
Event-Centric Temporal Knowledge Graph Construction: A Survey


Abstract
1. Introduction

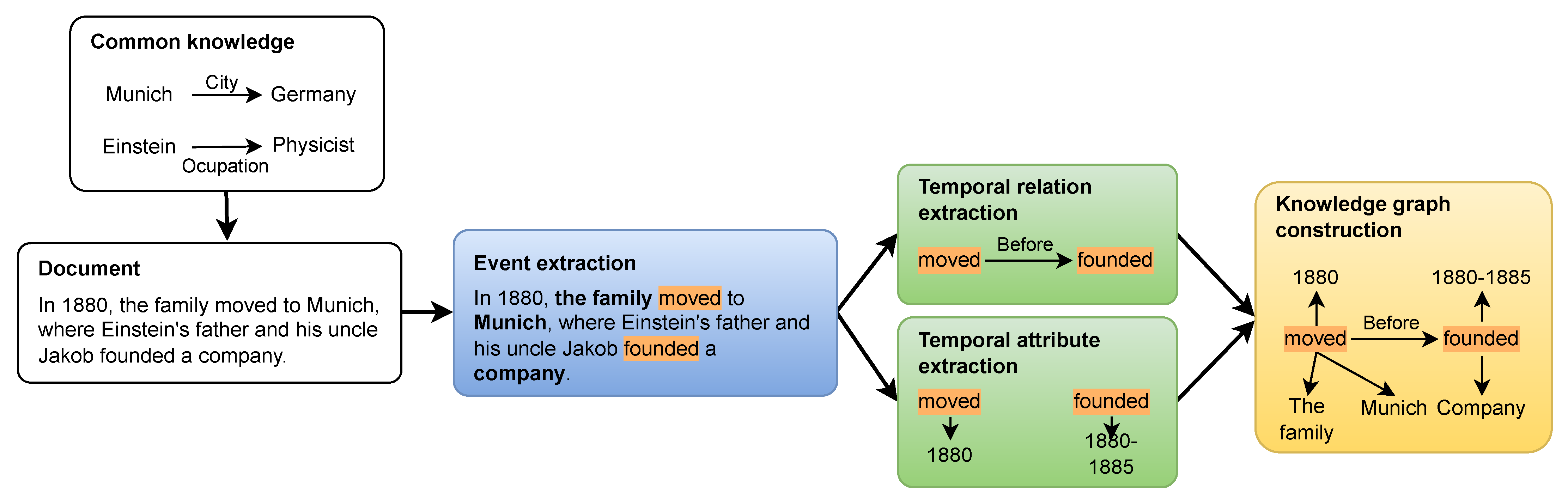{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | EE | EA | TR | ED | TC | Add. | Domain |
|---|---|---|---|---|---|---|---|
| Riloff (1993) [6] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Riloff (1995) [7] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Kim and Moldovan (1995) [8] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Grishman et al. (2005) [9] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Ahn (2006) [10] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Yang and Mitchell (2016) [11] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Chen et al. (2015) [12] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Nguyen et al. (2016) [13] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Sha et al. (2018) [14] | ✓ | ✓ | ✗ | ✗ | ✗ | SY | News |
| Liu et al. (2018) [15] | ✓ | ✓ | ✗ | ✗ | ✗ | SY | News |
| Liu et al. (2019) [16] | ✓ | ✓ | ✗ | ✗ | ✗ | SY, CL | News |
| Zhang et al. (2019) [17] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Zhang et al. (2020) [18] | ✗ | ✓ | ✗ | ✗ | ✗ | News | |
| Ji (2009) [19] | ✓ | ✓ | ✗ | ✗ | ✗ | CL | News |
| Zhu et al. (2014) [20] | ✓ | ✓ | ✗ | ✗ | ✗ | CL | News |
| Chen et al. (2009) [21] | ✓ | ✓ | ✗ | ✗ | ✗ | CL | News |
| Liu et al. (2020) [22] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Lu et al. (2021) [23] | ✓ | ✓ | ✗ | ✗ | ✗ | News | |
| Gaizauskas et al. (2006) [24] | ✗ | ✗ | ✓ | ✗ | ✗ | News | |
| Mani et al. (2006) [25] | ✗ | ✗ | ✓ | ✗ | ✗ | News | |
| Bethard (2013) [26] | ✓ | ✗ | ✓ | ✗ | ✗ | News | |
| Lin et al. (2016) [27] | ✗ | ✗ | ✓ | ✗ | ✗ | Medical | |
| Ning et al. (2017) [28] | ✗ | ✗ | ✓ | ✗ | ✗ | CK | News |
| Tourille et al. (2017) [29] | ✗ | ✗ | ✓ | ✗ | ✗ | Medical | |
| Dligach et al. (2017) [30] | ✗ | ✗ | ✓ | ✗ | ✗ | Medical | |
| Lin et al. (2019) [31] | ✗ | ✗ | ✓ | ✗ | ✗ | Medical | |
| Cheng and Miyao (2017) [32] | ✗ | ✗ | ✓ | ✗ | ✗ | SY | News |
| Leeuwenberg and Moens (2018) [33] | ✗ | ✗ | ✓ | ✓ | ✓ | News | |
| Zhou et al. (2021) [34] | ✗ | ✗ | ✓ | ✗ | ✗ | CL | Medical |
| Zhang et al. (2021) [35] | ✓ | ✗ | ✓ | ✗ | ✗ | SY | News |
| Xu et al. (2021) [36] | ✗ | ✗ | ✓ | ✗ | ✗ | SY | News |
| Mathur et al. (2021) [37] | ✗ | ✗ | ✓ | ✗ | ✗ | SY | News |
| Ning et al. (2018) [38] | ✗ | ✗ | ✓ | ✗ | ✗ | CK | News |
| Ning et al. (2019) [39] | ✗ | ✗ | ✓ | ✗ | ✗ | CK | News |
| Han et al. (2020) [40] | ✓ | ✗ | ✓ | ✗ | ✗ | CK | News, Medical |
| Leeuwenberg and Moens (2020) [41] | ✗ | ✗ | ✗ | ✓ | ✓ | Medical | |
| Vashishtha et al. (2019) [42] | ✗ | ✗ | ✓ | ✓ | ✓ | News | |
| Pan et al. (2011) [43] | ✗ | ✗ | ✗ | ✓ | ✗ | News | |
| Gusev et al. (2011) [44] | ✗ | ✗ | ✗ | ✓ | ✗ | News | |
| Vempala et al. (2018) [45] | ✗ | ✗ | ✗ | ✓ | ✗ | News | |
| Rospocher et al. (2016) [46] | ✓ | ✓ | ✓ | ✗ | ✓ | News | |
| Ma et al. (2021) [47] | ✓ | ✓ | ✓ | ✓ | ✓ | News | |
| Jindal and Roth (2013) [48] | ✓ | ✗ | ✗ | ✗ | ✗ | Medical |

- (a)
- Literature review for all tasks related to temporal event knowledge graph construction. We identify the tasks required for the automatic construction of event-centric temporal knowledge graphs and provide a review of research dealing with each of the tasks. We compare different approaches and identify the most successful model designs.
