
A Survey on Active Learning: State-of-the-Art, Practical Challenges and Research Directions


Abstract
1. Introduction
- The most important study in the field of active learning is the one presented by Burr Settles in 2009 [3]. It alone collects more than 6000 citations, which reflects its importance. The paper explains AL scenarios, query strategies, the analysis of different active learning techniques, some solutions to practical problems, and related research areas. In addition, Burr Settles presents several studies that explain the active learning technique from different perspectives such as [10,11].
- In [12], the authors present a comprehensive overview of the instance selection of active learners. Here, the authors introduced a novel taxonomy of active learning techniques, in which active learners were categorized, based on “how to select unlabeled instances for labeling”, into (1) active learning based only on the uncertainty of independent and identically distributed (IID) instances (we refer to this as information-based query strategies as in Section 3.1), and (2) active learning by further taking into account instance correlations (we refer to this as representation-based query strategies as in Section 3.2). Different active learning algorithms from each category were discussed including theoretical basics, different strengths/weaknesses, and practical comparisons.
- Kumar et al. introduced a very elegant overview of AL for classification, regression, and clustering techniques [13]. In that overview, the focus was on presenting different work scenarios of the active learning technique with classification, regression, and clustering.
- An experimental survey was presented in [16] to compare many active learners. The goal is to show how to fairly compare different active learners. Indeed, the study showed that using only one performance measure or one learning algorithm is not fair, and changing the algorithm or the performance metric may change the experimental results and thus the conclusions. In another study, to compare the most well-known active learners and investigate the relationship between classification algorithms and active learning strategies, a large experimental study was performed by using 75 datasets, different learners (5NN, C4.5 decision tree, naive Bayes (NB), support vector machines (SVMs) with radial basis function (RBF), and random forests (RFs)), and different active learners [17].
- There are also many surveys on how AL is employed in different applications. For example, in [18], a survey of active learning in multimedia annotation and retrieval was introduced. The focus of this survey was on two application areas: image/video annotation and content-based image retrieval. Sample selection strategies used in multimedia annotation and retrieval were categorized into five criteria: risk reduction, uncertainty, variety, density, and relevance. Moreover, different classification models such as multilabel learning and multiple-instance learning were discussed. In the same area, another recent small survey was also introduced in [19]. In a similar context, in [20], a literature review of active learning in natural language processing and related tasks such as information extraction, named entity recognition, text categorization, part-of-speech tagging, parsing, and word sense disambiguation was presented. In addition, in [21], an overview of some practical issues in using active learning in some real-world applications was given. Mehdi Elahi et al. introduced a survey of active learning in collaborative filtering recommender systems, where the active learning technique is employed to obtain data that better reflect users’ preferences; this enables the generation of better recommendations [22]. Another survey of AL for supervised remote sensing image classification was introduced in [23]. This survey covers only the main families of active learning algorithms that were used in the remote sensing community. Some experiments were also conducted to show the performance of some active learners that label uncertain pixels by using three challenging remote sensing datasets for multispectral and hyperspectral classification. Another recent survey that uses satellite-based Earth-observation missions for vegetation monitoring was introduced in [24].
- A review of deep active learning, which is one of the most important and recent reviews, has been presented in [25]. In this review, the main differences between classical AL algorithms, which always work in low-dimensional space, and deep active learning (DAL), which can be used in high-dimensional spaces, are discussed. Furthermore, this review also explains the problems of DAL, such as (i) the requirement for high training/labeling data, which is solved, for example, by using pseudolabeled data and generating new samples (i.e., data augmentation) by using generative adversarial networks (GANs), (ii) the challenge of computing uncertainty compared to classical ALs, and (iii) the processing pipeline of deep learning, because feature learning and classifier training are jointly optimized in deep learning. In the same field, another review of the DAL technique has been recently presented, and the goal is to explain (i) the challenge of training DAL on small datasets and (ii) the inability of neural networks to quantify reliable uncertainties on which the most commonly used query strategies are based [26]. To this end, a taxonomy of query strategies, which distinguishes between data-based, model-based, and prediction-based instance selection, was introduced besides the investigation of the applicability of these classes in recent research studies. In a related study, Qiang Hu et al. introduced some practical limitations of AL deep neural networks [27].
