
Research on Deep Q-Network Hybridization with Extended Kalman Filter in Maneuvering Decision of Unmanned Combat Aerial Vehicles

Abstract
1. Introduction
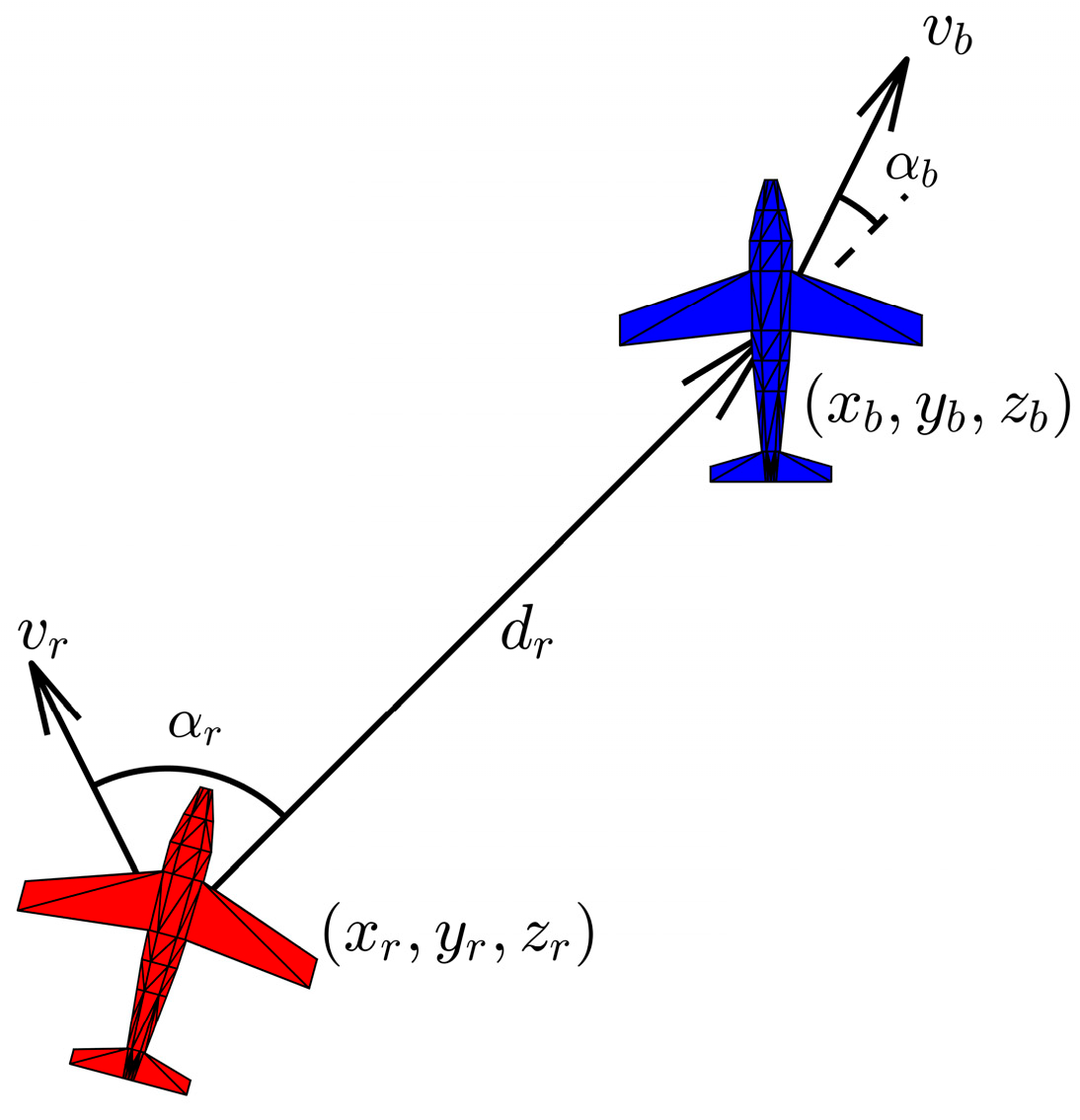
2. Description of Air Combat Confrontation
2.1. Motion Model and Maneuver Instructions for UCAV
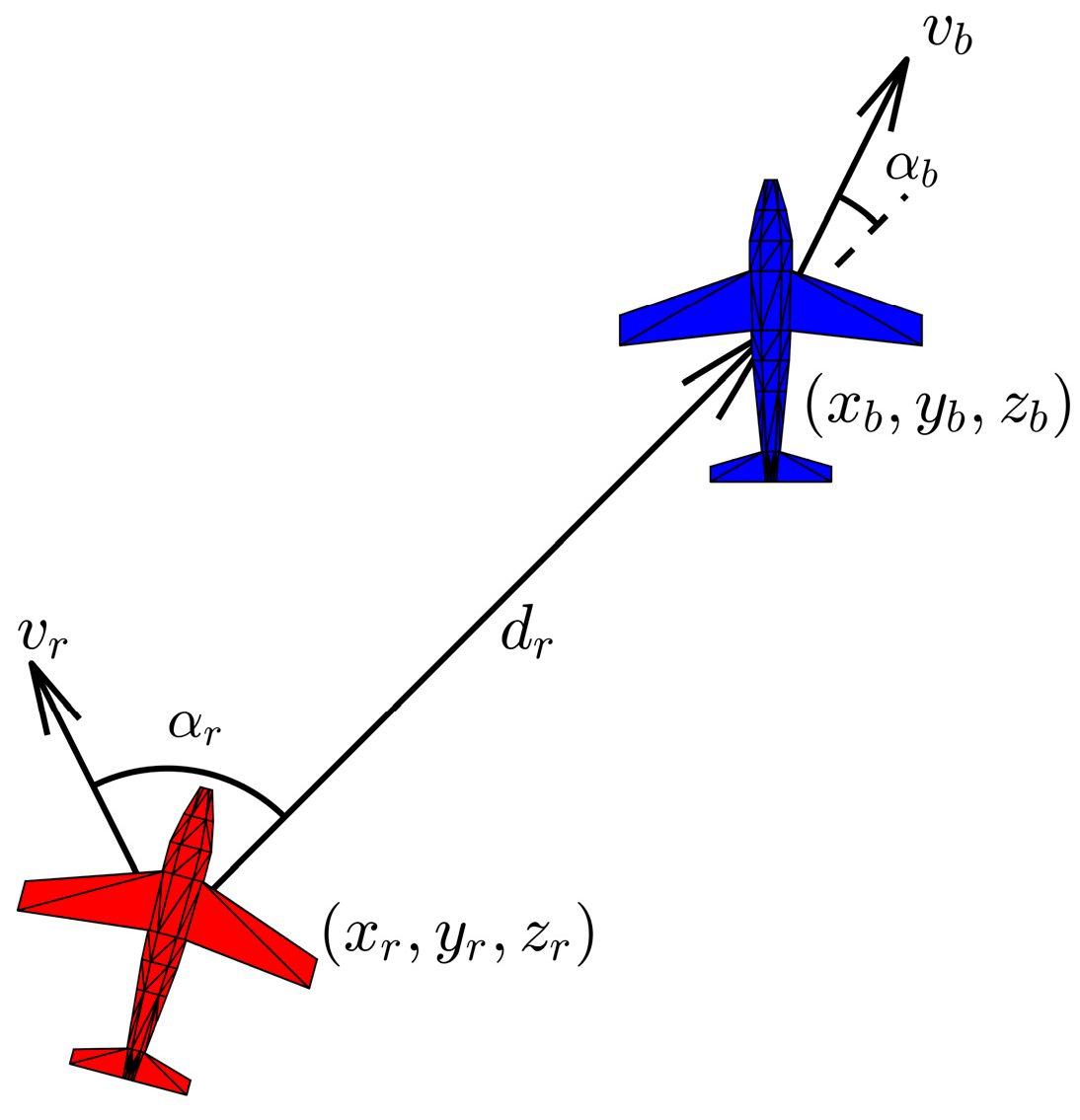
2.2. Design of Situation Assessment for Air Combat Environment
- 1.
