
Proposal of a Framework for Evaluating the Importance of Production and Maintenance Integration Supported by the Use of Ordinal Linguistic Fuzzy Modeling

 ,
,  and
and
Abstract
1. Introduction
2. Proposal of a Set of Indicators for Evaluating the Importance of the PM—MM Integration
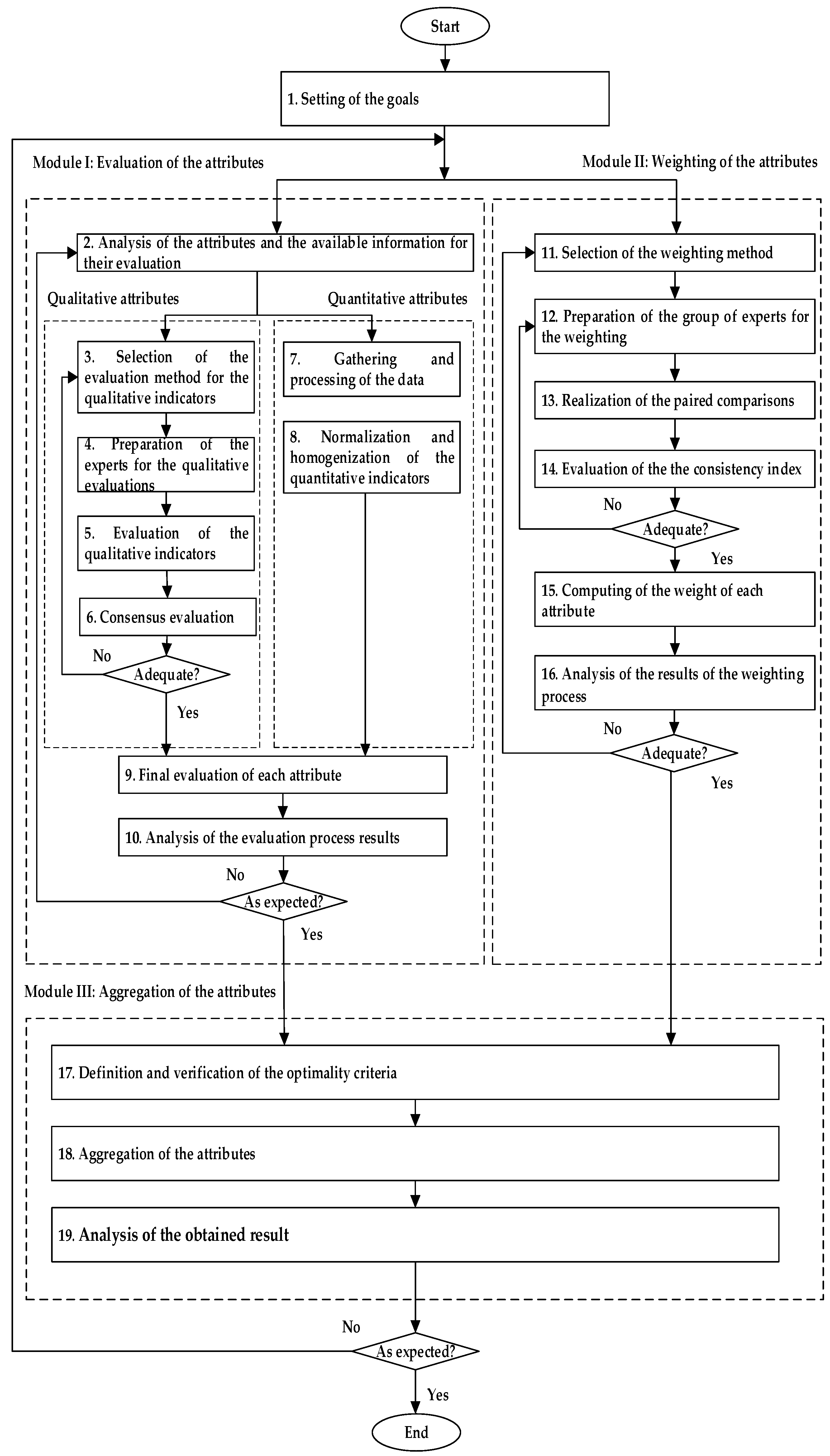
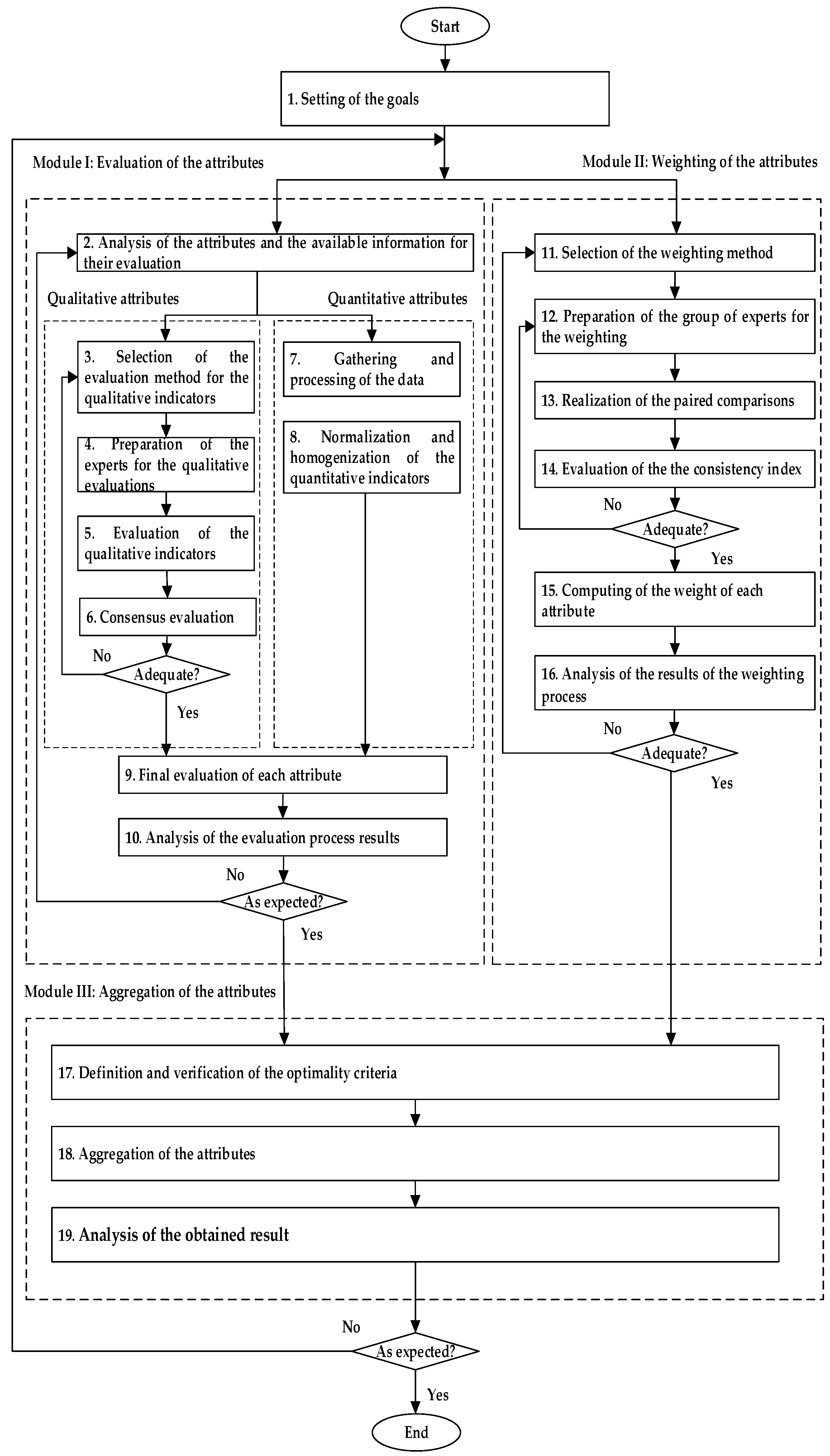
