1. Introduction
Life testing is an important approach to analyzing and evaluating the lifetime of a product which implicates the durability of the product. Life testing holds a significant position in reliability testing. The purpose of the life test can be generally categorized into three types:
(1) To find the life distribution of the product; (2) To obtain the statistical characteristics of the product’s life distribution; (3) To study the failure mechanism of the product.
The life test reveals the characteristics of the lifetime and failure mechanism of the product, which can be applied to make further reliability predictions and to improve the quality of the product. Therefore, life testing is crucial in modern industrial research.
According to the applied stress level, life tests can be classified into normal stress life tests and accelerated life stress tests. Normal stress life tests, namely, the traditional life test, collect data on the failure of the experimental object under normal conditions of use. For many reasons, such as the automation in the modern industry, the life span of products grows longer and it is hard to observe a sufficient number of product failures in a short period. Researchers accelerate the failure of the test object by changing the experimental conditions. Some common techniques include increasing the voltage and increasing the applied pressure.
The accelerated life stress test can be subdivided into a partially accelerated life test (PALT) and a fully accelerated life test (FALT). The difference between the two tests is whether all products are under increased stress. In a FALT, all products are under increased stress, which is also called the accelerated condition. During an accelerated life test, the experimenter would gather more failed units compared with the normal stress condition in a given amount of time. The researcher can extrapolate the lifetime characteristics of the product under normal stress from the lifetime and failure information of failed units under increased stress. To achieve this, it is necessary to find an index that reflects the magnitude of acceleration, called the acceleration factor, and then further build a physical model to describe the relationship between the acceleration factor and product life. Since the value of the acceleration factor is immeasurable and the life-stress model is not readily available in most cases, the partially accelerated life test (PALT) has a broader application than the fully accelerated life test (FALT). In PALT, experimental units were treated either under normal use stress conditions or accelerated stress conditions. Ref. [
1] divided the common life stress models into two categories: the step stress (SS) model and the constant stress (CS) model. In the CS life test, the units stay under a stabilized stress level, while in the SS life test, the pressure applied to the units increases step by step until the units break down.
The life test has two subcategories, one is called constant stress partial accelerated life test (CSPALT) and the other is called stepped stress partial accelerated life test (SSPALT). CSPALT and SSPALT are by far the most frequently used experimental methods in life testing. In CSPALT, units are always at normal use stress levels or fixed increased stress levels. This means that the stress level to which the sample is subjected does not change from the beginning of the test to the end of the test. Many studies on CSPALT have been conducted by scholars in recent years. Ref. [
2] designed CSPALTs to estimate the parameters of the Burr XII distribution with multiple sets of type I and type II censored data. Ref. [
3] assessed the superiority of estimates for CSPALTs using type I and type II censored data following Weibull distribution.
Censoring is a situation where an event occurs that is not observed or is not observable to the extent that the survival time cannot be accurately recorded. Censoring often needs to be factored into life tests. Right censoring usually occurs when a product survives longer than the observation time and is a frequent occurrence in lifespan tests. There are many different censoring schemes, and when the observation start time is the same, there are two types of censoring depending on the observation end time. For type I censoring, the observations of the remaining experimental subjects are uniformly cut off at a fixed time point, excluding the products that have failed. Type II censoring is that the observations are terminated when a predetermined amount of failure of the products is observed, and the percentage of censoring can be assumed to be predetermined. Due to the high reliability and long life of modern industrial products, a new censoring scheme, progressively type II censoring, is proposed. Consider a life test containing
n units and a predetermined censoring ratio
. When the first product fails,
units are randomly selected from the residual
units and the observation on them is terminated; when the second product fails,
units are randomly selected from the remaining
units and the observation on them is terminated; and when the
i product fails,
units are randomly selected from the residual
units and the observation on them is terminated. This censoring scheme can improve the efficiency of the experiment and reduce the cost, which can be seen in the case of [
4,
5].
The exponential distribution is often used to establish models about life due to its memory-less property. Assume that
X is an exponentially distributed random variable; then, the cumulative distribution function (CDF) and probability density function (PDF) are
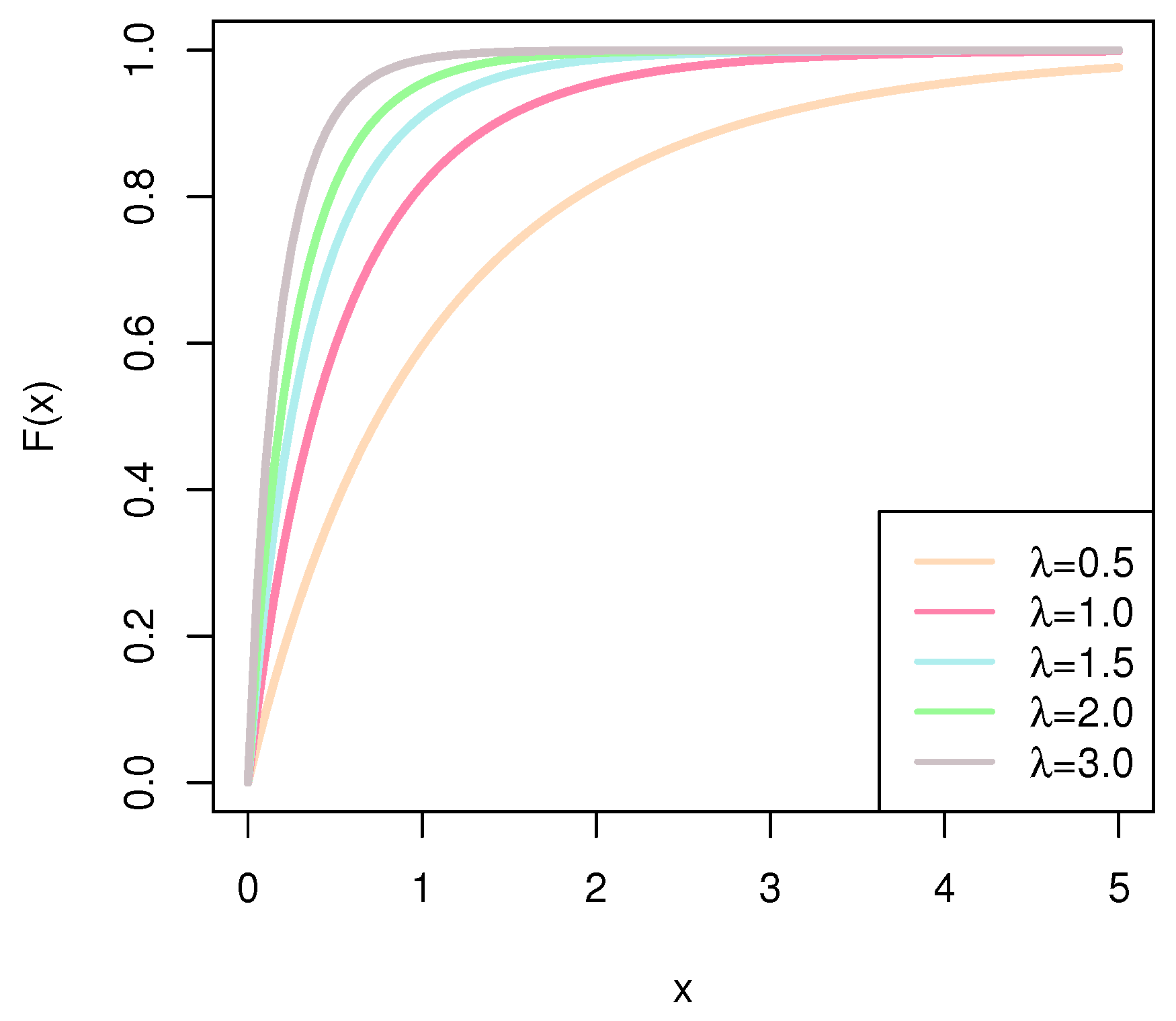
For the reliability analysis, the hazard rate function (HRF) describes the law of failure time and reflects the intensity of the probability of an individual’s instantaneous death at a point in time. The corresponding survival function (SF) represents the probability of an individual surviving. The HRF and SF are important tools for studying accelerated life tests and censored data. The expressions of the HRF and the SF of the exponential distribution are given by
The HRF of the exponential distribution is a constant value function with the value .
