
MemConFuzz: Memory Consumption Guided Fuzzing with Data Flow Analysis



Abstract
:1. Introduction
- (1)
- A novel algorithm is proposed to obtain locations of heap memory operations by taint analysis based on data dependency. The relation of data dependency is deduced from CPG (Code Property Graph). The location serves as an important indicator for seed selection.
- (2)
- A new algorithm for prioritizing seed selection is proposed based on data dependency for discovering memory consumption vulnerability. Input samples covering more heap operations and data-dependent functions will be assigned high scores, and they are chosen as seeds and assigned more energy in the fuzzing loop.
- (3)
2. Related Work
2.1. Static Techniques Based on Artificial Intelligence
2.2. Dynamic Execution Fuzzing Technique
3. Enhanced Heap Operation Location Based on Data Semantics
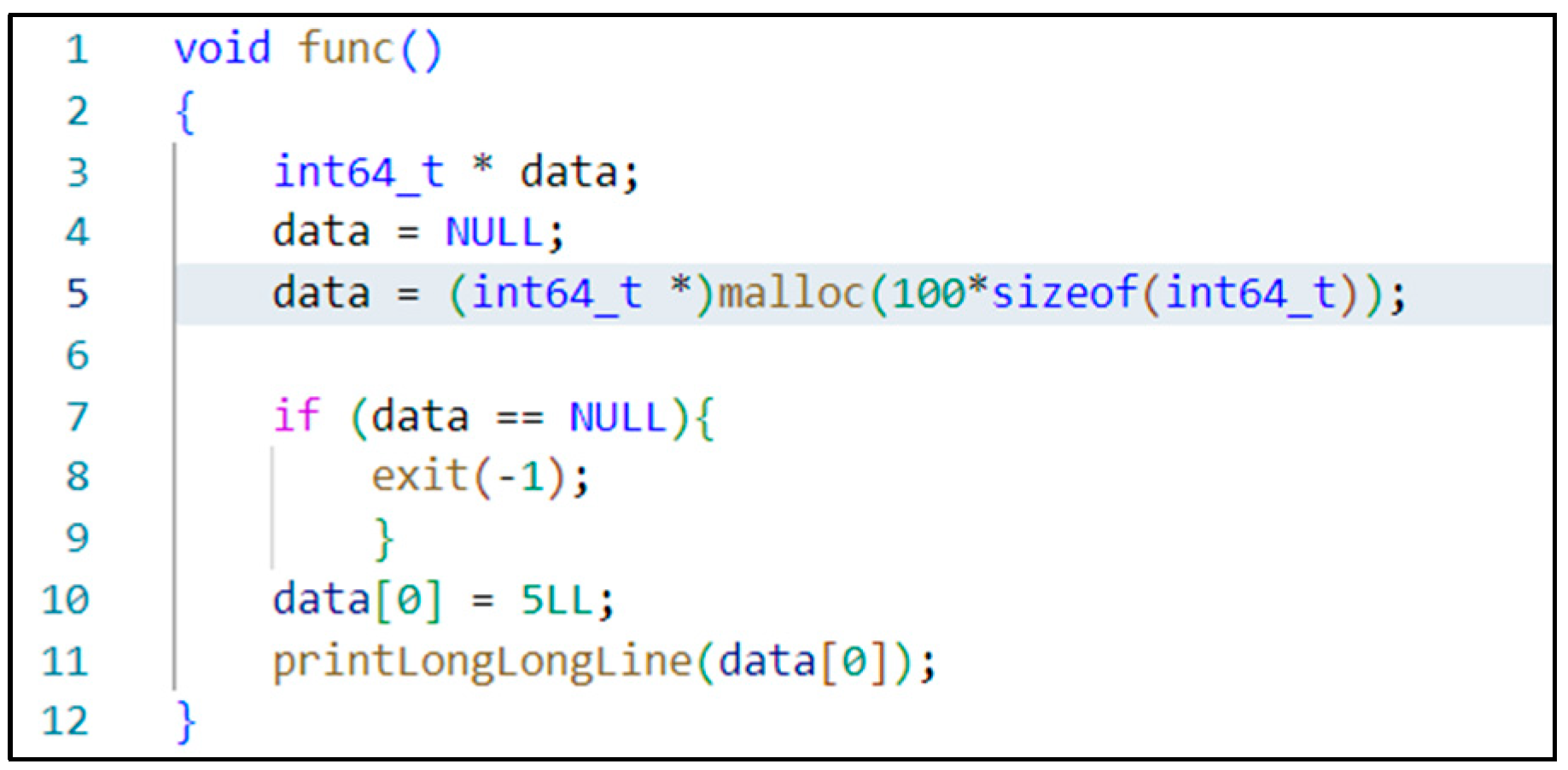
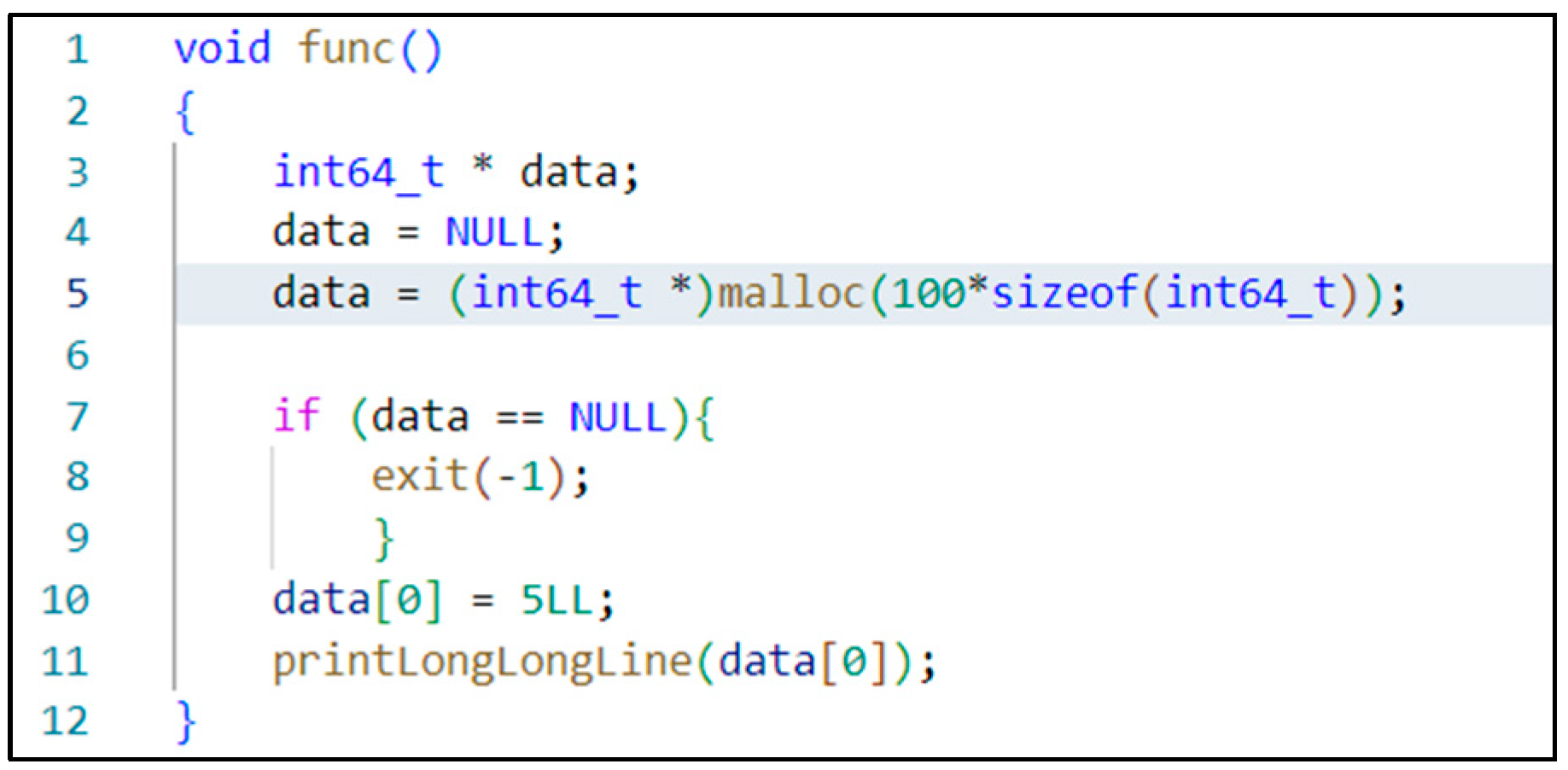
3.1. Examples of Memory Consumption Vulnerability
3.2. Location of Heap Operation Code Based on Data Semantic
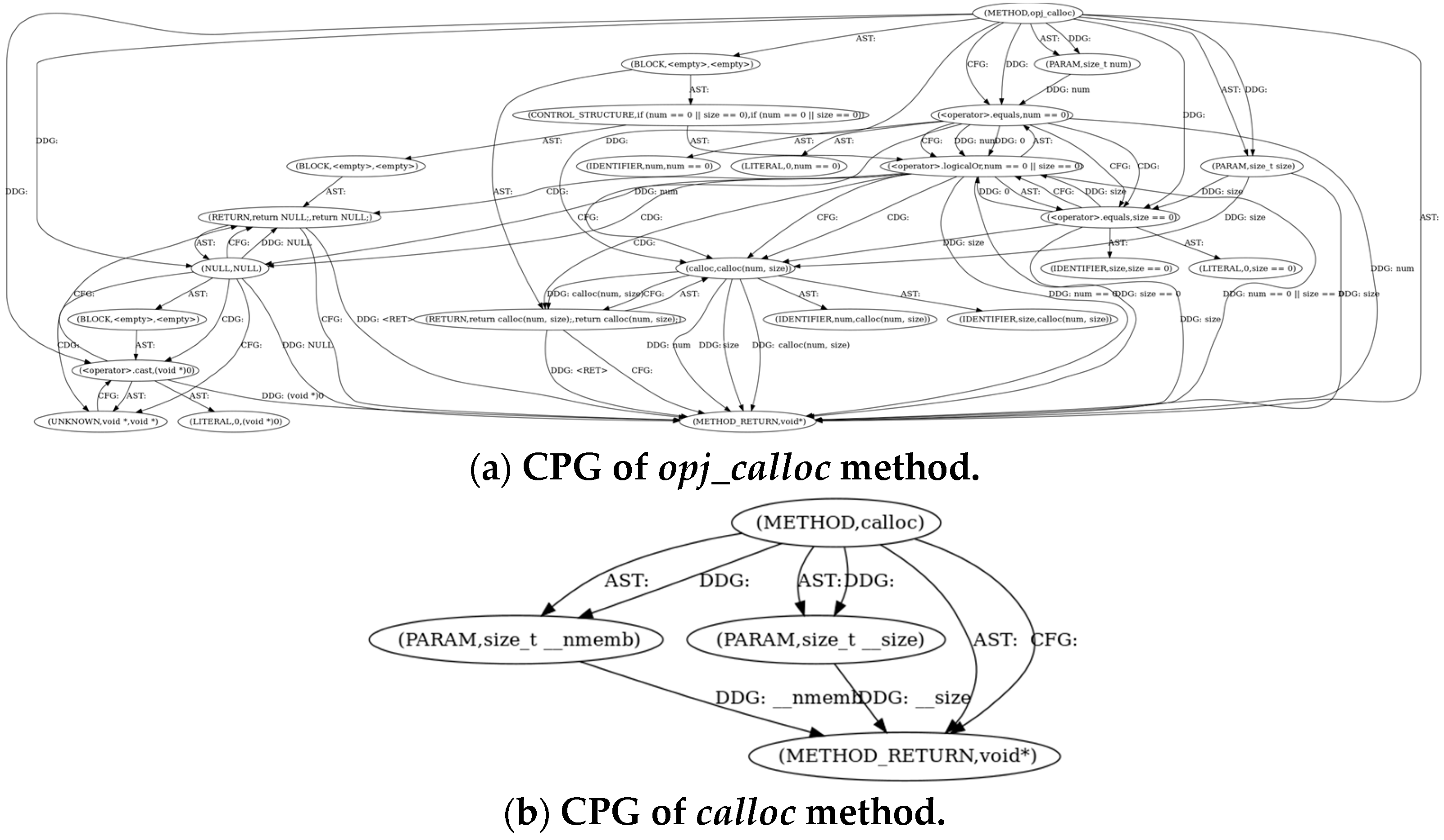
3.2.1. Construct CPG
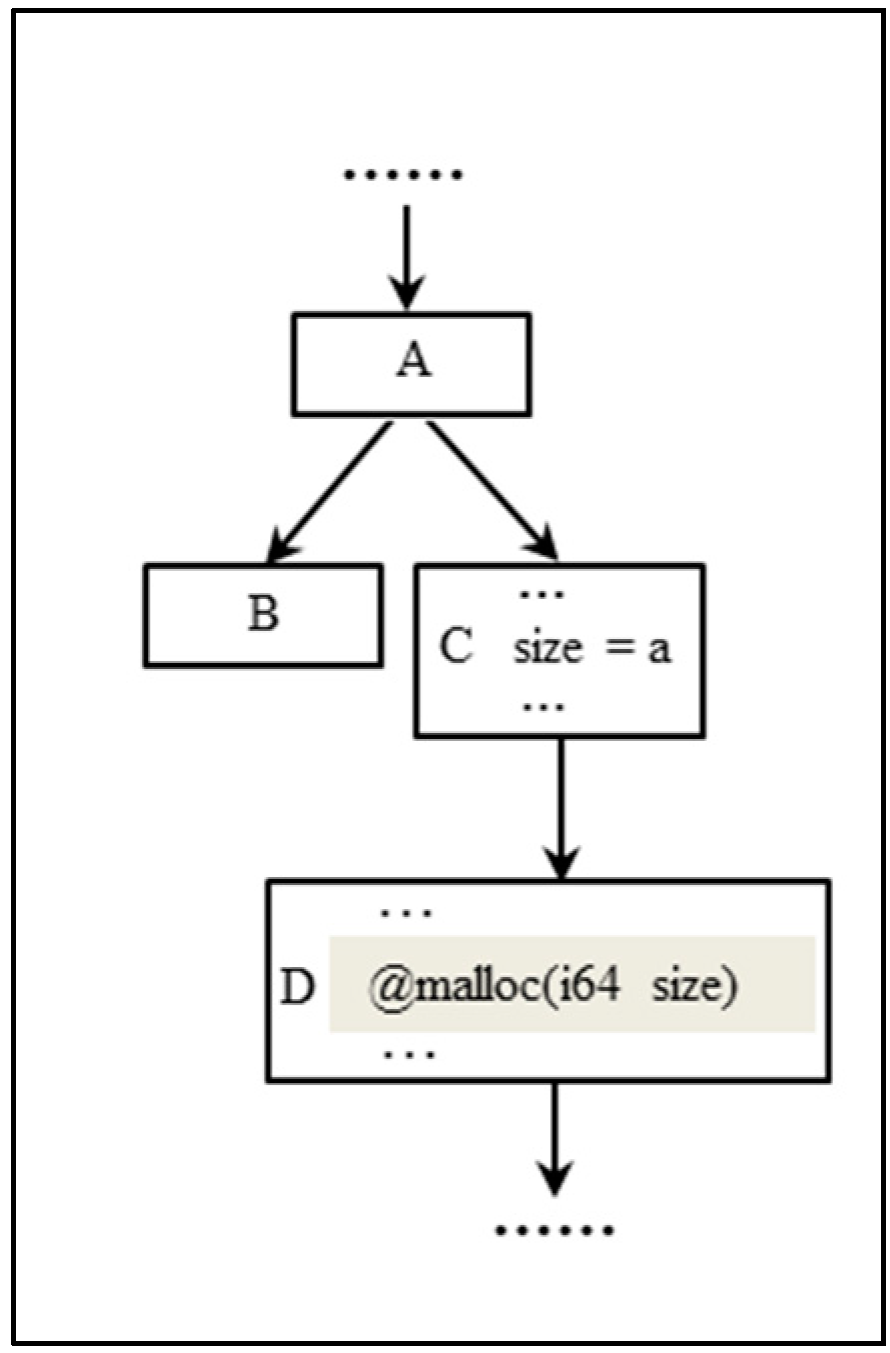
3.2.2. Location Extraction Based on Data Dependency
| Algorithm 1: Taint analysis approach for locating potentially vulnerable functions |
 |
4. MemConFuzz Model
4.1. Overview
4.2. Code Instrumentation at Locations of Suspected Heap Operation
4.3. Strategy of Seed Priority Selection
- (1)
- We use dataflow_funcs as the metric, which is instrumented during the static analysis stage to record the number of data-dependent functions triggered during execution. The more related functions that are triggered, the higher the seed priority.
