
A Bidirectional Long Short-Term Memory Autoencoder Transformer for Remaining Useful Life Estimation

Abstract
:1. Introduction
- We introduce a unique BiLSTM-DAE-based Transformer architecture for RUL prediction, distinguishing it from current Transformer-based approaches. Integrating the DAE enhances the robustness of feature representation, facilitating the Transformer network in learning temporal structures more effectively in the embedded space. To the best of our knowledge, this is the first successful attempt at combining Transformer architecture and a denoising autoencoder for aircraft engine RUL pre-diction;
- We employ the Transformer architecture for RUL prediction, known for its superior handling of long-range temporal dependencies compared to existing RNN architectures in the context of RUL prediction;
- We investigate the importance of features extracted from the BiLSTM-DAE in the realm of RUL prediction, and conducted a series of ablation studies;
- We conduct a series of experiments using four CMPASS turbofan engine datasets and demonstrate that our model’s performance surpasses or is on par with that of existing state-of-the-art methods.
2. Related Work
- While Chen et al. [48] employed a denoising autoencoder akin to a multi-layer perceptron for signal reconstruction, our model opted for BiLSTM networks to encode features, a choice better suited for preserving temporal information within raw signals;
- In our model, we introduced learnable positional encoding, a feature that distinguishes our approach from the study