Scholars have worked on mining other distributions as expanded extensions of the exponential distribution that can serve as models for simulating lifetimes. Ref. [
6] generalized an exponentiated exponential distribution to develop a transmuted exponentiated exponential distribution. Ref. [
7] introduced the Burr–Hatke–G family to simulate lifetimes.
The Burr–Hatke–G distribution family was constructed on the basis of the Burr–Hatke differential equation, which is given by
is a CDF of a continous random variable
X, while
is any non-negative function. The Burr–Hatke–G family has attracted a lot of attention from scholars, such as [
8,
9]. Inspired by them, the authors of [
10] proposed and analyzed a new lifetime distribution with one parameter, called the Burr–Hatke exponential (BHE) distribution, as an extension of the exponential distribution. Consider
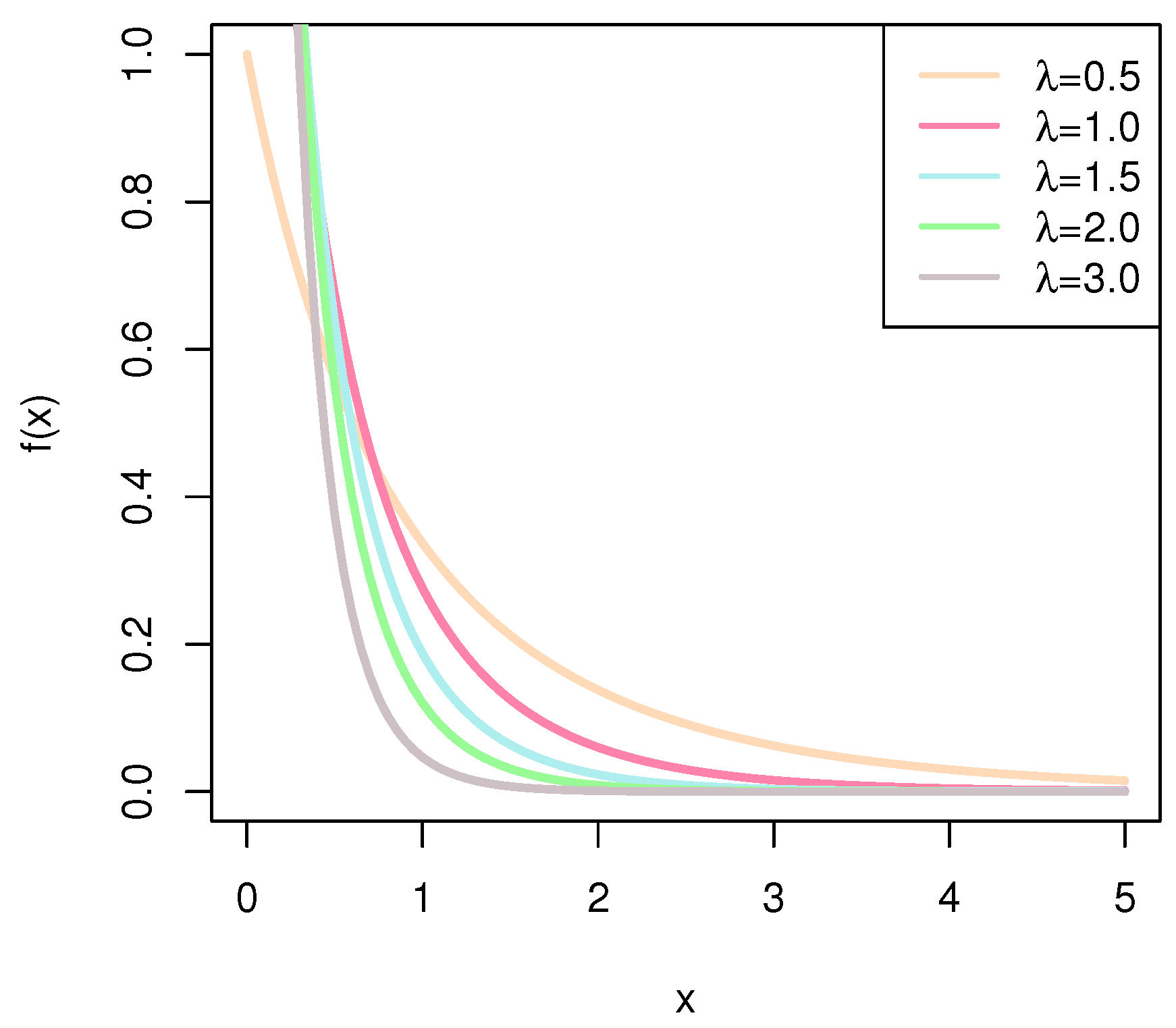
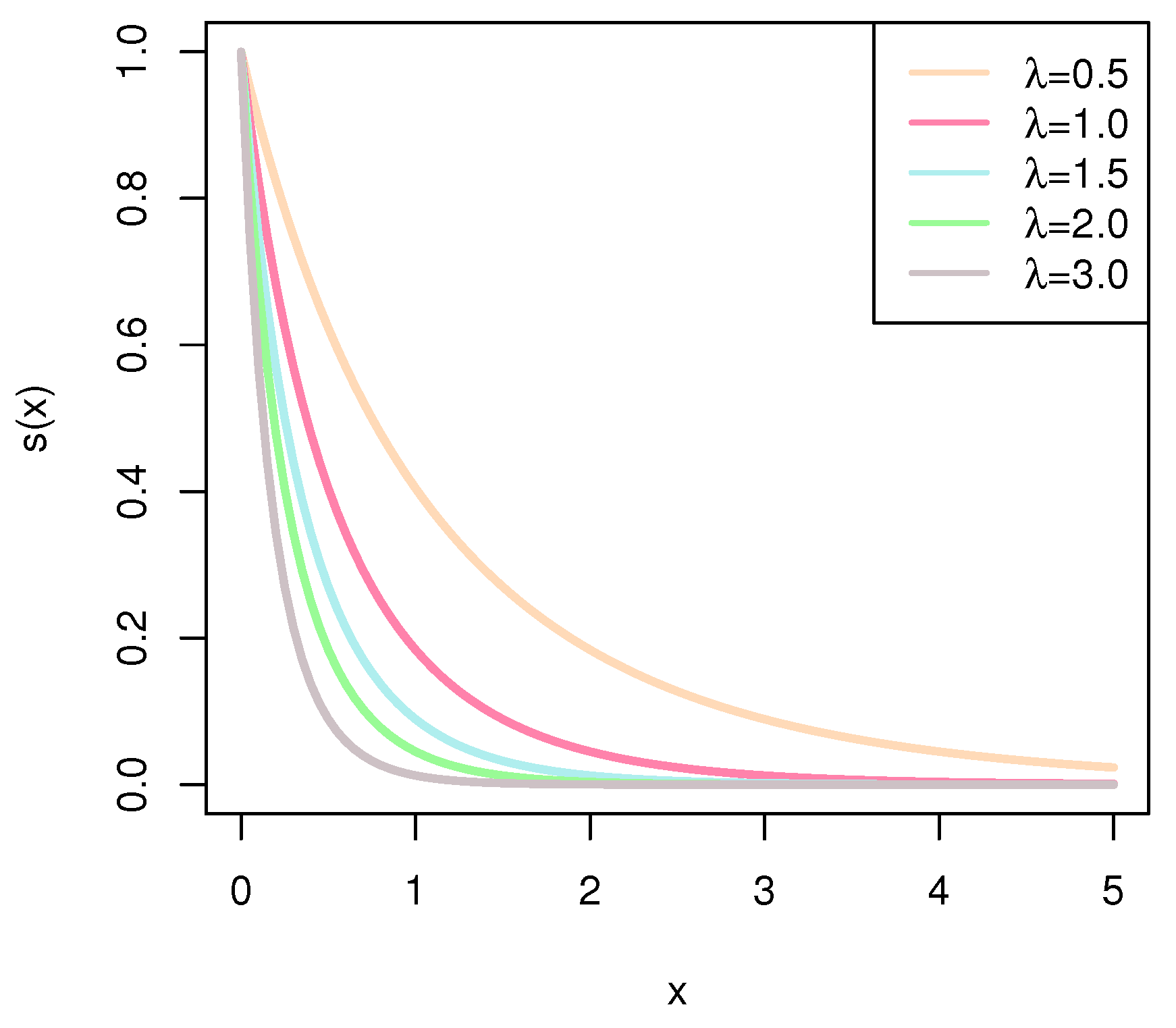
X as a random variable obeying Burr–Hatke exponential distribution. The cumulative distribution function, and probability density function, survival function, and hazard rate function of
X can be formulated, respectively, as
The Burr–Hatke exponential distribution has good properties. Firstly, the moments of BHE are discussed. The first-order moment, mathematical expectation, and second-order moment are calculated as follows:
where
The variance (
13) in BHE is easy to obtain.
Secondly, consider the asymptotics of BHE distribution. Let
, when
, the CDF, PDF, and HRF of BHE show the following convergence:
when
, the asymptotics shows
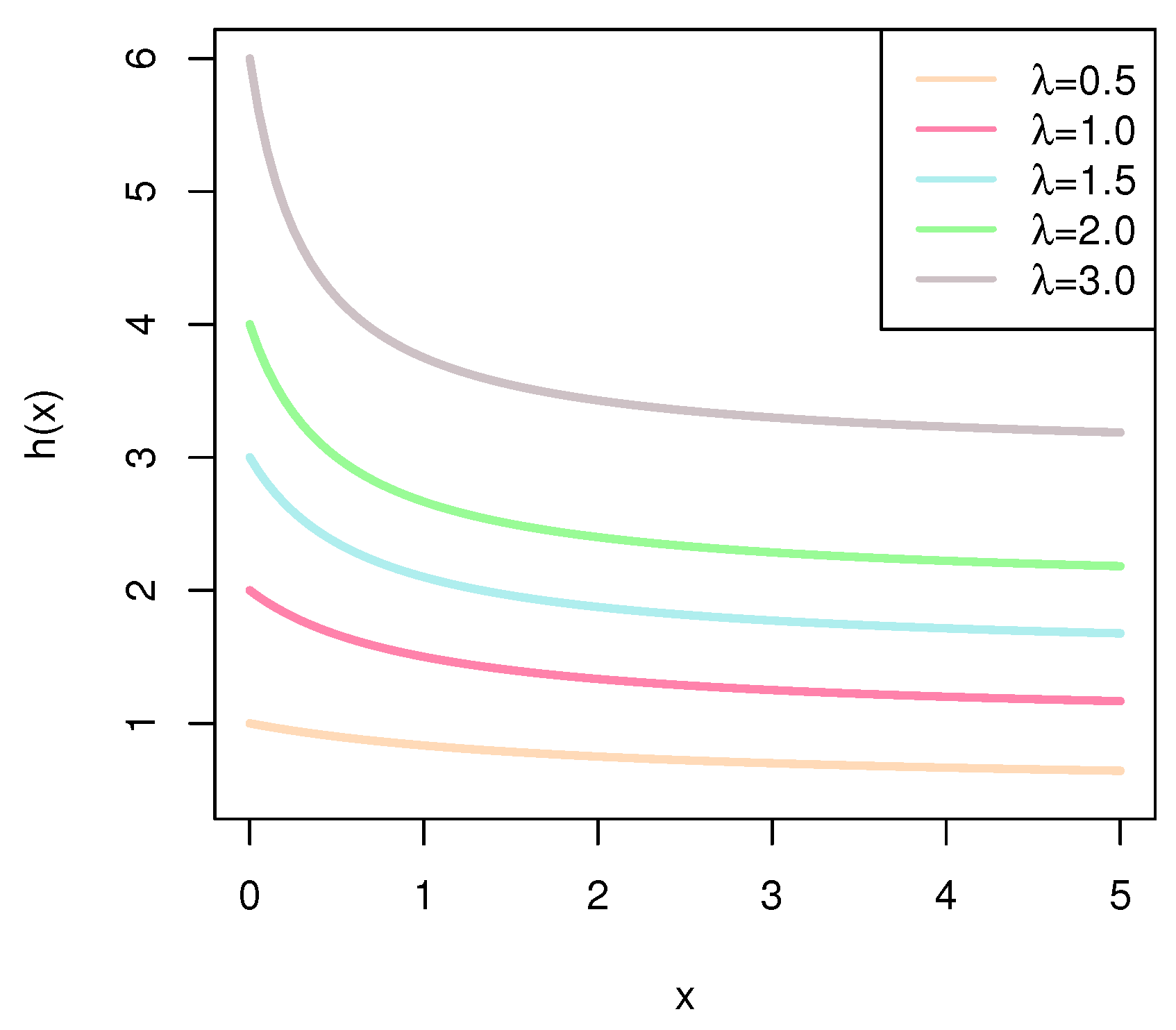
Notably, the HRF of BHE is a decreasing function, which can be seen in (
9). The descending function describes the probability of breakdown reducing over time, which means improvement exists during the living time. Ref. [
10] takes the opinion that it describes a situation where the probability of early death is high, and as time passes, the factors that could have caused the death initially reduce or disappear. In other words, there is some improvement in the sample that survives the initial period. Therefore, it may serve as a valuable model when analyzing data from reliability tests or medical fields that follow the decreasing pattern of HRF. Recently, much research on BHE has been conducted. Ref. [
10] used the classical likelihood and Bayesian method to estimate a BHE model’s parameter, based on data under hybrid censoring, and confirmed that the BHE model fits both datasets well relative to other distributions. Ref. [
11] estimated the BHE model parameter using the maximum likelihood method and considered BHE as an appropriate model for the right-skewed data. Ref. [
12] considered a Burr–Hatke exponential distribution for a model of software development cost and analyzed the model by applying software failure time data. Ref. [
9] using two real datasets illustrated that the BHE models fitted best compared with other models simulating lifetime empirically. Ref. [
13] concluded that the BHE model is suitable in the field of software reliability analysis. Ref. [
14] introduced the discrete BHE distribution and investigated its statistical properties insightfully.
