


Robust Exponential Graph Regularization Non-Negative Matrix Factorization Technology for Feature Extraction

Abstract
1. Introduction
- (1)
- A new robust graph embedding algorithm, i.e., REGNMF, for unsupervised subspace learning is proposed in this article. On the basis of Euclidean distance and exponential Laplacian matrix as robustness criteria, we introduce an iterative algorithm to address optimization problems.
- (2)
- Different from the traditional GNMF algorithm, REGNMF can not only successfully solve the SSS problems by introducing the matrix exponent but gain a part-based representation of data. Test sample points are mapped into a novel subspace by learning the base matrix without being affected by singular matrices.
- (3)
- REGNMF improves the robust capacity of existing NMF algorithms based on graph embedding. In the contrast to existing methods, REGNMF can recode part-based geometric information of samples to classify. Extensive experiments show that our proposed methods runs well and outperforms existing algorithms on most occasions, especially on noisy and corrupted databases.
2. Related Work
2.1. Matrix Exponent [27]
- (1)
- is a full rank matrix;
- (2)
- If the matrices M and N are commutative, that is , then ;
- (3)
- For any matrix M, exists, and ;
- (4)
- Suppose that T is a non-singular matrix, then ;
- (5)
- Assuming that are the eigenvectors of D, and the corresponding to eigenvalues are , then still are the eigenvectors corresponding to the eigenvalues of matrix .
2.2. Graph Regularization Non-Negative Matrix Factorization (GNMF) [23]
2.3. Low Rank Non-Negative Factorization (LRNF) [18]
3. Robust Exponential Graph Regularization Non-Negative Matrix Factorization
3.1. The Motivation of REGNMF