- (2)
- Like Memlock, we record the size of the allocated heap memory; the larger the heap memory that is allocated, the more power this input sample gets. The input samples with more power at the top of the queue are selected as seeds. We use new_max_size as a flag which represents the maximum memory newly consumed on the heap in history. When the flag is triggered, we increase the score of this seed and enlarge its mutation time.
- (3)
- In addition, when no data-dependent function has triggered and the new maximum allocated memory has not been reached, MemConFuzz still retains AFL’s path-coverage-based seed prioritization strategy to cover as many program branches as possible.
4.4. Proposed Model
| Algorithm 2: Memory Consumption Fuzzing |
 |
5. Experimental Results and Discussions
5.1. Evaluation Scheme
5.2. Experimental Results and Discussions
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AFL | America Fuzzy Lop |
| PUT | Program Under Test |
| UAF | Use-After-Free |
| CPG | Code Property Graph |
| CVE | Common Vulnerabilities and Exposures |
| SMT | Satisfiability Modulo Theories |
| CGF | Coverage-guide Greybox Fuzzing |
| DGF | Directed Greybox Fuzzing |
| DTA | Dynamic Taint Analysis |
| FTI | Fuzzing-Based Taint Inference |
| DDG | Data Dependency Graph |
| AST | Abstract Syntax Trees |
| CDG | Control Dependency Graph |
| CG | Call Graph |
| CFG | Control Flow Graph |
References
- Zalewski, M. American Fuzzing Lop. Available online: https://lcamtuf.coredump.cx/afl/ (accessed on 31 October 2022).
- Wen, C.; Wang, H.; Li, Y.; Qin, S.; Liu, Y.; Xu, Z.; Chen, H.; Xie, X.; Pu, G.; Liu, T. Memlock: Memory usage guided fuzzing. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, Seoul, Republic of Korea, 27 June 2020–19 July 2020; pp. 765–777. [Google Scholar] [CrossRef]
- Lemieux, C.; Padhye, R.; Sen, K.; Song, D. Perffuzz: Automatically generating pathological inputs. In Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, Amsterdam, The Netherlands, 16–21 July 2018; pp. 254–265. [Google Scholar]
- Rajpal, M.; Blum, W.; Singh, R. Not all bytes are equal: Neural byte sieve for fuzzing. arXiv 2017, arXiv:1711.04596. [Google Scholar]
- Godefroid, P.; Peleg, H.; Singh, R. Learn&fuzz: Machine learning for input fuzzing. In Proceedings of the 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), Urbana, IL, USA, 30 October–3 November 2017; pp. 50–59. [Google Scholar]
- She, D.; Pei, K.; Epstein, D.; Yang, J.; Ray, B.; Jana, S. Neuzz: Efficient fuzzing with neural program smoothing. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 803–817. [Google Scholar]
- Chen, P.; Chen, H. Angora: Efficient fuzzing by principled search. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 711–725. [Google Scholar]
- Cheng, L.; Zhang, Y.; Zhang, Y.; Wu, C.; Li, Z.; Fu, Y.; Li, H. Optimizing seed inputs in fuzzing with machine learning. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), Montreal, QC, Canada, 25–31 May 2019; pp. 244–245. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Zhu, Y.; Chen, Z. SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities. IEEE Trans. Dependable Secur. Comput. 2022, 19, 2244–2258. [Google Scholar] [CrossRef]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. Vuldeepecker: A deep learning-based system for vulnerability detection. arXiv 2018, arXiv:1801.01681. [Google Scholar]
- Zou, D.; Wang, S.; Xu, S.; Li, Z.; Jin, H. μVulDeePecker: A Deep Learning-Based System for Multiclass Vulnerability Detection. IEEE Trans. Dependable Secur. Comput. 2021, 18, 2224–2236. [Google Scholar] [CrossRef] [Green Version]
- LibFuzzer—A Library for Coverage-Guided Fuzz Testing. Available online: http://llvm.org/docs/LibFuzzer.html (accessed on 31 October 2022).
