1. Introduction
Nowadays, deep learning (DL) has achieved remarkable results in various applications such as image and speech recognition, natural language processing, image deblurring and denoising [
1,
2,
3,
4], super-resolution [
5], autonomous driving vehicles, and image generation [
6], among others. However, designing an effective deep learning model requires the tuning of a large number of hyperparameters, such as learning rate, mini-batch size, and features related to the shape and the structure of the network, which is often a tedious and time-consuming process. The crucial distinction between parameters and hyperparameters is that, while the parameters are changed during network training by backpropagation, the hyperparameters must be fixed upstream and remain fixed during the training process. Good or bad configuration of hyperparameters can range from the best result in the literature to complete divergence, even when considering the same methodology with the same data. To address this issue, researchers have explored different methods for automating the hyperparameter tuning, such as neural architecture search (NAS), which has gained significant attention in recent years [
7,
8,
9,
10,
11].
NAS is the process of automating the design of neural networks by searching for an optimal architecture and other hyperparameters that provide the best performance on a given task. The traditional approach for NAS involves searching of the entire space of possible architectures, which is computationally expensive and time-consuming. To tackle this challenge, researchers proposed the use of performance predictors (PPs) to estimate the performance of different architectures, thereby reducing the search space and speeding up the search process. PPs, once constructed, make the training of new hyperparameter configurations unnecessary, greatly reducing the computational cost from a green artificial intelligence (GreenAI) perspective [
12]. PPs are already known in the literature not only in the NAS context, but also as loss function in blind deblurring problems [
13] and memory prediction.
In this paper, we propose a green approach to hyperparameters tuning in deep learning, with the aim to minimize the environmental impact of the NAS process. We argue that the traditional approach to NAS can be resource-intensive and environmentally damaging due to the massive amounts of computation required. Our proposed methodology will leverage the use of PPs to optimize the search process while minimizing its environmental impact. In particular, our approach, an evolution of the work of Franchini et al. [
14], is to develop a PP by training only a small percentage of the possible hyperparameter configurations; this PP can be queried to find the best configurations without training them on the dataset.
Many of the methods in the literature in the NAS context are particularly focused on the exploration phase of hyperparameters, taking it for granted that each step will require comprehensive training of the methodology. Performance predictors oppose this view by attempting precisely to make each individual step more efficient. The environmental impact is often not taken into account in these contexts, as modern multinode structures allow multiple trainings to be carried out in parallel, significantly reducing time but with no reduction in energy impact. This is why the proposed method only exploits the power of multinode structures initially, and then continues almost without further calculation, thus imposing considerable energy savings.
The structure of this paper is as follows: in
Section 2, some state-of-the-art ideas of the NAS framework based on PPs in a green context will be presented, in
Section 3, the proposed novel method, named GreenNAS, with its algorithm will be explained, and in
Section 4, an application of GreenNAS to an image denoising problem will allow the evaluation of the effectiveness of the approach.
Section 5, in which future extensions of GreenNAS are envisaged, concludes the paper.
4. Numerical Experiment: A Denoising Application
To assess the performance of the suggested technique, we present a numerical experiment in the imaging context. We utilize all three stages of our approach and analyze the achieved results.
We consider the application of a CNN for the purpose of removing noise from images. During the process of image acquisition by various medical or astronomical different tools, Gaussian noise may be introduced into the image. This noise can prevent the ability to accurately read and understand the image. The process of removing artifacts by adding filters after the acquisition of the image can be time-consuming for two reasons. Firstly, filters often require the setup of hyperparameters, which involves several tests. Secondly, they are slow during the inference phase since they are global filters applied to the entire image, making it difficult to parallelize. To address these challenges, we propose the use of a CNN that learns how to remove Gaussian noise from an image. Once trained, the network can quickly clean images from noise, benefiting from the parallelization of convolutional filters. The decision to utilize a CNN for noise removal from images is justified by its proven effectiveness in image processing tasks. CNNs excel in capturing spatial dependencies and hierarchical features within images, making them well suited for noise removal applications. Additionally, their adaptability to diverse data distributions and robust performance across different image types enhance their appeal. While our primary focus is on noise removal, CNNs offer versatility beyond this specific task, with potential applications spanning image classification to object detection. By leveraging the inherent strengths of CNNs, we aim to address the challenge of noise removal while contributing to the broader discourse on the efficacy of deep learning techniques in image processing tasks. In this case we use original, uncorrupted images from the MNIST (Modified National Institute of Standards and Technology database) database [
25], which contains handwritten digits commonly used for image classification testing. In our case, we are interested in denoising corrupted images generated from these images, rather than their classification. The dataset used in the experiment consists of grayscale images with pixel values ranging from 0 to 255. After normalization in the range
, each image is centered in a
pixel box. To generate noisy images, the MNIST database is preprocessed by adding random Gaussian noise with a standard deviation of
.
Figure 1 shows some examples of original and corrupted images that belong to the train and test sets.
To address this image denoising problem, the proposed approach consists of three phases. In the first phase, the CNN hyperparameters are selected and the dataset of examples is generated. The considered hyperparameters include mini-batch size, learning rate, optimizer type, number of filters, and kernel size of a convolutional layer, as suggested in [
14]. With regard to the optimizer, the set of optimization algorithms to choose from includes stochastic gradient descent (SGD), SGD with momentum (
momentum hyperparameter), and AdaM. The set of learning rates is
and the one of mini-batch sizes is
. The CNN used has 4 convolutional layers, and each layer can have
filters with kernel dimensions of
. The hidden layers of the network are convolutions with padding, generating an output with the same size as the input. The activation function used is ReLU.
The entire dataset consists of
samples, and we choose to estimate
possible configurations. This number was chosen by sampling the space at
as in [
14]. A dataset of 75 examples is sufficient for training standard methodologies, such as RF and SVR [
26]. A larger dataset should be used if a neural network is employed as PPs. As consequence, we have to train only 75 CNNs until stopping condition is reached (maximum 20 epochs). The performance measure considered as a label of the built dataset is the mean square error (MSE) computed for the images in the test set. The configurations are chosen according to a uniform distribution in the hyperparameters space. In the second phase, using this dataset of 75 CCNs with the related final performance, we train SVR and RF. At least, in the third phase, with these trained models, we compute all the predicted scores for the entire dataset and we choose
CNN from each method: SVR, RF, and HYB. The choice of
m is a trade-off between the desired improvement in performance and the required computational time. The higher
m is, the more computational effort we will need for fully training the
m CNN for the 3 different performance predictors. The selection
is extreme in the sense of computational savings; it was, in fact, performed to fit better in the GreenAI context.
How to choose hyperparameters in Algorithm 1.
In the various steps of the proposed procedure, and particularly in Algorithm 1, several hyperparameters must be set to achieve the desired effectiveness in the GreenAI context.