3.2. Problem Formulation for REGNMF
3.3. The Optimal Solution
| Algorithm 1 REGNMF Algorithm. |
Input: Training set X, subspace dimensions d, the number of iterations iter, the current iteration number s, the regularization term coefficient , the matrices U and V, the weight matrix W, and the Laplacian matrix L. Initialization: The number of sample rows m and sample columns n, , , iter = 200, , ; 1. Use random functions to generate U and V factor matrices, , ; 2. Use the K-nearest neighbor algorithm to select the neighbor points of the to construct a neighborhood graph W; 3. According to , construct the Laplacian matrix L; 4. When s <= iter, loop: ➀ Iterate and Update U: ; ➁ Iterate and Update V: ; ➂ ; 5. If s > iter: end the loop; 6. Normalize matrices U and V: . Output: base matrix U and coefficient matrix V |
4. Experiment
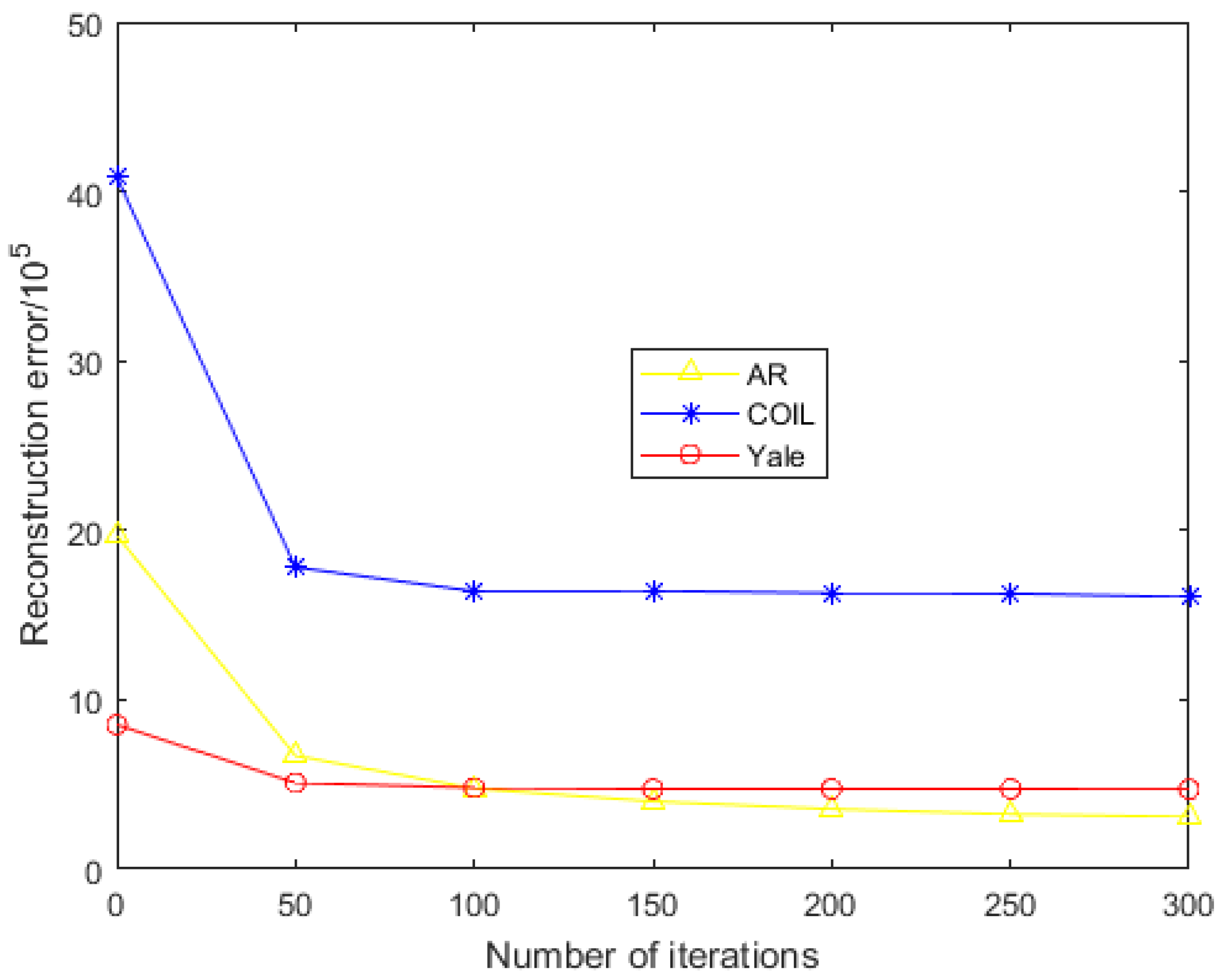
4.1. The AR Database Experiment
4.2. The COIL Database Experiment
4.3. Robustness Test for Random Pixel Destruction
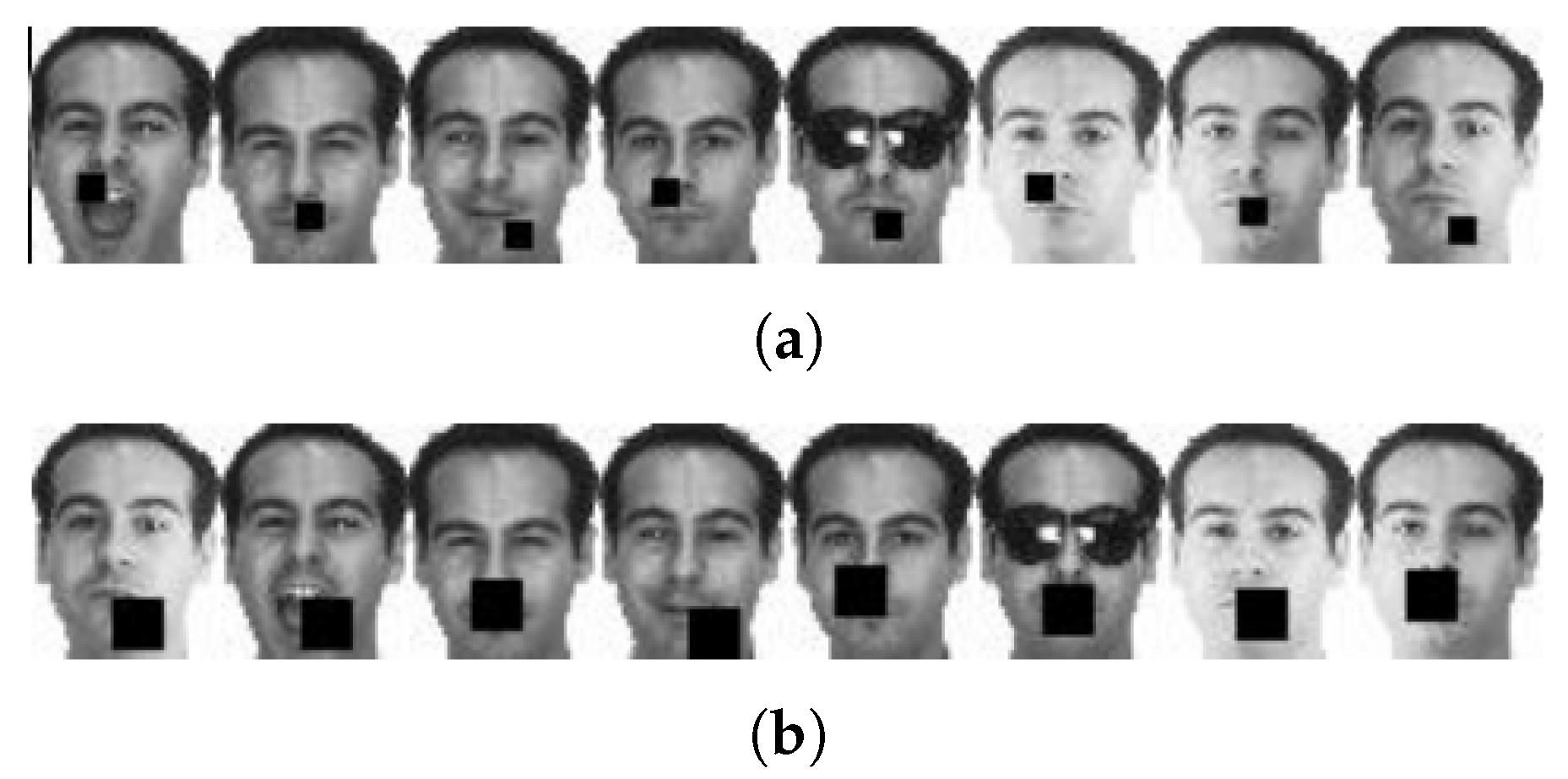
4.4. Robustness Test of Continuous Pixel Occlusion
4.5. Analysis of Results
- (1)
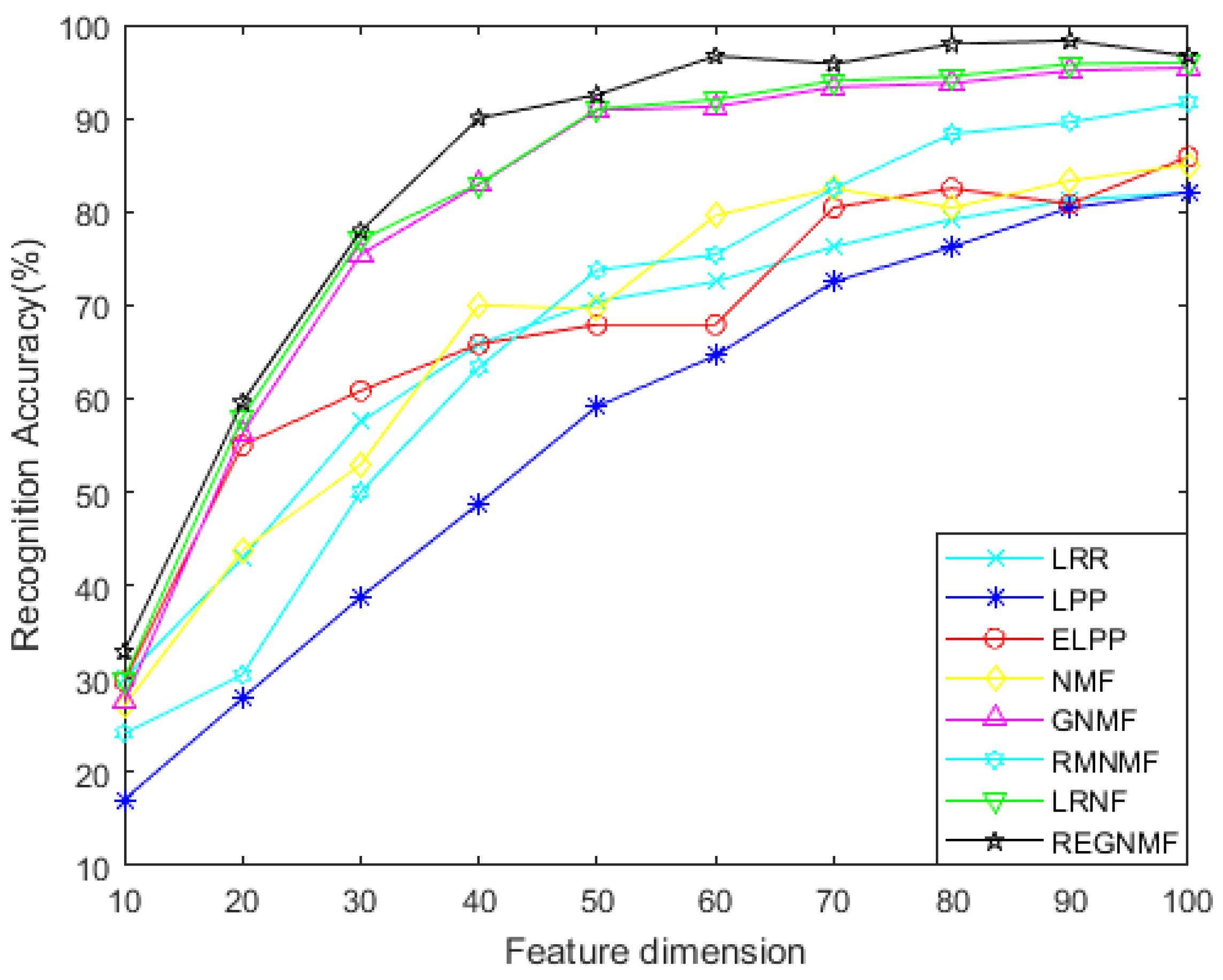
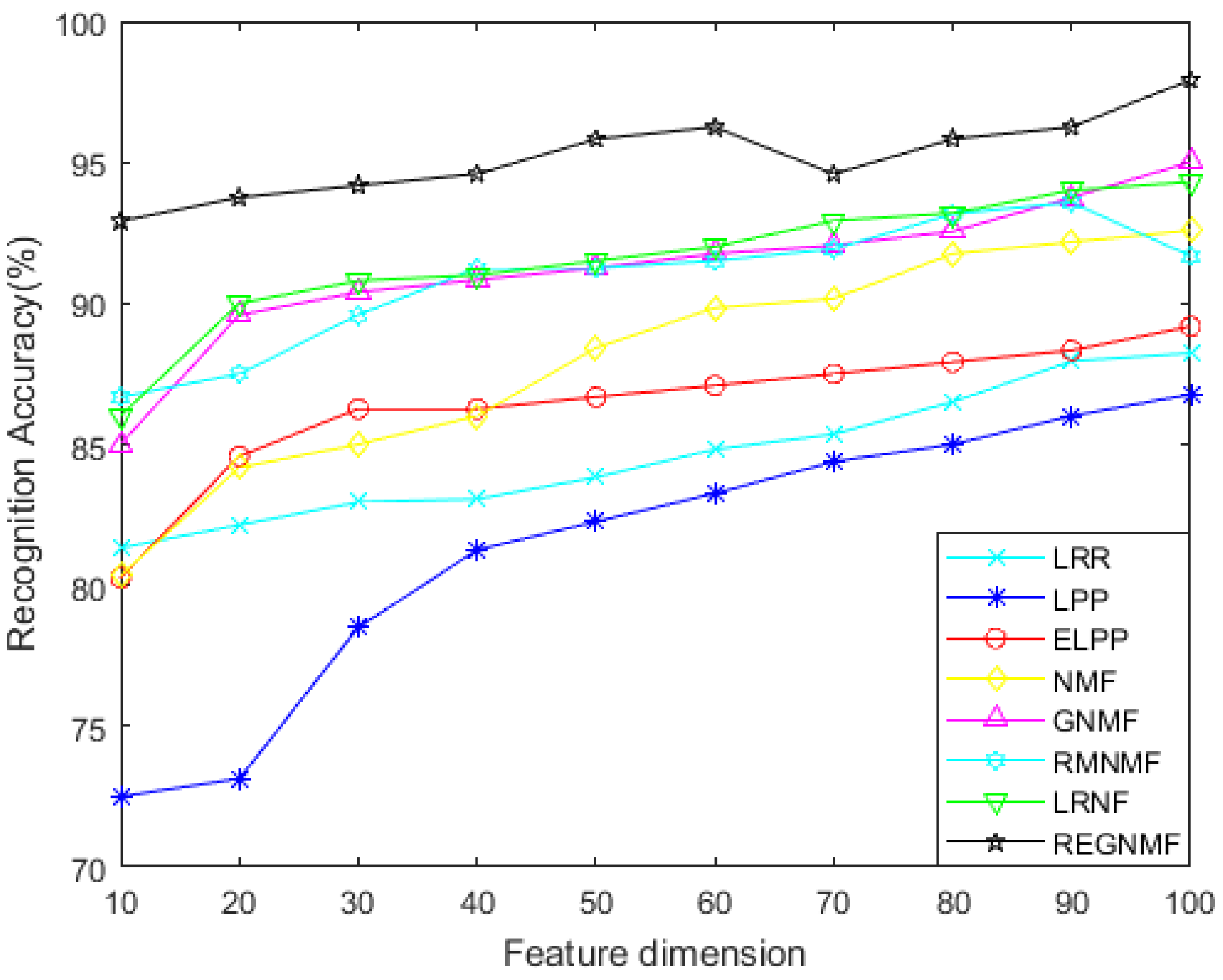
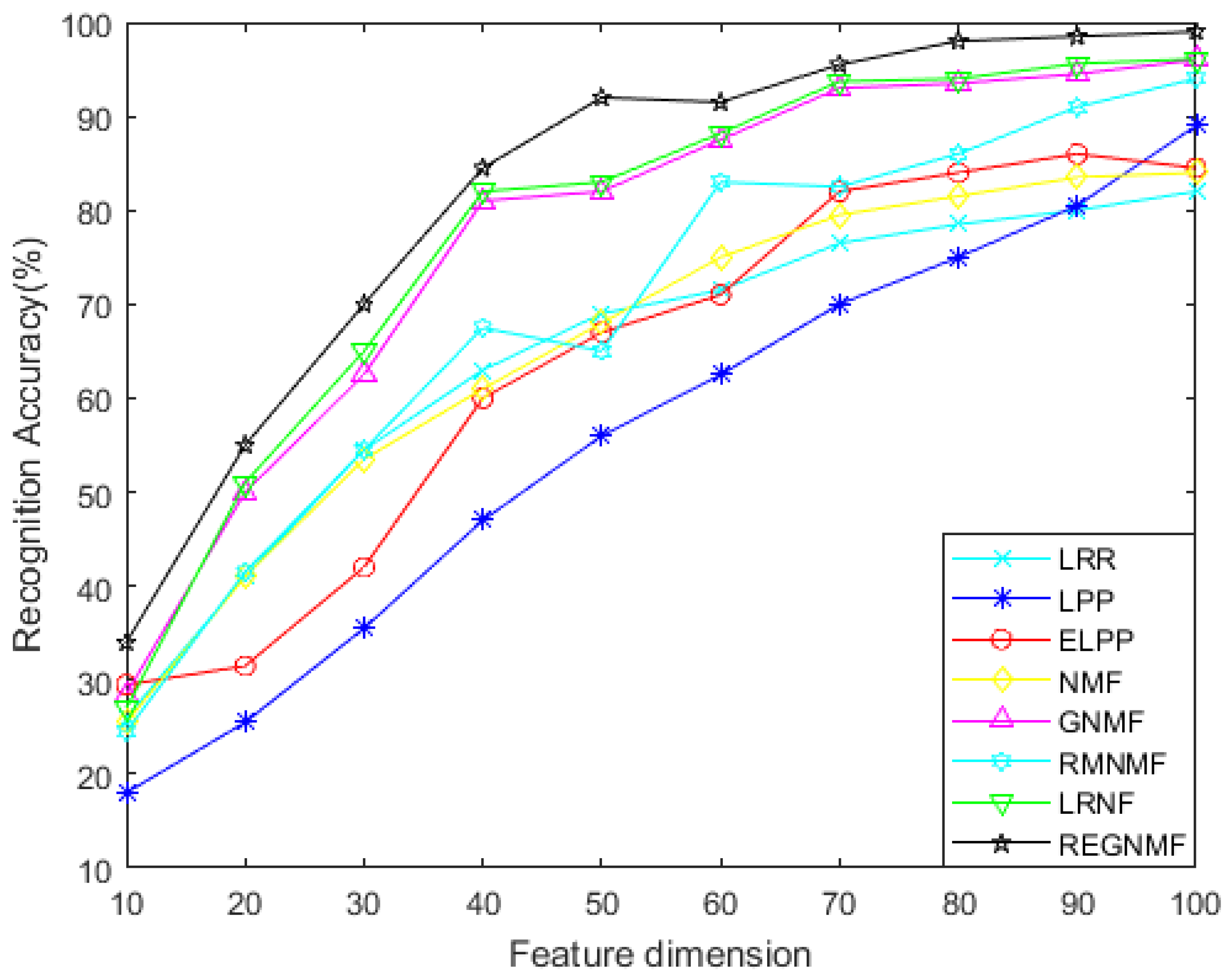
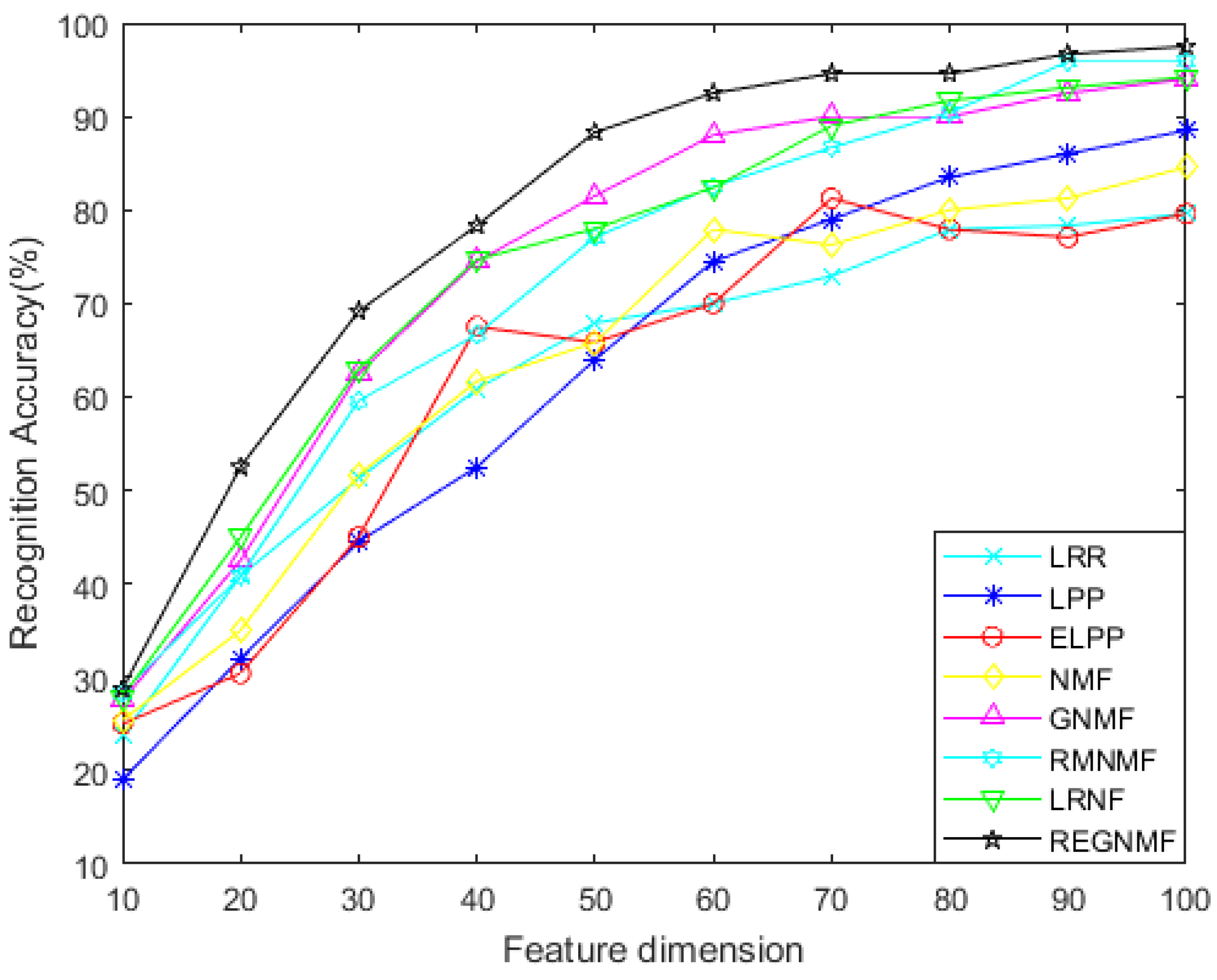
- For the noiseless data, Figure 2 and Figure 4 show the variation of each algorithm with the feature dimension for the AR and COIL databases. It can be seen that in most cases, the effect of REGNMF is significantly better than other algorithms, and the experiment on the COIL database indicates that the SSS problems are successfully solved.
- (2)
