

Efficient and Low Color Information Dependency Skin Segmentation Model


Abstract
1. Introduction
- We propose a lightweight skin segmentation method that is more suitable than previous methods for real-time application preprocessing.
- We used data augmentation techniques to reduce the color-information dependency of the model and demonstrated this experimentally.
2. Related Work
2.1. Thresholding-Based Method
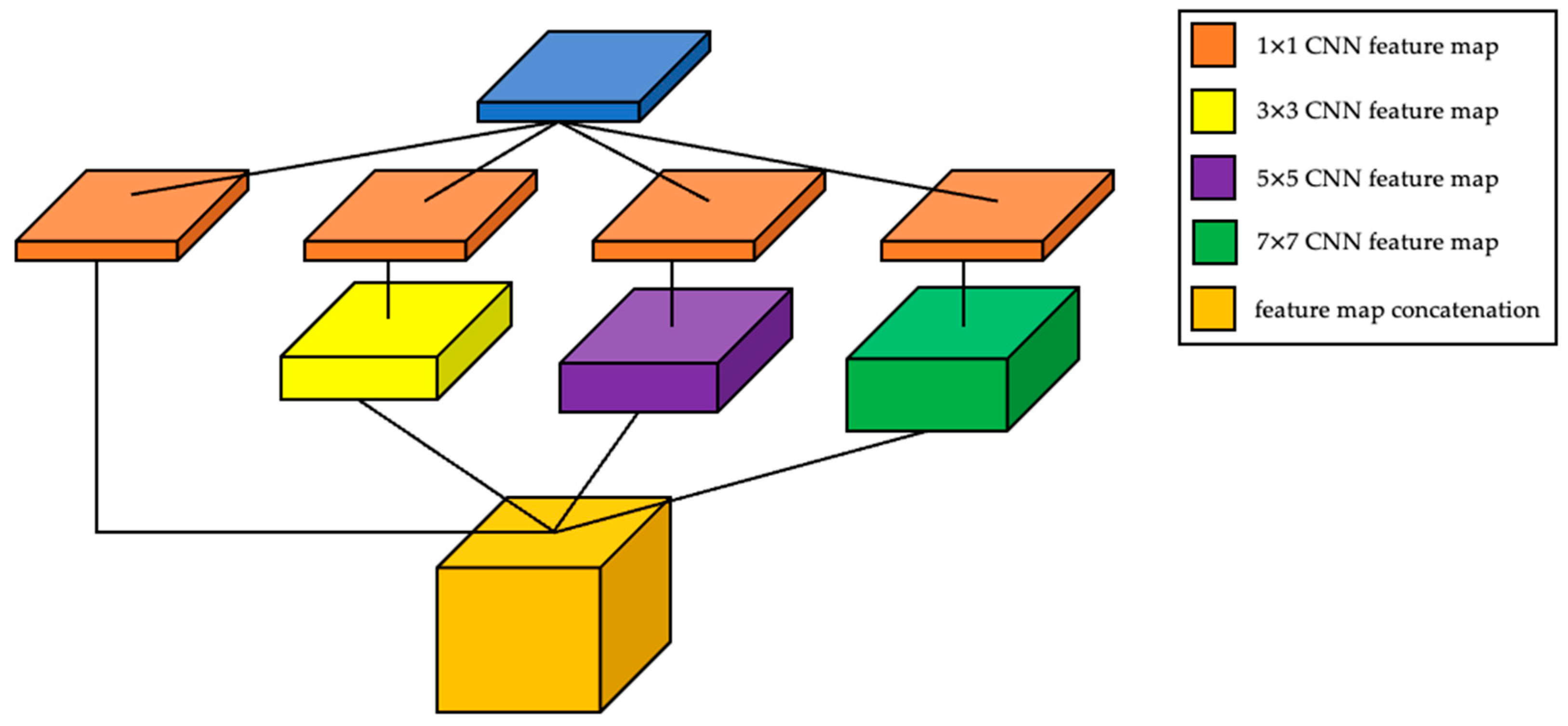
2.2. Deep-Learning-Based Method
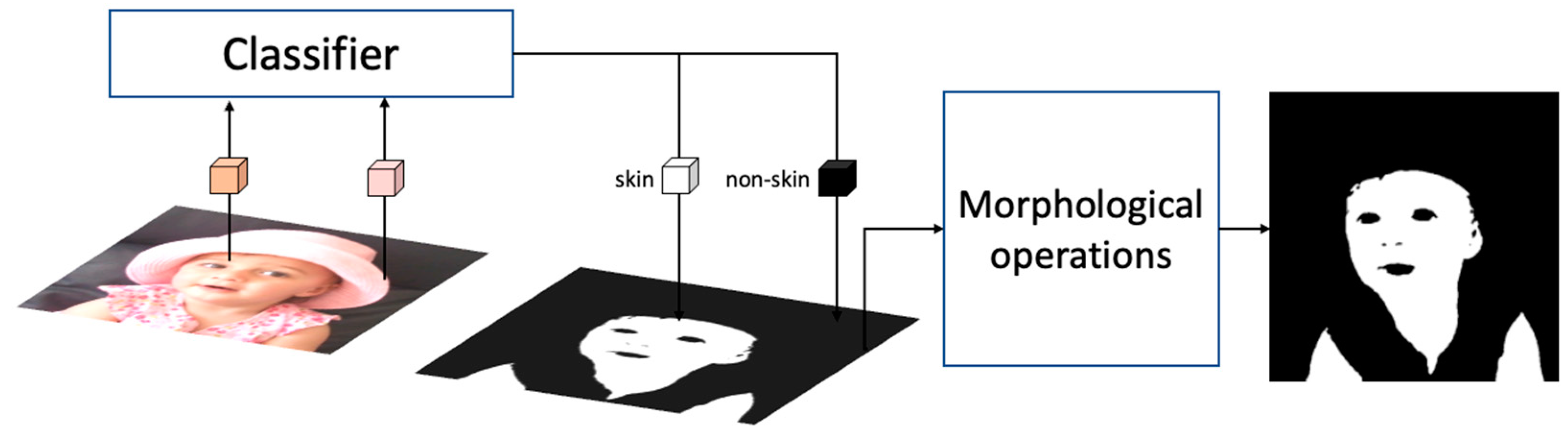
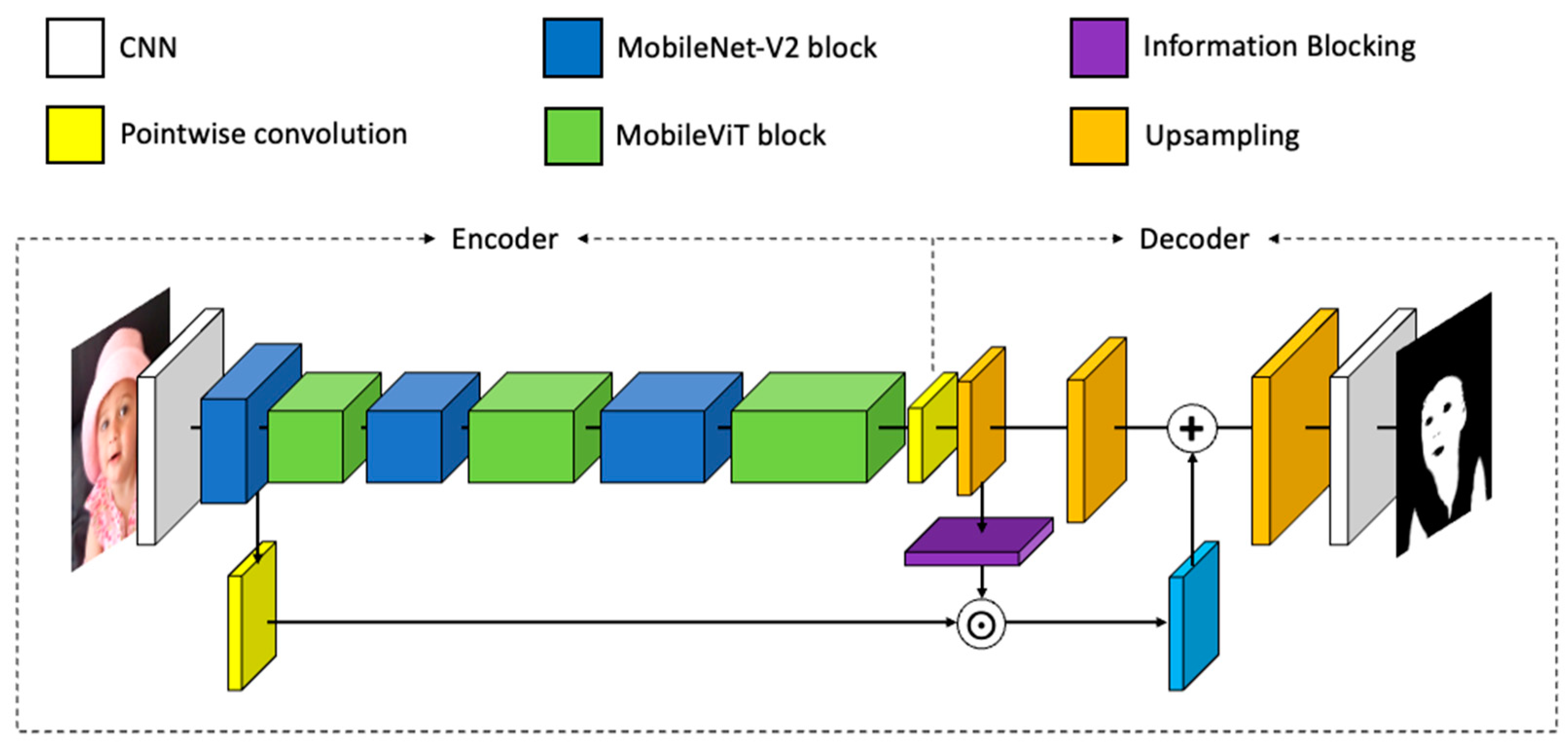
3. Method
3.1. Information Blocking
3.2. MobileViT
3.3. Simplified Channel Attention
3.4. Xu’s Data Augmentation
4. Experiments
4.1. Implementation Details
4.2. Datasets
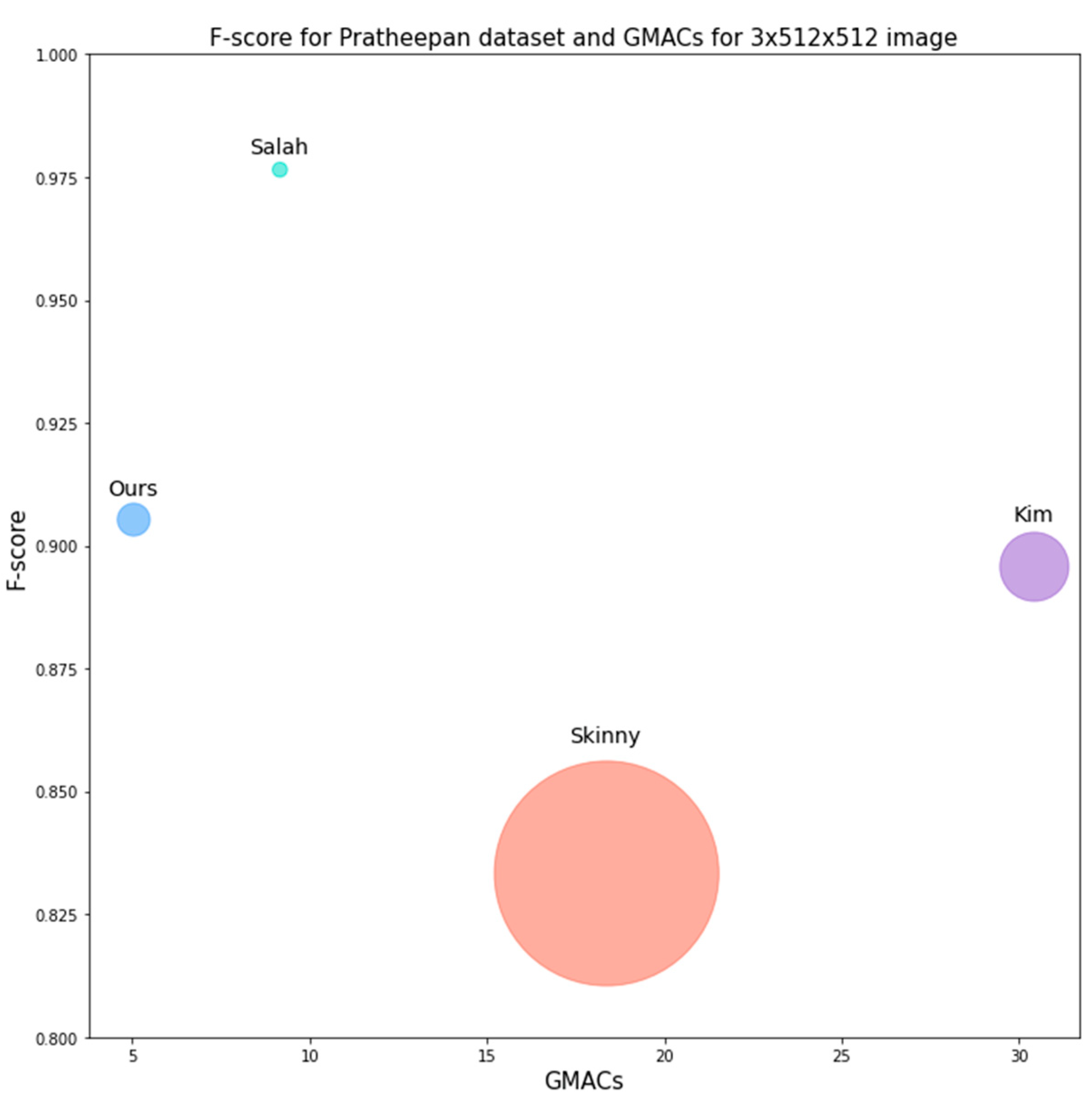
4.3. Performance for ECU and Pratheepan Datasets
4.4. Performance on Images Modified by the Xu’s Method
4.5. Performance for Gray Scale Images
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Harsha, B.K. Skin Detection in images based on Pattern Matching Algorithms-A Review. In Proceedings of the International Conference on Inventive Computation Technologies(ICICT), Coimbatore, India, 26–28 February 2020. [Google Scholar]
- Pujol, F.A.; Pujol, M.; Jimeno-Morenilla, A.; Pujol, M.J. Face detection based on skin color segmentation using fuzzy entropy. Entropy 2017, 19, 26. [Google Scholar] [CrossRef]
