
Integrating a Pareto-Distributed Scale into the Mixed Logit Model: A Mathematical Concept


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Conditional Logit Model
2.1. Derivations and Challenges
2.2. Research Question
3. The Mixed Logit and the Generalized Multinomial Logit Models
3.1. The Mixed Logit Model and Its Challenges
3.2. The Generalized Multinomial Logit Model and Its Challenges
4. Proposed Mixed Logit with Integrated Pareto-Distributed Scale Model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Simple Derivation of CL in Train [13]
Appendix B. Simple Derivation of CL in Marsili [25]
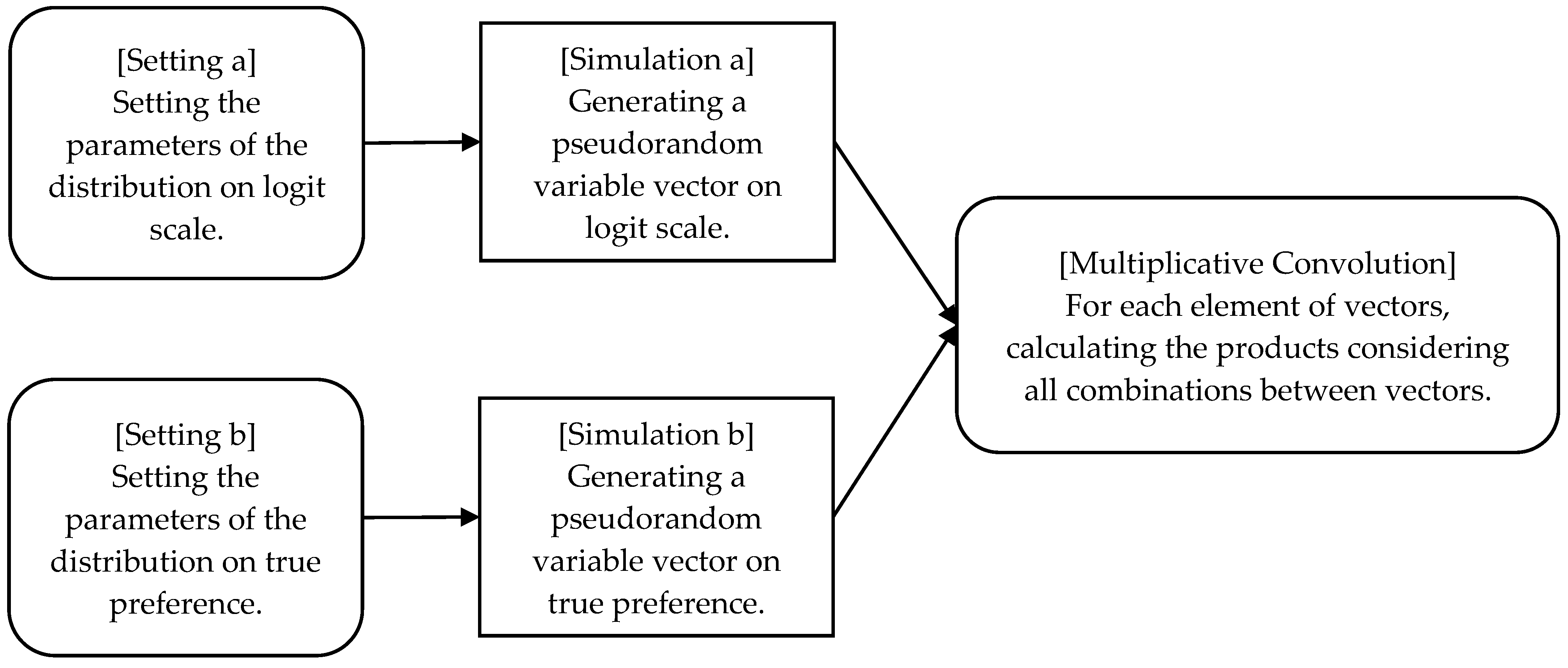
Appendix C. Simple Algorithm Diagram of the Simulations in This Paper
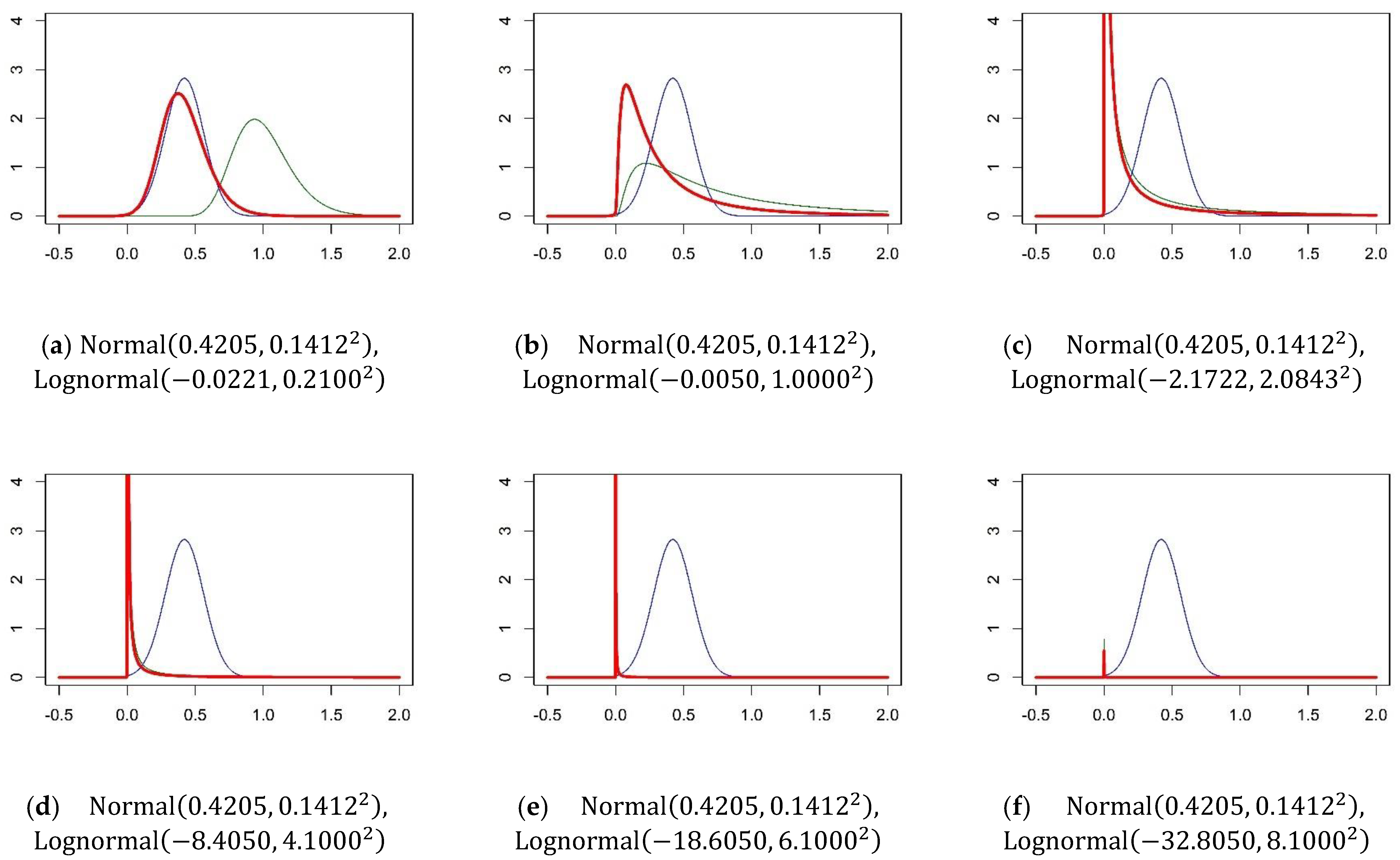
Appendix D. Properties of the Lognormal Distribution of the Logit Scale in the G-MNL Model
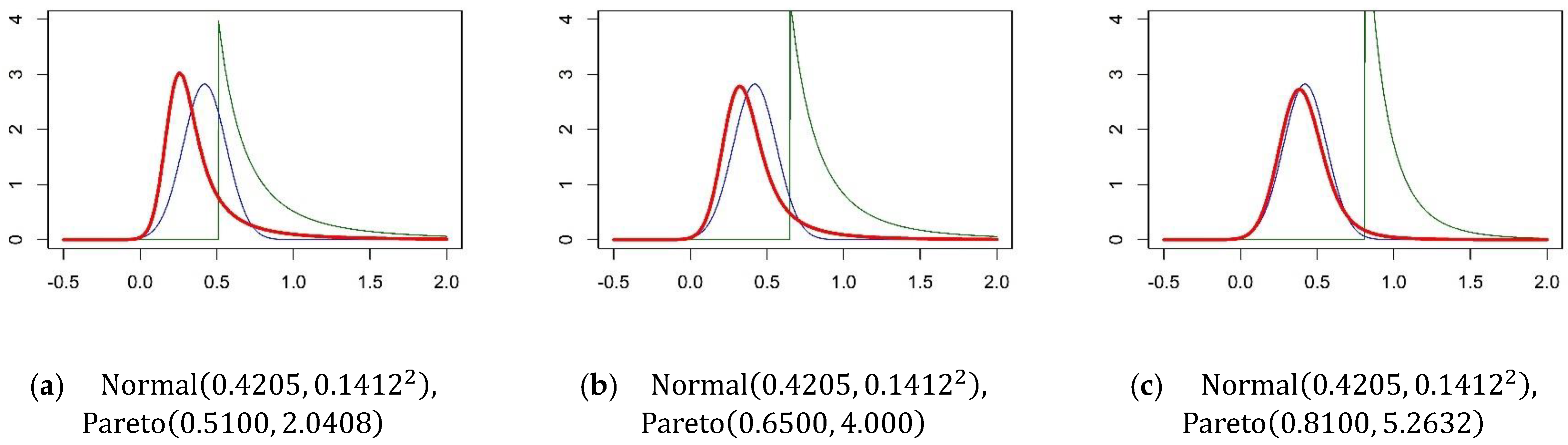
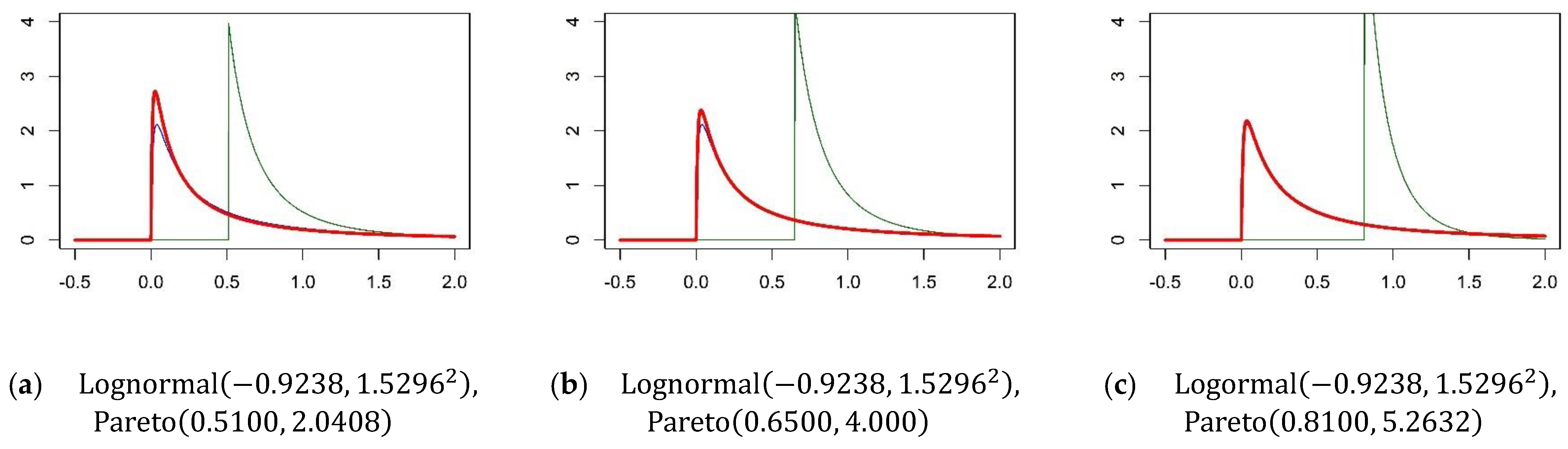
Appendix E. Properties of Type I Pareto Distribution of Logit Scale in the MIXL-iPS Model
References
- McFadden, D. Conditional logit analysis of qualitative choice behaviour. In Frontiers in Econometrics; Zarembka, P., Ed.; Academic Press: Berkwlly, CA, USA, 1974; pp. 105–142. [Google Scholar]
- Yellott, J.I. The relationship between Luce’s choice axiom, Thurstone’s theory of comparative judgment, and the double exponential distribution. J. Math. Psychol. 1977, 15, 109–144. [Google Scholar] [CrossRef]
- Luce, R.D. Individual Choice Behavior: A Theoretical Analysis; Wiley: New York, NY, USA, 1959. [Google Scholar]
- Thurstone, L.L. A law of comparative judgment. Psychol. Rev. 1927, 34, 273–286. [Google Scholar] [CrossRef]
- McKelvey, R.D.; Palfrey, T.R. Quantal response equilibria for normal form games. Games Econ. Behav. 1995, 10, 6–38. [Google Scholar] [CrossRef]
- Simon, H.A. Administrative Behavior: A Study of Decision-Making Processes in Administrative Organization; Macmillan Publishers: New York, NY, USA, 1947. [Google Scholar]
