1. Introduction
Currently, even though vehicles are upgraded to support a higher level of autonomy, humans are still their primary operators. Therefore, driver distraction is still a major problem that can disrupt and jeopardize transportation systems [
1,
2]. In general, driver distraction occurs when a driver’s attention is diverted, leading to a delay in recognizing vital information to keep vehicles running safely [
3]. Especially with the proliferation of in-vehicle multimedia devices and personal smart gadgets, diverse in-vehicle activities exacerbate driver distraction. To prevent potential hazards and incidents, warnings to distracted drivers need to be fast and precise, which shows the necessity of driver distraction detection (3D).
With the rapid development of advanced technologies, e.g., Artificial Intelligence and Internet of Things (IoT), the capabilities of in-vehicle devices have improved, such as sensing, communication, computing, etc. Intelligent vehicle systems are often equipped with rich computing capabilities to support various tasks. Particularly, data-driven approaches to deep learning models have been widely developed and applied to support 3D, e.g., with various core models that are trained on driver face poses [
4], driving actions [
5], electroencephalography signals [
6], and other sensed information to detect distractions, such as unfocused eyesight [
7], inattention [
6], and inappropriate operation [
5].
Traditional deep learning methods centrally process data, namely, vehicles need to upload signals, images, and other sensed data to a central server. After the collection of sensed data, the server will train the required model based on the data consolidated from multiple sensing devices, also known as smart vehicles. However, in this process, the data to be transmitted may contain private or sensitive information, such as travel trajectories and passenger profiles. It is vulnerable to being intercepted and attacked via network connections between vehicles and servers. Under the restrictions listed in recently announced data protection laws and regulations, more isolated data silos are formed and become unbreakable barriers to applying centralized model learning solutions [
8]. Therefore, federated learning (FL) is emerging as a feasible solution that can train models without private and sensitive information leaving its local repository [
8,
9].
Even though various solutions are proposed by using FL to upgrade the model learning paradigm of 3D [
10,
11,
12], they are still incapable of handling the dynamics and heterogeneity encountered in the daily usage of 3D. First, most recent research is conducted based on predefined experimental settings, in which clients possess preassigned data and exchange model parameters directly without any optimizations. Specifically, in more realistic scenarios, data can be sensed continuously. Since current solutions focus more on old data, if they are applied to the incremental data directly, it may make the model learning inefficient, leading to catastrophic forgetting of knowledge [
13]. Second, even though current solutions based on FL do not need to transmit raw data, it is still costly to train high-performance models based on more frequent and excessive client–server interactions [
9]. Finally, it is common to see that the availability of local data and computing powers of moving vehicles may change over time and place, and this may make current solutions inefficient at not only accommodating heterogeneous devices but also data with various distributions, uneven sizes, and missing label classes [
9,
14,
15].
To tackle the aforementioned challenges, this paper proposes an incremental and cost-efficient mechanism for federated meta-learning, named ICMFed, to support 3D. In general, ICMFed integrates incremental learning and meta-learning with federated learning to provide a novel learning paradigm that can be applied to address the dynamics and heterogeneity within real-world 3D scenarios. The main contributions of this work can be summarized as follows:
ICMFed introduces temporal factors on batches created according to sample sensed time ascendingly, which can ensure rapid and balanced extraction of features from gradually accumulated data. Meanwhile, by calculating the gradient similarity of model layers, a layer-wise model uploading process is implemented to reduce communication costs without degrading the model performance.
Taking advantage of meta-learning and federated learning, ICMFed can remedy the impact of heterogeneity in data and devices to learn the global meta-model by employing a weighted model aggregation strategy, which enhances the model aggregation process by an adaptive weight calculated based on the richness of local information.
Through the evaluation based on the 3D dataset collected by State Farm and two classical models, ICMFed can not only significantly elevate the learning performance, i.e., communication cost and learning accuracy, but also dramatically improve related service quality.
The remainder of this paper is organized as follows.
Section 2 summarizes related challenges and solutions. Then, ICMFed is presented and evaluated in
Section 3 and
Section 4, respectively. Finally,
Section 5 concludes this work and presents future research directions.
2. Challenges and Related Work
This section first introduces four challenges regarding the dynamics and heterogeneity encountered in incremental federated meta-learning (IFM), and accordingly, related solutions are discussed.
2.1. Emerging Challenges
First, as for the dynamics in real-world scenarios, the following two critical challenges are faced by 3D:
C1.1 Data Accumulation. While the 3D service is installed, the vehicles can continuously sense driver status and increase the samples to be used for model updates. In comparison to static scenarios where the training samples will not change frequently, data accumulation can cause pre-trained knowledge to be obsolete in processing new data [
13,
16].
C1.2 Communication Optimization. To train a model jointly, 3D services require frequent interaction between the clients and the server. Even though in IFM, model parameters are exchanged instead of entire data, which can reduce the network traffic [
8], the client–server interaction frequency increases to update the model iteratively, resulting in high latency to update the model on the fly [
9,
17,
18].
Moreover, the heterogeneity embedded in 3D is represented by two main aspects, namely:
C2.1 Data Heterogeneity. Due to the restriction in IFM, data sensed are stored locally to protect user privacy, and as a result, the local data of different users may vary to be non-iid (non-independent and identically distributed), i.e., different distribution of samples, uneven data quality, etc. Such heterogeneity can significantly complicate the learning process of IFM [
15,
18].
C2.2 Device Heterogeneity. The devices to support 3D may have different configurations in terms of software and hardware, e.g., operation systems, sensing capabilities, storage spaces, computing powers, etc. Moreover, on the device, more than one service is running in parallel, and as a result, the availability of learning resources may vary among them. Therefore, how to select proper clients becomes an emerging challenge in IFM to remedy the impact of such heterogeneity [
19,
20,
21].
2.2. Related Solutions
To tackle the abovementioned challenges, related solutions are proposed.
2.2.1. Solutions to Data Accumulation
The data accumulation of IFM can be solved by timely updating of global models or optimizing local training patterns. While considering incremental scenarios, if the global model or training task is not updated adequately and in a timely manner, it will lead to poor performance [
22,
23]. Current research commonly adopts a predefined configuration for model learning [
8,
15,
24]. Moreover, without modifying the model structure, several methods optimize local training patterns to improve knowledge retention on both old and new samples. For example, Wei et al. [
22] proposed a method named FedKL utilizing knowledge lock to maintain the previously learned knowledge. Yoon et al. [
25] introduced FedWeIT, allowing clients to leverage indirect experience from other clients to support continuous learning of federated knowledge. Le et al. [
26] suggested a weighted processing strategy for model updating to prevent catastrophic forgetting. However, to achieve the optimal performance of these methods, the training will become less efficient, especially to process non-iid data.
2.2.2. Solutions to Communication Optimization
There are two major approaches for communication optimization, i.e., minimizing the amount of data exchanges or reducing the size of data transmitted. Specifically, the first approach can be achieved by reducing model upload frequency [
27,
28], adjusting aggregation schedules [
28,
29,
30], and optimizing network topology [
9,
31]. In addition, technologies such as knowledge distillation [
10,
24] and sparse compression [
25,
32] can be used to compress parameters exchanged without degrading model performance. Finally, the significance of each model layer can be determined in order to perform layer-wise uploading based on user similarity [
33], model similarity [
34,
35], etc.
2.2.3. Solutions to Data Heterogeneity
Data heterogeneity, in general, can be addressed by knowledge distillation or meta-learning. Specifically, as for knowledge distillation, Lin et al. [
24] proposed a FedDF framework, combining federated learning with knowledge distillation. Shang et al. [
10] presented FedBiKD, which is a simple and effective federated bidirectional knowledge distillation framework. Moreover, meta-learning as the process of learning how to learn can guide local learning for better performance. There are many meta-learning algorithms, e.g., Model-Agnostic Meta-learning (MAML) [
36], First-Order Model-Agnostic Meta-learning (FOMAML) [
37], and Reptile [
38]. The joint utilization of meta-learning algorithms and federated learning enables quick, personalized, and heterogeneity-supporting training [
14,
15,
39]. Federated meta-learning (FM) offers various similar applications in transportation to overcome data heterogeneity, such as parking occupancy prediction [
40,
41] and bike volume prediction [
42].
