


Personalized Movie Recommendations Based on a Multi-Feature Attention Mechanism with Neural Networks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
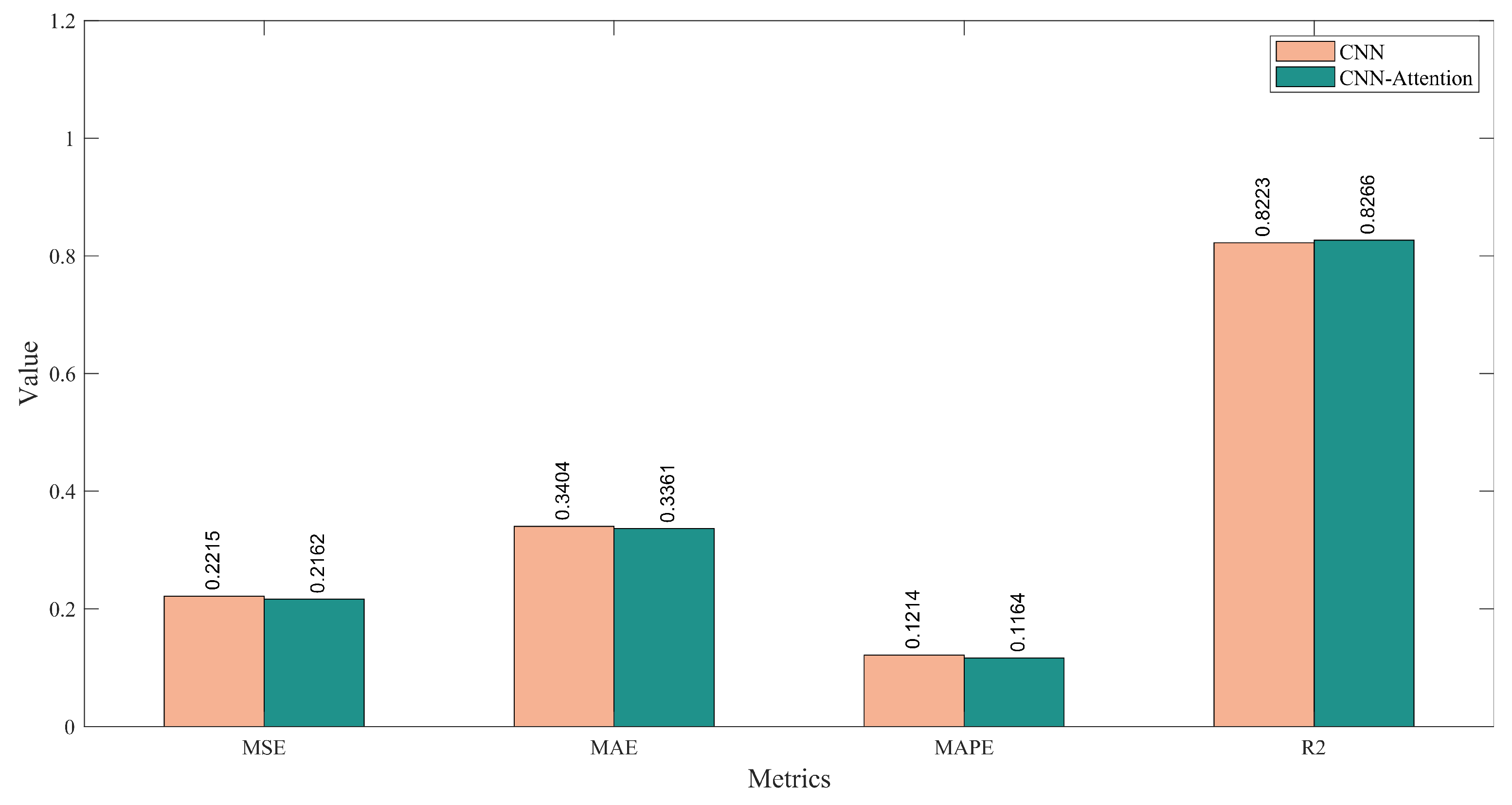{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
3. The Proposed Algorithm in This Paper
3.1. Overall Design of the Algorithm
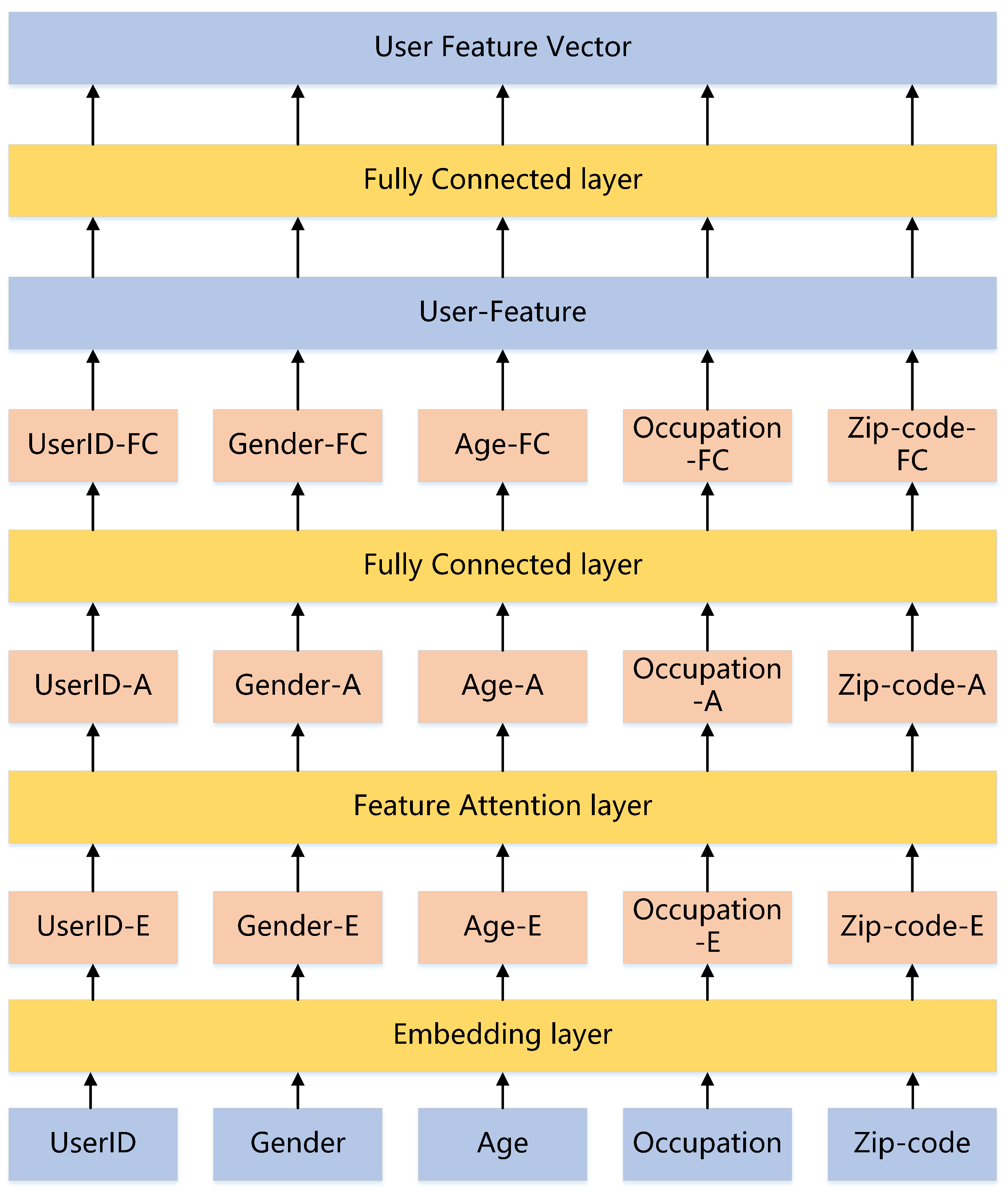
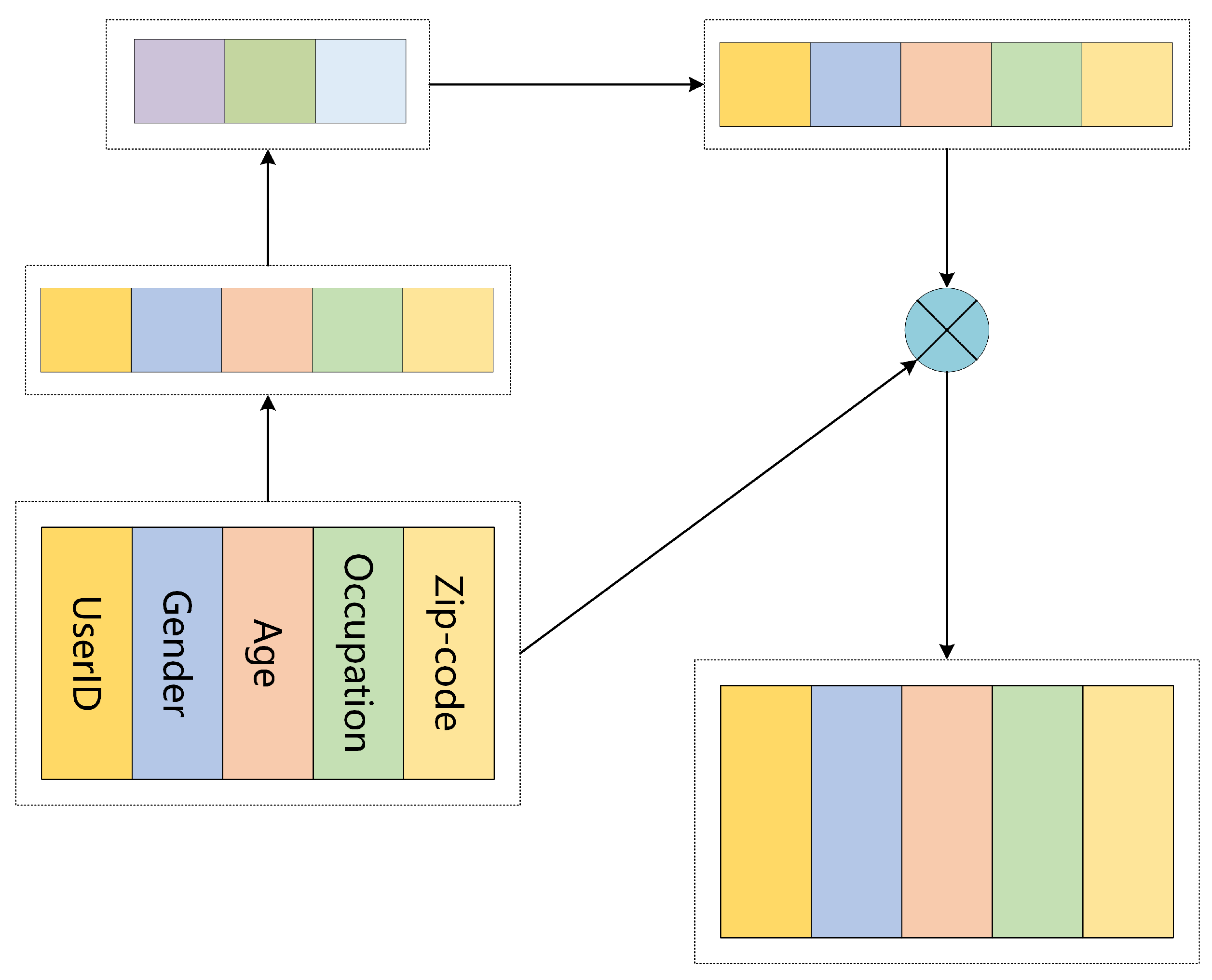
3.2. User Network Architecture Design
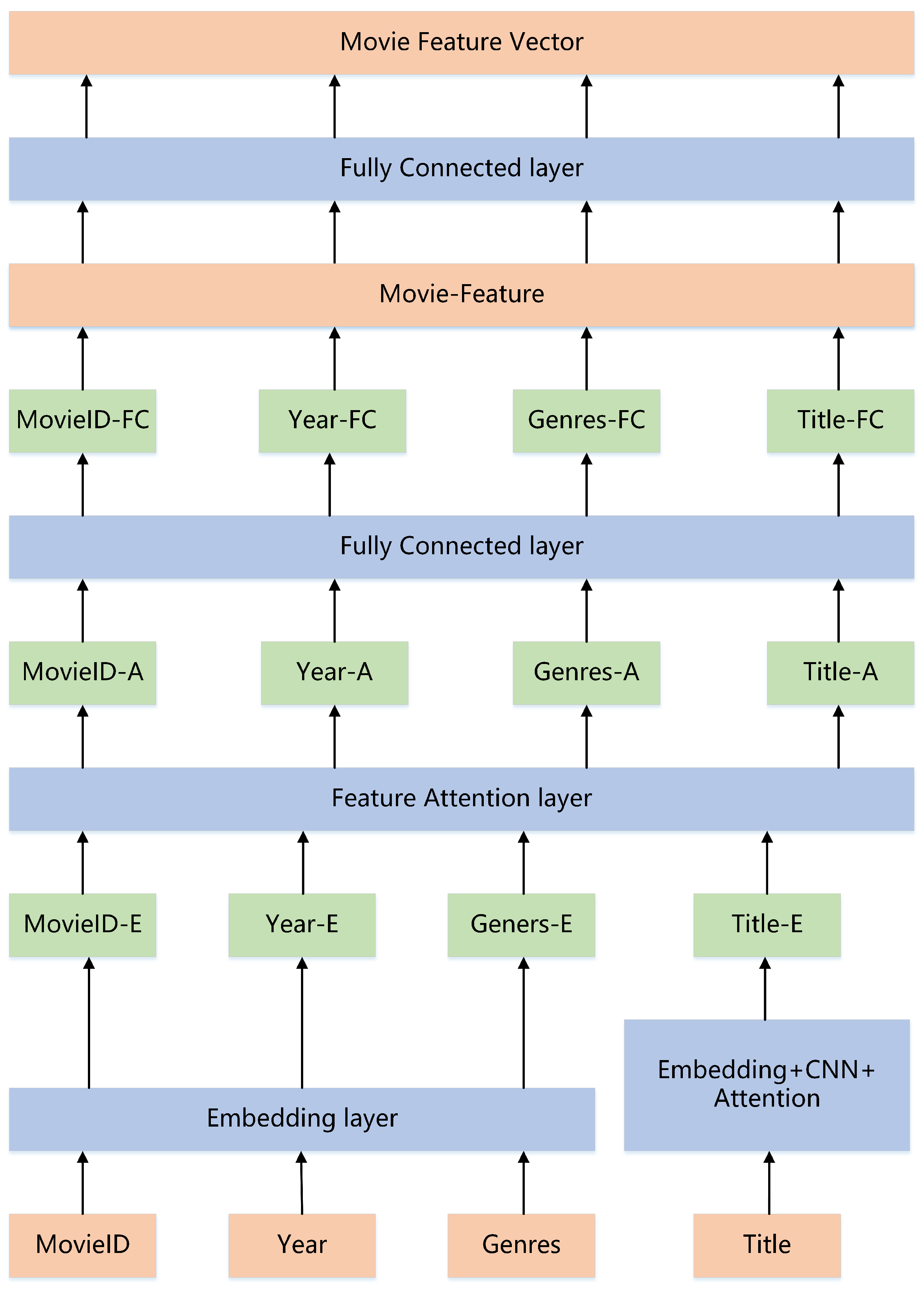
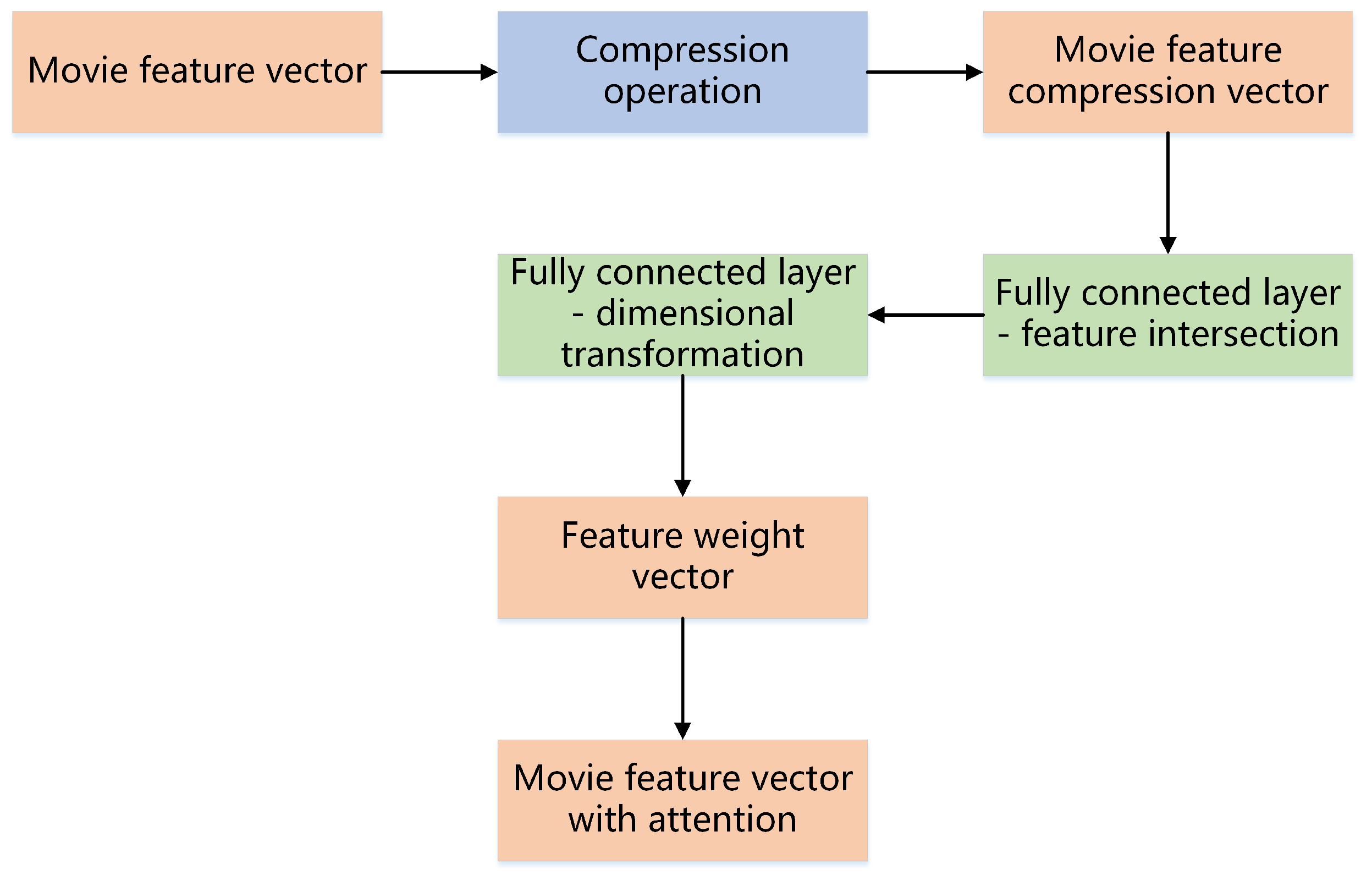
3.3. Movie Network Architecture Design
3.4. Movie Rating Prediction and Recommendation
4. Experimental Design and Analysis
4.1. Dataset Introduction
4.2. Experimental Environment Introduction
4.3. Evaluation Metrics
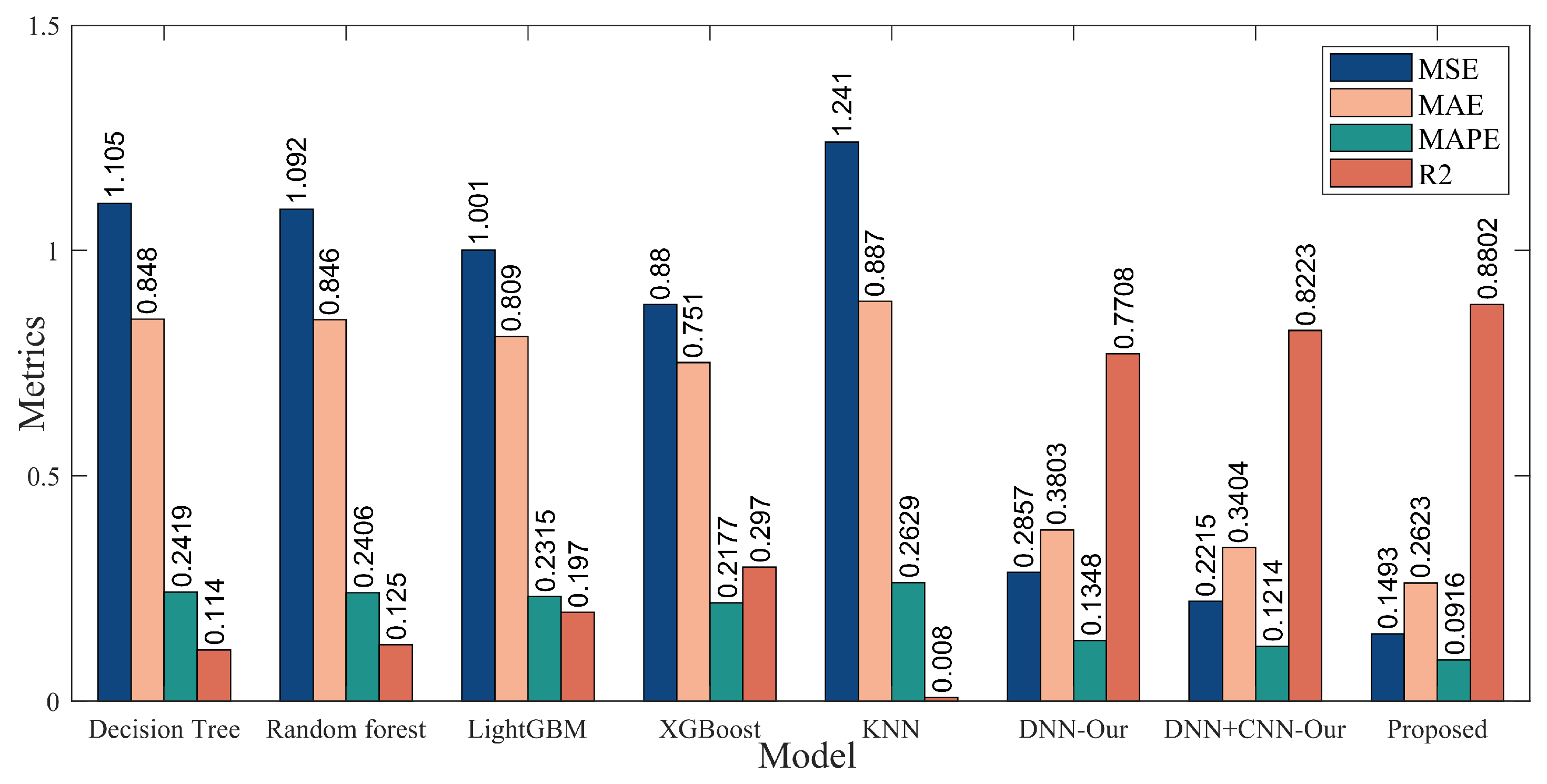
4.4. Performance Comparison with Classical Machine Learning Models
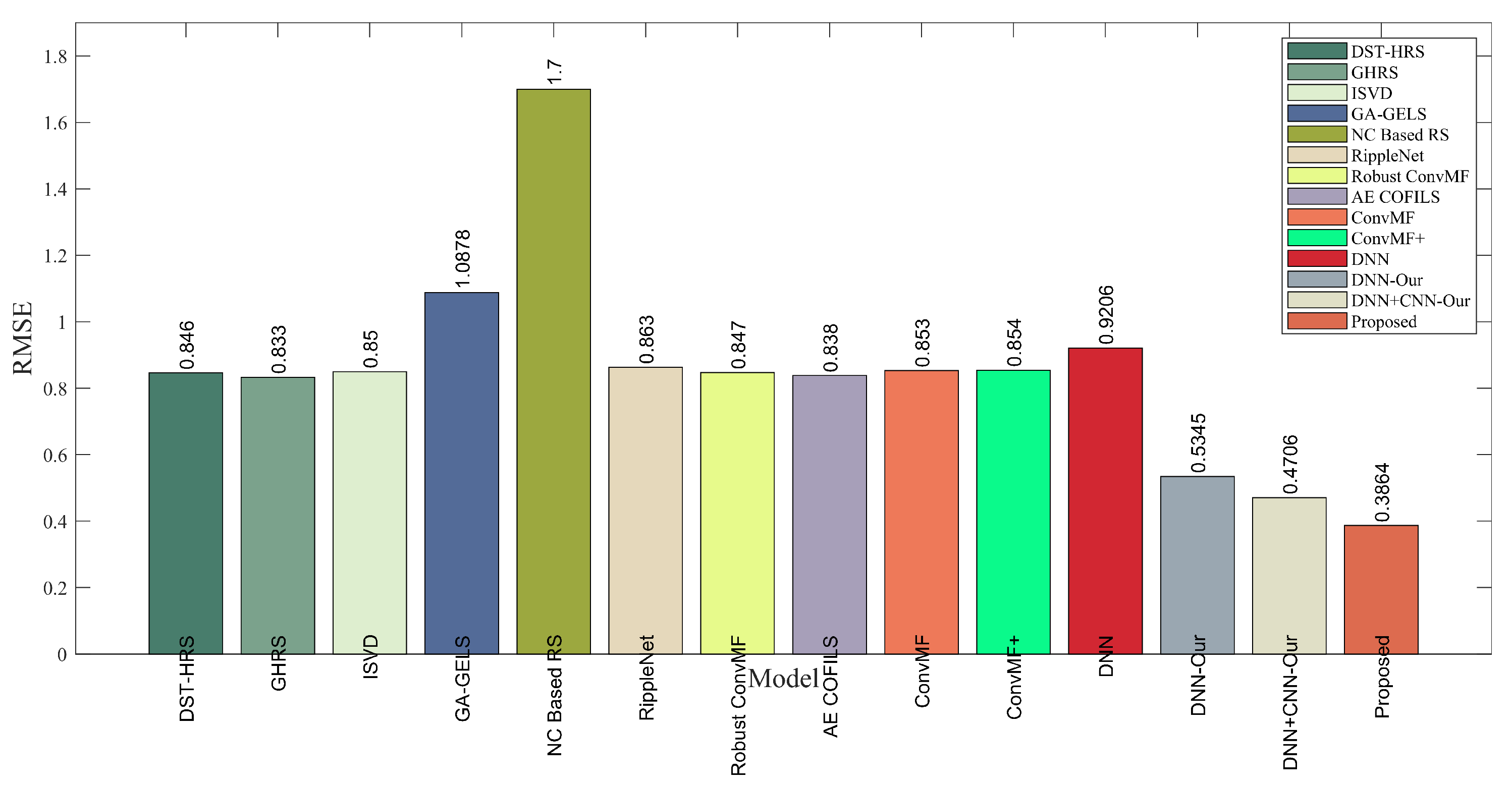
4.5. Performance Comparison with Some of the Major and Recent Models
4.6. Performance Analysis of Text Feature Extraction Based on CNN-Attention
4.7. Feature Attention-Based Feature Extraction Performance Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, C. An Advertising Recommendation Algorithm Based on Deep Learning Fusion Model. J. Sens. 2022, 2022, 1632735. [Google Scholar] [CrossRef]
- Zhao, K.; Ge, L. A survey on the internet of things security. In Proceedings of the 2013 Ninth International Conference on Computational Intelligence and Security, Emeishan, China, 14–15 December 2013; pp. 663–667. [Google Scholar]
