


Capacity-Raising Reversible Data Hiding Using Empirical Plus–Minus One in Dual Images

Abstract
:1. Introduction
2. Related Work
2.1. Reversible Data-Hiding Scheme Based on Dual Stegano Images Using Orientation Combinations
2.2. A Square-Lattice-Oriented Reversible Information-Hiding Scheme with Reversibility and Additivity for Dual Images
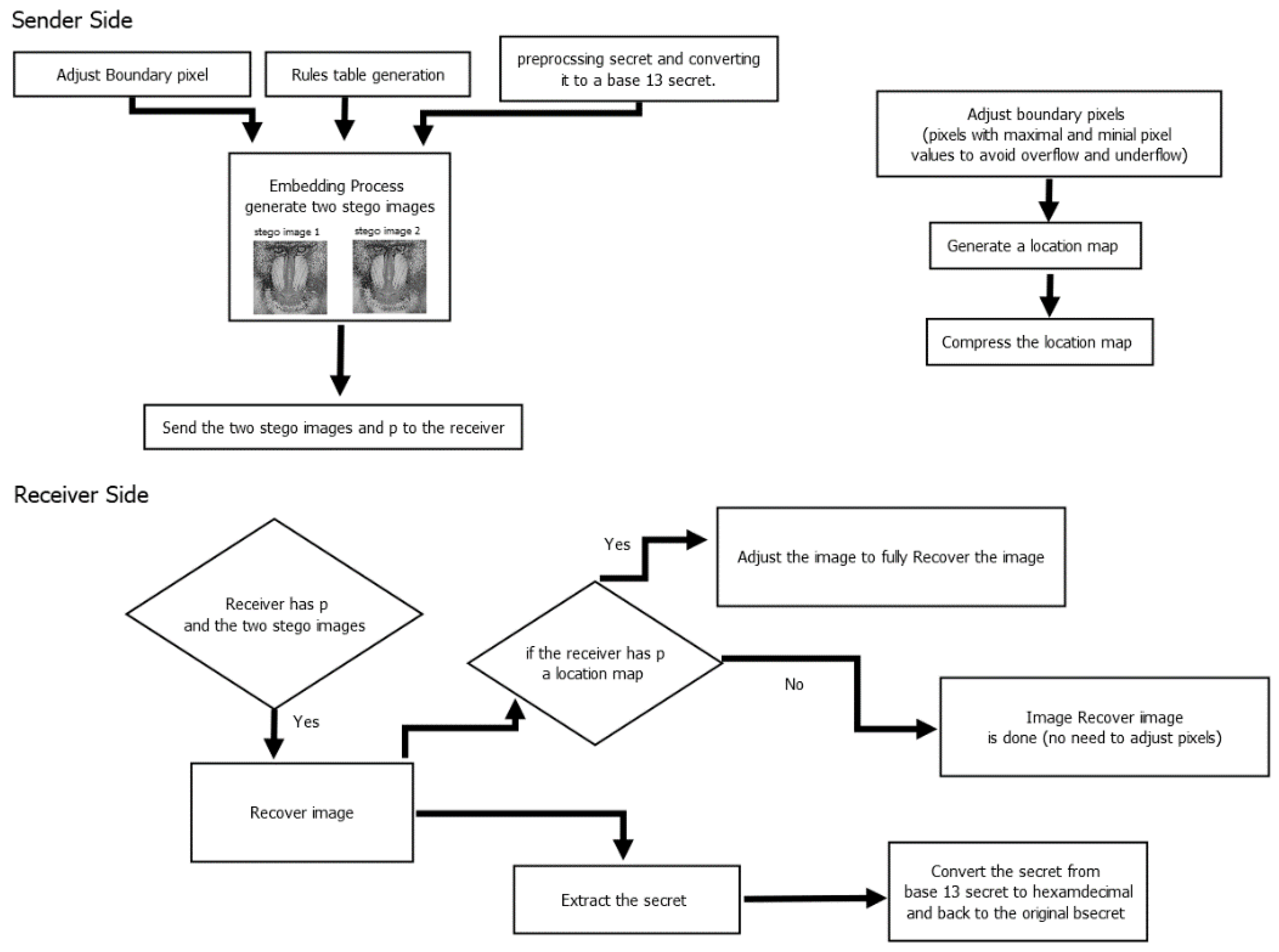
3. Proposed Method
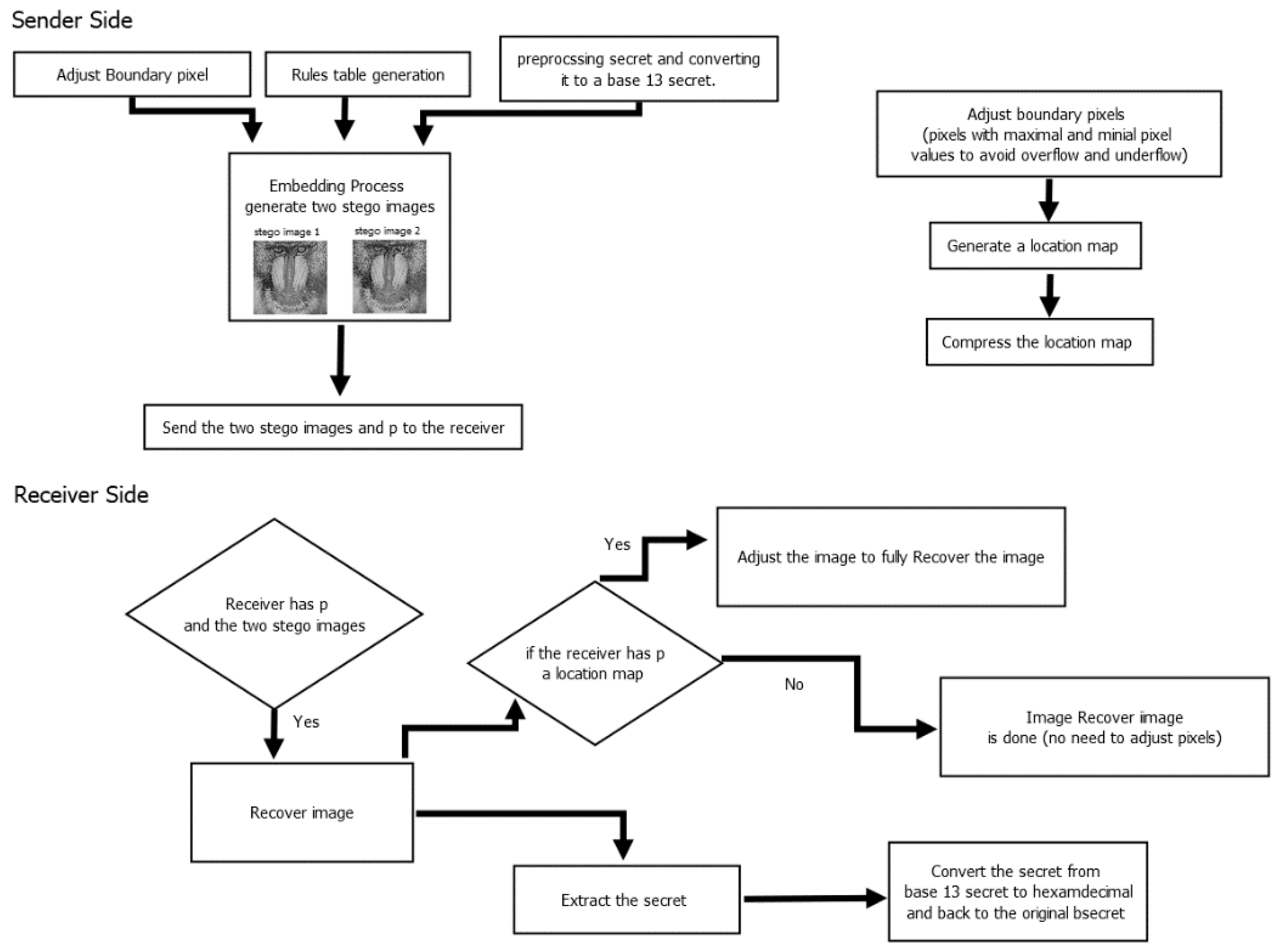
3.1. Proposed Method Framework
3.2. Preprocessing
3.2.1. Secret Preprocessing
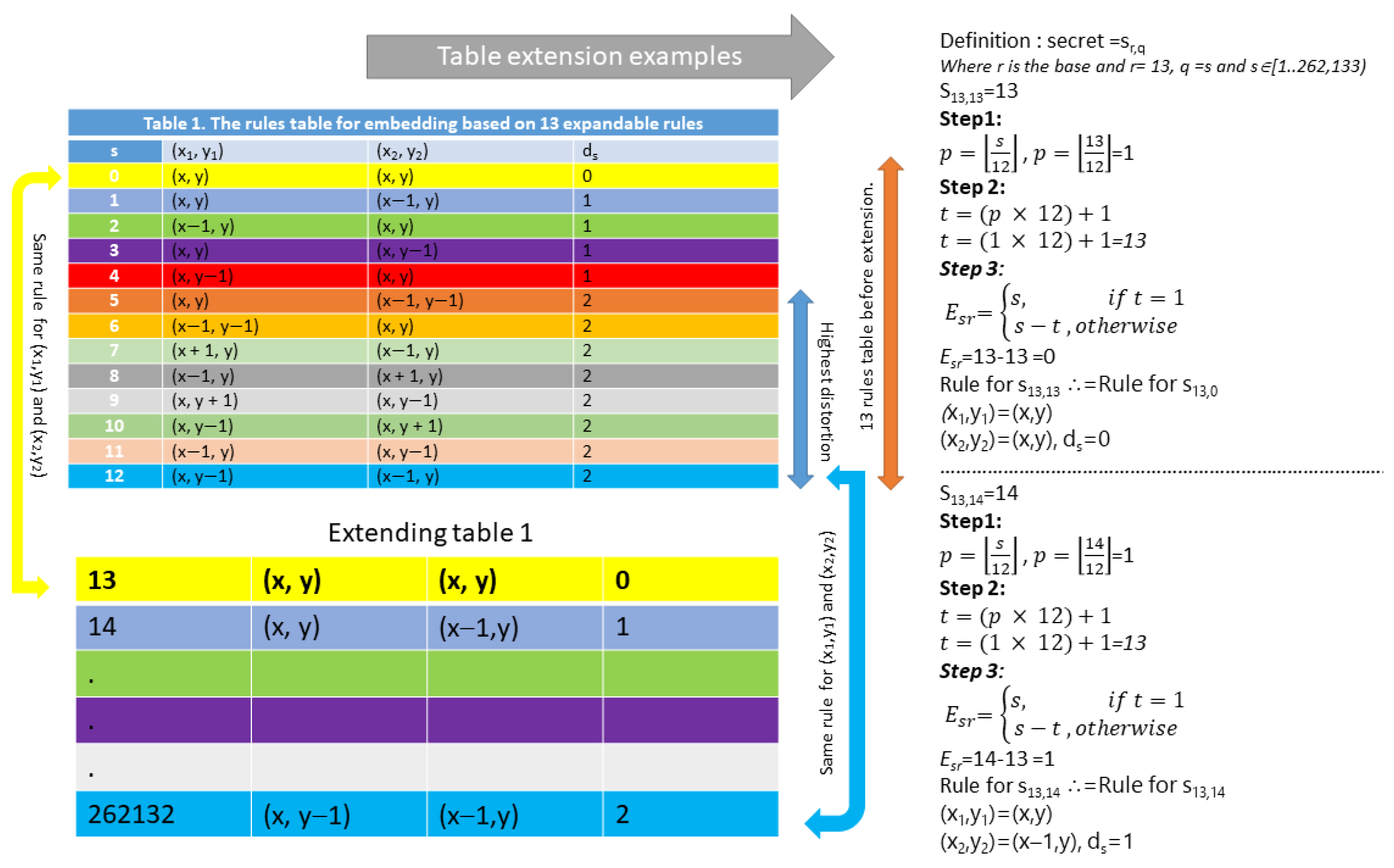
3.3. Rules Table Generation
3.4. Embedding Process
- In any entry, the difference in the modifications of the two stego images at neighboring pixels is at most 2 (low distortion ds), as seen in Table 1.