- Honggfuzz. Available online: http://honggfuzz.com/ (accessed on 31 October 2022).
- Serebryany, K. OSS-Fuzz-Google’s Continuous Fuzzing Service for Open Source Software. In Proceedings of the USENIX Security symposium, Vancouver, BC, Canada, 16–18 August 2017. [Google Scholar]
- Blazytko, T.; Bishop, M.; Aschermann, C.; Cappos, J.; Schlögel, M.; Korshun, N.; Abbasi, A.; Schweighauser, M.; Schinzel, S.; Schumilo, S. GRIMOIRE: Synthesizing structure while fuzzing. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 1985–2002. [Google Scholar]
- Wang, J.; Chen, B.; Wei, L.; Liu, Y. Superion: Grammar-aware greybox fuzzing. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 724–735. [Google Scholar]
- Padhye, R.; Lemieux, C.; Sen, K.; Papadakis, M.; Le Traon, Y. Semantic fuzzing with zest. In Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, Beijing, China, 15–19 July 2019; pp. 329–340. [Google Scholar]
- Gan, S.; Zhang, C.; Qin, X.; Tu, X.; Li, K.; Pei, Z.; Chen, Z. Collafl: Path sensitive fuzzing. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–23 May 2018; pp. 679–696. [Google Scholar]
- Odena, A.; Olsson, C.; Andersen, D.; Goodfellow, I. Tensorfuzz: Debugging neural networks with coverage-guided fuzzing. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 July 2019; pp. 4901–4911. [Google Scholar]
- Gao, Z.; Dong, W.; Chang, R.; Wang, Y.J.C.; Practice, C. Experience. Fw-fuzz: A code coverage-guided fuzzing framework for network protocols on firmware. Concurr. Comput. Pract. Exp. 2022, 34, e5756. [Google Scholar] [CrossRef]
- Peng, H.; Shoshitaishvili, Y.; Payer, M. T-Fuzz: Fuzzing by program transformation. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 697–710. [Google Scholar] [CrossRef]
- Stephens, N.; Grosen, J.; Salls, C.; Dutcher, A.; Wang, R.; Corbetta, J.; Shoshitaishvili, Y.; Kruegel, C.; Vigna, G. Driller: Augmenting fuzzing through selective symbolic execution. In Proceedings of the NDSS, San Diego, CA, USA, 21–24 February 2016; pp. 1–16. [Google Scholar]
- Shoshitaishvili, Y.; Wang, R.; Hauser, C.; Kruegel, C.; Vigna, G. Firmalice-automatic detection of authentication bypass vulnerabilities in binary firmware. In Proceedings of the NDSS, San Diego, CA, USA, 7 February 2015; pp. 1.1–8.1. [Google Scholar]
- Chipounov, V.; Kuznetsov, V.; Candea, G. S2E: A platform for in-vivo multi-path analysis of software systems. Acm Sigplan Not. 2011, 46, 265–278. [Google Scholar] [CrossRef] [Green Version]
- Cha, S.K.; Avgerinos, T.; Rebert, A.; Brumley, D. Unleashing mayhem on binary code. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 380–394. [Google Scholar]
- Godefroid, P.; Levin, M.Y.; Molnar, D. SAGE: Whitebox fuzzing for security testing. Commun. ACM 2012, 55, 40–44. [Google Scholar] [CrossRef]
- Yun, I.; Lee, S.; Xu, M.; Jang, Y.; Kim, T. QSYM: A practical concolic execution engine tailored for hybrid fuzzing. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 745–761. [Google Scholar]