- Wu, T.; Sun, F.; Dong, J.; Wang, Z.; Li, Y. Context-aware session recommendation based on recurrent neural networks. Comput. Electr. Eng. 2022, 100, 107916. [Google Scholar] [CrossRef]
- Yu, S.; Qiu, J.; Bao, X.; Guo, M.; Chen, X.; Sun, J. Movie Rating Prediction Recommendation Algorithm based on XGBoost-DNN. In Proceedings of the 2022 12th International Conference on Information Science and Technology (ICIST), Kaifeng, China, 14–16 October 2022; pp. 288–293. [Google Scholar]
- Li, J.; Xu, W.; Wan, W.; Sun, J. Movie recommendation based on bridging movie feature and user interest. J. Comput. Sci. 2018, 26, 128–134. [Google Scholar] [CrossRef]
- Zhang, Z.; Qiang, C.; Duan, S. Review of personalized movie recommendation algorithms. Comput. Knowl. Technol. 2021, 17, 80–81, 84. [Google Scholar] [CrossRef]
- Li, D. Movie recommendation system based on multi-feature fusion. Comput. Mod. 2019, 8, 121–126. [Google Scholar]
- Inan, E.; Tekbacak, F.; Ozturk, C. Moreopt: A goal programming based movie recommender system. J. Comput. Sci. 2018, 28, 43–50. [Google Scholar] [CrossRef]
- Sahu, S.; Kumar, R.; MohdShafi, P.; Shafi, J.; Kim, S.; Ijaz, M.F. A Hybrid Recommendation System of Upcoming Movies Using Sentiment Analysis of YouTube Trailer Reviews. Mathematics 2022, 10, 1568. [Google Scholar] [CrossRef]
- Fang, W.; Sha, Y.; Qi, M.; Sheng, V.S. Movie Recommendation Algorithm Based on Ensemble Learning. Intell. Autom. Soft Comput. 2022, 34, 609–622. [Google Scholar] [CrossRef]
- Jayalakshmi, S.; Ganesh, N.; Čep, R.; Senthil Murugan, J. Movie recommender systems: Concepts, methods, challenges, and future directions. Sensors 2022, 22, 4904. [Google Scholar] [CrossRef]