conducted by Chen et al. [48], which employed trigonometric functions to encode a fixed positional structure before the training process.
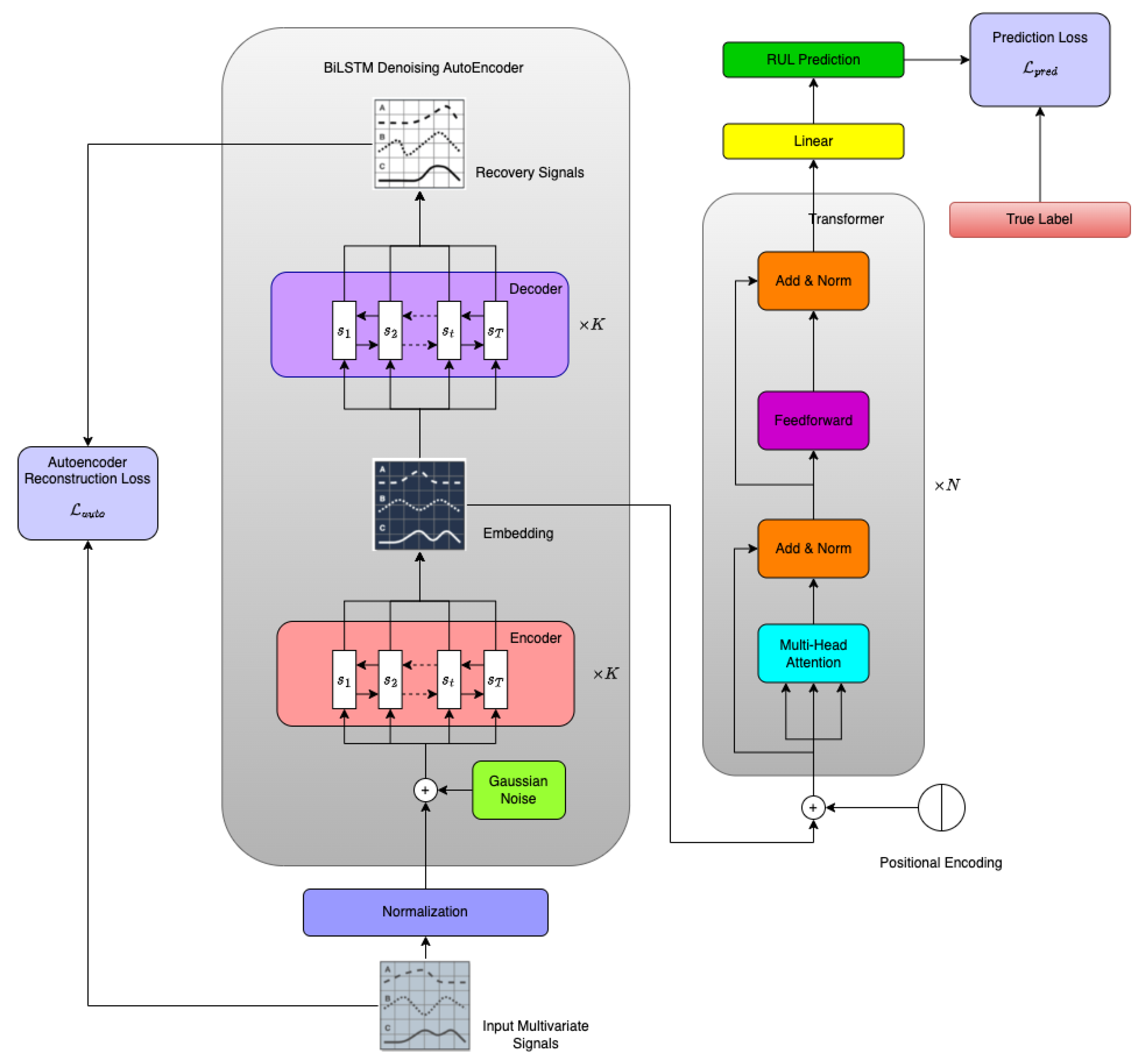
3. Methodology
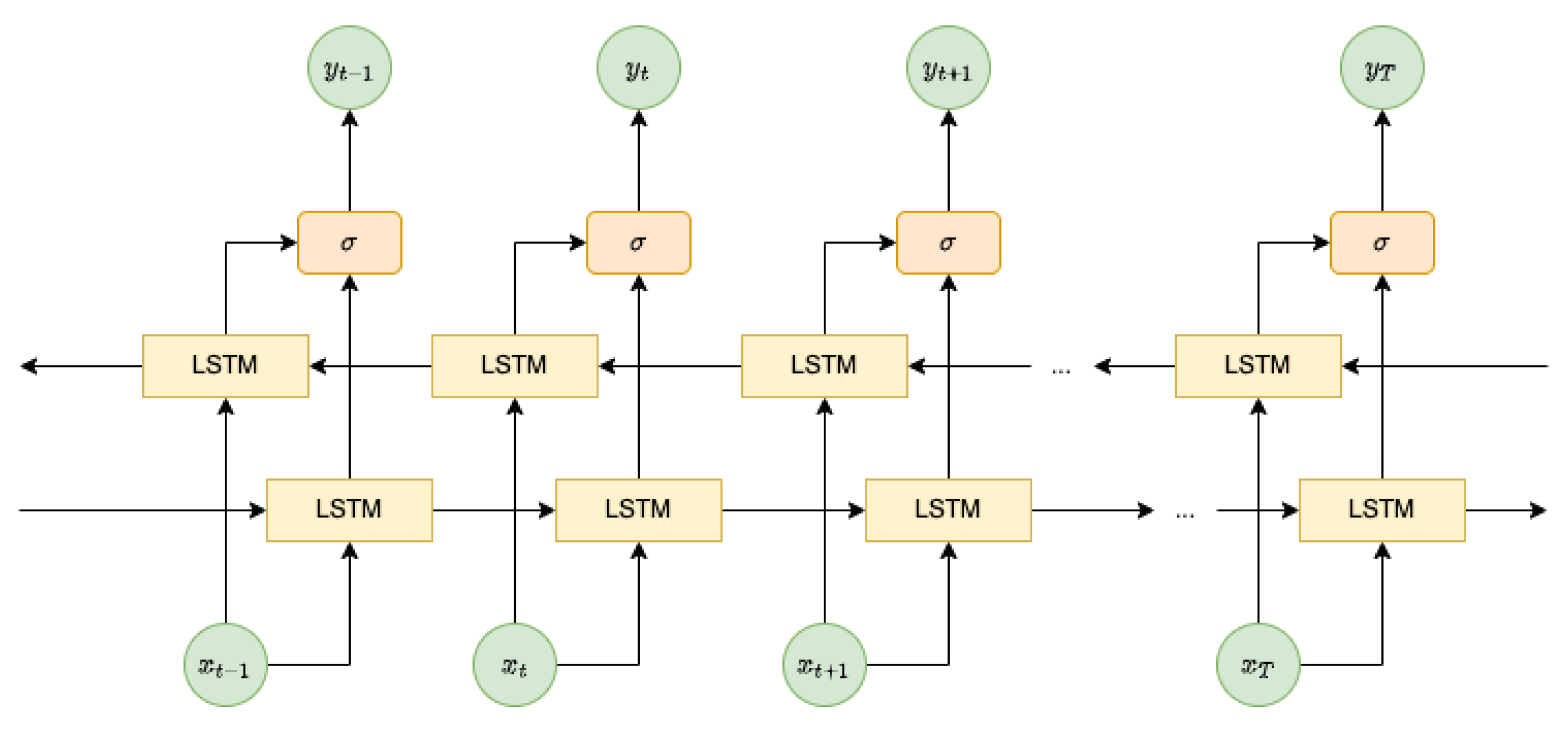
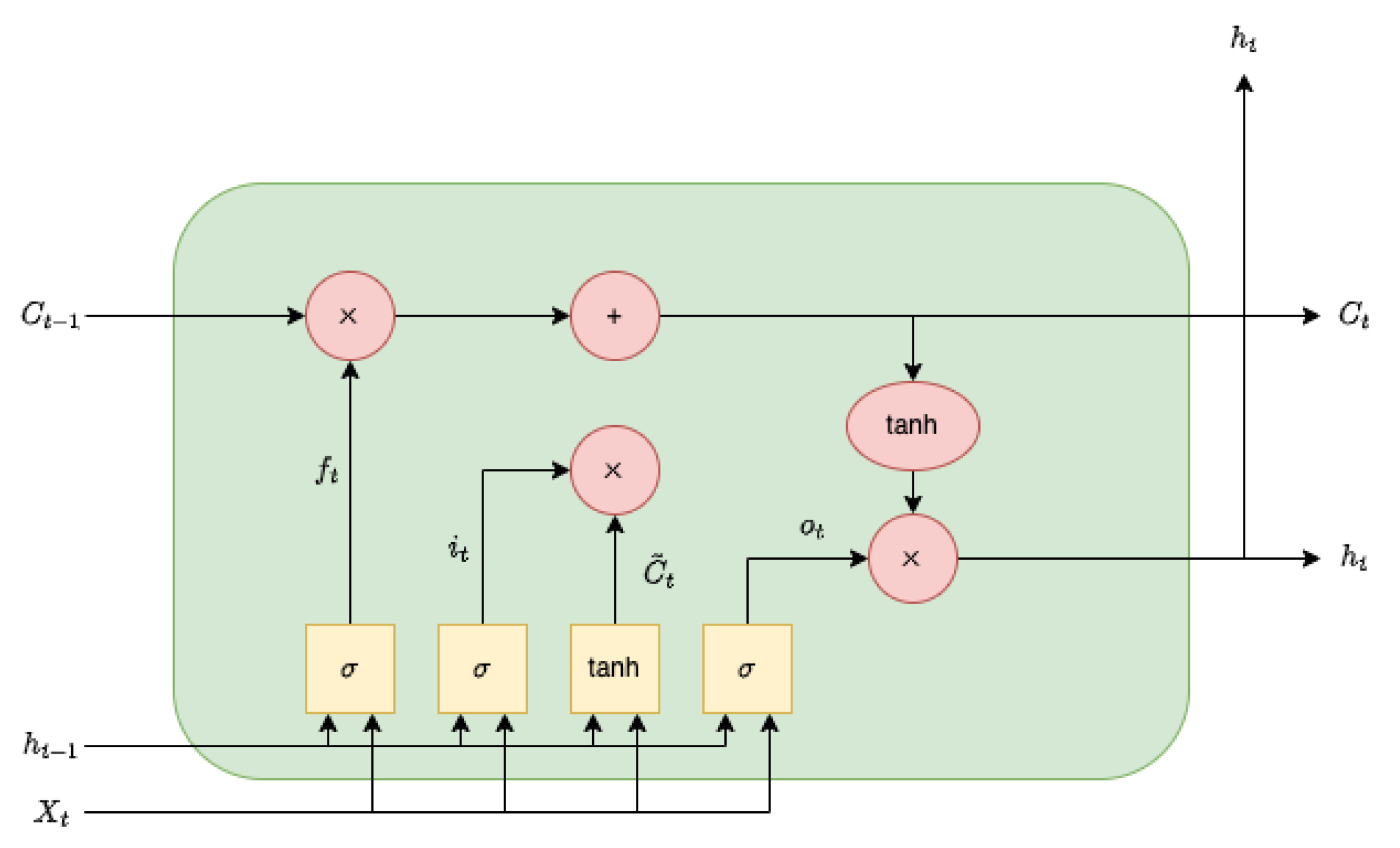
3.1. Bidirectional LSTM Autoencoder
- They are fed into the Transformer component as input data to predict the RUL for aircraft engines;
- They are inputted into the K-layer BiLSTM decoder of the BiLSTM-DAE module to reconstruct the original data before corruption. It is noteworthy that, although the number of layers for the BiLSTM encoder and decoder can differ, we keep them the same in our experiments.
3.2. Transformer and Multi-Head Attention
3.3. Learning
4. Experimental Results and Analysis
