

Multi-Objective Q-Learning-Based Brain Storm Optimization for Integrated Distributed Flow Shop and Distribution Scheduling Problems


Abstract
:1. Introduction
- A multi-objective integrated distributed flow shop and distribution scheduling problem is addressed. To clearly describe it, this work formulates a mathematical model with makespan and total weighted earliness and tardiness minimization;
- A multi-objective Q-learning-based brain storm optimization (MQBSO) is designed to handle the addressed problem. In MQBSO, a double-string representation approach is used to denote a solution, and a random method is employed to initialize the population. In the clustering phase, a dynamic clustering method is adopted to create clusters. In the generating phase, a Q-learning process is performed to guide MQBSO in choosing the generation strategy, where four actions, four states, a reward function, and an improved ε-greedy method are included. In the selecting phase, a new selection method is applied to obtain a better population;
- To examine the performance of MQBSO, experiments are implemented on a group of instances in comparison with four metaheuristics and a CPLEX solver. The experimental results reveal that MQBSO exhibits excellent performance.
2. Literature Review
2.1. Relevant Literature on IPDS
- Most studies considered a single factory at the production stage, while the distributed manufacturing system was not fully considered;
- Most research concentrated on a single-objective optimization which usually involved time and cost criteria, while not enough consideration was given to multi-objective optimization;
- Metaheuristics have become the mainstream method to cope with IPDS problems, and their outstanding performance has been verified.
2.2. Q-Learning Applied to Scheduling
2.3. Relevant Literature on BSO
3. Proposed Problem and Model
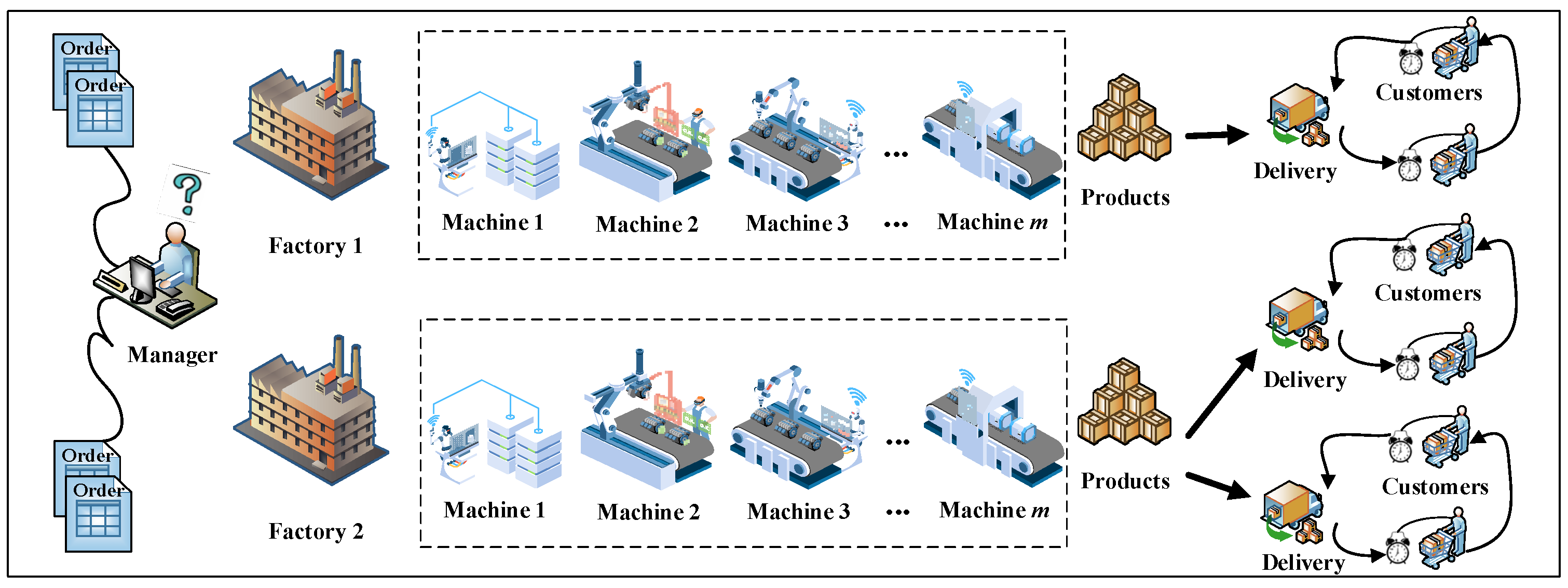
3.1. Problem Description
3.2. Mathematical Model
- At time zero, all machines must be available for use;
- Once a machine processes a job, it cannot process another one;
- At no time can a single job be worked on by multiple machines;
- Interrupting a job that has already started on a machine is not allowed;
- Each customer is visited only once;
- Vehicles must obey capacity limits.
4. BSO and Q-Learning
4.1. BSO
4.2. Q-Learning
5. Presented MQBSO Algorithm
5.1. Solution Representation and Initial Population
- Jobs that have been allocated to a factory are processed in a sequence that matches their assigned order on the machines;
- After the production of jobs, they are assigned in a sequential manner to a vehicle. The earlier the processing is completed, the sooner the vehicle is assigned. Meanwhile, vehicles are required not to exceed their maximum load capacity.
- Jobs are transported in the exact sequence in which they are loaded into the vehicle.
5.2. Clustering
5.3. Generating
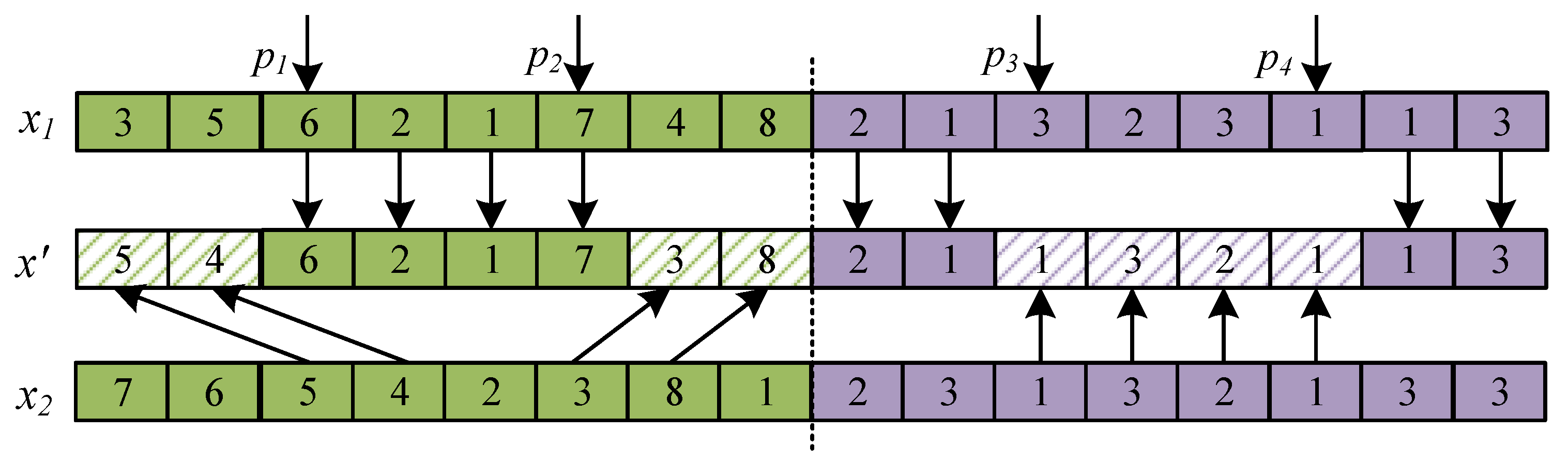
- A global search strategy is designed when utilizing two randomly chosen center or normal individuals to construct new individuals, where the sequence-based [43] and the two-point crossover [44] methods are adopted. The former is applied to update the job scheduling sequence string and the latter is utilized to update the factory assignment string. The main contents of these two methods are described below.
- Sequence-based crossover method: First, randomly have two job position indexes , . Then, jobs between them in the individual are copied to the same positions of a new individual . Finally, the missing jobs in are added as their appearance in the individual . Hence, the job scheduling sequence string of is obtained. Two-point crossover method: First, two factory position indexes , are generated at random. Then, extract factory assignments beyond and in and place them into the same positions of . Finally, the rest factory assignments in are filled with the elements at the same positions of . Thus, the factory assignment string of is acquired. By employing these two methods, a new individual is successfully produced. To clearly exhibit the generation process, Figure 3 depicts an illustrative example.