2. Active Learning: Background
2.1. Theoretical Background
- In the semisupervised technique, the unlabeled data is used to further improve the supervised classifier, which has been learned from the labeled data. To this end, the learner learns from a set of labeled data and then finds specific unlabeled points that can be correctly classified. These points are then labeled and added to the labeled dataset [28].
- The active learning technique usually starts with a large set of unlabeled data and a small set of labeled data. This labeled set is used to learn a hypothesis, and based on a specific query strategy, the informativeness of the unlabeled points is measured for selecting the least confident ones; unlike the semisupervised technique that selects the most certain points, active learners query the most uncertain ones [3,29,30]. The selected points are called query instances, and the learner asks an expert/annotator to label them. The newly labeled points are then added to the labeled data, and the hypothesis is updated based on the newly modified dataset [12,13,18].
2.2. Analysis of the AL Technique
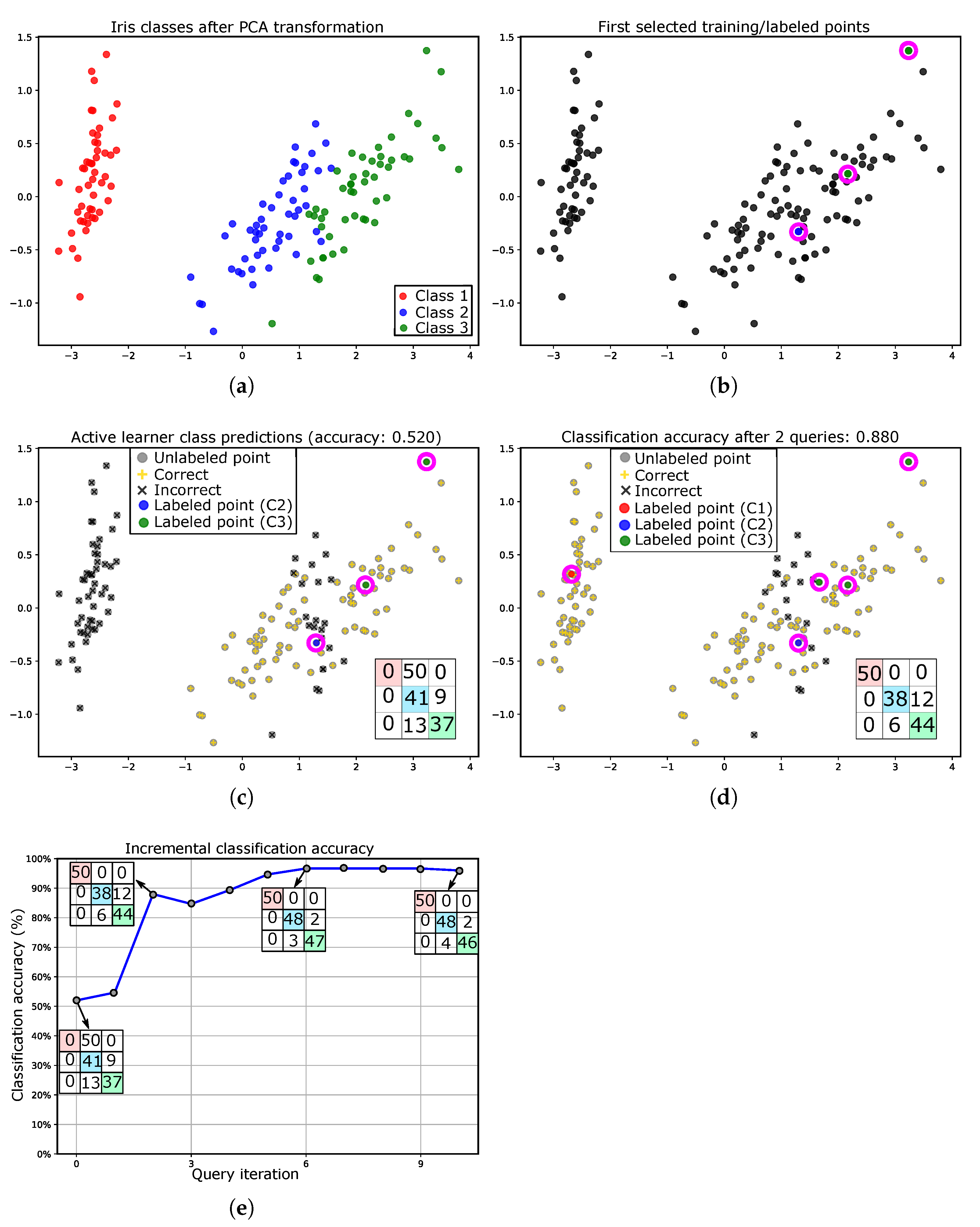
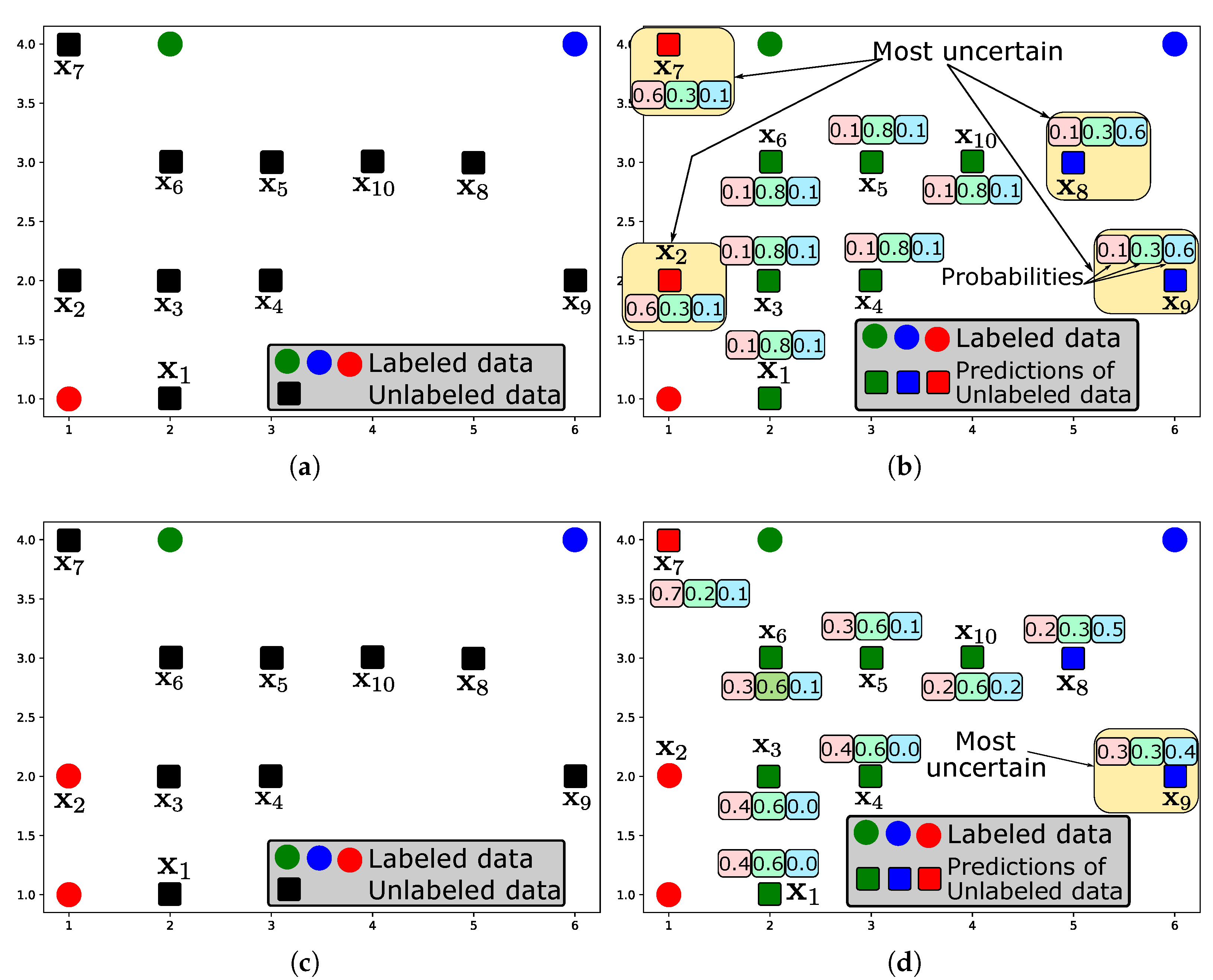
2.3. Illustrative Example
2.4. AL Scenarios
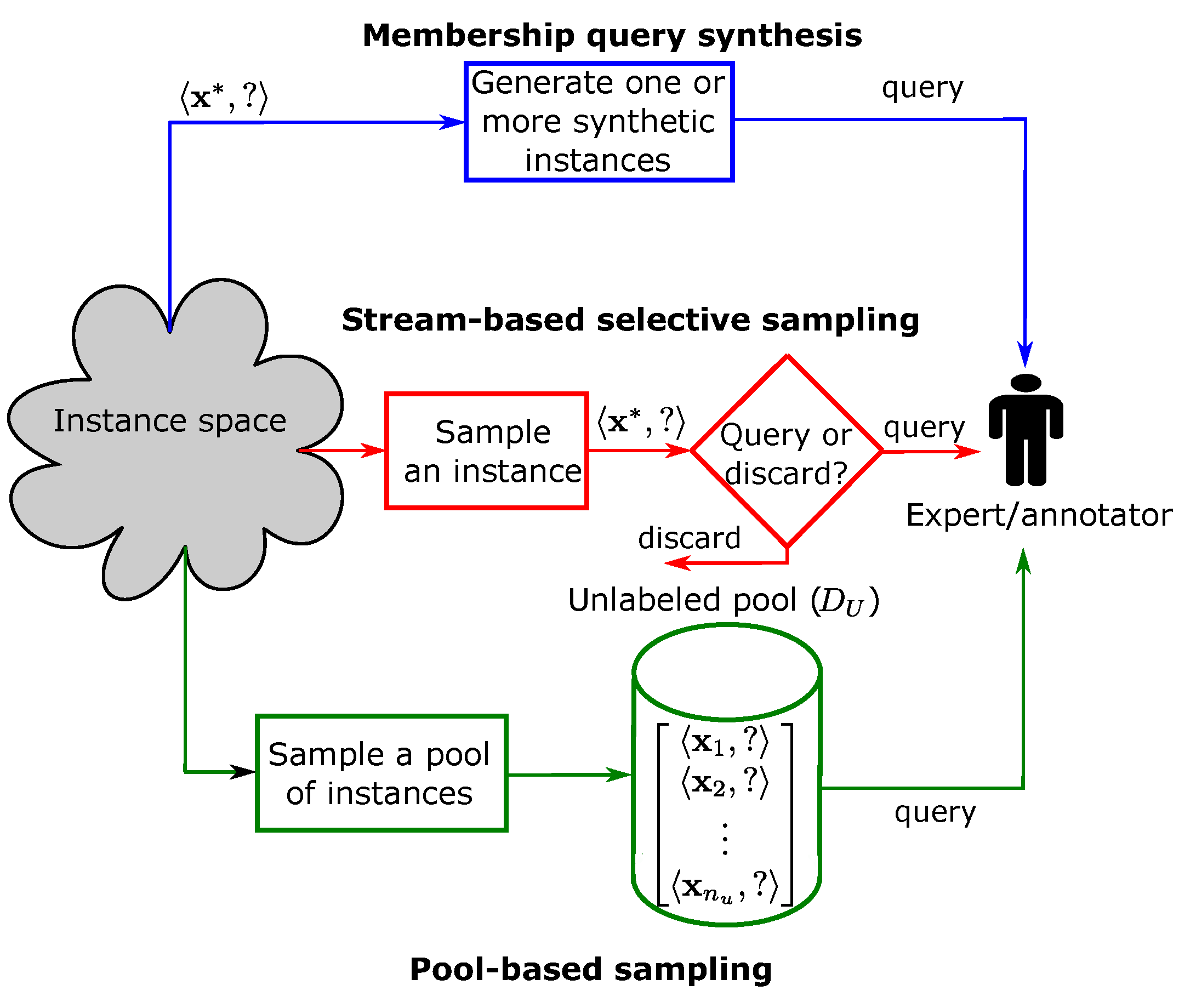
- In the membership query synthesis scenario, the active learner generates synthetic instances in the space and then requests labels for them (see Figure 2). This scenario is suitable for finite problem domains, and because no processing on unlabeled data is required in this scenario, the learner can quickly generate query instances [3]. The major limitation of this scenario is that it can artificially generate instances that are impossible to reasonably label [36]. For example, some of the artificially generated images for classifying handwritten characters contained no recognizable symbols [37].
- In the stream-based selective sampling scenario, the learning model decides whether to annotate the unlabeled point based on its information content [4]. This scenario is also referred to as sequential AL because the unlabeled data points are drawn iteratively, one at a time. In many studies such as [38,39], the selective sampling scenario was considered in a slightly different manner from the pool-based scenario (this scenario is explained below) because, in both scenarios, the queries are performed by selecting a set of instances sampled from a real data distribution, and the main difference between them is that the first scenario (selective sampling) scans the data sequentially, whereas the second scenario samples a large set of points (see Figure 2) [3]. This increases the applicability of the stream-based scenario when memory and/or processing power is limited, such as with mobile devices [3]. In practice, the data stream-based selective sampling scenario may not be suitable in nonstationary data environments due to the potential for data drift.
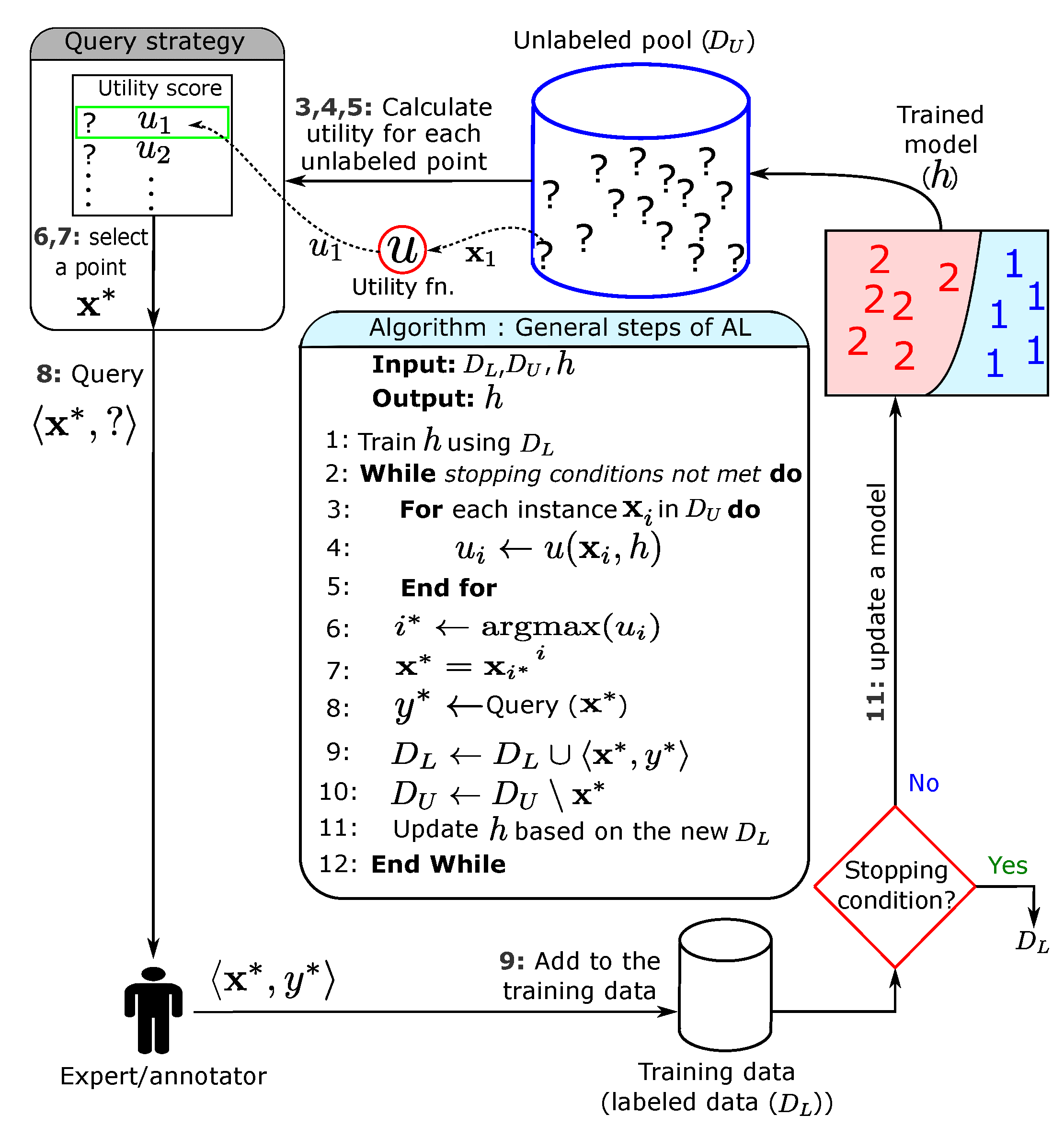
- The pool-based scenario is the most well-known scenario, in which a query strategy is used to measure the informativeness of some/all instances in the large set/pool of available unlabeled data to query some of them [40]. Figure 3 shows that there is labeled data () for training a model (h) and a large pool of unlabeled data (). The trained model is used to evaluate the information content of some/all of the unlabeled points in and ask the expert to label/annotate the most informative points. The newly annotated points are added to the training data to further improve the model. These steps show that this scenario is very computationally intensive, as it iteratively evaluates many/all instances in the pool. This process continues until a termination condition is met, such as reaching a certain number of queries (this is called query budget) or when there are no clear improvements in the performance of the trained model.
2.5. AL Components
- Data: The first component is the data which consists of labeled and unlabeled data. The unlabeled data () represents the pool from which a new point is selected, and the labeled portion of the data () is used to train a model (h).
- Learning algorithm: The trained model (h) on is the second component and it is used to evaluate the current annotation process and find the most uncertain parts within the space for querying new points there.
- Query strategy: The third component is the query strategy (this is also called the acquisition function [14]) which uses a specific utility function (u) for evaluating the instances in for selecting and querying the most informative and representative point(s) in . The active learners are classified in terms of the number of queries at a time into one query and batch active learners.
- –
- One query: Many studies assume that only one query is queried at a time, which means that the learning models should be retrained every time a new sample is added; hence, it is time-consuming [14]. Moreover, adding only one labeled point may not make a noticeable change in the learning model, especially for deep learning and large-scale models.
- –
- Batch query: In [4], the batch active learning technique was proposed. It is suitable for parallel environments (many experiments are running in parallel) to select many samples simultaneously. Simply put, if the batch size is k, a simple active learning strategy could be run repeatedly for k times to select the most informative k points. The problem here is that some similar points could be selected. Therefore, with batch active learning, the sample diversity and the amount of information that each point contains should be taken into consideration.
- Expert: The fourth component is the expert/labeler/annotator/oracle who annotates/labels the queried unlabeled points.
