2.1. Study Area and Data
In this study, daily weather data from Doha, Qatar is used. Qatar is located at latitude 25.35
N and longitude 51.03
E, in the eastern region of Saudi Arabia. It has a dry climate with low precipitation and exceedingly hot and humid summers. The temperature during the winter months, from December to February, remains above 10
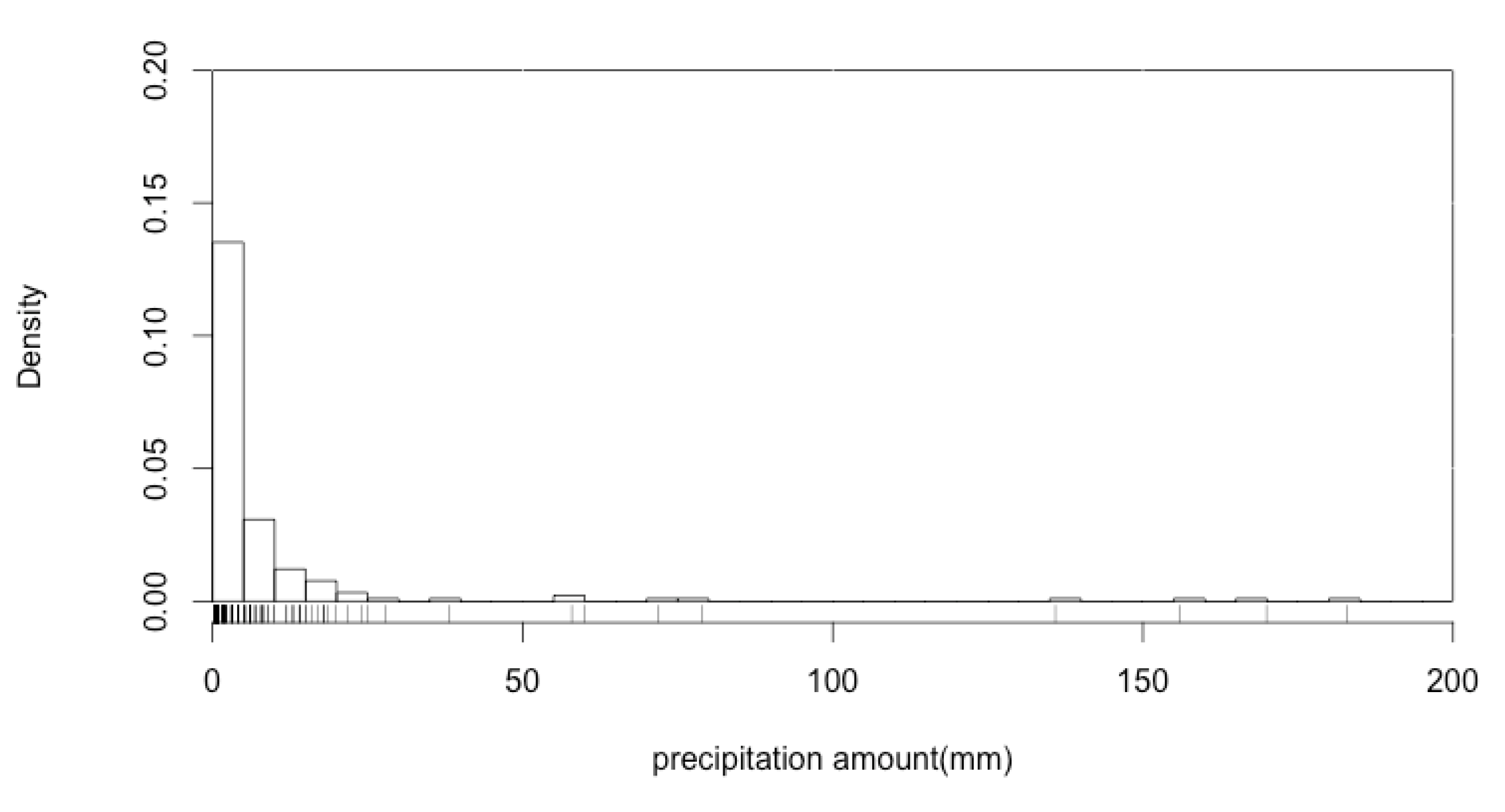
C and most of the precipitation occurs during this period. The region receives a small amount of precipitation, as shown in
Figure 1, which is highly unpredictable both in terms of time and space.