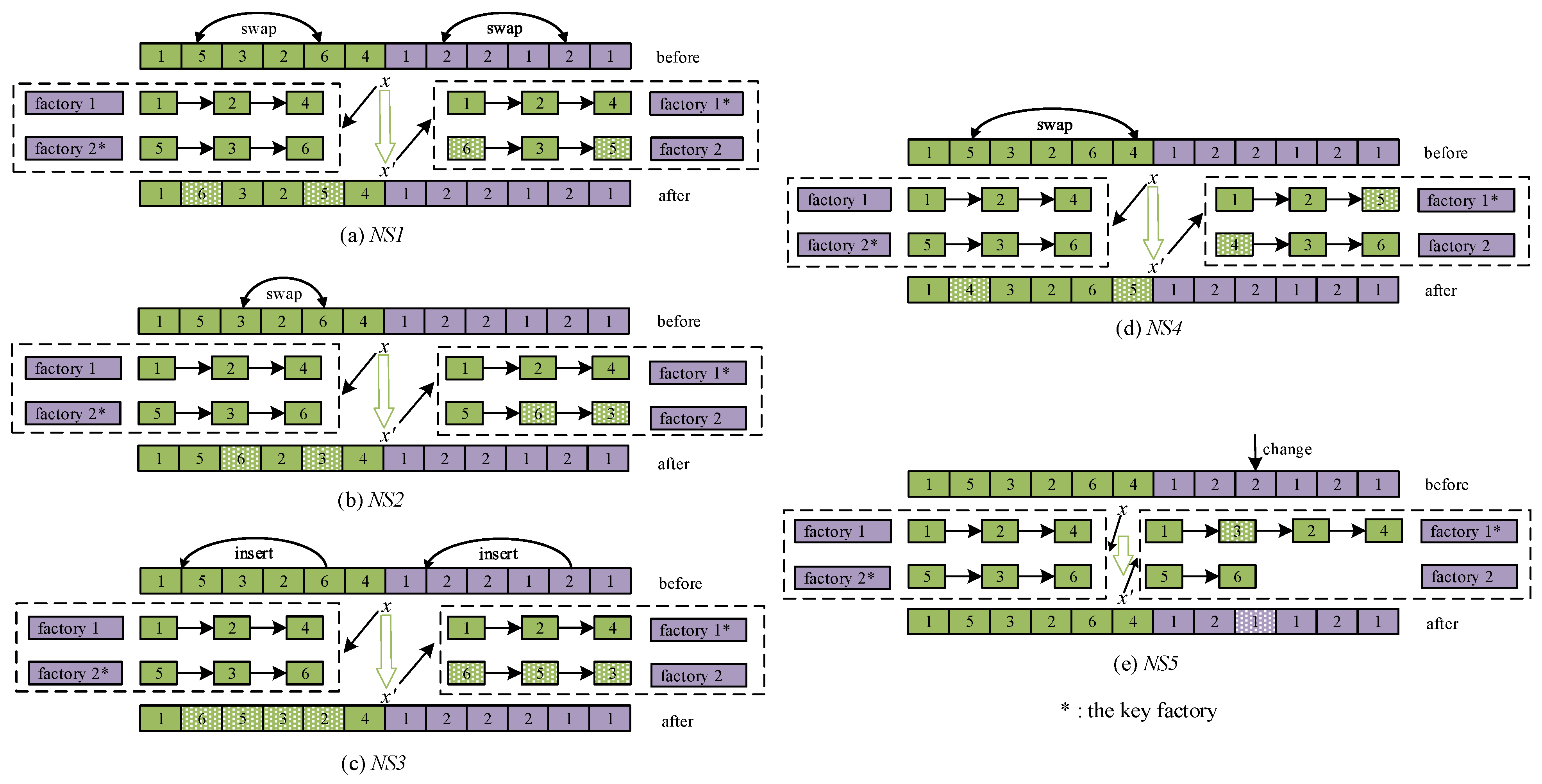
- A local search strategy is developed when using one randomly selected center or normal individual to construct new individuals, where five kinds of neighborhood structures, named NS1, NS2, NS3, NS4, and NS5 are introduced. The main idea of NS1 is as follows: randomly produce two job positions for a chosen individual, then swap these two jobs and exchange their respective factory assignments.
5.4. Selecting
5.5. Q-Learning Process
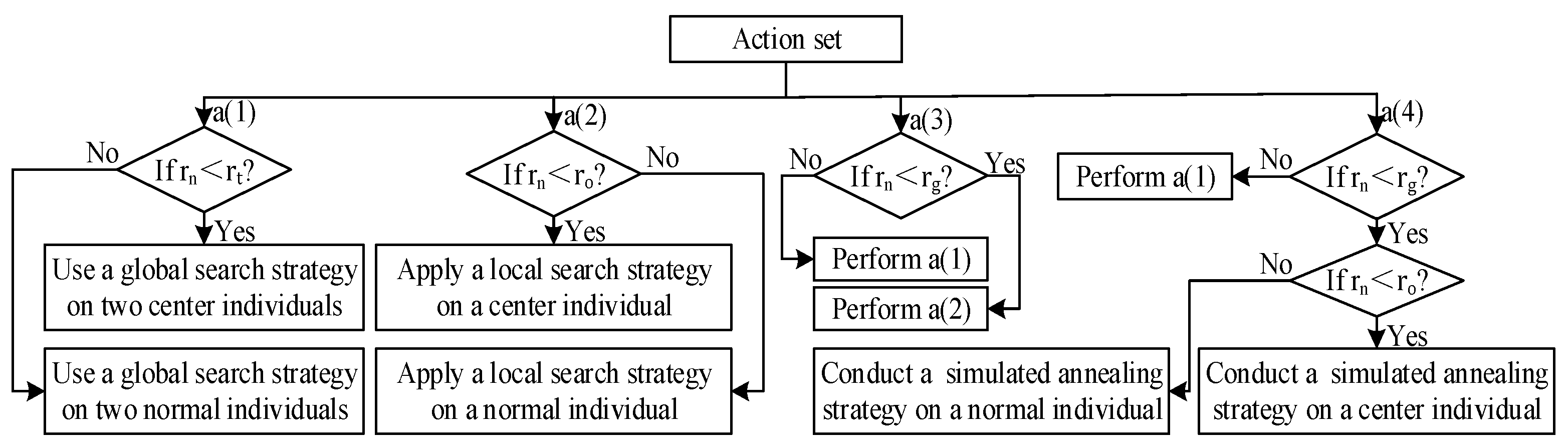
5.5.1. Action Set
5.5.2. State Set
5.5.3. Reward
| Algorithm 1: MQBSO |
| Input: Population size , three generation parameters , , , learning rate , discount rate , and a stopping condition . |
| Output: A non-dominated solution set. |
| Initialize the population and parameters (c.f. Section 5.1) |
| While the stopping condition is not reached do |
| Implement a dynamic clustering method in the clustering phase (c.f. Section 5.2). |
| Employ a Q-learning process in the generating phase (c.f. Section 5.3 and Section 5.5). |
| Apply a selection method in the selecting phase (c.f. Section 5.4). |
| Update the population state and Q-table. |
| End while |
6. Experimental Evaluations
6.1. Test Instances
6.2. Parameters Setting
6.3. Performance Metrics
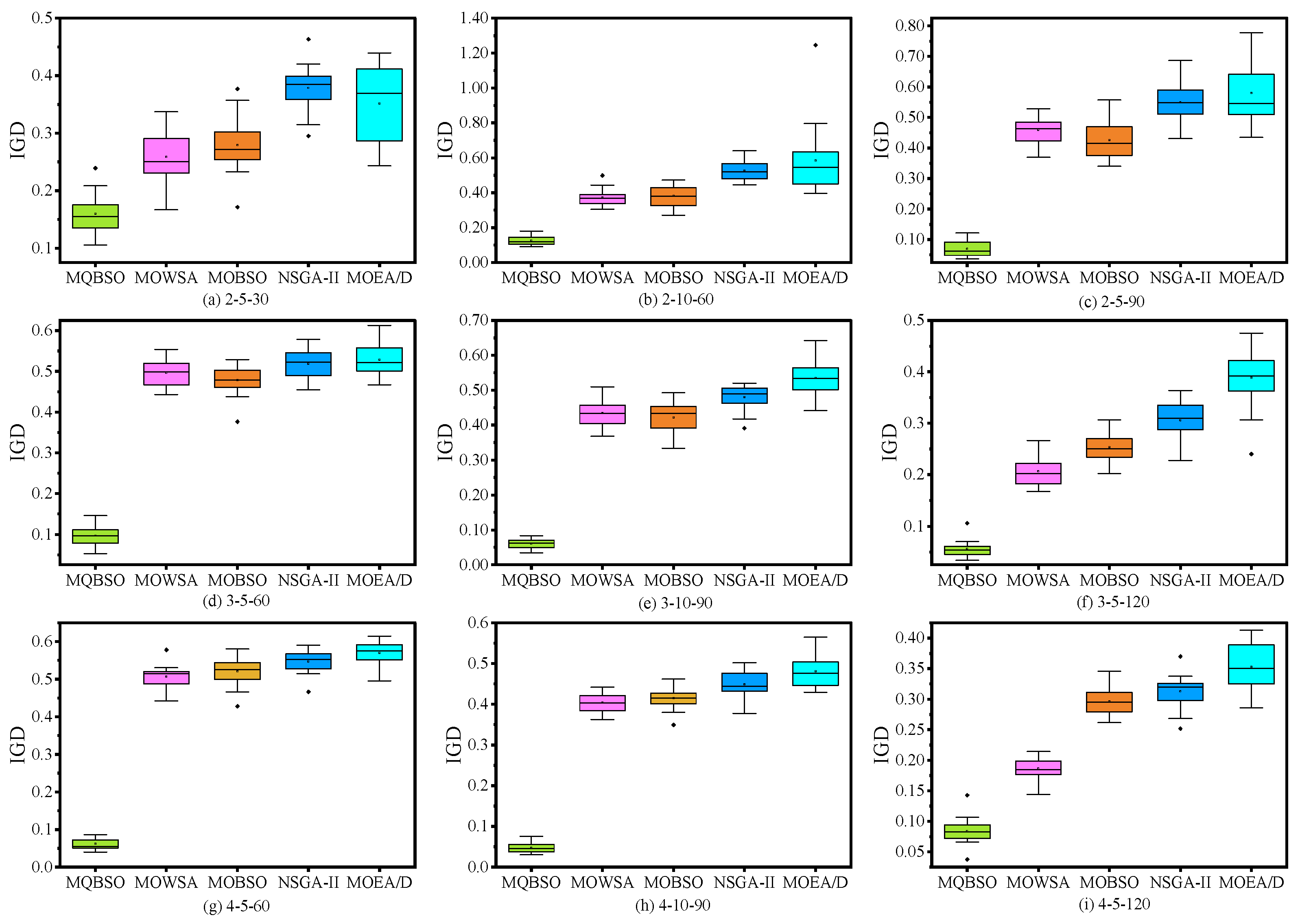
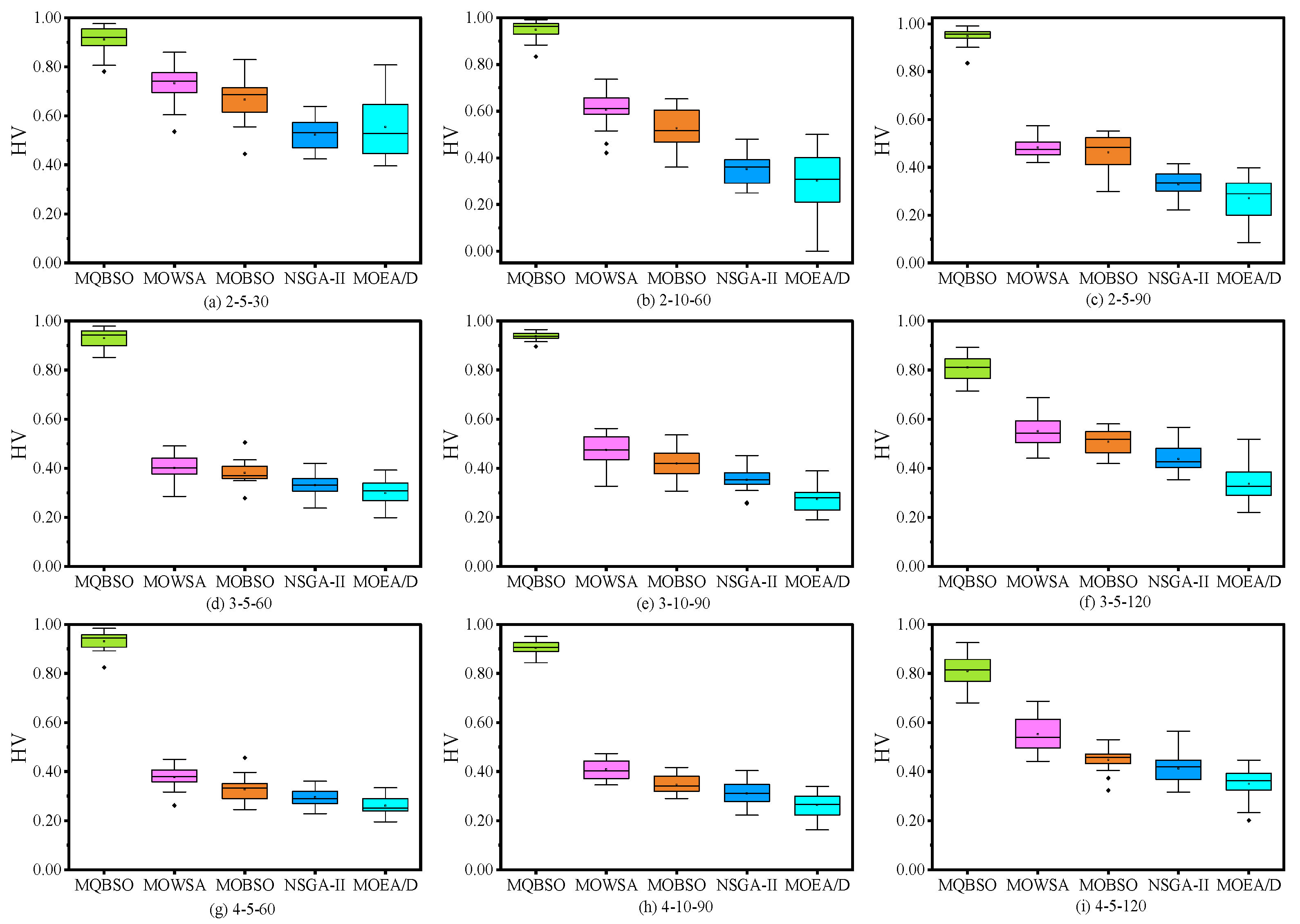
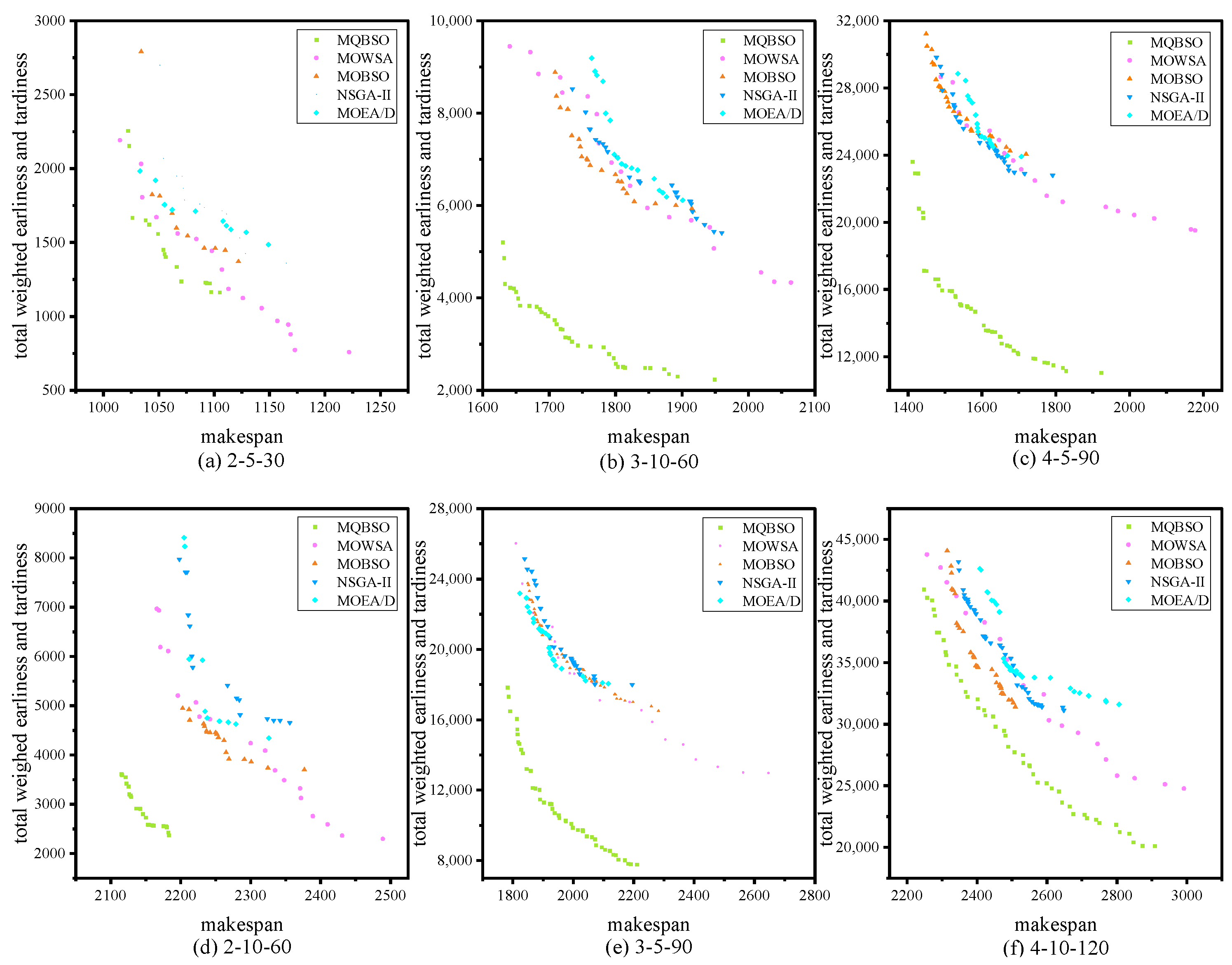
6.4. Experimental Results and Analysis
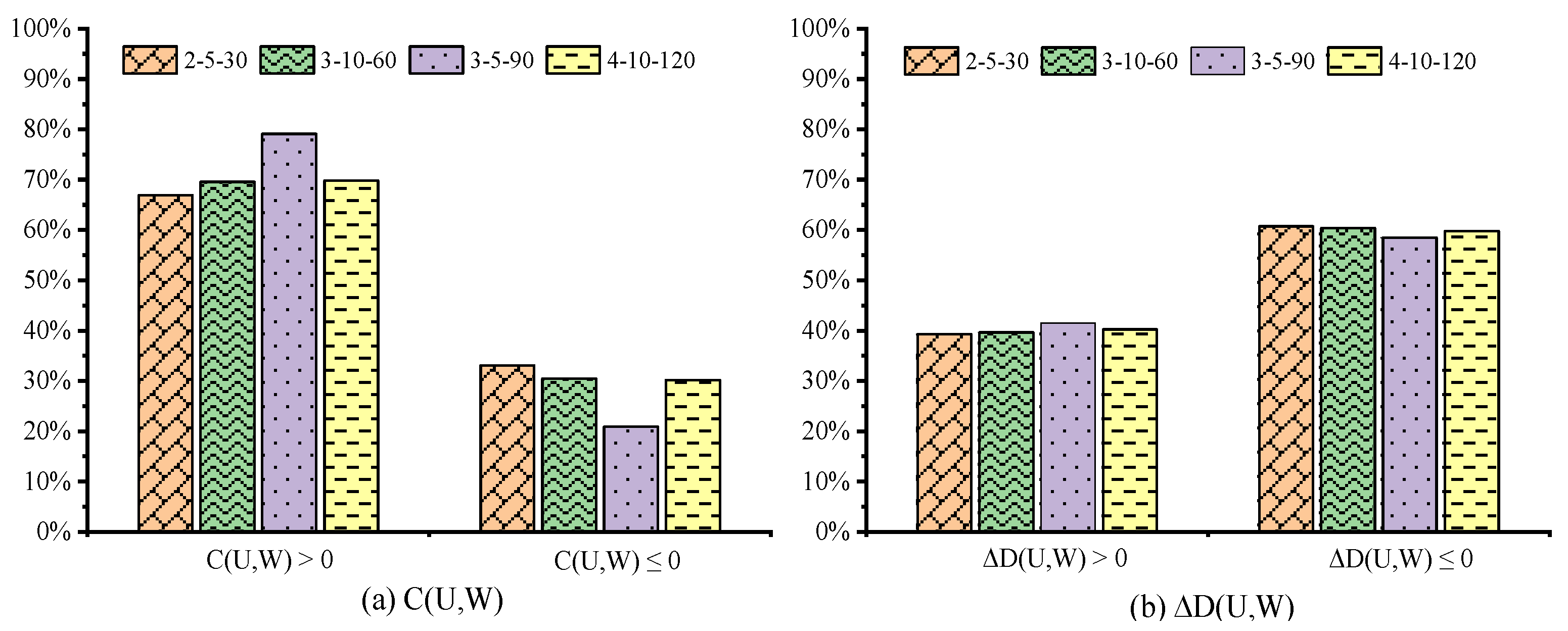
6.5. Effectiveness of the Q-Learning Process in MQBSO
6.6. Comparison of Five Algorithms in CPU Time
6.7. Comparison of MQBSO and CPLEX
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rafiei, H.; Safaei, F.; Rabbani, M. Integrated production-distribution planning problem in a competition-based four-echelon supply chain. Comput. Ind. Eng. 2018, 119, 85–99. [Google Scholar] [CrossRef]
- Ganji, M.; Kazemipoor, H.; Molana, S.M.H.; Sajadi, S.M. A green multi-objective integrated scheduling of production and distribution with heterogeneous fleet vehicle routing and time windows. J. Clean. Prod. 2020, 259, 120824. [Google Scholar] [CrossRef]
- Chandra, P.; Fisher, M.L. Coordination of production and distribution planning. Eur. J. Oper. Res. 1994, 72, 503–517. [Google Scholar] [CrossRef]
- Liu, L.; Liu, S. Integrated production and distribution problem of perishable products with a minimum total order weighted delivery time. Mathematics 2020, 8, 146. [Google Scholar] [CrossRef]
- Moons, S.; Ramaekers, K.; Caris, A.; Arda, Y. Integrating production scheduling and vehicle routing decisions at the operational decision level: A review and discussion. Comput. Ind. Eng. 2017, 104, 224–245. [Google Scholar] [CrossRef]
- Wang, J.J.; Wang, L. A bi-population cooperative memetic algorithm for distributed hybrid flow-shop scheduling. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 5, 947–961. [Google Scholar] [CrossRef]
- Shao, W.S.; Shao, Z.S.; Pi, D.C. Modeling and multi-neighborhood iterated greedy algorithm for distributed hybrid flow shop scheduling problem. Knowl.-Based Syst. 2020, 194, 105527. [Google Scholar] [CrossRef]
- Wang, J.J.; Wang, L. A knowledge-based cooperative algorithm for energy-efficient scheduling of distributed flow-shop. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 1805–1819. [Google Scholar] [CrossRef]
- Lu, C.; Gao, L.; Gong, W.Y.; Hu, C.Y.; Yan, X.S.; Li, X.Y. Sustainable scheduling of distributed permutation flow-shop with non-identical factory using a knowledge-based multi-objective memetic optimization algorithm. Swarm Evol. Comput. 2021, 60, 100803. [Google Scholar] [CrossRef]
- Shao, W.S.; Pi, D.C.; Shao, Z.S. Optimization of makespan for the distributed no-wait flow shop scheduling problem with iterated greedy algorithms. Knowl.-Based Syst. 2017, 137, 163–181. [Google Scholar] [CrossRef]
