This section begins with an overview of our GLAU approach (
Section 3.1). We then describe the form of our GLAU, clarify its nature, and detail its implementation with a global module (
Section 3.2), a local module (
Section 3.3), a fusion module (
Section 3.4), and computational complexity (
Section 3.5).
3.1. Overview of GLAUs
An image’s global and local information is crucial to portraying an image. Our fundamental motivation was to decouple the convolutional kernel’s generation process into two branches: one to describe the global information and the other to describe the local information. Formally, the GLAU is decoupled. However, in essence, in the global channel attention module, for each feature map, the mean and standard deviation are calculated in three directions along the spatial dimension, which fully considers the acquisition of local information. In the local spatial attention module, along the channel dimension, the mean and standard deviation are also calculated for each feature map, and the acquisition of global information is also fully considered. Second, for the feature maps generated by the two branches, the feature fusion is carried out through an efficient fusion module to obtain a better convolution kernel. Therefore, the GLAU’s ability to integrate global and local features is justified.
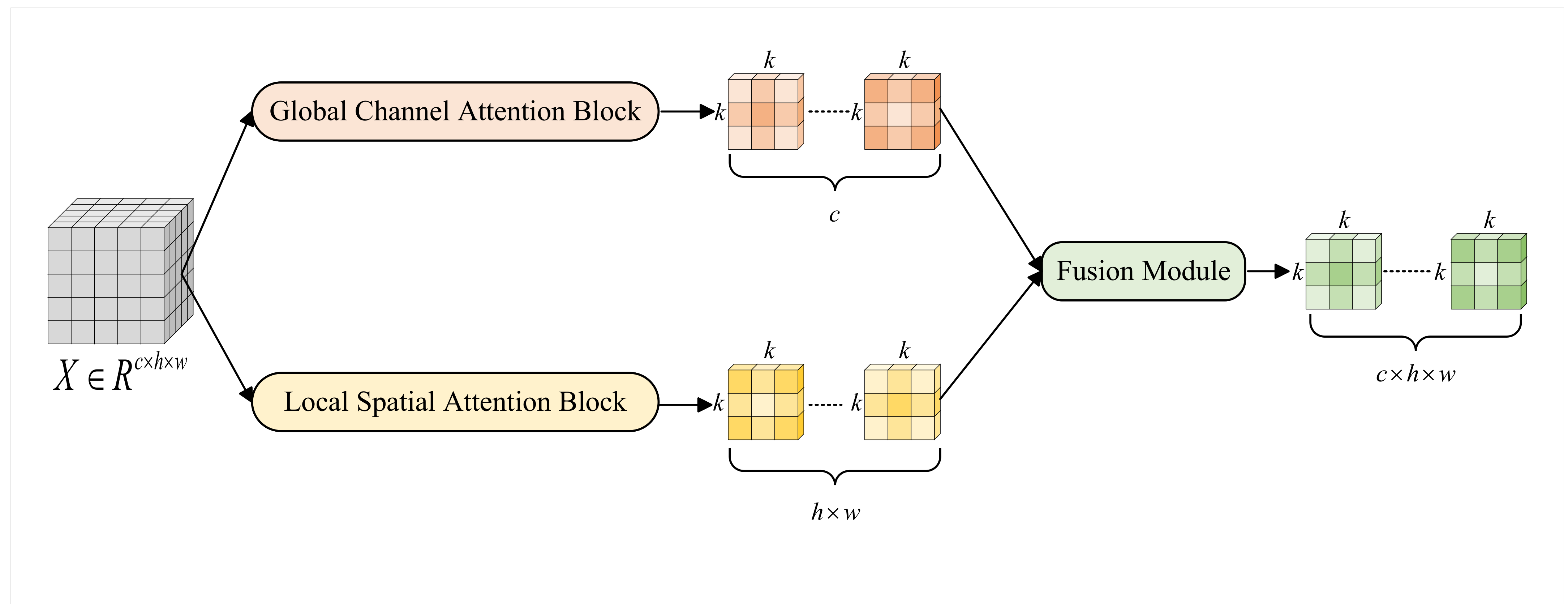
We propose a dynamic convolution method incorporating both global and local attention. We have devised a building block termed the Global and Local Attention Unit (GLAU). The GLAU can adaptively generate convolution kernels through a weighted fusion of global channel attention kernels and local spatial attention kernels. The detailed structure of the GLAU is illustrated in
Figure 1. We denote
as an input instance of the GLAU. The GLAU is designed to contain two branches and a fusion module. One of these branches is the global channel attention branch, and the other is the local spatial attention branch. The fusion module utilizes learnable parameters to integrate the two branches above.
