
Adaptive Parallel Scheduling Scheme for Smart Contract

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- RQ1
- How to solve cross-contracts calling conflicts in parallel execution? During parallel execution, conflicts can easily occur due to cross-contract calls, necessitating the re-execution of conflicting transactions, which can lower overall efficiency or even result in worse performance than serial execution. Simply employing parallel execution is not sufficient, and adjustments to the execution process are necessary.
- RQ2
- How to dynamically adjust the scheduling of smart contracts to achieve parallel execution? Static analysis of smart contracts is challenging when dynamic cross-contract invocations occur since the contract access patterns are not predictable [14]. The conflict between transactions is complex, and static analysis from smart contracts is not enough. The execution strategy based on static analysis and dynamically adjusted during execution is the most efficient solution.
- RQ3
- How to improve the implementation of parallel scheduling to achieve efficient usage of space and time? When implementing parallel scheduling in permissioned blockchains like ChainMaker, we have found it necessary to optimize the data structure for efficiency. It is crucial to consider how to better implement this technology in engineering practice.
- Smart contract dependency DAG from static analysis. By analyzing the relationship of the field characteristics of smart contracts, we build the contract dependency by constructing a contract dependency DAG.
- Conflict model from numerous experiments. We build a conflict model that describes the relationship between the conflicts of transactions and the number of parallel threads during the actual execution of transactions. Through a large number of experiments, we construct the distribution of the number of threads when TPS is optimal.