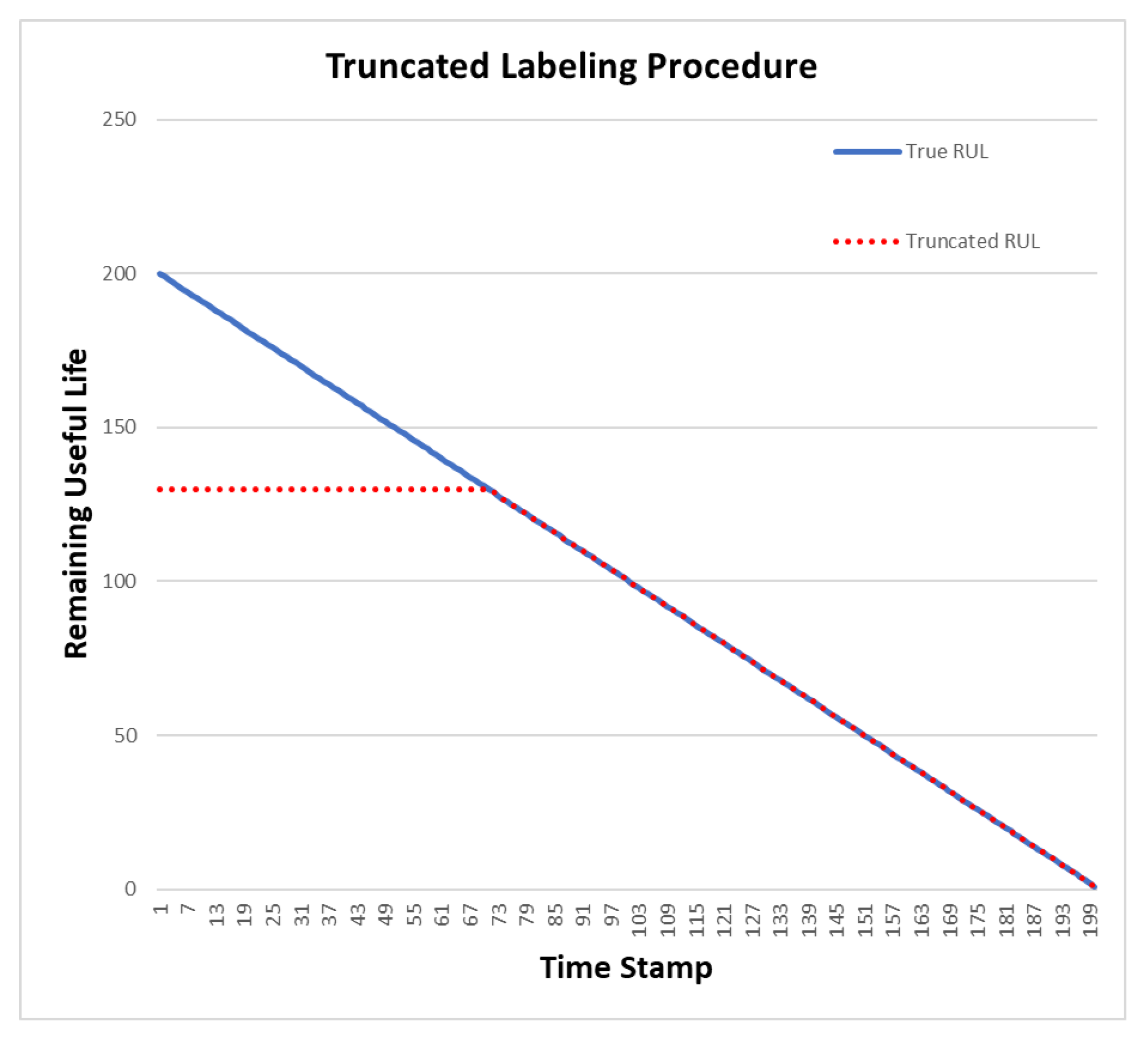
4.1. C-MAPSS Dataset and Preprocessing
4.2. Evaluation Metrics
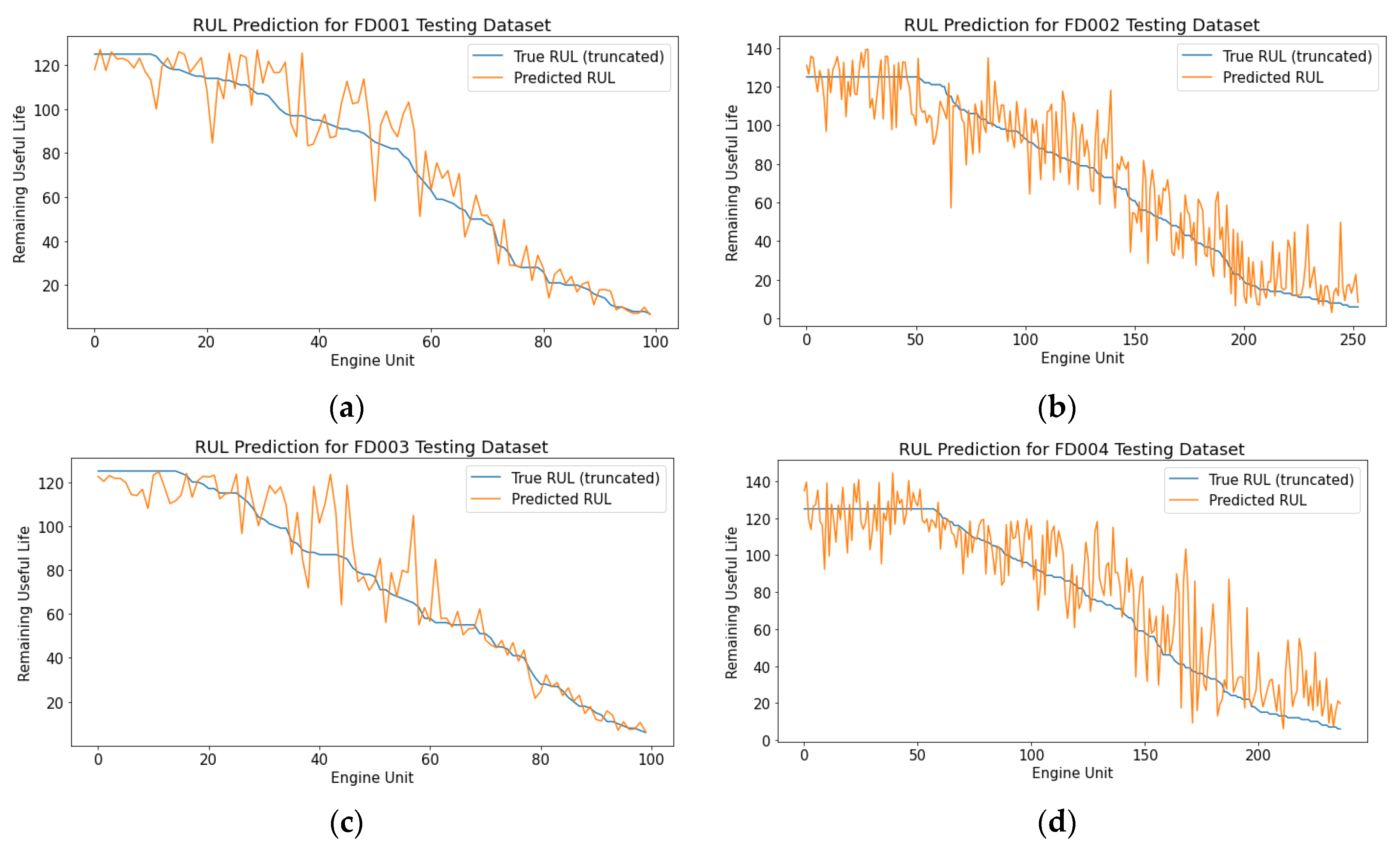
4.3. RUL Prediction
4.4. Ablation Study
- BiLSTM-DAE-Transformer: The proposed model that integrates the Transformer encoder and BiLSTM DAE;
- BiLSTM-DAE-Transformer-Noise: The proposed model that integrates the Transformer encoder and BiLSTM DAE with noisy input (original sensor readings plus small Gaussian noise);
- BiLSTM-DAE-LSTM: The model that integrates LSTM and BiLSTM DAE;
- BiLSTM-AE-Transformer: The proposed model without adding noise for DAE training;
- Transformer: The model with only a Transformer encoder for RUL prediction, and without any DAEs;
- LSTM: The model with only LSTM for RUL prediction, and without any DAEs.