3.2. Global Channel Attention Block
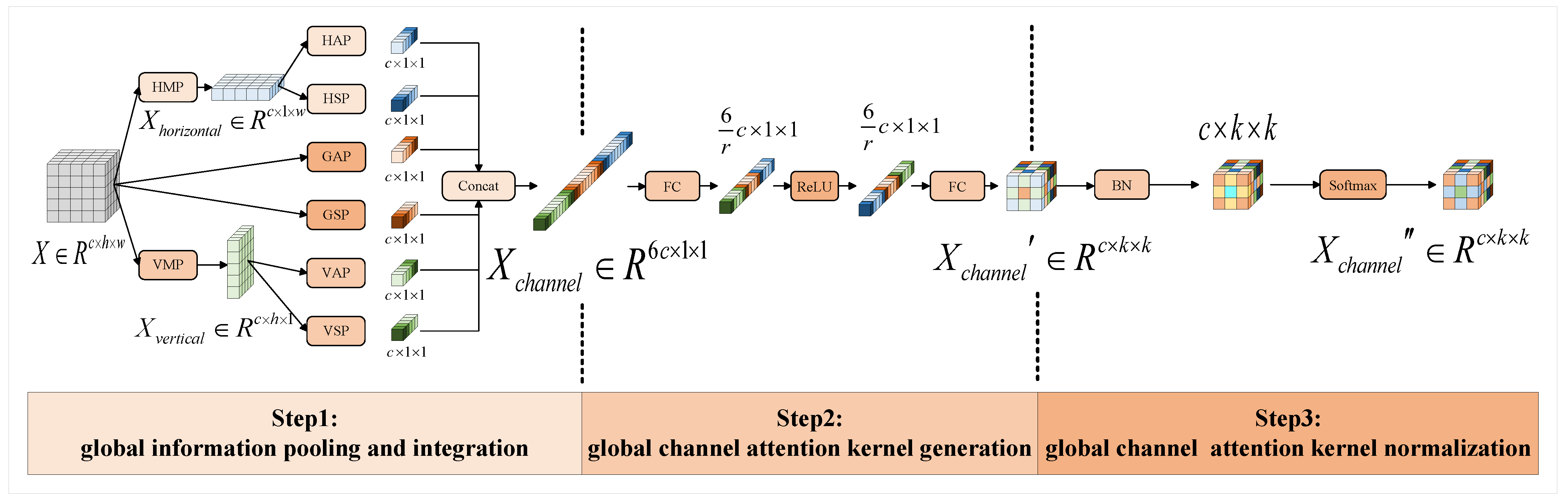
In the channel branch, we aim to find a global feature that accurately describes the global information of X. Instead of utilizing global average pooling, we employed two statistics—the mean and standard deviation—in three directions (horizontal, vertical, and spatial) to extract comprehensive global features. The process of deriving the global channel attention kernels consists of three steps: global information pooling and integration, generation of global channel attention kernels, and normalization of global channel attention kernels. Global information pooling and integration for extracting an intermediate global information representation is expressed as from X, where d is the number of global features; global channel attention kernel generation is for generating kernel from ; and the global channel attention kernel normalization operation consists of a batch normalization (BN) layer, where the BN layer is used to absorb the bias term produced by the fusion of the mean and standard deviation, and a softmax activation function, which converts the original channel attention weights from into probability distributions for the weighted combination of channels.
The detailed structure of the global channel attention block is illustrated in
Figure 2.
