
Exploiting Cross-Scale Attention Transformer and Progressive Edge Refinement for Retinal Vessel Segmentation

Abstract
1. Introduction
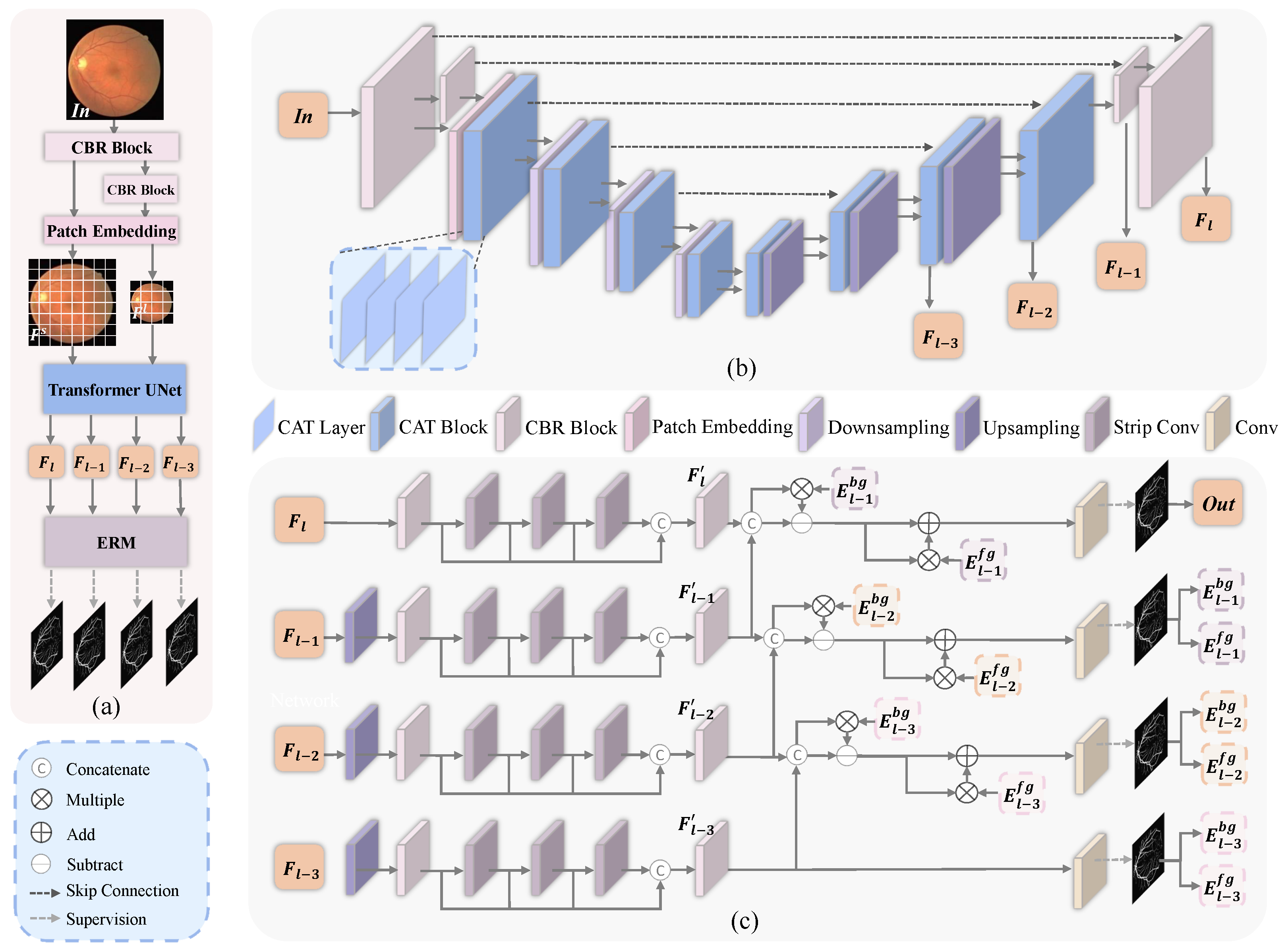
- Cross-scale Attention Transformer (CAT) is proposed as the basic unit in the transformer UNet. CAT fully exploits the dense similar structures with different scales in a retinal image and effectively fuses the features to improve the vessel segmentation performance.
- A progressive edge refinement module (ERM) is designed to refine the edges of foreground and background in the segmentation results. ERM can suppress non-vessel features and enhance vessel features, and then progressively refine the prediction mask.
- Comprehensive experiments and discussions are carried out to verify the effectiveness of the proposed method. The vessel segmentation performance outperforms the state-of-the-art methods on public retinal datasets.