- The comparison between BiLSTM-DAE-Transformer and BiLSTM-DAE-LSTM demonstrates that the Transformer architecture contributes to superior prediction performance, attributed to its ability to handle long sequences more effectively than LSTM;
- The comparison in prediction results between BiLSTM-DAE-Transformer and BiLSTM-AE-Transformer underscores the importance of the denoising autoencoder in our framework. The introduction of noise during DAE training enhances the robustness of feature representation;
- The comparison between BiLSTM-DAE-Transformer and the Transformer emphasizes the significance of the autoencoder component in our framework. The autoencoder embeds valuable information into a lower-dimensional space, facilitating Transformer architectures in capturing temporal structures within sequence data more efficiently;
- The contrast between BiLSTM-DAE-Transformer and BiLSTM-DAE-Transformer-Noise demonstrates the robust performance of our proposed model, even in the presence of contaminated sensor readings.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fan, Z.; Chang, K.; Ji, R.; Chen, G. Data Fusion for Optimal Condition-Based Aircraft Fleet Maintenance with Predictive Analytics. J. Adv. Inf. Fusion 2023, in press. [Google Scholar]
- Giantomassi, A.; Ferracuti, F.; Benini, A.; Ippoliti, G.; Longhi, S.; Petrucci, A. Hidden Markov Model for Health Estimation and Prognosis of Turbofan Engines. In Proceedings of the ASME 2011 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Washington, DC, USA, 28–31 August 2011; pp. 681–689. [Google Scholar]
- Lin, J.; Liao, G.; Chen, M.; Yin, H. Two-Phase Degradation Modeling and Remaining Useful Life Prediction Using Nonlinear Wiener Process. Comput. Ind. Eng. 2021, 160, 107533. [Google Scholar] [CrossRef]
- Yu, W.; Tu, W.; Kim, I.Y.; Mechefske, C. A Nonlinear-Drift-Driven Wiener Process Model for Remaining Useful Life Estimation Considering Three Sources of Variability. Reliab. Eng. Syst. Saf. 2021, 212, 107631. [Google Scholar] [CrossRef]
- Feng, D.; Xiao, M.; Liu, Y.; Song, H.; Yang, Z.; Zhang, L. A Kernel Principal Component Analysis–Based Degradation Model and Remaining Useful Life Estimation for the Turbofan Engine. Adv. Mech. Eng. 2016, 8, 1687814016650169. [Google Scholar] [CrossRef]
- Lv, Y.; Zheng, P.; Yuan, J.; Cao, X. A Predictive Maintenance Strategy for Multi-Component Systems Based on Components’ Remaining Useful Life Prediction. Mathematics 2023, 11, 3884. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, G.; Yang, F.; Zheng, Y.; Zhai, F. Prediction of Tool Remaining Useful Life Based on NHPP-WPHM. Mathematics 2023, 11, 1837. [Google Scholar] [CrossRef]
- Si, X.-S.; Wang, W.; Hu, C.-H.; Zhou, D.-H. Remaining Useful Life Estimation—A Review on the Statistical Data Driven Approaches. Eur. J. Oper. Res. 2011, 213, 1–14. [Google Scholar] [CrossRef]
- Li, W.; Lee, J.; Purl, J.; Greitzer, F.; Yousefi, B.; Laskey, K. Experimental Investigation of Demographic Factors Related to Phishing Susceptibility; University of Hawaii Manoa Library: Honolulu, HI, USA, 2020; ISBN 978-0-9981331-3-3. [Google Scholar]
- Greitzer, F.L.; Li, W.; Laskey, K.B.; Lee, J.; Purl, J. Experimental Investigation of Technical and Human Factors Related to Phishing Susceptibility. ACM Trans. Soc. Comput. 2021, 4, 8:1–8:48. [Google Scholar] [CrossRef]
- Li, W.; Finsa, M.M.; Laskey, K.B.; Houser, P.; Douglas-Bate, R. Groundwater Level Prediction with Machine Learning to Support Sustainable Irrigation in Water Scarcity Regions. Water 2023, 15, 3473. [Google Scholar] [CrossRef]
- Liu, W.; Zou, P.; Jiang, D.; Quan, X.; Dai, H. Computing River Discharge Using Water Surface Elevation Based on Deep Learning Networks. Water 2023, 15, 3759. [Google Scholar] [CrossRef]
- Fan, Z.; Chang, K.; Raz, A.K.; Harvey, A.; Chen, G. Sensor Tasking for Space Situation Awareness: Combining Reinforcement Learning and Causality. In Proceedings of the 2023 IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2023; pp. 1–9. [Google Scholar]