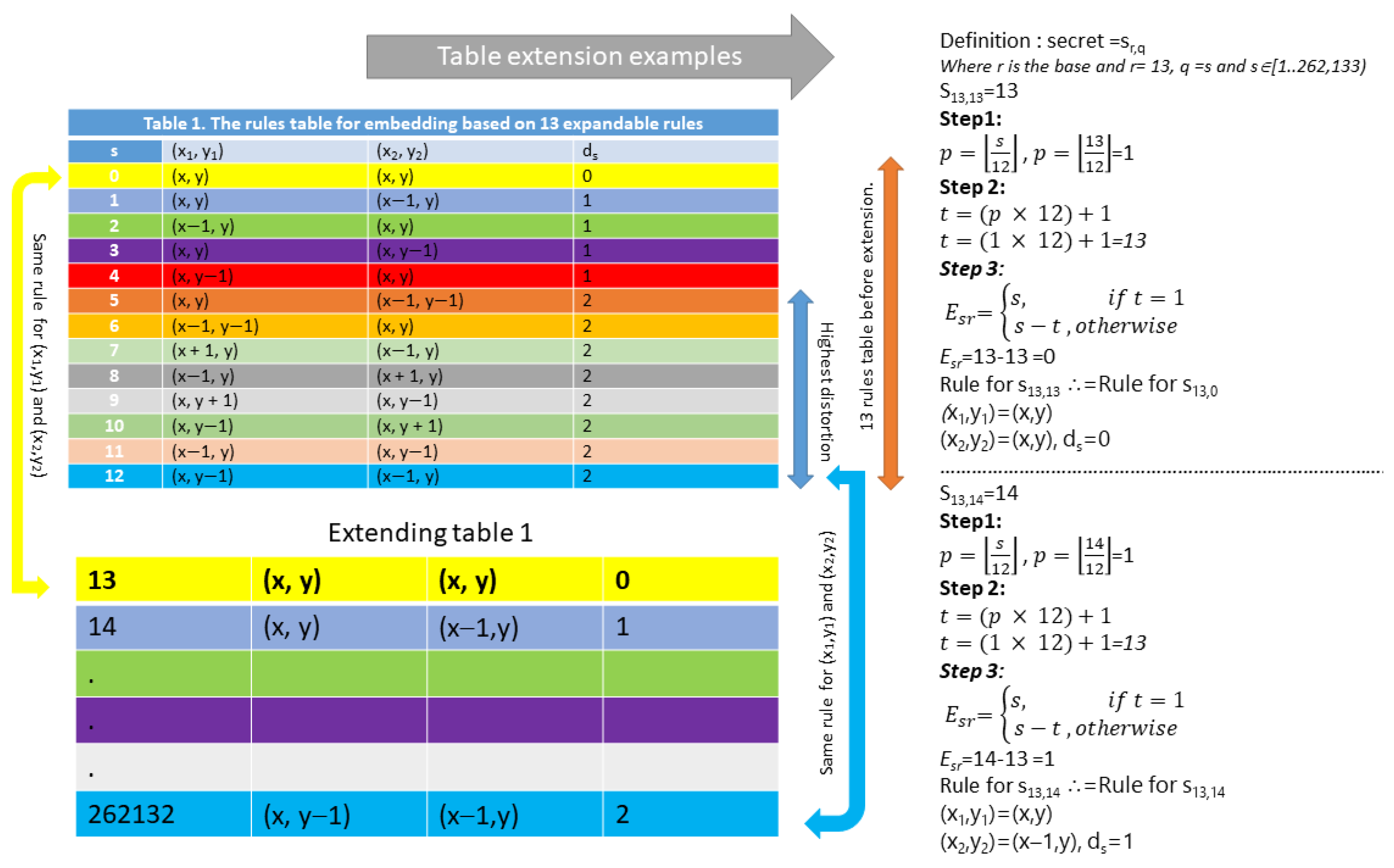
- The modification entry can be determined uniquely from stego image 1 and stego image 2 (hence extracting the hidden message). For example, during the extraction process, the rules used for embedding can be found, and these rules can be used to look up from the EQUATION to uniquely identify the entry. It should be noted that an additional value p (as defined in Equation (3)) is necessary to determine the actual entry used in the extended table. Figure 2 shows an example of how Table 1 can be extended to a table with 262,133 entries. Examples of the fourteenth and fifteenth entries (s = 13 and s = 14, respectively) are shown. From this figure, it is demonstrated that the table can be extended without altering the 13 rules. Each rule can be used for multiple table entries, and therefore the difference between neighboring pixels does not change when the table size increases. The maximum difference between neighboring pixels (distortion) is 2. Each next entry in the table references an entry that is already in Table 1; however, it should be noted that the table size increases to accommodate cases where the secret has more than 13 distinct characters. The table size depends on the size of the images used. For instance, the proposed method used 512 × 512 image sizes; therefore, the highest multiple of 13 (262,132) that was less than 262,144 (512 × 512) was found to be the maximum secret number, as can be seen in the last row (colored in blue) of the extended table in Figure 2. In Figure 2, the different colors represent entries that use different rules, while the same colors represent entries that use the same rule. Figure 3 demonstrates the embedding procedure. Figure 4 and Table 1 demonstrate the extraction procedure and how the entries alongside p are uniquely used during the extraction process.
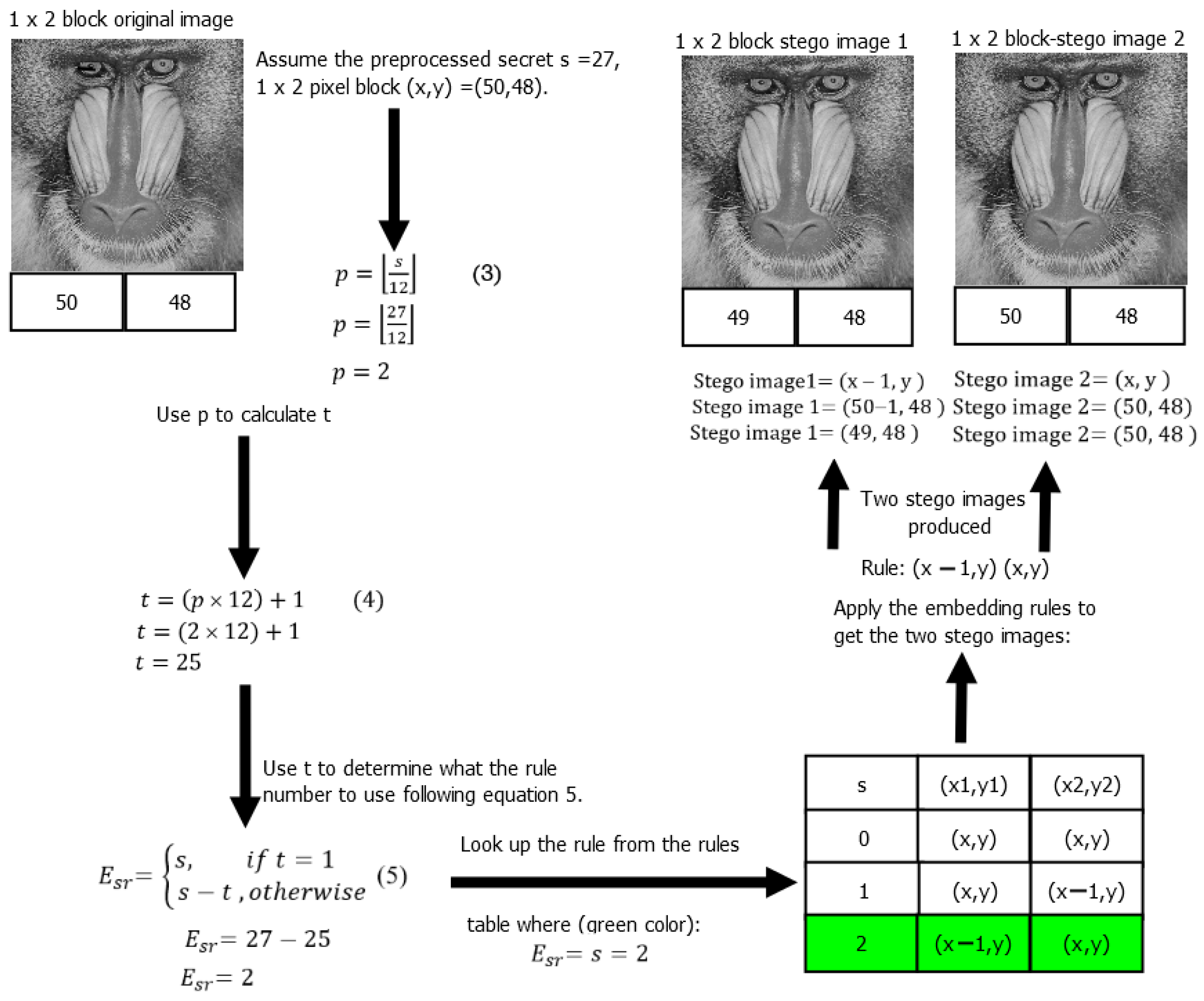
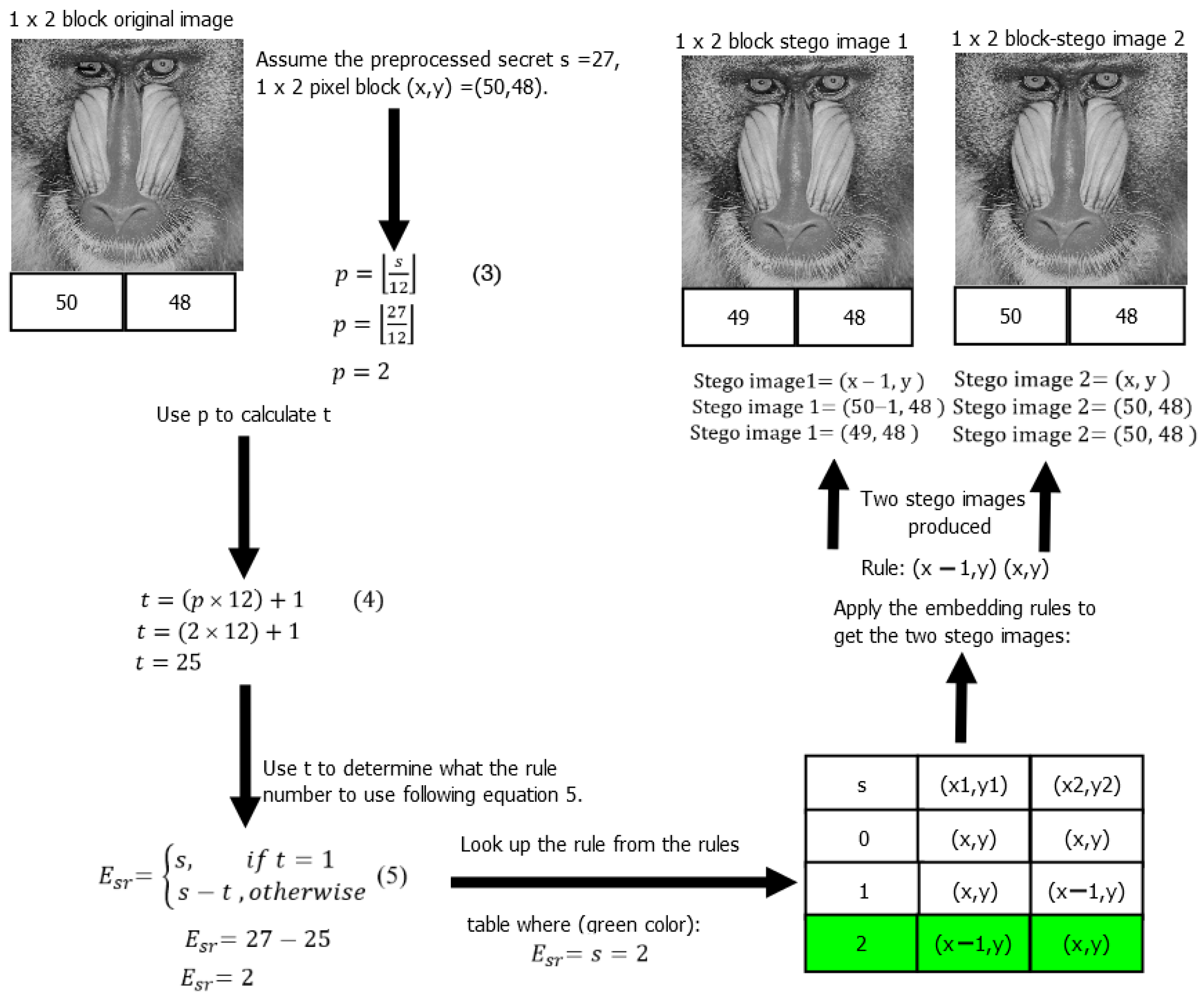
3.5. Embedding Example
- Stego image 1 = (50 − 1, 48), stego image 2 = (50, 48).
- Stego image 1 = (49, 48), Stego image 2 = (50, 48).