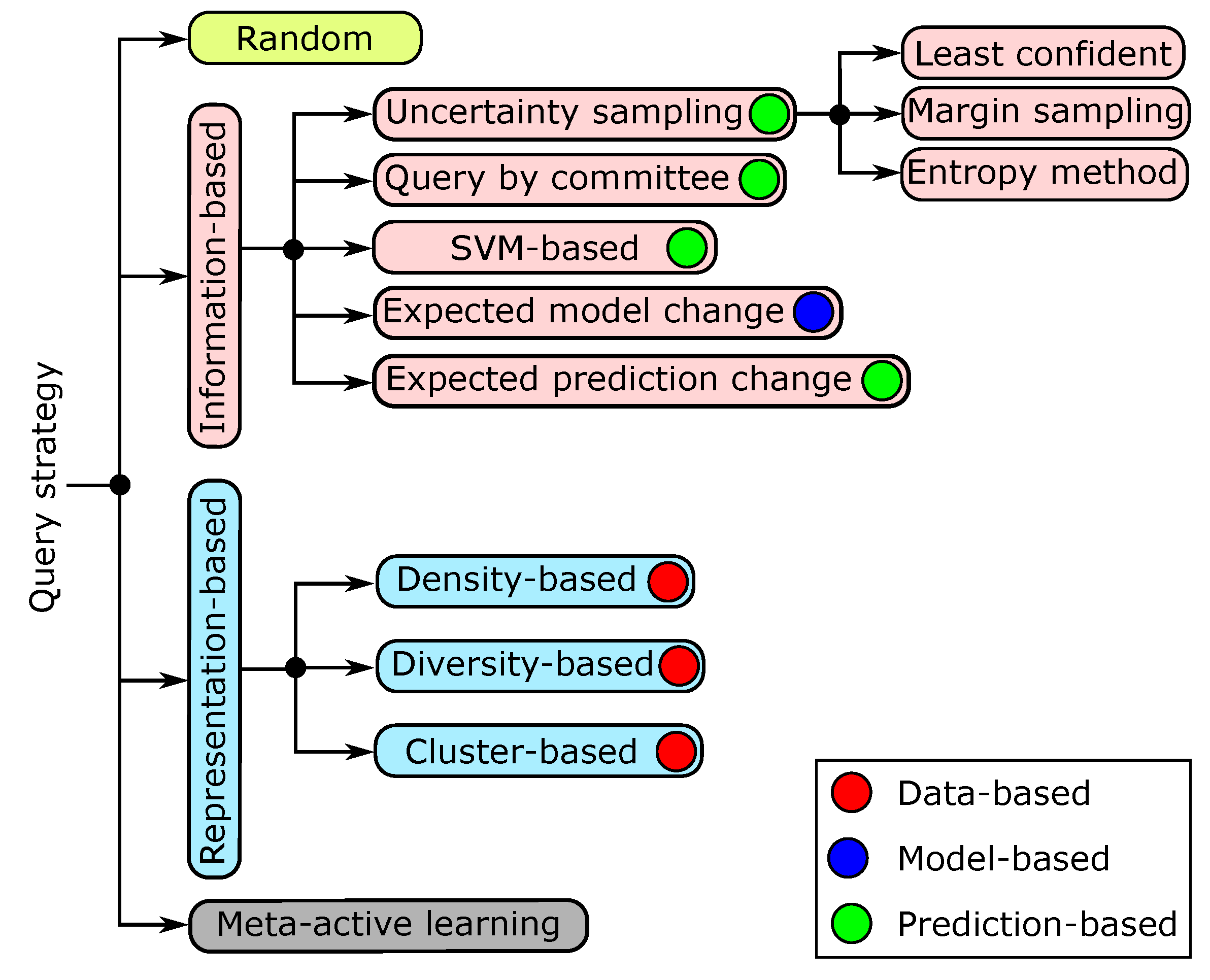
3. Query Strategy Frameworks
3.1. Information-Based Query Strategies
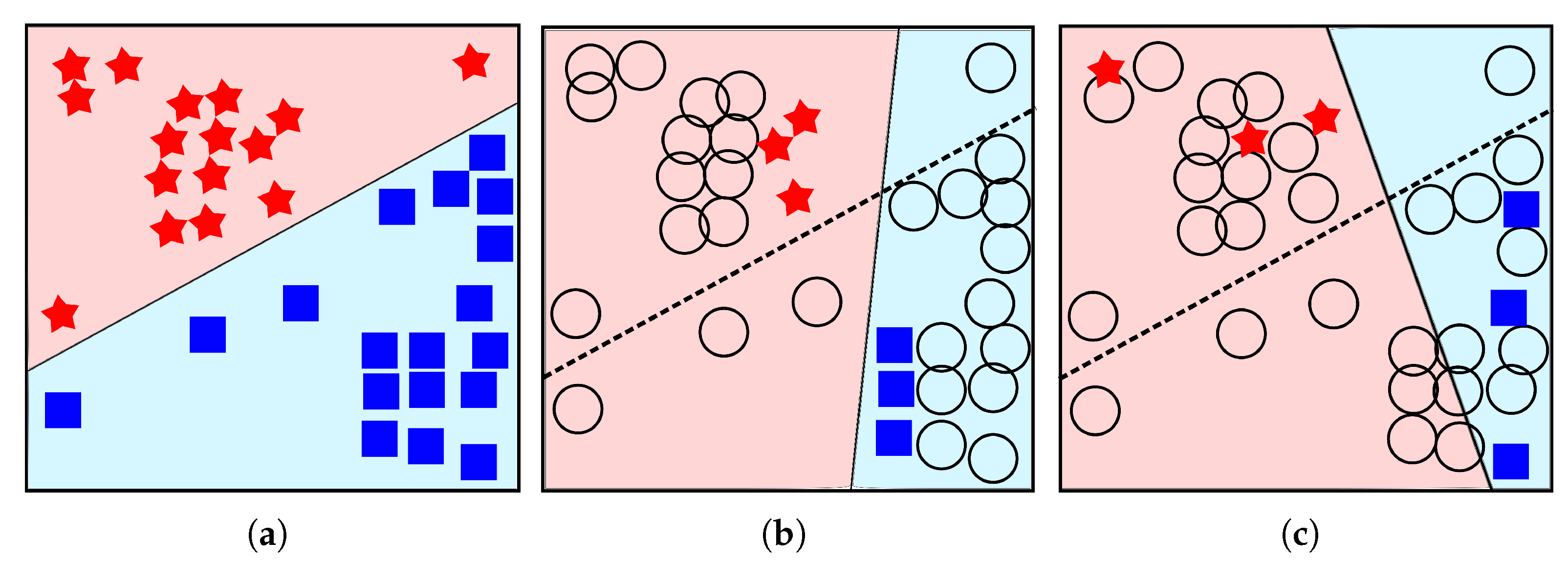
3.1.1. Uncertainty Sampling
Illustrative Example
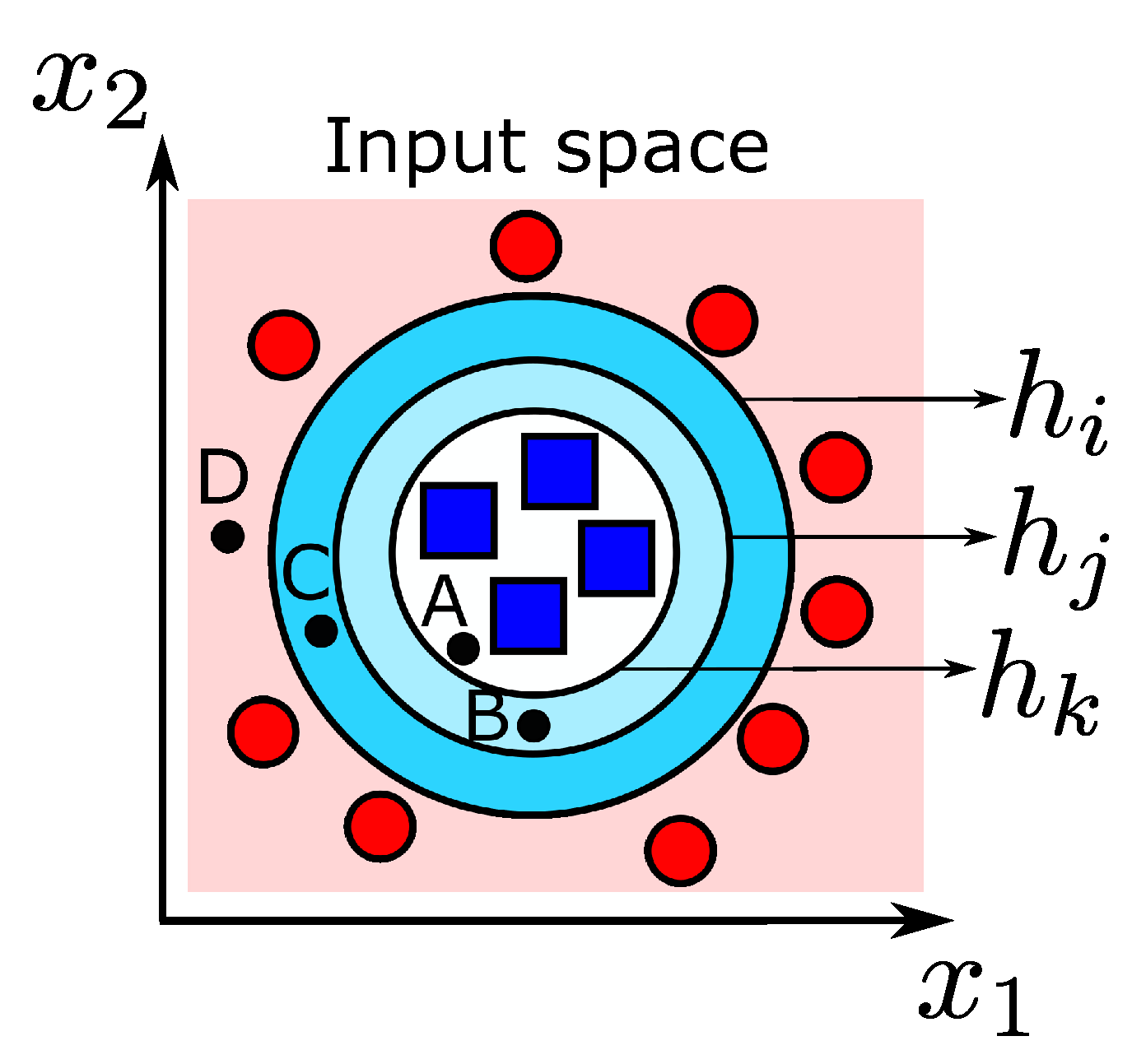
3.1.2. Query by Committee
3.1.3. SVMs-Based Approach
3.1.4. Expected Model Change
3.1.5. Expected Error/Prediction Change
3.1.6. Challenges of Information-Based Query Strategies
3.2. Representation-Based Query Strategies
3.2.1. Density-Based Approach
3.2.2. Cluster-Based Approach
3.2.3. Diversity-Based Approach
3.2.4. Challenges of the Representation-Based Strategies
3.3. Informative and Representative-Based Query Strategies
3.4. Meta-Active Learning
3.5. Other Classifications of AL
- Random: This is the most well-known and traditional method in which unlabeled points are queried randomly (i.e., this category does not use any knowledge about data or models).
- Data-based: This category has the lowest level of knowledge and works only with the raw data and the labels of the current labeled data. This category could be further divided into (i) strategies that rely only on measuring the representativeness of the points (i.e., representation-based) and (ii) strategies that rely on the data uncertainty by using information about data distribution and the distribution of the labels.
- Model-based: This category has knowledge about both the data and the model (without predictions). One clear example is the expected model change, where after training a model using some labeled points, the model queries a new unlabeled point that obtains the greatest impact on the model (e.g., model’s parameters such as expected weight change [58] and expected gradient length [57]), regardless of the resulting query label.
- Prediction-based: All types of knowledge are available in this category (from data, models, and predictions). A well-known example is the uncertainty sampling method, in which a new point is selected based on the predictions of the trained model. The most uncertain unlabeled point will be queried. However, there is a thin line between the model-based and prediction-based categories. In [26], it was mentioned that the prediction-based category searches for interclass uncertainty (i.e., the uncertainty between different classes), whereas the model-based category searches for intraclass uncertainty (i.e., the uncertainty within a class).
- Agnostic strategies: This approach makes no assumption about the correctness (or how accurate) of the decision boundaries of the trained model. In other words, this approach ignores all the information generated by the learning algorithm and uses only the information from the pool of unlabeled data. Therefore, this approach could be approximately the same as the representation-based approach in our classification.
- Nonagnostic strategies: This approach mainly depends on the trained model to select and query new unlabeled points. Therefore, this approach is very similar to the information-based approach we presented earlier.
