1. Introduction
In recent years, frequentist deep learning procedures have become extremely popular and highly successful in a wide variety of real-world applications, ranging from natural language to image analyses [
1]. These models iteratively apply some nonlinear transformations aiming at the optimal prediction of response variables from the outer layer features. This yields high flexibility in modeling complex conditional distributions of the responses. Each transformation yields another hidden layer of features, which are also called neurons. The architecture/structure of a deep neural network includes the specification of the nonlinear intra-layer transformations (
activation functions), the number of layers (
depth), the number of features at each layer (
width) and the connections between the neurons (
weights). In the standard (frequentist) settings, the resulting model is trained using some optimization procedure (e.g., stochastic gradient descent) with respect to its parameters to fit a particular objective (like minimization of the root mean squared error or negative log-likelihood). Very often, deep learning procedures outperform traditional statistical models, even when the latter are carefully designed and reflect expert knowledge [
2,
3,
4,
5,
6]. However, typically, one has to use huge datasets to be able to produce generalizable neural networks and avoid overfitting issues. Even though several regularization techniques (
and
penalties on the weights, dropout, batch normalization, etc.) have been developed for deep learning procedures to avoid overfitting of training datasets, the success of such approaches is not obvious. Further, these networks are usually far too confident in the estimates they deliver, making it difficult to trust the outcomes [
7].
As an alternative to frequentist deep learning approaches, Bayesian neural networks represent a very flexible class of models, which are quite robust to overfitting and allow for obtaining more reliable predictive uncertainties by taking into account uncertainty in parameter estimation [
7,
8]. However, they often remain heavily over-parametrized. Considering sparse versions of the fully dense network is equivalent to considering different submodels in a statistical context. Bayesian approaches for taking model uncertainty into account form a procedure that is now well established within statistical literature [
9]. Such methods both have potential for sparsification and for taking into account uncertainty concerning both the amount and the type of sparsification. Extensions of such methods to neural network settings have recently gained interest within the machine learning community [
10,
11,
12]. Challenges related to such approaches include both appropriate specifications of priors for different submodels and the construction of efficient training algorithms [
13]. Sparsification by frequentist type model selection is also possible, but in such settings, the uncertainty related to the model selection procedure is typically not considered, something referred to as
the quiet scandal of statistics [
14]. Bayesian model averaging procedures can overcome these limitations.
There are several implicit approaches for the sparsification of BNNs by shrinkage of weights through priors [
15,
16,
17,
18,
19,
20]. For example, Blundell et al. [
16] suggest a mixture of two zero-centered Gaussian densities (with one of the components having a very small variance). Ghosh et al. [
21], Louizos et al. [
22] independently generalize this approach using Horseshoe priors [
23] for the weights, which assume that each weight is conditionally independent, with a density represented as a scale mixture of normals, modeling both local shrinkage parameters and global shrinkage. Thus, Horseshoe priors provide even stronger shrinkage and automatic specification of the mixture component variances required in Blundell et al. [
16]. Some algorithmic procedures can also be seen to correspond to specific Bayesian priors, e.g., Molchanov et al. [
18] show that Gaussian dropout corresponds to BNNs with log uniform priors on the weight parameters.
The main computational procedure for performing Bayesian inference has been Markov chain Monte Carlo (MCMC). Until recently, inference on BNNs could not scale to large and high-dimensional data due to the limitations of standard MCMC approaches, the main numerical procedure in use. Several attempts based on subsampling techniques for MCMC, which are either approximate [
24,
25,
26,
27,
28] or exact [
28,
29,
30,
31], have been proposed, but none of these apply to the joined inference on models and parameters.
An alternative to the MCMC technique is to perform approximate but scalable Bayesian inference through variational Bayes, also known as variational inference [
32]. Due to the fast convergence properties of the variational methods, variational inference algorithms are typically orders of magnitude faster than MCMC algorithms in high-dimensional problems [
33]. Variational inference has various applications in latent variable models, such as mixture models [
34], hidden Markov models [
35] and graphical models [
36] in general. Graves [
37] and Blundell et al. [
16] suggested the use of scalable variational inference for Bayesian neural networks. This methodology was further improved by incorporating various variance reduction techniques, which are discussed in Gal [
38].
Some theoretical results for (sparse) BNN have started to appear in the literature. Posterior contraction rates for sparse BNNs are studied in [
10,
12,
39]. Similar results are obtained in [
40], focusing on classification. All these results are based on asymptotics with respect to the size of training sets, which might be questionable when the number of parameters (weights) in the networks is large compared to the number of observations. Most of these results are also limited to specific choices of priors and variational distributions. Empirical validations of procedures are therefore additionally valuable.
