
Multi-Keyword Searchable Identity-Based Proxy Re-Encryption from Lattices



Abstract
:1. Introduction
1.1. Problem Statements
- The encryption should resist quantum attacks.
- The encrypted file should be searchable. Moreover, the scheme should support multi-keyword to increase the flexibility of searchability.
- To reduce the file-sharing costs of the data owner, the scheme should support PRE.
- The encryption should avoid the cost of using certificates.
1.2. Contributions
- To resist quantum attacks, the security of the proposed scheme is based on the LWE problem from lattices.
- The flexibility of searchability is increased through the proposed multi-keyword search that supports AND and OR operations. The access structure is tree-based rather than LSSS-based, avoiding possible errors in the decryption and search phases.
- KGC only needs to assist users in generating private keys during the registration phase. The burden on the KGC is reduced since it does not involve other phases. Moreover, the risk of KGC being attacked by adversaries through the network can be reduced.
- The proposed scheme supports PRE to reduce file-sharing costs of the data owner. The concept of outsourcing computation is added to the scheme design. As the number of data users increases, the costs required for the data owner remain the same, and the proxy server will handle the increased workload.
- Users’ access rights are verified in both the search phase and the decryption phase to prevent adversaries from illegally accessing files.
- The proposed scheme is identity-based, which avoids the cost of using certificates.
2. Preliminaries
2.1. Lattices
2.2. Discrete Gaussians
- The discrete Gaussian distribution over is
- The sum of all is
- The Gaussian function on is
2.3. Inhomogeneous Short Integer Solution (ISIS)
2.4. Decisional Learning with Errors (D-LWE)
- The noisy pseudo-random sampler outputs pseudo-random samples , where is sampled from , is a consistent secret vector, and is a uniformly random vector.
- The truly random sampler outputs uniformly random samples in .
2.5. Trapdoor Functions
- Given a matrix and an invertible matrix . Output a matrix and a trapdoor of , where . Moreover, the trapdoor’s quality guaranteed that , where the function extracts the Euclidean length of the input, and the little-omega notation is an asymptotic notation.
- Given a matrix , a trapdoor of , an invertible matrix , a target , and a Gaussian parameter σ. Output a vector such that .
