
A Contrastive Model with Local Factor Clustering for Semi-Supervised Few-Shot Learning



Abstract
1. Introduction
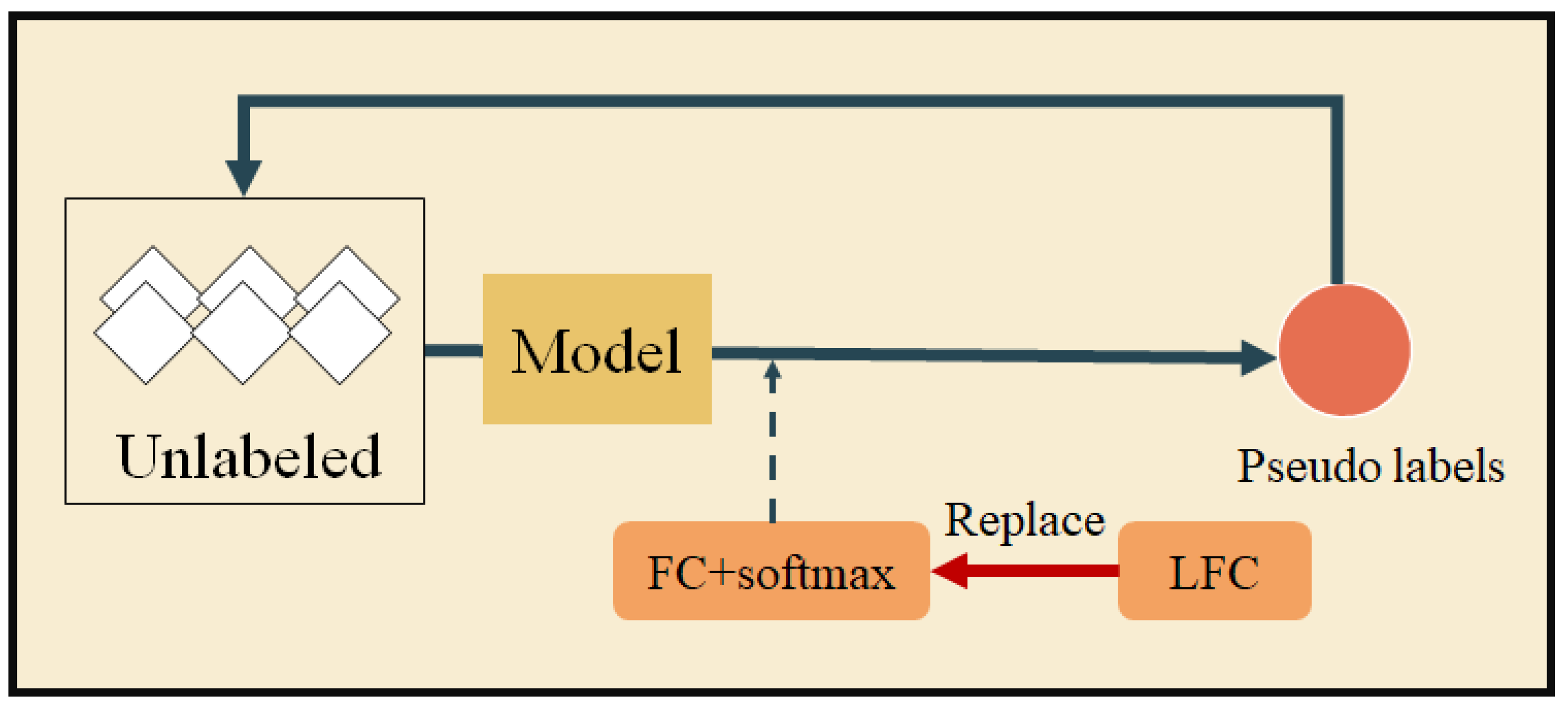
- We propose an easy but effective few-shot classification model with pseudo-labeling guided contrastive learning, which alleviates the embeddings mismatch problem and also narrows the distance between samples of the same class. And the PLCL module is more in line with the class-level classification objective.
- We further propose a local factor clustering module to better acquire accurate pseudo-labels, which combines the local feature information of labeled and unlabeled samples.