- In the experiment of adding noise, as shown in Table 1, the effect of the REGNMF method is far more effective than other algorithms under different noise densities, and the classification accuracy of image recognition is about 1–4% higher than other algorithms.
- (3)
- In the experiment with occlusion, it is clear from Figure 8 and Figure 9 that the REGNMF algorithm has better robustness and a higher face recognition rate, so it is more discriminative. In most cases, the classification accuracy of REGNMF and GNMF is much higher than that of other algorithms. This is because REGNMF, RMNMF, and GNMF join a graph regularizer, which takes the structure of the data into account while reducing the dimension. Therefore, the accuracy is higher.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hart, P.E.; Stork, D.G.; Duda, R.O. Pattern Classification; Wiley: Hoboken, NJ, USA, 2000. [Google Scholar]
- Turk, M.; Pentland, A. Eigenfaces for recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef] [PubMed]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Wan, M.; Li, M.; Yang, G.; Gai, S.; Jin, Z. Feature extraction using two-dimensional maximum embedding difference. Inf. Sci. 2014, 274, 55–69. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. Adv. Neural Inf. Process. Syst. 2001, 14, 585–591. [Google Scholar]
- Wan, M.; Lai, Z.; Yang, G.; Yang, Z.; Zhang, F.; Zheng, H. Local graph embedding based on maximum margin criterion via fuzzy set. Fuzzy Sets Syst. 2017, 318, 120–131. [Google Scholar]
- Roweis, S.T.; Saul, L.K. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef]
- Wan, M.; Chen, X.; Zhan, T.; Yang, G.; Tan, H.; Zheng, H. Low-rank 2D Local Discriminant Graph Embedding for Robust Image Feature Extraction. Pattern Recognit. 2023, 133, 109034. [Google Scholar]
- He, X. Locality preserving projections. Adv. Neural Inf. Process. Syst. 2003, 16, 186–197. [Google Scholar]