- (b)
- Identification of emerging advancements. We identify the directions in which systems for each of the tasks are likely to evolve in the future. We also provide our opinion on which approaches seem to be the most prospective for future systems.
- (c)
- Identification and proposal of open research problems. We summarize each of the areas and highlight promising future research directions. We also provide the main criteria that future work should achieve.
Formal Definition of an Event-Centric Knowledge Graph
- Nodes: The knowledge graph is comprised of a set of nodes representing individual events. Each node corresponds to a specific event.
- Attributes: Each node contains a set of attributes associated with the event. We denote the set of attributes as .
- Edges: The knowledge graph contains a set of directed edges between nodes and , where each edge represents a temporal relation. We denote a set of edges as , where each edge is a triplet of two nodes and a relation r from the set of valid relations R, which differs between different domains and use cases.
- Temporal consistency: A temporal knowledge graph ensures consistency between temporal relations so that events with temporal relations form valid timelines.
- Granularity: An event-centric knowledge graph needs to accommodate different levels of event granularities. An event might be a specific instance that occurred at a specific point in time or a general concept that can occur in multiple situations.
2. Motivation
3. Methodology
4. Schemas and Datasets
4.1. Schemas for Capturing Events
- Aim:
- The TimeML model seeks to identify and capture all mentions of events within the text and establish relations between these events.
- Coverage:
- It aims for comprehensive event recognition, encompassing a broad spectrum of event types.
- Annotations:
- TimeML employs XML tags to annotate text, marking event mentions and their attributes, temporal expressions, their meanings, and relationships between them.
- Additional Information:
- Documents in TimeML format often incorporate the recording of document creation times as a special time expression.
- Aim:
- The primary objective of the ACE event model is to provide more detailed information about each event, focusing on a predefined set of event types.
- Coverage:
- ACE defines a specific set of 34 event types, and the model is designed to capture events that fall within these predetermined categories.
- Annotations:
- ACE specifies a structured format for annotating text with details about events, including their attributes.
- Attributes:
- Each event type in the ACE model comes with a predefined set of attributes, which vary depending on the specific event type.
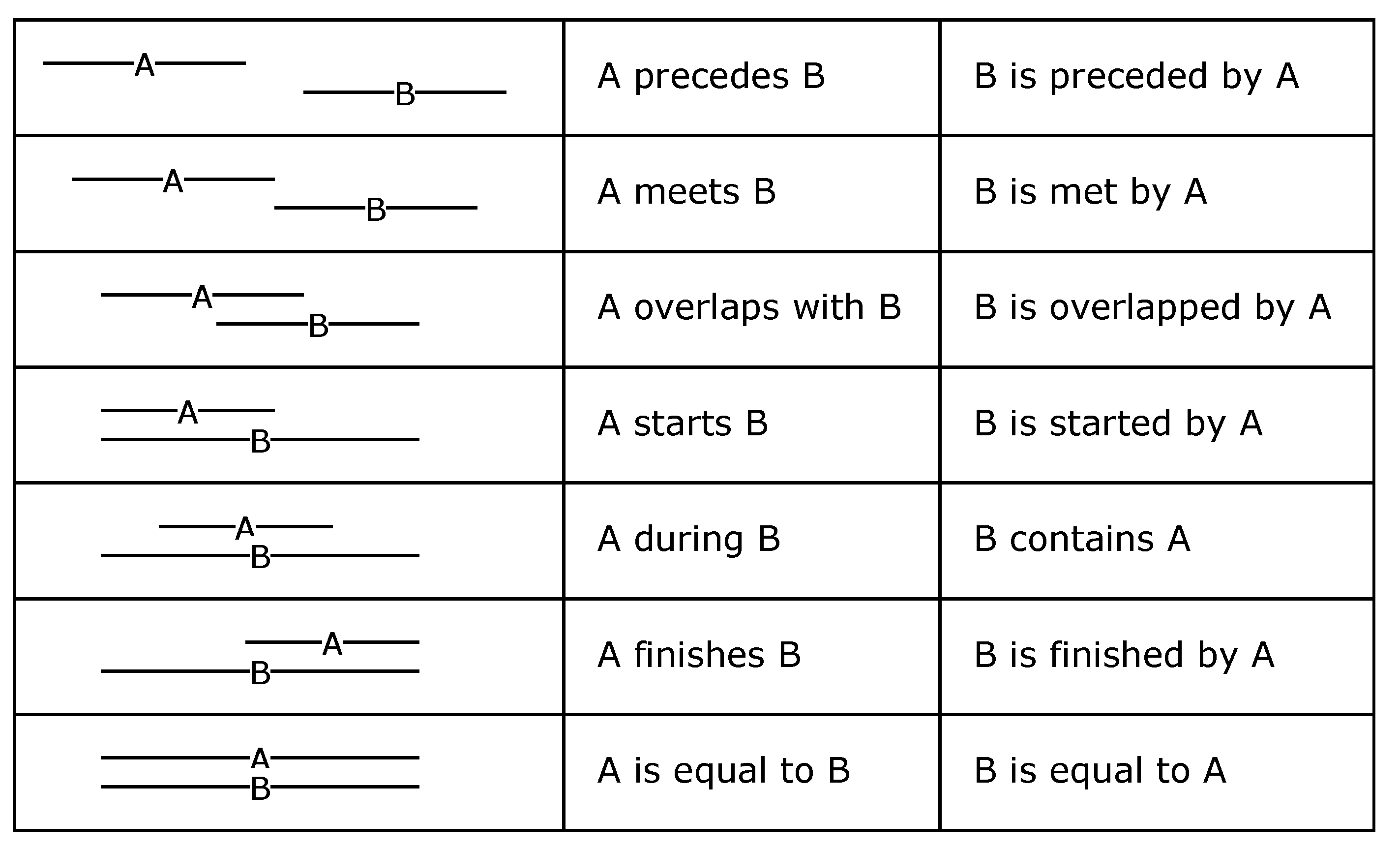
4.2. Schemas for Capturing Temporal Relations
4.3. Capturing Temporal Properties of Events
4.4. General Datasets for Temporal Description and Relation Extraction
4.5. Domain Specific Datasets
4.6. Datasets for More Precise Temporal Relation Extraction
4.7. Temporal Extraction for Non-English Languages
4.8. Other Similar Corpora
5. Event Extraction
5.1. Event Extraction Using Pattern Matching
5.2. Event Extraction Using Traditional Machine Learning
5.3. Event Extraction Using Neural Networks
5.4. Use of Pretrained Neural Language Models
5.5. Cross-Lingual Event Extraction
5.6. Transfer Learning
5.7. Discussion
6. Temporal Relation Extraction
6.1. Temporal Relation Extraction Using Traditional Machine Learning
6.2. Temporal Relation Extraction Using Neural Networks
6.3. Use of Pretrained Neural Language Models
6.4. Use of External Knowledge
6.5. Large Language Models
6.6. Discussion
7. Timeline and Knowledge Graph Construction
7.1. Constructing Temporal Knowledge Graphs
7.2. Estimating Event Timelines
7.3. Estimating Event Duration
7.4. Discussion
8. Discussion and Future Research Directions
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. Dbpedia–a large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Wang, Y.; Zhu, M.; Qu, L.; Spaniol, M.; Weikum, G. Timely yago: Harvesting, querying, and visualizing temporal knowledge from wikipedia. In Proceedings of the 13th International Conference on Extending Database Technology, Lausanne, Switzerland, 22–26 March 2010; pp. 697–700. [Google Scholar]
- Hwang, J.D.; Bhagavatula, C.; Le Bras, R.; Da, J.; Sakaguchi, K.; Bosselut, A.; Choi, Y. (Comet-) atomic 2020: On symbolic and neural commonsense knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 6384–6392. [Google Scholar]
- Riloff, E. Automatically constructing a dictionary for information extraction tasks. In Proceedings of the Eleventh National Conference on Artificial Intelligence, Washington, DC, USA, 11–15 July 1993; pp. 811–816. [Google Scholar]
- Riloff, E.; Shoen, J. Automatically acquiring conceptual patterns without an annotated corpus. In Proceedings of the Third Workshop on Very Large Corpora, Cambridge, MA, USA, 30 June 1995. [Google Scholar]
- Kim, J.T.; Moldovan, D.I. Acquisition of linguistic patterns for knowledge-based information extraction. IEEE Trans. Knowl. Data Eng. 1995, 7, 713–724. [Google Scholar]
- Grishman, R.; Westbrook, D.; Meyers, A. Nyu’s english ace 2005 system description. ACE 2005, 5, 2. [Google Scholar]
- Ahn, D. The stages of event extraction. In Proceedings of the Workshop on Annotating and Reasoning about Time and Events, Sydney, Australia, 23 July 2006; pp. 1–8. [Google Scholar]
- Yang, B.; Mitchell, T. Joint Extraction of Events and Entities within a Document Context. In Proceedings of the NAACL-HLT, San Diego, CA, USA, 17 June 2016; pp. 289–299. [Google Scholar]
- Chen, Y.; Xu, L.; Liu, K.; Zeng, D.; Zhao, J. Event extraction via dynamic multi-pooling convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 167–176. [Google Scholar]