In this paper, we consider a formal Bayesian approach for jointly taking into account
structural uncertainty and
parameter uncertainty in BNNs as a generalization of Bayesian methods developed for neural networks taking only parameter uncertainty into account. Similar model selection and model averaging approaches have been introduced within linear regression models [
9]. The approach is based on introducing latent binary variables corresponding to the inclusion–exclusion of particular weights within a given architecture. This is done by means of introducing spike-and-slab priors, consisting of a
“spike” component for the prior probability of a particular weight in the model to be zero and a
“slab” component modeling the prior distribution for weight otherwise. Such priors for the BNN setting have been suggested previously in Hubin [
41] and also in Polson and Ročková [
10], the latter mainly focused on theoretical aspects of this approach.
A computational procedure for joint inference on the models and parameters in the settings of BNNs was proposed in an early version of this paper [
11] and was then used in Bai et al. [
12]. Here, we go further, in that we introduce more flexible priors but also allow for more flexible variational approximations based on the multivariate Gaussian structures for inclusion indicators. Finally, we learn hyperparameters of the priors using the empirical Bayes procedure to avoid manual specification of them. Additionally, we consider a vast experimental setup with several alternative prediction procedures, including full Bayesian model averaging, posterior mean-based models and the median probability model, and perform a comprehensive experimental study comparing the suggested approach with several competing algorithms and several datasets. Last but not least, following Hubin [
41], we link the obtained
marginal inclusion probabilities to
binary dropout rates, which gives proper probabilistic reasoning for the latter. The inference algorithm is based on scalable stochastic variational inference.
Thus, the main contributions and innovations of the paper include broadly addressing the problems of Bayesian model selection and averaging in the context of neural networks by introducing relevant priors and proposing a scalable inference algorithm. This algorithm is based on a combination of variational approximation and the reparametrization trick, the latter extended to also handle the latent binary variables defining the model structure. The approach is tested on a vast set of experiments, ranging from tabular data to sound and image analysis. Within these experiments, comparisons to a set of carefully chosen and most relevant baselines are performed. These experiments demonstrate that incorporating structural uncertainty allows for the sparsification of the structure without losing accuracy compared to other pruning techniques. Further, by introducing a doubt decision in cases with high uncertainty, robust predictions under uncertainty are achieved.
The rest of the paper is organized as follows: the class of BNNs and the corresponding model space are mathematically defined in
Section 2. In
Section 3, we describe the inference problem, including several predictive inference possibilities, and the algorithm for training the suggested class of models. In
Section 4, the suggested approach is applied to the two classical benchmark datasets MNIST, FMNIST (for image classifications) as well as PHONEME (for sound classification). We also compare the results with some of the existing approaches for inference on BNNs. Finally, in
Section 5, some conclusions and suggestions for further research are given. Additional results are provided in the Appendix.
2. The Model
A neural network model links (possibly multidimensional) observations
and explanatory variables
via a probabilistic functional mapping with a vector of parameters
of the probability distribution of the response:
where
is some observation distribution, typically from the exponential family (
can correspond to mean and variance for Gaussian distribution, or a vector of probabilities for a categorical distribution or scale and shape parameters of Weibull). Further, the observations
are assumed inpdendent. To construct the vector of parameters
, one builds a sequence of building blocks of hidden layers through semi-affine transformations:
with
. Here,
L is the number of layers,
is the number of nodes within the corresponding layer, while
is a univariate function (further referred to as the
activation function).
Further,
, for
, are the weights (slope coefficients) for the inputs
of the
l-th layer (note that
and
). For
, we obtain the intercept/bias terms. Finally, we introduce latent binary indicators
turning the corresponding weights on if
and off otherwise. In our notation, we explicitly differentiate between discrete structural/model configurations defined by the set
(further referred to as models) constituting the model space
and parameters of the models, conditional on these configurations
. The use of such binary indicators is (in statistical science literature) a rather standard way to explicitly specify the model uncertainty in a given class of models and is used in, e.g., Raftery et al. [
9] or Clyde et al. [
42].