- Wang, A.; Zhao, S.; Liu, J.; Yang, J.; Liu, L.; Chen, G. Locality adaptive preserving projections for linear dimensionality reduction. Expert Syst. Appl. 2020, 151, 113352. [Google Scholar] [CrossRef]
- He, X.; Cai, D.; Yan, S.; Zhang, H.J. Neighborhood preserving embedding. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Washington, DC, USA, 17–21 October 2005; Volume 1, pp. 1208–1213. [Google Scholar]
- Gui, J.; Sun, Z.; Jia, W.; Hu, R.; Lei, Y.; Ji, S. Discriminant sparse neighborhood preserving embedding for face recognition. Pattern Recognit. 2012, 45, 2884–2893. [Google Scholar] [CrossRef]
- Wan, M.; Yao, Y.; Zhan, T.; Yang, G. Supervised Low-Rank Embedded Regression (SLRER) for Robust Subspace Learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1917–1927. [Google Scholar] [CrossRef]
- Abdi, H. Singular value decomposition (SVD) and generalized singular value decomposition. Encycl. Meas. Stat. 2007, 907, 912. [Google Scholar]
- Lee, D.; Seung, H.S. Algorithms for non-negative matrix factorization. Adv. Neural Inf. Process. Syst. 2001, 13, 556–562. [Google Scholar]
- Palmer, S.E. Hierarchical structure in perceptual representation. Cogn. Psychol. 1977, 9, 441–474. [Google Scholar] [CrossRef]
- Logothetis, N.K.; Sheinberg, D.L. Visual object recognition. Annu. Rev. Neurosci. 1996, 19, 577–621. [Google Scholar] [CrossRef]
- Lu, Y.; Lai, Z.; Li, X.; Zhang, D.; Wong, W.K.; Yuan, C. Learning parts-based and global representation for image classification. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3345–3360. [Google Scholar] [CrossRef]
- Lu, Y.; Yuan, C.; Zhu, W.; Li, X. Structurally incoherent low-rank non-negative matrix factorization for image classification. IEEE Trans. Image Process. 2018, 27, 5248–5260. [Google Scholar] [CrossRef]
