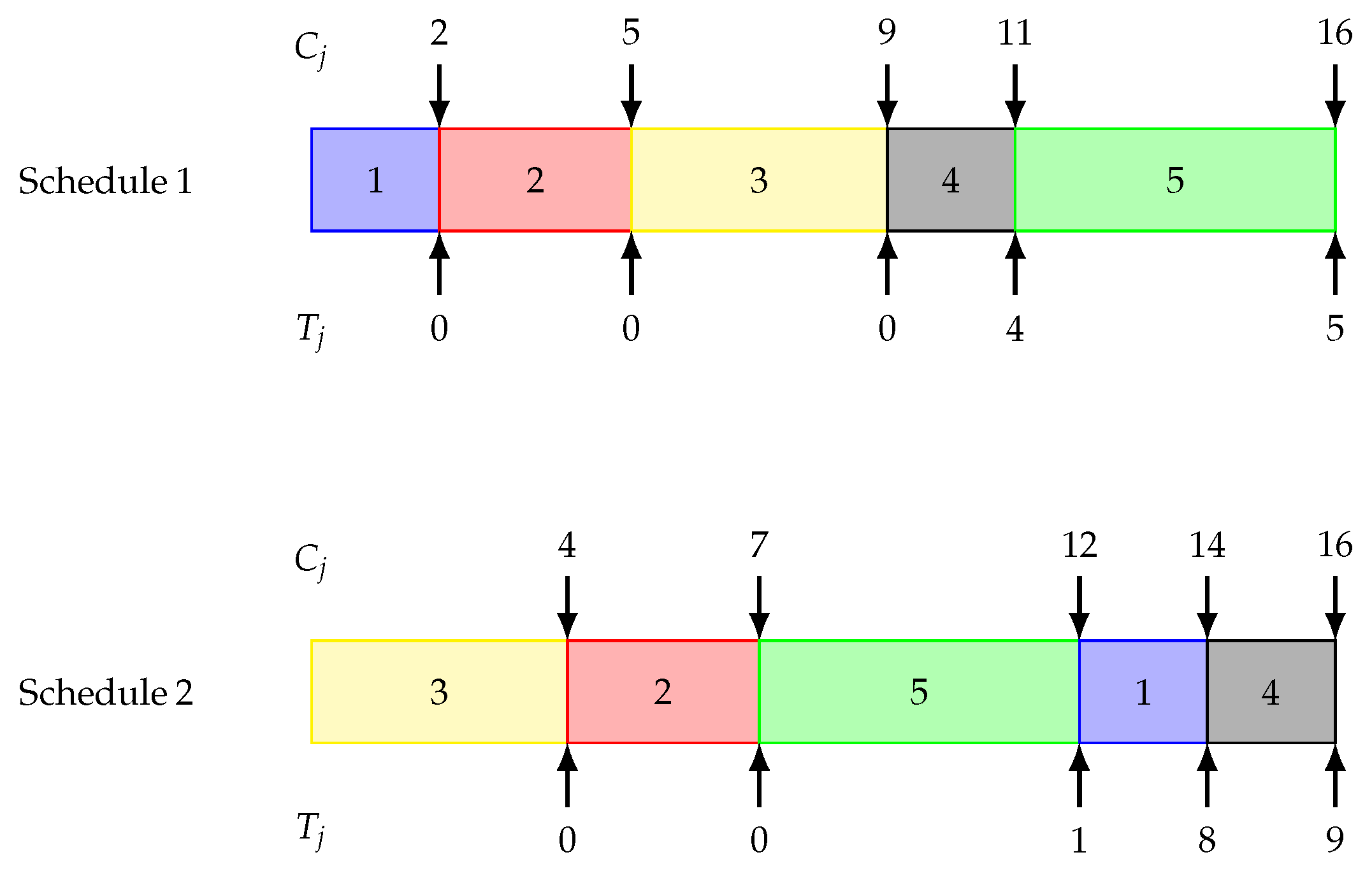
Consider the two distinct schedules shown in
Figure 1 for processing the five jobs:
Schedule 1: 1 → 2 → 3 → 4 → 5 and Schedule 2: 3 → 2 → 5 → 1 → 4. In schedule 1, job 4 has a tardiness of units, and job 5 has a tardiness of units. The total tardiness is 9.
Schedule 2: The tardiness of job 5 is unit, units for job 1, and units for job 4. The total tardiness is 18.
Figure 1.
Example schedules and their job tardiness values.
Figure 1.
Example schedules and their job tardiness values.
The example demonstrates that different processing sequences may yield objective values (total tardiness) that are significantly deviate from one another. The studied problem is to determine a schedule that attains the minimum tardiness penalty.