- Manogaran, G.; Varatharajan, R.; Priyan, M.K. Hybrid recommendation system for heart disease diagnosis based on multiple kernel learning with adaptive neuro-fuzzy inference system. Multimed. Tools Appl. 2018, 77, 4379–4399. [Google Scholar] [CrossRef]
- Yeung, K.F.; Yang, Y. A proactive personalized mobile news recommendation system. In Proceedings of the 2010 Developments in E-systems Engineering, London, UK, 6–8 September 2010; pp. 207–212. [Google Scholar]
- Lei, M. A study of shopping behavior based on Alibaba big data. Internet Things Technol. 2016, 6, 57–60. [Google Scholar]
- Yuan, X.; Zhang, P.; Wang, J. “State-Behavior” Modeling and Its Application in Analyzing Product Information Seeking Behavior of E-commerce Websites Users. Data Anal. Knowl. Discov. 2015, 31, 93–100. [Google Scholar]
- Asenova, M.; Chrysoulas, C. Personalized Micro-Service Recommendation System for Online News. Procedia Comput. Sci. 2019, 160, 610–615. [Google Scholar] [CrossRef]
- Peng, J.; Xu, J. Personalized Product Recommendation Model of Automatic Question Answering Robot Based on Deep Learning. J. Robot. 2022, 2022, 1256083. [Google Scholar] [CrossRef]
- Sun, P. Music Individualization Recommendation System Based on Big Data Analysis. Comput. Intell. Neurosci. 2022, 2022, 7646000. [Google Scholar] [CrossRef]
- Liu, K.F.; Zhang, Y.; Zhang, Q.X.; Wang, Y.G.; Gao, K.L. Chinese News Text Classification and Its Application Based on Combined-Convolutional Neural Network. J. Comput. 2022, 33, 1–14. [Google Scholar] [CrossRef]
