1. Introduction and Some Useful Tools
The random variable
X follows the lognormal distribution with parameters
and
, say
, if
X is absolutely continuous with values in
and has density function
with integer moments
for
.
The lognormal distribution can be defined as the probability distribution of a random variable X whose logarithm obeys the normal law of probability centered at ; moreover, it is believed by some that it is “as fundamental a distribution in statistics as the normal one” and thus a very useful distribution for representing variables that are the multiplicative product of many positive-valued independent factors. This follows from the central limit theorem, since X is a lognormal random variable equivalent to being a normal random variable.
The lognormal distribution has some nice properties. For example, the product of independent lognormal variables is still lognormal; furthermore, if
X is a lognormal random variable, then
,
and
are also lognormal for
. Because of its importance, the lognormal distribution, including the problem of moments, has been studied intensively by many researchers and has a wide range of applications in the natural sciences and in fields such as finance, economics, political science, sociology, philology, biology, and physical and industrial processes. Interestingly, insurance losses data analysis is positive, and the distribution is often unimodal hump-shaped, right-skewed, and with heavy tails. Although many parametric unimodal distributions have been used in the actuarial literature to model these data, their characteristics require more flexible models. In particular, the losses in the right tail, although rare in frequency, are in fact those that have the greatest impact on an insurer’s operations and could lead to the possible bankruptcy of the company. In such circumstances, heavy-tailed distributions have been shown to be reasonably competitive. Different classes of models can be considered to select a suitable distribution. For example, ref. [
1], Equation (
3), have successfully considered a mode-parametrised unimodal Gamma distribution. And again, ref. [
2], Equation (
5) consider a mode-parameterized lognormal distribution. Special mention should be made of the famous paper by [
3] which clearly demonstrated the moment non-uniqueness of a general lognormal distribution by explicitly writing an infinite family of different distributions all having the same moments as those of
. Integral transforms, such as the Laplace and Fourier transforms, of the lognormal distribution have received considerable attention in the literature for several decades. Since these integral transforms have no known closed form, considerable effort has been devoted to finding viable approximation methods. Recently, ref. [
4] presented two parametric approximations (Theorems 3 and 4) for the Laplace transform of the lognormal distribution.
These approximations improve as this parameter goes to infinity and can be used for numerical calculations. Another characterization property of the lognormal distribution using the Kullback–Leibler measure
between the probability density functions
g and its
r size-weighted counterpart
, with finite moments
, for
, have been provided by [
5], Theorem 1.
The authors claim that
becomes symmetric, i.e.,
, if and only if
g coincides with the lognormal density. Following [
5], we want to give a further characterization of
in the context of so-called fractional moments (see [
6]) this will allow us to prove that the lognormal density has the largest entropy among all densities sharing the same moments.
From now on, for the sake of calculation simplicity, in place of the general
distribution, we investigate the centered lognormal distribution
. Note that all its properties and related results hold also for its non-centered (
1).
Consider an indeterminate Stieltjes moment problem (books such as [
7,
8,
9], are widely known references on this topic and contain exhaustive details on the debate and progress made in the moment problems for a century; for more recent results, see [
10,
11]. For determinacy/indeterminacy criteria of moment problem by means of the entropic technique, see [
12].
Within the maximum entropy (MaxEnt, shortly) rationale, it is well known that can be considered having the largest entropy among all positive random variables X with assigned expected values and , respectively. This fact is not surprising in view of the maximal entropy property of the normal distribution once assigned and and taking into account the relationship between normal and lognormal distributions.
As a consequence, recalling the well-known fact that the logarithm function can be expressed as the pointwise limit of a sequence of simpler functions for every
(see Equation (
5) below), our goal will be realized by means of two distinct tools
- (a)
Firstly by the so-called fractional moments which will allow us to prove the lognormal has the largest entropy out all densities having the lognormal moments (Theorem 2 below);
- (b)
Then, by the so-called integer moments, which will allow us to prove, employing the complete sequence of integer moments solely, out densities having lognormal moments, the lognormal only may be reconstructed (Theorem 3 below). Equivalently, the lognormal is characterized by its integer moments, justifying the paper’s title, although it is not uniquely determined by lognormal moments.