- Ratcliff, R. A theory of memory retrieval. Psychol. Rev. 1978, 85, 59–108. [Google Scholar] [CrossRef]
- Bogacz, R.; Brown, E.; Moehlis, J.; Holmes, P.; Cohen, J.D. The physics of optimal decision making: A formal analysis of models of performance in two-alternative forced-choice tasks. Psychol. Rev. 2006, 113, 700–765. [Google Scholar] [CrossRef]
- Webb, R. The (neural) dynamics of stochastic choice. Manag. Sci. 2019, 65, 230–255. [Google Scholar] [CrossRef]
- Davis-Stober, C.P.; Brown, N.; Park, S.; Regenwetter, M. Recasting a biologically motivated computational model within a Fechnerian and random utility framework. J. Math. Psychol. 2017, 77, 156–164. [Google Scholar] [CrossRef]
- Hensher, D.; Rose, J.; Greene, W. Applied Choice Analysis; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Louviere, J.J.; Hensher, D.A.; Swait, J.D. Stated Choice Methods: Analysis and Applications; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Train, K. Discrete Choice Methods with Simulation; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Meißner, M.; Decker, R. Eye-tracking information processing in choice-based conjoint analysis. Int. J. Mark. Res. 2010, 52, 593–612. [Google Scholar] [CrossRef]
- Revelt, D.; Train, K. Mixed logit with repeated choices: Households’ choices of appliance efficiency level. Rev. Econ. Stat. 1998, 80, 647–657. [Google Scholar] [CrossRef]
- Hausman, J.A.; Wise, D.A. A conditional probit model for qualitative choice: Discrete decisions recognizing interdependence and heterogeneous preferences. Econometrica 1978, 46, 403–426. [Google Scholar] [CrossRef]
- McFadden, D.; Train, K. Mixed MNL models for discrete response. J. Appl. Econom. 2000, 15, 447–470. [Google Scholar] [CrossRef]
- Hess, S.; Train, K. Correlation and scale in mixed logit models. J. Choice Model. 2017, 23, 1–8. [Google Scholar] [CrossRef]