2.2.4. Solutions to Device Heterogeneity
In general, client heterogeneity can be resolved by client selection prior to task start and weighting during global aggregation. To simplify the learning process, random or full client selection is commonly utilized [
8,
26,
34], under the prerequisite that all clients need to be available with little performance disparity. Thus, more advanced strategies are designed to mitigate the unreliability among clients, e.g., a compensatory first-come-first-merge algorithm adopted by Wu et al. [
43], and the dynamic selection based on the status and availability of clients considered by Huang et al. [
44]. Moreover, aggregation weights are also widely discussed. Particularly, the size of local samples [
8,
31,
34] is the most common weight, but with drawbacks to handling IFM as the size of samples can change over time and place. Hence, weights relevant to the characteristics of devices are introduced, such as information richness [
30], temporal weight [
28,
30], etc.
In summary, as summarized in
Table 1, existing methods focus more on solving the optimization issues related to communication (i.e., C1.2), and also present visible progress in addressing the two challenges in heterogeneity (i.e., C2.1 and C2.2). However, it is still missing a solution that can resolve the four challenges encountered in IFM. Therefore, ICMFed is proposed with dedicatedly designed model learning and adaptation processes to not only boost the learning performance but also improve the service quality.
3. Methodology
To tackle the challenges mentioned above, an incremental and cost-efficient mechanism of federated meta-learning called ICMFed is proposed. As illustrated in
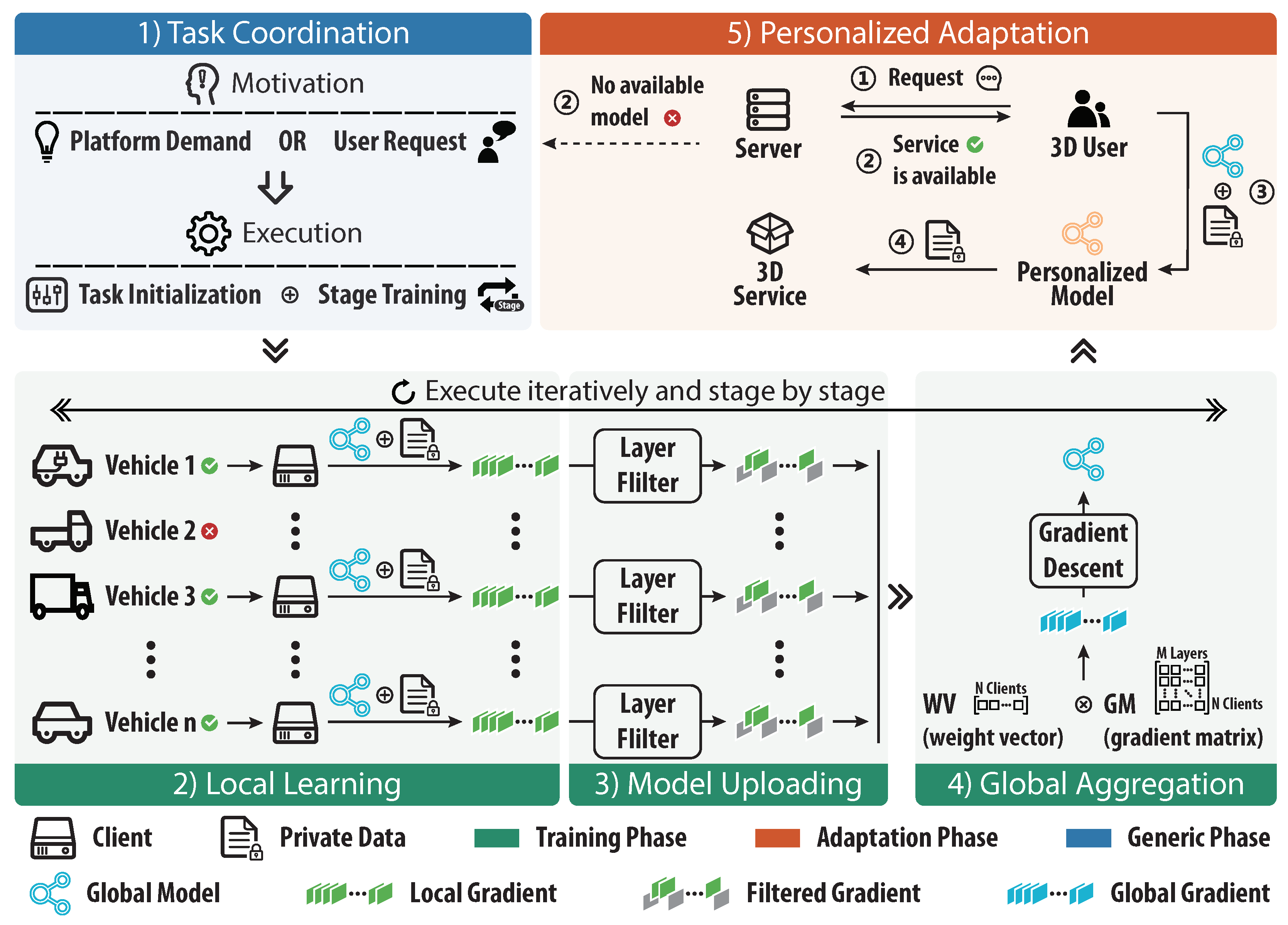
Figure 1, essentially, it comprises five consecutive stages, i.e., (1) Task Coordination: The server will start the task on demand and perform stage transition periodically in incremental scenarios; (2) Local learning: The participant vehicles, i.e., clients, will execute local meta-training based on their own data accumulated continuously; (3) Model uploading: Each client calculates and filters the gradients of layers of the updated local model, and then uploads them to the server dynamically; (4) Global aggregation: The server receives and aggregates the local model gradients to update the global model; (5) Personalized adaptation: Based on the trained global meta-knowledge, user vehicles can execute few rounds of local training to gain their personalized models. Additionally, stages 2–4 belong to the training phase, stage 5 is the adaptation phase, and stage 1 is the generic phase supporting both the training and adaptation phases.
In this section, we first define the problem and then describe in detail the five stages of ICMFed. In addition, the key notations and their explanations appearing below are summarized in
Table 2.
3.1. Problem Definition
For typical FL tasks, the basic framework typically consists of a server and client set
C. Each client
will perform local learning using private data, denoted as
. Especially in FM,
will be further split into a support set
and a query set
. Based on the support and query sets, FM aims to find a model initialization (i.e., meta-knowledge) that can perform well on heterogeneous clients to be quickly adapted with the local gradient descent defined in Formula (
1).
where
are the model parameters;
stands for the local learning rate, also commonly called inner learning rate; and
represents the loss function of client
c (by default, cross-entropy for 3D).
In the case of real-world applications of FM as in 3D, both the number of available clients and the size of local data may change dynamically, i.e., online statuses of participant vehicles and driver conditions sensed by in-vehicle devices may vary over time and place. Therefore, we divide the learning task into multiple stages, since the pre-trained knowledge in incremental scenarios may become invalid as it may drift while new data are sensed.
Therefore, the timing of stage transitions shall be determined, which is based on the number of training rounds in this work. The training objects within a stage
s are as static as FM, i.e., the client set for training
is fixed and takes data at initialization of stage
as training samples. When discussing the transition to a new stage
, new clients are selected as
while the incremental data
are updated according to Formula (
2).
In general, as indicated by Formula (
3), the goal of IFM is to maintain high model performance in each stage. Accordingly, ICMFed is designed to minimize the usage of communication resources and reduce the time consumption of model training through the five stages, i.e., task coordination, local learning, model uploading, global aggregation, and personalized adaptation.
3.2. Task Coordination
The main tasks of the server are to (1) start the learning tasks according to the actual needs, and (2) coordinate learning participants for the meta-knowledge. In general, the initialization of learning tasks is triggered by the server, when the performance of the deployed model decreases significantly, or users with limited local data in the learning consortium require a model to assist the 3D task. Moreover, the server is also responsible for the management of clients and the transition of stages. Note that when a task begins, the server will first select adequate clients as learning participants and then dispatch training-related information (such as the current global model, predefined hyperparameters, etc.) to them.
3.3. Local Learning
In each client, ICMFed conducts the local training through four steps, i.e., (1) training initialization, (2) data sampling, (3) model training, and (4) gradient calculation, which are described below.
3.3.1. Step 1: Training Initialization
Since the mechanism is targeted synchronously, each client will receive the most recent global model parameters
from the server at the beginning of each learning round. The initial model parameters of client
c in round
r of stage
s can be represented by Formula (
4).
where
is the initialized global model parameters of stage
s.