- Gong, D.W.; Han, Y.Y.; Sun, J.Y. A novel hybrid multi-objective artificial bee colony algorithm for blocking lot-streaming flow shop scheduling problems. Knowl.-Based Syst. 2018, 148, 115–130. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, L.; Wang, J.J. A cooperative coevolution algorithm for multi-objective fuzzy distributed hybrid flow shop. Knowl.-Based Syst. 2020, 194, 105536. [Google Scholar] [CrossRef]
- Fu, Y.P.; Hou, Y.S.; Wang, Z.F.; Wu, X.W.; Gao, K.Z.; Wang, L. A review of distributed scheduling problems in intelligent manufacturing systems. Tsinghua Sci. Technol. 2021, 26, 625–645. [Google Scholar] [CrossRef]
- Zhao, F.Q.; Shao, D.Q.; Wang, L.; Xu, T.P.; Zhu, N.N.; Jonrinal, D. An effective water wave optimization algorithm with problem-specific knowledge for the distributed assembly blocking flow-shop scheduling problem. Knowl.-Based Syst. 2022, 243, 108471. [Google Scholar] [CrossRef]
- Li, H.X.; Gao, K.Z.; Duan, P.Y.; Li, J.Q.; Zhang, L. A novel shuffled frog-leaping algorithm with reinforcement learning for distributed assembly hybrid flow shop scheduling. Int. J. Prod. Res. 2022, 61, 1233–1251. [Google Scholar] [CrossRef]
- Li, H.X.; Gao, K.Z.; Duan, P.Y.; Li, J.Q.; Zhang, L. An improved artificial bee colony algorithm with Q-learning for solving permutation flow-shop scheduling problems. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 2684–2693. [Google Scholar] [CrossRef]
- Luo, B.; Liu, D.; Huang, T.; Wang, D. Model-free optimal tracking control via critic-only Q-learning. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 2734–2744. [Google Scholar] [CrossRef] [PubMed]
- Cheng, L.X.; Tang, L.X.; Zhang, L.P.; Zhang, Z.K. Multi-objective Q-learning-based hyper-heuristic with Bi-criteria selection for energy-aware mixed shop scheduling. Swarm Evol. Comput. 2022, 69, 100985. [Google Scholar] [CrossRef]
- Bdeir, A.; Boeder, S.; Dernedde, T.; Tkachuk, K.; Falkner, J.K.; Schmidt-Thieme, L. RP-DQN: An application of Q-learning to vehicle routing problems. Adv. Artif. Intell. 2021, 12873, 3–16. [Google Scholar] [CrossRef]
- Shi, Y.H. Brain storm optimization algorithm. In International Conference in Swarm Intelligence; Springer: Berlin/Heidelberg, Germany, 2011; pp. 303–309. [Google Scholar]
- Potts, C.N. Analysis of a heuristic for one machine sequencing with release dates and delivery times. Oper. Res. 1980, 28, 1436–1441. [Google Scholar] [CrossRef]
- Chen, Z.L. Integrated production and outbound distribution scheduling: Review and extensions. Oper. Res. 2010, 58, 120–148. [Google Scholar] [CrossRef]
- Roberto, F.T.N.; Marcelo, S.N. An iterated greedy approach to integrate production by multiple parallel machines and distribution by a single capacitated vehicle. Swarm Evol. Comput. 2019, 44, 612–621. [Google Scholar] [CrossRef]
- Jia, Z.H.; Cui, Y.F.; Li, K. An ant colony-based algorithm for integrated scheduling on batch machines with non-identical capacities. Appl. Intell. 2022, 52, 1752–1769. [Google Scholar] [CrossRef]
- Yagmur, E.; Kesen, S.E. A memetic algorithm for joint production and distribution scheduling with due dates. Comput. Ind. Eng. 2020, 142, 106342. [Google Scholar] [CrossRef]
- Mohammadi, S.; Al-e-Hashem, S.M.; Rekik, Y. An integrated production scheduling and delivery route planning with multi-purpose machines: A case study from a furniture manufacturing company. Int. J. Prod. Econ. 2020, 219, 347–359. [Google Scholar] [CrossRef]
- Gharaei, A.; Jolai, F. A multi-agent approach to the integrated production scheduling and distribution problem in multi-factory supply chain. Appl. Soft Comput. 2018, 65, 577–589. [Google Scholar] [CrossRef]
- Fu, Y.P.; Hou, Y.S.; Chen, Z.H.; Pu, X.J.; Gao, K.Z.; Sadollah, A. Modelling and scheduling integration of distributed production and distribution problems via black widow optimization. Swarm Evol. Comput. 2021, 68, 101015. [Google Scholar] [CrossRef]