Weather data from 1983 to 2013 were used to develop a stochastic weather model. To compare calculation methods for evapotranspiration, data over the period from 1985 to 2013 were used. The data included basic weather factors, such as daily values of the mean, minimum, and maximum temperature (C), precipitation (mm), relative humidity (%), and wind speed (m/s). More detailed weather factors for calculating evapotranspiration were included from 1985.
To ignore the effects of leap years, we subtract the last day (i.e., 29 February) in a leap year. This gives us a simple model structure with an equal number of days in each year, with 365 days in every year.
In this study, missing values in the temperature data were replaced with the existing values of the same day in the previous year. This is because missing values found in our data were mostly consecutive and over a long period; for example, the worst case is that there were no data for the whole month. For precipitation, missing data values were considered as non-rainy days because in Qatar there were not many rainy days. All data processing and calculations were done with the statistical software package R.
2.2. Reconnaissance Drought Index (RDI)
In the last few decades, many drought indices have been developed as tools for assessing the severity of droughts. By incorporating the effects of relevant weather variables on the occurrence and intensity of droughts into a single numerical value, drought indices make it easy to establish strategies that could reduce the associated risks. Through the drought index, droughts could be classified as hyper-arid, arid, semi-arid, sub-humid, and humid. In this paper, we used a more recent drought index called the reconnaissance drought index (
RDI), introduced by Tsakiris et al. (2007) [
23]. The
RDI is a physically based, universal, and comprehensive index that depends on cumulative precipitation and potential evapotranspiration. Most drought indices are precipitation-based only and are not sufficiently effective at capturing the effects of droughts on crops and agricultural production. When assessing the severity of droughts, evapotranspiration is also required in order to provide the most realistic information on water scarcity and agricultural conditions. Therefore, the
RDI is a preferred index for use in agriculture in drought severity assessment and monitoring. It is also sensitive to changing climatic environments and flexible for different growing periods (Tsakiris et al. (2007) [
23]).
RDI is defined as the ratio of accumulated precipitation to potential evapotranspiration [
23]:
where
and
are the precipitation and potential evapotranspiration (
) for the
jth month of the
ith year and
n is the period in which we are interested. Based on this equation, we can calculate
RDI for any period in each year. Potential evapotranspiration (
) is the evaporation that occurs where there is a sufficient water supply, but in practice it is very hard to obtain. Therefore, in practice, we use an adjusted
RDI, which uses actual evapotranspiration (
) instead of potential evapotranspiration (
):
where
is the actual evapotranspiration
for the
jth month of the
ith year.
2.3. Evapotranspiration
Evapotranspiration consists of two processes that account for water loss to the atmosphere: evaporation and transpiration. While evaporation represents the water loss due to movement from the soil to the atmosphere, transpiration represents the water loss through plants. Since these two processes occur simultaneously, it is difficult to measure their effect separately. Therefore, we use evapotranspiration as a quantity that measures the combined effect of the two processes. Since the weather is the only factor that affects evapotranspiration, there are calculation methods using weather data. Several calculation methods have been developed and proposed to estimate evapotranspiration from weather data such as temperature, humidity, wind speed, and other weather parameters, such as solar radiation, pressure, and so on.
The FAO-56 Penman–Monteith (PM) method [
24] is recommended by the Food and Agriculture Organization of the United Nations (FAO) as a standardized method to calculate the reference evapotranspiration
. It has the following form:
where
is the reference evapotranspiration (mm/day),
is the net radiation at the crop surface (MJ/m
day),
G is the soil heat flux density (MJ/m
day),
is the mean air temperature at a 2 m height (
C),
is the wind speed at a 2 m height (m/s),
is the saturation vapor pressure (kPa),
is the actual vapor pressure (kPa),
is the slope of the vapor pressure curve (kPa/
C), and
is a psychometric constant (kPa/
C).
The limitation of using the PM formulation is that it requires extensive climatic data that are not easily available. Therefore, we test other simpler evapotranspiration formulations for compatibility with the PM formulation for Qatar, including those developed by Blaney and Criddle [
25], Hargreaves and Samani [
26], Jensen and Haise [
27], Linacre [
28], and Turc [
29]. This will be crucial for other arid regions where the available weather data are limited. The formulations of each of these methods are provided in
Appendix A.