| Algorithm 1 Embedding Algorithm Pseudocode. |
| Input: secret data s, cover image CI. |
| Output: 2 stego images |
| for i = 0 …H − 1 do |
| For j = 0 …W − 2 do |
| block = [(x, y), (x, y + 1) |
| p = floor(s/12) |
| if s < 12 then |
| t = 1; |
| else |
| t = p × 12 + 1; |
| end if |
| if t = 1 then |
| Esr = s; |
| else |
| Esr = s − t; |
| end if |
| stego1_block=[]; |
| stego2_block=[]; |
| for pixel in block do |
| adjust stego1_pixel &stego2_pixel using rules; |
| stego 1_block.append(stego1_pixel); |
| stego2_block.append(stego2_pixel); |
| end for |
| end for |
| end for |
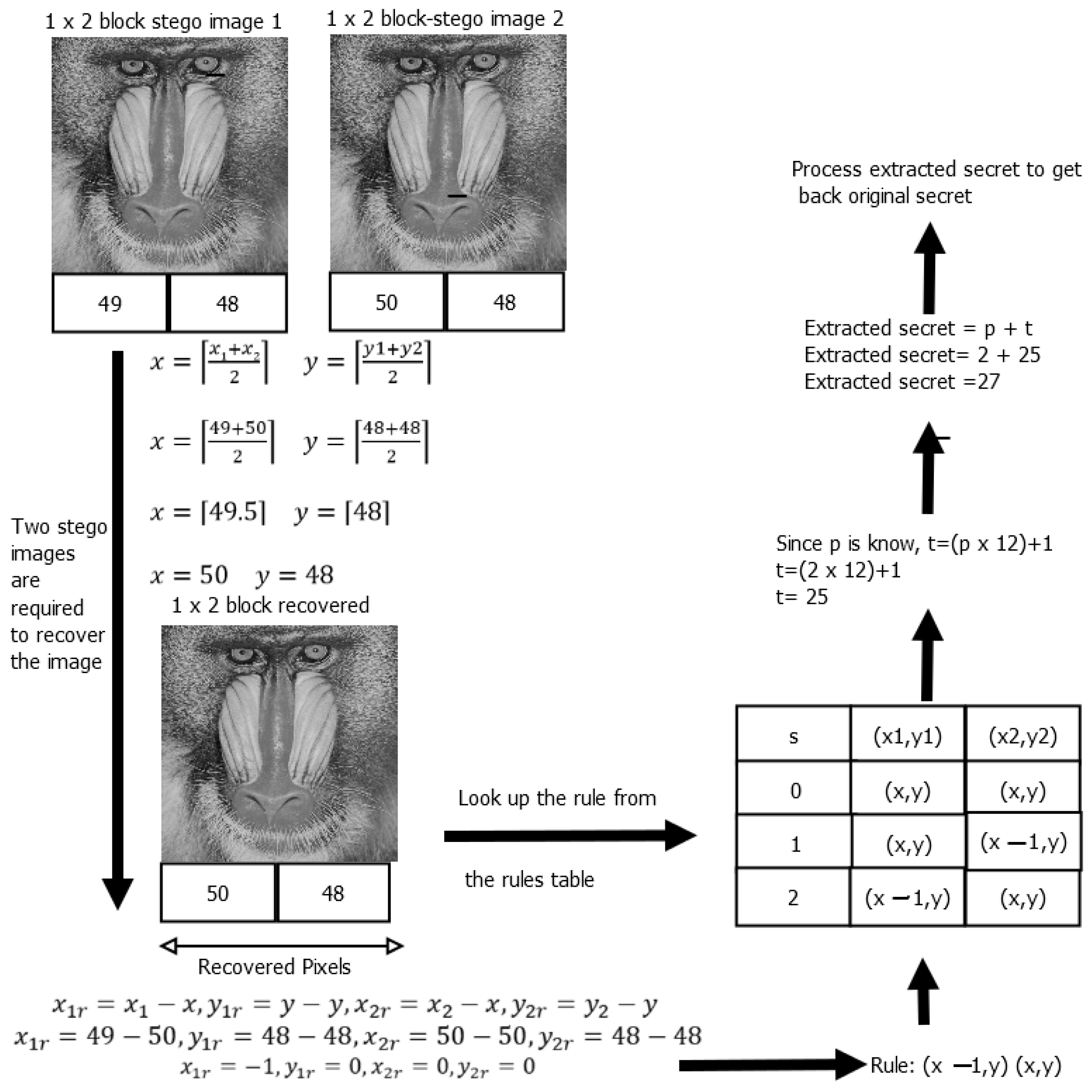
3.6. Extraction and Recovery Process
| Algorithm 2 Extraction and Recovery Algorithm Pseudocode. |
| Input: p, stego_image_1, stego_image_2. |
| Output: secret data s, cover image CI. |
| lookup_table = {table used during embedding process}; |
| recovered_image = …; |
| rule = {}; |
| for i in range(stego_image_1.width): |
| for j in range(stego_image_1.height): |
| x1, y1 = stego_image_1.get_pixel(i, j); |
| x2, y2 = stego_image_2.get_pixel(i, j); |
| x = (x1 + x2 + 1)//2; y = (y1 + y2 + 1)//2; |
| recovered_image.set_pixel(i, j, (x, y)); |
| rule[(i, j)] = (x1 − x, y1 − y, x2 − x, y2 − y); |
| end for |
| end for |
| secret_message = ‘ ’; |
| for i in range(stego_image_1.width): |
| for j in range(stego_image_1.height): |
| key = (rule[(i, j)][0], rule[(i, j)][1]); |
| secret_number = lookup_table[key]; |
| t = p × 12 + 1; |
| secret_message + = t+secret_number; |
| end for |
| end for |
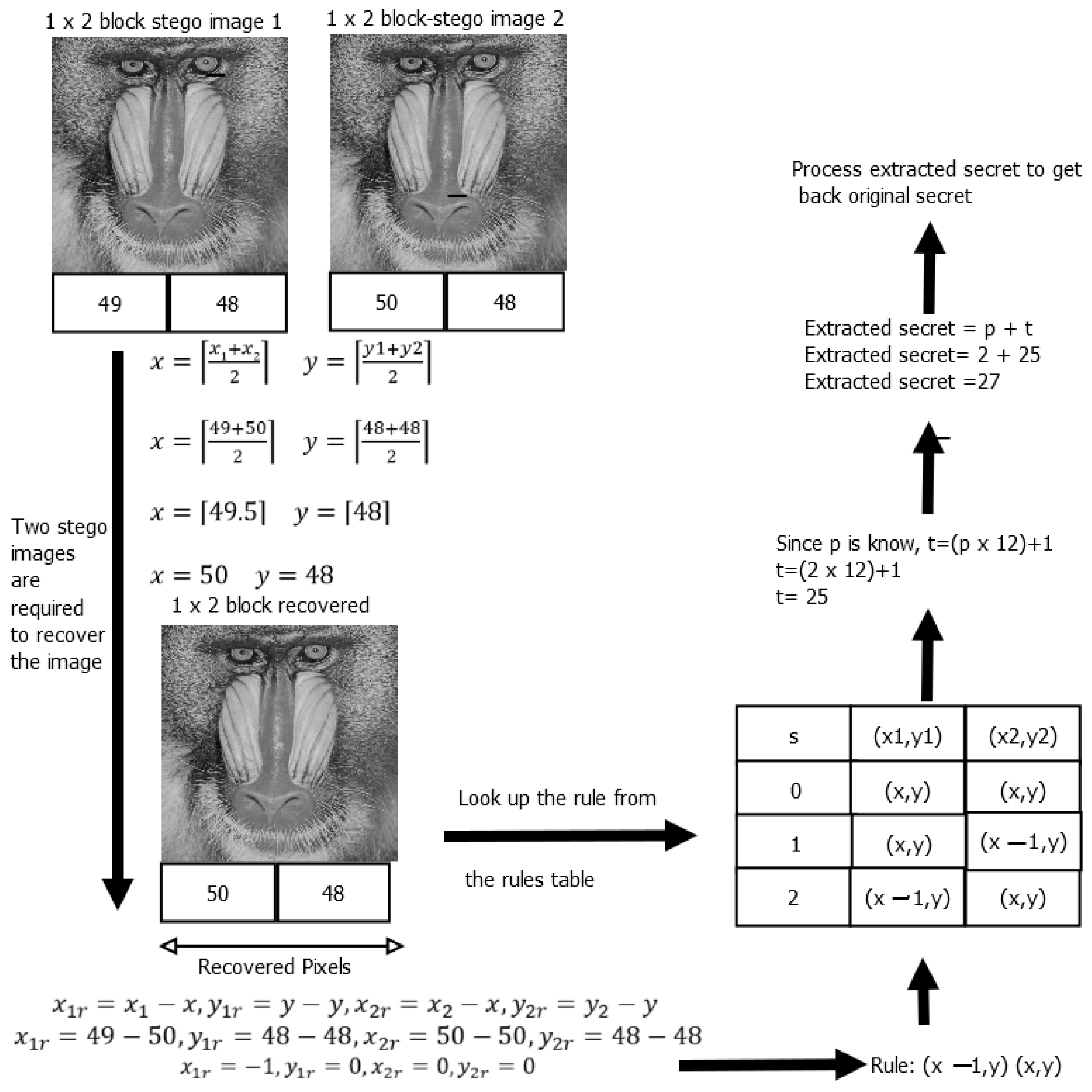
3.7. Extraction and Recovery Example
3.8. Additional Information
4. Experimental Results
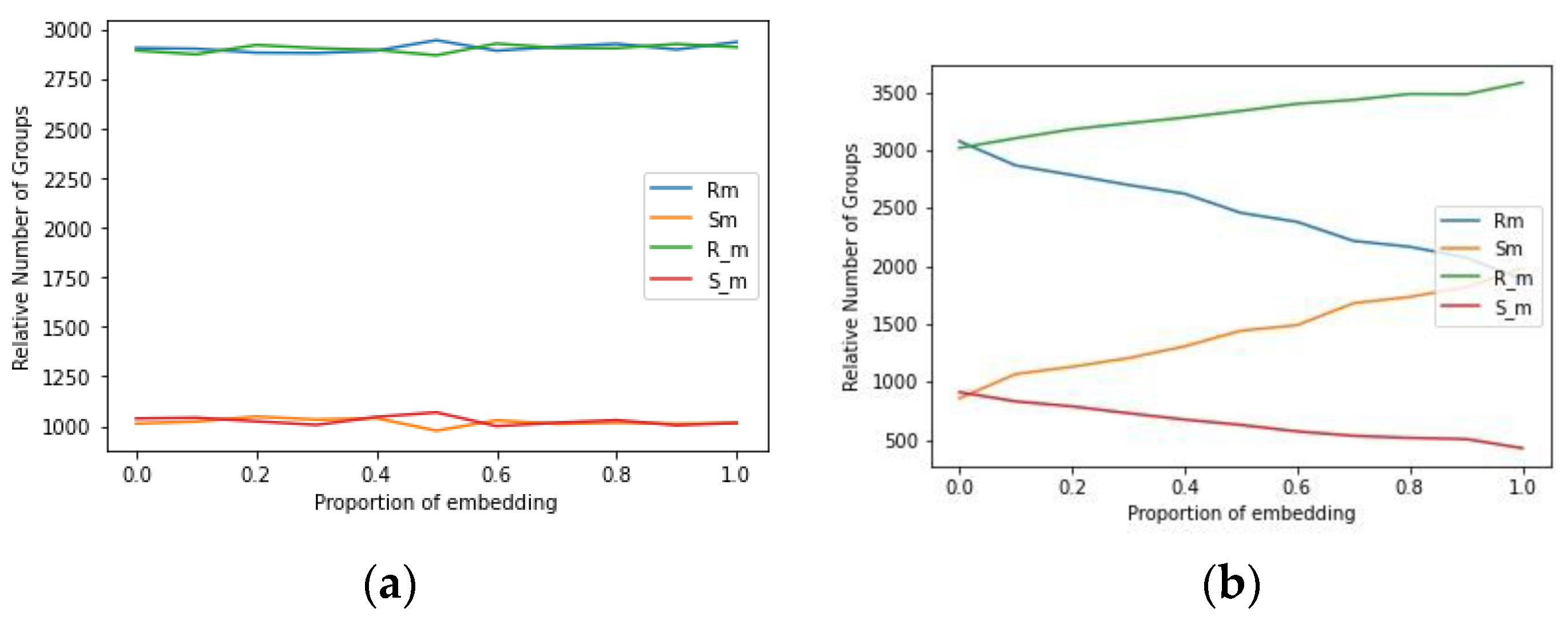