We formally define the studied problem as follows. The processing environment has a single machine and the given is a set of
n jobs
, in which job
i is associated with a processing time
and a due date
. In a particular schedule, the completion time of job
i is denoted by
. The tardiness of job
i is defined as
, reflecting job
i’s late completion deviated from its due date. If it is completed by the due date, the tardiness is zero. The objective is to determine a schedule whose total tardiness
is a minimum. In Ref. [
2], the three-field notation
is introduced as a canonical scheme to denote scheduling problems. The field
indicates the machine environment, e.g., a single machine, parallel machines, or flow shops; the second field
introduce job characteristics or restrictions, e.g., release dates, due dates, or setup times; and the last field
prescribes the objective to optimize, e.g., the makespan, the number of late jobs, or the total tardiness. The studied problem is described as
, where 1 indicates that a single machine is available for processing, and the third field
prescribes the objective function of total tardiness. The second field is empty as due date constraints are implicit in the objective function. The problem setting of
follows three assumptions commonly adopted in the literature: (1) The machine can process at most one job at any time. (2) No preemption or interruptions of jobs is allowed, i.e., once a job starts, it occupies the machine until its completion. (3) All cited variables and parameters have non-negative integer values.
The total tardiness minimization problem
is shown to be NP-hard by Du and Leung [
3]. It is, therefore, very unlikely that algorithms that can produce optimal solutions in a reasonable time can be designed. Beyond the optimization methods, machine learning techniques, due to their successful applications in for example [
1,
4,
5,
6], also provide another solution-finding approaches. This paper explores the application of Deep Q-Networks (DQNs) to the static single-machine total tardiness problem, advancing beyond traditional Q-learning techniques typically used in dynamic scheduling contexts. Our research uniquely addresses static scheduling where jobs and their respective processing times and due dates are predefined prior to the training phase, contrasting with prior studies that simulate job arrivals through Poisson distributions during the training interval. This methodological shift allows for a precise evaluation of DQNs’ capabilities in a controlled environment.
The core objective of this study is to rigorously compare different reward mechanisms within the DQN framework to optimize decision-making outcomes for scheduling problems. We differentiate between local rewards, which focus on the immediate consequences of job selections, and global rewards, which consider the long-term impact of decisions on the sequence of job completions. Our experimental setup involves a detailed investigation into mixed rewards, combining local and global incentives, versus exclusive use of global rewards. Additionally, we explore various methodologies for calculating global rewards, aiming to pinpoint the most effective approach for leveraging DQNs in reducing total tardiness. Through this comparative analysis, our research seeks to identify and validate the most robust method for deploying deep reinforcement learning in the context of static scheduling, ultimately enhancing the precision and reliability of scheduling decisions.
The rest of this paper is organized as follows.
Section 2 reviews related work in the literature on scheduling problems on total tardiness minimization and DQNs. The framework and the detailed design of constituents of our DQN are presented in
Section 3. To evaluate the performance of the proposed approach, we conducted computational experiments.
Section 4 includes the experiment design and the data generation scheme adopted in the computational study. The resultant computational statistics and elaborative analysis are given in
Section 5. We summarize this study and suggest future research directions in
Section 6.
2. Literature Review
Within the domain of single-machine total tardiness problems, a diversity of algorithmic approaches vies to address the inherent complexity. Exact algorithms, particularly dynamic programming and branch-and-bound methods, aspire to unravel the problem with unwavering accuracy, offering solutions of optimal caliber at the cost of computational intensity. Conversely, heuristic algorithms eschew the rigor of accuracy in favor of expediency, delivering robust solutions with commendable efficiency. Recently, the spotlight has shifted towards reinforcement learning (RL), an adaptive approach that progressively refines its decision-making process through continuous interaction with the problem space. Distinct from deterministic algorithms, RL’s iterative learning paradigm embodies a dynamic evolution of strategy, emphasizing resilience and adaptability. This burgeoning field holds promise for significant advancements in production scheduling, proposing a paradigm where algorithms are not merely solutions but entities capable of growth and self-improvement within their operational environments.
Dynamic programming (DP) and branch-and-bound (B&B) algorithms have been at the forefront of solving the single-machine total tardiness problem optimally. In
Table 2, we provide a consolidated overview of the diverse algorithms that have been proposed in the literature for tackling the single-machine total tardiness problem. Srinivasan [
7] developed a hybrid algorithm using DP that implements Emmons’ dominance conditions [
8], providing a fundamental understanding of job precedence relationships. Baker [
9] contributed to this approach with a chain DP algorithm that also utilizes these conditions for enhanced efficiency. Lawler [
10] furthered this line of work with a pseudo-polynomial algorithm tailored for the weighted tardiness problem, yielding a significant reduction in the worst-case running time to
or
, with
P and
representing the sum and maximum of processing times, respectively. To improve upon these methodologies, Potts and Van Wassenhove [
11] recommended augmentations to Lawler’s decomposition DP algorithm, integrating it with their refined decomposition theorem for more nuanced scheduling solutions.