- Wang, D. Analysis of Sentiment and Personalised Recommendation in Musical Performance. Comput. Intell. Neurosci. 2022, 2022, 2778181. [Google Scholar] [CrossRef]
- Zeng, F.; Tang, R.; Wang, Y. User Personalized Recommendation Algorithm Based on GRU Network Model in Social Networks. Mob. Inf. Syst. 2022, 2022, 1487586. [Google Scholar] [CrossRef]
- Chen, Z. Research on Movie Recommendation Algorithm Based on Convolutional Block Attention Module-Convolutional Neural Networks Model. Master’s Thesis, Anhui University of Science and Technology, Huainan, China, 2021. [Google Scholar]
- Zhang, J.; Li, G. A fusion collaborative filtering algorithm based on rating information entropy. J. Nanjing Univ. Posts Telecommun. (Nat. Sci. Ed.) 2021, 41, 71–76. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, C. Collaborative filtering recommendation algorithm combined with category preference. Comput. Appl. Softw. 2021, 38, 293–296. [Google Scholar]
- Chu, H.; Liu, Q.; Mou, C. Improved collaborative filtering recommendation algorithm for adjusted cosine similarity. J. Yantai Univ. Sci. Eng. Ed. 2021, 34, 330–336. [Google Scholar] [CrossRef]
- Yu, J.; Meng, J.; Wu, Q. Item collaborative filtering recommendation algorithm based on improved similarity measure. J. Comput. Appl. 2017, 37, 1387–1391, 1406. [Google Scholar]
- Zhao, Y. Research of Recommendation Algorithms Based on Convolutional Neural Network. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2021. [Google Scholar]
- Liu, F.; Wang, Q.; Hao, J. A Survey of Recommendation System based on Deep Neural Network. J. Shandong Norm. Univ. Nat. Sci. 2021, 36, 325–336. [Google Scholar]