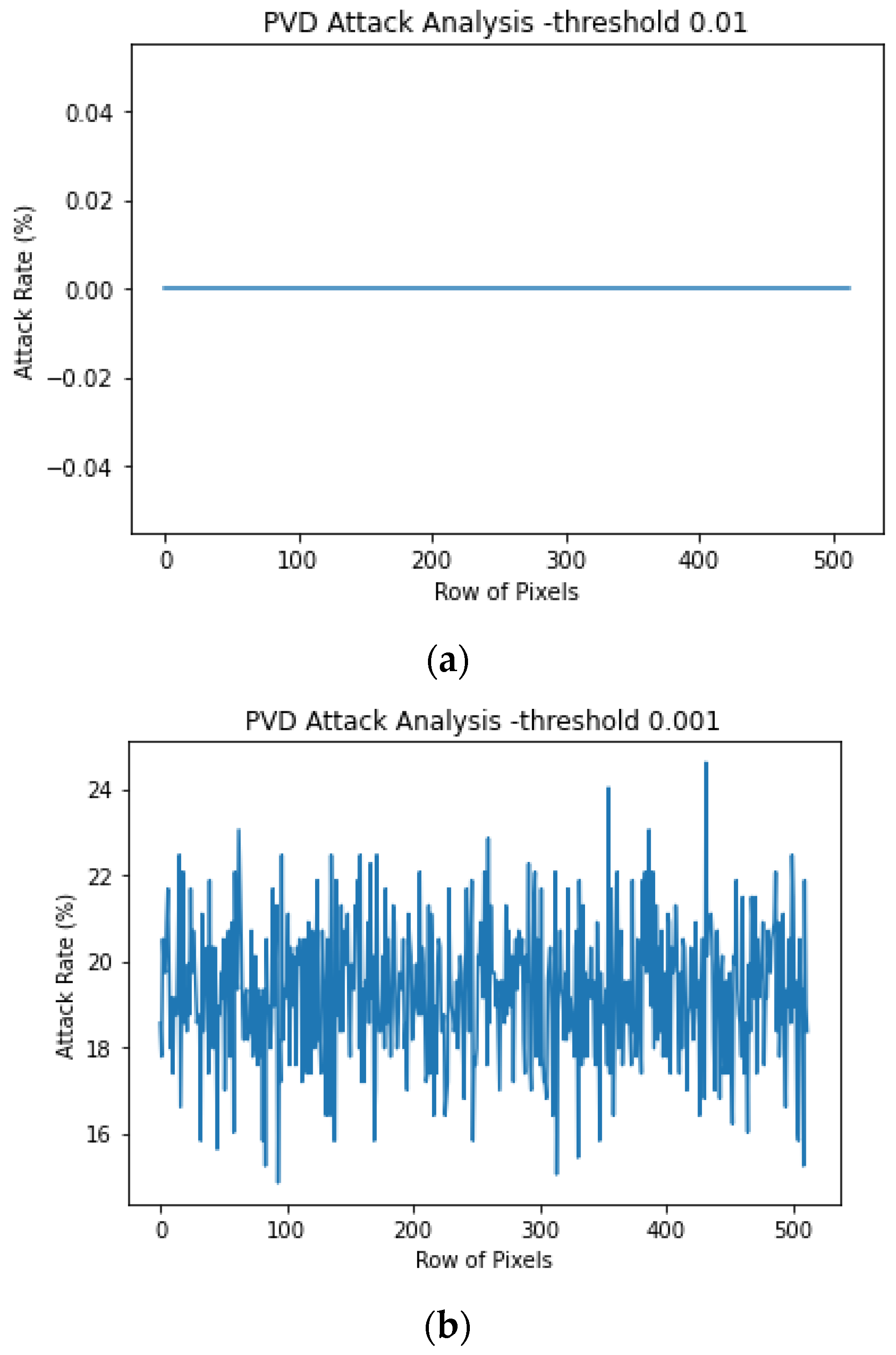
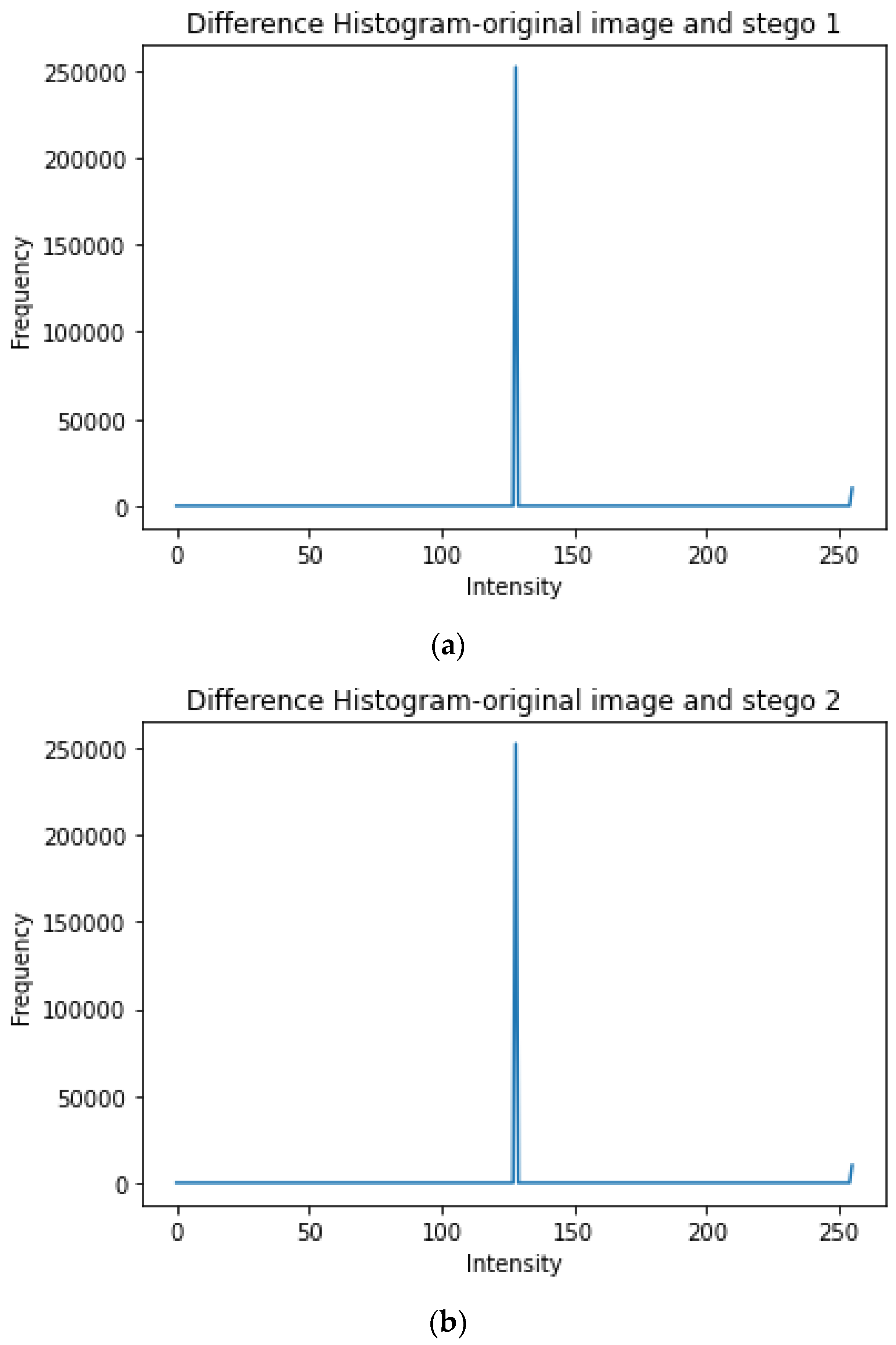
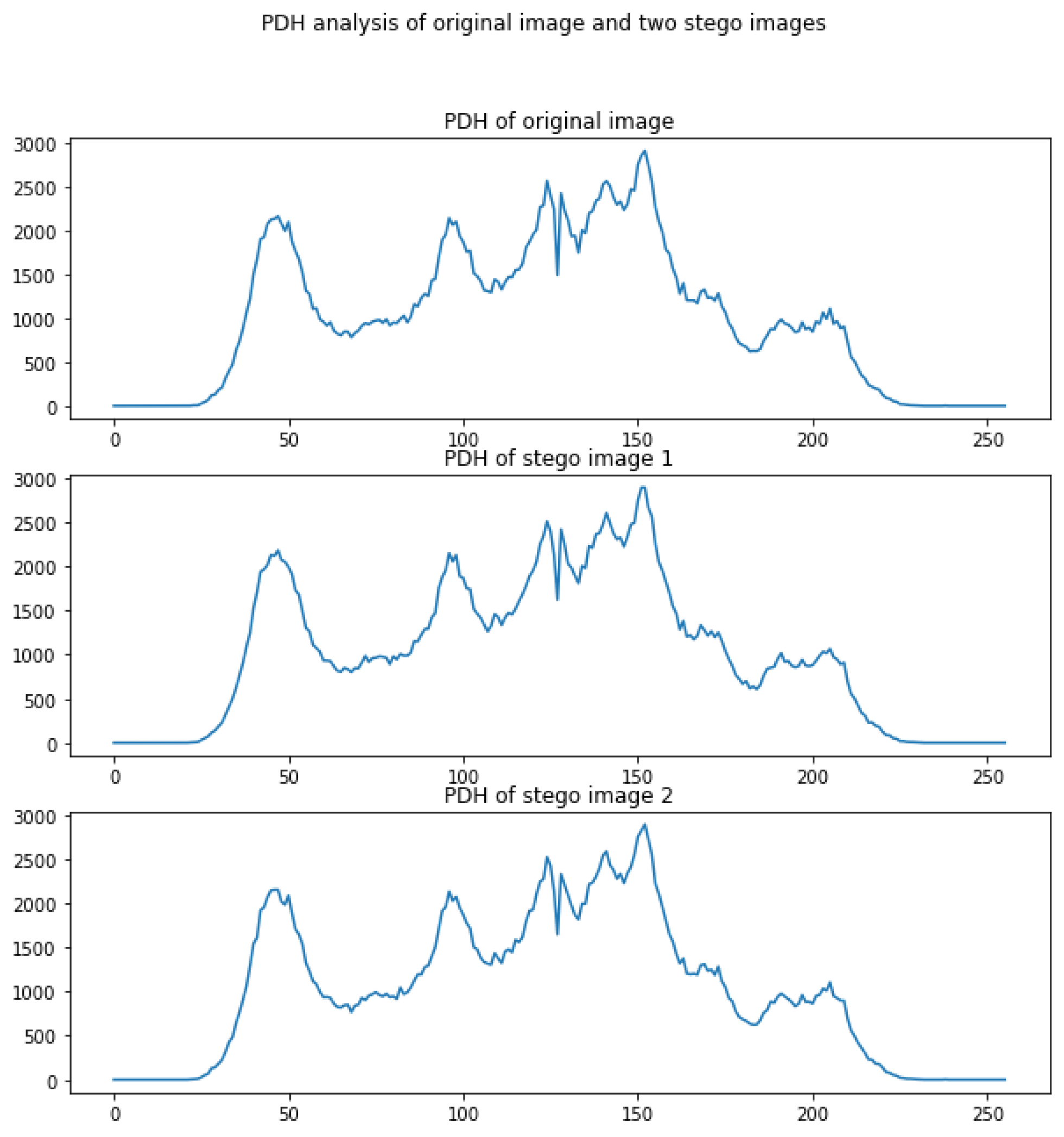
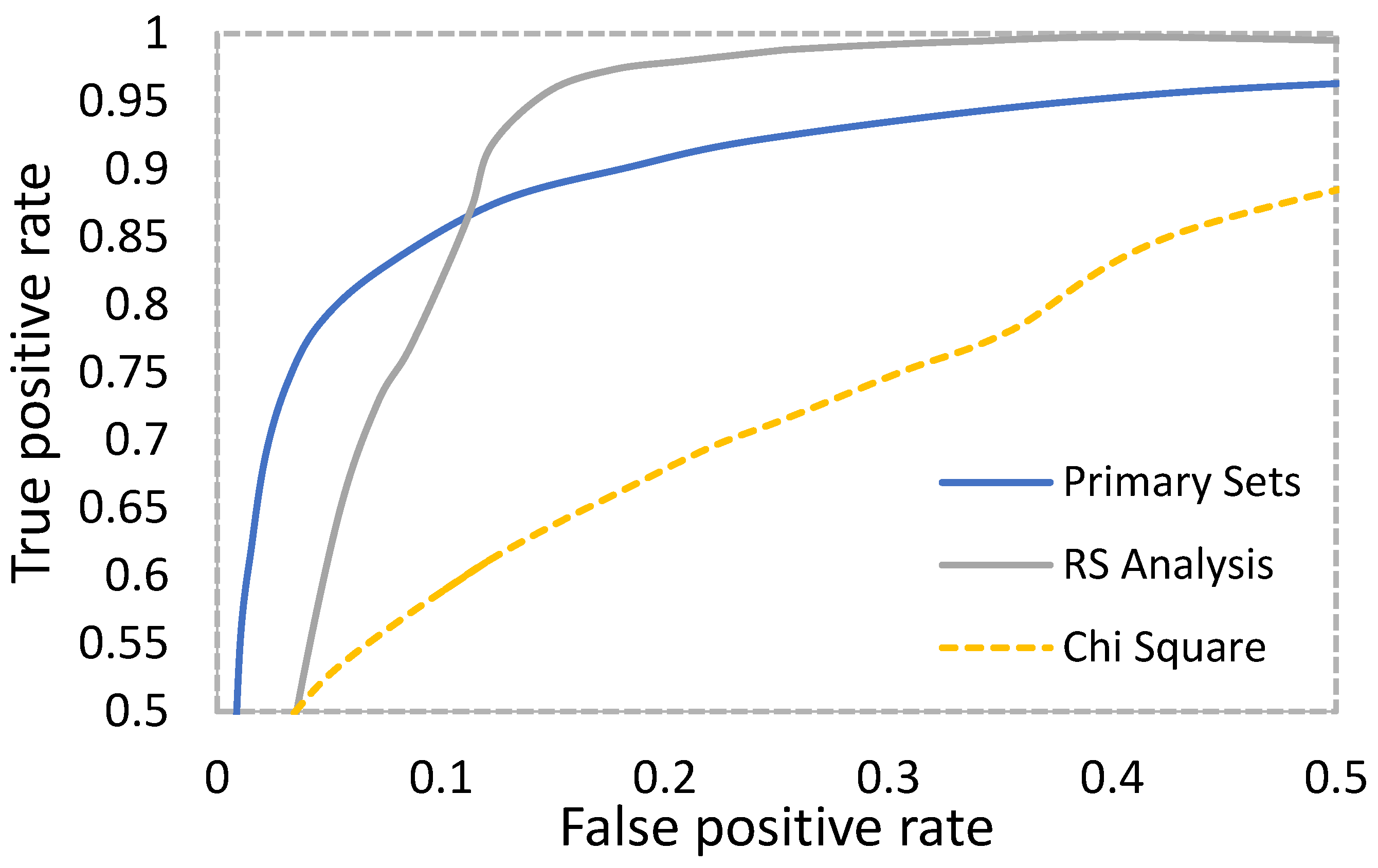
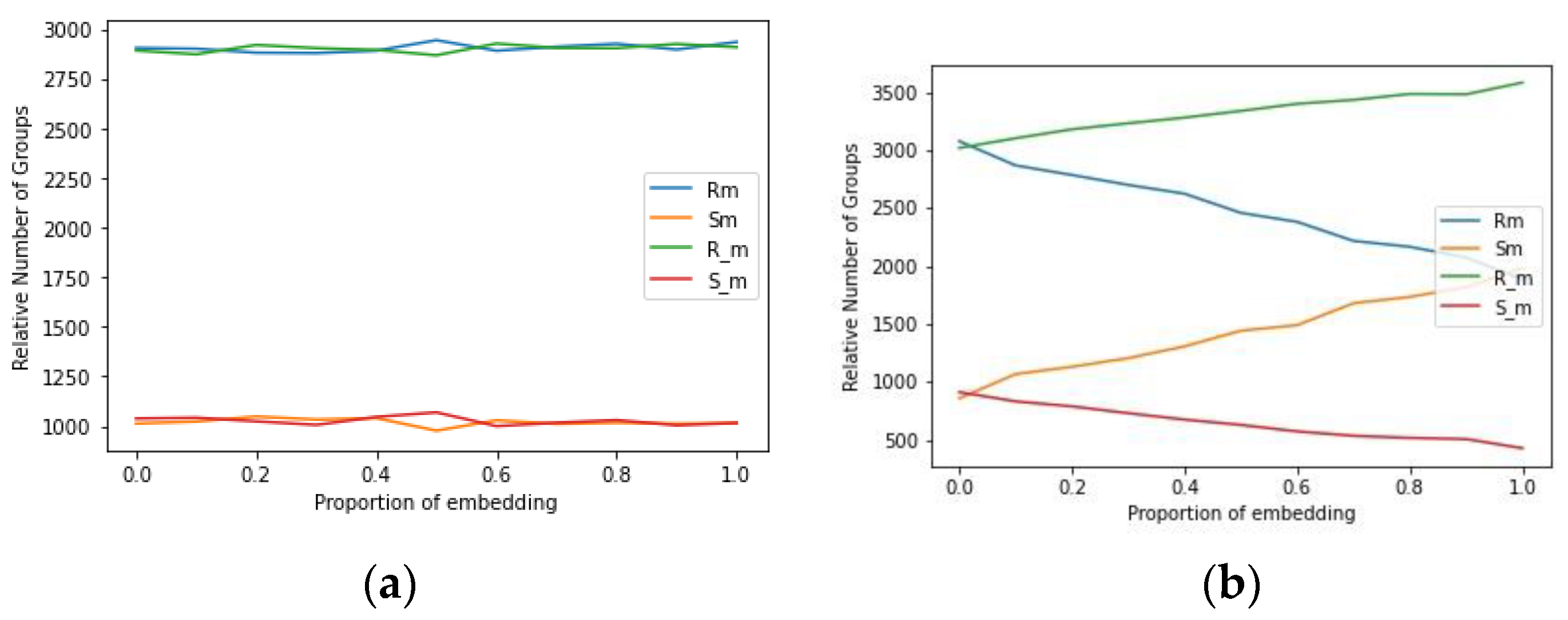
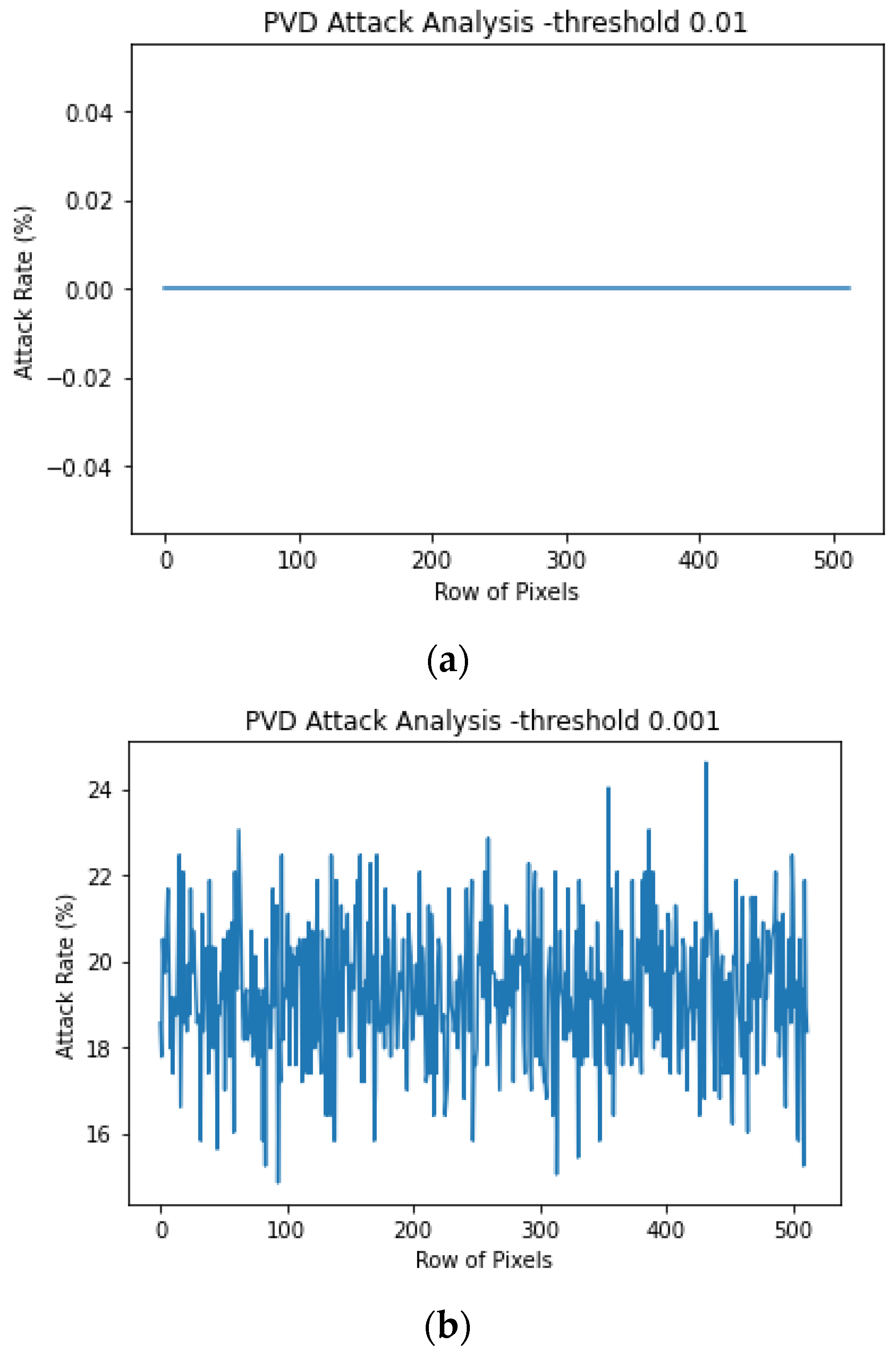
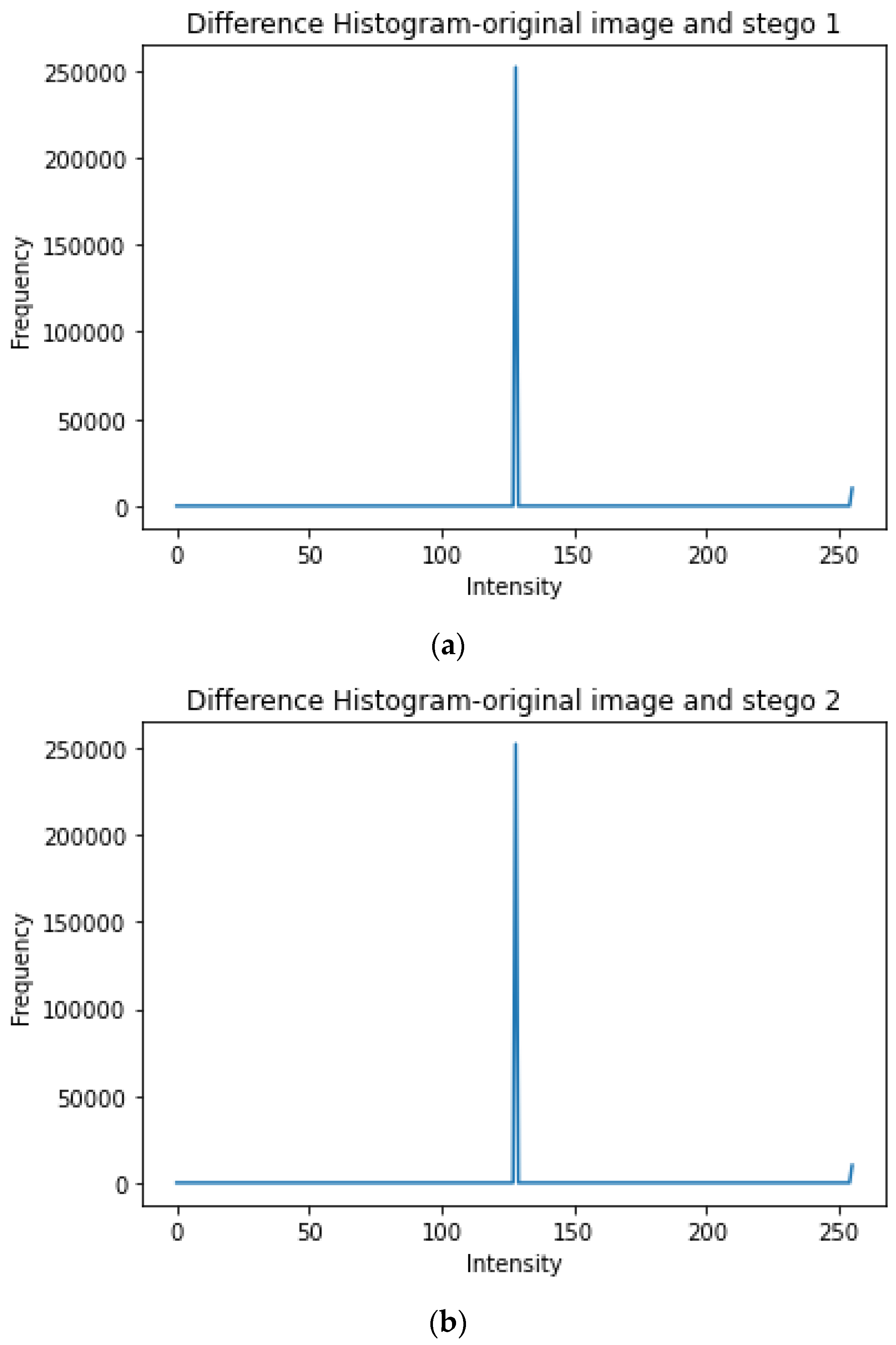
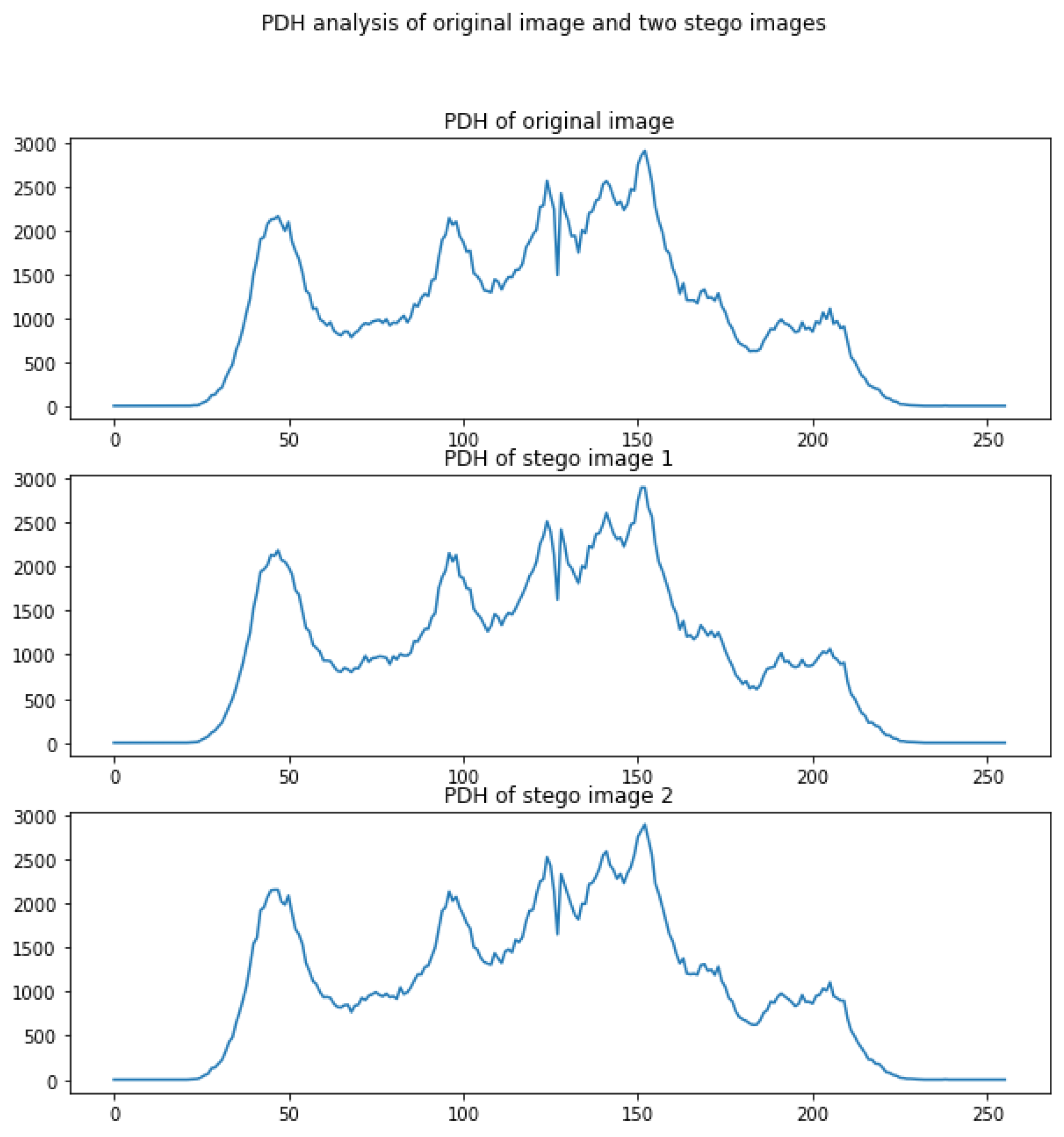
4.1. Security Analysis
- (a)
- The regular groups with RM and R-M;
- (b)
- The singular group with SM and S-M;
- (c)
- The unusable group.
- Find out the total number of POVs of the image.
- Sort the pixel values and calculate the average of the j-th group of pixels to the total concurrencies using Equation (10).
- 3.
- Compute the representative number of pixel value pairs in the j group, where nj = numbers of index 2j.
- 4.
- Compute the chi-square statistics using Equation (11).
- 5.
- Use the chi-square distribution characteristics to compute the image-hiding probability p using (12).
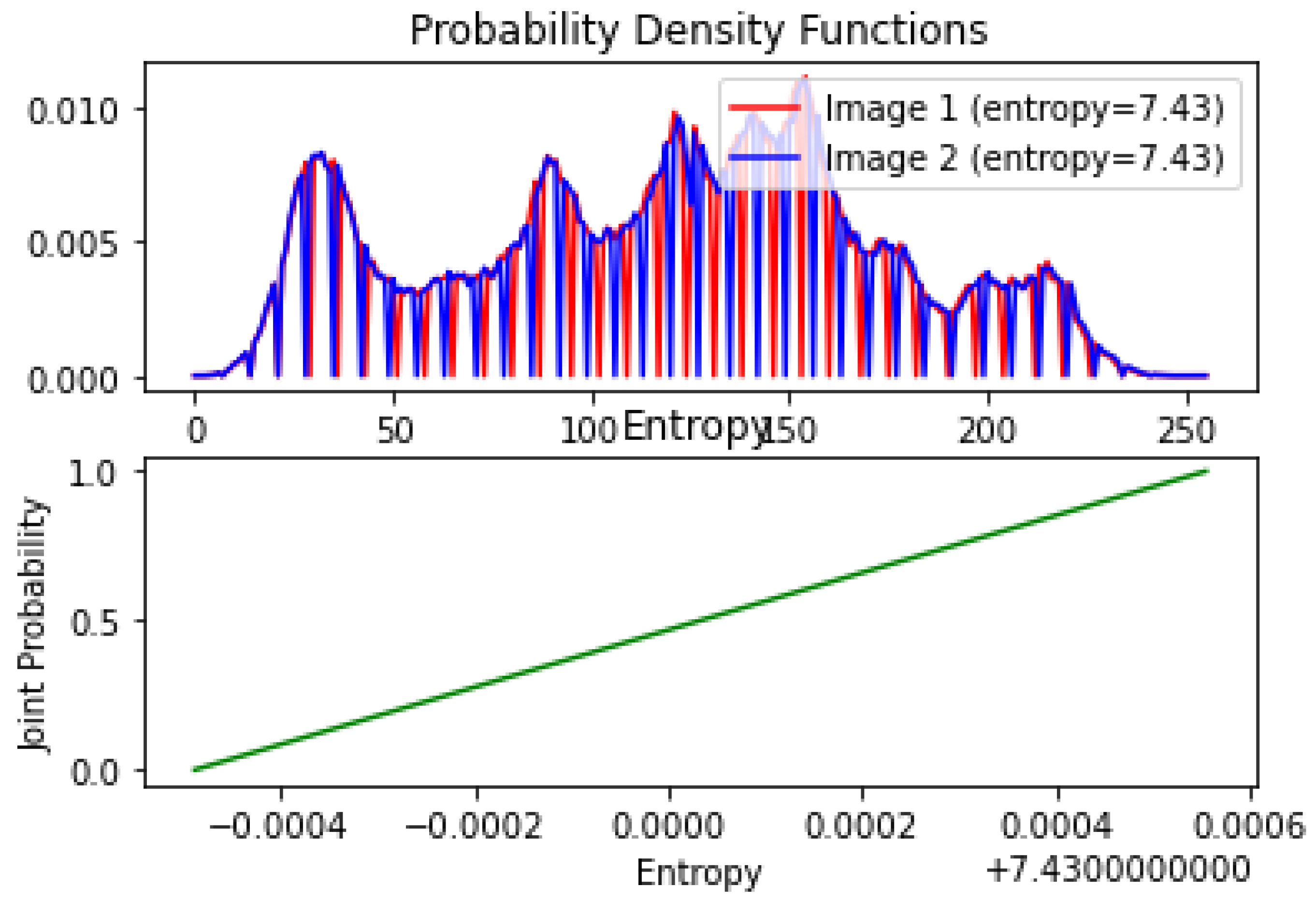
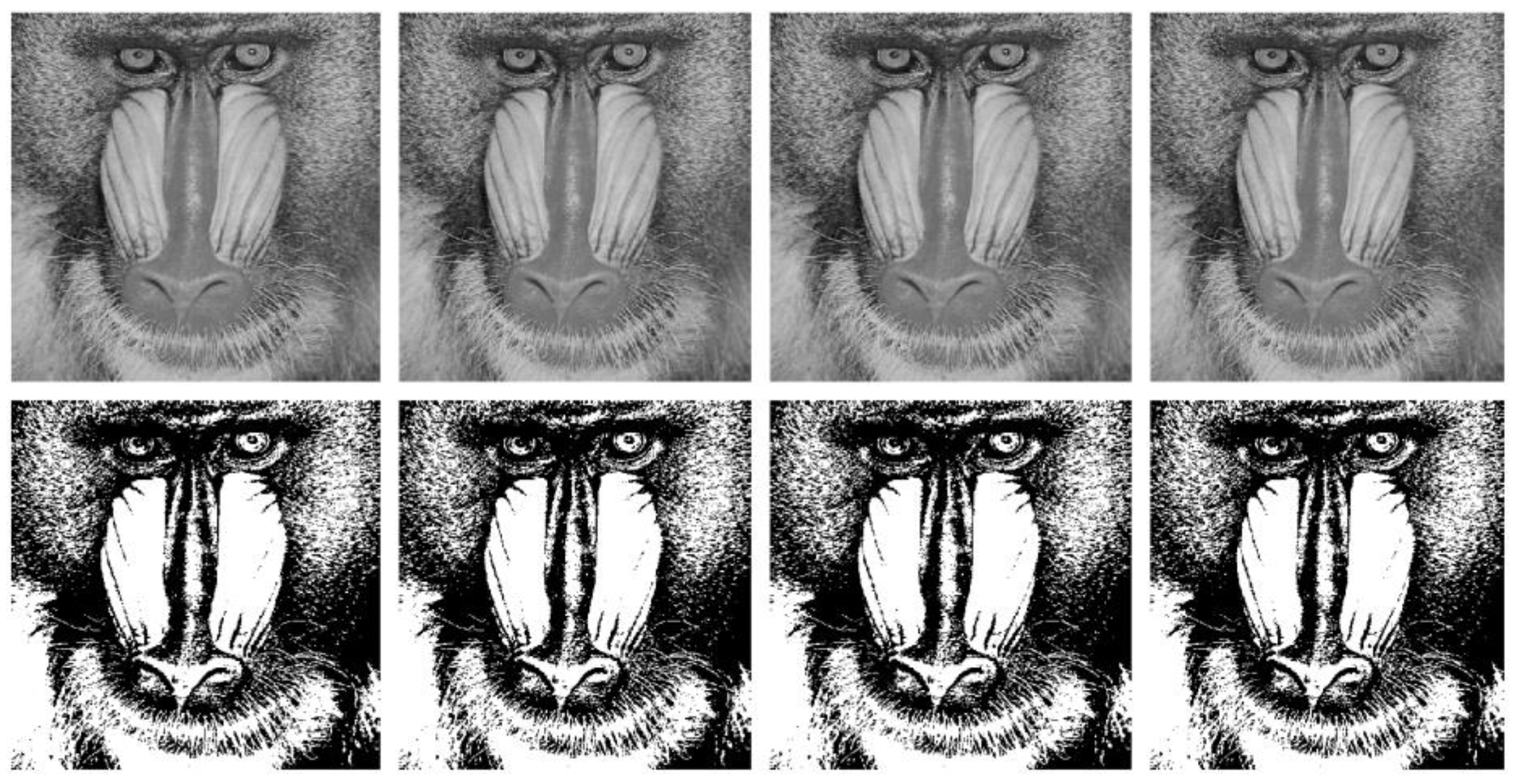
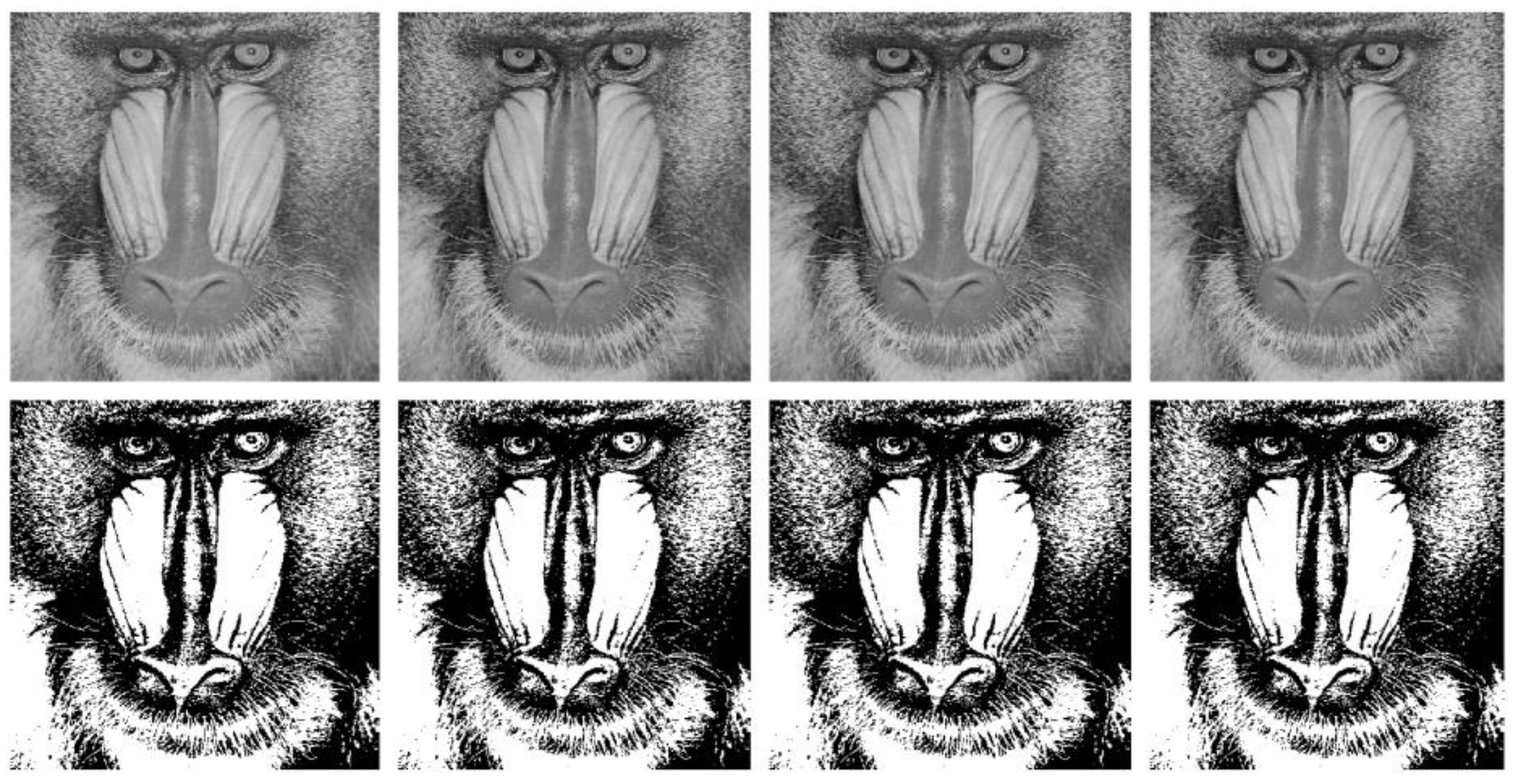
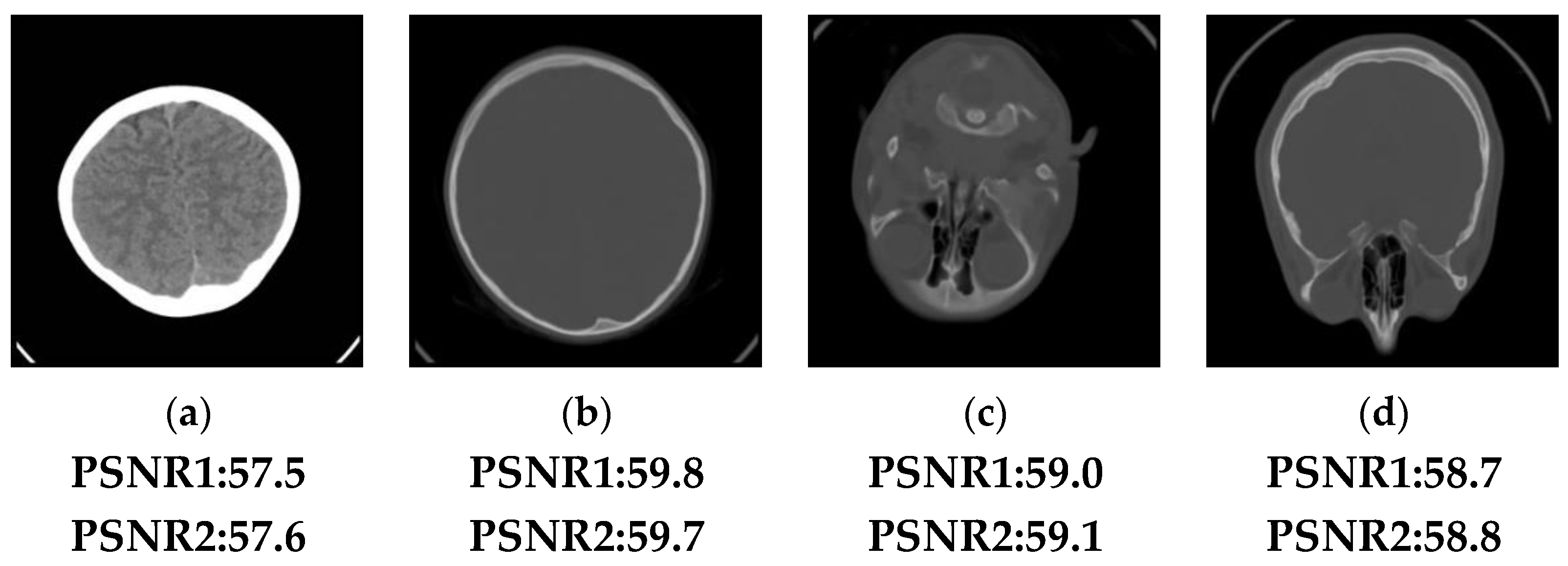
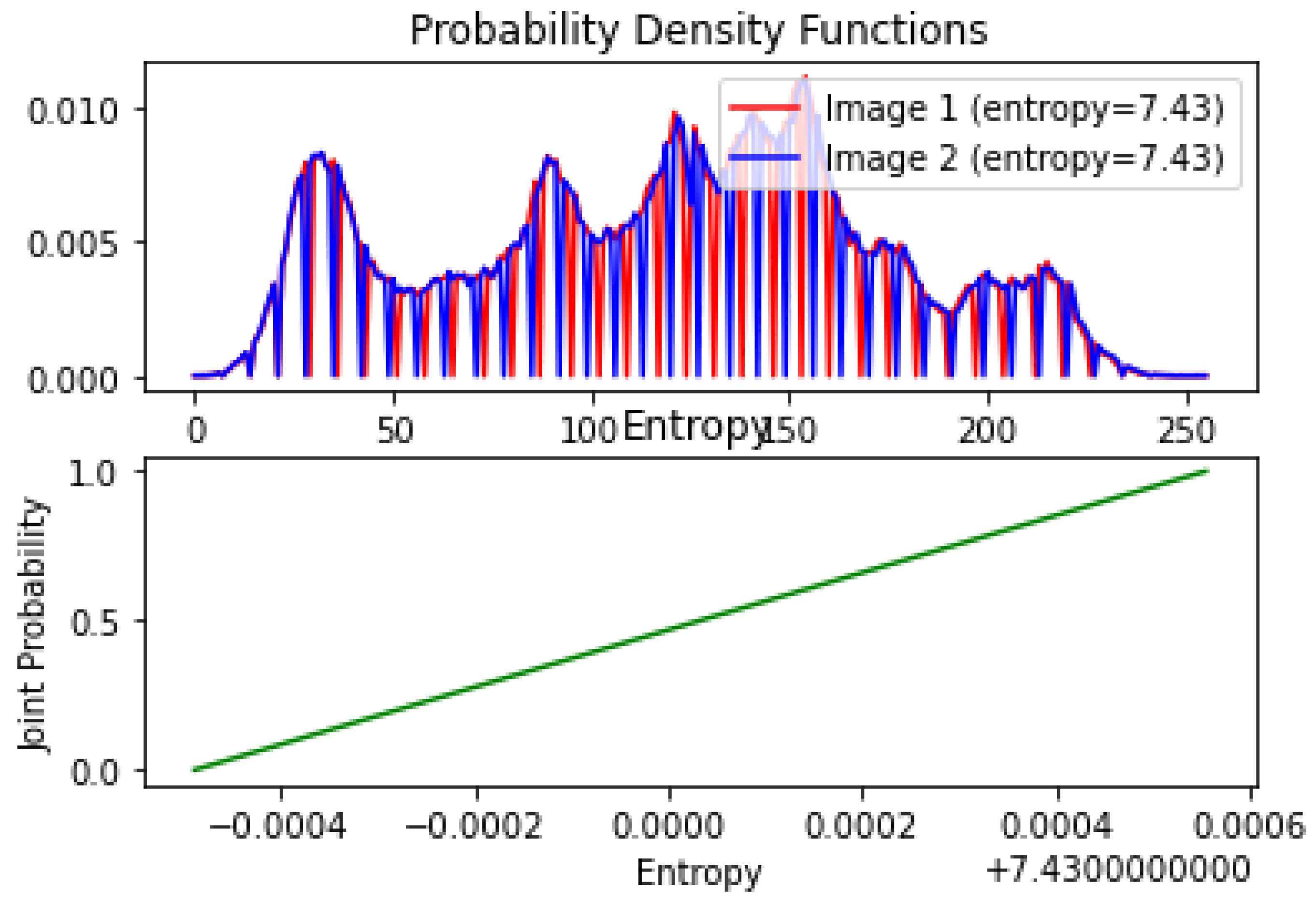
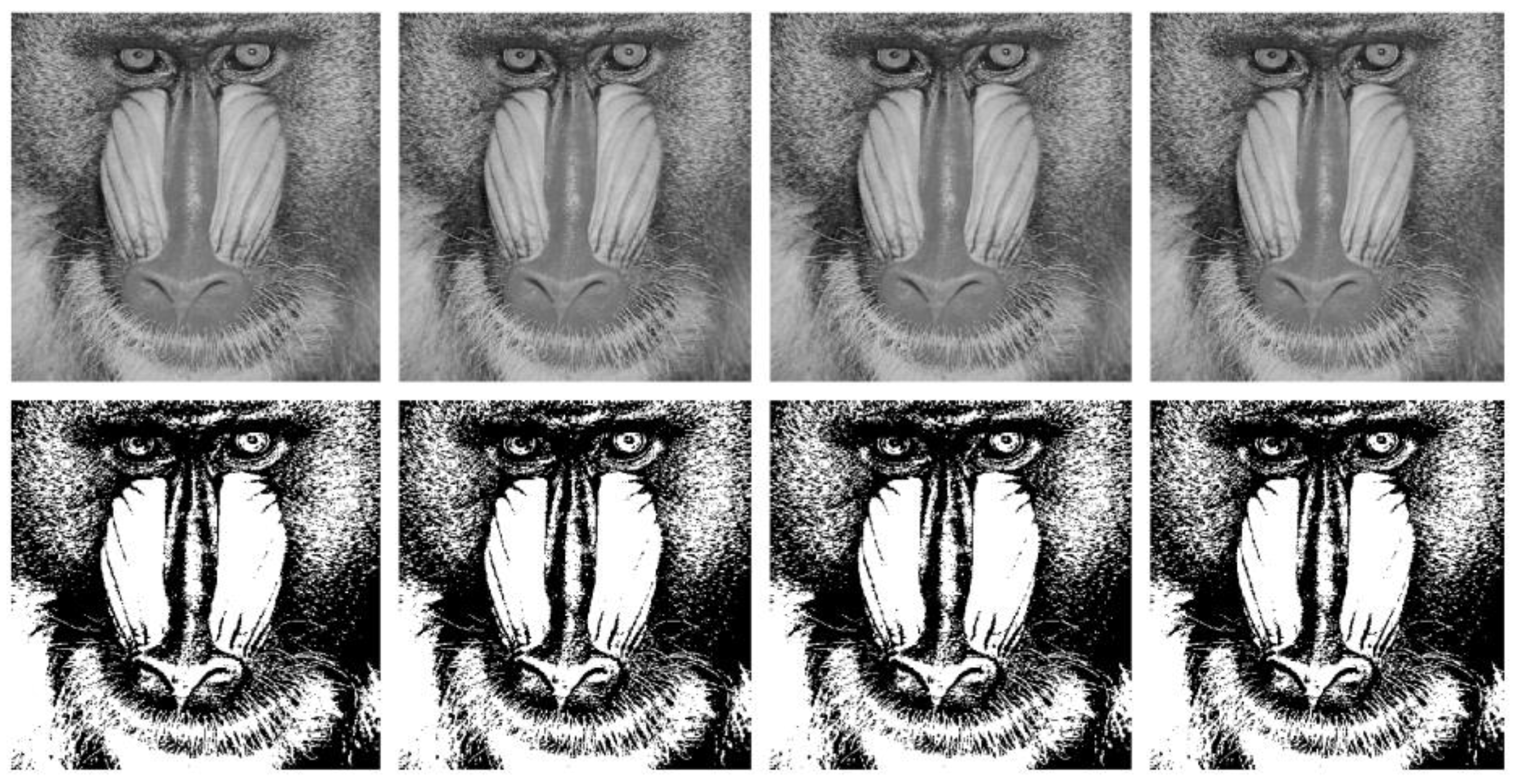
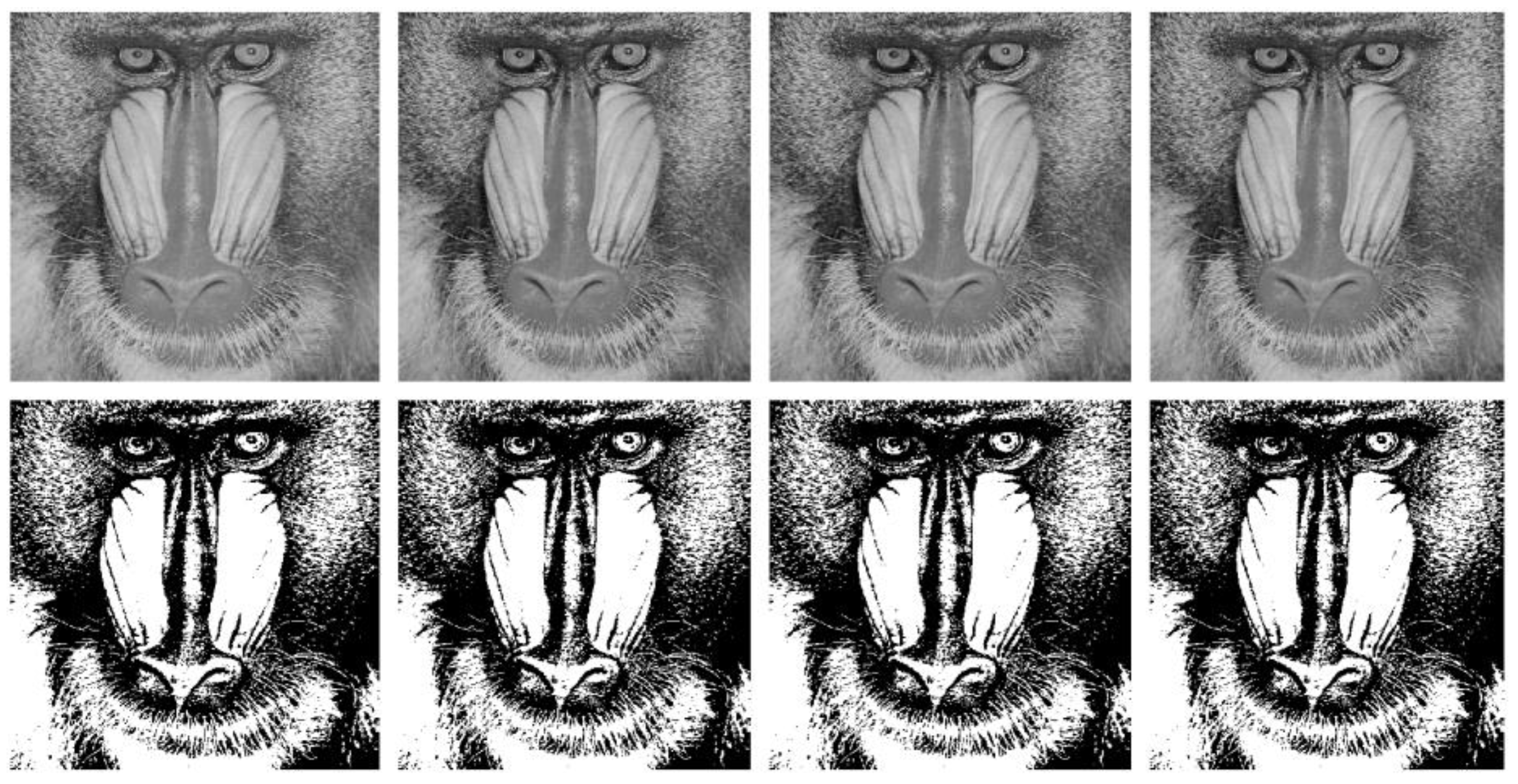
4.2. Visual Analysis
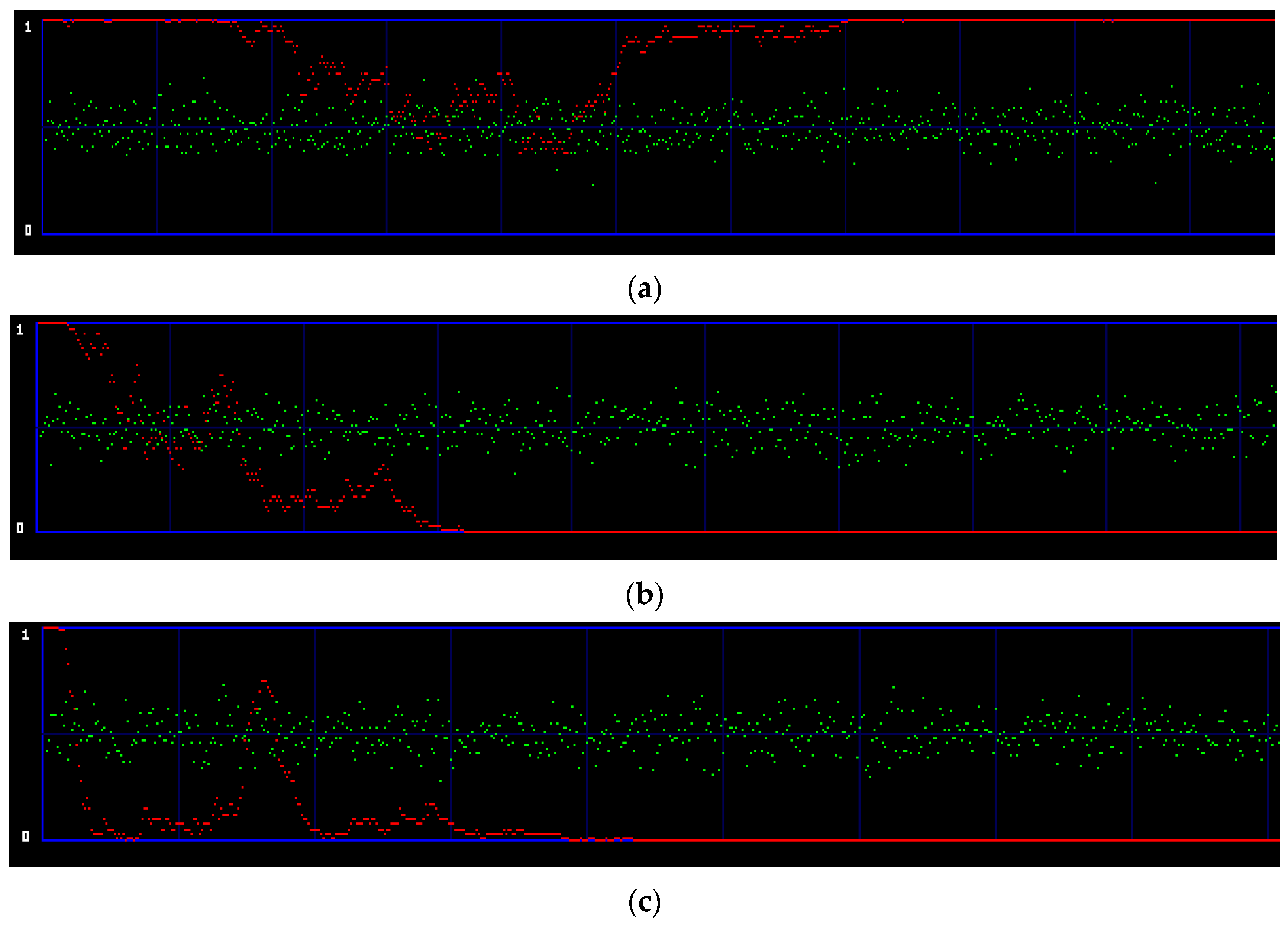
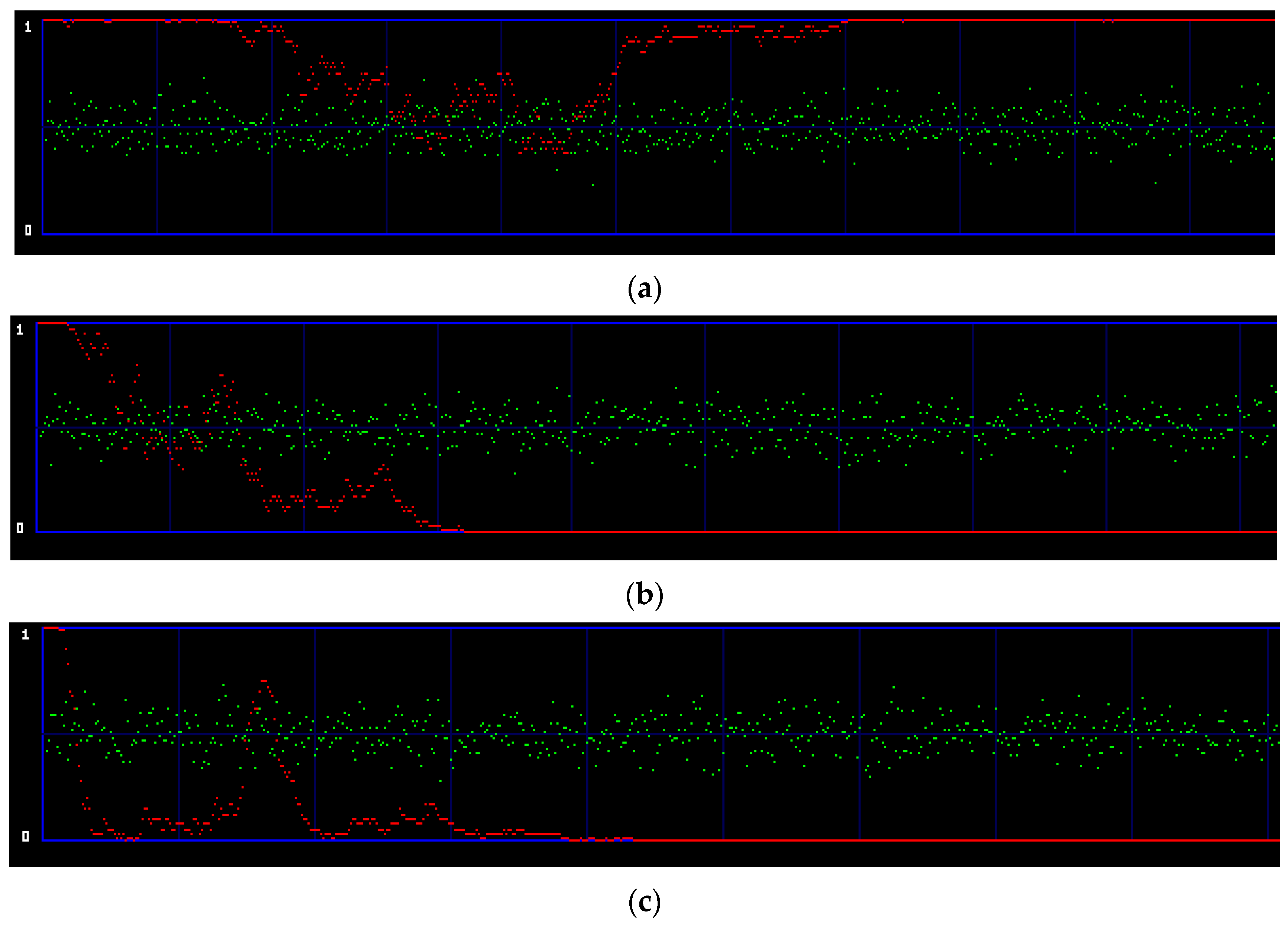
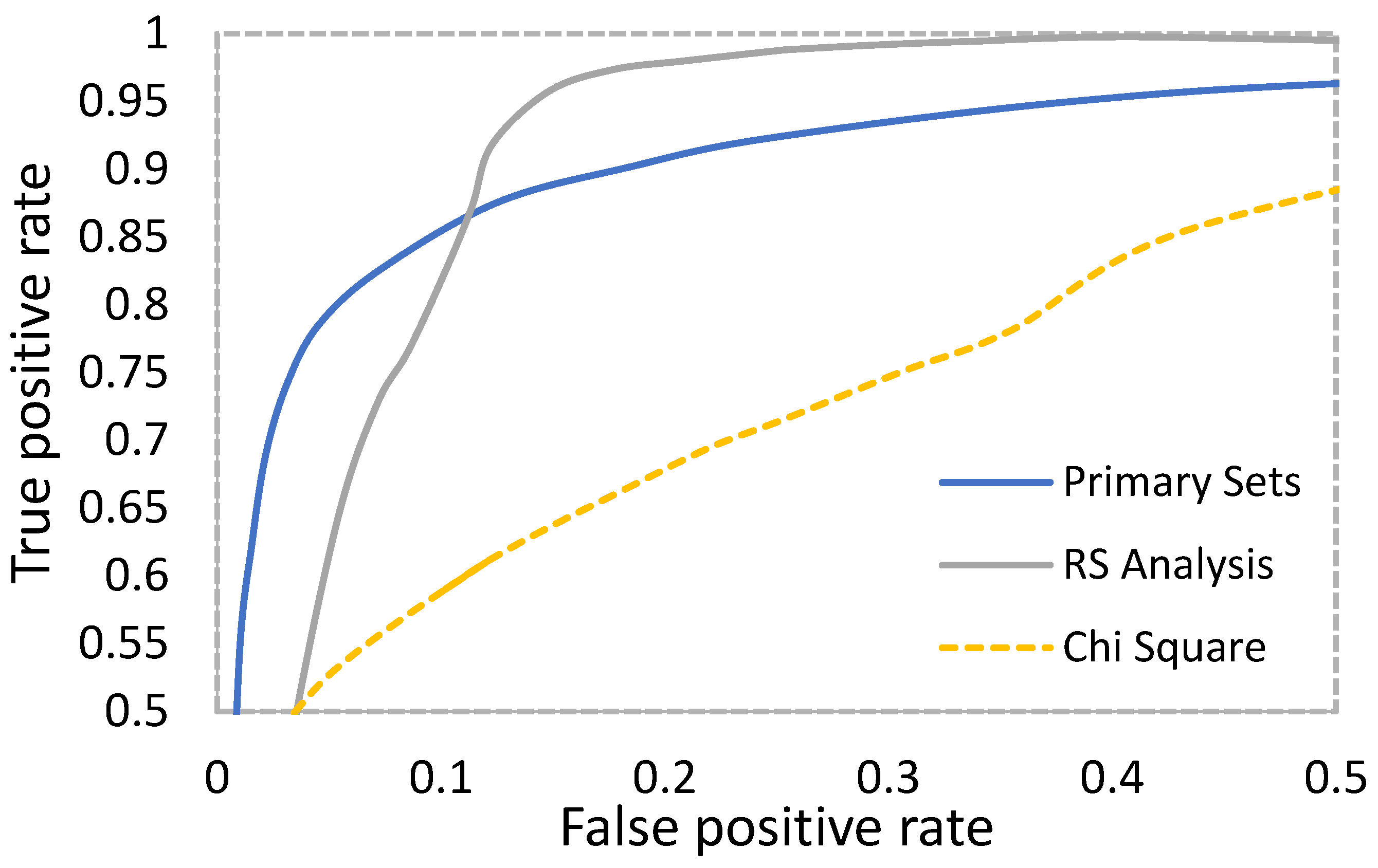
4.3. Stego Analysis Using StegoExpose
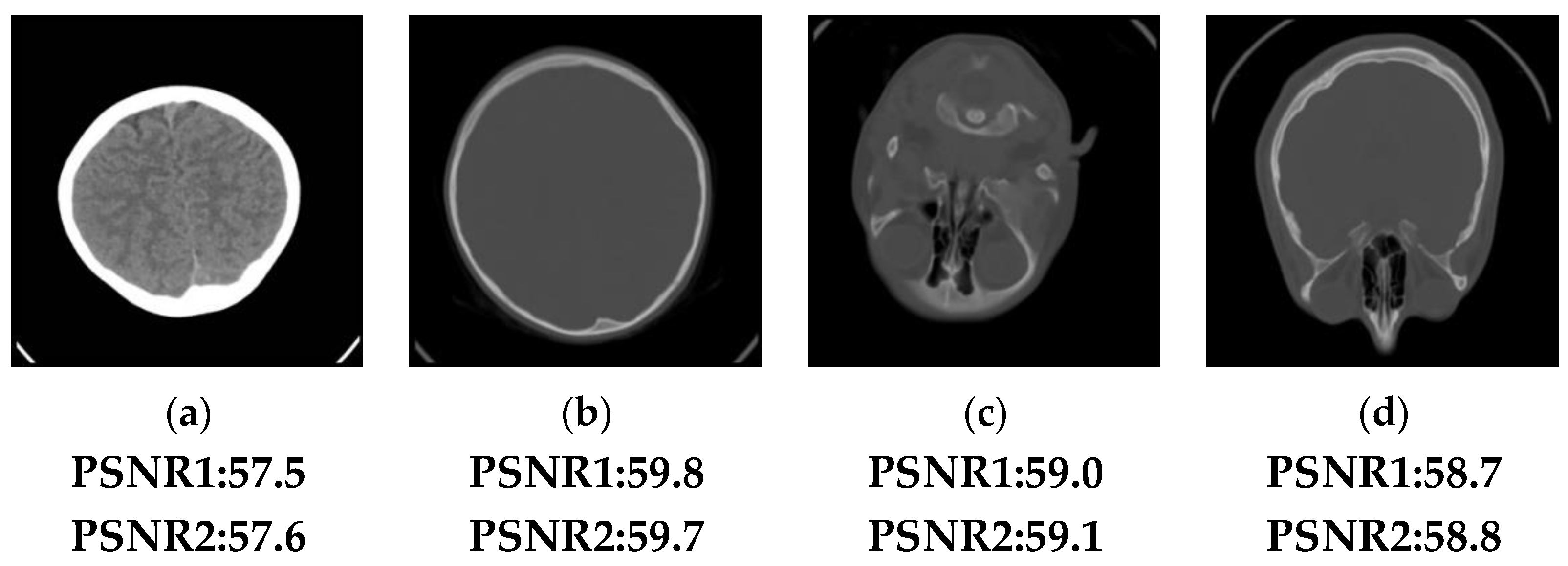
5. Application
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Al-Suqri, M.N.; Gillani, M. A Comparative Analysis of Information and Artificial Intelligence Toward National Security. IEEE Access 2022, 10, 64420–64434. [Google Scholar] [CrossRef]