First of all, global information pooling and integration refers to the average pooling (AP) and standard deviation pooling (SP) of the feature map
. Global average pooling (GAP) and global standard deviation pooling (GSP) can be calculated using the following equations:
Then, the two global statistics
and
are obtained. Before computing the horizontal and vertical statistics, maximum values are taken in the horizontal and vertical directions to ensure the extraction of the most significant features. We denote the operation that takes the maximum value as the horizontal maximum pooling (HMP) and vertical maximum pooling (VMP), and then the results of applying HMP and VMP to
are denoted as
and
. Similar to GAP and GSP, with Equations (
1) and (
2), we can perform horizontal average pooling (HAP), horizontal standard deviation pooling (HSP), vertical average pooling (VAP), and vertical standard deviation pooling (VSP) for
and
. Thus, the four direction-aware statistics
,
,
, and
are obtained. The concatenation of the six global statistics
along the channel dimension represents global information integration and the pooling output. Intermediate global information representations
are calculated as follows:
Secondly, we aimed to convert the comprehensive global information representation
into global channel attention kernels
. To accomplish this, we utilized two fully connected (FC) layers with a ReLU activation function sandwiched between them, effectively reducing the number of parameters while maximizing the utilization of global information for enhanced model expressiveness. Formally, the calculation of the global channel attention kernel
is as follows:
where
,
, and
is ReLU activation function.
Thirdly, the global channel attention weights are supposed to model the importance of the global information associated with individual channels to emphasize or suppress them accordingly. To achieve this, the global channel attention kernel
becomes a probability distribution for the weighted combination of channels
after a simple combination of the BN layer and the softmax activation function. The BN layer following the two fully connected layers accelerates training. It absorbs bias terms, while the sigmoid activation function acts as a gating mechanism, transforming the weighted channel combination into a probability distribution. Formally, the global channel attention kernel
is calculated as follows:
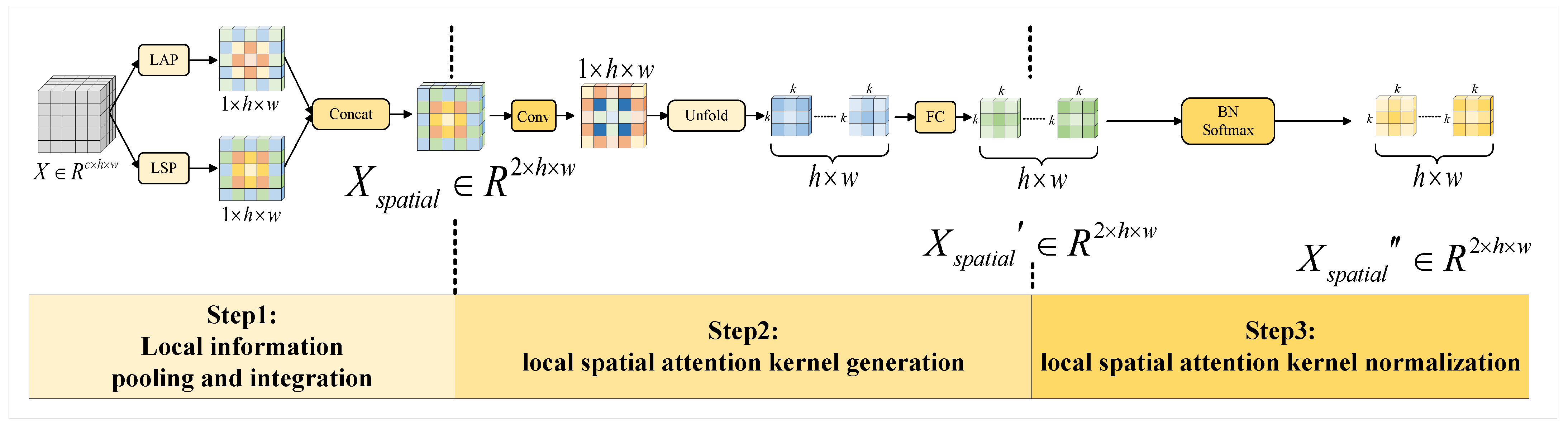
3.3. Local Spatial Attention Block
In the spatial branch, we focus on the relationship between each pixel in the space. We also utilize two statistics, the mean and standard deviation, to enhance information fusion across channels, similar to the global channel attention block. The method of obtaining the local spatial attention kernel is also a three-step process: local information pooling and integration, local spatial attention kernel generation, and local spatial attention kernel normalization. Local information pooling and integration for extracting an intermediate channel information representation is expressed as
from
X, where
d is the number of local features, and local spatial attention kernel generation is for generating a kernel
from
. This is pretty much the same as global channel attention kernel normalization, although the local spatial attention kernel is also composed of a BN layer and a softmax activation function, which converts the original spatial attention weights
from
into probability distributions for the weighted combination of
neighborhoods across all spatial locations. The detailed structure of the local spatial attention block is illustrated in
Figure 3.
