

Learned-Index-Based Semantic Keyword Query on Blockchain


Abstract
1. Introduction
- Designing an index that adapts to the blockchain structure: There are numerous outstanding indexes available in traditional databases. Nevertheless, traditional database indexes cannot be directly applied due to the constant updates of block numbers and unchanging data within blocks on blockchain. Therefore, designing and selecting appropriate indexes for blockchain presents a significant challenge.
- Ensuring the completeness and correctness of query results after using indexes: The purpose of constructing indexes is to avoid completely traversing data when performing data queries. In this case, ensuring there are no omissions in query results is a challenge. In addition, we build some indexes off-chain to ensure the performance and scalability of the blockchain. Therefore, when using those off-chain indexes, ensuring the correctness of the data query results is also a challenge that needs to be addressed.
- We propose a learned-index-based semantic keyword query architecture. In the architecture, we add header extension space within the blocks to record the semantic information in the data storage procedure so that our architecture provides semantics-empowered keyword queries.
- We propose a double-layer index structure. Specifically, an inter-block lookup table existence index is established for semantic information to quickly locate the block where the query results are located. A block-level recursive model index is constructed for each block to promptly search the query results. To maintain system efficiency, only the updated part is stored in each block. The query table index is stored in the extended block header while the learned index is stored off-chain.
- We propose a verifiable query algorithm based on our proposed architecture. In this algorithm, we use the double-layer index structure for keyword queries to realize efficient data queries and use the Merkle tree structure in blockchain to verify query results so as to avoid incorrect query results being caused by porting learned index construction and procedures stored off-chain.
- Experiments show that the lookup table index has advantages in construction time, query time, and storage space, and the learned index also has benefits in terms of query time and storage space. The experiment of deploying our architecture on a blockchain system shows that our architecture can effectively improve query efficiency. On the Wiki-CS dataset, the query speed is improved by more than 15 times. On the Ethereum dataset, the query speed is improved by about 100 times.
2. Related Work
2.1. Blockchain Data Query Processing
2.2. Learned Index
3. Problem Definition
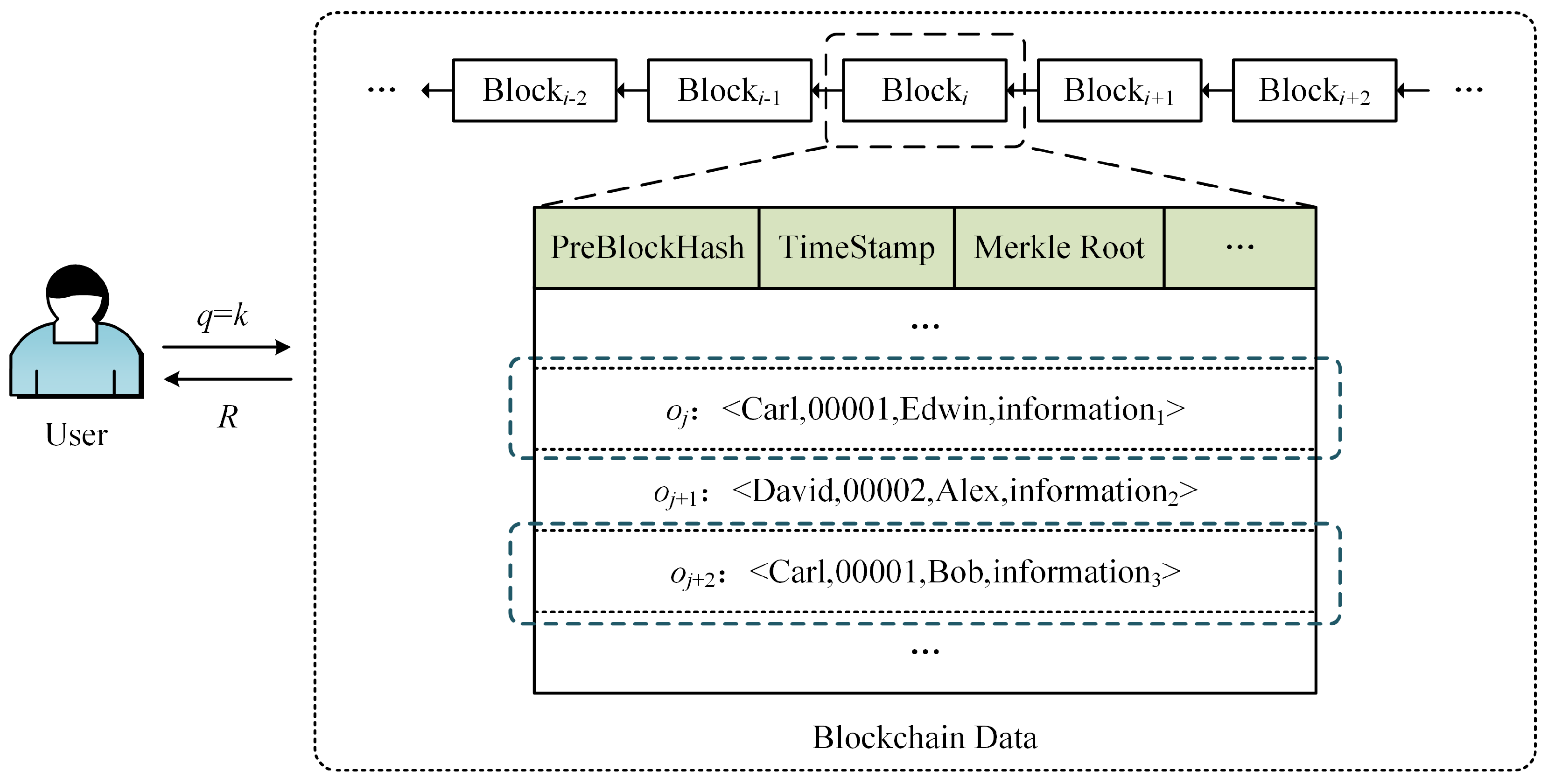
3.1. Data Query Definition
3.2. Architecture Goals
- Result completeness. The query results obtained by users need to be guaranteed to be complete.