3.3.2. Step 2: Data Sampling
Within a client c, the local data are sampled into a support set and a query set . Then, will again be split into B batches with their samples ordered ascendingly according to the created time. The main purpose of batch splitting is to maintain the temporal information in the model-updating step as described below.
3.3.3. Step 3: Model Updating
After the preparation of training samples, the client will update its local model parameters based on the support set, as shown in Formula (
5).
where
is the intermediate model parameter;
b stands for batch id;
represents the
batch of
; and
is named as timing factor to adjust the step size of gradient descent according to the temporal information of each batch.
Local models in ICMFed conduct multiple batch gradient descent inside a round, whereas the general local training of FM processes the dataset to generate one gradient descent for the model parameter learning. Moreover, ICMFed employs the optimization on the temporal batches based on the timing factors, to ensure that the model feature extraction process can be quickly adapted among clients to simplify and unify the model learning behavior.
3.3.4. Step 4: Gradient Calculation
ICMFed can support FOMAML or Reptile to calculate the gradient required in updating the global meta-model. In general, besides the gradient calculated based on the support set as in Reptile, FOMAML also needs the gradient from the query set. The two modes are expressed in Formula (
6) (FOMAML) and Formula (
7) (Reptile), respectively.
where
is the uploaded gradient of client
c in round
r of stage
s.
3.4. Model Uploading
After obtaining the uploaded gradients, clients need to upload the gradients to the server via the network. Note that as the number of clients grows or the model structure becomes more complicated, uploading multi-layer parameters will incur large communication costs. Therefore, an adaptive filter is proposed to upload valuable and critical layers without jeopardizing the overall model performance.
Accordingly, ICMFed applies the cosine similarity vector (CSV) as the measure of the layer filter [
45,
46]. CSV, expressed by Formula (
8), calculates the directional correlation of each layer between the local and global parameters in the adjacent round.
where
L is the number of model layers, which is a constant value in a task;
is the cosine similarity of layer
l, which can be expressed by Formula (
9).
where ∘ is the Hadamard Product; and
is a function to sum the elements in matrix
X. Based on hyperparameter
designed as a threshold for the layer filter, client
c will not upload the parameter of layer
l when
.
However, while the global model is already distributed in the form of model parameters, broadcasting the global parameters to clients every round would significantly increase communication costs. To reduce such cost, the global gradient can be obtained from continuous alterations in global models, as shown in Formula (
10).
where
, i.e., the parameters in the last round of the previous stage, where
R is the total learning rounds per stage. Note that no layer filtering is required in the first round of the first stage.
Following the layer filter, clients can upload parameters via the network, e.g., wireless communication with roadside devices.
3.5. Global Aggregation
After the receipt of local updates from the clients, the global aggregation is executed in the server in three steps, e.g., parameter collation, weight analysis, and model updating.
3.5.1. Step 1: Parameter Collation
The server will continuously receive the gradient parameters submitted by clients. In synchronous mode, the server will wait for all clients to upload parameters and then use the formed gradient matrix (GM, as defined in Formula (
11)) for the aggregation.
Note that if
is not successfully received in a predefined amount of waiting time, i.e., the value is null, it would be substituted by the corresponding layer of the previous global gradient, as indicated in Formula (
12).
3.5.2. Step 2: Weight Analysis
Existing FM mechanisms tend to aggregate directly to update the global model, but this is not suitable in IFM scenarios. As in incremental scenarios, the data heterogeneity of clients is amplified, and treating them equally will impact the overall model performance.
To tackle it, ICMFed designs a weight vector (WV) based on stage incremental proportion (SIP) and client information richness (CIR). Specifically, SIP indicates the proportion of newly sensed data in a stage, as shown in Formula (
13). CIR is the information entropy of the training data. WV can be quantified in three ways, i.e., SIP, CIR, and a mixture of the two, as given by Formula (
14).
where
is a normalization function, i.e., Softmax.
3.5.3. Step 3: Model Updating
Finally, global gradient and updated global model parameters in round
r of stage
s can be obtained according to Formula (
15) and Formula (
16), respectively.
where
stands for the global learning rate.
After the model updating, related training content will be distributed to the clients. The training contents include training configurations, updated model parameters, and flags to harmonize tasks.
3.6. Personalized Adaptation
Users who use 3D services can download the current global meta-model to train personalized models based on their local data as illustrated in Formula (
17).
where
u represents the target user; and
is the adaptation learning rate, which is recommended to be equal to
. With one or a few epochs of gradient descent, a personalized model can be learned and applied.
3.7. Algorithm of ICMFed
Besides the preparation of the learning in phase 1 of ICMFed, the training and adaptation phases present the main workflow of ICMFed in each stage. The algorithms of these two phases are described below, respectively.
3.7.1. Algorithm of Training Phase
As listed in Algorithm 1, this phase consists of two parts, namely:
| Algorithm 1 Training phase of ICMFed |
- PART 1:
Pseudocode for the server. - 1:
Initialize and start a task; - 2:
for stage do - 3:
Select clients and send the “SELECTED” signal; - 4:
Distribute the training configuration, e.g., model structure, hyperparameters, etc.; - 5:
for round do - 6:
Distribute current global model parameters to the selected clients; - 7:
Send “TRAIN” signal to the selected clients; - 8:
Wait for local parameters from the selected clients; - 9:
Receive local model gradient from each selected client; - 10:
Calculate aggregation weight ; - 11:
Update global model parameters according to Formula ( 16); - 12:
end for - 13:
if Task termination conditions are met then - 14:
Send “STOP” signal and distribute the latest global model to all clients; - 15:
else - 16:
Transit to the next stage; - 17:
end if - 18:
end for - PART 2:
Pseudocode for the client; - 19:
if “SELECTED” signal is received then - 20:
Prepare itself according to the training configurations; - 21:
Sample a support set with B batches and a query set ; - 22:
Initialize local model according to Formula ( 4); - 23:
else if “TRAIN” signal is received then - 24:
Update local model according to Formula ( 5); - 25:
Calculate gradient according to Formula ( 6) or Formula ( 7); - 26:
Upload local gradient and the required parameters to calculate aggregation weight; - 27:
else if “STOP” signal is received then - 28:
Stop local training; - 29:
end if
|
- 1.
Part 1 at the server. After the initialization of the task, the server will iteratively and periodically perform model training according to the settings. First, the server will choose qualified clients at the beginning of each learning round. Note that the server will perform model aggregation only after all selected clients upload their parameters or the predefined waiting time is exceeded. The termination conditions will be determined once a single training stage is completed. Particularly, the conditions can be the performance target, task execution time, etc.
- 2.
Part 2 at each client. The clients will take various actions based on the signals received from the server. When a client is selected to perform a training stage, it will sample the training dataset and initialize the local model training. In each training round, clients update and upload their local model after the receipt of the global meta-model parameters from the server. Clients perform their learning tasks through continuous interactions with the server.
3.7.2. Algorithm of Adaptation Phase
As indicated in Algorithm 2, this phase also consists of two parts. The server periodically makes the recently trained global meta-model available to be downloadable by users who require 3D capabilities (also known as the target users). Accordingly, the target clients can download available models on demand. Due to the advantages of FM, the model to support 3D services can benefit from the fast adaptation of meta-knowledge to be personalized.
| Algorithm 2 Adaptation phase of ICMFed |
- PART 1:
Pseudocode for the server. - 1:
Make the newly updated meta-model available; - 2:
if The model download request is received then - 3:
Validate the identity of the user; - 4:
Send the current model parameter to the client; - 5:
end if - PART 2:
Pseudocode for the target client. - Require:
The client has sent a model download request to the server; - 6:
Receive the latest meta-model from the server; - 7:
Start local adaptation and personalize meta-model according to Formula ( 17). - 8:
Deploy the personalized model.
|
4. Evaluation
In this section, the performance of ICMFed is evaluated and discussed. First, common settings are introduced. Next, ICMFed is compared with baselines by training different models to demonstrate its supremacy in supporting 3D in IFM. Finally, the discussion is presented to provide some insights from the results.
4.1. Common Settings
For fairness, common settings for evaluation dataset, models, scenarios, methods, and metrics are configured, and note that random operations mentioned below are executed under the same seed.