3. Framework for the Evaluation, Weighting, and Aggregation of Indicators Characterizing the Importance of the PM—MM Integration
3.1. Setting of the Goals
3.2. Module I: Evaluation of the Attributes
3.2.1. Analysis of the Attributes and the Available Information for Their Evaluation
3.2.2. Selection of the Evaluation Method for the Qualitative Indicators
3.2.3. Preparation of the Experts for the Qualitative Evaluations
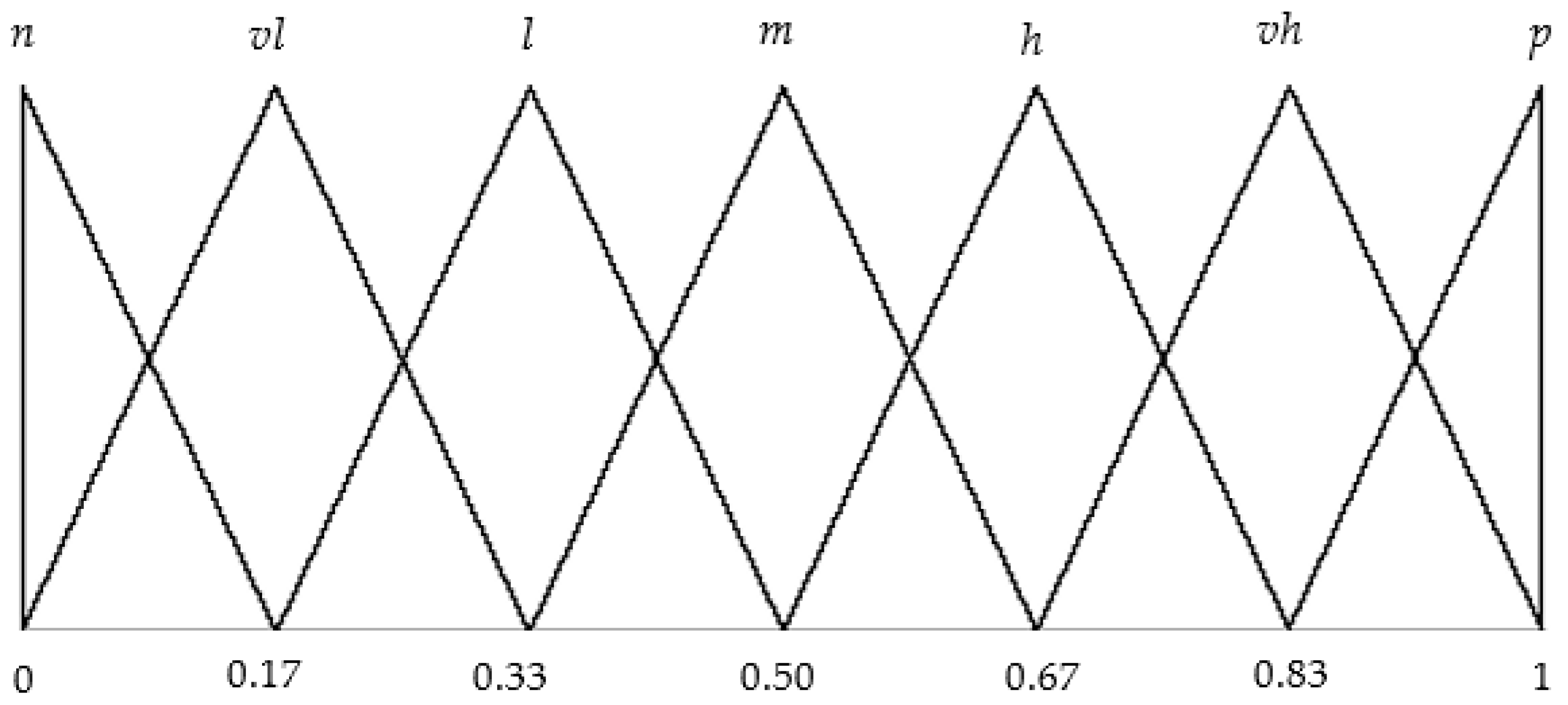
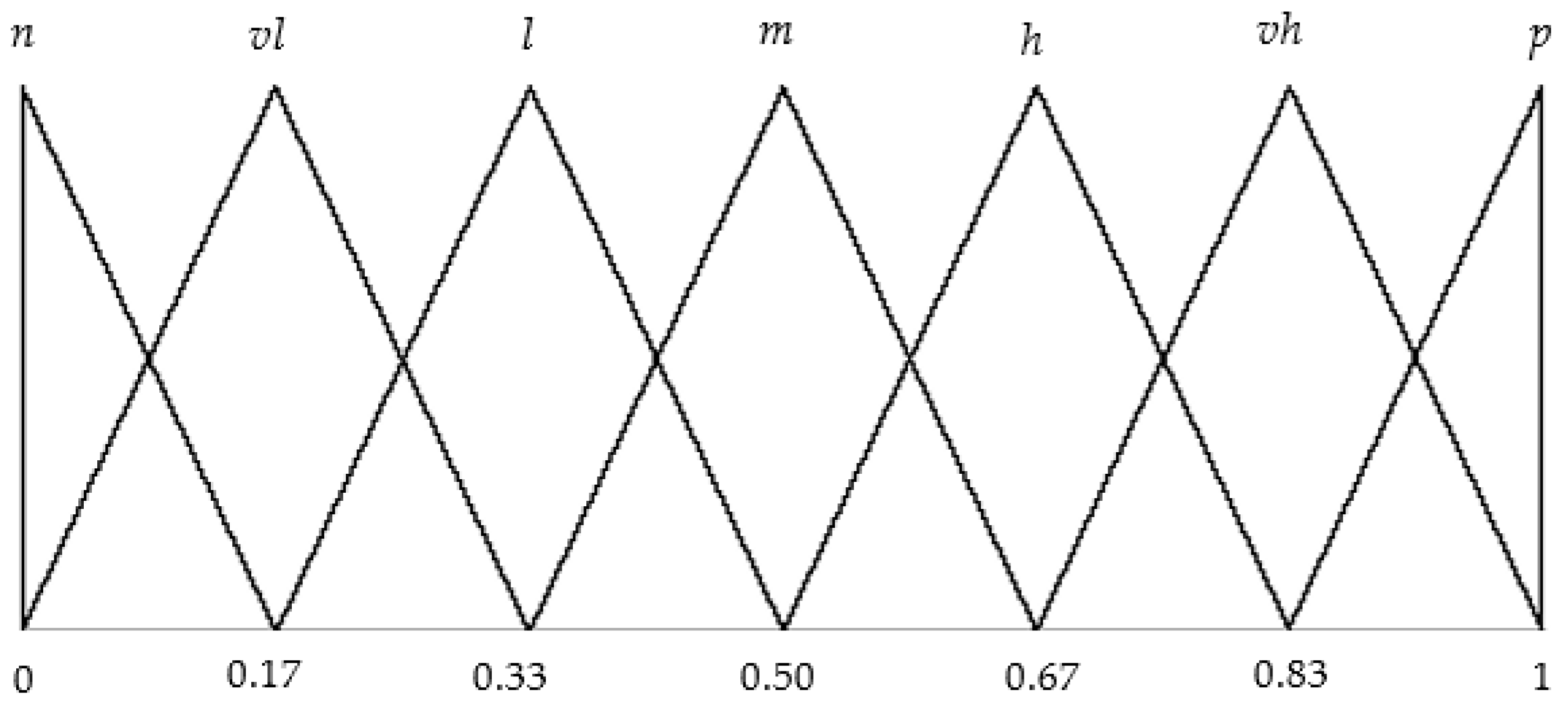
3.2.4. Evaluation of the Qualitative Indicators
3.2.5. Consensus Evaluation
- To obtain a vector for each indicator (attribute) , whose components are the linguistic terms established by the group of experts as a measure of the evaluation of the indicator .