- Wang, M.; Liang, J.; Chen, Y.; Jiang, Y.; Jiao, X.; Liu, H.; Zhao, X.; Sun, J. SAFL: Increasing and accelerating testing coverage with symbolic execution and guided fuzzing. In Proceedings of the 40th International Conference on Software Engineering: Companion Proceeedings, Gothenburg, Sweden, 27 May 2018––3 June 2018; pp. 61–64. [Google Scholar]
- Böhme, M.; Pham, V.-T.; Nguyen, M.-D.; Roychoudhury, A. Directed greybox fuzzing. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October 30–3 November 2017; pp. 2329–2344. [Google Scholar]
- Chen, H.; Xue, Y.; Li, Y.; Chen, B.; Xie, X.; Wu, X.; Liu, Y. Hawkeye: Towards a desired directed grey-box fuzzer. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 2095–2108. [Google Scholar]
- Coppik, N.; Schwahn, O.; Suri, N. Memfuzz: Using memory accesses to guide fuzzing. In Proceedings of the 2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST), Xi’an, China, 22–27 April 2019; pp. 48–58. [Google Scholar] [CrossRef]
- Nguyen, M.-D.; Bardin, S.; Bonichon, R.; Groz, R.; Lemerre, M. Binary-level Directed Fuzzing for Use-After-Free Vulnerabilities. In Proceedings of the RAID, San Sebastian, Spain, 14–15 October 2020; pp. 47–62. [Google Scholar]
- Wang, H.; Xie, X.; Li, Y.; Wen, C.; Li, Y.; Liu, Y.; Qin, S.; Chen, H.; Sui, Y. Typestate-guided fuzzer for discovering use-after-free vulnerabilities. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, Seoul, Republic of Korea, 27 June 202–19 July 2020; pp. 999–1010. [Google Scholar]
- Medicherla, R.K.; Komondoor, R.; Roychoudhury, A. Fitness guided vulnerability detection with greybox fuzzing. In Proceedings of the IEEE/ACM 42nd International Conference on Software Engineering Workshops, Seoul, Republic of Korea, 27 June 202–19 July 2020; pp. 513–520. [Google Scholar]
- Chen, J.; Diao, W.; Zhao, Q.; Zuo, C.; Lin, Z.; Wang, X.; Lau, W.C.; Sun, M.; Yang, R.; Zhang, K. IoTFuzzer: Discovering Memory Corruptions in IoT Through App-based Fuzzing. In Proceedings of the NDSS, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- You, W.; Zong, P.; Chen, K.; Wang, X.; Liao, X.; Bian, P.; Liang, B. Semfuzz: Semantics-based automatic generation of proof-of-concept exploits. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 2139–2154. [Google Scholar]
- Wang, W.; Sun, H.; Zeng, Q. Seededfuzz: Selecting and generating seeds for directed fuzzing. In Proceedings of the 2016 10th International Symposium on Theoretical Aspects of Software Engineering (TASE), Shanghai, China, 17–19 July 2016; pp. 49–56. [Google Scholar]
- Jain, V.; Rawat, S.; Giuffrida, C.; Bos, H. TIFF: Using input type inference to improve fuzzing. In Proceedings of the 34th Annual Computer Security Applications Conference, San Juan, PR, USA, 3–7 December 2018; pp. 505–517. [Google Scholar]
- Lemieux, C.; Sen, K. Fairfuzz: A targeted mutation strategy for increasing greybox fuzz testing coverage. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Virtual Event, 18–21 February 2018; pp. 475–485. [Google Scholar]