- Nguyen, T.H.; Cho, K.; Grishman, R. Joint event extraction via recurrent neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 300–309. [Google Scholar]
- Sha, L.; Qian, F.; Chang, B.; Sui, Z. Jointly extracting event triggers and arguments by dependency-bridge RNN and tensor-based argument interaction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Liu, X.; Luo, Z.; Huang, H. Jointly multiple events extraction via attention-based graph information aggregation. arXiv 2018, arXiv:1809.09078. [Google Scholar]
- Liu, J.; Chen, Y.; Liu, K.; Zhao, J. Neural cross-lingual event detection with minimal parallel resources. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 738–748. [Google Scholar]
- Zhang, J.; Qin, Y.; Zhang, Y.; Liu, M.; Ji, D. Extracting Entities and Events as a Single Task Using a Transition-Based Neural Model. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 5422–5428. [Google Scholar]
- Zhang, J.; Liu, M.; Zhang, Y. Topic-informed neural approach for biomedical event extraction. Artif. Intell. Med. 2020, 103, 101783. [Google Scholar] [CrossRef]
- Ji, H. Cross-lingual predicate cluster acquisition to improve bilingual event extraction by inductive learning. In Proceedings of the Workshop on Unsupervised and Minimally Supervised Learning of Lexical Semantics, Boulder, CO, USA, 5 June 2009; pp. 27–35. [Google Scholar]
- Zhu, Z.; Li, S.; Zhou, G.; Xia, R. Bilingual event extraction: A case study on trigger type determination. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 842–847. [Google Scholar]
- Chen, Z.; Ji, H. Can one language bootstrap the other: A case study on event extraction. In Proceedings of the NAACL HLT 2009 Workshop on Semi-Supervised Learning for Natural Language Processing, Boulder, CO, USA, 4 June 2009; pp. 66–74. [Google Scholar]
- Liu, J.; Chen, Y.; Liu, K.; Bi, W.; Liu, X. Event extraction as machine reading comprehension. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1641–1651. [Google Scholar]
- Lu, Y.; Lin, H.; Xu, J.; Han, X.; Tang, J.; Li, A.; Sun, L.; Liao, M.; Chen, S. Text2Event: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 16–20 November 2021; pp. 2795–2806. [Google Scholar]
- Gaizauskas, R.; Harkema, H.; Hepple, M.; Setzer, A. Task-oriented extraction of temporal information: The case of clinical narratives. In Proceedings of the Thirteenth International Symposium On Temporal Representation And Reasoning (time’06), Budapest, Hungary, 15–17 June 2006; pp. 188–195. [Google Scholar]
- Mani, I.; Verhagen, M.; Wellner, B.; Lee, C.; Pustejovsky, J. Machine learning of temporal relations. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 17–18 July 2006; pp. 753–760. [Google Scholar]
- Bethard, S. Cleartk-timeml: A minimalist approach to tempeval 2013. In Proceedings of the Second Joint Conference on Lexical and Computational Semantics (* SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), Atlanta, GA, USA, 14–15 June 2013; pp. 10–14. [Google Scholar]
- Lin, C.; Dligach, D.; Miller, T.A.; Bethard, S.; Savova, G.K. Multilayered temporal modeling for the clinical domain. J. Am. Med. Inform. Assoc. 2016, 23, 387–395. [Google Scholar] [CrossRef] [PubMed]
- Ning, Q.; Feng, Z.; Roth, D. A Structured Learning Approach to Temporal Relation Extraction. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 1027–1037. [Google Scholar]
- Tourille, J.; Ferret, O.; Neveol, A.; Tannier, X. Neural architecture for temporal relation extraction: A Bi-LSTM approach for detecting narrative containers. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 224–230. [Google Scholar]
- Dligach, D.; Miller, T.; Lin, C.; Bethard, S.; Savova, G. Neural temporal relation extraction. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, Valencia, Spain, 3–7 April 2017; pp. 746–751. [Google Scholar]
- Lin, C.; Miller, T.; Dligach, D.; Bethard, S.; Savova, G. A BERT-based universal model for both within-and cross-sentence clinical temporal relation extraction. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, Minneapolis, MN, USA, 7 June 2019; pp. 65–71. [Google Scholar]
- Cheng, F.; Miyao, Y. Classifying temporal relations by bidirectional LSTM over dependency paths. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1–6. [Google Scholar]
- Leeuwenberg, A.; Moens, M.F. Temporal Information Extraction by Predicting Relative Time-lines. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1237–1246. [Google Scholar]
- Zhou, Y.; Yan, Y.; Han, R.; Caufield, H.J.; Chang, K.W.; Sun, Y.; Ping, P.; Wang, W. Clinical Temporal Relation Extraction with Probabilistic Soft Logic Regularization and Global Inference. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI’21), Virtual, 2–9 February 2021. [Google Scholar]
- Zhang, S.; Huang, L.; Ning, Q. Extracting Temporal Event Relation with Syntactic-Guided Temporal Graph Transformer. arXiv 2021, arXiv:2104.09570. [Google Scholar]
- Xu, X.; Gao, T.; Wang, Y.; Xuan, X. Event temporal relation extraction with attention mechanism and graph neural network. Tsinghua Sci. Technol. 2021, 27, 79–90. [Google Scholar] [CrossRef]
- Mathur, P.; Jain, R.; Dernoncourt, F.; Morariu, V.; Tran, Q.H.; Manocha, D. TIMERS: Document-level Temporal Relation Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Virtual, 1–6 August 2021; pp. 524–533. [Google Scholar]
- Ning, Q.; Wu, H.; Peng, H.; Roth, D. Improving Temporal Relation Extraction with a Globally Acquired Statistical Resource. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 841–851. [Google Scholar]
- Ning, Q.; Subramanian, S.; Roth, D. An Improved Neural Baseline for Temporal Relation Extraction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6203–6209. [Google Scholar]
- Han, R.; Zhou, Y.; Peng, N. Domain Knowledge Empowered Structured Neural Net for End-to-End Event Temporal Relation Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 5717–5729. [Google Scholar]