In order to select the appropriate formulation, we compared the compatibility of each of these methods with the PM formulation by computing various statistical quantities, including, the Pearson’s correlation (
), root-mean-square error (RMSE), mean absolute error (MAE), and the maximum absolute error (MAXE). The computed values of these quantities based on the data from 1985 to 2014 are presented in
Table 1.
With the highest correlation
value and lowest RMSE, MAE, and MAXE error values, the Turc method shows the closest agreement with the PM method. The Turc method is given by the following piecewise continuous function or relative humidity
and requires only mean temperature,
(ºC), relative humidity,
(%), and mean solar radiation,
(W/m
day), which are variables that are easily obtainable over an arid region, such as Qatar, making the method suitable for common use. Therefore, the Turc method is selected as a method of evapotranspiration for the
RDI calculation in this paper.
Once we obtain
, the actual evapotranspiration specific to a certain crop can be easily calculated using the crop coefficient. While most of the effects from relevant weather conditions are reflected in
, the effect of the crop type on evapotranspiration is incorporated by adjusting
with the crop coefficient to obtain the crop evapotranspiration, denoted by
, which is given by:
where
is the crop coefficient. Every crop has its own crop coefficient values based on the growth environment, water requirements, and growth stages. Crop coefficients for specific crops at specific growth stages are provided by the Food and Agriculture Organization of the United Nations (FAO) [
24].
Table 2 shows the growth period and crop coefficients for Qatar. The growth period is separated into four growth stages; initial, development, mid-season, and late season. Typically, crop coefficients in mid-season have the largest values. Most crops in Qatar are grown in the winter months and harvested before the start of the summer months because the summer has very few rainy days.
Crop evapotranspiration for six crops, including alfalfa, bean, carrot, maize, tomato, and wheat, was calculated using observed and simulated weather data. Observed weather data from 1985 to 2013 and simulation data with the same length as the observation data were used. The mean, standard deviation, minimum, and maximum of crop evapotranspiration are presented in
Table 3. The mean crop evapotranspiration from tomatoes shows the largest value, while alfalfa shows the smallest value.
2.4. Temperature Model
We propose using the mean reversion process to develop the temperature model accounting for its seasonality, which repeats annually. We use an adjusted Ornstein–Uhlenbeck (O–U), suggested by [
13,
14] and given by
where
represents the daily temperature,
is the speed of mean reversion,
is the mean where the process reverts to,
is the volatility of the model, and
is the Wiener process, which is normally distributed with a mean of 0 and variance of
t. The solution to Equation (
6), a stochastic differential equation (SDE), is derived from Itô’s Lemma and is given by [
13]:
In this process,
,
, and
are parameters that need to be estimated from the data. Here, we use the least-squares method to estimate these parameters, where we assume that consecutive observations have a linear relation with normally distributed error. The following linear equation is applied to the solution of the SDE [
30]:
The relationship between the parameters of the linear equation and the solution of the SDE [
30] is then derived and described below.
and,
Here,
represents the time step between
t and
, so
is 1. Thus, rewriting with respect to parameters in the SDE, we have
and,
We can calculate the parameters of the least square fit as follows:
where
,
,
,
and
.
The mean values of the parameters in the SDE are calculated for each month of the year and are presented in
Table 4. The highest value of
is found in June and the smallest value is found in October. For a speed of mean reversion, August has a large value of
, which means it is drawn very strongly back to its mean value. Moreover, the value of
is close to the monthly mean temperature.
We also used the maximum likelihood estimation method to estimate these parameters and very similar results were obtained. (See
Appendix B for details).
2.6. Precipitation Model
We now present the precipitation model, which is required along with evapotranspiration for RDI calculation.
The most commonly used stochastic models for precipitation consist of a two-process formulation that models precipitation occurrence and amount. In the two-process model, a Markov chain is used to model precipitation occurrence, and a probability distribution is used to determine the precipitation amount on a wet day [
15,
16,
17,
18,
19,
31,
32]. In the following sections, we describe the first-order Markov chains used to model precipitation occurrence and consider several probability distributions for estimating the precipitation amount.