- Dynamically parallel scheduling. We propose an adaptive smart parallel scheduling that adapts the conflict factors and dynamically adjusts the serial and parallel scheduling of contracts based on conflict factors.
- Technical optimization in actual implementation. We use a bitmap to improve the usage of space and time, and we implement this scheme on ChainMaker and obtain the expected results.
2. Related Work
3. Preliminaries
3.1. Blockchain and Smart Contracts
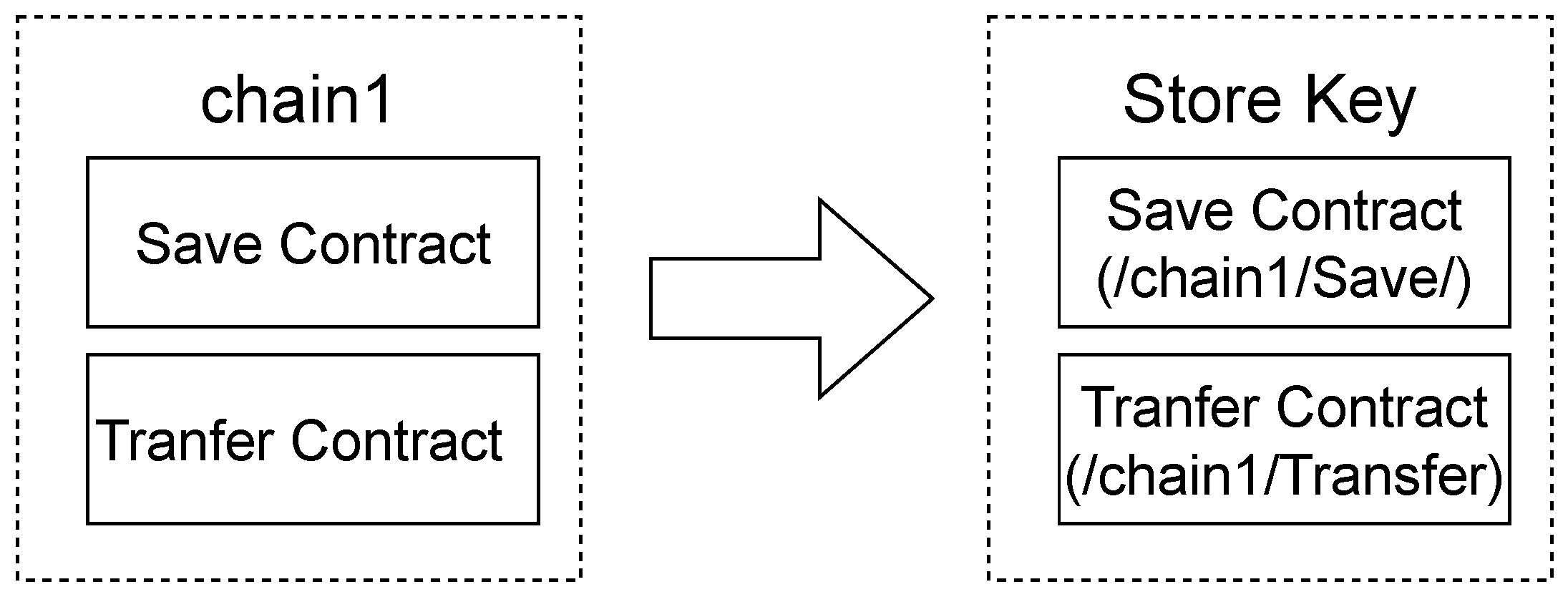
3.2. Namespace
3.3. Read–Write Set
4. Design
4.1. System Model
4.2. Components
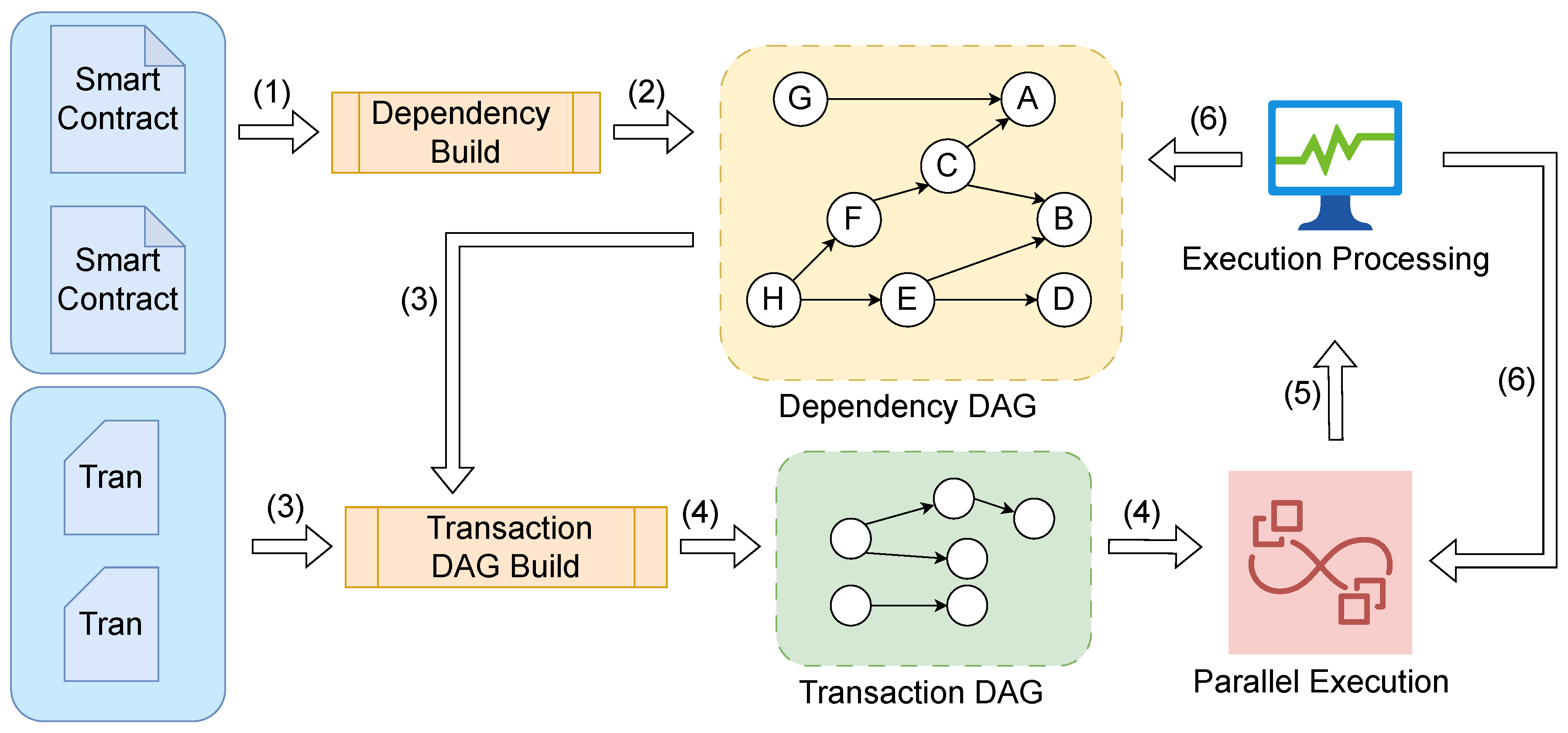
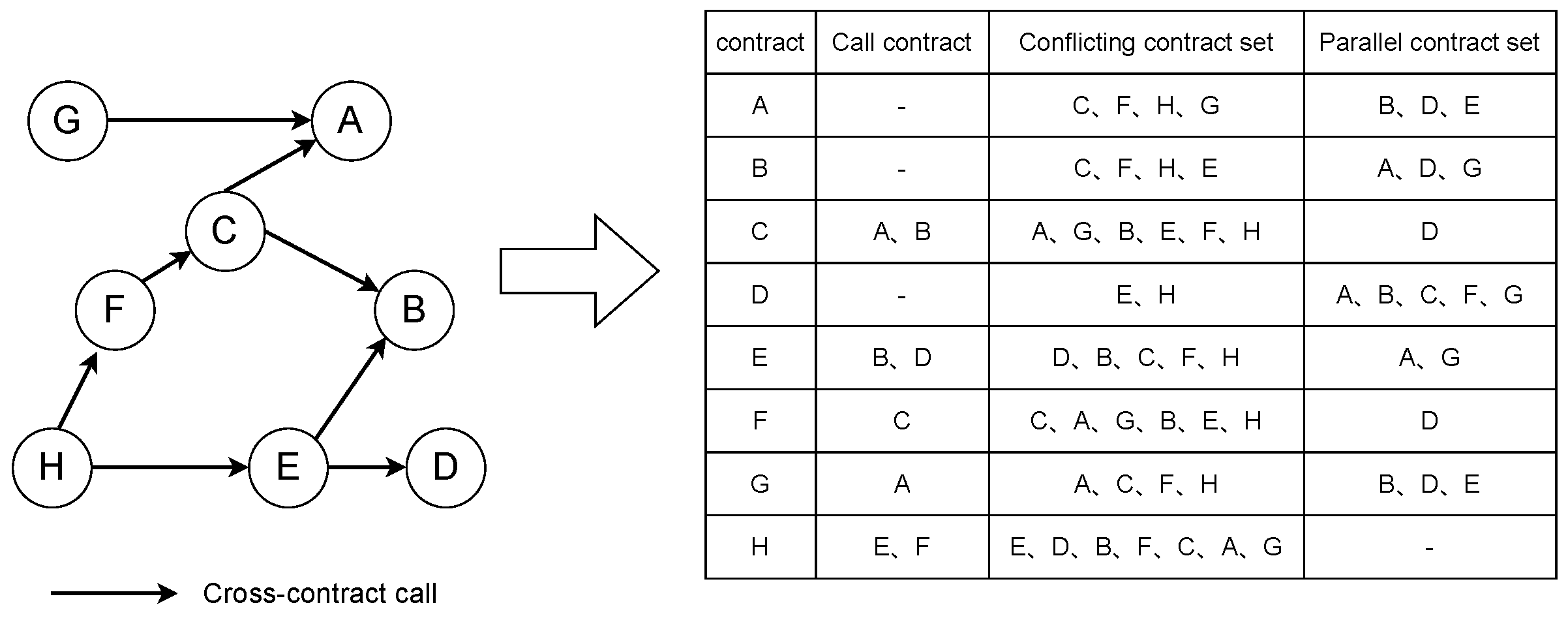
4.2.1. Contract Dependency DAG
4.2.2. Transaction DAG
4.2.3. Conflict Factors
4.2.4. Transaction Parallelism Score/Rate
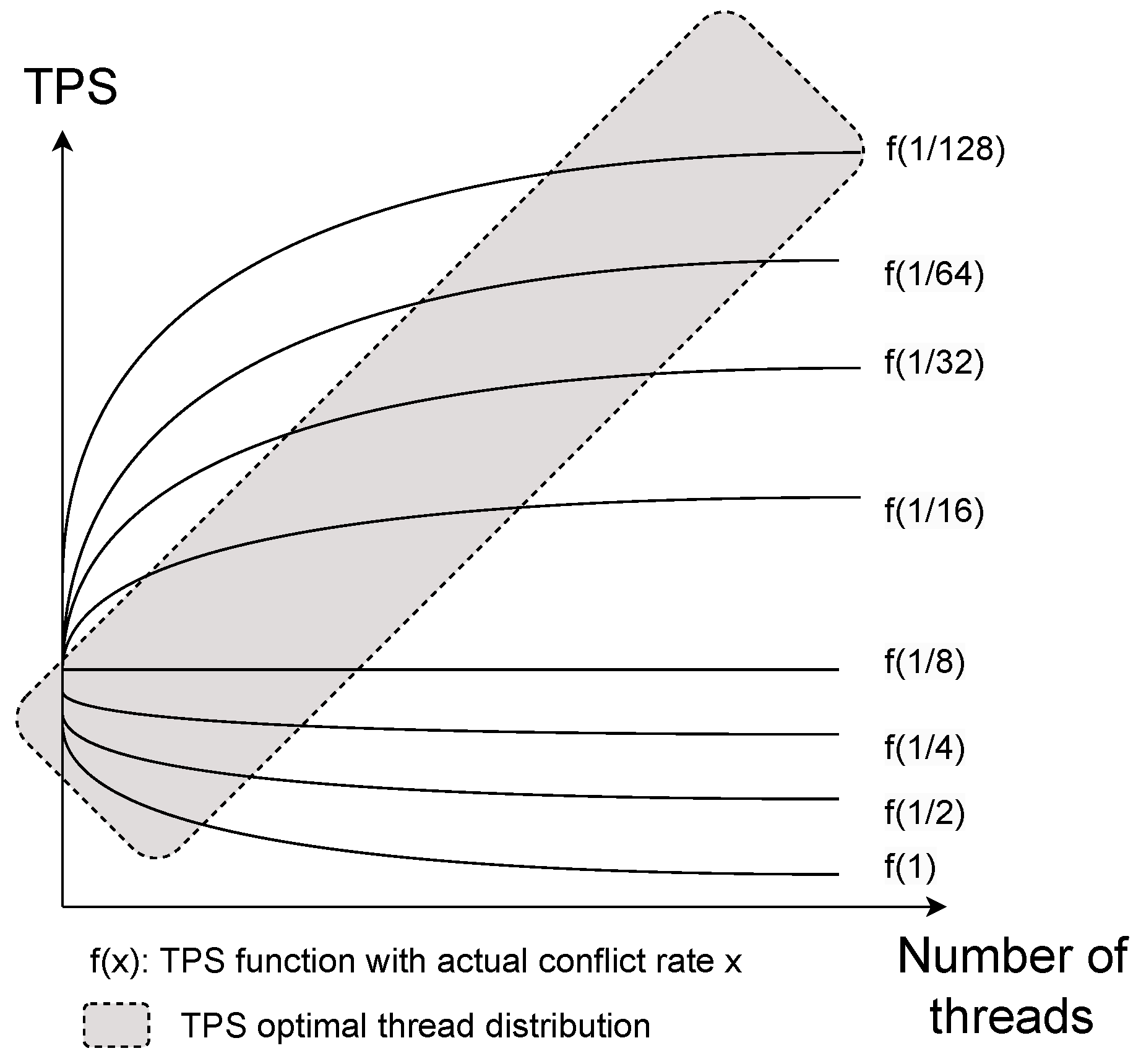
4.3. Conflict Model
- Under the low transaction conflict model, the number of threads is proportional to TPS; that is, in an environment with low transaction conflicts, the higher the number of threads within a certain range, the better.
- Under the high transaction conflict model, the number of threads is inversely proportional to TPS; that is, in an environment with high transaction conflicts, the lower the number of threads within a certain range, the better.
4.4. Smart Contract Dependency Build
- The contract itself;
- The contract’s descendant contracts (child contracts and grandchild contracts, etc.);
- The contract’s parent contracts (parent contracts, grandfather contracts, etc.);
- Other parent contracts of the contract’s descendant contracts.
| Algorithm 1 AddNode |
|
4.5. Transaction DAG Building
- The transaction DAG construction order depends on the order in which transactions are packaged in the block. The earlier the order, the more likely it is to be executed first.
- When each transaction is added to the transaction DAG, it is judged whether it has a dependency relationship with all previous transactions. If it exists, it is added to the latest dependent transaction set.