- You, W.; Wang, X.; Ma, S.; Huang, J.; Zhang, X.; Wang, X.; Liang, B. Profuzzer: On-the-fly input type probing for better zero-day vulnerability discovery. In Proceedings of the 2019 IEEE symposium on security and privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 769–786. [Google Scholar]
- Gan, S.; Zhang, C.; Chen, P.; Zhao, B.; Qin, X.; Wu, D.; Chen, Z. GREYONE: Data Flow Sensitive Fuzzing. In Proceedings of the USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020; pp. 2577–2594. [Google Scholar]
- Lattner, C.; Adve, V. LLVM: A compilation framework for lifelong program analysis & transformation. In Proceedings of the International Symposium on Code Generation and Optimization, San Jose, CA, USA, 20–24 March 2004; pp. 75–86. [Google Scholar]
- Serebryany, K.; Bruening, D.; Potapenko, A.; Vyukov, D. AddressSanitizer: A fast address sanity checker. In Proceedings of the Usenix Conference on Technical Conference, Boston, MA, USA, 13–15 June 2012. [Google Scholar]
- Openjpeg. An Open-Source JPEG 2000 Codec Written in C Language. Available online: https://github.com/uclouvain/openjpeg (accessed on 19 February 2023).
- Jasper. Image Processing/Coding Tool Kit. Available online: https://www.ece.uvic.ca/~frodo/jasper (accessed on 19 February 2023).
- GNU Binutils. Acollection of Binary Tools. Available online: https://www.gnu.org/software/binutils/ (accessed on 19 February 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Program | Version | SLoC | Type | MemConFuzz | AFL | MemLock | PerfFuzz |
|---|---|---|---|---|---|---|---|
| jasper | 2.0.14 | 44k | UA | 5 | 1 | 2 | 0 |
| ML | 208 | 212 | 190 | 28 | |||
| readelf | 2.28 | 1844k | UA | 219 | 86 | 182 | 39 |
| openjpeg | 2.3.0 | 243k | UA | 11 | 10 | 17 | 0 |
| Total Unique Crashes (Improvement) | 443 | 309 (+43.4%) | 391 (+13.3%) | 67 (+561.2%) | |||
| Program | Vulnerability | Type | MemConFuzz | AFL | MemLock | PerfFuzz |
|---|---|---|---|---|---|---|
| Time (h) | Time (h) | Time (h) | Time (h) | |||
| jasper | CVE-2016-8886 | UA | 2.6 | 10.2 | 1.5 | T/O |
| readelf | CVE-2017-9039 | UA | 0.1 | 0.1 | 0.1 | 0.1 |
| openjpeg | CVE-2017-12982 | UA | 2.2 | 12.8 | 5.5 | T/O |
| CVE-2019-6988 | UA | 12.5 | T/O | 14.8 | T/O | |
| Average Time Usage (Improvement) | 4.35 | 11.78 (2.71×) | 5.48 (1.26×) | 18.03 (4.14×) | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, C.; Cui, Z.; Guo, Y.; Xu, G.; Wang, Z. MemConFuzz: Memory Consumption Guided Fuzzing with Data Flow Analysis. Mathematics 2023, 11, 1222. https://doi.org/10.3390/math11051222
Du C, Cui Z, Guo Y, Xu G, Wang Z. MemConFuzz: Memory Consumption Guided Fuzzing with Data Flow Analysis. Mathematics. 2023; 11(5):1222. https://doi.org/10.3390/math11051222
Chicago/Turabian StyleDu, Chunlai, Zhijian Cui, Yanhui Guo, Guizhi Xu, and Zhongru Wang. 2023. "MemConFuzz: Memory Consumption Guided Fuzzing with Data Flow Analysis" Mathematics 11, no. 5: 1222. https://doi.org/10.3390/math11051222
APA StyleDu, C., Cui, Z., Guo, Y., Xu, G., & Wang, Z. (2023). MemConFuzz: Memory Consumption Guided Fuzzing with Data Flow Analysis. Mathematics, 11(5), 1222. https://doi.org/10.3390/math11051222