
SVSeq2Seq: An Efficient Computational Method for State Vectors in Sequence-to-Sequence Architecture Forecasting


Abstract
1. Introduction
2. Model Descriptions and Preliminaries
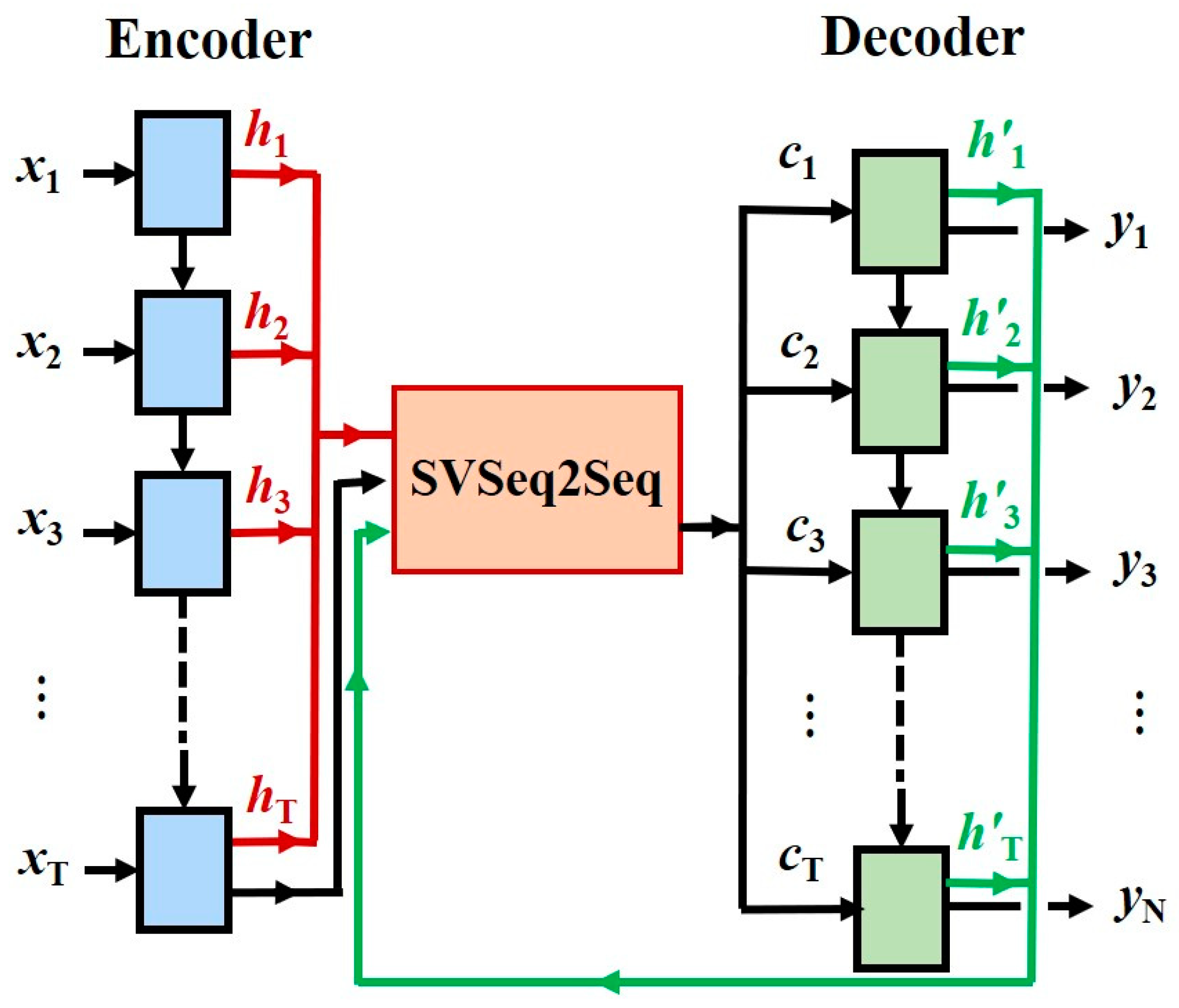
2.1. Encoder–Decoder Architecture of the RNN
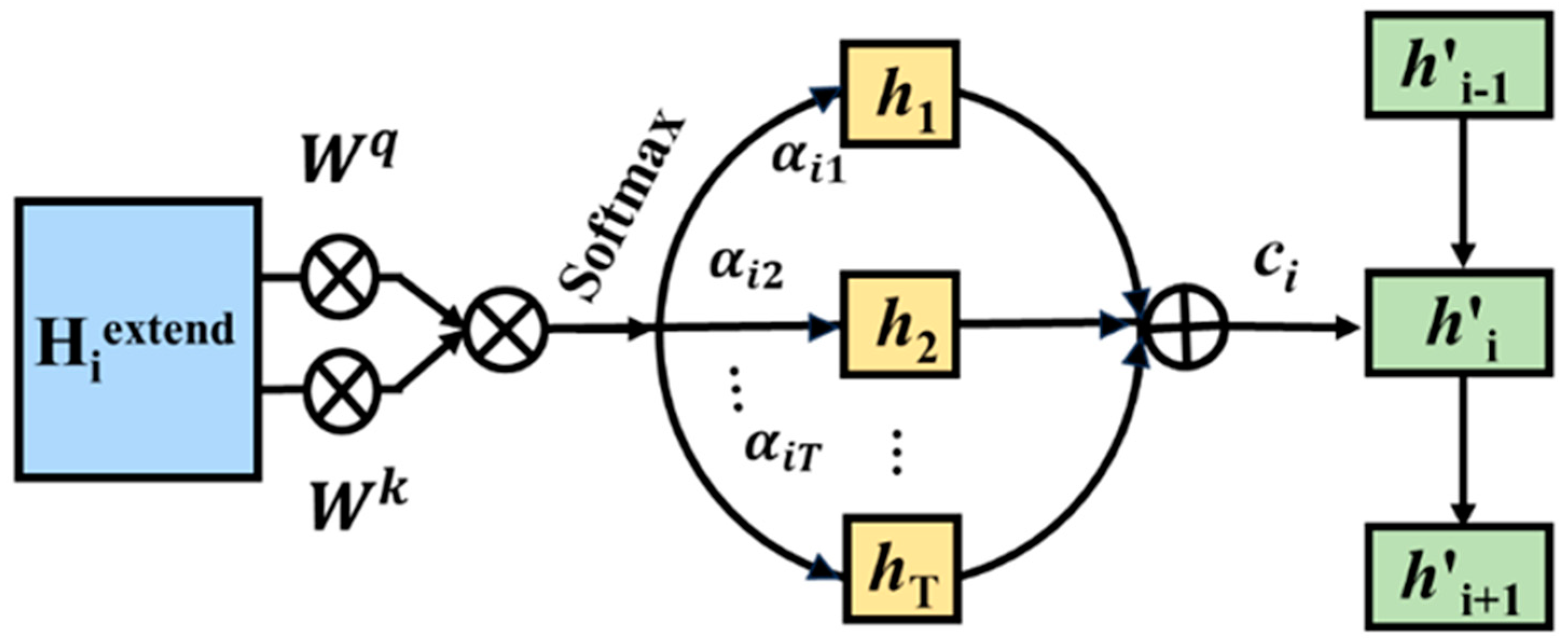
2.2. State Vector Computation
| Algorithm 1: State vectors |
| Input: The input vector of Encoder and Output: State vectors 1 for in do 2 Calculate and , Equation (7); 3 Calculate , Equation (8); 4 Express in vector form, Equation (9); 5 Make sure the elements in within [0, 1], Equation (10); 6 Take the elements of into Equation (5); 7 ends 8 Get |
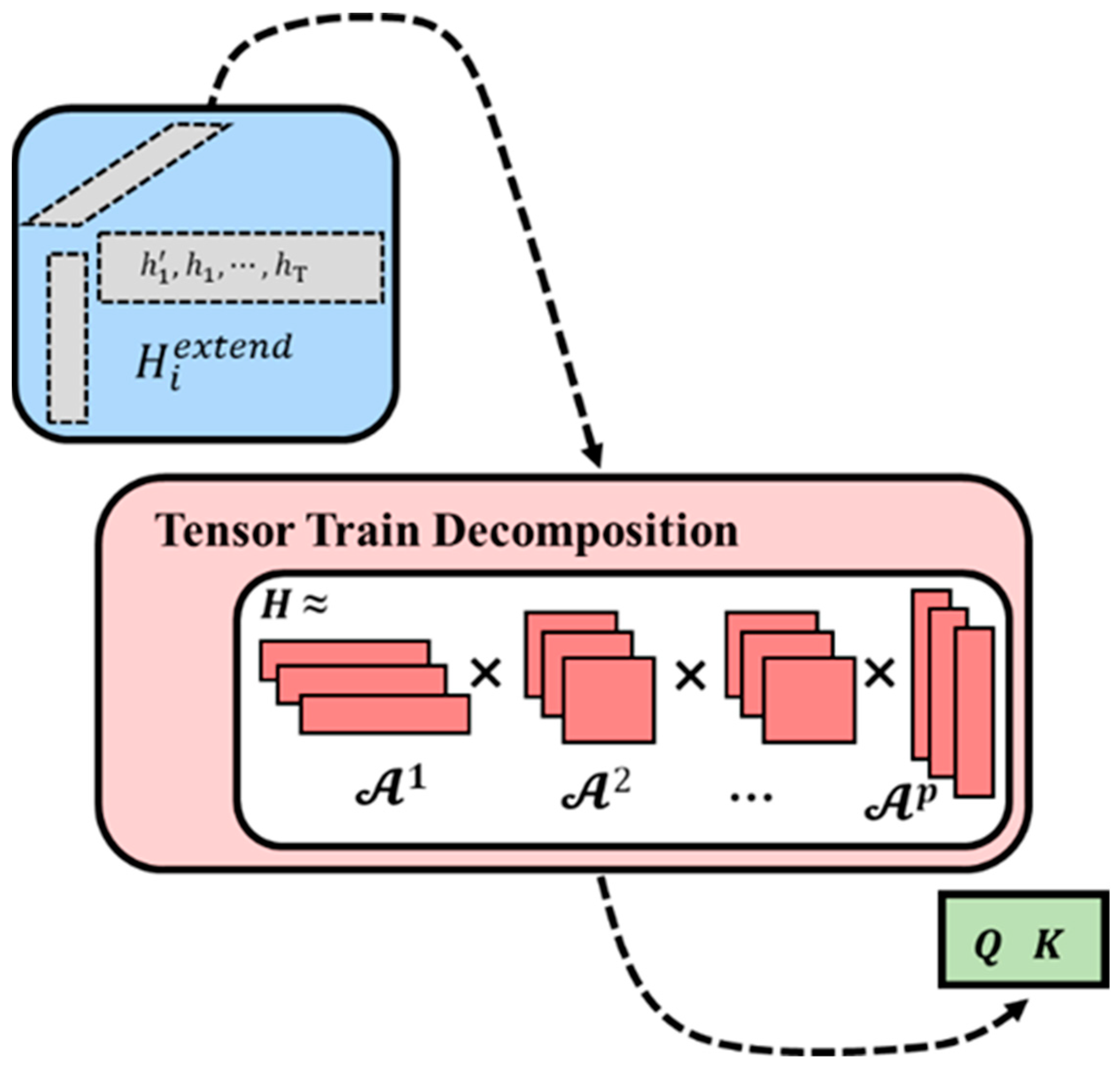
2.3. Tensor Train Networks
3. Experiment Results
3.1. Experimental Setup
3.2. Dataset Preparation
3.2.1. ETT Dataset
3.2.2. Weather Dataset
3.2.3. Electricity Dataset
3.2.4. Traffic Dataset
3.2.5. Solar-Energy Dataset
3.2.6. PEMS Dataset
3.3. MAE and MSE Calculation
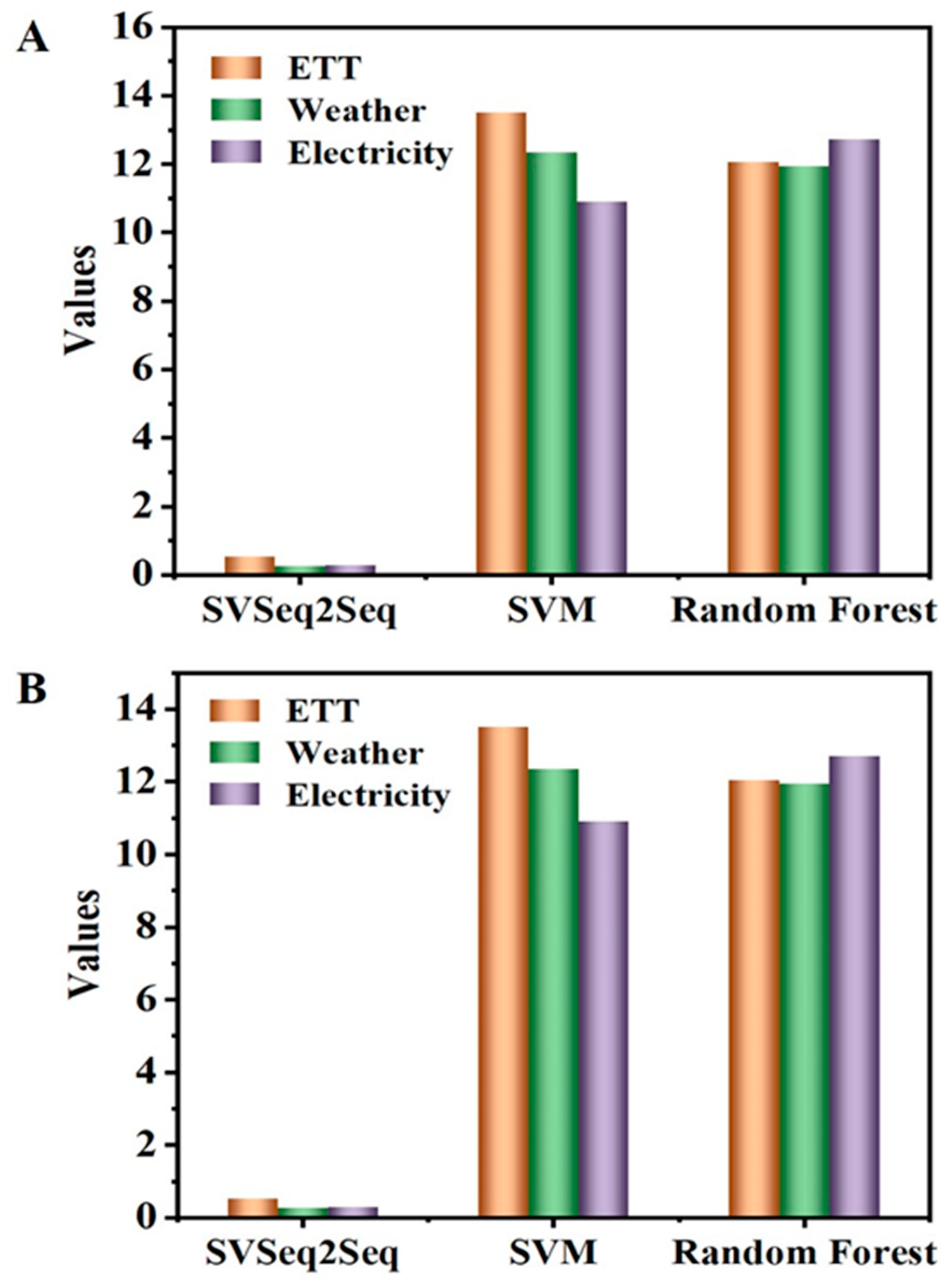
3.4. Comparison with Machine Learning-Based Methods
3.5. Comparison with Several Up-to-Date Methods