- Angle advantage function
- 2.
- Distance advantage function
- 3.
- Energy advantage function
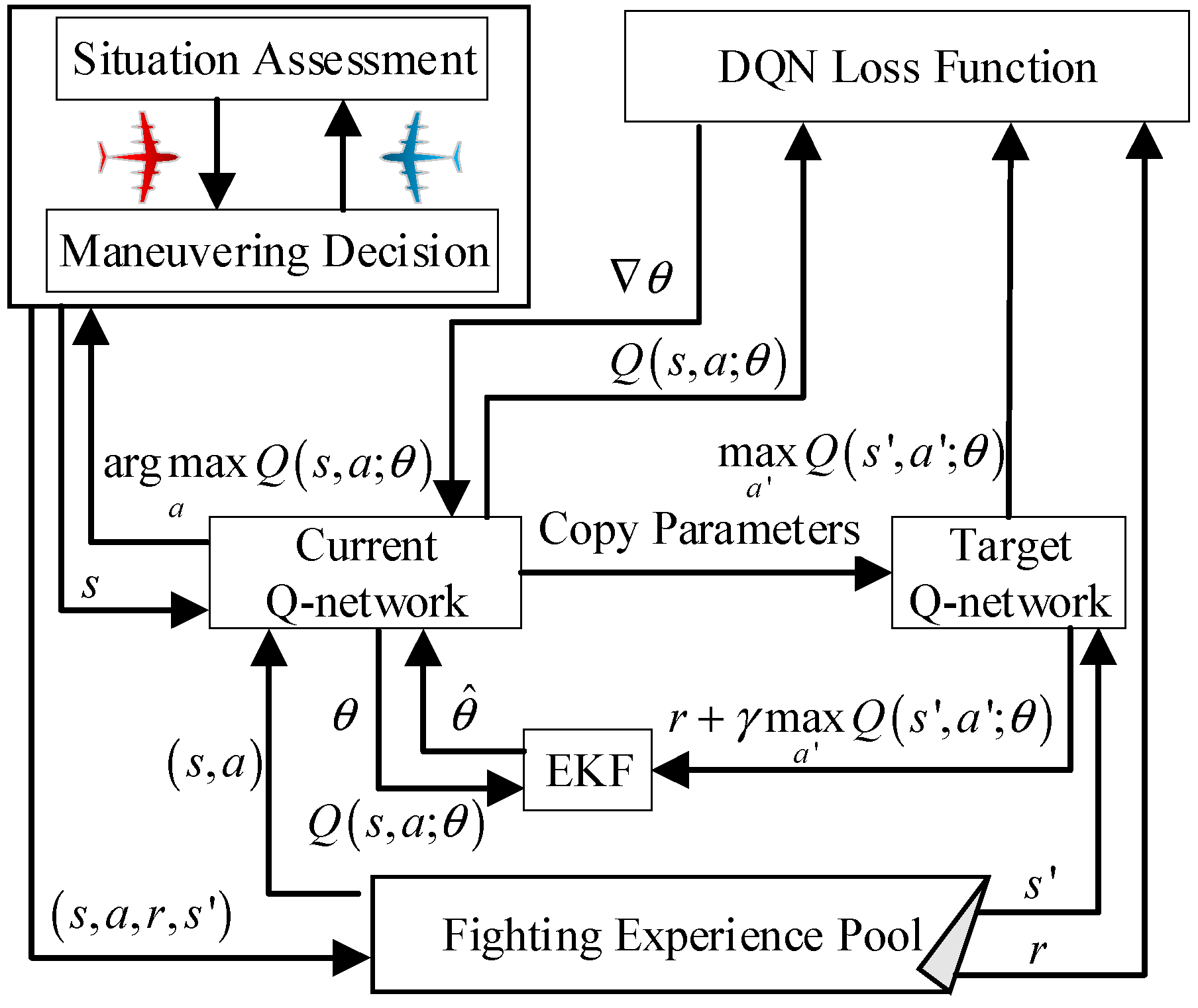
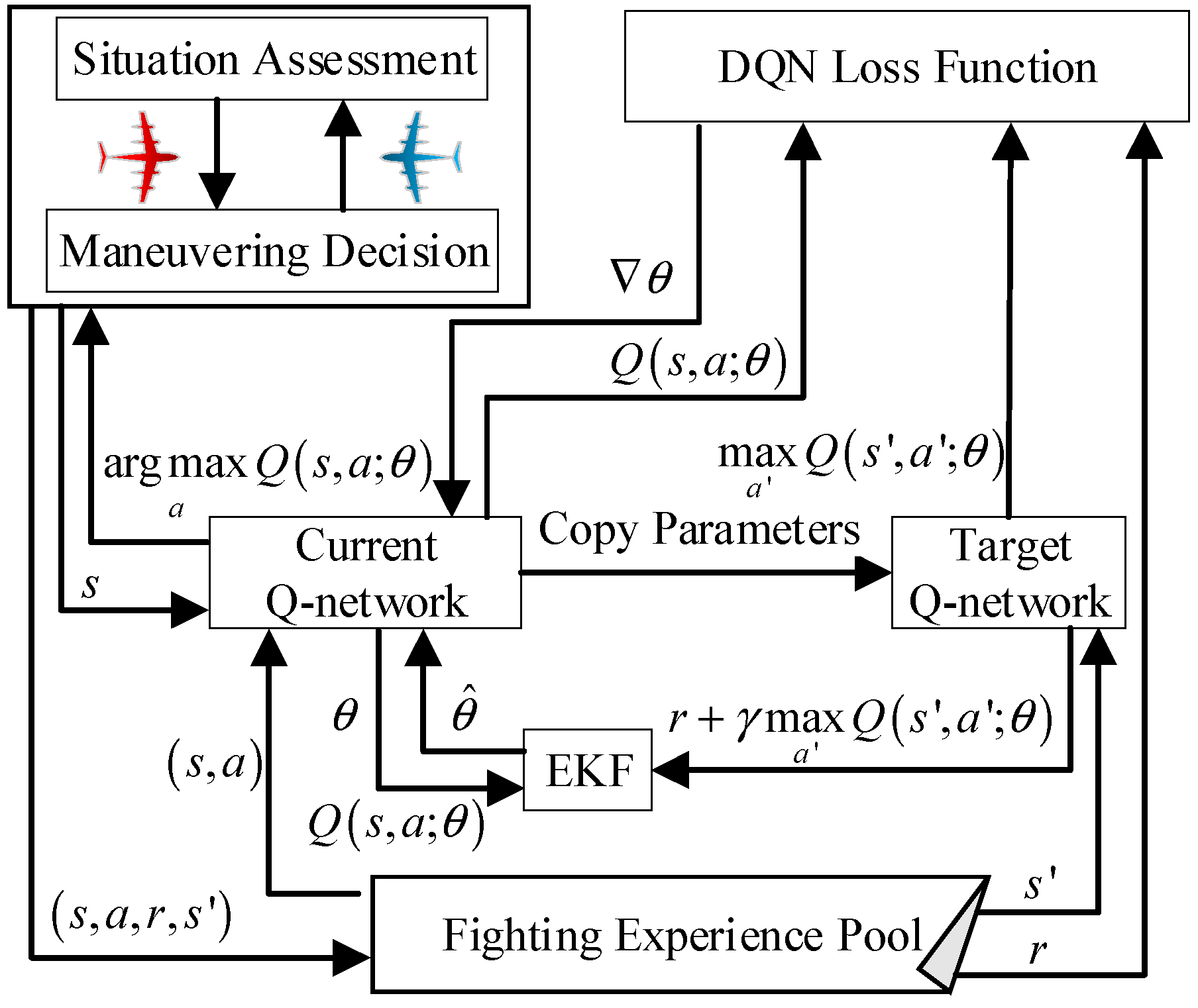
3. Deep Q-Network Hybridization with Extended Kalman Filter
3.1. Deep Q-Network Description
3.2. DQN-EKF Algorithm
- Step 1:
- Initialize the deep Q-network model, parameters, and its covariance matrix .