- A series of experiments and analyses are conducted to demonstrate the progressiveness and robustness of our approach on two datasets.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Acronyms | Descriptions |
|---|---|---|
| 1 | FSL | few-shot learning |
| 2 | SSFSL | semi-supervised few-shot learning |
| 3 | UCL | the unsupervised contrastive learning module |
| 4 | PLCL | the pseudo-labeling guided contrastive learning module |
| 5 | LFC | the local factor clustering strategy |
| 6 | MFC | the multi-factor clustering strategy from [12] |
| 7 | KC | the kmeans clustering strategy from [9] |
| 8 | CE loss | cross-entropy loss |
| 9 | GAP | global average pooling operation |
2. Related Work
2.1. Few-Shot Learning and Semi-Supervised Few-Shot Learning
2.2. Contrastive Learning
3. Methodology
3.1. Problem Formulation
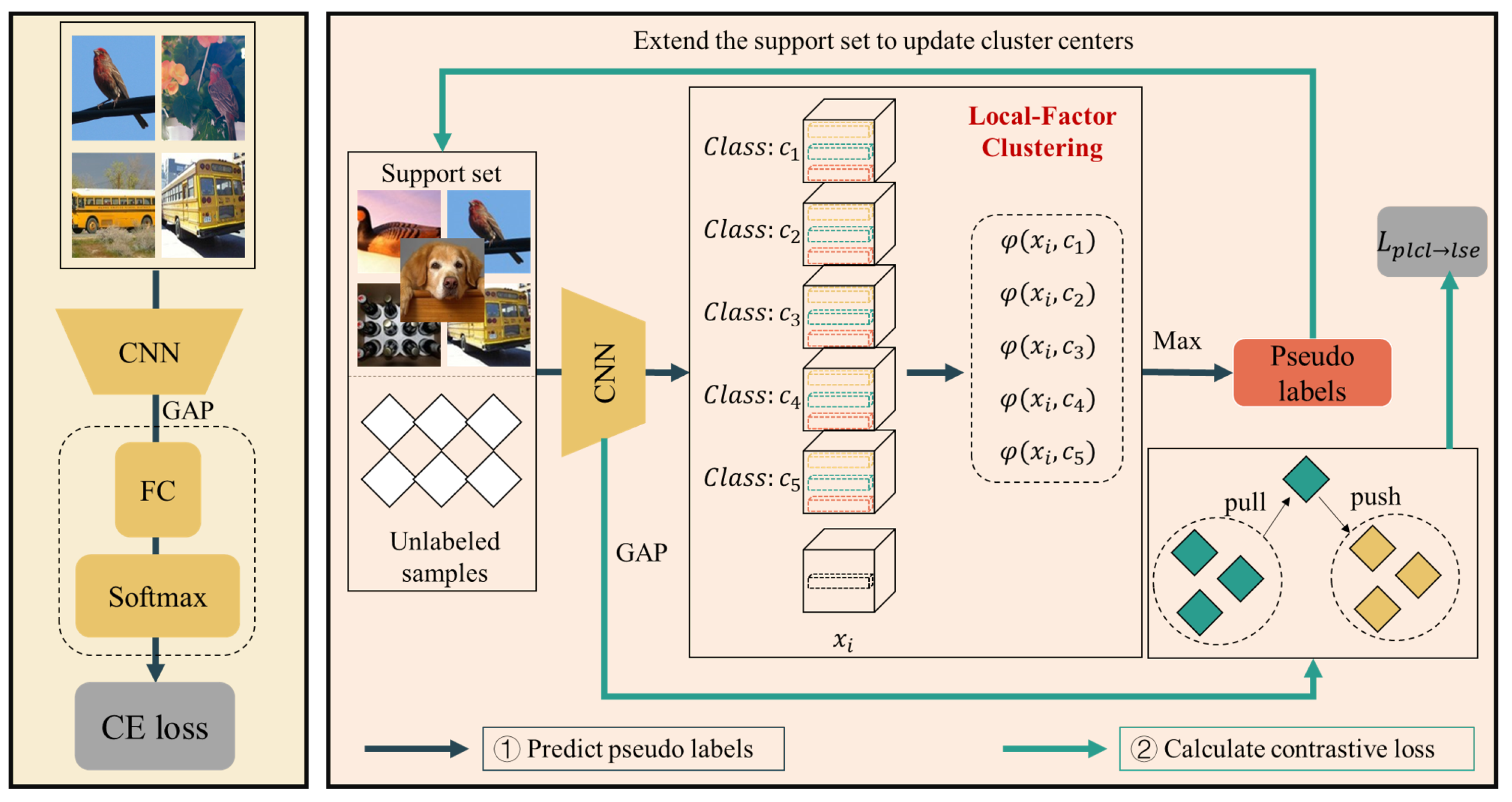
3.2. Pre-Training Feature Embeddings
3.3. Fine-Tuning Feature Embeddings Using LFC and PLCL
3.3.1. The Local Factor Clustering Module
3.3.2. The Pseudo-Labeling Guided Contrastive Learning Module
3.4. Testing Using LFC and Feature Embeddings
4. Experiment
4.1. Datasets
4.1.1. Mini-ImageNet
4.1.2. Tiered-ImageNet
4.2. Implementation Details
4.3. Experimental Results
4.3.1. Comparison with Advanced Methods
4.3.2. The Impact of Unlabeled Samples
4.3.3. The Impact of Nearest Neighbors
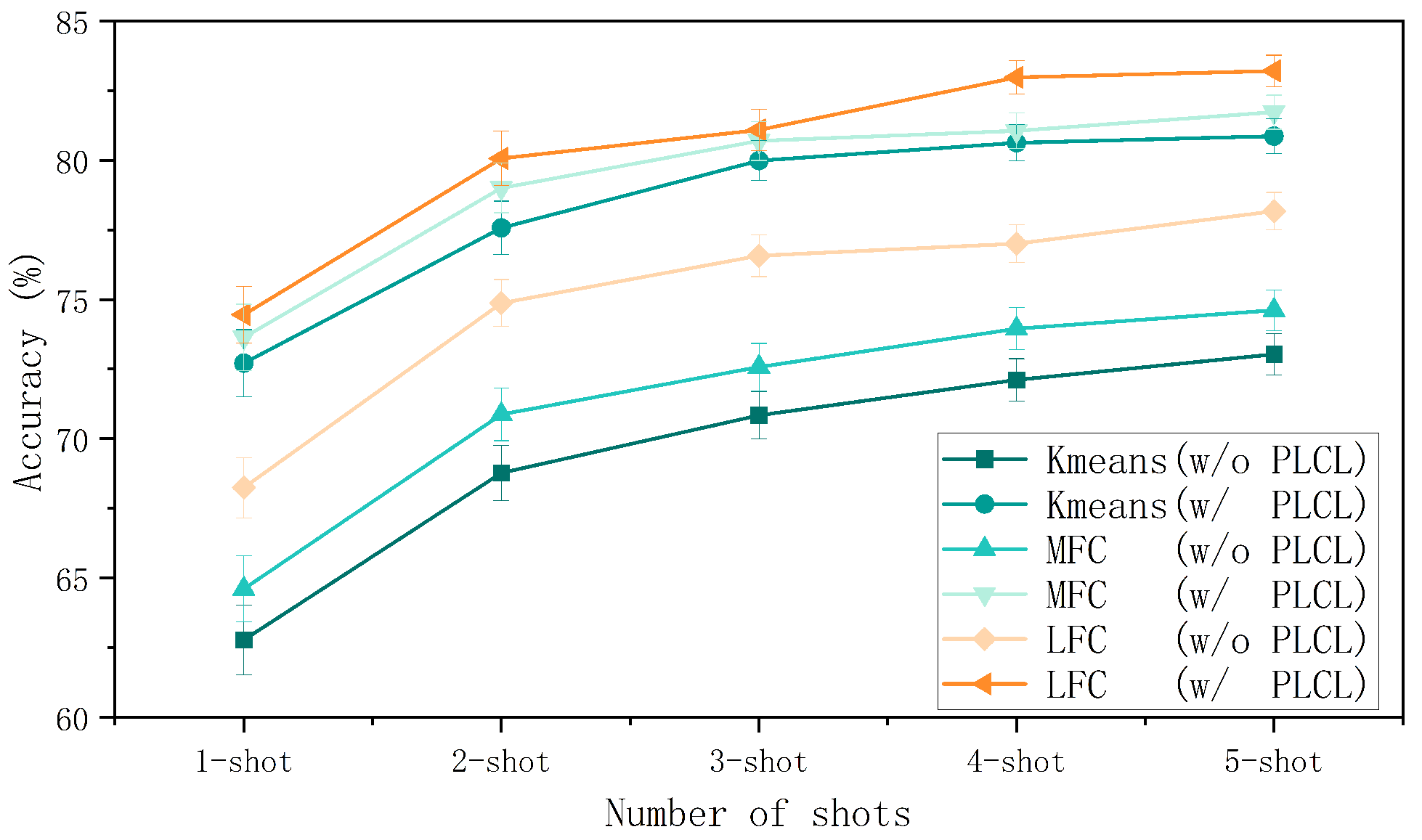
4.4. Ablation Study
4.4.1. The Influence of PLCL
4.4.2. The Influence of LFC
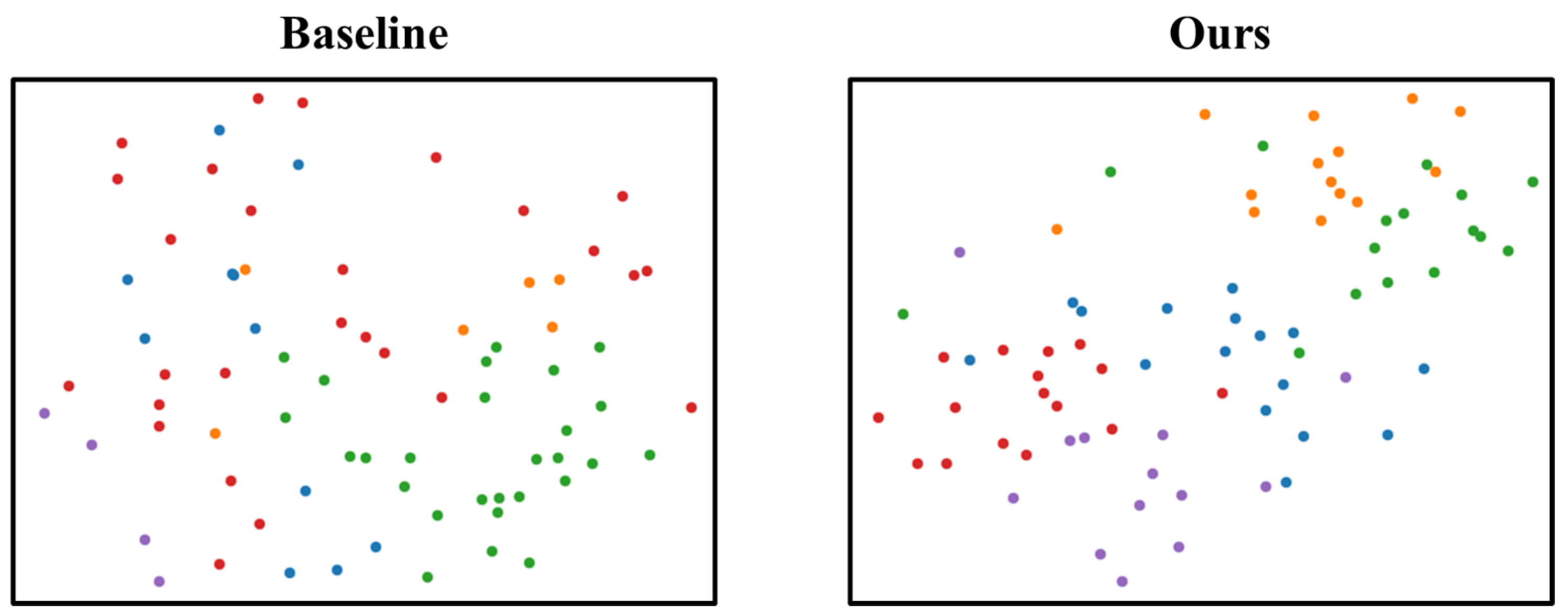
4.5. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fei-Fei, L.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3637–3645. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1126–1135. [Google Scholar]
- Dhillon, G.S.; Chaudhari, P.; Ravichandran, A.; Soatto, S. A baseline for few-shot image classification. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Yu, Z.; Chen, L.; Cheng, Z.; Luo, J. Transmatch: A transfer-learning scheme for semi-supervised few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12856–12864. [Google Scholar]