3.6. Ablation Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barbosa, A.; Bittencourt, I.; Siqueira, S.W.; Dermeval, D.; Cruz, N.J.T. A context-independent ontological linked data alignment approach to instance matching. Int. J. Semant. Web. Inf. 2022, 18, 1–29. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 2010, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; Volume 1406, p. 1078. [Google Scholar] [CrossRef]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. In Proceedings of the 35th Conference on Neural Information Processing Systems, Online, 6–14 December 2021; pp. 22419–22430. [Google Scholar] [CrossRef]
- Zhang, Y.; Yan, J. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar] [CrossRef]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are transformers effective for time series forecasting? In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar] [CrossRef]
- Das, A.; Kong, W.; Leach, A.; Mathur, S.; Sen, R.; Yu, R. Long-term forecasting with TiDE: Time-series dense encoder. Trans. Mach. Learn. Res. 2023, 2304, 08424. [Google Scholar] [CrossRef]
- Liu, M.; Zeng, A.; Chen, M.; Xu, Z.; Lai, Q.; Ma, L.; Xu, Q. Scinet: Time series modeling and forecasting with sample convolution and interaction. In Proceedings of the 36th Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 5816–5828. [Google Scholar] [CrossRef]
- Wu, H.; Hu, T.; Liu, Y.; Zhou, H.; Wang, J.; Long, M. Timesnet: Temporal 2d-variation modeling for general time series analysis. In Proceedings of the Eleventh International Conference on Learning Representations, Virtual Event, 25–29 April 2022; Volume 2210, p. 02186. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Held Virtually, 2–9 February 2021. [Google Scholar] [CrossRef]
- Li, C.; Li, D.; Zhang, Z.; Chu, D. MST-RNN: A multi-dimension spatiotemporal recurrent neural networks for recommending the next point of interest. Mathematics 2022, 10, 1838. [Google Scholar] [CrossRef]
- Sneha, J.; Zhao, J.; Fan, Y.; Li, J.; Lin, H.; Yan, C.; Chen, M. Time-varying sequence model. Mathematics 2023, 11, 336. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NeurIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar] [CrossRef]
- Rico, S.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar] [CrossRef]