2. Materials and Methods
2.1. Framework Overview
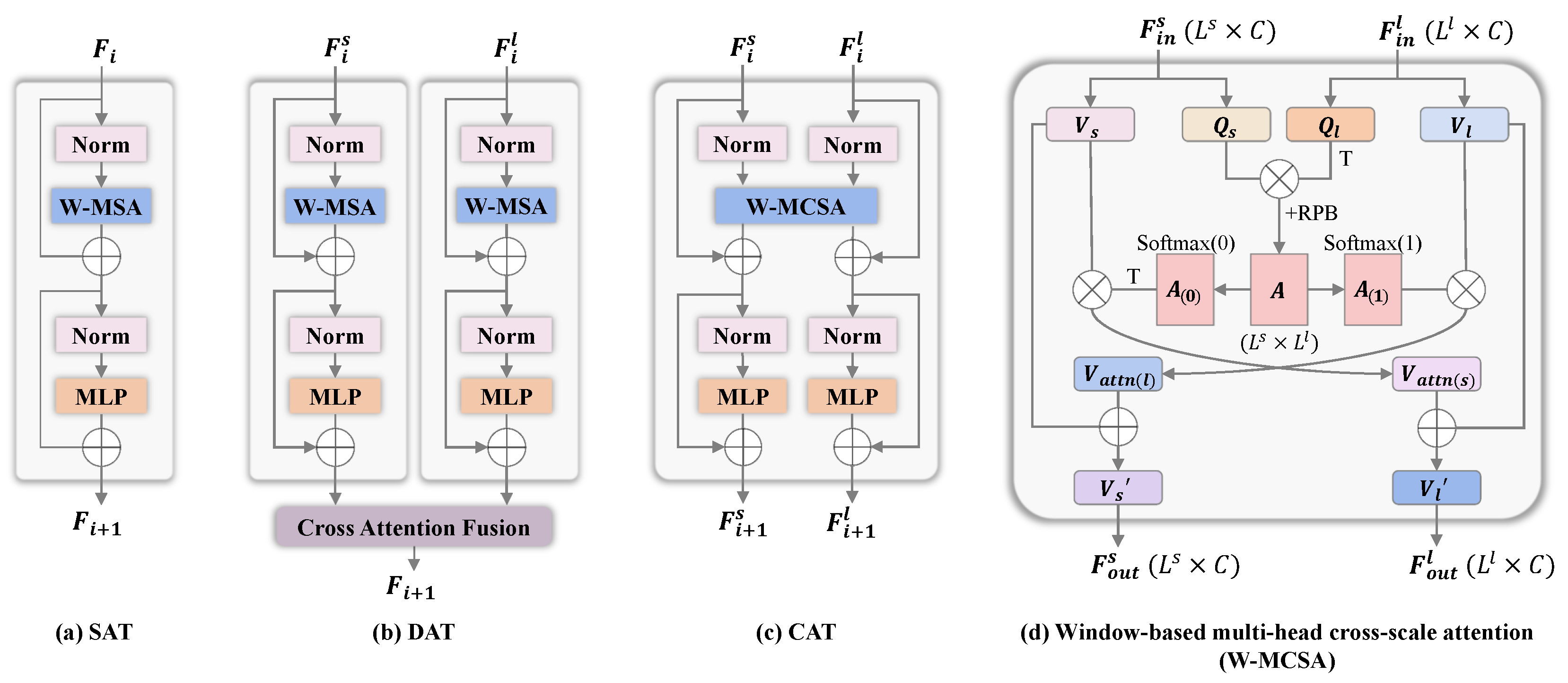
2.2. Cross-Scale Attention Transformer
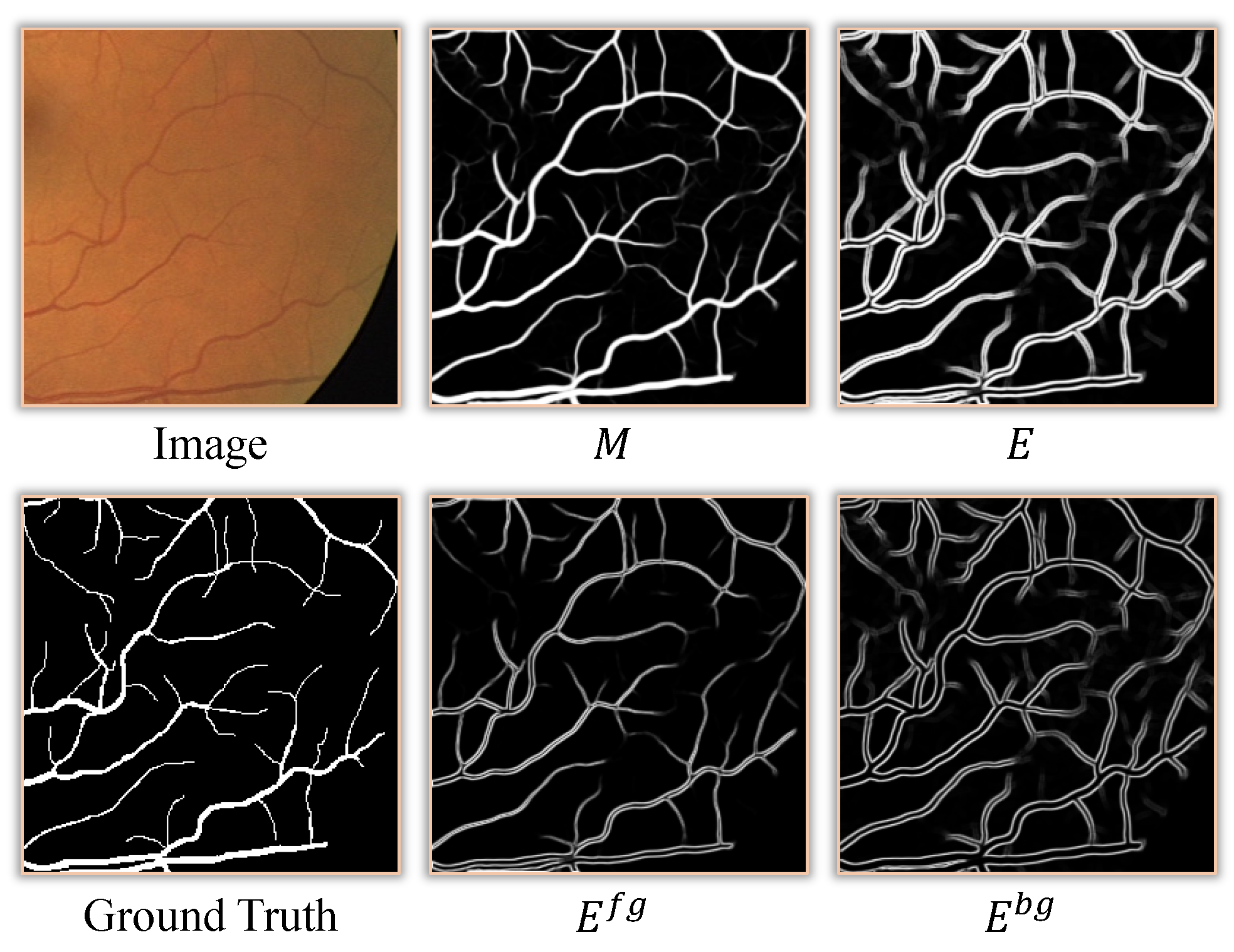
2.3. Edge Refinement Module
2.4. Network Details
3. Results
3.1. Datasets
3.2. Implementation Details
3.3. Evaluation Metrics
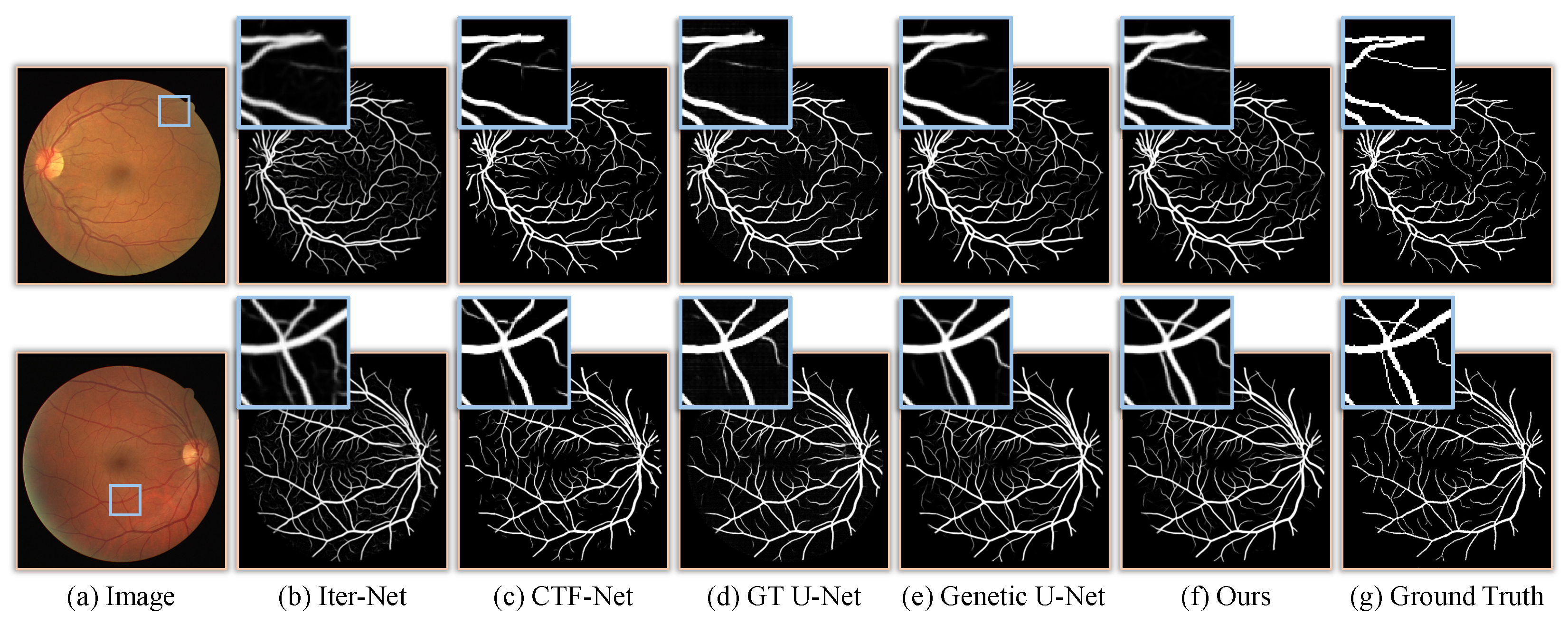
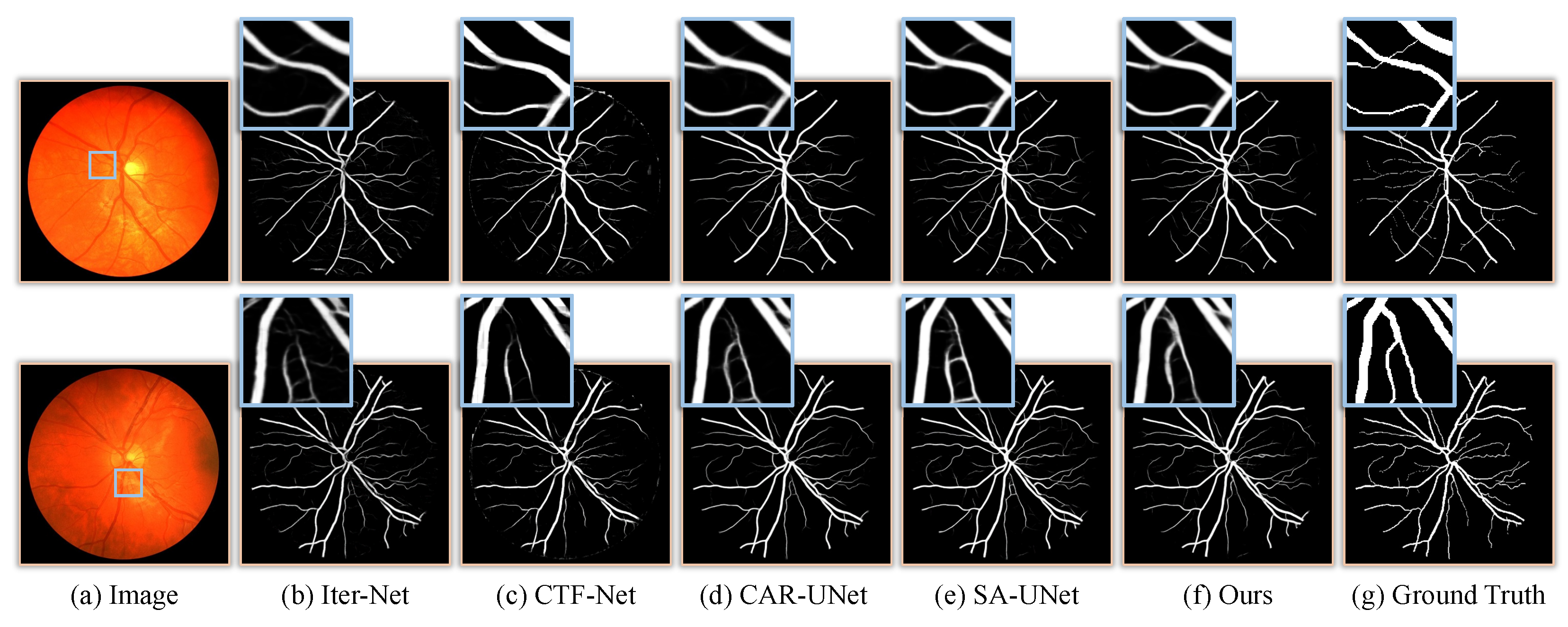
3.4. Results and Comparisons
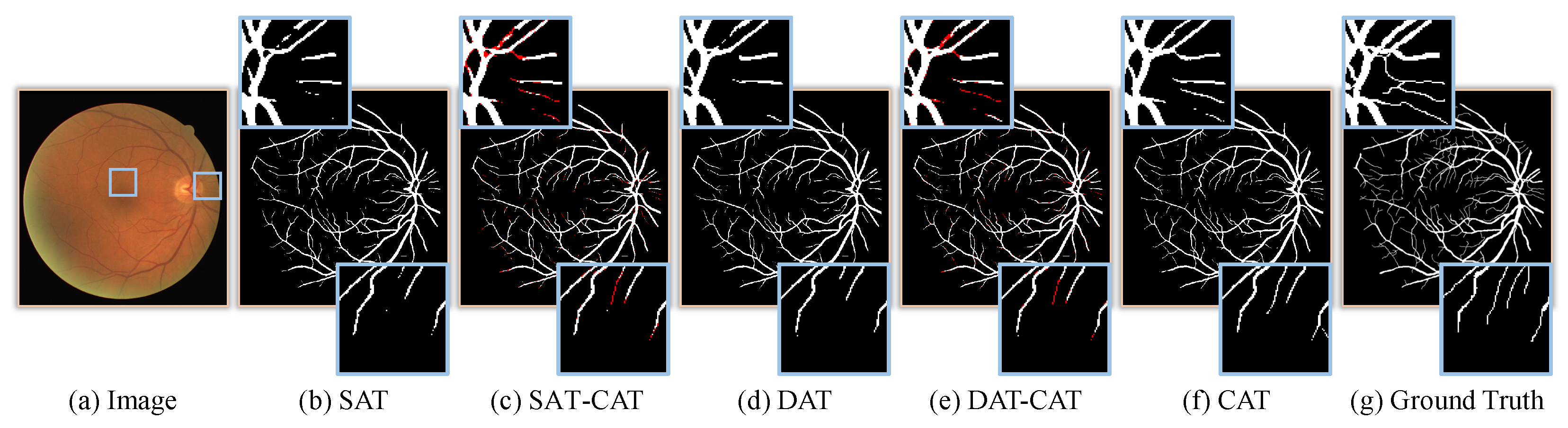
3.5. Ablation Study
4. Discussion
4.1. The Effect of Input Patch Size
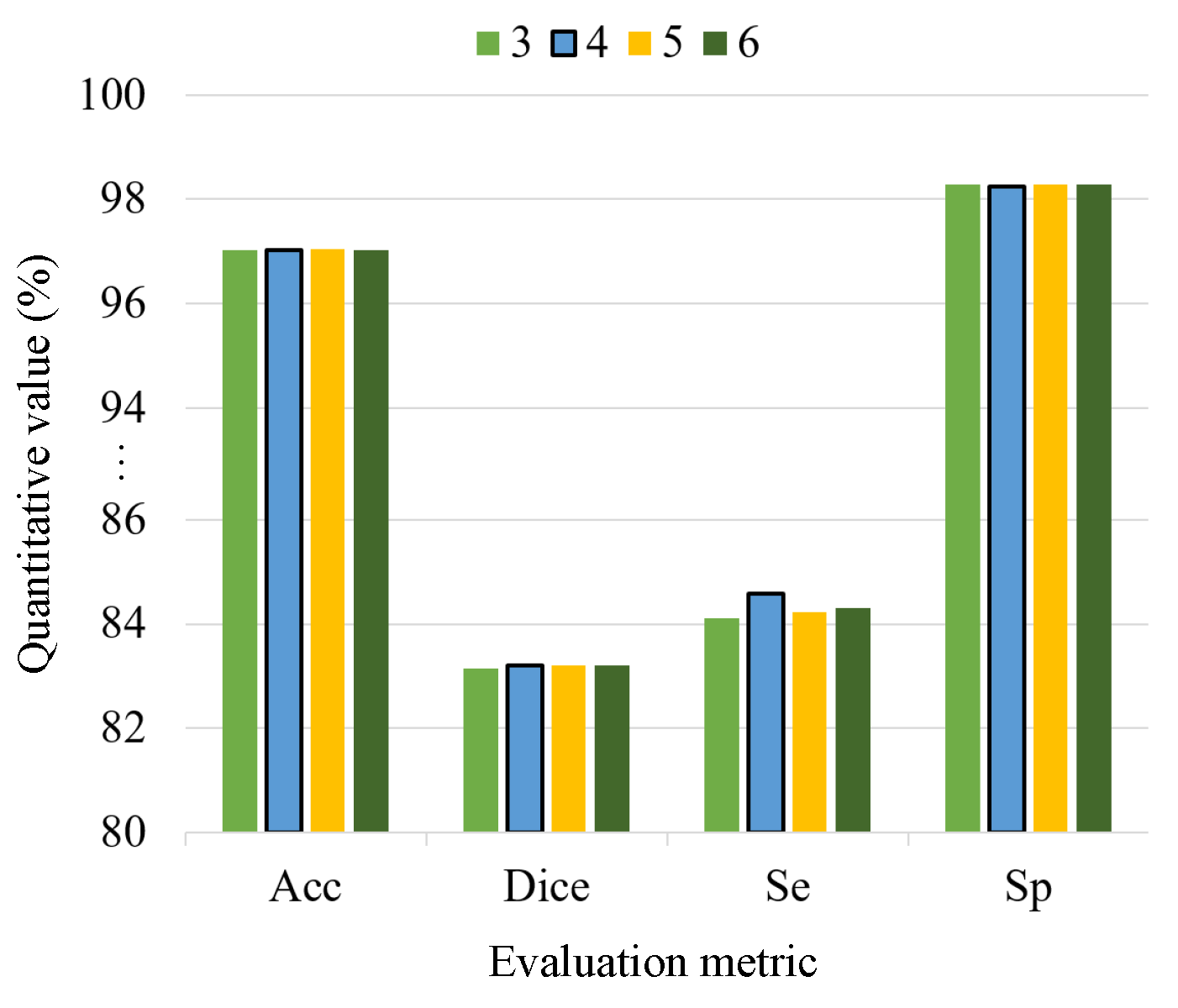
4.2. The Effect of CAT Layers
4.3. The Effect of Deep-Supervision Layers
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wong, T.Y.; Mitchell, P. Hypertensive retinopathy. N. Engl. J. Med. 2004, 351, 2310–2317. [Google Scholar] [CrossRef] [PubMed]
- Patton, N.; Aslam, T.; MacGillivray, T.; Pattie, A.; Deary, I.J.; Dhillon, B. Retinal vascular image analysis as a potential screening tool for cerebrovascular disease: A rationale based on homology between cerebral and retinal microvasculatures. J. Anat. 2005, 206, 319–348. [Google Scholar] [CrossRef] [PubMed]
- Zhu, C.; Zou, B.; Zhao, R.; Cui, J.; Duan, X.; Chen, Z.; Liang, Y. Retinal vessel segmentation in colour fundus images using extreme learning machine. Comput. Med. Imaging Graph. 2017, 55, 68–77. [Google Scholar] [CrossRef] [PubMed]
- Mendonca, A.; Campilho, A. Segmentation of retinal blood vessels by combining the detection of centerlines and morphological reconstruction. IEEE Trans. Med. Imaging 2006, 25, 1200–1213. [Google Scholar] [CrossRef]
- Zhang, J.; Dashtbozorg, B.; Bekkers, E.; Pluim, J.P.W.; Duits, R.; ter Haar Romeny, B.M. Robust retinal vessel segmentation via locally adaptive derivative frames in orientation scores. IEEE Trans. Med. Imaging 2016, 35, 2631–2644. [Google Scholar] [CrossRef]