4. Practical Challenges of AL in Real Environments
4.1. Noisy Labeled Data
4.2. The Imbalanced Data Problem
4.3. Low Query Budget
4.4. Variable Labeling Costs
4.5. Using Initial Knowledge for Training Learning Models
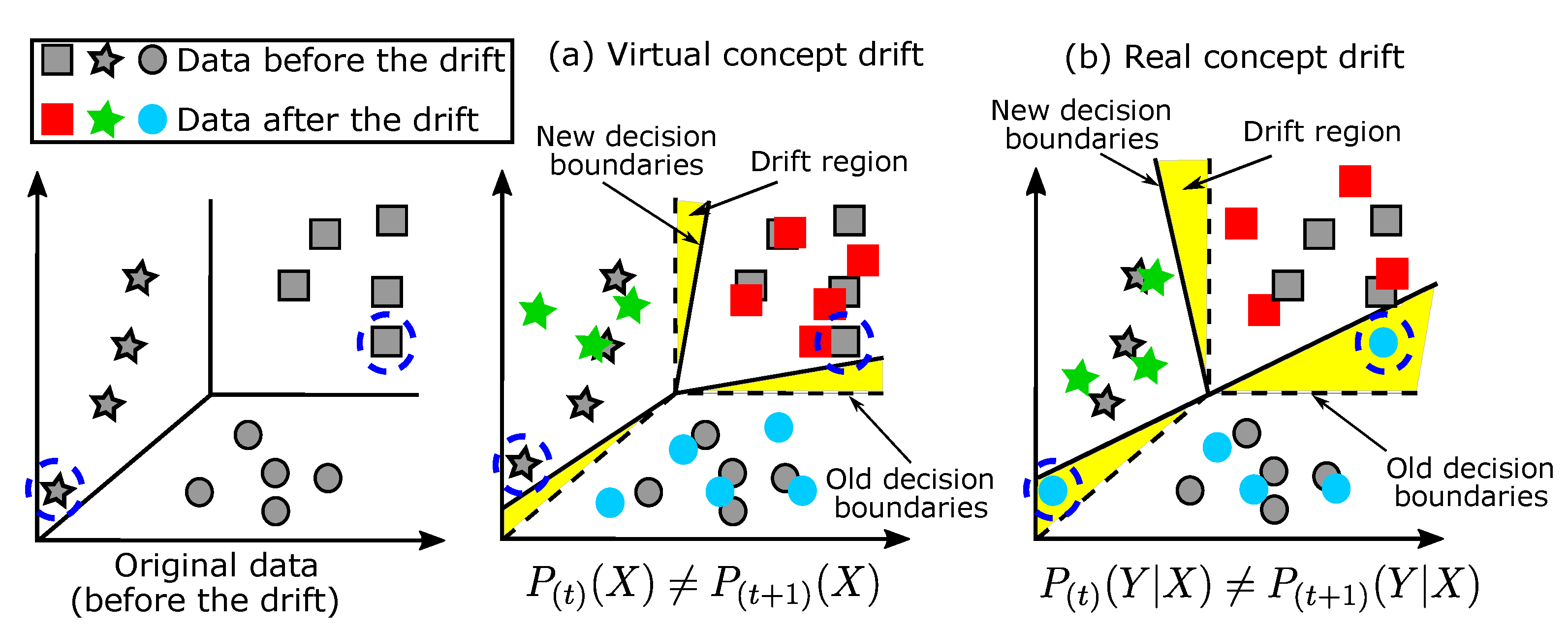
4.6. The Concept Drift Phenomenon in Data Streams
4.7. AL with Multilabel Applications
4.8. Stopping Criteria
4.9. AL with Outliers
4.10. AL in High-Dimensional Environments
4.11. ML-Based Active Learners
4.12. AL with Crowdsourcing Labelers
5. AL with Different Technologies (Research Areas)
5.1. AL with Deep Learning
5.2. Few-Shot Learning with AL
5.3. Active Data Acquisition
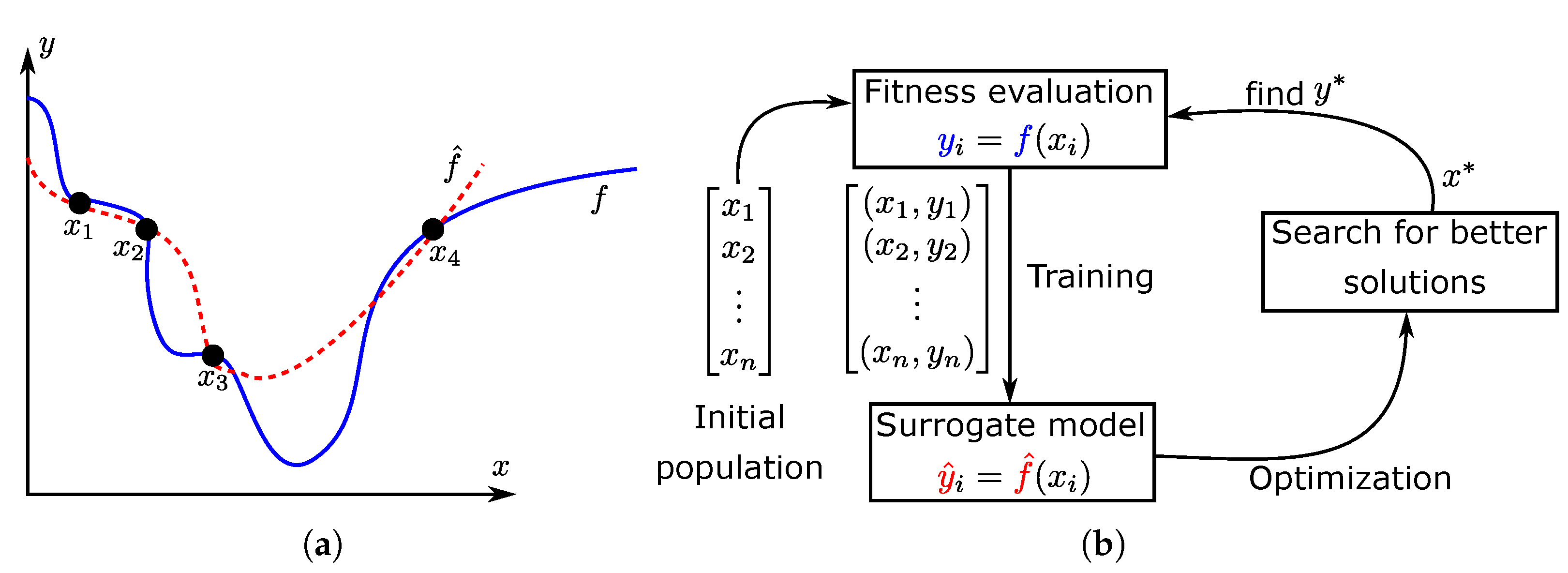
5.4. AL with Optimization
5.5. AL with Simulation
5.6. AL with Design of Experiments
5.7. Semisupervised Learning
5.8. AL with Distributed Environments
5.9. AL with Multitask
5.10. Explainable Active Learning (XAL)
6. Applications of AL
- In the field of natural language processing (NLP), AL has been used in the categorization of texts to find out which class each text belongs to as in [36,40,46]. Moreover, AL has been employed in named-entity relationships (NERs), given an unstructured text (the entity). NER is the process of identifying a word or phrase in that entity and classifying it as belonging to a particular class (the entity type)) [172,173]. AL is thus used here to reduce the required annotation cost while maximizing the performance of ML-based models [174]. In sentiment analysis, AL was employed for classifying the given text as positive or negative [175,176]. AL was also utilized in information extraction to extract some valuable information [177].
- AL has been employed in the image and video-related applications, for example, image classification [123,178]. In image segmentation, AL is used, for example, to find highly informative images and reduce the diversity in the training set [179,180]. For example, in [181], AL improved the results with only 22.69% of the available data. AL has been used for object detection and localization to detect objects [182,183]. This was clear in a recent study that introduced two metrics for quantifying the informativeness of an object hypothesis, allowing AL to be used to reduce the amount of annotated data to 25% of the available data and produce promising results [184]. One of the major challenges in remote sensing image classification is the complexity of the problem, limited funding in some cases, and high intraclass variance. These challenges can cause a learning model to fail if it is trained with a suboptimal dataset [23,185]. In this context, AL is used to rank the unlabeled pixels according to their uncertainty of their class membership and query the most uncertain pixels. In video annotation, AL could be employed to select which frames a user should annotate to obtain highly accurate tracks with minimal user effort [18,186]. In human activity recognition, the real environment depends on humans, so collecting and labeling data in a nonstationary environment is likely to be very expensive and unreliable. Therefore, AL could help here to reduce the required amount of labeled data by annotating novel activities and ignoring obsolete ones [187,188].
- In medical applications, AL plays a role in finding optimal solutions of many problems. For example, AL has been used for compound selection to help in the formation of target compounds in drug discovery [189]. Moreover, AL has been used for the selection of protein pairs that could interact (i.e., protein–protein interaction prediction) [190], for predicting the protein structure [191,192], and clinical annotation [193].
- In agriculture, AL has been used to select high-quality samples to develop efficient and intelligent ML systems as in [194,195]. AL has also been used for semantic segmentation of crops and weeds for agricultural robots as in [196]. Furthermore, AL was applied for detecting objects in various agricultural studies [197].
- In industry, AL has been employed to handle many problems. Trivially, it is used to reduce the labeling cost in ML-based problems by querying only informative unlabeled data. For example, in [198], a cost-sensitive active learner has been used to detect faults. In another direction, AL is used for quantifying the uncertainties to build cheap, fast, and accurate surrogate models [199,200]. In data acquisition, AL is used to build active inspection models that select some products in uncertain regions for further investigating these selected products with advanced inspections [144].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | C | d | N | Initial Data | Balanced Data | Query Budget | Stopping Cond. | Application |
|---|---|---|---|---|---|---|---|---|
| [118] | 2 | 4–500 | >5000 | √ | I | ≈50% | Q + U | General |
| [201] | 2 | 13 | 487 | √ (5%) | B | 120 | Q | Medical |
| [202] | M | >10,000 | >10,000 | √ | I | − | − | Material Science |
| [203] | M | ≈30 | <1000 | √() | I | − | − | General |
| [204] | M | 48 × 48 | 35,886 | √ | I | − | − | Multimedia |
| [205] | 2 | 20 | 3168 | √ (≈2%) | B | − | − | Acoustical signals |
| [206] | M | 176 | >50,000 | √ (≈40) | I | 234–288 | Q | Remote sensing |
| [207] | M | 352 × 320 | 617,775 | √ | B | ≈40% | Medical | |
| [208] | M | 7310 | − | B | 17.8% | Text Classification | ||
| [209] | M | 41 | 9159 | − | I | − | Network Traffic Classification | |
| [210] | M | H | >10,000 | √ (2%) | I | 50% | Q | Text Classification |
| [211] | M | − | 44,030 | − | I | 2000 | Q | Text Classification |
| [70] | M | <13 | <625 | x | I | 5% | Q | General |
| [69] | 2 | <9 | <600 | x | I | 30 | Q | General |
| [212] | M | H | 610 × 610 | √ (250) | I | Q | Remote sensing | |
| [213] | M | − | 2008 | √ () | I | 1750 | Q | Medical |
| [96] | M | 5–54 | 57k–830k | √ (500) | I | 20% | Q | General |
| [214] | M | H | 1.2M | √ (20%) | I | 40% | Q | Image classification and segmentation |
7. AL Packages/Software
- A modular active learning framework for Python (modAL) (https://modal-python.readthedocs.io/en/latest/, https://github.com/modAL-python/modAL [access date on 28 December 2022]) is a small package that implements the most common sampling methods, such as the least confident method, the margin sampling method, and the entropy-based method. This package is easy to use and employs simple Python functions, including Scikit-learn. It is also suitable for regression and classification problems [215]. Furthermore, it fits with stream-based sampling and multi-label strategies.
- Active learning in Python (ALiPy) (https://github.com/NUAA-AL/ALiPy [access date on 28 December 2022]) implements many sampling methods and is probably even the package with the largest selection of sampling methods [216]. Moreover, this package can be used for multilabel learning and active feature acquisition (when collecting all feature values for the whole dataset is expensive or time-consuming). Furthermore, the package gives the ability to use many noisy oracles/labelers.