The rest of the paper is structured as follows. In
Section 2, it is proved that the lognormal distribution is characterized by two fractional moments
and
, with
, and its entropy coincides with the entropy of
, which is the member of the class
with maximum entropy. In
Section 3, the lognormal density is recovered by its integer moment sequence using the MaxEnt technique, and it is further shown that the sequence of entropies associated with the MaxEnt densities converges to the entropy of
and hence, to the entropy of the lognormal distribution. Finally, by noting that the sequence of entropies of the MaxEnt densities is a Cauchy sequence, using its properties, it is concluded that the sequence of MaxEnt densities converges almost everywhere to the lognormal one.
Section 4 will illustrate the so-called Askey density previously found in the literature and labeled as “another continuous weight function for the lognormal moments”. Finally, in
Section 5, some charaterizations of the lognormal are listed.
2. Characterization of Lognormal via Fractional Moments
From [
13], p.59, we preliminarily recall the following well-known result: the MaxEnt density
constrained by the
n fractional moments
,
, and in addition to
and
for normalizing reasons, amounts to
where
, are the Lagrange multipliers calculated by imposing fractional moments
as constraints as stressed by the index
, and the corresponding entropy is given by
For more theoretical and numerical details on the topic, see [
6].
In an indeterminate Stieltjes moment problem, the totality of densities
g with support
forms the convex set
with some properties:
In
there is a unique density, say
, having largest differential entropy (shortly, entropy), being the continuous entropy functional
strictly concave and, over the convex set
,
H takes a maximum
. As a consequence, excluding
, every
has entropy
strictly.
belongs to , and in Theorem 2 below, the first main result will be proved, that is and then .
The following result, formalized in Lemma 1, is preliminary to the characterization of the lognormal distribution by fractional moments of appropriate order .
Lemma 1. The lognormal may be equivalently considered as MaxEnt density having two characterizing fractional moments , with .
Proof. From the elementary inequality for positive real number
the following one
is drawn with equality if and only if
. Next, setting
, with
, for each
two additional inequalities
involving
and
are drawn. As well recall the well-known fact that the logarithm function can be expressed as the pointwise limit of a sequence of simpler functions for every
Replacing in (
1)
and
with
and
, respectively, the continuous function sequence
is drawn with
Combining (
4) with (
6) allows us to concluding no entry
can be considered as probability density. From (
5) and each fixed
, the integrable function sequence
is pointwise convergent to
. Furthermore,
has mode
with
. From (
6), each entry
admits a maximum at
with
independent on
n, so that
is a sequence of positive, continuous, uniformly bounded, pointwisely convergent to
functions for all
. From (
1)–(
6), we have
Taking into account (
4), the piecewise continuous function
is defined as
In the next three items, the dominated convergence theorem will be used so that we need to construct a suitable positive piecewise continuous integrable function
,
(the so-called dominating function).
Assuming from (
8)
, then
for each
and each
n, and
holds, so that all the requirements of the dominated convergence theorem are satisfied, from which it follows that
As above recalled, none of the entries of the positive function sequence
can be considered as density; hence, the sequence
is improperly called an “entropy sequence”. Nevertheless, we will be able to prove that
Indeed, consider (
6), from which
Split just above integral
into
, take into account (
4), (
7) and (
8); then, find the upper bound for the sequence
from which arises the piecewise continuous and integrable dominating function
and then
for each
n. Consequently, from the dominated convergence theorem, (
10) is proved.
A similar result holds for the moment curves of
and of
for each
, with
. Combining item 1 with (
8), we know each
, from which each sequence entry
. As a consequence, the function
for each
satisfies
and, being piecewise continuous, is the required dominating function. For each
, the following relationship follows
Combining (
6)–(11) and replacing
with
in (
6), it can be concluded that the lognormal has to be considered MaxEnt distribution characterized by two fractional moments
with
. Then, Lemma 1 is proved.