- Hou, Y.S.; Fu, Y.P.; Gao, K.Z.; Zhang, H.; Sadollah, A. Modelling and optimization of integrated distributed flow shop scheduling and distribution problems with time windows. Expert Syst. Appl. 2021, 187. [Google Scholar] [CrossRef]
- Qin, H.; Li, T.; Teng, Y.; Wang, K. Integrated production and distribution scheduling in distributed hybrid flow shops. Memetic Comput. 2021, 13, 185–202. [Google Scholar] [CrossRef]
- Wang, L.; Pan, Z.X.; Wang, J.J. A review of reinforcement learning based intelligent optimization for manufacturing scheduling. Complex Syst. Model. Simul. 2021, 1, 257–270. [Google Scholar] [CrossRef]
- Zhao, F.; Di, S.; Wang, L. A hyperheuristic with Q-learning for the multiobjective energy-efficient distributed blocking flow shop scheduling problem. IEEE Trans. Cybern. 2022, 53, 3337–3350. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Gong, W.Y.; Lu, C. A reinforcement learning based RMOEA/D for bi-objective fuzzy flexible job shop scheduling. Expert Syst. Appl. 2022, 203, 117380. [Google Scholar] [CrossRef]
- Wang, H.X.; Sarker, B.R.; Li, J.; Li, J. Adaptive scheduling for assembly job shop with uncertain assembly times based on dual Q-learning. Int. J. Prod. Res. 2020, 59, 5867–5883. [Google Scholar] [CrossRef]
- Xu, P.; Luo, W.; Lin, X. BSO20: Efficient brain storm optimization for real-parameter numerical optimization. Complex Intell. Syst. 2021, 7, 2415–2436. [Google Scholar] [CrossRef]
- Cheng, S.; Zhang, M.; Ma, L.; Lu, H.; Wang, R.; Shi, Y.H. Brain storm optimization algorithm for solving knowledge spillover problems. Neural Comput. Appl. 2021, 35, 12247–12260. [Google Scholar] [CrossRef]
- Hao, J.H.; Li, J.Q.; Du, Y.; Song, M.X.; Duan, P.; Zhang, Y.Y. Solving distributed hybrid flowshop scheduling problems by a hybrid brain storm optimization algorithm. IEEE Access 2019, 7, 66879–66894. [Google Scholar] [CrossRef]
- Zhao, F.Q.; Hu, X.T.; Wang, L.; Xu, T.P.; Zhu, N.N.; Jonrinaldi. A reinforcement learning-driven brain storm optimisation algorithm for multi-objective energy-efficient distributed assembly no-wait flow shop scheduling problem. Int. J. Prod. Res. 2023, 61, 2854–2872. [Google Scholar] [CrossRef]
- Ma, X.M.; Fu, Y.P.; Gao, K.Z.; Zhu, L.H.; Sadollah, A. A multi-objective scheduling and routing problem for home health care services via brain storm optimization. Complex Syst. Model. Simul. 2023, 3, 32–46. [Google Scholar] [CrossRef]
- Ke, L. A brain storm optimization approach for the cumulative capacitated vehicle routing problem. Memetic Comput. 2018, 10, 411–421. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Technical note: Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Wang, G.C.; Gao, L.; Li, X.Y.; Li, P.G.; Tasgetiren, M.F. Energy-efficient distributed permutation flow shop scheduling problem using a multi-objective whale swarm algorithm. Swarm Evol. Comput. 2020, 57, 100716. [Google Scholar] [CrossRef]
- Fu, Y.P.; Tian, G.D.; Fard, A.M.H.; Ahmadi, A.; Zhang, C.Y. Stochastic multi-objective modelling and optimization of an energy-conscious distributed permutation flow shop scheduling problem with the total tardiness constraint. J. Clean. Prod. 2019, 226, 515–525. [Google Scholar] [CrossRef]
- Lu, C.; Gao, L.; Yi, J.; Li, X. Energy-efficient scheduling of distributed flow shop with heterogeneous factories: A real-world case from automobile industry in China. IEEE Trans. Ind. Inform. 2020, 17, 6687–6696. [Google Scholar] [CrossRef]
- Kuidi, M. A memetic algorithm with novel semi-constructive evolution operators for permutation flowshop scheduling problem. Appl. Soft Comput. 2020, 94, 106458. [Google Scholar] [CrossRef]
- Zitzler, E.; Deb, K.; Thiele, L. Comparison of multiobjective evolutionary algorithms: Empirical results. Evol. Comput. 2000, 8, 173–195. [Google Scholar] [CrossRef]
- Zhang, Q.F.; Li, H. A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Vallada, E.; Ruiz, R.; Framinan, J.M. New hard benchmark for flowshop scheduling problems minimising makespan. Eur. J. Oper. Res. 2015, 240, 666–677. [Google Scholar] [CrossRef]