- Lee, H.; Yoo, J.; Choi, S. Semi-supervised non-negative matrix factorization. IEEE Signal Process. Lett. 2009, 17, 4–7. [Google Scholar]
- Wang, J.; Tian, F.; Liu, C.H.; Wang, X. Robust semi-supervised non-negative matrix factorization. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Jia, Y.; Kwong, S.; Hou, J.; Wu, W. Semi-supervised non-negative matrix factorization with dissimilarity and similarity regularization. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2510–2521. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph regularized non-negative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1548–1560. [Google Scholar]
- Huang, J.; Nie, F.; Huang, H.; Ding, C. Robust manifold nonnegative matrix factorization. ACM Trans. Knowl. Discov. Data (TKDD) 2014, 8, 1–21. [Google Scholar]
- Yi, Y.; Wang, J.; Zhou, W.; Zheng, C.; Kong, J.; Qiao, S. Non-negative matrix factorization with locality constrained adaptive graph. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 427–441. [Google Scholar]
- Kuo, B.C.; Chang, K.Y. Feature extractions for small sample size classification problem. IEEE Trans. Geosci. Remote Sens. 2007, 45, 756–764. [Google Scholar] [CrossRef]
- Wang, S.J.; Chen, H.L.; Peng, X.J.; Zhou, C.G. Exponential locality preserving projections for SSS problems. Neurocomputing 2011, 74, 3654–3662. [Google Scholar] [CrossRef]
- Yuan, S.; Mao, X. Exponential elastic preserving projections for facial expression recognition. Neurocomputing 2018, 275, 711–724. [Google Scholar] [CrossRef]
