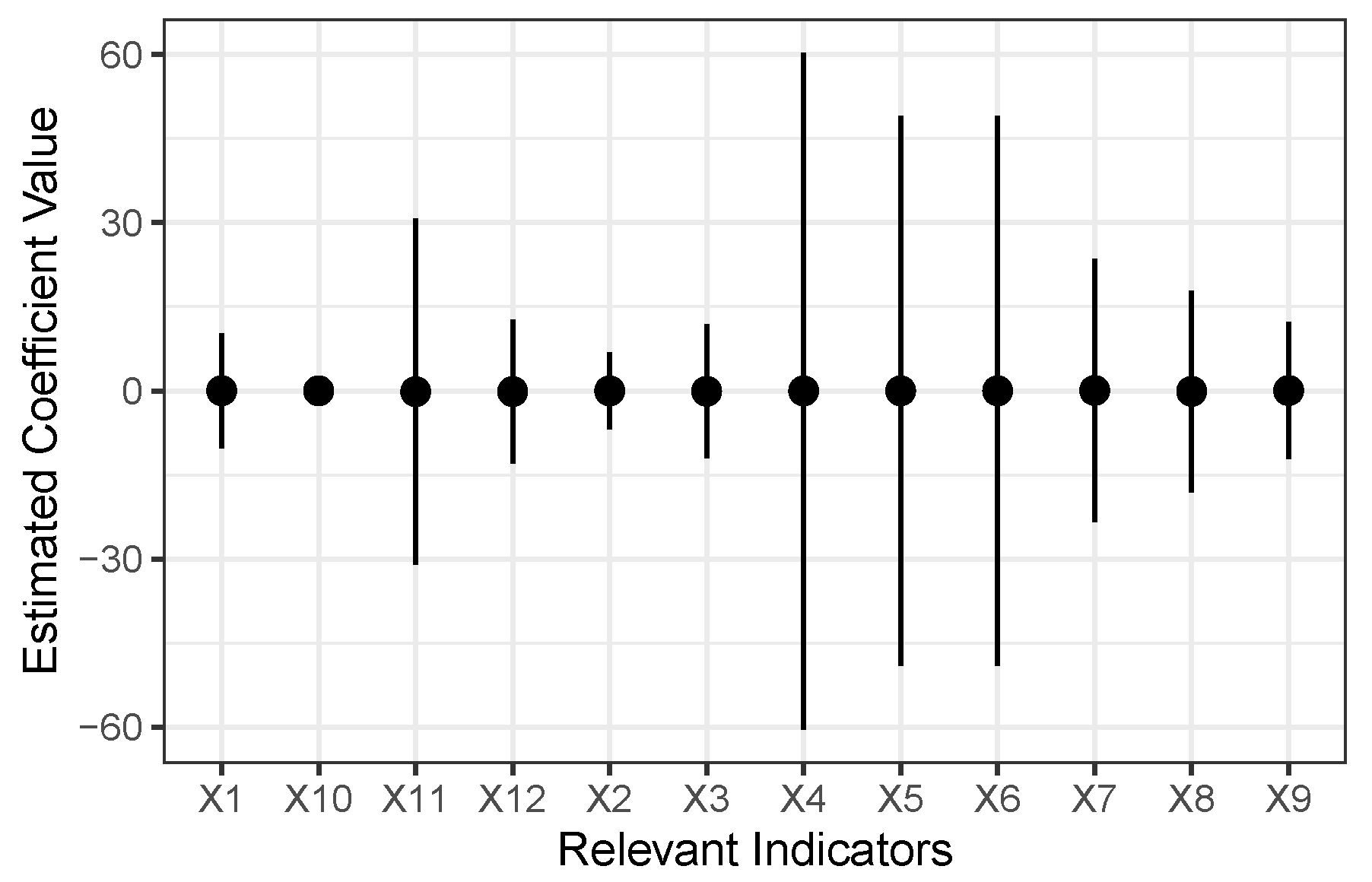
3.1. Bayesian Spatial–temporal Models
Spatial–temporal infected cases data can be represented as observations in N public health units in Ontario , where . Here, represents the number of bi-weekly infected cases observed in each unit.