- Gehring, H.; Homberger, J. A parallel hybrid evolutionary metaheuristic for the vehicle routing problem with time windows. In Proceedings of EUROGEN99; Springer: Berlin/Heidelberg, Germany, 1999; Volume 2, pp. 57–64. [Google Scholar]
- Karna, S.K.; Sahai, R. An overview on Taguchi method. Int. J. End. Math. Sci. 2012, 1, 1–7. [Google Scholar]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Wilcoxon, F.; Katti, S.K.; Wilcox, R.A. Critical values and probability levels for the Wilcoxon rank sum test and the Wilcoxon signed rank test. Sel. Tables Math. Stat. 1970, 1, 171–259. [Google Scholar]
- Hou, Y.S.; Wang, H.F.; Fu, Y.P.; Gao, K.Z.; Zhang, H. Multi-objective brain storm optimization for integrated scheduling of distributed flow shop and distribution with maximal processing quality and minimal total weighted earliness and tardiness. Comput. Ind. Eng. 2023, 179, 109217. [Google Scholar] [CrossRef]
- Li, F.; Chen, Z.L.; Tang, L. Integrated production, inventory and delivery problems: Complexity and algorithms. INFORMS J. Comput. 2017, 29, 232–250. [Google Scholar] [CrossRef]
- Wang, J.; Song, G.; Liang, Z.; Demeulemeester, E.; Hu, X.; Liu, J. Unrelated parallel machine scheduling with multiple time windows: An application to earth observation satellite scheduling. Comput. Oper. Res. 2023, 149, 106010. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Set of factories, . | |
| Set of machines, . | |
| Set of jobs, , where 0 means a virtual job. | |
| Set of vehicles at a factory, . | |
| The factory index, . | |
| The machine index, . | |
| The job index, . | |
| The vehicle index, . | |
| The production time of job on machine . | |
| The drive time between customers and . | |
| The drive time between factory and customer . | |
| The load of job . | |
| The service time at customer . | |
| The delivery time window of customer . | |
| The unit earliness weight of customer . | |
| The unit tardiness weight of customer . | |
| The maximum load capacity of the vehicle. | |
| An extremely positive integer. | |
| 1, if job is directly processed after job at factory , 0, otherwise. | |
| 1, if job is assigned to factory , 0, otherwise. | |
| 1, if customer is directly delivered after customer by vehicle , 0, otherwise. | |
| The completion time of job on machine . | |
| The delivery start time of vehicle . | |
| The arrival time at customer . | |
| The departure time from customer . | |
| The makespan criterion. | |
| The total weighted earliness and tardiness criterion. |
| Instance | Production | Distribution | Instance | Production | Distribution | ||
|---|---|---|---|---|---|---|---|
| 2-5-30 | 2 | VFR30_5_1 | C1_2_1 | 2-10-30 | 2 | VFR30_10_1 | C1_2_1 |
| 2-5-60 | 2 | VFR60_5_1 | C1_2_1 | 2-10-60 | 2 | VFR60_10_1 | C1_2_1 |
| 2-5-90 | 2 | VFR90_5_1 | C1_2_1 | 2-10-90 | 2 | VFR90_10_1 | C1_2_1 |
| 2-5-120 | 2 | VFR120_5_1 | C1_2_1 | 2-10-120 | 2 | VFR120_10_1 | C1_2_1 |
| 3-5-30 | 3 | VFR30_5_1 | C1_2_1 | 3-10-30 | 3 | VFR30_10_1 | C1_2_1 |
| 3-5-60 | 3 | VFR60_5_1 | C1_2_1 | 3-10-60 | 3 | VFR60_10_1 | C1_2_1 |
| 3-5-90 | 3 | VFR90_5_1 | C1_2_1 | 3-10-90 | 3 | VFR90_10_1 | C1_2_1 |
| 3-5-120 | 3 | VFR120_5_1 | C1_2_1 | 3-10-120 | 3 | VFR120_10_1 | C1_2_1 |
| 4-5-30 | 4 | VFR30_5_1 | C1_2_1 | 4-10-30 | 4 | VFR30_10_1 | C1_2_1 |
| 4-5-60 | 4 | VFR60_5_1 | C1_2_1 | 4-10-60 | 4 | VFR60_10_1 | C1_2_1 |
| 4-5-90 | 4 | VFR90_5_1 | C1_2_1 | 4-10-90 | 4 | VFR90_10_1 | C1_2_1 |
| 4-5-120 | 4 | VFR120_5_1 | C1_2_1 | 4-10-120 | 4 | VFR120_20_1 | C1_2_1 |
| No. | AIGD | ||||
|---|---|---|---|---|---|
| 1 | 20 | 0.20 | 0.20 | 0.20 | 0.1016 |
| 2 | 20 | 0.40 | 0.40 | 0.40 | 0.0927 |
| 3 | 20 | 0.60 | 0.60 | 0.60 | 0.0904 |
| 4 | 20 | 0.80 | 0.80 | 0.80 | 0.0861 |
| 5 | 40 | 0.20 | 0.40 | 0.60 | 0.1056 |
| 6 | 40 | 0.40 | 0.20 | 0.80 | 0.0852 |
| 7 | 40 | 0.60 | 0.80 | 0.20 | 0.0909 |
| 8 | 40 | 0.80 | 0.60 | 0.40 | 0.1232 |