- Jalab, H.A.; Omer, H.K. Human computer interface using hand gesture recognition based on neural network. In Proceedings of the National Symposium on Information Technology(NSITNSW), Riyadh, Saudi Arabia, 17–19 February 2015. [Google Scholar]
- Casado, C.A.; López, M.B. Face2PPG: An unsupervised pipeline for blood volume pulse extraction from faces. arXiv 2022, arXiv:2202.04101. [Google Scholar]
- Scherpf, M.; Emst, H.; Misera, L.; Schmidt, M. Skin Segmentation for Imaging Photoplethysmography Using a Specialized Deep Learning Approach. In Proceedings of the Computing in Cardiology (CinC), Brno, Czech Republic, 13–15 September 2021. [Google Scholar]
- De Haan, G.; Jeanne, V. Robust pulse rate from chrominance-based rPPG. IEEE Trans. Biomed. Eng. 2013, 60, 2878–2886. [Google Scholar] [CrossRef] [PubMed]
- Naji, S.; Jalab, H.A.; Kareem, S.A. A survey on skin detection in colored images. Artif. Intell. Rev. 2019, 52, 1041–1087. [Google Scholar] [CrossRef]
- Phung, S.L.; Bouzerdoum, A.; Chai, D. A novel skin color model in ycbcr color space and its application to human face detection. In Proceedings of the International on Image Processing, Rochester, NY, USA, 22–25 September 2002. [Google Scholar]
- Hajraoui, A.; Sabri, M. Face detection algorithm based on skin detection, watershed method and gabor filters. Int. J. Comput. Appl. 2014, 94, 33–39. [Google Scholar] [CrossRef]
- Tao, L. An FPGA-based parallel architecture for face detection using mixed color models. arXiv 2014, arXiv:1405.7032. [Google Scholar]