- Step 2:
- For each time step , perform the following sub-steps:
- (i)
- Prediction: Based on the state transition equation and process noise, predict the mean of state for the next time step and covariance .
- (ii)
- Correction: Calculate the Kalman gain based on the observation equation and observation noise and update the mean of state and covariance .
- (iii)
- Interaction: Based on the current state observation and the ε-greedy strategy, select an action and execute it using the main network with the optimal true parameter estimates to obtain the reward and the next state .
- Step 3:
- Repeat the above steps until the convergence condition is met or the maximum number of iterations is reached.
4. Simulation Experiments
4.1. Simulation Experiments Design
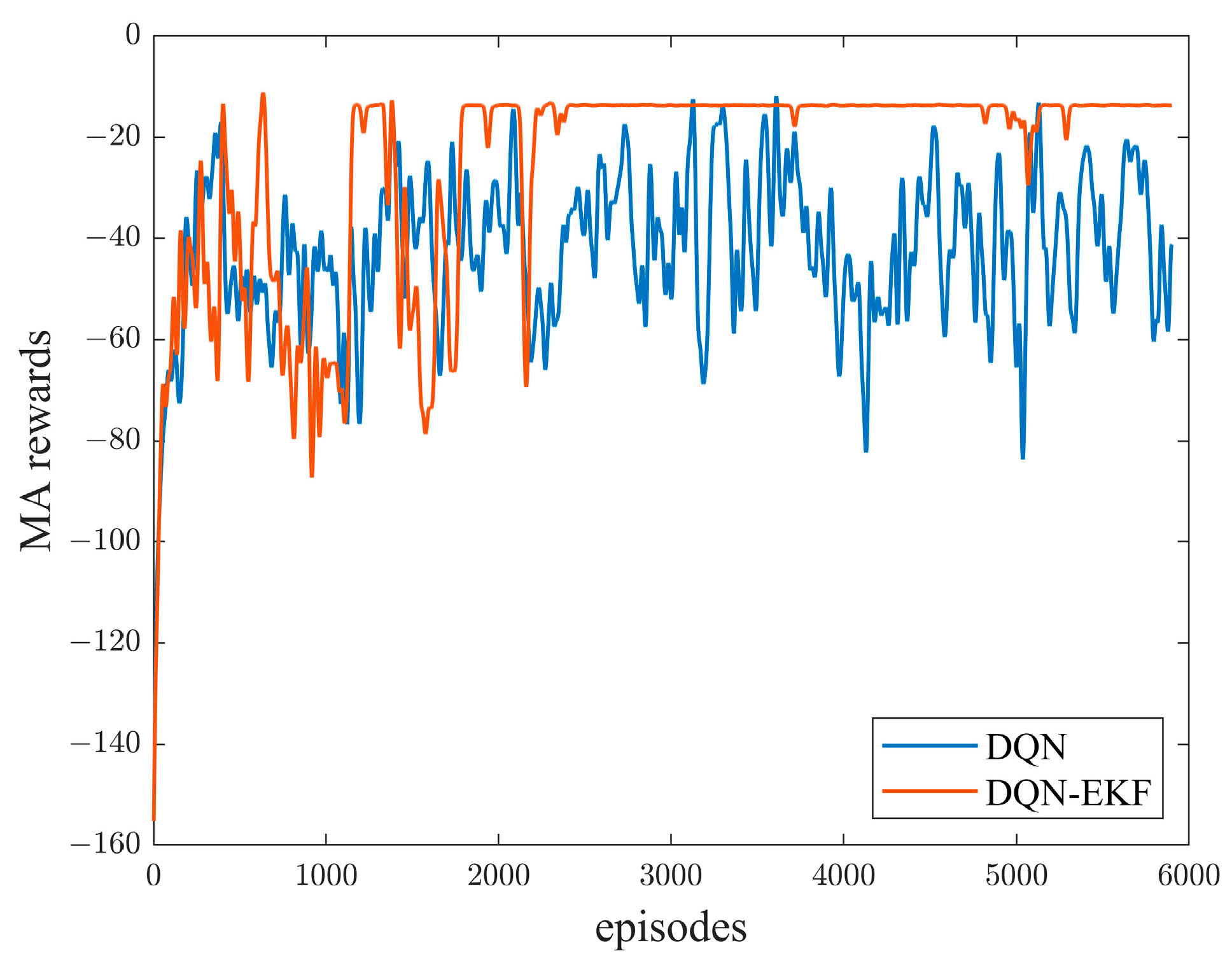
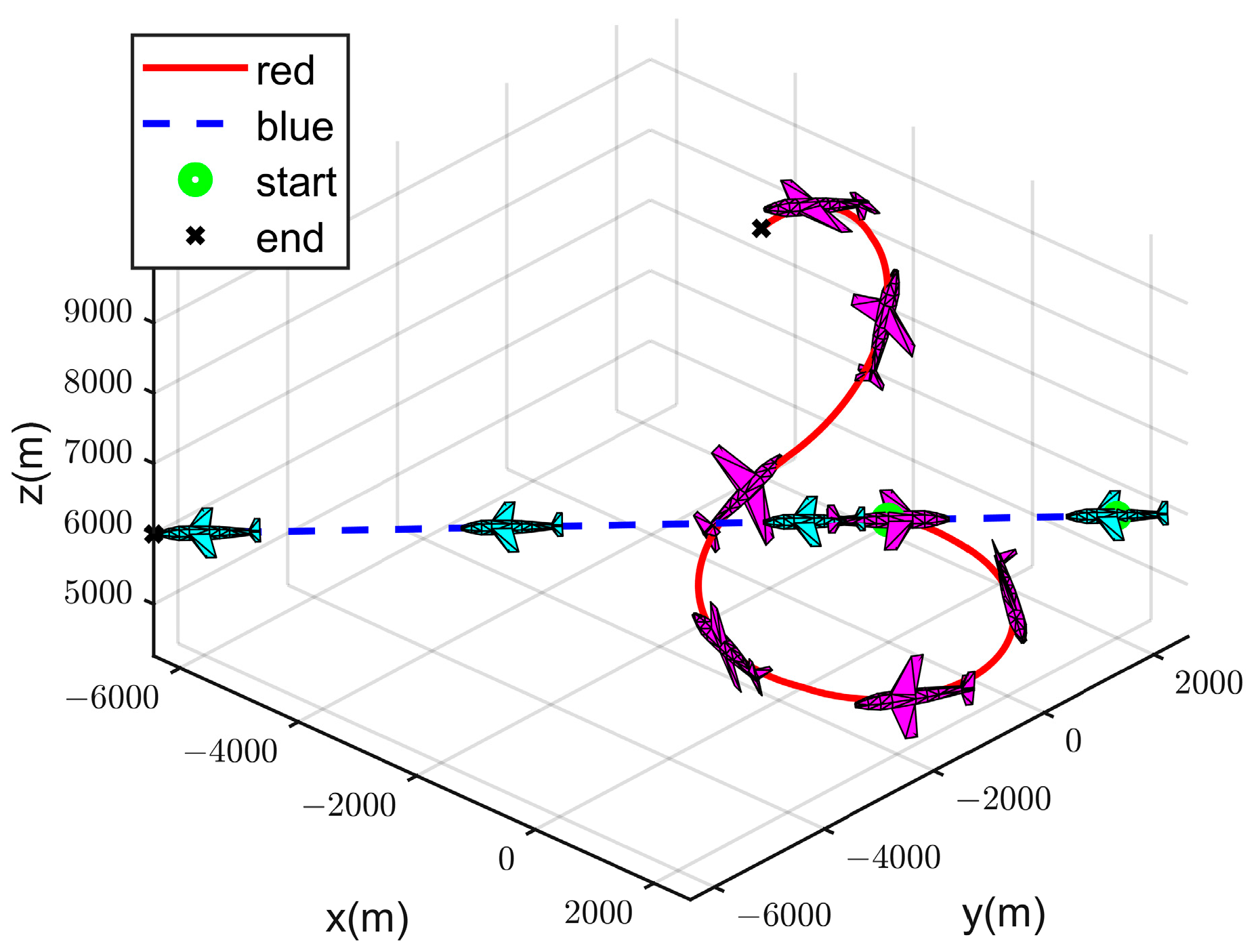
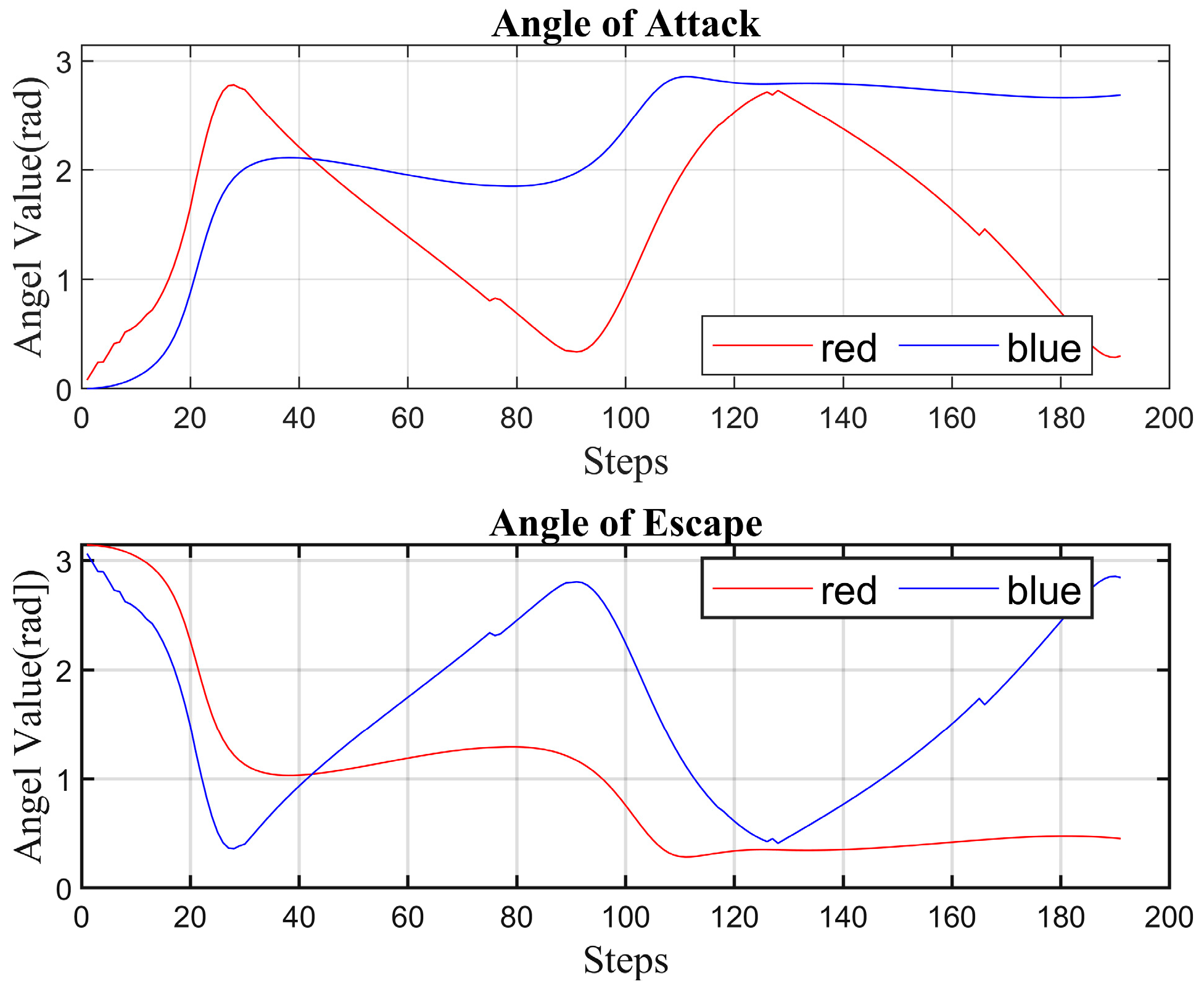
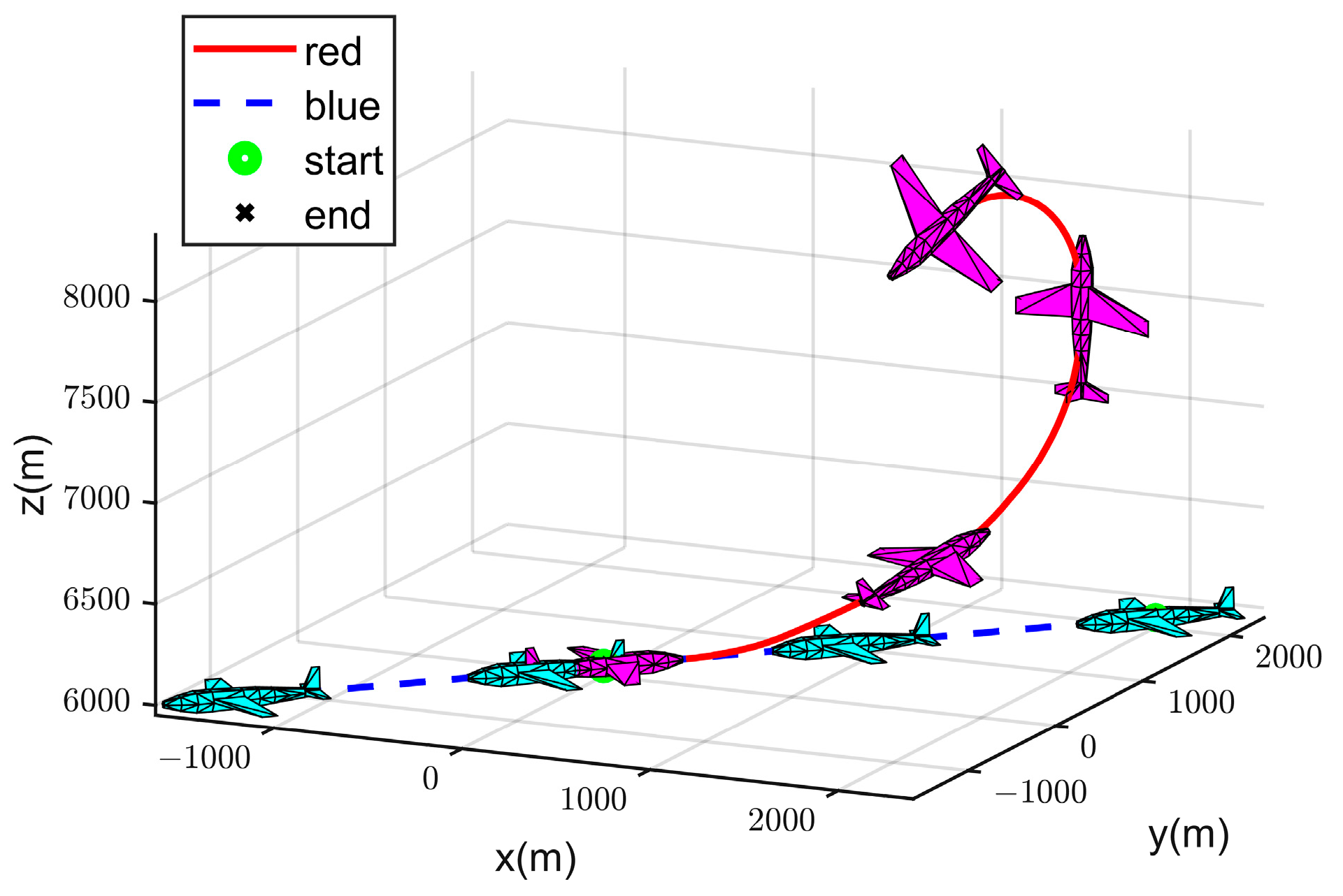
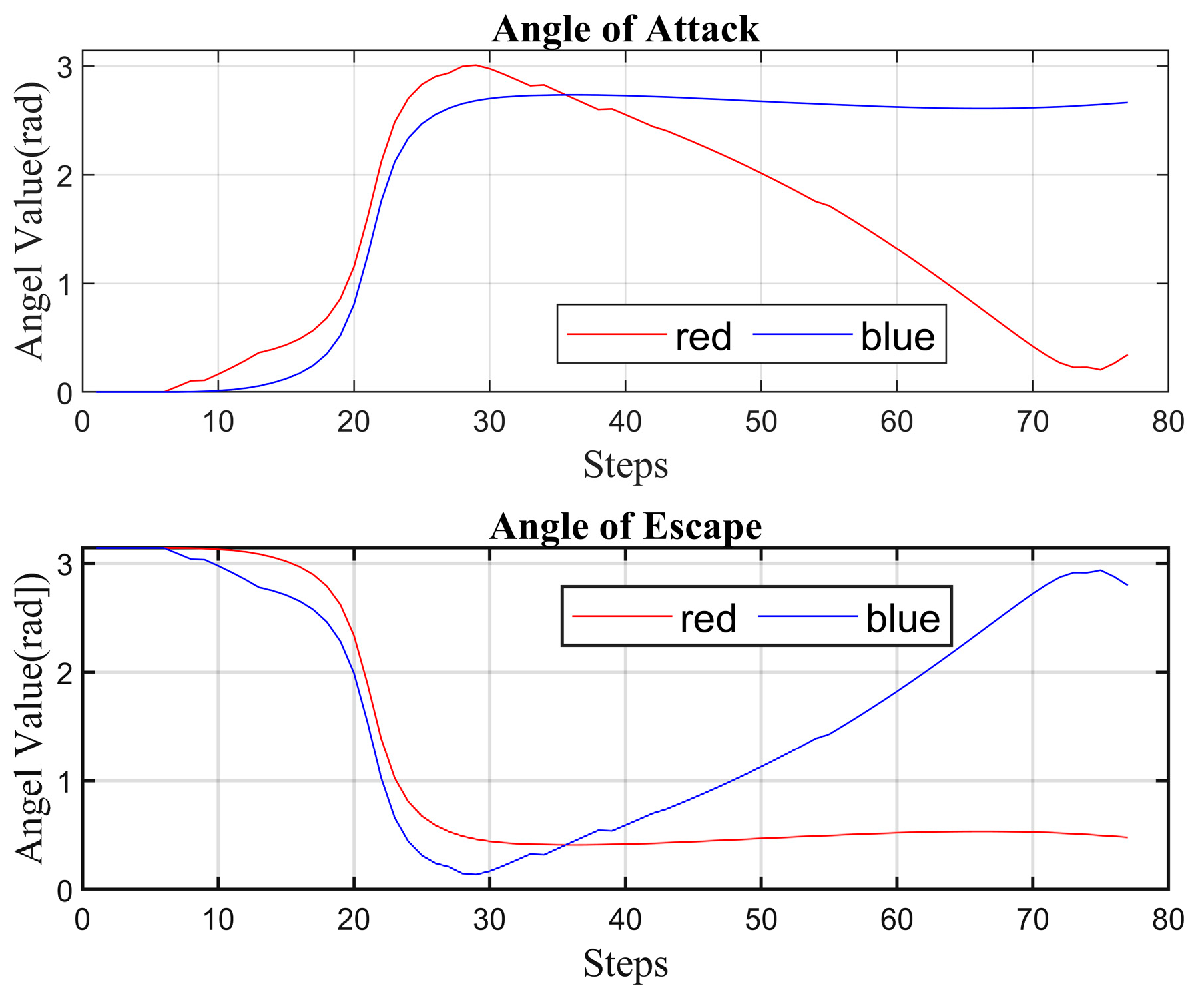