- Serban, I.V.; Sordoni, A.; Bengio, Y.; Courville, A.; Pineau, J. Building end-to-end dialogue systems using generative hierarchical neural network models. AAAI Conf. Artif. Intell. 2016, 1410, 3916. [Google Scholar] [CrossRef]
- Sordoni, A.; Bengio, Y.; Vahabi, H.; Lioma, C.; Simonsen, J.G.; Nie, J. A hierarchical recurrent encoder-decoder for generative context-aware query suggestion. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 553–562. [Google Scholar] [CrossRef]
- Serban, I.V.; Sordoni, A.; Lowe, R.; Charlin, L.; Pineau, J.; Courville, A.; Bengio, Y. A hierarchical latent variable encoder-decoder model for generating dialogues. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar] [CrossRef]
- Jason, W.; Chopra, S.; Bordes, A. Memory networks. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 7380–7382. [Google Scholar] [CrossRef]
- Fernando, T.; Denman, S.; McFadyen, A.; Sridharan, S.; Fookes, C. Tree memory networks for modelling long-term temporal dependencies. Neurocomputing 2018, 304, 64–81. [Google Scholar] [CrossRef]
- Cao, J.; Li, J.; Jiang, J. Link prediction for temporal heterogeneous networks based on the information lifecycle. Mathematics 2023, 11, 3541. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 1877–1901. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, H.; Wang, J.; Long, M. Non-stationary transformers: Rethinking the stationarity in time series forecasting. arXiv 2022, arXiv:2205.14415. [Google Scholar] [CrossRef]
- Nie, Y.; Nguyen, N.H.; Sinthong, P.; Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers. arXiv 2022, arXiv:2211.14730. [Google Scholar] [CrossRef]
- Singh, S.K.; Chopra, M.; Sharma, A.; Gill, S.S. A comparative study of generative adversarial networks for text-to-image synthesis. Int. J. Softw. Sci. Comp. 2022, 14, 1–12. [Google Scholar] [CrossRef]
- Román, O. A practical introduction to tensor networks: Matrix product states and projected entangled pair states. Ann. Phys. 2014, 349, 117–158. [Google Scholar] [CrossRef]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. Int. Conf. Mach. Learn. 2022, 2201, 12740. [Google Scholar] [CrossRef]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling long-and short-term temporal patterns with deep neural networks. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 95–104. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | MSE 1 | MAE 2 | ||||