- Chen, B. Research on Recommendation Algorithm Based on Comment Text. Master’s Thesis, Nanjing University of Posts and Telecommunications, Nanjing, China, 2021. [Google Scholar]
- Zhou, C.; Bai, J.; Song, J.; Liu, X.; Zhao, Z.; Chen, X.; Gao, J. Atrank: An attention-based user behavior modeling framework for recommendation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 4564–4571. [Google Scholar]
- Liu, Z. Research on Sequence Recommendation Method Based on Hybrid Neural Network. Master’s Thesis, Kunming University of Science and Technology, Kunming, China, 2021. [Google Scholar]
- Wang, Y.; Xu, S. Method of Multi-feature Fusion Based on Attention Mechanism in Malicious Software Detection. In Proceedings of the Artificial Intelligence and Security: 6th International Conference (ICAIS 2020), Hohhot, China, 17–20 July 2020; pp. 3–13. [Google Scholar]
- Li, M.; Yuan, L.; Wen, X.; Wang, J.; Xie, G.; Jia, Y. Multi-Scale Attention Network Based on Multi-Feature Fusion for Person Re-Identification. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Zhao, J.; Zhuang, F.; Ao, X.; He, Q.; Jiang, H.; Ma, L. Survey of Collaborative Filtering Recommender Systems. J. Cyber Secur. 2021, 6, 17–34. [Google Scholar]
- Roy, A.; Banerjee, S.; Sarkar, M.; Darwish, A.; Elhoseny, M.; Hassanien, A.E. Exploring New Vista of intelligent collaborative filtering: A restaurant recommendation paradigm. J. Comput. Sci. 2018, 27, 168–182. [Google Scholar] [CrossRef]