4.1.1. Evaluation Dataset
IFM tasks are evaluated through the State-Farm-Distracted-Driver-Detection (
https://www.kaggle.com/competitions/state-farm-distracted-driver-detection/data (accessed on 13 February 2023)) dataset. The dataset contains 10 classes of distracted driving situations, with a total of 22,424 labeled samples from 26 drivers. As summarized in
Table 3, each driver is considered as a client with heterogeneous data, where six drivers are randomly selected as evaluation clients and the remaining 20 are training clients. Local data of clients are split into support sets and query sets randomly and evenly while FOMAML is used. Moreover, images are zoomed in to focus on drivers and cropped to the size of
during pre-processing.
4.1.2. Evaluation Models
Evaluations are performed on two representative models, i.e., DenseNet-121 [
47] and EfficientNet-B0 [
48]. Training settings of each model are shown in
Table 4. Note that in general, to achieve a better performance, Reptile requires different update epochs and learning rates from FAMOML, but in this study, all these configurations remain the same to ease the comparison.
4.1.3. Evaluation Scenarios
To mimic real-world 3D tasks, namely, incremental scenarios implicated by IFM, two scenario settings are considered:
Stage Transition. Stage transition simulates the continuous upgrade of the meta-model for 3D services. For each task, 40 stages are created. To reduce the experimental variables and support the assumption of changes in data sensed, five training rounds are executed at each stage regularly.
Data Growth. Data growth simulates continuous sensing of driver data. For each training client, 5% data is given when a task is initialized, and in each subsequent round, it will have a 50% chance to increase by 0% to 0.5%. The new data may contain a copy of existing data to mimic user behaviors (i.e., some common actions happen more often). Note that this configuration is not applied in evaluation clients, i.e., the data for evaluation clients are static.
Meanwhile, a delay of 3–20 s is added to each client to simulate the realistic network status, while communication cost is measured by the actual volume of exchanged data. Note that a more realistic scenario would also consider the client growth, but due to the limitation in the number of drivers in the dataset, it is not implemented in this experiment.
4.1.4. Evaluation Methods
Based on the above models to process the datasets prepared in configured scenarios, the following four methods are compared to reveal the performance difference:
FedAvg [
8]: FedAvg is the most recognized and representative synchronous FL algorithm. It aggregates models with a weighted average based on size of client data. Although FedAvg does not involve meta-learning, it is considered here as an evaluation baseline.
FedMeta [
15]: FedMeta considers a combination of FL and three types of meta-learning algorithms, namely, MAML, FOMAML, and Meta-SGD. The one with FOMAML is chosen for this experiment. FedMeta aggregates the gradients through the average function.
FedReptile [
39]: FedReptile is a combination of FL and Reptile. FedReptile also aggregates the gradients through the average function.
ICMFed: ICMFed is the proposed method. It adopts two classical meta-learning algorithms for local training, namely, FOMAML [
37] and Reptile [
38]. Moreover, based on the importance of each layer update, local gradients will be filtered before uploading. Finally, ICMFed aggregates the gradients based on both SIP and CIR.
4.1.5. Evaluation Metrics
To comprehensively evaluate the performance of each method, two types of metrics are designed, namely, general metrics and service-quality metrics. Specifically, four general metrics are utilized, namely:
Average Accuracy (AA): Accuracy is the most common measurement in machine learning. AA of all evaluation clients is recorded in each round, as expressed by Formula (
18), where
,
,
, and
represent true positives, true negatives, false positives, and false negatives, respectively.
Average Loss (AL): Cross-entropy is employed as the loss function for this experiment. AL of all evaluation clients is recorded in each round, as by Formula (
19), where
X refers to data samples;
I is the number of label categories (i.e., 10 for the dataset used in this study), and
y and
p are ground truth and prediction result, respectively.
Training Time (TT): TT is the cumulative time of trained rounds, including both time spent at the server
and all clients
, as defined in Formula (
20). Note that since clients work in parallel, the maximum elapsed time among all clients is used as
.
Communication Cost (CC): Major communication cost occurs when clients upload gradients
and the server distributes models
, as shown in Formula (
21).
Moreover, three service-quality metrics are designed as follows:
Best Service Quality (BSQ): BSQ is the maximum AA for all stages in the task. It is the maximum
among all rounds and stages, as defined in Formula (
22).
Improvement of Service Quality (ISQ): ISQ indicates performance improvement during the continuous model upgrades. It is the average variation of
in each stage, as shown in Formula (
23).
Stability of Service Quality (SSQ): SSQ stands for performance stability during the model updating. It is the proportion of AA decline during the task, as defined in Formula (
24), where
is a mark of performance decline, and
is the average value of
.
4.2. Evaluation of Gradient Filter
Before the comparison with baselines, the effect of the threshold for the gradient filter should be analyzed, i.e., the value of
. In general,
controls the cosine similarity, and
, based on the fact that when the cosine similarity is negative, there exist opposite components of the two vectors. Thus, only non-negative
is considered. As shown in
Figure 2 and
Figure 3, the performance of the two tested models with different
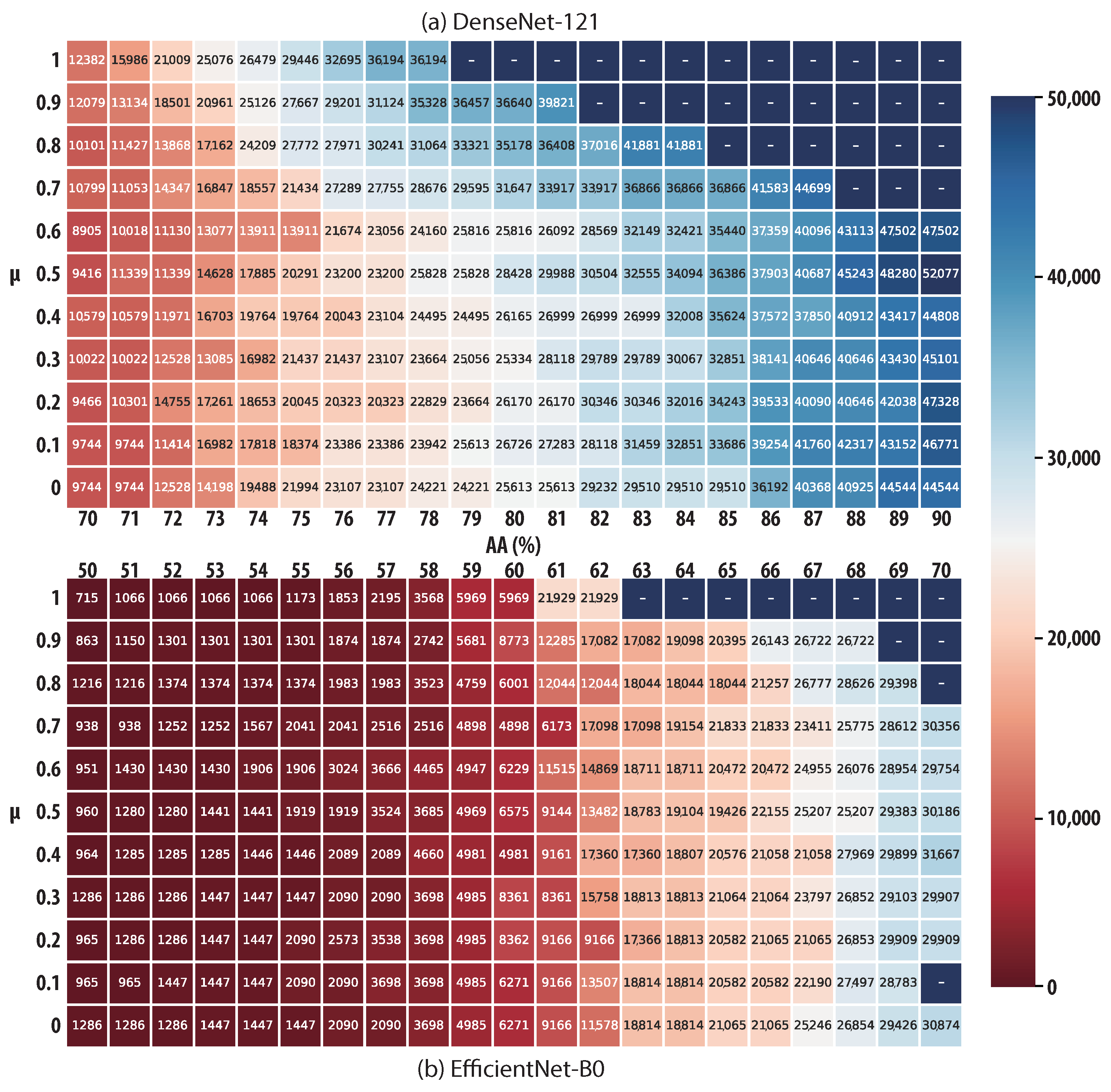
is examined by using FOMAML.