A three-stage hierarchical process in Bayesian spatial–temporal statistic models has been widely used [
9,
24]. The first stage consists of the model for infected cases where we assume
and
. For the second stage we place a regression equation on
, which includes an overall fixed effect (intercept, denoted
), covariate effects and spatial, temporal, spatial–temporal interaction effects. We specify the prior distributions on each of the unknown parameters in the third stage, which are usually defined as weakly informative with Gaussian distributions having zero mean and large variance since the spatial and temporal effects discussed as follows are defined under the Gaussian Markov Random Field (GMRF) and the precision matrix in these two effects are sparse.
The spatial component included in the spatial–temporal model we built is the Leroux CAR specification [
18]. A BYM specification [
8] is also considered, but the performance is not good as the models with Leroux CAR. BYM specification directly decomposes spatial component into structured one and unstructured one, while parameter
is introduced to balance spatial structured effect and unstructured effect. However, it was used in analyzing the COVID-19 infection risk in Spain with environmental variables [
21]. There are four ways to define the spatial–temporal interaction term [
25].
Table 1 indicates the four types of interactions and hence the four different models are considered (Note:
Table 1 reproduced from Schrödle and Held [
26]). Here, the log-risk is modeled as:
where
is the spatial component,
and
represent unstructured and structured temporal effects, respectively and
represents the space-time interaction term.
represents the vector of covariate coefficients;
is the COVID-19 relevant covariate data vector to be discussed in
Section 3.2. Denoting the vector of spatial effects by
, the Leroux CAR specification can be defined as:
The term represents the temporally structured effect where random walk of first order (RW1) is considered. That is , where is the variance component. Gaussian distribution is chosen for unstructured temporal effect : .
The identity matrices
correspond to the unstructured spatial (temporal) effect respectively, whereas
represent matrices that correspond to a specific structured temporal (spatial) effect (RW1) as follows. We also consider the random walk of second order (RW2), but the performance is not good as the one when RW1 is included.