- Bhaskaran, S.; Marappan, R.; Santhi, B. Design and Analysis of a Cluster-Based Intelligent Hybrid Recommendation System for E-Learning Applications. Mathematics 2021, 9, 197. [Google Scholar] [CrossRef]
- Zhu, W.; Xie, Y.; Huang, Q.; Zheng, Z.; Fang, X.; Huang, Y.; Sun, W. Graph Transformer Collaborative Filtering Method for Multi-Behavior Recommendations. Mathematics 2022, 10, 2956. [Google Scholar] [CrossRef]
- Bobadilla, J.; Serradilla, F.; Bernal, J. A new collaborative filtering metric that improves the behavior of recommender systems. Knowl.-Based Syst. 2010, 23, 520–528. [Google Scholar] [CrossRef]
- Yan, H.; Tang, Y. Collaborative filtering based on Gaussian mixture model and improved Jaccard similarity. IEEE Access 2019, 7, 118690–118701. [Google Scholar] [CrossRef]
- Zhang, X. Aircraft pitch motion response prediction research based on DNN. Flight Dyn. 2022, 40, 53–60. [Google Scholar]
- Zhang, H.; Yu, H.; Qiao, Y.; Xu, M. Research on college students’ abnormal behavior diagnosis model based on DNN. Mod. Electron. Tech. 2022, 45, 57–61. [Google Scholar]
- Liu, Y. Research and Application of Deep Neural Network Prediction Fused with Variational Mode Decomposition. Master’s Thesis, Changchun University of Technology, Changchun, China, 2022. [Google Scholar]
- Guo, G.; Zhang, J.; Thalmann, D. Merging trust in collaborative filtering to alleviate data sparsity and cold start. Knowl.-Based Syst. 2014, 57, 57–68. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Li, Y. Prediction of Shanghai-Shenzhen 300 Index Based on XGBoost-LSTM Neural Network. Master’s Thesis, Shandong University of Finance and Economics, Jinan, China, 2020. [Google Scholar]
