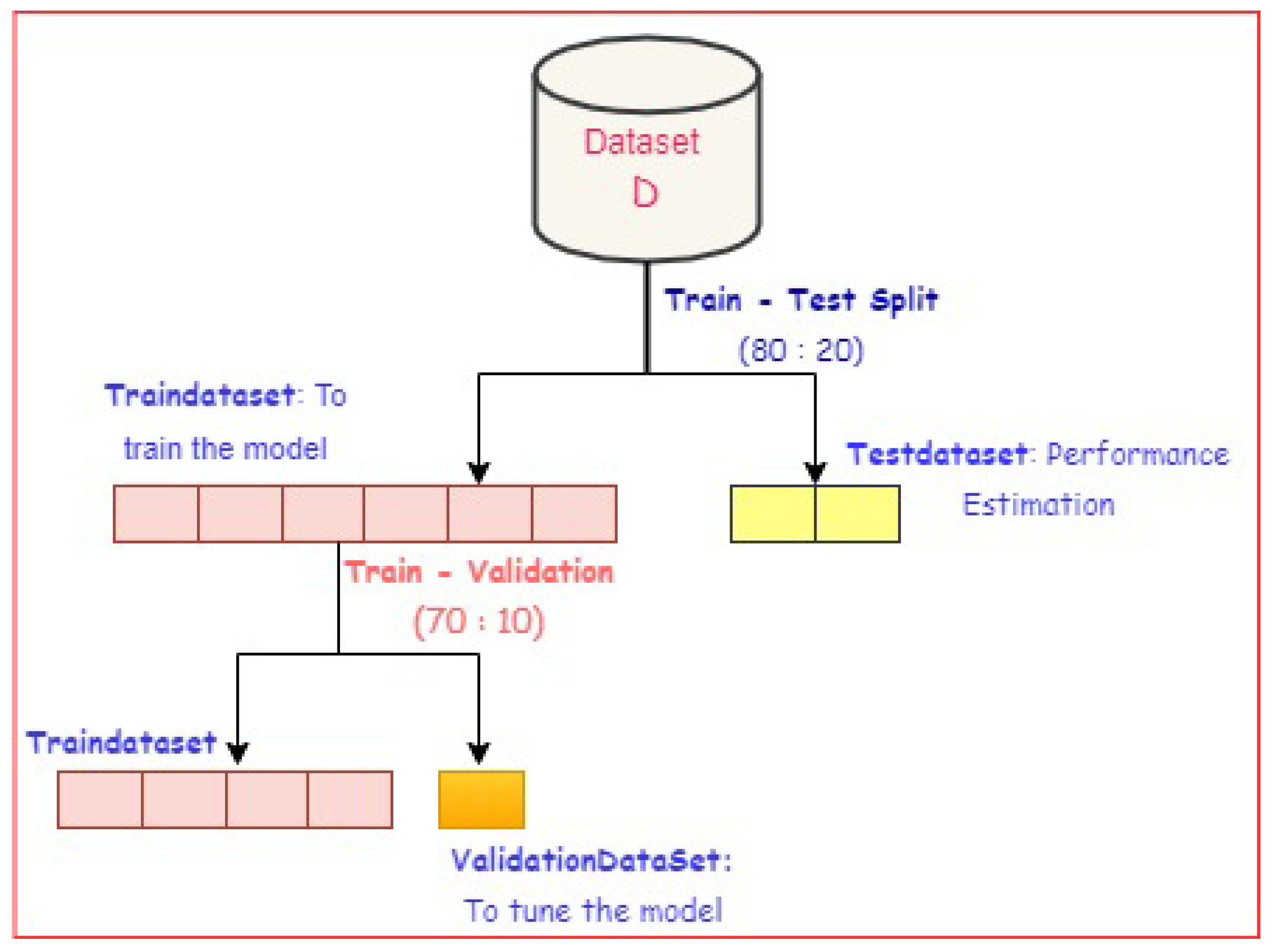
3.1. Deep Learning Using Transfer Learning
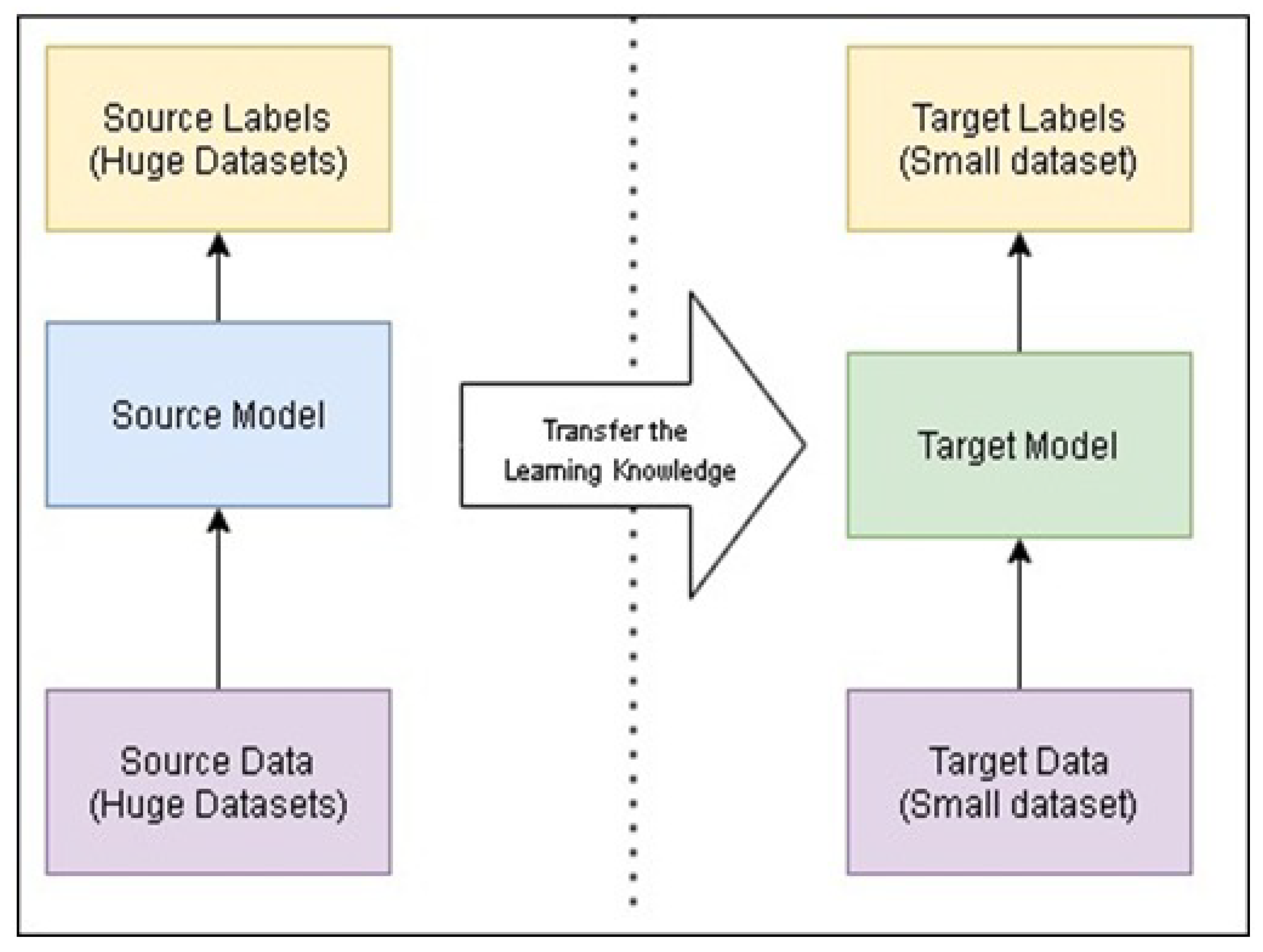
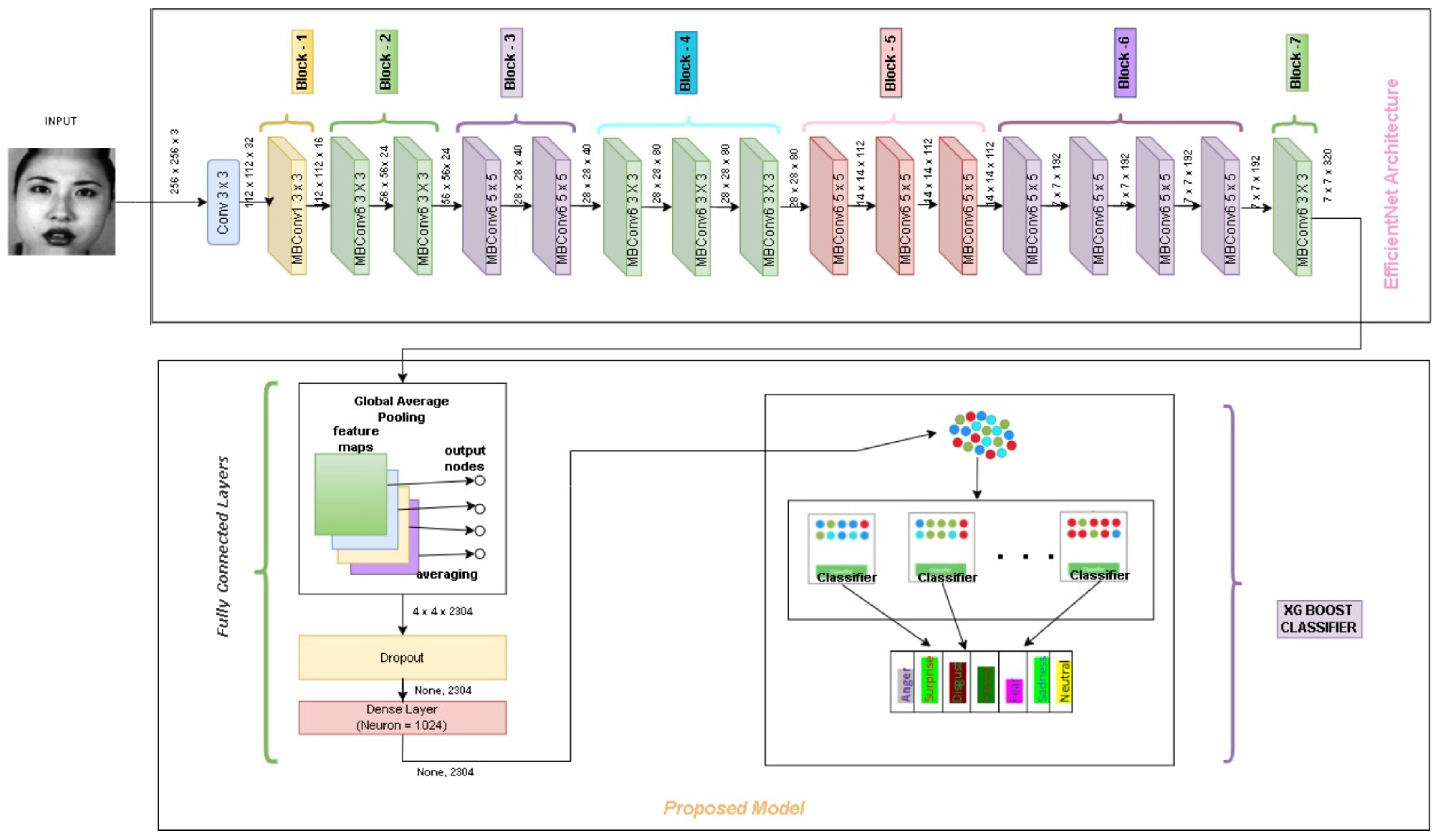
Reusing a model that has already been trained to solve a new issue is called transfer learning. Transfer learning has a number of advantages, but its major ones are reducing training time, improving neural network performance, and not requiring a lot of data. To the pre-trained model (EfficientNet), fully connected layers, namely global average pooling, dropout, and dense layer, are added. Lastly, to the pre-trained model, we added XGBoost for the classification.
FER is also done through pre-trained deep neural frameworks using appropriate Transfer Learning. Mahendran [
30] has the learning process in frameworks such as CNN. The visualization reveals preliminary features from input images from the first layer. The next layer identifies the complex features like texture or shape. So the same mechanism goes on towards identifying the complex features. Transfer learning is primarily advantageous