- Result correctness. The query results obtained by users need to be guaranteed to be correct.
- Query time. The time consumption of the data query needs to be small.
- Storage overhead. The storage overhead of the index needs to be small.
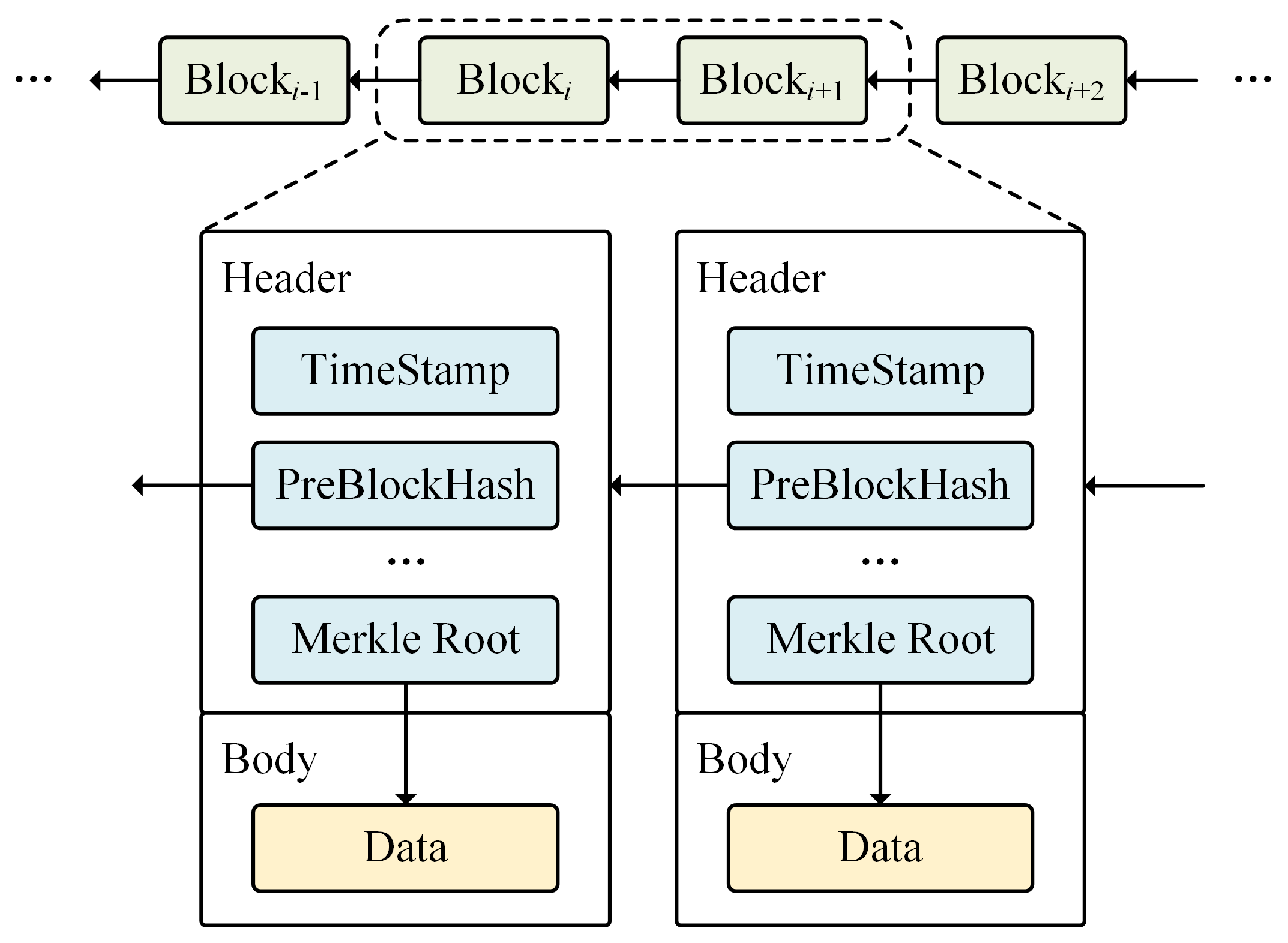
4. Architecture
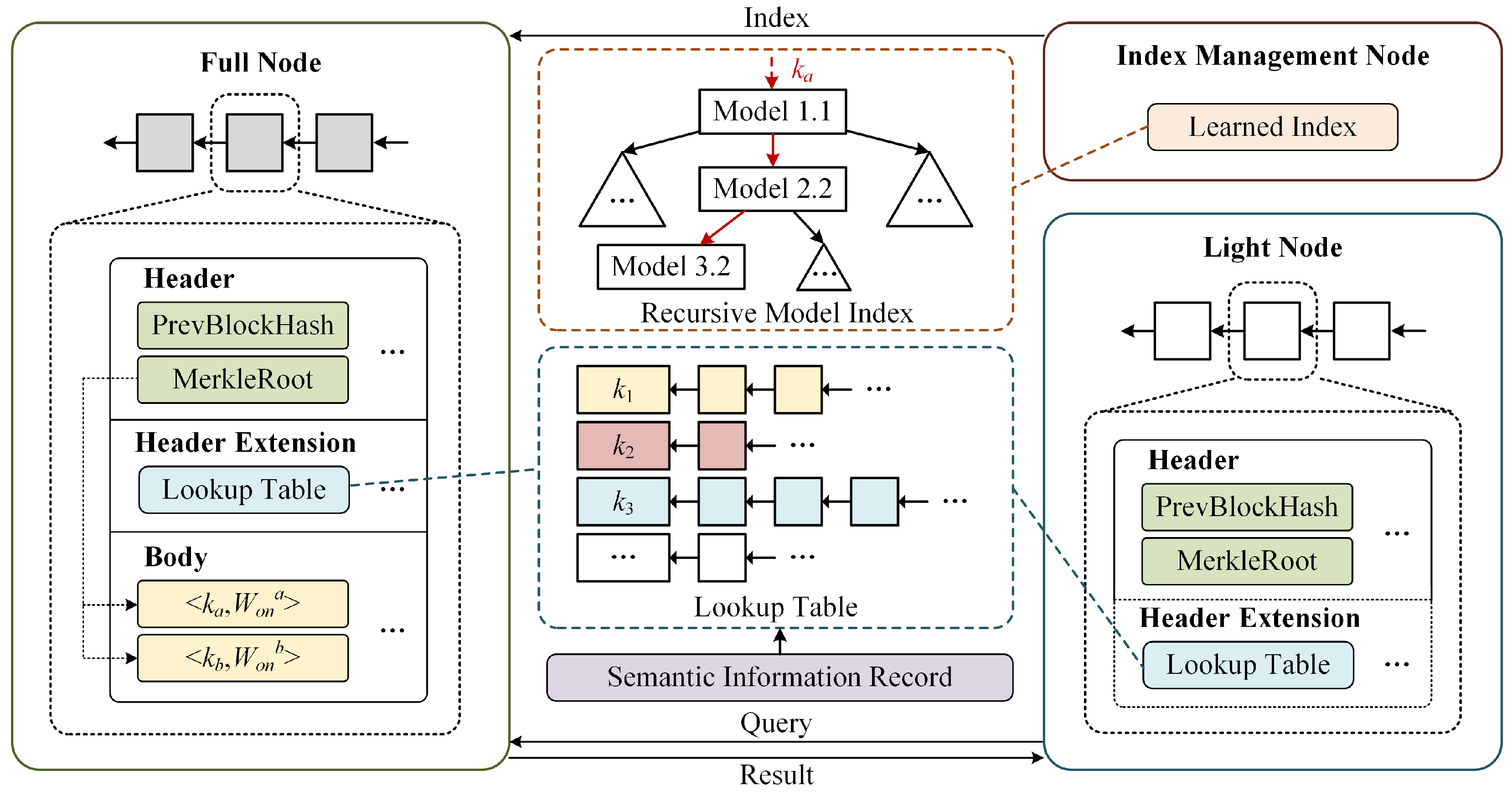
4.1. Architecture Overview
- Full nodes. Full nodes store all blockchain data, including the block header and body in blocks. Full nodes can participate in the consensus process to operate and maintain the blockchain system. Full nodes involved in system operation and maintenance are also called miner nodes in some blockchains.
- Light node. Light node only stores block header in blocks. The light node acts as the user’s client in the blockchain system. They cannot participate in the operation and maintenance of the system. Still, they can query the data from full nodes and verify the correction of the query results through the information in the block header.
- Index management node. The index management node is responsible for building and storing the learned index. The learned index is stored off chain, so the index management node does not have to participate in the work on blockchain. Full nodes can use the index stored by the index management nodes in the data query procedure.