- Al-Diri, B.; Hunter, A.; Steel, D. An active contour model for segmenting and measuring retinal vessels. IEEE Trans. Med. Imaging 2009, 28, 1488–1497. [Google Scholar] [CrossRef]
- Yang, J.; Lou, C.; Fu, J.; Feng, C. Vessel segmentation using multiscale vessel enhancement and a region based level set model. Comput. Med. Imaging Graph. 2020, 85, 101783. [Google Scholar] [CrossRef]
- Yin, Y.; Adel, M.; Bourennane, S. Retinal vessel segmentation using a probabilistic tracking method. Pattern Recognit. 2012, 45, 1235–1244. [Google Scholar] [CrossRef]
- Roychowdhury, S.; Koozekanani, D.D.; Parhi, K.K. Iterative vessel segmentation of fundus images. IEEE Trans. Biomed. Eng. 2015, 62, 1738–1749. [Google Scholar] [CrossRef]
- Ricci, E.; Perfetti, R. Retinal blood vessel segmentation using line operators and support vector classification. IEEE Trans. Med. Imaging 2007, 26, 1357–1365. [Google Scholar] [CrossRef]
- Lupascu, C.A.; Tegolo, D.; Trucco, E. FABC: Retinal vessel segmentation using AdaBoost. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1267–1274. [Google Scholar] [CrossRef]
- Alom, M.Z.; Yakopcic, C.; Hasan, M.; Taha, T.M.; Asari, V.K. Recurrent residual U-Net for medical image segmentation. J. Med. Imaging 2019, 6, 014006. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Guo, C.; Szemenyei, M.; Yi, Y.; Wang, W.; Chen, B.; Fan, C. Sa-unet: Spatial attention u-net for retinal vessel segmentation. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1236–1242. [Google Scholar]
- Li, X.; Jiang, Y.; Li, M.; Yin, S. Lightweight attention convolutional neural network for retinal vessel image segmentation. IEEE Trans. Ind. Inform. 2020, 17, 1958–1967. [Google Scholar] [CrossRef]
- Wang, C.; Xu, R.; Zhang, Y.; Xu, S.; Zhang, X. Retinal vessel segmentation via context guide attention net with joint hard sample mining strategy. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1319–1323. [Google Scholar]