A Bayesian approach is completed by specification of model priors
and parameter priors for each model
. Many kinds of priors can be considered. We follow our early preprint [
11] as well as even earlier ideas from Polson and Ročková [
10] and Hubin [
41] and consider the independent spike-and-slab weight priors combined with independent Beta Binomial priors for the latent inclusion indicators. However, unlike earlier works, we introduce a more flexible t-distribution, allowing for
“fat” tails for the slab components:
Here, we have a
degrees of freedom parameter for the t-distribution with a zero mean and a variance of
. Further,
is the delta mass or “spike” at zero, whilst
is the prior probability for including the weight
into the model. We will refer to our model as the Latent Binary Bayesian Neural Network (LBBNN) model.
4. Applications
In-depth studies of the suggested variational approximations in the context of
linear regression models have been performed in earlier studies, including multiple synthetic and real data examples with the aims of both recovering meaningful relations and predictions [
44,
50]. The results from these studies show that the approximations based on the suggested variational family distributions are reasonably precise and indeed scalable but can be biased. We will not address toy examples and simulation-based examples in this article and rather refer the curious readers to the very detailed and comprehensive studies in the references mentioned above, whilst we will address some more complex examples here. In particular, we will address the classification of MNIST [
51] and fashion-MNIST ([
52] FMNIST) images, as well as the PHONEME data [
53]. Both MNIST and FMNIST datasets comprise 70,000 grayscale images (size 28x28) from 10 categories (handwritten digits from 0 to 9, and “Top”, “Trouser”, “Pullover”, “Dress”, “Coat”, “Sandal”, “Shirt”, “Sneaker”, “Bag” and “Ankle Boot” Zalando’s fashion items, respectively), with 7000 images per category. The training sets consist of 60,000 images, and the test sets have 10,000 images. For the PHONEME dataset, we have 256 covariates and 5 classes in the responses. In this dataset, we have 3500 observations in the training set and 1000 observations in the test set. The PHONEME data are extracted from the TIMIT database (TIMIT Acoustic-Phonetic Continuous Speech Corpus, NTIS, US Dept of Commerce), which is a widely used resource for research in speech recognition. This dataset was formed by selecting five phonemes for classification based on a digitized speech from this database. The phonemes are transcribed as follows: “sh” as in “she”, “dcl” as in “dark”, “iy” as the vowel in “she”, “aa” as the vowel in “dark” and “ao” as the first vowel in “water”. Additionally, in the Appendix to the paper, we report results on the standard tabular UCI datasets
https://archive.ics.uci.edu/datasets (accessed on 25 January 2024), including credit approval data, bank marketing data, adult census data, dry beans data, pistachio data and raisins data.
4.1. Experimental Design
For the three datasets addressed in the main part of the paper, we use a feed-forward neural network with the ReLU activation function and multinomially distributed observations. For the two first examples, we have 10 classes and 784 input explanatory variables (pixels), while for the third one, we have 256 input variables and 5 classes. In all three cases, the network has 2 hidden layers with 400 and 600 neurons, correspondingly. Priors for the parameters and model indicators were chosen according to (3). The inference was performed using the suggested doubly stochastic variational inference approach (Algorithm 1) on 250 epochs with a batch size of 100.
M was set to 1 to reduce computational costs and because this choice of
M is argued to be sufficient in combination with the reparametrization trick [
38]. Up to 20 first epochs were used for pre-training of the models and parameters, as well as empirically (aka Empirical Bayes) estimating the hyperparameters of the priors (
) by adding them into the computational graph. After that, the main training cycle began (with fixed hyperparameters on the priors). We used the ADAM stochastic gradient ascent optimization [
54] with the diagonal matrix
in Algorithm 1 and the diagonal elements specified in
Table 1 and
Table A3 for pre-training, and the main training stage. After 250 training epochs, post-training was performed. When post-training the parameters, either with fixed marginal inclusion probabilities or with the median probability model, we ran an additional 50 epochs of the optimization routine, with
specified in the bottom rows of
Table 1 and
Table A1. For the fully Bayesian model averaging approach, we used both
and
. Even though
can give a poor Monte Carlo estimate of the prediction distribution, it can be of interest due to high sparsification. All the PyTorch implementations used in the experiments are available in our GitHub repository (
https://github.com/aliaksah/Variational-Inference-for-Bayesian-Neural-Networks-under-Model-and-Parameter-Uncertainty (accessed on 25 January 2024)).