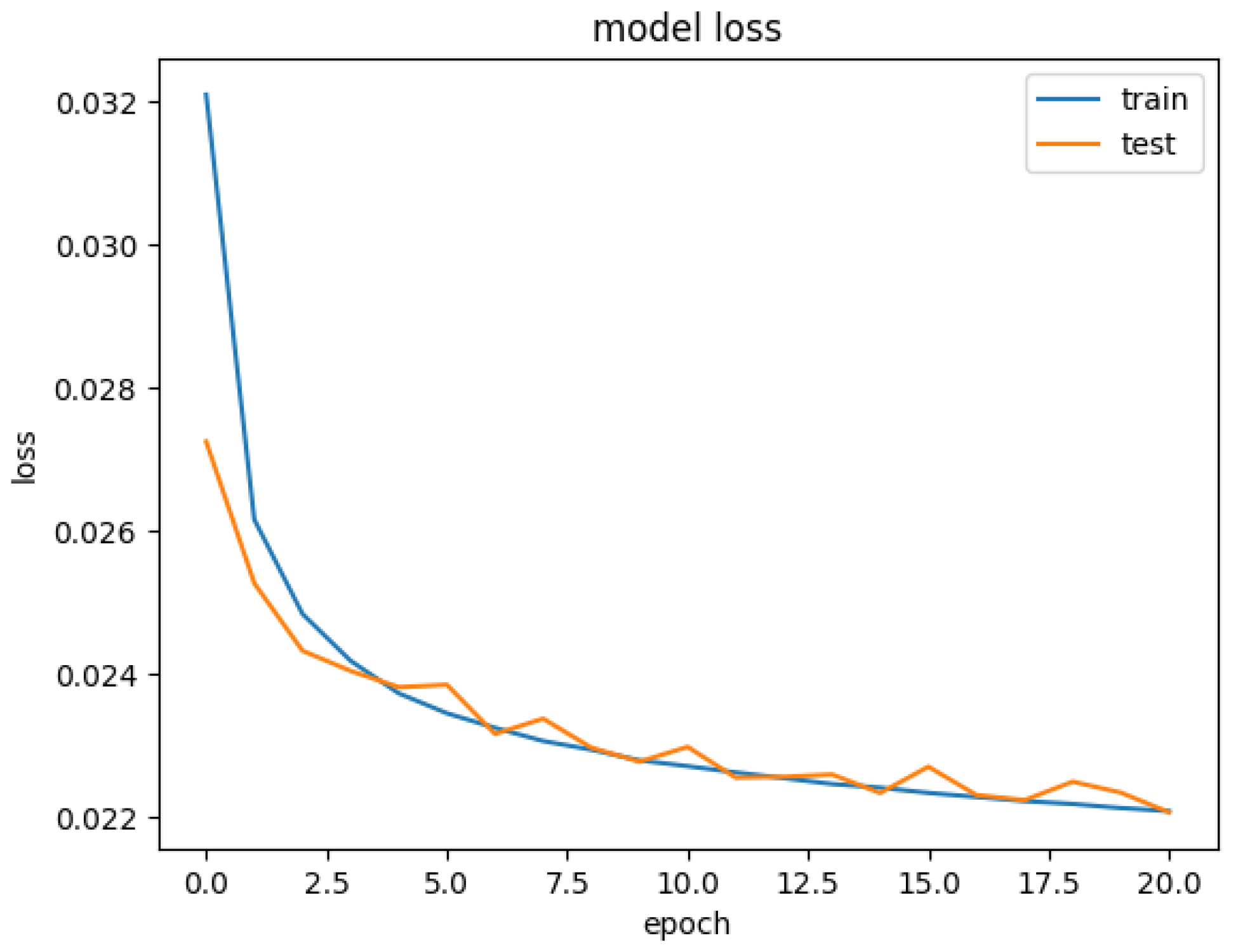
In particular, the number of epochs is set according to the considered application. Since the context of interest is that of energy conservation, for a deblurring image problem, a maximum of 20 epochs is well suited [
14]. To justify the choice of the number of epochs in the numerical section, we will report the loss function of the best configuration obtained.
Other very important ingredients characterizing the method are the choice of
, i.e., the space of hyperparameters, the selection of the size
n of the initial dataset of networks, for the initial dataset, the predictor-related hyperparameters, and the number of
m networks among the best predicted for the final trainings. With regard to
, the dependence on the features of the employed architecture is strong. In general, it is always appropriate to consider the hyperparameters that are crucial for the effectiveness of the optimizer, such as the mini-batch size and the learning rate [
27]. Other hyperparameters may be those related to the network architecture, such as the size of dense layers or convolutions. In choosing the ranges of these hyperparameters, is necessary to take into account that as these increase, both the training time of individual networks and the prediction time spent on unseen examples will grow. In real-time or near-real-time contexts it makes sense to take these factors into account [
28]. In our case, we carefully chose these hyperparameters in a way that places us well in a GreenAI context. In the example considered, the cardinality of the hyperparameter space is a few hundred thousand, but in examples with complex architectures, it can become prohibitively large, even of the order of
[
29].
The choice of hyperparameters forming directly determines n, in the sense that we choose of the entire . On the other hand, m should always be chosen by weighing the trade-off between accuracy and energy savings. In our application, the extreme case of was chosen, which implies full training of 3 CNNs, i.e., one for each predictor. This choice should depend on n and on the computational time available.
Finally, the choice of performance predictors and their related hyperparameters is crucial for the effectiveness of the method. In particular, in our case, an RF and an SVR were chosen for several reasons. Firstly, being in a GreenAI context, choosing a deep learning model may not be advisable due to the potential trade-off in the model interpretability it entails; in addition, there are also the need for a large dataset for training the PPs and an increase in the training time for each individual PP. Therefore, the most well-known and robust regressors in the literature were chosen. Of course, these regressors also required careful tuning of the hyperparameters, which was performed automatically using Optuna [
30]. Optuna is a machine-learning-specific automatic hyperparameter optimization software framework. We selected the maximum number of trials (20 in our case) and the hyperparameters to be optimized. The method creates a grid with all the declared combinations and iterates over this grid, evaluating the performance of different configurations. The best configuration is then kept in memory and returned at the end of the process. In our case, for SVR, we decided to optimize the parameter that controls overfitting
, the choice of of the kernel type (Gaussian, polynomial, or linear), and the hyperparameters related to the kernels, i.e., the degree in the polynomial
or the variance in the Gaussian
. In the case of RF (random forest), the following hyperparameters were optimized: the number of trees
and the number of features to consider for each tree
. The total time required for setting, on an AMD Ryzen 7 processor equipped with NVIDIA GeForce GTX 1650 GPU, the hyperparameters of RF and SVR is less than training a single CNN; therefore, we considered it by adding a unit to the sum of the CNNs that must be trained to perform the method.
In this context, particular attention should be given to steps 5 and 6 of Algorithm 1. Specifically, these steps indicate how the trained SVR and RF models predict the performances of all the networks in . While this operation may only take a few seconds on an average-powered computer for a dataset of a few hundred thousand examples, it could be a prohibitive task in a space of cardinality of . In such cases, the hypersurface delineated by SVR, being continuous, differentiable, and convex, can be approached using a gradient-based method to find its unique optimal point. However, in cases where exhaustive execution of steps 5 and 6 of Algorithm 1 is feasible, RF can also be used as a predictor.