4.6. Transaction Parallel Execution
4.7. Transaction Execution Processing
| Algorithm 2 ExectionProcessing |
|
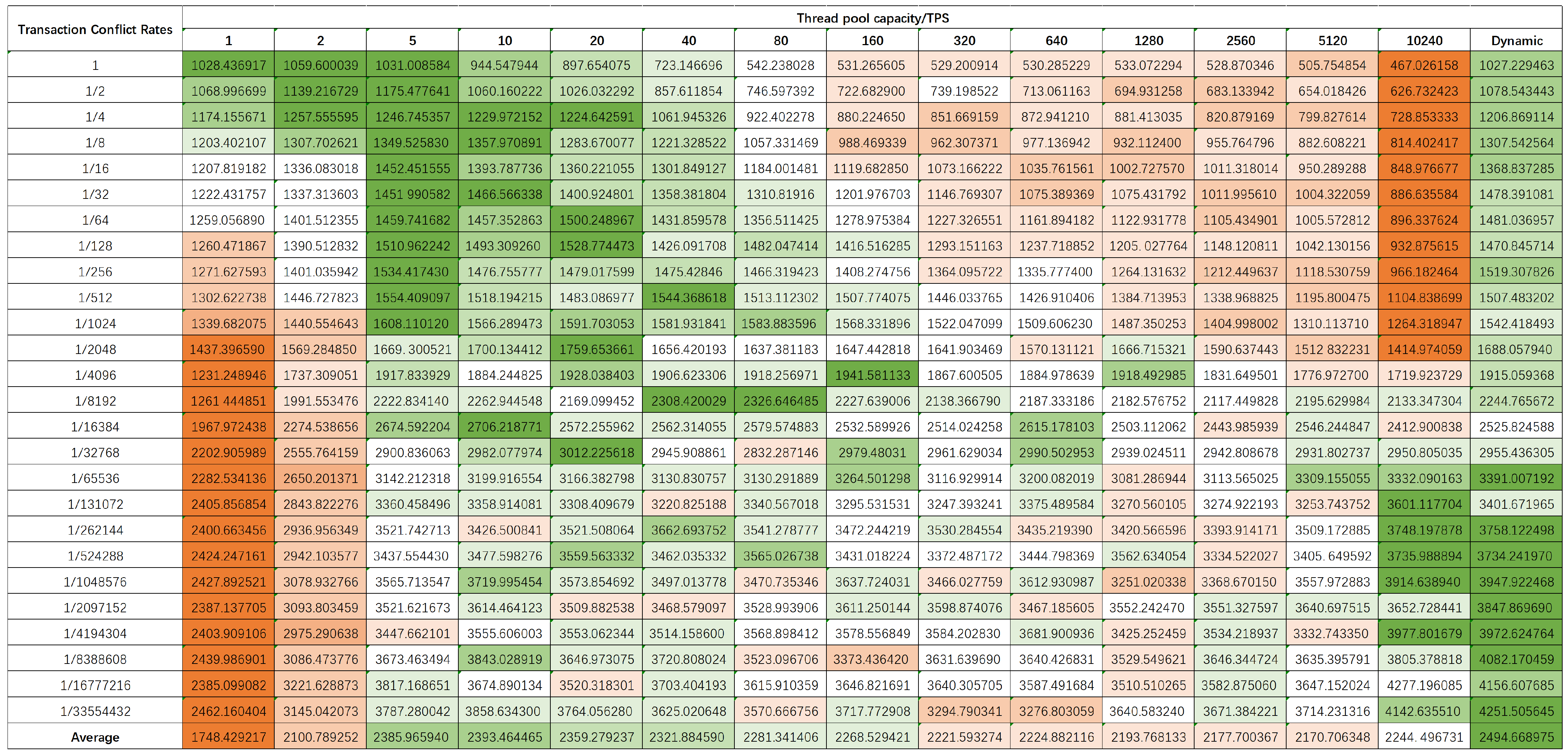
5. Evaluation
5.1. Experiment Setup
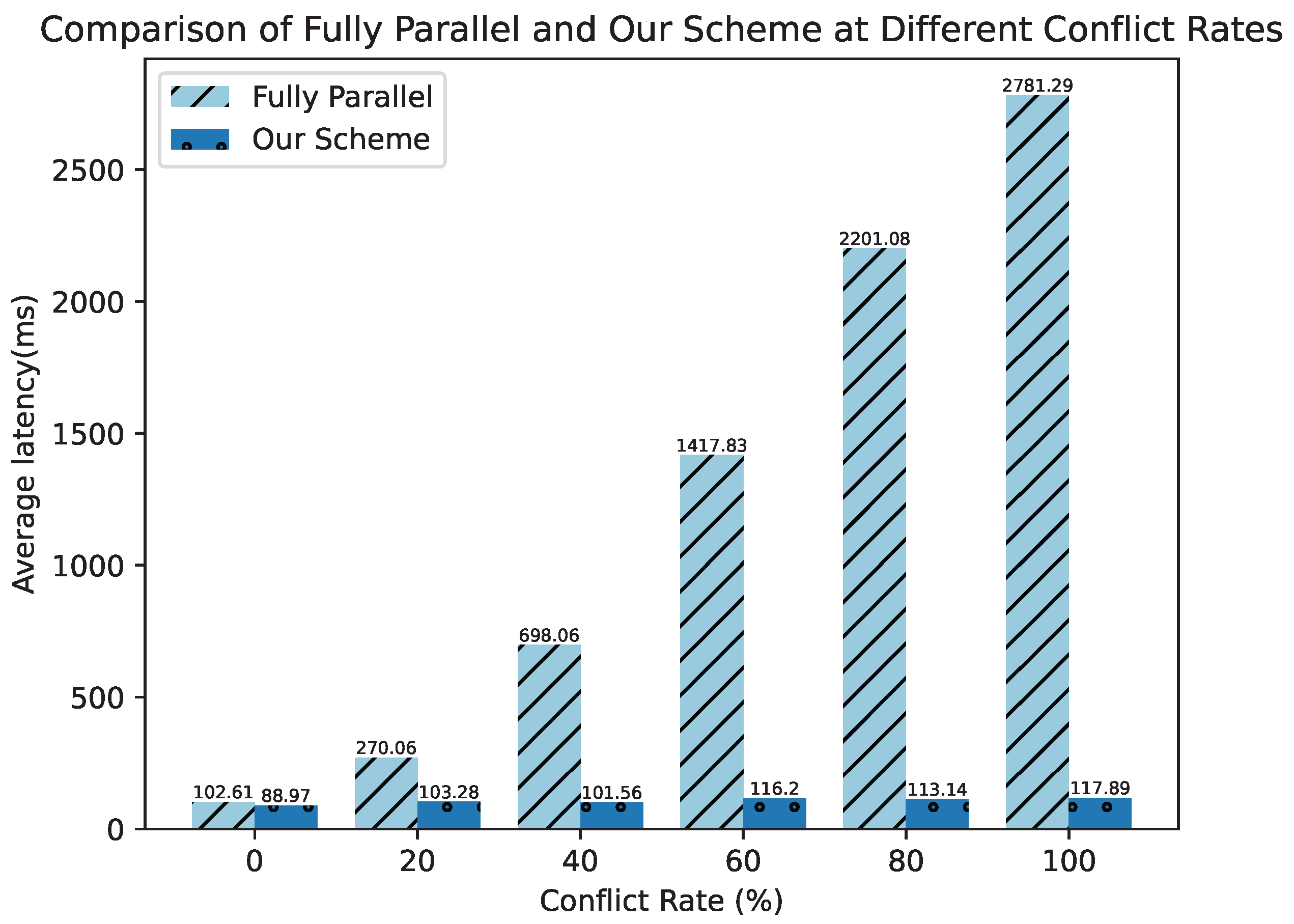
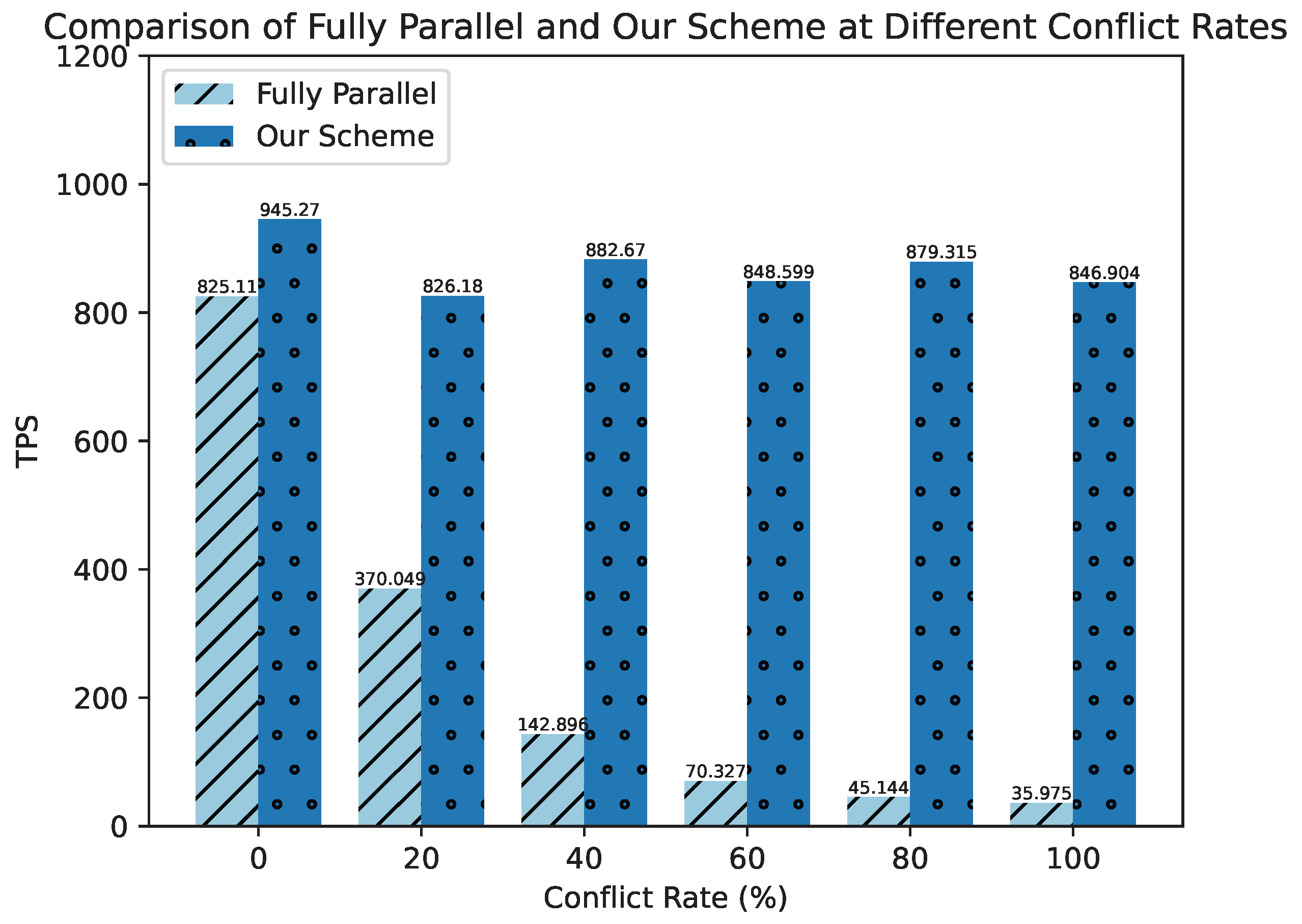
5.2. Evaluation Results
- Smart contract dependency DAG from static analysis;
- Conflict model from numerous experiments;
- Dynamically parallel scheduling;
- Technical optimization in actual implementation.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Experiments of Conflict Model

References
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Decentralized Business Review. 2008. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 8 April 2024).
- Szabo, N. Formalizing and securing relationships on public networks. First Monday 1997, 2, e548. [Google Scholar] [CrossRef]
- Alrubei, S.M.; Ball, E.A.; Rigelsford, J.M.; Willis, C.A. Latency and performance analyses of real-world wireless IoT-blockchain application. IEEE Sens. J. 2020, 20, 7372–7383. [Google Scholar] [CrossRef]
- Wang, Q.; Li, R.; Wang, Q.; Chen, S. Non-fungible token (NFT): Overview, evaluation, opportunities and challenges. arXiv 2021, arXiv:2105.07447. [Google Scholar]