- Dornaika, F.; Bosaghzadeh, A. Exponential local discriminant embedding and its application to face recognition. IEEE Trans. Cybern. 2013, 43, 921–934. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Fang, B.; Tang, Y.Y.; Shang, Z.; Xu, B. Generalized discriminant analysis: A matrix exponential approach. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2009, 40, 186–197. [Google Scholar] [CrossRef]
- Dornaika, F.; El Traboulsi, Y. Matrix exponential based semi-supervised discriminant embedding for image classification. Pattern Recognit. 2017, 61, 92–103. [Google Scholar] [CrossRef]
- Wu, G.; Feng, T.T.; Zhang, L.J.; Yang, M. Inexact implementation using Krylov subspace methods for large scale exponential discriminant analysis with applications to high dimensionality reduction problems. Pattern Recognit. 2017, 66, 328–341. [Google Scholar] [CrossRef]
- He, J.; Ding, L.; Cui, M.; Hu, Q.H. Marginal Fisher analysis based on matrix exponential transformation. Chin. J. Comput. 2014, 37, 2196–2205. [Google Scholar]
- Yaqin, G. Support vectors classification method based on matrix exponent boundary fisher projection. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 957–961. [Google Scholar]
- Ivanovs, J.; Boxma, O.; Mandjes, M. Singularities of the matrix exponent of a Markov additive process with one-sided jumps. Stoch. Process. Their Appl. 2010, 120, 1776–1794. [Google Scholar] [CrossRef]
- Lu, G.F.; Wang, Y.; Zou, J.; Wang, Z. Matrix exponential based discriminant locality preserving projections for feature extraction. Neural Netw. 2018, 97, 127–136. [Google Scholar] [CrossRef]
- Wang, S.J.; Yan, S.; Yang, J.; Zhou, C.G.; Fu, X. A general exponential framework for dimensionality reduction. IEEE Trans. Image Process. 2014, 23, 920–930. [Google Scholar] [CrossRef] [PubMed]