4.2. Double-Layer Query Index
4.2.1. Inter-Block Lookup Table Index
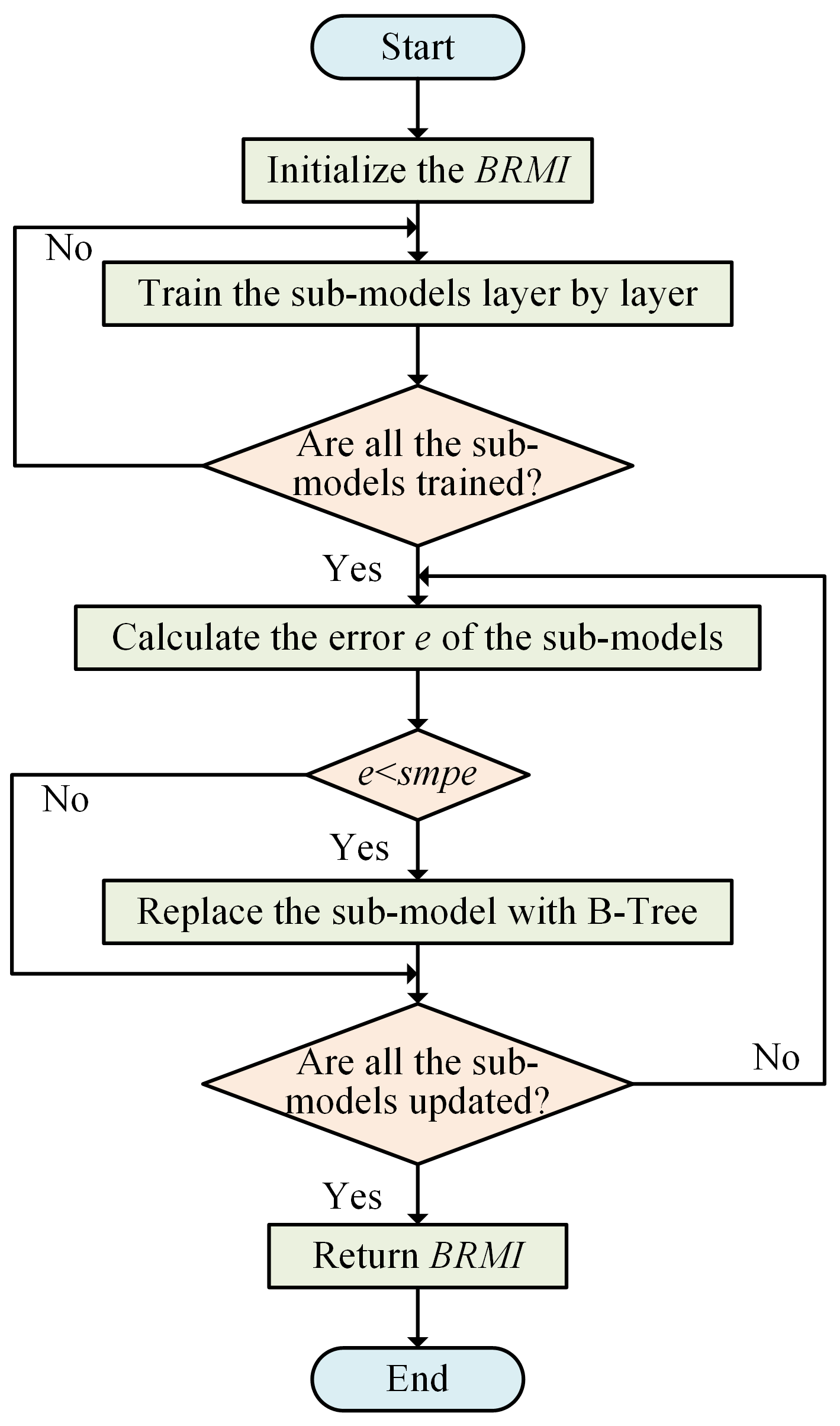
4.2.2. Intra-Block Recursive Model Index
5. Verifiable Query Algorithm
6. Experimental Analysis
6.1. Experimental Setup
6.1.1. Datasets
- Wiki-CS dataset (https://github.com/pmernyei/wiki-cs-dataset/raw/master/dataset, accessed on 1 August 2022). This dataset consists of 11,701 data with 300 columns of attributes. We selected the first column of data as the keyword attribute. In addition, in order to facilitate the establishment of the bitmap index as a comparative experiment, the first column attributes were summarized into 35.
- Ethereum dataset (https://www.ethereum.org/, accessed on 1 August 2022). The first 300,000 pieces of data in the Ethereum dataset were selected as the experimental data. According to the different size blocks set in the experiment, we recombined the data to build blocks, and selected the attribute (the account that initiates the transaction) as the keyword. The attribute is a username coded in hexadecimal code with 40 bits. To facilitate the establishment of the bitmap index as a comparative experiment, the attribute value was 500,000.
6.1.2. Experimental Settings
6.2. Index Evaluation
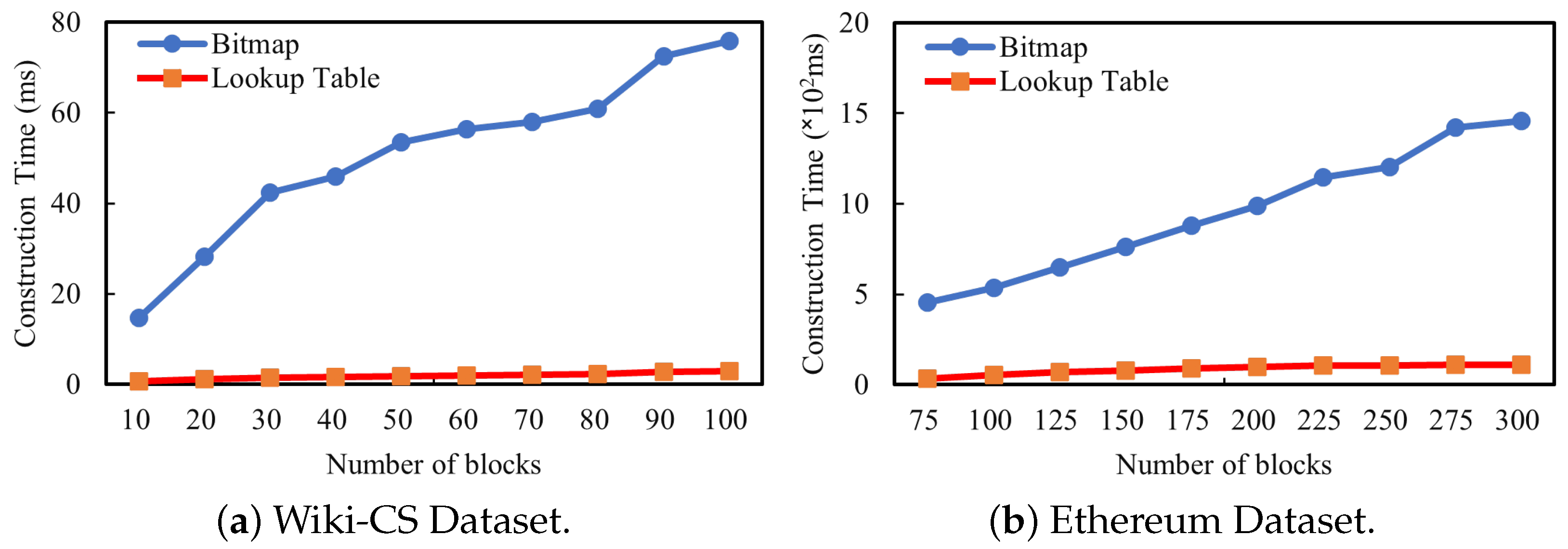
6.2.1. Lookup Table Index Evaluation
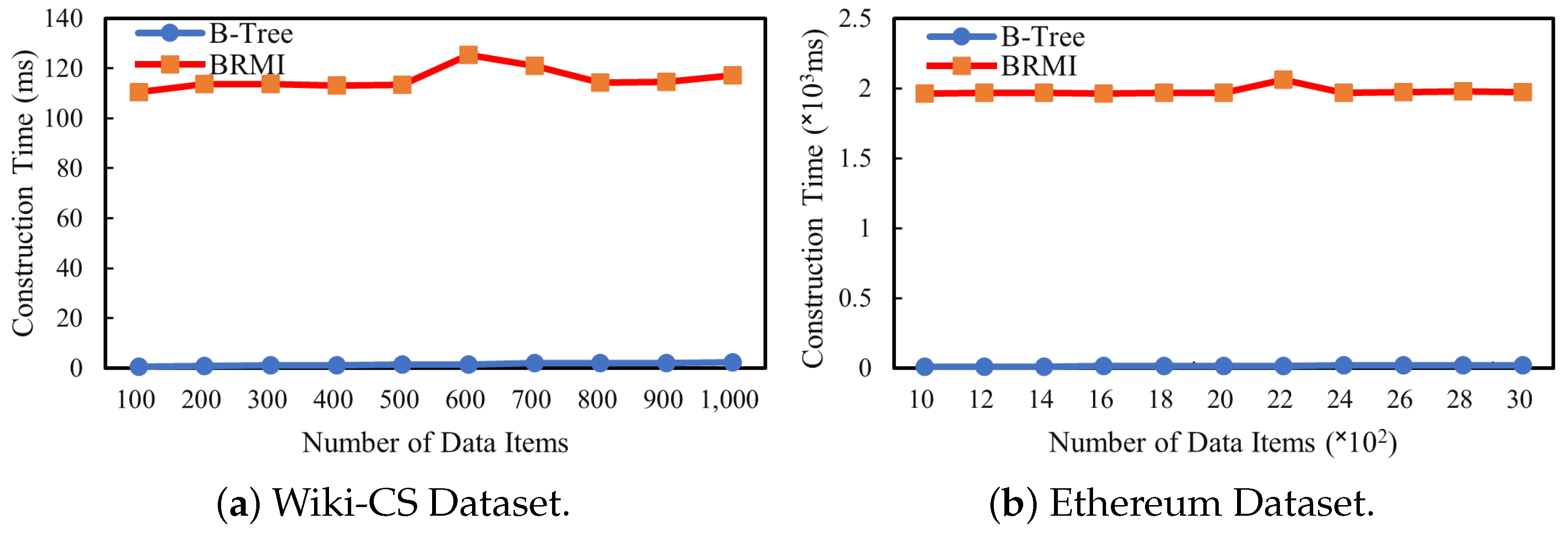
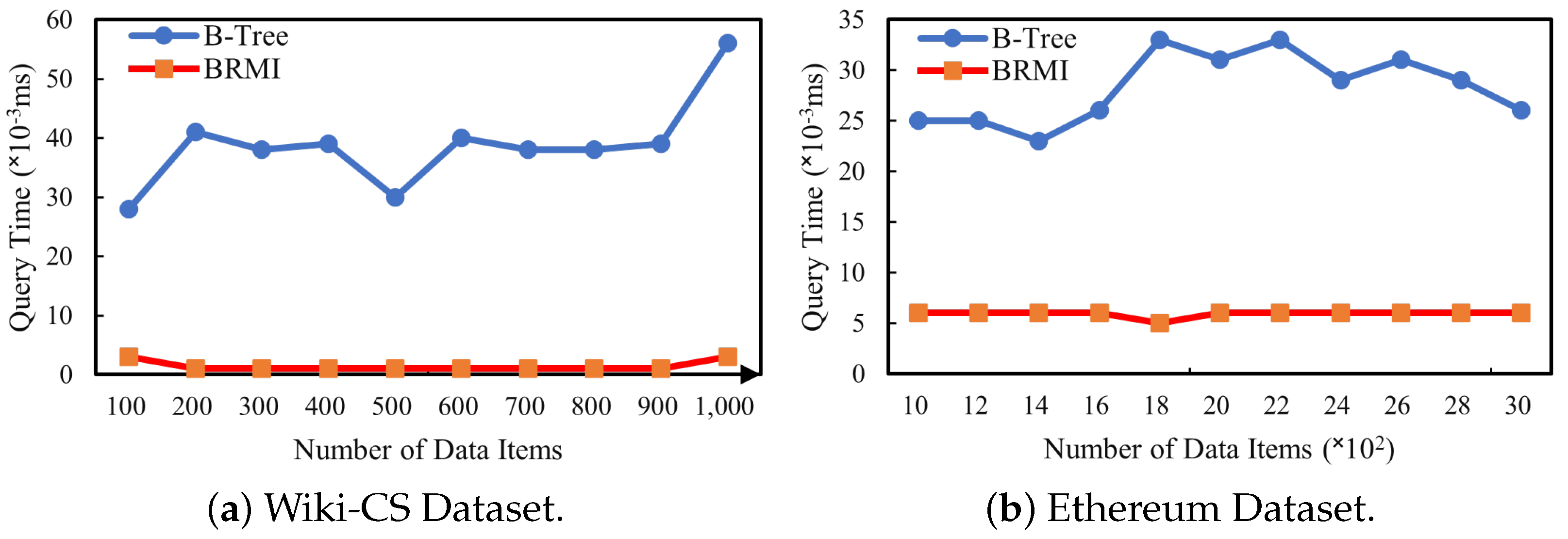
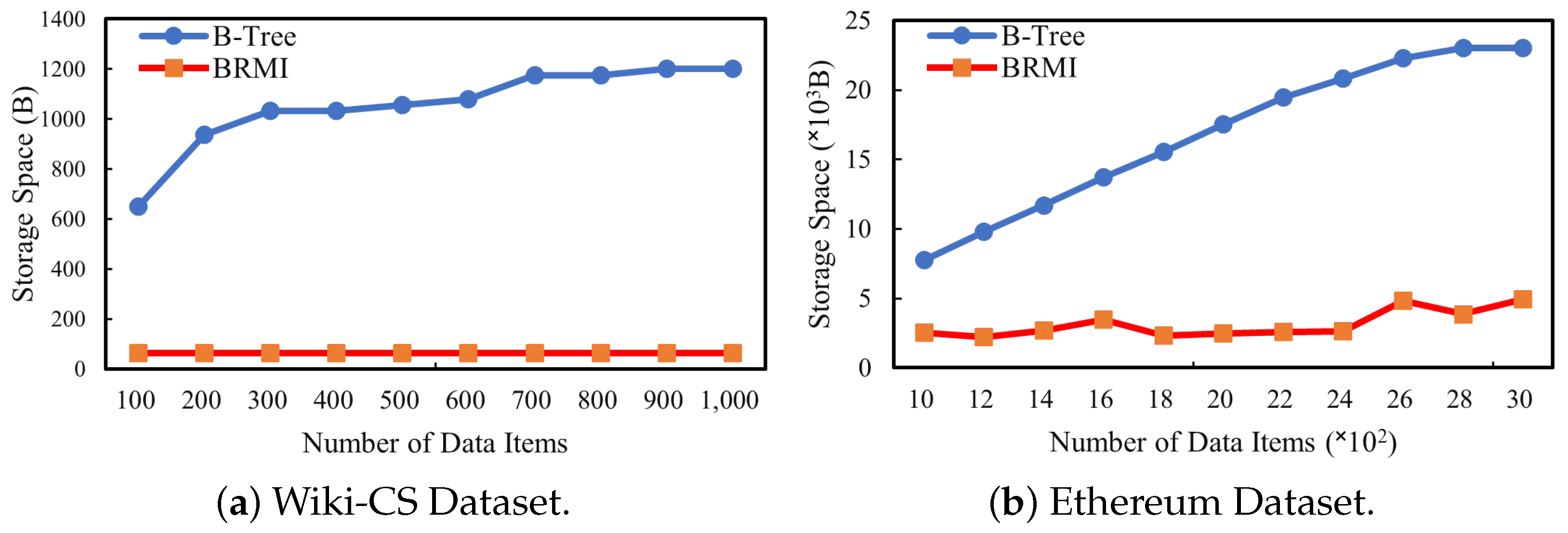
6.2.2. Learned Index Evaluation
6.2.3. Ablation Experiment
6.3. Architecture Cost
6.4. Verification Cost
7. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- El-Hindi, M.; Binnig, C.; Arasu, A.; Kossmann, D.; Ramamurthy, R. BlockchainDB—A Shared Database on Blockchains. Proc. Vldb Endow. 2019, 12, 1597–1609. [Google Scholar] [CrossRef]
- Li, Y.; Zheng, K.; Yan, Y.; Liu, Q.; Zhou, X. EtherQL: A Query Layer for Blockchain System. In Proceedings of the Database Systems for Advanced Applications (DASFAA 2017), PT II, Suzhou, China, 27–30 March 2017; Candan, S., Chen, L., Pedersen, T., Chang, L., Hua, W., Eds.; Soochow University: Suzhou, China, 2017; Volume 10178, pp. 556–567. [Google Scholar] [CrossRef]