4.1. Results
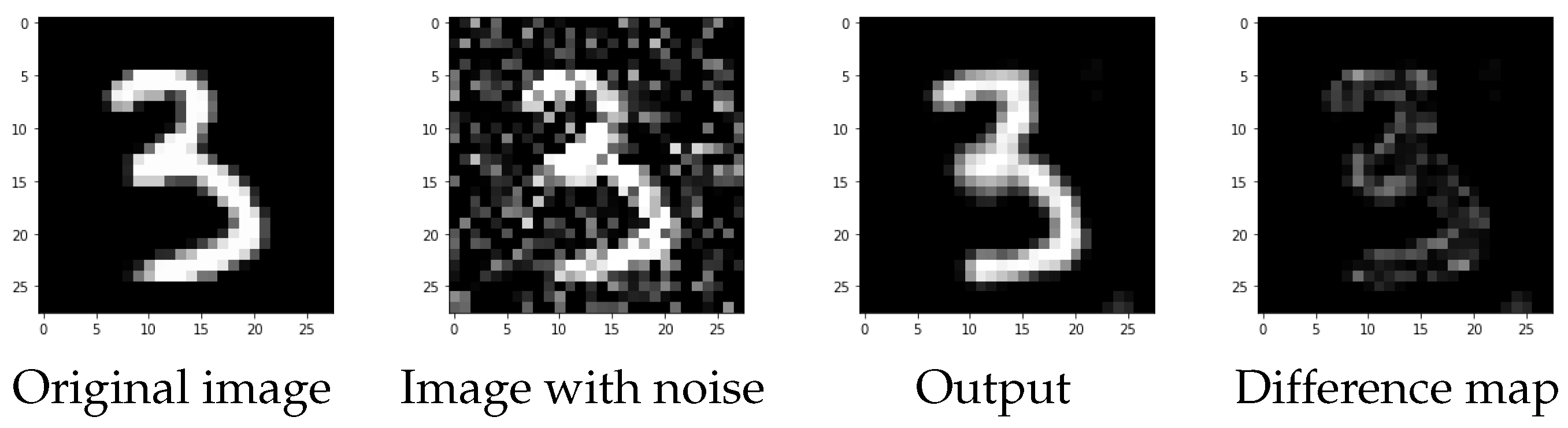
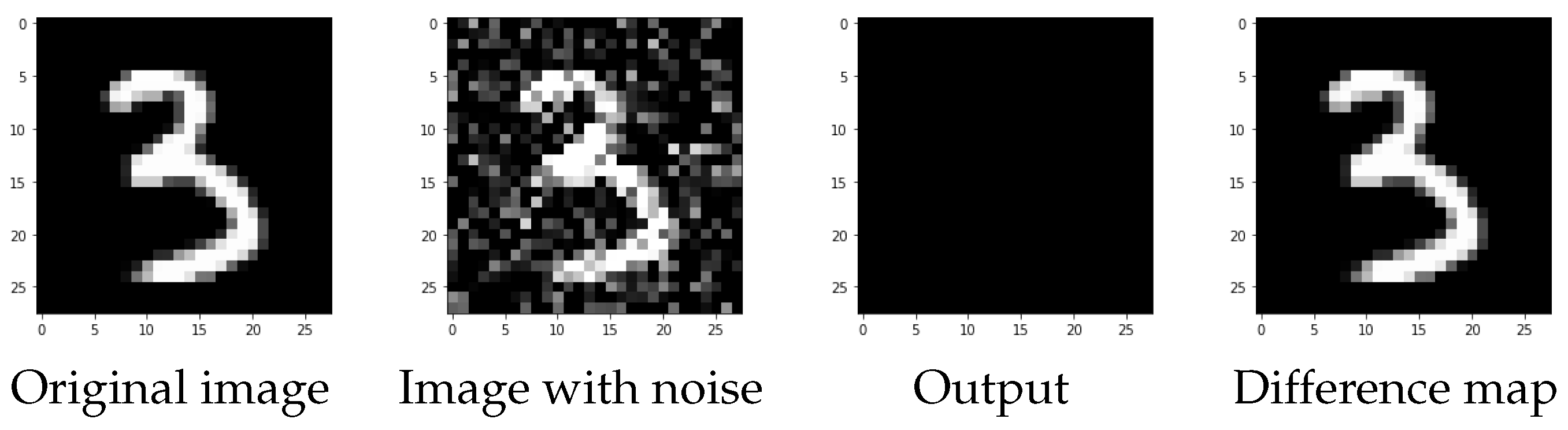
During the first phase of generating the CNN dataset, we observe that the selected networks exhibit different levels of performance. In this case, the predictors were trained with the MSE label as a measure of discrepancy, as in this case what is desired is an image as close as possible to the uncorrupted one. In the worst-case scenario, the MSE value, used as the performance measure, exceeds
, resulting in a completely flattened image where both the noise and the image itself disappear. In
Figure 2,
Figure 3 and
Figure 4, we provide examples of reconstructions, where we compare the original image, the input image with artifacts, the output image, and the difference between the predicted and original images for each configuration.
During the second phase, we use the dataset created in the first phase to train an SVR and an RF. In the third phase, once the predictor has undergone training, it can be utilized to search for the best possible configuration of hyperparameters, which can lead to the production of high-quality reconstructed images. In particular, we use SV, RF, and HYB to predict the MSE on the test set for all the configurations’ HS. We sort these performance predictors and we analyze, from a statistical point of view, the best 75 configurations of each PP.
In more detail, the histograms in
Figure 5,
Figure 6 and
Figure 7 were derived by isolating the best 75 CNNs of each method (SVR, RF, and HYB) based on the predicted performance measured on the test set. The distributions of hyperparameters were studied by considering these best configurations.
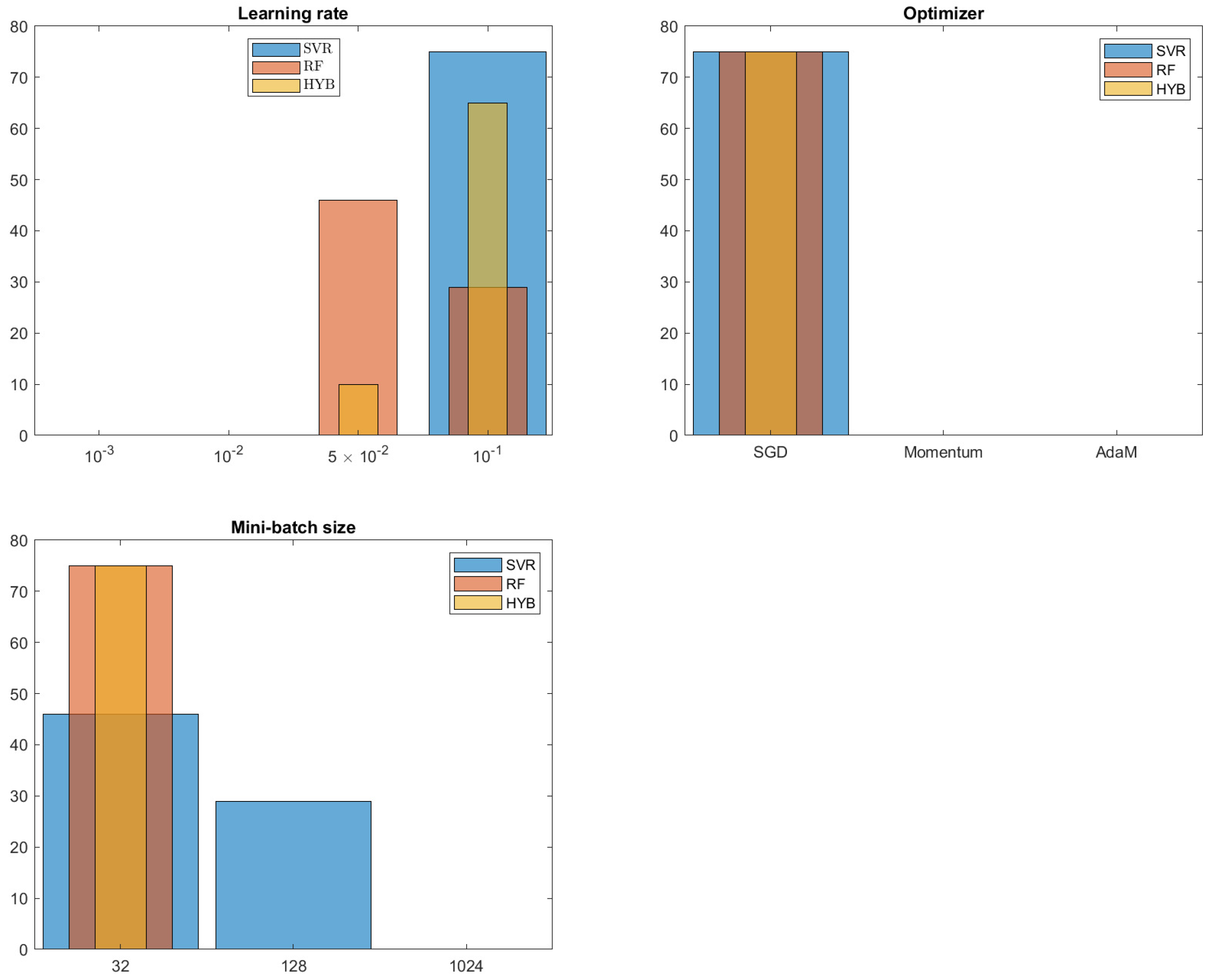
In
Figure 5, we see how the hyperparameters related to the optimizer are distributed. It is quite evident that almost all of the best predicted CNNs are in the configuration
.