- Mou, L.; Zhao, Y.; Fu, H.; Liu, Y.; Cheng, J.; Zheng, Y.; Su, P.; Yang, J.; Chen, L.; Frangi, A.F.; et al. CS2-Net: Deep learning segmentation of curvilinear structures in medical imaging. Med. Image Anal. 2021, 67, 101874. [Google Scholar] [CrossRef] [PubMed]
- Mou, L.; Chen, L.; Cheng, J.; Gu, Z.; Zhao, Y.; Liu, J. Dense dilated network with probability regularized walk for vessel detection. IEEE Trans. Med. Imaging 2019, 39, 1392–1403. [Google Scholar] [CrossRef] [PubMed]
- Nazir, N.; Sarwar, A.; Saini, B.S.; Shams, R. A robust deep learning approach for accurate segmentation of cytoplasm and nucleus in noisy pap smear images. Computation 2023, 11, 195. [Google Scholar] [CrossRef]
- Araújo, R.J.; Cardoso, J.S.; Oliveira, H.P. A deep learning design for improving topology coherence in blood vessel segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 93–101. [Google Scholar]
- Shin, S.Y.; Lee, S.; Yun, I.D.; Lee, K.M. Deep vessel segmentation by learning graphical connectivity. Med. Image Anal. 2019, 58, 101556. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Huang, S.; Li, J.; Xiao, Y.; Shen, N.; Xu, T. RTNet: Relation transformer network for diabetic retinopathy multi-lesion segmentation. IEEE Trans. Med. Imaging 2022, 41, 1596–1607. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Wang, S.; Wang, J.; Zeng, G.; Liu, W.; Zhang, Q.; Jin, Q.; Wang, Y. Gt u-net: A u-net like group transformer network for tooth root segmentation. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Strasbourg, France, 27 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 386–395. [Google Scholar]
- Shen, X.; Xu, J.; Jia, H.; Fan, P.; Dong, F.; Yu, B.; Ren, S. Self-attentional microvessel segmentation via squeeze-excitation transformer Unet. Comput. Med. Imaging Graph. 2022, 97, 102055. [Google Scholar] [CrossRef] [PubMed]