- McConaghy, T.; Marques, R.; Müller, A.; De Jonghe, D.; McConaghy, T.; McMullen, G.; Henderson, R.; Bellemare, S.; Granzotto, A. Bigchaindb: A Scalable Blockchain Database; white paper; BigChainDB: Berlin, Germany, 2016. [Google Scholar]
- Riegger, C.; Vincon, T.; Petrov, I. Efficient Data and Indexing Structure for Blockchains in Enterprise Systems. In Proceedings of the 20th International Conference on Information Integration and Web-Based Applications & Services, Assoc Comp Machinery, Hanoi, Vietnam, 4–6 December 2014; pp. 173–182. [Google Scholar] [CrossRef]
- Xu, Y.; Zhao, S.; Kong, L.; Zheng, Y.; Zhang, S.; Li, Q. ECBC: A High Performance Educational Certificate Blockchain with Efficient Query. In Theoretical Aspects of Computing–ICTAC 2017: 14th International Colloquium, Hanoi, Vietnam, 23–27 October 2017; Natl Fdn Sci & Technol Dev Vietnam; HUMAX VINA Co.: Hanoi, Vietnam, 2017; Volume 10580, pp. 288–304. [Google Scholar] [CrossRef]
- Zhou, E.; Hong, Z.; Xiao, Y.; Zhao, D.; Pei, Q.; Guo, S.; Akerkar, R. MSTDB: A Hybrid Storage-Empowered Scalable Semantic Blockchain Database. IEEE Trans. Knowl. Data Eng. 2022, 1–17. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Decent. Bus. Rev. 2008, 21260. [Google Scholar]
- Dinh, T.T.A.; Liu, R.; Zhang, M.; Chen, G.; Ooi, B.C.; Wang, J. Untangling Blockchain: A Data Processing View of Blockchain Systems. IEEE Trans. Knowl. Data Eng. 2018, 30, 1366–1385. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, C.; Xu, J.; Tang, Y.; Choi, B. GEM(2)-Tree: A Gas-Efficient Structure for Authenticated Range Queries in Blockchain. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE 2019), Macao, China, 8–11 April 2019; pp. 842–853. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, C.; Wang, H.; Xu, J.; Choi, B. Authenticated Keyword Search in Scalable Hybrid-Storage Blockchains. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE 2021), Chania, Greece, 19–22 April 2021; pp. 996–1007. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, C.; Xu, J. vChain: Enabling Verifiable Boolean Range Queries over Blockchain Databases. In Proceedings of the Sigmod’19: 2019 International Conference on Management of Data; Assoc Comp Machinery; ACM SIGMOD: New York, NY, USA, 2019; pp. 141–158. [Google Scholar] [CrossRef]