- Sun, N.; Li, C.-T.; Chan, H.; Le, B.D.; Islam, Z.; Zhang, L.Y.; Islam, R.; Armstrong, W. Defining Security Requirements with the Common Criteria: Applications, Adoptions, and Challenges. IEEE Access 2022, 10, 44756–44777. [Google Scholar] [CrossRef]
- Semertzis, I.; Rajkumar, V.S.; Stefanov, A.; Fransen, F.; Palensky, P. Quantitative Risk Assessment of Cyber Attacks on Cyber-Physical Systems using Attack Graphs. In Proceedings of the 10th Workshop on Modelling and Simulation of Cyber-Physical Energy Systems (MSCPES), Milan, Italy, 3 May 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Skendžić, A.; Kovačić, B.; Tijan, E. General data protection regulation—Protection of personal data in an organization. In Proceedings of the 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 1370–1375. [Google Scholar]
- Wahab, O.F.A.; Khalaf, A.A.M.; Hussein, A.I.; Hamed, H.F.A. Hiding Data Using Efficient Combination of RSA Cryptography, and Compression Steganography Techniques. IEEE Access 2021, 9, 31805–31815. [Google Scholar] [CrossRef]
- Wang, J.; Cheng, L.-M.; Su, T. Multivariate Cryptography Based on Clipped Hopfield Neural Network. IEEE Trans. Neural Networks Learn. Syst. 2016, 29, 353–363. [Google Scholar] [CrossRef] [PubMed]
- Han, D.; Li, Z.; Wang, M.; Xu, C.; Sharif, K. Privacy Preservation Authentication: Group Secret Handshake with Multiple Groups. Mathematics 2023, 11, 532. [Google Scholar] [CrossRef]
- Verma, N.; Singh, M. Steganography techniques in network security. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 1–7. [Google Scholar]