First, as shown in
Figure 2, different communication costs and rounds are required to reach AAs as indicated by the x-axis. It can be seen that when
is used, a more significant improvement in learning performance can be achieved, as ICMFed can save 3121.57% and 23.39% on average in DenseNet-121 and EfficientNet-B0, respectively. This shows the efficiency of the gradient filter in saving communication costs.
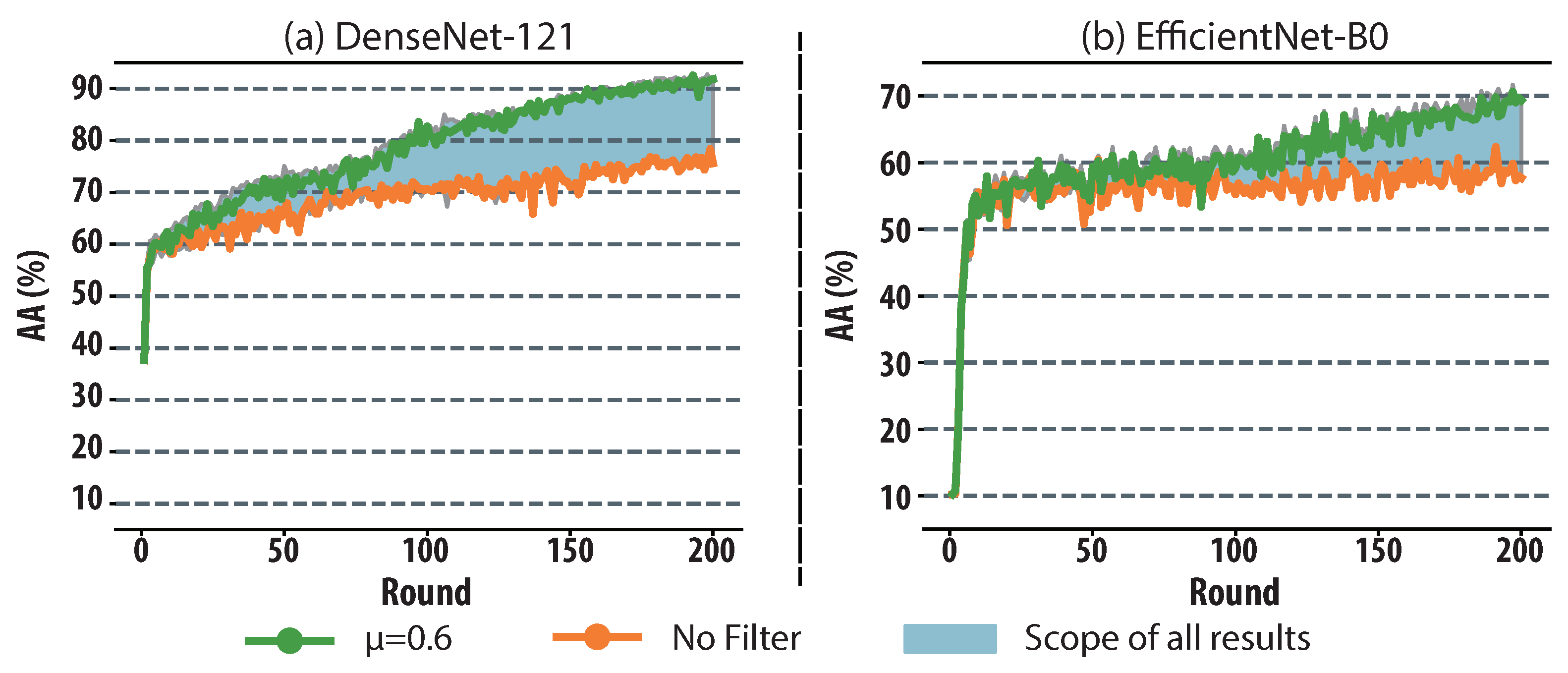
Moreover, as for learning stability, the AA curve under different
is presented in
Figure 3, in which the optimal results with
and the basic result without gradient filters are highlighted, respectively. It shows that the maximum and average improvement in AA are 29.57% and 13.47% in DenseNet-121, and 20.38% and 7.97% in EfficientNet-B0, respectively. Such results show that the amount of information to be transmitted through the network can be significantly reduced in each learning round.
4.3. Evaluation of General Metrics
Based on the above analysis, is used by default and accordingly, the three general metrics are used to compare the proposed ICMFed with the baselines.
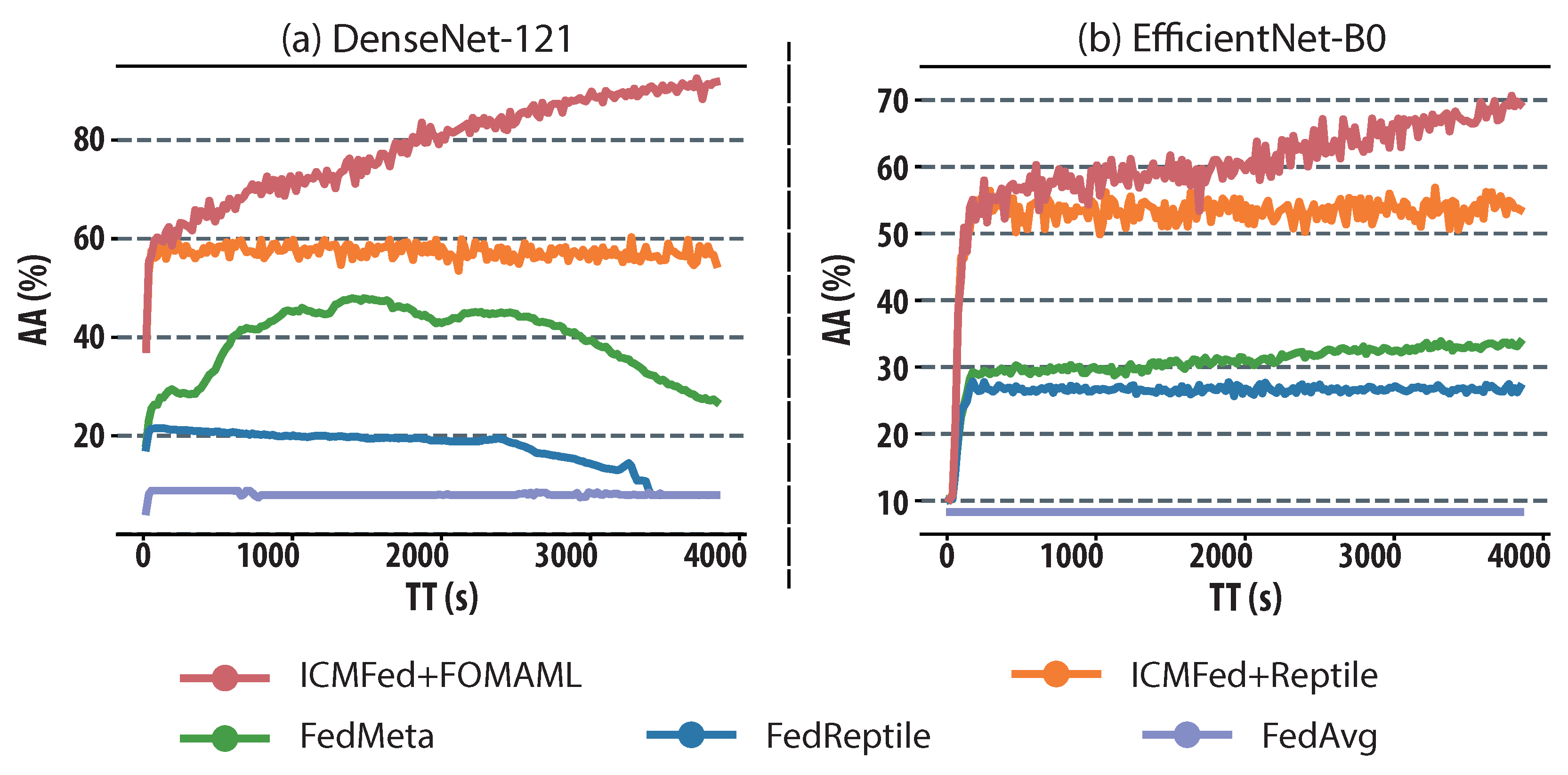
First, as shown in
Figure 4, under the same configuration, all the methods can surpass the baseline FedAvg, and FedMeta outperforms FedReptile with a clear gap between their AA curves. Unsurprisingly, ICMFed with FOMAML and Reptile show the same results as illustrated in the compared results between FedMeta (using FOMAML) and FedReptile, and more importantly, regardless of models to be trained; ICMFed can significantly improve AA, i.e., on average by 105.81% and 95.46% with FOMAML and 265.08% and 99.32% with Reptile.