- Leeuwenberg, A.; Moens, M.F. Towards extracting absolute event timelines from english clinical reports. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2710–2719. [Google Scholar] [CrossRef]
- Vashishtha, S.; Van Durme, B.; White, A.S. Fine-grained temporal relation extraction. arXiv 2019, arXiv:1902.01390. [Google Scholar]
- Pan, F.; Mulkar-Mehta, R.; Hobbs, J.R. Annotating and learning event durations in text. Comput. Linguist. 2011, 37, 727–752. [Google Scholar] [CrossRef]
- Gusev, A.; Chambers, N.; Khilnani, D.R.; Khaitan, P.; Bethard, S.; Jurafsky, D. Using query patterns to learn the duration of events. In Proceedings of the Ninth International Conference on Computational Semantics (IWCS 2011), Oxford, UK, 12–14 January 2011. [Google Scholar]
- Vempala, A.; Blanco, E.; Palmer, A. Determining event durations: Models and error analysis. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 164–168. [Google Scholar]
- Rospocher, M.; van Erp, M.; Vossen, P.; Fokkens, A.; Aldabe, I.; Rigau, G.; Soroa, A.; Ploeger, T.; Bogaard, T. Building event-centric knowledge graphs from news. J. Web Semant. 2016, 37, 132–151. [Google Scholar] [CrossRef]
- Ma, M.D.; Sun, J.; Yang, M.; Huang, K.H.; Wen, N.; Singh, S.; Han, R.; Peng, N. Eventplus: A temporal event understanding pipeline. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Demonstrations, Online, 6–11 June 2021; pp. 56–65. [Google Scholar]
- Jindal, P.; Roth, D. Extraction of events and temporal expressions from clinical narratives. J. Biomed. Inform. 2013, 46, S13–S19. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Nguyen, T.M.; Nguyen, T.H. One for all: Neural joint modeling of entities and events. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6851–6858. [Google Scholar]
- Han, X.; Gao, T.; Lin, Y.; Peng, H.; Yang, Y.; Xiao, C.; Liu, Z.; Li, P.; Zhou, J.; Sun, M. More Data, More Relations, More Context and More Openness: A Review and Outlook for Relation Extraction. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, Suzhou, China, 4–7 December 2020; pp. 745–758. [Google Scholar]
- Kumar, S. A survey of deep learning methods for relation extraction. arXiv 2017, arXiv:1705.03645. [Google Scholar]
- Pawar, S.; Palshikar, G.K.; Bhattacharyya, P. Relation extraction: A survey. arXiv 2017, arXiv:1712.05191. [Google Scholar]
- Smirnova, A.; Cudré-Mauroux, P. Relation extraction using distant supervision: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Liu, K. A survey on neural relation extraction. Sci. China Technol. Sci. 2020, 63, 1971–1989. [Google Scholar] [CrossRef]
- Bose, P.; Srinivasan, S.; Sleeman IV, W.C.; Palta, J.; Kapoor, R.; Ghosh, P. A survey on recent named entity recognition and relationship extraction techniques on clinical texts. Appl. Sci. 2021, 11, 8319. [Google Scholar] [CrossRef]
- Xiang, W.; Wang, B. A survey of event extraction from text. IEEE Access 2019, 7, 173111–173137. [Google Scholar] [CrossRef]
- Gumiel, Y.B.; Silva e Oliveira, L.E.; Claveau, V.; Grabar, N.; Paraiso, E.C.; Moro, C.; Carvalho, D.R. Temporal Relation Extraction in Clinical Texts: A Systematic Review. ACM Comput. Surv. (CSUR) 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Alfattni, G.; Peek, N.; Nenadic, G. Extraction of temporal relations from clinical free text: A systematic review of current approaches. J. Biomed. Inform. 2020, 108, 103488. [Google Scholar] [CrossRef] [PubMed]
- Abu-Salih, B. Domain-specific knowledge graphs: A survey. J. Netw. Comput. Appl. 2021, 185, 103076. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Yan, Z.; Tang, X. Hierarchical storyline generation based on event-centric temporal knowledge graph. In Proceedings of the International Symposium on Knowledge and Systems Sciences, Beijing, China, 11–12 June 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 149–159. [Google Scholar]
- Wang, X.; Liu, K.; Wang, D.; Wu, L.; Fu, Y.; Xie, X. Multi-level recommendation reasoning over knowledge graphs with reinforcement learning. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2098–2108. [Google Scholar]
- Bonifazi, G.; Cecchini, S.; Corradini, E.; Giuliani, L.; Ursino, D.; Virgili, L. Extracting time patterns from the lifespans of TikTok challenges to characterize non-dangerous and dangerous ones. Soc. Netw. Anal. Min. 2022, 12, 62. [Google Scholar] [CrossRef]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Sciarretta, L.; Ursino, D.; Virgili, L. A Space-Time Framework for Sentiment Scope Analysis in Social Media. Big Data Cogn. Comput. 2022, 6, 130. [Google Scholar] [CrossRef]
- Pustejovsky, J.; Saurí, R.; Setzer, A.; Gaizauskas, R.; Ingria, B. TimeML Annotation Guidelines; Brandeis University: Waltham, MA, USA, 2002; Volume 23. [Google Scholar]
- Walker, C.; Strassel, S.; Medero, J.; Maeda, K. ACE 2005 Multilingual Training Corpus; Linguistic Data Consortium: Philadelphia, PA, USA, 2005. [Google Scholar]
- Boguraev, B.; Pustejovsky, J.; Ando, R.; Verhagen, M. TimeBank evolution as a community resource for TimeML parsing. Lang. Resour. Eval. 2007, 41, 91–115. [Google Scholar] [CrossRef]
- Graff, D. The AQUAINT Corpus of English News Text; Linguistic Data Consortium: Philadelphia, PA, USA, 2002. [Google Scholar]
- Sun, W.; Rumshisky, A.; Uzuner, O. Evaluating temporal relations in clinical text: 2012 i2b2 Challenge. J. Am. Med. Inform. Assoc. 2013, 20, 806–813. [Google Scholar] [CrossRef]
- Mazur, P.; Dale, R. Wikiwars: A new corpus for research on temporal expressions. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; pp. 913–922. [Google Scholar]
- Allen, J.F.; Hayes, P.J. Moments and points in an interval-based temporal logic. Comput. Intell. 1989, 5, 225–238. [Google Scholar] [CrossRef]
- Saurí, R.; Littman, J.; Knippen, B.; Gaizauskas, R.; Setzer, A.; Pustejovsky, J. TimeML annotation guidelines. Version 2006, 1, 31. [Google Scholar]