- Fiebig, D.G.; Keane, M.P.; Louviere, J.; Wasi, N. The generalized multinomial logit model: Accounting for scale and coefficient heterogeneity. Mark. Sci. 2010, 29, 393–421. [Google Scholar] [CrossRef]
- Greene, W.H.; Hensher, D.A. Does scale heterogeneity across individuals matter? An empirical assessment of alternative logit models. Transportation 2010, 37, 413–428. [Google Scholar] [CrossRef]
- Ohdoko, T. Preliminary examination of generalized multinomial logit subclasses on choice experiments: Japanese undergraduate survey data on a takeaway cup of fair trade coffee. J. Inform. 2015, 6, 14–36, (with Japanese title and abstract). [Google Scholar]
- Adamska, J.; Bielak, Ł.; Janczura, J.; Wyłomańska, A. From multi-to univariate: A product random variable with an application to electricity market transactions: Pareto and student’s t-distribution Case. Mathematics 2022, 10, 3371. [Google Scholar] [CrossRef]
- Arnold, B.C. Pareto Distributions; Routledge: New York, NY, USA, 2015. [Google Scholar]
- Rezapour, M.; Ksaibati, K. Accommodating taste and scale heterogeneity for front-seat passenger’ choice of seat belt usage. Mathematics 2021, 9, 460. [Google Scholar] [CrossRef]
- Marsili, M. On the multinomial logit model. Phys. A Stat. Mech. Appl. 1999, 269, 9–15. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2006. [Google Scholar]
- Wang, H.; Yan, X.Y.; Wu, J. Free utility model for explaining the social gravity law. J. Stat. Mech. Theory Exp. 2021, 2021, 033418. [Google Scholar] [CrossRef]
- Brown, T.C.; Kingsley, D.; Peterson, G.L.; Flores, N.E.; Clarke, A.; Birjulin, A. Reliability of individual valuations of public and private goods: Choice consistency, response time, and preference refinement. J. Public Econ. 2008, 92, 1595–1606. [Google Scholar] [CrossRef]
- Swait, J.; Louviere, J. The role of the scale parameter in the estimation and comparison of multinomial logit models. J. Mark. Res. 1993, 30, 305–314. [Google Scholar] [CrossRef]