- Pool-based active learning in Python (libact) (https://libact.readthedocs.io/en/latest/, https://github.com/ntucllab/libact [access date on 28 December 2022]) is a package that provides not only well-known sampling methods but also the ability to combine multiple available sampling strategies in a multiarmed bandit to dynamically find the best approach in each case. The libact package was designed for high performance and therefore uses C as its programming language; therefore, it is relatively more complicated than the other software packages [217].One of the differences between the previous packages is the definition of high-density regions within the space. The modAL package defines the density as the sum of the distances (e.g., cosine or Euclidean similarity distance) to all other unlabeled samples, where a smaller distance is interpreted as a higher density (as reported in [99]). In contrast, ALiPy defines the density as the average distance to the 10 nearest neighbours as reported in [72]. Libact proposes an initial approach based on the K-means technique and the cosine similarity, which is similar to that of modAL. The libact documentation reports that the approach is based on [99], but the formula used differs slightly from the one in [72]. Furthermore, in some experiments (https://www.bi-scout.com/active-learning-pakete-im-vergleich [access date on 28 December 2022]), the libact and ALiPy packages obtained better results than modAL, which is due to the fact that the approaches of libact and ALiPy are cluster-based and therefore tend to examine the entire sample area, whereas the method of modAL focuses on the areas with the highest density.
- AlpacaTag is an active learning-based crowd annotation framework for sequence tagging, such as named-entity recognition (NER) (https://github.com/INK-USC/AlpacaTag [access date on 28 December 2022]) [218]. This software does not only select the most informative points, but also dynamically suggests annotations. Moreover, this package gives the ability to merge inconsistent labels from multiple annotators. Furthermore, the annotations can be done in real time.
- SimAL (https://github.com/Eng-Alaa/AL_SurveyPaper [access date on 28 December 2022]) is a new simple active learning package associated with this paper. Within the code of this package, the steps are very easy with the aim of making it clear for researchers with different programming levels. This package uses simple uncertainty sampling methods to find the most informative points. Furthermore, because the pipeline of deep learning is not highly consistent with AL as we mentioned before, this package introduces a simple framework to understand the steps of DAL clearly. Due to the simplicity of the code, it could be used as a starting point to build any AL or understand how it works. Also, this package does not depend on other complicated toolboxes, which is an advantage over other software packages. Furthermore, this package contains all the illustrative examples we have presented in this paper.
8. AL: Experimental Evaluation Metrics
- For imbalanced data, sensitivity (or true positive rate (TPR), hit rate, or recall), specificity (true negative rate (TNR), or inverse recall), and geometrical mean (GM) metrics are used. For example, the sensitivity and specificity metrics were used in [69,96] and GM was also used in [96]. Moreover, the false positive rate (FPR) was used in [96] when the data was imbalanced. In [70,219], with multiclass imbalanced datasets, the authors counted the number of annotated points from each minority class. This is referred to as the number of annotated points from the minority class (). This metric is useful and representative in showing how the active learner scans the minority class. As an extension of this metric, the authors in [70] counted the number of annotated points from each class to show how the active learner scans all classes, including the minority classes.
- Receiver operating characteristic (ROC) curve: This metric visually compares the performance of different active learners, where the active learner that obtains the largest area under the curve (AUC) is the best one [141]. This is suitable for binary classification problems. For multiclass datasets with imbalanced data, the multiclass area under the ROC curve (MAUC) is used [96,220]. This metric is an extension of the ROC curve that is only applicable in the case of two classes. This is done by averaging pairwise comparisons.
- In [70], the authors counted the number of runs in which the active learner failed to query points from all classes, and they called this metric the number of failures (NoF). This metric is more appropriate for multiclass data and imbalanced data to ensure that the active learner scans the space and finds representative points from all classes.
- Computation time: This metric is very effective because some active learners require high computational costs and therefore cannot query enough points in real time. For example, the active learner in [69] requires high computational time even in low-dimensional spaces.
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mitchell, T. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar]
- Settles, B. Active Learning Literature Survey; Computer Sciences Technical Report; Department of Computer Sciences, University of Wisconsin-Madison: Madison, WI, USA, 2009; p. 1648. [Google Scholar]
- Cohn, D.; Atlas, L.; Ladner, R. Improving generalization with active learning. Mach. Learn. 1994, 15, 201–221. [Google Scholar] [CrossRef]
- Wang, M.; Fu, K.; Min, F.; Jia, X. Active learning through label error statistical methods. Knowl.-Based Syst. 2020, 189, 105140. [Google Scholar] [CrossRef]
- Krawczyk, B. Active and adaptive ensemble learning for online activity recognition from data streams. Knowl.-Based Syst. 2017, 138, 69–78. [Google Scholar] [CrossRef]
- Wang, H.; Jin, Y.; Doherty, J. Committee-based active learning for surrogate-assisted particle swarm optimization of expensive problems. IEEE Trans. Cybern. 2017, 47, 2664–2677. [Google Scholar] [CrossRef]
- Sverchkov, Y.; Craven, M. A review of active learning approaches to experimental design for uncovering biological networks. PLoS Comput. Biol. 2017, 13, e1005466. [Google Scholar] [CrossRef]
- Cevik, M.; Ergun, M.A.; Stout, N.K.; Trentham-Dietz, A.; Craven, M.; Alagoz, O. Using active learning for speeding up calibration in simulation models. Med. Decis. Mak. 2016, 36, 581–593. [Google Scholar] [CrossRef]
- Settles, B. Curious Machines: Active Learning with Structured Instances. Ph.D. Thesis, University of Wisconsin-Madison, Madison, WI, USA, 2008. [Google Scholar]
- Settles, B. From theories to queries: Active learning in practice. In Proceedings of the Active Learning and Experimental Design Workshop in Conjunction with AISTATS 2010. JMLR Workshop and Conference Proceedings, Sardinia, Italy, 16 May 2011; pp. 1–18. [Google Scholar]
- Fu, Y.; Zhu, X.; Li, B. A survey on instance selection for active learning. Knowl. Inf. Syst. 2013, 35, 249–283. [Google Scholar] [CrossRef]
- Kumar, P.; Gupta, A. Active learning query strategies for classification, regression, and clustering: A survey. J. Comput. Sci. Technol. 2020, 35, 913–945. [Google Scholar]
- Hino, H. Active learning: Problem settings and recent developments. arXiv 2020, arXiv:2012.04225. [Google Scholar]
- Hanneke, S. A bound on the label complexity of agnostic active learning. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 353–360. [Google Scholar]
- Ramirez-Loaiza, M.E.; Sharma, M.; Kumar, G.; Bilgic, M. Active learning: An empirical study of common baselines. Data Min. Knowl. Discov. 2017, 31, 287–313. [Google Scholar] [CrossRef]
- Pereira-Santos, D.; Prudêncio, R.B.C.; de Carvalho, A.C. Empirical investigation of active learning strategies. Neurocomputing 2019, 326, 15–27. [Google Scholar] [CrossRef]
- Wang, M.; Hua, X.S. Active learning in multimedia annotation and retrieval: A survey. Acm Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–21. [Google Scholar] [CrossRef]
- Xu, Y.; Sun, F.; Zhang, X. Literature survey of active learning in multimedia annotation and retrieval. In Proceedings of the Fifth International Conference on Internet Multimedia Computing and Service, Huangshan, China, 17–18 August 2013; pp. 237–242. [Google Scholar]
- Olsson, F. A Literature Survey of Active Machine Learning in the Context of Natural Language Processing, SICS Technical Report T2009:06 -ISSN: 1100-3154. 2009. Available online: https://www.researchgate.net/publication/228682097_A_literature_survey_of_active_machine_learning_in_the_context_of_natural_language_processing (accessed on 15 December 2022).
- Lowell, D.; Lipton, Z.C.; Wallace, B.C. Practical obstacles to deploying active learning. arXiv 2018, arXiv:1807.04801. [Google Scholar]
- Elahi, M.; Ricci, F.; Rubens, N. A survey of active learning in collaborative filtering recommender systems. Comput. Sci. Rev. 2016, 20, 29–50. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A survey of active learning algorithms for supervised remote sensing image classification. IEEE J. Sel. Top. Signal Process. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Berger, K.; Rivera Caicedo, J.P.; Martino, L.; Wocher, M.; Hank, T.; Verrelst, J. A survey of active learning for quantifying vegetation traits from terrestrial earth observation data. Remote Sens. 2021, 13, 287. [Google Scholar] [CrossRef]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Gupta, B.B.; Chen, X.; Wang, X. A survey of deep active learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Schröder, C.; Niekler, A. A survey of active learning for text classification using deep neural networks. arXiv 2020, arXiv:2008.07267. [Google Scholar]
- Hu, Q.; Guo, Y.; Cordy, M.; Xie, X.; Ma, W.; Papadakis, M.; Le Traon, Y. Towards Exploring the Limitations of Active Learning: An Empirical Study. In Proceedings of the 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE), Melbourne, Australia, 15–19 November 2021; pp. 917–929. [Google Scholar]
- Sun, L.L.; Wang, X.Z. A survey on active learning strategy. In Proceedings of the 2010 International Conference on Machine Learning and Cybernetics, Qingdao, China, 11–14 July 2010; Volume 1, pp. 161–166. [Google Scholar]
- Bull, L.; Manson, G.; Worden, K.; Dervilis, N. Active Learning Approaches to Structural Health Monitoring. In Special Topics in Structural Dynamics; Springer: Berlin/Heidelberg, Germany, 2019; Volume 5, pp. 157–159. [Google Scholar]
- Pratama, M.; Lu, J.; Lughofer, E.; Zhang, G.; Er, M.J. An incremental learning of concept drifts using evolving type-2 recurrent fuzzy neural networks. IEEE Trans. Fuzzy Syst. 2016, 25, 1175–1192. [Google Scholar] [CrossRef]
- Abu-Mostafa, Y.S.; Magdon-Ismail, M.; Lin, H.T. Learning from Data; AMLBook: New York, NY, USA, 2012; Volume 4. [Google Scholar]
- Tharwat, A.; Schenck, W. Population initialization techniques for evolutionary algorithms for single-objective constrained optimization problems: Deterministic vs. stochastic techniques. Swarm Evol. Comput. 2021, 67, 100952. [Google Scholar] [CrossRef]
- Freund, Y.; Seung, H.S.; Shamir, E.; Tishby, N. Selective sampling using the query by committee algorithm. Mach. Learn. 1997, 28, 133–168. [Google Scholar] [CrossRef]
- Vapnik, V.N.; Chervonenkis, A.Y. On the uniform convergence of relative frequencies of events to their probabilities. In Measures of Complexity; Springer: Cham, Switzerland, 2015; pp. 11–30. [Google Scholar]
- Dasgupta, S.; Kalai, A.T.; Monteleoni, C. Analysis of perceptron-based active learning. In Proceedings of the 18th Annual Conference on Learning Theory, COLT 2005, Bertinoro, Italy, 27–30 June 2005; Springer: Berlin/Heidelberg, Germany; pp. 249–263. [Google Scholar]
- Angluin, D. Queries and concept learning. Mach. Learn. 1988, 2, 319–342. [Google Scholar] [CrossRef]
- Baum, E.B.; Lang, K. Query learning can work poorly when a human oracle is used. In Proceedings of the International Joint Conference on Neural Networks, Baltimore, MD, USA, 7–11 June 1992; Volume 8, p. 8. [Google Scholar]
- Moskovitch, R.; Nissim, N.; Stopel, D.; Feher, C.; Englert, R.; Elovici, Y. Improving the detection of unknown computer worms activity using active learning. In Proceedings of the Annual Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2007; pp. 489–493. [Google Scholar]
- Thompson, C.A.; Califf, M.E.; Mooney, R.J. Active learning for natural language parsing and information extraction. In Proceedings of the ICML, Bled, Slovenia, 27–30 June 1999; pp. 406–414. [Google Scholar]
- Lewis, D.D.; Gale, W.A. A sequential algorithm for training text classifiers: Corrigendum and additional data In Acm Sigir Forum; ACM: New York, NY, USA, 1995; Volume 29, pp. 13–19. [Google Scholar]
- Wang, L.; Hu, X.; Yuan, B.; Lu, J. Active learning via query synthesis and nearest neighbour search. Neurocomputing 2015, 147, 426–434. [Google Scholar] [CrossRef]
