



Reducing the Dimensionality of SPD Matrices with Neural Networks in BCI


Abstract
1. Introduction
2. Background Theory
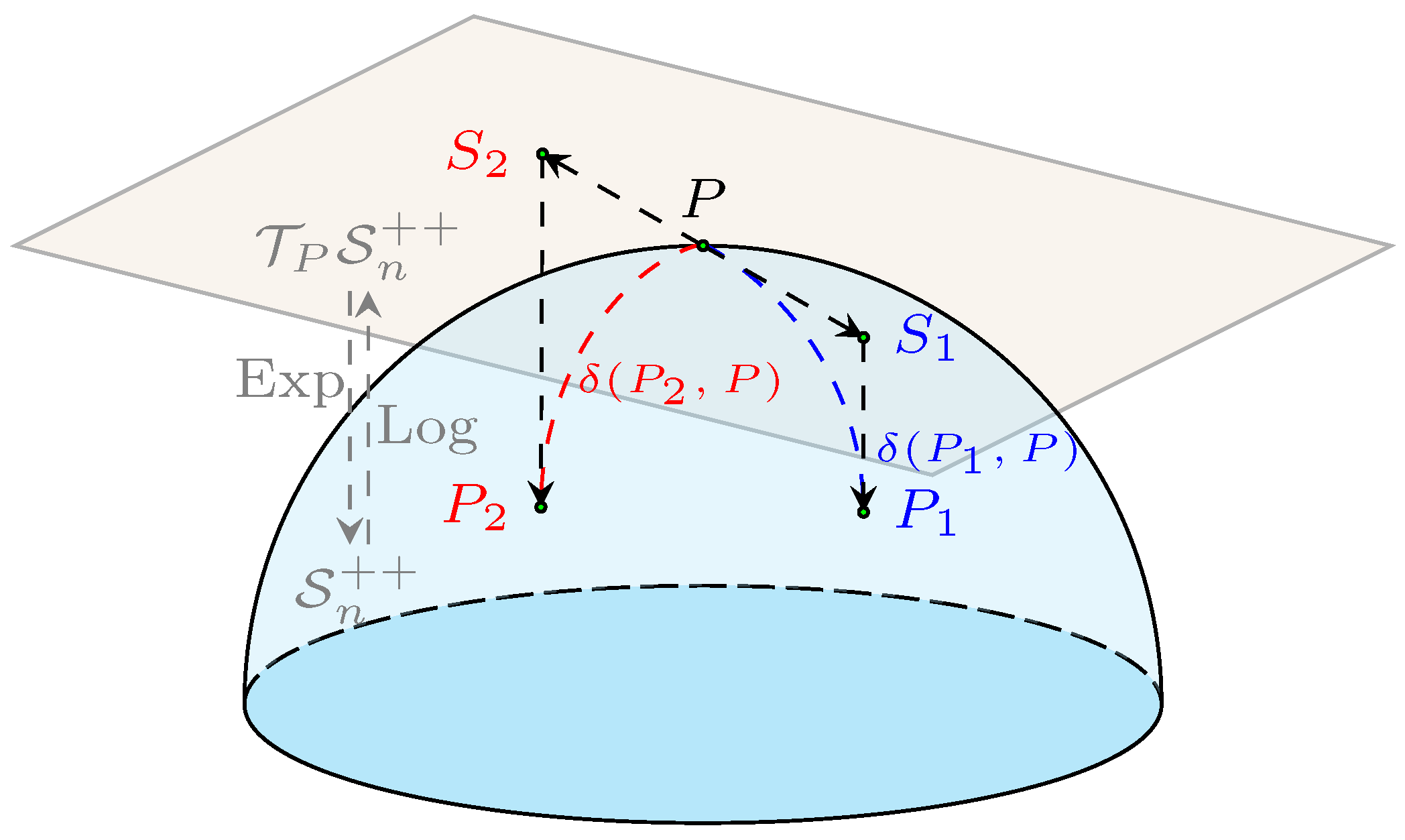
2.1. Geometry of SPD Manifolds
2.2. Dimensionality Reduction on SPD Manifolds
3. The Proposed SPD Manifold Network
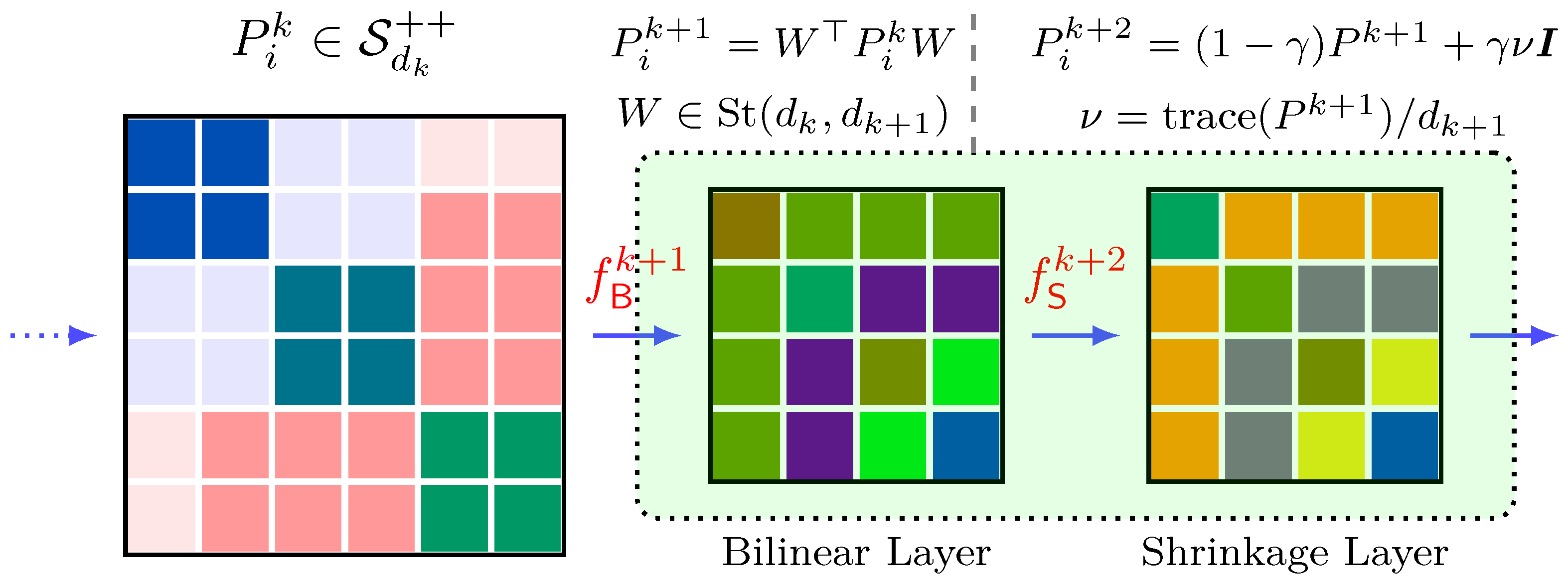