- Randomly choose a perturbation vector with , and divide into two parts :
- Compute
- Choose a vector from , and compute
- Output .
- Given a matrix ( is an arbitrary matrix), a trapdoor of , an invertible matrix , and a Gaussian parameter σ. Output a trapdoor of .
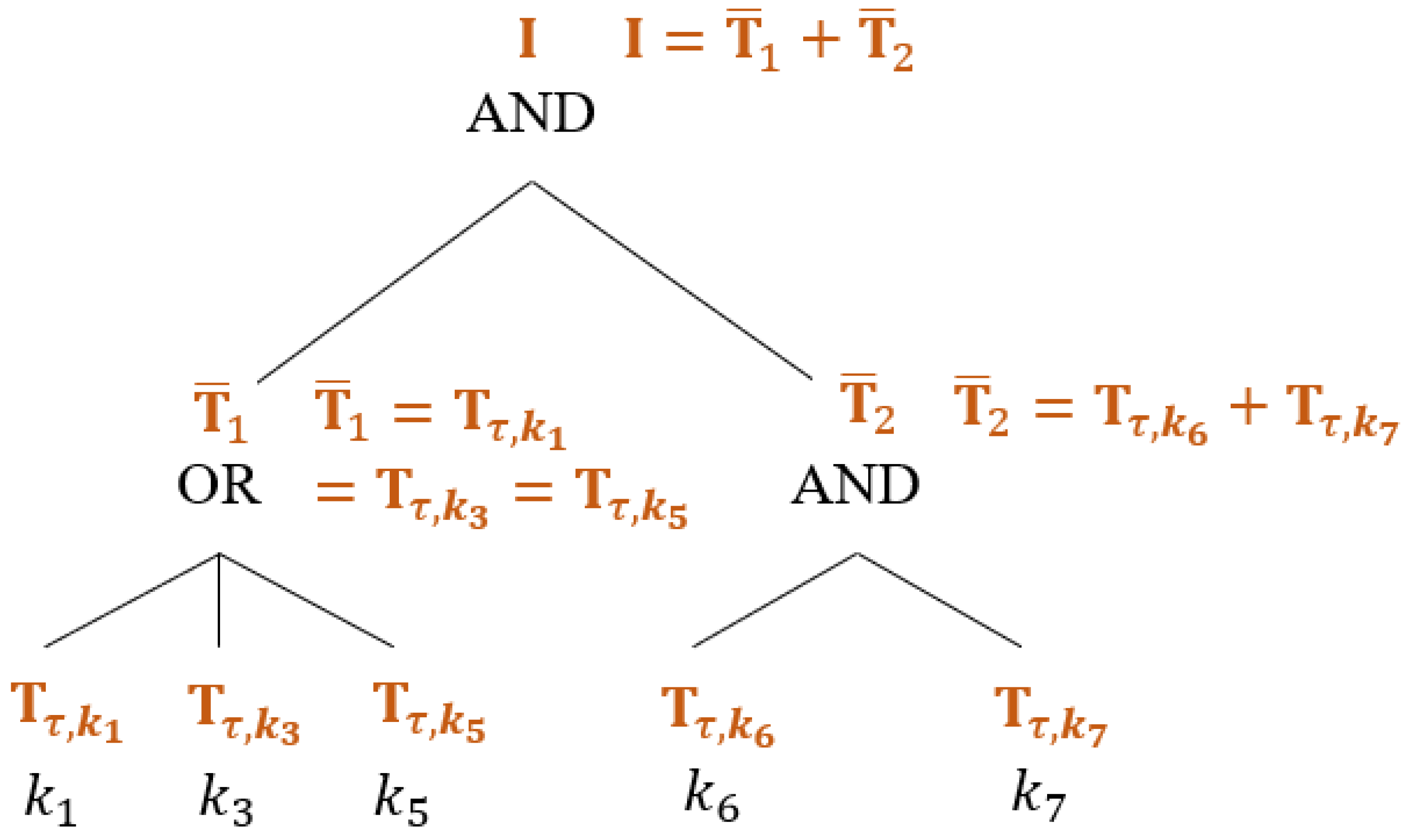
2.6. Tree-Based Access Structure
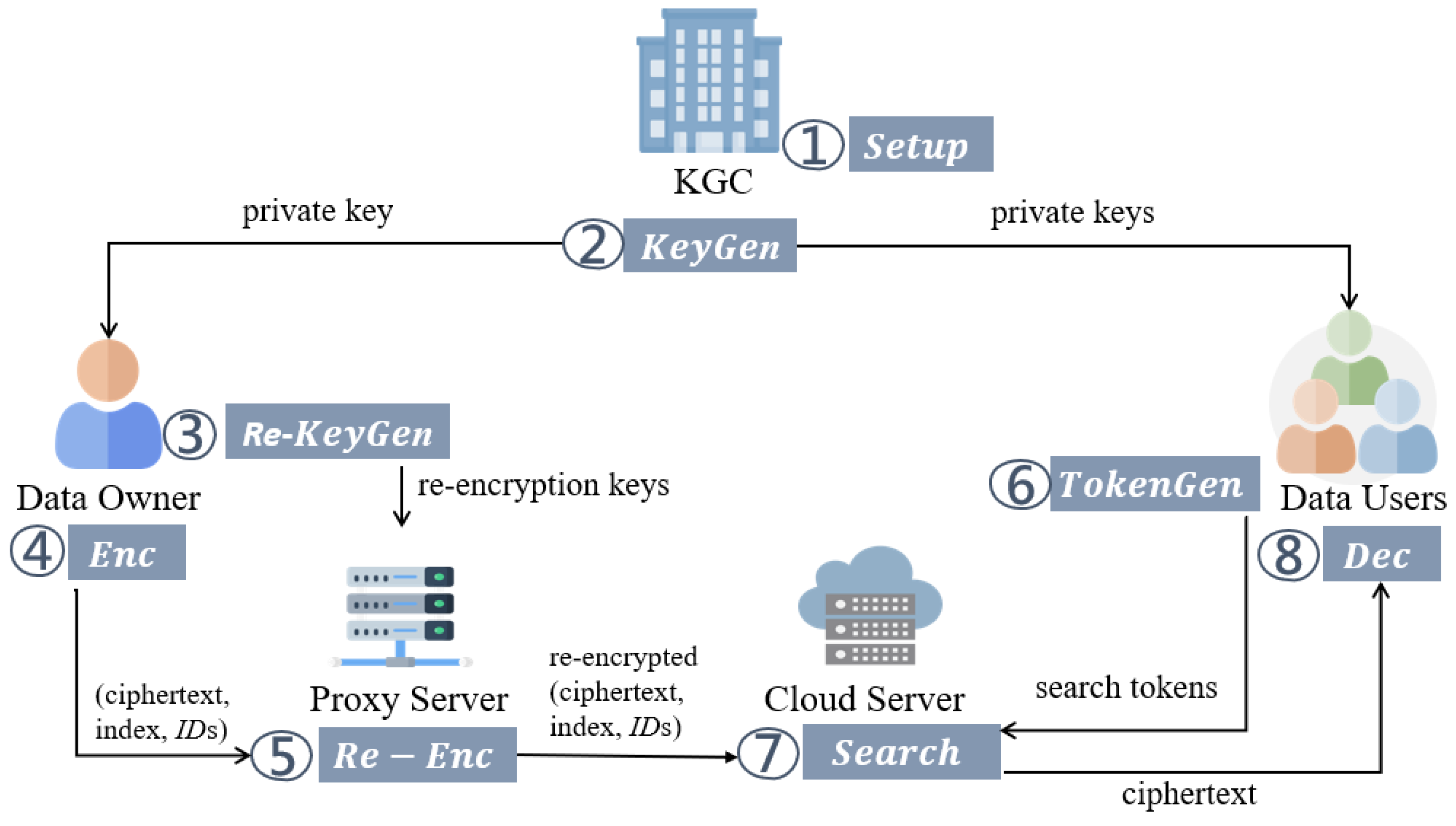
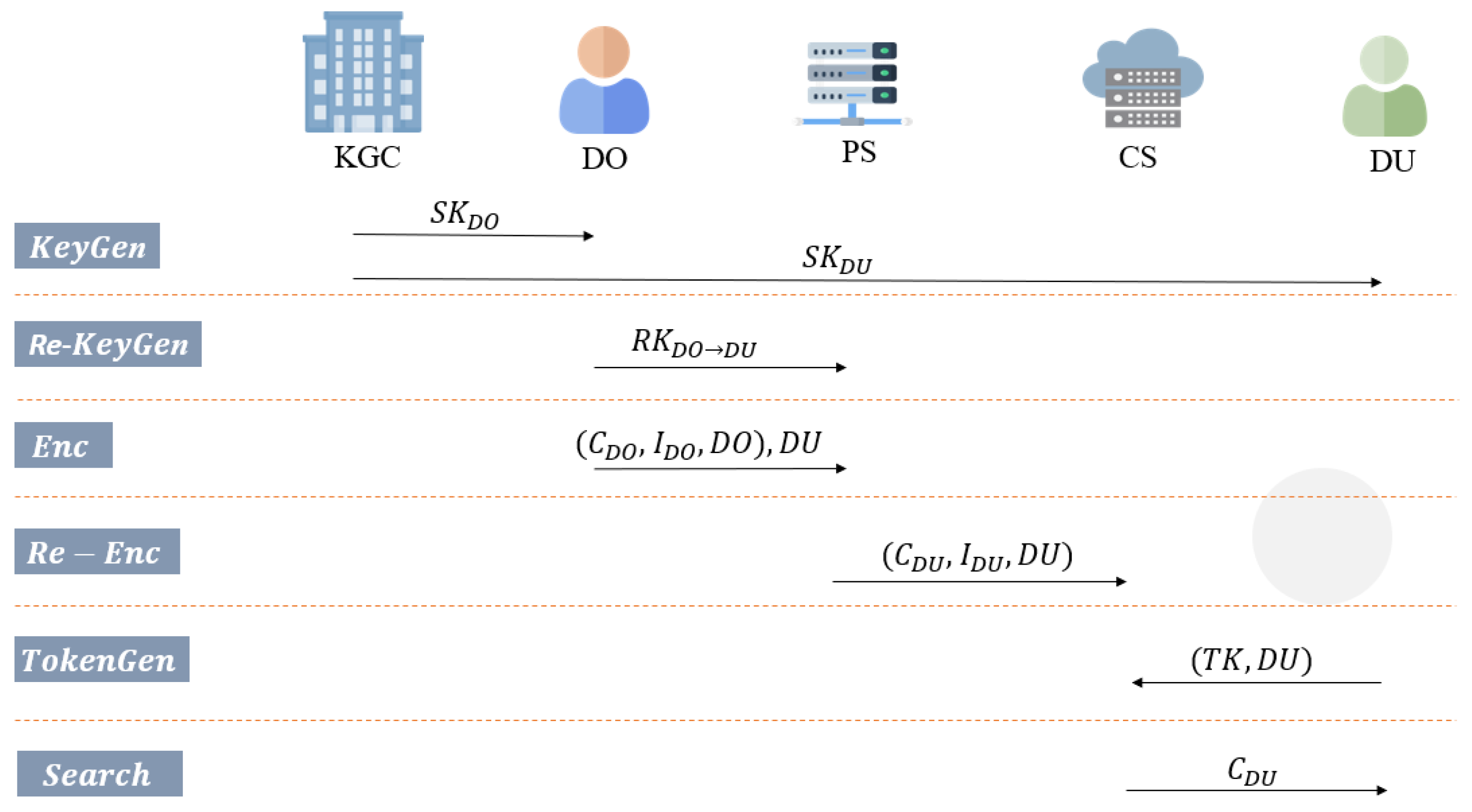
2.7. System Model
- Key Generation Center (KGC): KGC is fully trusted and is responsible for system setup and key distribution.
- Data Owner (DO): DO can pre-generate re-encryption keys and send them to PS before the encryption phase. Then, in the encryption phase, DO computes the ciphertext, index, and s (a set of DUs’ identities). Then, DO sends (ciphertext, index, s) to PS.
- Proxy Server (PS): PS is fully trusted and responsible for re-encryption. After receiving the re-encryption keys, ciphertext, index, and s from DO, PS re-encrypts the ciphertext and index. Finally, PS sends the re-encrypted results to CS.
- Cloud Server (CS): CS is honest-but-curious and responsible for data storage and search.
- Data User (DU): DU can send a search request with a search token to CS to download matching ciphertexts.