- Wang, H.; Xu, C.; Zhang, C.; Xu, J. vChain: A Blockchain System Ensuring Query Integrity. In Proceedings of the Sigmod’20: 2020 ACM SIGMOD International Conference on Management of Data; Assoc Comp Machinery; ACM SIGMOD: New York, NY, USA, 2020; pp. 2693–2696. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, Z.; Jin, C.; Zhou, A.; Yan, Y. SEBDB: Semantics hmpowered BlockChain DataBase. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE 2019), Macao, China, 8–11 April 2019; pp. 1820–1831. [Google Scholar]
- Ruan, P.; Dinh, T.T.A.; Lin, Q.; Zhang, M.; Chen, G.; Ooi, B.C. LineageChain: A fine-grained, secure and efficient data provenance system for blockchains. VLDB J. 2021, 30, 3–24. [Google Scholar] [CrossRef]
- Jia, D.; Xin, J.; Wang, Z.; Guo, W.; Wang, G. ElasticChain: Support Very Large Blockchain by Reducing Data Redundancy. In Proceedings of the Web and Big Data (APWEB-WAIM 2018), PT II, Macau, China, 23–25 July 2018; Cai, Y., Ishikawa, Y., Xu, J., Eds.; Volume 10988, pp. 440–454. [Google Scholar] [CrossRef]
- Jia, D.; Xin, J.; Wang, Z.; Guo, W.; Wang, G. Efficient Query Model for Storage Capacity Scalable Blockchain System. J. Softw. 2019, 30, 2655–2670. [Google Scholar]
- Lv, Y.; Liu, W.; Zhong, J.; Zhang, C.; Wang, K.; Wang, Z. An optimization model of electronic medical record query processing on blockchain. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence and Information Systems (ICAIIS’21), Chongqing, China, 28–30 May 2021. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, F.; Sharma, P.K.; Wang, T.; Wang, J.; Alfarraj, O.; Tolba, A. Data Query Mechanism Based on Hash Computing Power of Blockchain in Internet of Things. Sensors 2020, 20, 207. [Google Scholar] [CrossRef] [PubMed]
- Linoy, S.; Mandikhani, H.; Ray, S.; Lu, R.; Stakhanova, N.; Ghorbani, A. Scalable Privacy-Preserving Query Processing Over Ethereum Blockchain. In Proceedings of the 2019 IEEE International Conference on Blockchain (BLOCKCHAIN 2019), Atlanta, GA, USA, 14–17 July 2019; pp. 398–404. [Google Scholar] [CrossRef]