- Haffar, N.; Hkiri, E.; Zrigui, M. TimeML Annotation of Events and Temporal Expressions in Arabic Texts. In Proceedings of the Computational Collective Intelligence, Hendaye, France, 4–6 September 2019; Nguyen, N.T., Chbeir, R., Exposito, E., Aniorté, P., Trawiński, B., Eds.; Springer: Cham, Switzerland, 2019; pp. 207–218. [Google Scholar]
- Pustejovsky, J.; Hanks, P.; Sauri, R.; See, A.; Gaizauskas, R.; Setzer, A.; Radev, D.; Sundheim, B.; Day, D.; Ferro, L.; et al. The timebank corpus. In Proceedings of the Corpus Linguistics, Lancaster, UK, 28–31 March 2003; Volume 2003, p. 40. [Google Scholar]
- Pustejovsky, J.; Littman, J.; Saurí, R.; Verhagen, M. Timebank 1.2 Documentation; Linguistic Data Consortium: Philadelphia, PA, USA, 2006; pp. 6–11, Event London no. April. [Google Scholar]
- Verhagen, M.; Gaizauskas, R.; Schilder, F.; Hepple, M.; Katz, G.; Pustejovsky, J. Semeval-2007 task 15: Tempeval temporal relation identification. In Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), Prague, Czech Republic, 23–24 June 2007; pp. 75–80. [Google Scholar]
- Verhagen, M.; Sauri, R.; Caselli, T.; Pustejovsky, J. SemEval-2010 Task 13: TempEval-2. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; pp. 57–62. [Google Scholar]
- UzZaman, N.; Llorens, H.; Derczynski, L.; Allen, J.; Verhagen, M.; Pustejovsky, J. Semeval-2013 task 1: Tempeval-3: Evaluating time expressions, events, and temporal relations. In Proceedings of the Second Joint Conference on Lexical and Computational Semantics (* SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), Atlanta, GA, USA, 14–15 June 2013; pp. 1–9. [Google Scholar]
- Parker, R.; Graff, D.; Kong, J.; Chen, K.; Maeda, K. English Gigaword, 5th ed.; Linguistic Data Consortium: Philadelphia, PA, USA, 2011. [Google Scholar]
- Cassidy, T.; McDowell, B.; Chambers, N.; Bethard, S. An Annotation Framework for Dense Event Ordering; Technical Report; Carnegie-Mellon University: Pittsburgh, PA, USA, 2014. [Google Scholar]
- Zhong, X.; Sun, A.; Cambria, E. Time expression analysis and recognition using syntactic token types and general heuristic rules. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 420–429. [Google Scholar]
- Bethard, S.; Derczynski, L.; Savova, G.; Pustejovsky, J.; Verhagen, M. Semeval-2015 task 6: Clinical tempeval. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 806–814. [Google Scholar]
- Bethard, S.; Savova, G.; Chen, W.T.; Derczynski, L.; Pustejovsky, J.; Verhagen, M. Semeval-2016 task 12: Clinical tempeval. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 1052–1062. [Google Scholar]
- Bethard, S.; Savova, G.; Palmer, M.; Pustejovsky, J. SemEval-2017 Task 12: Clinical TempEval. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 565–572. [Google Scholar] [CrossRef]
- Caselli, T.; Miller, B.; van Erp, M.; Vossen, P.; Palmer, M.; Hovy, E.; Mitamura, T.; Caswell, D. Events and Stories in the News. In Proceedings of the Events and Stories in the News Workshop, Vancouver, BC, Canada, 4 August 2017. [Google Scholar]
- Naik, A.; Breitfeller, L.; Rose, C. TDDiscourse: A dataset for discourse-level temporal ordering of events. In Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue, Stockholm, Sweden, 11–13 September 2019; pp. 239–249. [Google Scholar]
- Hong, Y.; Zhang, T.; O’Gorman, T.; Horowit-Hendler, S.; Ji, H.; Palmer, M. Building a cross-document event-event relation corpus. In Proceedings of the 10th Linguistic Annotation Workshop held in conjunction with ACL 2016 (LAW-X 2016), Berlin, Germany, 11 August 2016; pp. 1–6. [Google Scholar]
- Bittar, A.; Amsili, P.; Denis, P.; Danlos, L. French TimeBank: An ISO-TimeML annotated reference corpus. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 130–134. [Google Scholar]
- Costa, F.; Branco, A. TimeBankPT: A TimeML annotated corpus of Portuguese. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012; pp. 3727–3734. [Google Scholar]
- Jeong, Y.S.; Kim, Z.M.; Do, H.W.; Lim, C.G.; Choi, H.J. Temporal information extraction from Korean texts. In Proceedings of the Nineteenth Conference on Computational Natural Language Learning, Beijing, China, 30–31 July 2015; pp. 279–288. [Google Scholar]
- Wonsever, D.; Rosá, A.; Malcuori, M.; Moncecchi, G.; Descoins, A. Event annotation schemes and event recognition in spanish texts. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, New Delhi, India, 11–17 March 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 206–218. [Google Scholar]
- Forăscu, C.; Tufiş, D. Romanian TimeBank: An annotated parallel corpus for temporal information. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012; pp. 3762–3766. [Google Scholar]
- Caselli, T.; Lenzi, V.B.; Sprugnoli, R.; Pianta, E.; Prodanof, I. Annotating events, temporal expressions and relations in Italian: The It-TimeML experience for the Ita-TimeBank. In Proceedings of the 5th Linguistic Annotation Workshop, Portland, OR, USA, 23–24 June 2011; pp. 143–151. [Google Scholar]
- Llorens, H.; Chambers, N.; UzZaman, N.; Mostafazadeh, N.; Allen, J.; Pustejovsky, J. Semeval-2015 task 5: Qa tempeval-evaluating temporal information understanding with question answering. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 792–800. [Google Scholar]
- Chen, W.; Wang, X.; Wang, W.Y. A Dataset for Answering Time-Sensitive Questions. arXiv 2021, arXiv:2108.06314. [Google Scholar]
- Li, L.; Wan, J.; Zheng, J.; Wang, J. Biomedical event extraction based on GRU integrating attention mechanism. BMC Bioinform. 2018, 19, 93–100. [Google Scholar] [CrossRef] [PubMed]
- Cinelli, L.P.; de Oliveira, J.F.; de Pinho, V.M.; Passos, W.L.; Padilla, R.; Braz, P.F.; Galves, B.; Dalvi, D.P.; Lewenfus, G.; Ferreira, J.O.; et al. Automatic event identification and extraction from daily drilling reports using an expert system and artificial intelligence. J. Pet. Sci. Eng. 2021, 205, 108939. [Google Scholar] [CrossRef]