□
Just to have an idea about how well
given in (
6) approximates the
density, look at the following graph (
Figure 1).
Here (top), as n increases tends to zero exponentially, leaving to presume that is uniformly convergent to . Consequently (bottom), the difference tends to zero uniformly. The order of magnitude of the error made gives an idea of how well approximates .
Lemma 1 allows us to reconnect to the fractional moments problem in the MaxEnt framework; in this setup, a crucial role is played by the following distribution characterization theorem, hereafter referred to as Lin’s theorem, due to Lin (1992).
Theorem 1 ([
14]).
A positive r.v. X is uniquely characterized by an infinite sequence of positive fractional moments with distinct exponents , , for some . Similarly, it can be shown that several other distributions, such as Gamma, generalized Gamma, Weibull, Rayleigh, Chi-Square, and Pareto, to name a few, can be considered as MaxEnt distributions characterized by a few fractional moments.
We are now able to demonstrate the first main result of this paper by means of the fractional moments technique.
Theorem 2 (Main Result-I).
Of all the densities with lognormal moments, the lognormal has the largest entropy, that isso that coincides with . Proof. For an arbitrary
, consider its moment curve
. In general,
except when
,
; in which case
holds. Let
be the MaxEnt approximation of
g, constrained by two fractional moments
picked up from
, with small and fixed
. Thanks to (11), the couple of values follows
. Recalling the entropy
of an arbitrary density
g is a continuous function of two expected values
, thanks to (
10), the relationship
can be set. Now, consider an arbitrary
, its moment curve
and a sequence of its fractional moments
satisfying Lin’s theorem conditions, with fixed small
and each
. For each
, with
, it holds
as the couple
, with
, characterizes
, in contrast to the couple
, with
, which does not characterize any of the remaining
. So,
holds for every
; combining the uniqueness of
in
with the fact that
too, it follows
. Consequently, Theorem 2 is proved. □
3. Characterization and Reconstruction of Lognormal via Its Integer Moments
Given that the moment problem for the lognormal density is indeterminate, one might expect that approximations based uniquely on a sequence of integer moments might either fail to converge or converge to a different distribution with the same moments. A difficult proof would no doubt be required, and perhaps a similar approximation might be numerically very unstable for more than a few moments. Theorem 2 allows us to solve the problem. Suppose in a positive distribution reconstruction process only the whole moment sequence is known, specifically the lognormal moments .
The question follows: using the MaxEnt method with lognormal moments as constraints, which distribution is reconstructed (in other words, identified or characterized) out of the infinitely many candidate distributions belonging to ? The expected answer is obvious: the one with the largest entropy.
Considering an indeterminate Stieltjes moment problem, [
15] - Thm. 7, have indeed shown that the MaxEnt approximation converges in entropy to
and, in combination with the Theorem 2, gives us the relation
Here, the index
refers to the fact that
is the MaxEnt approximation of the lognormal density based on using integer moments as constraints and having an analytical form analogous to (
2), in which the term
is replaced by
j.
In addition to the convergence in the entropy (14), the following also holds true.
Theorem 3 (Main Result-II).
The sequence converges a.e. to in so that almost everywhere. Equivalently, LN is characterized by the sequence of its integer moments. Proof. The proof is obtained combining together the following facts.
[
15] - Thm. 7, proved that the monotonically non-increasing sequence
converges to the quantity
finite, so that taking into account (14),
is a Cauchy sequence.
Consider the Kullback–Leibler distance between densities
and
As
and
share the same first
n moments
, the relationship below easily follows:
Recall Pinsker’s inequality ([
16], p. 390),
Collecting together items 1–3, Equation (15) and
arbitrary indices, it follows
so that
is a Cauchy sequence in
.
is the unique density in
with the largest entropy value
. Replacing
with
, letting
, recalling (14), the completeness of
and the items 1–3
so that
is uniformly convergent to
. It is standard that
has a subsequence pointwise convergent a.e. to
and the sequence itself converges a.e. to the same limit, which could explain the goodness of the approximation of
through the MaxEnt approximation
based on integer moments.