- Mukhopadhyay, U.; Skjellum, A.; Hambolu, O.; Oakley, J.; Yu, L.; Brooks, R. A brief survey of cryptocurrency systems. In Proceedings of the 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 745–752. [Google Scholar]
- Guo, B.; Lu, Z.; Tang, Q.; Xu, J.; Zhang, Z. Dumbo: Faster asynchronous bft protocols. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 9–13 November 2020; pp. 803–818. [Google Scholar]
- Zhang, Z.; Liu, X.; Feng, K.; Wan, M.; Li, M.; Dong, J.; Zhu, L. Phantasm: Adaptive Scalable Mining Toward Stable BlockDAG. IEEE Trans. Serv. Comput. 2023; early access. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, X.; Li, M.; Yin, H.; Zhu, L.; Khoussainov, B.; Gai, K. HCA: Hashchain-based Consensus Acceleration via Re-voting. IEEE Trans. Dependable Secur. Comput. 2023, 21, 775–788. [Google Scholar] [CrossRef]
- Zhang, Z.; Feng, K.; Chen, X.; Liu, X.; Sun, H. RHCA: Robust HCA via Consistent Revoting. Mathematics 2024, 12, 593. [Google Scholar] [CrossRef]
- Dickerson, T.; Gazzillo, P.; Herlihy, M.; Koskinen, E. Adding concurrency to smart contracts. In Proceedings of the ACM Symposium on Principles of Distributed Computing, Washington, DC, USA, 25–27 July 2017; pp. 303–312. [Google Scholar]
- Anjana, P.S.; Kumari, S.; Peri, S.; Rathor, S.; Somani, A. An Efficient Framework for Optimistic Concurrent Execution of Smart Contracts. arXiv 2018, arXiv:1809.01326. [Google Scholar]
- Yu, W.; Luo, K.; Ding, Y.; You, G.; Hu, K. A parallel smart contract model. In Proceedings of the 2018 International Conference on Machine Learning and Machine Intelligence, Vienna, Austria, 25–26 July 2018; pp. 72–77. [Google Scholar]
- Bartoletti, M.; Galletta, L.; Murgia, M. A true concurrent model of smart contracts executions. In Proceedings of the International Conference on Coordination Languages and Models, Valletta, Malta, 15–19 June 2020; pp. 243–260. [Google Scholar]
- Li, H.; Chen, Y.; Shi, X.; Bai, X.; Mo, N.; Li, W.; Guo, R.; Wang, Z.; Sun, Y. FISCO-BCOS: An Enterprise-grade Permissioned Blockchain System with High-performance. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 12–17 November 2023; pp. 1–17. [Google Scholar]
- Chainmaker. Available online: https://chainmaker.org.cn/home (accessed on 8 April 2024).