Second, as presented in
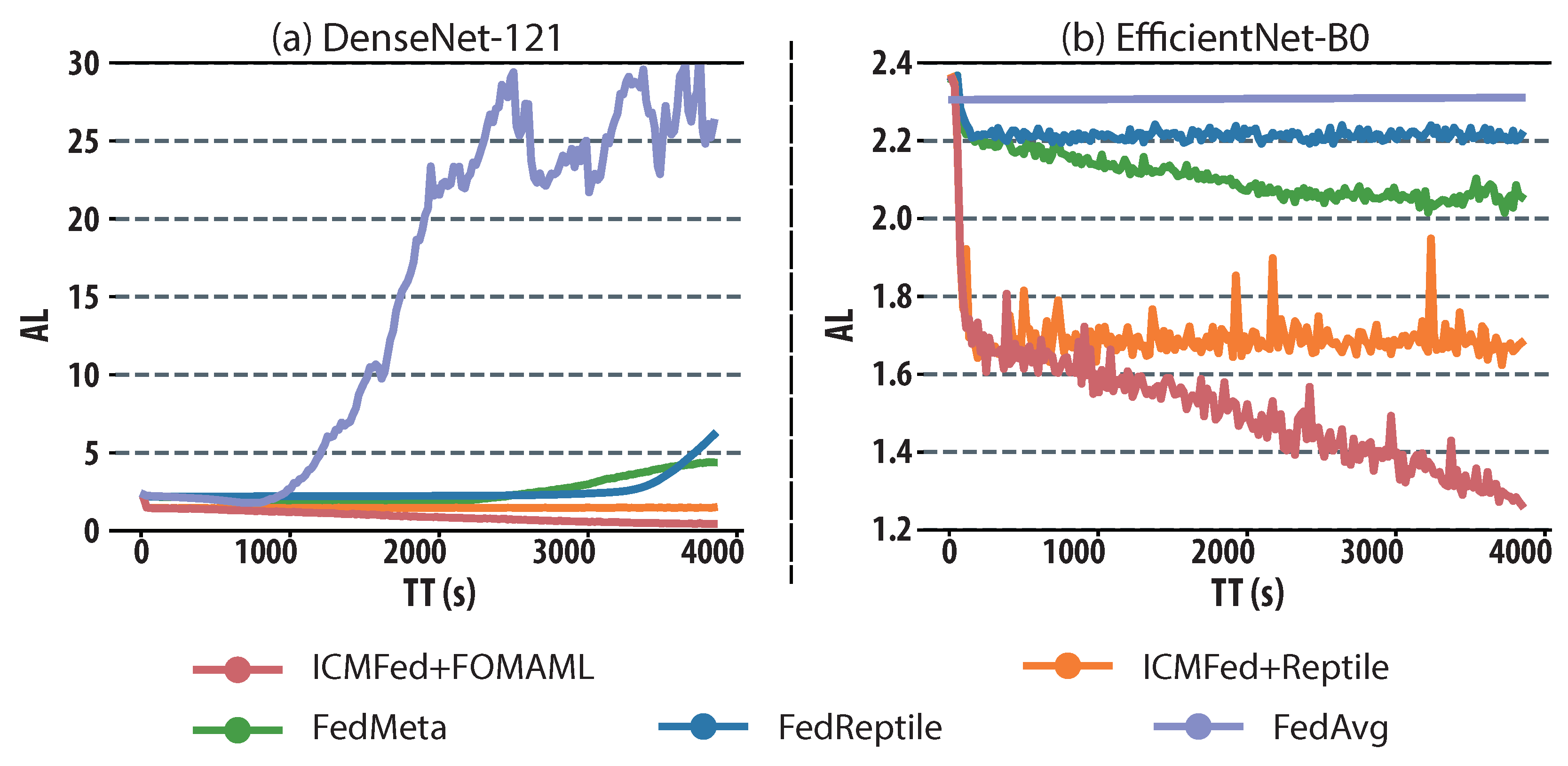
Figure 5, ICMFed can boost AL by about 57.03% and 28.52% with FOMAML and 38.58% and 23.27% with Reptile, while comparing to the baselines. Specifically, as shown in
Figure 5a, ICMFed can remediate the overfitting experienced in the baselines to train DenseNet-121. As shown in
Figure 5b, even though the AL curves of two ICMFed variants fluctuate, it can still have the best performance compared to the baselines.
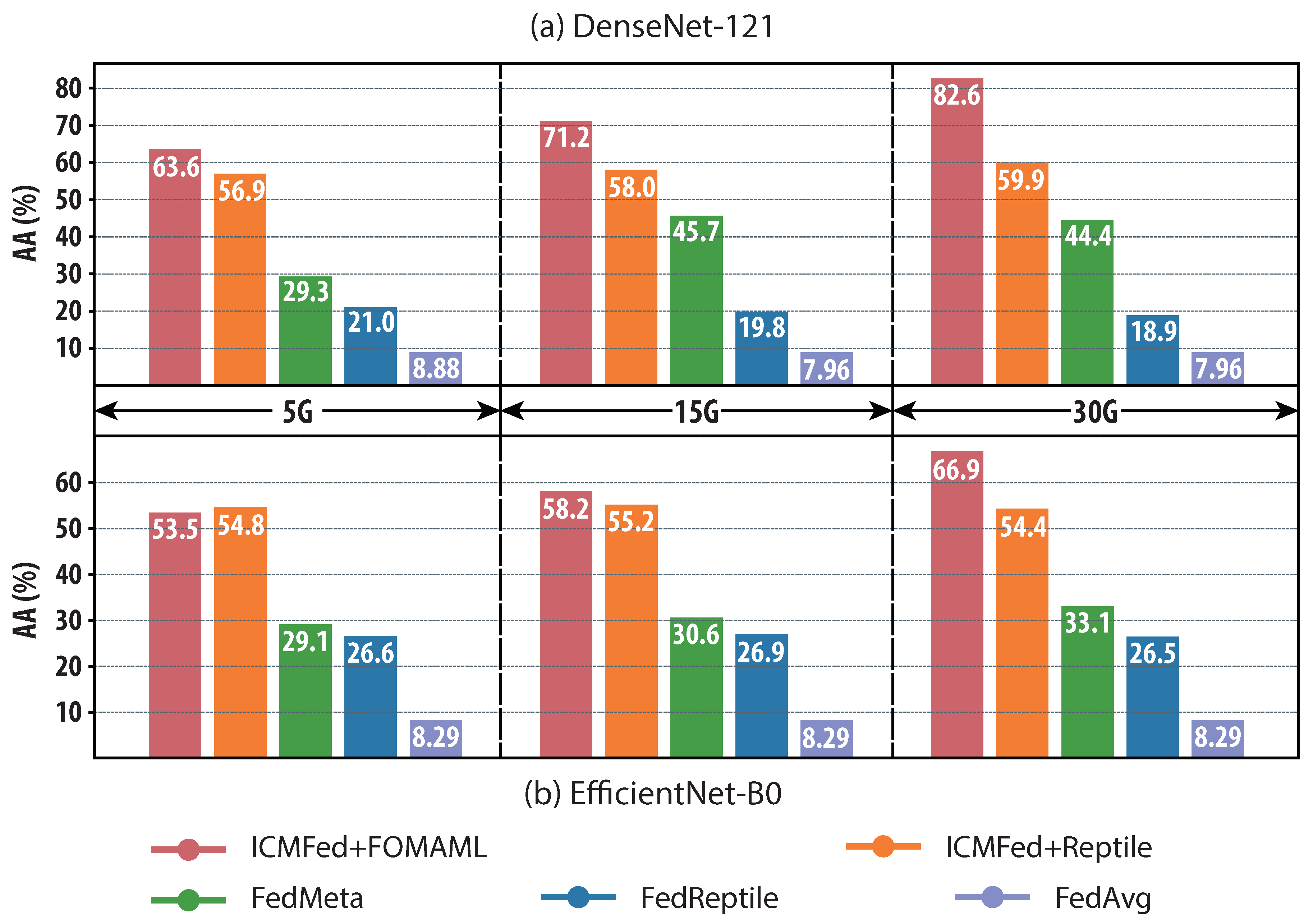
Finally,
Figure 6 demonstrates AA reached with the specified communication cost for each evaluated method. Five gigabytes (GB), fifteen GB, and thirty GB are chosen as the three communication cost thresholds. In general, DenseNet-121 requires less cost than EfficientNet-B0 to reach a higher AA. For the three testing cases in DenseNet-121, ICMFed can improve the reached AA on average by 312.34%, 369.50%, and 453.33% with FOMAML and 269.06%, 282.73%, and 301.55% with Reptile, respectively. As for the three cases in EfficientNet-B0, ICMFed can improve the reached AA on average by 243.25%, 269.31%, and 320.84% with FOMAML and 251.67%, 250.53%, and 241.83% with Reptile, respectively. In summary, ICMFed can improve overall performance by 297.16%.