- : Taking a security parameter as input, KGC outputs the public parameters and the master secret key .
- : With a user’s identity and as inputs, KGC computes the private key of the user.
- Re-KeyGen(): Taking DU’s identity , and as inputs, the user computes the re-encryption key .
- Enc(: Taking an identity , a one-bit message , and a keyword set as inputs, DO outputs the ciphertext and the index .
- Re-Enc(): Given the ciphertext , the index , DO’s identity , DU’s identity , and a re-encryption key as inputs, PS computes the re-encrypted ciphertext and re-encrypted index .
- TokenGen(): Taking a keyword-search policy , , and as inputs, DU can compute the search token .
- or : Given , , and as inputs, CS checks whether matches . If the result matches, CS sends to DU. Otherwise, CS sends ⊥ to DU.
- Dec(): With and , DU decrypts and gets the plaintext .
2.8. Security Model
2.8.1. Ciphertext Security
- : gives a target identity to . receives a polynomial number of samples from the D-LWE oracle.
- initializes the system and sends public parameters to .
- can adaptively issue the following queries multiple times:
- –
- query: gives an identity to . sends to .
- –
- query: gives an identity to . sends to .
- –
- KeyGen query gives an identity . If , aborts it. Otherwise, sends to .
- –
- Re-KeyGen query gives DO’s identity and DU’s identity . If , aborts it. Otherwise, sends to .
- : submits two messages () to . randomly chooses . Then, computes the ciphertext related to . Finally, sends to .
- : may do more queries as in .
- : Finally, answers a bit . If , wins the IND-CPA game.
2.8.2. Keyword-Search Security
- : gives a target identity and two target keywords to . randomly chooses and will use for the challenge. Furthermore, receives a polynomial number of samples from the D-LWE oracle.
- initializes the system and sends public parameters to .
- can adaptively issue the following queries multiple times:
- –
- query: gives an identity to . sends to .
- –
- query: gives an identity to . sends to .
- –
- KeyGen query gives an identity . If , aborts it. Otherwise, sends to .
- –
- Re-KeyGen query gives DO’s identity and DU’s indetiy . If , aborts it. Otherwise, sends to .
- –
- TokenGen query gives an identity and a keyword-search policy . If ( and ( contains or )), aborts it. Otherwise, sends to .
- : submits a signal to start the . computes the index related to . Finally, sends to .
- : may do more queries as in .
- : Finally, answers a bit . If , wins the IND-CKA game.
3. Related Works
3.1. Huang et al.’s [26] Traditional Multi-Keyword Attribute-Based SE Scheme
3.2. Wang et al.’s [27] Public Key SE Scheme from Lattices
3.3. Attribute-Based SE Schemes from Lattices
3.3.1. Liu et al.’s [17] Scheme
3.3.2. Varri et al.’s [20] Scheme
3.3.3. Chen’s [21] Scheme
3.3.4. Wang’s [22] Scheme
3.4. Zhang et al.’s [19] Identity-Based SE Scheme from Lattices
3.5. Wang et al.’s [18] Lattice-Based SE Schemes Supporting SPE
3.6. Lattice-Based SE Schemes Supporting PRE
3.6.1. Zhang et al.’s [29] Scheme
3.6.2. Hou et al.’s [30] Scheme
4. Construction
4.1. Algorithms
- Taking a security parameter , KGC sets up the system by the following steps:
- Select a Gaussian distribution , a Gaussian parameter , a prime q, four integers n, , l, and w, a keyword set , a random matrix , an invertible matrix , a random vector . Let .
- Select three hash functions , , and , where the output of or is an invertible matrix.
- Generate a matrix and a corresponding trapdoor of by invoking defined in Section 2.5, where is a gadget matrix defined in Section 2.5.
- Publish the public parameters and keep the master secret key .
In algorithm, is a special matrix that is public. can be an identity matrix and be public. Due to the difficulty of solving the ISIS problem defined in Section 2.3, even given , , , and , it is hard to find . Therefore, only the trapdoor needs to be kept secret. - With a user’s and as inputs, KGC runs to compute the user’s private key by the following steps:
- Compute .
- Set .
- Compute .
- Run DelTrap() defined in Section 2.5 to generate such that , where is a trapdoor of .
- Run SampleD () to generate so that .
- Set . and send it to the user.
will be treated as the public key associated with the user . However, because the number of bits of the matrix is relatively high, directly storing will consume a large storage space. Therefore, users only need to store the ID, and when users need to use A, they use the hash function to compute it. Anyone who knows the user ID can compute the corresponding . Similarly, users do not store directly, thereby reducing storage requirements. On the other hand, the determinants and should be small. Otherwise, it will affect the correctness of the proposed scheme. Since and need to be small, the difficulty for an adversary to compute an effective private key is equivalent to solving the ISIS problem. - )With , the user can compute the re-encryption key by the following steps:
- Compute .
- Set .
- Compute .
- Set .
- Compute .