- Satrio, T.A.; Prabowo, W.A.; Yuniati, T. Hiding Document Format Files Using Video Steganography Techniques with Least Significant Bit Method. In Proceedings of the IEEE International Conference on Communication, Networks and Satellite (COMNETSAT), Solo, Indonesia, 3–5 November 2022; pp. 399–406. [Google Scholar] [CrossRef]
- Adhiyaksa, F.A.; Amrulloh, M.M.; Mustaqim, T.; Tsaniya, H.; Studiawan, H.; Shiddiqi, A.M. Reversible Audio Data Hiding using Samples Greatest Common Factor and Audio Interpolation. In Proceedings of the IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; pp. 659–666. [Google Scholar] [CrossRef]
- Xie, J.; Wang, H.; Wu, D. Adaptive Image Steganography Using Fuzzy Enhancement and Gray Wolf Optimizer. IEEE Trans. Fuzzy Syst. 2022, 30, 4953–4964. [Google Scholar] [CrossRef]
- Hu, X.; Ni, J.; Shi, Y.-Q. Efficient JPEG Steganography Using Domain Transformation of Embedding Entropy. IEEE Signal Process. Lett. 2018, 25, 773–777. [Google Scholar] [CrossRef]
- Horng, J.-H.; Chang, C.-C.; Li, G.-L. Steganography Using Quotient Value Differencing and LSB Substitution for AMBTC Compressed Images. IEEE Access 2020, 8, 129347–129358. [Google Scholar] [CrossRef]
- Gutiérrez-Cárdenas, J.M. Secret Key Steganography with Message Obfuscation by Pseudo-random Number Generators. In Proceedings of the IEEE 38th International Computer Software and Applications Conference Workshops, Vasteras, Sweden, 21–25 July 2014; pp. 164–168. [Google Scholar]
- Wang, X.; Zhang, X.; Gao, M.; Tian, Y.; Wang, C.; Iu, H.H.-C. A Color Image Encryption Algorithm Based on Hash Table, Hilbert Curve and Hyper-Chaotic Synchronization. Mathematics 2023, 11, 567. [Google Scholar] [CrossRef]
- Lee, C.-F.; Huang, Y.-L. Reversible data hiding scheme based on dual stegano-images using orientation combinations. Telecommun. Syst. 2011, 52, 2237–2247. [Google Scholar] [CrossRef]