The above analyses show that compared to the baselines, ICMFed (especially the one equipped with FOMAML) can not only significantly reduce the communication cost but also dramatically improve the learning accuracy for both tested models.
4.4. Evaluation of Service-Quality Metrics
Based on the three service-quality metrics, the proposed ICMFed is further compared with the baselines. As illustrated in
Table 5, in general, ICMFed with FOMAML is better than the one with Reptile, even though they can both outperform other methods. Specifically, while compared to the three baselines, ICMFed with FOMAML can enhance service quality by 193.46% in DenseNet-121 and 116.42% in EfficientNet-B0, which is 71.24% and 77.57% for Reptile. Note that SSQ of ICMFed is slightly lower in EfficientNet-B0, which can be interpreted as its slight sacrifice of stability for better service quality.
In summary, an average improvement of 96.86% is achieved by ICMFed in service quality for both tested models.
4.5. Discussion
For experiment settings, the following two points are worth elaborating:
Heterogeneous Setting. Even though the abovementioned settings do not include a specific section to describe the heterogeneous settings, there are three heterogeneous settings in our experimental scenario. First, in the State-Farm-Distracted-Driver-Detection dataset, there is heterogeneity across driver data, as shown in
Table 3, and the clients are divided according to drivers to obtain data heterogeneity across clients. Second, random time delays for the clients are added to simulate heterogeneous communication conditions. Finally, during data increment, both the proportion of data growth and the probability of its occurrence may vary greatly between clients to simulate the heterogeneous data-aware process.
Model Selection. To fairly evaluate the methods, DenseNet-121 and EfficientNet-B0 are selected to perform the experiments. These are chosen because they are classic and widely used models, and can achieve state-of-the-art performance in computer vision with a representative and indicative value [
49,
50]. They are also widely used in other works as testing models [
51,
52,
53].
According to the above evaluations, the following observations can be drawn, namely:
Gradient filters are helpful in optimizing both learning cost and accuracy. Gradient filters are originally designed to save communication costs. Since the amount of information to be updated is reduced, the filter may impact the overall learning accuracy. However, the results show that the usage of gradient filters will not affect the model performance, and instead, it can slightly improve AA by using an appropriate threshold .
Meta-learning is effective to support 3D tasks in a personalized context. Based on the fast adaptation enabled by the meta-model, meta-learning combined with FL, i.e., FM, can enable the personalization of local models to better support 3D. Moreover, by using dedicated strategies proposed by ICMFed, the performance can be significantly improved to support IFM, which is more realistic.
ICMFed shows significant improvements compared to the baselines. According to the evaluation results in generic and service-quality metrics, ICMFed is cost-efficient to support IFM in 3D regardless of the models to be trained. Specifically, ICMFed equipped with FOMAML can outperform the one with Reptile under the same configuration.
5. Conclusions
To protect user privacy and gradually increasing process data, IFM is starting to be discussed to support 3D. In particular, four emerging challenges, i.e., data accumulation, communication optimization, data heterogeneity, and device heterogeneity, need to be addressed and hence, this paper proposes ICMFed, which can (1) achieve retention of knowledge by introducing a temporal factor associated with the batches created by sorting data created time-ascendingly in local training, (2) optimize the client–server interaction according to gradient filters of each model layer with communication costs reduced, (3) update the global model based on the weights measuring the differences of local updates in information richness to learn meta-learning efficiently, and (4) enhance 3D capability for each user based on the adaptation of the global meta-model to improve personalization.
According to the evaluation made on the State-Farm-Distracted-Driver-Detection dataset, ICMFed with FOMAML or Reptile can outperform the baselines to train both DenseNet-121 and EfficientNet-B0 models. Particularly, ICMFed can boost model accuracy by about 297.16% (when the target communication cost is reached), and improve service quality by about 96.86%.
In the future, first, the asynchronous mode of ICMFed will be studied to further improve the learning performance, especially the model update speed. Meanwhile, in asynchronous mode, the inference of global gradients on clients needs to be taken into account, i.e., due to the asynchronization, it cannot be inferred directly from the alterations between two adjacent rounds. In addition, the local gradients, whose creation time may vary, shall be aggregate-adaptive to remedy the impact of temporal difference. Finally, incentive mechanisms will be designed for ICMFed to attract more users to share their knowledge.
Author Contributions
Conceptualization, Z.G., S.L., J.H. and L.Y.; methodology, Z.G., S.L., J.H. and L.Y.; software, Z.G., S.L., J.H. and L.Y.; validation, Z.G., S.L., J.H. and L.Y.; formal analysis, Z.G., S.L., J.H., L.Y. and B.Z.; investigation, Z.G., S.L., J.H., L.Y. and B.Z.; resources, L.Y. and B.Z.; data curation, Z.G., S.L. and J.H.; writing—original draft preparation, Z.G.; writing—review and editing, S.L., J.H., L.Y. and B.Z.; visualization, Z.G. and L.Y.; supervision, S.L., J.H., L.Y. and B.Z.; project administration, L.Y. and B.Z.; funding acquisition, L.Y. and B.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China grant number 62002398 and GuangDong Basic and Applied Basic Research Foundation grant number 2023A1515012895.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| 3D | Driver Distraction Detection |
| AA | Average Accuracy |
| AL | Average Loss |
| BSQ | Best Service Quality |
| CC | Communication Cost |
| CIR | Client Information Richness |
| CSV | Cosine Similarity Vector |
| FL | Federated Learning |
| FM | Federated Meta-learning |
| FOMAML | First-Order Model-Agnostic Meta-learning |
| GB | Gigabyte |
| GM | Gradient Matrix |
| ICMFed | Incremental and Cost-efficient Mechanism of Federated Meta-learning |
| IFM | Incremental Federated Meta-learning |
| IoT | Internet of Things |
| ISQ | Improvement of Service Quality |
| MAML | Model-Agnostic Meta-learning |
| Non-IID | Non-Independent and Identically Distributed |
| SIP | Stage Incremental Proportion |
| SSQ | Stability of Service Quality |
| TT | Training Time |
| WV | Weight Vector |
References
- Qin, L.; Li, Z.R.; Chen, Z.; Bill, M.A.; Noyce, D.A. Understanding driver distractions in fatal crashes: An exploratory empirical analysis. J. Saf. Res. 2019, 69, 23–31. [Google Scholar] [CrossRef] [PubMed]
- Wundersitz, L. Driver distraction and inattention in fatal and injury crashes: Findings from in-depth road crash data. Traffic Inj. Prev. 2019, 20, 696–701. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.D.; Young, K.L.; Regan, M.A. Defining driver distraction. Driv. Distraction Theory Eff. Mitig. 2008, 13, 31–40. [Google Scholar]
- Hari, C.; Sankaran, P. Driver distraction analysis using face pose cues. Expert Syst. Appl. 2021, 179, 115036. [Google Scholar] [CrossRef]
- Aljasim, M.; Kashef, R. E2DR: A deep learning ensemble-based driver distraction detection with recommendations model. Sensors 2022, 22, 1858. [Google Scholar] [CrossRef]
- Li, G.; Yan, W.; Li, S.; Qu, X.; Chu, W.; Cao, D. A temporal–spatial deep learning approach for driver distraction detection based on EEG signals. IEEE Trans. Autom. Sci. Eng. 2021, 19, 2665–2677. [Google Scholar] [CrossRef]