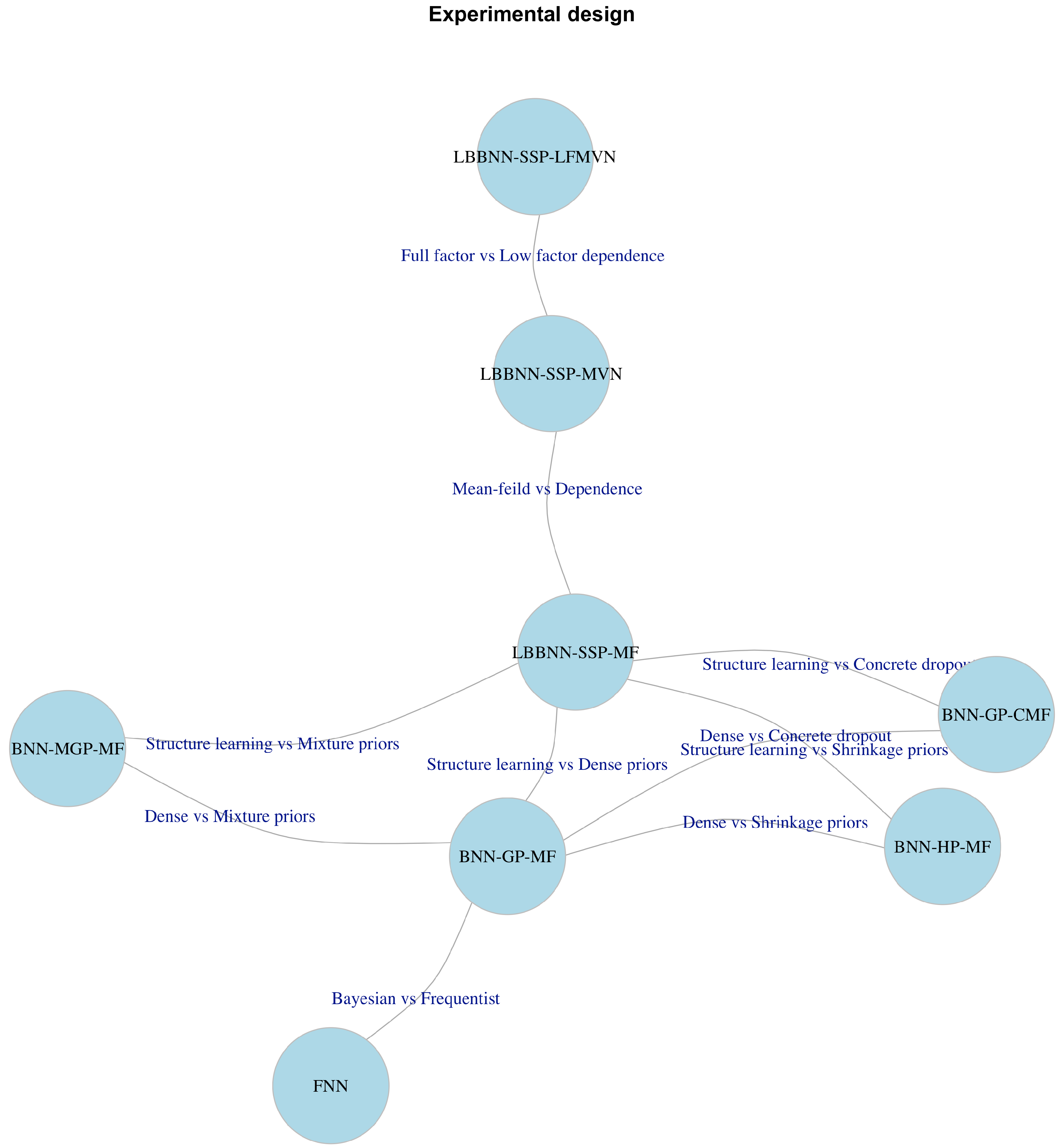
We report results for our model LBBNN applied with the spike-and-slab priors (SSP) combined with variational inference based on Mean-Field (MF), MVN (MVN) and Low Factor MVN (for LFMVN, the predictions’ results are reported in the Appendix) dependence structures between the latent indicators. We use the combined names LBBNN-SSP-MF, LBBNN-SSP-MVN and LBBNN-SSP-LFMVN, respectively, to denote the combination of model, prior and variational distribution.