because it is difficult to train a DCNN from scratch. Instead of reinventing the wheel, we will use the pre-trained weights and fine-tune the model for FER. Employing TL for FER provides promising results as well.
A DCNN model (EFficientNet) pre-trained with a large dataset with 1000 classes (e.g., ImageNet) is well suited for FER.
Figure 1 shows the general architecture of transfer learning. Here, the foundation of the convolutional is similar to that of pre-trained DCNN by excluding the classification stage. The existing classifier part in the model is replaced by newly added fully connected layers and a classifier. Overall, the module consists of a Convolutional Base to extract feature extraction, fully connected layers for fine-tuning the model, and an XGBoost Classifier.
EfficientNets is a collection of models (named as EfficientNet-B0 to B7). They are derived by compound scaling up the baseline network EfficientNet-B0. The benefit of EfficientNets manifests itself in two ways. First, it offers high accuracy. Second, it enhances the performance of the model by reducing the dimensionality and floating-point computational cost. Compounding scaling is used to produce various versions of EfficientNet. Compound Scaling refers to the utilization of a weighted scale containing three interconnected hyperparameters of the model (stated in Equation (
1)), namely depth
d, width w and resolution
r defined as:
where
A,
B and
are the constants that defines the resolution of the network.
Initially, the compound coefficient
∅ is set to 1, which defines the base compound configuration, EfficientNetB0. The same configuration is used in the grid search, for optimizing the co-efficients
A,
B and
such that:
where
A ≥ 1,
B≥ 1,
1
We achieved the optimal values for
A,
B and
as 1.2, 1.1 and 1.15 respectively, under the constraints stated in of (
2). If we change the value of
∅ in Equation (
1), the scaled versions of EfficientNet-B1 to B7 will be achieved. EfficientNet-B0 baseline architecture is used for feature extraction. The EfficientNet-B0 architecture consists of mainly 3 modules, the Stem, the Blocks and the Head.