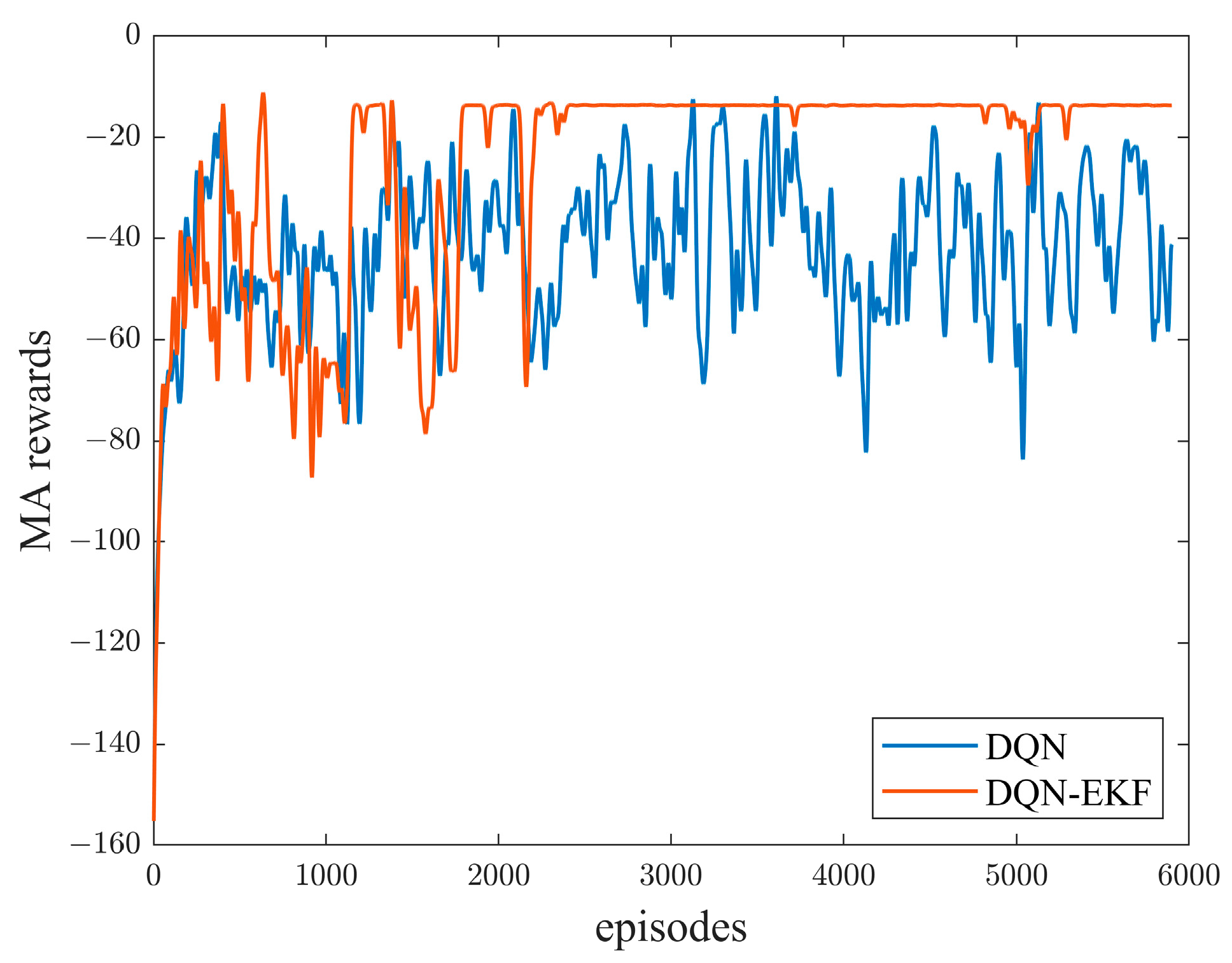
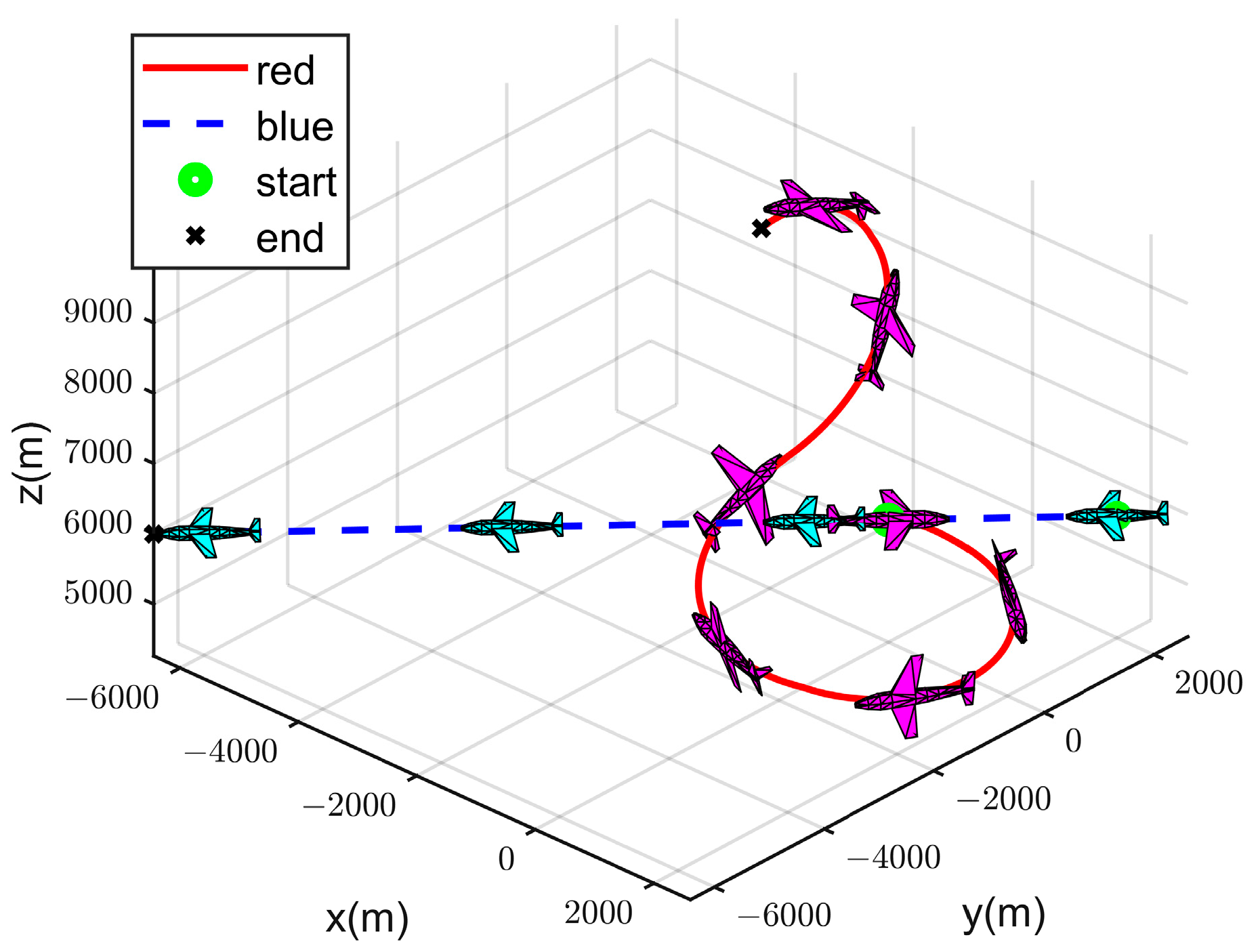
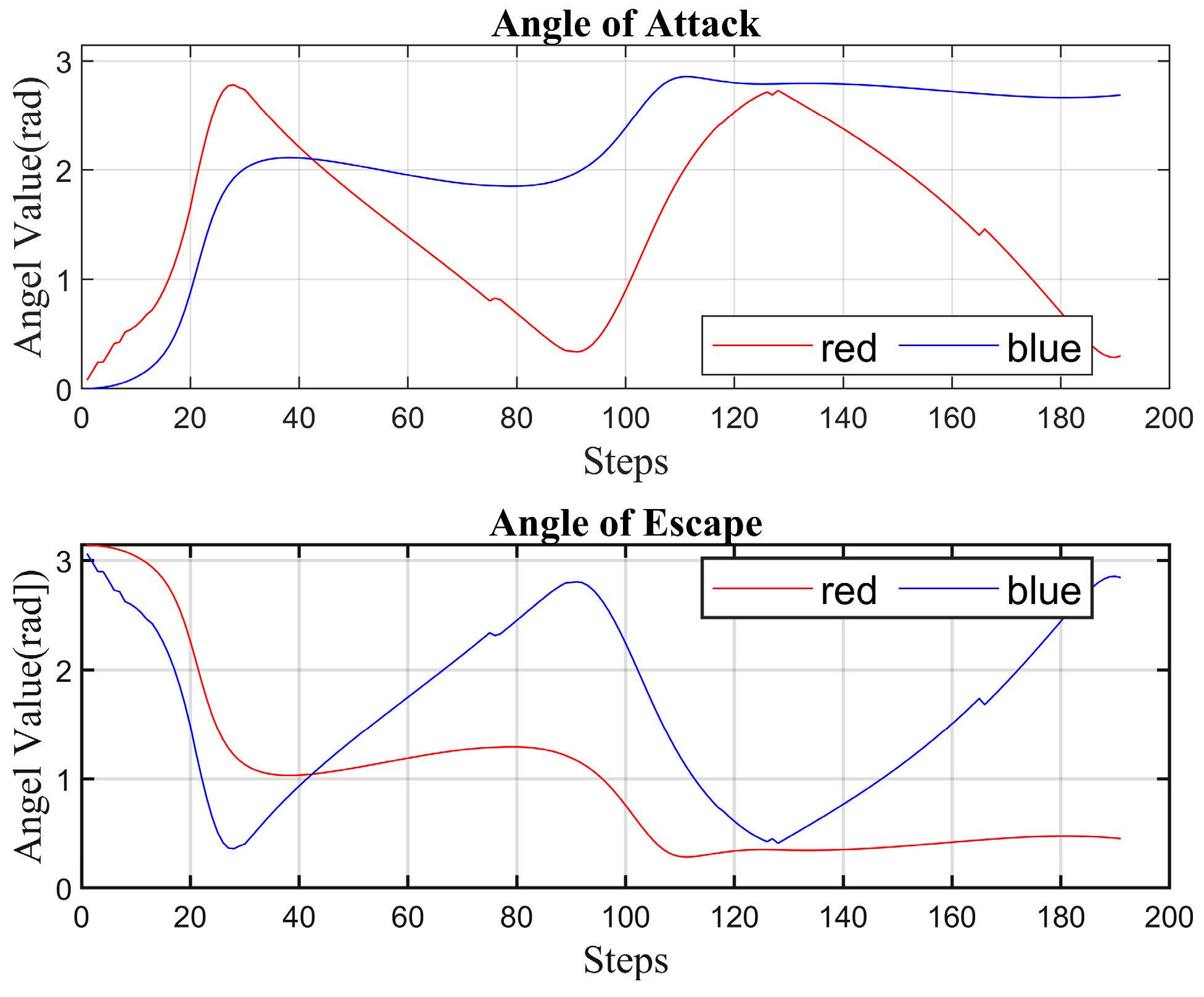
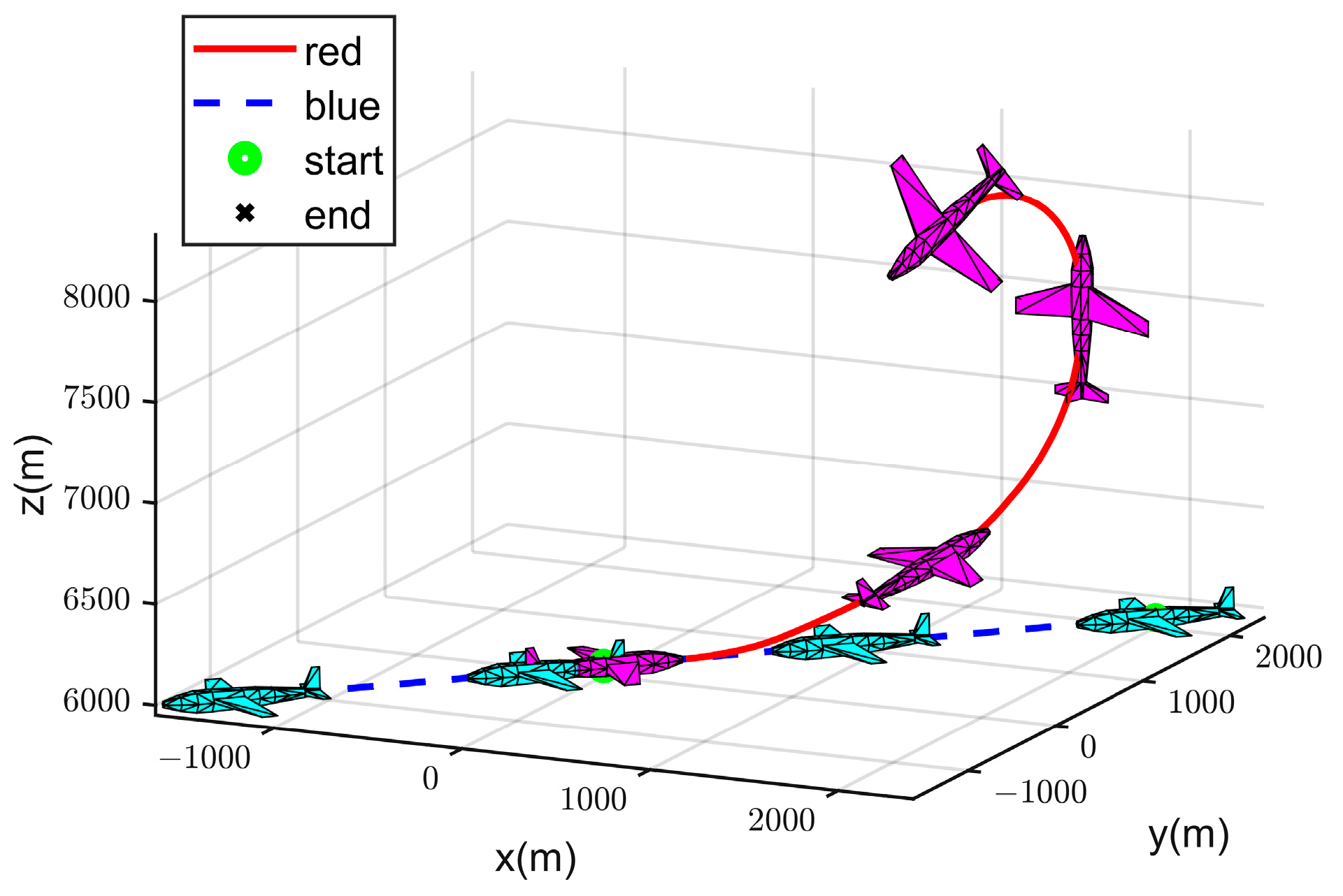
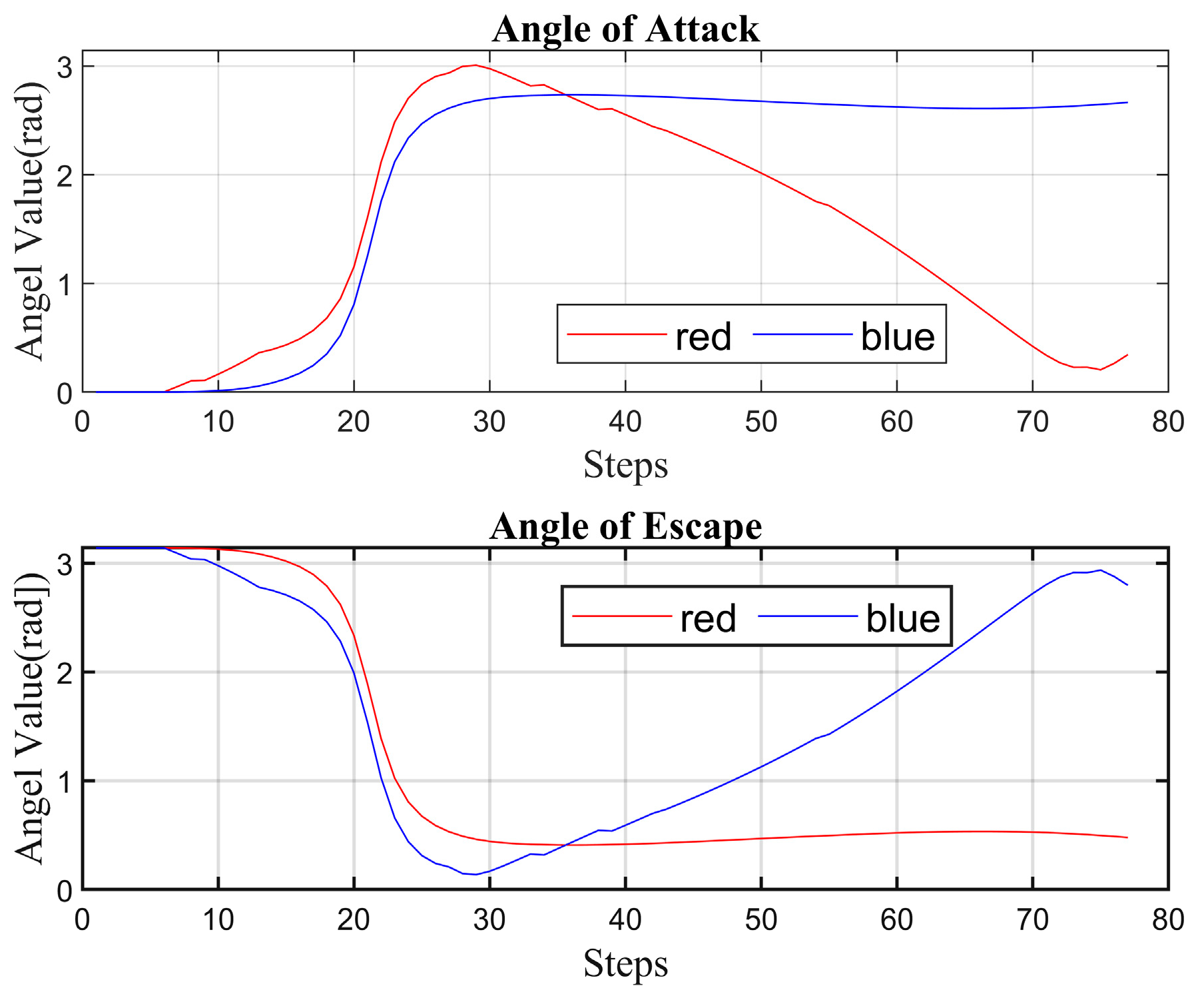
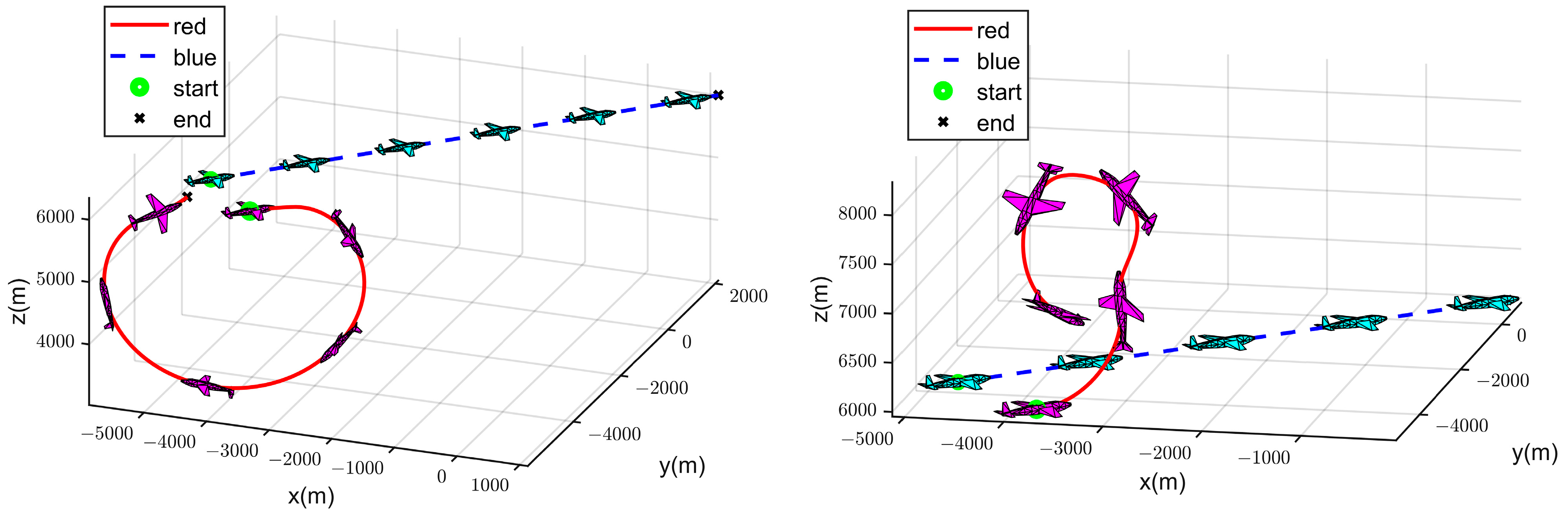
4.2. Simulation Experiment Analysis
- (I)
- Strategy 1
- (II)
- Strategy 2
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Byrnes, M.W. Nightfall: Machine autonomy in air-to-air combat. Air Space Power J. 2014, 28, 48–75. [Google Scholar]
- Sun, Z.; Yang, S.; Piao, H.; Chen, C.; Ge, J. A survey of air combat artificial intelligence. Acta Aeronaut. Astronaut. Sin. 2021, 42, 35–49. [Google Scholar]
- Jordan, J. The future of unmanned combat aerial vehicles: An analysis using the Three Horizons framework. Futures 2021, 134, 102848. [Google Scholar] [CrossRef]
- Hambling, D. AI outguns a human fighter pilot. New Sci. 2020, 247, 12. [Google Scholar] [CrossRef]