3.1. SPD-Mani-Net for Reducing Dimensionality
3.2. Bilinear Layer
3.3. Shrinkage Layer
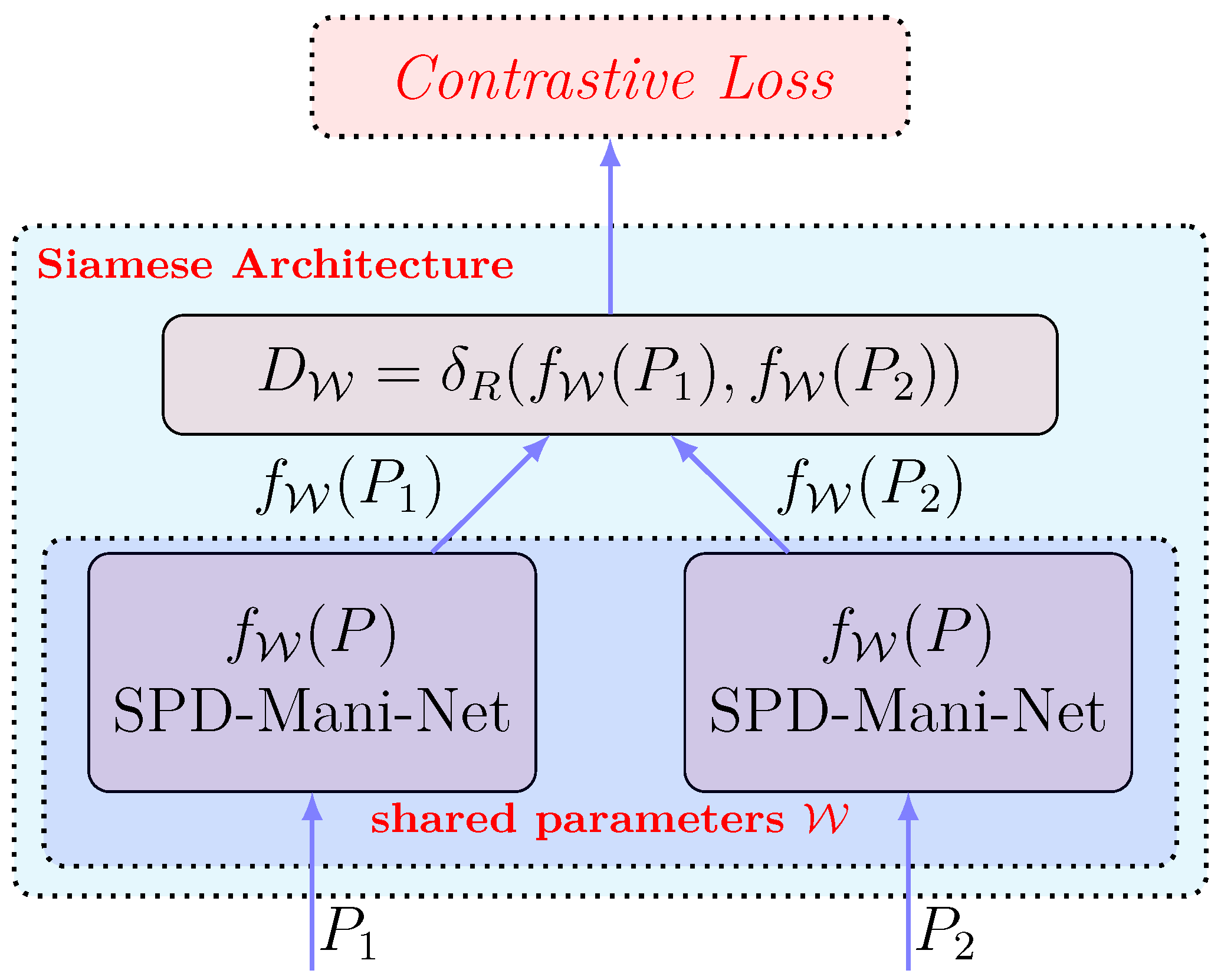
3.4. Siamese Architecture for Discriminative Learning
4. Transfer Learning
5. Experiments
5.1. Toy Data
- Ga-DR [17]: a linear method based on metric learning.
- Ga-PCA [18]: a linear method based on variance maximizing.
- DPLM [19]: a linear method based on distance preservation to local mean.
- SPD-Net [26]: a non-linear method based on the SPD-Net, including BiMap and ReEig layers.
- SPD-Mani-Net: A non-linear method based on the SPD-Mani-Net, including BiMap and shrinkage layers, as shown in Figure 3.