In summary, this study of the Burr–Hatke exponential distribution has significant implications in practice. Studies of the Burr–Hatke exponential distribution on both accelerated life testing and under type II censoring are missing. The parameter of the BHE distribution under CSPALT with progressive type II censoring is estimated in this article. The maximum likelihood estimates (MLEs) and their approximate confidence intervals (ACIs) of the parameter and accelerated factor have been concluded. Interval estimates based on the Bootstrap method and point estimates calculated using the Bayesian method are also given.
The study in this paper fills the gap of BHE distribution in CSPALT, extends CSPALT to more applicable situations in life tests, and provides a new model for life test samples with reduced hazard rate functions.
This paper is organized as follows. In
Section 2, the notation of the censored schemes and CSPALT is explained. In
Section 3, the procedures to obtain maximum likelihood estimates and the Fisher information matrix are shown. The approximate confidence intervals using the delta method are built up. In
Section 4, Boot-p confidence intervals based on Bootstrap methods are discussed. In
Section 5, Bayesian point estimates are presented, using the Metropolis–Hasting algorithm for sampling. In
Section 6, a Monte Carlo simulation study is performed to compare the implementation of the results of different estimates. In
Section 7, a real dataset of oil breakdown times is analyzed to investigate the estimations of the parameters. In
Section 8, the structure of the article is summarized and an outlook on the future work is provided.
2. Model Description
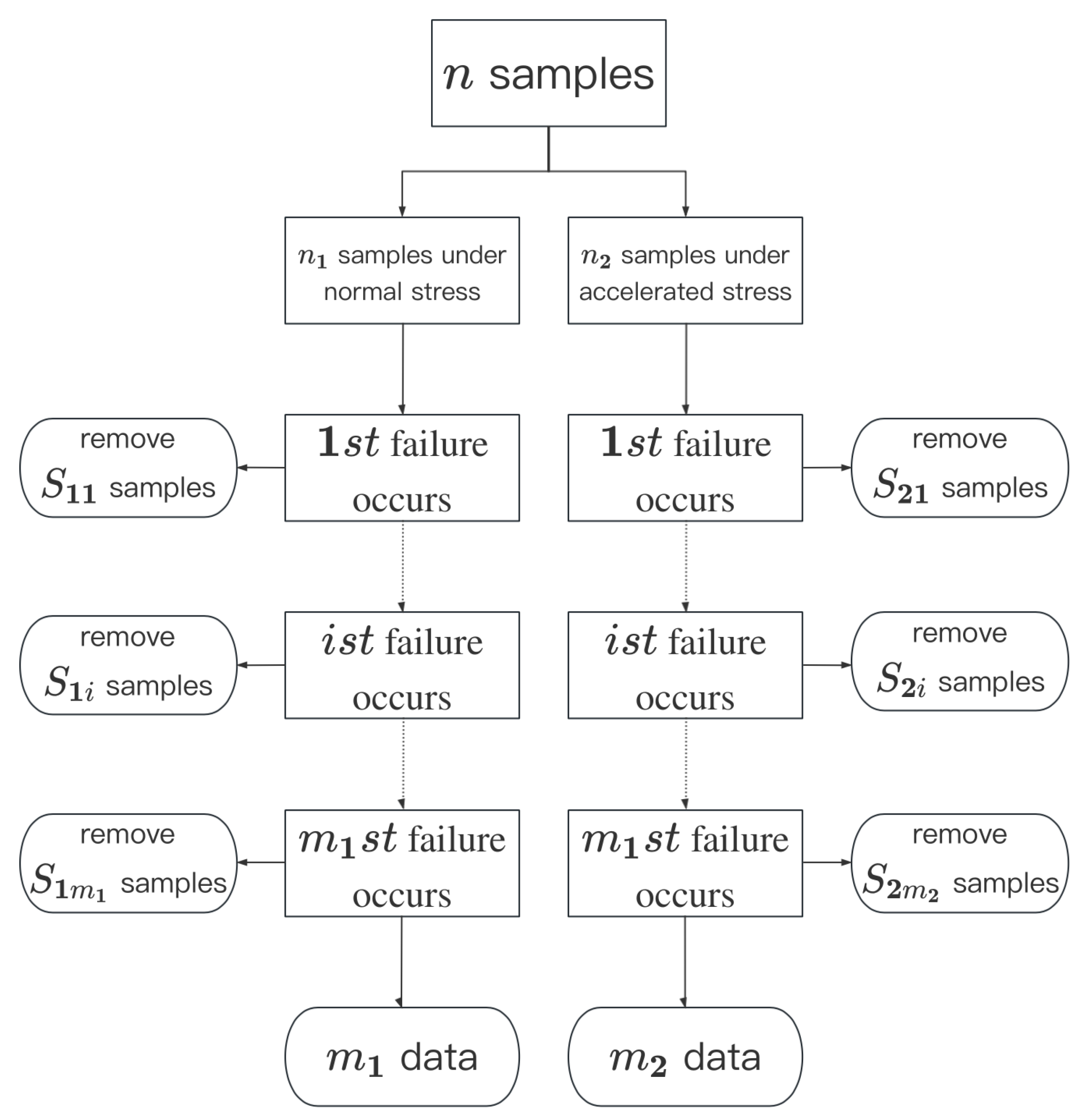
As a basis for subsequent estimation, the experimental approach to CSPALT under progressive type II censoring and the underlying assumptions about the model are as follows (
Figure 5):
Assume that the total amount of samples is n. To build up a CSPALT test, randomly select an sample as test group 1, which is under normal stress, and the residual , as group 2, is under the accelerated condition. Take progressively type II censoring into consideration, and set a sample size of , where for each test group; then, is the observed number of failures for each test group. The prefixed censoring scheme is , which means that when the ith failure is observed, remove randomly selected samples from the testing group.