- Salmaso, F.; Trisolini, M.; Colombo, C. A Machine Learning and Feature Engineering Approach for the Prediction of the Uncontrolled Re-Entry of Space Objects. Aerospace 2023, 10, 297. [Google Scholar] [CrossRef]
- Zhou, W. Condition State-Based Decision Making in Evolving Systems: Applications in Asset Management and Delivery. Ph.D. Thesis, George Mason University, Fairfax, VA, USA, 2023. [Google Scholar]
- Ravi, C.; Tigga, A.; Reddy, G.T.; Hakak, S.; Alazab, M. Driver Identification Using Optimized Deep Learning Model in Smart Transportation. ACM Trans. Internet Technol. 2022, 22, 84:1–84:17. [Google Scholar] [CrossRef]
- Ordóñez, C.; Sánchez Lasheras, F.; Roca-Pardiñas, J.; de Cos Juez, F.J. A Hybrid ARIMA–SVM Model for the Study of the Remaining Useful Life of Aircraft Engines. J. Comput. Appl. Math. 2019, 346, 184–191. [Google Scholar] [CrossRef]
- García Nieto, P.J.; García-Gonzalo, E.; Sánchez Lasheras, F.; de Cos Juez, F.J. Hybrid PSO–SVM-Based Method for Forecasting of the Remaining Useful Life for Aircraft Engines and Evaluation of Its Reliability. Reliab. Eng. Syst. Saf. 2015, 138, 219–231. [Google Scholar] [CrossRef]
- Benkedjouh, T.; Medjaher, K.; Zerhouni, N.; Rechak, S. Health Assessment and Life Prediction of Cutting Tools Based on Support Vector Regression. J. Intell. Manuf. 2015, 26, 213–223. [Google Scholar] [CrossRef]
- Wang, H.; Li, D.; Li, D.; Liu, C.; Yang, X.; Zhu, G. Remaining Useful Life Prediction of Aircraft Turbofan Engine Based on Random Forest Feature Selection and Multi-Layer Perceptron. Appl. Sci. 2023, 13, 7186. [Google Scholar] [CrossRef]
- Wang, Q.; Zheng, S.; Farahat, A.; Serita, S.; Gupta, C. Remaining Useful Life Estimation Using Functional Data Analysis. In Proceedings of the 2019 IEEE International Conference on Prognostics and Health Management (ICPHM), San Francisco, CA, USA, 17–20 June 2019; pp. 1–8. [Google Scholar]
- Rao, A.R.; Wang, H.; Gupta, C. Functional Approach for Two Way Dimension Reduction in Time Series. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 1099–1106. [Google Scholar]
- Wang, X.; Huang, T.; Zhu, K.; Zhao, X. LSTM-Based Broad Learning System for Remaining Useful Life Prediction. Mathematics 2022, 10, 2066. [Google Scholar] [CrossRef]
- Ensarioğlu, K.; İnkaya, T.; Emel, E. Remaining Useful Life Estimation of Turbofan Engines with Deep Learning Using Change-Point Detection Based Labeling and Feature Engineering. Appl. Sci. 2023, 13, 11893. [Google Scholar] [CrossRef]
- Yuan, M.; Wu, Y.; Lin, L. Fault Diagnosis and Remaining Useful Life Estimation of Aero Engine Using LSTM Neural Network. In Proceedings of the 2016 IEEE International Conference on Aircraft Utility Systems (AUS), Beijing, China, 10–12 October 2016; pp. 135–140. [Google Scholar]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Liu, Y. Remaining Useful Life Estimation of Engineered Systems Using Vanilla LSTM Neural Networks. Neurocomputing 2018, 275, 167–179. [Google Scholar] [CrossRef]
- Zheng, S.; Ristovski, K.; Farahat, A.; Gupta, C. Long Short-Term Memory Network for Remaining Useful Life Estimation. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017; pp. 88–95. [Google Scholar]
- Li, X.; Ding, Q.; Sun, J.-Q. Remaining Useful Life Estimation in Prognostics Using Deep Convolution Neural Networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef]
- Yu, W.; Kim, I.Y.; Mechefske, C. Remaining Useful Life Estimation Using a Bidirectional Recurrent Neural Network Based Autoencoder Scheme. Mech. Syst. Signal Process. 2019, 129, 764–780. [Google Scholar] [CrossRef]
- Zhao, C.; Huang, X.; Li, Y.; Yousaf Iqbal, M. A Double-Channel Hybrid Deep Neural Network Based on CNN and BiLSTM for Remaining Useful Life Prediction. Sensors 2020, 20, 7109. [Google Scholar] [CrossRef] [PubMed]
- Peng, C.; Wu, J.; Wang, Q.; Gui, W.; Tang, Z. Remaining Useful Life Prediction Using Dual-Channel LSTM with Time Feature and Its Difference. Entropy 2022, 24, 1818. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhao, Y. Multi-Scale Remaining Useful Life Prediction Using Long Short-Term Memory. Sustainability 2022, 14, 15667. [Google Scholar] [CrossRef]