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.; Huang, J.B. A Closer Look at Few-shot Classification. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Huang, H.; Zhang, J.; Zhang, J.; Wu, Q.; Xu, C. Ptn: A poisson transfer network for semi-supervised few-shot learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 19–21 May 2021; Volume 35, pp. 1602–1609. [Google Scholar]
- Ren, M.; Triantafillou, E.; Ravi, S.; Snell, J.; Swersky, K.; Tenenbaum, J.B.; Larochelle, H.; Zemel, R.S. Meta-learning for semi-supervised few-shot classification. In Proceedings of the 6th International Conference on Learning Representations ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Li, X.; Sun, Q.; Liu, Y.; Zhou, Q.; Zheng, S.; Chua, T.S.; Schiele, B. Learning to self-train for semi-supervised few-shot classification. Adv. Neural Inf. Process. Syst. 2019, 32, 10276–10286. [Google Scholar]
- Huang, K.; Geng, J.; Jiang, W.; Deng, X.; Xu, Z. Pseudo-loss confidence metric for semi-supervised few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 8671–8680. [Google Scholar]
- Ling, J.; Liao, L.; Yang, M.; Shuai, J. Semi-Supervised Few-shot Learning via Multi-Factor Clustering. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14544–14553. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4080–4090. [Google Scholar]
- Zhang, J.; Zhao, C.; Ni, B.; Xu, M.; Yang, X. Variational Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1685–1694. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. On the convergence theory of gradient-based model-agnostic meta-learning algorithms. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Online, 26–28 August 2020; pp. 1082–1092. [Google Scholar]
- Lee, K.; Maji, S.; Ravichandran, A.; Soatto, S. Meta-Learning with Differentiable Convex Optimization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10649–10657. [Google Scholar]