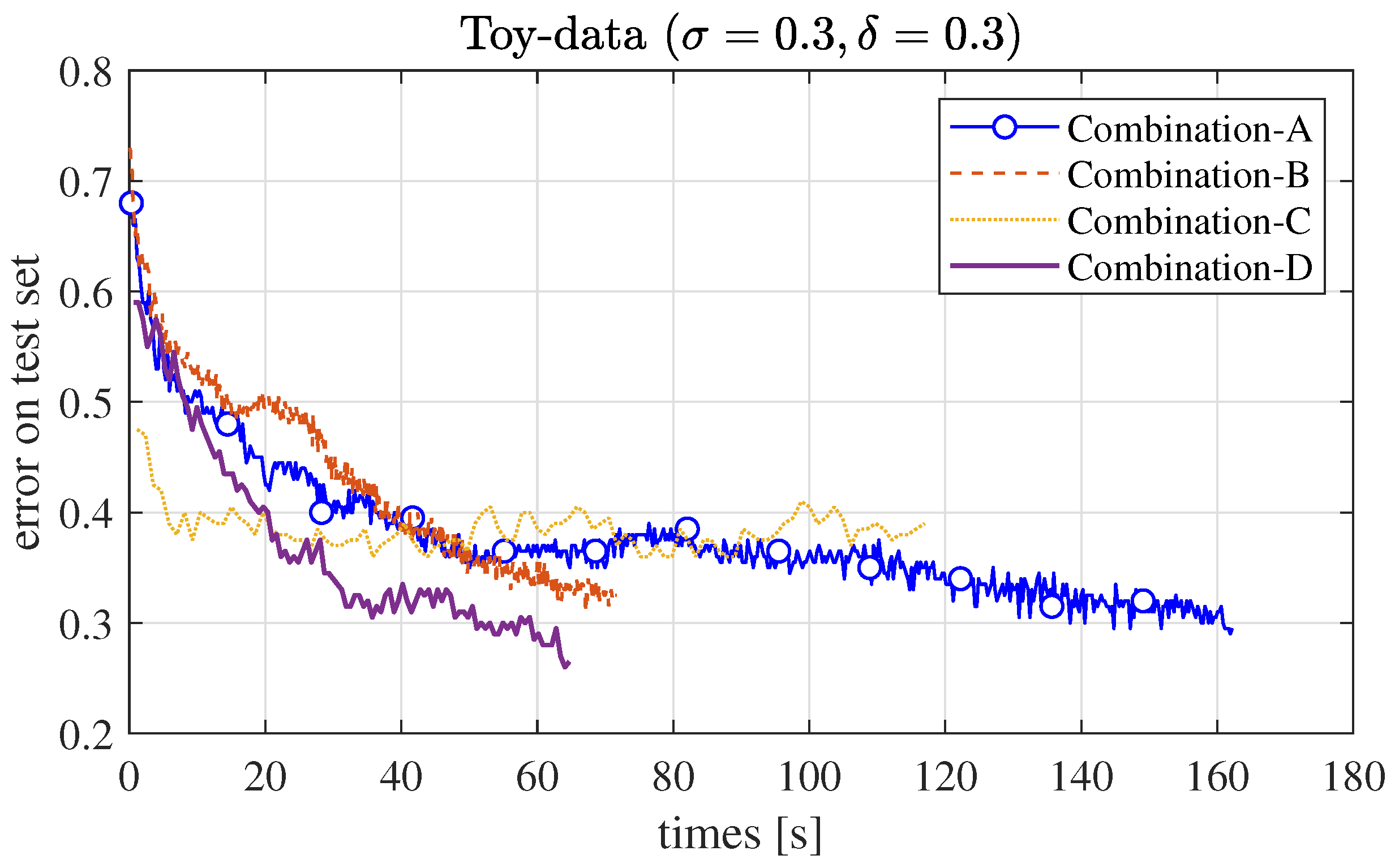
5.2. Ablation Study
5.3. EEG Signals from Motor Image BCIs
- Dataset IIIa, BCI competition III [48]: This dataset includes EEG signals from 60 channels and 3 subjects, who performed four types of tasks (left-hand, right-hand, foot, and tongue MI). In this experiment, only EEG signals corresponding to left- and right-hand MI were used for the present study. Training and testing sets were available for each subject. Both sets contain 45 trials for B1 and 30 trials per class for B2 and B3.
- Dataset IIa, BCI competition IV [49]: This dataset contains EEG signals consisting of 22 channels from 9 subjects, who performed four types of the same tasks as the last dataset. We also selected signals of left- and right-hand MI trials to enable a proper comparison. Training and testing sets were available for each subject, containing 72 trials per class from C1 to C9.