- Lyu, Y.; Zhang, Q.; Wen, Z.; Chen, A. Remaining Useful Life Prediction Based on Multi-Representation Domain Adaptation. Mathematics 2022, 10, 4647. [Google Scholar] [CrossRef]
- Deng, F.; Bi, Y.; Liu, Y.; Yang, S. Deep-Learning-Based Remaining Useful Life Prediction Based on a Multi-Scale Dilated Convolution Network. Mathematics 2021, 9, 3035. [Google Scholar] [CrossRef]
- Zhou, J.; Qin, Y.; Luo, J.; Wang, S.; Zhu, T. Dual-Thread Gated Recurrent Unit for Gear Remaining Useful Life Prediction. IEEE Trans. Ind. Inform. 2023, 19, 8307–8318. [Google Scholar] [CrossRef]
- Zhuang, L.; Xu, A.; Wang, X.-L. A Prognostic Driven Predictive Maintenance Framework Based on Bayesian Deep Learning. Reliab. Eng. Syst. Saf. 2023, 234, 109181. [Google Scholar] [CrossRef]
- Ding, A.; Qin, Y.; Wang, B.; Cheng, X.; Jia, L. An Elastic Expandable Fault Diagnosis Method of Three-Phase Motors Using Continual Learning for Class-Added Sample Accumulations. IEEE Trans. Ind. Electron. 2023, 1–10. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Sydney, Australia, 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Mo, Y.; Wu, Q.; Li, X.; Huang, B. Remaining Useful Life Estimation via Transformer Encoder Enhanced by a Gated Convolutional Unit. J. Intell. Manuf. 2021, 32, 1997–2006. [Google Scholar] [CrossRef]
- Ai, S.; Song, J.; Cai, G. Sequence-to-Sequence Remaining Useful Life Prediction of the Highly Maneuverable Unmanned Aerial Vehicle: A Multilevel Fusion Transformer Network Solution. Mathematics 2022, 10, 1733. [Google Scholar] [CrossRef]
- Zhang, Z.; Song, W.; Li, Q. Dual-Aspect Self-Attention Based on Transformer for Remaining Useful Life Prediction. IEEE Trans. Instrum. Meas. 2022, 71, 2505711. [Google Scholar] [CrossRef]
- Hu, Q.; Zhao, Y.; Ren, L. Novel Transformer-Based Fusion Models for Aero-Engine Remaining Useful Life Estimation. IEEE Access 2023, 11, 52668–52685. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Zuo, L.; Zhu, L.; Shen, H.T. Domain Adaptive Remaining Useful Life Prediction With Transformer. IEEE Trans. Instrum. Meas. 2022, 71, 3521213. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M. Convolutional Transformer: An Enhanced Attention Mechanism Architecture for Remaining Useful Life Estimation of Bearings. IEEE Trans. Instrum. Meas. 2022, 71, 3515010. [Google Scholar] [CrossRef]
- Chadha, G.S.; Shah, S.R.B.; Schwung, A.; Ding, S.X. Shared Temporal Attention Transformer for Remaining Useful Lifetime Estimation. IEEE Access 2022, 10, 74244–74258. [Google Scholar] [CrossRef]
- Zhang, Y.; Su, C.; Wu, J.; Liu, H.; Xie, M. Trend-Augmented and Temporal-Featured Transformer Network with Multi-Sensor Signals for Remaining Useful Life Prediction. Reliab. Eng. Syst. Saf. 2024, 241, 109662. [Google Scholar] [CrossRef]
- Chen, D.; Hong, W.; Zhou, X. Transformer Network for Remaining Useful Life Prediction of Lithium-Ion Batteries. IEEE Access 2022, 10, 19621–19628. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and Composing Robust Features with Denoising Autoencoders. In Proceedings of the 25th International Conference on Machine Learning, New York, NY, USA, 5–9 July 2008; Association for Computing Machinery: New York, NY, USA; pp. 1096–1103. [Google Scholar]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage Propagation Modeling for Aircraft Engine Run-to-Failure Simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Evanston, IL, USA, 7–10 October 2008; pp. 1–9. [Google Scholar]
- Wu, Q.; Ding, K.; Huang, B. Approach for Fault Prognosis Using Recurrent Neural Network. J. Intell. Manuf. 2020, 31, 1621–1633. [Google Scholar] [CrossRef]
- Sateesh Babu, G.; Zhao, P.; Li, X.-L. Deep Convolutional Neural Network Based Regression Approach for Estimation of Remaining Useful Life. In Database Systems for Advanced Applications; Navathe, S.B., Wu, W., Shekhar, S., Du, X., Wang, X.S., Xiong, H., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 214–228. [Google Scholar]
- Wang, J.; Wen, G.; Yang, S.; Liu, Y. Remaining Useful Life Estimation in Prognostics Using Deep Bidirectional LSTM Neural Network. In Proceedings of the 2018 Prognostics and System Health Management Conference (PHM-Chongqing), Chongqing, China, 26–28 October 2018; pp. 1037–1042. [Google Scholar]