□
4. Askey and Berg Densities Having Lognormal Moments
In the previous section, we showed that among the infinitely many densities in
, the lognormal
has the largest entropy. To our knowledge, there are two other densities in
, excluding the so-called Stieltjes classes (see [
17]),
and
, called Askey and Berg densities, respectively: we now want to investigate the connection between
and
. Theorem 3 gives us the opportunity to study the Askey density
, which is considered in the literature as different from
for the simple reason that this has a different analytical form. It might also be interesting to represent
by an analytical expression in which the full sequence
of the lognormal moments appears explicitly, which is consistent with the fact that
, since only the latter is characterized by the lognormal moment sequence.
In order to achieve this, the following three facts are brought together.
From Theorem 3, holds a.e.;
[
18] - Theorem 2.1, considered Jacobi’s theta function
where
, so that
and proved, as
,
Here, the symbol “” means asymptotically equal; that is, we write if .
Askey and Berg (see [
19], Equations (2.5) and (2.8) for details and further references), respectively, found the densities
and its one-parameter extension
The last one satisfies the property with as the normalizing constant and ; so it suffices to consider . Note that setting , .
Combining (16) with (17) and setting
, as
, the interesting result follows
In particular, (20) allows us to easily understand the validity of (17), i.e., the range of
q values for which Wang’s result is meaningful. We have numerical evidence that such a range of values is approximately
, which is equivalent to
.
Collecting together (17) and (18), as
, it follows that
that is,
is asymptotically equal to
.
As
, combining (16), (18) and (21), recalling
, exploiting the translation invariance of
and the identity
, we have
From Theorem 3, as
, it follows that
, so from (21),
can be explicitly formulated in terms of its moments, proving that the information content needed to characterize
reduces to that carried by the sequence of lognormal moments, confirming the above result
a.e.
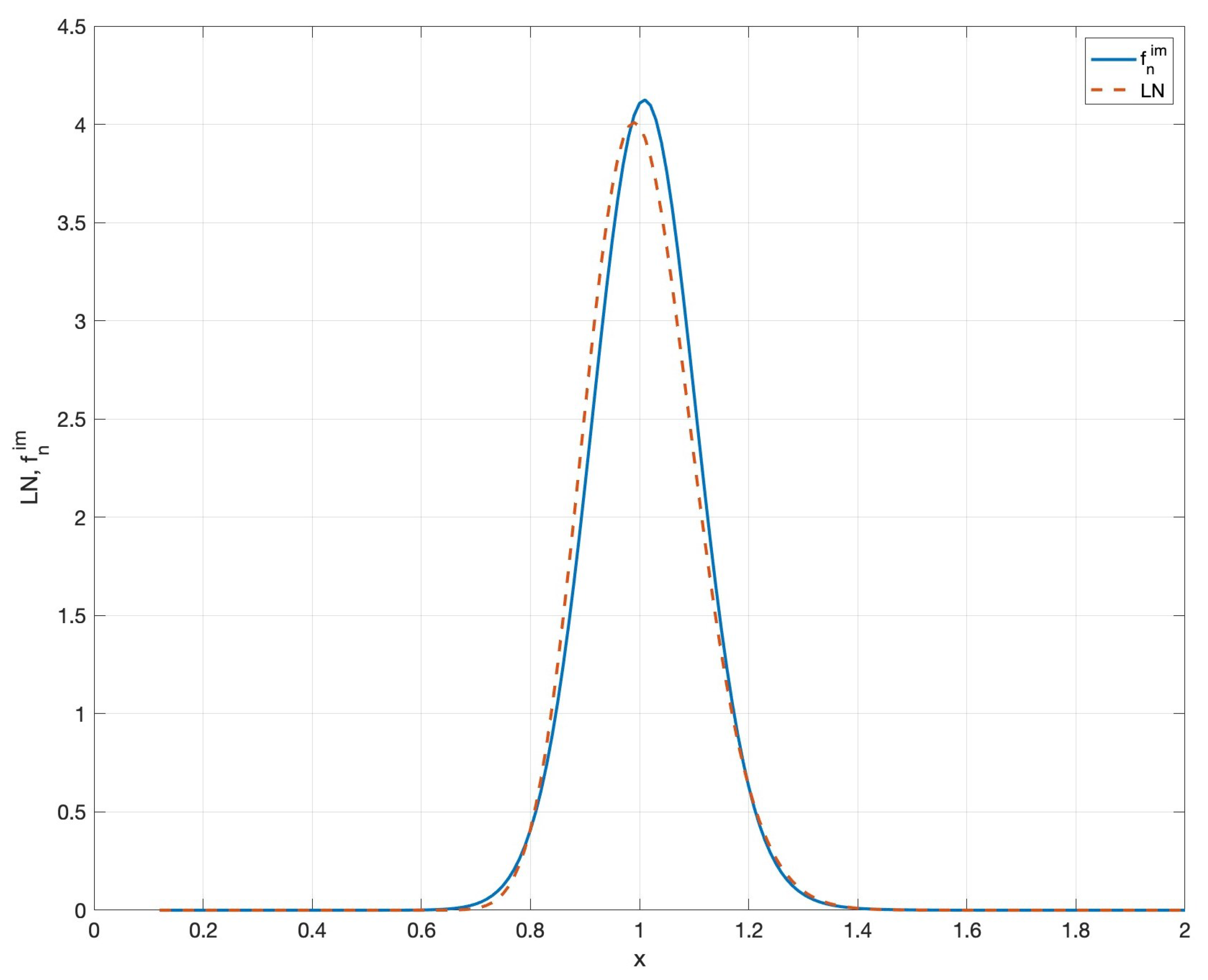
Example 1. Out of pure curiosity, we wonder what is like once the sequence of moments has been assigned. Considering the various convergence criteria outlined above, can be considered a good approximation of as n assumes high values. And that is what we’re going to do, with an example.