In addition, we also used several relevant
baselines. In particular, we addressed a standard Dense BNN with Gaussian priors and mean-field variational inference [
37], denoted as
BNN-GP-MF. This model is important in measuring how predictive power is changed due to the introduction of sparsity. Furthermore, we report the results for a Dense BNN with mixture priors (
BNN-MGP-MF), with two Gaussian components of the mixtures [
16], with probabilities of 0.5 for each and variances equal to 1 and
, correspondingly. Additionally, we have addressed two popular sparsity-inducing approaches, in particular, a dense network with Concrete dropout (
BNN-GP-CMF) [
47] and a dense network with Horseshoe priors (
BNN-HP-MF) [
22]. Finally, a frequentist fully connected neural network (
FNN) (with posthoc weight pruning) was used as a more basic baseline. We only report the results for
FNN in the Appendix to make the experimental design cleaner. All of the baseline methods (including the
FNN) also have 2 hidden layers with 400 and 600 neurons, respectively, corresponding to three layers of weights. They were trained for 250 epochs with an Adam optimizer (with a learning rate
for all involved parameters) and a batch size equal to 100. For the BNN with Horseshoe priors, we are reporting statistics separately before and after ad-hoc pruning (PRN) of the weights. Post-training (when necessary) was performed for an additional 50 epochs. For
FNN, for all three experiments, we performed weight and neuron pruning [
55] to have the same sparsity levels as those obtained by the Bayesian approaches to make them directly comparable. Pruning of
FNN was based on removing the corresponding share of weights/neurons having the smallest magnitude (absolute value). No uncertainty was taken into consideration and neither was structure learning considered for
FNNs. Main results for the specific baselines will be reported in
Table 2,
Table 3 and
Table 4, while additional results will be reported in the Appendix.
For prediction, several methods were described in
Section 3.4. All essentially boils down to choices on how to treat the model parameters
and the weights
. For
, we can either simulate (
SIM) from the (approximate) posterior or use the median probability model (
MED). An alternative for
BNN-HP-MF here is the pruning method (
PRN) applied in Louizos et al. [
22]. We also consider the choice of including all weights for some of the baseline methods (
ALL). For
, we consider either sampling from the (approximate) posterior (
SIM) or using the posterior mean (
MEA). Under this notation, the fully Bayesian model averaging from
Section 3.4 is denoted as
SIM SIM, whilst the posterior mean based model as
ALL MEA, the median probability model as
MED SIM and the the median probability model combined with parameter posterior mean as
MED MEA. The full experimental design and relations between the closest baselines are summarized in
Figure 2.
We then evaluated accuracies (
Acc—the proportion of the correctly classified samples)
Accuracies based on the median probability model (through either
or
) and the posterior mean models were also obtained. Finally, accuracies based on post-training of the parameters with fixed marginal inclusion probabilities and post-training of the median probability model were evaluated. For the cases when model averaging is addressed (