- Kolkur, S.; Kalbande, D.; Shimpi, P.; Bapat, C.; Jatakia, J. Human skin detection using RGB, HSV and YCbCr color models. arXiv 2017, arXiv:1708.02694. [Google Scholar]
- Störring, M. Computer Vision and Human Skin Colour. Ph.D. Thesis, Aalborg University, Aalborg, Denmark, 2004. [Google Scholar]
- Kakumanu, P.; Makrogiannis, S.; Bourbakis, N. A survey of skin-color modeling and detection methods. Pattern Recognit. 2007, 40, 1106–1122. [Google Scholar] [CrossRef]
- Tarasiewicz, T.; Nalepa, J.; Kawulok, M. Skinny A lightweight u-net for skin detection and segmentation. In Proceedings of the IEEE International Conference on Image Processing(ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020. [Google Scholar]
- Salah, K.B.; Othmani, M.; Kherallah, M. A novel approach for human skin detection using convolutional neural network. Vis. Comput. 2022, 38, 1833–1843. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Phung, S.L.; Bouzerdoum, A.; Chai, D. Skin segmentation using color pixel classification: Analysis and comparison. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 148–154. [Google Scholar] [CrossRef] [PubMed]
- Casati, J.P.B.; Moraes, D.R.; Rodrigues, E.L.L. SFA: A human skin image database based on FERET and AR facial images. In Proceedings of the IX Workshop on Computational Vision—WVC 2013, Rio de Janeiro, Brazil, 3–5 June 2013. [Google Scholar]
- Kim, Y.; Hwang, I.; Cho, N.I. Convolutional neural networks and training strategies for skin detection. In Proceedings of the IEEE International Conference on Image Processing(ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–15 June 2015. [Google Scholar]