where
if areas
k and
i are sharing the same boundary. As discussed in
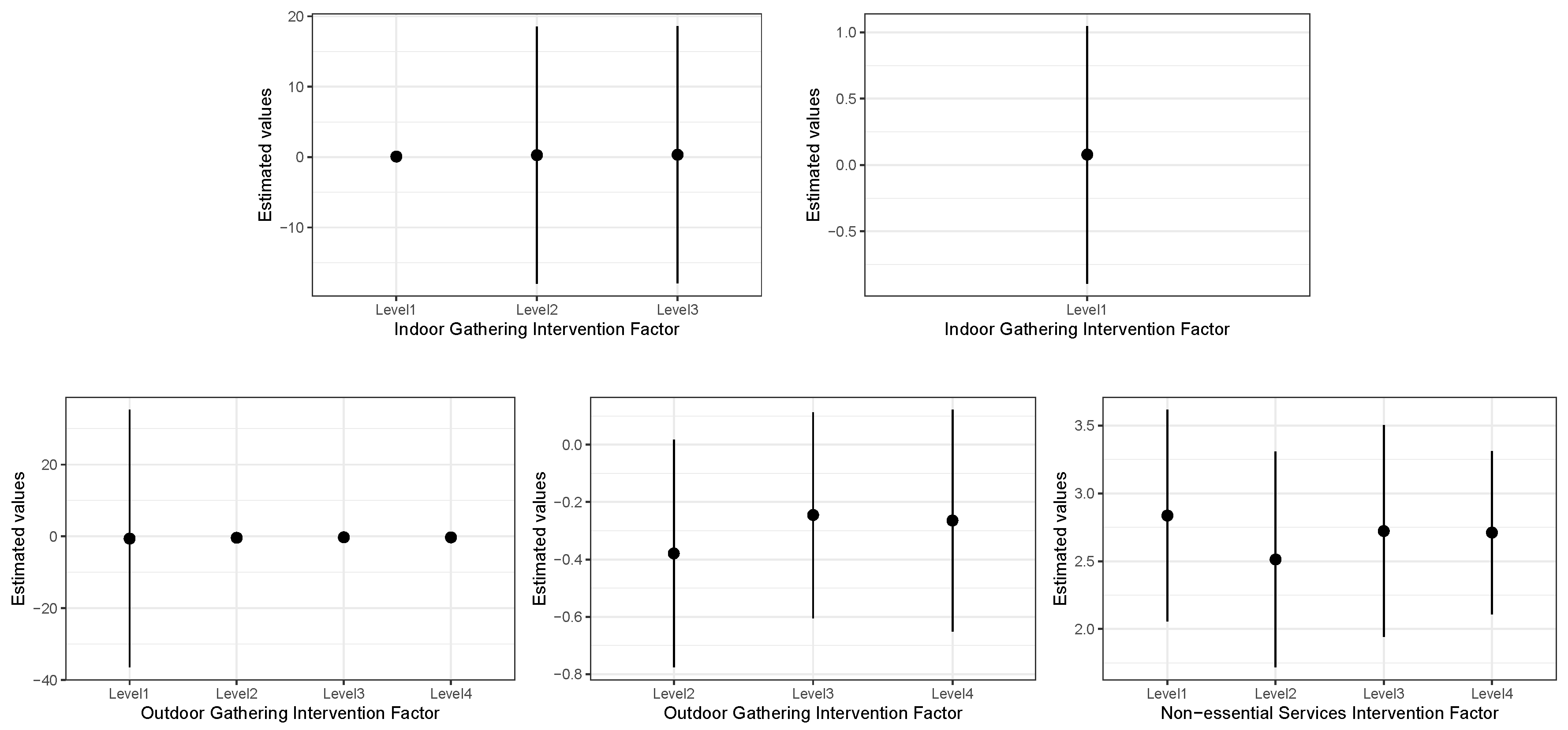
Section 2, there are three different policies selected and categorized as three different variables. The variable Indoor Gathering (IG) will be defined as 3 indicator variables according to the different restrictions level:
if the
i-th level gathering restriction was in place, and 0 otherwise, for
. The variables Outdoor Gathering (OG) and Non-essential service also can be defined as indicator variables according to the different restrictions level. These variables can also be included into the Bayesian Spatial–temporal Models to determine how they influence the infected risk:
The spatial component distribution can also be expressed as
Where
is a spatial smoothing parameter taking values between 0 and 1,
is an identity matrix of dimension
and
is the spatial neighboring matrix which corresponds to the structured spatial effect.
is the number of neighbors around area i. That is
, with
referring to neighbor regions i and j sharing a common boundary. When
, the Leroux CAR reduces to
, and when
, it is
. The unstructured temporal effect
is modelled as independent and identical normal distribution. That is,
. For the structured temporal effect
, a random walk of first order is considered. That is
. The interaction terms
are assumed to be a normal distribution as
, where
is the hyper-parameter and
is the matrix given by the Kronecker product of the corresponding matrices of the effects [
27]. This model can be built in R-INLA with generic1 option [
12].
3.2. Integrated Nested Laplace Approximation (INLA)
The model in
Section 3.1 can be fitted using the following modelling framework:
where
is a scalar representing the intercept; the coefficients
and
quantify the effect of additional relevant covariates
and policy covariates
on the response; and
are a set of functions defined in terms of spatially, temporally correlated effects and
is the interaction space and time effect;
represents the vector of biweekly COVID-19 infected cases,
N is the number of public health units in Ontario and
T is the number of biweeks observed. For the Bayesian Spatial–temporal model in
Section 3.1, we identify
,
,
and
. Upon varying the form of the functions
, this formulation can accommodate a wide range of models, from standard and hierarchical regression, to spatial and spatial–temporal models [
16,
28].