|---|---|---|---|---|---|---|
| SVSeq2Seq | SVM | RF | SVSeq2Seq | SVM | RF | |
| ETT | 0.528 | 12.971 | 14.562 | 0.524 | 13.518 | 12.057 |
| Weather | 0.259 | 14.732 | 11.604 | 0.260 | 12.351 | 11.943 |
| Electricity | 0.186 | 11.264 | 13.724 | 0.285 | 10.905 | 12.718 |
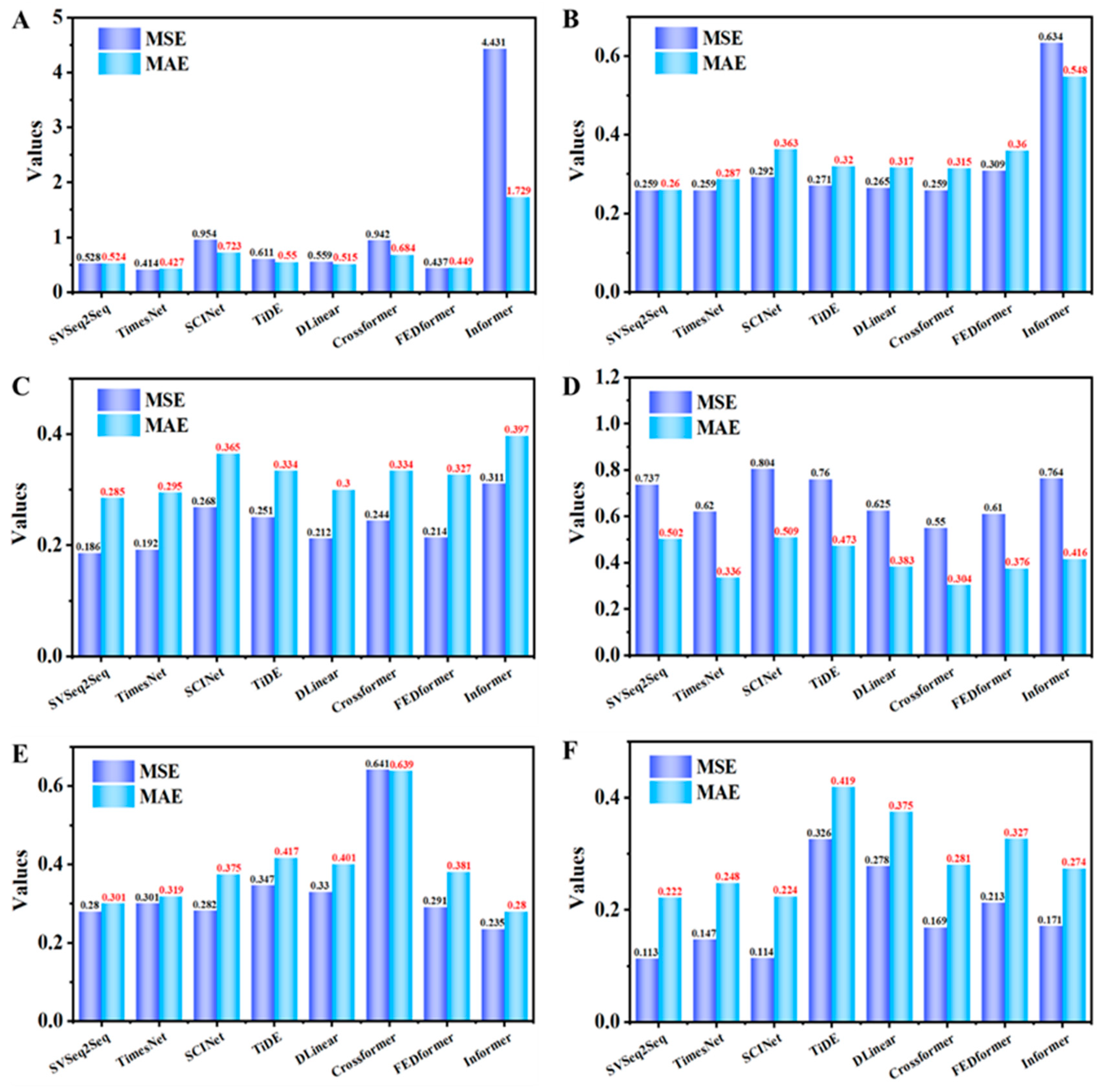
| Models | SVSeq2Seq | TimesNet | SCINet | TiDE | DLinear | Crossformer | FEDformer | Informer |
|---|---|---|---|---|---|---|---|---|
| ETT | 0.528 | 0.414 | 0.954 | 0.611 | 0.559 | 0.942 | 0.437 | 4.431 |
| Weather | 0.259 | 0.259 | 0.292 | 0.271 | 0.265 | 0.259 | 0.309 | 0.634 |
| Electricity | 0.186 | 0.192 | 0.268 | 0.251 | 0.212 | 0.244 | 0.214 | 0.311 |
| Traffic | 0.737 | 0.620 | 0.804 | 0.760 | 0.625 | 0.550 | 0.610 | 0.764 |
| Solar-Energy | 0.280 | 0.301 | 0.282 | 0.347 | 0.330 | 0.641 | 0.291 | 0.235 |
| PEMS | 0.113 | 0.147 | 0.114 | 0.326 | 0.278 | 0.169 | 0.213 | 0.171 |
| Models | SVSeq2Seq | TimesNet | SCINet | TiDE | DLinear | Crossformer | FEDformer | Informer |
|---|---|---|---|---|---|---|---|---|
| ETT | 0.524 | 0.427 | 0.723 | 0.550 | 0.515 | 0.684 | 0.449 | 1.729 |