- Tan, W.R.; Chan, C.S.; Yogarajah, P.; Condell, J. A fusion approach for efficient human skin detection. IEEE Trans. Ind. Inform. 2011, 8, 138–147. [Google Scholar] [CrossRef]
- Abdallah, A.S.; Bou El-Nasr, M.A.; Abbott, A.L. A new color image database for benchmarking of automatic face detection and human skin segmentation techniques. Int. J. Comput. Inf. Eng. 2007, 1, 3782–3786. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kawulok, M.; Kawulok, J.; Nalepa, J.; Smolka, B. Self-adaptive algorithm for segmenting skin region. EURASIP J. Adv. Signal Process. 2014, 170. [Google Scholar] [CrossRef]
- Park, H.; Siosund, L.; Yoo, Y.; Monet, N.; Bang, J.; Kwak, N. Sinet: Extreme lightweight portrait segmentation networks with spatial squeeze module and information blocking decoder. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Chen, L.; Chu, X.; Zhang, X.; Sun, J. Simple baselines for image restoration. In Proceedings of the Conference on Computer Vision—ECCV, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Xu, H.; Sarkar, A.; Abbott, A.L. Color Invariant Skin Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; p. 30. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Hanin, B.; Rolnick, D. How to start training: The effect of initialization and architecture. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2018; p. 31. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kim’s * | Skinny | Salah’s | Ours | |