- Uggeldahl, K.; Jacobsen, C.; Lundhede, T.H.; Olsen, S.B. Choice certainty in discrete choice experiments: Will eye tracking provide useful measures? J. Choice Model. 2016, 20, 35–48. [Google Scholar] [CrossRef]
- Hess, S.; Stathopoulos, A. Linking response quality to survey engagement: A combined random scale and latent variable approach. J. Choice Model. 2013, 7, 1–12. [Google Scholar] [CrossRef]
- Daly, A.; Hess, S.; Train, K. Assuring finite moments for willingness to pay in random coefficient models. Transportation 2012, 39, 19–31. [Google Scholar] [CrossRef]
- Hess, S.; Palma, D. Apollo: A flexible, powerful and customisable freeware package for choice model estimation and application. J. Choice Model. 2019, 32, 100170. [Google Scholar] [CrossRef]
- Mariel, P.; Artabe, A. Interpreting correlated random parameters in choice experiments. J. Environ. Econ. Manag. 2020, 103, 102363. [Google Scholar] [CrossRef]
- Grüne-Yanoff, T. What preferences for behavioral welfare economics? J. Econ. Methodol. 2022, 29, 153–165. [Google Scholar] [CrossRef]
- Rohatgi, V.K.; Saleh, A.M.E. An Introduction to Probability and Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Hess, S.; Rose, J.M. Can scale and coefficient heterogeneity be separated in random coefficients models? Transportation 2012, 39, 1225–1239. [Google Scholar] [CrossRef]
- Ruckdeschel, P.; Kohl, M. General purpose convolution algorithm in S4 classes by means of FFT. J. Stat. Softw. 2014, 59, 1–25. [Google Scholar] [CrossRef]
- Ankamah-Yeboah, I.; Asche, F.; Bronnmann, J.; Nielsen, M.; Nielsen, R. Consumer preference heterogeneity and preference segmentation: The case of ecolabeled salmon in Danish retail sales. Mar. Resour. Econ. 2020, 35, 159–176. [Google Scholar] [CrossRef]
- Haaijer, R.; Wedel, M.; Vriens, M.; Wansbeek, T. Utility covariances and context effects in conjoint MNP models. Mark. Sci. 1998, 17, 236–252. [Google Scholar] [CrossRef]