Consider the standard lognormal with density and entropy as , which guarantees is finite, according to Theorem 2 and [15], Thm. 7. Table 1 shows the entropy of the MaxEnt reconstruction with increasing n while Figure 2 displays density and . Here is the largest available value due to the numerical instability associated with the moment problem in the MaxEnt setup. From Table 1, it can be seen that as n increases, the difference tends to 0. Here, we observe that the entropy changes very little as we go from, say, six to ten moments. Since the entropy rapidly stabilizes as the number of moments increases, this suggests that the number of moments considered is high enough for the reconstructed density to be close to the estimated density . The example now illustrated provides an answer to the reasonable doubt outlined above: given that the moment problem for the lognormal density is indeterminate, one might expect that approximations based on a sequence of integer moments either fail to converge or converge to a different distribution with the same moments. 5. Final Remarks
At the end of this paper, we will briefly summarize the path taken and the main results obtained.
Due to the analytic form of the Shannon entropy functional and its concavity, there exists a (unique) maximum in correspondence of ; that is, this density has the maximum entropy in the class which contains all the distributions sharing the lognormal moment sequence with it. In the MaxEnt framework, represents the most entropy-representative element of the class . Moreover, using the fact that the characterizing moments of the lognormal distribution are given by and and that they can be assimilated to fractional moments whose orders and tend to , it has been proved by Theorem 2 that coincides with .
Now, considering the sequence of lognormal integer moments as constraints, we know that the MaxEnt approximation based on them, , converges in entropy, and also almost everywhere, to . Hence, by Theorem 3, converges almost everywhere to . Finally, it is possible to conclude that the lognormal distribution is characterized by the sequence of its integer moments. And this justifies the title of this paper.





{kind=link}
{kind=link}