- Shahnaz, F.; Berry, M.W.; Pauca, V.P.; Plemmons, R.J. Document clustering using nonnegative matrix factorization. Inf. Process. Manag. 2006, 42, 373–386. [Google Scholar] [CrossRef]
- Luo, X.; Zhou, M.; Xia, Y.; Zhu, Q. An efficient non-negative matrix-factorization-based approach to collaborative filtering for recommender systems. IEEE Trans. Ind. Inform. 2014, 10, 1273–1284. [Google Scholar]
- Wang, Y.X.; Zhang, Y.J. Nonnegative matrix factorization: A comprehensive review. IEEE Trans. Knowl. Data Eng. 2012, 25, 1336–1353. [Google Scholar]
- Liu, G.; Lin, Z.; Yu, Y. Robust subspace segmentation by low-rank representation. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Liu, G.; Yan, S. Latent low-rank representation for subspace segmentation and feature extraction. In Proceedings of the 2011 International Conference on Computer Vision, Washington, DC, USA, 6–13 November 2011; pp. 1615–1622. [Google Scholar]
- Wan, M.; Chen, X.; Zhao, C.; Zhan, T.; Yang, G. A new weakly supervised discrete discriminant hashing for robust data representation. Inf. Sci. 2022, 611, 335–348. [Google Scholar]
- Qiao, L.; Chen, S.; Tan, X. Sparsity preserving projections with applications to face recognition. Pattern Recognit. 2010, 43, 331–341. [Google Scholar] [CrossRef]
- Chen, H.T.; Chang, H.W.; Liu, T.L. Local discriminant embedding and its variants. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; pp. 846–853. [Google Scholar]
- Huang, H.; Liu, J.; Pan, Y. Semi-supervised marginal fisher analysis for hyperspectral image classification. Isprs Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 3, 377–382. [Google Scholar] [CrossRef]
- Kivinen, J. Additive versus exponentiated gradient updates for linear prediction. Inf. Comput. 1997, 132, 1–64. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | “Salt and Pepper” Noise (Density = 0.1) | Gaussian Noise (Density = 0.2) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | 6 | 2 | 3 | 4 | 5 | 6 | |