2.6.1. Precipitation Occurrence Model
The first-order Markov chain implicitly assumes that the probability of rain tomorrow depends only on whether it rained today or not and is described by the Markov property:
where time
and state space
. The Markov chain transition matrix that defines a probability that each event occurs is composed of transition probabilities, which are conditional probabilities of future state
j given state
i. The transition matrix, denoted by
, is given by
where
. The property of a transition matrix is that the total sum of each row must equal 1, i.e.,
The precipitation occurrence has two states: dry and wet. Therefore, the transition matrix is specified by two conditional probabilities, which are
Since there are only two states, transition probabilities at the same given state are complementary. So it is not necessary to estimate four transition probabilities, we only need to estimate one of each pair of transition probabilities. For instance, the probability of a dry day following a dry day is calculated using the probability of a wet day following the dry day, which is
. The probability transition matrix is defined as below.
Using the transition matrix, we can calculate the stationary state vector such that
. It implies a long-run relative frequency of precipitation occurrence and satisfies
, where
for all
i. Each element,
, denotes the probability of being in state
i. If this state vector is given by
then it must satisfy
Therefore, by solving the stationary probabilities
and
, we obtain:
The stationary probabilities are calculated for each month and are shown in
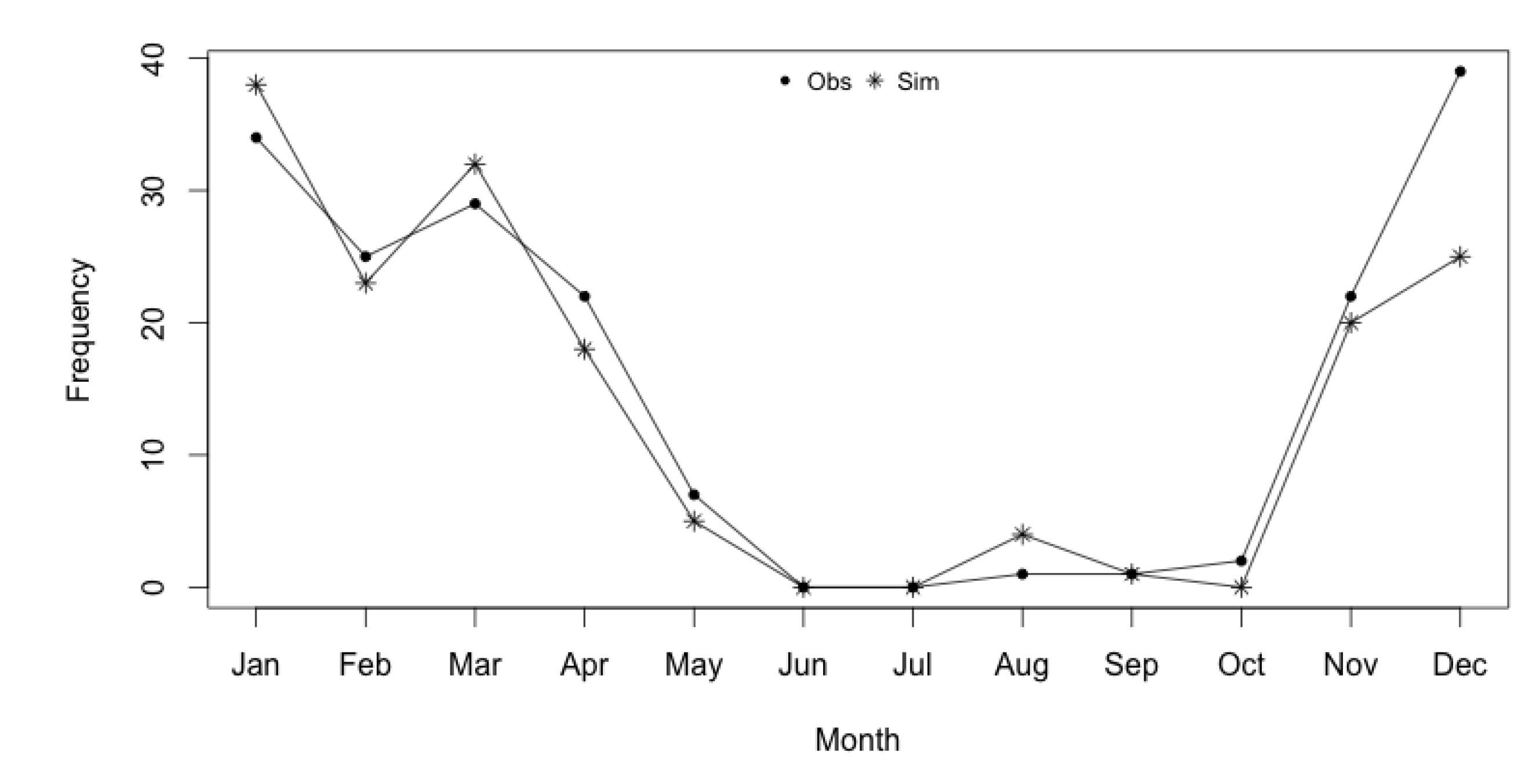
Table 6. We can see that most of the stationary probabilities for dry days are quite large, showing that Qatar does not have many wet days. Since there are no wet days in June and July from the data, stationary probabilities for dry days are one, as expected.