), we are additionally reporting accuracies when classification is only performed if the maximum model-averaged class probability exceeds 95%, as suggested by Posch et al. [
56]. Otherwise, a doubt decision is made ([
57] sec 2.1). In this case, we both report the accuracy within the classified images as well as the number of classified images. Finally, we are reporting the overall density level (the fraction of non-zero weights after model selection/sparsification), i.e.,
for different approaches. To guarantee reproducibility, summaries (medians, minimums, maximums) across 10 independent runs of the described experiment
were computed for all of these statistics. Estimates of the marginal inclusion probabilities
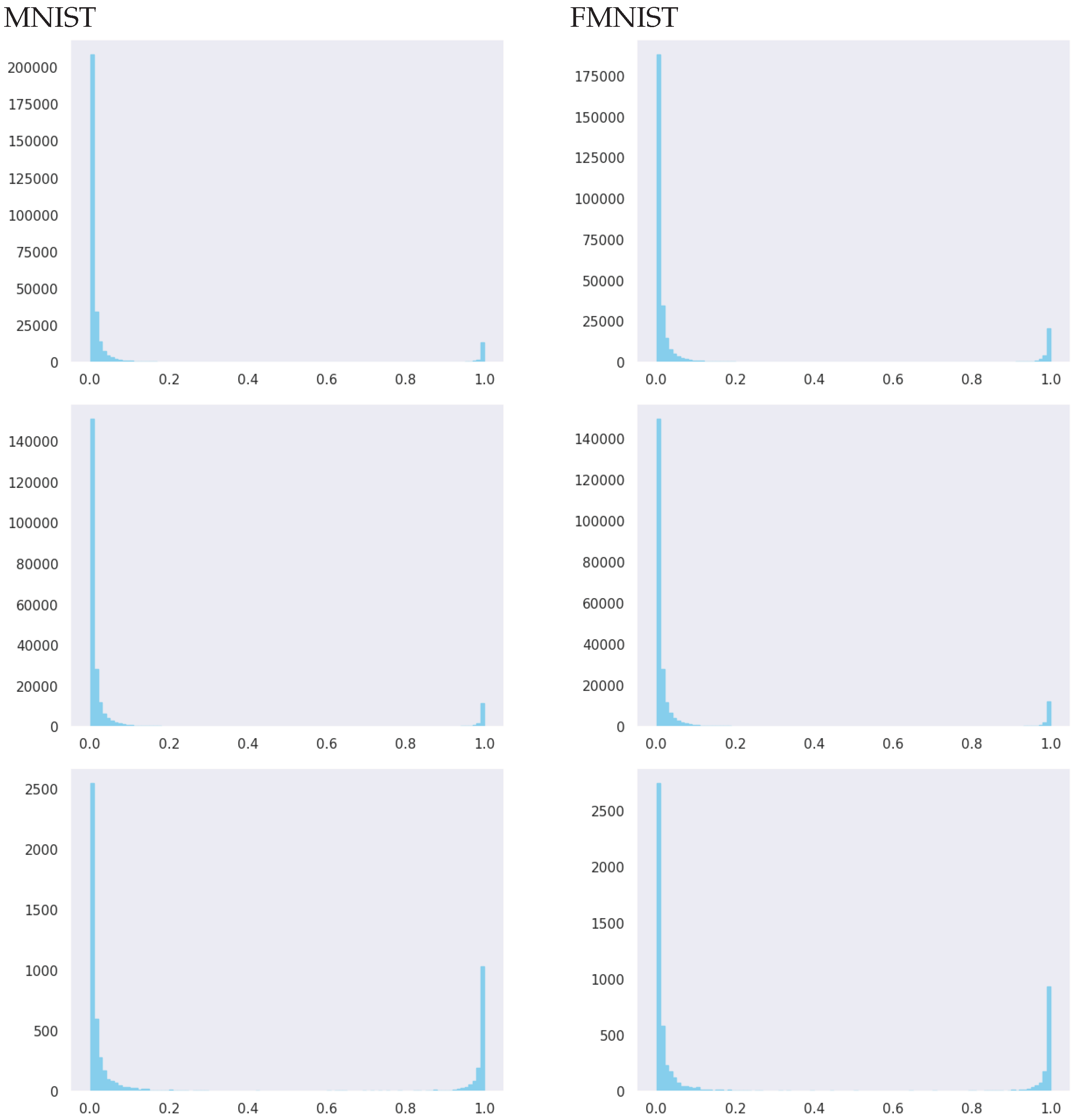
based on the suggested variational approximations were also computed for all of the weights. To compress the presentation of the results, we only present the mean marginal inclusion probabilities for each layer
l as
, summarized in
Table 5, but we also report non-aggregated histograms in
Figure A1 in the
Appendix A. Last but not least, to make the abbreviations used in the reported results clear, we provide a table with their short summaries in the
Abbreviations section of the paper.
4.1.1. MNIST
The results reported in
Table 2 and
Table 5 (with some additional results on LBBNN-SSP-LFMVN, FNN and post-training reported, respectively, in
Table A2,
Table A5 and
Table A8 in the Appendix) show that within our LBBNN approach: (a) model averaging across different BNNs (
) gives significantly higher accuracy than the accuracy of a random individual BNN from the model space (
); (b) the median probability model and posterior mean-based model also perform significantly better than a randomly sampled model. The performance of the median probability model and posterior mean-based model is, in fact, on par with full model averaging; (c) according to
Table 5, for the mean-field variational distribution, the majority of the weights of the models have very low marginal inclusion probabilities for the weights at layers 1 and 2, while more weights have high marginal inclusion probabilities at layer 3 (although also a significant reduction at this layer). This resembles the structure of convolutional neural networks (CNN), where, typically, one first has a set of sparse convolutional layers, followed by a few fully connected layers. Unlike CNNs, the structure of sparsification is learned automatically within our approach: (d) for the MVN with full rank structure within variational approximation, the input layer is the most dense, followed by extreme sparsification in the second layer and a moderate sparsification at layer 3; (e) the MVN approach with a low factor parametrization of the covariance matrix (results in the Appendix) only provides very moderate sparsification not exceeding 50% of the weight parameters; (f) variations of all of the performance metrics across simulations are low, showing stable behavior across the repeated experiments; (g) inference with a doubt option gives almost perfect accuracy; however, this comes at the price of rejecting the classification of some of the items.