| Weather | 0.260 | 0.287 | 0.363 | 0.320 | 0.317 | 0.315 | 0.360 | 0.548 |
| Electricity | 0.285 | 0.295 | 0.365 | 0.334 | 0.300 | 0.334 | 0.327 | 0.397 |
| Traffic | 0.502 | 0.336 | 0.509 | 0.473 | 0.383 | 0.304 | 0.376 | 0.416 |
| Solar-Energy | 0.301 | 0.319 | 0.375 | 0.417 | 0.401 | 0.639 | 0.381 | 0.280 |
| PEMS | 0.222 | 0.248 | 0.224 | 0.419 | 0.375 | 0.281 | 0.327 | 0.274 |
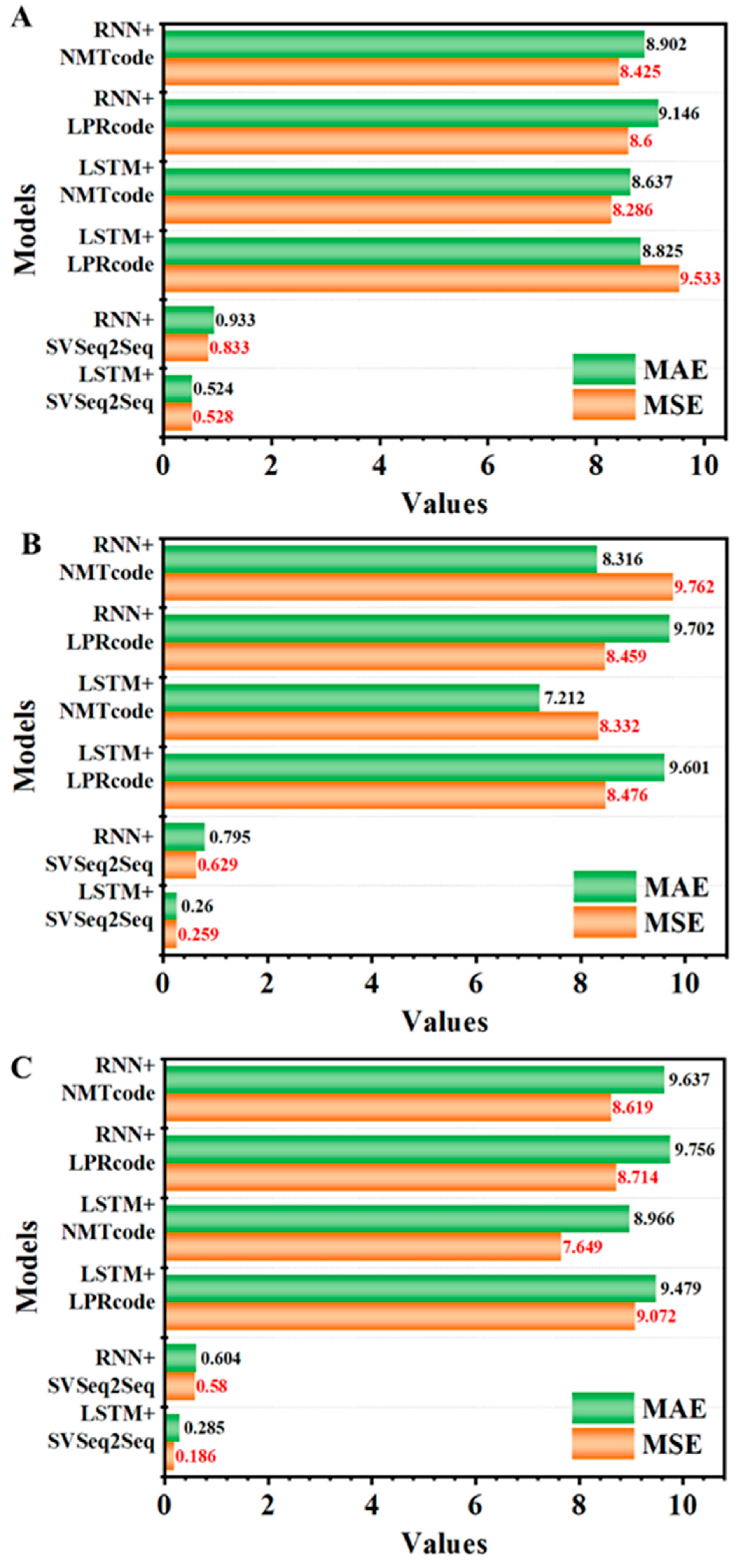
| Models | LSTM + SVSeq2Seq | RNN + SVSeq2Seq | LSTM + LPRcode | LSTM + NMTcode | RNN + LPRcode | RNN + NMTcode |
|---|---|---|---|---|---|---|
| ETT | 0.528 | 0.833 | 9.533 | 8.286 | 8.600 | 8.425 |
| Weather | 0.259 | 0.629 | 8.476 | 8.332 | 8.459 | 9.762 |
| Electricity | 0.186 | 0.580 | 9.072 | 7.649 | 8.714 | 8.619 |
| Models | LSTM + SVSeq2Seq | RNN + SVSeq2Seq | LSTM + LPRcode | LSTM + NMTcode | RNN + LPRcode | RNN + NMTcode |
|---|---|---|---|---|---|---|
| ETT | 0.524 | 0.933 | 8.825 | 8.637 | 9.146 | 8.902 |
| Weather | 0.260 | 0.795 | 9.601 | 7.212 | 9.702 | 8.316 |
| Electricity | 0.285 | 0.604 | 9.479 | 8.966 | 9.756 | 9.637 |
| Models | MSE 1 | MAE 2 | ||
|---|---|---|---|---|