|---|---|---|---|---|
| GMACs | 674.4MMACs 47 = 30.4278 | 18.37 | 34.96KMACs 512 512 = 9.16 | 5.04 |
| MobileViT + SINet | MobileViT + GDFN + SINet | MobileViT + GDFN + SCA + SINet | |
|---|---|---|---|
| GMACs | 5.88 | 6.17 | 5.04 |
| Input | Operation | Output |
|---|---|---|
| [] | CNN Batch normalization | [] |
| [] | MobileV2 * | [] |
| [] | [] | |
| [] | [] | |
| [] | [] | |
| [] | [] | |
| [] | MobileViT block | [] |
| [] | MobileV2 | [] |
| [] | MobileViT block | [] |
| [] | MobileV2 | [] |
| [] | MobileViT block | [] |
| [] | CNN Batch normalization | [] |
| [] | CNN Upsampling Batch normalization | [] |
| [] | Information Blocking | [] |
| [] | Upsampling Batch normalization | [] |
| [] | Upsampling CNN | [] |
| Method | ECU | Pratheepan | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F-Score | Precision | Recall | F-Score | |
| Kim’s | 0.8720 | 0.9122 | 0.8917 | 0.9003 | 0.8912 | 0.8957 |
| Skinny | 0.9253 | 0.9299 | 0.9230 | 0.8672 | 0.7475 | 0.8333 |
| Salah’s | - | - | - | 0.9801 | 0.9600 | 0.9765 |
| SINet * | 0.9230 | 0.9486 | 0.9333 | 0.8476 | 0.8168 | 0.8178 |
| Ours | 0.9574 | 0.9459 | 0.9501 | 0.9133 | 0.9041 | 0.9055 |
| Predicted Values | ECU | Pratheepan | ||
|---|---|---|---|---|
| Positive | Negative | Positive | Negative | |
| Positive | 99,505,194 | 3,964,144 | 3,451,822 | 225,831 |
| Negative | 5,533,018 | 410,872,818 | 256,364 | 16,256,424 |