- Sharma, M.; Bilgic, M. Evidence-based uncertainty sampling for active learning. Data Min. Knowl. Discov. 2017, 31, 164–202. [Google Scholar] [CrossRef]
- Scheffer, T.; Decomain, C.; Wrobel, S. Active hidden markov models for information extraction. In Proceedings of the International Symposium on Intelligent Data Analysis (IDA); Springer: Berlin/Heidelberg, Germany, 2001; pp. 309–318. [Google Scholar]
- Settles, B.; Craven, M. An analysis of active learning strategies for sequence labeling tasks. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 1070–1079. [Google Scholar]
- Schein, A.I.; Ungar, L.H. Active learning for logistic regression: An evaluation. Mach. Learn. 2007, 68, 235–265. [Google Scholar] [CrossRef]
- Tong, S.; Koller, D. Support vector machine active learning with applications to text classification. J. Mach. Learn. Res. 2001, 2, 45–66. [Google Scholar]
- Hernández-Lobato, J.M.; Adams, R. Probabilistic backpropagation for scalable learning of bayesian neural networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1861–1869. [Google Scholar]
- Fujii, A.; Inui, K.; Tokunaga, T.; Tanaka, H. Selective sampling for example-based word sense disambiguation. arXiv 1999, arXiv:cs/9910020. [Google Scholar]
- Seung, H.S.; Opper, M.; Sompolinsky, H. Query by committee. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 287–294. [Google Scholar]
- Abe, N. Query learning strategies using boosting and bagging. In Proceedings of the 15th International Conference on Machine Learning (ICML98), Madison, WI, USA, 24–27 July 1998; pp. 1–9. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Melville, P.; Yang, S.M.; Saar-Tsechansky, M.; Mooney, R. Active learning for probability estimation using Jensen-Shannon divergence. In Proceedings of the European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2005; pp. 268–279. [Google Scholar]
- Körner, C.; Wrobel, S. Multi-class ensemble-based active learning. In Proceedings of the European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; pp. 687–694. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Kremer, J.; Steenstrup Pedersen, K.; Igel, C. Active learning with support vector machines. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2014, 4, 313–326. [Google Scholar] [CrossRef]
- Schohn, G.; Cohn, D. Less is more: Active learning with support vector machines. In Proceedings of the ICML, Stanford, CA, USA, 29 June–2 July 2000; Volume 2, p. 6. [Google Scholar]
- Zhang, Y.; Lease, M.; Wallace, B. Active discriminative text representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Vezhnevets, A.; Buhmann, J.M.; Ferrari, V. Active learning for semantic segmentation with expected change. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 6–21 June 2012; pp. 3162–3169. [Google Scholar]
- Roy, N.; McCallum, A. Toward optimal active learning through sampling estimation of error reduction. In Proceedings of the International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Wu, Y.; Kozintsev, I.; Bouguet, J.Y.; Dulong, C. Sampling strategies for active learning in personal photo retrieval. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 529–532. [Google Scholar]
- Ienco, D.; Bifet, A.; Žliobaitė, I.; Pfahringer, B. Clustering based active learning for evolving data streams. In Proceedings of the International Conference on Discovery Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 79–93. [Google Scholar]
- Kang, J.; Ryu, K.R.; Kwon, H.C. Using cluster-based sampling to select initial training set for active learning in text classification. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2004; pp. 384–388. [Google Scholar]
- Brinker, K. Incorporating diversity in active learning with support vector machines. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 59–66. [Google Scholar]
- Xu, Z.; Akella, R.; Zhang, Y. Incorporating diversity and density in active learning for relevance feedback. In Proceedings of the European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2007; pp. 246–257. [Google Scholar]
- Osugi, T.; Kim, D.; Scott, S. Balancing exploration and exploitation: A new algorithm for active machine learning. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; 8p. [Google Scholar]
- Yin, C.; Qian, B.; Cao, S.; Li, X.; Wei, J.; Zheng, Q.; Davidson, I. Deep similarity-based batch mode active learning with exploration-exploitation. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 575–584. [Google Scholar]
- Huang, S.J.; Jin, R.; Zhou, Z.H. Active learning by querying informative and representative examples. Adv. Neural Inf. Process. Syst. 2010, 23, 892–900. [Google Scholar] [CrossRef] [PubMed]
- Cebron, N.; Berthold, M.R. Active learning for object classification: From exploration to exploitation. Data Min. Knowl. Discov. 2009, 18, 283–299. [Google Scholar] [CrossRef]
- Tharwat, A.; Schenck, W. Balancing Exploration and Exploitation: A novel active learner for imbalanced data. Knowl.-Based Syst. 2020, 210, 106500. [Google Scholar] [CrossRef]
- Tharwat, A.; Schenck, W. A Novel Low-Query-Budget Active Learner with Pseudo-Labels for Imbalanced Data. Mathematics 2022, 10, 1068. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Smeulders, A. Active learning using pre-clustering. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 79. [Google Scholar]
- Ebert, S.; Fritz, M.; Schiele, B. Ralf: A reinforced active learning formulation for object class recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3626–3633. [Google Scholar]
- Konyushkova, K.; Sznitman, R.; Fua, P. Learning active learning from data. Adv. Neural Inf. Process. Syst. 2017, 30, 4228–4238. [Google Scholar]
- Fang, M.; Li, Y.; Cohn, T. Learning how to active learn: A deep reinforcement learning approach. arXiv 2017, arXiv:1708.02383. [Google Scholar]
- Woodward, M.; Finn, C. Active one-shot learning. arXiv 2017, arXiv:1702.06559. [Google Scholar]
- Wassermann, S.; Cuvelier, T.; Casas, P. RAL-Improving stream-based active learning by reinforcement learning. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD) Workshop on Interactive Adaptive Learning (IAL), Würzburg, Germany, 16 September 2019. [Google Scholar]
- Baram, Y.; Yaniv, R.E.; Luz, K. Online choice of active learning algorithms. J. Mach. Learn. Res. 2004, 5, 255–291. [Google Scholar]
- Hsu, W.N.; Lin, H.T. Active learning by learning. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Chu, H.M.; Lin, H.T. Can active learning experience be transferred? In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 841–846. [Google Scholar]
- Frénay, B.; Hammer, B. Label-noise-tolerant classification for streaming data. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1748–1755. [Google Scholar]
- Donmez, P.; Carbonell, J.G. Proactive learning: Cost-sensitive active learning with multiple imperfect oracles. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 619–628. [Google Scholar]
- Yan, Y.; Rosales, R.; Fung, G.; Dy, J.G. Active learning from crowds. In Proceedings of the ICML, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Shu, Z.; Sheng, V.S.; Li, J. Learning from crowds with active learning and self-healing. Neural Comput. Appl. 2018, 30, 2883–2894. [Google Scholar] [CrossRef]
- Sheng, V.S.; Provost, F.; Ipeirotis, P.G. Get another label? improving data quality and data mining using multiple, noisy labelers. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 614–622. [Google Scholar]
- Fang, M.; Zhu, X. Active learning with uncertain labeling knowledge. Pattern Recognit. Lett. 2014, 43, 98–108. [Google Scholar] [CrossRef]
- Tuia, D.; Munoz-Mari, J. Learning user’s confidence for active learning. IEEE Trans. Geosci. Remote Sens. 2012, 51, 872–880. [Google Scholar] [CrossRef]
- Younesian, T.; Zhao, Z.; Ghiassi, A.; Birke, R.; Chen, L.Y. QActor: Active Learning on Noisy Labels. In Proceedings of the Asian Conference on Machine Learning, Virtual, 17–19 November 2021; pp. 548–563. [Google Scholar]
- Zhang, L.; Chen, C.; Bu, J.; Cai, D.; He, X.; Huang, T.S. Active learning based on locally linear reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2026–2038. [Google Scholar] [CrossRef]
- Elwell, R.; Polikar, R. Incremental learning of concept drift in nonstationary environments. IEEE Trans. Neural Netw. 2011, 22, 1517–1531. [Google Scholar] [CrossRef] [PubMed]
- Vaquet, V.; Hammer, B. Balanced SAM-kNN: Online Learning with Heterogeneous Drift and Imbalanced Data. In Proceedings of the International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2020; pp. 850–862. [Google Scholar]
- Wang, S.; Minku, L.L.; Yao, X. Dealing with Multiple Classes in Online Class Imbalance Learning. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 2118–2124. [Google Scholar]
- Gao, J.; Fan, W.; Han, J.; Yu, P.S. A general framework for mining concept-drifting data streams with skewed distributions. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; pp. 3–14. [Google Scholar]
- Chen, S.; He, H. SERA: Selectively recursive approach towards nonstationary imbalanced stream data mining. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 522–529. [Google Scholar]
- Zhang, Y.; Zhao, P.; Niu, S.; Wu, Q.; Cao, J.; Huang, J.; Tan, M. Online adaptive asymmetric active learning with limited budgets. IEEE Trans. Knowl. Data Eng. 2019, 33, 2680–2692. [Google Scholar] [CrossRef]
- Žliobaitė, I.; Bifet, A.; Pfahringer, B.; Holmes, G. Active learning with drifting streaming data. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 27–39. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, H.; Ding, Z.; Liu, Q.; Zhu, C. A comprehensive active learning method for multiclass imbalanced data streams with concept drift. Knowl.-Based Syst. 2021, 215, 106778. [Google Scholar] [CrossRef]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Chen, X.; Wang, X. A survey of deep active learning. arXiv 2020, arXiv:2009.00236. [Google Scholar] [CrossRef]
- Tomanek, K.; Hahn, U. A comparison of models for cost-sensitive active learning. In Proceedings of the Coling 2010: Posters, Beijing, China, 23–27 August 2010; pp. 1247–1255. [Google Scholar]
- Settles, B.; Craven, M.; Friedland, L. Active learning with real annotation costs. In Proceedings of the NIPS Workshop on Cost-Sensitive Learning, Vancouver, BC, Canada, 13 December 2008; Volume 1. [Google Scholar]
- Margineantu, D.D. Active cost-sensitive learning. In Proceedings of the IJCAI, Edinburgh, Scotland, 30 July–5 August 2005; Volume 5, pp. 1622–1623. [Google Scholar]
- Kapoor, A.; Horvitz, E.; Basu, S. Selective Supervision: Guiding Supervised Learning with Decision-Theoretic Active Learning. In Proceedings of the IJCAI, Hyderabad, India, 6–12 January 2007; Volume 7, pp. 877–882. [Google Scholar]
- Kee, S.; Del Castillo, E.; Runger, G. Query-by-committee improvement with diversity and density in batch active learning. Inf. Sci. 2018, 454, 401–418. [Google Scholar] [CrossRef]
- Yin, L.; Wang, H.; Fan, W.; Kou, L.; Lin, T.; Xiao, Y. Incorporate active learning to semi-supervised industrial fault classification. J. Process. Control. 2019, 78, 88–97. [Google Scholar] [CrossRef]
- He, G.; Li, Y.; Zhao, W. An uncertainty and density based active semi-supervised learning scheme for positive unlabeled multivariate time series classification. Knowl.-Based Syst. 2017, 124, 80–92. [Google Scholar] [CrossRef]
- Wang, Z.; Du, B.; Zhang, L.; Zhang, L. A batch-mode active learning framework by querying discriminative and representative samples for hyperspectral image classification. Neurocomputing 2016, 179, 88–100. [Google Scholar] [CrossRef]
- Straat, M.; Abadi, F.; Göpfert, C.; Hammer, B.; Biehl, M. Statistical mechanics of on-line learning under concept drift. Entropy 2018, 20, 775. [Google Scholar] [CrossRef] [PubMed]
- Lindstrom, P.; Mac Namee, B.; Delany, S.J. Drift detection using uncertainty distribution divergence. Evol. Syst. 2013, 4, 13–25. [Google Scholar] [CrossRef]
- Bifet, A.; Gavalda, R. Learning from time-changing data with adaptive windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; pp. 443–448. [Google Scholar]
- Gama, J.; Medas, P.; Castillo, G.; Rodrigues, P. Learning with drift detection. In Proceedings of the Brazilian Symposium on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2004; pp. 286–295. [Google Scholar]
- Syed, N.A.; Liu, H.; Sung, K.K. Handling concept drifts in incremental learning with support vector machines. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 317–321. [Google Scholar]
- Kolter, J.Z.; Maloof, M.A. Dynamic weighted majority: An ensemble method for drifting concepts. J. Mach. Learn. Res. 2007, 8, 2755–2790. [Google Scholar]
- Brinker, K. On active learning in multi-label classification. In From Data and Information Analysis to Knowledge Engineering; Springer: Berlin/Heidelberg, Germany, 2006; pp. 206–213. [Google Scholar]