- Liu, J.; Huang, X. Forecasting crude oil price using event extraction. IEEE Access 2021, 9, 149067–149076. [Google Scholar] [CrossRef]
- Event. Oxford English Dictionary; Oxford University Press: Oxford, UK, 2022. [Google Scholar]
- Caufield, J.H.; Zhou, Y.; Bai, Y.; Liem, D.A.; Garlid, A.O.; Chang, K.W.; Sun, Y.; Ping, P.; Wang, W. A comprehensive typing system for information extraction from clinical narratives. medRxiv 2019. [Google Scholar] [CrossRef]
- Ebner, S.; Xia, P.; Culkin, R.; Rawlins, K.; Van Durme, B. Multi-Sentence Argument Linking. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Guda, V.; Sanampudi, S.K. Rules based event extraction from natural language text. In Proceedings of the 2016 IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 20–21 May 2016; pp. 9–13. [Google Scholar]
- Piskorski, J.; Tanev, H.; Atkinson, M.; Goot, E.v.d.; Zavarella, V. Online news event extraction for global crisis surveillance. In Transactions on Computational Collective Intelligence V; Springer: Berlin/Heidelberg, Germany, 2011; pp. 182–212. [Google Scholar]
- Iqbal, K.; Khan, M.Y.; Wasi, S.; Mahboob, S.; Ahmed, T. On extraction of event information from social text streams: An unpretentious nlp solution. IJCSNS 2019, 19, 1. [Google Scholar]
- Cohen, K.B.; Verspoor, K.; Johnson, H.L.; Roeder, C.; Ogren, P.V.; Baumgartner, W.A., Jr.; White, E.; Tipney, H.; Hunter, L. High-Precision biological event extraction: Effects of system and of data. Comput. Intell. 2011, 27, 681–701. [Google Scholar] [CrossRef][Green Version]
- Kovačević, A.; Dehghan, A.; Filannino, M.; Keane, J.A.; Nenadic, G. Combining rules and machine learning for extraction of temporal expressions and events from clinical narratives. J. Am. Med. Inform. Assoc. 2013, 20, 859–866. [Google Scholar] [CrossRef]
- Hong, J.; Davoudi, A.; Yu, S.; Mowery, D.L. Annotation and extraction of age and temporally-related events from clinical histories. BMC Med. Inform. Decis. Mak. 2020, 20, 1–15. [Google Scholar] [CrossRef]
- Baradaran, R.; Minaei-Bidgoli, B. Event Extraction from Classical Arabic Texts. Int. Arab J. Inf. Technol. 2015, 12, 494–502. [Google Scholar]
- Saha, S.; Majumder, A.; Hasanuzzaman, M.; Ekbal, A. Bio-molecular event extraction using Support Vector Machine. In Proceedings of the 2011 Third International Conference on Advanced Computing, Seoul, Republic of Korea, 27–29 September 2011; pp. 298–303. [Google Scholar]
- Sinha, D.; Garain, U.; Bandyopadhyay, S. Event extraction from cancer genetics literature. In Proceedings of the 2015 Eighth International Conference on Advances in Pattern Recognition (ICAPR), Kolkata, India, 4–7 January 2015; pp. 1–6. [Google Scholar]
- Li, Z.; Liu, F.; Antieau, L.; Cao, Y.; Yu, H. Lancet: A high precision medication event extraction system for clinical text. J. Am. Med. Inform. Assoc. 2010, 17, 563–567. [Google Scholar] [CrossRef] [PubMed]
- Abdulkadhar, S.; Bhasuran, B.; Natarajan, J. Multiscale Laplacian graph kernel combined with lexico-syntactic patterns for biomedical event extraction from literature. Knowl. Inf. Syst. 2021, 63, 143–173. [Google Scholar] [CrossRef]
- Jain, P.; Bendapudi, H.; Rao, S. EEQUEST: An event extraction and query system. In Proceedings of the 9th Annual ACM India Conference, Gandhinagar, India, 21–23 October 2016; pp. 59–66. [Google Scholar]
- Smadi, M.; Qawasmeh, O. A supervised machine learning approach for events extraction out of Arabic tweets. In Proceedings of the 2018 Fifth International Conference on Social Networks Analysis, Management and Security (SNAMS), Valencia, Spain, 15–18 October 2018; pp. 114–119. [Google Scholar]
- Miwa, M.; Ananiadou, S. Adaptable, high recall, event extraction system with minimal configuration. BMC Bioinform. 2015, 16, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Han, X.; Kim, J.J.; Kwoh, C.K. Active learning for ontological event extraction incorporating named entity recognition and unknown word handling. J. Biomed. Semant. 2016, 7, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Majumder, A.; Ekbal, A.; Naskar, S.K. Bio-molecular event extraction by integrating multiple event-extraction systems. Sādhanā 2019, 44, 1–7. [Google Scholar] [CrossRef]
- Yi, S.X.; Li, C.Y. Exploring Multiple Embedded Features on Event Extraction. J. Phys. Conf. Ser. 2019, 1267, 012033. [Google Scholar] [CrossRef]
- Yu, W.; Yi, M.; Huang, X.; Yi, X.; Yuan, Q. Make it directly: Event extraction based on tree-LSTM and bi-GRU. IEEE Access 2020, 8, 14344–14354. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, Z.; Bai, L.; Wan, Y.; Cui, L.; Zhao, Q.; Hancock, E.R.; Philip, S.Y. Cross-Supervised Joint-Event-Extraction with Heterogeneous Information Networks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 278–285. [Google Scholar]
- Zeng, Y.; Yang, H.; Feng, Y.; Wang, Z.; Zhao, D. A convolution BiLSTM neural network model for Chinese event extraction. In Natural Language Understanding and Intelligent Applications; Springer: Berlin/Heidelberg, Germany, 2016; pp. 275–287. [Google Scholar]
- Sahoo, S.K.; Saha, S.; Ekbal, A.; Bhattacharyya, P. A platform for event extraction in hindi. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 2241–2250. [Google Scholar]
- Guo, K.; Jiang, T.; Zhang, H. Knowledge graph enhanced event extraction in financial documents. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 1322–1329. [Google Scholar]
- Wu, X.; Wang, T.; Fan, Y.; Yu, F. Chinese Event Extraction via Graph Attention Network. Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 1–12. [Google Scholar] [CrossRef]
- He, X.; Yu, B.; Ren, Y. SWACG: A Hybrid Neural Network Integrating Sliding Window for Biomedical Event Trigger Extraction. J. Imaging Sci. Technol. 2021, 65, 60502. [Google Scholar] [CrossRef]