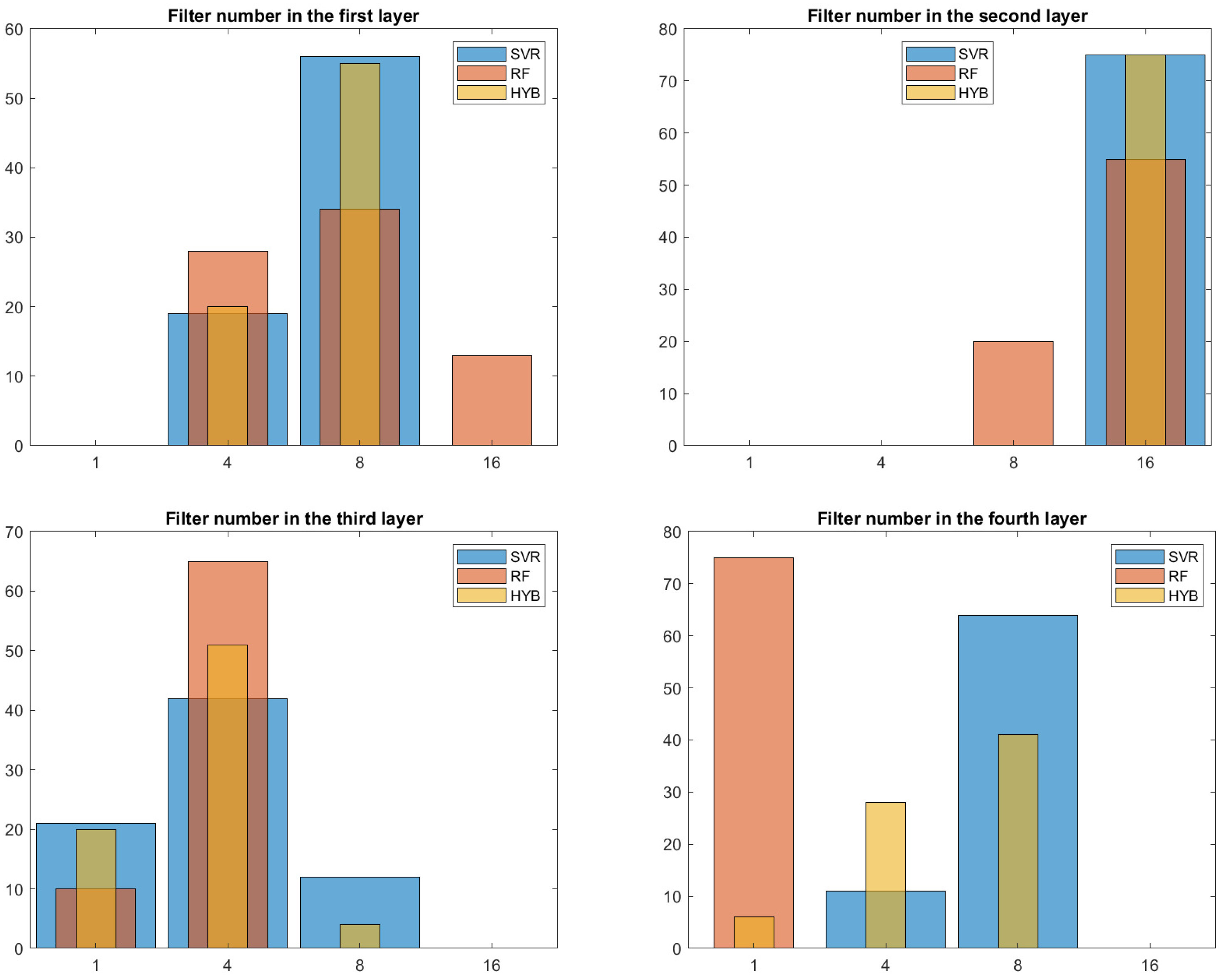
In the same way, in
Figure 6, we can observe how the hyperparameters related to the number of filters for each level of the CNN are distributed. In this case, the results are less clear-cut. We can suggest
for the first number of kernels, 16 for the second, 4 for the third, and 8 for the last.
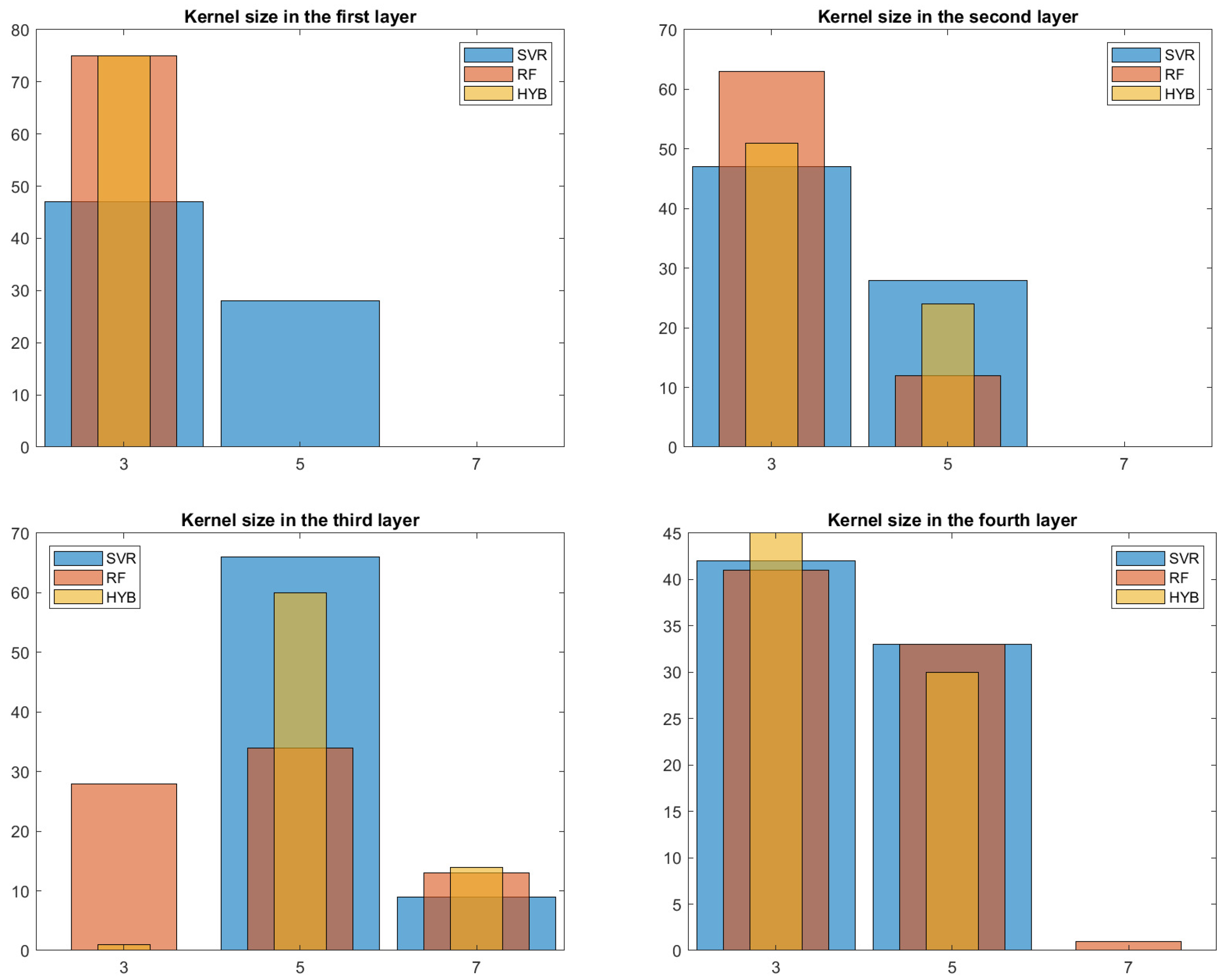
Finally, in
Figure 7, we can observe the distribution of the various kernel sizes; again, a slight preference toward smaller kernel sizes can be observed.