Stem: Stem has a convolutional Layer, (3 × 3) with kernel size, Batch normalization Layer, and a Swish activation. These 3 are integrated.
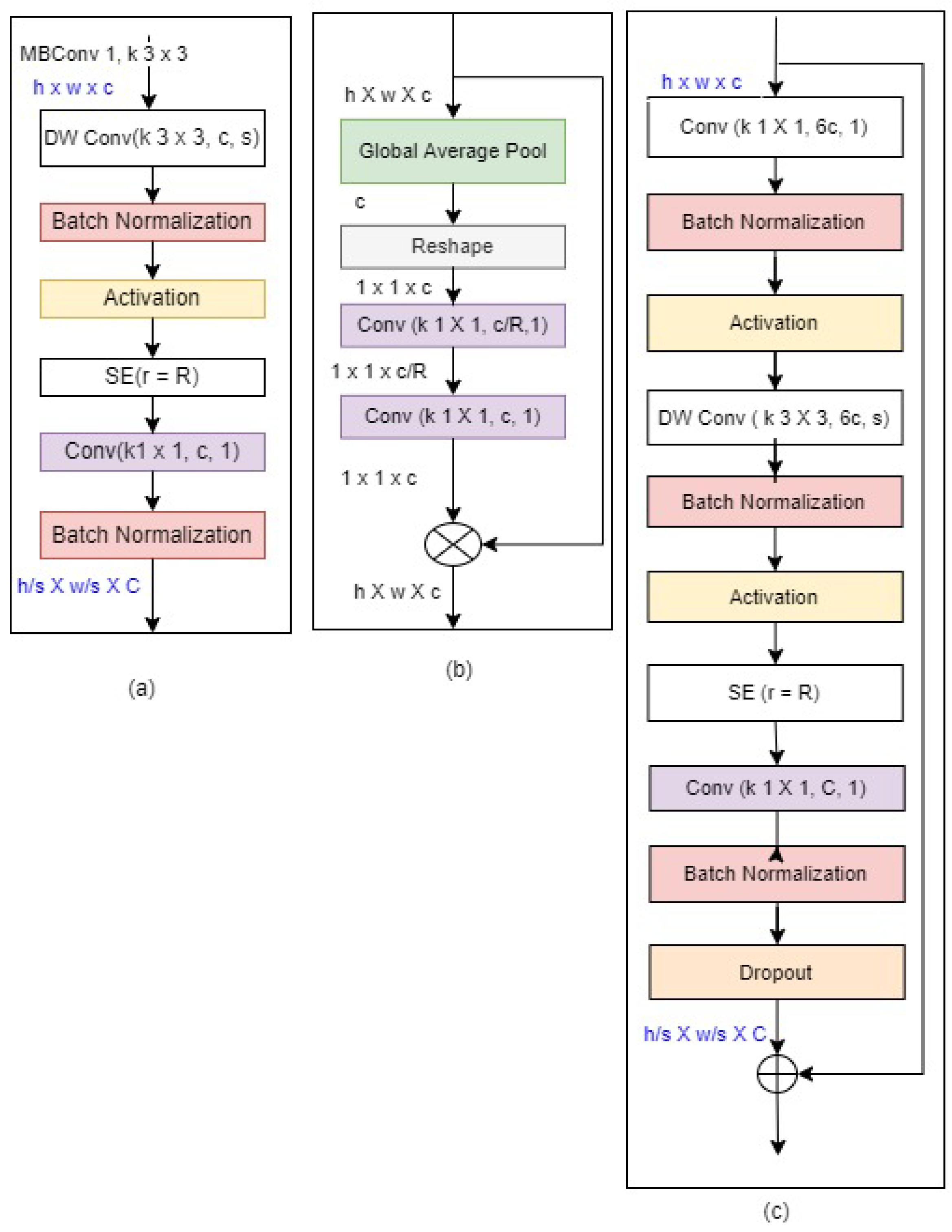
Blocks: Blocks consist of several Mobile inverted bottleneck convolutions (MBConv)
Figure 2. MBConv has different versions. In MBConvX, X denotes the expansion ratio. Basically, MBConv1 and MBConv6 is used in EfficientNet. MBConv1 and MBConv6 description is given below.
where
Figure 2.
EfficientNet Blocks: (a–c) are the 3 basic building blocks. h, w, and c are input with respect to height, width, and channel for all the MBConv blocks. The Output channel for the two blocks is denoted by C.
Figure 2.