2.6.2. Distribution of Precipitation Amount
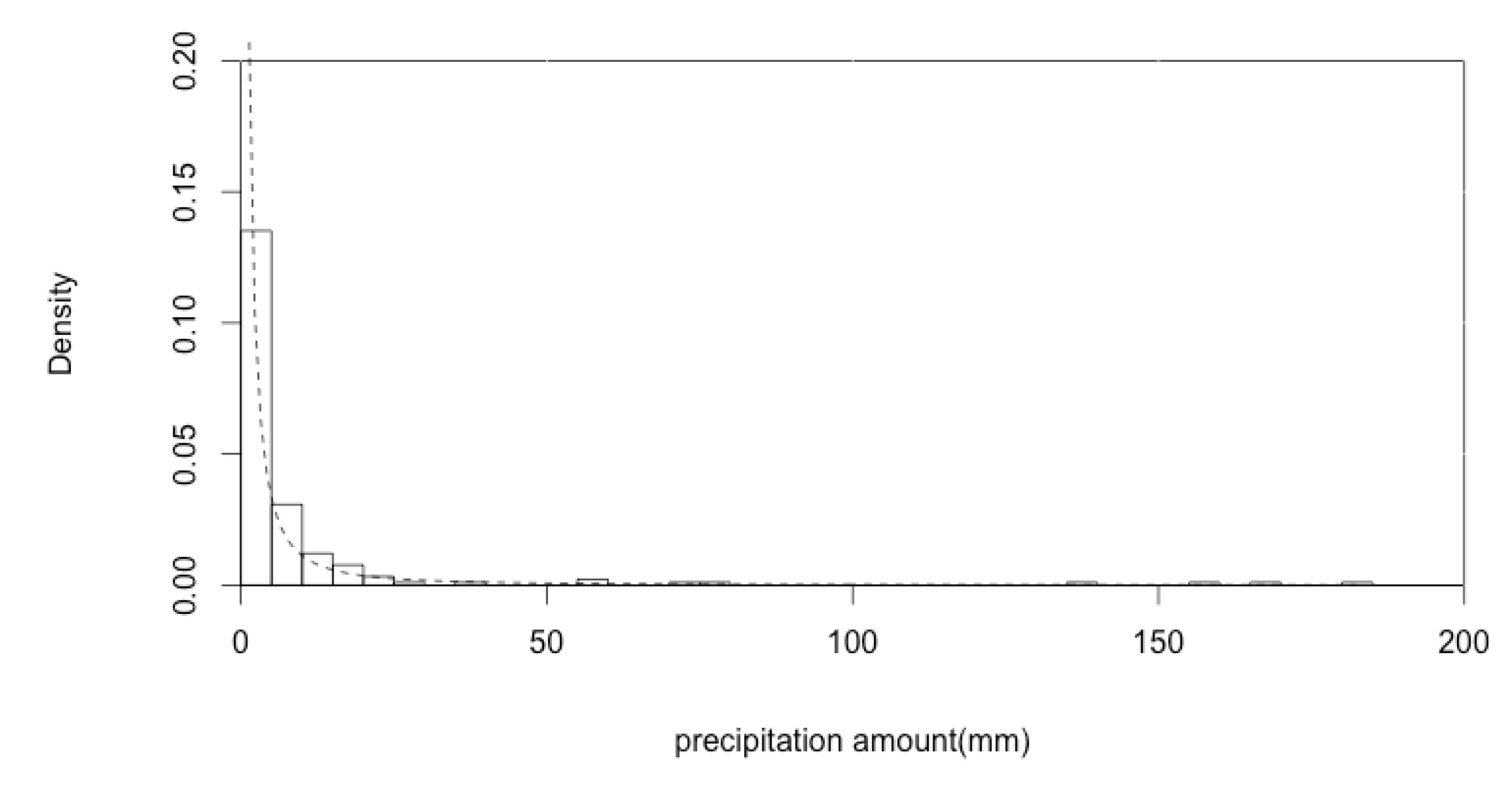
By accounting for the fact that there is an extreme amount of precipitation over 100 mm, we expect that distributions with thicker tails will perform better in estimating the precipitation amount. Therefore, we employed two extreme distributions, the generalized extreme value, and four-kappa distributions. Since these distributions have thicker tails, they can better capture extremely large amounts of precipitation in the simulation.