Before proceeding to the use of PPs, it is necessary to analyze their performance. Specifically, after finding the best configuration of hyperparameters with Optuna [
30], the predictors were trained on only 70 configurations, isolating 5 of them as test set for the PPs.
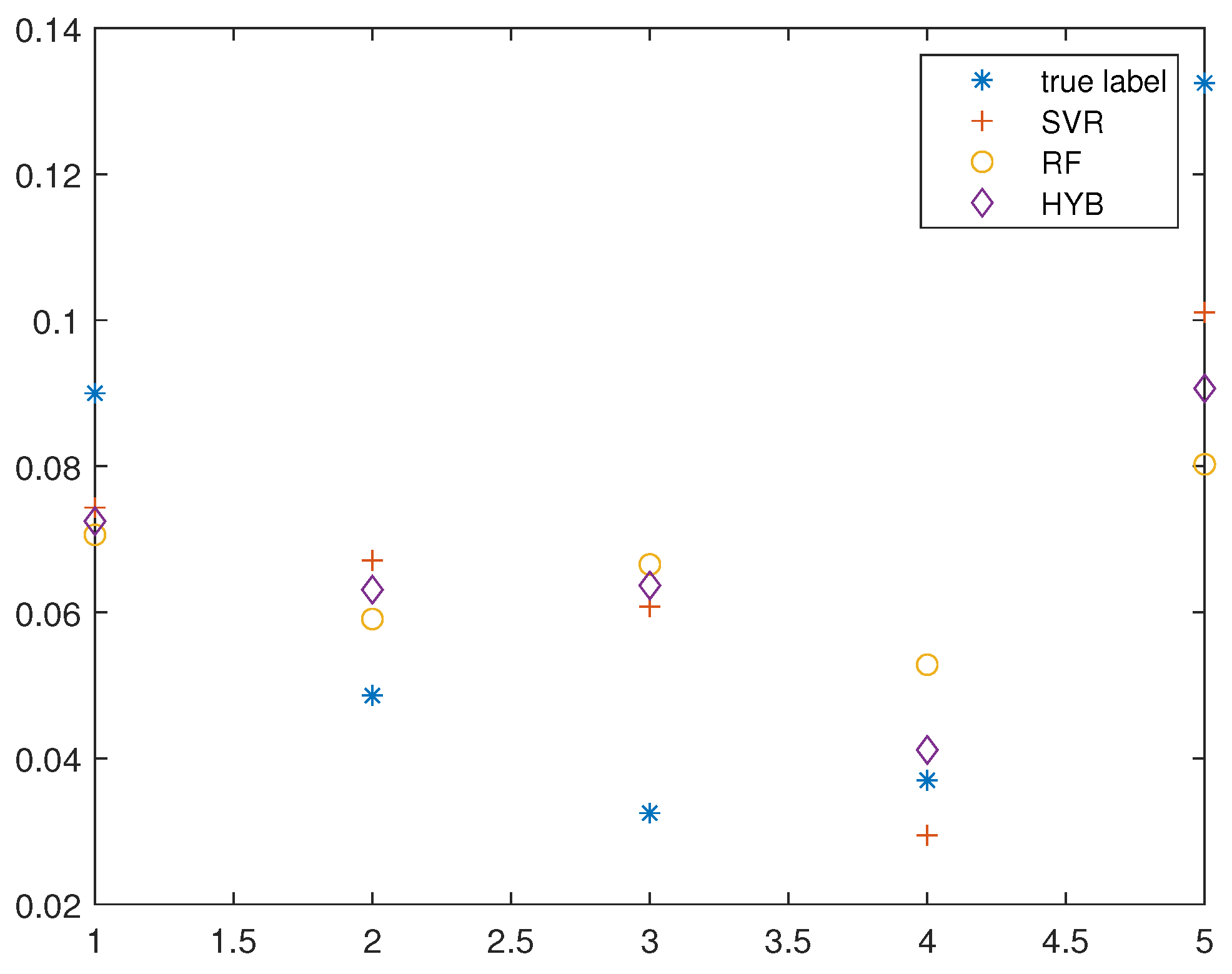
Shown in
Figure 8 is the performance of the three PPs with respect to these five unseen configurations. As it can be seen, the predictors are not perfect, but they enable the identification of good configurations versus those that will lead to poor performance at the end of the training phase. To make a more rigorous analysis of the PPs, we carried out a specific experiment aimed at looking specifically at the goodness of the PPs. Namely, 75 different CNNs were randomly extracted and divided into train set (80%) and test set (20%). This extraction was carried out in 1000 different draws, thus producing 1000 different train and test sets consisting of 75 different configurations as input and their final performance as output. At this point, the three different PPs were trained for each dataset and we report the average error and the related standard deviation. For the SVR-based predictor, the RMSE (root mean square error) is
, while the standard deviation is
. On the other hand, the version with RF achieves an
with standard deviation equal to
. The HYB predictor also performs best in the mean version, with an RMSE of
and a standard deviation equal to
. These results can also be considered partially satisfactory, but must also be evaluated taking into account the small number of configurations used. Having more computational resources available, it is possible to use the method proposed in [
14], which also takes into account the performance in the first epochs of the network.
Based on the results obtained, for any performance predictor, the best CNN can be devised by obtaining the three best CNNs. These three networks were trained until numerical stopping (maximum 20 epochs) on the training set and the performance on the test set was evaluated.
We report in
Table 1 the complete configurations of the top three networks obtained by means of the PPs. Furthermore,
Figure 9 shows the decreasing behavior of the loss for the test and the train sets in the best configuration; it is evident that the CNN achieves a suitable minimum point. Indeed, the loss function flattens out a lot in the later epochs.
On the other hand, for those configurations with a very bad performance (divergent), the learning process terminates after a few epochs through early stopping as it fails to decrease the loss function. Conversely, there may be some configurations that would require several epochs to obtain a good result, greatly increasing the computational time. The idea is to ignore these particularly slow networks since our context is GreenAI.