For other approaches, it is also the case that: (h) both using the posterior mean-based model and using sample averaging improves accuracy compared to a single sample from the parameter space; (i) variability in the estimates of the target parameters is low for the dense BNNs with Gaussian/mixture of Gaussians priors and BNN with Horseshoe priors and rather high for the Concrete dropout approach. When it comes to comparing our approach to baselines, we notice that: (j) dense approaches outperform sparse approaches in terms of the accuracy in general; (k) Concrete dropout marginally outperforms other approaches in terms of median accuracy; however, it exhibits large variance, whilst our full BNN and the compressed BNN with Horseshoe priors yield stable performance across experiments; (l) neither our approach nor baselines managed to reach state-of-the-art results in terms of hard classification accuracy of predictions [
58]; (m) including a 95% threshold for making a classification results in a very low number of classified cases for the Horseshoe priors (it is extremely underconfident), the Concrete dropout approach seems to be overconfident when conducting an inference with the doubt option (resulting in lower accuracy but a larger number of decisions), and the full BN and BNN with Gaussian and mixture of Gaussian priors give less classified cases than the Concrete dropout approach but reach significantly higher accuracy; (n) this might mean that the thresholds need to be calibrated towards the specific methods; (o) our approach under the mean-field variational approximation and the full-rank MVN structure of variational approximation yields the highest sparsity of weights when using the median probability model. Also, (p) post-training (results in the Appendix) does not seem to significantly improve either the predictive quality of the models or uncertainty handling; (q) all BNN for all considered sparsity levels on a given configuration of the network depth and widths are significantly outperforming the frequentist counterpart (with the corresponding same sparsity levels) in terms of the generalization error. Finally, in terms of computational time, (r) as expected, FNNs were the fastest in terms of time per epoch, while for the Bayesian approaches, we see a strong positive correlation between the number of parameters and computational time, where BNN-GP-CMF is the fastest method and LBBNN-SSP-MVN is the slowest. All times were obtained while training our models on a GeForce RTX 2080 Ti GPU card. Having said that, it is important to notice that the speed difference between the fastest and slowest Bayesian approach is less than three times. Given the fact that the time is also influenced by the implementation of different methods and a potentially different load of the server when running the experiments, this might be considered quite a tolerable difference in practice.
4.1.2. FMNIST
The same set of approaches, model specifications and tuning parameters of the algorithms as in the MNIST example were used for this application. The results (a)–(r) for FMNIST data, based on
Table 3 and
Table 5, and
Table A3 and
Table A9 in
Appendix A, are completely consistent with the results from the MNIST experiment; however, the predictive performances for all of the approaches are poorer on FMNIST. Also, whilst full BNN and BNN with Horseshoe priors on FMNIST obtbain lower sparsity levels than on MNIST, Concrete dropout here improves in this sense compared to the previous example. For FNN, the same conclusions as those obtained for the MNIST dataset are valid (see
Table A6 for details).
4.1.3. PHONEME
Finally, the same set of approaches, model specifications (except for having 256 input covariates and 5 classes of the responses) and tuning parameters of the algorithms as in the MNIST and FMNIST examples were used for the classification of PHONEME data. The results (a)–(r) for the PHONEME data, based on
Table 4 and
Table 5, and
Table A4 and
Table A10 in
Appendix A, are also overall consistent with the results from the MNIST and FMNIST experiments; however, predictive performances for all of the approaches are better than on FMNIST yet worse than on MNIST. All of the methods, where sparsifications are possible, gave a lower sparsity level for this example.
Yet, rather considerable sparsification is still shown to be feasible. For FNN, the same conclusions as those obtained for MNIST and FMNIST datasets are valid, though the deterioration of performance of FNN here was less drastic (see
Table A7 for details).
5. Discussion
In this paper, we have introduced the concept of Bayesian model (or structural) uncertainty in BNNs and suggested a scalable variational inference technique for approximating the joint posterior of models and the parameters of these models. Approximate posterior predictive distributions, with both models and parameters marginalized out, can be easily obtained. Furthermore, marginal inclusion probabilities give proper probabilistic interpretation to Bayesian binary dropout and allow for the performance of model (or architecture) selection. The latter allows for solving the overparametrization issue present in BNNs and can lead to more interpretable deep learning models in the future.
We provide image, sound and tabular dataset classification applications of the suggested technique, showing that it both allows for significantly sparsifying neural networks without a noticeable loss of predictive power and accurately handles the predictive uncertainty.