In this study, we also considered the probability distributions used in previous research, including the exponential, log-normal, and gamma distributions, and two extreme distributions, i.e., the general extreme value and four-kappa distributions, to simulate the precipitation amount. The parameters of these distributions are estimated using the maximum likelihood method (MLE), which is the most common method used to find parameters in statistics.
Once we have the precipitation occurrence sequence, the next step is to determine the precipitation amounts on wet days. Since the precipitation amount is generally small, we use a right-skewed probability distribution for the precipitation amount [
19]. Previously, many right-skewed probability distributions, including the exponential, log-normal, and gamma, were used to describe the distribution of the precipitation amount [
18,
33]. In this study, we consider exponential, log-normal, and gamma distributions, and two extreme probability distributions, the general extreme value distribution (GEVD) and four-kappa distribution (K4D). Functions for the probability distributions are given in
Table 7. The two extreme distributions have a thick tail, which could model the extreme amount of precipitation in the simulation. The probability distribution parameters are estimated using the maximum likelihood estimation (MLE), and the results are shown in
Table 8.
It would be preferable to fit probability distributions for each month. However, some months have very few or no rainy days in our data, making it challenging to find suitable probability distributions. Therefore, we use all the available precipitation data to estimate the probability distribution of precipitation amount in Qatar.
We determine which probability distributions show the best fit for the precipitation amount by using three model validation methods, the Kolmogorov–Smirnov (KS test), Akaike information criteria (AIC), and Bayesian information criteria (BIC). As described below, the KS test provides
p-values while both AIC and BIC provide values based on likelihood functions [
33].
Kolmogorov–Smirnov test (KS test [
33])
The Kolmogorov–Smirnov test is used to determine if a dataset comes from a specified distribution. It measures the differences between the empirical distribution of the sample and the cumulative distribution of the specified distribution, providing a test statistic, D, and p-values that can be used as criteria for hypothesis testing.
Akaike information criteria (AIC [
35])
Firstly, the AIC developed by Hirotugu Akaike was used to evaluate the performance of the model in a simple linear regression. It was created to select the model that has the smallest loss of information from the given data. It measures the loss based on a likelihood function and is defined by:
where
L is the likelihood function and
K is the number of parameters. In the formula, the negative log-likelihood term represents the loss of information and
contains a penalty corresponding to the number of parameters in the model. This penalty considers the number of parameters because the model performance improves with the number of parameters it has. By comparing AIC, the model with the smallest AIC is considered to have good performance.
Bayesian information criterion (BIC [
36])
Similar to AIC, BIC evaluates the model performance by using the likelihood, and the model with the smallest BIC is preferred. Compared to AIC, it has a larger penalty term for the number of parameters and observations. It is defined by
The results of the KS test, AIC, and BIC for all of the distributions are presented in
Table 9.
The p-values of all distributions except K4D are very small and much less than the significance level of 0.05, indicating that only K4D is a significant distribution resulting from the KS test. Furthermore, since the AIC and BIC values of K4D are among the smaller values, we choose to adopt the K4D distribution for the amount of precipitation on wet days.







{kind=link}
{kind=link}
{kind=link}