| LRR | 69.63 | 73.33 | 80.00 | 82.22 | 78.67 | 60.00 | 65.83 | 71.43 | 78.89 | 74.67 |
| LPP | 40.74 | 40.74 | 35.24 | 43.33 | 50.67 | 37.78 | 51.67 | 41.90 | 55.56 | 56.00 |
| ELPP | 49.30 | 51.67 | 54.76 | 61.11 | 69.33 | 47.04 | 50.00 | 52.86 | 61.11 | 63.33 |
| NMF | 65.93 | 70.00 | 79.05 | 82.22 | 73.33 | 64.44 | 67.50 | 73.33 | 81.11 | 80.00 |
| GNMF | 67.41 | 71.67 | 82.86 | 79.05 | 77.33 | 58.52 | 77.50 | 70.48 | 82.22 | 73.33 |
| RMNMF | 71.85 | 72.5 | 74.67 | 76.67 | 77.14 | 63.70 | 68.33 | 77.14 | 78.89 | 78.67 |
| LRNF | 72.59 | 76.67 | 76.19 | 81.11 | 74.67 | 70.37 | 68.33 | 79.05 | 74.44 | 73.33 |
| REGNMF | 74.07 | 76.67 | 83.81 | 85.56 | 81.33 | 75.56 | 75 | 80.95 | 83.33 | 82.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, M.; Cai, M.; Yang, G. Robust Exponential Graph Regularization Non-Negative Matrix Factorization Technology for Feature Extraction. Mathematics 2023, 11, 1716. https://doi.org/10.3390/math11071716
Wan M, Cai M, Yang G. Robust Exponential Graph Regularization Non-Negative Matrix Factorization Technology for Feature Extraction. Mathematics. 2023; 11(7):1716. https://doi.org/10.3390/math11071716
Chicago/Turabian StyleWan, Minghua, Mingxiu Cai, and Guowei Yang. 2023. "Robust Exponential Graph Regularization Non-Negative Matrix Factorization Technology for Feature Extraction" Mathematics 11, no. 7: 1716. https://doi.org/10.3390/math11071716
APA StyleWan, M., Cai, M., & Yang, G. (2023). Robust Exponential Graph Regularization Non-Negative Matrix Factorization Technology for Feature Extraction. Mathematics, 11(7), 1716. https://doi.org/10.3390/math11071716