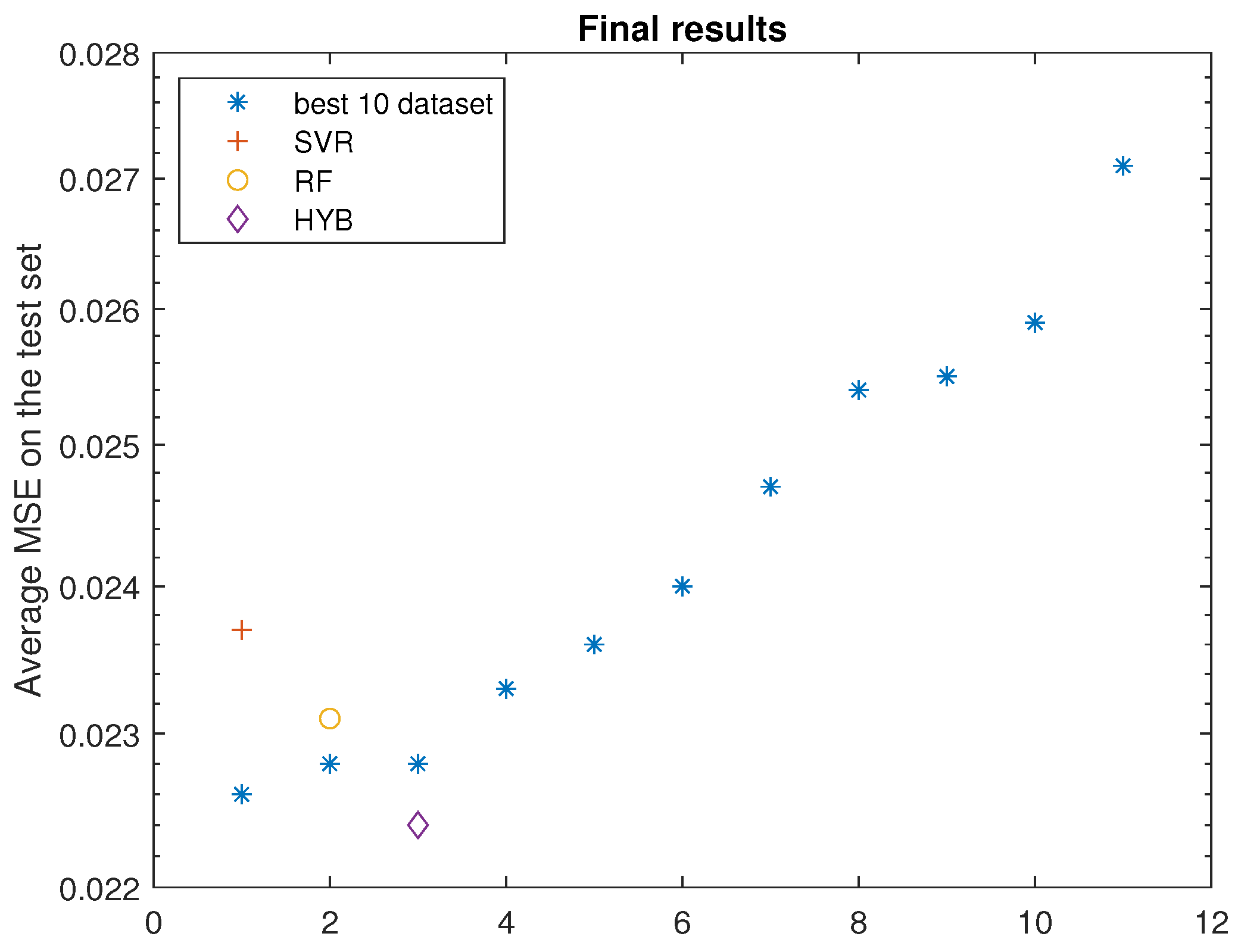
Finally,
Figure 10 shows, in addition to the actual performance on the test set of the best three networks found by the PP, the performance of the best ten networks of the original dataset.
As can be seen in the last figure, the best network found by the PP HYB achieves the best result of all, including the best in the dataset. The best networks predicted by SVR and RF also perform very well, showing a performance comparable to the best samples in the dataset. We highlight that these results were achieved by training for 20 epochs only on 78 networks, that is, about of the size of the hyperparameter space. We also emphasize that the entire process of training, testing, and prediction of PPs took about the same time and resources required for a single CNN training epoch.
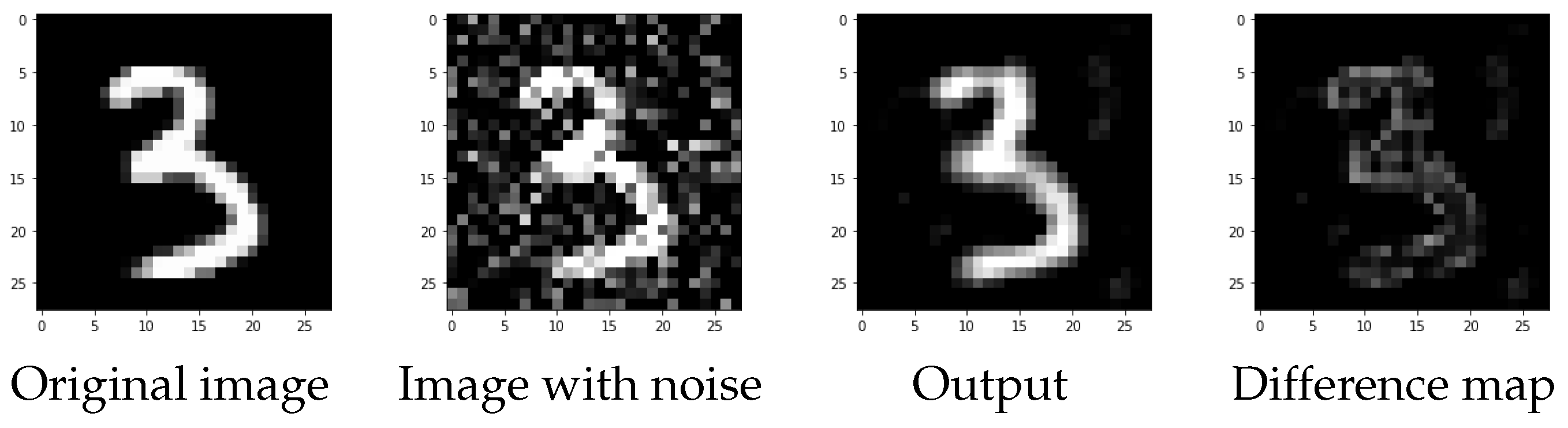
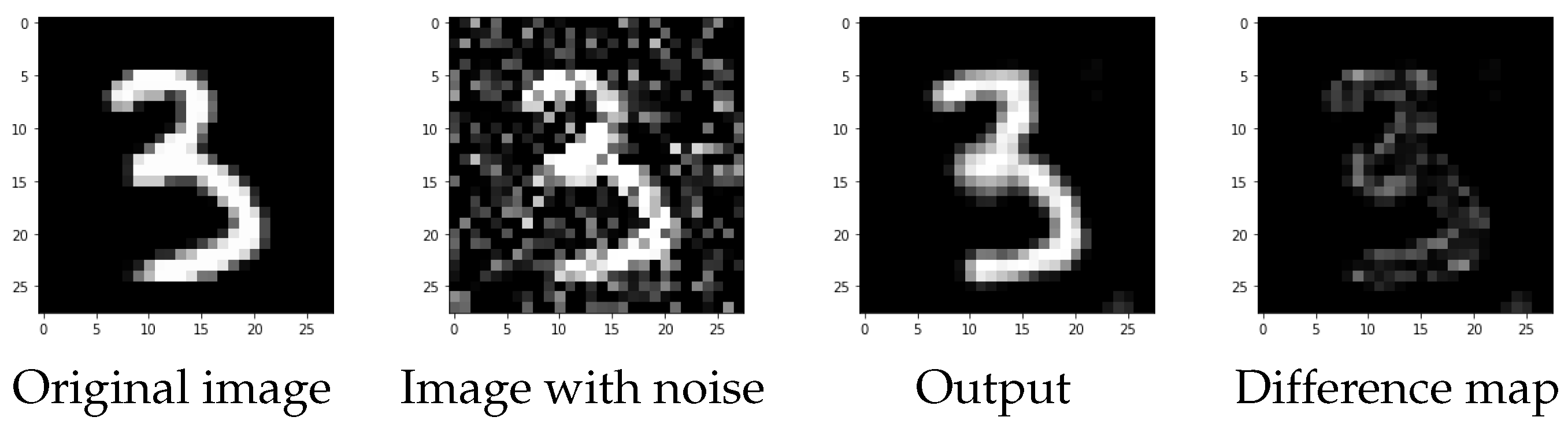
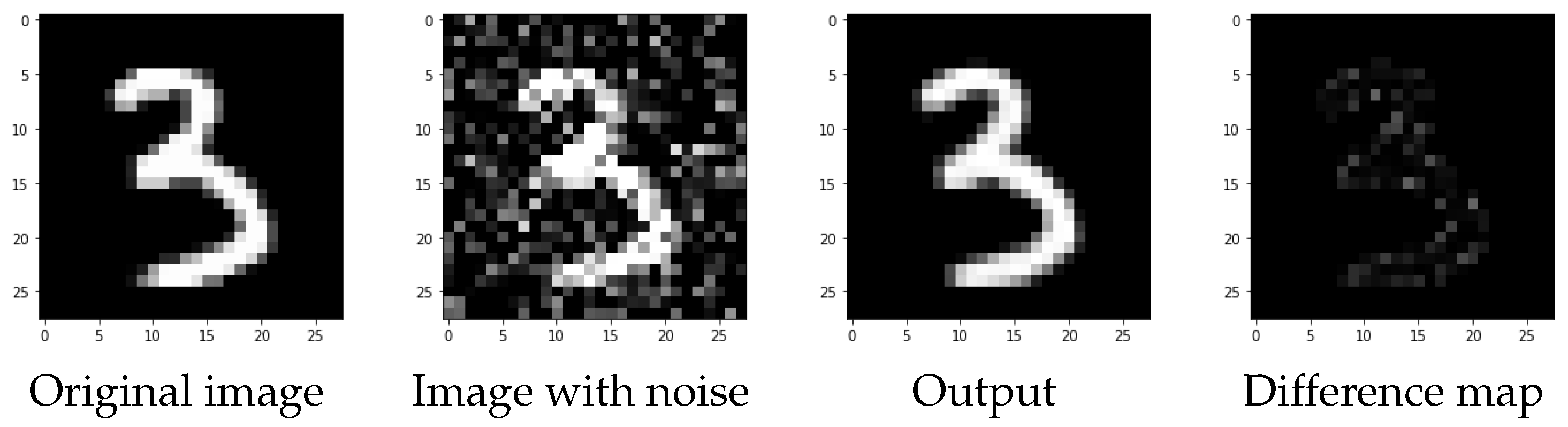
In
Figure 11, we can see the reconstruction of the best CNN determined by HYB PP on an element of the test set. As we can see, the reconstruction is very clear and only few pixels are visible in the difference map.
Comparison with other grid search methods without the use of PPs.
In the literature, there exists a variety of NAS methods based on the use of PPs and other techniques that address the problem following different ideas. A comparison of the proposed technique with the state of the art is beyond the scope of this paper, but a first comparison can be performed with grid search type methods. We highlight that grid search methods equipped with cross-validation techniques can be prohibitive; indeed, they would lead to training each individual hyperparameter configuration multiple times on different data splits. Therefore, we can adopt different ways to execute a comparison with a simple grid search. In the first approach, to keep the computational cost fixed, we randomly extracted 79 configurations from . In the second case, the grid search was conducted on about one-third of the entire , thus on 200,000 configurations, similar to a brute-force approach.