- Ju, M.; Nguyen, N.T.; Miwa, M.; Ananiadou, S. An ensemble of neural models for nested adverse drug events and medication extraction with subwords. J. Am. Med. Inform. Assoc. 2020, 27, 22–30. [Google Scholar] [CrossRef]
- Gao, J.; Luo, X.; Wang, H.; Wang, Z. Causal Event Extraction using Iterated Dilated Convolutions with Semantic Convolutional Filters. In Proceedings of the 2021 IEEE 33rd International Conference on Tools with Artificial Intelligence (ICTAI), Washington, DC, USA, 1–3 November 2021; pp. 619–623. [Google Scholar]
- El-allaly, E.D.; Sarrouti, M.; En-Nahnahi, N.; El Alaoui, S.O. MTTLADE: A multi-task transfer learning-based method for adverse drug events extraction. Inf. Process. Manag. 2021, 58, 102473. [Google Scholar] [CrossRef]
- Magge, A.; Tutubalina, E.; Miftahutdinov, Z.; Alimova, I.; Dirkson, A.; Verberne, S.; Weissenbacher, D.; Gonzalez-Hernandez, G. DeepADEMiner: A deep learning pharmacovigilance pipeline for extraction and normalization of adverse drug event mentions on Twitter. J. Am. Med. Inform. Assoc. 2021, 28, 2184–2192. [Google Scholar] [CrossRef] [PubMed]
- Lybarger, K.; Ostendorf, M.; Thompson, M.; Yetisgen, M. Extracting COVID-19 diagnoses and symptoms from clinical text: A new annotated corpus and neural event extraction framework. J. Biomed. Inform. 2021, 117, 103761. [Google Scholar] [CrossRef] [PubMed]
- Fan, B.; Fan, W.; Smith, C. Adverse drug event detection and extraction from open data: A deep learning approach. Inf. Process. Manag. 2020, 57, 102131. [Google Scholar] [CrossRef]
- Zhang, Z.; Kong, X.; Liu, Z.; Ma, X.; Hovy, E. A two-step approach for implicit event argument detection. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7479–7485. [Google Scholar]
- Li, B.; Fang, G.; Yang, Y.; Wang, Q.; Ye, W.; Zhao, W.; Zhang, S. Evaluating ChatGPT’s Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness. arXiv 2023, arXiv:2304.11633. [Google Scholar]
- Wei, X.; Cui, X.; Cheng, N.; Wang, X.; Zhang, X.; Huang, S.; Xie, P.; Xu, J.; Chen, Y.; Zhang, M.; et al. Zero-shot information extraction via chatting with chatgpt. arXiv 2023, arXiv:2302.10205. [Google Scholar]
- Gao, J.; Zhao, H.; Yu, C.; Xu, R. Exploring the feasibility of chatgpt for event extraction. arXiv 2023, arXiv:2303.03836. [Google Scholar]
- Zhang, T.; Whitehead, S.; Zhang, H.; Li, H.; Ellis, J.; Huang, L.; Liu, W.; Ji, H.; Chang, S.F. Improving event extraction via multimodal integration. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 270–278. [Google Scholar]
- Dorr, B.J.; Gaasterland, T. Exploiting aspectual features and connecting words for summarization-inspired temporal-relation extraction. Inf. Process. Manag. 2007, 43, 1681–1704. [Google Scholar] [CrossRef]
- Yuan, C.; Xie, Q.; Ananiadou, S. Zero-shot temporal relation extraction with chatgpt. arXiv 2023, arXiv:2304.05454. [Google Scholar]
- Chan, C.; Cheng, J.; Wang, W.; Jiang, Y.; Fang, T.; Liu, X.; Song, Y. Chatgpt evaluation on sentence level relations: A focus on temporal, causal, and discourse relations. arXiv 2023, arXiv:2304.14827. [Google Scholar]
- Shi, Y.; Xiao, Y.; Quan, P.; Lei, M.; Niu, L. Document-level relation extraction via graph transformer networks and temporal convolutional networks. Pattern Recognit. Lett. 2021, 149, 150–156. [Google Scholar] [CrossRef]
- Zhao, S.; Li, L.; Lu, H.; Zhou, A.; Qian, S. Associative attention networks for temporal relation extraction from electronic health records. J. Biomed. Inform. 2019, 99, 103309. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.; Miller, T.; Dligach, D.; Sadeque, F.; Bethard, S.; Savova, G. A BERT-based one-pass multi-task model for clinical temporal relation extraction. In Proceedings of the 19th SIGBioMed Workshop on Biomedical Language Processing, Online, 9 July 2020. [Google Scholar]
- Kanev, A.; Terekhov, V.; Chernenky, V.; Proletarsky, A. Metagraph Knowledge Base and Natural Language Processing Pipeline for Event Extraction and Time Concept Analysis. In Proceedings of the 2021 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus), St. Petersburg, Russia, 26–29 January 2021; pp. 2104–2109. [Google Scholar]
- Ray, P.P. ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things-Cyber-Phys. Syst. 2023, 3, 121–154. [Google Scholar] [CrossRef]
- Labrak, Y.; Rouvier, M.; Dufour, R. A zero-shot and few-shot study of instruction-finetuned large language models applied to clinical and biomedical tasks. arXiv 2023, arXiv:2307.12114. [Google Scholar]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2901–2908. [Google Scholar]
- Gottschalk, S.; Demidova, E. EventKG: A multilingual event-centric temporal knowledge graph. In Proceedings of the European Semantic Web Conference, Crete, Greece, 3–7 June 2018; pp. 272–287. [Google Scholar]
- Mo, C.; Wang, Y.; Jia, Y.; Liao, Q. Survey on temporal knowledge graph. In Proceedings of the 2021 IEEE Sixth International Conference on Data Science in Cyberspace (DSC), Shenzhen, China, 9–11 October 2021; pp. 294–300. [Google Scholar]
- Song, Y. Construction of Event Knowledge Graph based on Semantic Analysis. Teh. Vjesn. 2021, 28, 1640–1646. [Google Scholar]
- Leetaru, K.; Schrodt, P.A. Gdelt: Global data on events, location, and tone, 1979–2012. In Proceedings of the ISA Annual Convention, San Francisco, CA, USA, 3–6 April 2013; Volume 2, pp. 1–49. [Google Scholar]
- Zwolski, K. Integrating crisis early warning systems: Power in the community of practice. J. Eur. Integr. 2016, 38, 393–407. [Google Scholar] [CrossRef]
- Gottschalk, S.; Demidova, E.; Bernacchi, V.; Rogers, R. Ongoing events in Wikipedia: A cross-lingual case study. In Proceedings of the 2017 ACM on Web Science Conference, Troy, NY, USA, 25–28 June 2017; pp. 387–388. [Google Scholar]