- To obtain the quantity () of experts’ subgroups that is formed withing the group, in accordance with the coincidences in their evaluation of the attribute j:
- 3.
- For each linguistic term of the vector to obtain the number of experts that coincided in the assignation of it as the attribute j’s evaluation measure.
- 4.
- To obtain the experts proportion () that coincided in assigning the linguistic label (term) as the attribute j’s evaluation measure:
- 5.
- To calculate the consensus relation () using the following expression:
- : consensus relation reached by the experts in evaluating the indicator j.
- : expert proportion that coincided in assigning the term i as measure of the indicator .
- : subgroup of experts formed in accordance with the coincidence in the utilized term for evaluating the indicator .
- : normalized minimum distance between G consecutive linguistic terms of the scale.
- : normalized mean distance between the non-consecutive terms () of the scale employed the experts for evaluating the indicator .
- : normalized distance between the fuzzy numbers A and B both with a triangular membership function.
- : .
- : .
- and : representation of the triangular fuzzy numbers A and B, respectively, based on the confidence interval concept of level .
- : distance to the left between the triangular fuzzy numbers A and B.
- : distance to the right between the triangular fuzzy numbers A and B.
- 6.
- To select a linguistic quantifier that will represent the fuzzy majority concept.
- 7.
- Determination of the consensus level () reached over each attribute j.
- 8.
- Determination of the global consensus level () obtained in the evaluation of the attributes’ set.
3.2.6. Gathering and Processing of the Data
3.2.7. Normalization and Homogenization of the Quantitative Indicators
- : indicator (attribute) ’s normalized value.
- : current value of the indicator .
- : reference value of the indicator .
3.2.8. Final Evaluation of Each Attribute
- : i-th element of the term set to be aggregated, ordered in an increasing way in accordance with its cardinalities.
- : Cardinality of the element i.
- is calculated using Equation (19):
- = is a weight ordered vector associated to A such that: i j.
- : number of linguistic terms to be aggregated.
3.2.9. Analysis of the Evaluation Process Results
3.3. Module II: Weighting of the Attributes
3.3.1. Selection of the Weighting Method
3.3.2. Preparation of the Group of Experts for the Weighting
3.3.3. Realization of the Paired Comparisons
3.3.4. Evaluation of the Consistency Index
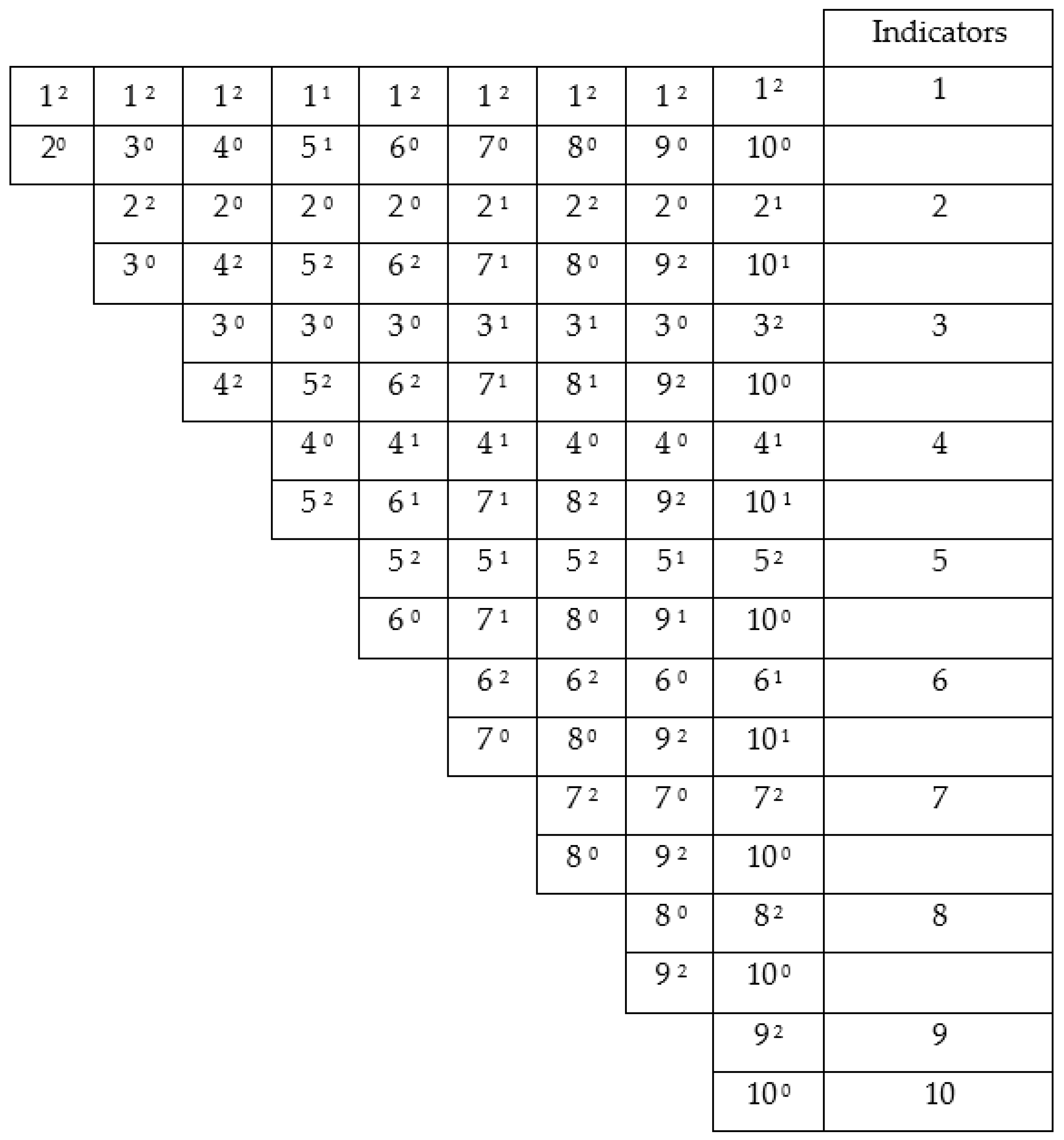
- Total inconsistency. It is defined when, in a triplet of attributes, the transitivity principle is totally violated, and this is based on the comparison scale that is proposed, for instance: if it occurs that = 2, = 2, and = 0, in this case, the triplet is assigned or given one inconsistency unit.
- Partial inconsistency. It is defined when in, a triplet of attributes, the transitivity principle is partially violated, for instance: if it occurs that = 2, = 2, and = 1, in this case, the triplet is assigned or given 0.5 inconsistency units.
- Consistent. Consistency is assumed when it is not possible to confirm that partial or total inconsistencies are present. In this case, we do not assign inconsistency units to the triplet.
- : units of inconsistency assigned to the attributes’ triplet .
- : number of triplets that are generated by a set of elements.