| 9 | 60 | 0.20 | 0.60 | 0.80 | 0.1005 |
| 10 | 60 | 0.40 | 0.80 | 0.60 | 0.0952 |
| 11 | 60 | 0.60 | 0.20 | 0.40 | 0.0939 |
| 12 | 60 | 0.80 | 0.40 | 0.20 | 0.0984 |
| 13 | 80 | 0.20 | 0.80 | 0.40 | 0.0931 |
| 14 | 80 | 0.40 | 0.60 | 0.20 | 0.0956 |
| 15 | 80 | 0.60 | 0.40 | 0.80 | 0.0868 |
| 16 | 80 | 0.80 | 0.20 | 0.60 | 0.0867 |
| Algorithm | Parameter | Levels | Value |
|---|---|---|---|
| MOWSA | population size | 20, 40, 60, 80 | 20 |
| crossover probability | 0.80, 0.85, 0.90, 0.95 | 0.85 | |
| mutation probability | 0.10, 0.15, 0.20, 0.25 | 0.15 | |
| MOBSO | 20, 40, 60, 80 | 80 | |
| 0.20, 0.40, 0.60, 0.80 | 0.80 | ||
| 0.20, 0.40, 0.60, 0.80 | 0.20 | ||
| 0.20, 0.40, 0.60, 0.80 | 0.60 | ||
| NSGA-II | population size | 20, 40, 60, 80 | 80 |
| mutation probability | 0.10, 0.15, 0.20, 0.25 | 0.15 | |
| MOEA/D | population size | 20, 40, 60, 80 | 40 |
| neighborhood size | 10, 15, 20, 25 | 25 |
| Instance | C(QB,WS) | C(WS,QB) | C(QB,BS) | C(BS,QB) | C(QB,GA) | C(GA,QB) | C(QB,EA) | C(EA,QB) |
|---|---|---|---|---|---|---|---|---|
| 2-5-30 | 0.7951 | 0.0161 | 0.9908 | 0.0000 | 0.9889 | 0.0000 | 0.9709 | 0.0031 |
| 2-5-60 | 0.9810 | 0.0000 | 0.9729 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 2-5-90 | 0.9735 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 2-5-120 | 0.9389 | 0.0000 | 0.9739 | 0.0018 | 0.9818 | 0.0000 | 1.0000 | 0.0000 |
| 2-10-30 | 0.0000 | 0.6810 | 0.0065 | 0.5785 | 0.0439 | 0.2361 | 0.0696 | 0.2504 |
| 2-10-60 | 0.9481 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 2-10-90 | 0.9297 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 2-10-120 | 0.9569 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 3-5-30 | 0.9782 | 0.0000 | 0.9519 | 0.0000 | 0.8082 | 0.1250 | 0.6868 | 0.2206 |
| 3-5-60 | 0.9306 | 0.0000 | 0.9731 | 0.0000 | 1.0000 | 0.0000 | 0.9750 | 0.0000 |
| 3-5-90 | 0.9816 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 3-5-120 | 0.9687 | 0.0024 | 0.9964 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 3-10-30 | 0.1077 | 0.5823 | 0.2163 | 0.5048 | 0.4705 | 0.2068 | 0.3565 | 0.2504 |
| 3-10-60 | 0.9921 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 3-10-90 | 0.9658 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 3-10-120 | 0.9764 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 4-5-30 | 0.8991 | 0.0000 | 0.9064 | 0.0000 | 0.1531 | 0.7797 | 0.0640 | 0.8341 |
| 4-5-60 | 0.9820 | 0.0000 | 0.9753 | 0.0000 | 0.9952 | 0.0000 | 1.0000 | 0.0000 |
| 4-5-90 | 0.9792 | 0.0000 | 0.9957 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 4-5-120 | 0.9464 | 0.0000 | 0.9918 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 4-10-30 | 0.6849 | 0.0225 | 0.9400 | 0.0038 | 0.1859 | 0.4120 | 0.1172 | 0.4602 |
| 4-10-60 | 0.9605 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 4-10-90 | 0.9796 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| 4-10-120 | 0.9796 | 0.0000 | 0.9981 | 0.0000 | 1.0000 | 0.0000 | 1.0000 | 0.0000 |
| Average | 0.8682 | 0.0543 | 0.9120 | 0.0454 | 0.8595 | 0.0733 | 0.8433 | 0.0841 |
| Instance | MQBSO | MOWSA | MOBSO | NSGA-II | MOEA/D |
|---|---|---|---|---|---|
| 2-5-30 | 0.1595 | 0.2585 | 0.2788 | 0.3784 | 0.3512 |
| 2-5-60 | 0.0668 | 0.4456 | 0.4132 | 0.5073 | 0.4948 |
| 2-5-90 | 0.0695 | 0.4587 | 0.4252 | 0.5485 | 0.5790 |
| 2-5-120 | 0.0946 | 0.2911 | 0.2813 | 0.4224 | 0.4837 |
| 2-10-30 | 0.4201 | 0.1777 | 0.2311 | 0.3187 | 0.3576 |
| 2-10-60 | 0.1246 | 0.3708 | 0.3807 | 0.5254 | 0.5820 |
| 2-10-90 | 0.1147 | 0.3676 | 0.4778 | 0.6540 | 0.9409 |
| 2-10-120 | 0.1023 | 0.3686 | 0.4377 | 0.6161 | 0.7933 |
| 3-5-30 | 0.1038 | 0.3638 | 0.3531 | 0.2781 | 0.2269 |
| 3-5-60 | 0.0963 | 0.4956 | 0.4784 | 0.5185 | 0.5287 |
| 3-5-90 | 0.0466 | 0.4270 | 0.4263 | 0.4711 | 0.4883 |
| 3-5-120 | 0.0558 | 0.2064 | 0.2535 | 0.3055 | 0.3883 |
| 3-10-30 | 0.1799 | 0.1421 | 0.1626 | 0.2380 | 0.2398 |
| 3-10-60 | 0.0561 | 0.4702 | 0.4462 | 0.5000 | 0.5307 |