5.4. EEG Signals from Motor Image Multi-Subject BCIs
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Congedo, M.; Barachant, A.; Bhatia, R. Riemannian geometry for EEG-based brain–computer interfaces; a primer and a review. Brain Comput. Interfaces 2017, 4, 155–174. [Google Scholar] [CrossRef]
- Blankertz, B.; Tomioka, R.; Lemm, S.; Kawanabe, M.; Muller, K.R. Optimizing spatial filters for robust EEG single-trial analysis. IEEE Signal Process. Mag. 2007, 25, 41–56. [Google Scholar] [CrossRef]
- Lotte, F.; Congedo, M.; Lécuyer, A.; Lamarche, F.; Arnaldi, B. A review of classification algorithms for EEG-based brain–computer interfaces. J. Neural Eng. 2007, 4, R1. [Google Scholar] [CrossRef] [PubMed]
- Yger, F.; Berar, M.; Lotte, F. Riemannian approaches in brain–computer interfaces: A review. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 25, 1753–1762. [Google Scholar] [CrossRef] [PubMed]
- Lotte, F.; Bougrain, L.; Cichocki, A.; Clerc, M.; Congedo, M.; Rakotomamonjy, A.; Yger, F. A review of classification algorithms for EEG-based brain–computer interfaces: A 10 year update. J. Neural Eng. 2018, 15, 031005. [Google Scholar] [CrossRef]
- Liu, X.; Liu, S.; Ma, Z. A Framework for Short Video Recognition Based on Motion Estimation and Feature Curves on SPD Manifolds. Appl. Sci. 2022, 12, 4669. [Google Scholar] [CrossRef]
- Tuzel, O.; Porikli, F.; Meer, P. Pedestrian detection via classification on riemannian manifolds. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1713–1727. [Google Scholar] [CrossRef]
- Barachant, A.; Bonnet, S.; Congedo, M.; Jutten, C. Multiclass brain–computer interface classification by Riemannian geometry. IEEE Trans. Biomed. Eng. 2011, 59, 920–928. [Google Scholar] [CrossRef]
- Wu, D.; Lance, B.J.; Lawhern, V.J.; Gordon, S.; Jung, T.P.; Lin, C.T. EEG-based user reaction time estimation using Riemannian geometry features. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 2157–2168. [Google Scholar] [CrossRef]
- Gao, W.; Ma, Z.; Gan, W.; Liu, S. Dimensionality reduction of SPD data based on riemannian manifold tangent spaces and isometry. Entropy 2021, 23, 1117. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. A well-conditioned estimator for large-dimensional covariance matrices. J. Multivar. Anal. 2004, 88, 365–411. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; Silva, V.d.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Förstner, W.; Moonen, B. A metric for covariance matrices. In Geodesy-the Challenge of the 3rd Millennium; Springer: Berlin/Heidelberg, Germany, 2003; pp. 299–309. [Google Scholar]
- Xie, X.; Yu, Z.L.; Lu, H.; Gu, Z.; Li, Y. Motor imagery classification based on bilinear sub-manifold learning of symmetric positive-definite matrices. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 25, 504–516. [Google Scholar] [CrossRef]
- Li, Y.; Lu, R. Locality preserving projection on SPD matrix Lie group: Algorithm and analysis. Sci. China-Inf. Sci. 2018, 61, 092104. [Google Scholar] [CrossRef]
- Harandi, M.; Salzmann, M.; Hartley, R. Dimensionality reduction on SPD manifolds: The emergence of geometry-aware methods. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 48–62. [Google Scholar] [CrossRef]
- Horev, I.; Yger, F.; Sugiyama, M. Geometry-aware principal component analysis for symmetric positive definite matrices. Mach. Learn. 2017, 106, 493–522. [Google Scholar] [CrossRef]