Then, the observation is given by .
Several key assumptions are made as follows:
- (1)
The lifetime of units in test group 1, under normal stress, follows a Burr–Hatke exponential distribution with CDF in (
6), PDF in (
7), SF in (
8), and HRF in (
9).
- (2)
The HRF of units in test group 2, under the accelerated condition is given by , and is the acceleration factor that satisfies .
Considering the above assumptions together, the HRF, SF, CDF, and PDF of the sample lifetime under accelerated stress conditions can be deduced with the following results.
The joint PDF of the observation
is the following.
where
6. Simulation Study
In this section, Monte Carlo simulations were conducted to judge the performance of the several methods mentioned above on parameter estimation.
Two sets of parameters are evaluated, as follows:
- (1)
with corresponding hyperparameters .
- (2)
with corresponding hyperparameters .
The value of the hyperparameter has a negligible effect on the results when the number of tests is large enough, so the value that makes the mean of the prior distribution the same as the original mean is chosen. Based on the theory part of the equation, the two sets of parameters are estimated separately. For all the interval estimates, the significant level is set at .
To ensure the reliability of the test, six distinct sets of censoring schemes and sample sizes are selected:
- (1)
- (2)
- (3)
- (4)
- (5)
- (6)
In the process of algorithm implementation, data following the BHE distribution under progressively type II censoring need to be generated as samples. Progressively type II censored data are generated via the following Algorithm 3 proposed by [
4].
| Algorithm 3: Progressively type II censored data |
1. Generate m independent samples from .
2. Set , where .
is the censored scheme. 3. Set , where . Then are the progressively type II censored samples from .
4. Calculate , where .
is the inverse of the aimed distribution function. Then are the progressively type II censored samples derived from the distribution with .
|
Applying the expressions for the CDF under normal stress (
6) and under accelerated stress (
22) to the above algorithm, progressively type II censored data under normal use stress and accelerated stress conditions are produced. The complete experimental data of the simulated CSPALT are available and used to compare the superiority and inferiority of the parameter estimation methods.
The performance of the proposed methods for estimates of the BHE distribution based on the CSPALT under progressively type II censoring is verified via Monte Carlo simulation using the R-package. In the framework of classical maximum likelihood, the maximum likelihood function is solved using the Newton–Raphson method, and the Hessian matrix is used to obtain the maximum likelihood estimates. In the optimization process, the beginning value of the parameters is a random selection. The matrix is inverted to obtain the variance in the estimates and to construct asymptotic interval estimates by combining asymptotic normality. The Bayesian estimators are obtained using the gamma prior of and the non-informative prior of . The MH algorithm and the Gibbs sampling are applied due to the posterior distribution being difficult to obtain.
Using maximum likelihood and the Bayesian method, estimates of and are obtained in the form of point estimates. The interval estimates are calculated using the maximum likelihood method and the bootstrap method. For each method of estimation, 5000 simulations were executed.
The criteria for judging the estimation effectiveness are as follows. For point estimation, there are two evaluation criteria, as follows:
- (1)
Mean square error (MSE), calculated as
- (2)
Average bias (AB), which is calculated as
For interval estimation, the judgment criteria are as follows:
- (1)
Coverage probability (CP), namely, the proportion of intervals containing the true values of parameters to all intervals;
- (2)
Average length (AL), that is, the distance from the maximum value to the minimum value of the interval.
The results of point and interval estimation are reported in the following tables.
To represent the coverage of the intervals more intuitively, the BCI and PBCI are plotted separately as follows (
Figure 6 and
Figure 7), and it can be seen that both BCI and PBCL are good interval estimations.The red lines show the true values of the parameters.
From
Table 1 and
Table 2, it can be seen that as the sample size
increases, the values of MSEs and ABs, the statistics reflecting the centrality of MLEs and BEs, decrease, respectively. It can be assumed that the estimation has good consistency. The classical MLE estimation outperforms the Bayesian estimation when the censored scheme is fixed. For a fixed number of units
, the estimates of the censored scheme [1], [3], [5] are superior to the estimates of [2], [4], [6], namely, The censoring that happens following the initial observed failure provides more precise estimates compared with the others, which is consistent with the findings of [
17].
From
Table 3 and
Table 4, it can be seen that as the number of samples
increases, the values of ALs of both ACIs and PBCIs decrease, respectively. The CPs of ACIs and PBCIs increase slightly, showing a tendency to converge to 95%, the values of the confidence interval.
In summary, both point estimates—the maximum likelihood estimate and the Bayesian estimate—show excellent performance, indicating the stability of both methods. The results of PBCI are poorer, and the estimation is also inefficient, requiring a long time to complete the iterations. The performance of ACI is much better than that of PBCI.
7. Real Data Analysis
In this section, real-time CSPALT life data are analyzed to further elaborate the estimation method described above. For additional clarification, we analyzed a real-time dataset of the oil breakdown time of insulating liquids. The life of many industrial components depends on the lifetime of electrical insulation. Accelerating conditions, such as turning up the voltage, can improve the efficiency of the life test. Ref. [
1] studied accelerated tests based on this background, applying different magnitudes of voltage to different experimental groups for the tests. The data for the empirical analysis in this paper are derived from this study. Ref. [
17], using this dataset and applying progressively type II censoring, compared the performance of several parameter estimations of Nadarajah–Haghighi distribution under CSPALT.
In the empirical analysis, the sample at 30 kV was used as data under the constant stress condition, and the sample at 32 kV was used as data under the accelerated stress condition. The data are presented as follows
Table 5.