- Perform SampleD() defined in Section 2.5 to get such that .
- Set .
The concept of re-encryption is to compute a matrix so that the matrix multiplied by will be equal to the matrix . Moreover, the determinant should be small, so it can be ignored in the search results or the decryption results. Otherwise, it will affect the correctness of those results. Since needs to be small, the difficulty for an adversary to compute an effective re-encryption key is equivalent to solving the ISIS problem. - Enc()Taking a one-bit message and a keyword set , DO encrypts with its by the following steps:
- Compute .
- Set .
- Sample noises and .
- Choose two secret vectors .
- Compute .
- Compute .
- Set the ciphertext .
- Compute .
- For to l,
- (a)
- if the keyword ,
- generate a random matrix .
- (b)
- if , perform the following steps:
- Compute .
- Compute .
- Set the index .
- Choose DUs’ identities s.
- Send (, , ), s) to PS.
To reduce the computation and transmission costs of DO by outsourced computing, DO encrypts the message with its public key. Then, DO sends the ciphertext, index, and DUs’ IDs to PS. When the number of DUs increases, DO only needs to increase the list of receivers without any other cost. Therefore, when the number of DUs is large, the proposed scheme can effectively reduce the burden on DO. - Re-Enc()Given the ciphertext , the index , DO’s identity , DU’s identity , and a re-encryption key , PS can transfer to by the following steps:
- Sample noises .
- Set .
- Compute .
- Set .
- Set .
- For to l, compute .
- Set .
- Upload () to CS.
PS computes an independent re-encrypted ciphertext and re-encrypted index for each DU. Moreover, the difficulty for an adversary to compute the re-encryption key from the ciphertext (or index) and the re-encrypted ciphertext (or re-encrypted index) is equivalent to solving the LWE problem. - TokenGen()Taking a keyword-search policy and the private key , the user can compute the search token by the following steps:
- Compute .
- Set .
- Compute .
- According to , generate invertible matrices . The detail of how to generate is described in Section 2.6.
- For to l,
- (a)
- if , then perform the following steps:
- Compute .
- Compute the inverse matrix of , such that , where is an identity matrix.
- Perform SampleD() to get such that .
- Set the search token .
- Send to CS.
In the proposed scheme, DU can generate tokens since it has a trapdoor specific to its public key . Therefore, KGC does not need to stay online to assist in generating tokens. On the other hand, through the method mentioned in Section 2.6, if a keyword set can exactly satisfy the keyword-search policy , then . Therefore, TK generated by the TokenGen algorithm will make the following equation hold: . - orGiven , , and , CS checks whether matches by the following steps:
- According to the keyword-search policy , for any keyword set exactly satisfying , CS performs the following steps:
- (a)
- Set .
- (b)
- for to l,
- if ,
- compute .
- (c)
- Compute .
- (d)
- If , send to DU.
- Return ⊥ to DU, if there are no matching search results.
By choosing appropriate parameter values, the size of the error term should be between and . Therefore, if the search token matches the index, the search result f should be less than . - Dec()With the ciphertext and private key , the user ID can decrypt by the following steps:
- Compute .
- If , return ; otherwise return .
By choosing appropriate parameter values, the size of the error term should be between and . Therefore, if the decrypted result is less than , the plaintext should be 0. Note that while DU may compute with the trapdoor , we recommend DU to store . Because computing it requires a SampleD operation, storing can reduce the computation cost for decryption.
4.2. Correctness
- Correctness in SearchSuppose , which means that the keyword set can exactly satisfy the keyword-search policy . Note that is an identity matrix.For the correctness of the search result, the absolute value of the error term must be less than .
- Correctness in DecryptionFor the correctness of the decryption result, the absolute value of the error term must be less than .
5. Security Proofs
5.1. Ciphertext Security
- : gives a target identity to . chooses two integers and sets . Then receives samples from the D-LWE oracle , where each .
- :
- –
- chooses and runs algorithm to generate the following parameters and hash functions .
- –
- sets , , and . Note that .
- –
- computes an invertible matrix and a small matrix such that , where is a gadget matrix defined in Section 2.5.
- –
- sets , and .
- –
- Finally, sends to .
- : may adaptively issue the following queries.
- –
- query: gives an identity to .
- *
- If , computes and sends it to .
- *
- If , sets and sends to .
- –
- query: gives an identity to .
- *
- If , computes and sends it to .
- *
- If ,
- ·
- if exists, returns to .
- ·
- else, computes an invertible matrix and a small matrix such that . stores and sends it to .
- –
- KeyGen query: gives an identity to .
- *
- If ,
- ·
- if exists, returns to .
- ·
- else, runs to generate . stores and sends it to .
- *
- If , aborts it.
- –
- Re-KeyGen query: gives DO’s identity and DU’s indetiy to .
- *
- If , runs Re-KeyGen() to generate and sends it to .
- *
- If , aborts it.
- : submits two different messages to . performs the following steps:
- –
- randomly chooses .
- –
- computes .