- Pekel, E. Estimation of soil moisture using decision tree regression. Theor. Appl. Climatol. 2020, 139, 1111–1119. [Google Scholar] [CrossRef]
- Shehadeh, A.; Alshboul, O.; Al Mamlook, R.E.; Hamedat, O. Machine learning models for predicting the residual value of heavy construction equipment: An evaluation of modified decision tree, LightGBM, and XGBoost regression. Autom. Constr. 2021, 129, 103827. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Khan, Z.; Iltaf, N.; Afzal, H.; Abbas, H. DST-HRS: A topic driven hybrid recommender system based on deep semantics. Comput. Commun. 2020, 156, 183–191. [Google Scholar] [CrossRef]
- Darban, Z.Z.; Valipour, M.H. GHRS: Graph-based hybrid recommendation system with application to movie recommendation. Expert Syst. Appl. 2022, 200, 116850. [Google Scholar] [CrossRef]
- Yuan, X.; Han, L.; Qian, S.; Xu, G.; Yan, H. Singular value decomposition based recommendation using imputed data. Knowl.-Based Syst. 2019, 163, 485–494. [Google Scholar] [CrossRef]
- Mohammadpour, T.; Bidgoli, A.M.; Enayatifar, R.; Javadi, H.H.S. Efficient clustering in collaborative filtering recommender system: Hybrid method based on genetic algorithm and gravitational emulation local search algorithm. Genomics 2019, 111, 1902–1912. [Google Scholar] [CrossRef]
- Bag, S.; Kumar, S.; Awasthi, A.; Tiwari, M.K. A noise correction-based approach to support a recommender system in a highly sparse rating environment. Decis. Support Syst. 2019, 118, 46–57. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Kim, D.; Park, C.; Oh, J.; Yu, H. Deep hybrid recommender systems via exploiting document context and statistics of items. Inf. Sci. 2017, 417, 72–87. [Google Scholar] [CrossRef]