- Lin, A.; Chen, B.; Xu, J.; Zhang, Z.; Lu, G.; Zhang, D. Ds-transunet: Dual swin transformer u-net for medical image segmentation. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; Van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef] [PubMed]
- Fraz, M.M.; Remagnino, P.; Hoppe, A.; Uyyanonvara, B.; Rudnicka, A.R.; Owen, C.G.; Barman, S.A. An ensemble classification-based approach applied to retinal blood vessel segmentation. IEEE Trans. Biomed. Eng. 2012, 59, 2538–2548. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Verma, M.; Nakashima, Y.; Nagahara, H.; Kawasaki, R. Iternet: Retinal image segmentation utilizing structural redundancy in vessel networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 3656–3665. [Google Scholar]
- Wang, K.; Zhang, X.; Huang, S.; Wang, Q.; Chen, F. Ctf-net: Retinal vessel segmentation via deep coarse-to-fine supervision network. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1237–1241. [Google Scholar]
- Guo, C.; Szemenyei, M.; Hu, Y.; Wang, W.; Zhou, W.; Yi, Y. Channel attention residual u-net for retinal vessel segmentation. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1185–1189. [Google Scholar]
- Boudegga, H.; Elloumi, Y.; Akil, M.; Bedoui, M.H.; Kachouri, R.; Abdallah, A.B. Fast and efficient retinal blood vessel segmentation method based on deep learning network. Comput. Med. Imaging Graph. 2021, 90, 101902. [Google Scholar] [CrossRef]
- Setiawan, A.W.; Mengko, T.R.; Santoso, O.S.; Suksmono, A.B. Color retinal image enhancement using CLAHE. In Proceedings of the International Conference on ICT for Smart Society, Orlando, FL, USA, 10–12 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–3. [Google Scholar]
- Li, Y.; Zhang, Y.; Liu, J.Y.; Wang, K.; Zhang, K.; Zhang, G.S.; Liao, X.F.; Yang, G. Global transformer and dual local attention network via deep-shallow hierarchical feature fusion for retinal vessel segmentation. IEEE Trans. Cybern. 2022, 53, 5826–5839. [Google Scholar] [CrossRef]