In
Table 2, we report a comparison of the results obtained and the number of configurations needed for the three methods. GreenNAS refers to the best result obtained with the proposed method (HYB). With
light grid search, we denote the method using the same number of configurations of GreenNAS, but randomly chosen in
. On the other hand,
heavy grid search employs many more configurations; in particular, it uses 200,000 configurations, and in this case about 85% of these need 20 epochs to obtain satisfactory results. The table can then be read with computational cost in the second row and performance in the third row. Since MSE is a discrepancy index, a lower value is better. We observe that the best result, albeit by a little, is obtained with the
heavy grid search method, but at a computational cost more than 250 times higher. When GreenNAS is compared with a grid search method that exploits the same computational resources, it is the proposed method that comes out on top. As many as 200,000 different configurations were trained to conduct the comparison with the method
heavy grid search; these were then used to demonstrate the robustness of the 75 considered configurations, providing the initial dataset.
Specifically, 100 different trials were conducted, in which 75 configurations were randomly drawn from among 200,000. With these configurations, the best network was then predicted with HYB and led to convergence. The mean and the related standard deviation of the 100 trials are . This result is coherent with that of the presented experiment; the small variance highlights that the method is particularly robust with respect to the choice of 75 configurations.
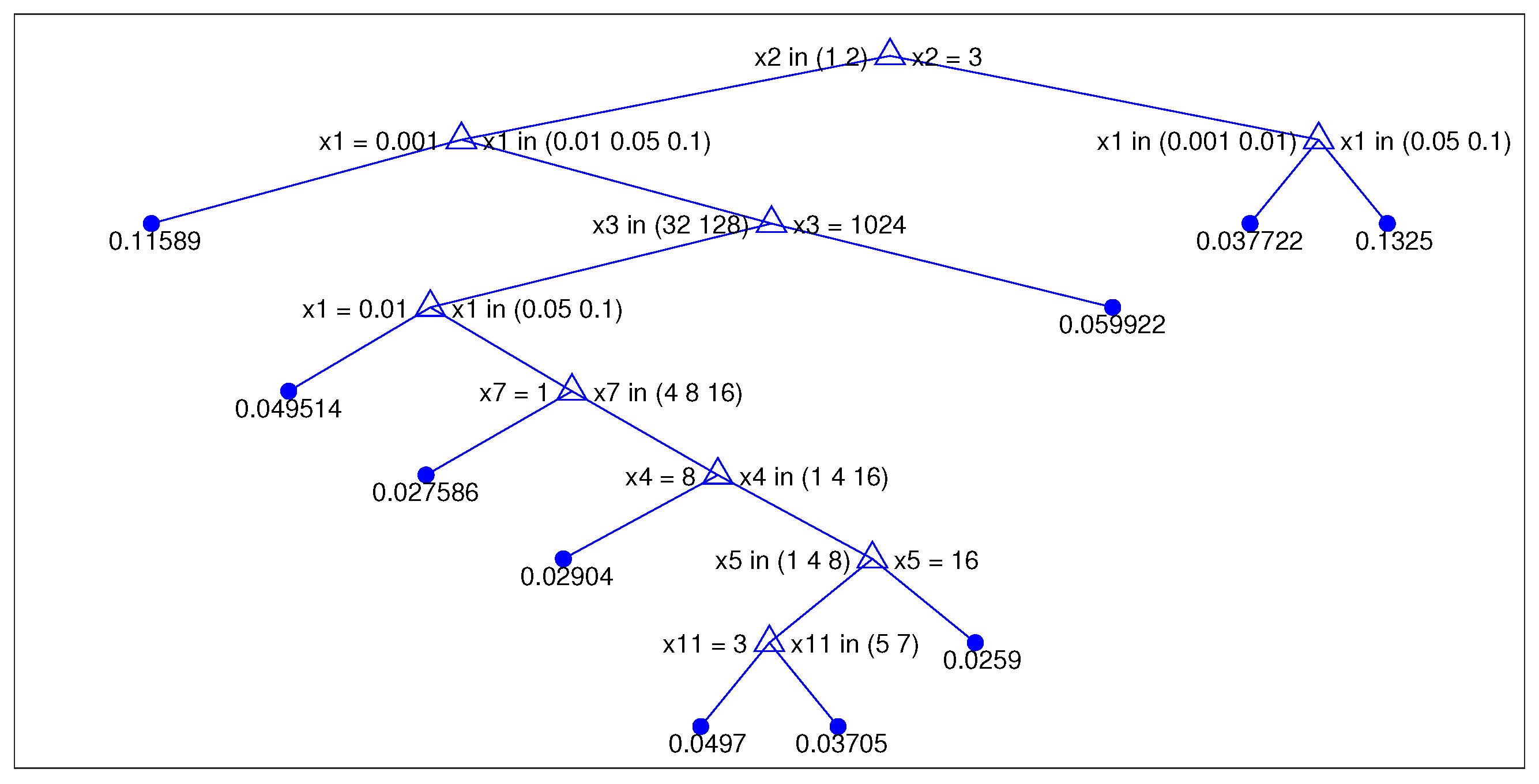
Interpretability of the method.