- Yang, Z.; Wang, J.; Zhu, Y. Few-shot classification with contrastive learning. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XX. Springer: Berlin/Heidelberg, Germany, 2022; pp. 293–309. [Google Scholar]
- Wei, X.S.; Xu, H.Y.; Zhang, F.; Peng, Y.; Zhou, W. An Embarrassingly Simple Approach to Semi-Supervised Few-Shot Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 14489–14500. [Google Scholar]
- Hou, Z.; Kung, S.Y. Semi-Supervised Few-Shot Learning from A Dependency-Discriminant Perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June2022; pp. 2817–2825. [Google Scholar]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, E.; Hwang, S.J.; Yang, Y. Learning to propagate labels: Transductive propagation network for few-shot learning. arXiv 2018, arXiv:1805.10002. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Ouali, Y.; Hudelot, C.; Tami, M. Spatial contrastive learning for few-shot classification. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Research Track: European Conference, ECML PKDD 2021, Bilbao, Spain, 13–17 September 2021; Proceedings, Part I 21. Springer: Berlin/Heidelberg, Germany, 2021; pp. 671–686. [Google Scholar]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting local descriptor based image-to-class measure for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7260–7268. [Google Scholar]
- Liu, C.; Fu, Y.; Xu, C.; Yang, S.; Li, J.; Wang, C.; Zhang, L. Learning a few-shot embedding model with contrastive learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 19–21 May 2021; Volume 35, pp. 8635–8643. [Google Scholar]
- Chen, J.; Gan, Z.; Li, X.; Guo, Q.; Chen, L.; Gao, S.; Chung, T.; Xu, Y.; Zeng, B.; Lu, W.; et al. Simpler, faster, stronger: Breaking the log-k curse on contrastive learners with flatnce. arXiv 2021, arXiv:2107.01152. [Google Scholar]