The spatial–temporal models fitted into this framework are built as Bayesian hierarchical models with three stages [
24]. The first stage is the model for infected cases given parameters
, where
denotes the observed cases. The second stage is the model on each parameter
. The third stage is the prior on the hyper-parameters
. Note:
and
.
The objectives of the Bayesian computation consist of calculating the marginal posterior distributions for each parameter and hyper-parameter:
represents the vector but no kth component. The first item we need compute is an approximation to the posterior marginal distribution of the hyper-parameters as
Next,
is needed to be approximated, and it is possible to re-express the vector of parameters as
and make use of the Laplace approximation again to obtain:
Here,
represents the Gaussian approximation to
and
is its mode. The approximation typically works very well, but it can be very expensive in computational terms. Rue et al. [
16] proposed the Simplified Laplace Approximation. Numerical integration is used to evaluate the conditional posteriors
and corresponding marginal posteriors
on a grid of selected values for
.
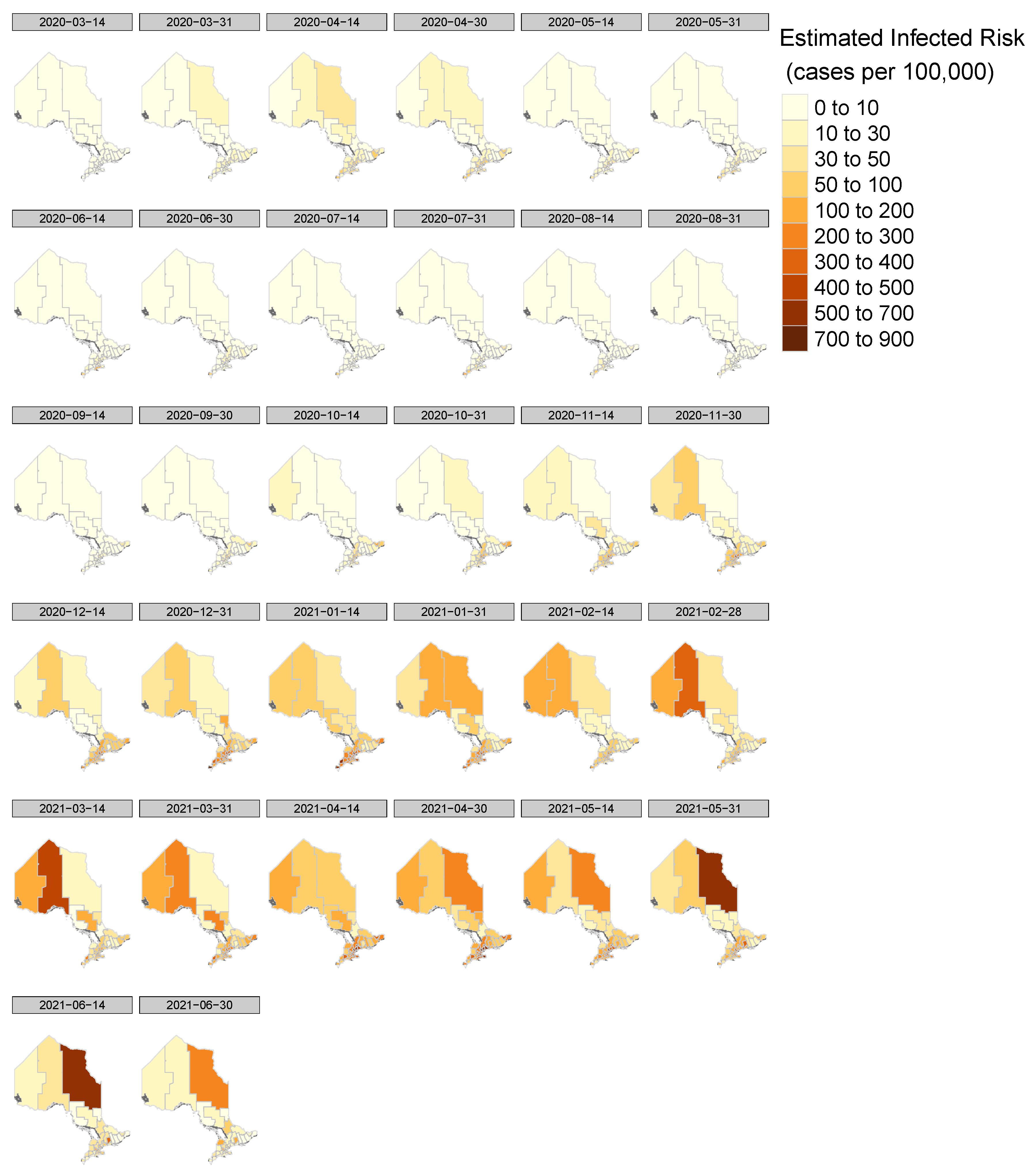
3.3. Area-to-Point (ATP) and Area-to-Area (ATA) Poisson Kriging
We assume
represents the public health unit in Ontario and
u is the point location centered in each 15 × 15 square cell we partitioned and we use
to index different points in units
. The 15 × 15 cells are chosen since it has better performance after we tried different cells, 5 × 5, 8 × 8, and 10 × 10, 15 × 15. The observed age-adjusted bi-weekly COVID-19 infection rate is then denoted as
, where
is the population size in public health unit
i. At each unit
i, the corresponding infected cases
can be assumed to follow a conditional Poisson distribution given local risk
:
Therefore, these cases are spatially correlated in either the population sizes or in the risks. The risk variable
itself can be distributed as an unknown distribution with mean value m, variance value
and variance function
[
5]. It is not realistic to just assume each unit
to its geographic centroid because the distances between these public health units are large. Also, they have different shapes and sizes. The spatial correlation of each unit needs to be considered. Area-to-Area (ATA) Kriging is used to predict the areal risks and we assume areal supports are disjointed [
29]. The estimated areal risk value