- –
- sets .
- –
- sets the ciphertext and sends it to .
- : may do more queries as in .
- : answers a bit to . If , answers the D-LWE assumption that the samples are from the noisy pseudo-random sampler . Otherwise, answers that the samples are from the truly random sampler .
5.2. Keyword-Search Security
- : gives a target identity and two target keywords to .
- –
- randomly chooses and will use for the challenge.
- –
- chooses two integers and sets . Then receives samples from the D-LWE oracle , where each .
- :
- –
- chooses and runs algorithm to generate the following parameters and hash functions .
- –
- sets , , and . Note that .
- –
- computes and its inverse matrix . Then stores .
- –
- computes the following matrices:
- *
- ,
- *
- .
Note that , and . - –
- computes an invertible matrix and a small matrix such that , where is a gadget matrix defined in Section 2.5.
- –
- sets , and .
- –
- Finally, sends to .
- : may adaptively issue the following queries.
- –
- query: gives an identity to .
- *
- If , computes and sends it to .
- *
- If , sets . Then, computes and sends to .
- –
- query: gives an identity to .
- *
- If , computes and sends it to .
- *
- If ,
- ·
- if exists, returns to .
- ·
- else, computes an invertible matrix and a small matrix such that . sets and stores it. Finally, stores and sends it to .
- –
- KeyGen query: gives an identity to .
- *
- If ,
- ·
- if exists, returns to .
- ·
- else, runs to generate . stores and sends it to .
- *
- If , aborts it.
- –
- Re-KeyGen query: gives DO’s identity and DU’s indetiy to .
- *
- If , runs Re-KeyGen() to generate and sends it to .
- *
- If , aborts it.
- –
- TokenGen query: gives an identity and a keyword-search policy to .
- *
- If ( and ( contains or )), aborts it.
- *
- Else, runs to generate . Then sends to .
- : submits a signal to start the phase. performs the following steps:
- –
- sets .
- –
- sets .
- –
- sets the index and sends it to .
- : may do more queries as in .
- : answers a bit to . If , answers the D-LWE assumption that the samples are from the noisy pseudo-random sampler . Otherwise, answers that the samples are from the truly random sampler .
6. Comparison
6.1. Transmission Cost
- Ciphertext size: Since the proposed scheme uses DelTrap to achieve ID-based features, the ciphertext size requires bits. On the other hand, all users use the same key for decryption in [20], so its ciphertext size can be shorter than other schemes. Moreover, [19,27,29,30] do not provide or detail the decryption phase.
- Index size: The proposed scheme supports multi-keyword search, which requires a multiple of l more index sizes. Therefore, the index size of the proposed scheme is .
- Token size: The proposed scheme supports multi-keyword search, which requires a multiple of l more token sizes. Therefore, the token size of the proposed scheme is .

{kind=link}
{kind=link}
{kind=link}
6.2. Computation Cost
6.3. Summary
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IBE | Identity-Based Encryption |
| ABE | Attribute-Based Encryption |
| SPE | Subset-Predicate Encryption |
| PRE | Proxy Re-Encryption |
| SE | Searchable Encryption |
| LWE | Learning With Error |
| D-LWE | Decisional Learning with Errors |
| ISIS | Inhomogeneous Short Integer Solution |
| KGC | Key Generation Center |
| DO | Data Owner |
| DU | Data User |
| PS | Proxy Server |
| CS | Cloud Server |
| IND-CPA | INDistinguishability under Chosen Plaintext Attacks |
| IND-CKA | INDistinguishability under Chosen Keyword Attacks |
| LSSS | Linear Secret Sharing Scheme |
| NIST | the National Institute of Standards and Technology |
Appendix A
| Algorithm A1 Setup |
| Require: A security parameter . |
| Ensure: The public parameters and the master secret key . |
|
| Algorithm A2 KeyGen |
| Require: , the user’s . |
| Ensure: The private key . |
|
| Algorithm A3 Re-KeyGen |
| Require: , the user’s , the delegate’s . |
| Ensure: The re-encryption key . |
|
| Algorithm A4 Encrypt |
| Require: , a one-bit message , a keyword set , and DO’s identity . |
| Ensure: The ciphertext , the index , , and DUs’ identities . |
|
| Algorithm A5 Re-Enc |
| Require: , , ), , and a re-encryption key |
| Ensure: The re-encrypted ciphertext , the re-encrypted index , and . |
|
| Algorithm A6 TokenGen |
| Require: , , , , and a keyword-search policy . |
| Ensure: A search token and . |
|
| Algorithm A7 Search |
| Require: , , , and . |
| Ensure: or ⊥. |
|
| Algorithm A8 Dec |
| Require: and . |
| Ensure: . |
|
References
- Shamir, A. Identity-based cryptosystems and signature schemes. In Proceedings of the Workshop on the Theory and Application of Cryptographic Techniques, Paris, France, 9–11 April 1984; Springer: Berlin/Heidelberg, Germany, 1984; pp. 47–53. [Google Scholar]