- Fang, J.; Yan, D.; Qiao, J.; Xue, J.; Yu, H. DADA: Driver attention prediction in driving accident scenarios. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4959–4971. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Shang, E.; Liu, H.; Yang, Z.; Du, J.; Ge, Y. FedBiKD: Federated Bidirectional Knowledge Distillation for Distracted Driving Detection. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Javed, A.R.; Hassan, M.A.; Shahzad, F.; Ahmed, W.; Singh, S.; Baker, T.; Gadekallu, T.R. Integration of blockchain technology and federated learning in vehicular (iot) networks: A comprehensive survey. Sensors 2022, 22, 4394. [Google Scholar] [CrossRef]
- Novikova, E.; Fomichov, D.; Kholod, I.; Filippov, E. Analysis of privacy-enhancing technologies in open-source federated learning frameworks for driver activity recognition. Sensors 2022, 22, 2983. [Google Scholar] [CrossRef] [PubMed]
- Feng, T.; Wang, M.; Yuan, H. Overcoming Catastrophic Forgetting in Incremental Object Detection via Elastic Response Distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9427–9436. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. Personalized federated learning: A meta-learning approach. arXiv 2020, arXiv:2002.07948. [Google Scholar]
- Chen, F.; Luo, M.; Dong, Z.; Li, Z.; He, X. Federated meta-learning with fast convergence and efficient communication. arXiv 2018, arXiv:1802.07876. [Google Scholar]
- Hussain, M.A.; Huang, S.A.; Tsai, T.H. Learning with Sharing: An Edge-optimized Incremental Learning Method for Deep Neural Networks. IEEE Trans. Emerg. Top. Comput. 2022. [Google Scholar] [CrossRef]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Nori, M.K.; Yun, S.; Kim, I.M. Fast federated learning by balancing communication trade-offs. IEEE Trans. Commun. 2021, 69, 5168–5182. [Google Scholar] [CrossRef]
- Nishio, T.; Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In Proceedings of the ICC 2019-2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- AbdulRahman, S.; Tout, H.; Ould-Slimane, H.; Mourad, A.; Talhi, C.; Guizani, M. A survey on federated learning: The journey from centralized to distributed on-site learning and beyond. IEEE Internet Things J. 2020, 8, 5476–5497. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain empowered asynchronous federated learning for secure data sharing in internet of vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4298–4311. [Google Scholar] [CrossRef]
- Wei, G.; Li, X. Knowledge Lock: Overcoming Catastrophic Forgetting in Federated Learning. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Chengdu, China, 16–19 May 2022; pp. 601–612. [Google Scholar]
- Dong, J.; Wang, L.; Fang, Z.; Sun, G.; Xu, S.; Wang, X.; Zhu, Q. Federated class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10164–10173. [Google Scholar]
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble distillation for robust model fusion in federated learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2351–2363. [Google Scholar]
- Yoon, J.; Jeong, W.; Lee, G.; Yang, E.; Hwang, S.J. Federated continual learning with weighted inter-client transfer. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 12073–12086. [Google Scholar]
- Le, J.; Lei, X.; Mu, N.; Zhang, H.; Zeng, K.; Liao, X. Federated continuous learning with broad network architecture. IEEE Trans. Cybern. 2021, 51, 3874–3888. [Google Scholar] [CrossRef]
- Qin, Z.; Li, G.Y.; Ye, H. Federated learning and wireless communications. IEEE Wireless Commun. 2021, 28, 134–140. [Google Scholar] [CrossRef]
- Liu, S.; Chen, Q.; You, L. Fed2a: Federated learning mechanism in asynchronous and adaptive modes. Electronics 2022, 11, 1393. [Google Scholar] [CrossRef]
- Chen, Y.; Ning, Y.; Slawski, M.; Rangwala, H. Asynchronous online federated learning for edge devices with non-iid data. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 15–24. [Google Scholar]
- You, L.; Liu, S.; Chang, Y.; Yuen, C. A triple-step asynchronous federated learning mechanism for client activation, interaction optimization, and aggregation enhancement. IEEE Internet Things J. 2022, 9, 24199–24211. [Google Scholar] [CrossRef]
- Mhaisen, N.; Abdellatif, A.A.; Mohamed, A.; Erbad, A.; Guizani, M. Optimal user-edge assignment in hierarchical federated learning based on statistical properties and network topology constraints. IEEE Trans. Netw. Sci. Eng. 2021, 9, 55–66. [Google Scholar] [CrossRef]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3400–3413. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, J.; Guo, S.; Xu, W. Layer-wised model aggregation for personalized federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10092–10101. [Google Scholar]
- Lian, Z.; Wang, W.; Su, C. COFEL: Communication-efficient and optimized federated learning with local differential privacy. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Lian, Z.; Wang, W.; Huang, H.; Su, C. Layer-based communication-efficient federated learning with privacy preservation. IEICE Trans. Inf. Syst. 2022, 105, 256–263. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999v3. [Google Scholar]
- Nichol, A.; Schulman, J. Reptile: A scalable metalearning algorithm. arXiv 2018, arXiv:1803.02999v1. [Google Scholar]
- Jiang, Y.; Konečnỳ, J.; Rush, K.; Kannan, S. Improving federated learning personalization via model agnostic meta learning. arXiv 2019, arXiv:1909.12488. [Google Scholar]
- Qu, H.; Liu, S.; Li, J.; Zhou, Y.; Liu, R. Adaptation and Learning to Learn (ALL): An Integrated Approach for Small-Sample Parking Occupancy Prediction. Mathematics 2022, 10, 2039. [Google Scholar] [CrossRef]
- Qu, H.; Liu, S.; Guo, Z.; You, L.; Li, J. Improving Parking Occupancy Prediction in Poor Data Conditions Through Customization and Learning to Learn. In Proceedings of the Knowledge Science, Engineering and Management: 15th International Conference, KSEM, Singapore, 6–8 August 2022; pp. 159–172. [Google Scholar]
- Li, W.; Wang, S. Federated meta-learning for spatial-temporal prediction. Neural Comput. Appl. 2022, 34, 10355–10374. [Google Scholar] [CrossRef]
- Wu, W.; He, L.; Lin, W.; Mao, R.; Maple, C.; Jarvis, S. SAFA: A semi-asynchronous protocol for fast federated learning with low overhead. IEEE Trans. Comp. 2020, 70, 655–668. [Google Scholar] [CrossRef]
- Huang, T.; Lin, W.; Wu, W.; He, L.; Li, K.; Zomaya, A.Y. An efficiency-boosting client selection scheme for federated learning with fairness guarantee. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1552–1564. [Google Scholar] [CrossRef]
- Li, D.; Li, J.; Fan, Y.; Lu, G.; Ge, J.; Liu, X. Printed label defect detection using twice gradient matching based on improved cosine similarity measure. Expert Syst. Appl. 2022, 204, 117372. [Google Scholar] [CrossRef]
- Yu, T.; Kumar, S.; Gupta, A.; Levine, S.; Hausman, K.; Finn, C. Gradient surgery for multi-task learning. Adv. Neural Inf. Process. Syst. 2020, 33, 5824–5836. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Nandhini, S.; Ashokkumar, K. An automatic plant leaf disease identification using DenseNet-121 architecture with a mutation-based henry gas solubility optimization algorithm. Neural Comput. Appl. 2022, 34, 5513–5534. [Google Scholar] [CrossRef]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Chetoui, M.; Akhloufi, M.A. Automated Detection of COVID-19 Cases using Recent Deep Convolutional Neural Networks and CT images. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Virtual, 1–5 November 2021; pp. 3297–3300. [Google Scholar]
- Oztekin, F.; Katar, O.; Sadak, F.; Yildirim, M.; Cakar, H.; Aydogan, M.; Ozpolat, Z.; Talo Yildirim, T.; Yildirim, O.; Faust, O.; et al. An Explainable Deep Learning Model to Prediction Dental Caries Using Panoramic Radiograph Images. Diagnostics 2023, 13, 226. [Google Scholar] [CrossRef]
- Jana, S.; Middya, A.I.; Roy, S. Participatory Sensing Based Urban Road Condition Classification using Transfer Learning. Mob. Netw. Appl. 2023, 45, 1–17. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}