- Tian, Y.; Wang, Y.; Krishnan, D.; Tenenbaum, J.B.; Isola, P. Rethinking few-shot image classification: A good embedding is all you need? In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 266–282. [Google Scholar]
- Oreshkin, B.; Rodríguez López, P.; Lacoste, A. TADAM: Task dependent adaptive metric for improved few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Kang, D.; Kwon, H.; Min, J.; Cho, M. Relational embedding for few-shot classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 8822–8833. [Google Scholar]
- Li, Z.; Wang, L.; Ding, S.; Yang, X.; Li, X. Few-Shot Classification With Feature Reconstruction Bias. In Proceedings of the 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Chiang Mai, Thailand, 7–10 November 2022; pp. 526–532. [Google Scholar]
- Wertheimer, D.; Tang, L.; Hariharan, B. Few-shot classification with feature map reconstruction networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 8012–8021. [Google Scholar]
- Wang, Y.; Xu, C.; Liu, C.; Zhang, L.; Fu, Y. Instance Credibility Inference for Few-Shot Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12833–12842. [Google Scholar]
- Lazarou, M.; Stathaki, T.; Avrithis, Y. Iterative label cleaning for transductive and semi-supervised few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 8751–8760. [Google Scholar]




| Number | Symbols | Descriptions |
|---|---|---|
| 1 | the base dataset and the novel dataset | |
| 2 | the original support set, the query set and the unlabeled dataset | |
| 3 | N | the number of categories in |
| 4 | the number of labeled, tested, and unlabeled samples per category | |
| 5 | the local feature descriptors for samples and class | |
| 6 | the expanded support set with unlabeled samples | |
| 7 | two different data augmentations | |
| 8 | feature embeddings after convolutional neural network | |
| 9 | the number of positive and negative sample pairs | |
| 10 | convolutional neural network with parameter | |
| 11 | network parameters obtained after training on the base dataset | |