Regarding the computational costs of optimization, in stochastic variational inference, the iteration cost consists of a product of the number of data points in a sample times the number of parameters in the variational distribution times the number of samples from the model. In our case, for the mean-field approximations, we are introducing only one additional parameter
for each weight. With underlying Gaussian structure on
, however, additional parameters of the covariance matrix are further introduced. The complexity of each optimization step is proportional to the number of parameters to optimize; thus, the deterioration in terms of computational time (as demonstrated in the experiments) is, although present, not at all drastic as compared to the fully connected BNN. For the FNN, however, we do not sample the parameters in each iteration to approximate the gradient; thus, the computations become further cheaper by a factor corresponding to the number of samples one addresses in BNNs. Yet, as demonstrated in the experiments of this paper, the deterioration of the training costs of BNNs is not that drastic as compared to FNNs (
Table A5,
Table A6 and
Table A7). Furthermore, the complexities of different methods are proportional to the number of “active” parameters involved in predictions, typically giving benefits to more sparse methods, which we obtain through model selection. See
Table 6 for more details.
Regarding practical recommendations, we suggest, based on our empirical results, using LBBNN-SSP-MF if one is interested in a reasonable trade-off between sparsity, predictive accuracy and uncertainty. One should make model averaging across several samples to increase the accuracy of the predictions or use the posterior mean-based model. One sample is typically not enough to have sufficient accuracy. For sparsification, the use of the median probability model is advised. Also, if a doubt decision is allowed for uncertain cases, one is expected to obtain almost perfect accuracy for the rest of the predictions. LBBNN-SSP-MVN and LBBNN-SSP-LFMVN are computationally more costly than LBBNN-SSP-MF and do not provide superior performance concerning the latter; thus, these two modifications are not recommended. If sparsity is not needed, standard BNN-GP-MF and BNN-MGP-MF are sufficient.
Currently, fairly simple prior distributions for both models and parameters are used. These prior distributions are assumed independent across the parameters of the neural network, which might not always be reasonable. Alternatively, both parameter and model priors can incorporate joint-dependent structures, which can further improve the sparsification of the configurations of neural networks. When it comes to the model priors with local structures and dependencies between the variables (neurons), one can mention the so-called dilution priors [
59]. These priors take care of the similarities between models by down-weighting the probabilities of the models with highly correlated variables. There are also numerous approaches to incorporate interdependencies between the model parameters via priors in different settings within simpler models [
60,
61,
62]. Obviously, in the context of inference in the joint parameter-model settings in BNNs, more research should be conducted on the choice of priors.
The main limitation of the article is the absence of a theoretical guarantee of selecting the true data-generative process under the combination of the addressed priors for BNNs. Also, the suggested methodology results in increased computational costs compared to the simpler BNNs and FNNs. Last but not least, the nature of that variational Bayes in an approximate technique is a limitation in itself, and we could not compare it to the ground truth under model and parameter uncertainty in BNNs, that is, to be obtained by exact MCMC sampling due to the fact that the latter is not feasible in the addressed high-dimensional settings. Theoretical guarantees on the convergence of the approximate variational inference procedure to the true target are also problematic under practical regularity conditions, which is a considerable limitation. Lastly, due to the computational challenges, only relatively small networks have been considered in this work. Evaluation of the methods on larger networks with billions of parameters is certainly of interest and should be conducted with further developments in computational technologies.
In this work, we restrict ourselves to a subclass of BNNs, defined by the inclusion–exclusion of particular weights within a given architecture. In the future, it can be of particular interest to extend the approach to the choice of the activation functions as well as the maximal depth and width of each layer of the BNN. This can be performed by a combination of a set of different activation functions for neurons within a layer on one hand and allowing skip connections from every layer to the response on the other hand. A more detailed discussion of these possibilities and ways to proceed is given in Hubin [
41]. Finally, theoretical and empirical studies of the accuracy of variational inference within these complex nonlinear models should be performed. Even within linear models, Carbonetto et al. [
44] have shown that the results can be strongly biased. Various approaches for reducing the bias in variational inference are developed. One can either use more flexible families of variational distributions by, for example, introducing auxiliary variables [
63,
64], normalizing flows [
65], diffusion-based variational distributions [
66] or addressing Jackknife to remove the bias [
67]. We leave these opportunities for further research.




{kind=link}
{kind=link}
{kind=link}