- Wang, B.; Qiu, S.; He, H. Dual encoding u-net for retinal vessel segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 84–92. [Google Scholar]
- Wu, H.; Wang, W.; Zhong, J.; Lei, B.; Wen, Z.; Qin, J. Scs-net: A scale and context sensitive network for retinal vessel segmentation. Med. Image Anal. 2021, 70, 102025. [Google Scholar] [CrossRef]
- Zhang, M.; Yu, F.; Zhao, J.; Zhang, L.; Li, Q. BEFD: Boundary enhancement and feature denoising for vessel segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 775–785. [Google Scholar]
- Li, Y.; Zhang, Y.; Cui, W.; Lei, B.; Kuang, X.; Zhang, T. Dual encoder-based dynamic-channel graph convolutional network with edge enhancement for retinal vessel segmentation. IEEE Trans. Med. Imaging 2022, 41, 1975–1989. [Google Scholar] [CrossRef]
- Wei, J.; Zhu, G.; Fan, Z.; Liu, J.; Rong, Y.; Mo, J.; Li, W.; Chen, X. Genetic u-net: Automatically designed deep networks for retinal vessel segmentation using a genetic algorithm. IEEE Trans. Med. Imaging 2022, 41, 292–307. [Google Scholar] [CrossRef]
- Zhou, Y.; Yu, H.; Shi, H. Study group learning: Improving retinal vessel segmentation trained with noisy labels. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 57–67. [Google Scholar]
- Wang, D.; Haytham, A.; Pottenburgh, J.; Saeedi, O.; Tao, Y. Hard attention net for automatic retinal vessel segmentation. IEEE J. Biomed. Health Inform. 2020, 24, 3384–3396. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Proceedings of the Artificial Intelligence and Statistics, PMLR, San Diego, CA, USA, 9–12 May 2015; pp. 562–570. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Acc (%) | Dice (%) | AUC (%) | Se (%) | Sp (%) |
|---|---|---|---|---|---|---|
| Dual E-Unet [38] | 2019 | 95.67 | 82.70 | 97.72 | 79.40 | 98.16 |