EfficientNet Blocks: (a–c) are the 3 basic building blocks. h, w, and c are input with respect to height, width, and channel for all the MBConv blocks. The Output channel for the two blocks is denoted by C.
The no. of layers in blocks are MBConv1, k3 × 3, MBConv6, k3 × 3 repeated twice, MBConv6, k5 × 5 is repeated twice, MBConv6, k3 × 3 is repeated thrice, MBConv6, k3 × 3 is repeated thrice, MBConv6, k5 × 5 is repeated thrice, MBConv6, k5 × 5 is repeated 4 times, MBConv6, k3 × 3, total 16 blocks exists.
Head: Head is a layer consisting of Convolution, Batch Normalization, Swish, Pooling, Dropout and Fully Connected layers. Head is represented as follows:
The detailed EfficietNet Architecture is represented in
Table 1. A Note to remember is that MBConv6, k5 × 5 and MBConv6, k3 × 3 but only the difference is that MBConv6, k5 × 5 is applied to a kernel size of 5 × 5.
3.2. Fully Connected Layer
This module consists of 3 layers Global Average Pooling, Dropout layer and Dense Layer.
Global Average Pooling: Global Average Pooling layers replace fully connected layers in traditional CNNs. In the final layer, the goal is for generating the feature sets corresponding to respective classification levels. We take the average of each feature map instead of designing a complete connected layers above the feature maps. The basic advantage of global average pooling is that it is very similar to the structure of convolutional structure by enforcing the relation between corresponding feature maps with respect to classes. Another advantage is to avoid over-fitting, as there are zero parameters to optimize in global average pooling. Global Average Pooling does something different. Average pooling is applied on. It uses average pooling on the spatial dimensions until each is one and leaves the other dimensions alone. Global Average Pooling layer does transformation of , feature set of size and feature map where corresponds to image dimension, and being the count of filters used.