| 3-10-90 | 0.0603 | 0.4344 | 0.4224 | 0.4797 | 0.5345 |
| 3-10-120 | 0.0506 | 0.2067 | 0.2748 | 0.3302 | 0.4071 |
| 4-5-30 | 0.2378 | 0.4851 | 0.4845 | 0.1161 | 0.1381 |
| 4-5-60 | 0.0616 | 0.5063 | 0.5201 | 0.5465 | 0.5696 |
| 4-5-90 | 0.0646 | 0.4412 | 0.4888 | 0.5184 | 0.5581 |
| 4-5-120 | 0.0842 | 0.1863 | 0.2955 | 0.3124 | 0.3523 |
| 4-10-30 | 0.1882 | 0.2383 | 0.2371 | 0.2016 | 0.2659 |
| 4-10-60 | 0.0511 | 0.4222 | 0.4571 | 0.4807 | 0.5007 |
| 4-10-90 | 0.0471 | 0.4030 | 0.4150 | 0.4480 | 0.4806 |
| 4-10-120 | 0.0477 | 0.2245 | 0.2720 | 0.3113 | 0.3809 |
| Average | 0.1077 | 0.3497 | 0.3714 | 0.4178 | 0.4655 |
| Instance | MQBSO | MOWSA | MOBSO | NSGA-II | MOEA/D |
|---|---|---|---|---|---|
| 2-5-30 | 0.9106 | 0.7331 | 0.6655 | 0.5222 | 0.5543 |
| 2-5-60 | 0.9537 | 0.5126 | 0.4992 | 0.3914 | 0.3804 |
| 2-5-90 | 0.9474 | 0.4825 | 0.4625 | 0.3292 | 0.2711 |
| 2-5-120 | 0.8697 | 0.5955 | 0.5678 | 0.3848 | 0.3024 |
| 2-10-30 | 0.3208 | 0.8071 | 0.7052 | 0.5291 | 0.5064 |
| 2-10-60 | 0.9489 | 0.6054 | 0.5272 | 0.3515 | 0.3027 |
| 2-10-90 | 0.9615 | 0.6476 | 0.4196 | 0.2637 | 0.0894 |
| 2-10-120 | 0.9062 | 0.5797 | 0.4067 | 0.2397 | 0.1076 |
| 3-5-30 | 0.8422 | 0.5379 | 0.4982 | 0.6579 | 0.6860 |
| 3-5-60 | 0.9302 | 0.4018 | 0.3822 | 0.3312 | 0.2990 |
| 3-5-90 | 0.9177 | 0.4260 | 0.4011 | 0.3464 | 0.3141 |
| 3-5-120 | 0.8111 | 0.5519 | 0.5074 | 0.4383 | 0.3359 |
| 3-10-30 | 0.5548 | 0.7481 | 0.6640 | 0.5827 | 0.5695 |
| 3-10-60 | 0.9583 | 0.4643 | 0.4265 | 0.3714 | 0.3171 |
| 3-10-90 | 0.9385 | 0.4756 | 0.4193 | 0.3525 | 0.2742 |
| 3-10-120 | 0.7802 | 0.5197 | 0.4477 | 0.3680 | 0.2821 |
| 4-5-30 | 0.7839 | 0.4464 | 0.4105 | 0.8864 | 0.8946 |
| 4-5-60 | 0.9305 | 0.3777 | 0.3268 | 0.2951 | 0.2602 |
| 4-5-90 | 0.9097 | 0.3970 | 0.3596 | 0.3166 | 0.2671 |
| 4-5-120 | 0.8098 | 0.5521 | 0.4477 | 0.4121 | 0.3497 |
| 4-10-30 | 0.6532 | 0.5663 | 0.5291 | 0.8053 | 0.8131 |
| 4-10-60 | 0.9167 | 0.4544 | 0.3952 | 0.3578 | 0.3262 |
| 4-10-90 | 0.9036 | 0.4083 | 0.3459 | 0.3110 | 0.2636 |
| 4-10-120 | 0.7958 | 0.5252 | 0.4558 | 0.4019 | 0.3179 |
| Average | 0.8440 | 0.5340 | 0.4696 | 0.4269 | 0.3785 |
| MQBSO vs. | Metric | ||||
|---|---|---|---|---|---|
| MOWSA | IGD | 290 | 10 | 4.00 | 0.0000 |
| HV | 279 | 21 | 3.69 | 0.0001 | |
| MOBSO | IGD | 294 | 6 | 4.11 | 0.0000 |
| HV | 288 | 12 | 3.94 | 0.0000 | |
| NSGA-II | IGD | 293 | 7 | 4.09 | 0.0000 |
| HV | 289 | 11 | 3.97 | 0.0000 | |
| MOEA/D | IGD | 294 | 6 | 4.11 | 0.0000 |
| HV | 288 | 12 | 3.94 | 0.0000 |
| Instance | C | IGD | HV | |||
|---|---|---|---|---|---|---|
| C(MQBSO,MBSO) | C(MBSO,MQBSO) | MQBSO | MBSO | MQBSO | MBSO | |
| 2-5-30 | 0.6230 | 0.1384 | 0.1716 | 0.2167 | 0.8012 | 0.6947 |
| 2-5-60 | 0.9721 | 0.0000 | 0.1210 | 0.3698 | 0.9096 | 0.4643 |
| 2-5-90 | 0.9746 | 0.0000 | 0.0997 | 0.3849 | 0.8930 | 0.4789 |
| 2-5-120 | 0.7014 | 0.1848 | 0.1085 | 0.1525 | 0.7541 | 0.6730 |
| 2-10-30 | 0.0000 | 0.8176 | 0.5289 | 0.1392 | 0.2769 | 0.8436 |
| 2-10-60 | 0.7192 | 0.0295 | 0.1888 | 0.1792 | 0.8035 | 0.5949 |
| 2-10-90 | 0.6700 | 0.1205 | 0.1949 | 0.2577 | 0.8191 | 0.6260 |
| 2-10-120 | 0.6206 | 0.2857 | 0.1464 | 0.1888 | 0.7612 | 0.6732 |
| 3-5-30 | 0.9776 | 0.0000 | 0.1142 | 0.3174 | 0.9177 | 0.5385 |
| 3-5-60 | 0.9564 | 0.0000 | 0.0905 | 0.4709 | 0.9189 | 0.3773 |
| 3-5-90 | 0.9871 | 0.0000 | 0.0564 | 0.3688 | 0.8724 | 0.4316 |
| 3-5-120 | 0.7571 | 0.1462 | 0.0621 | 0.0911 | 0.7148 | 0.6578 |
| 3-10-30 | 0.0450 | 0.6833 | 0.3210 | 0.1640 | 0.4751 | 0.7644 |
| 3-10-60 | 0.9878 | 0.0000 | 0.0696 | 0.3819 | z | 0.5006 |
| 3-10-90 | 0.9939 | 0.0000 | 0.0651 | 0.3697 | 0.9119 | 0.5338 |
| 3-10-120 | 0.7203 | 0.1812 | 0.0519 | 0.0906 | 0.7115 | 0.6547 |
| 4-5-30 | 0.9608 | 0.0000 | 0.0637 | 0.4683 | 0.9180 | 0.3940 |
| 4-5-60 | 0.9786 | 0.0000 | 0.0637 | 0.5151 | 0.8905 | 0.3329 |
| 4-5-90 | 0.9882 | 0.0000 | 0.0708 | 0.4126 | 0.8715 | 0.3920 |
| 4-5-120 | 0.5761 | 0.2595 | 0.0787 | 0.0961 | 0.7174 | 0.6761 |