| Iter-Net [32] | 2020 | 95.74 | 82.18 | 98.13 | 77.91 | 98.31 |
| CTF-Net [33] | 2020 | 95.67 | 82.41 | 97.88 | 78.49 | 98.13 |
| BEFD-UNet [40] | 2020 | 97.01 | 82.67 | 98.67 | 82.15 | 98.45 |
| HANet [44] | 2020 | 95.81 | 82.93 | 98.23 | 79.91 | 98.13 |
| SA-UNet [14] | 2021 | 96.98 | 82.63 | 98.64 | 82.12 | 98.40 |
| GT U-Net [27] | 2021 | 95.46 | 81.27 | 96.96 | 77.42 | 98.09 |
| SCS-Net [39] | 2021 | 96.97 | 81.89 | 98.37 | 82.89 | 98.38 |
| CAR-UNet [34] | 2021 | 96.99 | 82.53 | 98.52 | 81.35 | 98.49 |
| SGL [43] | 2021 | 97.05 | 83.16 | 98.86 | 83.80 | 98.34 |
| GT-DLA-dsHFF [37] | 2022 | 97.03 | 82.57 | 98.63 | 83.55 | 98.27 |
| DE-DCGCN-EE [41] | 2022 | 97.05 | 82.88 | 98.66 | 83.59 | 98.26 |
| Genetic U-Net [42] | 2022 | 97.07 | 83.14 | 98.85 | 83.00 | 98.43 |
| Ours | 2023 | 97.05 | 83.33 | 98.87 | 84.68 | 98.26 |
| Method | Year | Acc (%) | Dice (%) | AUC (%) | Se (%) | Sp (%) |
|---|---|---|---|---|---|---|
| Dual E-Unet [38] | 2019 | 96.61 | 80.37 | 98.12 | 80.74 | 98.21 |
| Iter-Net [32] | 2020 | 96.55 | 80.73 | 98.51 | 79.70 | 98.23 |
| CTF-Net [33] | 2020 | 96.48 | 82.20 | 98.47 | 79.48 | 98.42 |
| HANet [44] | 2020 | 96.73 | 81.91 | 98.81 | 81.86 | 98.44 |
| SA-UNet [14] | 2021 | 97.55 | 81.53 | 99.05 | 85.73 | 98.35 |
| CAR-UNet [34] | 2021 | 97.51 | 80.98 | 98.98 | 84.39 | 98.39 |
| SCS-Net [39] | 2021 | 97.44 | - | 98.67 | 83.65 | 98.39 |
| GT-DLA-dsHFF [37] | 2022 | 97.60 | - | 98.92 | 84.40 | 98.58 |
| DE-DCGCN-EE [41] | 2022 | 97.62 | 82.61 | 98.98 | 84.00 | 98.56 |
| Ours | 2023 | 97.66 | 82.36 | 98.77 | 86.59 | 98.42 |
| Method | Parameters | FLOPs |
|---|---|---|
| CAR-UNet [34] | 1.05 M | 2.10 M |
| Iter-Net [32] | 8.24 M | 16.48 M |
| SA-UNet [14] | 538.71 K | 1.07 G |
| CTF-Net [33] | 1.38 M | 3.43 G |
| Genetic U-Net [42] | 272.42 K | 8.23 G |
| GT U-Net [27] | 25.89 M | 55.32 G |
| DE-DCGCN-EE [41] | 14.11 M | 73.62 G |