| LSTM | RNN | LSTM | RNN | |
| ETT | 9.603 | 10.492 | 9.548 | 10.734 |
| Weather | 8.972 | 9.776 | 9.670 | 9.809 |
| Electricity | 9.747 | 10.946 | 9.249 | 10.385 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, G.; Qi, X.; Zhao, Q.; Wang, W.; Li, Y. SVSeq2Seq: An Efficient Computational Method for State Vectors in Sequence-to-Sequence Architecture Forecasting. Mathematics 2024, 12, 265. https://doi.org/10.3390/math12020265
Sun G, Qi X, Zhao Q, Wang W, Li Y. SVSeq2Seq: An Efficient Computational Method for State Vectors in Sequence-to-Sequence Architecture Forecasting. Mathematics. 2024; 12(2):265. https://doi.org/10.3390/math12020265
Chicago/Turabian StyleSun, Guoqiang, Xiaoyan Qi, Qiang Zhao, Wei Wang, and Yujun Li. 2024. "SVSeq2Seq: An Efficient Computational Method for State Vectors in Sequence-to-Sequence Architecture Forecasting" Mathematics 12, no. 2: 265. https://doi.org/10.3390/math12020265
APA StyleSun, G., Qi, X., Zhao, Q., Wang, W., & Li, Y. (2024). SVSeq2Seq: An Efficient Computational Method for State Vectors in Sequence-to-Sequence Architecture Forecasting. Mathematics, 12(2), 265. https://doi.org/10.3390/math12020265