Before the estimation of parameters, the goodness-of-fit of the dataset to the BHE distribution was verified. Firstly, the Kolmogorov–Smirnov test (KS test) was used to measure the distance of the data from the distribution. The KS distance and
p-value of data under the constant stress condition were calculated to be 0.2167 and 0.6062, respectively, and the KS distance and
p-value of data under the accelerated stress condition were 0.2959 and 0.1167, respectively; at the significance level
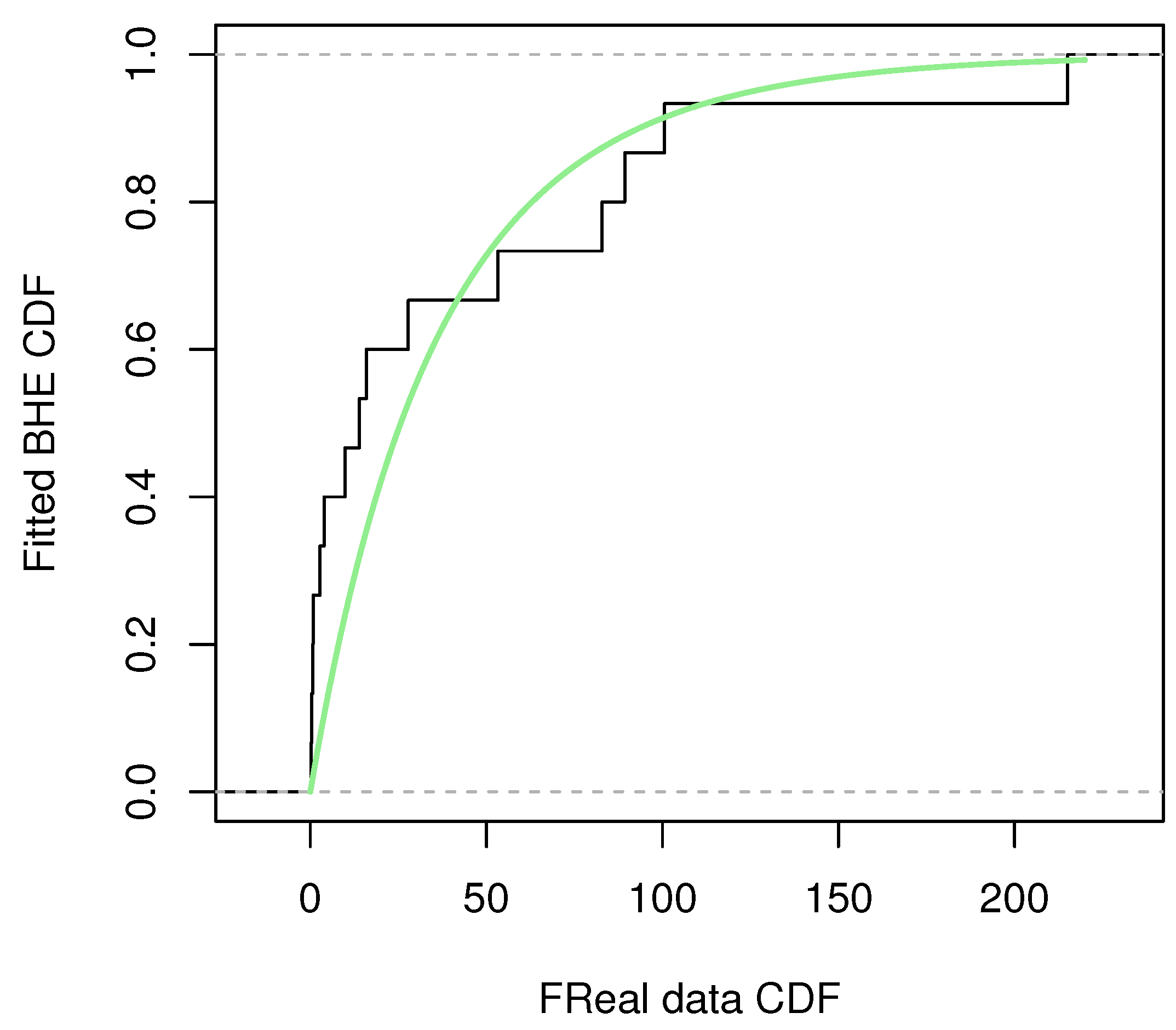
, the dataset is considered suitable for fitting with the BHE distribution. To visualize how precisely this dataset fits the BHE distribution, a plot of the dataset‘s cumulative distribution with the CDF of BHE is shown in
Figure 8 and
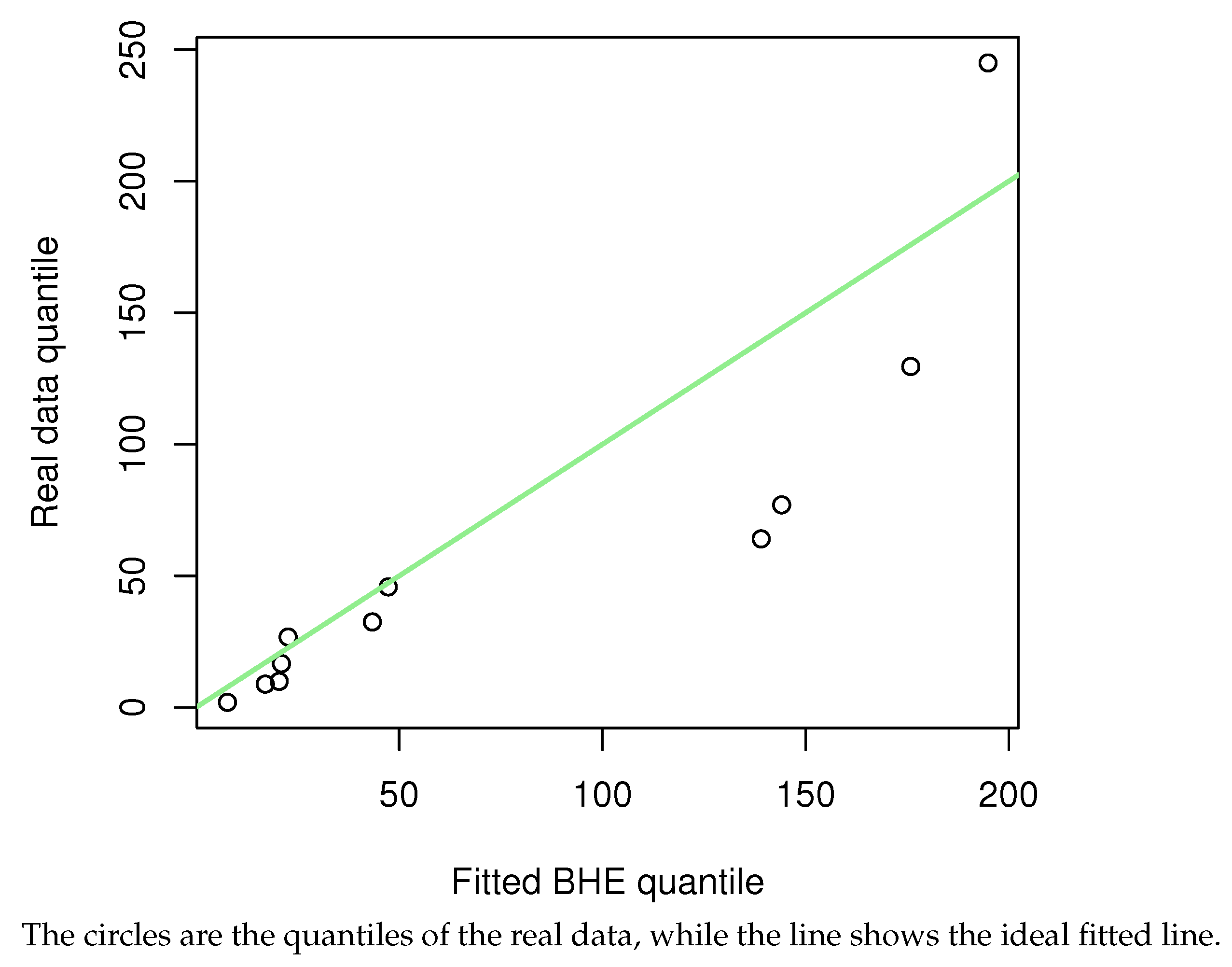