In parallel with DP, B&B strategies have also shown immense promise. Pioneering works by Elmaghraby [
12] and Shwimer [
13] introduced B&B algorithms that efficiently handle the intricacies of the total tardiness problem. The efforts by Rinnooy Kan et al. [
14] refined lower bound calculations for a broad cost function via a linear assignment relaxation, enhancing the precision of B&B techniques. Fisher [
15] utilized a dual problem approach grounded in Lagrangian relaxation to devise an algorithm with profound implications for computational speed and solution quality. Picard and Queyranne [
16] merged the complexities of the traveling salesman problem within a multipartite network into the B&B framework, leading to significant improvements in minimizing tardiness in single-machine scheduling scenarios. To cap these developments, Sen et al. [
17] exploited Emmons’ conditions to lay down job precedence relationships, paving the way for an implicit enumeration scheme that remarkably requires only
memory space, thereby combining the rigor of B&B algorithms with the practicality needed for real-world scheduling.
The study of heuristic algorithms for the single-machine total tardiness problem presents a diverse landscape of strategies, each with its unique approach to minimizing tardiness under varying constraints. Baker et al. [
18] explore priority rules for minimizing tardiness, emphasizing a “modified due-date rule” (MDD) that adapts efficiently to varying due-date constraints, where
.
C is the current completion time,
is the processing time of job
i, and
is the due date of job
i. Carroll and Donald [
19] introduced the COVERT rule with a computational complexity of
, targeting job shop sequencing by prioritizing jobs based on the descending order of their cost/processing time ratio. Applied to the
problem, this rule selects the next job by estimating the likelihood of job
i being tardy if not scheduled immediately, effectively calculating a priority index for sequencing decisions. Morton et al. [
20] proposed the Apparent Urgency (AU) heuristic for scheduling jobs at the decision time
t by prioritizing jobs using
, with
k adjusting for due date tightness and
as the average processing time, facilitating prioritization amidst potential job conflicts. Panwalkar et al. [
21] introduced the PSK heuristic, a construction method ordering jobs by the Shortest Processing Time (SPT). The PSK heuristic iterates through
n passes, selecting and scheduling an “active” job each time. The selection process, moving left to right through unscheduled jobs, determines an active job as one that would be tardy if scheduled next. An active job
i remains so unless a job
j to its right with
is found, implying job
j becomes the new active job. This process continues until a tardy-active job is found or the last unscheduled job is activated and scheduled. The PSK heuristic operates with a complexity of
.
Table 2.
Summary of exact algorithms for single-machine total tardiness problem.
Table 2.
Summary of exact algorithms for single-machine total tardiness problem.
| Reference | Main Results |
|---|
| Dynamic Programming (DP) |
| Srinivasan [7] | Hybrid algorithm incorporating Emmons’ dominance conditions. |
| Baker [9] | Chain DP algorithm utilizing Emmons’ conditions for efficiency. |
| Lawler [10] | Pseudo-polynomial algorithm for weighted tardiness with improved running time. |
| Potts and Van Wassenhove [11] | Enhancements to DP algorithm, including application of a revised decomposition theorem. |
| Branch-and-Bound (B&B) |
| Elmaghraby [12] | Early B&B algorithm for single-machine total tardiness scheduling. |
| Shwimer [13] | B&B algorithm tailored for the single-machine total tardiness problem. |
| Rinnooy Kan et al. [14] | Precise lower bounds via linear assignment relaxation. |
| Fisher [15] | Algorithm using a dual problem approach based on Lagrangian relaxation. |
| Picard and Queyrann [16] | Method integrating aspects of travelling salesman problem in B&B enumeration. |
| Sen et al. [17] | Implicit enumeration scheme based on job precedence relationships requiring storage. |
| Naidu [22] | Four decomposition conditions that can help the search process for finding exact solutions. |
A local search heuristic is an improvement method based on successive iterations of neighborhood construction and elite neighbor selection. Given an incumbent solution, the best one among its neighbor solutions is selected as the solution of the next iteration. The neighborhood can be defined in various ways. The procedure iterates until no more improvement is possible. For minimizing the total tardiness, local search heuristics, like those proposed by Fry et al. [
23], introduce an improvement method based on adjacent pairwise interchange (API) to reduce mean tardiness in single-machine scheduling. The effectiveness of the API heuristic remains consistent across various problem sizes and due date constraints. Holsenback and Russell [
24] present a heuristic leveraging Net Benefit of Relocation (NBR) to identify the optimal last job in a sequence, aiming to minimize total tardiness. Starting with an EDD schedule, the heuristic applies a dominance rule, inspired by Emmons’ conditions, and the NBR analysis to relocate jobs for improved tardiness outcomes. This process iterates until no further beneficial relocations are detected, with the algorithm exhibiting a complexity of
. Wilkerson and Irwin [
25] introduced the WI heuristic, a hybrid approach combining construction and local search techniques through adjacent job pairwise interchanges. The heuristic evaluates schedule efficiency using the loss function
, where
is the completion time of job
i and
its due date; while generally not guaranteeing optimality, conditions for achieving optimal schedules are specified. A key principle of the WI heuristic is prioritizing jobs with nearer due dates, except under certain conditions where shorter jobs precede, using this criterion to systematically build a job sequence. Ho and Chang [
26] introduce a hybrid heuristic incorporating construction and local search, defined by the Traffic Congestion Ratio (TCR) for single-machine scheduling (
) and potentially multi-machine (
) contexts. TCR is calculated as
, where
and
represent the average processing time and due date across
n jobs, respectively, and
m is the number of machines. They employ TCR to assess shop congestion and generate a priority index
for each job
i,
with
adjusted based on TCR and a constant
K. Jobs are initially sequenced by increasing
values, followed by improvements through adjacent pairwise interchanges.