- DeShazo, J.R.; Fermo, G. Designing choice sets for stated preference methods: The effects of complexity on choice consistency. J. Environ. Econ. Manag. 2002, 44, 123–143. [Google Scholar] [CrossRef]
- Matějka, F.; McKay, A. Rational inattention to discrete choices: A new foundation for the multinomial logit model. Am. Econ. Rev. 2015, 105, 272–298. [Google Scholar] [CrossRef]
- Fosgerau, M.; Melo, E.; de Palma, A.; Shum, M. Discrete choice and rational inattention: A general equivalence result. Int. Econ. Rev. 2020, 61, 1569–1589. [Google Scholar] [CrossRef]
- Friston, K.; Rigoli, F.; Ognibene, D.; Mathys, C.; Fitzgerald, T.; Pezzulo, G. Active inference and epistemic value. Cogn. Neurosci. 2015, 6, 187–214. [Google Scholar] [CrossRef]
- Grebitus, C.; Jutta, R.; Carolin, C.S. Visual attention and choice: A behavioral economics perspective on food decisions. J. Agric. Food Ind. Organ. 2015, 13, 73–81. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Dallas, A.C. Characterizing the pareto and power distributions. Ann. Inst. Stat. Math. 1976, 28, 491–497. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ohdoko, T.; Komatsu, S. Integrating a Pareto-Distributed Scale into the Mixed Logit Model: A Mathematical Concept. Mathematics 2023, 11, 4727. https://doi.org/10.3390/math11234727
Ohdoko T, Komatsu S. Integrating a Pareto-Distributed Scale into the Mixed Logit Model: A Mathematical Concept. Mathematics. 2023; 11(23):4727. https://doi.org/10.3390/math11234727
Chicago/Turabian StyleOhdoko, Taro, and Satoru Komatsu. 2023. "Integrating a Pareto-Distributed Scale into the Mixed Logit Model: A Mathematical Concept" Mathematics 11, no. 23: 4727. https://doi.org/10.3390/math11234727
APA StyleOhdoko, T., & Komatsu, S. (2023). Integrating a Pareto-Distributed Scale into the Mixed Logit Model: A Mathematical Concept. Mathematics, 11(23), 4727. https://doi.org/10.3390/math11234727