- Barbieri, J.; Alvim, L.G.; Braida, F.; Zimbrão, G. Autoencoders and recommender systems: COFILS approach. Expert Syst. Appl. 2017, 89, 81–90. [Google Scholar] [CrossRef]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional Matrix Factorization for Document Context-Aware Recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Zhang, L.; Luo, T.; Zhang, F.; Wu, Y. A recommendation model based on deep neural network. IEEE Access 2018, 6, 9454–9463. [Google Scholar] [CrossRef]
















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, S.; Guo, M.; Chen, X.; Qiu, J.; Sun, J. Personalized Movie Recommendations Based on a Multi-Feature Attention Mechanism with Neural Networks. Mathematics 2023, 11, 1355. https://doi.org/10.3390/math11061355
Yu S, Guo M, Chen X, Qiu J, Sun J. Personalized Movie Recommendations Based on a Multi-Feature Attention Mechanism with Neural Networks. Mathematics. 2023; 11(6):1355. https://doi.org/10.3390/math11061355
Chicago/Turabian StyleYu, Saisai, Ming Guo, Xiangyong Chen, Jianlong Qiu, and Jianqiang Sun. 2023. "Personalized Movie Recommendations Based on a Multi-Feature Attention Mechanism with Neural Networks" Mathematics 11, no. 6: 1355. https://doi.org/10.3390/math11061355
APA StyleYu, S., Guo, M., Chen, X., Qiu, J., & Sun, J. (2023). Personalized Movie Recommendations Based on a Multi-Feature Attention Mechanism with Neural Networks. Mathematics, 11(6), 1355. https://doi.org/10.3390/math11061355