- Davoudi, A.; Ghidary, S.S.; Sadatnejad, K. Dimensionality reduction based on distance preservation to local mean for symmetric positive definite matrices and its application in brain–computer interfaces. J. Neural Eng. 2017, 14, 036019. [Google Scholar] [CrossRef]
- Feng, S.; Hua, X.; Zhu, X. Matrix information geometry for spectral-based SPD matrix signal detection with dimensionality reduction. Entropy 2020, 22, 914. [Google Scholar] [CrossRef]
- Popović, B.; Janev, M.; Krstanović, L.; Simić, N.; Delić, V. Measure of Similarity between GMMs Based on Geometry-Aware Dimensionality Reduction. Mathematics 2022, 11, 175. [Google Scholar] [CrossRef]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. Proc. IEEE Comput. Soc. Conf. Comput. 2005, 1, 539–546. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. Proc. IEEE Comput. Soc. Conf. Comput. 2006, 2, 1735–1742. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep metric learning using triplet network. In Proceedings of the Similarity-Based Pattern Recognition: Third International Workshop, SIMBAD 2015, Copenhagen, Denmark, 12–14 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 84–92. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Huang, Z.; Van Gool, L. A riemannian network for spd matrix learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31, pp. 2036–2042. [Google Scholar]
- Zhang, T.; Zheng, W.; Cui, Z.; Zong, Y.; Li, C.; Zhou, X.; Yang, J. Deep manifold-to-manifold transforming network for skeleton-based action recognition. IEEE Trans. Multimed. 2020, 22, 2926–2937. [Google Scholar] [CrossRef]
- Dong, Z.; Jia, S.; Zhang, C.; Pei, M.; Wu, Y. Deep manifold learning of symmetric positive definite matrices with application to face recognition. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31, pp. 4009–4015. [Google Scholar]
- Bhatia, R. Positive Definite Matrices; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Zanini, P.; Congedo, M.; Jutten, C.; Said, S.; Berthoumieu, Y. Transfer learning: A Riemannian geometry framework with applications to brain–computer interfaces. IEEE Trans. Biomed. Eng. 2017, 65, 1107–1116. [Google Scholar] [CrossRef]
- Jiang, Q.; Zhang, Y.; Zheng, K. Motor imagery classification via kernel-based domain adaptation on an SPD manifold. Brain Sci. 2022, 12, 659. [Google Scholar] [CrossRef] [PubMed]
- Congedo, M.; Barachant, A.; Koopaei, E.K. Fixed point algorithms for estimating power means of positive definite matrices. IEEE Trans. Signal Process. 2017, 65, 2211–2220. [Google Scholar] [CrossRef]
- Absil, P.A.; Mahony, R.; Sepulchre, R. Optimization Algorithms on Matrix Manifolds; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Von Bünau, P.; Meinecke, F.C.; Király, F.C.; Müller, K.R. Finding stationary subspaces in multivariate time series. Phys. Rev. Lett. 2009, 103, 214101. [Google Scholar] [CrossRef] [PubMed]
- Miladinović, A.; Ajčević, M.; Jarmolowska, J.; Marusic, U.; Colussi, M.; Silveri, G.; Battaglini, P.P.; Accardo, A. Effect of power feature covariance shift on BCI spatial-filtering techniques: A comparative study. Comput. Meth. Programs Biomed. 2021, 198, 105808. [Google Scholar] [CrossRef]
- Horev, I.; Yger, F.; Sugiyama, M. Geometry-aware stationary subspace analysis. In Proceedings of the Asian Conference on Machine Learning, PMLR, Hamilton, New Zealand, 16–18 November 2016; Volume 63, pp. 430–444. [Google Scholar]