3.3.5. Computing of the Weight of Each Attribute
3.3.6. Analysis of the Results of the Weighting Process
3.4. Module III: Aggregation of the Attributes
3.4.1. Definition and Verification of the Optimality Criterion
3.4.2. Aggregation of the Attributes
3.4.3. Analysis of the Obtained Result
4. Results and Discussion
4.1. A Brief Description of the Case Study
4.2. Results of the Framework Application
A Partial Comparative Analysis in the Calculation of the PMII Index
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, Y.; He, Y.; Zhou, D.; Zhang, A.; Han, X.; Li, Y.; Wang, W. Functional risk-oriented integrated preventive maintenance considering product quality loss for multistate manufacturing systems. Int. J. Prod. Res. 2021, 59, 1003–1020. [Google Scholar] [CrossRef]
- Khatab, A.; Diallo, C.; Aghezzaf, E.-H.; Venkatadri, U. Integrated production quality and condition-based maintenance optimisation for a stochastically deteriorating manufacturing system. Int. J. Prod. Res. 2019, 57, 2480–2497. [Google Scholar] [CrossRef]
- Schutz, J.; Chelbi, A.; Rezg, N.; Ben Salem, S. Production and maintenance strategies for parallel machines with load transfer in case of failure. J. Qual. Maint. Eng. 2019, 25, 525–544. [Google Scholar] [CrossRef]
- Wakiru, J.M.; Pintelon, L.; Muchiri, P.; Chemweno, P. Integrated maintenance policies for performance improvement of a multi-unit repairable, one product manufacturing system. Prod. Plan. Control 2021, 32, 347–367. [Google Scholar] [CrossRef]
- Liu, Q.; Dong, M.; Chen, F.F. Single-machine-based joint optimization of predictive maintenance planning and production scheduling. Robot. Comput.-Integr. Manuf. 2018, 51, 238–247. [Google Scholar] [CrossRef]
- Ao, Y.; Zhang, H.; Wang, C. Research of Integrated Decision Model for Production Scheduling and Maintenance Planning with Economic Objective. Comput. Ind. Eng. 2019, 137, 106092. [Google Scholar] [CrossRef]
- Weinstein, L.; Cheng, C.-H. Integrating maintenance and production decisions in a hierarchical production planning environment. Comput. Oper. Res. 1999, 26, 1059–1074. [Google Scholar] [CrossRef]
- Kodali, R.; Mishra, R.P.; Anand, G. Justification of world class maintenance systems using analytic hierarchy constant sum method. J. Qual. Maint. Eng. 2009, 15, 47–77. [Google Scholar] [CrossRef]
- Robson, K.; Trimble, R.; MacIntyre, J. Creating and Sustaining a Maintenance Strategy: A Practical Guide. J. Bus. Adm. Res. 2013, 2, 77–83. [Google Scholar] [CrossRef]
- Robson, K.; Trimble, R.; MacIntyre, J. The inhibitors and enablers of maintenance and manufacturing strategy: A cross-case analysis. Int. J. Syst. Assur. Eng. Manag. 2014, 5, 107–117. [Google Scholar] [CrossRef]
- Garg, A.; Deshmukh, S.G. Flexibility in Maintenance: A Framework. Glob. J. Flex. Syst. Manag. 2009, 10, 21–34. [Google Scholar] [CrossRef]
- Naughton, M.D.; Tiernan, P. Individualising maintenance management: A proposed framework and case study. J. Qual. Maint. Eng. 2012, 18, 267–281. [Google Scholar] [CrossRef]