| 12 | network parameters obtained after training with the PLCL module |
| Train | Val | Test | ||
|---|---|---|---|---|
| mini-ImageNet | Classes | 64 | 16 | 20 |
| Images | 38,400 | 9600 | 12,000 | |
| tiered-ImageNet | Classes | 351 | 97 | 160 |
| Images | 448,695 | 124,261 | 206,209 |
| Methods | Backbone | mini-ImageNet | tiered-ImageNet | ||
|---|---|---|---|---|---|
| 5-Way 1-Shot | 5-Way 5-Shot | 5-Way 1-Shot | 5-Way 5-Shot | ||
| MatchingNet [3] | ConvNet-64 | 43.56 ± 0.84 | 55.31 ± 0.73 | - | - |
| ProtoNet [13] | ConvNet-64 | 49.42 ± 0.78 | 68.20 ± 0.66 | 53.31 ± 0.89 | 72.69 ± 0.74 |
| MAML [4] | ConvNet-64 | 48.70 ± 1.84 | 63.11 ± 0.92 | 51.67 ± 1.81 | 70.30 ± 1.75 |
| DN4 [26] | ConvNet-64 | 51.24 ± 0.74 | 71.02 ± 0.64 | - | - |
| RFS [29] | ResNet-12 | 64.80 ± 0.60 | 82.14 ± 0.43 | 71.52 ± 0.69 | 86.03 ± 0.49 |
| TADAM [30] | ResNet-12 | 58.50 ± 0.30 | 76.70 ± 0.30 | - | - |
| RENet [31] | ResNet-12 | 67.60 ± 0.44 | 82.58 ± 0.30 | 71.61 ± 0.51 | 85.28 ± 0.35 |
| SetFeat [32] | ResNet-12 | 68.32 ± 0.62 | 82.71 ± 0.41 | 68.32 ± 0.62 | 82.71 ± 0.41 |
| FRN [33] | ResNet-12 | 66.45 ± 0.19 | 82.83 ± 0.13 | 71.16 ± 0.22 | 86.01 ± 0.15 |
| infoPatch [27] | ResNet-12 | 67.67 ± 0.45 | 82.44 ± 0.31 | 71.51 ± 0.52 | 85.44 ± 0.35 |
| MetaOptNet [16] | ResNet-12 | 64.09 ± 0.62 | 80.00 ± 0.45 | 65.99 ± 0.72 | 81.56 ± 0.53 |
| TPN-semi [20] | ConvNet-64 | 52.78 ± 0.27 | 66.42 ± 0.21 | 55.74 ± 0.29 | 71.01 ± 0.23 |
| Mask soft k-means [9] | WRN-28-10 | 52.35 ± 0.89 | 67.67 ± 0.65 | 52.39 ± 0.44 | 69.88 ± 0.20 |
| TransMatch [6] | WRN-28-10 | 62.93 ± 1.11 | 81.19 ± 0.59 | 72.19 ± 1.27 | 82.12 ± 0.92 |
| LST [10] | ResNet-12 | 70.10 ± 1.90 | 78.70 ± 0.80 | 77.70 ± 1.60 | 85.20 ± 0.80 |
| LR + ICI [34] | ResNet-12 | 67.57 ± 0.97 | 79.07 ± 0.56 | 83.32 ± 0.87 | 89.06 ± 0.51 |
| iLPC [35] | ResNet-12 | 70.99 ± 0.91 | 81.06 ± 0.49 | 85.04 ± 0.79 | 89.63 ± 0.47 |
| Ours () | ResNet-12 | 71.66 ± 1.04 | 82.57 ± 0.56 | 86.07 ± 0.69 | 89.07 ± 0.01 |