- Virtanen, K.; Raivo, T.; Hamalainen, R.P. Modeling Pilot’s Sequential Maneuvering Decisions by a Multistage Influence Diagram. J. Guid. Control Dyn. 2004, 27, 665–677. [Google Scholar] [CrossRef]
- Smith, R.E.; Dike, B.A.; Ravichandran, B.; El-Fallah, A.; Mehra, R.K. Two-Sided, Genetics-Based Learning to Discover Novel Fighter Combat Maneuvers. Comput. Methods Appl. Mech. Eng. 2000, 186, 421–437. [Google Scholar] [CrossRef]
- Deng, K.; Peng, X.; Zhou, D. Study on Air Combat Decision Method of UAV Based on Matrix Game and Genetic Algorithm. Fire Control Command Control 2019, 44, 61–66. [Google Scholar]
- Li, S.; Ding, Y.; Gao, Z. UAV air combat maneuvering decision based on intuitionistic fuzzy game theory. Syst. Eng. Electron. 2019, 41, 1063–1070. [Google Scholar]
- He, X.; Jing, X.; Feng, C. Air Combat Maneuver Decision Based on MCTS Method. J. Air Force Eng. Univ. Nat. Sci. Ed. 2017, 18, 36–41. [Google Scholar]
- McGrew, J.S.; How, J.P.; Williams, B.; Roy, N. Air-Combat strategy using approximate dynamic programming. J. Guid. Control Dyn. 2010, 33, 1641–1654. [Google Scholar] [CrossRef]