- Wu, J.; Sheng, V.S.; Zhang, J.; Li, H.; Dadakova, T.; Swisher, C.L.; Cui, Z.; Zhao, P. Multi-label active learning algorithms for image classification: Overview and future promise. Acm Comput. Surv. (CSUR) 2020, 53, 1–35. [Google Scholar] [CrossRef] [PubMed]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Mining multi-label data. In Data Mining and Knowledge Discovery Handbook; Springer: Boston, MA, USA, 2009; pp. 667–685. [Google Scholar]
- Reyes, O.; Morell, C.; Ventura, S. Effective active learning strategy for multi-label learning. Neurocomputing 2018, 273, 494–508. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, H.; Hovy, E.; Ma, M. Confidence-based stopping criteria for active learning for data annotation. Acm Trans. Speech Lang. Process. (TSLP) 2010, 6, 1–24. [Google Scholar] [CrossRef]
- Li, M.; Sethi, I.K. Confidence-based active learning. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1251–1261. [Google Scholar]
- Nguyen, V.L.; Shaker, M.H.; Hüllermeier, E. How to measure uncertainty in uncertainty sampling for active learning. Mach. Learn. 2022, 111, 89–122. [Google Scholar] [CrossRef]
- Karamcheti, S.; Krishna, R.; Fei-Fei, L.; Manning, C.D. Mind your outliers! investigating the negative impact of outliers on active learning for visual question answering. arXiv 2021, arXiv:2107.02331. [Google Scholar]
- Klidbary, S.H.; Shouraki, S.B.; Ghaffari, A.; Kourabbaslou, S.S. Outlier robust fuzzy active learning method (ALM). In Proceedings of the 2017 7th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 26–27 October 2017; pp. 347–352. [Google Scholar]
- Napierala, K.; Stefanowski, J. Types of minority class examples and their influence on learning classifiers from imbalanced data. J. Intell. Inf. Syst. 2016, 46, 563–597. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar]
- Wang, K.; Zhang, D.; Li, Y.; Zhang, R.; Lin, L. Cost-effective active learning for deep image classification. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2591–2600. [Google Scholar] [CrossRef]
- Tran, T.; Do, T.T.; Reid, I.; Carneiro, G. Bayesian generative active deep learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6295–6304. [Google Scholar]
- Guo, Y.; Schuurmans, D. Discriminative batch mode active learning. Adv. Neural Inf. Process. Syst. 2007, 20, 593–600. [Google Scholar]
- Tomanek, K.; Wermter, J.; Hahn, U. An approach to text corpus construction which cuts annotation costs and maintains reusability of annotated data. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 486–495. [Google Scholar]
- Vijayanarasimhan, S.; Grauman, K. Large-scale live active learning: Training object detectors with crawled data and crowds. Int. J. Comput. Vis. 2014, 108, 97–114. [Google Scholar] [CrossRef]
- Long, C.; Hua, G.; Kapoor, A. Active visual recognition with expertise estimation in crowdsourcing. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3000–3007. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhang, J.; Wu, X.; Shengs, V.S. Active learning with imbalanced multiple noisy labeling. IEEE Trans. Cybern. 2014, 45, 1095–1107. [Google Scholar] [CrossRef]
- Siméoni, O.; Budnik, M.; Avrithis, Y.; Gravier, G. Rethinking deep active learning: Using unlabeled data at model training. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 1220–1227. [Google Scholar]
- Hossain, H.S.; Roy, N. Active deep learning for activity recognition with context aware annotator selection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1862–1870. [Google Scholar]
- Zhdanov, F. Diverse mini-batch active learning. arXiv 2019, arXiv:1901.05954. [Google Scholar]
- Sener, O.; Savarese, S. Active learning for convolutional neural networks: A core-set approach. arXiv 2017, arXiv:1708.00489. [Google Scholar]
- Wang, D.; Shang, Y. A new active labeling method for deep learning. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 112–119. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Bayesian convolutional neural networks with Bernoulli approximate variational inference. arXiv 2015, arXiv:1506.02158. [Google Scholar]
- Gal, Y.; Islam, R.; Ghahramani, Z. Deep bayesian active learning with image data. In Proceedings of the International Conference on Machine Learning, 6–11 August 2017; pp. 1183–1192. [Google Scholar]
- Kirsch, A.; Van Amersfoort, J.; Gal, Y. Batchbald: Efficient and diverse batch acquisition for deep bayesian active learning. Adv. Neural Inf. Process. Syst. 2019, 32, 7026–7037. [Google Scholar]
- Boney, R.; Ilin, A. Semi-supervised and active few-shot learning with prototypical networks. arXiv 2017, arXiv:1711.10856. [Google Scholar]
- Boney, R.; Ilin, A. Active one-shot learning with prototypical networks. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2019; pp. 583–588. [Google Scholar]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Attribute-based classification for zero-shot visual object categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 453–465. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.; Padmanabhan, B. On active learning for data acquisition. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi, Japan, 9–12 December 2002; pp. 562–569. [Google Scholar]
- Greiner, R.; Grove, A.J.; Roth, D. Learning cost-sensitive active classifiers. Artif. Intell. 2002, 139, 137–174. [Google Scholar] [CrossRef]
- Shim, J.; Kang, S.; Cho, S. Active inspection for cost-effective fault prediction in manufacturing process. J. Process. Control. 2021, 105, 250–258. [Google Scholar] [CrossRef]
- Jin, Y. A comprehensive survey of fitness approximation in evolutionary computation. Soft Comput. 2005, 9, 3–12. [Google Scholar] [CrossRef]
- Lye, K.O.; Mishra, S.; Ray, D.; Chandrashekar, P. Iterative surrogate model optimization (ISMO): An active learning algorithm for PDE constrained optimization with deep neural networks. Comput. Methods Appl. Mech. Eng. 2021, 374, 113575. [Google Scholar] [CrossRef]
- Karunakaran, D. Active Learning Methods for Dynamic Job Shop Scheduling Using Genetic Programming under Uncertain Environment. Ph.D. Dissertation, Open Access Te Herenga Waka-Victoria University of Wellington, Wellington, New Zealand, 2019. [Google Scholar]
- Zemmal, N.; Azizi, N.; Sellami, M.; Cheriguene, S.; Ziani, A.; AlDwairi, M.; Dendani, N. Particle swarm optimization based swarm intelligence for active learning improvement: Application on medical data classification. Cogn. Comput. 2020, 12, 991–1010. [Google Scholar] [CrossRef]
- Zemmal, N.; Azizi, N.; Sellami, M.; Cheriguene, S.; Ziani, A. A new hybrid system combining active learning and particle swarm optimisation for medical data classification. Int. J. Bio-Inspired Comput. 2021, 18, 59–68. [Google Scholar] [CrossRef]
- Lookman, T.; Balachandran, P.V.; Xue, D.; Yuan, R. Active learning in materials science with emphasis on adaptive sampling using uncertainties for targeted design. NPJ Comput. Mater. 2019, 5, 1–17. [Google Scholar] [CrossRef]
- Jinnouchi, R.; Miwa, K.; Karsai, F.; Kresse, G.; Asahi, R. On-the-fly active learning of interatomic potentials for large-scale atomistic simulations. J. Phys. Chem. Lett. 2020, 11, 6946–6955. [Google Scholar] [CrossRef]
- Chabanet, S.; El-Haouzi, H.B.; Thomas, P. Coupling digital simulation and machine learning metamodel through an active learning approach in Industry 4.0 context. Comput. Ind. 2021, 133, 103529. [Google Scholar] [CrossRef]
- Diaw, A.; Barros, K.; Haack, J.; Junghans, C.; Keenan, B.; Li, Y.; Livescu, D.; Lubbers, N.; McKerns, M.; Pavel, R.; et al. Multiscale simulation of plasma flows using active learning. Phys. Rev. E 2020, 102, 023310. [Google Scholar] [CrossRef] [PubMed]
- Hodapp, M.; Shapeev, A. In operando active learning of interatomic interaction during large-scale simulations. Mach. Learn. Sci. Technol. 2020, 1, 045005. [Google Scholar] [CrossRef]
- Smith, J.S.; Nebgen, B.; Lubbers, N.; Isayev, O.; Roitberg, A.E. Less is more: Sampling chemical space with active learning. J. Chem. Phys. 2018, 148, 241733. [Google Scholar] [CrossRef]
- Ahmed, W.; Jackson, J.M. Emerging Nanotechnologies for Manufacturing; Elsevier William Andrew: Waltham, MA, USA, 2015. [Google Scholar]
- Chen, C.T.; Gu, G.X. Generative deep neural networks for inverse materials design using backpropagation and active learning. Adv. Sci. 2020, 7, 1902607. [Google Scholar] [CrossRef]
- Zhang, C.; Amar, Y.; Cao, L.; Lapkin, A.A. Solvent selection for Mitsunobu reaction driven by an active learning surrogate model. Org. Process. Res. Dev. 2020, 24, 2864–2873. [Google Scholar] [CrossRef]
- Zhang, Y.; Wen, C.; Wang, C.; Antonov, S.; Xue, D.; Bai, Y.; Su, Y. Phase prediction in high entropy alloys with a rational selection of materials descriptors and machine learning models. Acta Mater. 2020, 185, 528–539. [Google Scholar] [CrossRef]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Tur, G.; Hakkani-Tür, D.; Schapire, R.E. Combining active and semi-supervised learning for spoken language understanding. Speech Commun. 2005, 45, 171–186. [Google Scholar] [CrossRef]
- Zhu, X.; Lafferty, J.; Ghahramani, Z. Combining active learning and semi-supervised learning using gaussian fields and harmonic functions. In Proceedings of the ICML 2003 Workshop on the Continuum from Labeled to Unlabeled Data in Machine Learning and Data Mining, Washington, DC, USA, 21–24 August 2003; Volume 3. [Google Scholar]
- Shen, P.; Li, C.; Zhang, Z. Distributed active learning. IEEE Access 2016, 4, 2572–2579. [Google Scholar] [CrossRef]
- Chen, X.; Wujek, B. Autodal: Distributed active learning with automatic hyperparameter selection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3537–3544. [Google Scholar]
- Huang, S.J.; Zong, C.C.; Ning, K.P.; Ye, H.B. Asynchronous Active Learning with Distributed Label Querying. In Proceedings of the International Joint Conferences on Artificial Intelligence Organization (IJCAI2021), Montrea, QC, Canada, 19–27 August 2021; pp. 2570–2576. [Google Scholar]
- Baxter, J. A Bayesian/information theoretic model of learning to learn via multiple task sampling. Mach. Learn. 1997, 28, 7–39. [Google Scholar] [CrossRef]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Zhang, Y. Multi-task active learning with output constraints. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Saha, A.; Rai, P.; Daumé, H., III; Venkatasubramanian, S. Active online multitask learning. In Proceedings of the ICML 2010 Workshop on Budget Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Ghai, B.; Liao, Q.V.; Zhang, Y.; Bellamy, R.; Mueller, K. Explainable active learning (xal) toward ai explanations as interfaces for machine teachers. Proc. ACM Hum.-Comput. Interact. 2021, 4, 1–28. [Google Scholar] [CrossRef]
- Phillips, R.; Chang, K.H.; Friedler, S.A. Interpretable active learning. In Proceedings of the Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; pp. 49–61. [Google Scholar]
- Zhu, X.; Zhang, P.; Lin, X.; Shi, Y. Active learning from stream data using optimal weight classifier ensemble. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40, 1607–1621. [Google Scholar]
- Tran, V.C.; Nguyen, N.T.; Fujita, H.; Hoang, D.T.; Hwang, D. A combination of active learning and self-learning for named entity recognition on twitter using conditional random fields. Knowl.-Based Syst. 2017, 132, 179–187. [Google Scholar] [CrossRef]
- Chen, Y.; Lasko, T.A.; Mei, Q.; Denny, J.C.; Xu, H. A study of active learning methods for named entity recognition in clinical text. J. Biomed. Inform. 2015, 58, 11–18. [Google Scholar] [CrossRef]
- Aldoğan, D.; Yaslan, Y. A comparison study on active learning integrated ensemble approaches in sentiment analysis. Comput. Electr. Eng. 2017, 57, 311–323. [Google Scholar] [CrossRef]
- Zhou, S.; Chen, Q.; Wang, X. Active deep learning method for semi-supervised sentiment classification. Neurocomputing 2013, 120, 536–546. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, P.; Guo, L. Mining multi-label data streams using ensemble-based active learning. In Proceedings of the 2012 SIAM International Conference on Data Mining, Anaheim, CA, USA, 26–28 April 2012; pp. 1131–1140. [Google Scholar]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef]
- Casanova, A.; Pinheiro, P.O.; Rostamzadeh, N.; Pal, C.J. Reinforced active learning for image segmentation. arXiv 2020, arXiv:2002.06583. [Google Scholar]
- Mahapatra, D.; Bozorgtabar, B.; Thiran, J.P.; Reyes, M. Efficient active learning for image classification and segmentation using a sample selection and conditional generative adversarial network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain; Springer: Berlin/Heidelberg, Germany, 2018; pp. 580–588. [Google Scholar]
- Nath, V.; Yang, D.; Landman, B.A.; Xu, D.; Roth, H.R. Diminishing uncertainty within the training pool: Active learning for medical image segmentation. IEEE Trans. Med. Imaging 2020, 40, 2534–2547. [Google Scholar] [CrossRef]
- Bietti, A. Active Learning for Object Detection on Satellite Images. 2012. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=31243e163e02eb151e5564ae8c01dcd5c7dc225a (accessed on 28 December 2022).