- Li, T.; Huang, R.; Chen, L.; Jensen, C.S.; Pedersen, T.B. Compression of Uncertain Trajectories in Road Networks. Proc. VLDB Endow. 2020, 13, 1050–1063. [Google Scholar] [CrossRef]
- Li, T.; Chen, L.; Jensen, C.S.; Pedersen, T.B. TRACE: Real-time Compression of Streaming Trajectories in Road Networks. Proc. VLDB Endow. 2021, 14, 1175–1187. [Google Scholar] [CrossRef]
- Li, T.; Chen, L.; Jensen, C.S.; Pedersen, T.B.; Gao, Y.; Hu, J. Evolutionary Clustering of Moving Objects. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE 2022), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 2399–2411. [Google Scholar] [CrossRef]
- Fernando, D.; Kulshrestha, S.; Herath, J.D.; Mahadik, N.; Ma, Y.; Bai, C.; Yang, P.; Yan, G.; Lu, S. SciBlock: A Blockchain-Based Tamper-Proof Non-Repudiable Storage for Scientific Workflow Provenance. In Proceedings of the 2019 IEEE 5th International Conference on Collaboration and Internet Computing (CIC 2019), Los Angeles, CA, USA, 12–14 December 2019; pp. 81–90. [Google Scholar] [CrossRef]
- Song, Y.; Gu, Y.; Li, F.; Yu, G. Survey on AI Powered New Techniques for Query Processing and Optimization. J. Front. Comput. Sci. Technol. 2020, 14, 1081–1103. [Google Scholar]
- Song, Y.; Gu, Y.; Li, T.; Qi, J.; Liu, Z.; Jensen, C.S.; Yu, G. CHGNN: A Semi-Supervised Contrastive Hypergraph Learning Network. arXiv 2023, arXiv:2303.06213. [Google Scholar]
- Sakurai, Y.; Yoshikawa, M.; Uemura, S.; Kojima, H. The A-tree: An Index Structure for High-Dimensional Spaces Using Relative Approximation. In Proceedings of the 26th International Conference on Very Large Data Bases, Cairo, Egypt, 10–14 September 2000; Morgan Kaufmann: Burlington, MA, USA, 2000; pp. 516–526. [Google Scholar]
- Kraska, T.; Beutel, A.; Chi, E.H.; Dean, J.; Polyzotis, N. The Case for Learned Index Structures. In Proceedings of the SIGMOD’18: 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; Das, G., Jermaine, C., Bernstein, P., Eldawy, A., Eds.; pp. 489–504. [Google Scholar] [CrossRef]
- Kraska, T.; Alizadeh, M.; Beutel, A.; Chi, E.H.; Kristo, A.; Leclerc, G.; Madden, S.; Mao, H.; Nathan, V. SageDB: A Learned Database System. In Proceedings of the 9th Biennial Conference on Innovative Data Systems Research, CIDR, Asilomar, CA, USA, 13–16 January 2019. [Google Scholar]