- Du, P.; Liu, H. Study on air combat tactics decision-making based on Bayesian networks. In Proceedings of the 2010 2nd International Conference on Information Management and Engineering, Chengdu, China, 16–18 April 2010; pp. 252–256. [Google Scholar]
- Ji, H.; Yu, M.; Yang, J. Research on the Air Combat Countermeasure Generation of Fighter Mid-Range Turn. In Proceedings of the 2018 2nd International Conference on Artificial Intelligence Applications and Technologies (AIAAT2018), Shanghai, China, 8–10 August 2018; pp. 522–527. [Google Scholar]
- Xu, J.; Guo, Q.; Xiao, L.; Li, Z.; Zhang, G. Autonomous Decision-Making Method for Combat Mission of UAV based on Deep Reinforcement Learning. In Proceedings of the 2019 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chengdu, China, 20–22 December 2019; pp. 538–544. [Google Scholar]
- Pope, A.P.; Ide, J.S.; Micovic, D.; Diaz, H.; Rosenbluth, D.; Ritholtz, L.; Twedt, J.C.; Walker, T.T.; Alcedo, K.; Javorsek, D. Hierarchical Reinforcement Learning for Air-to-Air Combat. In Proceedings of the 2021 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 15–18 June 2021; pp. 275–284. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Srichandan, A.; Dhingra, J.; Hota, M.K. An Improved Q-learning Approach with Kalman Filter for Self-balancing Robot Using OpenAI. J. Control Autom. Electr. Syst. 2021, 32, 1521–1530. [Google Scholar] [CrossRef]
- Mohammaddadi, G.; Pariz, N.; Karimpour, A. Extended modal Kalman filter. Int. J. Dyn. Control 2017, 19, 728–738. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Value |
|---|---|
| memory capacity | 20,000 |
| discounted factor | 0.9 |
| batch size | 64 |
| learning rate | 0.008 |
| ε-greedy value | 0.95–0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruan, J.; Qin, Y.; Wang, F.; Huang, J.; Wang, F.; Guo, F.; Hu, Y. Research on Deep Q-Network Hybridization with Extended Kalman Filter in Maneuvering Decision of Unmanned Combat Aerial Vehicles. Mathematics 2024, 12, 261. https://doi.org/10.3390/math12020261
Ruan J, Qin Y, Wang F, Huang J, Wang F, Guo F, Hu Y. Research on Deep Q-Network Hybridization with Extended Kalman Filter in Maneuvering Decision of Unmanned Combat Aerial Vehicles. Mathematics. 2024; 12(2):261. https://doi.org/10.3390/math12020261
Chicago/Turabian StyleRuan, Juntao, Yi Qin, Fei Wang, Jianjun Huang, Fujie Wang, Fang Guo, and Yaohua Hu. 2024. "Research on Deep Q-Network Hybridization with Extended Kalman Filter in Maneuvering Decision of Unmanned Combat Aerial Vehicles" Mathematics 12, no. 2: 261. https://doi.org/10.3390/math12020261
APA StyleRuan, J., Qin, Y., Wang, F., Huang, J., Wang, F., Guo, F., & Hu, Y. (2024). Research on Deep Q-Network Hybridization with Extended Kalman Filter in Maneuvering Decision of Unmanned Combat Aerial Vehicles. Mathematics, 12(2), 261. https://doi.org/10.3390/math12020261