- Royo Sánchez, J.A.; Berges Muro, L.; Lope Domingo, M.A.; Aguilar Martín, J.J.; González Pedraza, R. Production and Maintenance Integrated Resource Planning Management System. In Proceedings of the 17th OrthoGES European Maintenance Congress, Barcelona, Spain, 11–13 May 2004. [Google Scholar]
- Jonsson, P. Towards an holistic understanding of disruptions in Operations Management. J. Oper. Manag. 2000, 18, 701–718. [Google Scholar] [CrossRef]
- Swanson, L. An empirical study of the relationship between production technology and maintenance management. Int. J. Prod. Econ. 1997, 53, 199–207. [Google Scholar] [CrossRef]
- Pinjala, S.K.; Pintelon, L.; Vereecke, A. An empirical investigation on the relationship between business and maintenance strategies. Int. J. Prod. Econ. 2006, 104, 214–229. [Google Scholar] [CrossRef]
- McKone, K.E.; Schroeder, R.G.; Cua, K.O. The impact of total productive maintenance practices on manufacturing performance. J. Oper. Manag. 2001, 19, 39–58. [Google Scholar] [CrossRef]
- Crespo Márquez, A.; Gupta, J. Contemporary maintenance management: Process, framework and supporting pillars. Int. J. Manag. Sci. 2006, 34, 313–326. [Google Scholar] [CrossRef]
- Espinilla, M.; Andrés, R.; Martínez, F.J.; Martínez, L. A 360 degree performance appraisal model dealing with heterogeneous information and dependent criteria. Inf. Sci. 2013, 222, 459–471. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E.; Verdegay, J.L. A model of consensus in group decision making under linguistic assessments. Fuzzy Sets Syst. 1996, 78, 73–87. [Google Scholar] [CrossRef]
- Xu, Z. EOWA and EWG Operators for aggregating linguistic labels based on linguistic preference relations. Int. J. Uncertain. Fuzziness Knowlege-Based Syst. 2004, 12, 791–810. [Google Scholar] [CrossRef]
- Peláez, J.I.; Doña, J.M.; Gómez Ruiz, J.A. Analysis of OWA operators in decision making for modelling the majority concept. Appl. Math. Comput. 2007, 186, 1263–1275. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E. Aggregation Operators for Linguistic Weighted Information. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 1997, 27, 646–656. [Google Scholar] [CrossRef]
- Cabrerizo, F.J.; Alonso, S.; Herrera-Viedma, E. A consensus model for group decisions making problems with unbalance fuzzy linguistic information. Int. J. Inf. Technol. Decis. Mak. 2008, 8, 109–131. [Google Scholar] [CrossRef]
- Wang, L.; Xue, H. Group Decision-Making Method Based on Expert Classification Consensus Information Integration. Symmetry 2020, 12, 1180. [Google Scholar] [CrossRef]
- Labella, Á.; Rodríguez, R.M.; Alzahrani, A.A.; Martínez, L.A. Consensus Model for Extended Comparative Linguistic Expressions with Symbolic Translation. Mathematics 2020, 8, 2198. [Google Scholar] [CrossRef]
- Morillas, A. Introducción al Análisis de Datos Difusos. Curso de Doctorado en Economía Cuantitativa. Departamento de Estadística y Econometría, Universidad de Málaga, Málaga, Spain. 2000. Available online: https://www.studocu.com/latam/document/universidad-tecnologica-de-la-habana-jose-antonio-echeverria/ingenieria-de-software-i/antonio-morillas-raya-introduccion-al-analisis-de-datos-difusos/17491208 (accessed on 18 December 2023).