| Ours () | ResNet-12 | 74.46 ± 1.21 | 83.21 ± 0.57 | 87.06 ± 0.91 | 90.21 ± 0.57 |
| R= | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| 0 | 52.24 ± 0.81 | 72.32 ± 0.65 |
| 30 | 71.66 ± 1.04 | 81.20 ± 0.55 |
| 50 | 72.80 ± 1.09 | 82.57 ± 0.56 |
| 100 | 74.46 ± 1.21 | 83.21 ± 0.57 |
| k= | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| 1 | 74.50 ± 1.20 | 83.26 ± 0.59 |
| 3 | 74.46 ± 1.21 | 83.21 ± 0.57 |
| 5 | 74.43 ± 1.21 | 83.30 ± 0.56 |
| 7 | 74.35 ± 1.19 | 83.18 ± 0.57 |
| Method | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| MFC + UCL | 73.55 ± 1.19 | 81.64 ± 0.61 |
| MFC + PLCL | 73.65 ± 1.19 (↑ 0.10) | 81.77 ± 0.61 (↑ 0.13) |
| LFC + UCL | 74.33 ± 1.21 | 83.00 ± 0.57 |
| LFC + PLCL | 74.46 ± 1.21 (↑ 0.13) | 83.21 ± 0.57 (↑ 0.21) |
| Method | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| KC [9] | 62.79 ± 1.25% | 73.04 ± 0.74% |
| MFC [12] | 64.62 ± 1.18% | 74.62 ± 0.73% |
| LFC | 68.25 ± 1.18% | 78.18 ± 0.67% |
| KC + PLCL | 72.72 ± 1.21% | 80.87 ± 0.63% |
| MFC + PLCL | 73.65 ± 1.19% | 81.77 ± 0.61% |
| LFC + PLCL (Ours) | 74.46 ± 1.21% | 83.21 ± 0.57% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, H.; Liu, Y.; Shi, D.; Cheng, X. A Contrastive Model with Local Factor Clustering for Semi-Supervised Few-Shot Learning. Mathematics 2023, 11, 3394. https://doi.org/10.3390/math11153394
Lin H, Liu Y, Shi D, Cheng X. A Contrastive Model with Local Factor Clustering for Semi-Supervised Few-Shot Learning. Mathematics. 2023; 11(15):3394. https://doi.org/10.3390/math11153394
Chicago/Turabian StyleLin, Hexiu, Yukun Liu, Daming Shi, and Xiaochun Cheng. 2023. "A Contrastive Model with Local Factor Clustering for Semi-Supervised Few-Shot Learning" Mathematics 11, no. 15: 3394. https://doi.org/10.3390/math11153394
APA StyleLin, H., Liu, Y., Shi, D., & Cheng, X. (2023). A Contrastive Model with Local Factor Clustering for Semi-Supervised Few-Shot Learning. Mathematics, 11(15), 3394. https://doi.org/10.3390/math11153394