- Brust, C.A.; Käding, C.; Denzler, J. Active learning for deep object detection. arXiv 2018, arXiv:1809.09875. [Google Scholar]
- Kao, C.C.; Lee, T.Y.; Sen, P.; Liu, M.Y. Localization-aware active learning for object detection. In Proceedings of the Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018; pp. 506–522. [Google Scholar]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.F.; Emery, W.J. Active learning methods for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2218–2232. [Google Scholar] [CrossRef]
- Liao, H.; Chen, L.; Song, Y.; Ming, H. Visualization-based active learning for video annotation. IEEE Trans. Multimed. 2016, 18, 2196–2205. [Google Scholar] [CrossRef]
- Mohamad, S.; Sayed-Mouchaweh, M.; Bouchachia, A. Online active learning for human activity recognition from sensory data streams. Neurocomputing 2020, 390, 341–358. [Google Scholar] [CrossRef]
- Hossain, H.S.; Khan, M.A.A.H.; Roy, N. Active learning enabled activity recognition. Pervasive Mob. Comput. 2017, 38, 312–330. [Google Scholar] [CrossRef]
- Reker, D.; Schneider, G. Active-learning strategies in computer-assisted drug discovery. Drug Discov. Today 2015, 20, 458–465. [Google Scholar] [CrossRef]
- Mohamed, T.P.; Carbonell, J.G.; Ganapathiraju, M.K. Active learning for human protein-protein interaction prediction. BMC Bioinform. 2010, 11, S57. [Google Scholar] [CrossRef]
- Osmanbeyoglu, H.U.; Wehner, J.A.; Carbonell, J.G.; K Ganapathiraju, M. Active Learning for Membrane Protein Structure Prediction. BMC Bioinf. 2010, 11 (Suppl. 1), S58. [Google Scholar] [CrossRef]
- Warmuth, M.K.; Rätsch, G.; Mathieson, M.; Liao, J.; Lemmen, C. Active Learning in the Drug Discovery Process. In Proceedings of the NIPS, Vancouver, BC, Canada, 3–8 December 2001; pp. 1449–1456. [Google Scholar]
- Figueroa, R.L.; Zeng-Treitler, Q.; Ngo, L.H.; Goryachev, S.; Wiechmann, E.P. Active learning for clinical text classification: Is it better than random sampling? J. Am. Med. Inform. Assoc. 2012, 19, 809–816. [Google Scholar] [CrossRef]
- Yang, Y.; Li, Y.; Yang, J.; Wen, J. Dissimilarity-based active learning for embedded weed identification. Turk. J. Agric. For. 2022, 46, 390–401. [Google Scholar] [CrossRef]
- Yang, J.; Lan, G.; Li, Y.; Gong, Y.; Zhang, Z.; Ercisli, S. Data quality assessment and analysis for pest identification in smart agriculture. Comput. Electr. Eng. 2022, 103, 108322. [Google Scholar] [CrossRef]
- Sheikh, R.; Milioto, A.; Lottes, P.; Stachniss, C.; Bennewitz, M.; Schultz, T. Gradient and log-based active learning for semantic segmentation of crop and weed for agricultural robots. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 1350–1356. [Google Scholar]
- Chandra, A.L.; Desai, S.V.; Balasubramanian, V.N.; Ninomiya, S.; Guo, W. Active learning with point supervision for cost-effective panicle detection in cereal crops. Plant Methods 2020, 16, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Peng, P.; Zhang, W.; Zhang, Y.; Xu, Y.; Wang, H.; Zhang, H. Cost sensitive active learning using bidirectional gated recurrent neural networks for imbalanced fault diagnosis. Neurocomputing 2020, 407, 232–245. [Google Scholar] [CrossRef]
- Agarwal, D.; Srivastava, P.; Martin-del Campo, S.; Natarajan, B.; Srinivasan, B. Addressing uncertainties within active learning for industrial IoT. In Proceedings of the 2021 IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 14 June–31 July 2021; pp. 557–562. [Google Scholar]
- Rahman, M.; Khan, A.; Anowar, S.; Al-Imran, M.; Verma, R.; Kumar, D.; Kobayashi, K.; Alam, S. Leveraging Industry 4.0—Deep Learning, Surrogate Model and Transfer Learning with Uncertainty Quantification Incorporated into Digital Twin for Nuclear System. arXiv 2022, arXiv:2210.00074. [Google Scholar]
- El-Hasnony, I.M.; Elzeki, O.M.; Alshehri, A.; Salem, H. Multi-label active learning-based machine learning model for heart disease prediction. Sensors 2022, 22, 1184. [Google Scholar] [CrossRef]
- Yadav, C.S.; Pradhan, M.K.; Gangadharan, S.M.P.; Chaudhary, J.K.; Singh, J.; Khan, A.A.; Haq, M.A.; Alhussen, A.; Wechtaisong, C.; Imran, H.; et al. Multi-Class Pixel Certainty Active Learning Model for Classification of Land Cover Classes Using Hyperspectral Imagery. Electronics 2022, 11, 2799. [Google Scholar] [CrossRef]
- Zhao, G.; Dougherty, E.; Yoon, B.J.; Alexander, F.; Qian, X. Efficient active learning for Gaussian process classification by error reduction. Adv. Neural Inf. Process. Syst. 2021, 34, 9734–9746. [Google Scholar]
- Yao, L.; Wan, Y.; Ni, H.; Xu, B. Action unit classification for facial expression recognition using active learning and SVM. Multimed. Tools Appl. 2021, 80, 24287–24301. [Google Scholar] [CrossRef]
- Karlos, S.; Aridas, C.; Kanas, V.G.; Kotsiantis, S. Classification of acoustical signals by combining active learning strategies with semi-supervised learning schemes. Neural Comput. Appl. 2021, 35, 3–20. [Google Scholar] [CrossRef]
- Xu, M.; Zhao, Q.; Jia, S. Multiview Spatial-Spectral Active Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Wu, X.; Chen, C.; Zhong, M.; Wang, J.; Shi, J. COVID-AL: The diagnosis of COVID-19 with deep active learning. Med. Image Anal. 2021, 68, 101913. [Google Scholar] [CrossRef] [PubMed]
- Al-Tamimi, A.K.; Bani-Isaa, E.; Al-Alami, A. Active learning for Arabic text classification. In Proceedings of the 2021 International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, 17–18 March 2021; pp. 123–126. [Google Scholar]
- Shahraki, A.; Abbasi, M.; Taherkordi, A.; Jurcut, A.D. Active learning for network traffic classification: A technical study. IEEE Trans. Cogn. Commun. Netw. 2021, 8, 422–439. [Google Scholar] [CrossRef]
- Liu, Q.; Zhu, Y.; Liu, Z.; Zhang, Y.; Wu, S. Deep Active Learning for Text Classification with Diverse Interpretations. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Online, 1–5 November 2021; pp. 3263–3267. [Google Scholar]
- Prabhu, S.; Mohamed, M.; Misra, H. Multi-class text classification using BERT-based active learning. arXiv 2021, arXiv:2104.14289. [Google Scholar]
- Cao, X.; Yao, J.; Xu, Z.; Meng, D. Hyperspectral image classification with convolutional neural network and active learning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4604–4616. [Google Scholar] [CrossRef]
- Rodríguez-Pérez, R.; Miljković, F.; Bajorath, J. Assessing the information content of structural and protein–ligand interaction representations for the classification of kinase inhibitor binding modes via machine learning and active learning. J. Cheminform. 2020, 12, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Sinha, S.; Ebrahimi, S.; Darrell, T. Variational adversarial active learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5972–5981. [Google Scholar]
- Danka, T.; Horvath, P. modAL: A modular active learning framework for Python. arXiv 2018, arXiv:1805.00979. [Google Scholar]
- Tang, Y.P.; Li, G.X.; Huang, S.J. ALiPy: Active learning in python. arXiv 2019, arXiv:1901.03802. [Google Scholar]
- Yang, Y.Y.; Lee, S.C.; Chung, Y.A.; Wu, T.E.; Chen, S.A.; Lin, H.T. libact: Pool-based active learning in python. arXiv 2017, arXiv:1710.00379. [Google Scholar]
- Lin, B.Y.; Lee, D.H.; Xu, F.F.; Lan, O.; Ren, X. AlpacaTag: An active learning-based crowd annotation framework for sequence tagging. In Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Yu, H.; Yang, X.; Zheng, S.; Sun, C. Active learning from imbalanced data: A solution of online weighted extreme learning machine. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1088–1103. [Google Scholar] [CrossRef]
- Hand, D.J.; Till, R.J. A simple generalisation of the area under the ROC curve for multiple class classification problems. Mach. Learn. 2001, 45, 171–186. [Google Scholar] [CrossRef]









| Notation | Meaning | Notation | Meaning |
|---|---|---|---|
| Labeled data | Unlabeled data | ||
| No. of labeled points | No. of unlabeled points | ||
| The ith data point | Label of | ||
| Q | Query budget | d | No. of dimensions of the instance space |
| The selected/queried point | The label of | ||
| Y | Label space | X | Feature space |
| Hypotheses space | L | Loss function | |
| R or | out-of-sample error (or risk) | or | In-sample error (or empirical risk) |
| h | Learning model (or hypothesis) | Joint distribution of X and Y | |
| Size of the hypotheses space | Small number | ||
| u | Utility function | Utility score of | |
| Utility function (information-based) | Utility function (representation-based) |
| ML | Optimization | Simulation | DoE | |
|---|---|---|---|---|
| Simulate (search for) | Target fn. | Objective/fitness fn. | Real-world process | Experiment/process |
| Goal | Find the optimal learning model that trained on training data and generalizes well to unseen data | Find optimal solution | Calibration: find optimal parameter’s combinations | Find relationship between input and output parameters in a process |
| AL is used to | Reduce no. labeled points | Reduce no. of fitness evaluations | Reduce no. of evaluated parameters | Reduce no. of experiments |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tharwat, A.; Schenck, W. A Survey on Active Learning: State-of-the-Art, Practical Challenges and Research Directions. Mathematics 2023, 11, 820. https://doi.org/10.3390/math11040820
Tharwat A, Schenck W. A Survey on Active Learning: State-of-the-Art, Practical Challenges and Research Directions. Mathematics. 2023; 11(4):820. https://doi.org/10.3390/math11040820
Chicago/Turabian StyleTharwat, Alaa, and Wolfram Schenck. 2023. "A Survey on Active Learning: State-of-the-Art, Practical Challenges and Research Directions" Mathematics 11, no. 4: 820. https://doi.org/10.3390/math11040820
APA StyleTharwat, A., & Schenck, W. (2023). A Survey on Active Learning: State-of-the-Art, Practical Challenges and Research Directions. Mathematics, 11(4), 820. https://doi.org/10.3390/math11040820