- Liu, J.; Li, P.; Cheng, R.; Asokan, N.; Song, D. Parallel and asynchronous smart contract execution. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 1097–1108. [Google Scholar] [CrossRef]
- Digitale, J.C.; Martin, J.N.; Glymour, M.M. Tutorial on directed acyclic graphs. J. Clin. Epidemiol. 2022, 142, 264–267. [Google Scholar] [CrossRef] [PubMed]
- Jin, C.; Pang, S.; Qi, X.; Zhang, Z.; Zhou, A. A high performance concurrency protocol for smart contracts of permissioned blockchain. IEEE Trans. Knowl. Data Eng. 2021, 34, 5070–5083. [Google Scholar] [CrossRef]
- Piduguralla, M.; Chakraborty, S.; Anjana, P.S.; Peri, S. An Efficient Framework for Execution of Smart Contracts in Hyperledger Sawtooth. arXiv 2023, arXiv:2302.08452. [Google Scholar]
- Miller, A. Permissioned and permissionless blockchains. In Blockchain for Distributed Systems Security; Wiley-IEEE Press: Hoboken, NJ, USA, 2019; pp. 193–204. [Google Scholar]
- ChainmakerCode Homepage. Available online: https://git.chainmaker.org.cn/ (accessed on 8 April 2024).



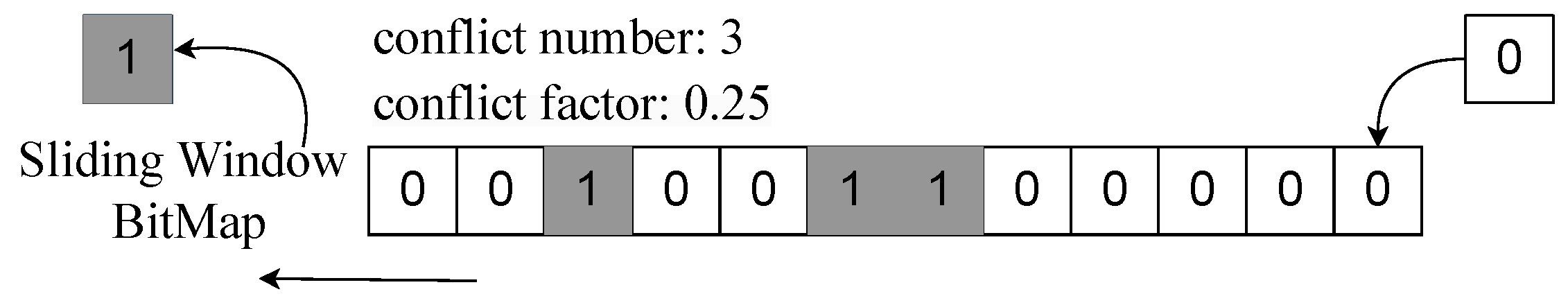
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Ao, M.; Sun, J.; Wang, G.; Li, Y.; Li, C.; Shao, Z. Adaptive Parallel Scheduling Scheme for Smart Contract. Mathematics 2024, 12, 1347. https://doi.org/10.3390/math12091347
Yang W, Ao M, Sun J, Wang G, Li Y, Li C, Shao Z. Adaptive Parallel Scheduling Scheme for Smart Contract. Mathematics. 2024; 12(9):1347. https://doi.org/10.3390/math12091347
Chicago/Turabian StyleYang, Wenjin, Meng Ao, Jing Sun, Guoan Wang, Yongxuan Li, Chunhai Li, and Zhuguang Shao. 2024. "Adaptive Parallel Scheduling Scheme for Smart Contract" Mathematics 12, no. 9: 1347. https://doi.org/10.3390/math12091347
APA StyleYang, W., Ao, M., Sun, J., Wang, G., Li, Y., Li, C., & Shao, Z. (2024). Adaptive Parallel Scheduling Scheme for Smart Contract. Mathematics, 12(9), 1347. https://doi.org/10.3390/math12091347