- Brooks, D.; Schwander, O.; Barbaresco, F.; Schneider, J.Y.; Cord, M. Riemannian batch normalization for SPD neural networks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Wang, J.; Hua, X.; Zeng, X. Spectral-based spd matrix representation for signal detection using a deep neutral network. Entropy 2020, 22, 585. [Google Scholar] [CrossRef]
- Nguyen, X.S. Geomnet: A neural network based on riemannian geometries of spd matrix space and cholesky space for 3d skeleton-based interaction recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 10–17 October 2021; pp. 13379–13389. [Google Scholar]
- Suh, Y.J.; Kim, B.H. Riemannian embedding banks for common spatial patterns with EEG-based SPD neural networks. In Proceedings of the Association for the Advancement of Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 854–862. [Google Scholar]
- Wang, R.; Wu, X.J.; Chen, Z.; Xu, T.; Kittler, J. DreamNet: A Deep Riemannian Manifold Network for SPD Matrix Learning. In Proceedings of the 6th Asian Conference on Computer Vision (ACCV 2022), Macao, China, 4–8 December 2022; pp. 3241–3257. [Google Scholar]
- Blankertz, B.; Lemm, S.; Treder, M.; Haufe, S.; Müller, K.R. Single-trial analysis and classification of ERP components—A tutorial. Neuroimage 2011, 56, 814–825. [Google Scholar] [CrossRef]
- Lotte, F. Signal processing approaches to minimize or suppress calibration time in oscillatory activity-based brain–computer interfaces. Proc. IEEE 2015, 103, 871–890. [Google Scholar] [CrossRef]
- Rodrigues, P.L.C.; Jutten, C.; Congedo, M. Riemannian procrustes analysis: Transfer learning for brain–computer interfaces. IEEE Trans. Biomed. Eng. 2018, 66, 2390–2401. [Google Scholar] [CrossRef] [PubMed]
- Lotte, F.; Guan, C. Regularizing common spatial patterns to improve BCI designs: Unified theory and new algorithms. IEEE Trans. Biomed. Eng. 2010, 58, 355–362. [Google Scholar] [CrossRef] [PubMed]
- Lotte, F.; Guan, C. Learning from other subjects helps reducing brain–computer interface calibration time. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 614–617. [Google Scholar]
- Harandi, M.T.; Salzmann, M.; Hartley, R. From manifold to manifold: Geometry-aware dimensionality reduction for SPD matrices. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 17–32. [Google Scholar]
- Schlögl, A.; Lee, F.; Bischof, H.; Pfurtscheller, G. Characterization of four-class motor imagery EEG data for the BCI-competition 2005. J. Neural Eng. 2005, 2, L14. [Google Scholar] [CrossRef]
- Leeb, R.; Brunner, C.; Müller-Putz, G.; Schlögl, A.; Pfurtscheller, G. BCI Competition 2008–Graz Data Set B; Graz University of Technology: Graz, Austria, 2008; pp. 1–6. [Google Scholar]
- Nishiyama, A.; Tanaka, S.; Tuszynski, J.A. Non-Equilibrium ϕ4 Theory in a Hierarchy: Towards Manipulating Holograms in Quantum Brain Dynamics. Dynamics 2023, 3, 1–17. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.1 | 0.1 | 0.3 | 0.3 | 0.3 | 0.5 | 0.5 | 0.5 | ||
| 0.1 | 0.3 | 0.5 | 0.1 | 0.3 | 0.5 | 0.1 | 0.3 | 0.5 | ||
| Ga-DR [17] | 100% | 91% | 40% | 84% | 62.5% | 32.5% | 53.5% | 48.5% | 34.5% | |
| Ga-PCA [18] | 73% | 87% | 52.5% | 60.5% | 38% | 34% | 44% | 36% | 28% | |
| DPLM [19] | 100% | 56.5% | 33% | 84.5% | 47.5% | 26% | 47.5% | 59% | 32% | |
| SPD-Net [26] | 100% | 89.5% | 52% | 87.5% | 69% | 47.5% | 63.5% | 56% | 41.5% | |
| SPD-Mani-Net | 100% | 99% | 84% | 89% | 67.5% | 54.5% | 64% | 65% | 51.5% | |
| Shrinkage Layer | Siamese Architecture | Type | |
|---|---|---|---|
| Combination A | SPD-Net | ||
| Combination B | ✓ | SPD-Net | |
| Combination C | ✓ | SPD-Mani-Net | |
| Combination D | ✓ | ✓ | SPD-Mani-Net |