- Su, G.-D.; Liu, Y.; Chang, C.-C. A square lattice oriented reversible information hiding scheme with reversibility and adaptivity for dual images. J. Vis. Commun. Image Represent. 2019, 64, 102618. [Google Scholar] [CrossRef]
- USC-SIPI Image Database. Available online: https://sipi.usc.edu/database/ (accessed on 29 September 2022).
- Lee, C.F.; Wang, K.H.; Chang, C.C.; Huang, Y.L. A reversible data hiding scheme based on dual steganographic images. In Proceedings of the 3rd International Conference on Ubiquitous Information Management and Communication, Suwon, Republic of Korea, 15–16 January 2009; pp. 228–237. [Google Scholar]
- Liu, Y.; Chang, C.-C. A turtle shell-based visual secret sharing scheme with reversibility and authentication. Multimedia Tools Appl. 2018, 77, 25295–25310. [Google Scholar] [CrossRef]
- Lin, J.-Y.; Liu, Y.; Chang, C.-C. A real-time dual-image-based reversible data hiding scheme using turtle shells. J. Real-Time Image Process. 2019, 16, 673–684. [Google Scholar] [CrossRef]
- Hameed, M.A.; Hassaballah, M.; Aly, S.; Awad, A.I. An Adaptive Image Steganography Method Based on Histogram of Oriented Gradient and PVD-LSB Techniques. IEEE Access 2019, 7, 185189–185204. [Google Scholar] [CrossRef]
- Zhou, N.; Zhang, M.; Wang, H.; Ke, Y.; Di, F. Separable Reversible Data Hiding Scheme in Homomorphic Encrypted Domain Based on NTRU. IEEE Access 2020, 8, 81412–81424. [Google Scholar] [CrossRef]
- Jhong, C.-L.; Wu, H.-L. Grayscale-Invariant Reversible Data Hiding Based on Multiple Histograms Modification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5888–5901. [Google Scholar] [CrossRef]