- Sahai, A.; Waters, B. Fuzzy identity-based encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Aarhus, Denmark, 22–26 May 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 457–473. [Google Scholar]
- Katz, J.; Maffei, M.; Malavolta, G.; Schröder, D. Subset predicate encryption and its applications. In Proceedings of the Cryptology and Network Security: 16th International Conference, CANS 2017, Hong Kong, China, 30 November–2 December 2017; Springer: Berlin/Heidelberg, Germany, 2018; pp. 115–134. [Google Scholar]
- Blaze, M.; Bleumer, G.; Strauss, M. Divertible protocols and atomic proxy cryptography. In Proceedings of the Advances in Cryptology—EUROCRYPT’98: International Conference on the Theory and Application of Cryptographic Techniques, Espoo, Finland, 31 May–4 June 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 127–144. [Google Scholar]
- Green, M.; Ateniese, G. Identity-based proxy re-encryption. In Proceedings of the Applied Cryptography and Network Security: 5th International Conference, ACNS 2007, Zhuhai, China, 5–8 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 288–306. [Google Scholar]
- Liang, X.; Cao, Z.; Lin, H.; Shao, J. Attribute based proxy re-encryption with delegating capabilities. In Proceedings of the 4th International Symposium on Information, Computer, and Communications Security, Sydney, Australia, 10–12 March 2009; pp. 276–286. [Google Scholar]
- Song, D.X.; Wagner, D.; Perrig, A. Practical techniques for searches on encrypted data. In Proceedings of the 2000 IEEE Symposium on Security and Privacy, S&P, Berkeley, CA, USA, 14–17 May 2000; IEEE: Piscataway, NJ, USA, 2000; pp. 44–55. [Google Scholar]
- Boneh, D.; Di Crescenzo, G.; Ostrovsky, R.; Persiano, G. Public key encryption with keyword search. In Proceedings of the Advances in Cryptology-EUROCRYPT 2004: International Conference on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, 2–6 May 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 506–522. [Google Scholar]
- Hwang, Y.H.; Lee, P.J. Public key encryption with conjunctive keyword search and its extension to a multi-user system. In Proceedings of the Pairing-Based Cryptography–Pairing 2007: First International Conference, Tokyo, Japan, 2–4 July 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 2–22. [Google Scholar]
- Shor, P.W. Algorithms for quantum computation: Discrete logarithms and factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, NM, USA, 20–22 November 1994; IEEE: Piscataway, NJ, USA, 1994; pp. 124–134. [Google Scholar]
- Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Kyber: A CCA-secure module-lattice-based KEM. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 353–367. [Google Scholar]
- Ajtai, M. Generating hard instances of lattice problems. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, Hiladelphia, PA, USA, 22–24 May 1996; pp. 99–108. [Google Scholar]
- Hoffstein, J.; Pipher, J.; Silverman, J.H. NTRU: A ring-based public key cryptosystem. In Proceedings of the International Algorithmic Number Theory Symposium, Burlington, VT, USA, 13–18 June 2004; Springer: Berlin/Heidelberg, Germany, 1998; pp. 267–288. [Google Scholar]
- Regev, O. On lattices, learning with errors, random linear codes, and cryptography. In Proceedings of the Thirty-Seventh Annual ACM Symposium on Theory of Computing, Baltimore, MD, USA, 22–24 May 2005; pp. 84–93. [Google Scholar]
- Boyen, X. Attribute-based functional encryption on lattices. In Proceedings of the Theory of Cryptography Conference, Tokyo, Japan, 3–6 March 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 122–142. [Google Scholar]
- Singh, K.; Rangan, C.P.; Banerjee, A. Lattice based identity based unidirectional proxy re-encryption scheme. In Proceedings of the International Conference on Security, Privacy, and Applied Cryptography Engineering, Pune, India, 18–22 October 2004; Springer: Berlin/Heidelberg, Germany, 2014; pp. 76–91. [Google Scholar]
- Liu, L.; Wang, S.; He, B.; Zhang, D. A keyword-searchable abe scheme from lattice in cloud storage environment. IEEE Access 2019, 7, 109038–109053. [Google Scholar] [CrossRef]
- Wang, P.; Chen, B.; Xiang, T.; Wang, Z. Lattice-based public key searchable encryption with fine-grained access control for edge computing. Future Gener. Comput. Syst. 2022, 127, 373–383. [Google Scholar] [CrossRef]
- Zhang, X.; Tang, Y.; Wang, H.; Xu, C.; Miao, Y.; Cheng, H. Lattice-based proxy-oriented identity-based encryption with keyword search for cloud storage. Inf. Sci. 2019, 494, 193–207. [Google Scholar] [CrossRef]
- Varri, U.S.; Pasupuleti, S.K.; Kadambari, K. CP-ABSEL: Ciphertext-policy attribute-based searchable encryption from lattice in cloud storage. Peer Peer Netw. Appl. 2021, 14, 1290–1302. [Google Scholar] [CrossRef]
- Chen, X.J. Lattice-Based Searchable Attribute-Based Encryption Supporting Dynamic Membership Management. Master’s Thesis, National Sun Yet-sen University, Kaohsiung, Taiwan, 2021. [Google Scholar]