- Ding, J.; Minhas, U.F.; Yu, J.; Wang, C.; Do, J.; Li, Y.; Zhang, H.; Chandramouli, B.; Gehrke, J.; Kossmann, D.; et al. ALEX: An Updatable Adaptive Learned Index. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 969–984. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Block nth | LT Space | Optimized LT Space |
|---|---|---|---|
| Wiki-CS | 20 | 2052 | 104 |
| 40 | 4052 | 98 | |
| 60 | 6096 | 95 | |
| 80 | 8152 | 103 | |
| 100 | 10,140 | 102 | |
| Ethereum | 100 | 138,832 | 1222 |
| 150 | 198,448 | 1248 | |
| 200 | 256,380 | 1125 | |
| 250 | 315,016 | 1216 | |
| 300 | 373,792 | 1118 |
| Dataset | Data Items | Merkle Layers | Space (B) | Times (ms) |
|---|---|---|---|---|
| Wiki-CS | 100 | 8 | 256 | 9.9997 |
| 200 | 9 | 288 | 11.7108 | |
| 300 | 10 | 320 | 12.8352 | |
| 400 | 10 | 320 | 12.1373 | |
| 500 | 10 | 320 | 11.6045 | |
| 600 | 11 | 352 | 12.7743 | |
| 700 | 11 | 352 | 11.9689 | |
| 800 | 11 | 352 | 12.9789 | |
| 900 | 11 | 352 | 12.7546 | |
| 1000 | 11 | 352 | 12.863 | |
| Ethereum | 1000 | 11 | 352 | 12.2373 |
| 1200 | 12 | 384 | 12.6396 | |
| 1400 | 12 | 384 | 12.3958 | |
| 1600 | 12 | 384 | 12.6824 | |
| 1800 | 12 | 384 | 12.3308 | |
| 2000 | 13 | 384 | 12.7679 | |
| 2200 | 13 | 416 | 13.1738 | |
| 2400 | 13 | 416 | 13.9893 | |
| 2600 | 13 | 416 | 13.7485 | |
| 2800 | 13 | 416 | 14.0407 | |
| 3000 | 13 | 416 | 13.6439 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Z.; Xin, J.; Hao, K.; Wang, Z.; Zhu, W. Learned-Index-Based Semantic Keyword Query on Blockchain. Mathematics 2023, 11, 2055. https://doi.org/10.3390/math11092055
Yao Z, Xin J, Hao K, Wang Z, Zhu W. Learned-Index-Based Semantic Keyword Query on Blockchain. Mathematics. 2023; 11(9):2055. https://doi.org/10.3390/math11092055
Chicago/Turabian StyleYao, Zhongming, Junchang Xin, Kun Hao, Zhiqiong Wang, and Wancheng Zhu. 2023. "Learned-Index-Based Semantic Keyword Query on Blockchain" Mathematics 11, no. 9: 2055. https://doi.org/10.3390/math11092055
APA StyleYao, Z., Xin, J., Hao, K., Wang, Z., & Zhu, W. (2023). Learned-Index-Based Semantic Keyword Query on Blockchain. Mathematics, 11(9), 2055. https://doi.org/10.3390/math11092055