| Modification | Skinny | SINet | Ours | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F-Score | Precision | Recall | F-Score | Precision | Recall | F-Score | |
| Hue | 0.1845 | 0.0675 | 0.0834 | 0.9180 | 0.9419 | 0.9265 | 0.9519 | 0.9380 | 0.9428 |
| Saturation | 0.8857 | 0.8686 | 0.8640 | 0.9198 | 0.9484 | 0.9311 | 0.9539 | 0.9455 | 0.9480 |
| Value | 0.8978 | 0.8410 | 0.8468 | 0.9191 | 0.9500 | 0.9316 | 0.9559 | 0.9453 | 0.9489 |
| Total | 0.6560 | 0.5923 | 0.5980 | 0.9190 | 0.9468 | 0.9298 | 0.9539 | 0.9430 | 0.9466 |
| Metric | Skinny | SINet | Ours |
|---|---|---|---|
| Precision | 0.9349 | 0.8815 | 0.8819 |
| Recall | 0.4405 | 0.7661 | 0.8288 |
| F-score | 0.5692 | 0.7855 | 0.8419 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, H.; Lee, K.; Oh, J.; Lee, E.C. Efficient and Low Color Information Dependency Skin Segmentation Model. Mathematics 2023, 11, 2057. https://doi.org/10.3390/math11092057
You H, Lee K, Oh J, Lee EC. Efficient and Low Color Information Dependency Skin Segmentation Model. Mathematics. 2023; 11(9):2057. https://doi.org/10.3390/math11092057
Chicago/Turabian StyleYou, Hojoon, Kunyoung Lee, Jaemu Oh, and Eui Chul Lee. 2023. "Efficient and Low Color Information Dependency Skin Segmentation Model" Mathematics 11, no. 9: 2057. https://doi.org/10.3390/math11092057
APA StyleYou, H., Lee, K., Oh, J., & Lee, E. C. (2023). Efficient and Low Color Information Dependency Skin Segmentation Model. Mathematics, 11(9), 2057. https://doi.org/10.3390/math11092057