- Wang, D.R. Multi-Keyword Searchable Attribute-Based Encryption Supporting Dynamic Membership Management from Lattices. Master’s Thesis, National Sun Yet-sen University, Kaohsiung, Taiwan, 2022. [Google Scholar]
- Regev, O. On lattices, learning with errors, random linear codes, and cryptography. J. ACM 2009, 56, 1–40. [Google Scholar] [CrossRef]
- Micciancio, D.; Peikert, C. Trapdoors for lattices: Simpler, tighter, faster, smaller. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Cambridge, UK, 15–19 April 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 700–718. [Google Scholar]
- Genise, N.; Micciancio, D. Faster Gaussian sampling for trapdoor lattices with arbitrary modulus. In Proceedings of the Advances in Cryptology–EUROCRYPT 2018: 37th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Tel Aviv, Israel, 29 April–3 May 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 174–203. [Google Scholar]
- Huang, Q.; Yan, G.; Wei, Q. Attribute-based expressive and ranked keyword search over encrypted documents in cloud computing. IEEE Trans. Serv. Comput. 2022, 16, 957–968. [Google Scholar] [CrossRef]
- Wang, P.; Xiang, T.; Li, X.; Xiang, H. Public key encryption with conjunctive keyword search on lattice. J. Inf. Secur. Appl. 2020, 51, 102433. [Google Scholar] [CrossRef]
- Wang, Y. Lattice Ciphertext Policy Attribute-based Encryption in the Standard Model. Int. J. Netw. Secur. 2014, 16, 444–451. [Google Scholar]
- Zhang, E.; Hou, Y.; Li, G. A lattice-based searchable encryption scheme with the validity period control of files. Multimed. Tools Appl. 2021, 80, 4655–4672. [Google Scholar] [CrossRef]
- Hou, Y.; Yao, W.; Li, X. A Lattice-Based Semantic Aware Multi-Keyword Searchable Encryption for Multi-User Environments. SSRN 2022. [Google Scholar] [CrossRef]
| Notation | Meaning |
|---|---|
| Public parameters | |
| A security parameter | |
| A Gaussian distribution | |
| A Gaussian parameter | |
| q | A modulo prime number |
| n | The dimension of a vector space |
| m | The number of vectors of a basis |
| l | The number of keywords |
| w | A key generated by DelTrap has w bits |
| more than the original private key | |
| A keyword set | |
| The i-th keyword | |
| A random matrix | |
| The transpose of a matrix | |
| An invertible matrix | |
| A random vector | |
| , , | Hash functions |
| A trapdoor of | |
| A user’s identity | |
| s | A set of users’ identities |
| The private key of | |
| One-bit message | |
| A Search token | |
| A keyword-search policy | |
| An invertible matrix belongs to and is related to | |
| f | A flag used to determine search results |
| Quantum Resistant | Multi- Keyword | Offline KGC | Proxy Re-Encryption | Authentication | Not LSSS-Based | Functional Encryption | ||
|---|---|---|---|---|---|---|---|---|
| Decryption | Search | |||||||
| [26] | ✗ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ABE |
| [27] | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | IBE |
| [17] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ABE |
| [20] | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ABE |
| [21] | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ABE |
| [22] | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ | ABE |
| [19] | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | IBE |
| [18] | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ | SPE |
| [29] | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ |
| [30] | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ |
| Ours | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | IBE |
| Meaning | |
|---|---|
| n | The dimension of a vector space |
| m | The number of vectors of a basis |
| q | A modulo prime number |
| N | |
| s | The number of attributes used in ABE |
| The number of bits of a set used in SPE | |
| The number of random values to generate secret shares in LSSS | |
| l | The number of keywords |
| w | A key generated by DelTrap has w bits more than the original private key |
| A security parameter |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, E.-S.; Fan, C.-I. Multi-Keyword Searchable Identity-Based Proxy Re-Encryption from Lattices. Mathematics 2023, 11, 3830. https://doi.org/10.3390/math11183830
Zhuang E-S, Fan C-I. Multi-Keyword Searchable Identity-Based Proxy Re-Encryption from Lattices. Mathematics. 2023; 11(18):3830. https://doi.org/10.3390/math11183830
Chicago/Turabian StyleZhuang, Er-Shuo, and Chun-I Fan. 2023. "Multi-Keyword Searchable Identity-Based Proxy Re-Encryption from Lattices" Mathematics 11, no. 18: 3830. https://doi.org/10.3390/math11183830
APA StyleZhuang, E.-S., & Fan, C.-I. (2023). Multi-Keyword Searchable Identity-Based Proxy Re-Encryption from Lattices. Mathematics, 11(18), 3830. https://doi.org/10.3390/math11183830