- Rogers, R. Digital Methods; MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Singhal, P.; Guare, L.; Morse, C.; Lucas, A.; Byrska-Bishop, M.; Guerraty, M.A.; Kim, D.; Ritchie, M.D.; Verma, A. DETECT: Feature extraction method for disease trajectory modeling in electronic health records. AMIA Summits Transl. Sci. Proc. 2023, 2023, 487. [Google Scholar]
- Fatemi, M.; Killian, T.W.; Subramanian, J.; Ghassemi, M. Medical dead-ends and learning to identify high-risk states and treatments. Adv. Neural Inf. Process. Syst. 2021, 34, 4856–4870. [Google Scholar]




| Dataset | Year | Domain | Amount of Data | Documents Origin |
|---|---|---|---|---|
| TimeBank 1.1 | 2003 | News | 186 documents | Original |
| TimeBank 1.2 | 2006 | News | 183 documents | Original |
| AQUAINT | 2002 | News | 73 documents | Original |
| TempEval | 2007 | News | 183 documents | TimeBank 1.2 |
| TempEval-2 | 2010 | News | 183 documents | TimeBank 1.2 |
| TempEval-3 | 2013 | News | 61 k TimeBank tokens 34 k AQUAINT tokens 666 k new silver tokens 20 k new gold tokens 20 k new evaluation tokens | TimeBank 1.2 AQUAINT Gigaword |
| TB-Dense | 2014 | News | 36 documents | TimeBank 1.2 |
| MATRES | 2018 | News | 36 documents | TimeBank-Dense |
| Tweets | 2017 | 942 documents (18 k tokens) | Original |
| Dataset | Year | Domain | Amount of Data |
|---|---|---|---|
| WikiWars | 2010 | Wikipedia articles about famous wars | 22 documents 120 k tokens |
| i2b2 2012 | 2012 | Discharge summaries | 310 documents 178 k tokens |
| THYME (TempEval 2015) | 2015 | Notes on colon cancer | 440 documents |
| THYME (TempEval 2016) | 2016 | Notes on colon cancer | 600 documents |
| THYME (TempEval 2017) | 2017 | Notes on colon and brain cancer | 591 colon documents 595 brain documents |
| Dataset | Year | Domain | Amount of Data |
|---|---|---|---|
| Event StoryLine Corpus | 2018 | News articles | 281 documents |
| Fine-grained temporal relations [42] | 2019 | English Web Treebank | 250 k tokens |
| Leeuwenberg and Moens [41] | 2020 | Discharge summaries | 310 summaries |
| TDDiscourse | 2019 | News articles | 36 documents |
| Cross-document event corpus | 2016 | News articles | 125 documents |
| Dataset | Language | Number of Tokens |
|---|---|---|
| ACE 2005 [66] | English, Arabic, Chinese | 750,000 |
| FR-TB [88] | French | 61,000 |
| Korean TB [90] | Korean | — |
| Spanish TB [91] | Spanish | 68,000 |
| IT-TimeBank [93] | Italian | 150,000 |
| TimeBank-PT [89] | Portuguese | 70,000 |
| Ro-TimeBank [92] | Romanian | 65,375 |
| Arabic TB [73] | Arabic | 95,782 |
| System | Extraction Method | Corpus | Event Identification | Event Classification | Argument Identification | Argument Role Classification |
|---|---|---|---|---|---|---|
| AutoSlog [6] | Semi automatic pattern generation | MUC-4 | - | - | - | - |
| PALKA [8] | Automatic pattern generation with labeled corpus | MUC-4 | - | - | - | - |
| AutoSlog-TS [7] | Automatic pattern generation without labeled corpus | MUC-4 | - | - | - | - |
| NYU’s ACE 2005 [9] | Event extraction and entity coreference using machine learning | ACE 2005 | - | - | - | - |
| Chen et al. (2015) [12] | Convolutional neural networks | ACE 2005 | 0.735 | 0.691 | 0.591 | 0.535 |
| Nguyen et al. (2016) [13] | Recurrent neural networks | ACE 2005 | 0.719 | 0.693 | 0.628 | 0.554 |
| Sha et al. (2018) [14] | Recurrent neural networks with depencency bridges | ACE 2005 | - | 0.719 | 0.677 | 0.587 |
| Zhang et al. (2017) [136] | Multimodal event extraction | ACE, ERE | - | 0.693 | - | 0.559 |
| Zhang et al. (2019) [17] | Transition-based neural model | ACE 2005 | 0.761 | 0.738 | 0.574 | 0.533 |
| System | Model Used | Corpus | EE | ET |
|---|---|---|---|---|
| Verhagen et al. (2006) [76] | Hand-crafted rules | TimeBank | - | 0.64 |
| Mani et al. (2006) [25] | SVM and ME models | TimeBank Opinion Corpus | 0.625 | 0.761 |
| Bethard (2013) [26] | ME model | TimeBank AQUAINT Verb-clause | 0.31 | - |
| Lin et al. (2016) [27] | SVM | THYME i2b2 2012 | 0.645 | 0.83 |
| Ning et al. (2017) [28] | structured perceptron | TimeBank AQUAINT Verb-clause TB Dense | 0.403 | - |
| System | Model | Contains Only | F-Score |
|---|---|---|---|
| Dataset: THYME | |||
| Tourille et al. (2017) [29] | Bi-LSTM | ✗ | 0.683 |
| Dligach et al. (2017) [30] | CNN | ✓ | EE: 0.54, ET: 0.71 |
| Lin et al. (2019) [31] | BERT | ✓ | 0.684 |
| Dataset: TimeBank-Dense | |||
| Cheng and Miyao (2017) [32] | Bi-LSTM | ✗ | EE: 0.53, ET: 0.47 |
| Leeuwenberg and Moens (2018) [33] | Bi-LSTM | ✗ | 0.561 |
| Zhou et al. (2021) [34] | soft logic | ✗ | 0.652 |
| Zhang et al. (2021) [35] | BERT + GNN | ✗ | 0.667 |
| Xu et al. (2021) [36] | BERT + GNN | ✗ | 0.732 |
| Mathur et al. (2021) [37] | BERT + GNN | ✗ | 0.678 |
| Yuan et al. (2023) [138] | ChatGPT | ✗ | 0.366 |
| Chan et al. (2023) [139] | ChatGPT | ✗ | 0.233 |
| Dataset: i2b2 2012 | |||
| Zhou et al. (2021) [34] | Soft logic | ✗ | 0.802 |
| Dataset: MATRES | |||
| Zhang et al. (2021) [35] | BERT + GNN | ✗ | 0.793 |
| Mathur et al. (2021) [37] | BERT + GNN | ✗ | 0.823 |
| Yuan et al. (2023) [138] | ChatGPT | ✗ | 0.193 |
| Chan et al. (2023) [139] | ChatGPT | ✗ | 0.350 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Knez, T.; Žitnik, S. Event-Centric Temporal Knowledge Graph Construction: A Survey. Mathematics 2023, 11, 4852. https://doi.org/10.3390/math11234852
Knez T, Žitnik S. Event-Centric Temporal Knowledge Graph Construction: A Survey. Mathematics. 2023; 11(23):4852. https://doi.org/10.3390/math11234852
Chicago/Turabian StyleKnez, Timotej, and Slavko Žitnik. 2023. "Event-Centric Temporal Knowledge Graph Construction: A Survey" Mathematics 11, no. 23: 4852. https://doi.org/10.3390/math11234852
APA StyleKnez, T., & Žitnik, S. (2023). Event-Centric Temporal Knowledge Graph Construction: A Survey. Mathematics, 11(23), 4852. https://doi.org/10.3390/math11234852