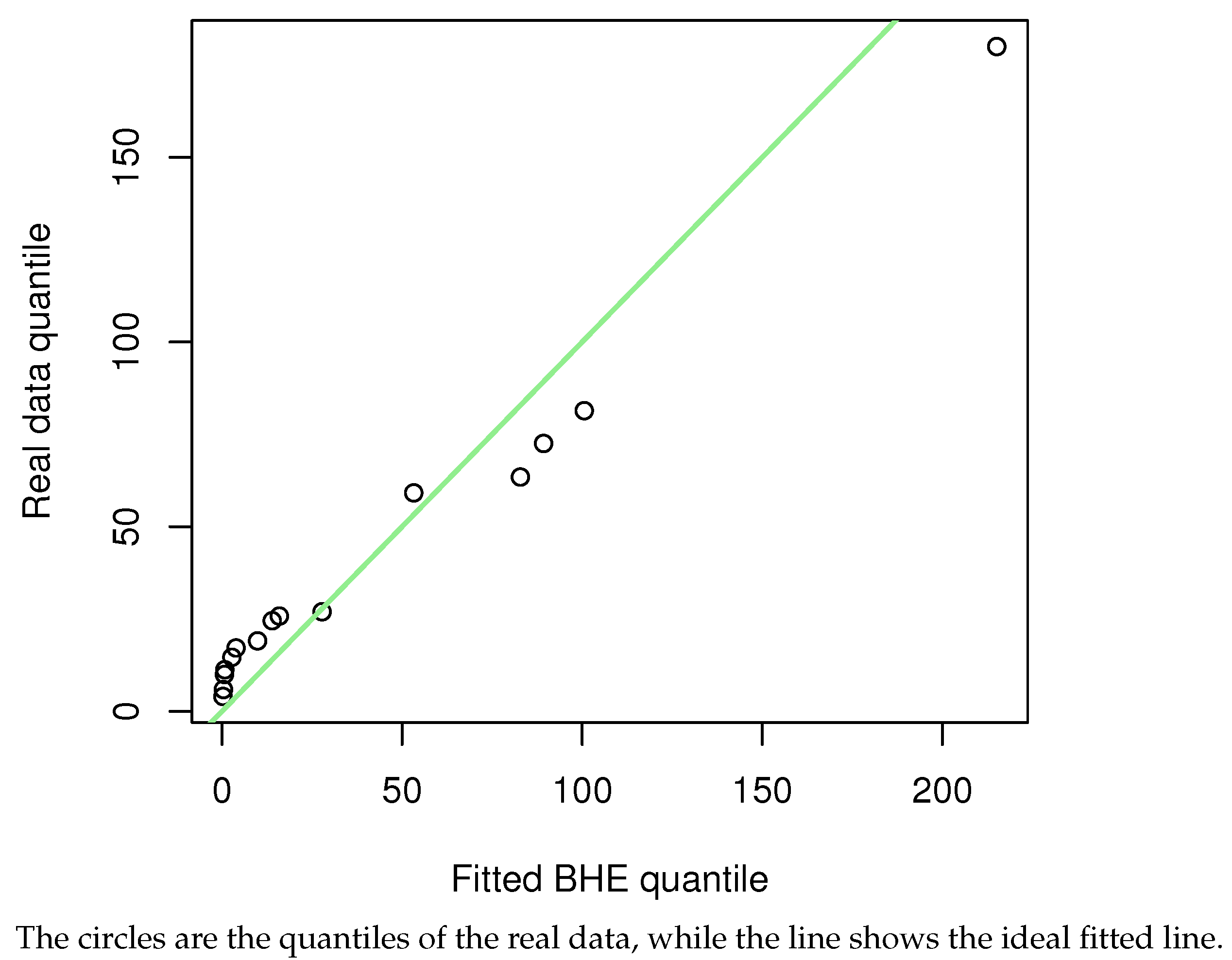
Figure 9. The green line shows the CDF of BHE distribution. Quantile–quantile plots (QQ plots) (
Figure 10 and
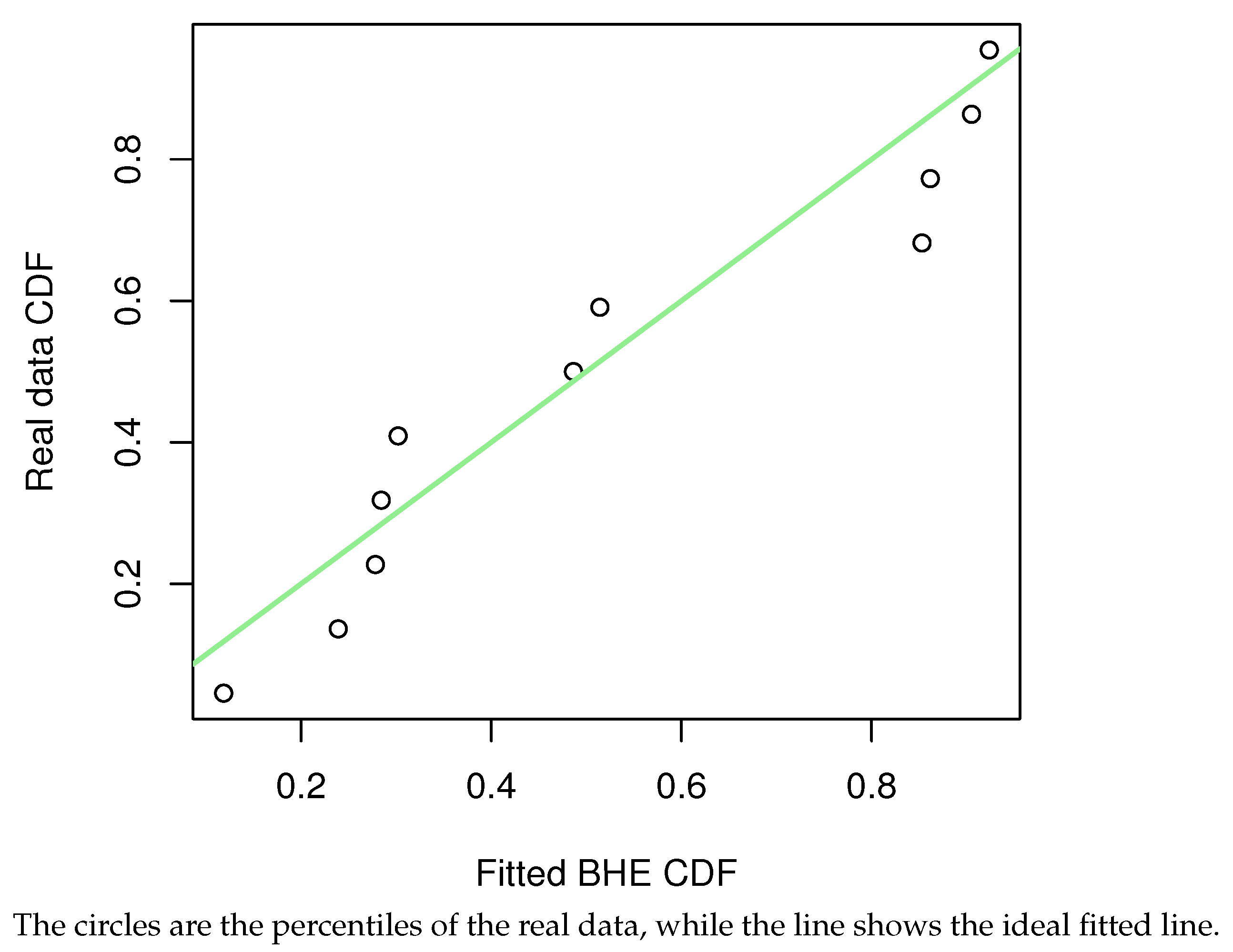
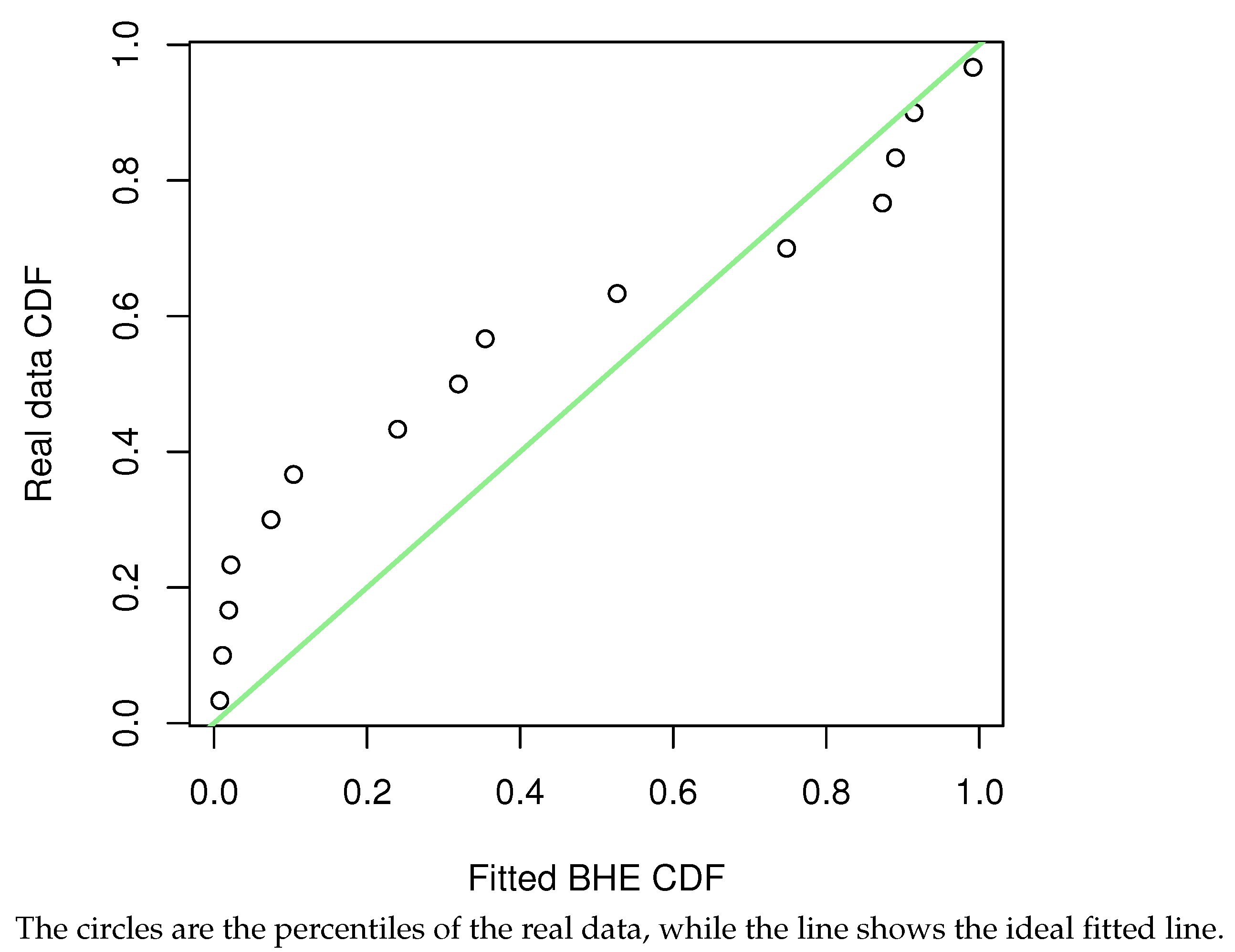
Figure 11) were further plotted, and the results were obtained as follows. The percentage–percentage plot (PP plot) (
Figure 12 and
Figure 13) are also presented. The conclusion is the same as the result of the KS test, that is, the model can be fitted using the BHE distribution for this dataset.
Considering the small sample size, a progressively type II censored scheme is selected with a small amount of censoring. The censored data are obtained as follows
Table 6:
Under this assumption, point and interval estimates of the acceleration factor and the unknown parameter are obtained using the principles and algorithms in
Section 3,
Section 4 and
Section 5. The results of parameter estimation are shown in the following
Table 7.
In the Bayesian estimation, the parameter of the trial cast density normal distribution is chosen to be 0.001, and the hyperparameter of the gamma prior distribution is , which matches the sample characteristics. The following conclusions can be obtained:
- (1)
The results of MLE and BE are similar, indicating that the BHE model is consistent with the data.
- (2)
The ACI of parameters and contains the results of MLE and BE, and the length of the interval is small.
- (3)
The results of PBCI with illustrate the instability of PBCI, which is consistent with the conclusions in the Simulation Study section.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}