| 4-10-30 | 0.3218 | 0.3746 | 0.1525 | 0.1183 | 0.6851 | 0.7460 |
| 4-10-60 | 0.9904 | 0.0000 | 0.0632 | 0.3645 | 0.8812 | 0.4630 |
| 4-10-90 | 0.9934 | 0.0000 | 0.0487 | 0.3538 | 0.8665 | 0.4476 |
| 4-10-120 | 0.7838 | 0.1182 | 0.0540 | 0.0966 | 0.7224 | 0.6465 |
| Average | 0.7625 | 0.1391 | 0.1244 | 0.2737 | 0.7928 | 0.5669 |
| Average CPU Time (s) | |||||
|---|---|---|---|---|---|
| MQBSO | MOWSA | MOBSO | NSGA-II | MOEA/D | |
| 30 | 48.338 | 44.144 | 48.624 | 21.072 | 33.675 |
| 60 | 143.127 | 152.184 | 170.268 | 67.990 | 106.256 |
| 90 | 275.020 | 358.952 | 347.227 | 142.793 | 250.765 |
| 120 | 470.585 | 638.195 | 582.547 | 249.867 | 474.062 |
| Average | 234.268 | 298.369 | 287.166 | 120.430 | 216.189 |
| Job | Processing Time | Time Window | Load | Unit Earliness and Tardiness Weight | |||
|---|---|---|---|---|---|---|---|
| 36 | 45 | 105 | 130 | 20 | 0.2 | 0.4 | |
| 79 | 82 | 193 | 253 | 20 | 0.3 | 0.2 | |
| 21 | 19 | 162 | 192 | 30 | 0.2 | 0.3 | |
| 16 | 82 | 190 | 294 | 10 | 0.4 | 0.3 | |
| 23 | 57 | 141 | 160 | 20 | 0.2 | 0.3 | |
| 31 | 73 | 157 | 192 | 10 | 0.3 | 0.2 | |
| 29 | 90 | 234 | 300 | 10 | 0.2 | 0.3 | |
| 95 | 3 | 311 | 345 | 40 | 0.1 | 0.2 | |
| 45 | 30 | 308 | 353 | 20 | 0.3 | 0.2 | |
| 50 | 93 | 278 | 364 | 20 | 0.2 | 0.4 | |
| 54 | 86 | 332 | 378 | 20 | 0.3 | 0.5 | |
| 54 | 20 | 371 | 400 | 10 | 0.4 | 0.5 | |
| 0 | 999 | 52 | 70 | 55 | 76 | 94 | 54 | 23 | 45 | 44 | 12 | 94 | 113 | |
| 999 | 0 | 43 | 47 | 53 | 70 | 86 | 60 | 35 | 53 | 18 | 44 | 37 | 46 | |
| 52 | 43 | 0 | 89 | 94 | 113 | 129 | 24 | 33 | 75 | 22 | 48 | 76 | 70 | |
| 70 | 47 | 89 | 0 | 35 | 37 | 46 | 107 | 37 | 45 | 22 | 67 | 53 | 75 | |
| 55 | 53 | 94 | 35 | 0 | 21 | 39 | 105 | 12 | 18 | 16 | 29 | 53 | 70 | |
| 76 | 70 | 113 | 37 | 21 | 0 | 18 | 125 | 43 | 27 | 36 | 93 | 33 | 37 | |
| 94 | 86 | 129 | 46 | 39 | 18 | 0 | 143 | 28 | 39 | 47 | 56 | 35 | 53 | |
| 54 | 60 | 24 | 107 | 105 | 125 | 143 | 0 | 25 | 36 | 48 | 69 | 23 | 35 | |
| 23 | 35 | 33 | 37 | 12 | 43 | 28 | 25 | 0 | 12 | 33 | 44 | 53 | 75 | |
| 45 | 53 | 75 | 45 | 18 | 27 | 39 | 36 | 12 | 0 | 23 | 34 | 107 | 37 | |
| 44 | 18 | 22 | 22 | 16 | 36 | 47 | 48 | 33 | 23 | 0 | 84 | 18 | 22 | |
| 12 | 44 | 48 | 67 | 29 | 93 | 56 | 69 | 44 | 34 | 84 | 0 | 24 | 107 | |
| 94 | 37 | 76 | 53 | 53 | 33 | 35 | 23 | 53 | 107 | 18 | 24 | 0 | 17 | |
| 113 | 46 | 70 | 75 | 70 | 37 | 53 | 35 | 75 | 37 | 22 | 107 | 17 | 0 |
| Weight | CPLEX | MQBSO | |||
|---|---|---|---|---|---|
| Output | Time (s) | Output | Time (s) | ||
| 8 | 246.000 | 25.140 | 246.000 | 2.828 | |
| 292.050 | 2242 | 300.500 | 2.213 | ||
| 322.700 | 245 | 324.000 | 2.203 | ||
| 10 | 307.000(AOV) | 3600 | 307.000 | 3.383 | |
| 428.800(AOV) | 3600 | 419.500 | 2.474 | ||
| 499.300(AOV) | 3600 | 498.000 | 2.894 | ||
| 12 | 360.000(AOV) | 3600 | 360.000 | 2.187 | |
| 583.650(AOV) | 3600 | 571.500 | 3.347 | ||
| 767.800(AOV) | 3600 | 723.000 | 4.079 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Xu, J.; Qiao, Y. Multi-Objective Q-Learning-Based Brain Storm Optimization for Integrated Distributed Flow Shop and Distribution Scheduling Problems. Mathematics 2023, 11, 4306. https://doi.org/10.3390/math11204306
Zhang S, Xu J, Qiao Y. Multi-Objective Q-Learning-Based Brain Storm Optimization for Integrated Distributed Flow Shop and Distribution Scheduling Problems. Mathematics. 2023; 11(20):4306. https://doi.org/10.3390/math11204306
Chicago/Turabian StyleZhang, Shuo, Jianyou Xu, and Yingli Qiao. 2023. "Multi-Objective Q-Learning-Based Brain Storm Optimization for Integrated Distributed Flow Shop and Distribution Scheduling Problems" Mathematics 11, no. 20: 4306. https://doi.org/10.3390/math11204306
APA StyleZhang, S., Xu, J., & Qiao, Y. (2023). Multi-Objective Q-Learning-Based Brain Storm Optimization for Integrated Distributed Flow Shop and Distribution Scheduling Problems. Mathematics, 11(20), 4306. https://doi.org/10.3390/math11204306