Firstly, we perform the local information pooling and integration operation on the feature map
that fuses channel information, and thus we find the mean and variance of input X in the channel dimension, which are called local average pooling (LAP) and local standard deviation pooling (LSP), respectively. Two locally related statistics are obtained, denoted as
and
. By concatenating these two statistics
, the intermediate channel information representation
is calculated as follows:
Secondly, considering the efficiency and conceptual clarity, we adopted a three-layer network design consisting of a convolutional layer, an unfold operation, and a fully connected layer. The first convolutional layer is employed to adjust the channel dimension. Subsequently, the unfold operation generates the convolution kernel by extracting all
neighborhoods for each pixel in
. Finally, the last fully connected layer captures the complexity of the neighborhood features. Formally, the output of the local spatial attention kernel generation is calculated as follows:
where
Thirdly, similar to the normalization of global channel attention kernels, the normalization of local spatial attention kernels assesses the significance of global information within individual
neighborhoods across all spatial locations, thereby emphasizing or suppressing them accordingly. Formally, the local spatial attention kernel
is calculated as follows:
3.4. Fusion Module
We then fused the obtained global channel attention kernel in the fusion module with the local spatial attention kernel. Usually, in a specific task, we do not know how to assign these two types of weights to be more beneficial to the results or how to adjust the combination of addition and multiplication to be more beneficial to the results. Therefore, we used a more general form to weight these two types of weights, where
and
are two learnable parameters and both are required to be positive. By introducing these two parameters, the allocation of global channel attention weights and local spatial attention weights would be more appropriate. For simplicity, we define
and
. The computation of the proposed fusion module is as follows:
The parameter controls the additive combination of the global channel attention kernel and local spatial attention kernel, while does the same for their multiplicative combination.
Compared with existing methods, our dynamic convolutions have two important different characteristics. Firstly, our dynamic convolution kernels can be applied to integrate global and local information at each convolution layer. Secondly, our dynamic convolution kernels are adaptively learned from the input data according to the spatial and channel positions. Therefore, our dynamic convolution kernels are spatially specific and channel-specific. Thanks to the above two characteristics, our dynamic convolutions have a more efficient and accurate feature representation ability while requiring fewer learnable parameters. Modified CNNs incorporating GLAUs are referred to as “GLAUNets”.
3.5. Computational Complexity
In the following analysis, we use these notations: n is the number of pixels; c: is the channel number; k is the kernel size; and r is the squeeze ratio in the global channel attention block.
Table 1 shows a comparison of the parameter, space, time complexity, and average inference time between the standard convolution (Conv), depth-wise convolution (DwConv), the Decoupled Dynamic Filter (DDF) networks [
42], and our GLAU method.
Number of parameters. In the DDF, it has as the parameter for the spatial filter branch and for the channel filter branch for a total of parameters. Similar to the DDF, our GLAU also has two branches. Among them, in the local spatial attention block, while first passing through a convolutional layer, this step has parameters, and then throughout the unfold operation, this step has parameters. In the global channel attention block, for the first fully connected layer, we have parameters, and the second fully connected layer has parameters. Overall, our GLAU has parameters. Depending on the values of r, k, and c (usually set to 0.0625, 3, and 256, respectively), the number of parameters for the GLAU can be even lower than a standard convolution layer.
Time complexity. The GLAU’s local spatial attention block requires floating-point operations (FLOPs), the global channel attention block requires FLOPs, and the fusion module requires 2 FLOPs. In total, the GLAU requires FLOPs and for its time complexity. Because , the term can be ignored. Therefore, the time complexity of the GLAU is approximately equal to , which is similar to that of depth-wise convolution and better than a standard convolution with a time complexity of .
Space complexity. Standard and depth-wise convolutions do not generate content-adaptive kernels. The GLAU has design motivations similar to the DDF, as both have two branches. Therefore, the spatial complexities of the two are to the same order of magnitude.
Following the DDF [
42], we re-compared the inference latency of the four methods on our devices (see
Table 1). We had a slightly higher latency than DwConv and the DDF but a faster one than standard static convolution.
In conclusion, the GLAU has a time complexity similar to the DDF and significantly better than standard static convolution. It is worth noting that although GLAU generation involves a data-dependent convolutional kernel, the parameters of the GLAU are still much smaller than those of standard convolutional layers.







{kind=link}
{kind=link}
{kind=link}
{kind=link}