in an arbitrary unit
thus can be expressed as a weighted linear combination of the K neighboring available areal infection rates:
where
is the biweekly age-adjusted infection rate in each public health unit i. The areal weights
can be calculated through the following system:
where
. The areal covariances are approximated by averaging point-to-point covariances
calculated between any two points which can discretize the units
and
:
where
and
represent the number of points discretizing the corresponding two areas
and
. The weights
are calculated as the product of population sizes in each 15 km × 15 km square cell centered on the points
and
:
. Therefore, the sum of population size in each cell within unit is equal to the population size in each unit:
and
. The kriging variance for estimated areal risk in unit
is computed as:
where
is the covariance within the same area
:
and
is the indicator function. Alternatively, kriging may be used to predict a value
also in use of
K neighboring areal infection rates
[
29]. The predicted point risk
can also be expressed as a weighted linear combination. Here,
represents the point location whose risk value will be estimated.
The system of linear equations that is used to compute the kriging weights is similar to the one used for calculating weights in the ATA kriging method. However, the area-to-area covariances
on the right-side of first equation in (11) are replaced by area-to-point covariances
approximated as follows:
where
is the number of points in area
. The area-to-point kriging variance is estimated as:
In order to solve systems of equations, the covariance
or equivalently the point-to-point semivariogram
is needed. It can be computed through the relationship [
30,
31]:
here,
is the vector of distances. The second term on the right side is calculated by averaging point-to-point semivariogram values in the same unit for any pairs of units separated by given distances
:
where
and
are the number of points in units
and
respectively,
is the number of pairs of units given distances
. The area-to-area semivariogram value,
, is also estimated through point-to-point semivariograms:
The estimating point-support semivariogram procedure starts with the choice of an initial one
and the estimation is best tackled using an iterative procedure until the difference between theoretically regularized areal semivariogram and experimental areal semivariogram is small [
32,
33].









{kind=link}
{kind=link}
{kind=link}