An interesting observation about the use of RF as a PP is based on the fact that this is a particularly interpretable method. Indeed, by focusing on a single tree, we can detect which characteristics are to be considered most important for the regression.
It is very interesting to note that the features related to the optimizer are the closest to the root node: they are, therefore, the most important for the decision tree (
Figure 12). In fact, in the first node, the split is performed by considering the type of optimizer (1 SGD, 2 momentum, and 3 AdaM); in the second level, the choice of a value for the learning rate is considered, and in the third, the size of the mini-batch is considered.
4.2. A Second Experiment: A Dense Neural Network for Classification
In a second experiment, we consider a multiple classification problem. In particular, we take into account a fully connected network consisting of three dense hidden layers in addition to the input and output layer. The network classifies, through a combination of softmax and categorical cross-entropy, the 10 handwritten digits of the MNIST dataset [
25].
In this case, the hyperparameters depending on the optimization procedure will be optimizer type, learning rate, mini-batch size, dimension, and activation function of the three hidden layers. As in the first experiment regarding the optimizer, the set of optimization algorithms to choose from include SGD, SGD with momentum (0.9 momentum hyperparameter), and AdaM. The set of learning rates is , and that of mini-batch sizes is . For the hidden dense layer, we consider for the dimension and ReLU, tanh, and sigmoid as activation functions. The entire dataset consists of 124,416 samples, and we choose to estimate possible configurations for the initial dataset (). In this case, the performance used is the accuracy on the test set, which is a set of 10,000 digits never seen during the training phase.
It is well known that the MNIST classification problem by an ANN is a very simple problem; thus, we consider only 15 epochs to evaluate the accuracy of the obtained solution for each different hyperparameter configuration. In the first phase of this experiment, the 12 configurations are chosen with uniform distribution; in the second phase, we build the three PPs using the dataset just created and final accuracies for the labels. In the third phase, we predict all the possible configurations with the three PPs and we choose only the best hyperparameter configuration for each PP ().
4.3. Results
In our case, we therefore trained 12 different networks, chosen at random in , for 15 epochs each, to create the starting dataset. Using this dataset, the three PPs, RF, SVR, and HYB, were trained. These PPs were then asked to predict the entire . Then, the best network was devised and executed to obtain the numerical solution. In summary, the proposed algorithm has the execution cost near equal to 16 networks, which is the executions of 12 networks for the initial dataset, the computational cost equivalent to one network for setting SVR and RF hyperparameters and to train these regressors and, finally, the execution of the 3 final best networks.
We report in
Table 3 the predicted and actual results (on the test set) of the original classifier compared with the best configurations returned by PPs. As can be seen, the method returns three configurations better than the one used by the original code.
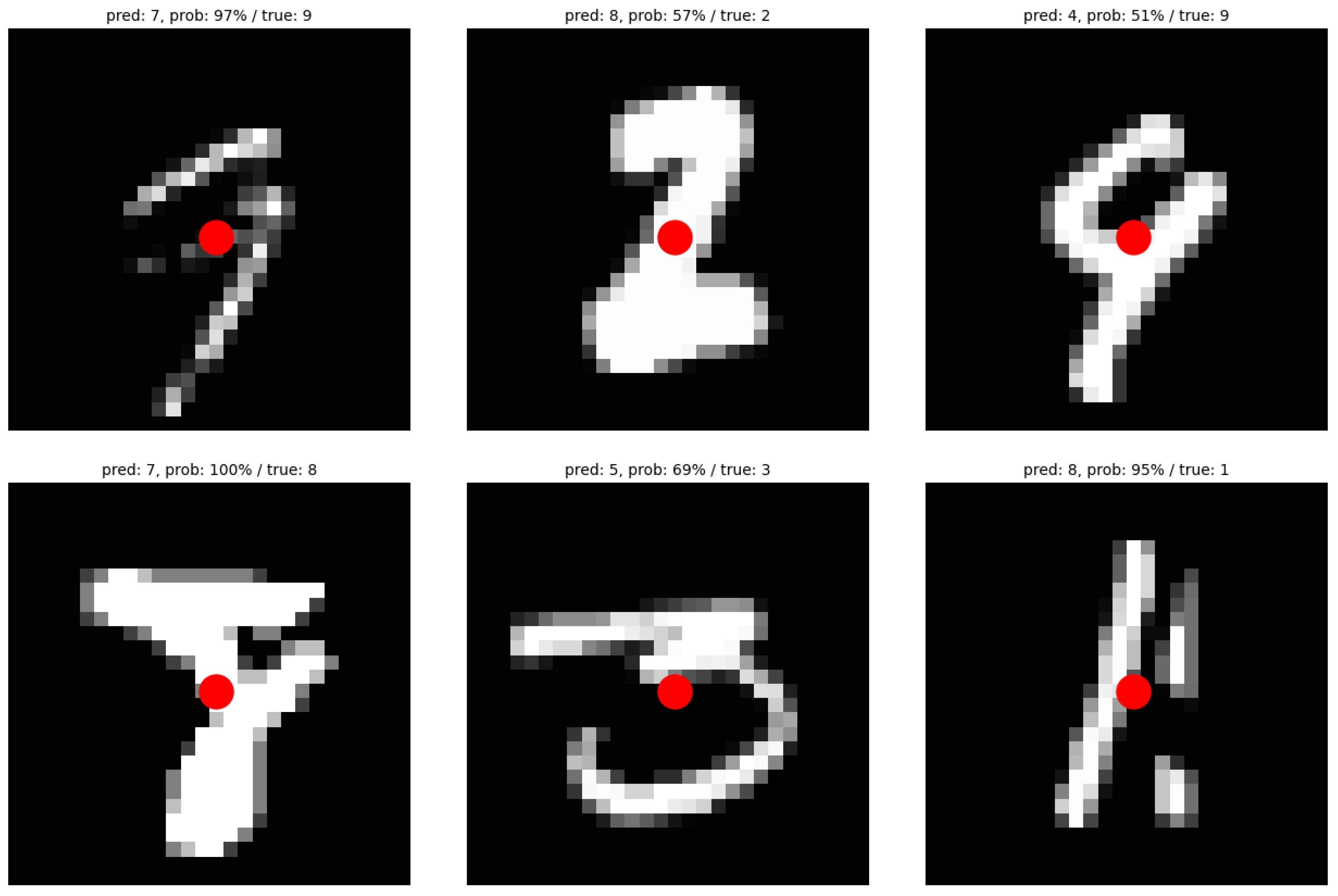
Finally, we report in
Figure 13 some of the errors made in the classification phase on the test set of the best network devised by the proposed algorithm.
For each digit, in addition to the image display, we report the predicted label, the probability with which that label is predicted (value returned by softmax), and the true label. We can see in
Figure 13 how for several images it is really difficult, even with the human eye, to predict the correct label.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}