- Delgado, M.; Verdegay, J.L.; Vila, M.A. On Aggregation Operations of Linguistic Labels. Int. J. Intell. Syst. 1993, 8, 351–370. [Google Scholar] [CrossRef]
- Agarski, B.; Budak, I.; Kosec, B.; Hodolic, J. An approach to multi-criteria environmental evaluation with multiple weight assignment. Environ. Model. Assess. 2012, 17, 255–266. [Google Scholar] [CrossRef]
- Díaz Cazañas, R.; Delgado Sobrino, D.R. On the integration of production and maintenance planning at the tactical level: Proposal of a contribution procedure. Appl. Mech. Mater. 2014, 474, 35–41. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Indicators | Theoretical Conceptions |
|---|---|
| In processes highly depend on equipment, the need of integration is higher than in those manpower-based processes [11,12,13,14,15,16]. |
| Companies with different competitive priorities follow different maintenance strategies [11,16]. |
| If this results in a high value, the maintenance strategy should focus more on reducing the mean time between interventions. It requires higher coordination between both departments to take advantage of opportunity windows in the production program. |
| As maintainability decreases, the integration between both systems should increase to reduce the negative impact over availability. |
| This has to be considered by the maintenance department in order to develop prevention or consequences’ reduction strategies, definition of critical equipment, among others. According to [15], functional areas with low to no buffers should work in a coordinated way, otherwise small equipment interruptions can affect the whole system. |
| This should be considered in order to eliminate problems caused by information redundancy. The higher its level, the higher the needs of integration in areas such as inventory and suppliers’ management, design, and implementation of IT solutions in both systems, etc. [13]. |
| If it is high, it demands higher integration, which can lead to development of an autonomous maintenance and/or outsourcing maintenance strategy. |
| As with the competitiveness-driven approach, the processes-based management approach forces the integration in the management of these processes, being a key and a particular case of the processes of PM and MM. |
| It is one of the elements that supports maintenance quality [11]. If it results in a high value, the need for integration decreases. Otherwise, it indicates the need for a coordinated work in the search of strategies to reach the required availability. |
| This decreases the tensions in reaching coordination between production and maintenance planning, because it avoids process interruptions by unexpected breakdowns or planned maintenance interventions that can overlap with production orders [14]. |
| Indicators | E1 | E2 | E3 | E4 | E5 | E6 | E7 | E8 | F.E |
|---|---|---|---|---|---|---|---|---|---|
| 1 | vh | p | vh | vh | vh | vh | vh | p | vh |
| 2 | h | h | m | h | h | vh | h | h | h |
| 4 | vh | vh | h | vh | vh | vh | h | vh | vh |
| 5 | h | h | h | h | p | h | h | h | h |
| 7 | h | h | h | h | h | h | h | h | h |
| 8 | h | h | h | l | m | h | h | h | h |
| 9 | m | m | m | l | m | m | m | m | m |
| 10 | h | m | h | h | h | h | m | h | h |
| Indicators | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0.750 | 0.250 | 0.625 | h | |
| 2 | 3 | 0 | 0 | 0 | 0.125 | 0.750 | 0.125 | 0 | 0.593 | h | |
| 4 | 2 | 0 | 0 | 0 | 0 | 0.250 | 0.750 | 0 | 0.625 | h | |
| 5 | 2 | 0 | 0 | 0 | 0 | 0.875 | 0 | 0.125 | 0.73 | vh | |