Finally, the decomposition heuristics by Potts and Van Wassenhove [
27] optimize the sequence placement of the longest job
j through a set of guiding inequalities. These inequalities ensure a strategic fit for job
j at a position
k, considering the cumulative processing times of preceding jobs and the due times of subsequent jobs, maintaining job
j’s precedence in the face of adjacent job comparisons, and securing job
j as the last in the sequence when due. This systematic use of inequalities within the DEC/WI/D heuristic effectively drives down total tardiness, with the heuristic proving robust across scenarios and showcasing a computational complexity of
, even when position
k selections are randomized. The comprehensive results captured in
Table 3 underscore the effectiveness of heuristic strategies in solving the single-machine total tardiness problem. These results, computed by Koulamas and Christos [
28] for construction heuristics and local search methods, and by Potts and Van Wassenhove [
27] for decomposition heuristics, offer insightful benchmarks for the performance of each approach.
Recent advancements in machine learning, particularly reinforcement learning (RL), have significantly impacted addressing complex scheduling challenges, demonstrating considerable promise. RL’s adaptability and intelligent decision-making in dynamic environments position it as a powerful tool for optimizing scheduling processes.
Table 4 presents a concise summary of significant research efforts employing reinforcement learning in single-machine scheduling. The pioneering work of Wang and Usher [
29] in applying Q-learning to single-machine scheduling aimed at minimizing mean tardiness showcases the efficacy of a state–action value table to navigate through various dispatching rules—Earliest Due Date (EDD), Shortest Processing Time (SPT), and First In First Out (FIFO)—based on the job queue’s status. Their study not only validates Q-learning’s potential in policy refinement but also elucidates significant factors affecting RL’s effectiveness in production scheduling environments.
Building on this foundation, Kong and Wu [
30] extended RL applications to meet three distinct scheduling objectives, employing unique state representations like average slack and maximum slack of jobs in the buffer. This approach demonstrates RL’s flexibility in optimizing scheduling goals through appropriate dispatch rule selection. Similarly, Idrees et al. [
31] navigated a dual-objective scheduling dilemma, juxtaposing job tardiness minimization with the cost implications of additional labor. Their strategic use of queue length as a state space and exploring multiple action strategies emphasizes RL’s nuanced decision-making prowess, underscored by the lambda-SMART algorithm for online policy optimization.
Xanthopoulos et al. [
32] ventured into dynamic scheduling realms under uncertainty, combining RL with Fuzzy Logic and multi-objective evolutionary optimization. Their approach, aimed at minimizing earliness and tardiness, leverages a state representation embodying the total workload and mean slack, underscoring the adaptability of RL to dynamic scheduling environments. Further, Li et al. [
33] evaluated the performance of various RL algorithms, including Q-learning, Sarsa, Watkins’s Q(
), and Sarsa(
), in online single-machine scheduling. Their focus on dynamically selecting the next job from the queue for processing illustrates the comprehensive potential of RL in reducing total tardiness and enhancing scheduling performance. Bouška et al. [
34] designed a deep neural network for estimating the objective value using Lawler’s decomposition and the symmetric decomposition of Della Croce et al. [
35]. They also presented a novel method for generating instances. The optimality gaps yielded by their model is only 0.26% for a large job set of 800 jobs. for a more comprehensive review on ML applications in machine scheduling, the reader is referred to [
1,
36].
Despite these contributions, the exploration of RL in single-machine scheduling remains relatively untapped, presenting a rich area for further investigation. Our research builds upon this limited but foundational work, offering new avenues to delve deeper into the potential of RL in optimizing single-machine scheduling tasks. By exploring innovative state representations, action strategies, and algorithmic improvements, our research advances the application of reinforcement learning in the single-machine total tardiness problem by employing Deep Q-Networks (DQNs), diverging from the conventional Q-learning approaches prevalent in the existing literature. Focusing on a specific set of states and actions, our aim is to enhance operational efficiency and introduce innovative perspectives on the use of RL in scheduling tasks.
4. Computational Study
To evaluate the proposed DQN, we conduct a computational study. This section describes the data instances and the computing platform. We follow the guidelines from Hall and Posner [
39] for generating the test instances, in which the due dates of jobs tend to increase progressively. This approach mimics realistic scheduling scenarios where earlier jobs have closer deadlines, while later jobs are allotted more time. Processing times (
) for each job
i are sampled from a normal distribution with a mean (
) of 10 units and a standard deviation (
) of 5 units:
To ensure feasibility, processing times are adjusted to be at least 1 unit:
Due dates (
) for each job
i are derived by adding a normally distributed increment to a base due date, with an increment per job, ensuring they progressively increase:
Due dates are adjusted to be no earlier than the job’s completion time:
The combined dataset of processing times and due dates is represented as:
Each row represents a job, containing its processing time and due date, enabling further scheduling analysis or optimization.