Dropout: While using DCNN, co-adaptation is the drawback when training a model. This indicated that the neuron are very dependent on other neurons. They influence each other considerably and are not independent enough regarding their inputs. It is very common to find in some situation that some neurons have a predictive capacity that is more significant than others. These kind of state can be avoided and the weights must be distributed to prevent over-fitting. There are various regularization methods which can be applied for regulating co-adaptation and high predictive capacity of of some neurons. To resolve this problem Dropout can be used. Depending on whether the model is DCNN, or a CNN or a Recurrent Neural Network (RNN) different dropout methods can be used. Here in our work we have used standard dropout method. The modeling of dropout layer on a neuron mathematically represented as follows:
where:
denotes the desired results.
is the probability of the real-valued representations.
If = 1 the neuron holding a real value is de-activated else activated.
The next layer we have is dense layer. In the neural network, a dense layer deeply connects to its next layer. Each of the neuron links to every neuron of its next layer. The neuron in this dense layer represents the neuron’s matrix-vector multiplications. Every neuron in the dense layer unit receives output from each neuron in the preceding layers in the model. The dense layer units perform matrix-vector cross product. In product, the row vector of the output from the previous layers is identical to the column vector of the dense layer. The major hyper parameters to tune in this layer are units and activation function. The very basic and necessary parameter in dense layer is units. In dense layer, size is defined by units which is always greater than 1. Activation function aids in transforming the input values to neurons. Basically it produces non-linearity into the network where relationship of input and output values are learnt.


 ,
, 



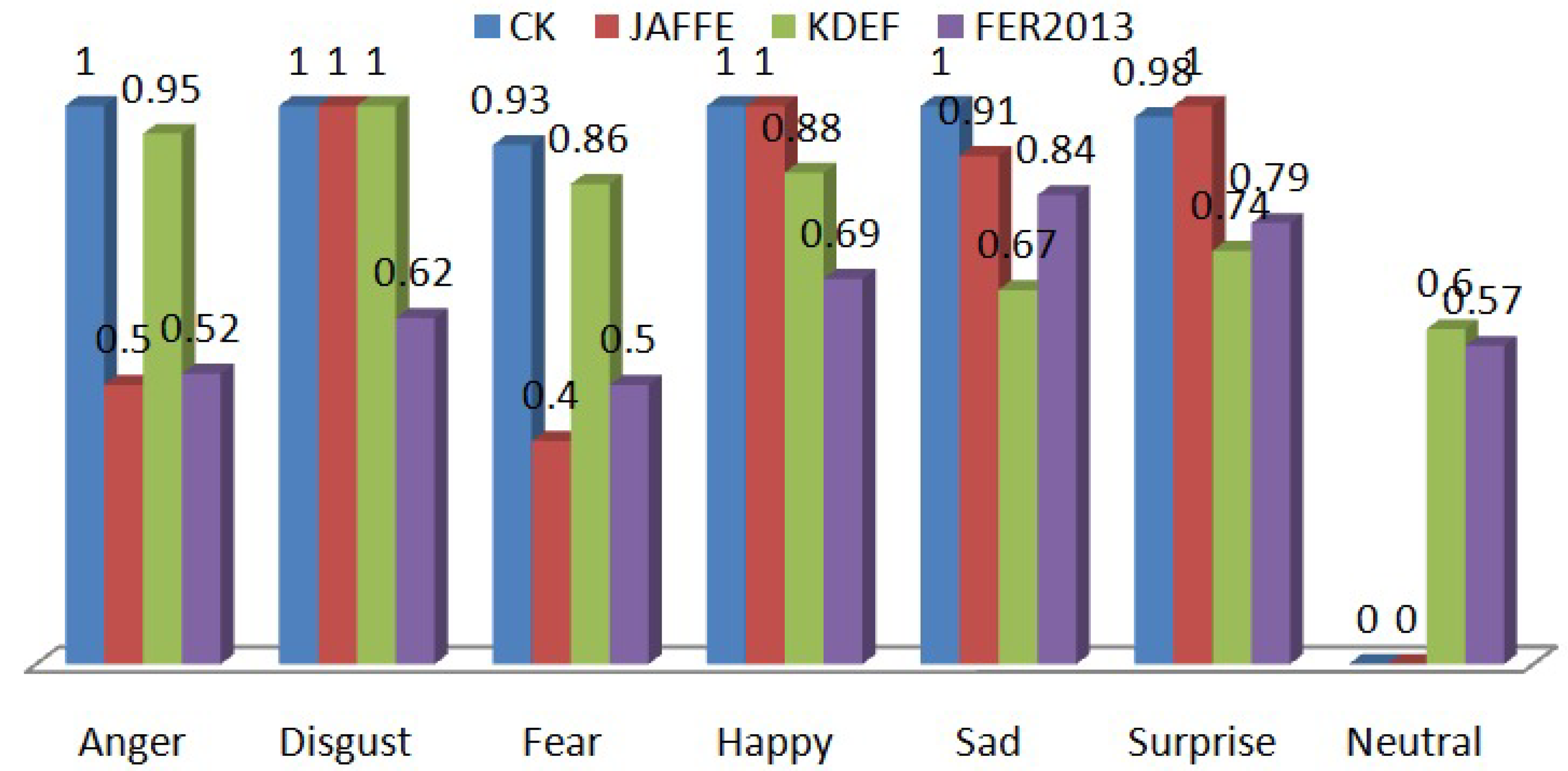
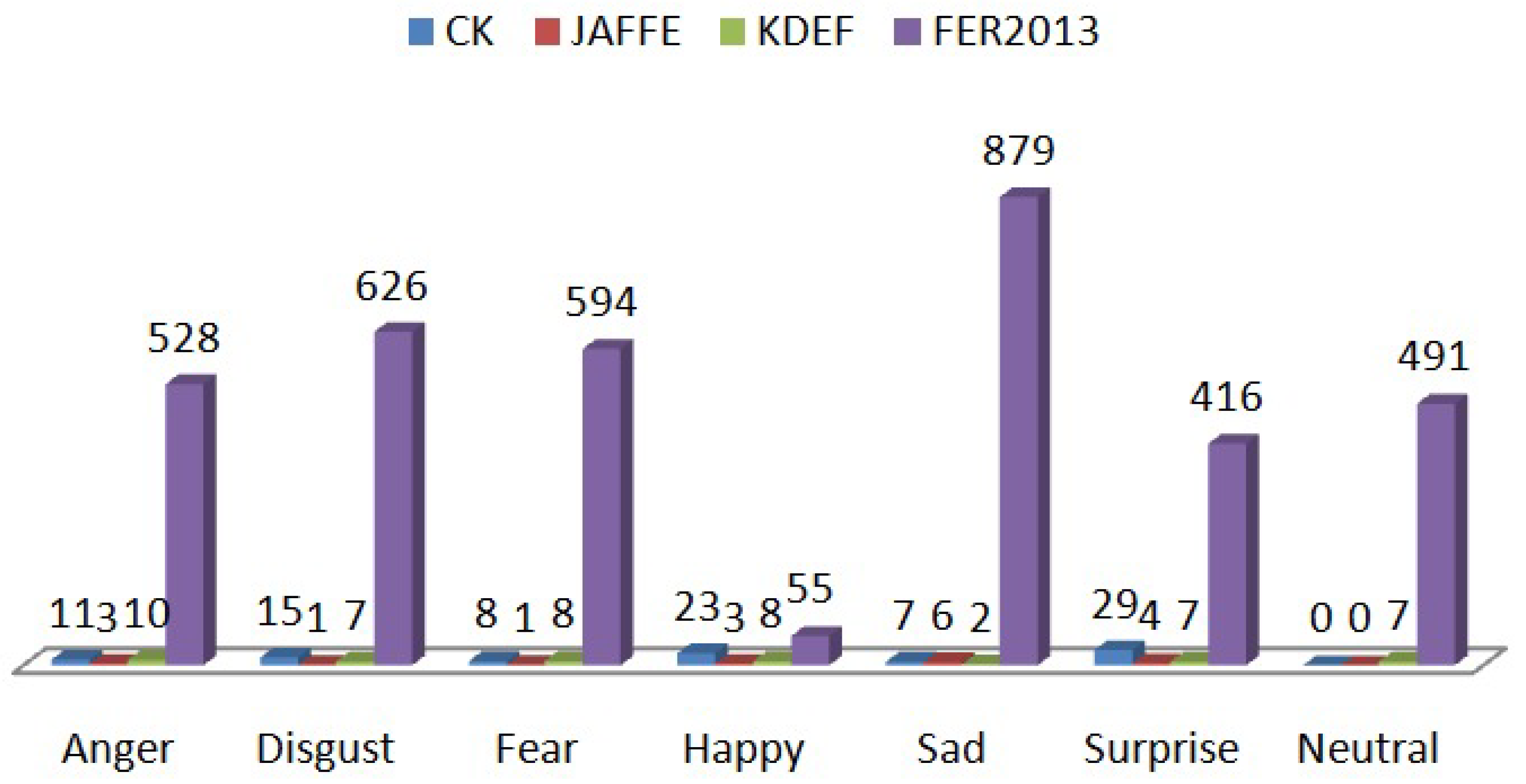

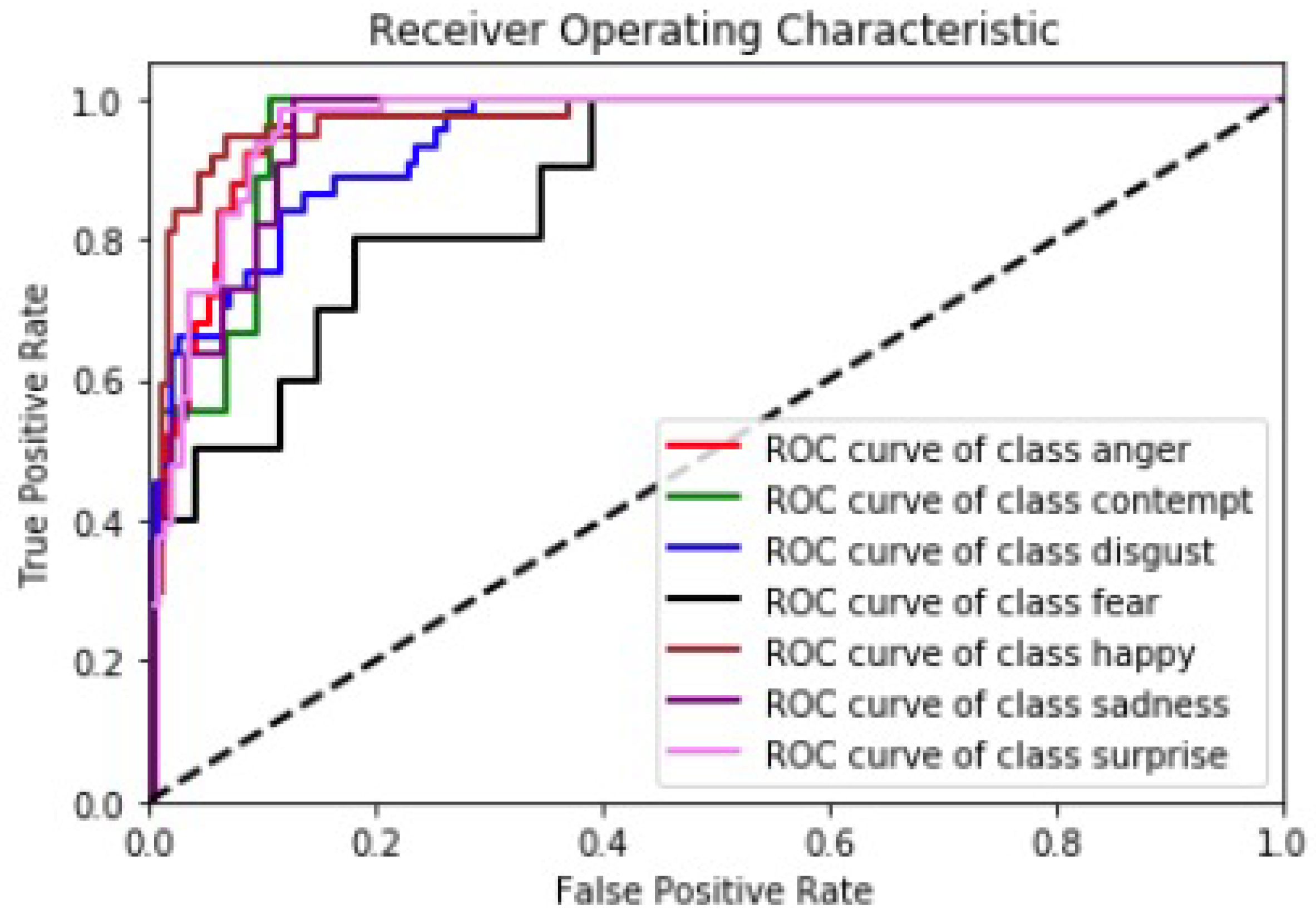
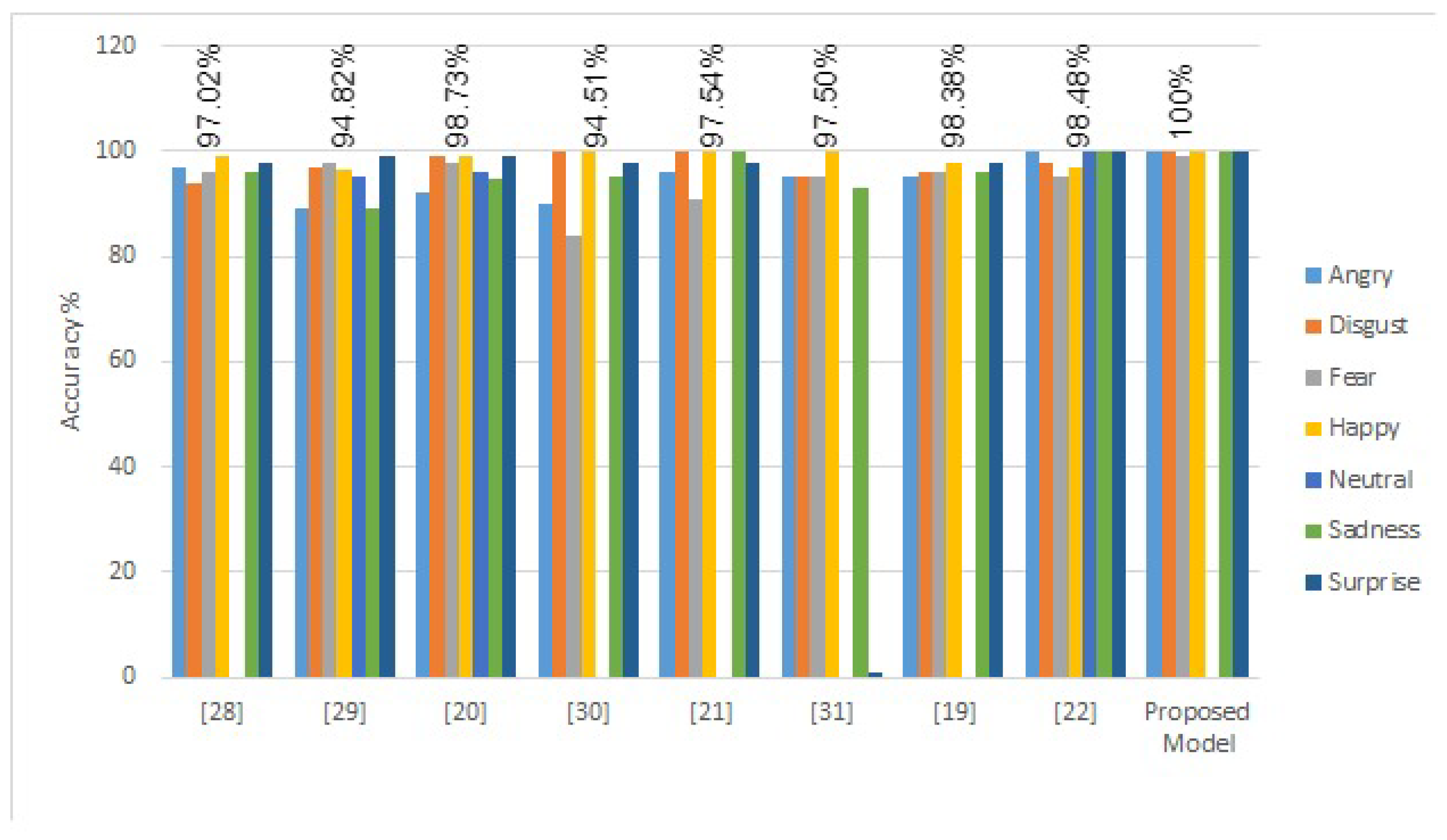

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}