| 7 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | p | |
| 8 | 3 | 0 | 0 | 0.125 | 0.125 | 0.750 | 0 | 0 | 0.593 | h | |
| 9 | 2 | 0 | 0 | 0.125 | 0.875 | 0 | 0 | 0 | 0.781 | p | |
| 10 | 3 | 0 | 0 | 0 | 0.250 | 0.750 | 0 | 0 | 0.625 | h |
| Indicators | Score | Range | Weight |
|---|---|---|---|
| 1 | 17 | 10 | 0.182 |
| 2 | 6 | 4 | 0.072 |
| 3 | 4 | 2 | 0.036 |
| 4 | 7 | 5 | 0.091 |
| 5 | 15 | 8.5 | 0.155 |
| 6 | 10 | 7 | 0.127 |
| 7 | 8 | 6 | 0.109 |
| 8 | 5 | 3 | 0.055 |
| 9 | 15 | 8.5 | 0.155 |
| 10 | 3 | 1 | 0.018 |
| Indicators | Evaluation | Term to Aggregate | Weight |
|---|---|---|---|
| 1 | vh | vh | 0.182 |
| 2 | h | h | 0.072 |
| 3 | vh | vh | 0.036 |
| 4 | vh | vh | 0.091 |
| 5 | h | h | 0.155 |
| 6 | h | h | 0.127 |
| 7 | h | h | 0.109 |
| 8 | h | h | 0.055 |
| 9 | m | m | 0.155 |
| 10 | h | l | 0.018 |
| Iterations | Terms to Aggregate | i | j | k | |||
|---|---|---|---|---|---|---|---|
| 1 | h, m | 3 | 4 | 0.500 | 0.500 | 4 | h |
| Iterations | Terms to Aggregate | i | j | k | |||
|---|---|---|---|---|---|---|---|
| 1 | vh, l | 2 | 5 | 0.667 | 0.333 | 4 | h |
| 2 | h, h | 4 | 4 | 0.671 | 0.329 | 4 | h |
| 3 | h, h | 4 | 4 | 0.665 | 0.335 | 4 | h |
| 4 | vh, h | 4 | 5 | 0.688 | 0.312 | 5 | vh |
| 5 | h, vh | 4 | 5 | 0.333 | 0.667 | 4 | h |
| 6 | h, h | 4 | 4 | 0.667 | 0.333 | 4 | h |
| 7 | h, h | 4 | 4 | 0.681 | 0.319 | 4 | h |
| 8 | h, h | 4 | 4 | 0.652 | 0.348 | 4 | h |
| 9 | vh, h | 4 | 5 | 0.667 | 0.333 | 5 | vh |
| Indicators | Evaluation | Term to Aggregate | Weight | |
|---|---|---|---|---|
| 1 | vh | vh | 0 | 0 |
| 3 | vh | vh | 0 | 0 |
| 4 | vh | vh | 0 | 0 |
| 2 | h | h | 0.2 | 0.2 |
| 5 | h | h | 0.2 | 0.2 |
| 6 | h | h | 0.2 | 0.2 |
| 7 | h | h | 0.2 | 0.2 |
| 8 | h | h | 0.2 | 0.2 |
| 9 | m | m | 0 | 0 |
| 10 | h | l | 0 | 0 |
| Iterations | Terms to Aggregate | i | j | k | |||
|---|---|---|---|---|---|---|---|
| 1 | h, h | 4 | 4 | 0.2 | 0.8 | 4 | h |
| 2 | h, h | 4 | 4 | 0.2 | 0.8 | 4 | h |
| 3 | h, h | 4 | 4 | 0.2 | 0.8 | 4 | h |
| 4 | h, h | 4 | 4 | 0.2 | 0.8 | 4 | h |
| 5 | h, vh | 4 | 5 | 0.0 | 1.0 | 4 | h |
| 6 | h, vh | 4 | 5 | 0.0 | 1.0 | 4 | h |
| 7 | h, vh | 4 | 5 | 0.0 | 1.0 | 4 | h |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Díaz Cazañas, R.; Delgado Sobrino, D.R.; De La Paz Martínez, E.M.; Petru, J.; Díaz Tejeda, C.D. Proposal of a Framework for Evaluating the Importance of Production and Maintenance Integration Supported by the Use of Ordinal Linguistic Fuzzy Modeling. Mathematics 2024, 12, 338. https://doi.org/10.3390/math12020338
Díaz Cazañas R, Delgado Sobrino DR, De La Paz Martínez EM, Petru J, Díaz Tejeda CD. Proposal of a Framework for Evaluating the Importance of Production and Maintenance Integration Supported by the Use of Ordinal Linguistic Fuzzy Modeling. Mathematics. 2024; 12(2):338. https://doi.org/10.3390/math12020338
Chicago/Turabian StyleDíaz Cazañas, Ronald, Daynier Rolando Delgado Sobrino, Estrella María De La Paz Martínez, Jana Petru, and Carlos Daniel Díaz Tejeda. 2024. "Proposal of a Framework for Evaluating the Importance of Production and Maintenance Integration Supported by the Use of Ordinal Linguistic Fuzzy Modeling" Mathematics 12, no. 2: 338. https://doi.org/10.3390/math12020338
APA StyleDíaz Cazañas, R., Delgado Sobrino, D. R., De La Paz Martínez, E. M., Petru, J., & Díaz Tejeda, C. D. (2024). Proposal of a Framework for Evaluating the Importance of Production and Maintenance Integration Supported by the Use of Ordinal Linguistic Fuzzy Modeling. Mathematics, 12(2), 338. https://doi.org/10.3390/math12020338