- Zhang, C.; Lim, P.; Qin, A.K.; Tan, K.C. Multiobjective Deep Belief Networks Ensemble for Remaining Useful Life Estimation in Prognostics. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2306–2318. [Google Scholar] [CrossRef] [PubMed]
- Kong, Z.; Cui, Y.; Xia, Z.; Lv, H. Convolution and Long Short-Term Memory Hybrid Deep Neural Networks for Remaining Useful Life Prognostics. Appl. Sci. 2019, 9, 4156. [Google Scholar] [CrossRef]
- Mo, H.; Lucca, F.; Malacarne, J.; Iacca, G. Multi-Head CNN-LSTM with Prediction Error Analysis for Remaining Useful Life Prediction. In Proceedings of the 2020 27th Conference of Open Innovations Association (FRUCT), Trento, Italy, 7–9 September 2020; pp. 164–171. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Units |
|---|---|---|
| T2 | Total temperature at fan inlet | R |
| T24 | Total temperature at LPC inlet | R |
| T30 | Total temperature at HPC inlet | R |
| T50 | Total temperature at LPT inlet | R |
| P2 | Pressure at fan inlet | psia |
| P15 | Total pressure in bypass duct | psia |
| P30 | Total pressure at HPC outlet | psia |
| Nf | Physical fan speed | rpm |
| Ne | Physical core speed | rpm |
| epr | Engine pressure ratio | - |
| Ps30 | Static pressure at HPC outlet | psia |
| Phi | Ratio of fuel flow to Ps30 | pps/psi |
| NRf | Corrected fan speed | rpm |
| NRe | Corrected core speed | rpm |
| BPR | Bypass ratio | - |
| farB | Burner fuel/air ratio | - |
| htBleed | Bleed Enthalpy | - |
| Bf-dmd | Demanded fan speed | rpm |
| PCNfR-dmd | Demanded corrected fan speed | rpm |
| W31 | HPT coolant bleed | lbm/s |
| W32 | LPT coolant bleed | lbm/s |
| Dataset | FD001 | FD002 | FD003 | FD004 |
|---|---|---|---|---|
| No. of Training Trajectories | 100 | 260 | 100 | 249 |
| No. of Testing Trajectories | 100 | 259 | 100 | 248 |
| Operating Conditions | 1 | 6 | 1 | 6 |
| Fault Modes | 1 | 1 | 2 | 2 |
| Method | FD001 | FD002 | FD003 | FD004 | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | Score | RMSE | Score | RMSE | Score | RMSE | Score | |
| MLP | 37.56 | 18,000 | 80.03 | 7,800,000 | 37.39 | 17,400 | 77.37 | 5,620,000 |
| SVR | 20.96 | 1380 | 42.00 | 590,000 | 21.05 | 1600 | 45.35 | 371,000 |
| CNN | 18.45 | 1290 | 30.29 | 13,600 | 19.82 | 1600 | 29.16 | 7890 |
| LSTM | 16.14 | 338 | 24.49 | 4450 | 16.18 | 852 | 28.17 | 5550 |
| BiLSTM | 13.65 | 295 | 23.18 | 4130 | 13.74 | 317 | 24.86 | 5430 |
| DBNE | 17.27 | 523 | 37.28 | 49,800 | 18.47 | 574 | 30.96 | 12,100 |
| B-LSTM | 12.45 | 279 | 15.36 | 4250 | 13.37 | 356 | 16.24 | 5220 |
| GCT | 11.27 | - | 22.81 | - | 11.42 | - | 24.86 | - |
| CNN + LSTM | 16.16 | 303 | 20.44 | 3440 | 17.12 | 1420 | 23.25 | 4630 |
| DAST | 11.43 | 203 | 15.25 | 924.96 | 11.32 | 154 | 18.36 | 1490 |
| Multi-head CNN + LSTM | 12.19 | 259 | 19.93 | 4350 | 12.85 | 343 | 22.89 | 4340 |
| Proposed Method | 10.98 | 186 | 16.12 | 2937 | 11.14 | 252 | 18.15 | 3840 |
| Model | RMSE | Difference |
|---|---|---|
| BiLSTM-DAE-Transformer | 10.98 | - |
| BiLSTM-DAE-Transformer-Noise | 11.31 | 0.33 |
| BiLSTM-DAE-LSTM | 15.24 | 4.26 |
| BiLSTM-AE-Transformer | 12.44 | 1.46 |
| Transformer | 13.02 | 2.04 |
| LSTM | 16.14 | 5.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Z.; Li, W.; Chang, K.-C. A Bidirectional Long Short-Term Memory Autoencoder Transformer for Remaining Useful Life Estimation. Mathematics 2023, 11, 4972. https://doi.org/10.3390/math11244972
Fan Z, Li W, Chang K-C. A Bidirectional Long Short-Term Memory Autoencoder Transformer for Remaining Useful Life Estimation. Mathematics. 2023; 11(24):4972. https://doi.org/10.3390/math11244972
Chicago/Turabian StyleFan, Zhengyang, Wanru Li, and Kuo-Chu Chang. 2023. "A Bidirectional Long Short-Term Memory Autoencoder Transformer for Remaining Useful Life Estimation" Mathematics 11, no. 24: 4972. https://doi.org/10.3390/math11244972
APA StyleFan, Z., Li, W., & Chang, K.-C. (2023). A Bidirectional Long Short-Term Memory Autoencoder Transformer for Remaining Useful Life Estimation. Mathematics, 11(24), 4972. https://doi.org/10.3390/math11244972