| IIIa of Competition III | IIa of Competition IV | |
|---|---|---|
| Number of subjects | 3 | 9 |
| Number of channels | 60 | 22 |
| Number of classes | 4 | 4 |
| Trials per class | 60 | 144 |
| Sampling rate | 250 Hz | 250 Hz |
| Filter Bank | bandpass 8–30 Hz | bandpass 8–30 Hz |
| Accuracy | Mean ± Std | BCI Competition III Dataset IIIa | BCI Competition IV Dataset IIa | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Subject | B1 | B2 | B3 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
| MDRM [8] | 78.5 ± 16.1 | 97.8 | 63.3 | 88.3 | 88.2 | 52.8 | 92.4 | 71.5 | 58.3 | 64.6 | 75 | 95.8 | 94.4 |
| CSP+LDA [2] | 79.4 ± 16.8 | 95.6 | 61.7 | 93.3 | 88.9 | 51.4 | 96.5 | 70.1 | 54.9 | 71.5 | 81.3 | 93.8 | 93.8 |
| Ga-DR [17] | 78.2 ± 14.9 | 96.7 | 68.3 | 85 | 87.5 | 53.5 | 92.4 | 73.6 | 57.6 | 68.0 | 70.8 | 94.4 | 91.6 |
| Ga-PCA [18] | 68.5 ± 13.0 | 80 | 63.3 | 68.3 | 77.8 | 50 | 84.7 | 64.5 | 53.4 | 56.9 | 56.2 | 84.0 | 84.0 |
| DPLM [19] | 75.6 ± 15.3 | 85.6 | 63.3 | 75 | 89.6 | 56.9 | 93.1 | 70.8 | 56.9 | 58.3 | 68.0 | 95.1 | 94.4 |
| SPD-Net [26] | 76.9 ± 17.1 | 97.7 | 66.7 | 88.3 | 84.7 | 56.3 | 93.8 | 68.1 | 56.9 | 62.5 | 56.3 | 95.8 | 95.1 |
| SPD-Mani-Net | 83.1 ± 14.9 | 100 | 66.7 | 98.3 | 94.4 | 57.6 | 93.1 | 75 | 71.5 | 66.7 | 83.3 | 96.5 | 94.4 |
| Accuracy | Mean ± Std | BCI Competition III Dataset IIIa | BCI Competition IV Dataset IIa | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Subject | B1 | B2 | B3 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
| MDRM [8] | 43.61 ± 16.71 | 67.78 | 39.17 | 27.50 | 61.46 | 27.08 | 64.93 | 39.93 | 25.00 | 22.22 | 61.46 | 46.88 | 39.93 |
| SPD-Net [26] | 45.75 ± 17.56 | 70.56 | 36.67 | 38.33 | 66.67 | 26.74 | 69.80 | 37.50 | 25.35 | 26.04 | 55.21 | 60.07 | 36.11 |
| SPD-Mani-Net | 48.21 ± 15.73 | 65.00 | 33.33 | 35.00 | 65.28 | 28.13 | 68.75 | 45.49 | 29.51 | 34.03 | 51.74 | 64.58 | 57.64 |
| SPD-Mani-Net+Reg | 53.28 ± 17.78 | 83.30 | 43.30 | 32.50 | 61.11 | 33.33 | 69.44 | 42.71 | 39.24 | 32.99 | 62.85 | 69.44 | 69.10 |
| Kappa | Mean ± Std | BCI Competition III Dataset IIIa | BCI Competition IV Dataset IIa | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Subject | B1 | B2 | B3 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
| MDRM [8] | 0.25 ± 0.22 | 0.57 | 0.19 | 0.03 | 0.49 | 0.02 | 0.53 | 0.20 | 0.00 | 0.00 | 0.49 | 0.29 | 0.20 |
| SPD-Net [26] | 0.28 ± 0.24 | 0.61 | 0.16 | 0.18 | 0.56 | 0.02 | 0.60 | 0.17 | 0.00 | 0.01 | 0.40 | 0.47 | 0.15 |
| SPD-Mani-Net | 0.31 ± 0.21 | 0.53 | 0.11 | 0.13 | 0.54 | 0.04 | 0.58 | 0.27 | 0.06 | 0.12 | 0.35 | 0.53 | 0.44 |
| SPD-Mani-Net+Reg | 0.37 ± 0.24 | 0.78 | 0.24 | 0.10 | 0.48 | 0.11 | 0.59 | 0.23 | 0.18 | 0.10 | 0.50 | 0.59 | 0.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Z.; Li, H.; Zhao, D.; Pan, C. Reducing the Dimensionality of SPD Matrices with Neural Networks in BCI. Mathematics 2023, 11, 1570. https://doi.org/10.3390/math11071570
Peng Z, Li H, Zhao D, Pan C. Reducing the Dimensionality of SPD Matrices with Neural Networks in BCI. Mathematics. 2023; 11(7):1570. https://doi.org/10.3390/math11071570
Chicago/Turabian StylePeng, Zhen, Hongyi Li, Di Zhao, and Chengwei Pan. 2023. "Reducing the Dimensionality of SPD Matrices with Neural Networks in BCI" Mathematics 11, no. 7: 1570. https://doi.org/10.3390/math11071570
APA StylePeng, Z., Li, H., Zhao, D., & Pan, C. (2023). Reducing the Dimensionality of SPD Matrices with Neural Networks in BCI. Mathematics, 11(7), 1570. https://doi.org/10.3390/math11071570