| GT-DLA-dsHFF [37] | 26.09 M | 118.62 G |
| Ours | 291.56 M | 71.15 G |
| Framework | Transformer Block | ERM | Metrics | ||||||
|---|---|---|---|---|---|---|---|---|---|
| SAT | DAT | CAT | Acc (%) | Dice (%) | AUC (%) | Se (%) | Sp (%) | ||
| Transformer UNet | ✓ | 96.90 | 82.18 | 98.60 | 82.09 | 98.32 | |||
| ✓ | 96.93 | 82.44 | 98.66 | 82.86 | 98.30 | ||||
| ✓ | 97.01 | 82.99 | 98.79 | 83.73 | 98.30 | ||||
| ✓ | ✓ | 97.00 | 82.74 | 98.74 | 82.50 | 98.31 | |||
| ✓ | ✓ | 97.01 | 82.91 | 98.77 | 83.39 | 98.34 | |||
| ✓ | ✓ | 97.05 | 83.33 | 98.87 | 84.68 | 98.26 | |||
| CAT Layers | Param. | Acc (%) | Dice (%) | Se (%) | Sp (%) | Training Time |
|---|---|---|---|---|---|---|
| 522.54 M | 97.04 | 83.28 | 84.45 | 98.27 | 10.13 h | |
| 291.56 M | 97.05 | 83.33 | 84.68 | 98.26 | 7.78 h | |
| 284.32 M | 97.03 | 83.23 | 84.51 | 98.26 | 6.93 h | |
| 168.83 M | 97.03 | 83.20 | 84.41 | 98.26 | 6.03 h |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Y.; Zhang, Y.; Zhu, L.; Cai, L.; Qian, Y. Exploiting Cross-Scale Attention Transformer and Progressive Edge Refinement for Retinal Vessel Segmentation. Mathematics 2024, 12, 264. https://doi.org/10.3390/math12020264
Yuan Y, Zhang Y, Zhu L, Cai L, Qian Y. Exploiting Cross-Scale Attention Transformer and Progressive Edge Refinement for Retinal Vessel Segmentation. Mathematics. 2024; 12(2):264. https://doi.org/10.3390/math12020264
Chicago/Turabian StyleYuan, Yunyi, Yingkui Zhang, Lei Zhu, Li Cai, and Yinling Qian. 2024. "Exploiting Cross-Scale Attention Transformer and Progressive Edge Refinement for Retinal Vessel Segmentation" Mathematics 12, no. 2: 264. https://doi.org/10.3390/math12020264
APA StyleYuan, Y., Zhang, Y., Zhu, L., Cai, L., & Qian, Y. (2024). Exploiting Cross-Scale Attention Transformer and Progressive Edge Refinement for Retinal Vessel Segmentation. Mathematics, 12(2), 264. https://doi.org/10.3390/math12020264