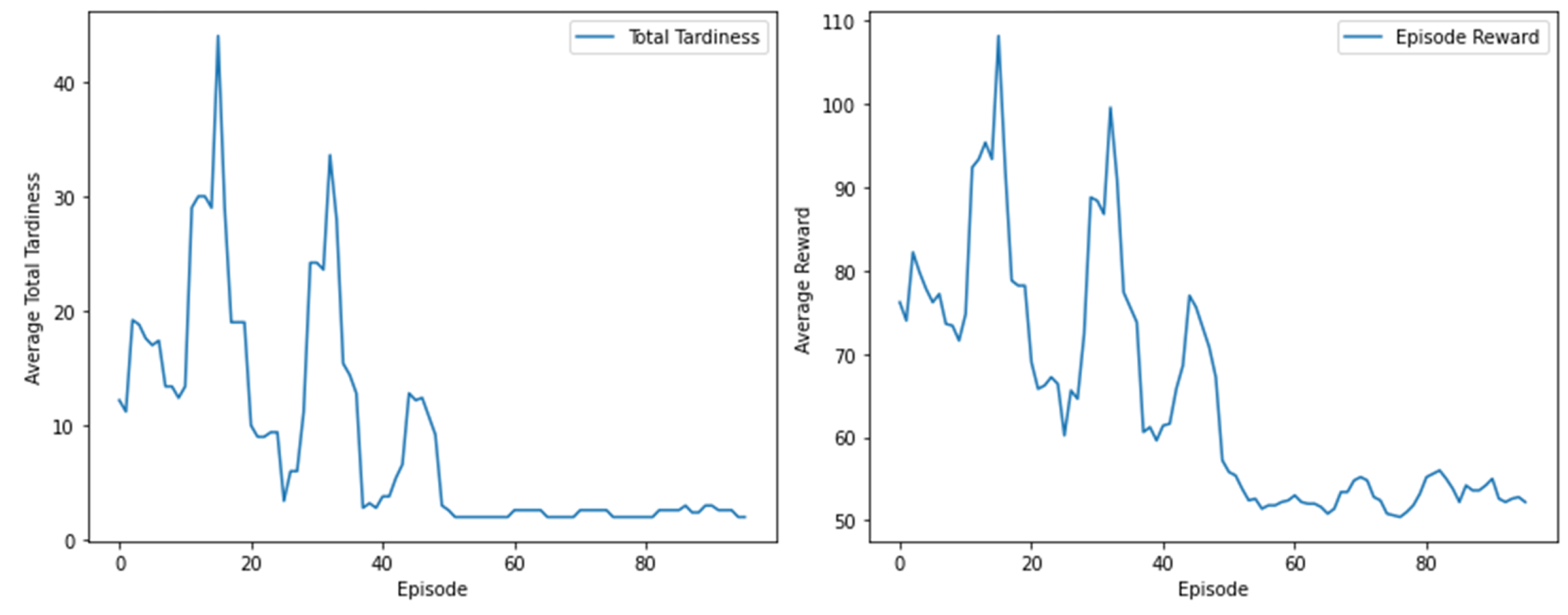
The experiments were carried out on a system equipped with a GTX 1080Ti GPU, an Intel i7-8700k 3.7GHz CPU, and Python 3.7. The environment was managed using Anaconda, with the primary libraries beinggym version 0.19.0 and pytorch version 1.13.1, which were instrumental in creating the RL environment and the neural network, respectively. The neural network model used for the RL agent had 20 and 40 hidden units. The training process utilized a batch size of 32, a learning rate of 0.01, an exploration parameter of 0.2, and a discount factor of 0.9. The target network was updated every 100 iterations and the replay buffer had a capacity of 100. Training was performed on over 100 episodes.