- StegoExpose Steganalysis Tool. Available online: https://www.wetstonetech.com/products/stegohunt-steganography-detection/ (accessed on 31 March 2023).
- Kaggle Database. Available online: https://www.kaggle.com/datasets/vbookshelf/computed-tomography-ct-images (accessed on 15 March 2023).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| s | (x1, y1) | (x2, y2) | ds |
|---|---|---|---|
| 0 | (x, y) | (x, y) | 0 |
| 1 | (x, y) | (x − 1, y) | 1 |
| 2 | (x − 1, y) | (x, y) | 1 |
| 3 | (x, y) | (x, y − 1) | 1 |
| 4 | (x, y − 1) | (x, y) | 1 |
| 5 | (x, y) | (x − 1, y − 1) | 2 |
| 6 | (x − 1, y − 1) | (x, y) | 2 |
| 7 | (x + 1, y) | (x − 1, y) | 2 |
| 8 | (x − 1, y) | (x + 1, y) | 2 |
| 9 | (x, y + 1) | (x, y − 1) | 2 |
| 10 | (x, y − 1) | (x, y + 1) | 2 |
| 11 | (x − 1, y) | (x, y − 1) | 2 |
| 12 | (x, y − 1) | (x − 1, y) | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.-T.; Weng, C.-Y.; Shongwe, N.S. Capacity-Raising Reversible Data Hiding Using Empirical Plus–Minus One in Dual Images. Mathematics 2023, 11, 1764. https://doi.org/10.3390/math11081764
Huang C-T, Weng C-Y, Shongwe NS. Capacity-Raising Reversible Data Hiding Using Empirical Plus–Minus One in Dual Images. Mathematics. 2023; 11(8):1764. https://doi.org/10.3390/math11081764
Chicago/Turabian StyleHuang, Cheng-Ta, Chi-Yao Weng, and Njabulo Sinethemba Shongwe. 2023. "Capacity-Raising Reversible Data Hiding Using Empirical Plus–Minus One in Dual Images" Mathematics 11, no. 8: 1764. https://doi.org/10.3390/math11081764
APA StyleHuang, C.-T., Weng, C.-Y., & Shongwe, N. S. (2023). Capacity-Raising Reversible Data Hiding Using Empirical Plus–Minus One in Dual Images. Mathematics, 11(8), 1764. https://doi.org/10.3390/math11081764