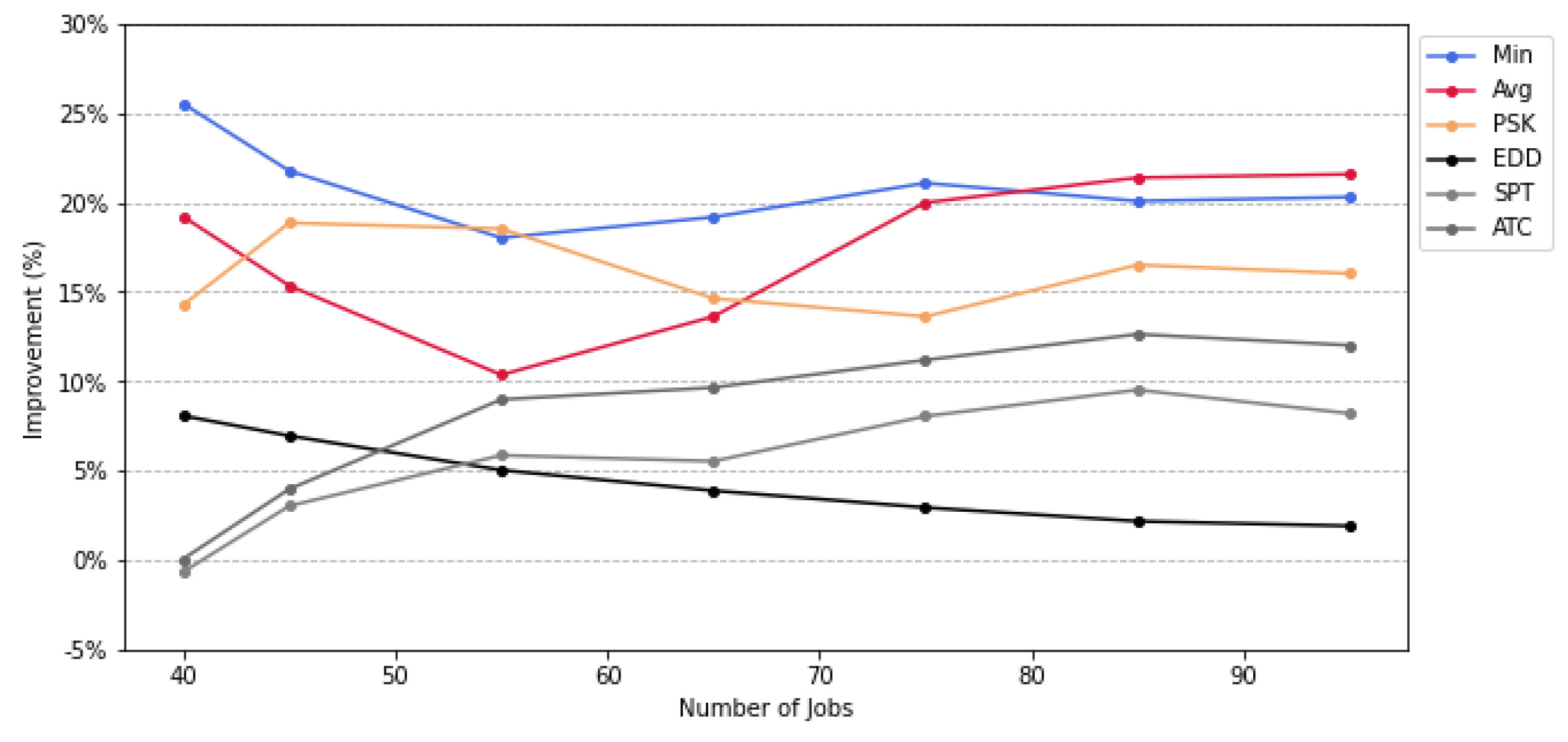
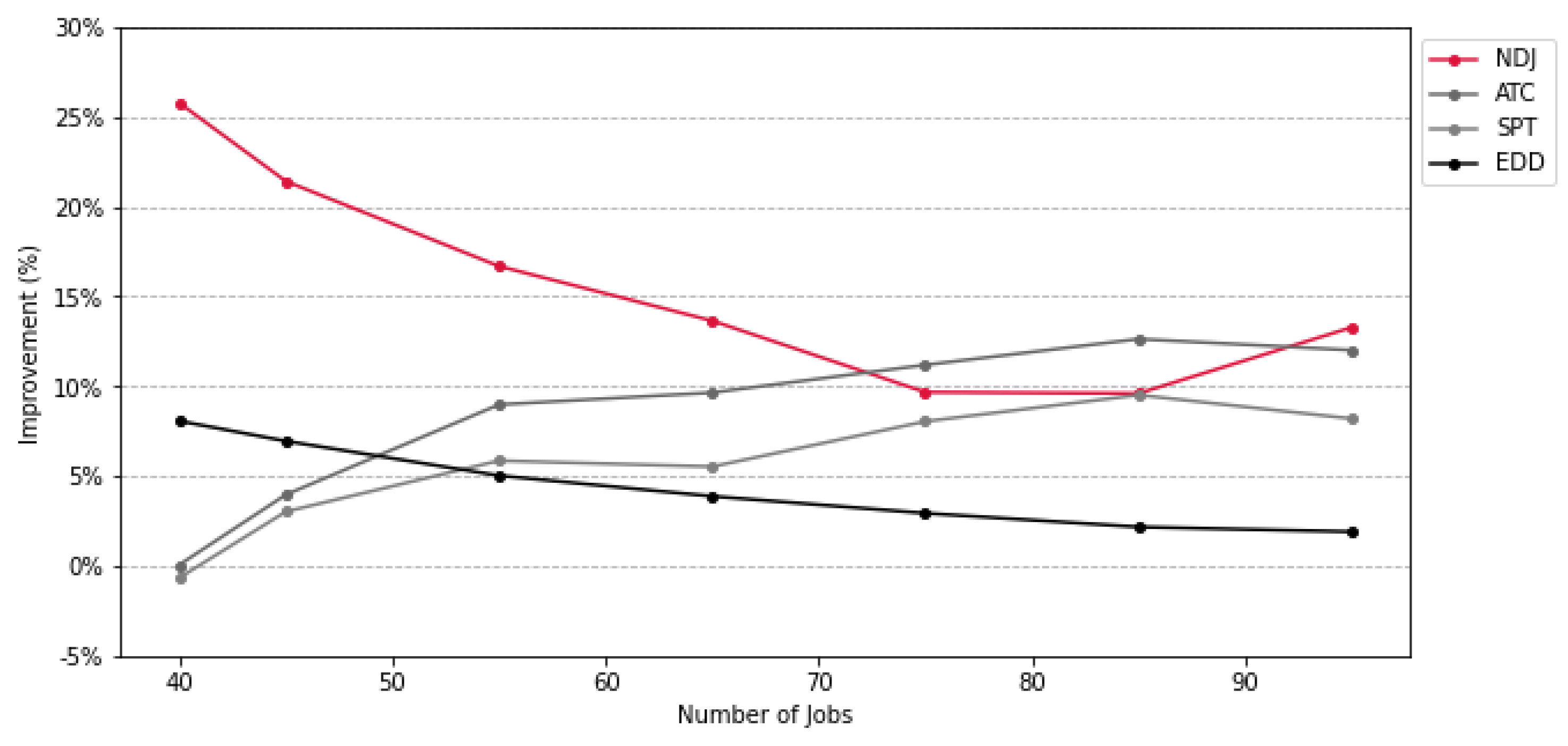
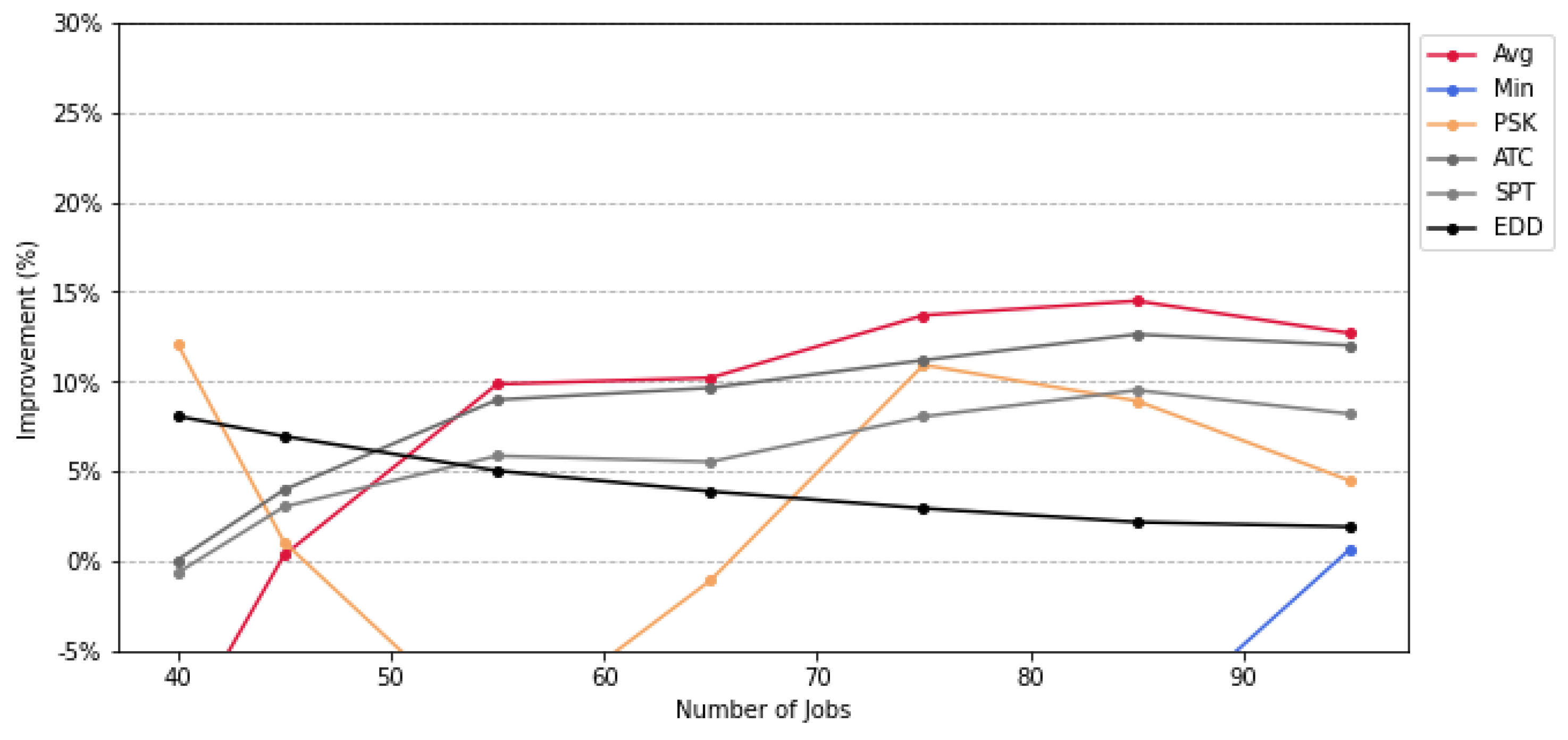
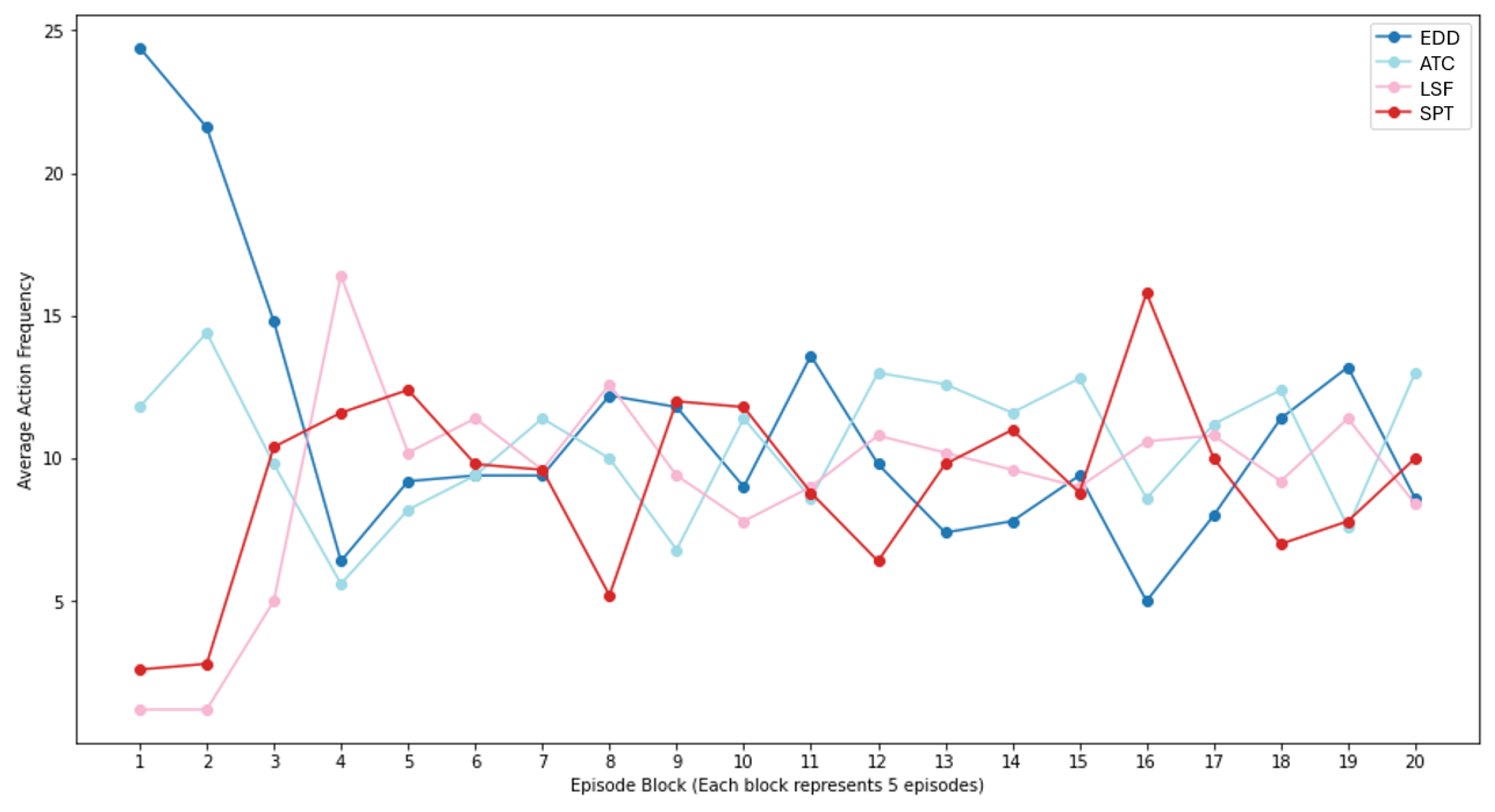
For the experiments, we generated 100 jobs and implemented the DQN using seven different reward strategies. These strategies were compared with four heuristic baselines, i.e., ATC (Apparent Tardiness Cost), EDD (Earliest Due Date), SPT (Shortest Processing Time), and LSF (Least Slack First). We evaluated the final total tardiness of the schedules produced by the DQN and the baselines across a range of job sizes from 40 to 100, in increments of 10 jobs, derived from the generated job set.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}